Chris Lamb: Favourite books of 2022: Fiction
 This post marks the beginning my yearly roundups of the favourite books and movies that I read and watched in 2022 that I plan to publish over the next few days.
Just as I did for 2020 and 2021, I won't reveal precisely how many books I read in the last year. I didn't get through as many books as I did in 2021, though, but that's partly due to reading a significant number of long nineteenth-century novels in particular, a fair number of those books that American writer Henry James once referred to as "large, loose, baggy monsters."
However, in today's post I'll be looking at my favourite books that are typically filed under fiction, with 'classic' fiction following tomorrow.
Works that just missed the cut here include John O'Brien's Leaving Las Vegas, Colson Whitehead's Sag Harbor and possibly The Name of the Rose by Umberto Eco, or Elif Batuman's The Idiot. I also feel obliged to mention (or is that show off?) that I also read the 1,079-page Infinite Jest by David Foster Wallace, but I can't say it was a favourite, let alone recommend others unless they are in the market for a good-quality under-monitor stand.
This post marks the beginning my yearly roundups of the favourite books and movies that I read and watched in 2022 that I plan to publish over the next few days.
Just as I did for 2020 and 2021, I won't reveal precisely how many books I read in the last year. I didn't get through as many books as I did in 2021, though, but that's partly due to reading a significant number of long nineteenth-century novels in particular, a fair number of those books that American writer Henry James once referred to as "large, loose, baggy monsters."
However, in today's post I'll be looking at my favourite books that are typically filed under fiction, with 'classic' fiction following tomorrow.
Works that just missed the cut here include John O'Brien's Leaving Las Vegas, Colson Whitehead's Sag Harbor and possibly The Name of the Rose by Umberto Eco, or Elif Batuman's The Idiot. I also feel obliged to mention (or is that show off?) that I also read the 1,079-page Infinite Jest by David Foster Wallace, but I can't say it was a favourite, let alone recommend others unless they are in the market for a good-quality under-monitor stand.
Mona (2021) Pola Oloixarac Mona is the story of a young woman who has just been nominated for the 'most important literary award in Europe'. Mona sees the nomination as a chance to escape her substance abuse on a Californian campus and so speedily decamps to the small village in the depths of Sweden where the nominees must convene for a week before the overall winner is announced. Mona didn't disappear merely to avoid pharmacological misadventures, though, but also to avoid the growing realisation that she is being treated as something of an anthropological curiosity at her university: a female writer of colour treasured for her flourish of exotic diversity that reflects well upon her department. But Mona is now stuck in the company of her literary competitors who all have now gathered from around the world in order to do what writers do: harbour private resentments, exchange empty flattery, embody the selfsame racialised stereotypes that Mona left the United States to avoid, stab rivals in the back, drink too much, and, of course, go to bed together. But as I read Mona, I slowly started to realise that something else is going on. Why does Mona keep finding traces of violence on her body, the origins of which she cannot or refuses to remember? There is something eerily defensive about her behaviour and sardonic demeanour in general as well. A genre-bending and mind-expanding novel unfolded itself, and, without getting into spoiler territory, Mona concludes with such a surprising ending that, according to Adam Thirlwell:
Perhaps we need to rethink what is meant by a gimmick. If a gimmick is anything that we want to reject as extra or excessive or ill-fitting, then it may be important to ask what inhibitions or arbitrary conventions have made it seem like excess, and to revel in the exorbitant fictional constructions it produces. [...]Mona is a savage satire of the literary world, but it's also a very disturbing exploration of trauma and violence. The success of the book comes in equal measure from the author's commitment to both ideas, but also from the way the psychological damage component creeps up on you. And, as implied above, the last ten pages are quite literally out of this world.
My Brilliant Friend (2011)
The Story of a New Name (2012)
Those Who Leave and Those Who Stay (2013)
The Story of the Lost Child (2014)
Elena Ferrante
Elena Ferrante's Neopolitan Quartet follows two girls, both brilliant in their own way. Our protagonist-narrator is Elena, a studious girl from the lower rungs of the middle class of Naples who is inspired to be more by her childhood friend, Lila. Lila is, in turn, far more restricted by her poverty and class, but can transcend it at times through her fiery nature, which also brands her as somewhat unique within their inward-looking community. The four books follow the two girls from the perspective of Elena as they grow up together in post-war Italy, where they drift in-and-out of each other's lives due to the vicissitudes of change and the consequences of choice. All the time this is unfolding, however, the narrative is very always slightly charged by the background knowledge revealed on the very first page that Lila will, many years later, disappear from Elena's life.
