Roadkiller was a Soekris net5501 router I used as my main gateway
between 2010 and 2016 (for
r seau and
t l phone).
It was upgraded to FreeBSD 8.4-p12 (2014-06-06) and
pkgng. It was
retired in favor of
octavia around 2016.
Roughly 10 years later (2024-01-24), I found it in a drawer and, to my
surprised, it booted. After wrangling with a
RS-232 USB adapter,
a
null modem cable, and bit rates, I even logged in:
comBIOS ver. 1.33 20070103 Copyright (C) 2000-2007 Soekris Engineering.
net5501
0512 Mbyte Memory CPU Geode LX 500 Mhz
Pri Mas WDC WD800VE-00HDT0 LBA Xlt 1024-255-63 78 Gbyte
Slot Vend Dev ClassRev Cmd Stat CL LT HT Base1 Base2 Int
-------------------------------------------------------------------
0:01:2 1022 2082 10100000 0006 0220 08 00 00 A0000000 00000000 10
0:06:0 1106 3053 02000096 0117 0210 08 40 00 0000E101 A0004000 11
0:07:0 1106 3053 02000096 0117 0210 08 40 00 0000E201 A0004100 05
0:08:0 1106 3053 02000096 0117 0210 08 40 00 0000E301 A0004200 09
0:09:0 1106 3053 02000096 0117 0210 08 40 00 0000E401 A0004300 12
0:20:0 1022 2090 06010003 0009 02A0 08 40 80 00006001 00006101
0:20:2 1022 209A 01018001 0005 02A0 08 00 00 00000000 00000000
0:21:0 1022 2094 0C031002 0006 0230 08 00 80 A0005000 00000000 15
0:21:1 1022 2095 0C032002 0006 0230 08 00 00 A0006000 00000000 15
4 Seconds to automatic boot. Press Ctrl-P for entering Monitor.
______
____ __ ___ ___
Welcome to FreeBSD! __ '__/ _ \/ _ \
__ __/ __/
1. Boot FreeBSD [default] _ _ \___ \___
2. Boot FreeBSD with ACPI enabled ____ _____ _____
3. Boot FreeBSD in Safe Mode _ \ / ____ __ \
4. Boot FreeBSD in single user mode _) (___
5. Boot FreeBSD with verbose logging _ < \___ \
6. Escape to loader prompt _) ____) __
7. Reboot
____/ _____/ _____/
Select option, [Enter] for default
or [Space] to pause timer 5
Copyright (c) 1992-2013 The FreeBSD Project.
Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994
The Regents of the University of California. All rights reserved.
FreeBSD is a registered trademark of The FreeBSD Foundation.
FreeBSD 8.4-RELEASE-p12 #5: Fri Jun 6 02:43:23 EDT 2014
root@roadkiller.anarc.at:/usr/obj/usr/src/sys/ROADKILL i386
gcc version 4.2.2 20070831 prerelease [FreeBSD]
Timecounter "i8254" frequency 1193182 Hz quality 0
CPU: Geode(TM) Integrated Processor by AMD PCS (499.90-MHz 586-class CPU)
Origin = "AuthenticAMD" Id = 0x5a2 Family = 5 Model = a Stepping = 2
Features=0x88a93d<FPU,DE,PSE,TSC,MSR,CX8,SEP,PGE,CMOV,CLFLUSH,MMX>
AMD Features=0xc0400000<MMX+,3DNow!+,3DNow!>
real memory = 536870912 (512 MB)
avail memory = 506445824 (482 MB)
kbd1 at kbdmux0
K6-family MTRR support enabled (2 registers)
ACPI Error: A valid RSDP was not found (20101013/tbxfroot-309)
ACPI: Table initialisation failed: AE_NOT_FOUND
ACPI: Try disabling either ACPI or apic support.
