With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up I d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. For now, we ll be using a custom ISO image, while waiting for the above-mentioned merge-proposal to be landed. Furthermore, as the Debian archive is going through major transitions builds of the unstable branch of d-i don t currently work. So I implemented a small backport, producing updated netcfg and netcfg-static for Bookworm, which can be used as localudebs/ during the d-i build.
Let s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
Now let s download the custom mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes, as mentioned above.
TODO: localudebs/
Next we ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
Finally, let s launch the installer using a custom preseed.cfg file, that will automatically install Netplan for us in the target system. A minimal preseed file could look like this:
For this demo, we re installing the full netplan.io package (incl. Python CLI), as the netplan-generator package was not yet split out as an independent binary in the Bookworm cycle. You can choose the preseed file from a set of different variants to test the different configurations:
We re using the custom linux kernel and initrd.gz here to be able to pass the PRESEED_URL as a parameter to the kernel s cmdline directly. Launching this VM should bring up the normal debian-installer in its netboot/gtk form:
Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
Done! After the installation finished you can reboot into your virgin Debian Bookworm system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was written by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
Finally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
In our case we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more join the discussion at Salsa:installer-team/netcfg and find us at GitHub:netplan.
Time really flies when you are really busy you have fun! Our Montr al
Debian User Group met on Sunday March 31st and I only just found the time to
write our report :)
This time around, 9 of us we met at EfficiOS's offices1 to
chat, hang out and work on Debian and other stuff!
Here is what we did:
pollo:
did some clerical work for the DebConf videoteam
tried to book a plane ticket for DC24
triaged #1067620 (dependency problem with whipper)
Pictures
Here are pictures of the event. Well, one picture (thanks Tassia!) of the event
itself and another one of the crisp Italian lager I drank at the bar after the
event :)
Maintainers, amongst other things, of the great LTTng.
Joachim Breitner wrote about a Convenient sandboxed development environment and thus reminded me to blog about MicroVM. I ve toyed around with it a little but not yet seriously used it as I m currently not coding.
MicroVM is a nix based project to configure and run minimal VMs. It can mount and thus reuse the hosts nix store inside the VM and thus has a very small disk footprint. I use MicroVM on a debian system using the nix package manager.
The MicroVM author uses the project to host production services. Otherwise I consider it also a nice way to learn about NixOS after having started with the nix package manager and before making the big step to NixOS as my main system.
The guests root filesystem is a tmpdir, so one must explicitly define folders that should be mounted from the host and thus be persistent across VM reboots.
I defined the VM as a nix flake since this is how I started from the MicroVM projects example:
description = "Haskell dev MicroVM";
inputs.impermanence.url = "github:nix-community/impermanence";
inputs.microvm.url = "github:astro/microvm.nix";
inputs.microvm.inputs.nixpkgs.follows = "nixpkgs";
outputs = self, impermanence, microvm, nixpkgs :
let
persistencePath = "/persistent";
system = "x86_64-linux";
user = "thk";
vmname = "haskell";
nixosConfiguration = nixpkgs.lib.nixosSystem
inherit system;
modules = [
microvm.nixosModules.microvm
impermanence.nixosModules.impermanence
( pkgs, ... :
environment.persistence.$ persistencePath =
hideMounts = true;
users.$ user =
directories = [
"git" ".stack"
];
;
;
environment.sessionVariables =
TERM = "screen-256color";
;
environment.systemPackages = with pkgs; [
ghc
git
(haskell-language-server.override supportedGhcVersions = [ "94" ]; )
htop
stack
tmux
tree
vcsh
zsh
];
fileSystems.$ persistencePath .neededForBoot = nixpkgs.lib.mkForce true;
microvm =
forwardPorts = [
from = "host"; host.port = 2222; guest.port = 22;
from = "guest"; host.port = 5432; guest.port = 5432; # postgresql
];
hypervisor = "qemu";
interfaces = [
type = "user"; id = "usernet"; mac = "00:00:00:00:00:02";
];
mem = 4096;
shares = [
# use "virtiofs" for MicroVMs that are started by systemd
proto = "9p";
tag = "ro-store";
# a host's /nix/store will be picked up so that no
# squashfs/erofs will be built for it.
source = "/nix/store";
mountPoint = "/nix/.ro-store";
proto = "virtiofs";
tag = "persistent";
source = "~/.local/share/microvm/vms/$ vmname /persistent";
mountPoint = persistencePath;
socket = "/run/user/1000/microvm-$ vmname -persistent";
];
socket = "/run/user/1000/microvm-control.socket";
vcpu = 3;
volumes = [];
writableStoreOverlay = "/nix/.rwstore";
;
networking.hostName = vmname;
nix.enable = true;
nix.nixPath = ["nixpkgs=$ builtins.storePath <nixpkgs> "];
nix.settings =
extra-experimental-features = ["nix-command" "flakes"];
trusted-users = [user];
;
security.sudo =
enable = true;
wheelNeedsPassword = false;
;
services.getty.autologinUser = user;
services.openssh =
enable = true;
;
system.stateVersion = "24.11";
systemd.services.loadnixdb =
description = "import hosts nix database";
path = [pkgs.nix];
wantedBy = ["multi-user.target"];
requires = ["nix-daemon.service"];
script = "cat $ persistencePath /nix-store-db-dump nix-store --load-db";
;
time.timeZone = nixpkgs.lib.mkDefault "Europe/Berlin";
users.users.$ user =
extraGroups = [ "wheel" "video" ];
group = "user";
isNormalUser = true;
openssh.authorizedKeys.keys = [
"ssh-rsa REDACTED"
];
password = "";
;
users.users.root.password = "";
users.groups.user = ;
)
];
;
in
packages.$ system .default = nixosConfiguration.config.microvm.declaredRunner;
;
I start the microVM with a templated systemd user service:
The above service definition creates a dump of the hosts nix store db so that it can be imported in the guest. This is necessary so that the guest can actually use what is available in /nix/store. There is an effort for an overlayed nix store that would be preferable to this hack.
Finally the microvm is started inside a tmux session named microvm . This way I can use the VM with SSH or through the console and also access the qemu console.
And for completeness the virtiofsd service:
[Unit]
Description=serve host persistent folder for dev VM
AssertPathIsDirectory=%h/.local/share/microvm/vms/%i/persistent
[Service]
ExecStart=%h/.local/state/nix/profile/bin/virtiofsd \
--socket-path=$ XDG_RUNTIME_DIR /microvm-%i-persistent \
--shared-dir=%h/.local/share/microvm/vms/%i/persistent \
--gid-map :995:%G:1: \
--uid-map :1000:%U:1:
More people are searching for alternatives to Google.
Mainstream hard discs are incredibly big.
Mainstream internet connection is incredibly fast.
Google is bleeding talent.
Most of the building blocks are available as free software.
Success depends on your definition
My definition of success is:
A mildly technical computer user (able to install software) has access to a search engine that provides them with superior search results compared to Google for at least a few predefined areas of interest.
The exact algorithm used by Google Search to rank websites is a secret even to most Googlers. Still it is clear, that it relies heavily on big data: billions of queries, a comprehensive web index and user behaviour data. - All this is not available to us.
A distributed search engine however can instead rely on user input. Every admin of one node seeds the node ranking with their personal selection of trusted sites. They connect their node with nodes of people they trust. This results in a web of (transitive) trust much like pgp.
For comparison, imagine you are searching for something in a world without computers: You ask the people around you. They probably forward your question to their peers.
I already had a look at YaCy. It is active, somewhat usable and has a friendly maintainer. Unfortunately I consider the codebase to show its age. It takes a lot of time for a newcomer to find their way around and it contains a lot of cruft. Nevertheless, YaCy is a good example that a decentralized search software can be done even by a small team or just one person.
I myself started working on a software in Haskell and keep my notes here: Populus:DezInV. Since I m learning Haskell along the way, there is nothing there to see yet. Additionally I took a yak shaving break to learn nix.
By the way: DuckDuckGo is not the alternative. And while I would encourage you to also try Yandex for a second opinion, I don t consider this a solution.
Unseen Academicals is the 37th Discworld novel and includes many of
the long-standing Ankh-Morpork cast, but mostly as supporting characters.
The main characters are a new (and delightful) bunch with their own
concerns. You arguably could start reading here if you really wanted to,
although you would risk spoiling several previous books (most notably
Thud!) and will miss some references
that depend on familiarity with the cast.
The Unseen University is, like most institutions of its sort, funded by an
endowment that allows the wizards to focus on the pure life of the mind
(or the stomach). Much to their dismay, they have just discovered that an
endowment that amounts to most of their food budget requires that they
field a football team.
Glenda runs the night kitchen at the Unseen University. Given the deep
and abiding love that wizards have for food, there is both a main kitchen
and a night kitchen. The main kitchen is more prestigious, but the night
kitchen is responsible for making pies, something that Glenda is quietly
but exceptionally good at.
Juliet is Glenda's new employee. She is exceptionally beautiful, not very
bright, and a working class girl of the Ankh-Morpork streets down to her
bones. Trevor Likely is a candle dribbler, responsible for assisting the
Candle Knave in refreshing the endless university candles and ensuring
that their wax is properly dribbled, although he pushes most of that work
off onto the infallibly polite and oddly intelligent Mr. Nutt.
Glenda, Trev, and Juliet are the sort of people who populate the great
city of Ankh-Morpork. While the people everyone has heard of have
political crises, adventures, and book plots, they keep institutions like
the Unseen University running. They read romance novels, go to the
football games, and nurse long-standing rivalries. They do not expect the
high mucky-mucks to enter their world, let alone mess with their game.
I approached Unseen Academicals with trepidation because I normally
don't get along as well with the Discworld wizard books. I need not have
worried; Pratchett realized that the wizards would work better as
supporting characters and instead turns the main plot (or at least most of
it; more on that later) over to the servants. This was a brilliant
decision. The setup of this book is some of the best of Discworld up to
this point.
Trev is a streetwise rogue with an uncanny knack for kicking around a can
that he developed after being forbidden to play football by his dear old
mum. He falls for Juliet even though their families support different
football teams, so you may think that a Romeo and Juliet spoof is
coming. There are a few gestures of one, but Pratchett deftly avoids the
pitfalls and predictability and instead makes Juliet one of the best
characters in the book by playing directly against type. She is one of
the characters that Pratchett is so astonishingly good at, the ones that
are so thoroughly themselves that they transcend the stories they're put
into.
The heart of this book, though, is Glenda.
Glenda enjoyed her job. She didn't have a career; they were for people
who could not hold down jobs.
She is the kind of person who knows where she fits in the world and likes
what she does and is happy to stay there until she decides something isn't
right, and then she changes the world through the power of common sense
morality, righteous indignation, and sheer stubborn persistence.
Discworld is full of complex and subtle characters fencing with each
other, but there are few things I have enjoyed more than Glenda being a
determinedly good person. Vetinari of course recognizes and respects (and
uses) that inner core immediately.
Unfortunately, as great as the setup and characters are, Unseen
Academicals falls apart a bit at the end. I was eagerly reading the
story, wondering what Pratchett was going to weave out of the stories of
these individuals, and then it partly turned into yet another wizard book.
Pratchett pulled another of his deus ex machina tricks for the
climax in a way that I found unsatisfying and contrary to the tone of the
rest of the story, and while the characters do get reasonable endings, it
lacked the oomph I was hoping for. Rincewind is as determinedly one-note
as ever, the wizards do all the standard wizard things, and the plot just
isn't that interesting.
I liked Mr. Nutt a great deal in the first part of the book, and I wish he
could have kept that edge of enigmatic competence and unflappableness.
Pratchett wanted to tell a different story that involved more angst and
self-doubt, and while I appreciate that story, I found it less engaging
and a bit more melodramatic than I was hoping for. Mr. Nutt's reactions
in the last half of the book were believable and fit his background, but
that was part of the problem: he slotted back into an archetype that I
thought Pratchett was going to twist and upend.
Mr. Nutt does, at least, get a fantastic closing line, and as usual there
are a lot of great asides and quotes along the way, including possibly the
sharpest and most biting Vetinari speech of the entire series.
The Patrician took a sip of his beer. "I have told this to few
people, gentlemen, and I suspect never will again, but one day when I
was a young boy on holiday in Uberwald I was walking along the bank of
a stream when I saw a mother otter with her cubs. A very endearing
sight, I'm sure you will agree, and even as I watched, the mother
otter dived into the water and came up with a plump salmon, which she
subdued and dragged on to a half-submerged log. As she ate it, while
of course it was still alive, the body split and I remember to this
day the sweet pinkness of its roes as they spilled out, much to the
delight of the baby otters who scrambled over themselves to feed on
the delicacy. One of nature's wonders, gentlemen: mother and children
dining on mother and children. And that's when I first learned about
evil. It is built into the very nature of the universe. Every world
spins in pain. If there is any kind of supreme being, I told myself,
it is up to all of us to become his moral superior."
My dissatisfaction with the ending prevents Unseen Academicals
from rising to the level of Night Watch,
and it's a bit more uneven than the best books of the series. Still,
though, this is great stuff; recommended to anyone who is reading the
series.
Followed in publication order by I Shall Wear Midnight.
Rating: 8 out of 10
With the release of Libntlm version 1.8 the release tarball can be reproduced on several distributions. We also publish a signed minimal source-only tarball, produced by git-archive which is the same format used by Savannah, Codeberg, GitLab, GitHub and others. Reproducibility of both tarballs are tested continuously for regressions on GitLab through a CI/CD pipeline. If that wasn t enough to excite you, the Debian packages of Libntlm are now built from the reproducible minimal source-only tarball. The resulting binaries are reproducible on several architectures.
What does that even mean? Why should you care? How you can do the same for your project? What are the open issues? Read on, dear reader
This article describes my practical experiments with reproducible release artifacts, following up on my earlier thoughts that lead to discussion on Fosstodon and a patch by Janneke Nieuwenhuizen to make Guix tarballs reproducible that inspired me to some practical work.
Let s look at how a maintainer release some software, and how a user can reproduce the released artifacts from the source code. Libntlm provides a shared library written in C and uses GNU Make, GNU Autoconf, GNU Automake, GNU Libtool and gnulib for build management, but these ideas should apply to most project and build system. The following illustrate the steps a maintainer would take to prepare a release:
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make distcheck
gpg -b libntlm-1.8.tar.gz
The generated files libntlm-1.8.tar.gz and libntlm-1.8.tar.gz.sig are published, and users download and use them. This is how the GNU project have been doing releases since the late 1980 s. That is a testament to how successful this pattern has been! These tarballs contain source code and some generated files, typically shell scripts generated by autoconf, makefile templates generated by automake, documentation in formats like Info, HTML, or PDF. Rarely do they contain binary object code, but historically that happened.
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. I blogged earlier how to mitigate this risk by using signed minimal source-only tarballs.
The risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions such as Trisquel, Guix, Debian/Ubuntu or Fedora ship generated files coming from the tarball into the binary *.deb or *.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built through a typical autoconf -fi && ./configure && make install sequence, and never wrote the code to rebuild everything. This can also happen if the build rules are written but are buggy, shipping the old artifact. When a security problem is found, this can lead to time-consuming situations, as it may be that patching the relevant source code and rebuilding the package is not sufficient: the vulnerable generated object from the tarball would be shipped into the binary package instead of a rebuilt artifact. For architecture-specific binaries this rarely happens, since object code is usually not included in tarballs although for 10+ years I shipped the binary Java JAR file in the GNU Libidn release tarball, until I stopped shipping it. For interpreted languages and especially for generated content such as HTML, PDF, shell scripts this happens more than you would like.
Publishing minimal source-only tarballs enable easier auditing of a project s code, to avoid the need to read through all generated files looking for malicious content. I have taken care to generate the source-only minimal tarball using git-archive. This is the same format that GitLab, GitHub etc offer for the automated download links on git tags. The minimal source-only tarballs can thus serve as a way to audit GitLab and GitHub download material! Consider if/when hosting sites like GitLab or GitHub has a security incident that cause generated tarballs to include a backdoor that is not present in the git repository. If people rely on the tag download artifact without verifying the maintainer PGP signature using GnuPG, this can lead to similar backdoor scenarios that we had for XZUtils but originated with the hosting provider instead of the release manager. This is even more concerning, since this attack can be mounted for some selected IP address that you want to target and not on everyone, thereby making it harder to discover.
With all that discussion and rationale out of the way, let s return to the release process. I have added another step here:
make srcdist
gpg -b libntlm-1.8-src.tar.gz
Now the release is ready. I publish these four files in the Libntlm s Savannah Download area, but they can be uploaded to a GitLab/GitHub release area as well. These are the SHA256 checksums I got after building the tarballs on my Trisquel 11 aramo laptop:
So how can you reproduce my artifacts? Here is how to reproduce them in a Ubuntu 22.04 container:
podman run -it --rm ubuntu:22.04
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make dist srcdist
sha256sum libntlm-*.tar.gz
You should see the exact same SHA256 checksum values. Hooray!
This works because Trisquel 11 and Ubuntu 22.04 uses the same version of git, autoconf, automake, and libtool. These tools do not guarantee the same output content for all versions, similar to how GNU GCC does not generate the same binary output for all versions. So there is still some delicate version pairing needed.
Ideally, the artifacts should be possible to reproduce from the release artifacts themselves, and not only directly from git. It is possible to reproduce the full tarball in a AlmaLinux 8 container replace almalinux:8 with rockylinux:8 if you prefer RockyLinux:
podman run -it --rm almalinux:8
dnf update -y
dnf install -y make wget gcc
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8.tar.gz
tar xfa libntlm-1.8.tar.gz
cd libntlm-1.8
./configure
make dist
sha256sum libntlm-1.8.tar.gz
The source-only minimal tarball can be regenerated on Debian 11:
podman run -it --rm debian:11
apt-get update
apt-get install -y --no-install-recommends make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
make -f cfg.mk srcdist
sha256sum libntlm-1.8-src.tar.gz
As the Magnus Opus or chef-d uvre, let s recreate the full tarball directly from the minimal source-only tarball on Trisquel 11 replace docker.io/kpengboy/trisquel:11.0 with ubuntu:22.04 if you prefer.
podman run -it --rm docker.io/kpengboy/trisquel:11.0
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make wget git ca-certificates
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8-src.tar.gz
tar xfa libntlm-1.8-src.tar.gz
cd libntlm-v1.8
./bootstrap
./configure
make dist
sha256sum libntlm-1.8.tar.gz
Yay! You should now have great confidence in that the release artifacts correspond to what s in version control and also to what the maintainer intended to release. Your remaining job is to audit the source code for vulnerabilities, including the source code of the dependencies used in the build. You no longer have to worry about auditing the release artifacts.
I find it somewhat amusing that the build infrastructure for Libntlm is now in a significantly better place than the code itself. Libntlm is written in old C style with plenty of string manipulation and uses broken cryptographic algorithms such as MD4 and single-DES. Remember folks: solving supply chain security issues has no bearing on what kind of code you eventually run. A clean gun can still shoot you in the foot.
Side note on naming: GitLab exports tarballs with pathnames libntlm-v1.8/ (i.e.., PROJECT-TAG/) and I ve adopted the same pathnames, which means my libntlm-1.8-src.tar.gz tarballs are bit-by-bit identical to GitLab s exports and you can verify this with tools like diffoscope. GitLab name the tarball libntlm-v1.8.tar.gz (i.e., PROJECT-TAG.ARCHIVE) which I find too similar to the libntlm-1.8.tar.gz that we also publish. GitHub uses the same git archive style, but unfortunately they have logic that removes the v in the pathname so you will get a tarball with pathname libntlm-1.8/ instead of libntlm-v1.8/ that GitLab and I use. The content of the tarball is bit-by-bit identical, but the pathname and archive differs. Codeberg (running Forgejo) uses another approach: the tarball is called libntlm-v1.8.tar.gz (after the tag) just like GitLab, but the pathname inside the archive is libntlm/, otherwise the produced archive is bit-by-bit identical including timestamps. Savannah s CGIT interface uses archive name libntlm-1.8.tar.gz with pathname libntlm-1.8/, but otherwise file content is identical. Savannah s GitWeb interface provides snapshot links that are named after the git commit (e.g., libntlm-a812c2ca.tar.gz with libntlm-a812c2ca/) and I cannot find any tag-based download links at all. Overall, we are so close to get SHA256 checksum to match, but fail on pathname within the archive. I ve chosen to be compatible with GitLab regarding the content of tarballs but not on archive naming. From a simplicity point of view, it would be nice if everyone used PROJECT-TAG.ARCHIVE for the archive filename and PROJECT-TAG/ for the pathname within the archive. This aspect will probably need more discussion.
Side note on git archive output: It seems different versions of git archive produce different results for the same repository. The version of git in Debian 11, Trisquel 11 and Ubuntu 22.04 behave the same. The version of git in Debian 12, AlmaLinux/RockyLinux 8/9, Alpine, ArchLinux, macOS homebrew, and upcoming Ubuntu 24.04 behave in another way. Hopefully this will not change that often, but this would invalidate reproducibility of these tarballs in the future, forcing you to use an old git release to reproduce the source-only tarball. Alas, GitLab and most other sites appears to be using modern git so the download tarballs from them would not match my tarballs even though the content would.
Side note on ChangeLog: ChangeLog files were traditionally manually curated files with version history for a package. In recent years, several projects moved to dynamically generate them from git history (using tools like git2cl or gitlog-to-changelog). This has consequences for reproducibility of tarballs: you need to have the entire git history available! The gitlog-to-changelog tool also output different outputs depending on the time zone of the person using it, which arguable is a simple bug that can be fixed. However this entire approach is incompatible with rebuilding the full tarball from the minimal source-only tarball. It seems Libntlm s ChangeLog file died on the surgery table here.
So how would a distribution build these minimal source-only tarballs? I happen to help on the libntlm package in Debian. It has historically used the generated tarballs as the source code to build from. This means that code coming from gnulib is vendored in the tarball. When a security problem is discovered in gnulib code, the security team needs to patch all packages that include that vendored code and rebuild them, instead of merely patching the gnulib package and rebuild all packages that rely on that particular code. To change this, the Debian libntlm package needs to Build-Depends on Debian s gnulib package. But there was one problem: similar to most projects that use gnulib, Libntlm depend on a particular git commit of gnulib, and Debian only ship one commit. There is no coordination about which commit to use. I have adopted gnulib in Debian, and add a git bundle to the *_all.deb binary package so that projects that rely on gnulib can pick whatever commit they need. This allow an no-network GNULIB_URL and GNULIB_REVISION approach when running Libntlm s ./bootstrap with the Debian gnulib package installed. Otherwise libntlm would pick up whatever latest version of gnulib that Debian happened to have in the gnulib package, which is not what the Libntlm maintainer intended to be used, and can lead to all sorts of version mismatches (and consequently security problems) over time. Libntlm in Debian is developed and tested on Salsa and there is continuous integration testing of it as well, thanks to the Salsa CI team.
Side note on git bundles: unfortunately there appears to be no reproducible way to export a git repository into one or more files. So one unfortunate consequence of all this work is that the gnulib *.orig.tar.gz tarball in Debian is not reproducible any more. I have tried to get Git bundles to be reproducible but I never got it to work see my notes in gnulib s debian/README.source on this aspect. Of course, source tarball reproducibility has nothing to do with binary reproducibility of gnulib in Debian itself, fortunately.
One open question is how to deal with the increased build dependencies that is triggered by this approach. Some people are surprised by this but I don t see how to get around it: if you depend on source code for tools in another package to build your package, it is a bad idea to hide that dependency. We ve done it for a long time through vendored code in non-minimal tarballs. Libntlm isn t the most critical project from a bootstrapping perspective, so adding git and gnulib as Build-Depends to it will probably be fine. However, consider if this pattern was used for other packages that uses gnulib such as coreutils, gzip, tar, bison etc (all are using gnulib) then they would all Build-Depends on git and gnulib. Cross-building those packages for a new architecture will therefor require git on that architecture first, which gets circular quick. The dependency on gnulib is real so I don t see that going away, and gnulib is a Architecture:all package. However, the dependency on git is merely a consequence of how the Debian gnulib package chose to make all gnulib git commits available to projects: through a git bundle. There are other ways to do this that doesn t require the git tool to extract the necessary files, but none that I found practical ideas welcome!
Finally some brief notes on how this was implemented. Enabling bootstrappable source-only minimal tarballs via gnulib s ./bootstrap is achieved by using the GNULIB_REVISION mechanism, locking down the gnulib commit used. I have always disliked git submodules because they add extra steps and has complicated interaction with CI/CD. The reason why I gave up git submodules now is because the particular commit to use is not recorded in the git archive output when git submodules is used. So the particular gnulib commit has to be mentioned explicitly in some source code that goes into the git archive tarball. Colin Watson added the GNULIB_REVISION approach to ./bootstrap back in 2018, and now it no longer made sense to continue to use a gnulib git submodule. One alternative is to use ./bootstrap with --gnulib-srcdir or --gnulib-refdir if there is some practical problem with the GNULIB_URL towards a git bundle the GNULIB_REVISION in bootstrap.conf.
The srcdist make rule is simple:
git archive --prefix=libntlm-v1.8/ -o libntlm-v1.8.tar.gz HEAD
Making the make dist generated tarball reproducible can be more complicated, however for Libntlm it was sufficient to make sure the modification times of all files were set deterministically to the timestamp of the last commit in the git repository. Interestingly there seems to be a couple of different ways to accomplish this, Guix doesn t support minimal source-only tarballs but rely on a .tarball-timestamp file inside the tarball. Paul Eggert explained what TZDB is using some time ago. The approach I m using now is fairly similar to the one I suggested over a year ago. If there are problems because all files in the tarball now use the same modification time, there is a solution by Bruno Haible that could be implemented.
Side note on git tags: Some people may wonder why not verify a signed git tag instead of verifying a signed tarball of the git archive. Currently most git repositories uses SHA-1 for git commit identities, but SHA-1 is not a secure hash function. While current SHA-1 attacks can be detected and mitigated, there are fundamental doubts that a git SHA-1 commit identity uniquely refers to the same content that was intended. Verifying a git tag will never offer the same assurance, since a git tag can be moved or re-signed at any time. Verifying a git commit is better but then we need to trust SHA-1. Migrating git to SHA-256 would resolve this aspect, but most hosting sites such as GitLab and GitHub does not support this yet. There are other advantages to using signed tarballs instead of signed git commits or git tags as well, e.g., tar.gz can be a deterministically reproducible persistent stable offline storage format but .git sub-directory trees or git bundles do not offer this property.
Doing continous testing of all this is critical to make sure things don t regress. Libntlm s pipeline definition now produce the generated libntlm-*.tar.gz tarballs and a checksum as a build artifact. Then I added the 000-reproducability job which compares the checksums and fails on mismatches. You can read its delicate output in the job for the v1.8 release. Right now we insists that builds on Trisquel 11 match Ubuntu 22.04, that PureOS 10 builds match Debian 11 builds, that AlmaLinux 8 builds match RockyLinux 8 builds, and AlmaLinux 9 builds match RockyLinux 9 builds. As you can see in pipeline job output, not all platforms lead to the same tarballs, but hopefully this state can be improved over time. There is also partial reproducibility, where the full tarball is reproducible across two distributions but not the minimal tarball, or vice versa.
If this way of working plays out well, I hope to implement it in other projects too.
What do you think? Happy Hacking!
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
write build-ids to debian binary control files,
so that the build-id (more specifically, the ELF note
.note.gnu.build-id) wound up in the Debian apt archive metadata.
I ve always thought this was super cool, and seeing as how Michael Stapelberg
blogged
some great pointers around the ecosystem, including the fancy new debuginfod
service, and the
find-dbgsym-packages
helper, which uses these same headers, I don t think I m the only one.
At work I ve been using a lot of rust,
specifically, async rust using tokio. To try and work on
my style, and to dig deeper into the how and why of the decisions made in these
frameworks, I ve decided to hack up a project that I ve wanted to do ever
since 2015 write a debug filesystem. Let s get to it.
Back to the Future
Time to admit something. I really love Plan 9. It s
just so good. So many ideas from Plan 9 are just so prescient, and everything
just feels right. Not just right like, feels good like, correct. The
bit that I ve always liked the most is 9p, the network protocol for serving
a filesystem over a network. This leads to all sorts of fun programs, like the
Plan 9 ftp client being a 9p server you mount the ftp server and access
files like any other files. It s kinda like if fuse were more fully a part
of how the operating system worked, but fuse is all running client-side. With
9p there s a single client, and different servers that you can connect to,
which may be backed by a hard drive, remote resources over something like SFTP, FTP, HTTP or even purely synthetic.
The interesting (maybe sad?) part here is that 9p wound up outliving Plan 9
in terms of adoption 9p is in all sorts of places folks don t usually expect.
For instance, the Windows Subsystem for Linux uses the 9p protocol to share
files between Windows and Linux. ChromeOS uses it to share files with Crostini,
and qemu uses 9p (virtio-p9) to share files between guest and host. If you re
noticing a pattern here, you d be right; for some reason 9p is the go-to protocol
to exchange files between hypervisor and guest. Why? I have no idea, except maybe
due to being designed well, simple to implement, and it s a lot easier to validate the data being shared
and validate security boundaries. Simplicity has its value.
As a result, there s a lot of lingering 9p support kicking around. Turns out
Linux can even handle mounting 9p filesystems out of the box. This means that I
can deploy a filesystem to my LAN or my localhost by running a process on top
of a computer that needs nothing special, and mount it over the network on an
unmodified machine unlike fuse, where you d need client-specific software
to run in order to mount the directory. For instance, let s mount a 9p
filesystem running on my localhost machine, serving requests on 127.0.0.1:564
(tcp) that goes by the name mountpointname to /mnt.
Linux will mount away, and attach to the filesystem as the root user, and by default,
attach to that mountpoint again for each local user that attempts to use
it. Nifty, right? I think so. The server is able
to keep track of per-user access and authorization
along with the host OS.
