
We re coming closer to the
Debian/stretch stable release and similar to what we had with
#newinwheezy and
#newinjessie it s time for #newinstretch!
Hideki Yamane already started the game by blogging about
GitHub s Icon font, fonts-octicons and Arturo Borrero Gonzalez wrote a nice article about
nftables in Debian/stretch.
One package that isn t new but its tools are used by many of us is
util-linux, providing many essential system utilities. We have util-linux v2.25.2 in Debian/jessie and in Debian/stretch there will be util-linux >=v2.29.2. There are many new options available and we also have a few new tools available.
Tools that have been taken over from other packages
- last: used to be shipped via sysvinit-utils in Debian/jessie
- lastb: used to be shipped via sysvinit-utils in Debian/jessie
- mesg: used to be shipped via sysvinit-utils in Debian/jessie
- mountpoint: used to be shipped via initscripts in Debian/jessie
- sulogin: used to be shipped via sysvinit-utils in Debian/jessie
New tools
- lsipc: show information on IPC facilities, e.g.:
root@ff2713f55b36:/# lsipc
RESOURCE DESCRIPTION LIMIT USED USE%
MSGMNI Number of message queues 32000 0 0.00%
MSGMAX Max size of message (bytes) 8192 - -
MSGMNB Default max size of queue (bytes) 16384 - -
SHMMNI Shared memory segments 4096 0 0.00%
SHMALL Shared memory pages 18446744073692774399 0 0.00%
SHMMAX Max size of shared memory segment (bytes) 18446744073692774399 - -
SHMMIN Min size of shared memory segment (bytes) 1 - -
SEMMNI Number of semaphore identifiers 32000 0 0.00%
SEMMNS Total number of semaphores 1024000000 0 0.00%
SEMMSL Max semaphores per semaphore set. 32000 - -
SEMOPM Max number of operations per semop(2) 500 - -
SEMVMX Semaphore max value 32767 - -
lslogins: display information about known users in the system, e.g.:
root@ff2713f55b36:/# lslogins
UID USER PROC PWD-LOCK PWD-DENY LAST-LOGIN GECOS
0 root 2 0 1 root
1 daemon 0 0 1 daemon
2 bin 0 0 1 bin
3 sys 0 0 1 sys
4 sync 0 0 1 sync
5 games 0 0 1 games
6 man 0 0 1 man
7 lp 0 0 1 lp
8 mail 0 0 1 mail
9 news 0 0 1 news
10 uucp 0 0 1 uucp
13 proxy 0 0 1 proxy
33 www-data 0 0 1 www-data
34 backup 0 0 1 backup
38 list 0 0 1 Mailing List Manager
39 irc 0 0 1 ircd
41 gnats 0 0 1 Gnats Bug-Reporting System (admin)
100 _apt 0 0 1
65534 nobody 0 0 1 nobody
lsns: list system namespaces, e.g.:
root@ff2713f55b36:/# lsns
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 2 1 root bash
4026531837 user 2 1 root bash
4026532473 mnt 2 1 root bash
4026532474 uts 2 1 root bash
4026532475 ipc 2 1 root bash
4026532476 pid 2 1 root bash
4026532478 net 2 1 root bash
setpriv: run a program with different privilege settings
zramctl: tool to quickly set up zram device parameters, to reset zram devices, and to query the status of used zram devices
New features/options
addpart (show or change the real-time scheduling attributes of a process):
--reload reload prompts on running agetty instances
blkdiscard (discard the content of sectors on a device):
-p, --step <num> size of the discard iterations within the offset
-z, --zeroout zero-fill rather than discard
chrt (show or change the real-time scheduling attributes of a process):
-d, --deadline set policy to SCHED_DEADLINE
-T, --sched-runtime <ns> runtime parameter for DEADLINE
-P, --sched-period <ns> period parameter for DEADLINE
-D, --sched-deadline <ns> deadline parameter for DEADLINE
fdformat (do a low-level formatting of a floppy disk):
-f, --from <N> start at the track N (default 0)
-t, --to <N> stop at the track N
-r, --repair <N> try to repair tracks failed during the verification (max N retries)
fdisk (display or manipulate a disk partition table):
-B, --protect-boot don't erase bootbits when creating a new label
-o, --output <list> output columns
--bytes print SIZE in bytes rather than in human readable format
-w, --wipe <mode> wipe signatures (auto, always or never)
-W, --wipe-partitions <mode> wipe signatures from new partitions (auto, always or never)
New available columns (for -o):
gpt: Device Start End Sectors Size Type Type-UUID Attrs Name UUID
dos: Device Start End Sectors Cylinders Size Type Id Attrs Boot End-C/H/S Start-C/H/S