cryptosoft0: <software crypto> on motherboard
pcib0 pcibus 0 on motherboard
pci0: <PCI bus> on pcib0
Geode LX: Soekris net5501 comBIOS ver. 1.33 20070103 Copyright (C) 2000-2007
pci0: <encrypt/decrypt, entertainment crypto> at device 1.2 (no driver attached)
vr0: <VIA VT6105M Rhine III 10/100BaseTX> port 0xe100-0xe1ff mem 0xa0004000-0xa00040ff irq 11 at device 6.0 on pci0
vr0: Quirks: 0x2
vr0: Revision: 0x96
miibus0: <MII bus> on vr0
ukphy0: <Generic IEEE 802.3u media interface> PHY 1 on miibus0
ukphy0: none, 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto, auto-flow
vr0: Ethernet address: 00:00:24:cc:93:44
vr0: [ITHREAD]
vr1: <VIA VT6105M Rhine III 10/100BaseTX> port 0xe200-0xe2ff mem 0xa0004100-0xa00041ff irq 5 at device 7.0 on pci0
vr1: Quirks: 0x2
vr1: Revision: 0x96
miibus1: <MII bus> on vr1
ukphy1: <Generic IEEE 802.3u media interface> PHY 1 on miibus1
ukphy1: none, 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto, auto-flow
vr1: Ethernet address: 00:00:24:cc:93:45
vr1: [ITHREAD]
vr2: <VIA VT6105M Rhine III 10/100BaseTX> port 0xe300-0xe3ff mem 0xa0004200-0xa00042ff irq 9 at device 8.0 on pci0
vr2: Quirks: 0x2
vr2: Revision: 0x96
miibus2: <MII bus> on vr2
ukphy2: <Generic IEEE 802.3u media interface> PHY 1 on miibus2
ukphy2: none, 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto, auto-flow
vr2: Ethernet address: 00:00:24:cc:93:46
vr2: [ITHREAD]
vr3: <VIA VT6105M Rhine III 10/100BaseTX> port 0xe400-0xe4ff mem 0xa0004300-0xa00043ff irq 12 at device 9.0 on pci0
vr3: Quirks: 0x2
vr3: Revision: 0x96
miibus3: <MII bus> on vr3
ukphy3: <Generic IEEE 802.3u media interface> PHY 1 on miibus3
ukphy3: none, 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, auto, auto-flow
vr3: Ethernet address: 00:00:24:cc:93:47
vr3: [ITHREAD]
isab0: <PCI-ISA bridge> at device 20.0 on pci0
isa0: <ISA bus> on isab0
atapci0: <AMD CS5536 UDMA100 controller> port 0x1f0-0x1f7,0x3f6,0x170-0x177,0x376,0xe000-0xe00f at device 20.2 on pci0
ata0: <ATA channel> at channel 0 on atapci0
ata0: [ITHREAD]
ata1: <ATA channel> at channel 1 on atapci0
ata1: [ITHREAD]
ohci0: <OHCI (generic) USB controller> mem 0xa0005000-0xa0005fff irq 15 at device 21.0 on pci0
ohci0: [ITHREAD]
usbus0 on ohci0
ehci0: <AMD CS5536 (Geode) USB 2.0 controller> mem 0xa0006000-0xa0006fff irq 15 at device 21.1 on pci0
ehci0: [ITHREAD]
usbus1: EHCI version 1.0
usbus1 on ehci0
cpu0 on motherboard
pmtimer0 on isa0
orm0: <ISA Option ROM> at iomem 0xc8000-0xd27ff pnpid ORM0000 on isa0
atkbdc0: <Keyboard controller (i8042)> at port 0x60,0x64 on isa0
atkbd0: <AT Keyboard> irq 1 on atkbdc0
kbd0 at atkbd0
atkbd0: [GIANT-LOCKED]
atkbd0: [ITHREAD]
atrtc0: <AT Real Time Clock> at port 0x70 irq 8 on isa0
ppc0: parallel port not found.