WHEREIN I STYX WITH IT
Since I wanted to push myself a bit more with rust and tokio specifically,
I opted to implement the whole stack myself, without third party libraries on
the critical path where I could avoid it. The 9p protocol (sometimes called
Styx, the original name for it) is incredibly simple. It s a series of client
to server requests, which receive a server to client response. These are,
respectively, T messages, which transmit a request to the server, which
trigger an R message in response (Reply messages). These messages are
TLV payload
with a very straight forward structure so straight forward, in fact, that I
was able to implement a working server off nothing more than a handful of man
pages.
Later on after the basics worked, I found a more complete
spec page
that contains more information about the
unix specific variant
that I opted to use (9P2000.u rather than 9P2000) due to the level
of Linux specific support for the 9P2000.u variant over the 9P2000
protocol.
MR ROBOTO
The backend stack over at zoo is rust and tokio
running i/o for an HTTP and WebRTC server. I figured I d pick something
fairly similar to write my filesystem with, since 9P can be implemented
on basically anything with I/O. That means tokio tcp server bits, which
construct and use a 9p server, which has an idiomatic Rusty API that
partially abstracts the raw R and T messages, but not so much as to
cause issues with hiding implementation possibilities. At each abstraction
level, there s an escape hatch allowing someone to implement any of
the layers if required. I called this framework
arigato which can be found over on
docs.rs and
crates.io.
/// Simplified version of the arigato File trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.File.html
trait File
/// OpenFile is the type returned by this File via an Open call.
typeOpenFile: OpenFile;
/// Return the 9p Qid for this file. A file is the same if the Qid is
/// the same. A Qid contains information about the mode of the file,
/// version of the file, and a unique 64 bit identifier.
fnqid(&self) -> Qid;
/// Construct the 9p Stat struct with metadata about a file.
async fnstat(&self) -> FileResult<Stat>;
/// Attempt to update the file metadata.
async fnwstat(&mut self, s: &Stat) -> FileResult<()>;
/// Traverse the filesystem tree.
async fnwalk(&self, path: &[&str]) -> FileResult<(Option<Self>, Vec<Self>)>;
/// Request that a file's reference be removed from the file tree.
async fnunlink(&mut self) -> FileResult<()>;
/// Create a file at a specific location in the file tree.
async fncreate(
&mut self,
name: &str,
perm: u16,
ty: FileType,
mode: OpenMode,
extension: &str,
) -> FileResult<Self>;
/// Open the File, returning a handle to the open file, which handles
/// file i/o. This is split into a second type since it is genuinely
/// unrelated -- and the fact that a file is Open or Closed can be
/// handled by the arigato server for us.
async fnopen(&mut self, mode: OpenMode) -> FileResult<Self::OpenFile>;
/// Simplified version of the arigato OpenFile trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.OpenFile.html
trait OpenFile
/// iounit to report for this file. The iounit reported is used for Read
/// or Write operations to signal, if non-zero, the maximum size that is
/// guaranteed to be transferred atomically.
fniounit(&self) -> u32;
/// Read some number of bytes up to buf.len() from the provided
/// offset of the underlying file. The number of bytes read is
/// returned.
async fnread_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
/// Write some number of bytes up to buf.len() from the provided
/// offset of the underlying file. The number of bytes written
/// is returned.
fnwrite_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
Thanks, decade ago paultag!
Let s do it! Let s use arigato to implement a 9p filesystem we ll call
debugfs that will serve all the debug
files shipped according to the Packages metadata from the apt archive. We ll
fetch the Packages file and construct a filesystem based on the reported
Build-Id entries. For those who don t know much about how an apt repo
works, here s the 2-second crash course on what we re doing. The first is to
fetch the Packages file, which is specific to a binary architecture (such as
amd64, arm64 or riscv64). That architecture is specific to a
component (such as main, contrib or non-free). That component is
specific to a suite, such as stable, unstable or any of its aliases
(bullseye, bookworm, etc). Let s take a look at the Packages.xz file for
the unstable-debugsuite, maincomponent, for all amd64 binaries.
This will return the Debian-style
rfc2822-like headers,
which is an export of the metadata contained inside each .deb file which
apt (or other tools that can use the apt repo format) use to fetch
information about debs. Let s take a look at the debug headers for the
netlabel-tools package in unstable which is a package named
netlabel-tools-dbgsym in unstable-debug.
So here, we can parse the package headers in the Packages.xz file, and store,
for each Build-Id, the Filename where we can fetch the .deb at. Each
.deb contains a number of files but we re only really interested in the
files inside the .deb located at or under /usr/lib/debug/.build-id/,
which you can find in debugfs under
rfc822.rs. It s
crude, and very single-purpose, but I m feeling a bit lazy.
Who needs dpkg?!
For folks who haven t seen it yet, a .deb file is a special type of
.ar file, that contains (usually)
three files inside debian-binary, control.tar.xz and data.tar.xz.
The core of an .ar file is a fixed size (60 byte) entry header,
followed by the specified size number of bytes.
[8 byte .ar file magic]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
...
First up was to implement a basic ar parser in
ar.rs. Before we get
into using it to parse a deb, as a quick diversion, let s break apart a .deb
file by hand something that is a bit of a rite of passage (or at least it
used to be? I m getting old) during the Debian nm (new member) process, to take
a look at where exactly the .debug file lives inside the .deb file.
$ ar x netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ ls
control.tar.xz debian-binary
data.tar.xz netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ tar --list -f data.tar.xz grep '.debug$'
./usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
Since we know quite a bit about the structure of a .deb file, and I had to
implement support from scratch anyway, I opted to implement a (very!) basic
debfile parser using HTTP Range requests. HTTP Range requests, if supported by
the server (denoted by a accept-ranges: bytes HTTP header in response to an
HTTP HEAD request to that file) means that we can add a header such as
range: bytes=8-68 to specifically request that the returned GET body be the
byte range provided (in the above case, the bytes starting from byte offset 8
until byte offset 68). This means we can fetch just the ar file entry from
the .deb file until we get to the file inside the .deb we are interested in
(in our case, the data.tar.xz file) at which point we can request the body
of that file with a final range request. I wound up writing a struct to
handle a read_at-style API surface in
hrange.rs, which
we can pair with ar.rs above and start to find our data in the .deb remotely
without downloading and unpacking the .deb at all.
After we have the body of the data.tar.xz coming back through the HTTP
response, we get to pipe it through an xz decompressor (this kinda sucked in
Rust, since a tokioAsyncRead is not the same as an http Body response is
not the same as std::io::Read, is not the same as an async (or sync)
Iterator is not the same as what the xz2 crate expects; leading me to read
blocks of data to a buffer and stuff them through the decoder by looping over
the buffer for each lzma2 packet in a loop), and tarfile parser (similarly
troublesome). From there we get to iterate over all entries in the tarfile,
stopping when we reach our file of interest. Since we can t seek, but gdb
needs to, we ll pull it out of the stream into a Cursor<Vec<u8>> in-memory
and pass a handle to it back to the user.
From here on out its a matter of
gluing together a File traited struct
in debugfs, and serving the filesystem over TCP using arigato. Done
deal!
A quick diversion about compression
I was originally hoping to avoid transferring the whole tar file over the
network (and therefore also reading the whole debug file into ram, which
objectively sucks), but quickly hit issues with figuring out a way around
seeking around an xz file. What s interesting is xz has a great primitive
to solve this specific problem (specifically, use a block size that allows you
to seek to the block as close to your desired seek position just before it,
only discarding at most block size - 1 bytes), but data.tar.xz files
generated by dpkg appear to have a single mega-huge block for the whole file.
I don t know why I would have expected any different, in retrospect. That means
that this now devolves into the base case of How do I seek around an lzma2
compressed data stream ; which is a lot more complex of a question.
Thankfully, notoriously brilliant tianon was
nice enough to introduce me to Jon Johnson
who did something super similar adapted a technique to seek inside a
compressed gzip file, which lets his service
oci.dag.dev
seek through Docker container images super fast based on some prior work
such as soci-snapshotter, gztool, and
zran.c.
He also pulled this party trick off for apk based distros
over at apk.dag.dev, which seems apropos.
Jon was nice enough to publish a lot of his work on this specifically in a
central place under the name targz
on his GitHub, which has been a ton of fun to read through.
The gist is that, by dumping the decompressor s state (window of previous
bytes, in-memory data derived from the last N-1 bytes) at specific
checkpoints along with the compressed data stream offset in bytes and
decompressed offset in bytes, one can seek to that checkpoint in the compressed
stream and pick up where you left off creating a similar block mechanism
against the wishes of gzip. It means you d need to do an O(n) run over the
file, but every request after that will be sped up according to the number
of checkpoints you ve taken.
Given the complexity of xz and lzma2, I don t think this is possible
for me at the moment especially given most of the files I ll be requesting
will not be loaded from again especially when I can just cache the debug
header by Build-Id. I want to implement this (because I m generally curious
and Jon has a way of getting someone excited about compression schemes, which
is not a sentence I thought I d ever say out loud), but for now I m going to
move on without this optimization. Such a shame, since it kills a lot of the
work that went into seeking around the .deb file in the first place, given
the debian-binary and control.tar.gz members are so small.
The Good
First, the good news right? It works! That s pretty cool. I m positive
my younger self would be amused and happy to see this working; as is
current day paultag. Let s take debugfs out for a spin! First, we need
to mount the filesystem. It even works on an entirely unmodified, stock
Debian box on my LAN, which is huge. Let s take it for a spin:
And, let s prove to ourselves that this actually mounted before we go
trying to use it:
$ mount grep build-id
192.168.0.2 on /usr/lib/debug/.build-id type 9p (rw,relatime,aname=unstable-debug,access=user,trans=tcp,version=9p2000.u,port=564)
Slick. We ve got an open connection to the server, where our host
will keep a connection alive as root, attached to the filesystem provided
in aname. Let s take a look at it.
$ ls /usr/lib/debug/.build-id/
00 0d 1a 27 34 41 4e 5b 68 75 82 8E 9b a8 b5 c2 CE db e7 f3
01 0e 1b 28 35 42 4f 5c 69 76 83 8f 9c a9 b6 c3 cf dc E7 f4
02 0f 1c 29 36 43 50 5d 6a 77 84 90 9d aa b7 c4 d0 dd e8 f5
03 10 1d 2a 37 44 51 5e 6b 78 85 91 9e ab b8 c5 d1 de e9 f6
04 11 1e 2b 38 45 52 5f 6c 79 86 92 9f ac b9 c6 d2 df ea f7
05 12 1f 2c 39 46 53 60 6d 7a 87 93 a0 ad ba c7 d3 e0 eb f8
06 13 20 2d 3a 47 54 61 6e 7b 88 94 a1 ae bb c8 d4 e1 ec f9
07 14 21 2e 3b 48 55 62 6f 7c 89 95 a2 af bc c9 d5 e2 ed fa
08 15 22 2f 3c 49 56 63 70 7d 8a 96 a3 b0 bd ca d6 e3 ee fb
09 16 23 30 3d 4a 57 64 71 7e 8b 97 a4 b1 be cb d7 e4 ef fc
0a 17 24 31 3e 4b 58 65 72 7f 8c 98 a5 b2 bf cc d8 E4 f0 fd
0b 18 25 32 3f 4c 59 66 73 80 8d 99 a6 b3 c0 cd d9 e5 f1 fe
0c 19 26 33 40 4d 5a 67 74 81 8e 9a a7 b4 c1 ce da e6 f2 ff
Outstanding. Let s try using gdb to debug a binary that was provided by
the Debian archive, and see if it ll load the ELF by build-id from the
right .deb in the unstable-debug suite:
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Yes! Yes it will!
$ file /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
/usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter *empty*, BuildID[sha1]=e59f81f6573dadd5d95a6e4474d9388ab2777e2a, for GNU/Linux 3.2.0, with debug_info, not stripped
The Bad
Linux s support for 9p is mainline, which is great, but it s not robust.
Network issues or server restarts will wedge the mountpoint (Linux can t
reconnect when the tcp connection breaks), and things that work fine on local
filesystems get translated in a way that causes a lot of network chatter for
instance, just due to the way the syscalls are translated, doing an ls, will
result in a stat call for each file in the directory, even though linux had
just got a stat entry for every file while it was resolving directory names.
On top of that, Linux will serialize all I/O with the server, so there s no
concurrent requests for file information, writes, or reads pending at the same
time to the server; and read and write throughput will degrade as latency
increases due to increasing round-trip time, even though there are offsets
included in the read and write calls. It works well enough, but is
frustrating to run up against, since there s not a lot you can do server-side
to help with this beyond implementing the 9P2000.L variant (which, maybe is
worth it).
The Ugly
Unfortunately, we don t know the file size(s) until we ve actually opened the
underlying tar file and found the correct member, so for most files, we don t
know the real size to report when getting a stat. We can t parse the tarfiles
for every stat call, since that d make ls even slower (bummer). Only
hiccup is that when I report a filesize of zero, gdb throws a bit of a
fit; let s try with a size of 0 to start:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 0 Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
warning: Discarding section .note.gnu.build-id which has a section size (24) larger than the file size [in module /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug]
[...]
This obviously won t work since gdb will throw away all our hard work because
of stat s output, and neither will loading the real size of the underlying
file. That only leaves us with hardcoding a file size and hope nothing else
breaks significantly as a result. Let s try it again:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 954M Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Much better. I mean, terrible but better. Better for now, anyway.
Kilroy was here
Do I think this is a particularly good idea? I mean; kinda. I m probably going
to make some fun 9parigato-based filesystems for use around my LAN, but I
don t think I ll be moving to use debugfs until I can figure out how to
ensure the connection is more resilient to changing networks, server restarts
and fixes on i/o performance. I think it was a useful exercise and is a pretty
great hack, but I don t think this ll be shipping anywhere anytime soon.
Along with me publishing this post, I ve pushed up all my repos; so you
should be able to play along at home! There s a lot more work to be done
on arigato; but it does handshake and successfully export a working
9P2000.u filesystem. Check it out on on my github at
arigato,
debugfs
and also on crates.io
and docs.rs.
At least I can say I was here and I got it working after all these years.
It has been a very busy couple of weeks as we worked against some major transitions and a security fix that required a rebuild of the $world. I am happy to report that against all odds we have a beta release! You can read all about it here: https://kubuntu.org/news/kubuntu-24-04-beta-released/ Post beta freeze I have already begun pushing our fixes for known issues today. A big one being our new branding! Very exciting times in the Kubuntu world.
In the snap world I will be using my free time to start knocking out KDE applications ( not covered by the project ). I have also recruited some help, so you should start seeing these pop up in the edge channel very soon!
Now that we are nearing the release of Noble Numbat, my contract is coming to an end with Kubuntu. If you would like to see Plasma 6 in the next release and in a PPA for Noble, please consider donating to extend my contract at https://kubuntu.org/donate !
On a personal level, I am still looking to help with my grandson and you can find that here: https://www.gofundme.com/f/in-loving-memory-of-william-billy-dean-scalf
Thanks for stopping by,
Scarlett
Getting the Belgian eID to work on Linux
systems should be fairly easy, although some people do struggle with it.
For that reason, there is a lot of third-party documentation out there
in the form of blog posts, wiki pages, and other kinds of things.
Unfortunately, some of this documentation is simply wrong. Written by
people who played around with things until it kind of worked, sometimes
you get a situation where something that used to work in the past (but
wasn't really necessary) now stopped working, but it's still added to
a number of locations as though it were the gospel.
And then people follow these instructions and now things don't work
anymore.
One of these revolves around OpenSC.
OpenSC is an open source smartcard library that has support for a
pretty
large
number of smartcards, amongst which the Belgian eID. It provides a
PKCS#11 module as well as a
number of supporting tools.
For those not in the know, PKCS#11 is a standardized C API for
offloading cryptographic operations. It is an API that can be used when
talking to a hardware cryptographic module, in order to make that module
perform some actions, and it is especially popular in the open source
world, with support in
NSS,
amongst others. This library is written and maintained by mozilla, and
is a low-level cryptographic library that is used by Firefox (on all
platforms it supports) as well as by Google Chrome and other browsers
based on that (but only on Linux, and as I understand it, only for
linking with smartcards; their BoringSSL library is used for other
things).
The official eID software that we ship through
eid.belgium.be,
also known as "BeID", provides a PKCS#11 module for the Belgian eID, as
well as a number of support tools to make interacting with the card
easier, such as the "eID viewer", which provides the ability to read
data from the card, and validate their signatures. While the very first
public version of this eID PKCS#11 module was originally based on
OpenSC, it has since been reimplemented as a PKCS#11 module in its own
right, with no lineage to OpenSC whatsoever anymore.
About five years ago, the Belgian eID card was renewed. At the time, a
new physical appearance was the most obvious difference with the old
card, but there were also some technical, on-chip, differences that are
not so apparent. The most important one here, although it is not the
only one, is the fact that newer eID cards now use a NIST
P-384 elliptic curve-based private
keys, rather than the RSA-based
ones that were used in the past. This change required some changes to
any PKCS#11 module that supports the eID; both the BeID one, as well as
the OpenSC card-belpic driver that is written in support of the Belgian
eID.
Obviously, the required changes were implemented for the BeID module;
however, the OpenSC card-belpic driver was not updated. While I did do
some preliminary work on the required changes, I was unable to get it to
work, and eventually other things took up my time so I never finished
the implementation. If someone would like to finish the work that I
started, the preliminal patch that I
wrote
could be a good start -- but like I said, it doesn't yet work. Also,
you'll probably be interested in the official
documentation
of the eID card.
Unfortunately, in the mean time someone added the Applet 1.8 ATR to the
card-belpic.c file, without also implementing the required changes to
the driver so that the PKCS#11 driver actually supports the eID card.
The result of this is that if you have OpenSC installed in NSS for
either Firefox or any Chromium-based browser, and it gets picked up
before the BeID PKCS#11 module, then NSS will stop looking and pass all
crypto operations to the OpenSC PKCS#11 module rather than to the
official eID PKCS#11 module, and things will not work at all, causing a
lot of confusion.
I have therefore taken the following two steps:
The official eID packages now
conflict
with the OpenSC PKCS#11 module. Specifically only the PKCS#11 module,
not the rest of OpenSC, so you can theoretically still use its tools.
This means that once we release this new version of the eID software,
when you do an upgrade and you have OpenSC installed, it will remove
the PKCS#11 module and anything that depends on it. This is normal
and expected.
I have filed a pull
request against OpenSC
that removes the Applet 1.8 ATR from the driver, so that OpenSC will
stop claiming that it supports the 1.8 applet.
When the pull request is accepted, we will update the official eID
software to make the conflict versioned, so that as soon as it works
again you will again be able to install the OpenSC and BeID packages at
the same time.
In the mean time, if you have the OpenSC PKCS#11 module installed on
your system, and your eID authentication does not work, try removing it.
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I d share it as a tale of how huh, that s weird can be a powerful threat-hunting tool but only if you ve got the time to keep pulling at the thread.
Prelude to an Adventure
Our story begins back in March 2008.
I was working at Engine Yard (EY), a now largely-forgotten Rails-focused hosting company, which pioneered several advances in Rails application deployment.
Probably EY s greatest claim to lasting fame is that they helped launch a little code hosting platform you might have heard of, by providing them free infrastructure when they were little more than a glimmer in the Internet s eye.
I am, of course, talking about everyone s favourite Microsoft product: GitHub.
Since GitHub was in the right place, at the right time, with a compelling product offering, they quickly started to gain traction, and grow their userbase.
With growth comes challenges, amongst them the one we re focusing on today: SSH login times.
Then, as now, GitHub provided SSH access to the git repos they hosted, by SSHing to git@github.com with publickey authentication.
They were using the standard way that everyone manages SSH keys: the ~/.ssh/authorized_keys file, and that became a problem as the number of keys started to grow.
The way that SSH uses this file is that, when a user connects and asks for publickey authentication, SSH opens the ~/.ssh/authorized_keys file and scans all of the keys listed in it, looking for a key which matches the key that the user presented.
This linear search is normally not a huge problem, because nobody in their right mind puts more than a few keys in their ~/.ssh/authorized_keys, right?
Of course, as a popular, rapidly-growing service, GitHub was gaining users at a fair clip, to the point that the one big file that stored all the SSH keys was starting to visibly impact SSH login times.
This problem was also not going to get any better by itself.
Something Had To Be Done.
EY management was keen on making sure GitHub ran well, and so despite it not really being a hosting problem, they were willing to help fix this problem.
For some reason, the late, great, Ezra Zygmuntowitz pointed GitHub in my direction, and let me take the time to really get into the problem with the GitHub team.
After examining a variety of different possible solutions, we came to the conclusion that the least-worst option was to patch OpenSSH to lookup keys in a MySQL database, indexed on the key fingerprint.
We didn t take this decision on a whim it wasn t a case of yeah, sure, let s just hack around with OpenSSH, what could possibly go wrong? .
We knew it was potentially catastrophic if things went sideways, so you can imagine how much worse the other options available were.
Ensuring that this wouldn t compromise security was a lot of the effort that went into the change.
In the end, though, we rolled it out in early April, and lo! SSH logins were fast, and we were pretty sure we wouldn t have to worry about this problem for a long time to come.
Normally, you d think patching OpenSSH to make mass SSH logins super fast would be a good story on its own.
But no, this is just the opening scene.
Chekov s Gun Makes its Appearance
Fast forward a little under a month, to the first few days of May 2008.
I get a message from one of the GitHub team, saying that somehow users were able to access other users repos over SSH.
Naturally, as we d recently rolled out the OpenSSH patch, which touched this very thing, the code I d written was suspect number one, so I was called in to help.
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
Eventually, after more than a little debugging, we discovered that, somehow, there were two users with keys that had the same key fingerprint.
This absolutely shouldn t happen it s a bit like winning the lottery twice in a row1 unless the users had somehow shared their keys with each other, of course.
Still, it was worth investigating, just in case it was a web application bug, so the GitHub team reached out to the users impacted, to try and figure out what was going on.
The users professed no knowledge of each other, neither admitted to publicising their key, and couldn t offer any explanation as to how the other person could possibly have gotten their key.
Then things went from weird to what the ? .
Because another pair of users showed up, sharing a key fingerprint but it was a different shared key fingerprint.
The odds now have gone from winning the lottery multiple times in a row to as close to this literally cannot happen as makes no difference.
Once we were really, really confident that the OpenSSH patch wasn t the cause of the problem, my involvement in the problem basically ended.
I wasn t a GitHub employee, and EY had plenty of other customers who needed my help, so I wasn t able to stay deeply involved in the on-going investigation of The Mystery of the Duplicate Keys.
However, the GitHub team did keep talking to the users involved, and managed to determine the only apparent common factor was that all the users claimed to be using Debian or Ubuntu systems, which was where their SSH keys would have been generated.
That was as far as the investigation had really gotten, when along came May 13, 2008.
Chekov s Gun Goes Off
With the publication of DSA-1571-1, everything suddenly became clear.
Through a well-meaning but ultimately disasterous cleanup of OpenSSL s randomness generation code, the Debian maintainer had inadvertently reduced the number of possible keys that could be generated by a given user from bazillions to a little over 32,000.
With so many people signing up to GitHub some of them no doubt following best practice and freshly generating a separate key it s unsurprising that some collisions occurred.
You can imagine the sense of oooooooh, so that s what s going on! that rippled out once the issue was understood.
I was mostly glad that we had conclusive evidence that my OpenSSH patch wasn t at fault, little knowing how much more contact I was to have with Debian weak keys in the future, running a huge store of known-compromised keys and using them to find misbehaving Certificate Authorities, amongst other things.
Lessons Learned
While I ve not found a description of exactly when and how Luciano Bello discovered the vulnerability that became CVE-2008-0166, I presume he first came across it some time before it was disclosed likely before GitHub tripped over it.
The stable Debian release that included the vulnerable code had been released a year earlier, so there was plenty of time for Luciano to have discovered key collisions and go hmm, I wonder what s going on here? , then keep digging until the solution presented itself.
The thought hmm, that s odd , followed by intense investigation, leading to the discovery of a major flaw is also what ultimately brought down the recent XZ backdoor.
The critical part of that sequence is the ability to do that intense investigation, though.
When I reflect on my brush with the Debian weak keys vulnerability, what sticks out to me is the fact that I didn t do the deep investigation.
I wonder if Luciano hadn t found it, how long it might have been before it was found.
The GitHub team would have continued investigating, presumably, and perhaps they (or I) would have eventually dug deep enough to find it.
But we were all super busy myself, working support tickets at EY, and GitHub feverishly building features and fighting the fires in their rapidly-growing service.
As it was, Luciano was able to take the time to dig in and find out what was happening, but just like the XZ backdoor, I feel like we, as an industry, got a bit lucky that someone with the skills, time, and energy was on hand at the right time to make a huge difference.
It s a luxury to be able to take the time to really dig into a problem, and it s a luxury that most of us rarely have.
Perhaps an understated takeaway is that somehow we all need to wrestle back some time to follow our hunches and really dig into the things that make us go hmm .
Support My Hunches
If you d like to help me be able to do intense investigations of mysterious software phenomena, you can shout me a refreshing beverage on ko-fi.
the odds are actually probably more like winning the lottery about twenty times in a row.
The numbers involved are staggeringly huge, so it s easiest to just approximate it as really, really unlikely .
It is, sadly, not entirely surprising that Facebook is censoring articles critical of Meta.
The Kansas Reflector published an artical about Meta censoring environmental articles about climate change deeming them too controversial .
Facebook then censored the article about Facebook censorship, and then after an independent site published a copy of the climate change article, Facebook censored it too.
The CNN story says Facebook apologized and said it was a mistake and was fixing it.
Color me skeptical, because today I saw this:
Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they removed my post about the social network Mastodon (click that link for screenshot). A post that, incidentally, had been made 10 months prior to being removed.
While they ultimately reversed themselves, I subsequently wrote Facebook s Blocking Decisions Are Deliberate Including Their Censorship of Mastodon.
That this same pattern has played out a second time again with something that is a very slight challenege to Facebook seems to validate my conclusion. Facebook lets all sort of hateful garbage infest their site, but anything about climate change or their own censorship gets removed, and this pattern persists for years.
There s a reason I prefer Mastodon these days. You can find me there as @jgoerzen@floss.social.
So. I ve written this blog post. And then I m going to post it to Facebook. Let s see if they try to censor me for a third time. Bring it, Facebook.
Here are my notes about copying PGP keys to external hardware devices such as
Yubikeys. Let me begin by saying that the gpg tools are pretty bad at this.
MAKE A COUPLE OF BACKUPS OF ~/.gnupg/ TO DIFFERENT ENCRYPTED USB STICKS
BEFORE YOU START. GPG WILL MESS UP YOUR KEYS. SERIOUSLY.
For example, would you believe me if I said that saving changes results in
the removal of your private key? Well
check this
out.
Now that you have multiple safe, offline backups of your keys, here are my notes.
apt install yubikey-manager scdaemon
Plug the Yubikey in, see if it s recognized properly:
ykman list
gpg --card-status
Change the default PIN (123456) and Admin PIN (12345678):
gpg --card-edit
gpg/card> admin
gpg/card> passwd
Look at the openpgp information and change the maximum number of retries, if
you like. I have seen this failing a couple of times, unplugging the Yubikey
and putting it back in worked.
ykman openpgp info
ykman openpgp access set-retries 7 7 7
Copy your keys. MAKE A BACKUP OF ~/.gnupg/ BEFORE YOU DO THIS.
gpg --edit-key $KEY_ID
gpg> keytocard # follow the prompts to copy the first key
Now choose the next key and copy that one too. Repeat till all subkeys are
copied.
gpg> key 1
gpg> keytocard
Typing gpg --card-status you should be able to see all your keys on the
Yubikey now.
Using the key on another machine
How do you use your PGP keys on the Yubikey on other systems?
Go to another system, if it does have a ~/.gnupg directory already move it
somewhere else.
It s been a while that I haven t posted anything on my blog, the truth is that Freexian has been doing very well in the last years and that I have a hard time to allocate time to write articles or even to contribute to my usual Debian projects the exception being debusine since that s part of the Freexian work (have a look at our most recent announce!).
That being said, given Freexian s growth and in the hope to reduce my workload, we are looking to extend our team with Debian members of more varied backgrounds and skills, so they can help us in areas like sales / marketing / project management. Have a look at our announce on debian-jobs@lists.debian.org.
As a mission-oriented company, we are looking to work with persons already involved in Debian (or persons who were waiting the right opportunity to get involved). All our collaborators can spend 20% of their paid work time on the Debian projects they care about.
This article has been originally posted on November 4, 2023, and has
been updated (at the bottom) since.
Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut piecepack I ve been working on for quite some
time.
I started drawing a plan with measures before breakfast, then decided to
change some important details, restarted from scratch, did a quick dig
through the bookbinding materials and settled on 2 mm cardboard for the
structure, black fabric-like paper for the outside and a scrap of paper
with a manuscript print for the inside.
Then we had the only day with no rain among the five, so some time was
spent doing things outside, but on the next day I quickly finished two
boxes, at two different heights.
The weather situation also meant that while I managed to take passable
pictures of the first stages of the box making in natural light, the
last few stages required some creative artificial lightning, even if it
wasn t that late in the evening. I need to build1 myself a
light box.
And then decided that since they are C6 sized, they also work well for
postcards or for other A6 pieces of paper, so I will probably need
to make another one when the piecepack set will be finally finished.
The original plan was to use a linocut of the piecepack suites as the
front cover; I don t currently have one ready, but will make it while
printing the rest of the piecepack set. One day :D
One of the boxes was temporarily used for the plastic piecepack I got
with the book, and that one works well, but since it s a set with
standard suites I think I will want to make another box, using some of
the paper with fleur-de-lis that I saw in the stash.
I ve also started to write detailed instructions: I will publish them as
soon as they are ready, and then either update this post, or they will
be mentioned in an additional post if I will have already made more
boxes in the meanwhile.
Update 2024-03-25: the instructions have been published on my craft
patterns website
Earlier today, I have just released debputy version 0.1.21
to Debian unstable. In the blog post, I will highlight some
of the new features.
