
After prompts from Wookey and Steve McIntyre, I decided to look at
#285559 and
#633884 for perl cross-build support and then port that support forward to the current perl in Wheezy and on to the version of perl currently in experimental. The first patch is for perl 5.8, the second for perl 5.12, neither of which is available currently in Debian. snapshot.debian.org provided the 5.12 source but then that no longer cross-builds with the patch.
The problem, as with any cross build, is that the build must avoid trying to execute binaries compiled within the build to achieve the test results required by ./configure (or in the case of perl, Configure).
dpkg-cross has one collection of cache values but the intention was always to migrate the package-specific support data into the packages themselves and keep the architecture-specific data in dpkg-cross or dpkg-dev. Therefore, the approach taken in #633884 would be correct, if only there was a way of ensuring that the cached values remain in sync with the relevant Debian package.
I'll note here that I am aware of other ways of cross-building perl, this is particularly concerned with cross-building the Debian configuration of perl as a Debian package and using Debian or Emdebian cross-compilers. After all, the objective is to support bootstrapping Debian onto new architectures. However, I fully expect this to be just as usable with Ubuntu packages of perl compiled with, e.g. Linaro cross-compilers but I haven't yet looked at the differences between perl in Debian vs Ubuntu in any detail.
I've just got perl 5.14.2 cross-building for armel using the Emdebian gcc-4.4 cross-compiler (4.4.5-8) on a Debian sid amd64 machine without errors (it needs testing, which I'll look at later), so now is the time to document how it is done and what needs to be fixed. I've already discussed part of this with the current perl maintainers in Debian and, subject to just how the update mechanism works, have outline approval for pushing these changes into the Debian package and working with upstream where appropriate. The cache data itself might live in a separate source package which will use a strict dependency on perl to ensure that it remains in sync with the version which it can cross-build. Alternatively, if I can correctly partition the cache data between architecture-specific (and therefore generated from the existing files) and package_$version specific, then it may be possible to push a much smaller patch into the Debian perl package. This would start with some common data, calculate the arch-specific data and then look for some version-specific data, gleaned from Debian porter boxes whilst the version is in Debian experimental.
The key point is that I've offered to provide this support for the long term, ensuring that we don't end up with future stable releases of Debian having a perl package which cannot be cross-built. (To achieve that, we will also end up with versions of perl in Debian testing which also cross-build.)
This cross-build is still using dpkg-cross paths, not MultiArch paths, and this will need to be changed eventually. (e.g. by the source package providing two binaries, one which uses MultiArch and one which expects dpkg-cross paths.) The changes include patches for the upstream Makefile.SH, debian/rules and the cache data itself. Depending on where the cache data finally lives, the new support might or might not use the upstream Cross/ directory as the current contents date from the Zaurus support and don't appear to be that useful for current versions of perl.
The cache data itself has several problems:
- It is tightly tied to the version of perl which generated it.
- It is, as expected, architecture-dependent
- It is, unfortunately, very sensitive to the specific configuration used by the distribution itself
That last point is important because it means that the cache data is not useful upstream as a block. It also means that generating the cache data for a specific Debian package means running the generation code on the native architecture with all of the Debian build-dependencies installed for the full perl build. This is going to complicate the use of this method for new architectures like arm64.
My objective for the long term maintenance of this code is to create sufficient data that a new architecture can be bootstrapped by judicious use of some form of template. Quite how that works out, only time will tell. I expect that this will involve isolating the data which is truly architecture-specific which doesn't change between perl versions from the data which is related to the tests for build-dependencies which does change between perl versions and then work out how to deal with any remainder. A new architecture for a specific perl version should then just be a case of populating the arch-specific data such as the size of a pointer/char and the format specifiers for long long etc. alongside the existing (and correct) data for the current version of perl.