Whilst the quartet has the formal properties of a bildungsroman, its subject and conception are almost entirely different. In particular, the books are driven far more by character and incident than spectacular adventures in picturesque Italy. In fact, quite the opposite takes place: these are four books where ordinary-seeming occurrences take on an unexpected radiance against a background of poverty, ignorance, violence and other threats, often bringing to mind the films of the Italian neorealism movement. Brilliantly rendered from beginning to end, Ferrante has a seemingly studious eye for interpreting interactions and the psychology of adolescence and friendship. Some utterances indeed, perhaps even some glances are dissected at length over multiple pages, something that Vittorio De Sica's classic Bicycle Thieves (1948) could never do.
Potential readers should not take any notice of the saccharine cover illustrations on most editions of the books. The quartet could even win an award for the most misleading artwork, potentially rivalling even Vladimir Nabokov's Lolita. I wouldn't be at all surprised if it is revealed that the drippy illustrations and syrupy blurbs ("a rich, intense and generous-hearted story ") turn out to be part of a larger metatextual game that Ferrante is playing with her readers. This idiosyncratic view of mine is partially supported by the fact that each of the four books has been given a misleading title, the true ambiguity of which often only becomes clear as each of the four books comes into sharper focus.
Readers of the quartet often fall into debating which is the best of the four. I've heard from more than one reader that one has 'too much Italian politics' and another doesn't have enough 'classic' Lina moments. The first book then possesses the twin advantages of both establishing the environs and finishing with a breathtaking ending that is both satisfying and a cliffhanger as well but does this make it 'the best'? I prefer to liken the quartet more like the different seasons of The Wire (2002-2008) where, personal favourites and preferences aside, although each season is undoubtedly unique, it would take a certain kind of narrow-minded view of art to make the claim that, say, series one of The Wire is 'the best' or that the season that focuses on the Baltimore docks 'is boring'. Not to sound like a neo-Wagnerian, but each of them adds to final result in its own. That is to say, both The Wire and the Neopolitan Quartet achieve the rare feat of making the magisterial simultaneously intimate.
Out There: Stories (2022) Kate Folk Out There is a riveting collection of disturbing short stories by first-time author Kate Fork. The title story first appeared in the New Yorker in early 2020 imagines a near-future setting where a group of uncannily handsome artificial men called 'blots' have arrived on the San Francisco dating scene with the secret mission of sleeping with women, before stealing their personal data from their laptops and phones and then (quite literally) evaporating into thin air. Folk's satirical style is not at all didactic, so it rarely feels like she is making her points in a pedantic manner. But it's clear that the narrator of Out There is recounting her frustration with online dating. in a way that will resonate with anyone who s spent time with dating apps or indeed the contemporary hyper-centralised platform-based internet in general. Part social satire, part ghost story and part comic tales, the blurring of the lines between these factors is only one of the things that makes these stories so compelling. But whilst Folk constructs crazy scenarios and intentionally strange worlds, she also manages to also populate them with characters that feel real and genuinely sympathetic. Indeed, I challenge you not to feel some empathy for the 'blot' in the companion story Big Sur which concludes the collection, and it complicates any primary-coloured view of the dating world of consisting entirely of predatory men. And all of this is leavened with a few stories that are just plain surreal. I don't know what the deal is with Dating a Somnambulist (available online on Hobart Pulp), but I know that I like it.