uart0: <16550 or compatible> at port 0x3f8-0x3ff irq 4 flags 0x10 on isa0
uart0: [FILTER]
uart0: console (19200,n,8,1)
uart1: <16550 or compatible> at port 0x2f8-0x2ff irq 3 on isa0
uart1: [FILTER]
Timecounter "TSC" frequency 499903982 Hz quality 800
Timecounters tick every 1.000 msec
IPsec: Initialized Security Association Processing.
usbus0: 12Mbps Full Speed USB v1.0
usbus1: 480Mbps High Speed USB v2.0
ad0: 76319MB <WDC WD800VE-00HDT0 09.07D09> at ata0-master UDMA100
ugen0.1: <AMD> at usbus0
uhub0: <AMD OHCI root HUB, class 9/0, rev 1.00/1.00, addr 1> on usbus0
ugen1.1: <AMD> at usbus1
uhub1: <AMD EHCI root HUB, class 9/0, rev 2.00/1.00, addr 1> on usbus1
GEOM: ad0s1: geometry does not match label (255h,63s != 16h,63s).
uhub0: 4 ports with 4 removable, self powered
Root mount waiting for: usbus1
Root mount waiting for: usbus1
uhub1: 4 ports with 4 removable, self powered
Trying to mount root from ufs:/dev/ad0s1a
The last log rotation is from 2016:
[root@roadkiller /var/log]# stat /var/log/wtmp
65 61783 -rw-r--r-- 1 root wheel 208219 1056 "Nov 1 05:00:01 2016" "Jan 18 22:29:16 2017" "Jan 18 22:29:16 2017" "Nov 1 05:00:01 2016" 16384 4 0 /var/log/wtmp
Interestingly, I switched between eicat and teksavvy on December
11th. Which year? Who knows!
Dec 11 16:38:40 roadkiller mpd: [eicatL0] LCP: authorization successful
Dec 11 16:41:15 roadkiller mpd: [teksavvyL0] LCP: authorization successful
Never realized those good old logs had a "oh dear forgot the year"
issue (that's something like Y2K except just "Y", I guess).
That was probably 2015, because the log dates from 2017, and the last
entry is from November of the year after the above:
[root@roadkiller /var/log]# stat mpd.log
65 47113 -rw-r--r-- 1 root wheel 193008 71939195 "Jan 18 22:39:18 2017" "Jan 18 22:39:59 2017" "Jan 18 22:39:59 2017" "Apr 2 10:41:37 2013" 16384 140640 0 mpd.log
It looks like the system was installed in 2010:
[root@roadkiller /var/log]# stat /
63 2 drwxr-xr-x 21 root wheel 2120 512 "Jan 18 22:34:43 2017" "Jan 18 22:28:12 2017" "Jan 18 22:28:12 2017" "Jul 18 22:25:00 2010" 16384 4 0 /
... so it lived for about 6 years, but still works after almost
14
years, which I find utterly amazing.
Another amazing thing is that there's tuptime installed on that
server! That is a software I
thought I discovered later and then
sponsored in Debian, but turns out I was already using it then!