Generating the cache data natively
The perl build repeats twice (three builds in total) and each build provides and requires slightly different cache data - static, debug and shared. Therefore, the maintenance code will need to provide a script which can run the correct configuration step for each mode, copy out the cache data for each one and clean up. The script will need to run inside a buildd chroot on a porter box (I'm looking at using abel.debian.org and harris.debian.org for this work so far) so that the derived data matches what the corresponding Debian native build would use. The data then needs slight modification - typically to replace the absolute paths with PERL_BUILD_DIR. It may also be necessary to change the value of cc, ranlib and other compiler-related values to the relevant cross-compiler executables. That should be possible to arrange within the build of the cache data support package itself, allowing new cache files to be dropped in directly from the porter box.
The configuration step may need to be optimised within debian/rules of perl itself as it currently proceeds on from the bare configuration to do some actual building but I need to compare the data to see if a bare config is modified later. The test step can be omitted already. Each step is performed as:
DEB_BUILD_OPTIONS="nocheck" fakeroot debian/rules perl.static
That is repeated for perl.debug and libperl.so.$(VERSION) where $VERSION comes from :
/bin/bash debian/config.debian --full-version
The files to be copied out are:
- bitcount.h - architecture-specific (may be identical between similar architectures like armel & armhf)
- config.h - architecture & build specific, config.h.debug, config.h.static, config.h.shared.
- config.sh - architecture & build specific config.sh.debug, config.sh.static, config.sh.shared.
- uudmap.h - architecture-specific (may be identical between similar architectures like armel & armhf)
There is a lot of scope for templating of some form here, e.g. config.h.debug is 4,686 lines long but only 41 of those lines differ between amd64 and armhf for the same version of perl (and some of those can be identified from existing architecture-specific constants) which should make for a much smaller patch.
Architecture-specific cache data for perl
So far, the existing patches only deal with armel and armhf. If I compare the differences between armel & armhf, it comes down to:
- compiler names (config.h.*)
- architecture names (config.sh.*)
- architecture-based paths (config.sh.*)
However, comparing armel and armhf doesn't provide sufficient info for deriving arm64 or mips etc. Comparing the same versions for armhf and amd64 shows the range of differences more clearly. Typical architecture differences exist like the size of a long, flags to denote if the compiler can cast negative floats to 32bit ints and the sprintf format specifier strings for handling floats and doubles. The data also includes some less expected ones like:
armhf: #define Netdb_host_t const void * /**/
amd64: #define Netdb_host_t char * /**/
I'm not at all sure why that is arch-specific - if anyone knows, email codehelp @ d.o - same address if anyone fancies helping out ....
Cross-builds and debclean
When playing with the cross-build, remember to use the cross-build clean support, not just debclean:
dpkg-architecture -aarmel -c fakeroot debian/rules clean
That wasted quite a bit of my time initially with having to blow away the entire tree, unpack it from original apt sources and repatch it. (Once Wheezy is out, may actually investigate getting debclean to support the -a switch).
OK, that's an introduction, I'm planning on pushing the cross-build support code onto github soon-ish and doing some testing of the cross-built perl binaries in a chroot on an armel box. I'll detail that in another blog post when it's available.
Next step is to look at perl 5.16 and then current perl upstream git to see how to get Makefile.SH fixed for the long term.

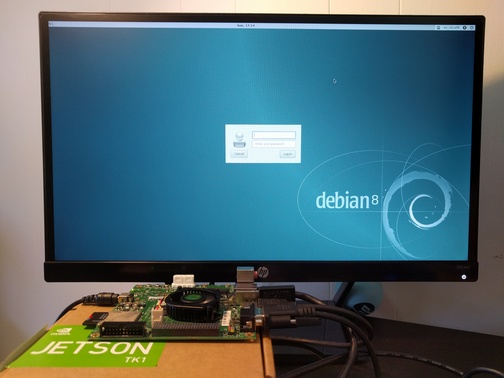 I became interested in running Debian on NVIDIA's Tegra platform recently. NVIDIA is doing a great job getting support for Tegra upstream (u-boot, kernel, X.org and other projects). As part of ensuring good Debian support for Tegra, I wanted to install Debian on a Jetson TK1, a development board from NVIDIA based on the Tegra K1 chip (Tegra 124), a 32-bit ARM chip.
