While teaching this semester a class on concurrent programming, I
realized during the labs that most of the students couldn't properly
debug their code. They are at the end of a 2-year cursus, know many
different programming languages and frameworks, but when it comes to
tracking down a bug in their own code, they often lacked the
basics. Instead of debugging for them I tried to give them general
directions that they could apply for the next bugs. I will try here to
summarize the very first basic things to know about
debugging. Because, remember, writing software is 90% debugging, and
10% introducing new bugs (that is not from me, but I could not find
the original quote).
So here is my take at
Debugging 101.
Use the right tools
Many good tools exist to assist you in writing correct software, and
it would put you behind in terms of productivity not to use
them. Editors which catch syntax errors while you write them, for
example, will help you a lot. And there are many features out there in
editors, compilers, debuggers, which will prevent you from introducing
trivial bugs. Your editor should be your friend; explore its features
and customization options, and find an efficient workflow with them,
that you like and can improve over time. The best way to fix bugs is
not to have them in the first place, obviously.
Test early, test often
I've seen students writing code for one hour before running
make,
that would fail so hard that hundreds of lines of errors and warnings
were outputted. There are two main reasons doing this is a bad idea:
- You have to debug all the errors at once, and the complexity of
solving many bugs, some dependent on others, is way higher than the
complexity of solving a single bug. Moreover, it's discouraging.
- Wrong assumptions you made at the beginning will make the following
lines of code wrong. For example if you chose the wrong data
structure for storing some information, you will have to fix all the
code using that structure. It's less painful to realize earlier it
was the wrong one to choose, and you have more chances of knowing
that if you compile and execute often.
I recommend to test your code (compilation
and execution) every few
lines of code you write. When something breaks, chances are it will
come from the last line(s) you wrote. Compiler errors will be shorter,
and will point you to the same place in the code. Once you get more
confident using a particular language or framework, you can write
more lines at once without testing. That's a slow process, but it's
ok. If you set up the right keybinding for compiling and executing
from within your editor, it shouldn't be painful to test early and
often.
Read the logs
Spot the places where your program/compiler/debugger writes text, and
read it carefully. It can be your terminal (quite often), a file in
your current directory, a file in
/var/log/, a web page on a local
server, anything. Learn where different software write logs on your
system, and integrate reading them in your workflow. Often, it will be
your only information about the bug. Often, it will tell you where the
bug lies. Sometimes, it will even give you hints on how to fix it.
You may have to filter out a lot of garbage to find relevant
information about your bug. Learn to spot some keywords like
error
or
warning. In long stacktraces, spot the lines concerning your
files; because more often, your code is to be blamed, rather than
deeper library code.
grep the logs with relevant keywords. If you
have the option, colorize the output. Use
tail -f to follow a file
getting updated. There are so many ways to grasp logs, so find what
works best with you and never forget to use it!
Print foobar
That one doesn't concern compilation errors (unless it's a
Makefile
error, in that case this file is your code anyway).
When the program logs and output failed to give you where an error
occured (oh hi
Segmentation fault!), and before having to dive into
a memory debugger or system trace tool, spot the portion of your
program that causes the bug and add in there some
print
statements. You can either
print("foo") and
print("bar"), just to
know that your program reaches or not a certain place in your code, or
print(some_faulty_var) to get more insights on your program
state. It will give you precious information.
stderr >> "foo" >> endl;
my_db.connect(); // is this broken?
stderr >> "bar" >> endl;
In the example above, you can be sure it is the connection to the
database
my_db that is broken if you get
foo and not
bar on your
standard error.
(That is an hypothetical example. If you know something can break,
such as a database connection, then you should always enclose it in a
try/
catch structure).
Isolate and reproduce the bug
This point is linked to the previous one. You may or may not have
isolated the line(s) causing the bug, but maybe the issue is not
always raised. It can depend on many other things: the program or
function parameters, the network status, the amount of memory
available, the decisions of the OS scheduler, the user rights on the
system or on some files, etc. More generally, any assumption you made
on any external dependency can appear to be wrong (even if it's right
99% of the time). According to the context, try to isolate the set of
conditions that trigger the bug. It can be as simple as "when there is
no internet connection", or as complicated as "when the CPU load of
some external machine is too high, it's a leap year, and the input
contains illegal utf-8 characters" (ok, that one is fucked up; but it
surely happens!). But you need to reliably be able to reproduce the
bug, in order to be sure later that you indeed fixed it.
Of course when the bug is triggered at every run, it can be
frustrating that your program never works but it will in general be
easier to fix.
RTFM
Always read the documentation before reaching out for help. Be it
man, a book, a website or a wiki, you will find precious information
there to assist you in using a language or a specific library. It can
be quite intimidating at first, but it's often organized the same
way. You're likely to find a search tool, an API reference, a
tutorial, and many examples. Compare your code against them. Check in
the FAQ, maybe your bug and its solution are already referenced there.
You'll rapidly find yourself getting used to the way documentation is
organized, and you'll be more and more efficient at finding instantly
what you need. Always keep the doc window open!
Google and Stack Overflow are your friends
Let's be honest: many of the bugs you'll encounter have been
encountered before. Learn to write efficient queries on search
engines, and use the knowledge you can find on questions&answers
forums like Stack Overflow. Read the answers and comments. Be wise
though, and never
blindly copy and
paste
code from there. It can be as bad as introducing malicious security
issues into your code, and you won't learn anything. Oh, and don't
copy and paste anyway. You have to be sure you understand every single
line, so better write them by hand; it's also better for memorizing
the issue.
Take notes
Once you have identified and solved a particular bug, I advise to
write about it. No need for shiny interfaces: keep a list of your bugs
along with their solutions in one or many text files, organized by
language or framework, that you can easily
grep.
It can seem slightly cumbersome to do so, but it proved (at least to
me) to be very valuable. I can often recall I have encountered some
buggy situation in the past, but don't always remember the
solution. Instead of losing all the debugging time again, I search in
my bug/solution list first, and when it's a hit I'm more than happy I
kept it.
Further
reading degugging
Remember this was only
Debugging 101, that is, the very first steps
on how to debug code on your own, instead of getting frustrated and
helplessly stare at your screen without knowing where to begin. When
you'll write more software, you'll get used to more efficient
workflows, and you'll discover tools that are here to assist you in
writing bug-free code and spotting complex bugs efficiently. Listed
below are
some of the tools or general ideas used to debug more
complex software. They belong more to a software engineering course
than a Debugging 101 blog post. But it's good to know as soon as
possible these exist, and if you read the manuals there's no reason
you can't rock with them!
- Loggers. To make the "foobar" debugging more efficient, some
libraries are especially designed for the task of logging out
information about a running program. They often have way more
features than a simple
print statement (at the price of being
over-engineered for simple programs): severity levels (info,
warning, error, fatal, etc), output in rotating files, and
many more.
- Version control. Following the evolution of a program in time,
over multiple versions, contributors and forks, is a hard
task. That's where version control plays: it allows you to keep the
entire history of your program, and switch to any previous
version. This way you can identify more easily when a bug was
introduced (and by whom), along with the patch (a set of changes to
a code base) that introduced it. Then you know where to apply your
fix. Famous version control tools include Git, Subversion, and
Mercurial.
- Debuggers. Last but not least, it wouldn't make sense to talk
about debugging without mentioning debuggers. They are tools to
inspect the state of a program (for example the type and value of
variables) while it is running. You can pause the program, and
execute it line by line, while watching the state evolve. Sometimes
you can also manually change the value of variables to see what
happens. Even though some of them are hard to use, they are very
valuable tools, totally worth diving into!
Don't hesitate to comment on this, and provide your debugging 101
tips! I'll be happy to update the article with valuable feedback.
Happy debugging!


