With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up I d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. For now, we ll be using a custom ISO image, while waiting for the above-mentioned merge-proposal to be landed. Furthermore, as the Debian archive is going through major transitions builds of the unstable branch of d-i don t currently work. So I implemented a small backport, producing updated netcfg and netcfg-static for Bookworm, which can be used as localudebs/ during the d-i build.
Let s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
Now let s download the custom mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes, as mentioned above.
TODO: localudebs/
Next we ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
Finally, let s launch the installer using a custom preseed.cfg file, that will automatically install Netplan for us in the target system. A minimal preseed file could look like this:
For this demo, we re installing the full netplan.io package (incl. Python CLI), as the netplan-generator package was not yet split out as an independent binary in the Bookworm cycle. You can choose the preseed file from a set of different variants to test the different configurations:
We re using the custom linux kernel and initrd.gz here to be able to pass the PRESEED_URL as a parameter to the kernel s cmdline directly. Launching this VM should bring up the normal debian-installer in its netboot/gtk form:
Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
Done! After the installation finished you can reboot into your virgin Debian Bookworm system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was written by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
Finally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
In our case we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more join the discussion at Salsa:installer-team/netcfg and find us at GitHub:netplan.
Joachim Breitner wrote about a Convenient sandboxed development environment and thus reminded me to blog about MicroVM. I ve toyed around with it a little but not yet seriously used it as I m currently not coding.
MicroVM is a nix based project to configure and run minimal VMs. It can mount and thus reuse the hosts nix store inside the VM and thus has a very small disk footprint. I use MicroVM on a debian system using the nix package manager.
The MicroVM author uses the project to host production services. Otherwise I consider it also a nice way to learn about NixOS after having started with the nix package manager and before making the big step to NixOS as my main system.
The guests root filesystem is a tmpdir, so one must explicitly define folders that should be mounted from the host and thus be persistent across VM reboots.
I defined the VM as a nix flake since this is how I started from the MicroVM projects example:
description = "Haskell dev MicroVM";
inputs.impermanence.url = "github:nix-community/impermanence";
inputs.microvm.url = "github:astro/microvm.nix";
inputs.microvm.inputs.nixpkgs.follows = "nixpkgs";
outputs = self, impermanence, microvm, nixpkgs :
let
persistencePath = "/persistent";
system = "x86_64-linux";
user = "thk";
vmname = "haskell";
nixosConfiguration = nixpkgs.lib.nixosSystem
inherit system;
modules = [
microvm.nixosModules.microvm
impermanence.nixosModules.impermanence
( pkgs, ... :
environment.persistence.$ persistencePath =
hideMounts = true;
users.$ user =
directories = [
"git" ".stack"
];
;
;
environment.sessionVariables =
TERM = "screen-256color";
;
environment.systemPackages = with pkgs; [
ghc
git
(haskell-language-server.override supportedGhcVersions = [ "94" ]; )
htop
stack
tmux
tree
vcsh
zsh
];
fileSystems.$ persistencePath .neededForBoot = nixpkgs.lib.mkForce true;
microvm =
forwardPorts = [
from = "host"; host.port = 2222; guest.port = 22;
from = "guest"; host.port = 5432; guest.port = 5432; # postgresql
];
hypervisor = "qemu";
interfaces = [
type = "user"; id = "usernet"; mac = "00:00:00:00:00:02";
];
mem = 4096;
shares = [
# use "virtiofs" for MicroVMs that are started by systemd
proto = "9p";
tag = "ro-store";
# a host's /nix/store will be picked up so that no
# squashfs/erofs will be built for it.
source = "/nix/store";
mountPoint = "/nix/.ro-store";
proto = "virtiofs";
tag = "persistent";
source = "~/.local/share/microvm/vms/$ vmname /persistent";
mountPoint = persistencePath;
socket = "/run/user/1000/microvm-$ vmname -persistent";
];
socket = "/run/user/1000/microvm-control.socket";
vcpu = 3;
volumes = [];
writableStoreOverlay = "/nix/.rwstore";
;
networking.hostName = vmname;
nix.enable = true;
nix.nixPath = ["nixpkgs=$ builtins.storePath <nixpkgs> "];
nix.settings =
extra-experimental-features = ["nix-command" "flakes"];
trusted-users = [user];
;
security.sudo =
enable = true;
wheelNeedsPassword = false;
;
services.getty.autologinUser = user;
services.openssh =
enable = true;
;
system.stateVersion = "24.11";
systemd.services.loadnixdb =
description = "import hosts nix database";
path = [pkgs.nix];
wantedBy = ["multi-user.target"];
requires = ["nix-daemon.service"];
script = "cat $ persistencePath /nix-store-db-dump nix-store --load-db";
;
time.timeZone = nixpkgs.lib.mkDefault "Europe/Berlin";
users.users.$ user =
extraGroups = [ "wheel" "video" ];
group = "user";
isNormalUser = true;
openssh.authorizedKeys.keys = [
"ssh-rsa REDACTED"
];
password = "";
;
users.users.root.password = "";
users.groups.user = ;
)
];
;
in
packages.$ system .default = nixosConfiguration.config.microvm.declaredRunner;
;
I start the microVM with a templated systemd user service:
The above service definition creates a dump of the hosts nix store db so that it can be imported in the guest. This is necessary so that the guest can actually use what is available in /nix/store. There is an effort for an overlayed nix store that would be preferable to this hack.
Finally the microvm is started inside a tmux session named microvm . This way I can use the VM with SSH or through the console and also access the qemu console.
And for completeness the virtiofsd service:
[Unit]
Description=serve host persistent folder for dev VM
AssertPathIsDirectory=%h/.local/share/microvm/vms/%i/persistent
[Service]
ExecStart=%h/.local/state/nix/profile/bin/virtiofsd \
--socket-path=$ XDG_RUNTIME_DIR /microvm-%i-persistent \
--shared-dir=%h/.local/share/microvm/vms/%i/persistent \
--gid-map :995:%G:1: \
--uid-map :1000:%U:1:
Unseen Academicals is the 37th Discworld novel and includes many of
the long-standing Ankh-Morpork cast, but mostly as supporting characters.
The main characters are a new (and delightful) bunch with their own
concerns. You arguably could start reading here if you really wanted to,
although you would risk spoiling several previous books (most notably
Thud!) and will miss some references
that depend on familiarity with the cast.
The Unseen University is, like most institutions of its sort, funded by an
endowment that allows the wizards to focus on the pure life of the mind
(or the stomach). Much to their dismay, they have just discovered that an
endowment that amounts to most of their food budget requires that they
field a football team.
Glenda runs the night kitchen at the Unseen University. Given the deep
and abiding love that wizards have for food, there is both a main kitchen
and a night kitchen. The main kitchen is more prestigious, but the night
kitchen is responsible for making pies, something that Glenda is quietly
but exceptionally good at.
Juliet is Glenda's new employee. She is exceptionally beautiful, not very
bright, and a working class girl of the Ankh-Morpork streets down to her
bones. Trevor Likely is a candle dribbler, responsible for assisting the
Candle Knave in refreshing the endless university candles and ensuring
that their wax is properly dribbled, although he pushes most of that work
off onto the infallibly polite and oddly intelligent Mr. Nutt.
Glenda, Trev, and Juliet are the sort of people who populate the great
city of Ankh-Morpork. While the people everyone has heard of have
political crises, adventures, and book plots, they keep institutions like
the Unseen University running. They read romance novels, go to the
football games, and nurse long-standing rivalries. They do not expect the
high mucky-mucks to enter their world, let alone mess with their game.
I approached Unseen Academicals with trepidation because I normally
don't get along as well with the Discworld wizard books. I need not have
worried; Pratchett realized that the wizards would work better as
supporting characters and instead turns the main plot (or at least most of
it; more on that later) over to the servants. This was a brilliant
decision. The setup of this book is some of the best of Discworld up to
this point.
Trev is a streetwise rogue with an uncanny knack for kicking around a can
that he developed after being forbidden to play football by his dear old
mum. He falls for Juliet even though their families support different
football teams, so you may think that a Romeo and Juliet spoof is
coming. There are a few gestures of one, but Pratchett deftly avoids the
pitfalls and predictability and instead makes Juliet one of the best
characters in the book by playing directly against type. She is one of
the characters that Pratchett is so astonishingly good at, the ones that
are so thoroughly themselves that they transcend the stories they're put
into.
