Petter Reinholdtsen: 45 orphaned Debian packages moved to git, 391 to go
Nine days ago, I started migrating orphaned Debian packages with no
version control system listed in debian/control of the source to git.
At the time there were 438 such packages. Now there are 391,
according to the UDD. In reality it is slightly less, as there is a
delay between uploads and UDD updates. In the nine days since, I have
thus been able to work my way through ten percent of the packages. I
am starting to run out of steam, and hope someone else will also help
brushing some dust of these packages. Here is a recipe how to do it.
I start by picking a random package by querying the UDD for a list of
10 random packages from the set of remaining packages:
Next, I visit http://salsa.debian.org/debian and search for the package name, to ensure no git repository already exist. If it does, I clone it and try to get it to an uploadable state, and add the Vcs-* entries in d/control to make the repository more widely known. These packages are a minority, so I will not cover that use case here. For packages without an existing git repository, I run the following script debian-snap-to-salsa to prepare a git repository with the existing packaging.PGPASSWORD="udd-mirror" psql --port=5432 --host=udd-mirror.debian.net \ --username=udd-mirror udd -c "select source from sources \ where release = 'sid' and (vcs_url ilike '%anonscm.debian.org%' \ OR vcs_browser ilike '%anonscm.debian.org%' or vcs_url IS NULL \ OR vcs_browser IS NULL) AND maintainer ilike '%packages@qa.debian.org%' \ order by random() limit 10;"
#!/bin/sh
#
# See also https://bugs.debian.org/804722#31
set -e
# Move to this Standards-Version.
SV_LATEST=4.7.0
PKG="$1"
if [ -z "$PKG" ]; then
echo "usage: $0 "
exit 1
fi
if [ -e "$ PKG -salsa" ]; then
echo "error: $ PKG -salsa already exist, aborting."
exit 1
fi
if [ -z "ALLOWFAILURE" ] ; then
ALLOWFAILURE=false
fi
# Fetch every snapshotted source package. Manually loop until all
# transfers succeed, as 'gbp import-dscs --debsnap' do not fail on
# download failures.
until debsnap --force -v $PKG $ALLOWFAILURE ; do sleep 1; done
mkdir $ PKG -salsa; cd $ PKG -salsa
git init
# Specify branches to override any debian/gbp.conf file present in the
# source package.
gbp import-dscs --debian-branch=master --upstream-branch=upstream \
--pristine-tar ../source-$PKG/*.dsc
# Add Vcs pointing to Salsa Debian project (must be manually created
# and pushed to).
if ! grep -q ^Vcs- debian/control ; then
awk "BEGIN s=1 /^\$/ if (s==1) print \"Vcs-Browser: https://salsa.debian.org/debian/$PKG\"; print \"Vcs-Git: https://salsa.debian.org/debian/$PKG.git\" ; s=0 print " < debian/control > debian/control.new && mv debian/control.new debian/control
git commit -m "Updated vcs in d/control to Salsa." debian/control
fi
# Tell gbp to enforce the use of pristine-tar.
inifile +inifile debian/gbp.conf +create +section DEFAULT +key pristine-tar +value True
git add debian/gbp.conf
git commit -m "Added d/gbp.conf to enforce the use of pristine-tar." debian/gbp.conf
# Update to latest Standards-Version.
SV="$(grep ^Standards-Version: debian/control awk ' print $2 ')"
if [ $SV_LATEST != $SV ]; then
sed -i "s/\(Standards-Version: \)\(.*\)/\1$SV_LATEST/" debian/control
git commit -m "Updated Standards-Version from $SV to $SV_LATEST." debian/control
fi
if grep -q pkg-config debian/control; then
sed -i s/pkg-config/pkgconf/ debian/control
git commit -m "Replaced obsolete pkg-config build dependency with pkgconf." debian/control
fi
if grep -q libncurses5-dev debian/control; then
sed -i s/libncurses5-dev/libncurses-dev/ debian/control
git commit -m "Replaced obsolete libncurses5-dev build dependency with libncurses-dev." debian/control
fi
