With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up I d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. For now, we ll be using a custom ISO image, while waiting for the above-mentioned merge-proposal to be landed. Furthermore, as the Debian archive is going through major transitions builds of the unstable branch of d-i don t currently work. So I implemented a small backport, producing updated netcfg and netcfg-static for Bookworm, which can be used as localudebs/ during the d-i build.
Let s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
Now let s download the custom mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes, as mentioned above.
TODO: localudebs/
Next we ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
Finally, let s launch the installer using a custom preseed.cfg file, that will automatically install Netplan for us in the target system. A minimal preseed file could look like this:
For this demo, we re installing the full netplan.io package (incl. Python CLI), as the netplan-generator package was not yet split out as an independent binary in the Bookworm cycle. You can choose the preseed file from a set of different variants to test the different configurations:
We re using the custom linux kernel and initrd.gz here to be able to pass the PRESEED_URL as a parameter to the kernel s cmdline directly. Launching this VM should bring up the normal debian-installer in its netboot/gtk form:
Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
Done! After the installation finished you can reboot into your virgin Debian Bookworm system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was written by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
Finally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
In our case we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more join the discussion at Salsa:installer-team/netcfg and find us at GitHub:netplan.
Nation is a stand-alone young adult fantasy novel. It was
published in the gap between Discworld novels Making Money and Unseen
Academicals.
Nation starts with a plague. The Russian influenza has ravaged
Britain, including the royal family. The next in line to the throne is
off on a remote island and must be retrieved and crowned as soon as
possible, or an obscure provision in Magna Carta will cause no end of
trouble. The Cutty Wren is sent on this mission, carrying the
Gentlemen of Last Resort.
Then comes the tsunami.
In the midst of fire raining from the sky and a wave like no one has ever
seen, Captain Roberts tied himself to the wheel of the Sweet Judy
and steered it as best he could, straight into an island. The sole
survivor of the shipwreck: one Ermintrude Fanshaw, daughter of the
governor of some British island possessions. Oh, and a parrot.
Mau was on the Boys' Island when the tsunami came, going through his rite
of passage into manhood. He was to return to the Nation the next morning
and receive his tattoos and his adult soul. He survived in a canoe. No
one else in the Nation did.
Terry Pratchett considered Nation to be his best book. It is not
his best book, at least in my opinion; it's firmly below the top tier of
Discworld novels, let alone Night Watch.
It is, however, an interesting and enjoyable book that tackles gods and
religion with a sledgehammer rather than a knife.
It's also very, very dark and utterly depressing at the start, despite a
few glimmers of Pratchett's humor. Mau is the main protagonist at first,
and the book opens with everyone he cares about dying. This is the place
where I thought Pratchett diverged the most from his Discworld style: in
Discworld, I think most of that would have been off-screen, but here we
follow Mau through the realization, the devastation, the disassociation,
the burials at sea, the thoughts of suicide, and the complete upheaval of
everything he thought he was or was about to become. I found the start of
this book difficult to get through. The immediate transition into
potentially tragic misunderstandings between Mau and Daphne (as Ermintrude
names herself once there is no one to tell her not to) didn't help.
As I got farther into the book, though, I warmed to it. The best parts
early on are Daphne's baffled but scientific attempts to understand Mau's
culture and her place in it. More survivors arrive, and they start to
assemble a community, anchored in large part by Mau's stubborn
determination to do what's right even though he's lost all of his
moorings. That community eventually re-establishes contact with the rest
of the world and the opening plot about the British monarchy, but not
before Daphne has been changed profoundly by being part of it.
I think Pratchett worked hard at keeping Mau's culture at the center of
the story. It's notable that the community that reforms over the course
of the book essentially follows the patterns of Mau's lost Nation and
incorporates Daphne into it, rather than (as is so often the case) the
other way around. The plot itself is fiercely anti-colonial in a way that
mostly worked. Still, though, it's a quasi-Pacific-island culture written
by a white British man, and I had some qualms.
Pratchett quite rightfully makes it clear in the afterward that this is an
alternate world and Mau's culture is not a real Pacific island culture.
However, that also means that its starkly gender-essentialist nature was a
free choice, rather than one based on some specific culture, and I found
that choice somewhat off-putting. The religious rituals are all gendered,
the dwelling places are gendered, and one's entire life course in Mau's
world seems based on binary classification as a man or a woman. Based on
Pratchett's other books, I assume this was more an unfortunate default
than a deliberate choice, but it's still a choice he could have avoided.
The end of this book wrestles directly with the relative worth of Mau's
culture versus that of the British. I liked most of this, but the twists
that Pratchett adds to avoid the colonialist results we saw in our world
stumble partly into the trap of making Mau's culture valuable by British
standards. (I'm being a bit vague here to avoid spoilers.) I think it is
very hard to base this book on a different set of priorities and still
bring the largely UK, US, and western European audience along, so I don't
blame Pratchett for failing to do it, but I'm a bit sad that the world
still revolved around a British axis.
This felt quite similar to Discworld to me in its overall sensibilities,
but with the roles of moral philosophy and humor reversed. Discworld
novels usually start with some larger-than-life characters and an absurd
plot, and then the moral philosophy sneaks up behind you when you're not
looking and hits you over the head. Nation starts with the moral
philosophy: Mau wrestles with his gods and the problem of evil in a way
that reminded me of Job, except with a far different pantheon and rather
less tolerance for divine excuses on the part of the protagonist. It's
the humor, instead, that sneaks up on you and makes you laugh when the
plot is a bit too much. But the mix arrives at much the same place: the
absurd hand-in-hand with the profound, and all seen from an angle that
makes it a bit easier to understand.
I'm not sure I would recommend Nation as a good place to start with
Pratchett. I felt like I benefited from having read a lot of Discworld
to build up my willingness to trust where Pratchett was going. But it has
the quality of writing of late Discworld without the (arguable) need to
read 25 books to understand all of the backstory. Regardless,
recommended, and you'll never hear Twinkle Twinkle Little Star in
quite the same way again.
Rating: 8 out of 10
The XKCD comic Code Quality [1] inspired me to test out emoji in source. I really should have done this years ago when that XKCD was first published.
The following code compiles in gcc and runs in the way that anyone who wants to write such code would want it to run. The hover text in the XKCD comic is correct. You could have a style guide for such programming, store error messages in the doctor and nurse emoji for example.
#include <stdio.h>
int main()
int = 1, = 2;
printf(" =%d, =%d\n", , );
return 0;
To get this to display correctly in Debian you need to install the fonts-noto-color-emoji package (used by the KDE emoji picker that runs when you press Windows-. among other things) and restart programs that use emoji. The Konsole terminal emulator will probably need it s profile settings changed to work with this if you ran Konsole before installing fonts-noto-color-emoji. The Kitty terminal emulator works if you restart it after installing fonts-noto-color-emoji.
This web page gives a list of HTML codes for emoji [2]. If I start writing real code with emoji variable names then I ll have to update my source to HTML conversion script (which handles <>" and repeated spaces) to convert emoji.
I spent a couple of hours on this and I think it s worth it. I have filed several Debian bug reports about improvements needed to issues related to emoji.
The Stars, Like Dust is usually listed as the first book in
Asimov's lesser-known Galactic Empire Trilogy since it takes place before
Pebble in the Sky. Pebble in the
Sky was published first, though, so I count it as the second book. It is
very early science fiction with a few mystery overtones.
Buying books produces about 5% of the pleasure of reading them while
taking much less than 5% of the time. There was a time in my life when I
thoroughly enjoyed methodically working through a used book store, list in
hand, tracking down cheap copies to fill in holes in series. This means
that I own a lot of books that I thought at some point that I would want
to read but never got around to, often because, at the time, I was feeling
completionist about some series or piece of world-building. From time to
time, I get the urge to try to read some of them.
Sometimes this is a poor use of my time.
The Galactic Empire series is from Asimov's first science fiction period,
after the Foundation series but contemporaneous with their
collection into novels. They're set long, long before Foundation,
but after humans have inhabited numerous star systems and Earth has become
something of a backwater. That process is just starting in The
Stars, Like Dust: Earth is still somewhere where an upper-class son might
be sent for an education, but it has been devastated by nuclear wars and
is well on its way to becoming an inward-looking relic on the edge of
galactic society.
Biron Farrill is the son of the Lord Rancher of Widemos, a wealthy noble
whose world is one of those conquered by the Tyranni. In many other SF
novels, the Tyranni would be an alien race; here, it's a hierarchical and
authoritarian human civilization. The book opens with Biron discovering a
radiation bomb planted in his dorm room. Shortly after, he learns that
his father had been arrested. One of his fellow students claims to be on
Biron's side against the Tyranni and gives him false papers to travel to
Rhodia, a wealthy world run by a Tyranni sycophant.
Like most books of this era, The Stars, Like Dust is a short novel
full of plot twists. Unlike some of its contemporaries, it's not devoid
of characterization, but I might have liked it better if it were. Biron
behaves like an obnoxious teenager when he's not being an arrogant ass.
There is a female character who does a few plot-relevant things and at no
point is sexually assaulted, so I'll give Asimov that much, but the gender
stereotypes are ironclad and there is an entire subplot focused on what I
can only describe as seduction via petty jealousy.
The writing... well, let me quote a typical passage:
There was no way of telling when the threshold would be reached.
Perhaps not for hours, and perhaps the next moment. Biron remained
standing helplessly, flashlight held loosely in his damp hands. Half
an hour before, the visiphone had awakened him, and he had been at
peace then. Now he knew he was going to die.
Biron didn't want to die, but he was penned in hopelessly, and there
was no place to hide.
Needless to say, Biron doesn't die. Even if your tolerance for pulp
melodrama is high, 192 small-print pages of this sort of thing is
wearying.
Like a lot of Asimov plots, The Stars, Like Dust has some of the
shape of a mystery novel. Biron, with the aid of some newfound companions
on Rhodia, learns of a secret rebellion against the Tyranni and attempts
to track down its base to join them. There are false leads, disguised
identities, clues that are difficult to interpret, and similar classic
mystery trappings, all covered with a patina of early 1950s imaginary
science. To me, it felt constructed and artificial in ways that made the
strings Asimov was pulling obvious. I don't know if someone who likes
mystery construction would feel differently about it.
The worst part of the plot thankfully doesn't come up much. We learn
early in the story that Biron was on Earth to search for a long-lost
document believed to be vital to defeating the Tyranni. The nature of
that document is revealed on the final page, so I won't spoil it, but if
you try to think of the stupidest possible document someone could have
built this plot around, I suspect you will only need one guess. (In
Asimov's defense, he blamed Galaxy editor H.L. Gold for persuading
him to include this plot, and disavowed it a few years later.)
The Stars, Like Dust is one of the worst books I have ever read.
The characters are overwrought, the politics are slapdash and build on
broad stereotypes, the romantic subplot is dire and plays out mainly via
Biron egregiously manipulating his petulant love interest, and the writing
is annoying. Sometimes pulp fiction makes up for those common flaws
through larger-than-life feats of daring, sweeping visions of future
societies, and ever-escalating stakes. There is little to none of that
here. Asimov instead provides tedious political maneuvering among a class
of elitist bankers and land owners who consider themselves natural
leaders. The only places where the power structures of this future
government make sense are where Asimov blatantly steals them from either
the Roman Empire or the Doge of Venice.
The one thing this book has going for it the thing, apart from
bloody-minded completionism, that kept me reading is that the technology
is hilariously weird in that way that only 1940s and 1950s science fiction
can be. The characters have access to communication via some sort of
interstellar telepathy (messages coded to a specific person's "brain
waves") and can travel between stars through hyperspace jumps, but each
jump is manually calculated by referring to the pilot's (paper!) volumes of
the Standard Galactic Ephemeris. Communication between ships (via
"etheric radio") requires manually aiming a radio beam at the area in
space where one thinks the other ship is. It's an unintentionally
entertaining combination of technology that now looks absurdly primitive
and science that is so advanced and hand-waved that it's obviously made
up.
I also have to give Asimov some points for using spherical coordinates.
It's a small thing, but the coordinate systems in most SF novels and TV
shows are obviously not fit for purpose.
I spent about a month and a half of this year barely reading, and while
some of that is because I finally tackled a few projects I'd been putting
off for years, a lot of it was because of this book. It was only 192
pages, and I'm still curious about the glue between Asimov's
Foundation and Robot series, both of which I devoured as a
teenager. But every time I picked it up to finally finish it and start
another book, I made it about ten pages and then couldn't take any more.
Learn from my error: don't try this at home, or at least give up if the
same thing starts happening to you.
Followed by The Currents of Space.
Rating: 2 out of 10
I am upstream and Debian package maintainer of
python-debianbts, which is a Python library that allows for
querying Debian s Bug Tracking System (BTS). python-debianbts is used by
reportbug, the standard tool to report bugs in Debian, and therefore the glue
between the reportbug and the BTS.
debbugs, the software that powers Debian s BTS, provides a SOAP
interface for querying the BTS. Unfortunately, SOAP is not a very popular
protocol anymore, and I m facing the second migration to another underlying
SOAP library as they continue to become unmaintained over time. Zeep, the
library I m currently considering, requires a WSDL file in order to work
with a SOAP service, however, debbugs does not provide one. Since I m not
familiar with WSDL, I need help from someone who can create a WSDL file for
debbugs, so I can migrate python-debianbts away from pysimplesoap to zeep.