Package boilerplate reduction with automatic relationship substvar
Last month, I started a discussion on rethinking how we do
relationship substvars such as the $ misc:Depends . These
generally ends up being boilerplate runes in the form of
Depends: $ misc:Depends , $ shlibs:Depends where you
as the packager has to remember exactly which runes apply
to your package.
My proposed solution was to automatically apply these substvars
and this feature has now been implemented in debputy. It is
also combined with the feature where essential packages should
use Pre-Depends by default for dpkg-shlibdeps related
dependencies.
I am quite excited about this feature, because I noticed with
libcleri that we are now down to 3-5 fields for defining
a simple library package. Especially since most C library
packages are trivial enough that debputy can auto-derive
them to be Multi-Arch: same.
As an example, the libcleric1 package is down to 3
fields (Package, Architecture, Description)
with Section and Priority being inherited from the
Source stanza. I have submitted a MR to show case the
boilerplate reduction at
https://salsa.debian.org/siridb-team/libcleri/-/merge_requests/3.
The removal of libcleric1 (= $ binary:Version ) in that MR
relies on another existing feature where debputy can auto-derive
a dependency between an arch:any-dev package and the library
package based on the .so symlink for the shared library.
The arch:any restriction comes from the fact that arch:all and
arch:any packages are not built together, so debputy cannot
reliably see across the package boundaries during the build (and
therefore refuses to do so at all).
Packages that have already migrated to debputy can use
debputy migrate-from-dh to detect any unnecessary
relationship substitution variables in case you want to clean
up. The removal of Multi-Arch: same and intra-source
dependencies must be done manually and so only be done so
when you have validated that it is safe and sane to do. I was
willing to do it for the show-case MR, but I am less confident
that would bother with these for existing packages in general.
Note: I summarized the discussion of the automatic relationship
substvar feature earlier this month in
https://lists.debian.org/debian-devel/2024/03/msg00030.html
for those who want more details.
PS: The automatic relationship substvars feature will also
appear in debhelper as a part of compat 14.
Language Server (LSP) and Linting
I have long been frustrated by our poor editor support for Debian packaging files.
To this end, I started working on a Language Server (LSP) feature in debputy
that would cover some of our standard Debian packaging files. This release
includes the first version of said language server, which covers the following
files:
debian/control
debian/copyright (the machine readable variant)
debian/changelog (mostly just spelling)
debian/rules
debian/debputy.manifest (syntax checks only; use debputy check-manifest
for the full validation for now)
Most of the effort has been spent on the Deb822 based files such as debian/control,
which comes with diagnostics, quickfixes, spellchecking (but only for relevant fields!),
and completion suggestions.
Since not everyone has a LSP capable editor and because sometimes you just want
diagnostics without having to open each file in an editor, there is also a batch
version for the diagnostics via debputy lint. Please see debputy(1) for
how debputy lint compares with lintian if you are curious about which
tool to use at what time.
To help you getting started, there is a now debputy lsp editor-config command that
can provide you with the relevant editor config glue. At the moment, emacs (via
eglot) and vim with vim-youcompleteme are supported.
For those that followed the previous blog posts on writing the language server, I would
like to point out that the command line for running the language server has changed
to debputy lsp server and you no longer have to tell which format it is. I have
decided to make the language server a "polyglot" server for now, which I will
hopefully not regret... Time will tell. :)
Anyhow, to get started, you will want:
Specifically for emacs, I also learned two things after the upload. First, you
can auto-activate eglot via eglot-ensure. This badly feature interacts with
imenu on debian/changelog for reasons I do not understand (causing a several
second start up delay until something times out), but it works fine for the other
formats. Oddly enough, opening a changelog file and then activating eglot does
not trigger this issue at all. In the next version, editor config for emacs will
auto-activate eglot on all files except debian/changelog.
The second thing is that if you install elpa-markdown-mode, emacs will accept
and process markdown in the hover documentation provided by the language server.
Accordingly, the editor config for emacs will also mention this package from
the next version on.
Finally, on a related note, Jelmer and I have been looking at moving some of this
logic into a new package called debpkg-metadata. The point being to support
easier reuse of linting and LSP related metadata - like pulling a list of known
fields for debian/control or sharing logic between lintian-brush and
debputy.
Minimal integration mode for Rules-Requires-Root
One of the original motivators for starting debputy was to be able to get rid of
fakeroot in our build process. While this is possible, debputy currently does
not support most of the complex packaging features such as maintscripts and debconf.
Unfortunately, the kind of packages that need fakeroot for static ownership tend
to also require very complex packaging features.
To bridge this gap, the new version of debputy supports a very minimal integration
with dh via the dh-sequence-zz-debputy-rrr. This integration mode keeps
the vast majority of debhelper sequence in place meaning most dh add-ons
will continue to work with dh-sequence-zz-debputy-rrr. The sequence only
replaces the following commands:
dh_fixperms
dh_gencontrol
dh_md5sums
dh_builddeb
The installations feature of the manifest will be disabled in this integration
mode to avoid feature interactions with debhelper tools that expect
debian/<pkg> to contain the materialized package.
On a related note, the debputy migrate-from-dh command now supports a
--migration-target option, so you can choose the desired level of integration
without doing code changes. The command will attempt to auto-detect the desired
integration from existing package features such as a build-dependency on a relevant
dh sequence, so you do not have to remember this new option every time once
the migration has started. :)
This post is the second and final part of my Malaysia-Thailand trip. Feel free to check out the Malaysia part here if you haven t already. Kuala Lumpur to Bangkok is around 1500 km by road, and so I took a Malaysian Airlines flight to travel to Bangkok. The flight staff at the Kuala Lumpur only asked me for a return/onward flight and Thailand immigration asked a few questions but did not check any documents (obviously they checked and stamped my passport ;)). The currency of Thailand is the Thai baht, and 1 Thai baht = 2.5 Indian Rupees. The Thailand time is 1.5 hours ahead of Indian time (For example, if it is 12 noon in India, it will be 13:30 in Thailand).
I landed in Bangkok at around 3 PM local time. Fletcher was in Bangkok that time, leaving for Pattaya and we had booked the same hostel. So I took a bus to Pattaya from the airport. The next bus for which the tickets were available was at 7 PM, so I took tickets for that one. The bus ticket cost was 143 Thai Baht. I didn t buy SIM at the airport, thinking there must be better deals in the city. As a consequence, there was no way to contact Fletcher through internet. Although I had a few minutes call remaining out of my international roaming pack.
A welcome sign at Bangkok's Suvarnabhumi airport.
Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
Our accommodation was near Jomtien beach, so I got off at the last stop, as the bus terminates at the Jomtien beach. Then I decided to walk towards my accommodation. I was using OsmAnd for navigation. However, the place was not marked on OpenStreetMap, and it turned out I missed the street my hostel was on and walked around 1 km further as I was chasing a similarly named incorrect hostel on OpenStreetMap. Then I asked for help from two men sitting at a caf . One of them said he will help me find the street my hostel is on. So, I walked with him, and he told me he lives in Thailand for many years, but he is from Kuwait. He also gave me valuable information. Like, he told me about shared hail-and-ride songthaews which run along the Jomtien Second Road and charge 10 Baht for any distance on their route. This tip significantly reduced our expenses. Further, he suggested me 7-Eleven shops for buying a local SIM. Like Malaysia, Thailand has 24/7 7-Eleven convenience stores, a lot of them not even 100 m apart.
The Kuwaiti person dropped me at the address where my hostel was. I tried searching for a person in-charge of that hostel, and soon I realized there was no reception. After asking for help from locals for some time, I bumped into Fletcher, who also came to this address and was searching for the same. After finding a friend, I felt a sigh of relief. Adjacent to the property, there was a hairdresser shop. We went there and asked about this property. The woman called the owner, and she also told us the required passcodes to go inside. Our accommodation was in a room on the second floor, which required us to put a passcode for opening. We entered the passcode and entered the room. So, we stayed at this hostel which had no reception. Due to this, it took 2 hours to find our room and enter. It reminded me of a difficult experience I had in Albania, where me and Akshat were not able to find our apartment in one of the hottest days and the owner didn t know our language.
Traveling from the place where the bus dropped me to the hostel, I saw streets were filled with bars and massage parlors, which was expected. Prostitutes were everywhere. We went out at night towards the beach and also roamed around in 7-Elevens to buy a SIM card for myself. I got a SIM for 7 day unlimited internet for 399 baht. Turns out that the rates of SIM cards at the airport were not so different from inside the city.
Road near Jomtien beach in Pattaya
Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
Jomtien Beach in Pattaya.
In terms of speaking English, locals didn t know English at all in both Pattaya and Bangkok. I normally don t expect locals to know English in a non-English speaking country, but the fact that Bangkok is one of the most visited places by tourists made me expect locals to know some English. Talking to locals is an integral part of travel for me, which I couldn t do a lot in Thailand. This aspect is much more important for me than going to touristy places.
So, we were in Pattaya. Next morning, Fletcher and I went to Tiger park using shared songthaew. After that, we planned to visit Pattaya Floating market which is near the Tiger Park, but we felt the ticket prices were higher than it was worth. Fletcher had to leave for Bangkok on that day. I suggested him to go to Suvarnabhumi Airport from the Jomtien beach bus terminal (this was the route I took the last day in opposite direction) to avoid traffic congestion inside Bangkok, as he can follow up with metro once he reaches the airport. From the floating market, we were walking in sweltering heat to reach the Jomtien beach. I tried asking for a lift and eventually got successful as a scooty stopped, and surprisingly the person gave a ride to both of us. He was from Delhi, so maybe that s the reason he stopped for us. Then we took a songthaew to the bus terminal and after having lunch, Fletcher left for Bangkok.
A welcome sign at Pattaya Floating market.
This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
Next day I went to Bangkok, but Fletcher already left for Kuala Lumpur. Here I had booked a private room in a hotel (instead of a hostel) for four nights, mainly because of my luggage. This costed 5600 INR for four nights. It was 2 km from the metro station, which I used to walk both sides. In Bangkok, I visited Sukhumvit and Siam by metro. Going to some areas require crossing the Chao Phraya river. For this, I took Chao Phraya Express Boat for going to places like Khao San road and Wat Arun. I would recommend taking the boat ride as it had very good views. In Bangkok, I met a person from Pakistan staying in my hotel and so here also I got some company. But by the time I met him, my days were almost over. So, we went to a random restaurant selling Indian food where we ate some paneer dish with naan and that restaurant person was from Myanmar.
Wat Arun temple stamps your hand upon entry
Wat Arun temple
Khao San Road
A food stall at Khao San Road
Chao Phraya Express Boat
For eating, I mainly relied on fruits and convenience stores. Bananas were very tasty. This was the first time I saw banana flesh being yellow. Mangoes were delicious and pineapples were smaller and flavorful. I also ate Rose Apple, which I never had before. I had Chhole Kulche once in Sukhumvit. That was a little expensive as it costed 164 baht. I also used to buy premix coffee packets from 7-Eleven convenience stores and prepare them inside the stores.
Banana with yellow flesh
Fruits at a stall in Bangkok
Trimmed pineapples from Thailand.
Corn in Bangkok.
A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
My booking from Bangkok to Delhi was in Air India flight, and they were serving alcohol in the flight. I chose red wine, and this was my first time having alcohol in a flight.
Red wine being served in Air India
Notes
In this whole trip spanning two weeks, I did not pay for drinking water (except for once in Pattaya which was 9 baht) and toilets. Bangkok and Kuala Lumpur have plenty of malls where you should find a free-of-cost toilet nearby. For drinking water, I relied mainly on my accommodation providing refillable water for my bottle.
Thailand seemed more expensive than Malaysia on average. Malaysia had discounted price due to the Chinese New year.
I liked Pattaya more than Bangkok. Maybe because Pattaya has beach and Bangkok doesn t. Pattaya seemed more lively, and I could meet and talk to a few people as opposed to Bangkok.
Chao Phraya River express boat costs 150 baht for one day where you can hop on and off to any boat.
My effort to improve transparency and confidence of public apt archives continues. I started to work on this in Apt Archive Transparency in which I mention the debdistget project in passing. Debdistget is responsible for mirroring index files for some public apt archives. I ve realized that having a publicly auditable and preserved mirror of the apt repositories is central to being able to do apt transparency work, so the debdistget project has become more central to my project than I thought. Currently I track Trisquel, PureOS, Gnuinos and their upstreams Ubuntu, Debian and Devuan.
Debdistget download Release/Package/Sources files and store them in a git repository published on GitLab. Due to size constraints, it uses two repositories: one for the Release/InRelease files (which are small) and one that also include the Package/Sources files (which are large). See for example the repository for Trisquel release files and the Trisquel package/sources files. Repositories for all distributions can be found in debdistutils archives GitLab sub-group.
The reason for splitting into two repositories was that the git repository for the combined files become large, and that some of my use-cases only needed the release files. Currently the repositories with packages (which contain a couple of months worth of data now) are 9GB for Ubuntu, 2.5GB for Trisquel/Debian/PureOS, 970MB for Devuan and 450MB for Gnuinos. The repository size is correlated to the size of the archive (for the initial import) plus the frequency and size of updates. Ubuntu s use of Apt Phased Updates (which triggers a higher churn of Packages file modifications) appears to be the primary reason for its larger size.
Working with large Git repositories is inefficient and the GitLab CI/CD jobs generate quite some network traffic downloading the git repository over and over again. The most heavy user is the debdistdiff project that download all distribution package repositories to do diff operations on the package lists between distributions. The daily job takes around 80 minutes to run, with the majority of time is spent on downloading the archives. Yes I know I could look into runner-side caching but I dislike complexity caused by caching.
Fortunately not all use-cases requires the package files. The debdistcanary project only needs the Release/InRelease files, in order to commit signatures to the Sigstore and Sigsum transparency logs. These jobs still run fairly quickly, but watching the repository size growth worries me. Currently these repositories are at Debian 440MB, PureOS 130MB, Ubuntu/Devuan 90MB, Trisquel 12MB, Gnuinos 2MB. Here I believe the main size correlation is update frequency, and Debian is large because I track the volatile unstable.
So I hit a scalability end with my first approach. A couple of months ago I solved this by discarding and resetting these archival repositories. The GitLab CI/CD jobs were fast again and all was well. However this meant discarding precious historic information. A couple of days ago I was reaching the limits of practicality again, and started to explore ways to fix this. I like having data stored in git (it allows easy integration with software integrity tools such as GnuPG and Sigstore, and the git log provides a kind of temporal ordering of data), so it felt like giving up on nice properties to use a traditional database with on-disk approach. So I started to learn about Git-LFS and understanding that it was able to handle multi-GB worth of data that looked promising.
Fairly quickly I scripted up a GitLab CI/CD job that incrementally update the Release/Package/Sources files in a git repository that uses Git-LFS to store all the files. The repository size is now at Ubuntu 650kb, Debian 300kb, Trisquel 50kb, Devuan 250kb, PureOS 172kb and Gnuinos 17kb. As can be expected, jobs are quick to clone the git archives: debdistdiff pipelines went from a run-time of 80 minutes down to 10 minutes which more reasonable correlate with the archive size and CPU run-time.