Ian Campbell enabled u-boot and Linux kernel support and added support in the installer for this device about a year ago. I updated some kernel options since there has been a lot of progress upstream in the meantime, performed a lot of tests and documented the installation process on the Debian wiki. Wookey made substantial improvements to the wiki as well.
If you're interested in a good 32-bit ARM development platform, give
I became interested in running Debian on NVIDIA's Tegra platform recently. NVIDIA is doing a great job getting support for Tegra upstream (u-boot, kernel, X.org and other projects). As part of ensuring good Debian support for Tegra, I wanted to install Debian on a Jetson TK1, a development board from NVIDIA based on the Tegra K1 chip (Tegra 124), a 32-bit ARM chip.
Ian Campbell enabled u-boot and Linux kernel support and added support in the installer for this device about a year ago. I updated some kernel options since there has been a lot of progress upstream in the meantime, performed a lot of tests and documented the installation process on the Debian wiki. Wookey made substantial improvements to the wiki as well.
If you're interested in a good 32-bit ARM development platform, give  A big update of all related packages (tex-common 6.04, texlive-bin 2015.20150524.37493-7, texlive-base/lang/extra package 2015.20151016-1) due to the move to support multi-arch. Of course, the regular updates of the TeX Live are included, too. With this change it should be possible to run a multi-arch system with only one TeX Live installed.
A big update of all related packages (tex-common 6.04, texlive-bin 2015.20150524.37493-7, texlive-base/lang/extra package 2015.20151016-1) due to the move to support multi-arch. Of course, the regular updates of the TeX Live are included, too. With this change it should be possible to run a multi-arch system with only one TeX Live installed.
 Thanks to the excellent support and testing of the Multi-arch guys, in particular Thorsten Glaser, Helmut Grohne, Johannes Schauer, and Wookey, I learned a lot about multi-arch, and I hope that the current setup is safe. All the packages but the various lib* packages are tagged as Multi-Arch: foreign, while the lib packages are tagged Multi-Arch: same. Anyway, if you find a bug concerning multi-arch, that is that some of the programs exhibit architecture information, please let us know via a bug report.
Updated packages
acro, alegreya, amiri, assoccnt, attachfile, babel-french, babel-hungarian, barr, beebe, biblatex-philosophy, bidi, bnumexpr, caption, chemfig, chemformula, chemmacros, cjk-gs-integrate, csplain, dantelogo, dataref, dtxgen, dvipdfmx-def, dvips, eledmac, elements, fcolumn, fithesis, fontspec, genealogytree, gradstudentresume, gtl, jfontmaps, knuth-local, koma-script, kotex-oblivoir, kotex-plain, kotex-utf, kpathsea, l3build, l3experimental, l3kernel, l3packages, latex, latexconfig, ledmac, ltxfileinfo, lualatex-math, luamplib, luatex, luatexbase, luatexja, luatexko, make4ht, mcf2graph, mflogo, modiagram, multiexpand, newtx, odsfile, old-arrows, paracol, pdfpages, pdftex, plain, pst-stru, pxchfon, randomwalk, reledmac, resumecls, rubik, selnolig, showhyphens, siunitx, suftesi, tetex, teubner, tex4ebook, tex4ht, texlive-scripts, tikzsymbols, tipfr, tools, tudscr, uassign, unicode-math, unravel, visualfaq, xepersian, xetex-def, xint.
New packages
archaeologie, ctablestack, dynamicnumber, exercises, fibeamer, h2020proposal, imfellenglish, lstbayes, tempora, xellipsis.
Enjoy.
Thanks to the excellent support and testing of the Multi-arch guys, in particular Thorsten Glaser, Helmut Grohne, Johannes Schauer, and Wookey, I learned a lot about multi-arch, and I hope that the current setup is safe. All the packages but the various lib* packages are tagged as Multi-Arch: foreign, while the lib packages are tagged Multi-Arch: same. Anyway, if you find a bug concerning multi-arch, that is that some of the programs exhibit architecture information, please let us know via a bug report.
