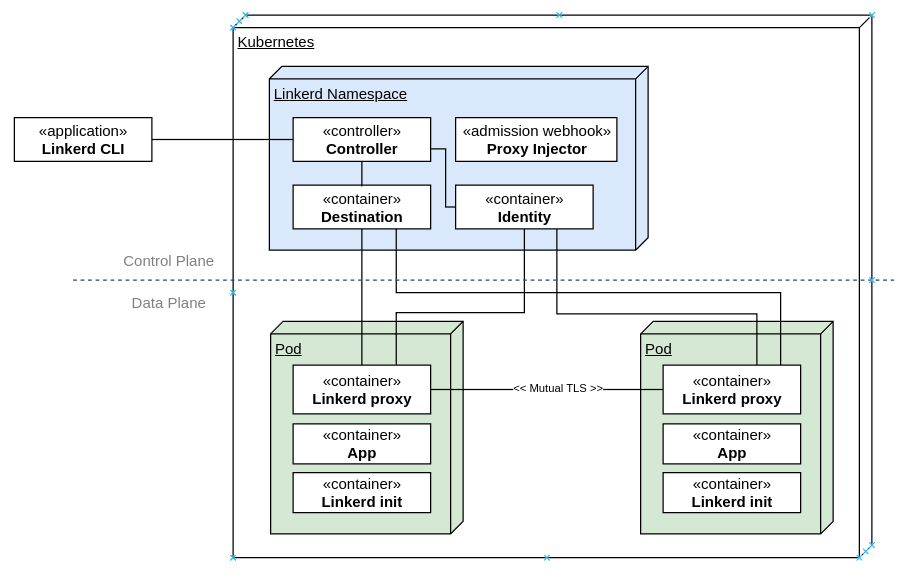
kpcyrd: Writing a Linux executable from scratch with x86_64-unknown-none and Rust
I recently mentioned on the internet I did work in this direction and a friend of mine asked me to write a blogpost on this. I didn t blog for a long time (keeping all the goodness for myself hehe), so here we go. To set the scene, let s assume we want to make an exectuable binary for x86_64 Linux that s supposed to be extremely portable. It should work on both Debian and Arch Linux. It should work on systems without glibc like Alpine Linux. It should even work in a
This is going to install everything you need to use Rust on Linux (this tutorial assumes you re following along on Linux btw). Usually it s still using a system linker (by calling the
I don t know if/how this is made available by Linux distributions, so I recommend following along with rust installed from rustup.
Anyway, we re creating a new project with cargo, this creates a new directory that we can then change into (you might ve done this before):
There s going to be a file named
There s a second file named
Alrighty, leaving this file empty is not valid but we re going to walk through the individual steps so we re going to try to build with an empty file first. At this point I would like to credit this chapter of a fasterthanli.me series and a blogpost by Philipp Oppermann, this tutorial is merely an 2023 update and makes it work with stable Rust. Let s run the build:
Since this doesn t use a libc (oh right, I forgot to mention this up to this point actually), this also means there s no
Running the build again:
Rust noticed we didn t define a main function and suggest we add one. This isn t what we want though so we ll politely decline and inform Rust we don t have a main and it shouldn t attempt to call it. We re adding
Running the build again:
Rust is asking us for a panic handler, basically I m going to jump to this address if something goes terribly wrong and execute whatever you put there . Eventually we would put some code there to just exit the program, but for now an infinitely loop will do. This is likely going to get stripped away anyway by the compiler if it notices our program has no code-branches leading to a panic and the code is unused. Our
Running the build again:
Neat, it worked! What happens if we run it?
Oops. Let s try to disassemble it:
Ok that looks pretty from scratch to me . The file contains no cpu instructions. Also note how our infinity loop is not present (as predicted).
Making a basic program and executing it
Ok let s try to make a valid program that basically just cleanly exits. First let s try to add some cpu instructions and verify they re indeed getting executed. Lemme introduce, the
Writing Rust
Ok but even though cpu instructions can be fun at times, I d rather not deal with them most of the time (this might strike you as odd, considering this blog post). Instead let s try to define a function in Rust and call into that instead. We re going to define this function as unsafe (btw none of this is taking advantage of the safety guarantees by Rust in case it wasn t obvious. This tutorial is mostly going to stick to unsafe Rust, but for bigger projects you can attempt to reduce your usage of
Adding functions
Ok we re getting closer but we aren t quite there yet. Let s try to write an
Printing text
Ok let s try to do a quick hello world, to do this we re going to call the
FROM scratch Docker container. In a more serious setting you would statically link musl-libc with your Rust program, but today we re in a silly-goofy mood so we re going to try to make this work without a libc. And we re also going to use Rust for this, more specifically the stable release channel of Rust, so this blog post won t use any nightly-only features that might still change/break. If you re using a Rust 1.0 version that was recent at the time of writing or later (>= 1.68.0 according to my computer), you should be able to try this at home just fine .
This tutorial assumes you have no prior programming experience in any programming language, but it s going to involve some x86_64 assembly. If you already know what a syscall is, you ll be just fine. If this is your first exposure to programming you might still be able to follow along, but it might be a wild ride.
