Thomas Koch: Minimal overhead VMs with Nix and MicroVM

Posted on March 17, 2024
Joachim Breitner wrote about a Convenient sandboxed development environment and thus reminded me to blog about MicroVM. I ve toyed around with it a little but not yet seriously used it as I m currently not coding.
MicroVM is a nix based project to configure and run minimal VMs. It can mount and thus reuse the hosts nix store inside the VM and thus has a very small disk footprint. I use MicroVM on a debian system using the nix package manager.
The MicroVM author uses the project to host production services. Otherwise I consider it also a nice way to learn about NixOS after having started with the nix package manager and before making the big step to NixOS as my main system.
The guests root filesystem is a tmpdir, so one must explicitly define folders that should be mounted from the host and thus be persistent across VM reboots.
I defined the VM as a nix flake since this is how I started from the MicroVM projects example:
description = "Haskell dev MicroVM";
inputs.impermanence.url = "github:nix-community/impermanence";
inputs.microvm.url = "github:astro/microvm.nix";
inputs.microvm.inputs.nixpkgs.follows = "nixpkgs";
outputs = self, impermanence, microvm, nixpkgs :
let
persistencePath = "/persistent";
system = "x86_64-linux";
user = "thk";
vmname = "haskell";
nixosConfiguration = nixpkgs.lib.nixosSystem
inherit system;
modules = [
microvm.nixosModules.microvm
impermanence.nixosModules.impermanence
( pkgs, ... :
environment.persistence.$ persistencePath =
hideMounts = true;
users.$ user =
directories = [
"git" ".stack"
];
;
;
environment.sessionVariables =
TERM = "screen-256color";
;
environment.systemPackages = with pkgs; [
ghc
git
(haskell-language-server.override supportedGhcVersions = [ "94" ]; )
htop
stack
tmux
tree
vcsh
zsh
];
fileSystems.$ persistencePath .neededForBoot = nixpkgs.lib.mkForce true;
microvm =
forwardPorts = [
from = "host"; host.port = 2222; guest.port = 22;
from = "guest"; host.port = 5432; guest.port = 5432; # postgresql
];
hypervisor = "qemu";
interfaces = [
type = "user"; id = "usernet"; mac = "00:00:00:00:00:02";
];
mem = 4096;
shares = [
# use "virtiofs" for MicroVMs that are started by systemd
proto = "9p";
tag = "ro-store";
# a host's /nix/store will be picked up so that no
# squashfs/erofs will be built for it.
source = "/nix/store";
mountPoint = "/nix/.ro-store";
proto = "virtiofs";
tag = "persistent";
source = "~/.local/share/microvm/vms/$ vmname /persistent";
mountPoint = persistencePath;
socket = "/run/user/1000/microvm-$ vmname -persistent";
];
socket = "/run/user/1000/microvm-control.socket";
vcpu = 3;
volumes = [];
writableStoreOverlay = "/nix/.rwstore";
;
networking.hostName = vmname;
nix.enable = true;
nix.nixPath = ["nixpkgs=$ builtins.storePath <nixpkgs> "];
nix.settings =
extra-experimental-features = ["nix-command" "flakes"];
trusted-users = [user];
;
security.sudo =
enable = true;
wheelNeedsPassword = false;
;
services.getty.autologinUser = user;
services.openssh =
enable = true;
;
system.stateVersion = "24.11";
systemd.services.loadnixdb =
description = "import hosts nix database";
path = [pkgs.nix];
wantedBy = ["multi-user.target"];
requires = ["nix-daemon.service"];
script = "cat $ persistencePath /nix-store-db-dump nix-store --load-db";
;
time.timeZone = nixpkgs.lib.mkDefault "Europe/Berlin";
users.users.$ user =
extraGroups = [ "wheel" "video" ];
group = "user";
isNormalUser = true;
openssh.authorizedKeys.keys = [
"ssh-rsa REDACTED"
];
password = "";
;
users.users.root.password = "";
users.groups.user = ;
)
];
;
in
packages.$ system .default = nixosConfiguration.config.microvm.declaredRunner;
;
[Unit]
Description=MicroVM for Haskell development
Requires=microvm-virtiofsd-persistent@.service
After=microvm-virtiofsd-persistent@.service
AssertFileNotEmpty=%h/.local/share/microvm/vms/%i/flake/flake.nix
[Service]
Type=forking
ExecStartPre=/usr/bin/sh -c "[ /nix/var/nix/db/db.sqlite -ot %h/.local/share/microvm/nix-store-db-dump ] nix-store --dump-db >%h/.local/share/microvm/nix-store-db-dump"
ExecStartPre=ln -f -t %h/.local/share/microvm/vms/%i/persistent/ %h/.local/share/microvm/nix-store-db-dump
ExecStartPre=-%h/.local/state/nix/profile/bin/tmux new -s microvm -d
ExecStart=%h/.local/state/nix/profile/bin/tmux new-window -t microvm: -n "%i" "exec %h/.local/state/nix/profile/bin/nix run --impure %h/.local/share/microvm/vms/%i/flake"
[Unit]
Description=serve host persistent folder for dev VM
AssertPathIsDirectory=%h/.local/share/microvm/vms/%i/persistent
[Service]
ExecStart=%h/.local/state/nix/profile/bin/virtiofsd \
--socket-path=$ XDG_RUNTIME_DIR /microvm-%i-persistent \
--shared-dir=%h/.local/share/microvm/vms/%i/persistent \
--gid-map :995:%G:1: \
--uid-map :1000:%U:1:
 More ICFP-inspired experiments using the
More ICFP-inspired experiments using the  Norman Ramsey shows a formula
Norman Ramsey shows a formula
 Reading
Reading 


 Just to recap my life since December:
Just to recap my life since December:
 The War on Time
Whoosh! I ve been incredibly quiet on my blog for the last 2-3 months. It s been a crazy time but I ll catch up and explain everything over the next few entries.