Updated packages
acro, alegreya, amiri, assoccnt, attachfile, babel-french, babel-hungarian, barr, beebe, biblatex-philosophy, bidi, bnumexpr, caption, chemfig, chemformula, chemmacros, cjk-gs-integrate, csplain, dantelogo, dataref, dtxgen, dvipdfmx-def, dvips, eledmac, elements, fcolumn, fithesis, fontspec, genealogytree, gradstudentresume, gtl, jfontmaps, knuth-local, koma-script, kotex-oblivoir, kotex-plain, kotex-utf, kpathsea, l3build, l3experimental, l3kernel, l3packages, latex, latexconfig, ledmac, ltxfileinfo, lualatex-math, luamplib, luatex, luatexbase, luatexja, luatexko, make4ht, mcf2graph, mflogo, modiagram, multiexpand, newtx, odsfile, old-arrows, paracol, pdfpages, pdftex, plain, pst-stru, pxchfon, randomwalk, reledmac, resumecls, rubik, selnolig, showhyphens, siunitx, suftesi, tetex, teubner, tex4ebook, tex4ht, texlive-scripts, tikzsymbols, tipfr, tools, tudscr, uassign, unicode-math, unravel, visualfaq, xepersian, xetex-def, xint.
New packages
archaeologie, ctablestack, dynamicnumber, exercises, fibeamer, h2020proposal, imfellenglish, lstbayes, tempora, xellipsis.
Enjoy.


 I promised to write about this a long time, ooops... :-)
Another ARM port in Debian - yay!
arm64 is officially a release architecture for Jessie, aka Debian
version 8. That's taken a lot of manual porting and development effort
over the last couple of years, and it's also taken a lot of CPU time -
there are ~21,000 source packages in Debian Jessie! As is often the
case for a brand new architecture like arm64 (or AArch64, to use ARM's
own terminology), hardware can be really difficult to get hold of. In
time this will cease to be an issue as hardware becomes more
commoditised, but in Debian we really struggled to get hold of
equipment for a very long time during the early part of the port.
First bring-up in Debian Ports
To start with, we could use ARM's own AArch64 software models to
build the first few packages. This worked, but only very slowly. Then
Chen Baozi and the folks running
the
I promised to write about this a long time, ooops... :-)
Another ARM port in Debian - yay!
arm64 is officially a release architecture for Jessie, aka Debian
version 8. That's taken a lot of manual porting and development effort
over the last couple of years, and it's also taken a lot of CPU time -
there are ~21,000 source packages in Debian Jessie! As is often the
case for a brand new architecture like arm64 (or AArch64, to use ARM's
own terminology), hardware can be really difficult to get hold of. In
time this will cease to be an issue as hardware becomes more
commoditised, but in Debian we really struggled to get hold of
equipment for a very long time during the early part of the port.