How did we get here?
Back in the olden days, reportbug was querying the BTS by parsing its HTML
output. While this worked, it tightly coupled the user-facing
presentation of the BTS with critical functionality of the bug reporting tool.
The setup was fragile, prone to breakage, and did not allow changing anything
in the BTS frontend for fear of breaking reportbug itself.
In 2007, I started to work on reportbug-ng, a user-friendly alternative
to reportbug, targeted at users not comfortable using the command line. Early
on, I decided to use the BTS SOAP interface instead of parsing HTML like
reportbug did. 2008, I extracted the code that dealt with the BTS into a
separate Python library, and after some collaboration with the reportbug
maintainers, reportbug adopted python-debianbts in 2011 and has used it ever
since.
2015, I was working on porting python-debianbts to Python 3.
During that process, it turned out that its major dependency, SoapPy was pretty
much unmaintained for years and blocking the Python3 transition. Thanks to the
help of Gaetano Guerriero, who ported python-debianbts to
pysimplesoap, the migration was unblocked and could proceed.
In 2024, almost ten years later, pysimplesoap seems to be unmaintained as well,
and I have to look again for alternatives. The most promising one right now
seems to be zeep. Unfortunately, zeep requires a WSDL file for working with
a SOAP service, which debbugs does not provide.
How can you help?
reportbug (and thus python-debianbts) is used by thousands of users and I have
a certain responsibility to keep things working properly. Since I simply don t
know enough about WSDL to create such a file for debbugs myself, I m looking
for someone who can help me with this task.
If you re familiar with SOAP, WSDL and optionally debbugs, please get in
touch with me. I don t speak Pearl, so I m not
really able to read debbugs code, but I do know some things about the SOAP
requests and replies due to my work on python-debianbts, so I m sure we can
work something out.
There is a WSDL file for a debbugs version used by GNU, but I
don t think it s official and it currently does not work with zeep. It may be a
good starting point, though.
The future of debbugs API
While we can probably continue to support debbugs SOAP interface for a while,
I don t think it s very sustainable in the long run. A simpler, well documented
REST API that returns JSON seems more appropriate nowadays. The queries and
replies that debbugs currently supports are simple enough to design a REST API
with JSON around it. The benefit would be less complex libraries on the client
side and probably easier maintainability on the server side as well. debbugs
maintainer seemed to be in agreement with this idea back in
2018. I created an attempt to define a new API
(HTML render), but somehow we got stuck and no progress has been
made since then. I m still happy to help shaping such an API for debbugs, but I
can t really implement anything in debbugs itself, as it is written in Perl,
which I m not familiar with.
Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they ve kicked me off Go Roam, so I ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don t expect to use all of the data allowance, but I didn t want to have to worry about unexpected excess charges.
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
(There s a handy zte.js script to allow doing this from the device web interface.)
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
Unseen Academicals is the 37th Discworld novel and includes many of
the long-standing Ankh-Morpork cast, but mostly as supporting characters.
The main characters are a new (and delightful) bunch with their own
concerns. You arguably could start reading here if you really wanted to,
although you would risk spoiling several previous books (most notably
Thud!) and will miss some references
that depend on familiarity with the cast.
The Unseen University is, like most institutions of its sort, funded by an
endowment that allows the wizards to focus on the pure life of the mind
(or the stomach). Much to their dismay, they have just discovered that an
endowment that amounts to most of their food budget requires that they
field a football team.
Glenda runs the night kitchen at the Unseen University. Given the deep
and abiding love that wizards have for food, there is both a main kitchen
and a night kitchen. The main kitchen is more prestigious, but the night
kitchen is responsible for making pies, something that Glenda is quietly
but exceptionally good at.
Juliet is Glenda's new employee. She is exceptionally beautiful, not very
bright, and a working class girl of the Ankh-Morpork streets down to her
bones. Trevor Likely is a candle dribbler, responsible for assisting the
Candle Knave in refreshing the endless university candles and ensuring
that their wax is properly dribbled, although he pushes most of that work
off onto the infallibly polite and oddly intelligent Mr. Nutt.
Glenda, Trev, and Juliet are the sort of people who populate the great
city of Ankh-Morpork. While the people everyone has heard of have
political crises, adventures, and book plots, they keep institutions like
the Unseen University running. They read romance novels, go to the
football games, and nurse long-standing rivalries. They do not expect the
high mucky-mucks to enter their world, let alone mess with their game.
I approached Unseen Academicals with trepidation because I normally
don't get along as well with the Discworld wizard books. I need not have
worried; Pratchett realized that the wizards would work better as
supporting characters and instead turns the main plot (or at least most of
it; more on that later) over to the servants. This was a brilliant
decision. The setup of this book is some of the best of Discworld up to
this point.
Trev is a streetwise rogue with an uncanny knack for kicking around a can
that he developed after being forbidden to play football by his dear old
mum. He falls for Juliet even though their families support different
football teams, so you may think that a Romeo and Juliet spoof is
coming. There are a few gestures of one, but Pratchett deftly avoids the
pitfalls and predictability and instead makes Juliet one of the best
characters in the book by playing directly against type. She is one of
the characters that Pratchett is so astonishingly good at, the ones that
are so thoroughly themselves that they transcend the stories they're put
into.
The heart of this book, though, is Glenda.
Glenda enjoyed her job. She didn't have a career; they were for people
who could not hold down jobs.
She is the kind of person who knows where she fits in the world and likes
what she does and is happy to stay there until she decides something isn't
right, and then she changes the world through the power of common sense
morality, righteous indignation, and sheer stubborn persistence.
Discworld is full of complex and subtle characters fencing with each
other, but there are few things I have enjoyed more than Glenda being a
determinedly good person. Vetinari of course recognizes and respects (and
uses) that inner core immediately.
Unfortunately, as great as the setup and characters are, Unseen
Academicals falls apart a bit at the end. I was eagerly reading the
story, wondering what Pratchett was going to weave out of the stories of
these individuals, and then it partly turned into yet another wizard book.
Pratchett pulled another of his deus ex machina tricks for the
climax in a way that I found unsatisfying and contrary to the tone of the
rest of the story, and while the characters do get reasonable endings, it
lacked the oomph I was hoping for. Rincewind is as determinedly one-note
as ever, the wizards do all the standard wizard things, and the plot just
isn't that interesting.
I liked Mr. Nutt a great deal in the first part of the book, and I wish he
could have kept that edge of enigmatic competence and unflappableness.
Pratchett wanted to tell a different story that involved more angst and
self-doubt, and while I appreciate that story, I found it less engaging
and a bit more melodramatic than I was hoping for. Mr. Nutt's reactions
in the last half of the book were believable and fit his background, but
that was part of the problem: he slotted back into an archetype that I
thought Pratchett was going to twist and upend.
Mr. Nutt does, at least, get a fantastic closing line, and as usual there
are a lot of great asides and quotes along the way, including possibly the
sharpest and most biting Vetinari speech of the entire series.
The Patrician took a sip of his beer. "I have told this to few
people, gentlemen, and I suspect never will again, but one day when I
was a young boy on holiday in Uberwald I was walking along the bank of
a stream when I saw a mother otter with her cubs. A very endearing
sight, I'm sure you will agree, and even as I watched, the mother
otter dived into the water and came up with a plump salmon, which she
subdued and dragged on to a half-submerged log. As she ate it, while
of course it was still alive, the body split and I remember to this
day the sweet pinkness of its roes as they spilled out, much to the
delight of the baby otters who scrambled over themselves to feed on
the delicacy. One of nature's wonders, gentlemen: mother and children
dining on mother and children. And that's when I first learned about
evil. It is built into the very nature of the universe. Every world
spins in pain. If there is any kind of supreme being, I told myself,
it is up to all of us to become his moral superior."
My dissatisfaction with the ending prevents Unseen Academicals
from rising to the level of Night Watch,
and it's a bit more uneven than the best books of the series. Still,
though, this is great stuff; recommended to anyone who is reading the
series.
Followed in publication order by I Shall Wear Midnight.
Rating: 8 out of 10
I have mailed to a Debian bug on allegro4.4 describing my reasoning regarding the allegro libraries in short, allegro4.4 is pretty much dead upstream, and my interest was basically to keep alex4 (which is cool) in Debian, but since it migrated to non-free, my interest in allegro4.4 has waned. So, if anybody would like to still see allegro4.4 in Debian, please step up now and help out. Since it is dead upstream, my reasoning is that it is better to remove it from Debian if no maintainer who wants to help steps up.
Previously Tobias Hansen has helped out, but now it is 8 (!) years since his last upload of either package. (Please don t interpret this as judgement, I am very happy for the help he has provided and all the work he has done on the packages).
Allegro5 is another deal still active upstream, and I have kept it up to date in Debian, and while I have held the latest upload a short while because of the time_t transition, it will come sooner or later There I am also waiting on a final decision on this bug from upstream. Other than that allegro 5 is in a very good state, and I will keep maintaining it as long as I can. But help would of course be appreciated on allegro5 too.
With the release of Libntlm version 1.8 the release tarball can be reproduced on several distributions. We also publish a signed minimal source-only tarball, produced by git-archive which is the same format used by Savannah, Codeberg, GitLab, GitHub and others. Reproducibility of both tarballs are tested continuously for regressions on GitLab through a CI/CD pipeline. If that wasn t enough to excite you, the Debian packages of Libntlm are now built from the reproducible minimal source-only tarball. The resulting binaries are reproducible on several architectures.
What does that even mean? Why should you care? How you can do the same for your project? What are the open issues? Read on, dear reader
This article describes my practical experiments with reproducible release artifacts, following up on my earlier thoughts that lead to discussion on Fosstodon and a patch by Janneke Nieuwenhuizen to make Guix tarballs reproducible that inspired me to some practical work.
Let s look at how a maintainer release some software, and how a user can reproduce the released artifacts from the source code. Libntlm provides a shared library written in C and uses GNU Make, GNU Autoconf, GNU Automake, GNU Libtool and gnulib for build management, but these ideas should apply to most project and build system. The following illustrate the steps a maintainer would take to prepare a release:
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make distcheck
gpg -b libntlm-1.8.tar.gz
The generated files libntlm-1.8.tar.gz and libntlm-1.8.tar.gz.sig are published, and users download and use them. This is how the GNU project have been doing releases since the late 1980 s. That is a testament to how successful this pattern has been! These tarballs contain source code and some generated files, typically shell scripts generated by autoconf, makefile templates generated by automake, documentation in formats like Info, HTML, or PDF. Rarely do they contain binary object code, but historically that happened.
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. I blogged earlier how to mitigate this risk by using signed minimal source-only tarballs.
The risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions such as Trisquel, Guix, Debian/Ubuntu or Fedora ship generated files coming from the tarball into the binary *.deb or *.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built through a typical autoconf -fi && ./configure && make install sequence, and never wrote the code to rebuild everything. This can also happen if the build rules are written but are buggy, shipping the old artifact. When a security problem is found, this can lead to time-consuming situations, as it may be that patching the relevant source code and rebuilding the package is not sufficient: the vulnerable generated object from the tarball would be shipped into the binary package instead of a rebuilt artifact. For architecture-specific binaries this rarely happens, since object code is usually not included in tarballs although for 10+ years I shipped the binary Java JAR file in the GNU Libidn release tarball, until I stopped shipping it. For interpreted languages and especially for generated content such as HTML, PDF, shell scripts this happens more than you would like.
Publishing minimal source-only tarballs enable easier auditing of a project s code, to avoid the need to read through all generated files looking for malicious content. I have taken care to generate the source-only minimal tarball using git-archive. This is the same format that GitLab, GitHub etc offer for the automated download links on git tags. The minimal source-only tarballs can thus serve as a way to audit GitLab and GitHub download material! Consider if/when hosting sites like GitLab or GitHub has a security incident that cause generated tarballs to include a backdoor that is not present in the git repository. If people rely on the tag download artifact without verifying the maintainer PGP signature using GnuPG, this can lead to similar backdoor scenarios that we had for XZUtils but originated with the hosting provider instead of the release manager. This is even more concerning, since this attack can be mounted for some selected IP address that you want to target and not on everyone, thereby making it harder to discover.
With all that discussion and rationale out of the way, let s return to the release process. I have added another step here:
make srcdist
gpg -b libntlm-1.8-src.tar.gz
Now the release is ready. I publish these four files in the Libntlm s Savannah Download area, but they can be uploaded to a GitLab/GitHub release area as well. These are the SHA256 checksums I got after building the tarballs on my Trisquel 11 aramo laptop:
So how can you reproduce my artifacts? Here is how to reproduce them in a Ubuntu 22.04 container:
podman run -it --rm ubuntu:22.04
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make dist srcdist
sha256sum libntlm-*.tar.gz
You should see the exact same SHA256 checksum values. Hooray!
This works because Trisquel 11 and Ubuntu 22.04 uses the same version of git, autoconf, automake, and libtool. These tools do not guarantee the same output content for all versions, similar to how GNU GCC does not generate the same binary output for all versions. So there is still some delicate version pairing needed.