The heart of this book, though, is Glenda.
Glenda enjoyed her job. She didn't have a career; they were for people
who could not hold down jobs.
She is the kind of person who knows where she fits in the world and likes
what she does and is happy to stay there until she decides something isn't
right, and then she changes the world through the power of common sense
morality, righteous indignation, and sheer stubborn persistence.
Discworld is full of complex and subtle characters fencing with each
other, but there are few things I have enjoyed more than Glenda being a
determinedly good person. Vetinari of course recognizes and respects (and
uses) that inner core immediately.
Unfortunately, as great as the setup and characters are, Unseen
Academicals falls apart a bit at the end. I was eagerly reading the
story, wondering what Pratchett was going to weave out of the stories of
these individuals, and then it partly turned into yet another wizard book.
Pratchett pulled another of his deus ex machina tricks for the
climax in a way that I found unsatisfying and contrary to the tone of the
rest of the story, and while the characters do get reasonable endings, it
lacked the oomph I was hoping for. Rincewind is as determinedly one-note
as ever, the wizards do all the standard wizard things, and the plot just
isn't that interesting.
I liked Mr. Nutt a great deal in the first part of the book, and I wish he
could have kept that edge of enigmatic competence and unflappableness.
Pratchett wanted to tell a different story that involved more angst and
self-doubt, and while I appreciate that story, I found it less engaging
and a bit more melodramatic than I was hoping for. Mr. Nutt's reactions
in the last half of the book were believable and fit his background, but
that was part of the problem: he slotted back into an archetype that I
thought Pratchett was going to twist and upend.
Mr. Nutt does, at least, get a fantastic closing line, and as usual there
are a lot of great asides and quotes along the way, including possibly the
sharpest and most biting Vetinari speech of the entire series.
The Patrician took a sip of his beer. "I have told this to few
people, gentlemen, and I suspect never will again, but one day when I
was a young boy on holiday in Uberwald I was walking along the bank of
a stream when I saw a mother otter with her cubs. A very endearing
sight, I'm sure you will agree, and even as I watched, the mother
otter dived into the water and came up with a plump salmon, which she
subdued and dragged on to a half-submerged log. As she ate it, while
of course it was still alive, the body split and I remember to this
day the sweet pinkness of its roes as they spilled out, much to the
delight of the baby otters who scrambled over themselves to feed on
the delicacy. One of nature's wonders, gentlemen: mother and children
dining on mother and children. And that's when I first learned about
evil. It is built into the very nature of the universe. Every world
spins in pain. If there is any kind of supreme being, I told myself,
it is up to all of us to become his moral superior."
My dissatisfaction with the ending prevents Unseen Academicals
from rising to the level of Night Watch,
and it's a bit more uneven than the best books of the series. Still,
though, this is great stuff; recommended to anyone who is reading the
series.
Followed in publication order by I Shall Wear Midnight.
Rating: 8 out of 10
With the release of Libntlm version 1.8 the release tarball can be reproduced on several distributions. We also publish a signed minimal source-only tarball, produced by git-archive which is the same format used by Savannah, Codeberg, GitLab, GitHub and others. Reproducibility of both tarballs are tested continuously for regressions on GitLab through a CI/CD pipeline. If that wasn t enough to excite you, the Debian packages of Libntlm are now built from the reproducible minimal source-only tarball. The resulting binaries are reproducible on several architectures.
What does that even mean? Why should you care? How you can do the same for your project? What are the open issues? Read on, dear reader
This article describes my practical experiments with reproducible release artifacts, following up on my earlier thoughts that lead to discussion on Fosstodon and a patch by Janneke Nieuwenhuizen to make Guix tarballs reproducible that inspired me to some practical work.
Let s look at how a maintainer release some software, and how a user can reproduce the released artifacts from the source code. Libntlm provides a shared library written in C and uses GNU Make, GNU Autoconf, GNU Automake, GNU Libtool and gnulib for build management, but these ideas should apply to most project and build system. The following illustrate the steps a maintainer would take to prepare a release:
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make distcheck
gpg -b libntlm-1.8.tar.gz
The generated files libntlm-1.8.tar.gz and libntlm-1.8.tar.gz.sig are published, and users download and use them. This is how the GNU project have been doing releases since the late 1980 s. That is a testament to how successful this pattern has been! These tarballs contain source code and some generated files, typically shell scripts generated by autoconf, makefile templates generated by automake, documentation in formats like Info, HTML, or PDF. Rarely do they contain binary object code, but historically that happened.
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. I blogged earlier how to mitigate this risk by using signed minimal source-only tarballs.
The risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions such as Trisquel, Guix, Debian/Ubuntu or Fedora ship generated files coming from the tarball into the binary *.deb or *.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built through a typical autoconf -fi && ./configure && make install sequence, and never wrote the code to rebuild everything. This can also happen if the build rules are written but are buggy, shipping the old artifact. When a security problem is found, this can lead to time-consuming situations, as it may be that patching the relevant source code and rebuilding the package is not sufficient: the vulnerable generated object from the tarball would be shipped into the binary package instead of a rebuilt artifact. For architecture-specific binaries this rarely happens, since object code is usually not included in tarballs although for 10+ years I shipped the binary Java JAR file in the GNU Libidn release tarball, until I stopped shipping it. For interpreted languages and especially for generated content such as HTML, PDF, shell scripts this happens more than you would like.
Publishing minimal source-only tarballs enable easier auditing of a project s code, to avoid the need to read through all generated files looking for malicious content. I have taken care to generate the source-only minimal tarball using git-archive. This is the same format that GitLab, GitHub etc offer for the automated download links on git tags. The minimal source-only tarballs can thus serve as a way to audit GitLab and GitHub download material! Consider if/when hosting sites like GitLab or GitHub has a security incident that cause generated tarballs to include a backdoor that is not present in the git repository. If people rely on the tag download artifact without verifying the maintainer PGP signature using GnuPG, this can lead to similar backdoor scenarios that we had for XZUtils but originated with the hosting provider instead of the release manager. This is even more concerning, since this attack can be mounted for some selected IP address that you want to target and not on everyone, thereby making it harder to discover.
With all that discussion and rationale out of the way, let s return to the release process. I have added another step here:
make srcdist
gpg -b libntlm-1.8-src.tar.gz
Now the release is ready. I publish these four files in the Libntlm s Savannah Download area, but they can be uploaded to a GitLab/GitHub release area as well. These are the SHA256 checksums I got after building the tarballs on my Trisquel 11 aramo laptop:
So how can you reproduce my artifacts? Here is how to reproduce them in a Ubuntu 22.04 container:
podman run -it --rm ubuntu:22.04
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make dist srcdist
sha256sum libntlm-*.tar.gz
You should see the exact same SHA256 checksum values. Hooray!
This works because Trisquel 11 and Ubuntu 22.04 uses the same version of git, autoconf, automake, and libtool. These tools do not guarantee the same output content for all versions, similar to how GNU GCC does not generate the same binary output for all versions. So there is still some delicate version pairing needed.
Ideally, the artifacts should be possible to reproduce from the release artifacts themselves, and not only directly from git. It is possible to reproduce the full tarball in a AlmaLinux 8 container replace almalinux:8 with rockylinux:8 if you prefer RockyLinux:
podman run -it --rm almalinux:8
dnf update -y
dnf install -y make wget gcc
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8.tar.gz
tar xfa libntlm-1.8.tar.gz
cd libntlm-1.8
./configure
make dist
sha256sum libntlm-1.8.tar.gz
The source-only minimal tarball can be regenerated on Debian 11:
podman run -it --rm debian:11
apt-get update
apt-get install -y --no-install-recommends make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
make -f cfg.mk srcdist
sha256sum libntlm-1.8-src.tar.gz
As the Magnus Opus or chef-d uvre, let s recreate the full tarball directly from the minimal source-only tarball on Trisquel 11 replace docker.io/kpengboy/trisquel:11.0 with ubuntu:22.04 if you prefer.
podman run -it --rm docker.io/kpengboy/trisquel:11.0
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make wget git ca-certificates
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8-src.tar.gz
tar xfa libntlm-1.8-src.tar.gz
cd libntlm-v1.8
./bootstrap
./configure
make dist
sha256sum libntlm-1.8.tar.gz
Yay! You should now have great confidence in that the release artifacts correspond to what s in version control and also to what the maintainer intended to release. Your remaining job is to audit the source code for vulnerabilities, including the source code of the dependencies used in the build. You no longer have to worry about auditing the release artifacts.