If you haven t already, install rustup (possibly also available in your package manager, who knows?)
# when asked, press enter to confirm default settings
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs sh
cc binary, and errors out if none is present), but instead we re going to use rustup to install an additional target:
rustup target add x86_64-unknown-none
cargo new hack-the-planet
cd hack-the-planet
Cargo.toml, we don t need to make any changes there, but the one that was auto-generated for me at the time of writing looks like this:
[package]
name = "hack-the-planet"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
src/main.rs, it s going to contain some pre-generated hello world, but we re going to delete it and create a new, empty file:
rm src/main.rs
touch src/main.rs
$ cargo build --release --target x86_64-unknown-none
Compiling hack-the-planet v0.1.0 (/hack-the-planet)
error[E0463]: can't find crate for std
= note: the x86_64-unknown-none target may not support the standard library
= note: std is required by hack_the_planet because it does not declare #![no_std]
error[E0601]: main function not found in crate hack_the_planet
= note: consider adding a main function to src/main.rs
Some errors have detailed explanations: E0463, E0601.
For more information about an error, try rustc --explain E0463 .
error: could not compile hack-the-planet due to 2 previous errors
std standard library. Usually the standard library of Rust still uses the system libc to do syscalls, but since we specify our libc as none this means std won t be available (use std::fs::rename won t work). There are still other functions we can use and import, for example there s core that s effectively a second standard library, but much smaller.
To opt-out of the std standard library, we can put #![no_std] into src/main.rs:
#![no_std]
$ cargo build --release --target x86_64-unknown-none
Compiling hack-the-planet v0.1.0 (/hack-the-planet)
error[E0601]: main function not found in crate hack_the_planet
--> src/main.rs:1:11
1 #![no_std]
^ consider adding a main function to src/main.rs
For more information about this error, try rustc --explain E0601 .
error: could not compile hack-the-planet due to previous error
#![no_main] to our file and src/main.rs now looks like this:
#![no_std]
#![no_main]
$ cargo build
Compiling hack-the-planet v0.1.0 (/hack-the-planet)
error: #[panic_handler] function required, but not found
error: language item required, but not found: eh_personality
= note: this can occur when a binary crate with #![no_std] is compiled for a target where eh_personality is defined in the standard library
= help: you may be able to compile for a target that doesn't need eh_personality , specify a target with --target or in .cargo/config
error: could not compile hack-the-planet due to 2 previous errors
src/main.rs now looks like this:
#![no_std]
#![no_main]
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
loop
$ cargo build --release --target x86_64-unknown-none
Compiling hack-the-planet v0.1.0 (/hack-the-planet)
Finished release [optimized] target(s) in 0.16s
$ target/x86_64-unknown-none/release/hack-the-planet
Segmentation fault (core dumped)
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Making a basic program and executing it
Ok let s try to make a valid program that basically just cleanly exits. First let s try to add some cpu instructions and verify they re indeed getting executed. Lemme introduce, the INT 3 instruction in x86_64 assembly. In binary it s also known as the 0xCC opcode. It crashes our program in a slightly different way, so if the error message changes, we know it worked. The other tutorials use a #[naked] function for the entry point, but since this feature isn t stabilized at the time of writing we re going to use the global_asm! macro. Also don t worry, I m not going to introduce every assembly instruction individually. Our program now looks like this:
#![no_std]
#![no_main]
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
loop
global_asm!
".global _start",
"_start:",
"int 3"
Running the build again (ok basically from now on the build is always going to be expected to work unless I say otherwise):
$ cargo build --release --target x86_64-unknown-none
Compiling hack-the-planet v0.1.0 (/hack-the-planet)
Finished release [optimized] target(s) in 0.11s
Let s try to disassemble the binary again:
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001210 <_start>:
1210: cc int3
And sure enough, there s a cc instruction that was identified as int3. Let s try to run this:
$ target/x86_64-unknown-none/release/hack-the-planet
Trace/breakpoint trap (core dumped)
The error message of the crash is now slightly different because it s hitting our breakpoint cpu instruction. Funfact btw, if you run this in strace you can see this isn t making any system calls (aka not talking to the kernel at all, it just crashes):
$ strace -f ./hack-the-planet
execve("./hack-the-planet", ["./hack-the-planet"], 0x74f12430d1d8 /* 39 vars */) = 0
--- SIGTRAP si_signo=SIGTRAP, si_code=SI_KERNEL, si_addr=NULL ---
+++ killed by SIGTRAP (core dumped) +++
[1] 2796457 trace trap (core dumped) strace -f ./hack-the-planet
Let s try to make a program that does a clean shutdown. To do this we inform the kernel with a system call that we may like to exit. We can get more info on this with man 2 exit and it defines exit like this:
[[noreturn]] void _exit(int status);
On Linux this syscall is actually called _exit and exit is implemented as a libc function, but we don t care about any of that today, it s going to do the job just fine. Also note how it takes a single argument of type int. In C-speak this means signed 32 bit , i32 in Rust.