[root@roadkiller /var]# tuptime
System startups: 19 since 21:20:16 11/07/15
System shutdowns: 0 ok - 18 bad
System uptime: 85.93 % - 1 year, 11 days, 10 hours, 3 minutes and 36 seconds
System downtime: 14.07 % - 61 days, 15 hours, 22 minutes and 45 seconds
System life: 1 year, 73 days, 1 hour, 26 minutes and 20 seconds
Largest uptime: 122 days, 9 hours, 17 minutes and 6 seconds from 08:17:56 02/02/16
Shortest uptime: 5 minutes and 4 seconds from 21:55:00 01/18/17
Average uptime: 19 days, 19 hours, 28 minutes and 37 seconds
Largest downtime: 57 days, 1 hour, 9 minutes and 59 seconds from 20:45:01 11/22/16
Shortest downtime: -1 years, 364 days, 23 hours, 58 minutes and 12 seconds from 22:30:01 01/18/17
Average downtime: 3 days, 5 hours, 51 minutes and 43 seconds
Current uptime: 18 minutes and 23 seconds since 22:28:13 01/18/17
Actual up/down times:
[root@roadkiller /var]# tuptime -t
No. Startup Date Uptime Shutdown Date End Downtime
1 21:20:16 11/07/15 1 day, 0 hours, 40 minutes and 12 seconds 22:00:28 11/08/15 BAD 2 minutes and 37 seconds
2 22:03:05 11/08/15 1 day, 9 hours, 41 minutes and 57 seconds 07:45:02 11/10/15 BAD 3 minutes and 24 seconds
3 07:48:26 11/10/15 20 days, 2 hours, 41 minutes and 34 seconds 10:30:00 11/30/15 BAD 4 hours, 50 minutes and 21 seconds
4 15:20:21 11/30/15 19 minutes and 40 seconds 15:40:01 11/30/15 BAD 6 minutes and 5 seconds
5 15:46:06 11/30/15 53 minutes and 55 seconds 16:40:01 11/30/15 BAD 1 hour, 1 minute and 38 seconds
6 17:41:39 11/30/15 6 days, 16 hours, 3 minutes and 22 seconds 09:45:01 12/07/15 BAD 4 days, 6 hours, 53 minutes and 11 seconds
7 16:38:12 12/11/15 50 days, 17 hours, 56 minutes and 49 seconds 10:35:01 01/31/16 BAD 10 minutes and 52 seconds
8 10:45:53 01/31/16 1 day, 21 hours, 28 minutes and 16 seconds 08:14:09 02/02/16 BAD 3 minutes and 48 seconds
9 08:17:56 02/02/16 122 days, 9 hours, 17 minutes and 6 seconds 18:35:02 06/03/16 BAD 10 minutes and 16 seconds
10 18:45:18 06/03/16 29 days, 17 hours, 14 minutes and 43 seconds 12:00:01 07/03/16 BAD 12 minutes and 34 seconds
11 12:12:35 07/03/16 31 days, 17 hours, 17 minutes and 26 seconds 05:30:01 08/04/16 BAD 14 minutes and 25 seconds
12 05:44:26 08/04/16 15 days, 1 hour, 55 minutes and 35 seconds 07:40:01 08/19/16 BAD 6 minutes and 51 seconds
13 07:46:52 08/19/16 7 days, 5 hours, 23 minutes and 10 seconds 13:10:02 08/26/16 BAD 3 minutes and 45 seconds
14 13:13:47 08/26/16 27 days, 21 hours, 36 minutes and 14 seconds 10:50:01 09/23/16 BAD 2 minutes and 14 seconds
15 10:52:15 09/23/16 60 days, 10 hours, 52 minutes and 46 seconds 20:45:01 11/22/16 BAD 57 days, 1 hour, 9 minutes and 59 seconds
16 21:55:00 01/18/17 5 minutes and 4 seconds 22:00:04 01/18/17 BAD 11 minutes and 15 seconds
17 22:11:19 01/18/17 8 minutes and 42 seconds 22:20:01 01/18/17 BAD 1 minute and 20 seconds
18 22:21:21 01/18/17 8 minutes and 40 seconds 22:30:01 01/18/17 BAD -1 years, 364 days, 23 hours, 58 minutes and 12 seconds
19 22:28:13 01/18/17 20 minutes and 17 seconds
The last few entries are actually the tests I'm running now, it seems
this machine thinks we're now on 2017-01-18 at ~22:00, while we're
actually 2024-01-24 at ~12:00 local:
Wed Jan 18 23:05:38 EST 2017
FreeBSD/i386 (roadkiller.anarc.at) (ttyu0)
login: root
Password:
Jan 18 23:07:10 roadkiller login: ROOT LOGIN (root) ON ttyu0
Last login: Wed Jan 18 22:29:16 on ttyu0
Copyright (c) 1992-2013 The FreeBSD Project.
Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994
The Regents of the University of California. All rights reserved.