bsd: Slice Start End Sectors Cylinders Size Type Bsize Cpg Fsize
sgi: Device Start End Sectors Cylinders Size Type Id Attrs
sun: Device Start End Sectors Cylinders Size Type Id Flags
findmnt (find a (mounted) filesystem):
-J, --json use JSON output format
-M, --mountpoint <dir> the mountpoint directory
-x, --verify verify mount table content (default is fstab)
--verbose print more details
flock (manage file locks from shell scripts):
-F, --no-fork execute command without forking
--verbose increase verbosity
getty (open a terminal and set its mode):
--reload reload prompts on running agetty instances
hwclock (query or set the hardware clock):
--get read hardware clock and print drift corrected result
--update-drift update drift factor in /etc/adjtime (requires --set or --systohc)
ldattach (attach a line discipline to a serial line):
-c, --intro-command <string> intro sent before ldattach
-p, --pause <seconds> pause between intro and ldattach
logger (enter messages into the system log):
-e, --skip-empty do not log empty lines when processing files
--no-act do everything except the write the log
--octet-count use rfc6587 octet counting
-S, --size <size> maximum size for a single message
--rfc3164 use the obsolete BSD syslog protocol
--rfc5424[=<snip>] use the syslog protocol (the default for remote);
<snip> can be notime, or notq, and/or nohost
--sd-id <id> rfc5424 structured data ID
--sd-param <data> rfc5424 structured data name=value
--msgid <msgid> set rfc5424 message id field
--socket-errors[=<on off auto>] print connection errors when using Unix sockets
losetup (set up and control loop devices):
-L, --nooverlap avoid possible conflict between devices
--direct-io[=<on off>] open backing file with O_DIRECT
-J, --json use JSON --list output format
New available --list column:
DIO access backing file with direct-io
lsblk (list information about block devices):
-J, --json use JSON output format
New available columns (for --output):
HOTPLUG removable or hotplug device (usb, pcmcia, ...)
SUBSYSTEMS de-duplicated chain of subsystems
lscpu (display information about the CPU architecture):
-y, --physical print physical instead of logical IDs
New available column:
DRAWER logical drawer number
lslocks (list local system locks):
-J, --json use JSON output format
-i, --noinaccessible ignore locks without read permissions
nsenter (run a program with namespaces of other processes):
-C, --cgroup[=<file>] enter cgroup namespace
--preserve-credentials do not touch uids or gids
-Z, --follow-context set SELinux context according to --target PID
rtcwake (enter a system sleep state until a specified wakeup time):
--date <timestamp> date time of timestamp to wake
--list-modes list available modes
-r, --reorder <dev> fix partitions order (by start offset)
sfdisk (display or manipulate a disk partition table):
New Commands:
-J, --json <dev> dump partition table in JSON format
-F, --list-free [<dev> ...] list unpartitioned free areas of each device
-r, --reorder <dev> fix partitions order (by start offset)
--delete <dev> [<part> ...] delete all or specified partitions
--part-label <dev> <part> [<str>] print or change partition label
--part-type <dev> <part> [<type>] print or change partition type
--part-uuid <dev> <part> [<uuid>] print or change partition uuid
--part-attrs <dev> <part> [<str>] print or change partition attributes
New Options:
-a, --append append partitions to existing partition table
-b, --backup backup partition table sectors (see -O)
--bytes print SIZE in bytes rather than in human readable format
--move-data[=<typescript>] move partition data after relocation (requires -N)
--color[=<when>] colorize output (auto, always or never)
colors are enabled by default
-N, --partno <num> specify partition number
-n, --no-act do everything except write to device
--no-tell-kernel do not tell kernel about changes
-O, --backup-file <path> override default backup file name
-o, --output <list> output columns
-w, --wipe <mode> wipe signatures (auto, always or never)
-W, --wipe-partitions <mode> wipe signatures from new partitions (auto, always or never)
-X, --label <name> specify label type (dos, gpt, ...)