I find it somewhat amusing that the build infrastructure for Libntlm is now in a significantly better place than the code itself. Libntlm is written in old C style with plenty of string manipulation and uses broken cryptographic algorithms such as MD4 and single-DES. Remember folks: solving supply chain security issues has no bearing on what kind of code you eventually run. A clean gun can still shoot you in the foot.
Side note on naming: GitLab exports tarballs with pathnames libntlm-v1.8/ (i.e.., PROJECT-TAG/) and I ve adopted the same pathnames, which means my libntlm-1.8-src.tar.gz tarballs are bit-by-bit identical to GitLab s exports and you can verify this with tools like diffoscope. GitLab name the tarball libntlm-v1.8.tar.gz (i.e., PROJECT-TAG.ARCHIVE) which I find too similar to the libntlm-1.8.tar.gz that we also publish. GitHub uses the same git archive style, but unfortunately they have logic that removes the v in the pathname so you will get a tarball with pathname libntlm-1.8/ instead of libntlm-v1.8/ that GitLab and I use. The content of the tarball is bit-by-bit identical, but the pathname and archive differs. Codeberg (running Forgejo) uses another approach: the tarball is called libntlm-v1.8.tar.gz (after the tag) just like GitLab, but the pathname inside the archive is libntlm/, otherwise the produced archive is bit-by-bit identical including timestamps. Savannah s CGIT interface uses archive name libntlm-1.8.tar.gz with pathname libntlm-1.8/, but otherwise file content is identical. Savannah s GitWeb interface provides snapshot links that are named after the git commit (e.g., libntlm-a812c2ca.tar.gz with libntlm-a812c2ca/) and I cannot find any tag-based download links at all. Overall, we are so close to get SHA256 checksum to match, but fail on pathname within the archive. I ve chosen to be compatible with GitLab regarding the content of tarballs but not on archive naming. From a simplicity point of view, it would be nice if everyone used PROJECT-TAG.ARCHIVE for the archive filename and PROJECT-TAG/ for the pathname within the archive. This aspect will probably need more discussion.
Side note on git archive output: It seems different versions of git archive produce different results for the same repository. The version of git in Debian 11, Trisquel 11 and Ubuntu 22.04 behave the same. The version of git in Debian 12, AlmaLinux/RockyLinux 8/9, Alpine, ArchLinux, macOS homebrew, and upcoming Ubuntu 24.04 behave in another way. Hopefully this will not change that often, but this would invalidate reproducibility of these tarballs in the future, forcing you to use an old git release to reproduce the source-only tarball. Alas, GitLab and most other sites appears to be using modern git so the download tarballs from them would not match my tarballs even though the content would.
Side note on ChangeLog: ChangeLog files were traditionally manually curated files with version history for a package. In recent years, several projects moved to dynamically generate them from git history (using tools like git2cl or gitlog-to-changelog). This has consequences for reproducibility of tarballs: you need to have the entire git history available! The gitlog-to-changelog tool also output different outputs depending on the time zone of the person using it, which arguable is a simple bug that can be fixed. However this entire approach is incompatible with rebuilding the full tarball from the minimal source-only tarball. It seems Libntlm s ChangeLog file died on the surgery table here.
So how would a distribution build these minimal source-only tarballs? I happen to help on the libntlm package in Debian. It has historically used the generated tarballs as the source code to build from. This means that code coming from gnulib is vendored in the tarball. When a security problem is discovered in gnulib code, the security team needs to patch all packages that include that vendored code and rebuild them, instead of merely patching the gnulib package and rebuild all packages that rely on that particular code. To change this, the Debian libntlm package needs to Build-Depends on Debian s gnulib package. But there was one problem: similar to most projects that use gnulib, Libntlm depend on a particular git commit of gnulib, and Debian only ship one commit. There is no coordination about which commit to use. I have adopted gnulib in Debian, and add a git bundle to the *_all.deb binary package so that projects that rely on gnulib can pick whatever commit they need. This allow an no-network GNULIB_URL and GNULIB_REVISION approach when running Libntlm s ./bootstrap with the Debian gnulib package installed. Otherwise libntlm would pick up whatever latest version of gnulib that Debian happened to have in the gnulib package, which is not what the Libntlm maintainer intended to be used, and can lead to all sorts of version mismatches (and consequently security problems) over time. Libntlm in Debian is developed and tested on Salsa and there is continuous integration testing of it as well, thanks to the Salsa CI team.
Side note on git bundles: unfortunately there appears to be no reproducible way to export a git repository into one or more files. So one unfortunate consequence of all this work is that the gnulib *.orig.tar.gz tarball in Debian is not reproducible any more. I have tried to get Git bundles to be reproducible but I never got it to work see my notes in gnulib s debian/README.source on this aspect. Of course, source tarball reproducibility has nothing to do with binary reproducibility of gnulib in Debian itself, fortunately.
One open question is how to deal with the increased build dependencies that is triggered by this approach. Some people are surprised by this but I don t see how to get around it: if you depend on source code for tools in another package to build your package, it is a bad idea to hide that dependency. We ve done it for a long time through vendored code in non-minimal tarballs. Libntlm isn t the most critical project from a bootstrapping perspective, so adding git and gnulib as Build-Depends to it will probably be fine. However, consider if this pattern was used for other packages that uses gnulib such as coreutils, gzip, tar, bison etc (all are using gnulib) then they would all Build-Depends on git and gnulib. Cross-building those packages for a new architecture will therefor require git on that architecture first, which gets circular quick. The dependency on gnulib is real so I don t see that going away, and gnulib is a Architecture:all package. However, the dependency on git is merely a consequence of how the Debian gnulib package chose to make all gnulib git commits available to projects: through a git bundle. There are other ways to do this that doesn t require the git tool to extract the necessary files, but none that I found practical ideas welcome!
Finally some brief notes on how this was implemented. Enabling bootstrappable source-only minimal tarballs via gnulib s ./bootstrap is achieved by using the GNULIB_REVISION mechanism, locking down the gnulib commit used. I have always disliked git submodules because they add extra steps and has complicated interaction with CI/CD. The reason why I gave up git submodules now is because the particular commit to use is not recorded in the git archive output when git submodules is used. So the particular gnulib commit has to be mentioned explicitly in some source code that goes into the git archive tarball. Colin Watson added the GNULIB_REVISION approach to ./bootstrap back in 2018, and now it no longer made sense to continue to use a gnulib git submodule. One alternative is to use ./bootstrap with --gnulib-srcdir or --gnulib-refdir if there is some practical problem with the GNULIB_URL towards a git bundle the GNULIB_REVISION in bootstrap.conf.
The srcdist make rule is simple:
git archive --prefix=libntlm-v1.8/ -o libntlm-v1.8.tar.gz HEAD
Making the make dist generated tarball reproducible can be more complicated, however for Libntlm it was sufficient to make sure the modification times of all files were set deterministically to the timestamp of the last commit in the git repository. Interestingly there seems to be a couple of different ways to accomplish this, Guix doesn t support minimal source-only tarballs but rely on a .tarball-timestamp file inside the tarball. Paul Eggert explained what TZDB is using some time ago. The approach I m using now is fairly similar to the one I suggested over a year ago. If there are problems because all files in the tarball now use the same modification time, there is a solution by Bruno Haible that could be implemented.
Side note on git tags: Some people may wonder why not verify a signed git tag instead of verifying a signed tarball of the git archive. Currently most git repositories uses SHA-1 for git commit identities, but SHA-1 is not a secure hash function. While current SHA-1 attacks can be detected and mitigated, there are fundamental doubts that a git SHA-1 commit identity uniquely refers to the same content that was intended. Verifying a git tag will never offer the same assurance, since a git tag can be moved or re-signed at any time. Verifying a git commit is better but then we need to trust SHA-1. Migrating git to SHA-256 would resolve this aspect, but most hosting sites such as GitLab and GitHub does not support this yet. There are other advantages to using signed tarballs instead of signed git commits or git tags as well, e.g., tar.gz can be a deterministically reproducible persistent stable offline storage format but .git sub-directory trees or git bundles do not offer this property.