Next we need to figure out the syscall number of this syscall. These numbers are cpu architecture specific for some reason (idk, idc). We re looking these numbers up with ripgrep in /usr/include/asm/:
$ rg __NR_exit /usr/include/asm
/usr/include/asm/unistd_64.h
64:#define __NR_exit 60
235:#define __NR_exit_group 231
/usr/include/asm/unistd_x32.h
53:#define __NR_exit (__X32_SYSCALL_BIT + 60)
206:#define __NR_exit_group (__X32_SYSCALL_BIT + 231)
/usr/include/asm/unistd_32.h
5:#define __NR_exit 1
253:#define __NR_exit_group 252
Since we re on x86_64 the correct value is the one in unistd_64.h, 60. Also, on x86_64 the syscall number goes into the rax cpu register, the status argument goes in the rdi register. The return value of the syscall is going to be placed in the rax register after the syscall is done, but for exit the execution is never given back to us. Let s try to write 60 into the rax register and 69 into the rdi register. To copy into registers we re going to use the mov destination, source instruction to copy from source to destination. With these registers setup we can use the syscall cpu instruction to hand execution over to the kernel. Don t worry, there s only one more assembly instruction coming and for everything else we re going to use Rust.
Our code now looks like this:
#![no_std]
#![no_main]
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
loop
global_asm!
".global _start",
"_start:",
"mov rax, 60",
"mov rdi, 69",
"syscall"
Build the binary, run it and print the exit code:
$ cargo build --release --target x86_64-unknown-none
$ target/x86_64-unknown-none/release/hack-the-planet; echo $?
69
Nice. Rust is quite literally putting these cpu instructions into the binary for us, nothing else.
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001210 <_start>:
1210: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
1217: 48 c7 c7 45 00 00 00 mov $0x45,%rdi
121e: 0f 05 syscall
Running this with strace shows the program does exactly one thing.
$ strace -f ./hack-the-planet
execve("./hack-the-planet", ["./hack-the-planet"], 0x70699fe8c908 /* 39 vars */) = 0
exit(69) = ?
+++ exited with 69 +++
#![no_std]
#![no_main]
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
loop
global_asm!
".global _start",
"_start:",
"int 3"
$ cargo build --release --target x86_64-unknown-none
Compiling hack-the-planet v0.1.0 (/hack-the-planet)
Finished release [optimized] target(s) in 0.11s
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001210 <_start>:
1210: cc int3
$ target/x86_64-unknown-none/release/hack-the-planet
Trace/breakpoint trap (core dumped)
$ strace -f ./hack-the-planet
execve("./hack-the-planet", ["./hack-the-planet"], 0x74f12430d1d8 /* 39 vars */) = 0
--- SIGTRAP si_signo=SIGTRAP, si_code=SI_KERNEL, si_addr=NULL ---
+++ killed by SIGTRAP (core dumped) +++
[1] 2796457 trace trap (core dumped) strace -f ./hack-the-planet
[[noreturn]] void _exit(int status);
$ rg __NR_exit /usr/include/asm
/usr/include/asm/unistd_64.h
64:#define __NR_exit 60
235:#define __NR_exit_group 231
/usr/include/asm/unistd_x32.h
53:#define __NR_exit (__X32_SYSCALL_BIT + 60)
206:#define __NR_exit_group (__X32_SYSCALL_BIT + 231)
/usr/include/asm/unistd_32.h
5:#define __NR_exit 1
253:#define __NR_exit_group 252
#![no_std]
#![no_main]
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
loop
global_asm!
".global _start",
"_start:",
"mov rax, 60",
"mov rdi, 69",
"syscall"
$ cargo build --release --target x86_64-unknown-none
$ target/x86_64-unknown-none/release/hack-the-planet; echo $?
69
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001210 <_start>:
1210: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
1217: 48 c7 c7 45 00 00 00 mov $0x45,%rdi
121e: 0f 05 syscall
$ strace -f ./hack-the-planet
execve("./hack-the-planet", ["./hack-the-planet"], 0x70699fe8c908 /* 39 vars */) = 0
exit(69) = ?
+++ exited with 69 +++
Writing Rust
Ok but even though cpu instructions can be fun at times, I d rather not deal with them most of the time (this might strike you as odd, considering this blog post). Instead let s try to define a function in Rust and call into that instead. We re going to define this function as unsafe (btw none of this is taking advantage of the safety guarantees by Rust in case it wasn t obvious. This tutorial is mostly going to stick to unsafe Rust, but for bigger projects you can attempt to reduce your usage of unsafe to opt back into normal safe Rust), it also declares the function with #[no_mangle] so the function name is preserved as main and we can call it from our global_asm entry point. Lastely, when our program is started it s going to get the stack address passed in one of the cpu registers, this value is expected to be passed to our function as an argument. Our function declares ! as return type, which means it never returns:
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
// TODO: this is missing
This won t compile yet, we need to add our assembly for the exit syscall back in.
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
asm!(
"syscall",
in("rax") 60,
in("rdi") 0,
options(noreturn)
);
This time we re using the asm! macro, this is a slightly more declarative approach. We want to run the syscall cpu instruction with 60 in the rax register, and this time we want the rdi register to be zero, to indicate a successful exit. We also use options(noreturn) so Rust knows it should assume execution does not resume after this assembly is executed (the Linux kernel guarantees this). We modify our global_asm! entrypoint to call our new main function, and to copy the stack address from rsp into the register for the first argument rdi because it would otherwise get lost forever:
global_asm!