Ideally, the artifacts should be possible to reproduce from the release artifacts themselves, and not only directly from git. It is possible to reproduce the full tarball in a AlmaLinux 8 container replace almalinux:8 with rockylinux:8 if you prefer RockyLinux:
podman run -it --rm almalinux:8
dnf update -y
dnf install -y make wget gcc
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8.tar.gz
tar xfa libntlm-1.8.tar.gz
cd libntlm-1.8
./configure
make dist
sha256sum libntlm-1.8.tar.gz
The source-only minimal tarball can be regenerated on Debian 11:
podman run -it --rm debian:11
apt-get update
apt-get install -y --no-install-recommends make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
make -f cfg.mk srcdist
sha256sum libntlm-1.8-src.tar.gz
As the Magnus Opus or chef-d uvre, let s recreate the full tarball directly from the minimal source-only tarball on Trisquel 11 replace docker.io/kpengboy/trisquel:11.0 with ubuntu:22.04 if you prefer.
podman run -it --rm docker.io/kpengboy/trisquel:11.0
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make wget git ca-certificates
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8-src.tar.gz
tar xfa libntlm-1.8-src.tar.gz
cd libntlm-v1.8
./bootstrap
./configure
make dist
sha256sum libntlm-1.8.tar.gz
Yay! You should now have great confidence in that the release artifacts correspond to what s in version control and also to what the maintainer intended to release. Your remaining job is to audit the source code for vulnerabilities, including the source code of the dependencies used in the build. You no longer have to worry about auditing the release artifacts.
I find it somewhat amusing that the build infrastructure for Libntlm is now in a significantly better place than the code itself. Libntlm is written in old C style with plenty of string manipulation and uses broken cryptographic algorithms such as MD4 and single-DES. Remember folks: solving supply chain security issues has no bearing on what kind of code you eventually run. A clean gun can still shoot you in the foot.
Side note on naming: GitLab exports tarballs with pathnames libntlm-v1.8/ (i.e.., PROJECT-TAG/) and I ve adopted the same pathnames, which means my libntlm-1.8-src.tar.gz tarballs are bit-by-bit identical to GitLab s exports and you can verify this with tools like diffoscope. GitLab name the tarball libntlm-v1.8.tar.gz (i.e., PROJECT-TAG.ARCHIVE) which I find too similar to the libntlm-1.8.tar.gz that we also publish. GitHub uses the same git archive style, but unfortunately they have logic that removes the v in the pathname so you will get a tarball with pathname libntlm-1.8/ instead of libntlm-v1.8/ that GitLab and I use. The content of the tarball is bit-by-bit identical, but the pathname and archive differs. Codeberg (running Forgejo) uses another approach: the tarball is called libntlm-v1.8.tar.gz (after the tag) just like GitLab, but the pathname inside the archive is libntlm/, otherwise the produced archive is bit-by-bit identical including timestamps. Savannah s CGIT interface uses archive name libntlm-1.8.tar.gz with pathname libntlm-1.8/, but otherwise file content is identical. Savannah s GitWeb interface provides snapshot links that are named after the git commit (e.g., libntlm-a812c2ca.tar.gz with libntlm-a812c2ca/) and I cannot find any tag-based download links at all. Overall, we are so close to get SHA256 checksum to match, but fail on pathname within the archive. I ve chosen to be compatible with GitLab regarding the content of tarballs but not on archive naming. From a simplicity point of view, it would be nice if everyone used PROJECT-TAG.ARCHIVE for the archive filename and PROJECT-TAG/ for the pathname within the archive. This aspect will probably need more discussion.
Side note on git archive output: It seems different versions of git archive produce different results for the same repository. The version of git in Debian 11, Trisquel 11 and Ubuntu 22.04 behave the same. The version of git in Debian 12, AlmaLinux/RockyLinux 8/9, Alpine, ArchLinux, macOS homebrew, and upcoming Ubuntu 24.04 behave in another way. Hopefully this will not change that often, but this would invalidate reproducibility of these tarballs in the future, forcing you to use an old git release to reproduce the source-only tarball. Alas, GitLab and most other sites appears to be using modern git so the download tarballs from them would not match my tarballs even though the content would.
Side note on ChangeLog: ChangeLog files were traditionally manually curated files with version history for a package. In recent years, several projects moved to dynamically generate them from git history (using tools like git2cl or gitlog-to-changelog). This has consequences for reproducibility of tarballs: you need to have the entire git history available! The gitlog-to-changelog tool also output different outputs depending on the time zone of the person using it, which arguable is a simple bug that can be fixed. However this entire approach is incompatible with rebuilding the full tarball from the minimal source-only tarball. It seems Libntlm s ChangeLog file died on the surgery table here.
So how would a distribution build these minimal source-only tarballs? I happen to help on the libntlm package in Debian. It has historically used the generated tarballs as the source code to build from. This means that code coming from gnulib is vendored in the tarball. When a security problem is discovered in gnulib code, the security team needs to patch all packages that include that vendored code and rebuild them, instead of merely patching the gnulib package and rebuild all packages that rely on that particular code. To change this, the Debian libntlm package needs to Build-Depends on Debian s gnulib package. But there was one problem: similar to most projects that use gnulib, Libntlm depend on a particular git commit of gnulib, and Debian only ship one commit. There is no coordination about which commit to use. I have adopted gnulib in Debian, and add a git bundle to the *_all.deb binary package so that projects that rely on gnulib can pick whatever commit they need. This allow an no-network GNULIB_URL and GNULIB_REVISION approach when running Libntlm s ./bootstrap with the Debian gnulib package installed. Otherwise libntlm would pick up whatever latest version of gnulib that Debian happened to have in the gnulib package, which is not what the Libntlm maintainer intended to be used, and can lead to all sorts of version mismatches (and consequently security problems) over time. Libntlm in Debian is developed and tested on Salsa and there is continuous integration testing of it as well, thanks to the Salsa CI team.
Side note on git bundles: unfortunately there appears to be no reproducible way to export a git repository into one or more files. So one unfortunate consequence of all this work is that the gnulib *.orig.tar.gz tarball in Debian is not reproducible any more. I have tried to get Git bundles to be reproducible but I never got it to work see my notes in gnulib s debian/README.source on this aspect. Of course, source tarball reproducibility has nothing to do with binary reproducibility of gnulib in Debian itself, fortunately.
One open question is how to deal with the increased build dependencies that is triggered by this approach. Some people are surprised by this but I don t see how to get around it: if you depend on source code for tools in another package to build your package, it is a bad idea to hide that dependency. We ve done it for a long time through vendored code in non-minimal tarballs. Libntlm isn t the most critical project from a bootstrapping perspective, so adding git and gnulib as Build-Depends to it will probably be fine. However, consider if this pattern was used for other packages that uses gnulib such as coreutils, gzip, tar, bison etc (all are using gnulib) then they would all Build-Depends on git and gnulib. Cross-building those packages for a new architecture will therefor require git on that architecture first, which gets circular quick. The dependency on gnulib is real so I don t see that going away, and gnulib is a Architecture:all package. However, the dependency on git is merely a consequence of how the Debian gnulib package chose to make all gnulib git commits available to projects: through a git bundle. There are other ways to do this that doesn t require the git tool to extract the necessary files, but none that I found practical ideas welcome!
Finally some brief notes on how this was implemented. Enabling bootstrappable source-only minimal tarballs via gnulib s ./bootstrap is achieved by using the GNULIB_REVISION mechanism, locking down the gnulib commit used. I have always disliked git submodules because they add extra steps and has complicated interaction with CI/CD. The reason why I gave up git submodules now is because the particular commit to use is not recorded in the git archive output when git submodules is used. So the particular gnulib commit has to be mentioned explicitly in some source code that goes into the git archive tarball. Colin Watson added the GNULIB_REVISION approach to ./bootstrap back in 2018, and now it no longer made sense to continue to use a gnulib git submodule. One alternative is to use ./bootstrap with --gnulib-srcdir or --gnulib-refdir if there is some practical problem with the GNULIB_URL towards a git bundle the GNULIB_REVISION in bootstrap.conf.
The srcdist make rule is simple:
git archive --prefix=libntlm-v1.8/ -o libntlm-v1.8.tar.gz HEAD
Making the make dist generated tarball reproducible can be more complicated, however for Libntlm it was sufficient to make sure the modification times of all files were set deterministically to the timestamp of the last commit in the git repository. Interestingly there seems to be a couple of different ways to accomplish this, Guix doesn t support minimal source-only tarballs but rely on a .tarball-timestamp file inside the tarball. Paul Eggert explained what TZDB is using some time ago. The approach I m using now is fairly similar to the one I suggested over a year ago. If there are problems because all files in the tarball now use the same modification time, there is a solution by Bruno Haible that could be implemented.
Side note on git tags: Some people may wonder why not verify a signed git tag instead of verifying a signed tarball of the git archive. Currently most git repositories uses SHA-1 for git commit identities, but SHA-1 is not a secure hash function. While current SHA-1 attacks can be detected and mitigated, there are fundamental doubts that a git SHA-1 commit identity uniquely refers to the same content that was intended. Verifying a git tag will never offer the same assurance, since a git tag can be moved or re-signed at any time. Verifying a git commit is better but then we need to trust SHA-1. Migrating git to SHA-256 would resolve this aspect, but most hosting sites such as GitLab and GitHub does not support this yet. There are other advantages to using signed tarballs instead of signed git commits or git tags as well, e.g., tar.gz can be a deterministically reproducible persistent stable offline storage format but .git sub-directory trees or git bundles do not offer this property.
Doing continous testing of all this is critical to make sure things don t regress. Libntlm s pipeline definition now produce the generated libntlm-*.tar.gz tarballs and a checksum as a build artifact. Then I added the 000-reproducability job which compares the checksums and fails on mismatches. You can read its delicate output in the job for the v1.8 release. Right now we insists that builds on Trisquel 11 match Ubuntu 22.04, that PureOS 10 builds match Debian 11 builds, that AlmaLinux 8 builds match RockyLinux 8 builds, and AlmaLinux 9 builds match RockyLinux 9 builds. As you can see in pipeline job output, not all platforms lead to the same tarballs, but hopefully this state can be improved over time. There is also partial reproducibility, where the full tarball is reproducible across two distributions but not the minimal tarball, or vice versa.
If this way of working plays out well, I hope to implement it in other projects too.
What do you think? Happy Hacking!
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
write build-ids to debian binary control files,
so that the build-id (more specifically, the ELF note
.note.gnu.build-id) wound up in the Debian apt archive metadata.
I ve always thought this was super cool, and seeing as how Michael Stapelberg
blogged
some great pointers around the ecosystem, including the fancy new debuginfod
service, and the
find-dbgsym-packages
helper, which uses these same headers, I don t think I m the only one.
At work I ve been using a lot of rust,
specifically, async rust using tokio. To try and work on
my style, and to dig deeper into the how and why of the decisions made in these
frameworks, I ve decided to hack up a project that I ve wanted to do ever
since 2015 write a debug filesystem. Let s get to it.
Back to the Future
Time to admit something. I really love Plan 9. It s
just so good. So many ideas from Plan 9 are just so prescient, and everything
just feels right. Not just right like, feels good like, correct. The
bit that I ve always liked the most is 9p, the network protocol for serving
a filesystem over a network. This leads to all sorts of fun programs, like the
Plan 9 ftp client being a 9p server you mount the ftp server and access
files like any other files. It s kinda like if fuse were more fully a part
of how the operating system worked, but fuse is all running client-side. With
9p there s a single client, and different servers that you can connect to,
which may be backed by a hard drive, remote resources over something like SFTP, FTP, HTTP or even purely synthetic.
The interesting (maybe sad?) part here is that 9p wound up outliving Plan 9
in terms of adoption 9p is in all sorts of places folks don t usually expect.
For instance, the Windows Subsystem for Linux uses the 9p protocol to share
files between Windows and Linux. ChromeOS uses it to share files with Crostini,
and qemu uses 9p (virtio-p9) to share files between guest and host. If you re
noticing a pattern here, you d be right; for some reason 9p is the go-to protocol
to exchange files between hypervisor and guest. Why? I have no idea, except maybe
due to being designed well, simple to implement, and it s a lot easier to validate the data being shared
and validate security boundaries. Simplicity has its value.
As a result, there s a lot of lingering 9p support kicking around. Turns out
Linux can even handle mounting 9p filesystems out of the box. This means that I
can deploy a filesystem to my LAN or my localhost by running a process on top
of a computer that needs nothing special, and mount it over the network on an
unmodified machine unlike fuse, where you d need client-specific software
to run in order to mount the directory. For instance, let s mount a 9p
filesystem running on my localhost machine, serving requests on 127.0.0.1:564
(tcp) that goes by the name mountpointname to /mnt.
Linux will mount away, and attach to the filesystem as the root user, and by default,
attach to that mountpoint again for each local user that attempts to use
it. Nifty, right? I think so. The server is able
to keep track of per-user access and authorization
along with the host OS.
WHEREIN I STYX WITH IT
Since I wanted to push myself a bit more with rust and tokio specifically,
I opted to implement the whole stack myself, without third party libraries on
the critical path where I could avoid it. The 9p protocol (sometimes called
Styx, the original name for it) is incredibly simple. It s a series of client
to server requests, which receive a server to client response. These are,
respectively, T messages, which transmit a request to the server, which
trigger an R message in response (Reply messages). These messages are
TLV payload
with a very straight forward structure so straight forward, in fact, that I
was able to implement a working server off nothing more than a handful of man
pages.