-Y, --label-nested <name> specify nested label type (dos, bsd)
Available columns (for -o):
gpt: Device Start End Sectors Size Type Type-UUID Attrs Name UUID
dos: Device Start End Sectors Cylinders Size Type Id Attrs Boot End-C/H/S Start-C/H/S
bsd: Slice Start End Sectors Cylinders Size Type Bsize Cpg Fsize
sgi: Device Start End Sectors Cylinders Size Type Id Attrs
sun: Device Start End Sectors Cylinders Size Type Id Flags
swapon (enable devices and files for paging and swapping):
-o, --options <list> comma-separated list of swap options
New available columns (for --show):
UUID swap uuid
LABEL swap label
unshare (run a program with some namespaces unshared from the parent):
-C, --cgroup[=<file>] unshare cgroup namespace
--propagation slave shared private unchanged modify mount propagation in mount namespace
-s, --setgroups allow deny control the setgroups syscall in user namespaces
Deprecated / removed options
sfdisk (display or manipulate a disk partition table):
-c, --id change or print partition Id
--change-id change Id
--print-id print Id
-C, --cylinders <number> set the number of cylinders to use
-H, --heads <number> set the number of heads to use
-S, --sectors <number> set the number of sectors to use
-G, --show-pt-geometry deprecated, alias to --show-geometry
-L, --Linux deprecated, only for backward compatibility
-u, --unit S deprecated, only sector unit is supported
 It was pointed out to me that I have not blogged about this, so better now than never:
Since 2021 I am together with four other hosts producing a regular podcast about Haskell, the Haskell Interlude. Roughly every two weeks two of us interview someone from the Haskell Community, and we chat for approximately an hour about how they came to Haskell, what they are doing with it, why they are doing it and what else is on their mind. Sometimes we talk to very famous people, like Simon Peyton Jones, and sometimes to people who maybe should be famous, but aren t quite yet.
For most episodes we also have a transcript, so you can read the interviews instead, if you prefer, and you should find the podcast on most podcast apps as well. I do not know how reliable these statistics are, but supposedly we regularly have around 1300 listeners. We don t get much feedback, however, so if you like the show, or dislike it, or have feedback, let us know (for example on the Haskell Disourse, which has a thread for each episode).
At the time of writing, we released 40 episodes. For the benefit of my (likely hypothetical) fans, or those who want to train an AI voice model for nefarious purposes, here is the list of episodes co-hosted by me:
Can t decide where to start? The one with Ryan Trinkle might be my favorite.
Thanks to the Haskell Foundation and its sponsors for supporting this podcast (hosting, editing, transscription).
It was pointed out to me that I have not blogged about this, so better now than never:
Since 2021 I am together with four other hosts producing a regular podcast about Haskell, the Haskell Interlude. Roughly every two weeks two of us interview someone from the Haskell Community, and we chat for approximately an hour about how they came to Haskell, what they are doing with it, why they are doing it and what else is on their mind. Sometimes we talk to very famous people, like Simon Peyton Jones, and sometimes to people who maybe should be famous, but aren t quite yet.
For most episodes we also have a transcript, so you can read the interviews instead, if you prefer, and you should find the podcast on most podcast apps as well. I do not know how reliable these statistics are, but supposedly we regularly have around 1300 listeners. We don t get much feedback, however, so if you like the show, or dislike it, or have feedback, let us know (for example on the Haskell Disourse, which has a thread for each episode).
At the time of writing, we released 40 episodes. For the benefit of my (likely hypothetical) fans, or those who want to train an AI voice model for nefarious purposes, here is the list of episodes co-hosted by me:
Can t decide where to start? The one with Ryan Trinkle might be my favorite.
Thanks to the Haskell Foundation and its sponsors for supporting this podcast (hosting, editing, transscription).
 It s been quite a few months since the most recent updates about Flathub last year. We ve been busy behind the scenes, so I d like to share what we ve been up to at Flathub and why and what s coming up from us this year. I want to focus on:
It s been quite a few months since the most recent updates about Flathub last year. We ve been busy behind the scenes, so I d like to share what we ve been up to at Flathub and why and what s coming up from us this year. I want to focus on:
 In Mexico, we have the great luck to live among vestiges of long-gone
cultures, some that were conquered and in some way got adapted and
survived into our modern, mostly-West-Europan-derived society, and
some that thrived but disappeared many more centuries ago. And
although not everybody feels the same way, in my family we have always
enjoyed visiting archaeological sites when I was a child and today.