".global _start",
"_start:",
"mov rdi, rsp",
"call main"
Our full program now looks like this:
#![no_std]
#![no_main]
use core::arch::asm;
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
loop
global_asm!
".global _start",
"_start:",
"mov rdi, rsp",
"call main"
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
asm!(
"syscall",
in("rax") 60,
in("rdi") 0,
options(noreturn)
);
After building and disassembling this the Rust compiler is slowly starting to do work for us:
$ cargo build --release --target x86_64-unknown-none
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001210 <_start>:
1210: 48 89 e7 mov %rsp,%rdi
1213: e8 08 00 00 00 call 1220 <main>
1218: cc int3
1219: cc int3
121a: cc int3
121b: cc int3
121c: cc int3
121d: cc int3
121e: cc int3
121f: cc int3
0000000000001220 <main>:
1220: 50 push %rax
1221: b8 3c 00 00 00 mov $0x3c,%eax
1226: 31 ff xor %edi,%edi
1228: 0f 05 syscall
122a: 0f 0b ud2
The mov and syscall instructions are still the same, but it noticed it can XOR the rdi register with itself to set it to zero. It s using x86 assembly language (the 32 bit variant of x86_64, that also happens to work on x86_64) to do so, that s why the register is refered to as edi in the disassembly. You can also see it s inserting a bunch of 0xCC instructions (for alignment) and Rust puts the opcodes 0x0F 0x0B at the end of the function to force an invalid opcode exception so the program is guaranteed to crash in case the exit syscall doesn t do it.
This code still executes as expected:
$ strace -f ./hack-the-planet
execve("./hack-the-planet", ["./hack-the-planet"], 0x72dae7e5dc08 /* 39 vars */) = 0
exit(0) = ?
+++ exited with 0 +++
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
// TODO: this is missing
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
asm!(
"syscall",
in("rax") 60,
in("rdi") 0,
options(noreturn)
);
global_asm!
".global _start",
"_start:",
"mov rdi, rsp",
"call main"
#![no_std]
#![no_main]
use core::arch::asm;
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
loop
global_asm!
".global _start",
"_start:",
"mov rdi, rsp",
"call main"
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
asm!(
"syscall",
in("rax") 60,
in("rdi") 0,
options(noreturn)
);
$ cargo build --release --target x86_64-unknown-none
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001210 <_start>:
1210: 48 89 e7 mov %rsp,%rdi
1213: e8 08 00 00 00 call 1220 <main>
1218: cc int3
1219: cc int3
121a: cc int3
121b: cc int3
121c: cc int3
121d: cc int3
121e: cc int3
121f: cc int3
0000000000001220 <main>:
1220: 50 push %rax
1221: b8 3c 00 00 00 mov $0x3c,%eax
1226: 31 ff xor %edi,%edi
1228: 0f 05 syscall
122a: 0f 0b ud2
$ strace -f ./hack-the-planet
execve("./hack-the-planet", ["./hack-the-planet"], 0x72dae7e5dc08 /* 39 vars */) = 0
exit(0) = ?
+++ exited with 0 +++
Adding functions
Ok we re getting closer but we aren t quite there yet. Let s try to write an exit function for our assembly that we can then call like a normal function. Remember that it takes a signed 32 bit integer that s supposed to go into rdi.
unsafe fn exit(status: i32) -> !
asm!(
"syscall",
in("rax") 60,
in("rdi") status,
options(noreturn)
);
Actually, since this function doesn t take any raw pointers and any i32 is valid for this syscall we re going to remove the unsafe marker of this function. When doing this we still need to use unsafe within the function for our inline assembly.
fn exit(status: i32) -> !
unsafe
asm!(
"syscall",
in("rax") 60,
in("rdi") status,
options(noreturn)
);
Let s call this function from our main, and also remove the infinity loop of the panic handler with a call to exit(1):
#![no_std]
#![no_main]
use core::arch::asm;
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
exit(1);
global_asm!
".global _start",
"_start:",
"mov rdi, rsp",
"call main"
fn exit(status: i32) -> !
unsafe
asm!(
"syscall",
in("rax") 60,
in("rdi") status,
options(noreturn)
);
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
exit(0);
Running this still works, but interestingly the generated assembly didn t change at all:
$ cargo build --release --target x86_64-unknown-none
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001210 <_start>:
1210: 48 89 e7 mov %rsp,%rdi
1213: e8 08 00 00 00 call 1220 <main>
1218: cc int3
1219: cc int3
121a: cc int3
121b: cc int3
121c: cc int3
121d: cc int3
121e: cc int3
121f: cc int3
0000000000001220 <main>:
1220: 50 push %rax
1221: b8 3c 00 00 00 mov $0x3c,%eax
1226: 31 ff xor %edi,%edi
1228: 0f 05 syscall
122a: 0f 0b ud2
Rust noticed there s no need to make it a separate function at runtime and instead merged the instructions of the exit function directly into our main. It also noticed the 0 argument in exit(0) means rdi is supposed to be zero and uses the XOR optimization mentioned before.