Later on after the basics worked, I found a more complete
spec page
that contains more information about the
unix specific variant
that I opted to use (9P2000.u rather than 9P2000) due to the level
of Linux specific support for the 9P2000.u variant over the 9P2000
protocol.
MR ROBOTO
The backend stack over at zoo is rust and tokio
running i/o for an HTTP and WebRTC server. I figured I d pick something
fairly similar to write my filesystem with, since 9P can be implemented
on basically anything with I/O. That means tokio tcp server bits, which
construct and use a 9p server, which has an idiomatic Rusty API that
partially abstracts the raw R and T messages, but not so much as to
cause issues with hiding implementation possibilities. At each abstraction
level, there s an escape hatch allowing someone to implement any of
the layers if required. I called this framework
arigato which can be found over on
docs.rs and
crates.io.
/// Simplified version of the arigato File trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.File.html
trait File
/// OpenFile is the type returned by this File via an Open call.
typeOpenFile: OpenFile;
/// Return the 9p Qid for this file. A file is the same if the Qid is
/// the same. A Qid contains information about the mode of the file,
/// version of the file, and a unique 64 bit identifier.
fnqid(&self) -> Qid;
/// Construct the 9p Stat struct with metadata about a file.
async fnstat(&self) -> FileResult<Stat>;
/// Attempt to update the file metadata.
async fnwstat(&mut self, s: &Stat) -> FileResult<()>;
/// Traverse the filesystem tree.
async fnwalk(&self, path: &[&str]) -> FileResult<(Option<Self>, Vec<Self>)>;
/// Request that a file's reference be removed from the file tree.
async fnunlink(&mut self) -> FileResult<()>;
/// Create a file at a specific location in the file tree.
async fncreate(
&mut self,
name: &str,
perm: u16,
ty: FileType,
mode: OpenMode,
extension: &str,
) -> FileResult<Self>;
/// Open the File, returning a handle to the open file, which handles
/// file i/o. This is split into a second type since it is genuinely
/// unrelated -- and the fact that a file is Open or Closed can be
/// handled by the arigato server for us.
async fnopen(&mut self, mode: OpenMode) -> FileResult<Self::OpenFile>;
/// Simplified version of the arigato OpenFile trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.OpenFile.html
trait OpenFile
/// iounit to report for this file. The iounit reported is used for Read
/// or Write operations to signal, if non-zero, the maximum size that is
/// guaranteed to be transferred atomically.
fniounit(&self) -> u32;
/// Read some number of bytes up to buf.len() from the provided
/// offset of the underlying file. The number of bytes read is
/// returned.
async fnread_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
/// Write some number of bytes up to buf.len() from the provided
/// offset of the underlying file. The number of bytes written
/// is returned.
fnwrite_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
Thanks, decade ago paultag!
Let s do it! Let s use arigato to implement a 9p filesystem we ll call
debugfs that will serve all the debug
files shipped according to the Packages metadata from the apt archive. We ll
fetch the Packages file and construct a filesystem based on the reported
Build-Id entries. For those who don t know much about how an apt repo
works, here s the 2-second crash course on what we re doing. The first is to
fetch the Packages file, which is specific to a binary architecture (such as
amd64, arm64 or riscv64). That architecture is specific to a
component (such as main, contrib or non-free). That component is
specific to a suite, such as stable, unstable or any of its aliases
(bullseye, bookworm, etc). Let s take a look at the Packages.xz file for
the unstable-debugsuite, maincomponent, for all amd64 binaries.
This will return the Debian-style
rfc2822-like headers,
which is an export of the metadata contained inside each .deb file which
apt (or other tools that can use the apt repo format) use to fetch
information about debs. Let s take a look at the debug headers for the
netlabel-tools package in unstable which is a package named
netlabel-tools-dbgsym in unstable-debug.
So here, we can parse the package headers in the Packages.xz file, and store,
for each Build-Id, the Filename where we can fetch the .deb at. Each
.deb contains a number of files but we re only really interested in the
files inside the .deb located at or under /usr/lib/debug/.build-id/,
which you can find in debugfs under
rfc822.rs. It s
crude, and very single-purpose, but I m feeling a bit lazy.
Who needs dpkg?!
For folks who haven t seen it yet, a .deb file is a special type of
.ar file, that contains (usually)
three files inside debian-binary, control.tar.xz and data.tar.xz.
The core of an .ar file is a fixed size (60 byte) entry header,
followed by the specified size number of bytes.
[8 byte .ar file magic]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
...
First up was to implement a basic ar parser in
ar.rs. Before we get
into using it to parse a deb, as a quick diversion, let s break apart a .deb
file by hand something that is a bit of a rite of passage (or at least it
used to be? I m getting old) during the Debian nm (new member) process, to take
a look at where exactly the .debug file lives inside the .deb file.
$ ar x netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ ls
control.tar.xz debian-binary
data.tar.xz netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ tar --list -f data.tar.xz grep '.debug$'
./usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
Since we know quite a bit about the structure of a .deb file, and I had to
implement support from scratch anyway, I opted to implement a (very!) basic
debfile parser using HTTP Range requests. HTTP Range requests, if supported by
the server (denoted by a accept-ranges: bytes HTTP header in response to an
HTTP HEAD request to that file) means that we can add a header such as
range: bytes=8-68 to specifically request that the returned GET body be the
byte range provided (in the above case, the bytes starting from byte offset 8
until byte offset 68). This means we can fetch just the ar file entry from
the .deb file until we get to the file inside the .deb we are interested in
(in our case, the data.tar.xz file) at which point we can request the body
of that file with a final range request. I wound up writing a struct to
handle a read_at-style API surface in
hrange.rs, which
we can pair with ar.rs above and start to find our data in the .deb remotely
without downloading and unpacking the .deb at all.
After we have the body of the data.tar.xz coming back through the HTTP
response, we get to pipe it through an xz decompressor (this kinda sucked in
Rust, since a tokioAsyncRead is not the same as an http Body response is
not the same as std::io::Read, is not the same as an async (or sync)
Iterator is not the same as what the xz2 crate expects; leading me to read
blocks of data to a buffer and stuff them through the decoder by looping over
the buffer for each lzma2 packet in a loop), and tarfile parser (similarly
troublesome). From there we get to iterate over all entries in the tarfile,
stopping when we reach our file of interest. Since we can t seek, but gdb
needs to, we ll pull it out of the stream into a Cursor<Vec<u8>> in-memory
and pass a handle to it back to the user.
From here on out its a matter of
gluing together a File traited struct
in debugfs, and serving the filesystem over TCP using arigato. Done
deal!
A quick diversion about compression
I was originally hoping to avoid transferring the whole tar file over the
network (and therefore also reading the whole debug file into ram, which
objectively sucks), but quickly hit issues with figuring out a way around
seeking around an xz file. What s interesting is xz has a great primitive
to solve this specific problem (specifically, use a block size that allows you
to seek to the block as close to your desired seek position just before it,
only discarding at most block size - 1 bytes), but data.tar.xz files
generated by dpkg appear to have a single mega-huge block for the whole file.
I don t know why I would have expected any different, in retrospect. That means
that this now devolves into the base case of How do I seek around an lzma2
compressed data stream ; which is a lot more complex of a question.
Thankfully, notoriously brilliant tianon was
nice enough to introduce me to Jon Johnson
who did something super similar adapted a technique to seek inside a
compressed gzip file, which lets his service
oci.dag.dev
seek through Docker container images super fast based on some prior work
such as soci-snapshotter, gztool, and
zran.c.
He also pulled this party trick off for apk based distros
over at apk.dag.dev, which seems apropos.
Jon was nice enough to publish a lot of his work on this specifically in a
central place under the name targz
on his GitHub, which has been a ton of fun to read through.
The gist is that, by dumping the decompressor s state (window of previous
bytes, in-memory data derived from the last N-1 bytes) at specific
checkpoints along with the compressed data stream offset in bytes and
decompressed offset in bytes, one can seek to that checkpoint in the compressed
stream and pick up where you left off creating a similar block mechanism
against the wishes of gzip. It means you d need to do an O(n) run over the
file, but every request after that will be sped up according to the number
of checkpoints you ve taken.
Given the complexity of xz and lzma2, I don t think this is possible
for me at the moment especially given most of the files I ll be requesting
will not be loaded from again especially when I can just cache the debug
header by Build-Id. I want to implement this (because I m generally curious
and Jon has a way of getting someone excited about compression schemes, which
is not a sentence I thought I d ever say out loud), but for now I m going to
move on without this optimization. Such a shame, since it kills a lot of the
work that went into seeking around the .deb file in the first place, given
the debian-binary and control.tar.gz members are so small.
The Good
First, the good news right? It works! That s pretty cool. I m positive
my younger self would be amused and happy to see this working; as is
current day paultag. Let s take debugfs out for a spin! First, we need
to mount the filesystem. It even works on an entirely unmodified, stock
Debian box on my LAN, which is huge. Let s take it for a spin:
And, let s prove to ourselves that this actually mounted before we go
trying to use it:
$ mount grep build-id
192.168.0.2 on /usr/lib/debug/.build-id type 9p (rw,relatime,aname=unstable-debug,access=user,trans=tcp,version=9p2000.u,port=564)
Slick. We ve got an open connection to the server, where our host
will keep a connection alive as root, attached to the filesystem provided
in aname. Let s take a look at it.
$ ls /usr/lib/debug/.build-id/
00 0d 1a 27 34 41 4e 5b 68 75 82 8E 9b a8 b5 c2 CE db e7 f3
01 0e 1b 28 35 42 4f 5c 69 76 83 8f 9c a9 b6 c3 cf dc E7 f4
02 0f 1c 29 36 43 50 5d 6a 77 84 90 9d aa b7 c4 d0 dd e8 f5
03 10 1d 2a 37 44 51 5e 6b 78 85 91 9e ab b8 c5 d1 de e9 f6
04 11 1e 2b 38 45 52 5f 6c 79 86 92 9f ac b9 c6 d2 df ea f7
05 12 1f 2c 39 46 53 60 6d 7a 87 93 a0 ad ba c7 d3 e0 eb f8
06 13 20 2d 3a 47 54 61 6e 7b 88 94 a1 ae bb c8 d4 e1 ec f9
07 14 21 2e 3b 48 55 62 6f 7c 89 95 a2 af bc c9 d5 e2 ed fa
08 15 22 2f 3c 49 56 63 70 7d 8a 96 a3 b0 bd ca d6 e3 ee fb
09 16 23 30 3d 4a 57 64 71 7e 8b 97 a4 b1 be cb d7 e4 ef fc
0a 17 24 31 3e 4b 58 65 72 7f 8c 98 a5 b2 bf cc d8 E4 f0 fd
0b 18 25 32 3f 4c 59 66 73 80 8d 99 a6 b3 c0 cd d9 e5 f1 fe
0c 19 26 33 40 4d 5a 67 74 81 8e 9a a7 b4 c1 ce da e6 f2 ff
Outstanding. Let s try using gdb to debug a binary that was provided by
the Debian archive, and see if it ll load the ELF by build-id from the
right .deb in the unstable-debug suite:
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Yes! Yes it will!
$ file /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
/usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter *empty*, BuildID[sha1]=e59f81f6573dadd5d95a6e4474d9388ab2777e2a, for GNU/Linux 3.2.0, with debug_info, not stripped
The Bad
Linux s support for 9p is mainline, which is great, but it s not robust.
Network issues or server restarts will wedge the mountpoint (Linux can t
reconnect when the tcp connection breaks), and things that work fine on local
filesystems get translated in a way that causes a lot of network chatter for
instance, just due to the way the syscalls are translated, doing an ls, will
result in a stat call for each file in the directory, even though linux had
just got a stat entry for every file while it was resolving directory names.
On top of that, Linux will serialize all I/O with the server, so there s no
concurrent requests for file information, writes, or reads pending at the same
time to the server; and read and write throughput will degrade as latency
increases due to increasing round-trip time, even though there are offsets
included in the read and write calls. It works well enough, but is
frustrating to run up against, since there s not a lot you can do server-side
to help with this beyond implementing the 9P2000.L variant (which, maybe is
worth it).
The Ugly
Unfortunately, we don t know the file size(s) until we ve actually opened the
underlying tar file and found the correct member, so for most files, we don t
know the real size to report when getting a stat. We can t parse the tarfiles
for every stat call, since that d make ls even slower (bummer). Only
hiccup is that when I report a filesize of zero, gdb throws a bit of a
fit; let s try with a size of 0 to start:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 0 Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
warning: Discarding section .note.gnu.build-id which has a section size (24) larger than the file size [in module /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug]
[...]
This obviously won t work since gdb will throw away all our hard work because
of stat s output, and neither will loading the real size of the underlying
file. That only leaves us with hardcoding a file size and hope nothing else
breaks significantly as a result. Let s try it again:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 954M Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Much better. I mean, terrible but better. Better for now, anyway.
Kilroy was here
Do I think this is a particularly good idea? I mean; kinda. I m probably going
to make some fun 9parigato-based filesystems for use around my LAN, but I
don t think I ll be moving to use debugfs until I can figure out how to
ensure the connection is more resilient to changing networks, server restarts
and fixes on i/o performance. I think it was a useful exercise and is a pretty
great hack, but I don t think this ll be shipping anywhere anytime soon.