First bring-up in Debian Ports
To start with, we could use ARM's own AArch64 software models to
build the first few packages. This worked, but only very slowly. Then
Chen Baozi and the folks running
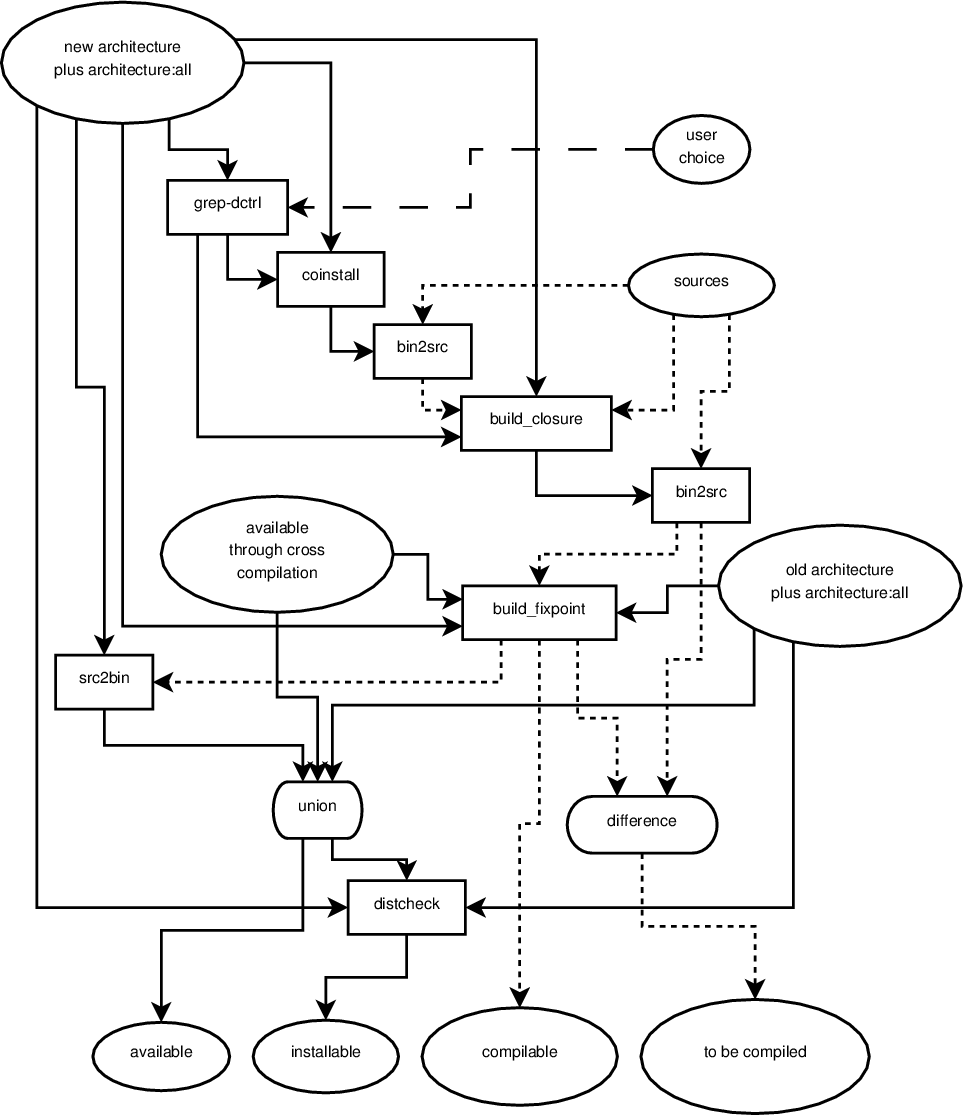
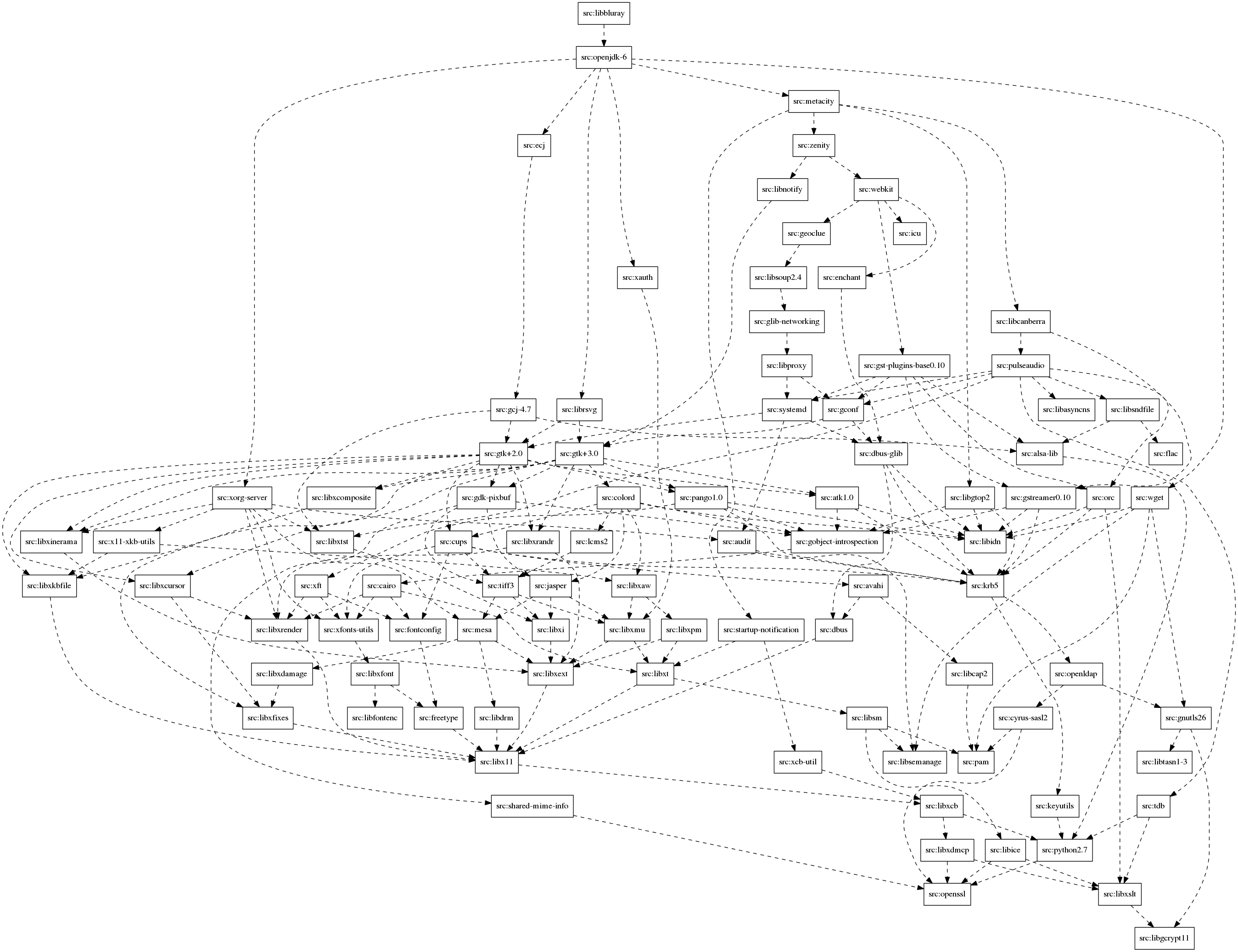
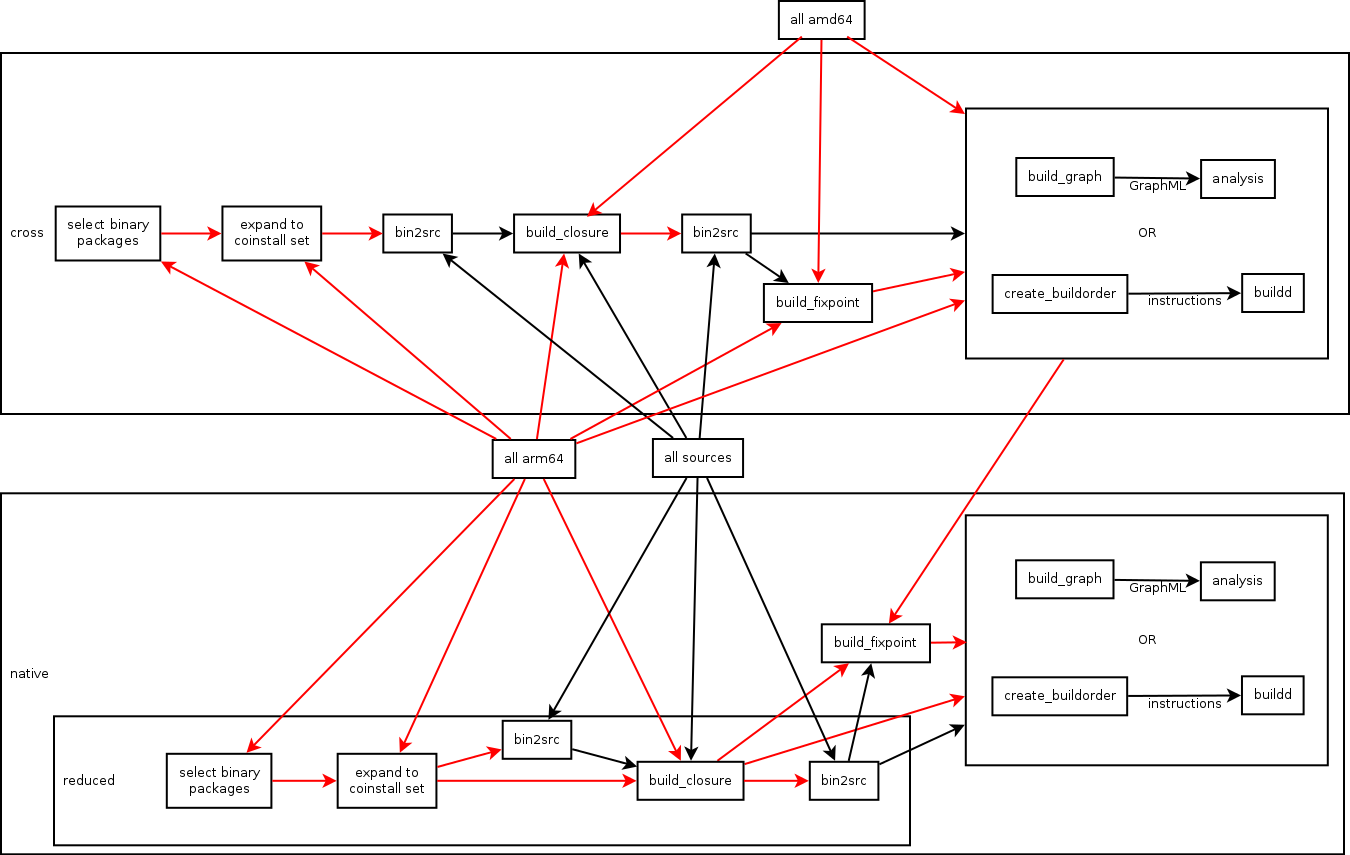
