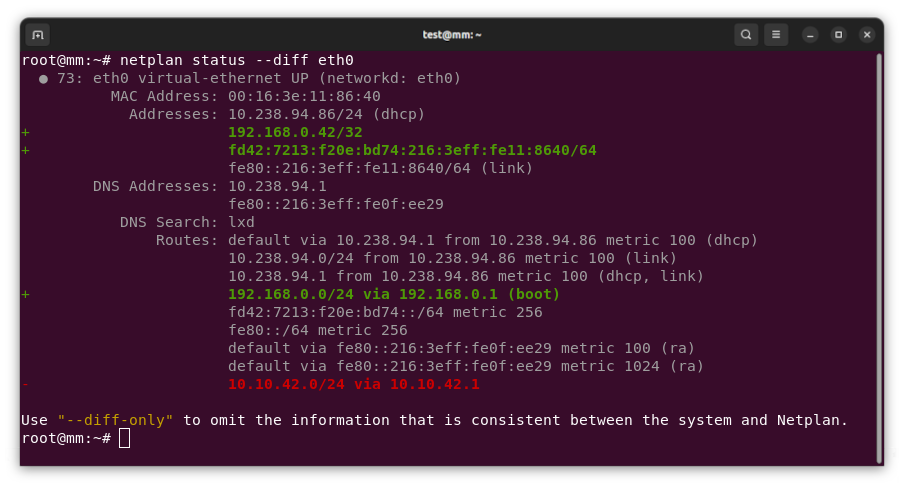
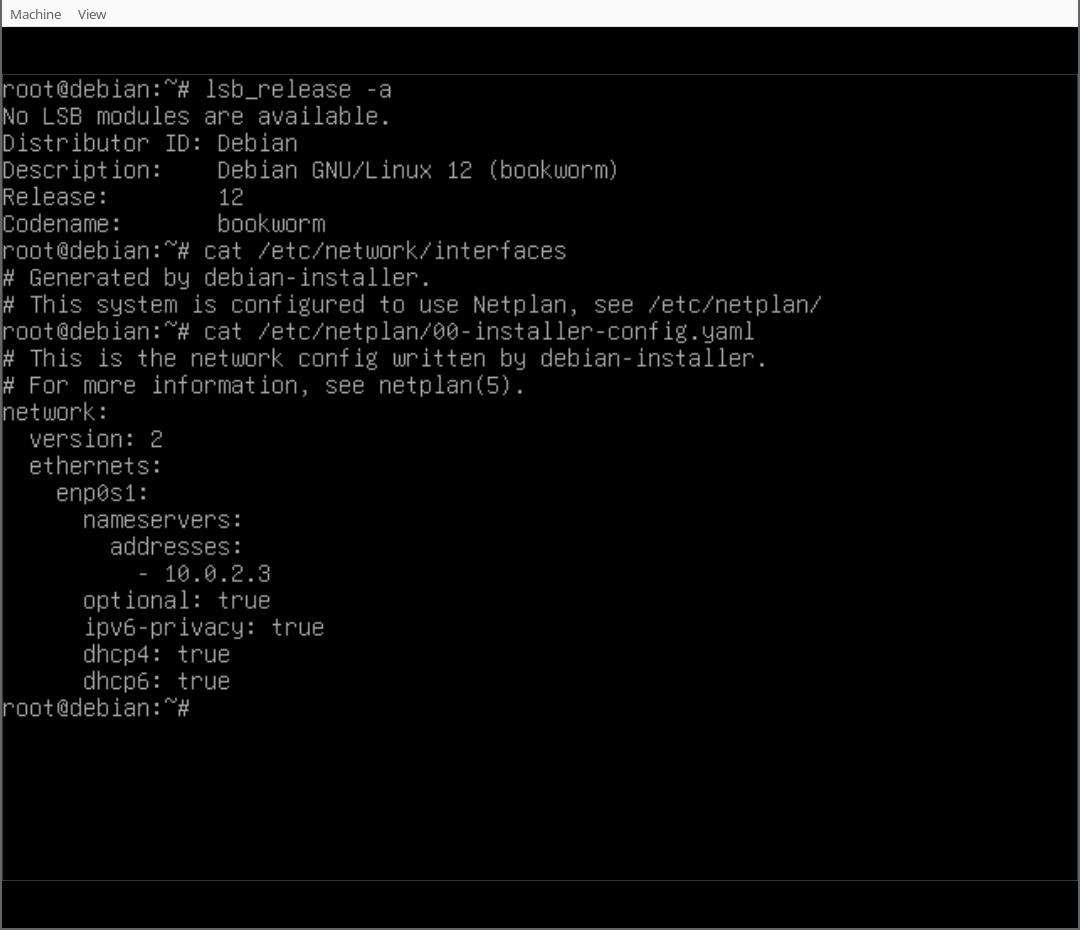
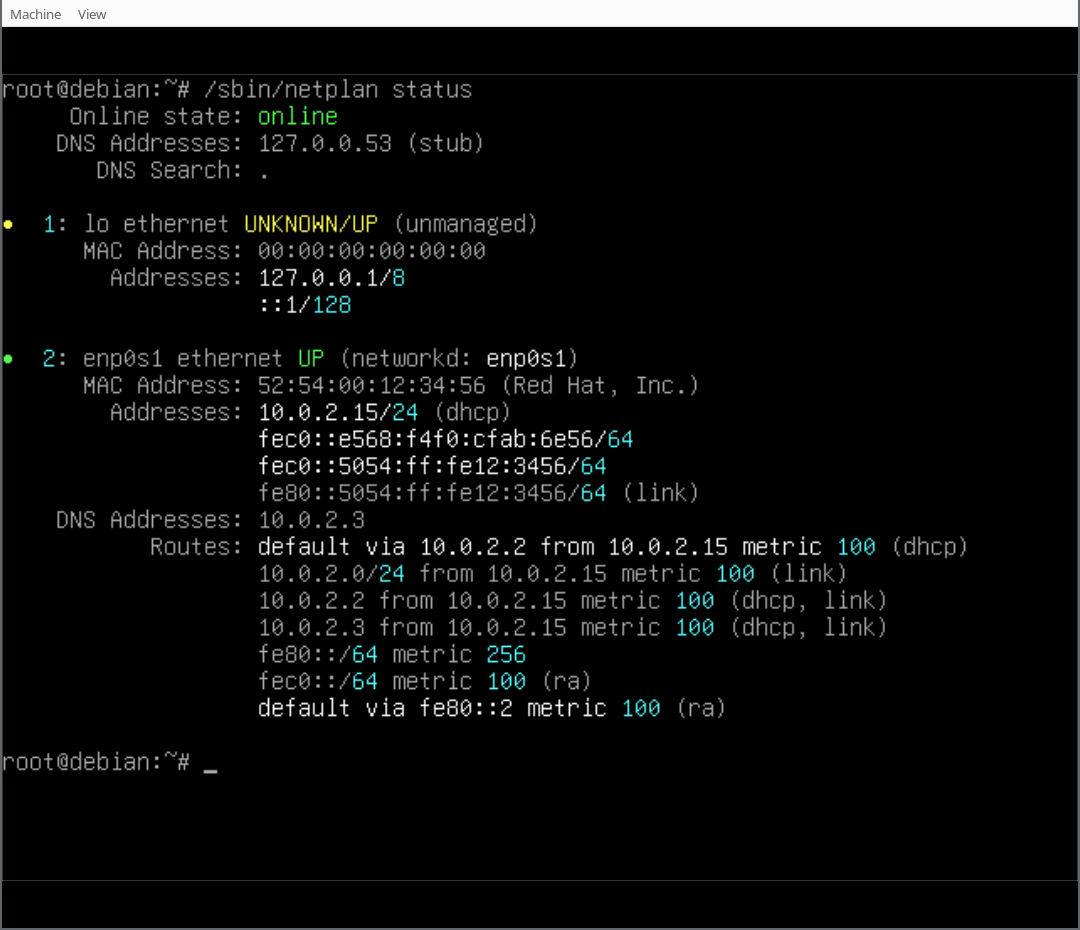
Russell Coker: Humane AI Pin
I wrote a blog post The Shape of Computers [1] exploring ideas of how computers might evolve and how we can use them. One of the devices I mentioned was the Humane AI Pin, which has just been the recipient of one of the biggest roast reviews I ve ever seen [2], good work Marques Brownlee! As an aside I was once given a product to review which didn t work nearly as well as I think it should have worked so I sent an email to the developers saying sorry this product failed to work well so I can t say anything good about it and didn t publish a review.
One of the first things that caught my attention in the review is the note that the AI Pin doesn t connect to your phone. I think that everything should connect to everything else as a usability feature. For security we don t want so much connecting and it s quite reasonable to turn off various connections at appropriate times for security, the Librem5 is an example of how this can be done with hardware switches to disable Wifi etc. But to just not have connectivity is bad.
The next noteworthy thing is the external battery which also acts as a magnetic attachment from inside your shirt. So I guess it s using wireless charging through your shirt. A magnetically attached external battery would be a great feature for a phone, you could quickly swap a discharged battery for a fresh one and keep using it. When I tried to make the PinePhonePro my daily driver [3] I gave up and charging was one of the main reasons. One thing I learned from my experiment with the PinePhonePro is that the ratio of charge time to discharge time is sometimes more important than battery life and being able to quickly swap batteries without rebooting is a way of solving that. The reviewer of the AI Pin complains later in the video about battery life which seems to be partly due to wireless charging from the detachable battery and partly due to being physically small. It seems the phablet form factor is the smallest viable personal computer at this time.
The review glosses over what could be the regarded as the 2 worst issues of the device. It does everything via the cloud (where the cloud means a computer owned by someone I probably shouldn t trust ) and it records everything. Strange that it s not getting the hate the Google Glass got.