Along with me publishing this post, I ve pushed up all my repos; so you
should be able to play along at home! There s a lot more work to be done
on arigato; but it does handshake and successfully export a working
9P2000.u filesystem. Check it out on on my github at
arigato,
debugfs
and also on crates.io
and docs.rs.
At least I can say I was here and I got it working after all these years.
When I first started studying computer science setting up a programming project was easy, write source code files and a Makefile and that was it. IRC was the only IM system and email was the only other communications system that was used much. Writing Makefiles is difficult but products like the Borland Turbo series of IDEs did all that for you so you could just start typing code and press a function key to compile and run (F5 from memory).
Over the years the requirements and expectations of computer use have grown significantly. The typical office worker is now doing many more things with computers than serious programmers used to do. Running an IM system, an online document editing system, and a series of web apps is standard for companies nowadays. Developers have to do all that in addition to tools for version control, continuous integration, bug reporting, and feature tracking. The development process is also more complex with extra steps for reproducible builds, automated tests, and code coverage metrics for the tests. I wonder how many programmers who started in the 90s would have done something else if faced with Github as their introduction.
How much of this is good? Having the ability to send instant messages all around the world is great. Having dozens of different ways of doing so is awful. When a company uses multiple IM systems such as MS-Teams and Slack and forces some of it s employees to use them both it s getting ridiculous. Having different friend groups on different IM systems is anti-social networking. In the EU the Digital Markets Act [1] forces some degree of interoperability between different IM systems and as it s impossible to know who s actually in the EU that will end up being world-wide.
In corporations document management often involves multiple ways of storing things, you have Google Docs, MS Office online, hosted Wikis like Confluence, and more. Large companies tend to use several such systems which means that people need to learn multiple systems to be able to work and they also need to know which systems are used by the various groups that they communicate with. Microsoft deserves some sort of award for the range of ways they have for managing documents, Sharepoint, OneDrive, Office Online, attachments to Teams rooms, and probably lots more.
During WW2 the predecessor to the CIA produced an excellent manual for simple sabotage [2]. If something like that was written today the section General Interference with Organisations and Production would surely have something about using as many incompatible programs and web sites as possible in the work flow. The proliferation of software required for work is a form of denial of service attack against corporations.
The efficiency of companies doesn t really bother me. It sucks that companies are creating a demoralising workplace that is unpleasant for workers. But the upside is that the biggest companies are the ones doing the worst things and are also the most afflicted by these problems. It s almost like the Bureau of Sabotage in some of Frank Herbert s fiction [3].
The thing that concerns me is the effect of multiple standards on free software development. We have IRC the most traditional IM support system which is getting replaced by Matrix but we also have some projects using Telegram, and Jabber hasn t gone away. I m sure there are others too. There are also multiple options for version control (although github seems to dominate the market), forums, bug trackers, etc. Reporting bugs or getting support in free software often requires interacting with several of them. Developing free software usually involves dealing with the bug tracking and documentation systems of the distribution you use as well as the upstream developers of the software. If the problem you have is related to compatibility between two different pieces of free software then you can end up dealing with even more bug tracking systems.
There are real benefits to some of the newer programs to track bugs, write documentation, etc. There is also going to be a cost in changing which gives an incentive for the older projects to keep using what has worked well enough for them in the past,
How can we improve things? Use only the latest tools? Prioritise ease of use? Aim more for the entry level contributors?
Utkarsh Gupta
did 19.5h (out of 0.0h assigned and 48.75h from previous period), thus carrying over 29.25h to the next month.
Evolution of the situation
In March, we have released 31 DLAs.
Adrian Bunk was responsible for updating gtkwave not only in LTS, but also in unstable, stable, and old-stable as well. This update involved an upload of a new upstream release of gtkwave to each target suite to address 82 separate CVEs. Guilhem Moulin prepared an update of libvirt which was particularly notable, as it fixed multiple vulnerabilities which would lead to denial of service or information disclosure.
In addition to the normal security updates, multiple LTS contributors worked at getting various packages updated in more recent Debian releases, including gross for bullseye/bookworm (by Adrian Bunk), imlib2 for bullseye, jetty9 and tomcat9/10 for bullseye/bookworm (by Markus Koschany), samba for bullseye, py7zr for bullseye (by Santiago Ruano Rinc n), cacti for bullseye/bookwork (by Sylvain Beucler), and libmicrohttpd for bullseye (by Thorsten Alteholz). Additionally, Sylvain actively coordinated with cacti upstream concerning an incomplete fix for CVE-2024-29894.
Thanks to our sponsors
Sponsors that joined recently are in bold.
Contributing to Debian
is part of Freexian s mission. This article
covers the latest achievements of Freexian and their collaborators. All of this
is made possible by organizations subscribing to our
Long Term Support contracts and
consulting services.
P.S. We ve completed over a year of writing these blogs. If you have any
suggestions on how to make them better or what you d like us to cover, or any
other opinions/reviews you might have, et al, please let us know by dropping an
email to us. We d be
happy to hear your thoughts. :)
SSO Authentication for jitsi.debian.social, by Stefano Rivera
Debian.social s jitsi instance has been getting
some abuse by (non-Debian) people sharing sexually explicit content on the
service. After playing whack-a-mole with this for a month, and shutting the
instance off for another month, we opened it up again and the abuse immediately
re-started.
Stefano sat down and wrote an
SSO Implementation
that hooks into Jitsi s existing JWT SSO support. This requires everyone using
jitsi.debian.social to have a Salsa account.
With only a little bit of effort, we could change this in future, to only
require an account to open a room, and allow guests to join the call.
/usr-move, by Helmut Grohne
The biggest task this month was sending mitigation patches for all of the
/usr-move issues arising from package renames due to the 2038 transition. As a
result, we can now say that every affected package in unstable can either be
converted with dh-sequence-movetousr or has an open bug report. The package
set relevant to debootstrap except for the set that has to be uploaded
concurrently has been moved to /usr and is awaiting migration. The move of
coreutils happened to affect piuparts which hard codes the location of
/bin/sync and received multiple updates as a result.
Miscellaneous contributions
Stefano Rivera uploaded a stable release update to python3.11 for bookworm,
fixing a use-after-free crash.
Stefano uploaded a new version of python-html2text, and updated
python3-defaults to build with it.
In support of Python 3.12, Stefano dropped distutils as a Build-Dependency
from a few packages, and uploaded a complex set of patches to python-mitogen.
Stefano landed some merge requests to clean up dead code in dh-python,
removed the flit plugin, and uploaded it.
Stefano uploaded new upstream versions of twisted, hatchling,
python-flexmock, python-authlib, python mitogen, python-pipx, and xonsh.
Stefano requested removal of a few packages supporting the Opsis HDMI2USB
hardware that DebConf Video team used to use for HDMI capture, as they are
not being maintained upstream. They started to FTBFS, with recent sdcc
changes.
DebConf 24 is getting ready to open registration, Stefano spent some time
fixing bugs in the website, caused by infrastructure updates.
Stefano reviewed all the DebConf 23 travel reimbursements, filing requests
for more information from SPI where our records mismatched.
Roberto C. S nchez worked on facilitating the transfer of upstream
maintenance responsibility for the dormant Shorewall project to a new team
led by the current maintainer of the Shorewall packages in Debian.
Colin Watson fixed build failures in celery-haystack-ng, db1-compat,
jsonpickle, libsdl-perl, kali, knews, openssh-ssh1,
python-json-log-formatter, python-typing-extensions, trn4, vigor, and
wcwidth. Some of these were related to the 64-bit time_t transition, since
that involved enabling -Werror=implicit-function-declaration.
Colin fixed an
off-by-one error in neovim,
which was already causing a build failure in Ubuntu and would eventually have
caused a build failure in Debian with stricter toolchain settings.
Colin added an sshd@.service template to
openssh to help newer systemd versions make containers and VMs SSH-accessible
over AF_VSOCK sockets.
Following the xz-utils backdoor, Colin
spent some time testing and discussing OpenSSH upstream s proposed
inline systemd notification patch,
since the current implementation via libsystemd was part of the attack vector
used by that backdoor.
Utkarsh reviewed and sponsored some Go packages for Lena Voytek and Rajudev.
Utkarsh also helped Mitchell Dzurick with the adoption of pyparted package.
Helmut sent 10 patches for cross build failures.
Helmut partially fixed architecture cross bootstrap tooling to deal with
changes in linux-libc-dev and the recent gcc-for-host changes and also
fixed a 64bit-time_t FTBFS in libtextwrap.
Thorsten Alteholz uploaded several packages from debian-printing: cjet,
lprng, rlpr and epson-inkjet-printer-escpr were affected by the newly enabled
compiler switch -Werror=implicit-function-declaration. Besides fixing these
serious bugs, Thorsten also worked on other bugs and could fix one or the
other.
Carles updated simplemonitor and python-ring-doorbell packages with new
upstream versions.
Santiago also reviewed applications for the
improving Salsa CI in Debian
GSoC 2024 project. We received applications from four very talented
candidates. The selection process is currently ongoing. A huge thanks to all
of them!
As part of the DebConf 24 organization, Santiago has taken part in the
Content team discussions.
I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to Openreach FTTP, provided by Aquiss, but I worry about what happens if there s a cable cut somewhere or some other long lasting problem. Worst case I could tether to my work phone, or try to find some local coworking space to use while things get sorted, but I felt like arranging a backup option was a wise move.
Step 1 turned out to be sorting out recursive DNS. It s been many moons since I had to deal with running DNS in a production setting, and I ve mostly done my best to avoid doing it at home too. dnsmasq has done a decent job at providing for my needs over the years, covering DHCP, DNS (+ tftp for my test device network). However I just let it slave off my ISP s nameservers, which means if that link goes down it ll no longer be able to resolve anything outside the house.
One option would have been to either point to a different recursive DNS server (Cloudfare s 1.1.1.1 or Google s Public DNS being the common choices), but I ve no desire to share my lookup information with them. As another approach I could have done some sort of failover of resolv.conf when the primary network went down, but then I would have to get into moving files around based on networking status and that felt a bit clunky.
So I decided to finally setup a proper local recursive DNS server, which is something I ve kinda meant to do for a while but never had sufficient reason to look into. Last time I did this I did it with BIND 9 but there are more options these days, and I decided to go with unbound, which is primarily focused on recursive DNS.
One extra wrinkle, pointed out by Lars, is that having dynamic name information from DHCP hosts is exceptionally convenient. I ve kept dnsmasq as the local DHCP server, so I wanted to be able to forward local queries there.
I m doing all of this on my RB5009, running Debian. Installing unbound was a simple matter of apt install unbound. I needed 2 pieces of configuration over the default, one to enable recursive serving for the house networks, and one to enable forwarding of queries for the local domain to dnsmasq. I originally had specified the wildcard address for listening, but this caused problems with the fact my router has many interfaces and would sometimes respond from a different address than the request had come in on.
/etc/unbound/unbound.conf.d/network-resolver.conf
server:
domain-insecure: "example.org"
do-not-query-localhost: no
forward-zone:
name: "example.org"
forward-addr: 127.0.0.1@5353
I then had to configure dnsmasq to not listen on port 53 (so unbound could), respond to requests on the loopback interface (I have dnsmasq restricted to only explicitly listed interfaces), and to hand out unbound as the appropriate nameserver in DHCP requests - once dnsmasq is not listening on port 53 it no longer does this by default.
/etc/dnsmasq.d/behind-unbound
With these minor changes in place I now have local recursive DNS being handled by unbound, without losing dynamic local DNS for DHCP hosts. As an added bonus I now get 10/10 on Test IPv6 - previously I was getting dinged on the ability for my DNS server to resolve purely IPv6 reachable addresses.
Next step, actually sorting out a backup link.
Welcome to the March 2024 report from the Reproducible Builds project! In our reports, we attempt to outline what we have been up to over the past month, as well as mentioning some of the important things happening more generally in software supply-chain security. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Table of contents:
Arch Linux minimal container userland now 100% reproducible
In remarkable news, Reproducible builds developer kpcyrd reported that that the Arch Linux minimal container userland is now 100% reproducible after work by developers dvzv and Foxboron on the one remaining package. This represents a real world , widely-used Linux distribution being reproducible.
Their post, which kpcyrd suffixed with the question now what? , continues on to outline some potential next steps, including validating whether the container image itself could be reproduced bit-for-bit. The post, which was itself a followup for an Arch Linux update earlier in the month, generated a significant number of replies.
Validating Debian s build infrastructure after the XZ backdoor
From our mailing list this month, Vagrant Cascadian wrote about being asked about trying to perform concrete reproducibility checks for recent Debian security updates, in an attempt to gain some confidence about Debian s build infrastructure given that they performed builds in environments running the high-profile XZ vulnerability.
Vagrant reports (with some caveats):
So far, I have not found any reproducibility issues; everything I tested I was able to get to build bit-for-bit identical with what is in the
Debian archive.
That is to say, reproducibility testing permitted Vagrant and Debian to claim with some confidence that builds performed when this vulnerable version of XZ was installed were not interfered with.
Functional package managers (FPMs) and reproducible builds (R-B) are technologies and methodologies that are conceptually very different from the traditional software deployment model, and that have promising properties for software supply chain security. This thesis aims to evaluate the impact of FPMs and R-B on the security of the software supply chain and propose improvements to the FPM model to further improve trust in the open source supply chain. PDF
Julien s paper poses a number of research questions on how the model of distributions such as GNU Guix and NixOS can be leveraged to further improve the safety of the software supply chain , etc.
Software and source code identification with GNU Guix and reproducible builds
In a long line of commendably detailed blog posts, Ludovic Court s, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier have together published two interesting posts on the GNU Guix blog this month. In early March, Ludovic Court s, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier wrote about software and source code identification and how that might be performed using Guix, rhetorically posing the questions: What does it take to identify software ? How can we tell what software is running on a machine to determine, for example, what security vulnerabilities might affect it?
Later in the month, Ludovic Court s wrote a solo post describing adventures on the quest for long-term reproducible deployment. Ludovic s post touches on GNU Guix s aim to support time travel , the ability to reliably (and reproducibly) revert to an earlier point in time, employing the iconic image of Harold Lloyd hanging off the clock in Safety Last! (1925) to poetically illustrate both the slapstick nature of current modern technology and the gymnastics required to navigate hazards of our own making.
Two new Rust-based tools for post-processing determinism
Zbigniew J drzejewski-Szmek announced add-determinism, a work-in-progress reimplementation of the Reproducible Builds project s own strip-nondeterminism tool in the Rust programming language, intended to be used as a post-processor in RPM-based distributions such as Fedora
In addition, Yossi Kreinin published a blog post titled refix: fast, debuggable, reproducible builds that describes a tool that post-processes binaries in such a way that they are still debuggable with gdb, etc.. Yossi post details the motivation and techniques behind the (fast) performance of the tool.
Distribution work
In Debian this month, since the testing framework no longer varies the build path, James Addison performed a bulk downgrade of the bug severity for issues filed with a level of normal to a new level of wishlist. In addition, 28 reviews of Debian packages were added, 38 were updated and 23 were removed this month adding to ever-growing knowledge about identified issues. As part of this effort, a number of issue types were updated, including Chris Lamb adding a new ocaml_include_directories toolchain issue [] and James Addison adding a new filesystem_order_in_java_jar_manifest_mf_include_resource issue [] and updating the random_uuid_in_notebooks_generated_by_nbsphinx to reference a relevant discussion thread [].
In addition, Roland Clobus posted his 24th status update of reproducible Debian ISO images. Roland highlights that the images for Debian unstable often cannot be generated due to changes in that distribution related to the 64-bit time_t transition.
Lastly, Bernhard M. Wiedemann posted another monthly update for his reproducibility work in openSUSE.
Mailing list highlights
Elsewhere on our mailing list this month:
Website updates
There were made a number of improvements to our website this month, including:
Pol Dellaiera noticed the frequent need to correctly cite the website itself in academic work. To facilitate easier citation across multiple formats, Pol contributed a Citation File Format (CIF) file. As a result, an export in BibTeX format is now available in the Academic Publications section. Pol encourages community contributions to further refine the CITATION.cff file. Pol also added an substantial new section to the buy in page documenting the role of Software Bill of Materials (SBOMs) and ephemeral development environments. [][]
Bernhard M. Wiedemann added a new commandments page to the documentation [][] and fixed some incorrect YAML elsewhere on the site [].
Chris Lamb add three recent academic papers to the publications page of the website. []
Mattia Rizzolo and Holger Levsen collaborated to add Infomaniak as a sponsor of amd64 virtual machines. [][][]
Roland Clobus updated the stable outputs page, dropping version numbers from Python documentation pages [] and noting that Python s set data structure is also affected by the PYTHONHASHSEED functionality. []
Delta chat clients now reproducible
Delta Chat, an open source messaging application that can work over email, announced this month that the Rust-based core library underlying Delta chat application is now reproducible.
diffoscopediffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 259, 260 and 261 to Debian and made the following additional changes:
New features:
Add support for the zipdetails tool from the Perl distribution. Thanks to Fay Stegerman and Larry Doolittle et al. for the pointer and thread about this tool. []
Bug fixes:
Don t identify Redis database dumps as GNU R database files based simply on their filename. []
Add a missing call to File.recognizes so we actually perform the filename check for GNU R data files. []
Don t crash if we encounter an .rdb file without an equivalent .rdx file. (#1066991)
Correctly check for 7z being available and not lz4 when testing 7z. []
Prevent a traceback when comparing a contentful .pyc file with an empty one. []
Testsuite improvements:
Fix .epub tests after supporting the new zipdetails tool. []
Don t use parenthesis within test skipping messages, as PyTest adds its own parenthesis. []
Factor out Python version checking in test_zip.py. []
Skip some Zip-related tests under Python 3.10.14, as a potential regression may have been backported to the 3.10.x series. []
Actually test 7z support in the test_7z set of tests, not the lz4 functionality. (Closes: reproducible-builds/diffoscope#359). []
In addition, Fay Stegerman updated diffoscope s monkey patch for supporting the unusual Mozilla ZIP file format after Python s zipfile module changed to detect potentially insecure overlapping entries within .zip files. (#362)
Chris Lamb also updated the trydiffoscope command line client, dropping a build-dependency on the deprecated python3-distutils package to fix Debian bug #1065988 [], taking a moment to also refresh the packaging to the latest Debian standards []. Finally, Vagrant Cascadian submitted an update for diffoscope version 260 in GNU Guix. []
Upstream patches
This month, we wrote a large number of patches, including:
I don t have the hardware to test this firmware, but the build produces the same hashes for the firmware so it s safe to say that the firmware should keep working.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In March, an enormous number of changes were made by Holger Levsen:
Initial work to clean up a messy NetBSD-related script. [][]
Roland Clobus:
Show the installer log if the installer fails to build. []
Avoid the minus character (i.e. -) in a variable in order to allow for tags in openQA. []
Update the schedule of Debian live image builds. []
Vagrant Cascadian:
Maintenance on the virt* nodes is completed so bring them back online. []
Use the fully qualified domain name in configuration. []
Node maintenance was also performed by Holger Levsen, Mattia Rizzolo [][] and Vagrant Cascadian [][][][]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Getting the Belgian eID to work on Linux
systems should be fairly easy, although some people do struggle with it.
For that reason, there is a lot of third-party documentation out there
in the form of blog posts, wiki pages, and other kinds of things.
Unfortunately, some of this documentation is simply wrong. Written by
people who played around with things until it kind of worked, sometimes
you get a situation where something that used to work in the past (but
wasn't really necessary) now stopped working, but it's still added to
a number of locations as though it were the gospel.
And then people follow these instructions and now things don't work
anymore.
One of these revolves around OpenSC.
OpenSC is an open source smartcard library that has support for a
pretty
large
number of smartcards, amongst which the Belgian eID. It provides a
PKCS#11 module as well as a
number of supporting tools.
For those not in the know, PKCS#11 is a standardized C API for
offloading cryptographic operations. It is an API that can be used when
talking to a hardware cryptographic module, in order to make that module
perform some actions, and it is especially popular in the open source
world, with support in
NSS,
amongst others. This library is written and maintained by mozilla, and
is a low-level cryptographic library that is used by Firefox (on all
platforms it supports) as well as by Google Chrome and other browsers
based on that (but only on Linux, and as I understand it, only for
linking with smartcards; their BoringSSL library is used for other
things).
The official eID software that we ship through
eid.belgium.be,
also known as "BeID", provides a PKCS#11 module for the Belgian eID, as
well as a number of support tools to make interacting with the card
easier, such as the "eID viewer", which provides the ability to read
data from the card, and validate their signatures. While the very first
public version of this eID PKCS#11 module was originally based on
OpenSC, it has since been reimplemented as a PKCS#11 module in its own
right, with no lineage to OpenSC whatsoever anymore.
About five years ago, the Belgian eID card was renewed. At the time, a
new physical appearance was the most obvious difference with the old
card, but there were also some technical, on-chip, differences that are
not so apparent. The most important one here, although it is not the
only one, is the fact that newer eID cards now use a NIST
P-384 elliptic curve-based private
keys, rather than the RSA-based
ones that were used in the past. This change required some changes to
any PKCS#11 module that supports the eID; both the BeID one, as well as
the OpenSC card-belpic driver that is written in support of the Belgian
eID.
Obviously, the required changes were implemented for the BeID module;
however, the OpenSC card-belpic driver was not updated. While I did do
some preliminary work on the required changes, I was unable to get it to
work, and eventually other things took up my time so I never finished
the implementation. If someone would like to finish the work that I
started, the preliminal patch that I
wrote
could be a good start -- but like I said, it doesn't yet work. Also,
you'll probably be interested in the official
documentation
of the eID card.
Unfortunately, in the mean time someone added the Applet 1.8 ATR to the
card-belpic.c file, without also implementing the required changes to
the driver so that the PKCS#11 driver actually supports the eID card.
The result of this is that if you have OpenSC installed in NSS for
either Firefox or any Chromium-based browser, and it gets picked up
before the BeID PKCS#11 module, then NSS will stop looking and pass all
crypto operations to the OpenSC PKCS#11 module rather than to the
official eID PKCS#11 module, and things will not work at all, causing a
lot of confusion.
I have therefore taken the following two steps:
The official eID packages now
conflict
with the OpenSC PKCS#11 module. Specifically only the PKCS#11 module,
not the rest of OpenSC, so you can theoretically still use its tools.
This means that once we release this new version of the eID software,
when you do an upgrade and you have OpenSC installed, it will remove
the PKCS#11 module and anything that depends on it. This is normal
and expected.
I have filed a pull
request against OpenSC
that removes the Applet 1.8 ATR from the driver, so that OpenSC will
stop claiming that it supports the 1.8 applet.
When the pull request is accepted, we will update the official eID
software to make the conflict versioned, so that as soon as it works
again you will again be able to install the OpenSC and BeID packages at
the same time.
In the mean time, if you have the OpenSC PKCS#11 module installed on
your system, and your eID authentication does not work, try removing it.
ceb and I are members of the Derril Water Solar Park cooperative.
We were recently invited to vote on whether the coop should bid for a Contract for Difference, in a government green electricity auction.
We ve voted No.
Green electricity from your mainstream supplier is a lie
For a while ceb and I have wanted to contribute directly to green energy provision. This isn t really possible in the mainstream consumer electricy market.
Mainstream electricity suppliers 100% green energy tariffs are pure greenwashing. In a capitalist boondoogle, they basically divvy up the electricity so that customers on the (typically more expensive) green tariff get the green electricity, and the other customers get whatever is left. (Of course the electricity is actually all mixed up by the National Grid.) There are fewer people signed up for these tariffs than there is green power generated, so this basically means signing up for a green tariff has no effect whatsoever, other than giving evil people more money.
Ripple
About a year ago we heard about Ripple. The structure is a little complicated, but the basic upshot is:
Ripple promote and manage renewable energy schemes. The schemes themselves are each an individual company; the company is largely owned by a co-operative. The co-op is owned by consumers of electricity in the UK., To stop the co-operative being an purely financial investment scheme, shares ownership is limited according to your electricity usage. The electricity is be sold on the open market, and the profits are used to offset members electricity bills. (One gotcha from all of this is that for this to work your electricity billing provider has to be signed up with Ripple, but ours, Octopus, is.)
It seemed to us that this was a way for us to directly cause (and pay for!) the actual generation of green electricity.
So, we bought shares in one these co-operatives: we are co-owners of the Derril Water Solar Farm. We signed up for the maximum: funding generating capacity corresponding to 120% of our current electricity usage. We paid a little over 5000 for our shares.
Contracts for Difference
The UK has a renewable energy subsidy scheme, which goes by the name of Contracts for Difference. The idea is that a renewable energy generation company bids in advance, saying that they ll sell their electricity at Y price, for the duration of the contract (15 years in the current round). The lowest bids win. All the electricity from the participating infrastructure is sold on the open market, but if the market price is low the government makes up the difference, and if the price is high, the government takes the winnings.
This is supposedly good for giving a stable investment environment, since the price the developer is going to get now doesn t depends on the electricity market over the next 15 years. The CfD system is supposed to encourage development, so you can only apply before you ve commissioned your generation infrastructure.
Ripple and CfD
Ripple recently invited us to agree that the Derril Water co-operative should bid in the current round of CfDs.
If this goes ahead, and we are one of the auction s winners, the result would be that, instead of selling our electricity at the market price, we ll sell it at the fixed CfD price.
This would mean that our return on our investment (which show up as savings on our electricity bills) would be decoupled from market electricity prices, and be much more predictable.
They can t tell us the price they d want to bid at, and future electricity prices are rather hard to predict, but it s clear from the accompanying projections that they think we d be better off on average with a CfD.
The documentation is very full of financial projections and graphs; other factors aren t really discussed in any detail.
The rules of the co-op didn t require them to hold a vote, but very sensibly, for such a fundamental change in the model, they decided to treat it roughly the same way as for a rules change: they re hoping to get 75% Yes votes.
Voting No
The reason we re in this co-op at all is because we want to directly fund renewable electricity.
Participating in the CfD auction would involve us competing with capitalist energy companies for government subsidies. Subsidies which are supposed to encourage the provision of green electricity.