Doing continous testing of all this is critical to make sure things don t regress. Libntlm s pipeline definition now produce the generated libntlm-*.tar.gz tarballs and a checksum as a build artifact. Then I added the 000-reproducability job which compares the checksums and fails on mismatches. You can read its delicate output in the job for the v1.8 release. Right now we insists that builds on Trisquel 11 match Ubuntu 22.04, that PureOS 10 builds match Debian 11 builds, that AlmaLinux 8 builds match RockyLinux 8 builds, and AlmaLinux 9 builds match RockyLinux 9 builds. As you can see in pipeline job output, not all platforms lead to the same tarballs, but hopefully this state can be improved over time. There is also partial reproducibility, where the full tarball is reproducible across two distributions but not the minimal tarball, or vice versa.
If this way of working plays out well, I hope to implement it in other projects too.
What do you think? Happy Hacking!
Utkarsh Gupta
did 19.5h (out of 0.0h assigned and 48.75h from previous period), thus carrying over 29.25h to the next month.
Evolution of the situation
In March, we have released 31 DLAs.
Adrian Bunk was responsible for updating gtkwave not only in LTS, but also in unstable, stable, and old-stable as well. This update involved an upload of a new upstream release of gtkwave to each target suite to address 82 separate CVEs. Guilhem Moulin prepared an update of libvirt which was particularly notable, as it fixed multiple vulnerabilities which would lead to denial of service or information disclosure.
In addition to the normal security updates, multiple LTS contributors worked at getting various packages updated in more recent Debian releases, including gross for bullseye/bookworm (by Adrian Bunk), imlib2 for bullseye, jetty9 and tomcat9/10 for bullseye/bookworm (by Markus Koschany), samba for bullseye, py7zr for bullseye (by Santiago Ruano Rinc n), cacti for bullseye/bookwork (by Sylvain Beucler), and libmicrohttpd for bullseye (by Thorsten Alteholz). Additionally, Sylvain actively coordinated with cacti upstream concerning an incomplete fix for CVE-2024-29894.
Thanks to our sponsors
Sponsors that joined recently are in bold.
Contributing to Debian
is part of Freexian s mission. This article
covers the latest achievements of Freexian and their collaborators. All of this
is made possible by organizations subscribing to our
Long Term Support contracts and
consulting services.
P.S. We ve completed over a year of writing these blogs. If you have any
suggestions on how to make them better or what you d like us to cover, or any
other opinions/reviews you might have, et al, please let us know by dropping an
email to us. We d be
happy to hear your thoughts. :)
SSO Authentication for jitsi.debian.social, by Stefano Rivera
Debian.social s jitsi instance has been getting
some abuse by (non-Debian) people sharing sexually explicit content on the
service. After playing whack-a-mole with this for a month, and shutting the
instance off for another month, we opened it up again and the abuse immediately
re-started.
Stefano sat down and wrote an
SSO Implementation
that hooks into Jitsi s existing JWT SSO support. This requires everyone using
jitsi.debian.social to have a Salsa account.
With only a little bit of effort, we could change this in future, to only
require an account to open a room, and allow guests to join the call.
/usr-move, by Helmut Grohne
The biggest task this month was sending mitigation patches for all of the
/usr-move issues arising from package renames due to the 2038 transition. As a
result, we can now say that every affected package in unstable can either be
converted with dh-sequence-movetousr or has an open bug report. The package
set relevant to debootstrap except for the set that has to be uploaded
concurrently has been moved to /usr and is awaiting migration. The move of
coreutils happened to affect piuparts which hard codes the location of
/bin/sync and received multiple updates as a result.
Miscellaneous contributions
Stefano Rivera uploaded a stable release update to python3.11 for bookworm,
fixing a use-after-free crash.
Stefano uploaded a new version of python-html2text, and updated
python3-defaults to build with it.
In support of Python 3.12, Stefano dropped distutils as a Build-Dependency
from a few packages, and uploaded a complex set of patches to python-mitogen.
Stefano landed some merge requests to clean up dead code in dh-python,
removed the flit plugin, and uploaded it.
Stefano uploaded new upstream versions of twisted, hatchling,
python-flexmock, python-authlib, python mitogen, python-pipx, and xonsh.
Stefano requested removal of a few packages supporting the Opsis HDMI2USB
hardware that DebConf Video team used to use for HDMI capture, as they are
not being maintained upstream. They started to FTBFS, with recent sdcc
changes.
DebConf 24 is getting ready to open registration, Stefano spent some time
fixing bugs in the website, caused by infrastructure updates.
Stefano reviewed all the DebConf 23 travel reimbursements, filing requests
for more information from SPI where our records mismatched.
Roberto C. S nchez worked on facilitating the transfer of upstream
maintenance responsibility for the dormant Shorewall project to a new team
led by the current maintainer of the Shorewall packages in Debian.
Colin Watson fixed build failures in celery-haystack-ng, db1-compat,
jsonpickle, libsdl-perl, kali, knews, openssh-ssh1,
python-json-log-formatter, python-typing-extensions, trn4, vigor, and
wcwidth. Some of these were related to the 64-bit time_t transition, since
that involved enabling -Werror=implicit-function-declaration.
Colin fixed an
off-by-one error in neovim,
which was already causing a build failure in Ubuntu and would eventually have
caused a build failure in Debian with stricter toolchain settings.
Colin added an sshd@.service template to
openssh to help newer systemd versions make containers and VMs SSH-accessible
over AF_VSOCK sockets.
Following the xz-utils backdoor, Colin
spent some time testing and discussing OpenSSH upstream s proposed
inline systemd notification patch,
since the current implementation via libsystemd was part of the attack vector
used by that backdoor.
Utkarsh reviewed and sponsored some Go packages for Lena Voytek and Rajudev.
Utkarsh also helped Mitchell Dzurick with the adoption of pyparted package.
Helmut sent 10 patches for cross build failures.
Helmut partially fixed architecture cross bootstrap tooling to deal with
changes in linux-libc-dev and the recent gcc-for-host changes and also
fixed a 64bit-time_t FTBFS in libtextwrap.
Thorsten Alteholz uploaded several packages from debian-printing: cjet,
lprng, rlpr and epson-inkjet-printer-escpr were affected by the newly enabled
compiler switch -Werror=implicit-function-declaration. Besides fixing these
serious bugs, Thorsten also worked on other bugs and could fix one or the
other.
Carles updated simplemonitor and python-ring-doorbell packages with new
upstream versions.
Santiago also reviewed applications for the
improving Salsa CI in Debian
GSoC 2024 project. We received applications from four very talented
candidates. The selection process is currently ongoing. A huge thanks to all
of them!
As part of the DebConf 24 organization, Santiago has taken part in the
Content team discussions.
I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to Openreach FTTP, provided by Aquiss, but I worry about what happens if there s a cable cut somewhere or some other long lasting problem. Worst case I could tether to my work phone, or try to find some local coworking space to use while things get sorted, but I felt like arranging a backup option was a wise move.
Step 1 turned out to be sorting out recursive DNS. It s been many moons since I had to deal with running DNS in a production setting, and I ve mostly done my best to avoid doing it at home too. dnsmasq has done a decent job at providing for my needs over the years, covering DHCP, DNS (+ tftp for my test device network). However I just let it forward to my ISP s nameservers, which means if that link goes down it ll no longer be able to resolve anything outside the house.
One option would have been to either point to a different recursive DNS server (Cloudfare s 1.1.1.1 or Google s Public DNS being the common choices), but I ve no desire to share my lookup information with them. As another approach I could have done some sort of failover of resolv.conf when the primary network went down, but then I would have to get into moving files around based on networking status and that felt a bit clunky.
So I decided to finally setup a proper local recursive DNS server, which is something I ve kinda meant to do for a while but never had sufficient reason to look into. Last time I did this I did it with BIND 9 but there are more options these days, and I decided to go with unbound, which is primarily focused on recursive DNS.
One extra wrinkle, pointed out by Lars, is that having dynamic name information from DHCP hosts is exceptionally convenient. I ve kept dnsmasq as the local DHCP server, so I wanted to be able to forward local queries there.
I m doing all of this on my RB5009, running Debian. Installing unbound was a simple matter of apt install unbound. I needed 2 pieces of configuration over the default, one to enable recursive serving for the house networks, and one to enable forwarding of queries for the local domain to dnsmasq. I originally had specified the wildcard address for listening, but this caused problems with the fact my router has many interfaces and would sometimes respond from a different address than the request had come in on.
/etc/unbound/unbound.conf.d/network-resolver.conf
server:
domain-insecure: "example.org"
do-not-query-localhost: no
forward-zone:
name: "example.org"
forward-addr: 127.0.0.1@5353
I then had to configure dnsmasq to not listen on port 53 (so unbound could), respond to requests on the loopback interface (I have dnsmasq restricted to only explicitly listed interfaces), and to hand out unbound as the appropriate nameserver in DHCP requests - once dnsmasq is not listening on port 53 it no longer does this by default.
/etc/dnsmasq.d/behind-unbound
With these minor changes in place I now have local recursive DNS being handled by unbound, without losing dynamic local DNS for DHCP hosts. As an added bonus I now get 10/10 on Test IPv6 - previously I was getting dinged on the ability for my DNS server to resolve purely IPv6 reachable addresses.
Next step, actually sorting out a backup link.
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I d share it as a tale of how huh, that s weird can be a powerful threat-hunting tool but only if you ve got the time to keep pulling at the thread.
Prelude to an Adventure
Our story begins back in March 2008.
I was working at Engine Yard (EY), a now largely-forgotten Rails-focused hosting company, which pioneered several advances in Rails application deployment.
Probably EY s greatest claim to lasting fame is that they helped launch a little code hosting platform you might have heard of, by providing them free infrastructure when they were little more than a glimmer in the Internet s eye.
I am, of course, talking about everyone s favourite Microsoft product: GitHub.
Since GitHub was in the right place, at the right time, with a compelling product offering, they quickly started to gain traction, and grow their userbase.
With growth comes challenges, amongst them the one we re focusing on today: SSH login times.
Then, as now, GitHub provided SSH access to the git repos they hosted, by SSHing to git@github.com with publickey authentication.
They were using the standard way that everyone manages SSH keys: the ~/.ssh/authorized_keys file, and that became a problem as the number of keys started to grow.
The way that SSH uses this file is that, when a user connects and asks for publickey authentication, SSH opens the ~/.ssh/authorized_keys file and scans all of the keys listed in it, looking for a key which matches the key that the user presented.
This linear search is normally not a huge problem, because nobody in their right mind puts more than a few keys in their ~/.ssh/authorized_keys, right?
Of course, as a popular, rapidly-growing service, GitHub was gaining users at a fair clip, to the point that the one big file that stored all the SSH keys was starting to visibly impact SSH login times.
This problem was also not going to get any better by itself.
Something Had To Be Done.
EY management was keen on making sure GitHub ran well, and so despite it not really being a hosting problem, they were willing to help fix this problem.
For some reason, the late, great, Ezra Zygmuntowitz pointed GitHub in my direction, and let me take the time to really get into the problem with the GitHub team.
After examining a variety of different possible solutions, we came to the conclusion that the least-worst option was to patch OpenSSH to lookup keys in a MySQL database, indexed on the key fingerprint.
We didn t take this decision on a whim it wasn t a case of yeah, sure, let s just hack around with OpenSSH, what could possibly go wrong? .
We knew it was potentially catastrophic if things went sideways, so you can imagine how much worse the other options available were.
Ensuring that this wouldn t compromise security was a lot of the effort that went into the change.
In the end, though, we rolled it out in early April, and lo! SSH logins were fast, and we were pretty sure we wouldn t have to worry about this problem for a long time to come.
Normally, you d think patching OpenSSH to make mass SSH logins super fast would be a good story on its own.
But no, this is just the opening scene.
Chekov s Gun Makes its Appearance
Fast forward a little under a month, to the first few days of May 2008.
I get a message from one of the GitHub team, saying that somehow users were able to access other users repos over SSH.
Naturally, as we d recently rolled out the OpenSSH patch, which touched this very thing, the code I d written was suspect number one, so I was called in to help.
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
Eventually, after more than a little debugging, we discovered that, somehow, there were two users with keys that had the same key fingerprint.
This absolutely shouldn t happen it s a bit like winning the lottery twice in a row1 unless the users had somehow shared their keys with each other, of course.
Still, it was worth investigating, just in case it was a web application bug, so the GitHub team reached out to the users impacted, to try and figure out what was going on.
The users professed no knowledge of each other, neither admitted to publicising their key, and couldn t offer any explanation as to how the other person could possibly have gotten their key.
Then things went from weird to what the ? .
Because another pair of users showed up, sharing a key fingerprint but it was a different shared key fingerprint.
The odds now have gone from winning the lottery multiple times in a row to as close to this literally cannot happen as makes no difference.
Once we were really, really confident that the OpenSSH patch wasn t the cause of the problem, my involvement in the problem basically ended.
I wasn t a GitHub employee, and EY had plenty of other customers who needed my help, so I wasn t able to stay deeply involved in the on-going investigation of The Mystery of the Duplicate Keys.
However, the GitHub team did keep talking to the users involved, and managed to determine the only apparent common factor was that all the users claimed to be using Debian or Ubuntu systems, which was where their SSH keys would have been generated.
That was as far as the investigation had really gotten, when along came May 13, 2008.
Chekov s Gun Goes Off
With the publication of DSA-1571-1, everything suddenly became clear.
Through a well-meaning but ultimately disasterous cleanup of OpenSSL s randomness generation code, the Debian maintainer had inadvertently reduced the number of possible keys that could be generated by a given user from bazillions to a little over 32,000.
With so many people signing up to GitHub some of them no doubt following best practice and freshly generating a separate key it s unsurprising that some collisions occurred.
You can imagine the sense of oooooooh, so that s what s going on! that rippled out once the issue was understood.
I was mostly glad that we had conclusive evidence that my OpenSSH patch wasn t at fault, little knowing how much more contact I was to have with Debian weak keys in the future, running a huge store of known-compromised keys and using them to find misbehaving Certificate Authorities, amongst other things.
Lessons Learned
While I ve not found a description of exactly when and how Luciano Bello discovered the vulnerability that became CVE-2008-0166, I presume he first came across it some time before it was disclosed likely before GitHub tripped over it.
The stable Debian release that included the vulnerable code had been released a year earlier, so there was plenty of time for Luciano to have discovered key collisions and go hmm, I wonder what s going on here? , then keep digging until the solution presented itself.
The thought hmm, that s odd , followed by intense investigation, leading to the discovery of a major flaw is also what ultimately brought down the recent XZ backdoor.
The critical part of that sequence is the ability to do that intense investigation, though.
When I reflect on my brush with the Debian weak keys vulnerability, what sticks out to me is the fact that I didn t do the deep investigation.
I wonder if Luciano hadn t found it, how long it might have been before it was found.
The GitHub team would have continued investigating, presumably, and perhaps they (or I) would have eventually dug deep enough to find it.
But we were all super busy myself, working support tickets at EY, and GitHub feverishly building features and fighting the fires in their rapidly-growing service.
As it was, Luciano was able to take the time to dig in and find out what was happening, but just like the XZ backdoor, I feel like we, as an industry, got a bit lucky that someone with the skills, time, and energy was on hand at the right time to make a huge difference.
It s a luxury to be able to take the time to really dig into a problem, and it s a luxury that most of us rarely have.
Perhaps an understated takeaway is that somehow we all need to wrestle back some time to follow our hunches and really dig into the things that make us go hmm .
Support My Hunches
If you d like to help me be able to do intense investigations of mysterious software phenomena, you can shout me a refreshing beverage on ko-fi.
the odds are actually probably more like winning the lottery about twenty times in a row.
The numbers involved are staggeringly huge, so it s easiest to just approximate it as really, really unlikely .
FTP master
This month I accepted 147 and rejected 12 packages. The overall number of packages that got accepted was 151.
If you file an RM bug, please do check whether there are reverse dependencies as well and file RM bugs for them. It is annoying and time-consuming when I have to do the moreinfo dance.
Debian LTS
This was my hundred-seventeenth month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian.