 . Internet shutdowns impact women
. Internet shutdowns impact women 






 I even tried the same with xvkbd but no avail. I do use mate as my desktop-manager so maybe the instructions need some refinement ????
$ cat /etc/lightdm/lightdm-gtk-greeter.conf grep keyboard
I even tried the same with xvkbd but no avail. I do use mate as my desktop-manager so maybe the instructions need some refinement ????
$ cat /etc/lightdm/lightdm-gtk-greeter.conf grep keyboard I released version 2.6 of
I released version 2.6 of 

 PTI News, Nov 27, 2020
PTI News, Nov 27, 2020  Justice Chandrachud If you don t like a channel then don t watch it. 11th November 2020 .
Justice Chandrachud If you don t like a channel then don t watch it. 11th November 2020 .  Information and Broadcasting Ministry bringing OTT services as well as news within its ambit.
Information and Broadcasting Ministry bringing OTT services as well as news within its ambit.  Here is my monthly update covering what I have been doing in the free software world during October 2020 (
Here is my monthly update covering what I have been doing in the free software world during October 2020 (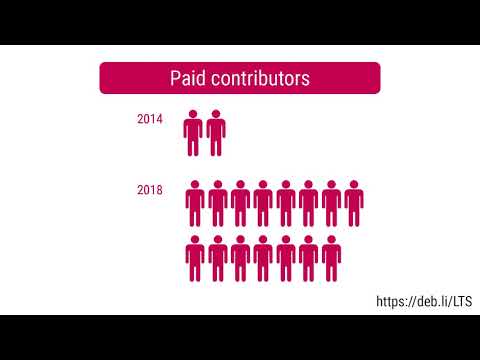
 For almost a decade, I ve been very slowly making progress on a multicast IPTV
system. Recently I ve made a significant leap forward in this project, and I
wanted to write a little on the topic so I ll have something to look at when I
pick this up next. I was aspiring to have a useable system by the end of today,
but for a couple of reasons, it wasn t possible.
When I started thinking about this project, it was still common to watch
broadcast television. Over time the design of this system has been changing as
new technologies have become available. Multicast IP is probably the only
constant, although I m now looking at IPv6 rather than IPv4.
Initially, I d been looking at DVB-T PCI cards.
For almost a decade, I ve been very slowly making progress on a multicast IPTV
system. Recently I ve made a significant leap forward in this project, and I
wanted to write a little on the topic so I ll have something to look at when I
pick this up next. I was aspiring to have a useable system by the end of today,
but for a couple of reasons, it wasn t possible.
When I started thinking about this project, it was still common to watch
broadcast television. Over time the design of this system has been changing as
new technologies have become available. Multicast IP is probably the only
constant, although I m now looking at IPv6 rather than IPv4.
Initially, I d been looking at DVB-T PCI cards.  Two Raspberry Pis with DVB hats installed, TV antenna sockets showing
Two Raspberry Pis with DVB hats installed, TV antenna sockets showing
 In this, our next exciting installment of STM32 and Rust for USB device
drivers, we're going to look at what the STM32 calls the 'packet memory area'.
If you've been reading along with the course, including reading up on the
In this, our next exciting installment of STM32 and Rust for USB device
drivers, we're going to look at what the STM32 calls the 'packet memory area'.
If you've been reading along with the course, including reading up on the
 Hopefully, by next time, we'll have layered some more pleasant routines on our
PMA code, and begun a foray into the setup necessary before we can begin
handling interrupts and start turning up on a USB port.
Hopefully, by next time, we'll have layered some more pleasant routines on our
PMA code, and begun a foray into the setup necessary before we can begin
handling interrupts and start turning up on a USB port.