The LFS storage size for those repositories are at Ubuntu 15GB, Debian 8GB, Trisquel 1.7GB, Devuan 1.1GB, PureOS/Gnuinos 420MB. This is for a couple of days worth of data. It seems native Git is better at compressing/deduplicating data than Git-LFS is: the combined size for Ubuntu is already 15GB for a couple of days data compared to 8GB for a couple of months worth of data with pure Git. This may be a sub-optimal implementation of Git-LFS in GitLab but it does worry me that this new approach will be difficult to scale too. At some level the difference is understandable, Git-LFS probably store two different Packages files around 90MB each for Trisquel as two 90MB files, but native Git would store it as one compressed version of the 90MB file and one relatively small patch to turn the old files into the next file. So the Git-LFS approach surprisingly scale less well for overall storage-size. Still, the original repository is much smaller, and you usually don t have to pull all LFS files anyway. So it is net win.
Throughout this work, I kept thinking about how my approach relates to Debian s snapshot service. Ultimately what I would want is a combination of these two services. To have a good foundation to do transparency work I would want to have a collection of all Release/Packages/Sources files ever published, and ultimately also the source code and binaries. While it makes sense to start on the latest stable releases of distributions, this effort should scale backwards in time as well. For reproducing binaries from source code, I need to be able to securely find earlier versions of binary packages used for rebuilds. So I need to import all the Release/Packages/Sources packages from snapshot into my repositories. The latency to retrieve files from that server is slow so I haven t been able to find an efficient/parallelized way to download the files. If I m able to finish this, I would have confidence that my new Git-LFS based approach to store these files will scale over many years to come. This remains to be seen. Perhaps the repository has to be split up per release or per architecture or similar.
Another factor is storage costs. While the git repository size for a Git-LFS based repository with files from several years may be possible to sustain, the Git-LFS storage size surely won t be. It seems GitLab charges the same for files in repositories and in Git-LFS, and it is around $500 per 100GB per year. It may be possible to setup a separate Git-LFS backend not hosted at GitLab to serve the LFS files. Does anyone know of a suitable server implementation for this? I had a quick look at the Git-LFS implementation list and it seems the closest reasonable approach would be to setup the Gitea-clone Forgejo as a self-hosted server. Perhaps a cloud storage approach a la S3 is the way to go? The cost to host this on GitLab will be manageable for up to ~1TB ($5000/year) but scaling it to storing say 500TB of data would mean an yearly fee of $2.5M which seems like poor value for the money.
I realized that ultimately I would want a git repository locally with the entire content of all apt archives, including their binary and source packages, ever published. The storage requirements for a service like snapshot (~300TB of data?) is today not prohibitly expensive: 20TB disks are $500 a piece, so a storage enclosure with 36 disks would be around $18.000 for 720TB and using RAID1 means 360TB which is a good start. While I have heard about ~TB-sized Git-LFS repositories, would Git-LFS scale to 1PB? Perhaps the size of a git repository with multi-millions number of Git-LFS pointer files will become unmanageable? To get started on this approach, I decided to import a mirror of Debian s bookworm for amd64 into a Git-LFS repository. That is around 175GB so reasonable cheap to host even on GitLab ($1000/year for 200GB). Having this repository publicly available will make it possible to write software that uses this approach (e.g., porting debdistreproduce), to find out if this is useful and if it could scale. Distributing the apt repository via Git-LFS would also enable other interesting ideas to protecting the data. Consider configuring apt to use a local file:// URL to this git repository, and verifying the git checkout using some method similar to Guix s approach to trusting git content or Sigstore s gitsign.
A naive push of the 175GB archive in a single git commit ran into pack size limitations:
remote: fatal: pack exceeds maximum allowed size (4.88 GiB)
however breaking up the commit into smaller commits for parts of the archive made it possible to push the entire archive. Here are the commands to create this repository:
git init git lfs install git lfs track 'dists/**' 'pool/**' git add .gitattributes git commit -m"Add Git-LFS track attributes." .gitattributes time debmirror --method=rsync --host ftp.se.debian.org --root :debian --arch=amd64 --source --dist=bookworm,bookworm-updates --section=main --verbose --diff=none --keyring /usr/share/keyrings/debian-archive-keyring.gpg --ignore .git . git add dists project git commit -m"Add." -a git remote add origin git@gitlab.com:debdistutils/archives/debian/mirror.git git push --set-upstream origin --all for d in pool//; do echo $d; time git add $d; git commit -m"Add $d." -a git push done
The resulting repository size is around 27MB with Git LFS object storage around 174GB. I think this approach would scale to handle all architectures for one release, but working with a single git repository for all releases for all architectures may lead to a too large git repository (>1GB). So maybe one repository per release? These repositories could also be split up on a subset of pool/ files, or there could be one repository per release per architecture or sources.
Finally, I have concerns about using SHA1 for identifying objects. It seems both Git and Debian s snapshot service is currently using SHA1. For Git there is SHA-256 transition and it seems GitLab is working on support for SHA256-based repositories. For serious long-term deployment of these concepts, it would be nice to go for SHA256 identifiers directly. Git-LFS already uses SHA256 but Git internally uses SHA1 as does the Debian snapshot service.
What do you think? Happy Hacking!
Introduction
There have been many experiments with the sizes of computers, some of which have stayed around and some have gone away. The trend has been to make computers smaller, the early computers had buildings for them. Recently for come classes computers have started becoming as small as could be reasonably desired. For example phones are thin enough that they can blow away in a strong breeze, smart watches are much the same size as the old fashioned watches they replace, and NUC type computers are as small as they need to be given the size of monitors etc that they connect to.
This means that further development in the size and shape of computers will largely be determined by human factors.
I think we need to consider how computers might be developed to better suit humans and how to write free software to make such computers usable without being constrained by corporate interests.
Those of us who are involved in developing OSs and applications need to consider how to adjust to the changes and ideally anticipate changes. While we can t anticipate the details of future devices we can easily predict general trends such as being smaller, higher resolution, etc.
Desktop/Laptop PCs
When home computers first came out it was standard to have the keyboard in the main box, the Apple ][ being the most well known example. This has lost popularity due to the demand to have multiple options for a light keyboard that can be moved for convenience combined with multiple options for the box part. But it still pops up occasionally such as the Raspberry Pi 400 [1] which succeeds due to having the computer part being small and light. I think this type of computer will remain a niche product. It could be used in a add a screen to make a laptop as opposed to the add a keyboard to a tablet to make a laptop model but a tablet without a keyboard is more useful than a non-server PC without a display.
The PC as box with connections for keyboard, display, etc has a long future ahead of it. But the sizes will probably decrease (they should have stopped making PC cases to fit CD/DVD drives at least 10 years ago). The NUC size is a useful option and I think that DVD drives will stop being used for software soon which will allow a range of smaller form factors.
The regular laptop is something that will remain useful, but the tablet with detachable keyboard devices could take a lot of that market. Full functionality for all tasks requires a keyboard because at the moment text editing with a touch screen is an unsolved problem in computer science [2].
The Lenovo Thinkpad X1 Fold [3] and related Lenovo products are very interesting. Advances in materials allow laptops to be thinner and lighter which leaves the screen size as a major limitation to portability. There is a conflict between desiring a large screen to see lots of content and wanting a small size to carry and making a device foldable is an obvious solution that has recently become possible. Making a foldable laptop drives a desire for not having a permanently attached keyboard which then makes a touch screen keyboard a requirement. So this means that user interfaces for PCs have to be adapted to work well on touch screens. The Think line seems to be continuing the history of innovation that it had when owned by IBM. There are also a range of other laptops that have two regular screens so they are essentially the same as the Thinkpad X1 Fold but with two separate screens instead of one folding one, prices are as low as $600US.
I think that the typical interfaces for desktop PCs (EG MS-Windows and KDE) don t work well for small devices and touch devices and the Android interface generally isn t a good match for desktop systems. We need to invent more options for this. This is not a criticism of KDE, I use it every day and it works well. But it s designed for use cases that don t match new hardware that is on sale. As an aside it would be nice if Lenovo gave samples of their newest gear to people who make significant contributions to GUIs. Give a few Thinkpad Fold devices to KDE people, a few to GNOME people, and a few others to people involved in Wayland development and see how that promotes software development and future sales.
We also need to adopt features from laptops and phones into desktop PCs. When voice recognition software was first released in the 90s it was for desktop PCs, it didn t take off largely because it wasn t very accurate (none of them recognised my voice). Now voice recognition in phones is very accurate and it s very common for desktop PCs to have a webcam or headset with a microphone so it s time for this to be re-visited. GPS support in laptops is obviously useful and can work via Wifi location, via a USB GPS device, or via wwan mobile phone hardware (even if not used for wwan networking). Another possibility is using the same software interfaces as used for GPS on laptops for a static definition of location for a desktop PC or server.
The Interesting New Things
Watch Like
The wrist-watch [4] has been a standard format for easy access to data when on the go since it s military use at the end of the 19th century when the practical benefits beat the supposed femininity of the watch. So it seems most likely that they will continue to be in widespread use in computerised form for the forseeable future. For comparison smart phones have been in widespread use as pocket watches for about 10 years.
The question is how will watch computers end up? Will we have Dick Tracy style watch phones that you speak into? Will it be the current smart watch functionality of using the watch to answer a call which goes to a bluetooth headset? Will smart watches end up taking over the functionality of the calculator watch [5] which was popular in the 80 s? With today s technology you could easily have a fully capable PC strapped to your forearm, would that be useful?
Phone Like
Folding phones (originally popularised as Star Trek Tricorders) seem likely to have a long future ahead of them. Engineering technology has only recently developed to the stage of allowing them to work the way people would hope them to work (a folding screen with no gaps). Phones and tablets with multiple folds are coming out now [6]. This will allow phones to take much of the market share that tablets used to have while tablets and laptops merge at the high end. I ve previously written about Convergence between phones and desktop computers [7], the increased capabilities of phones adds to the case for Convergence.
Folding phones also provide new possibilities for the OS. The Oppo OnePlus Open and the Google Pixel Fold both have a UI based around using the two halves of the folding screen for separate data at some times. I think that the current user interfaces for desktop PCs don t properly take advantage of multiple monitors and the possibilities raised by folding phones only adds to the lack. My pet peeve with multiple monitor setups is when they don t make it obvious which monitor has keyboard focus so you send a CTRL-W or ALT-F4 to the wrong screen by mistake, it s a problem that also happens on a single screen but is worse with multiple screens. There are rumours of phones described as three fold (where three means the number of segments with two folds between them), it will be interesting to see how that goes.
Will phones go the same way as PCs in terms of having a separation between the compute bit and the input device? It s quite possible to have a compute device in the phone form factor inside a secure pocket which talks via Bluetooth to another device with a display and speakers. Then you could change your phone between a phone-size display and a tablet sized display easily and when using your phone a thief would not be able to easily steal the compute bit (which has passwords etc). Could the watch part of the phone (strapped to your wrist and difficult to steal) be the active part and have a tablet size device as an external display? There are already announcements of smart watches with up to 1GB of RAM (same as the Samsung Galaxy S3), that s enough for a lot of phone functionality.
The Rabbit R1 [8] and the Humane AI Pin [9] have some interesting possibilities for AI speech interfaces. Could that take over some of the current phone use? It seems that visually impaired people have been doing badly in the trend towards touch screen phones so an option of a voice interface phone would be a good option for them. As an aside I hope some people are working on AI stuff for FOSS devices.
Laptop Like
One interesting PC variant I just discovered is the Higole 2 Pro portable battery operated Windows PC with 5.5 touch screen [10]. It looks too thick to fit in the same pockets as current phones but is still very portable. The version with built in battery is $AU423 which is in the usual price range for low end laptops and tablets. I don t think this is the future of computing, but it is something that is usable today while we wait for foldable devices to take over.
The recent release of the Apple Vision Pro [11] has driven interest in 3D and head mounted computers. I think this could be a useful peripheral for a laptop or phone but it won t be part of a primary computing environment. In 2011 I wrote about the possibility of using augmented reality technology for providing a desktop computing environment [12]. I wonder how a Vision Pro would work for that on a train or passenger jet.
Another interesting thing that s on offer is a laptop with 7 touch screen beside the keyboard [13]. It seems that someone just looked at what parts are available cheaply in China (due to being parts of more popular devices) and what could fit together. I think a keyboard should be central to the monitor for serious typing, but there may be useful corner cases where typing isn t that common and a touch-screen display is of use. Developing a range of strange hardware and then seeing which ones get adopted is a good thing and an advantage of Ali Express and Temu.
Useful Hardware for Developing These Things
I recently bought a second hand Thinkpad X1 Yoga Gen3 for $359 which has stylus support [14], and it s generally a great little laptop in every other way. There s a common failure case of that model where touch support for fingers breaks but the stylus still works which allows it to be used for testing touch screen functionality while making it cheap.
The PineTime is a nice smart watch from Pine64 which is designed to be open [15]. I am quite happy with it but haven t done much with it yet (apart from wearing it every day and getting alerts etc from Android). At $50 when delivered to Australia it s significantly more expensive than most smart watches with similar features but still a lot cheaper than the high end ones. Also the Raspberry Pi Watch [16] is interesting too.
The PinePhonePro is an OK phone made to open standards but it s hardware isn t as good as Android phones released in the same year [17]. I ve got some useful stuff done on mine, but the battery life is a major issue and the screen resolution is low. The Librem 5 phone from Purism has a better hardware design for security with switches to disable functionality [18], but it s even slower than the PinePhonePro. These are good devices for test and development but not ones that many people would be excited to use every day.
Wwan hardware (for accessing the phone network) in M.2 form factor can be obtained for free if you have access to old/broken laptops. Such devices start at about $35 if you want to buy one. USB GPS devices also start at about $35 so probably not worth getting if you can get a wwan device that does GPS as well.
What We Must Do
Debian appears to have some voice input software in the pocketsphinx package but no documentation on how it s to be used. This would be a good thing to document, I spent 15 mins looking at it and couldn t get it going.
To take advantage of the hardware features in phones we need software support and we ideally don t want free software to lag too far behind proprietary software which IMHO means the typical Android setup for phones/tablets.
Support for changing screen resolution is already there as is support for touch screens. Support for adapting the GUI to changed screen size is something that needs to be done even today s hardware of connecting a small laptop to an external monitor doesn t have the ideal functionality for changing the UI. There also seem to be some limitations in touch screen support with multiple screens, I haven t investigated this properly yet, it definitely doesn t work in an expected manner in Ubuntu 22.04 and I haven t yet tested the combinations on Debian/Unstable.
ML is becoming a big thing and it has some interesting use cases for small devices where a smart device can compensate for limited input options. There s a lot of work that needs to be done in this area and we are limited by the fact that we can t just rip off the work of other people for use as training data in the way that corporations do.
Security is more important for devices that are at high risk of theft. The vast majority of free software installations are way behind Android in terms of security and we need to address that. I have some ideas for improvement but there is always a conflict between security and usability and while Android is usable for it s own special apps it s not usable in a I want to run applications that use any files from any other applicationsin any way I want sense. My post about Sandboxing Phone apps is relevant for people who are interested in this [19]. We also need to extend security models to cope with things like ok google type functionality which has the potential to be a bug and the emerging class of LLM based attacks.