FreeBSD 8.4-RELEASE-p12 (ROADKILL) #5: Fri Jun 6 02:43:23 EDT 2014
Reminders:
* commit stuff in /etc
* reload firewall (in screen!):
pfctl -f /etc/pf.conf ; sleep 1
* vim + syn on makes pf.conf more readable
* monitoring the PPPoE uplink:
tail -f /var/log/mpd.log
Current problems:
* sometimes pf doesn't start properly on boot, if pppoe failed to come up, use
this to resume:
/etc/rc.d/pf start
it will kill your shell, but fix NAT (2012-08-10)
* babel fails to start on boot (2013-06-15):
babeld -D -g 33123 tap0 vr3
* DNS often fails, tried messing with unbound.conf (2014-10-05) and updating
named.root (2016-01-28) and performance tweaks (ee63689)
* asterisk and mpd4 are deprecated and should be uninstalled when we're sure
their replacements (voipms + ata and mpd5) are working (2015-01-13)
* if IPv6 fails, it's because netblocks are not being routed upstream. DHCPcd
should do this, but doesn't start properly, use this to resume (2015-12-21):
/usr/local/sbin/dhcpcd -6 --persistent --background --timeout 0 -C resolv.conf ng0
This machine is doomed to be replaced with the new omnia router, Indiegogo
campaign should ship in april 2016: http://igg.me/at/turris-omnia/x
(I really like the
motd I left myself there. In theory, I guess this
could just start connecting to the internet again if I still had the
same PPPoE/ADSL link I had almost a decade ago; obviously, I
do
not.)
Not sure how the system figured the 2017 time: the onboard clock
itself believes we're in 1980, so clearly the
CMOS battery has
(understandably) failed:
> ?
comBIOS Monitor Commands
boot [drive][:partition] INT19 Boot
reboot cold boot
download download a file using XMODEM/CRC
flashupdate update flash BIOS with downloaded file
time [HH:MM:SS] show or set time
date [YYYY/MM/DD] show or set date
d[b w d] [adr] dump memory bytes/words/dwords
e[b w d] adr value [...] enter bytes/words/dwords
i[b w d] port input from 8/16/32-bit port
o[b w d] port value output to 8/16/32-bit port
run adr execute code at adr
cmosread [adr] read CMOS RAM data
cmoswrite adr byte [...] write CMOS RAM data
cmoschecksum update CMOS RAM Checksum
set parameter=value set system parameter to value
show [parameter] show one or all system parameters
?/help show this help
> show
ConSpeed = 19200
ConLock = Enabled
ConMute = Disabled
BIOSentry = Enabled
PCIROMS = Enabled
PXEBoot = Enabled
FLASH = Primary
BootDelay = 5
FastBoot = Disabled
BootPartition = Disabled
BootDrive = 80 81 F0 FF
ShowPCI = Enabled
Reset = Hard
CpuSpeed = Default
> time
Current Date and Time is: 1980/01/01 00:56:47
Another bit of archeology: I had documented various outages with my
ISP... back in 2003!