Firstly, I d like to get out a few details about the last Ubuntu Developer Summit that took place in Copenhagen, Denmark in October. I m usually really good at getting my blog post out by the end of UDS or a day or two after, but this time it just flew by so incredibly fast for me that I couldn t keep up. It was a bit shorter than usual at 4 days, as apposed to the usual 5. The reason I heard for that was that people commented in previous post-UDS surveys that 5 days were too long, which is especially understandable for Canonical staff who are often in sprints (away from home) for the week before the UDS as well. I think the shorter period works well, it might need a bit more fine-tuning, I think the summary session at the end wasn t that useful because, like me, there wasn t enough time for people to process the vast amount of data generated during UDS and give nice summaries on it. Overall, it was a great get-together of people who care about Ubuntu and also many areas of interest outside of Ubuntu.
Copenhagen, Denmark
I didn t take many photos this UDS, my camera is broken and only takes blurry pics (not my fault I swear!). So I just ended up taking a few pictures with my phone. Go
The War on Time
Whoosh! I ve been incredibly quiet on my blog for the last 2-3 months. It s been a crazy time but I ll catch up and explain everything over the next few entries.
Firstly, I d like to get out a few details about the last Ubuntu Developer Summit that took place in Copenhagen, Denmark in October. I m usually really good at getting my blog post out by the end of UDS or a day or two after, but this time it just flew by so incredibly fast for me that I couldn t keep up. It was a bit shorter than usual at 4 days, as apposed to the usual 5. The reason I heard for that was that people commented in previous post-UDS surveys that 5 days were too long, which is especially understandable for Canonical staff who are often in sprints (away from home) for the week before the UDS as well. I think the shorter period works well, it might need a bit more fine-tuning, I think the summary session at the end wasn t that useful because, like me, there wasn t enough time for people to process the vast amount of data generated during UDS and give nice summaries on it. Overall, it was a great get-together of people who care about Ubuntu and also many areas of interest outside of Ubuntu.
Copenhagen, Denmark
I didn t take many photos this UDS, my camera is broken and only takes blurry pics (not my fault I swear!). So I just ended up taking a few pictures with my phone. Go 
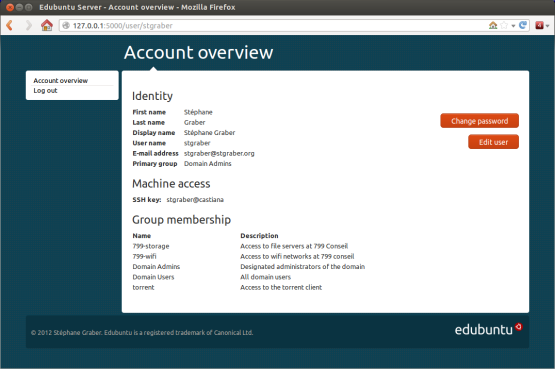
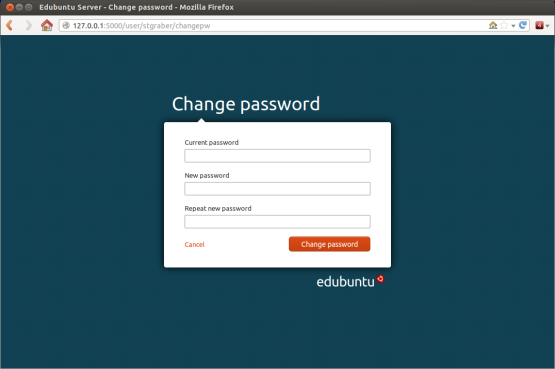
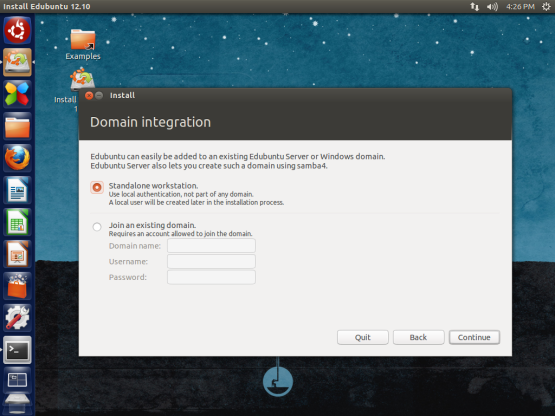
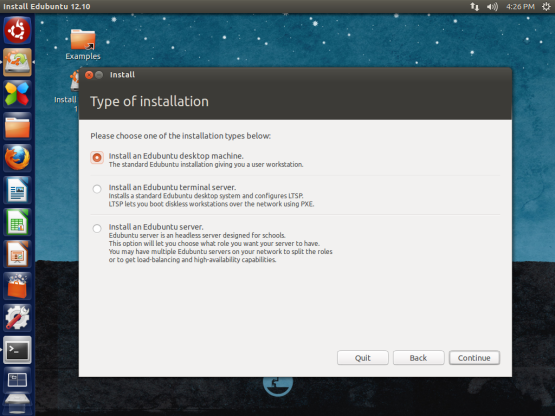
 The Road ahead for Edubuntu to 14.04 and beyond
The Road ahead for Edubuntu to 14.04 and beyond


 While almost everyone has already worked with cryptographic signatures,
they are usually only used as black boxes, without taking a closer look.
This article intends to shed some lights behind the scenes.
Let's take a look at some signature. In ascii-armoured form or behind
a clearsigned message one often does only see something like this:
While almost everyone has already worked with cryptographic signatures,
they are usually only used as black boxes, without taking a closer look.
This article intends to shed some lights behind the scenes.
Let's take a look at some signature. In ascii-armoured form or behind