During my allocated time I uploaded:
[DLA 3770-1] libnet-cidr-lite-perl security update for one CVE to fix IP parsing and ACLs based on the result
Unfortunately XZ happened at the end of month and I had to delay/intentionally delayed other uploads: they will appear as DLA-3781-1 and DLA-3784-1 in April
I also continued to work on qtbase-opensource-src and last but not least did a week of FD.
Debian ELTS
This month was the sixty-eighth ELTS month. During my allocated time I uploaded:
[ELA-1062-1]libnet-cidr-lite-perl security update for one CVE to improve parsing of IP addresses in Jessie and Stretch
Due to XZ I also delayed the uploads here. They will appear as ELA-1069-1 and DLA-1070-1 in April
I also continued on an update for qtbase-opensource-src in Stretch (and LTS and other releases as well) and did a week of FD.
Debian Printing
This month I uploaded new upstream or bugfix versions of:
The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The DPL is the official representative of representative of The Debian Project tasked with managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last Bits from the DPL
post to Debian recently and his hopes for the future of Debian.
Recently, we sat with the two present candidates for the DPL position asking
questions to find out who they really are in a series of interviews about
their platforms, visions for Debian, lives, and even their favorite text
editors. The interviews were conducted by disaster2life (Yashraj Moghe) and
made available from video and audio transcriptions:
Voting for the position starts on April 6, 2024.
Editors' note:
This is our official return to Debian interviews, readers should stay tuned
for more upcoming interviews with Developers and other important figures in
Debian as part of our "Meet your Debian Developer" series. We used the
following tools and services: Turboscribe.ai for the
transcription from the audio and video files, IRC: Oftc.net for
communication, Jitsi meet for interviews, and
Open Broadcaster Software (OBS) for editing and
video. While we encountered many technical difficulties in the return to this
process, we are still able and proud to present the transcripts of the
interviews edited only in a few areas for readability.
2024 Debian Project Leader Candidate: Sruthi Chandran
Sruthi's interview
Hi Sruthi, so for the first question, who are you and could you tell us a little
bit about yourself?
[Sruthi]:
I usually talk about me whenever I am talking about answering the question who
am I, I usually say like I am a librarian turned free software enthusiast and
a Debian Developer. So I had no technical background and I learned, I was
introduced to free software through my husband and then I learned Debian
packaging, and eventually I became a Debian Developer. So I always give my
example to people who say I am not technically inclined, I don't have technical
background so I can't contribute to free software.
So yeah, that's what I refer to myself.
For the next question, could you tell me what do you do in Debian, and could
you mention your story up until here today?
[Sruthi]:
Okay, so let me start from my initial days in Debian. I started contributing to
Debian, my first contribution was a Tibetan font. We went to a Tibetan place
and they were saying they didn't have a font in Linux.
So that's how I started contributing. Then I moved on to Ruby packages, then I
have some JavaScript and Go packages, all dependencies of GitLab. So I was
involved with maintaining GitLab for some time, now I'm not very active there.
But yeah, so GitLab was the main package I was contributing to since I
contributed since 2016 to maybe like 2020 or something. Later I have come
[over to] packaging. Now I am part of some of the teams, delegated teams, like
community team and outreach team, as well as the Debconf committee. And the
biggest, I think, my activity in Debian, I would say is organizing Debconf
2023. So it was a great experience and yeah, so that's my story in Debian.
So what are three key terms about you and your candidacy?
[Sruthi]:
Okay, let me first think about it. For candidacy, I can start with diversity is
one point I started expressing from the first time I contested for DPL. But to
be honest, that's the main point I want to bring.
[Yashraj]:
So for diversity, if you could break down your thoughts on diversity and make
them, [about] your three points including diversity.
[Sruthi]:
So in addition to, eventually when starting it was just diversity. Now I have
like a bit more ideas, like community, like I want to be a leader for the
Debian community. More than, I don't know, maybe people may not agree, but I
would say I want to be a leader of Debian community rather than a Debian operating system.
I connect to community more and third point I would say.
The term of a DPL lasts for an year. So what do you think during, what would you
try to do during that, that you can't do from your position now?
[Sruthi]:
Okay. So I, like, I am very happy with the structure of Debian and how things
work in Debian. Like you can do almost a lot of things, like almost all things
without being a DPL.
Whatever change you want to bring about or whatever you want to do, you can do
without being a DPL. Anyone, like every DD has the same rights. Only things I
feel [the] DPL has hold on are mainly the budget or the funding part, which like,
that's where they do the decision making part.
And then comes like, and one advantage of DPL driving some idea is that somehow
people tend to listen to that with more, like, tend to give more attention to
what DPL is saying rather than a normal DD. So I wanted to, like, I have
answered some of the questions on how to, how I plan to do the financial
budgeting part, how I want to handle, like, and the other thing is using the
extra attention that I get as a DPL, I would like to obviously start with the
diversity aspect in Debian. And yeah, like, I, what I want to do is not, like,
be a leader and say, like, take Debian to one direction where I want to go, but
I would rather take suggestions and inputs from the whole community and go about
with that.
So yes, that's what I would say.
And taking a less serious question now, what is your preferred text editor?
[Sruthi]:
Vim.
[Yashraj]:
Vim, wholeheartedly team Vim?
[Sruthi]:
Yes.
[Yashraj]:
Great. Well, this was made in Vim, all the text for this.
[Sruthi]:
So, like, since you mentioned extra data, I'll give my example, like, it's just
a fun note, when I started contributing to Debian, as I mentioned, I didn't have
any knowledge about free software, like Debian, and I was not used to even
using Linux. So, and I didn't have experience with these text editors. So, when
I started contributing, I used to do the editing part using gedit.
So, that's how I started. Eventually, I moved to Nano, and once I reached Vim,
I didn't move on.
Team Vim. Next question. What, what do you think is the importance of
the Debian project in the world today? And where would you like to see it in
10 years, like 10 years into the future?
[Sruthi]:
Okay. So, Debian, as we all know, is referred to as the universal operating
system without, like, it is said for a reason. We have hundreds and hundreds of
operating systems, like Linux, distributions based on Debian.
So, I believe Debian, like even now, Debian has good influence on the, at least
on the Linux or Linux ecosystem. So, what we implement in Debian has, like, is
going to affect quite a lot of, like, a very good percentage of people using
Linux. So, yes.
So, I think Debian is one of the leading Linux distributions. And I think in
10 years, we should be able to reach a position, like, where we are not, like,
even now, like, even these many years after having Linux, we face a lot of
problems in newer and newer hardware coming up and installing on them is a big
problem. Like, firmwares and all those things are getting more and more
complicated.
Like, it should be getting simpler, but it's getting more and more complicated.
So, I, one thing I would imagine, like, I don't know if we will ever reach
there, but I would imagine that eventually with the Debian, we should be able
to have some, at least a few of the hardware developers or hardware producers
have Debian pre-installed and those kind of things. Like, not, like, become,
I'm not saying it's all, it's also available right now.
What I'm saying is that it becomes prominent enough to be opted as, like, default
distro.
What part of Debian has made you And what part of the project has kept you going
all through these years?
[Sruthi]:
Okay. So, I started to contribute in 2016, and I was part of the team doing
GitLab packaging, and we did have a lot of training workshops and those kind of
things within India. And I was, like, I had interacted with some of the Indian
DDs, but I never got, like, even through chat or mail.
I didn't have a lot of interaction with the rest of the world, DDs. And the 2019
Debconf changed my whole perspective about Debian. Before that, I wasn't, like,
even, I was interested in free software.
I was doing the technical stuff and all. But after DebConf, my whole idea has
been, like, my focus changed to the community. Debian community is a very
welcoming, very interesting community to be with.
And so, I believe that, like, 2019 DebConf was a for me. And that kept, from
2019, my focus has been to how to support, like, how, I moved to the community
part of Debian from there. Then in 2020 I became part of the community team,
and, like, I started being part of other teams.
So, these, I would say, the Debian community is the one, like, aspect of Debian
that keeps me whole, keeps me held on to the Debian ecosystem as a whole.
Continuing to speak about Debian, what do you think, what is the first thing that
comes to your mind when you think of Debian, like, the word, the community,
what's the first thing?
[Sruthi]:
I think I may sound like a broken record or something.
[Yashraj]:
No, no.