[root@roadkiller ~/bin]# cat ppp_stats/downtimes.txt
11/03/2003 18:24:49 218
12/03/2003 09:10:49 118
12/03/2003 10:05:57 680
12/03/2003 10:14:50 106
12/03/2003 10:16:53 6
12/03/2003 10:35:28 146
12/03/2003 10:57:26 393
12/03/2003 11:16:35 5
12/03/2003 11:16:54 11
13/03/2003 06:15:57 18928
13/03/2003 09:43:36 9730
13/03/2003 10:47:10 23
13/03/2003 10:58:35 5
16/03/2003 01:32:36 338
16/03/2003 02:00:33 120
16/03/2003 11:14:31 14007
19/03/2003 00:56:27 11179
19/03/2003 00:56:43 5
19/03/2003 00:56:53 0
19/03/2003 00:56:55 1
19/03/2003 00:57:09 1
19/03/2003 00:57:10 1
19/03/2003 00:57:24 1
19/03/2003 00:57:25 1
19/03/2003 00:57:39 1
19/03/2003 00:57:40 1
19/03/2003 00:57:44 3
19/03/2003 00:57:53 0
19/03/2003 00:57:55 0
19/03/2003 00:58:08 0
19/03/2003 00:58:10 0
19/03/2003 00:58:23 0
19/03/2003 00:58:25 0
19/03/2003 00:58:39 1
19/03/2003 00:58:42 2
19/03/2003 00:58:58 5
19/03/2003 00:59:35 2
19/03/2003 00:59:47 3
19/03/2003 01:00:34 3
19/03/2003 01:00:39 0
19/03/2003 01:00:54 0
19/03/2003 01:01:11 2
19/03/2003 01:01:25 1
19/03/2003 01:01:48 1
19/03/2003 01:02:03 1
19/03/2003 01:02:10 2
19/03/2003 01:02:20 3
19/03/2003 01:02:44 3
19/03/2003 01:03:45 3
19/03/2003 01:04:39 2
19/03/2003 01:05:40 2
19/03/2003 01:06:35 2
19/03/2003 01:07:36 2
19/03/2003 01:08:31 2
19/03/2003 01:08:38 2
19/03/2003 01:10:07 3
19/03/2003 01:11:05 2
19/03/2003 01:12:03 3
19/03/2003 01:13:01 3
19/03/2003 01:13:58 2
19/03/2003 01:14:59 5
19/03/2003 01:15:54 2
19/03/2003 01:16:55 2
19/03/2003 01:17:50 2
19/03/2003 01:18:51 3
19/03/2003 01:19:46 2
19/03/2003 01:20:46 2
19/03/2003 01:21:42 3
19/03/2003 01:22:42 3
19/03/2003 01:23:37 2
19/03/2003 01:24:38 3
19/03/2003 01:25:33 2
19/03/2003 01:26:33 2
19/03/2003 01:27:30 3
19/03/2003 01:28:55 2
19/03/2003 01:29:56 2
19/03/2003 01:30:50 2
19/03/2003 01:31:42 3
19/03/2003 01:32:36 3
19/03/2003 01:33:27 2
19/03/2003 01:34:21 2
19/03/2003 01:35:22 2
19/03/2003 01:36:17 3
19/03/2003 01:37:18 2
19/03/2003 01:38:13 3
19/03/2003 01:39:39 2
19/03/2003 01:40:39 2
19/03/2003 01:41:35 3
19/03/2003 01:42:35 3
19/03/2003 01:43:31 3
19/03/2003 01:44:31 3
19/03/2003 01:45:53 3
19/03/2003 01:46:48 3
19/03/2003 01:47:48 2
19/03/2003 01:48:44 3
19/03/2003 01:49:44 2
19/03/2003 01:50:40 3
19/03/2003 01:51:39 1
19/03/2003 11:04:33 19
19/03/2003 18:39:36 2833
19/03/2003 18:54:05 825
19/03/2003 19:04:00 454
19/03/2003 19:08:11 210
19/03/2003 19:41:44 272
19/03/2003 21:18:41 208
24/03/2003 04:51:16 6
27/03/2003 04:51:20 5
30/03/2003 04:51:25 5
31/03/2003 08:30:31 255
03/04/2003 08:30:36 5
06/04/2003 01:16:00 621
06/04/2003 22:18:08 17
06/04/2003 22:32:44 13
09/04/2003 22:33:12 28
12/04/2003 22:33:17 6
15/04/2003 22:33:22 5
17/04/2003 15:03:43 18
20/04/2003 15:03:48 5
23/04/2003 15:04:04 16
23/04/2003 21:08:30 339
23/04/2003 21:18:08 13
23/04/2003 23:34:20 253
26/04/2003 23:34:45 25
29/04/2003 23:34:49 5
02/05/2003 13:10:01 185
05/05/2003 13:10:06 5
08/05/2003 13:10:11 5
09/05/2003 14:00:36 63928