a clearsigned message one often does only see something like this:
 I am transitioning my
I am transitioning my 






 One of the things I most like about WNBR is its diversity. Not everybody goes for the same reasons. As people who read me often will know, I took part because I believe (and act accordingly!) that the bicycle is the best, most efficient vehicle in by far most of the situations we face day to day, but we need to raise awareness in everybody that the bicycle is just one more vehicle: On one side, we have the right to safely ride on the streets, like any other vehicle. On the other side, we must be responsible, safe drivers, just as we want car drivers to be.
Ok, and I will recognize it before anybody complains that I sound too idealistic: I took part of the WNBR because it is _tons_ of fun. This year, we were between 300 and 500 people (depending on whom you ask). Compared to 2008, I felt less tension, more integration, more respect within the group. Of course, it is only natural in the society I live in that most of the participants were men, but the proportion of women really tends to even out. Also, many more people joined fully or partially in the nude (as nudity is not required, it is just an invitation). There was a great display of creativity, people painted with all kinds of interesting phrases and designs, some really beautiful.
One of the things I most like about WNBR is its diversity. Not everybody goes for the same reasons. As people who read me often will know, I took part because I believe (and act accordingly!) that the bicycle is the best, most efficient vehicle in by far most of the situations we face day to day, but we need to raise awareness in everybody that the bicycle is just one more vehicle: On one side, we have the right to safely ride on the streets, like any other vehicle. On the other side, we must be responsible, safe drivers, just as we want car drivers to be.
Ok, and I will recognize it before anybody complains that I sound too idealistic: I took part of the WNBR because it is _tons_ of fun. This year, we were between 300 and 500 people (depending on whom you ask). Compared to 2008, I felt less tension, more integration, more respect within the group. Of course, it is only natural in the society I live in that most of the participants were men, but the proportion of women really tends to even out. Also, many more people joined fully or partially in the nude (as nudity is not required, it is just an invitation). There was a great display of creativity, people painted with all kinds of interesting phrases and designs, some really beautiful.
 Oh, one more point, important to me: This is one of the best ways to show that we bikers are not athletes or anything like that. We were people ranging from very thin to quite fat, from very young to quite old. And that is even more striking when we show our whole equipment. If we can all bike around... So can you!
Some links, with obvious nudity warnings in case you are offended by looking at innocent butts and similar stuff:
Oh, one more point, important to me: This is one of the best ways to show that we bikers are not athletes or anything like that. We were people ranging from very thin to quite fat, from very young to quite old. And that is even more striking when we show our whole equipment. If we can all bike around... So can you!
Some links, with obvious nudity warnings in case you are offended by looking at innocent butts and similar stuff: