Jan Wagner: Backing up Windows (the hard way)
 Sometimes you need to do things you don't like and you don't know where you will end up.
Sometimes you need to do things you don't like and you don't know where you will end up.In our household there exists one (production) system running Windows. Don't ask why and please no recommandations how to substitute it. Some things are hard to (ex)change, for example your love partner. Looking into Backup with rsync on Windows (WSL) I needed to start a privileged powershell, so I first started an unprivileged one:
powershell
Start-Process powershell -Verb runAs
Add-WindowsCapability -Online -Name OpenSSH.Server~~~~0.0.1.0
Get-NetFirewallRule -Name *ssh*
Start-Service sshd
Set-Service -Name sshd -StartupType 'Automatic'
.ssh directory with the correct permissions by connecting to localhost and creating the known_hosts file.
ssh user@127.0.0.1
rsync I cheated a bit and used chocolately by running choco install rsync, but there is also an issue requesting rsync support for the OpenSSH server which includes an archive with a rsync.exe and libraries which may also fit. You can place those files for example into C:\Windows\System32\OpenSSH so they are in the PATH.
So here we are. Now I can solve all my other issues with BackupPC, Windows firewall and the network challenges to get access to the isolated dedicated network of the windows system.
 Here is my monthly update covering what I have been doing in the free software world (
Here is my monthly update covering what I have been doing in the free software world ( Since some time everybody (read developer) want to run his new
Since some time everybody (read developer) want to run his new 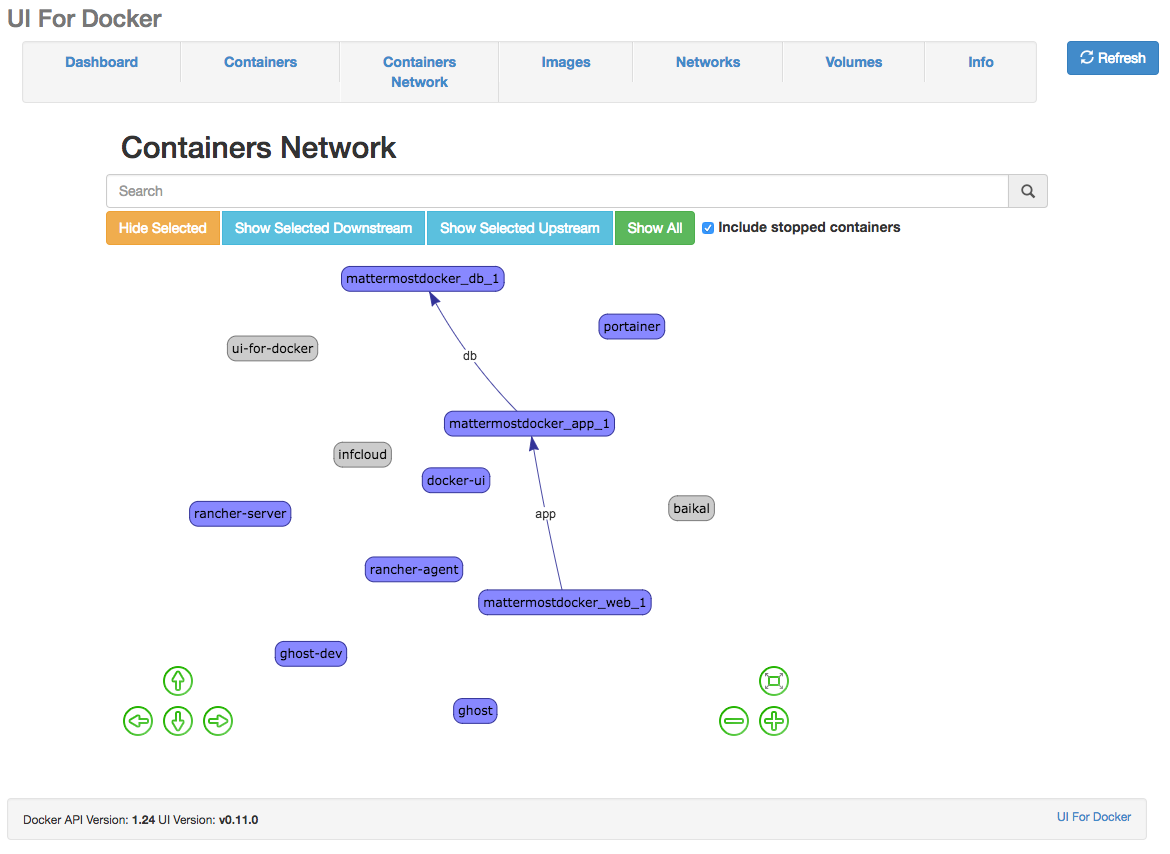
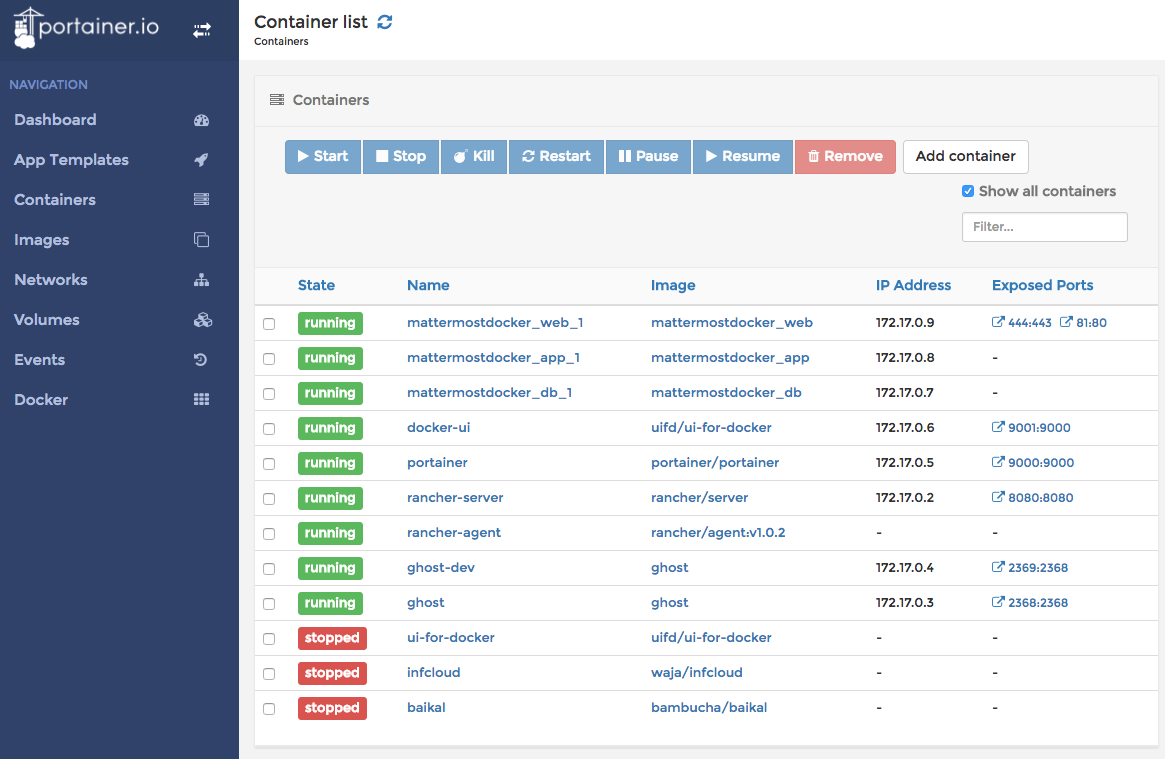
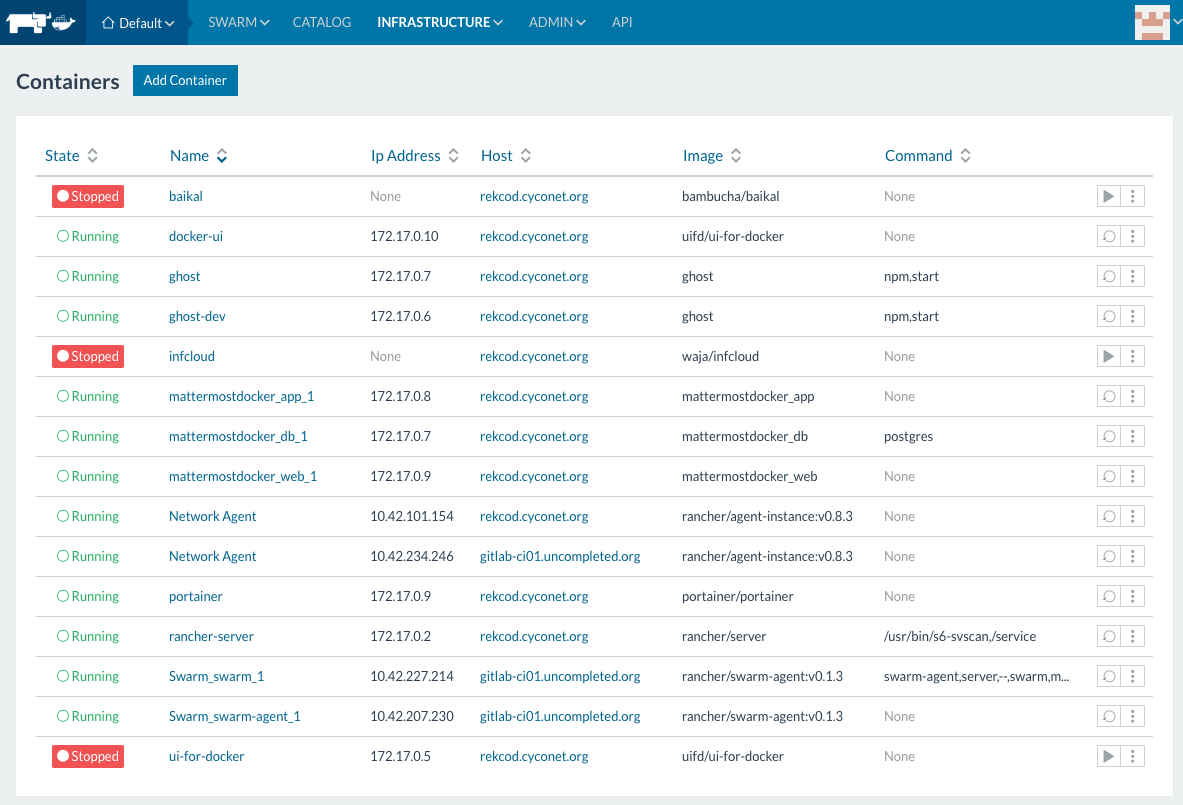 For the use cases, we are facing,
For the use cases, we are facing, 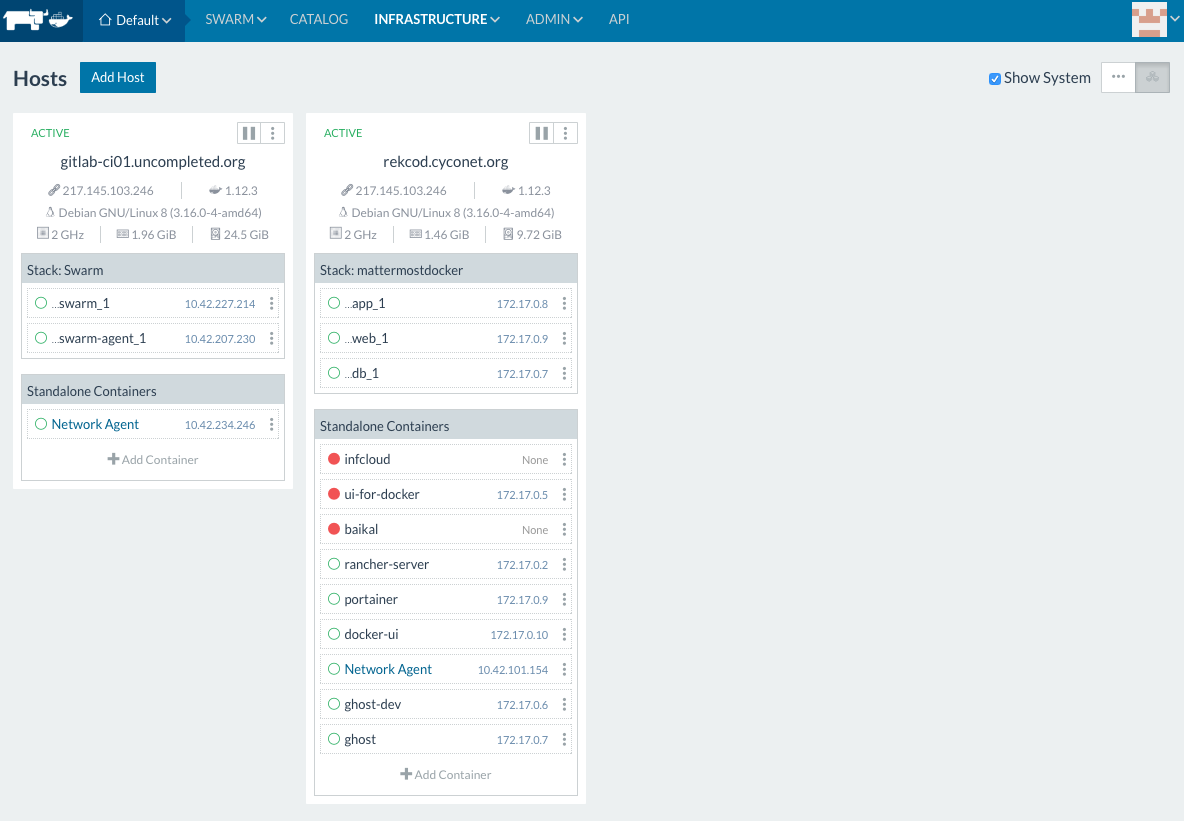
 When looking around to implement a nginx in front of a Docker web application, in most cases nginx itself is also a Docker container.
When looking around to implement a nginx in front of a Docker web application, in most cases nginx itself is also a Docker container. 

 Looking into this with
Looking into this with  In case you have spare time at the weekend ahead, it may be worth to spend it with great
In case you have spare time at the weekend ahead, it may be worth to spend it with great  This year
This year