Some of the regulars that follow this blog (or its syndicators) will
remember Xochicalco, as it was the destination we chose for the
daytrip back in the day, in DebConf6 (May 2006).
In Mexico, we have the great luck to live among vestiges of long-gone
cultures, some that were conquered and in some way got adapted and
survived into our modern, mostly-West-Europan-derived society, and
some that thrived but disappeared many more centuries ago. And
although not everybody feels the same way, in my family we have always
enjoyed visiting archaeological sites when I was a child and today.
Some of the regulars that follow this blog (or its syndicators) will
remember Xochicalco, as it was the destination we chose for the
daytrip back in the day, in DebConf6 (May 2006).


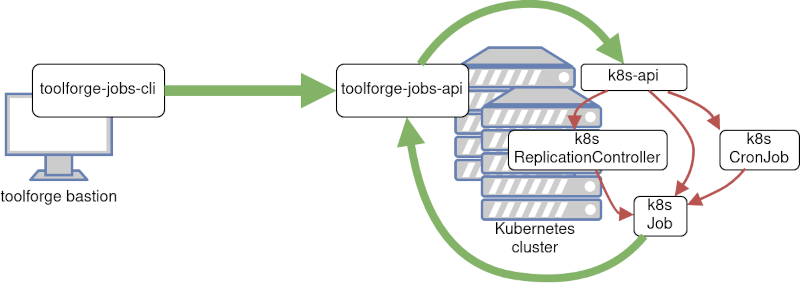 This post was originally published in the
This post was originally published in the 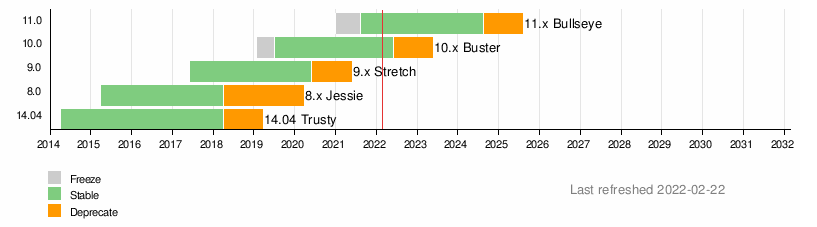 Back then, our reasoning was that skipping to Debian 11 Bullseye would be more difficult for our users, especially because greater jump in version
numbers for the underlying runtimes. Additionally, all the migration work started before Debian 11 Bullseye was released. Our original intention was
for the migration to be completed before the release. For a couple of reasons the project was delayed, and when it was time to restart the project we
decided to continue with the original idea.
We had some work done to get Debian 10 Buster working correctly with the grid, and supporting Debian 11 Bullseye would require an additional effort. We
didn t even check if Grid Engine could be installed in the latest Debian release. For the grid, in general, the engineering effort to do a N+1 upgrade is
lower than doing a N+2 upgrade. If we had tried a N+2 upgrade directly, things would have been much slower and difficult for us, and for our users.
In that sense, our conclusion was to not skip Debian 10 Buster.
Back then, our reasoning was that skipping to Debian 11 Bullseye would be more difficult for our users, especially because greater jump in version
numbers for the underlying runtimes. Additionally, all the migration work started before Debian 11 Bullseye was released. Our original intention was
for the migration to be completed before the release. For a couple of reasons the project was delayed, and when it was time to restart the project we
decided to continue with the original idea.
We had some work done to get Debian 10 Buster working correctly with the grid, and supporting Debian 11 Bullseye would require an additional effort. We
didn t even check if Grid Engine could be installed in the latest Debian release. For the grid, in general, the engineering effort to do a N+1 upgrade is
lower than doing a N+2 upgrade. If we had tried a N+2 upgrade directly, things would have been much slower and difficult for us, and for our users.
In that sense, our conclusion was to not skip Debian 10 Buster.