Since main is not calling any unsafe functions anymore we could mark it as safe too, but in the next few functions we re going to deal with file descriptors and raw pointers, so this is likely the only safe function we re going to write in this tutorial so let s just keep the unsafe marker.
unsafe fn exit(status: i32) -> !
asm!(
"syscall",
in("rax") 60,
in("rdi") status,
options(noreturn)
);
fn exit(status: i32) -> !
unsafe
asm!(
"syscall",
in("rax") 60,
in("rdi") status,
options(noreturn)
);
#![no_std]
#![no_main]
use core::arch::asm;
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
exit(1);
global_asm!
".global _start",
"_start:",
"mov rdi, rsp",
"call main"
fn exit(status: i32) -> !
unsafe
asm!(
"syscall",
in("rax") 60,
in("rdi") status,
options(noreturn)
);
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
exit(0);
$ cargo build --release --target x86_64-unknown-none
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001210 <_start>:
1210: 48 89 e7 mov %rsp,%rdi
1213: e8 08 00 00 00 call 1220 <main>
1218: cc int3
1219: cc int3
121a: cc int3
121b: cc int3
121c: cc int3
121d: cc int3
121e: cc int3
121f: cc int3
0000000000001220 <main>:
1220: 50 push %rax
1221: b8 3c 00 00 00 mov $0x3c,%eax
1226: 31 ff xor %edi,%edi
1228: 0f 05 syscall
122a: 0f 0b ud2
Printing text
Ok let s try to do a quick hello world, to do this we re going to call the write syscall. Looking it up with man 2 write:
ssize_t write(int fd, const void buf[.count], size_t count);
The write syscall takes 3 arguments and returns a signed size_t. In Rust this is called isize. In C size_t is an unsigned integer type that can hold any value of sizeof(...) for the given platform, ssize_t can only store half of that because it uses one of the bits to indicate an error has occured (the first s means signed, write returns -1 in case of an error).
The arguments for write are:
- the file descriptor to write to.
stdout is located on file descriptor 1.
- a pointer/address to some memory.
- the number of bytes that should be written, starting at the given address.
Let s also lookup the syscall number of write:
% rg __NR_write /usr/include/asm
/usr/include/asm/unistd_64.h
5:#define __NR_write 1
24:#define __NR_writev 20
/usr/include/asm/unistd_32.h
8:#define __NR_write 4
150:#define __NR_writev 146
/usr/include/asm/unistd_x32.h
5:#define __NR_write (__X32_SYSCALL_BIT + 1)
323:#define __NR_writev (__X32_SYSCALL_BIT + 516)
The value we re looking for is 1. Let s write our write function (heh).
unsafe fn write(fd: i32, buf: *const u8, count: usize) -> isize
let r0;
asm!(
"syscall",
inlateout("rax") 1 => r0,
in("rdi") fd,
in("rsi") buf,
in("rdx") count,
lateout("rcx") _,
lateout("r11") _,
options(nostack, preserves_flags)
);
r0
Now that s a lot of stuff at once. Since this syscall is actually going to hand execution back to our program we need to let Rust know which cpu registers the syscall is writing to, so Rust doesn t attempt to use them to store data (that would be silently overwritten by the syscall). inlateout("raw") 1 => r0 means we re writing a value to the register and want the result back in variable r0. in("rdi") fd means we want to write the value of fd into the rdi register. lateout("rcx") _ means the Linux kernel may write to that register (so the previous value may get lost), but we don t want to store the value anywhere (the underscore acts as a dummy variable name).
This doesn t compile just yet though
$ cargo build --release --target x86_64-unknown-none
Compiling hack-the-planet v0.1.0 (/hack-the-planet)
error: incompatible types for asm inout argument
--> src/main.rs:35:26
35 inlateout("rax") 1 => r0,
^ ^^ type isize
type i32
= note: asm inout arguments must have the same type, unless they are both pointers or integers of the same size
error: could not compile hack-the-planet due to previous error
Rust has inferred the type of r0 is isize since that s what our function returns, but the type of the input value for the register was inferred to be i32. We re going to select a specific number type to fix this.
unsafe fn write(fd: i32, buf: *const u8, count: usize) -> isize
let r0;
asm!(
"syscall",
inlateout("rax") 1isize => r0,
in("rdi") fd,
in("rsi") buf,
in("rdx") count,
lateout("rcx") _,
lateout("r11") _,
options(nostack, preserves_flags)
);
r0
We can now call our new write function like this:
write(1, b"Hello world\n".as_ptr(), 12);
We need to set the number of bytes we want to write explicitly because there s no concept of null-byte termination in the write system call, it s quite literally write the next X bytes, starting from this address . Our program now looks like this:
#![no_std]
#![no_main]
use core::arch::asm;
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
exit(1);
global_asm!