[Sruthi]:
Again, I would say the Debian community, like, it's the people who makes
Debian, that makes Debian special.
Like, apart from that, if I say, I would say I'm very, like, one part of Debian
that makes me very happy is the, how the governing system of Debian works, the
Debian constitution and all those things, like, it's a very unique thing for
Debian. And, and it's like, when people say you can't work without a proper,
like, establishment or even somebody deciding everything for you, it's
difficult. When people say, like, we have been, Debian has been proving
it for quite a long time now, that it's possible.
So, so that's one thing I believe, like, that's one unique point. And I am very
proud about that.
What areas do you think Debian is failing in, how can it (that standing) be improved?
[Sruthi]:
So, I think where Debian is failing now is getting new people into Debian.
Like, I don't remember, like, exactly the answer. But I remember hearing
someone mention, like, the average age of a Debian Developer is, like, above 40
or 45 or something, like, exact age, I don't remember.
But it's like, Debian is getting old. Like, the people in Debian are getting old
and we are not getting enough of new people into Debian. And that's very
important to have people, like, new people coming up.
Otherwise, eventually, like, after a few years, nobody, like, we won't have
enough people to take the project forward. So, yeah, I believe that is where we
need to work on. We are doing some efforts, like, being part of GSOC or
outreachy and having maybe other events, like, local events. Like, we used to
have a lot of Debian packaging workshops in India. And those kind of, I think,
in Brazil and all, they all have, like, local communities are doing. But we are
not very successful in retaining the people who maybe come and try out things.
But we are not very good at retaining the people, like, retaining people who
come. So, we need to work on those things. Right now, I don't have a solid
answer for that.
But one thing, like, I was thinking about is, like, having a Debian specific
outreach project, wherein the focus will be about the Debian, like, starting
will be more on, like, usually what happens in GSOC and outreach is that people
come, have the, do the contributions, and they go back. Like, they don't have
that connection with the Debian, like, Debian community or Debian project. So,
what I envision with these, the Debian outreach, the Debian specific outreach
is that we have some part of the internship, like, even before starting the
internship, we have some sessions and, like, with the people in Debian having,
like, getting them introduced to the Debian philosophy and Debian community and
Debian, how Debian works.
And those things, we focus on that. And then we move on to the technical
internship parts. So, I believe this could do some good in having, like, when
you have people you can connect to, you tend to stay back in a project mode.
When you feel something more than, like, right now, we have so many technical
stuff to do, like, the choice for a college student is endless. So, if they
want, if they stay back for something, like, maybe for Debian, I would say, we
need to have them connected to the Debian project before we go into technical
parts. Like, technical parts, like, there are other things as well, where they
can go and do the technical part, but, like, they can come here, like, yeah.
So, that's what I was saying. Focused outreach projects is one thing. That's
just one.
That's not enough. We need more of, like, more ideas to have more new people
come up. And I'm very happy with, like, the DebConf thing. We tend to get more
and more people from the places where we have a DebConf. Brazil is an example.
After the Debconf, they have quite a good improvement on Debian contributors.
And I think in India also, it did give a good result. Like, we have more people
contributing and staying back and those things. So, yeah.
So, these were the things I would say, like, we can do to improve.
For the final question, what field in free software do you, what
field in free software generally do you think requires the most work to be
put into it? What do you think is Debian's part in that field?
[Sruthi]:
Okay. Like, right now, what comes to my mind is the free software licenses
parts. Like, we have a lot of free software licenses, and there are non-free
software licenses.
But currently, I feel free software is having a big problem in enforcing these
licenses. Like, there are, there may be big corporations or like some people who
take up the whole, the code and may not follow the whole, for example, the GPL
licenses. Like, we don't know how much of those, how much of the free softwares
are used in the bigger things.
Yeah, I agree. There are a lot of corporations who are afraid to touch free
software. But there would be good amount of free software, free work that
converts into property, things violating the free software licenses and those
things.
And we do not have the kind of like, we have SFLC, SFC, etc. But still, we do
not have the ability to go behind and trace and implement the licenses. So,
enforce those licenses and bring people who are violating the licenses forward
and those kind of things is challenging because one thing is it takes time,
like, and most importantly, money is required for the legal stuff.
And not always people who like people who make small software, or maybe big,
but they may not have the kind of time and money to have these things enforced.
So, that's a big challenge free software is facing, especially in our current
scenario. I feel we are having those, like, we need to find ways how we can get
it sorted.
I don't have an answer right now what to do. But this is a challenge I felt
like and Debian's part in that. Yeah, as I said, I don't have a solution for
that.
But the Debian, so DFSG and Debian sticking on to the free software licenses is
a good support, I think.
So, that was the final question, Do you have anything else you want to mention
for anyone watching this?
[Sruthi]:
Not really, like, I am happy, like, I think I was able to answer the questions.
And yeah, I would say who is watching. I won't say like, I'm the best DPL
candidate, you can't have a better one or something.
I stand for a reason. And if you believe in that, or the Debian community and
Debian diversity, and those kinds of things, if you believe it, I hope you
would be interested, like, you would want to vote for me. That's it.
Like, I'm not, I'll make it very clear. I'm not doing a technical leadership
part here. So, those, I can't convince people who want technical leadership to
vote for me.
But I would say people who connect with me, I hope they vote for me.
New netplan status diff subcommand, finding differences between configuration and system state
As the maintainer and lead developer for Netplan, I m proud to announce the general availability of Netplan v1.0 after more than 7 years of development efforts. Over the years, we ve so far had about 80 individual contributors from around the globe. This includes many contributions from our Netplan core-team at Canonical, but also from other big corporations such as Microsoft or Deutsche Telekom. Those contributions, along with the many we receive from our community of individual contributors, solidify Netplan as a healthy and trusted open source project. In an effort to make Netplan even more dependable, we started shipping upstream patch releases, such as 0.106.1 and 0.107.1, which make it easier to integrate fixes into our users custom workflows.
With the release of version 1.0 we primarily focused on stability. However, being a major version upgrade, it allowed us to drop some long-standing legacy code from the libnetplan1 library. Removing this technical debt increases the maintainability of Netplan s codebase going forward. The upcoming Ubuntu 24.04 LTS and Debian 13 releases will ship Netplan v1.0 to millions of users worldwide.
Highlights of version 1.0
In addition to stability and maintainability improvements, it s worth looking at some of the new features that were included in the latest release:
Simultaneous WPA2 & WPA3 support.
Introduction of a stable libnetplan1 API.
Mellanox VF-LAG support for high performance SR-IOV networking.
New hairpin and port-mac-learning settings, useful for VXLAN tunnels with FRRouting.
New netplan status diff subcommand, finding differences between configuration and system state.
Besides those highlights of the v1.0 release, I d also like to shed some light on new functionality that was integrated within the past two years for those upgrading from the previous Ubuntu 22.04 LTS which used Netplan v0.104:
We added support for the management of new network interface types, such as veth, dummy, VXLAN, VRF or InfiniBand (IPoIB).
Wireless functionality was improved by integrating Netplan with NetworkManager on desktop systems, adding support for WPA3 and adding the notion of a regulatory-domain, to choose proper frequencies for specific regions.
To improve maintainability, we moved to Meson as Netplan s buildsystem, added upstream CI coverage for multiple Linux distributions and integrations (such as Debian testing, NetworkManager, snapd or cloud-init), checks for ABI compatibility, and automatic memory leak detection.
We increased consistency between the supported backend renderers (systemd-networkd and NetworkManager), by matching physical network interfaces on permanent MAC address, when the match.macaddress setting is being used, and added new hardware offloading functionality for high performance networking, such as Single-Root IO Virtualisation virtual function link-aggregation (SR-IOV VF-LAG).
The much improved Netplan documentation, that is now hosted on Read the Docs , and new command line subcommands, such as netplan status, make Netplan a well vested tool for declarative network management and troubleshooting.
Integrations
Those changes pave the way to integrate Netplan in 3rd party projects, such as system installers or cloud deployment methods. By shipping the new python3-netplan Python bindings to libnetplan, it is now easier than ever to access Netplan functionality and network validation from other projects. We are proud that the Debian Cloud Team chose Netplan to be the default network management tool in their official cloud-images for Debian Bookworm and beyond. Ubuntu s NetworkManager package now uses Netplan as it s default backend on Ubuntu 23.10 Desktop systems and beyond. Further integrations happened with cloud-init and the Calamares installer.