09/05/2003 16:58:52 2
11/05/2003 23:08:48 2
14/05/2003 23:08:53 6
17/05/2003 23:08:58 5
20/05/2003 23:09:03 5
23/05/2003 23:09:08 5
26/05/2003 23:09:14 5
29/05/2003 23:00:10 3
29/05/2003 23:03:01 10
01/06/2003 23:03:05 4
04/06/2003 23:03:10 5
07/06/2003 23:03:38 28
10/06/2003 23:03:50 12
13/06/2003 23:03:55 6
14/06/2003 07:42:20 3
14/06/2003 14:37:08 3
15/06/2003 20:08:34 3
18/06/2003 20:08:39 6
21/06/2003 20:08:45 6
22/06/2003 03:05:19 138
22/06/2003 04:06:28 3
25/06/2003 04:06:58 31
28/06/2003 04:07:02 4
01/07/2003 04:07:06 4
04/07/2003 04:07:11 5
07/07/2003 04:07:16 5
12/07/2003 04:55:20 6
12/07/2003 19:09:51 1158
12/07/2003 22:14:49 8025
15/07/2003 22:14:54 6
16/07/2003 05:43:06 18
19/07/2003 05:43:12 6
22/07/2003 05:43:17 5
23/07/2003 18:18:55 183
23/07/2003 18:19:55 9
23/07/2003 18:29:15 158
23/07/2003 19:48:44 4604
23/07/2003 20:16:27 3
23/07/2003 20:37:29 1079
23/07/2003 20:43:12 342
23/07/2003 22:25:51 6158
Fascinating.
I suspect the (
IDE!) hard drive might be failing as I saw two new
files created in
/var that I didn't remember seeing before:
-rw-r--r-- 1 root wheel 0 Jan 18 22:55 3@T3
-rw-r--r-- 1 root wheel 0 Jan 18 22:55 DY5
So I shutdown the machine, possibly for the last time:
Waiting (max 60 seconds) for system process bufdaemon' to stop...done
Waiting (max 60 seconds) for system process syncer' to stop...
Syncing disks, vnodes remaining...3 3 0 1 1 0 0 done
All buffers synced.
Uptime: 36m43s
usbus0: Controller shutdown
uhub0: at usbus0, port 1, addr 1 (disconnected)
usbus0: Controller shutdown complete
usbus1: Controller shutdown
uhub1: at usbus1, port 1, addr 1 (disconnected)
usbus1: Controller shutdown complete
The operating system has halted.
Please press any key to reboot.
I'll finally note this was the last
FreeBSD server I personally
operated. I also used FreeBSD to setup the core routers at
Koumbit but those were
replaced with Debian recently as
well.
Thanks Soekris, that was some sturdy hardware. Hopefully this new
Protectli router will live up to that "decade
plus" challenge.
Not sure what the fate of this device will be: I'll bring it to the
next Montreal Debian & Stuff to see if anyone's interested,
contact me if you can't show up and want this thing.
 Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they ve kicked me off Go Roam, so I ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don t expect to use all of the data allowance, but I didn t want to have to worry about unexpected excess charges.
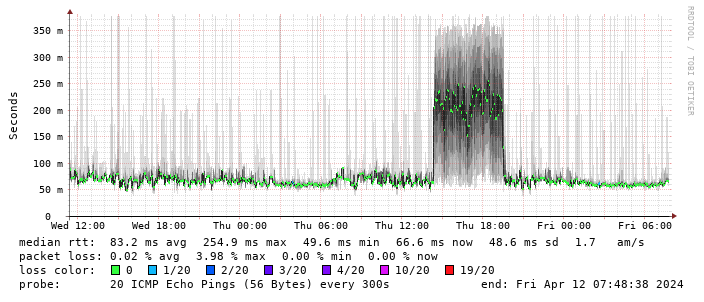
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they ve kicked me off Go Roam, so I ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don t expect to use all of the data allowance, but I didn t want to have to worry about unexpected excess charges.
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
 (There s a handy zte.js script to allow doing this from the device web interface.)