Solaris (1961) Stanislaw Lem When Kelvin arrives at the planet Solaris to study the strange ocean that covers its surface, instead of finding an entirely physical scientific phenomenon, he soon discovers a previously unconscious memory embodied in the physical manifestation of a long-dead lover. The other scientists on the space station slowly reveal that they are also plagued with their own repressed corporeal memories. Many theories are put forward as to why all this is occuring, including the idea that Solaris is a massive brain that creates these incarnate memories. Yet if that is the case, the planet's purpose in doing so is entirely unknown, forcing the scientists to shift focus and wonder whether they can truly understand the universe without first understanding what lies within their own minds and in their desires. This would be an interesting outline for any good science fiction book, but one of the great strengths of Solaris is not only that it withholds from the reader why the planet is doing anything it does, but the book is so forcefully didactic in its dislike of the hubris, destructiveness and colonial thinking that can accompany scientific exploration. In one of its most vitriolic passages, Lem's own anger might be reaching out to the reader:
We are humanitarian and chivalrous; we don t want to enslave other races, we simply want to bequeath them our values and take over their heritage in exchange. We think of ourselves as the Knights of the Holy Contact. This is another lie. We are only seeking Man. We have no need of other worlds. We need mirrors. We don t know what to do with other worlds. A single world, our own, suffices us; but we can t accept it for what it is. We are searching for an ideal image of our own world: we go in quest of a planet, of a civilisation superior to our own, but developed on the basis of a prototype of our primaeval past. At the same time, there is something inside us that we don t like to face up to, from which we try to protect ourselves, but which nevertheless remains since we don t leave Earth in a state of primal innocence. We arrive here as we are in reality, and when the page is turned, and that reality is revealed to us that part of our reality that we would prefer to pass over in silence then we don t like it anymore.An overwhelming preoccupation with this idea infuses Solaris, and it turns out to be a common theme in a lot of Lem's work of this period, such as in his 1959 'anti-police procedural' The Investigation. Perhaps it not a dislike of exploration in general or the modern scientific method in particular, but rather a savage critique of the arrogance and self-assuredness that accompanies most forms of scientific positivism, or at least pursuits that cloak themselves under the guise of being a laudatory 'scientific' pursuit:
Man has gone out to explore other worlds and other civilizations without having explored his own labyrinth of dark passages and secret chambers and without finding what lies behind doorways that he himself has sealed.I doubt I need to cite specific instances of contemporary scientific pursuits that might meet Lem's punishing eye today, and the fact that his critique works both in 2022 and 1961 perhaps tells us more about the human condition than we'd care to know. Another striking thing about Solaris isn't just the specific Star Trek and Stargate SG-1 episodes that I retrospectively realised were purloined from the book, but that almost the entire register of Star Trek: The Next Generation in particular seems to be rehearsed here. That is to say, TNG presents itself as hard and fact-based 'sci-fi' on the surface, but, at its core, there are often human, existential and sometimes quite enormously emotionally devastating human themes being discussed such as memory, loss and grief. To take one example from many, the painful memories that the planet Solaris physically materialises in effect asks us to seriously consider what it actually is taking place when we 'love' another person: is it merely another 'mirror' of ourselves? (And, if that is the case, is that... bad?) It would be ahistorical to claim that all popular science fiction today can be found rehearsed in Solaris, but perhaps it isn't too much of a stretch:
[Solaris] renders unnecessary any more alien stories. Nothing further can be said on this topic ...] Possibly, it can be said that when one feels the urge for such a thing, one should simply reread Solaris and learn its lessons again. Kim Stanley Robinson [...]I could go on praising this book for quite some time; perhaps by discussing the extreme framing devices used within the book at one point, the book diverges into a lengthy bibliography of fictional books-within-the-book, each encapsulating a different theory about what the mechanics and/or function of Solaris is, thereby demonstrating that 'Solaris studies' as it is called within the world of the book has been going on for years with no tangible results, which actually leads to extreme embarrassment and then a deliberate and willful blindness to the 'Solaris problem' on the part of the book's scientific community. But I'll leave it all here before this review gets too long... Highly recommended, and a likely reread in 2023.