 This post was originally published in the
This post was originally published in the  This post was originally published in the
This post was originally published in the 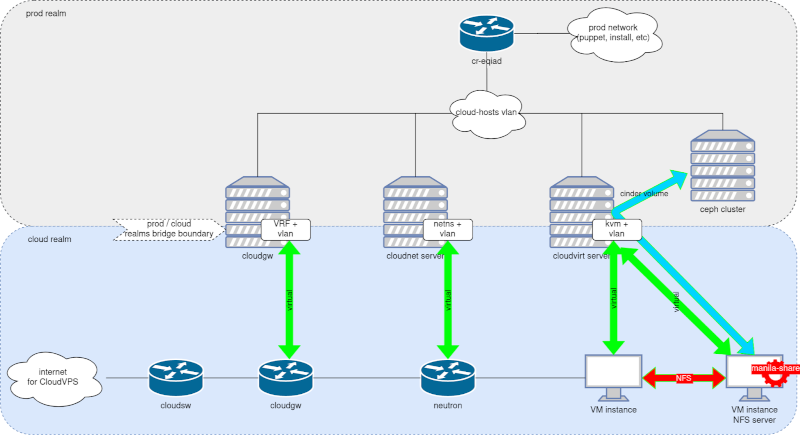









 This post was originally published in the
This post was originally published in the 
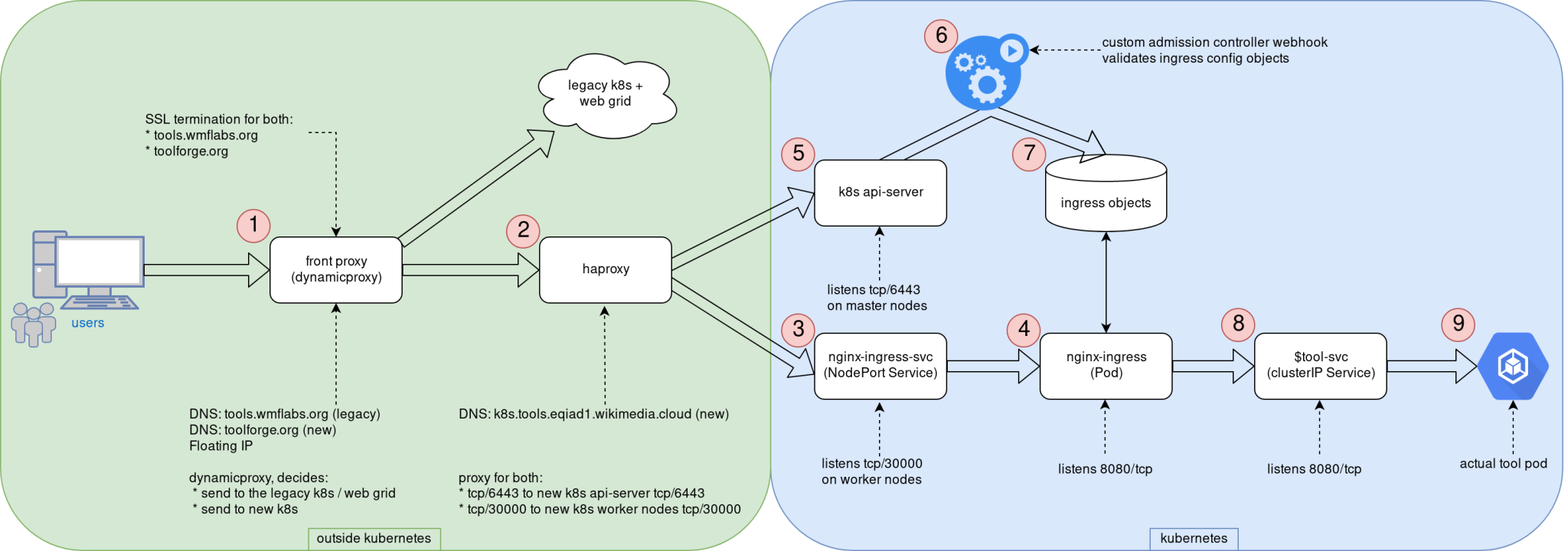
 Debian Stretch feels like an excellent release by the Debian project.
The final
Debian Stretch feels like an excellent release by the Debian project.
The final 

 Here is my monthly update covering what I have been doing in the free software world (
Here is my monthly update covering what I have been doing in the free software world (






.png){kind=link}
_Manila_Skyline_-_panoramio.jpg){kind=link}
{kind=link}
{kind=link}