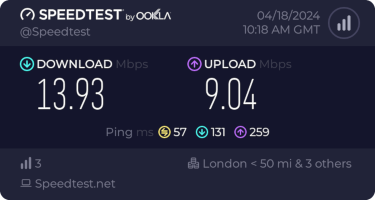
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
(There s a handy zte.js script to allow doing this from the device web interface.)
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
 This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
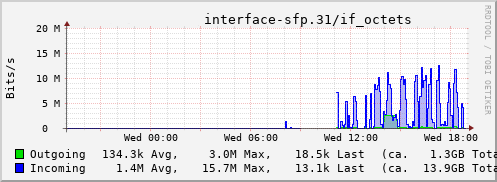
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to











 Edited 2023-08-25 01:32 BST to correct a slip.
Edited 2023-08-25 01:32 BST to correct a slip.
 At the end of the series while a slightly progressive end is shown, in reality you are left wondering whether the decision taken by the protagonist and the woman having just no agency. The hero knowing he is superior to her because of her perceived weakness. A deep-rooted malaise that is difficult to break out of. His father too and the relationship the hero longs for to have with his father who is no more. He does share some of his feelings with his mum, which touches the cord of probably every child whose mother father left them early and all those things they wanted to talk or would have chatted out if they knew this would be the last conversation they will ever have with them. Couldn t even say sorry for all the wrongs and the pain we have given them. There are just too many layers in the webseries that I would need to see it a few times to be aware of. I could sense the undercurrents but sometimes you need to see such series or movies multiple times to understand them or it could simply be the case of me being just too thick. There are also poems and poems as we know may have multiple meanings and is or can be more contextual to the person reading it rather than the creator.
At the end, while it does show a positive end, in reality I feel there is no redemption for us. I am talking about men. We are too proud, too haughty and too insecure. And if things don t go the way we want, it s the women who pay the price
At the end of the series while a slightly progressive end is shown, in reality you are left wondering whether the decision taken by the protagonist and the woman having just no agency. The hero knowing he is superior to her because of her perceived weakness. A deep-rooted malaise that is difficult to break out of. His father too and the relationship the hero longs for to have with his father who is no more. He does share some of his feelings with his mum, which touches the cord of probably every child whose mother father left them early and all those things they wanted to talk or would have chatted out if they knew this would be the last conversation they will ever have with them. Couldn t even say sorry for all the wrongs and the pain we have given them. There are just too many layers in the webseries that I would need to see it a few times to be aware of. I could sense the undercurrents but sometimes you need to see such series or movies multiple times to understand them or it could simply be the case of me being just too thick. There are also poems and poems as we know may have multiple meanings and is or can be more contextual to the person reading it rather than the creator.
At the end, while it does show a positive end, in reality I feel there is no redemption for us. I am talking about men. We are too proud, too haughty and too insecure. And if things don t go the way we want, it s the women who pay the price 


 src:developers-reference translations wanted
I've just uploaded developers-reference 12.19, bringing the German
translation status back to 100% complete, thanks to Carsten Schoenert. Some
other translations however could use some updates:
src:developers-reference translations wanted
I've just uploaded developers-reference 12.19, bringing the German
translation status back to 100% complete, thanks to Carsten Schoenert. Some
other translations however could use some updates:
 The voting period for the Debian Project Leader election has ended, with all of the votes tallied we announce the winner is: Jonathan Carter, who has been elected for the forth time.
Congratulations! The new term for the project leader started on 2023-04-21.
279 of 997 Developers voted using the
The voting period for the Debian Project Leader election has ended, with all of the votes tallied we announce the winner is: Jonathan Carter, who has been elected for the forth time.
Congratulations! The new term for the project leader started on 2023-04-21.
279 of 997 Developers voted using the 

 The nineteenth release of
The nineteenth release of  (no site yet)
(no site yet) in October 2021. they generally seem to keep up with
shipping. update (august 2022): they rolled out a second line of
laptops (12th gen), first batch shipped, second batch
in October 2021. they generally seem to keep up with
shipping. update (august 2022): they rolled out a second line of
laptops (12th gen), first batch shipped, second batch