Brokeback Mountain (1997) Annie Proulx Brokeback Mountain began as a short story by American author Annie Proulx which appeared in the New Yorker in 1997, although it is now more famous for the 2005 film adaptation directed by Taiwanese filmmaker Ang Lee. Both versions follow two young men who are hired for the summer to look after sheep at a range under the 'Brokeback' mountain in Wyoming. Unexpectedly, however, they form an intense emotional and sexual attachment, yet life intervenes and demands they part ways at the end of the summer. Over the next twenty years, though, as their individual lives play out with marriages, children and jobs, they continue reuniting for brief albeit secret liaisons on camping trips in remote settings. There's no feigned shyness or self-importance in Brokeback Mountain, just a close, compassionate and brutally honest observation of a doomed relationship and a bone-deep feeling for the hardscrabble life in the post-War West. To my mind, very few books have captured so acutely the desolation of a frustrated and repressed passion, as well as the particular flavour of undirected anger that can accompany this kind of yearning. That the original novella does all this in such a beautiful way (and without the crutch of the Wyoming landscape to look at ) is a tribute to Proulx's skills as a writer. Indeed, even without the devasting emotional undertones, Proulx's descriptions of the mountains and scree of the West is likely worth the read alone.
Luster (2020) Raven Leilani Edie is a young Black woman living in New York whose life seems to be spiralling out of control. She isn't good at making friends, her career is going nowhere, and she has no close family to speak of as well. She is, thus, your typical NYC millennial today, albeit seen through a lens of Blackness that complicates any reductive view of her privilege or minority status. A representative paragraph might communicate the simmering tone:
Before I start work, I browse through some photos of friends who are doing better than me, then an article on a black teenager who was killed on 115th for holding a weapon later identified as a showerhead, then an article on a black woman who was killed on the Grand Concourse for holding a weapon later identified as a cell phone, then I drown myself in the comments section and do some online shopping, by which I mean I put four dresses in my cart as a strictly theoretical exercise and then let the page expire.She starts a sort-of affair with an older white man who has an affluent lifestyle in nearby New Jersey. Eric or so he claims has agreed upon an 'open relationship' with his wife, but Edie is far too inappropriate and disinhibited to respect any boundaries that Eric sets for her, and so Edie soon becomes deeply entangled in Eric's family life. It soon turns out that Eric and his wife have a twelve-year-old adopted daughter, Akila, who is also wait for it Black. Akila has been with Eric's family for two years now and they aren t exactly coping well together. They don t even know how to help her to manage her own hair, let alone deal with structural racism. Yet despite how dark the book's general demeanour is, there are faint glimmers of redemption here and there. Realistic almost to the end, Edie might finally realise what s important in her life, but it would be a stretch to say that she achieves them by the final page. Although the book is full of acerbic remarks on almost any topic (Dogs: "We made them needy and physically unfit. They used to be wolves, now they are pugs with asthma."), it is the comments on contemporary race relations that are most critically insightful. Indeed, unsentimental, incisive and funny, Luster had much of what I like in Colson Whitehead's books at times, but I can't remember a book so frantically fast-paced as this since the Booker-prize winning The Sellout by Paul Beatty or Sam Tallent's Running the Light.








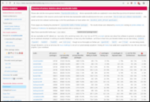
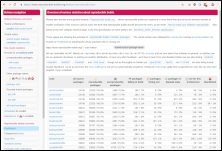
 The following contributors got their Debian Developer accounts in the last two months:
The following contributors got their Debian Developer accounts in the last two months:
 Sometimes you need to do things you don't like and you don't know where you will end up.
Sometimes you need to do things you don't like and you don't know where you will end up.