the  My last update about ongoing development of botch, the bootstrap/build ordering
tool chain, was three months ago with the
My last update about ongoing development of botch, the bootstrap/build ordering
tool chain, was three months ago with the 

 WebRTC: premium voice/video chat in modern browsers, no plugin required
WebRTC: premium voice/video chat in modern browsers, no plugin required
 Another member of Debian's GSoC program,
Another member of Debian's GSoC program, 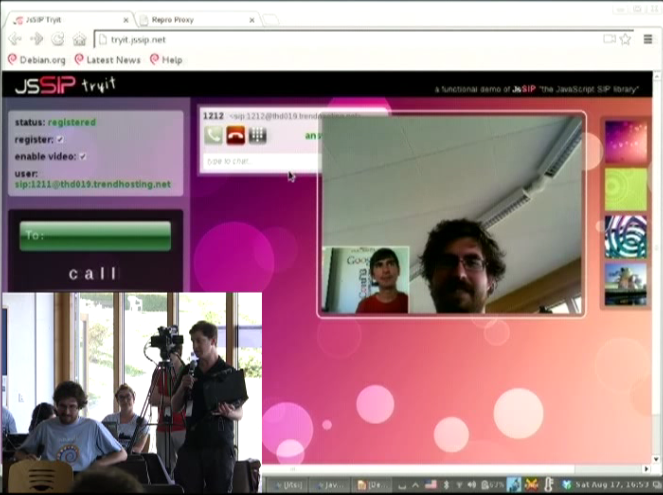 As the grand finale, we took
As the grand finale, we took 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}