I will write more posts about these thing.
Please write comments mentioning FOSS hardware and software projects that address these issues and also documentation for such things.
Recently, I got a new laptop and had to set it up so I could start using it. But
I wasn't really in the mood to go through the same old steps which I had
explained in this post earlier. I was complaining about
this to my colleague, and there came the suggestion of why not copy the entire
disk to the new laptop. Though it sounded like an interesting idea to me, I had
my doubts, so here is what I told him in return.
I don't have the tools to open my old laptop and connect the new disk over
USB to my new laptop.
I use full disk encryption, and my old laptop has a 512GB disk, whereas the
new laptop has a 1TB NVME, and I'm not so familiar with resizing LUKS.
He promptly suggested both could be done. For step 1, just expose the disk using
NVME over TCP and connect it over the network and do a full disk copy, and the
rest is pretty simple to achieve. In short, he suggested the following:
Export the disk using nvmet-tcp from the old laptop.
Do a disk copy to the new laptop.
Resize the partition to use the full 1TB.
Resize LUKS.
Finally, resize the BTRFS root disk.
Exporting Disk over NVME TCP
The easiest way suggested by my colleague to do this is using
systemd-storagetm.service.
This service can be invoked by simply booting into storage-target-mode.target
by specifying rd.systemd.unit=storage-target-mode.target. But he suggested not
to use this as I need to tweak the dracut initrd image to involve network
services as well as configuring WiFi from this mode is a painful thing to do.
So alternatively, I simply booted both my laptops with GRML rescue CD. And the
following step was done to export the NVME disk on my current laptop using the
nvmet-tcp module of Linux:
modprobenvmet-tcp
cd/sys/kernel/config/nvmet
mkdirports/0
cdports/0
echo"ipv4">addr_adrfam
echo0.0.0.0>addr_traaddr
echo4420>addr_trsvcid
echotcp>addr_trtype
cd/sys/kernel/config/nvmet/subsystems
mkdirtestnqn
echo1>testnqn/allow_any_host
mkdirtestnqn/namespaces/1
cdtestnqn
# replace the device name with the disk you want to exportecho"/dev/nvme0n1">namespaces/1/device_path
echo1>namespaces/1/enable
ln-s"../../subsystems/testnqn"/sys/kernel/config/nvmet/ports/0/subsystems/testnqn
These steps ensure that the device is now exported using NVME over TCP. The next
step is to detect this on the new laptop and connect the device:
Finally, nvme list shows the device which is connected to the new laptop,
and we can proceed with the next step, which is to do the disk copy.
Copying the Disk
I simply used the dd command to copy the root disk to my new laptop. Since
the new laptop didn't have an Ethernet port, I had to rely only on WiFi, and it
took about 7 and a half hours to copy the entire 512GB to the new laptop. The
speed at which I was copying was about 18-20MB/s. The other option would have
been to create an initial partition and file system and do an rsync of the root
disk or use BTRFS itself for file system transfer.
Resizing Partition and LUKS Container
The final part was very easy. When I launched parted, it detected that the
partition table does not match the disk size and asked if it can fix it, and I
said yes. Next, I had to install cloud-guest-utils to get growpart to
fix the second partition, and the following command extended the partition to
the full 1TB:
growpart/dev/nvem0n1p2
Next, I used cryptsetup-resize to increase the LUKS container size.
Finally, I rebooted into the disk, and everything worked fine. After logging
into the system, I resized the BTRFS file system. BTRFS requires the system to
be mounted for resize, so I could not attempt it in live boot.
btfsfielsystemresizemax/
Conclussion
The only benefit of this entire process is that I have a new laptop, but I still
feel like I'm using my existing laptop. Typically, setting up a new laptop takes
about a week or two to completely get adjusted, but in this case, that entire
time is saved.
An added benefit is that I learned how to export disks using NVME over TCP,
thanks to my colleague. This new knowledge adds to the value of the experience.
Many of us grew up used to having some news sources we could implicitly trust, such as well-positioned newspapers and radio or TV news programs. We knew they would only hire responsible journalists rather than risk diluting public trust and losing their brand s value. However, with the advent of the Internet and social media, we are witnessing what has been termed the post-truth phenomenon. The undeniable freedom that horizontal communication has given us automatically brings with it the emergence of filter bubbles and echo chambers, and truth seems to become a group belief.
Contrary to my original expectations, the core topic of the book is not about how current-day media brings about post-truth mindsets. Instead it goes into a much deeper philosophical debate: What is truth? Does truth exist by itself, objectively, or is it a social construct? If activists with different political leanings debate a given subject, is it even possible for them to understand the same points for debate, or do they truly experience parallel realities?
The author wrote this book clearly prompted by the unprecedented events that took place in 2020, as the COVID-19 crisis forced humanity into isolation and online communication. Donald Trump is explicitly and repeatedly presented throughout the book as an example of an actor that took advantage of the distortions caused by post-truth.