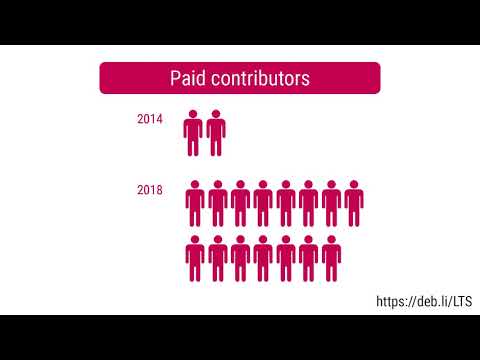
 Since some time everybody (read developer) want to run his new
Since some time everybody (read developer) want to run his new 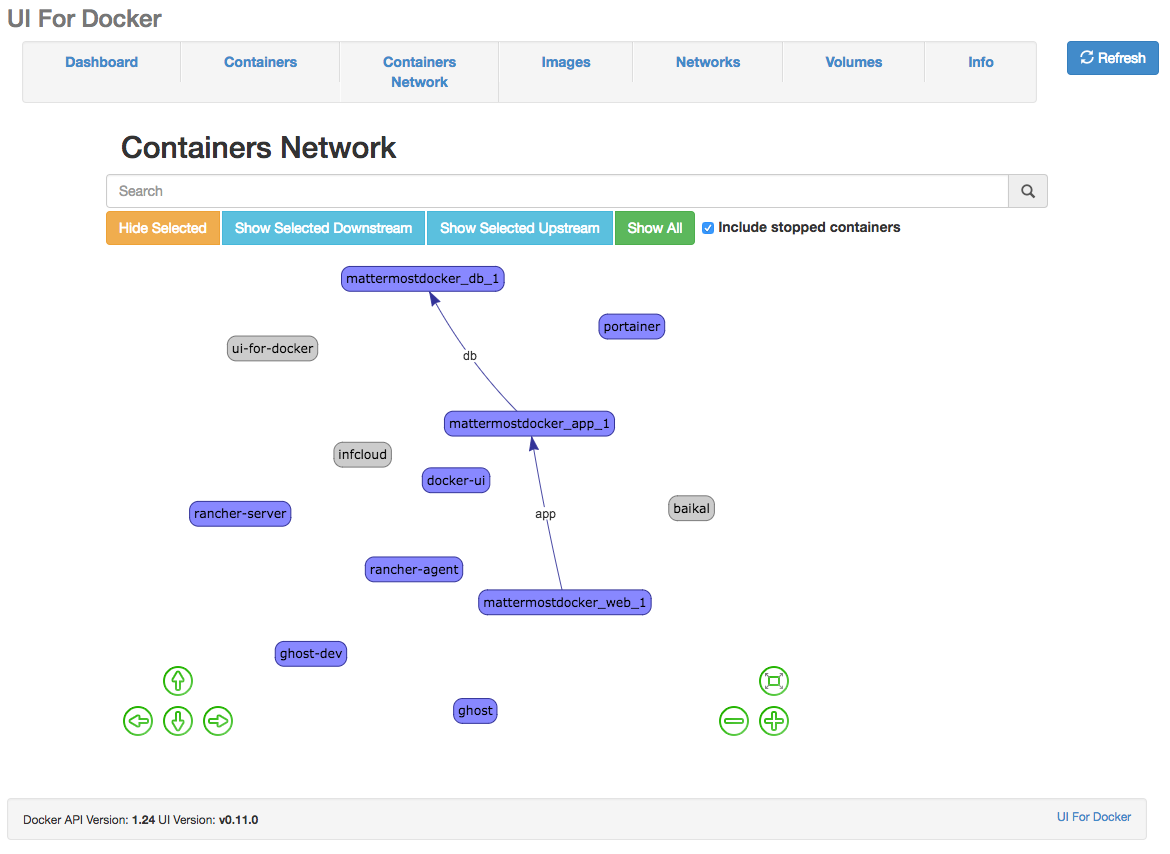