".global _start",
"_start:",
"mov rdi, rsp",
"call main"
fn exit(status: i32) -> !
unsafe
asm!(
"syscall",
in("rax") 60,
in("rdi") status,
options(noreturn)
);
unsafe fn write(fd: i32, buf: *const u8, count: usize) -> isize
let r0;
asm!(
"syscall",
inlateout("rax") 1isize => r0,
in("rdi") fd,
in("rsi") buf,
in("rdx") count,
lateout("rcx") _,
lateout("r11") _,
options(nostack, preserves_flags)
);
r0
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
write(1, b"Hello world\n".as_ptr(), 12);
exit(0);
Let s try to build and disassemble it:
$ cargo build --release --target x86_64-unknown-none
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001220 <_start>:
1220: 48 89 e7 mov %rsp,%rdi
1223: e8 08 00 00 00 call 1230 <main>
1228: cc int3
1229: cc int3
122a: cc int3
122b: cc int3
122c: cc int3
122d: cc int3
122e: cc int3
122f: cc int3
0000000000001230 <main>:
1230: 50 push %rax
1231: 48 8d 35 d5 ef ff ff lea -0x102b(%rip),%rsi # 20d <_start-0x1013>
1238: b8 01 00 00 00 mov $0x1,%eax
123d: ba 0c 00 00 00 mov $0xc,%edx
1242: bf 01 00 00 00 mov $0x1,%edi
1247: 0f 05 syscall
1249: b8 3c 00 00 00 mov $0x3c,%eax
124e: 31 ff xor %edi,%edi
1250: 0f 05 syscall
1252: 0f 0b ud2
This time there are 2 syscalls, first write, then exit. For write it s setting up the 3 arguments in our cpu registers (rdi, rsi, rdx). The lea instruction subtracts 0x102b from the rip register (the instruction pointer) and places the result in the rsi register. This is effectively saying an address relative to wherever this code was loaded into memory . The instruction pointer is going to point directly behind the opcodes of the lea instruction, so 0x1238 - 0x102b = 0x20d. This address is also pointed out in the disassembly as a comment.
We don t see the string in our disassembly but we can convert our 0x20d hex to 525 in decimal and use dd to read 12 bytes from that offset, and sure enough:
$ dd bs=1 skip=525 count=12 if=target/x86_64-unknown-none/release/hack-the-planet
Hello world
12+0 records in
12+0 records out
Execute our binary with strace also shows the new write syscall (and the bytes that are being written mixed up in the output).
$ strace -f ./hack-the-planet
execve("./hack-the-planet", ["./hack-the-planet"], 0x74493abe64a8 /* 39 vars */) = 0
write(1, "Hello world\n", 12Hello world
) = 12
exit(0) = ?
+++ exited with 0 +++
After running strip on it to remove some symbols the binary is so small, if you open it in a text editor it fits on a screenshot:

ssize_t write(int fd, const void buf[.count], size_t count);
stdout is located on file descriptor 1.% rg __NR_write /usr/include/asm
/usr/include/asm/unistd_64.h
5:#define __NR_write 1
24:#define __NR_writev 20
/usr/include/asm/unistd_32.h
8:#define __NR_write 4
150:#define __NR_writev 146
/usr/include/asm/unistd_x32.h
5:#define __NR_write (__X32_SYSCALL_BIT + 1)
323:#define __NR_writev (__X32_SYSCALL_BIT + 516)
unsafe fn write(fd: i32, buf: *const u8, count: usize) -> isize
let r0;
asm!(
"syscall",
inlateout("rax") 1 => r0,
in("rdi") fd,
in("rsi") buf,
in("rdx") count,
lateout("rcx") _,
lateout("r11") _,
options(nostack, preserves_flags)
);
r0
$ cargo build --release --target x86_64-unknown-none
Compiling hack-the-planet v0.1.0 (/hack-the-planet)
error: incompatible types for asm inout argument
--> src/main.rs:35:26
35 inlateout("rax") 1 => r0,
^ ^^ type isize
type i32
= note: asm inout arguments must have the same type, unless they are both pointers or integers of the same size
error: could not compile hack-the-planet due to previous error
unsafe fn write(fd: i32, buf: *const u8, count: usize) -> isize
let r0;
asm!(
"syscall",
inlateout("rax") 1isize => r0,
in("rdi") fd,
in("rsi") buf,
in("rdx") count,
lateout("rcx") _,
lateout("r11") _,
options(nostack, preserves_flags)
);
r0
write(1, b"Hello world\n".as_ptr(), 12);
#![no_std]
#![no_main]
use core::arch::asm;
use core::arch::global_asm;
use core::panic::PanicInfo;
#[panic_handler]
fn panic(_info: &PanicInfo) -> !
exit(1);
global_asm!
".global _start",
"_start:",
"mov rdi, rsp",
"call main"
fn exit(status: i32) -> !
unsafe
asm!(
"syscall",
in("rax") 60,
in("rdi") status,
options(noreturn)
);
unsafe fn write(fd: i32, buf: *const u8, count: usize) -> isize
let r0;
asm!(
"syscall",
inlateout("rax") 1isize => r0,
in("rdi") fd,
in("rsi") buf,
in("rdx") count,
lateout("rcx") _,
lateout("r11") _,
options(nostack, preserves_flags)
);
r0
#[no_mangle]
unsafe fn main(_stack_top: *const u8) -> !
write(1, b"Hello world\n".as_ptr(), 12);
exit(0);
$ cargo build --release --target x86_64-unknown-none
$ objdump -d target/x86_64-unknown-none/release/hack-the-planet
target/x86_64-unknown-none/release/hack-the-planet: file format elf64-x86-64
Disassembly of section .text:
0000000000001220 <_start>:
1220: 48 89 e7 mov %rsp,%rdi
1223: e8 08 00 00 00 call 1230 <main>
1228: cc int3
1229: cc int3
122a: cc int3
122b: cc int3
122c: cc int3
122d: cc int3
122e: cc int3
122f: cc int3
0000000000001230 <main>:
1230: 50 push %rax
1231: 48 8d 35 d5 ef ff ff lea -0x102b(%rip),%rsi # 20d <_start-0x1013>
1238: b8 01 00 00 00 mov $0x1,%eax
123d: ba 0c 00 00 00 mov $0xc,%edx
1242: bf 01 00 00 00 mov $0x1,%edi
1247: 0f 05 syscall
1249: b8 3c 00 00 00 mov $0x3c,%eax
124e: 31 ff xor %edi,%edi
1250: 0f 05 syscall
1252: 0f 0b ud2
$ dd bs=1 skip=525 count=12 if=target/x86_64-unknown-none/release/hack-the-planet
Hello world
12+0 records in
12+0 records out
$ strace -f ./hack-the-planet
execve("./hack-the-planet", ["./hack-the-planet"], 0x74493abe64a8 /* 39 vars */) = 0
write(1, "Hello world\n", 12Hello world
) = 12
exit(0) = ?
+++ exited with 0 +++
 It's been a year since I started exploring
It's been a year since I started exploring 

 In Mexico, we have the great luck to live among vestiges of long-gone
cultures, some that were conquered and in some way got adapted and
survived into our modern, mostly-West-Europan-derived society, and
some that thrived but disappeared many more centuries ago. And
although not everybody feels the same way, in my family we have always
enjoyed visiting archaeological sites when I was a child and today.
Some of the regulars that follow this blog (or its syndicators) will
remember Xochicalco, as it was the destination we chose for the
daytrip back in the day, in DebConf6 (May 2006).
In Mexico, we have the great luck to live among vestiges of long-gone
cultures, some that were conquered and in some way got adapted and
survived into our modern, mostly-West-Europan-derived society, and
some that thrived but disappeared many more centuries ago. And
although not everybody feels the same way, in my family we have always
enjoyed visiting archaeological sites when I was a child and today.
Some of the regulars that follow this blog (or its syndicators) will
remember Xochicalco, as it was the destination we chose for the
daytrip back in the day, in DebConf6 (May 2006).


 From November 2nd to 4th, 2022, the 19th edition of
From November 2nd to 4th, 2022, the 19th edition of
 A huge number of people visited the booth, and the beginners (mainly students)
who didn't know Debian, asked what our group was about and we explained various
concepts such as what Free Software is, GNU/Linux distribution and Debian
itself. We also received people from the Brazilian Free Software community and
from other Latin American countries who were already using a GNU/Linux
distribution and, of course, many people who were already using Debian. We had
some special visitors as Jon maddog Hall, Debian Developer Emeritus Ot vio
Salvador, Debian Developer Eriberto Mota, and Debian Maintainers Guilherme de
Paula Segundo and Paulo Kretcheu.
A huge number of people visited the booth, and the beginners (mainly students)
who didn't know Debian, asked what our group was about and we explained various
concepts such as what Free Software is, GNU/Linux distribution and Debian
itself. We also received people from the Brazilian Free Software community and
from other Latin American countries who were already using a GNU/Linux
distribution and, of course, many people who were already using Debian. We had
some special visitors as Jon maddog Hall, Debian Developer Emeritus Ot vio
Salvador, Debian Developer Eriberto Mota, and Debian Maintainers Guilherme de
Paula Segundo and Paulo Kretcheu.
 Photo from left to right: Leonardo, Paulo, Eriberto and Ot vio.
Photo from left to right: Leonardo, Paulo, Eriberto and Ot vio.
 Photo from left to right: Paulo, Fabian (Argentina) and Leonardo.
In addition to talking a lot, we distributed Debian stickers that were produced
a few months ago with Debian's sponsorship to be distributed at DebConf22
(and that were left over), and we sold several Debian
Photo from left to right: Paulo, Fabian (Argentina) and Leonardo.
In addition to talking a lot, we distributed Debian stickers that were produced
a few months ago with Debian's sponsorship to be distributed at DebConf22
(and that were left over), and we sold several Debian

 We also had 3 talks included in Latinoware official schedule.
We also had 3 talks included in Latinoware official schedule.
 Photo Paulo in his talk.
Many thanks to Latinoware organization for once again welcoming the Debian
community and kindly providing spaces for our participation, and we
congratulate all the people involved in the organization for the success of
this important event for our community. We hope to be present again in 2023.
We also thank Jonathan Carter for approving financial support from Debian for
our participation at Latinoware.
Photo Paulo in his talk.
Many thanks to Latinoware organization for once again welcoming the Debian
community and kindly providing spaces for our participation, and we
congratulate all the people involved in the organization for the success of
this important event for our community. We hope to be present again in 2023.
We also thank Jonathan Carter for approving financial support from Debian for
our participation at Latinoware.
 V rias pessoas visitaram o estande e aquelas mais iniciantes (principalmente
estudantes) que n o conheciam o Debian, perguntavam do que se tratava o nosso
grupo e a gente explicava v rios conceitos como o que Software Livre,
distribui o GNU/Linux e o Debian propriamente dito. Tamb m recebemos pessoas
da comunidade de Software Livre brasileira e de outros pa ses da Am rica Latina
que j utilizavam uma distribui o GNU/Linux e claro, muitas pessoas que j
utilizavam Debian. Tivemos algumas visitas especiais como do Jon maddog Hall,
do Desenvolvedor Debian Emeritus Ot vio Salvador, do Desenvolvedor Debian
V rias pessoas visitaram o estande e aquelas mais iniciantes (principalmente
estudantes) que n o conheciam o Debian, perguntavam do que se tratava o nosso
grupo e a gente explicava v rios conceitos como o que Software Livre,
distribui o GNU/Linux e o Debian propriamente dito. Tamb m recebemos pessoas
da comunidade de Software Livre brasileira e de outros pa ses da Am rica Latina
que j utilizavam uma distribui o GNU/Linux e claro, muitas pessoas que j
utilizavam Debian. Tivemos algumas visitas especiais como do Jon maddog Hall,
do Desenvolvedor Debian Emeritus Ot vio Salvador, do Desenvolvedor Debian
 Foto da esquerda pra direita: Leonardo, Paulo, Eriberto e Ot vio.
Foto da esquerda pra direita: Leonardo, Paulo, Eriberto e Ot vio.
 Foto da esquerda pra direita: Paulo, Fabian (Argentina) e Leonardo.
Al m de conversarmos bastante, distribu mos adesivos do Debian que foram
produzidos alguns meses atr s com o patroc nio do Debian para serem distribu dos
na DebConf22(e que haviam sobrado), e vendemos v rias
Foto da esquerda pra direita: Paulo, Fabian (Argentina) e Leonardo.
Al m de conversarmos bastante, distribu mos adesivos do Debian que foram
produzidos alguns meses atr s com o patroc nio do Debian para serem distribu dos
na DebConf22(e que haviam sobrado), e vendemos v rias

 Tamb m tivemos 3 palestras inseridas na programa o oficial do Latinoware.
Tamb m tivemos 3 palestras inseridas na programa o oficial do Latinoware.
 Foto Paulo na palestra.
Agradecemos a organiza o do Latinoware por receber mais uma vez a comunidade
Debian e gentilmente ceder os espa os para a nossa participa o, e parabenizamos
a todas as pessoas envolvidas na organiza o pelo sucesso desse importante
evento para a nossa comunidade. Esperamos estar presentes novamente em 2023.
Agracemos tamb m ao Jonathan Carter por aprovar o suporte financeiro do Debian
para a nossa participa o no Latinoware.
Foto Paulo na palestra.
Agradecemos a organiza o do Latinoware por receber mais uma vez a comunidade
Debian e gentilmente ceder os espa os para a nossa participa o, e parabenizamos
a todas as pessoas envolvidas na organiza o pelo sucesso desse importante
evento para a nossa comunidade. Esperamos estar presentes novamente em 2023.
Agracemos tamb m ao Jonathan Carter por aprovar o suporte financeiro do Debian
para a nossa participa o no Latinoware.


 And all of this is because I can read, write, articulate. Perhaps many of them may not even have a voice or a platform.
Even to get this temporary progressive disability certificate there is more than 4 months of running from one place to the other, 4 months of culmination of work. This I can share and tell from my experience, who knows how much else others might have suffered for the same. In my case a review will happen after 5 years, in most other cases they have given only 1 year. Of course, this does justify people s jobs and perhaps partly it may be due to that. Such are times where I really miss that I am unable to hear otherwise could have fleshed out lot more other people s sufferings.
And just so people know/understand this is happening in the heart of the city whose population easily exceeds 6 million plus and is supposed to be a progressive city. I do appreciate and understand the difficulties that the doctors are placed under.
And all of this is because I can read, write, articulate. Perhaps many of them may not even have a voice or a platform.
Even to get this temporary progressive disability certificate there is more than 4 months of running from one place to the other, 4 months of culmination of work. This I can share and tell from my experience, who knows how much else others might have suffered for the same. In my case a review will happen after 5 years, in most other cases they have given only 1 year. Of course, this does justify people s jobs and perhaps partly it may be due to that. Such are times where I really miss that I am unable to hear otherwise could have fleshed out lot more other people s sufferings.
And just so people know/understand this is happening in the heart of the city whose population easily exceeds 6 million plus and is supposed to be a progressive city. I do appreciate and understand the difficulties that the doctors are placed under.