The user interface based on laser projection of menus on the palm of your hand is an interesting concept. I d rather have a Bluetooth attached tablet or something for operations that can t be conveniently done with voice. The reviewer harshly criticises the laser projection interface later in the video, maybe technology isn t yet adequate to implement this properly.
The first criticism of the device in the review part of the video is of the time taken to answer questions, especially when Internet connectivity is poor. His question who designed the Washington Monument took 8 seconds to start answering it in his demonstration. I asked the Alpaca LLM the same question running on 4 cores of a E5-2696 and it took 10 seconds to start answering and then printed the words at about speaking speed. So if we had a free software based AI device for this purpose it shouldn t be difficult to get local LLM computation with less delay than the Humane device by simply providing more compute power than 4 cores of a E5-2696v3. How does a 32 core 1.05GHz Mali G72 from 2017 (as used in the Galaxy Note 9) compare to 4 cores of a 2.3GHz Intel CPU from 2015? Passmark says that Intel CPU can do 48GFlop with all 18 cores so 4 cores can presumably do about 10GFlop which seems less than the claimed 20-32GFlop of the Mali G72. It seems that with the right software even older Android phones could give adequate performance for a local LLM. The Alpaca model I m testing with takes 4.2G of RAM to run which is usable in a Note 9 with 8G of RAM or a Pixel 8 Pro with 12G. A Pixel 8 Pro could have 4.2G of RAM reserved for a LLM and still have as much RAM for other purposes as my main laptop as of a few months ago. I consider the speed of Alpaca on my workstation to be acceptable but not great. If we can get FOSS phones running a LLM at that speed then I think it would be great for a first version we can always rely on newer and faster hardware becoming available.
Marques notes that the cause of some of the problems is likely due to a desire to make it a separate powerful product in the future and that if they gave it phone connectivity in the start they would have to remove that later on. I think that the real problem is that the profit motive is incompatible with good design. They want to have a product that s stand-alone and justifies the purchase price plus subscription and that means not making it a phone accessory . While I think that the best thing for the user is to allow it to talk to a phone, a PC, a car, and anything else the user wants. He compares it to the Apple Vision Pro which has the same issue of trying to be a stand-alone computer but not being properly capable of it.
One of the benefits that Marques cites for the AI Pin is the ability to capture voice notes. Dictaphones have been around for over 100 years and very few people have bought them, not even in the 80s when they became cheap. While almost everyone can occasionally benefit from being able to make a note of an idea when it s not convenient to write it down there are few people who need it enough to carry a separate device, not even if that device is tiny. But a phone as a general purpose computing device with microphone can easily be adapted to such things. One possibility would be to program a phone to start a voice note when the volume up and down buttons are pressed at the same time or when some other condition is met. Another possibility is to have a phone have a hotkey function that varies by what you are doing, EG if bushwalking have the hotkey be to take a photo or if on a flight have it be taking a voice note. On the Mobile Apps page on the Debian wiki I created a section for categories of apps that I think we need [4]. In that section I added the following list:
- Voice input for dictation
- Voice assistant like Google/Apple
- Voice output
- Full operation for visually impaired people
- [1] https://etbe.coker.com.au/2024/03/13/shape-computers/
- [2] https://www.youtube.com/watch?v=TitZV6k8zfA
- [3] https://etbe.coker.com.au/2023/10/11/pinephone-status/
- [4] https://wiki.debian.org/MobileApps
- [5] https://www.youtube.com/watch?v=0O2yTG3n1Vc
- [6] https://etbe.coker.com.au/2023/05/29/considering-convergence/
- [7] https://etbe.coker.com.au/2024/04/26/convergence-vs-transference/
 With
With 
 Time really flies when
Time really flies when 

 (There s a handy
(There s a handy  This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
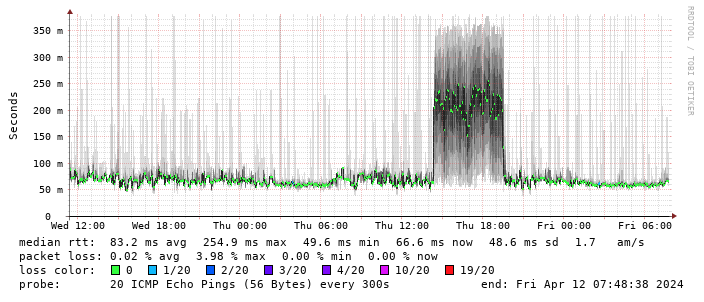
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
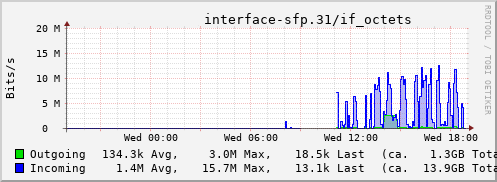 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.

 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to

 Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the 
 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze

 The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The Project Leader is the official representative of The Debian Project tasked with
managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last
The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The Project Leader is the official representative of The Debian Project tasked with
managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last