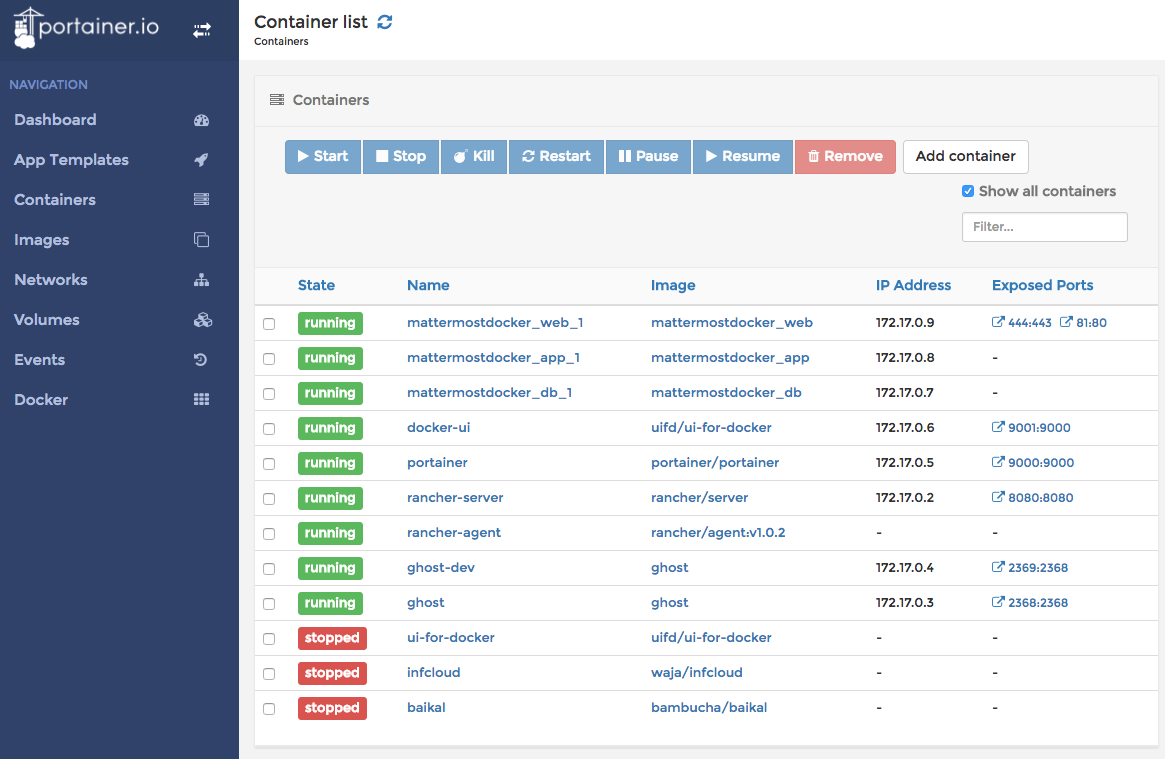
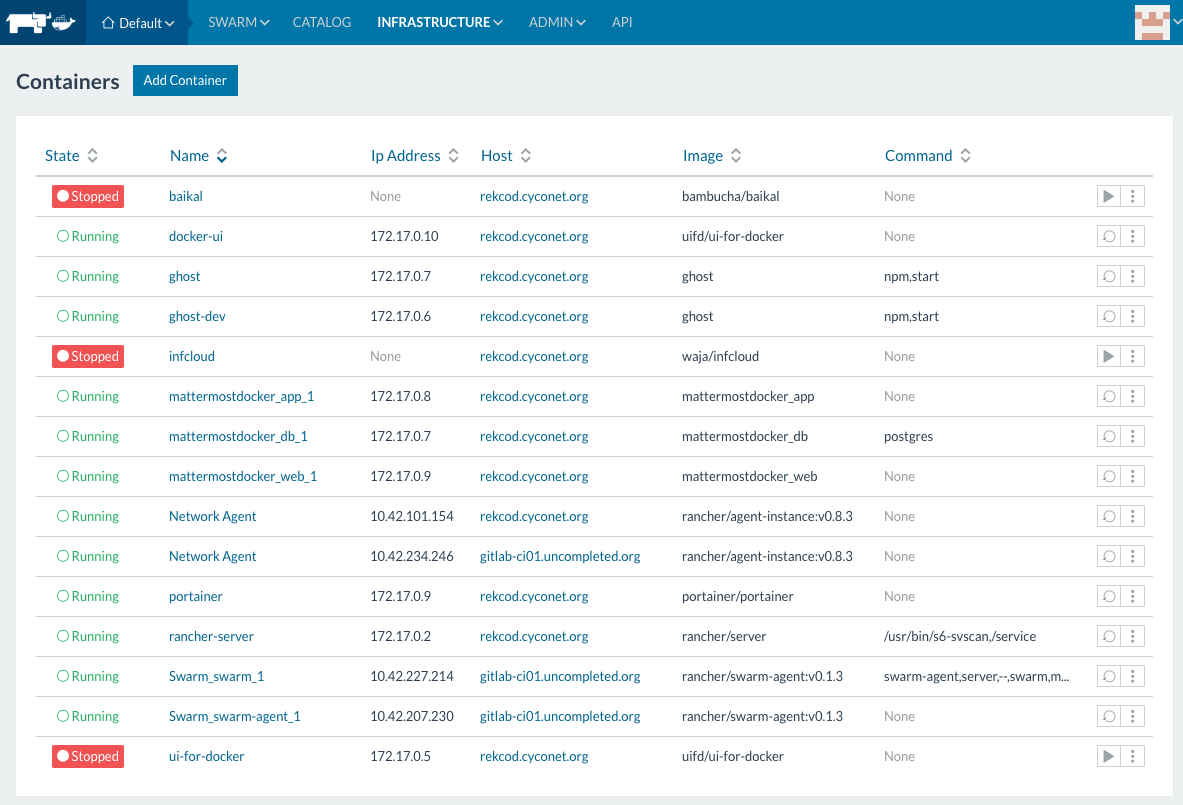 For the use cases, we are facing,
For the use cases, we are facing, 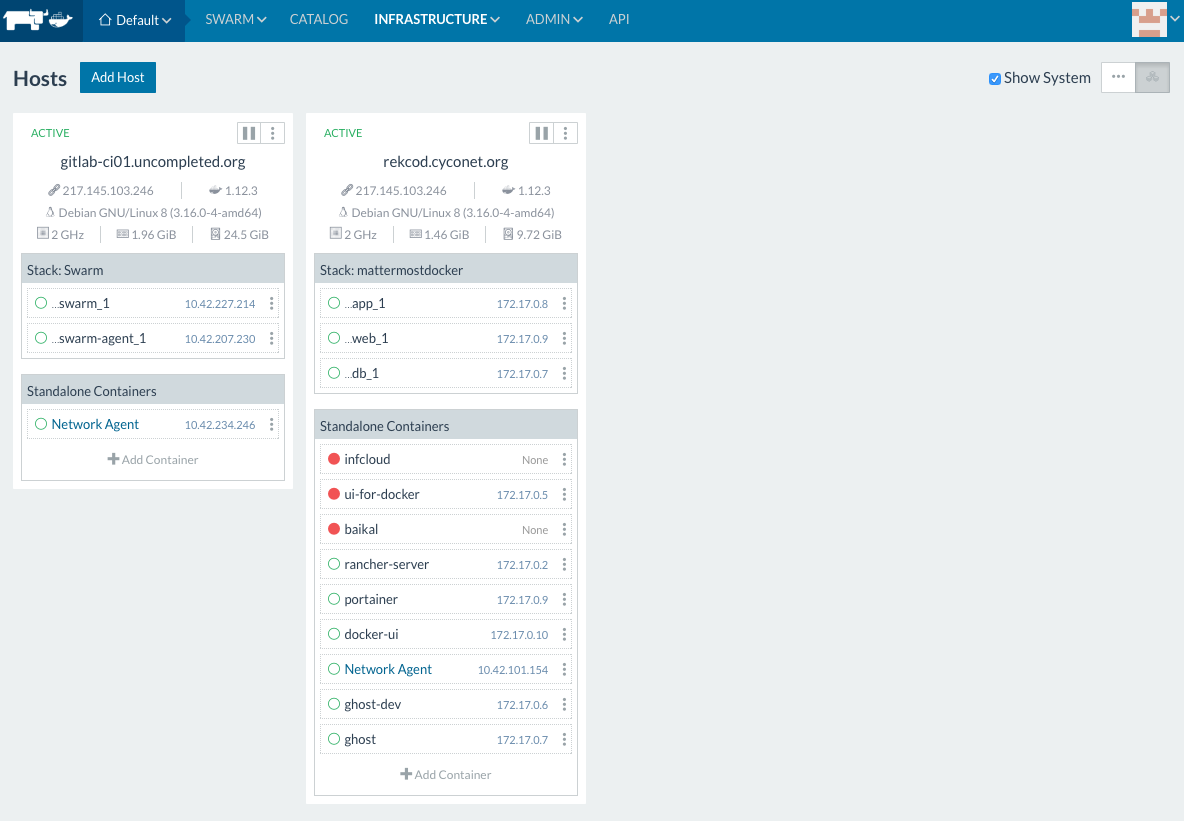
 When looking around to implement a nginx in front of a Docker web application, in most cases nginx itself is also a Docker container.
When looking around to implement a nginx in front of a Docker web application, in most cases nginx itself is also a Docker container. 