The first chapter frames the narrative from the perspective of information flow over the last several decades, on how the emergence of horizontal, uncensored communication free of editorial oversight started empowering the netizens and created a temporary information flow utopia. But soon afterwards, algorithmic gatekeepers started appearing, creating a set of personalized distortions on reality; users started getting news aligned to what they already showed interest in. This led to an increase in polarization and the growth of narrative-framing-specific communities that served as echo chambers for disjoint views on reality. This led to the growth of conspiracy theories and, necessarily, to the science denial and pseudoscience that reached unimaginable peaks during the COVID-19 crisis. Finally, when readers decide based on completely subjective criteria whether a scientific theory such as global warming is true or propaganda, or question what most traditional news outlets present as facts, we face the phenomenon known as fake news. Fake news leads to post-truth, a state where it is impossible to distinguish between truth and falsehood, and serves only a rhetorical function, making rational discourse impossible.
Toward the end of the first chapter, the tone of writing quickly turns away from describing developments in the spread of news and facts over the last decades and quickly goes deep into philosophy, into the very thorny subject pursued by said discipline for millennia: How can truth be defined? Can different perspectives bring about different truth values for any given idea? Does truth depend on the observer, on their knowledge of facts, on their moral compass or in their honest opinions?
Zoglauer dives into epistemology, following various thinkers ideas on what can be understood as truth: constructivism (whether knowledge and truth values can be learnt by an individual building from their personal experience), objectivity (whether experiences, and thus truth, are universal, or whether they are naturally individual), and whether we can proclaim something to be true when it corresponds to reality. For the final chapter, he dives into the role information and knowledge play in assigning and understanding truth value, as well as the value of second-hand knowledge: Do we really own knowledge because we can look up facts online (even if we carefully check the sources)? Can I, without any medical training, diagnose a sickness and treatment by honestly and carefully looking up its symptoms in medical databases?
Wrapping up, while I very much enjoyed reading this book, I must confess it is completely different from what I expected. This book digs much more into the abstract than into information flow in modern society, or the impact on early 2020s politics as its editorial description suggests. At 160 pages, the book is not a heavy read, and Zoglauer s writing style is easy to follow, even across the potentially very deep topics it presents. Its main readership is not necessarily computing practitioners or academics. However, for people trying to better understand epistemology through its expressions in the modern world, it will be a very worthy read.
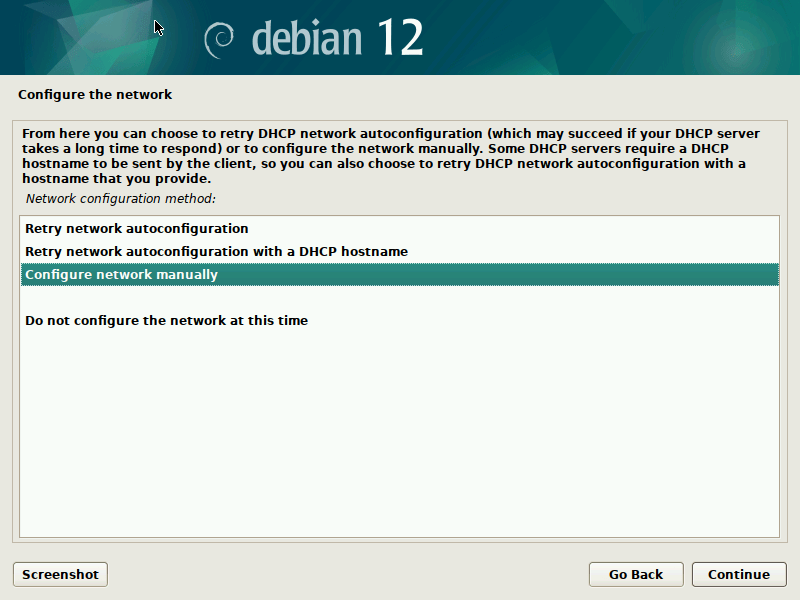
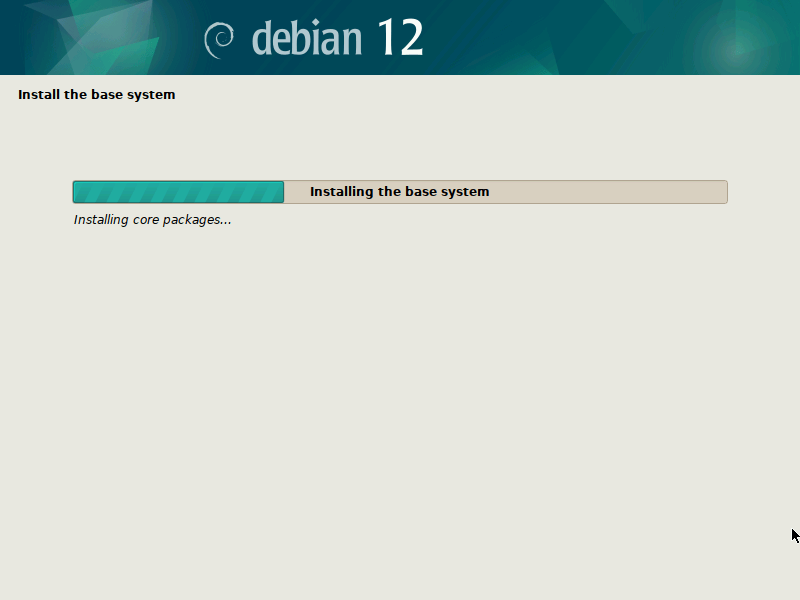
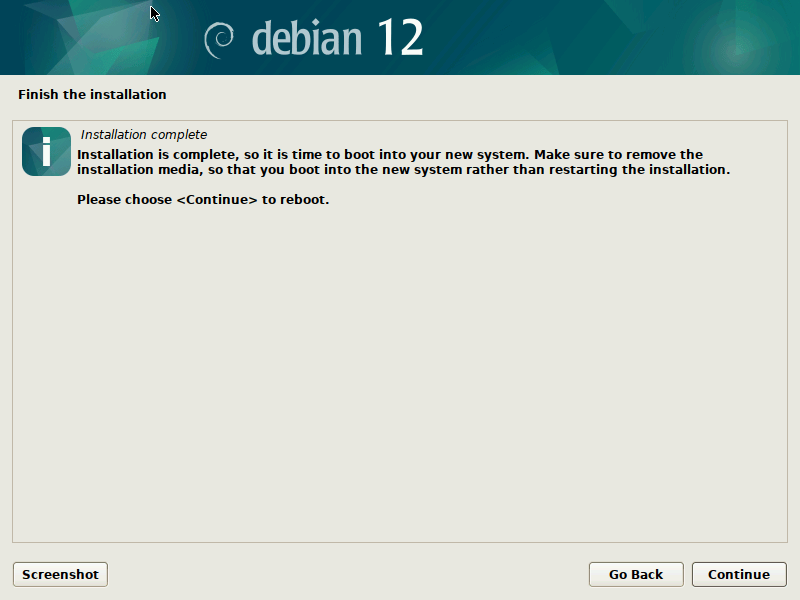
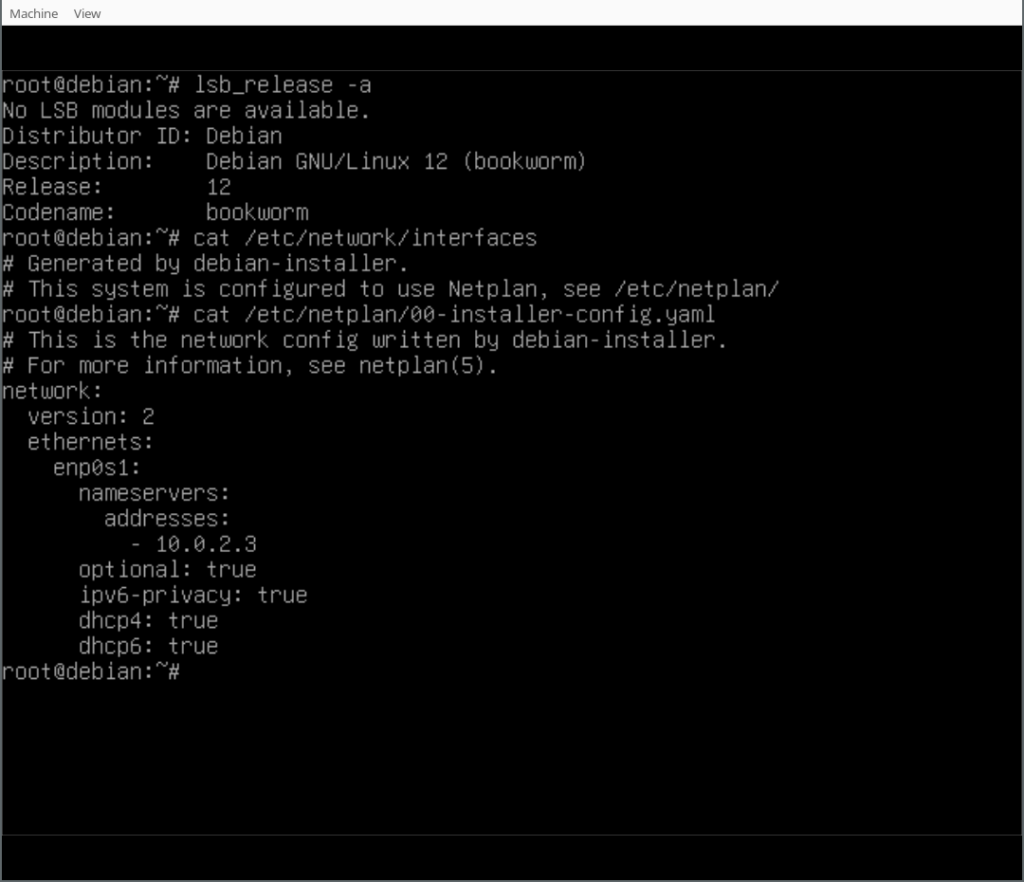
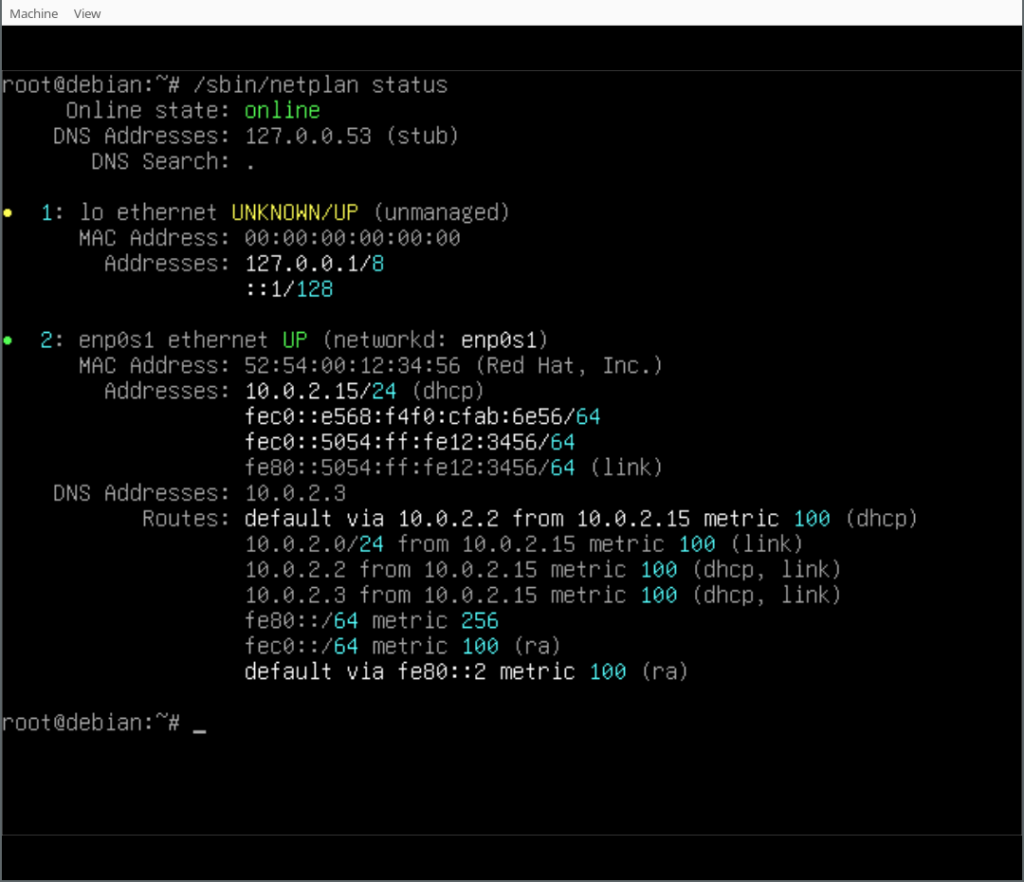
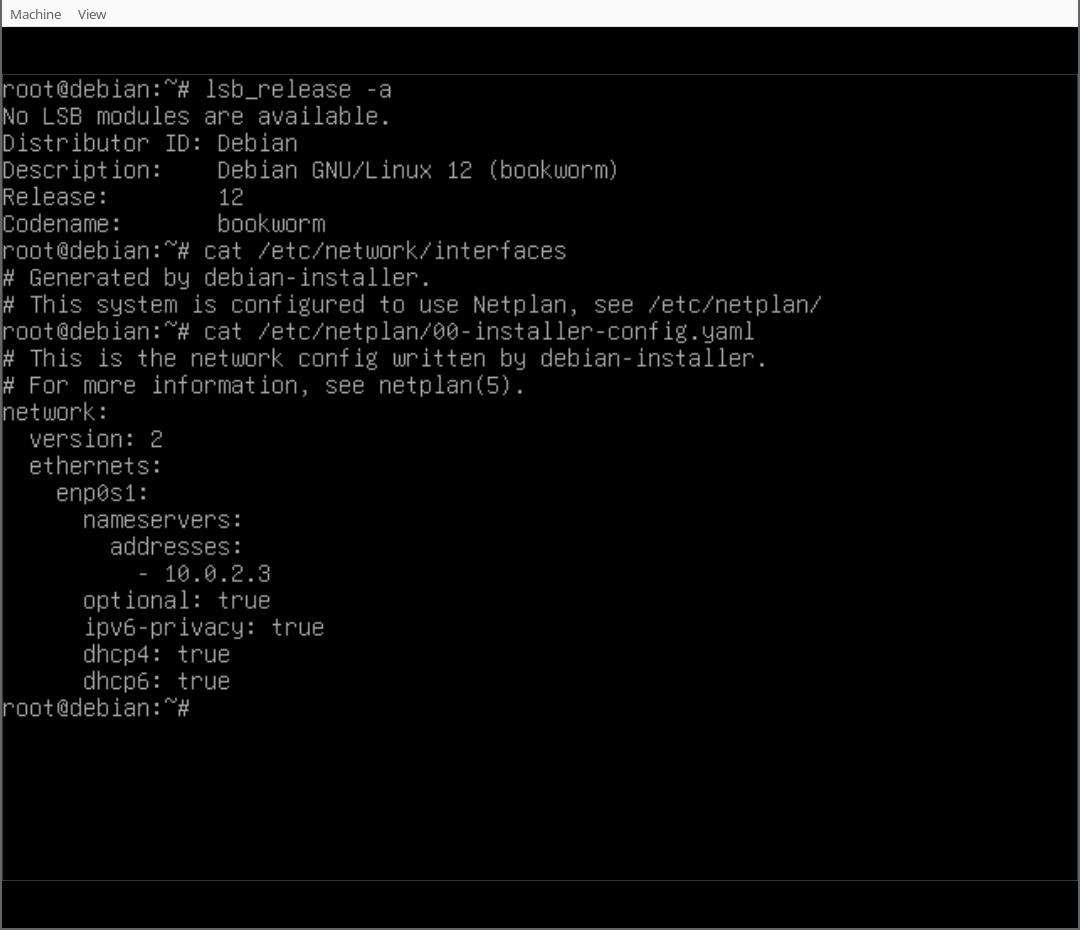
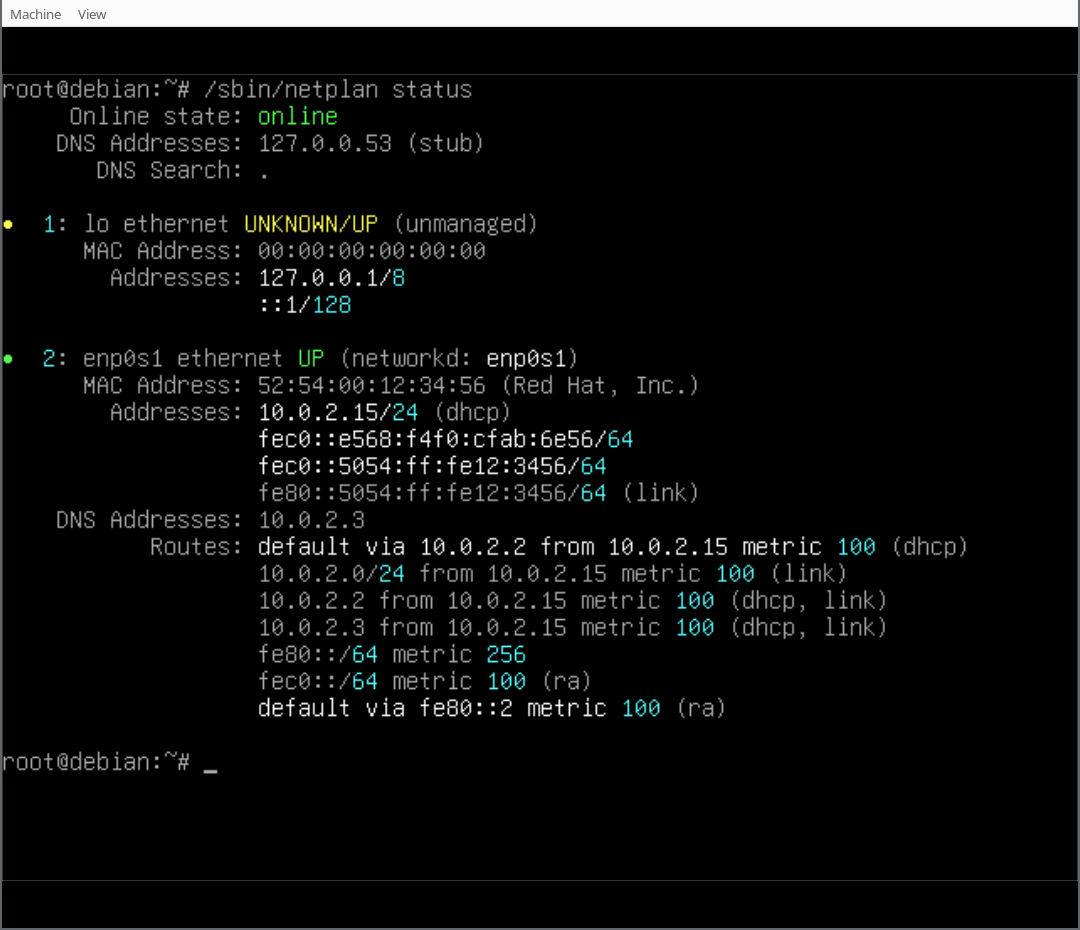
 Time really flies when
Time really flies when 


 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
 Getting the
Getting the  Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the 
 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze

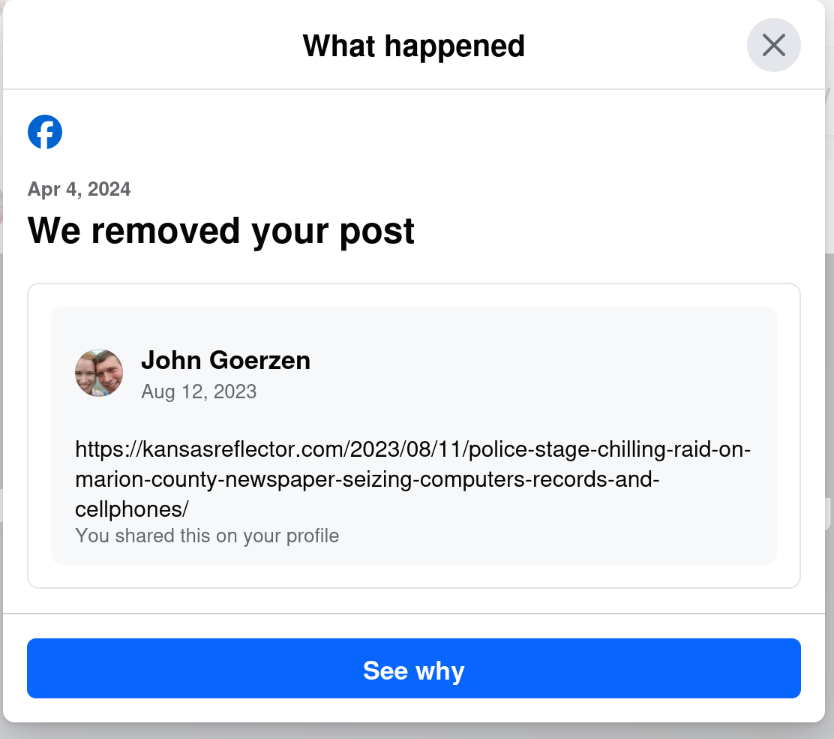 Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
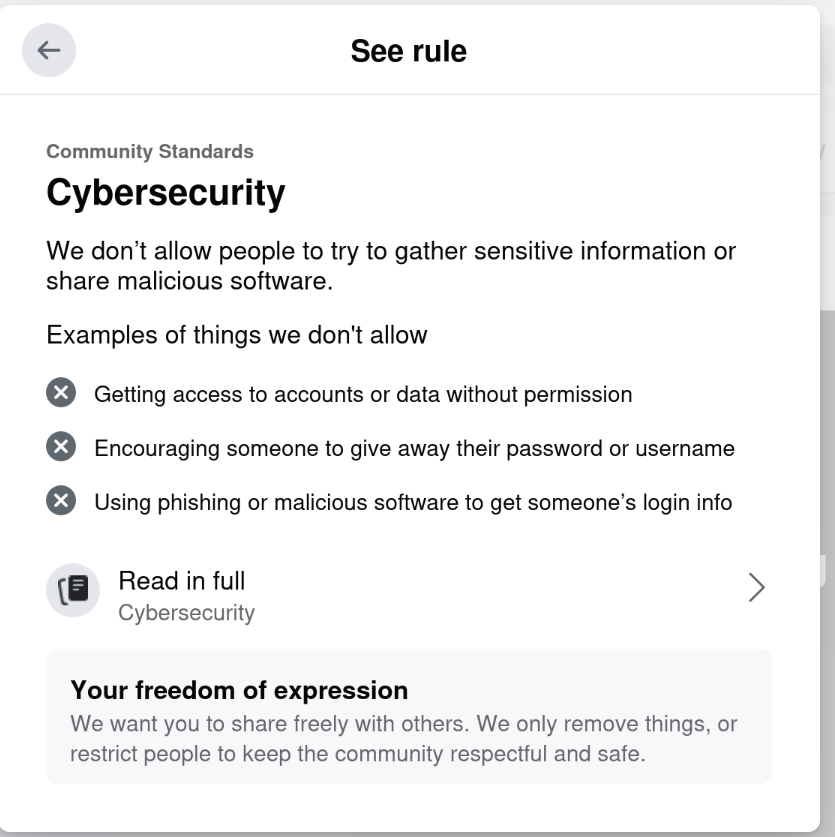 Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they
Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they 


 Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut
Thanks to All Saints Day, I ve just had a 5 days weekend. One of those
days I woke up and decided I absolutely needed a cartonnage box for the
cardboard and linocut  One of the boxes was temporarily used for the plastic piecepack I got
with the
One of the boxes was temporarily used for the plastic piecepack I got
with the  A welcome sign at Bangkok's Suvarnabhumi airport.
A welcome sign at Bangkok's Suvarnabhumi airport.
 Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
 Road near Jomtien beach in Pattaya
Road near Jomtien beach in Pattaya
 Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
 Jomtien Beach in Pattaya.
Jomtien Beach in Pattaya.
 A welcome sign at Pattaya Floating market.
A welcome sign at Pattaya Floating market.
 This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
 Wat Arun temple stamps your hand upon entry
Wat Arun temple stamps your hand upon entry
 Wat Arun temple
Wat Arun temple
 Khao San Road
Khao San Road
 A food stall at Khao San Road
A food stall at Khao San Road
 Chao Phraya Express Boat
Chao Phraya Express Boat
 Banana with yellow flesh
Banana with yellow flesh
 Fruits at a stall in Bangkok
Fruits at a stall in Bangkok
 Trimmed pineapples from Thailand.
Trimmed pineapples from Thailand.
 Corn in Bangkok.
Corn in Bangkok.
 A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
 In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
 Red wine being served in Air India
Red wine being served in Air India
 Recently, I got a new laptop and had to set it up so I could start using it. But
I wasn't really in the mood to go through the same old steps which I had
explained in this
Recently, I got a new laptop and had to set it up so I could start using it. But
I wasn't really in the mood to go through the same old steps which I had
explained in this 