With a working build, I have a look at the build rules if I want to remove some more dust. I normally try to move to debhelper compat level 13, which involves removing debian/compat and modifying debian/control to build depend on debhelper-compat (=13). I also test with 'Rules-Requires-Root: no' in debian/control and verify in debian/rules that hardening is enabled, and include all of these if the package still build. If it fail to build with level 13, I try with 12, 11, 10 and so on until I find a level where it build, as I do not want to spend a lot of time fixing build issues. Some times, when I feel inspired, I make sure debian/copyright is converted to the machine readable format, often by starting with 'debhelper -cc' and then cleaning up the autogenerated content until it matches realities. If I feel like it, I might also clean up non-dh-based debian/rules files to use the short style dh build rules. Once I have removed all the dust I care to process for the package, I run 'gbp dch' to generate a debian/changelog entry based on the commits done so far, run 'dch -r' to switch from 'UNRELEASED' to 'unstable' and get an editor to make sure the 'QA upload' marker is in place and that all long commit descriptions are wrapped into sensible lengths, run 'debcommit --release -a' to commit and tag the new debian/changelog entry, run 'debuild -S' to build a source only package, and 'dput ../perl-byacc_2.0-10_source.changes' to do the upload. During the entire process, and many times per step, I run 'debuild' to verify the changes done still work. I also some times verify the set of built files using 'find debian' to see if I can spot any problems (like no file in usr/bin any more or empty package). I also try to fix all lintian issues reported at the end of each 'debuild' run. If I find Debian specific patches, I try to ensure their metadata is fairly up to date and some times I even try to reach out to upstream, to make the upstream project aware of the patches. Most of my emails bounce, so the success rate is low. For projects with no Homepage entry in debian/control I try to track down one, and for packages with no debian/watch file I try to create one. But at least for some of the packages I have been unable to find a functioning upstream, and must skip both of these. If I could handle ten percent in nine days, twenty people could complete the rest in less then five days. I use approximately twenty minutes per package, when I have twenty minutes spare time to spend. Perhaps you got twenty minutes to spare too? As usual, if you use Bitcoin and want to show your support of my activities, please send Bitcoin donations to my address 15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.git remote add origin git@salsa.debian.org:debian/perl-byacc.git git push --set-upstream origin master upstream pristine-tar git push --tags
 With
With 
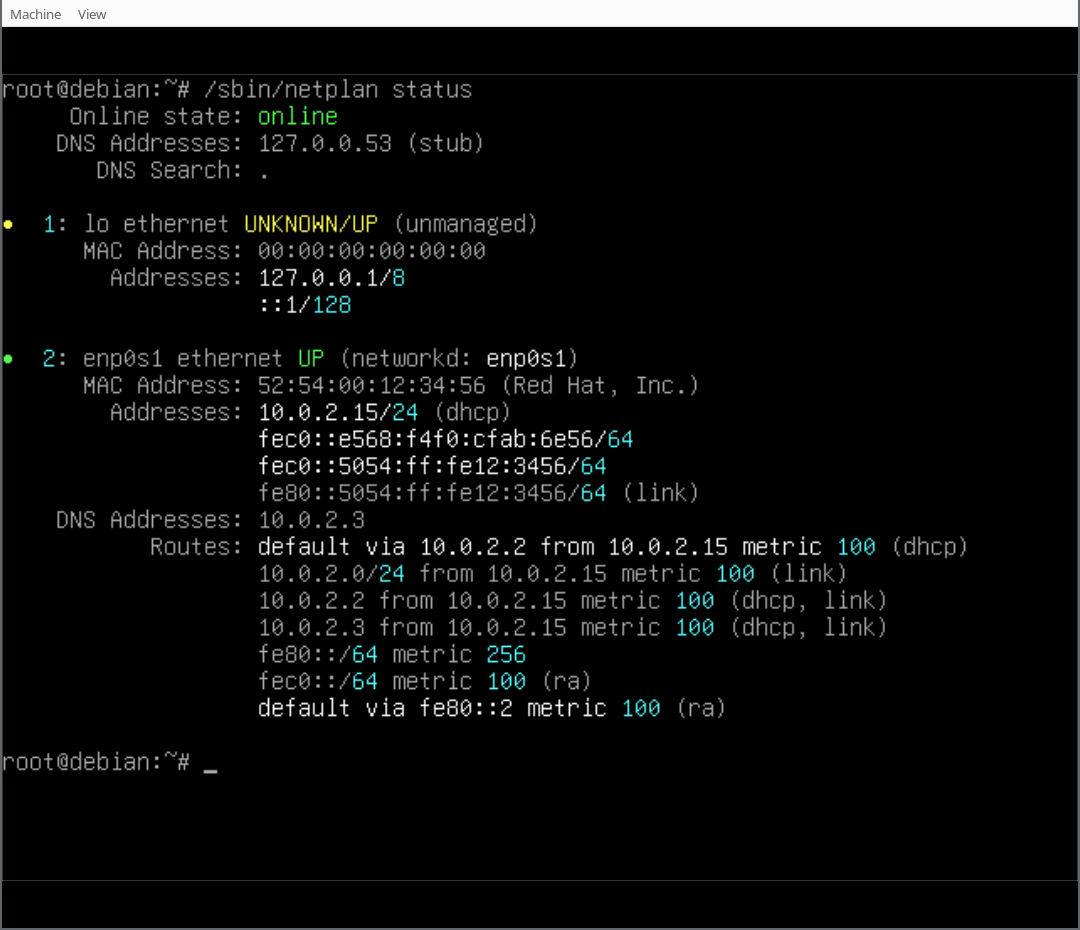
 (There s a handy
(There s a handy 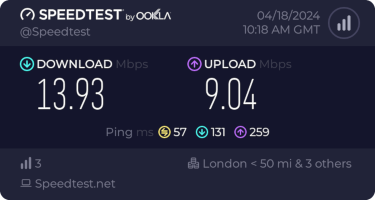 This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
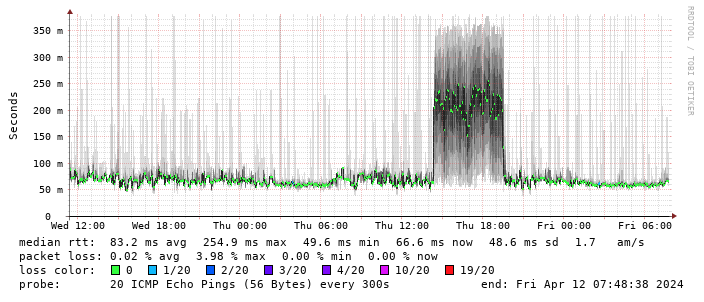
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
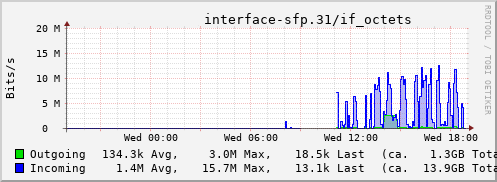 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.

 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
 Getting the
Getting the  Now that we are back from our six month period in Argentina, we
decided to adopt a kitten, to bring more diversity into our
lives. Perhaps this little girl will teach us to think outside the
box!
Now that we are back from our six month period in Argentina, we
decided to adopt a kitten, to bring more diversity into our
lives. Perhaps this little girl will teach us to think outside the
box!



 Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the 
 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