It seems to us that participating in this auction would remove most of the difference between what we hoped to do by investing in Derril Water, and just participating in the normal consumer electricity market.
In particular, if we do win in the auction, that s probably directly removing the funding and investment support model for other, market-investor-funded, projects.
In other words, our buying into Derril Water ceases to be an additional green energy project, changing (in its minor way) the UK s electricity mix. It becomes a financial transaction much more tenously connected (if connected at all) to helping mitigate the climate emergency.
So our conclusion was that we must vote against.
Now that we are back from our six month period in Argentina, we
decided to adopt a kitten, to bring more diversity into our
lives. Perhaps this little girl will teach us to think outside the
box!
Yesterday we witnessed a solar eclipse Mexico City was not in the
totality range (we reached ~80%), but it was a great experience to go
with the kids. A couple dozen thousand people gathered for a massive
picnic in las islas, the main area inside our university campus.
Afterwards, we went briefly back home, then crossed the city to fetch
the little kitten. Of course, the kids were unanimous: Her name is
Eclipse.
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I d share it as a tale of how huh, that s weird can be a powerful threat-hunting tool but only if you ve got the time to keep pulling at the thread.
Prelude to an Adventure
Our story begins back in March 2008.
I was working at Engine Yard (EY), a now largely-forgotten Rails-focused hosting company, which pioneered several advances in Rails application deployment.
Probably EY s greatest claim to lasting fame is that they helped launch a little code hosting platform you might have heard of, by providing them free infrastructure when they were little more than a glimmer in the Internet s eye.
I am, of course, talking about everyone s favourite Microsoft product: GitHub.
Since GitHub was in the right place, at the right time, with a compelling product offering, they quickly started to gain traction, and grow their userbase.
With growth comes challenges, amongst them the one we re focusing on today: SSH login times.
Then, as now, GitHub provided SSH access to the git repos they hosted, by SSHing to git@github.com with publickey authentication.
They were using the standard way that everyone manages SSH keys: the ~/.ssh/authorized_keys file, and that became a problem as the number of keys started to grow.
The way that SSH uses this file is that, when a user connects and asks for publickey authentication, SSH opens the ~/.ssh/authorized_keys file and scans all of the keys listed in it, looking for a key which matches the key that the user presented.
This linear search is normally not a huge problem, because nobody in their right mind puts more than a few keys in their ~/.ssh/authorized_keys, right?
Of course, as a popular, rapidly-growing service, GitHub was gaining users at a fair clip, to the point that the one big file that stored all the SSH keys was starting to visibly impact SSH login times.
This problem was also not going to get any better by itself.
Something Had To Be Done.
EY management was keen on making sure GitHub ran well, and so despite it not really being a hosting problem, they were willing to help fix this problem.
For some reason, the late, great, Ezra Zygmuntowitz pointed GitHub in my direction, and let me take the time to really get into the problem with the GitHub team.
After examining a variety of different possible solutions, we came to the conclusion that the least-worst option was to patch OpenSSH to lookup keys in a MySQL database, indexed on the key fingerprint.
We didn t take this decision on a whim it wasn t a case of yeah, sure, let s just hack around with OpenSSH, what could possibly go wrong? .
We knew it was potentially catastrophic if things went sideways, so you can imagine how much worse the other options available were.
Ensuring that this wouldn t compromise security was a lot of the effort that went into the change.
In the end, though, we rolled it out in early April, and lo! SSH logins were fast, and we were pretty sure we wouldn t have to worry about this problem for a long time to come.
Normally, you d think patching OpenSSH to make mass SSH logins super fast would be a good story on its own.
But no, this is just the opening scene.
Chekov s Gun Makes its Appearance
Fast forward a little under a month, to the first few days of May 2008.
I get a message from one of the GitHub team, saying that somehow users were able to access other users repos over SSH.
Naturally, as we d recently rolled out the OpenSSH patch, which touched this very thing, the code I d written was suspect number one, so I was called in to help.
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
Eventually, after more than a little debugging, we discovered that, somehow, there were two users with keys that had the same key fingerprint.
This absolutely shouldn t happen it s a bit like winning the lottery twice in a row1 unless the users had somehow shared their keys with each other, of course.
Still, it was worth investigating, just in case it was a web application bug, so the GitHub team reached out to the users impacted, to try and figure out what was going on.
The users professed no knowledge of each other, neither admitted to publicising their key, and couldn t offer any explanation as to how the other person could possibly have gotten their key.
Then things went from weird to what the ? .
Because another pair of users showed up, sharing a key fingerprint but it was a different shared key fingerprint.
The odds now have gone from winning the lottery multiple times in a row to as close to this literally cannot happen as makes no difference.
Once we were really, really confident that the OpenSSH patch wasn t the cause of the problem, my involvement in the problem basically ended.
I wasn t a GitHub employee, and EY had plenty of other customers who needed my help, so I wasn t able to stay deeply involved in the on-going investigation of The Mystery of the Duplicate Keys.
However, the GitHub team did keep talking to the users involved, and managed to determine the only apparent common factor was that all the users claimed to be using Debian or Ubuntu systems, which was where their SSH keys would have been generated.
That was as far as the investigation had really gotten, when along came May 13, 2008.
Chekov s Gun Goes Off
With the publication of DSA-1571-1, everything suddenly became clear.
Through a well-meaning but ultimately disasterous cleanup of OpenSSL s randomness generation code, the Debian maintainer had inadvertently reduced the number of possible keys that could be generated by a given user from bazillions to a little over 32,000.
With so many people signing up to GitHub some of them no doubt following best practice and freshly generating a separate key it s unsurprising that some collisions occurred.
You can imagine the sense of oooooooh, so that s what s going on! that rippled out once the issue was understood.
I was mostly glad that we had conclusive evidence that my OpenSSH patch wasn t at fault, little knowing how much more contact I was to have with Debian weak keys in the future, running a huge store of known-compromised keys and using them to find misbehaving Certificate Authorities, amongst other things.
Lessons Learned
While I ve not found a description of exactly when and how Luciano Bello discovered the vulnerability that became CVE-2008-0166, I presume he first came across it some time before it was disclosed likely before GitHub tripped over it.
The stable Debian release that included the vulnerable code had been released a year earlier, so there was plenty of time for Luciano to have discovered key collisions and go hmm, I wonder what s going on here? , then keep digging until the solution presented itself.
The thought hmm, that s odd , followed by intense investigation, leading to the discovery of a major flaw is also what ultimately brought down the recent XZ backdoor.
The critical part of that sequence is the ability to do that intense investigation, though.
When I reflect on my brush with the Debian weak keys vulnerability, what sticks out to me is the fact that I didn t do the deep investigation.
I wonder if Luciano hadn t found it, how long it might have been before it was found.
The GitHub team would have continued investigating, presumably, and perhaps they (or I) would have eventually dug deep enough to find it.
But we were all super busy myself, working support tickets at EY, and GitHub feverishly building features and fighting the fires in their rapidly-growing service.
As it was, Luciano was able to take the time to dig in and find out what was happening, but just like the XZ backdoor, I feel like we, as an industry, got a bit lucky that someone with the skills, time, and energy was on hand at the right time to make a huge difference.
It s a luxury to be able to take the time to really dig into a problem, and it s a luxury that most of us rarely have.
Perhaps an understated takeaway is that somehow we all need to wrestle back some time to follow our hunches and really dig into the things that make us go hmm .
Support My Hunches
If you d like to help me be able to do intense investigations of mysterious software phenomena, you can shout me a refreshing beverage on ko-fi.
the odds are actually probably more like winning the lottery about twenty times in a row.
The numbers involved are staggeringly huge, so it s easiest to just approximate it as really, really unlikely .
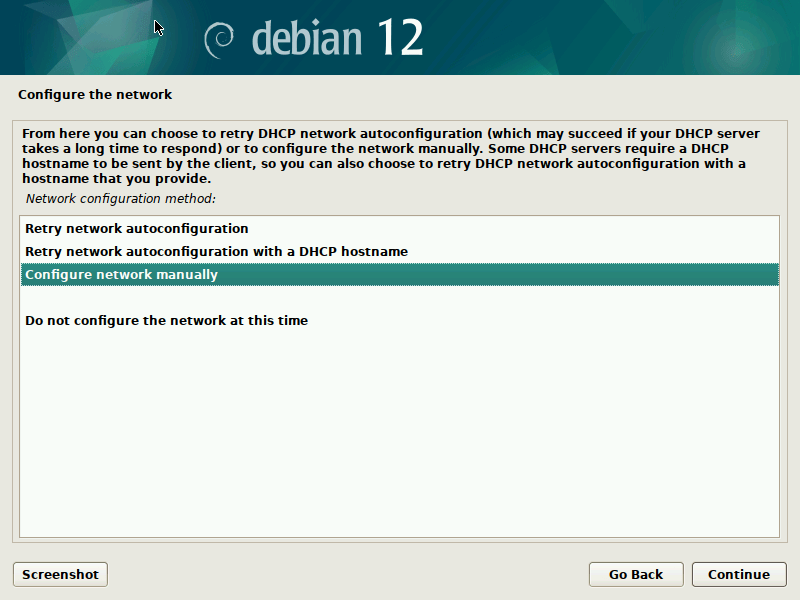
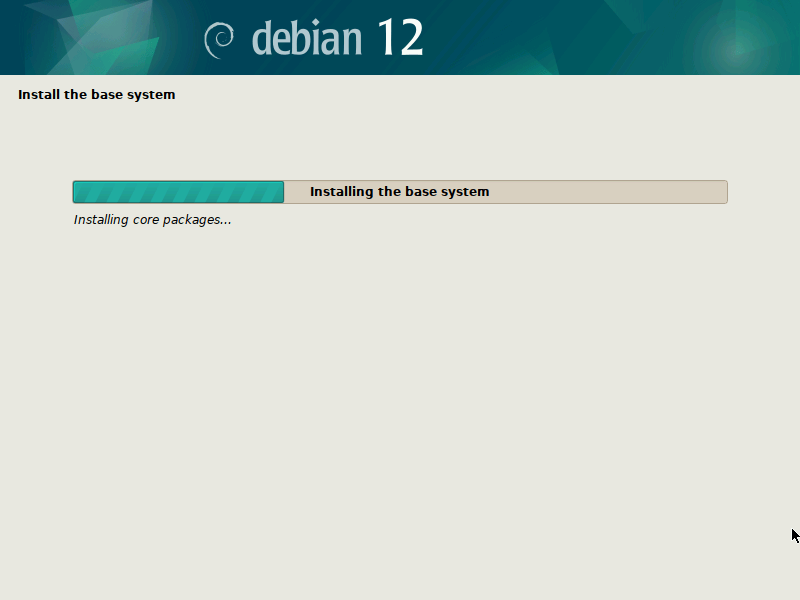
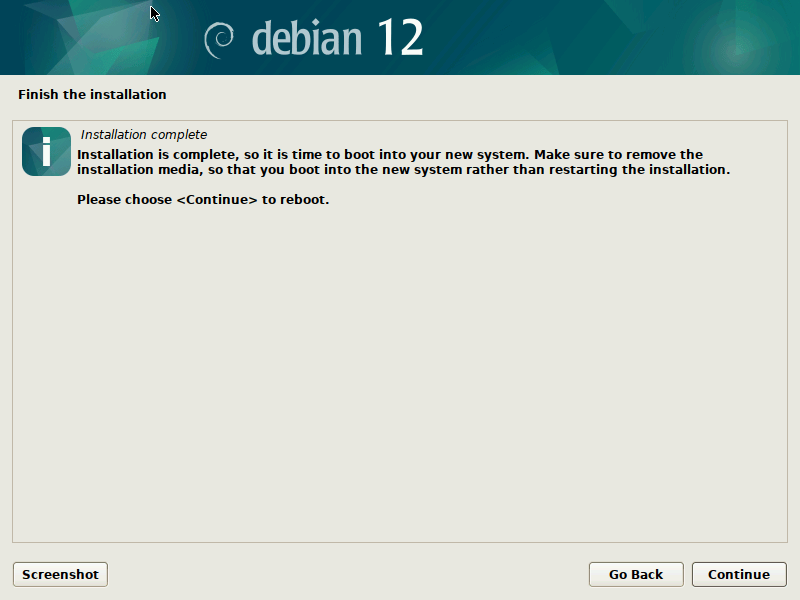
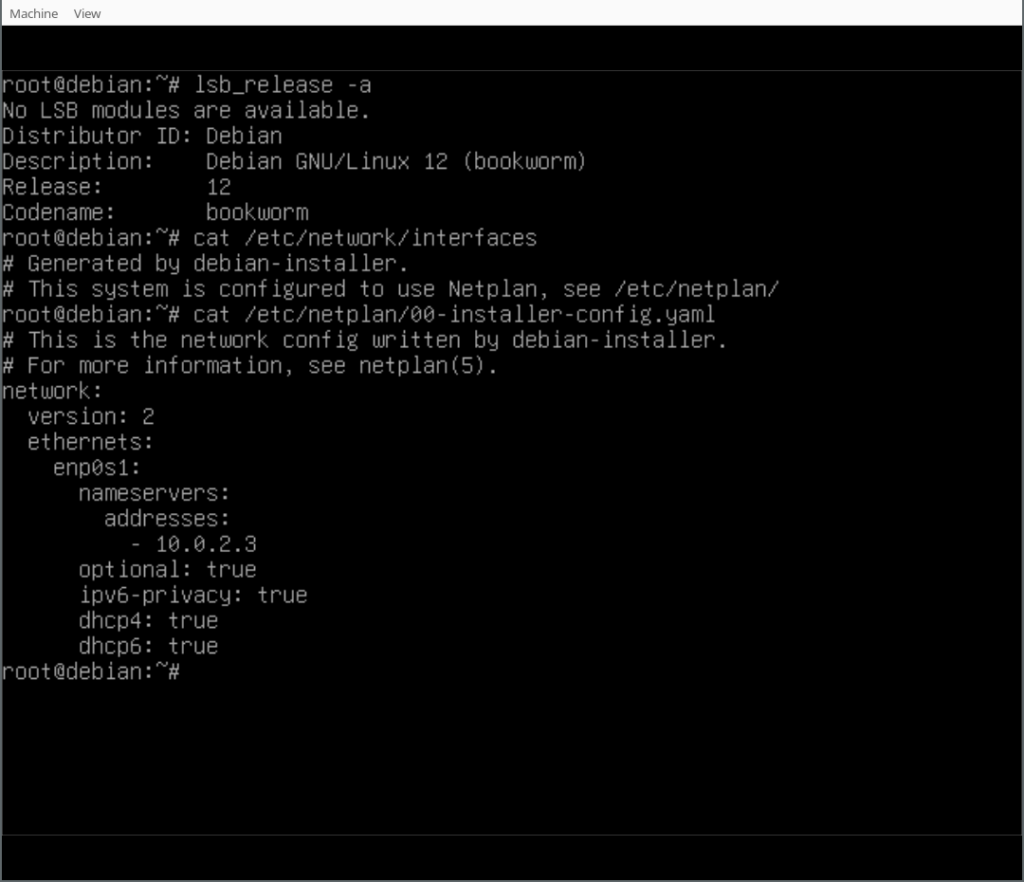
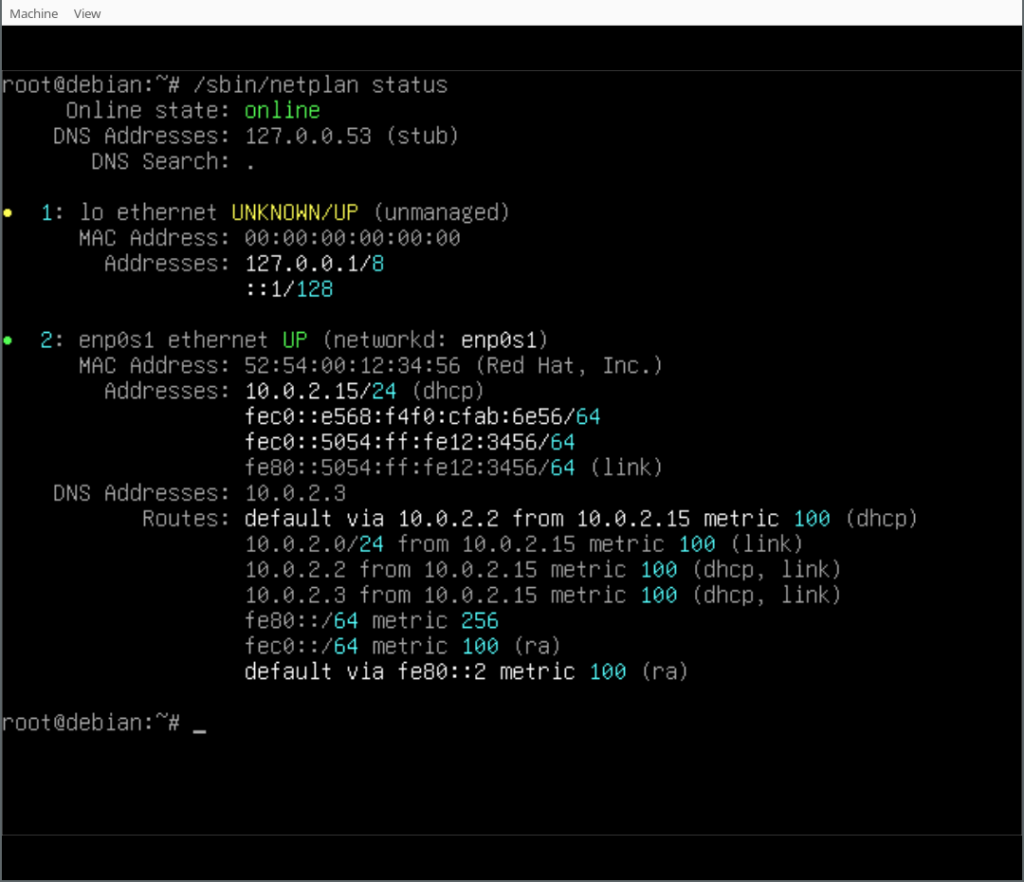
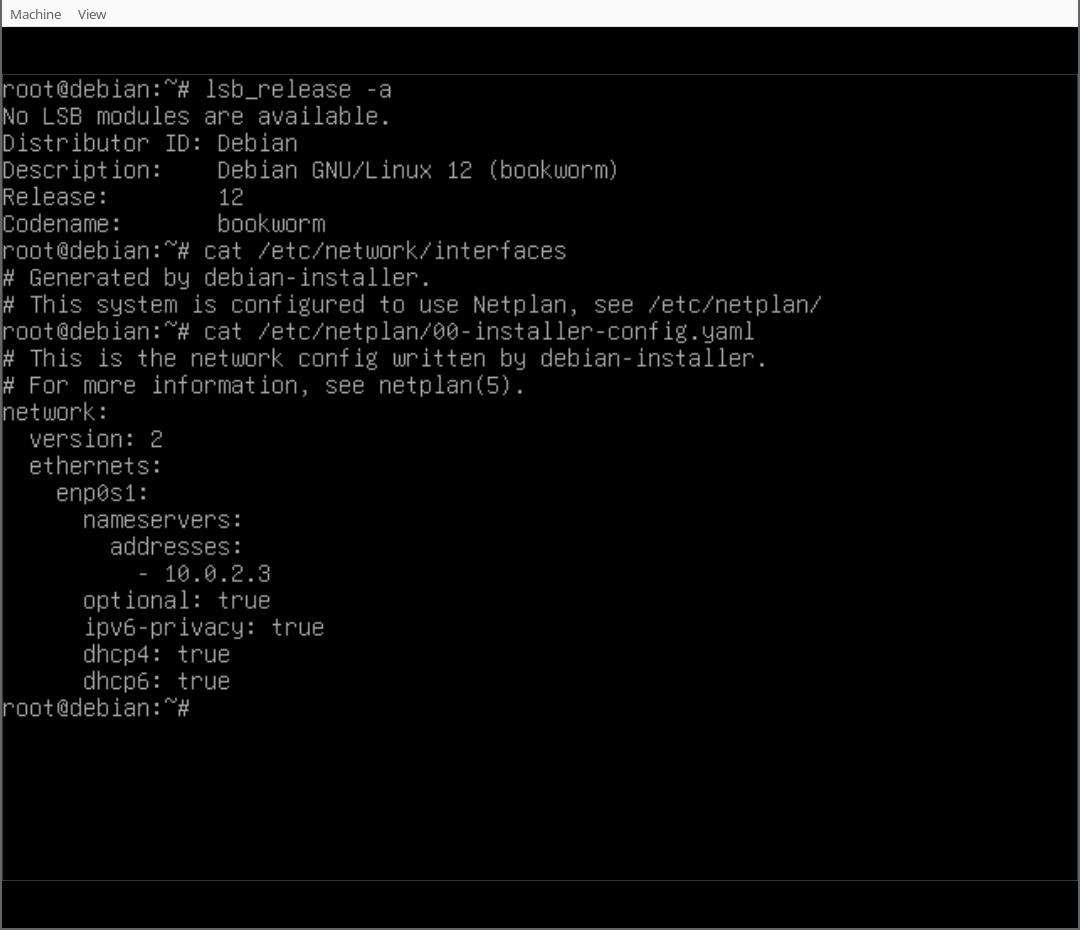
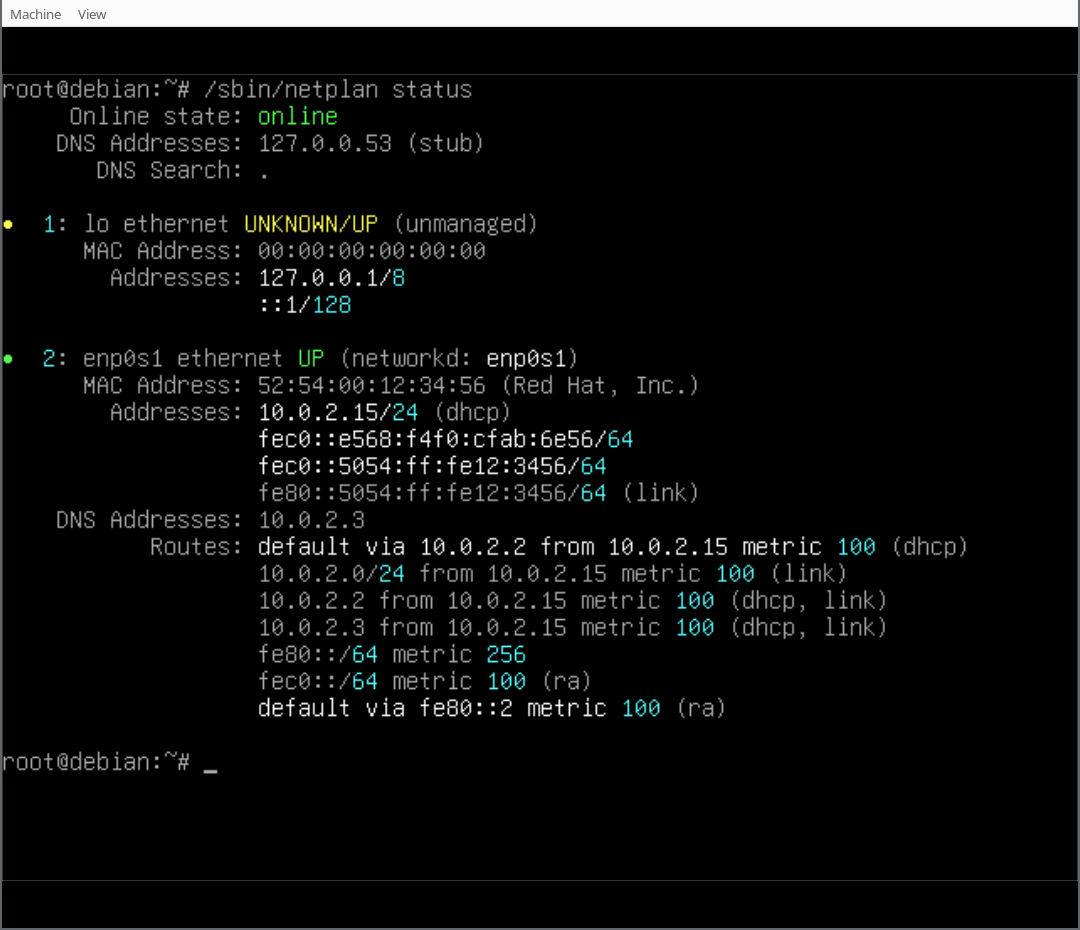
 I am upstream and
I am upstream and  Having
Having 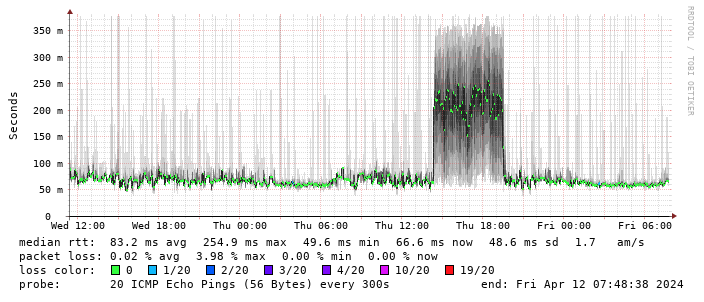 (There s a handy
(There s a handy 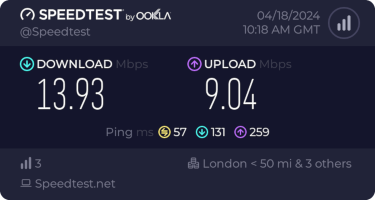 This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
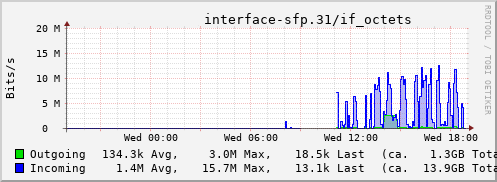 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.

 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to












 Getting the
Getting the  Now that we are back from our six month period in Argentina, we
decided to adopt a kitten, to bring more diversity into our
lives. Perhaps this little girl will teach us to think outside the
box!
Now that we are back from our six month period in Argentina, we
decided to adopt a kitten, to bring more diversity into our
lives. Perhaps this little girl will teach us to think outside the
box!



 Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the 
 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