Please check out the Netplan version 1.0 release on GitHub! If you want to learn more, follow our activities on Netplan.io, GitHub, Launchpad, IRC or our Netplan Developer Diaries blog on discourse.
The twentyfirst release of littler as a
CRAN package
landed on CRAN just now, following in the now eighteen year history (!!)
as a package started by Jeff in 2006, and joined
by me a few weeks later.
littler
is the first command-line interface for R as it predates
Rscript. It allows for piping as well for shebang
scripting via #!, uses command-line arguments more
consistently and still starts
faster. It also always loaded the methods package which
Rscript only began to do in recent years.
littler
lives on Linux and Unix, has its difficulties on macOS due to
yet-another-braindeadedness there (who ever thought case-insensitive
filesystems as a default were a good idea?) and simply does not exist on
Windows (yet the build system could be extended see RInside for
an existence proof, and volunteers are welcome!). See the FAQ
vignette on how to add it to your PATH. A few examples
are highlighted at the Github repo:, as well
as in the examples
vignette.
This release contains another fair number of small changes and
improvements to some of the scripts I use daily to build or test
packages, adds a new front-end ciw.r for the
recently-released ciw package
offering a CRAN Incoming Watcher , a new helper
installDeps2.r (extending installDeps.r), a
new doi-to-bib converter, allows a different temporary directory setup I
find helpful, deals with one corner deployment use, and more.
The full change description follows.
Changes in littler
version 0.3.20 (2024-03-23)
Changes in examples scripts
New (dependency-free) helper installDeps2.r to
install dependencies
Scripts rcc.r, tt.r,
tttf.r, tttlr.r use env argument
-S to set -t to r
tt.r can now fill in inst/tinytest if
it is present
New script ciw.r wrapping new package ciw
tttf.t can now use devtools
and its loadall
New script doi2bib.r to call the DOI converter REST
service (following a skeet by Richard McElreath)
Changes in package
The CI setup uses checkout@v4 and the r-ci-setup action
The Suggests: is a little tighter as we do not list all packages
optionally used in the the examples (as R does not check for it
either)
The package load messag can account for the rare build of R under
different architecture (Berwin Turlach in #117 closing
#116)
In non-vanilla mode, the temporary directory initialization in
re-run allowing for a non-standard temp dir via config settings
My CRANberries
service provides a comparison to the
previous release. Full details for the littler
release are provided as usual at the ChangeLog
page, and also on the package docs website.
The code is available via the GitHub repo, from
tarballs and now of course also from its CRAN page and
via install.packages("littler"). Binary packages are
available directly in Debian as
well as (in a day or two) Ubuntu binaries at
CRAN thanks to the tireless Michael Rutter.
Comments and suggestions are welcome at the GitHub repo.
If you like this or other open-source work I do, you can sponsor me at
GitHub.
Closing arguments in the trial between various people and Craig Wright over whether he's Satoshi Nakamoto are wrapping up today, amongst a bewildering array of presented evidence. But one utterly astonishing aspect of this lawsuit is that expert witnesses for both sides agreed that much of the digital evidence provided by Craig Wright was unreliable in one way or another, generally including indications that it wasn't produced at the point in time it claimed to be. And it's fascinating reading through the subtle (and, in some cases, not so subtle) ways that that's revealed.
One of the pieces of evidence entered is screenshots of data from Mind Your Own Business, a business management product that's been around for some time. Craig Wright relied on screenshots of various entries from this product to support his claims around having controlled meaningful number of bitcoin before he was publicly linked to being Satoshi. If these were authentic then they'd be strong evidence linking him to the mining of coins before Bitcoin's public availability. Unfortunately the screenshots themselves weren't contemporary - the metadata shows them being created in 2020. This wouldn't fundamentally be a problem (it's entirely reasonable to create new screenshots of old material), as long as it's possible to establish that the material shown in the screenshots was created at that point. Sadly, well.
One part of the disclosed information was an email that contained a zip file that contained a raw database in the format used by MYOB. Importing that into the tool allowed an audit record to be extracted - this record showed that the relevant entries had been added to the database in 2020, shortly before the screenshots were created. This was, obviously, not strong evidence that Craig had held Bitcoin in 2009. This evidence was reported, and was responded to with a couple of additional databases that had an audit trail that was consistent with the dates in the records in question. Well, partially. The audit record included session data, showing an administrator logging into the data base in 2011 and then, uh, logging out in 2023, which is rather more consistent with someone changing their system clock to 2011 to create an entry, and switching it back to present day before logging out. In addition, the audit log included fields that didn't exist in versions of the product released before 2016, strongly suggesting that the entries dated 2009-2011 were created in software released after 2016. And even worse, the order of insertions into the database didn't line up with calendar time - an entry dated before another entry may appear in the database afterwards, indicating that it was created later. But even more obvious? The database schema used for these old entries corresponded to a version of the software released in 2023.
This is all consistent with the idea that these records were created after the fact and backdated to 2009-2011, and that after this evidence was made available further evidence was created and backdated to obfuscate that. In an unusual turn of events, during the trial Craig Wright introduced further evidence in the form of a chain of emails to his former lawyers that indicated he had provided them with login details to his MYOB instance in 2019 - before the metadata associated with the screenshots. The implication isn't entirely clear, but it suggests that either they had an opportunity to examine this data before the metadata suggests it was created, or that they faked the data? So, well, the obvious thing happened, and his former lawyers were asked whether they received these emails. The chain consisted of three emails, two of which they confirmed they'd received. And they received a third email in the chain, but it was different to the one entered in evidence. And, uh, weirdly, they'd received a copy of the email that was submitted - but they'd received it a few days earlier. In 2024.
And again, the forensic evidence is helpful here! It turns out that the email client used associates a timestamp with any attachments, which in this case included an image in the email footer - and the mysterious time travelling email had a timestamp in 2024, not 2019. This was created by the client, so was consistent with the email having been sent in 2024, not being sent in 2019 and somehow getting stuck somewhere before delivery. The date header indicates 2019, as do encoded timestamps in the MIME headers - consistent with the mail being sent by a computer with the clock set to 2019.
But there's a very weird difference between the copy of the email that was submitted in evidence and the copy that was located afterwards! The first included a header inserted by gmail that included a 2019 timestamp, while the latter had a 2024 timestamp. Is there a way to determine which of these could be the truth? It turns out there is! The format of that header changed in 2022, and the version in the email is the new version. The version with the 2019 timestamp is anachronistic - the format simply doesn't match the header that gmail would have introduced in 2019, suggesting that an email sent in 2022 or later was modified to include a timestamp of 2019.
This is by no means the only indication that Craig Wright's evidence may be misleading (there's the whole argument that the Bitcoin white paper was written in LaTeX when general consensus is that it's written in OpenOffice, given that's what the metadata claims), but it's a lovely example of a more general issue.
Our technology chains are complicated. So many moving parts end up influencing the content of the data we generate, and those parts develop over time. It's fantastically difficult to generate an artifact now that precisely corresponds to how it would look in the past, even if we go to the effort of installing an old OS on an old PC and setting the clock appropriately (are you sure you're going to be able to mimic an entirely period appropriate patch level?). Even the version of the font you use in a document may indicate it's anachronistic. I'm pretty good at computers and I no longer have any belief I could fake an old document.
(References: this Dropbox, under "Expert reports", "Patrick Madden". Initial MYOB data is in "Appendix PM7", further analysis is in "Appendix PM42", email analysis is "Sixth Expert Report of Mr Patrick Madden")
Utkarsh Gupta
did 11.25h (out of 26.75h assigned and 33.25h from previous period), thus carrying over 48.75 to the next month.
Evolution of the situation
In February, we have released 17 DLAs.
The number of DLAs published during February was a bit lower than usual, as there was much work going on in the area of triaging CVEs (a number of which turned out to not affect Debia buster, and others which ended up being duplicates, or otherwise determined to be invalid). Of the packages which did receive updates, notable were sudo (to fix a privilege management issue), and iwd and wpa (both of which suffered from authentication bypass vulnerabilities).
While this has already been already announced in the Freexian blog, we would like to mention here the start of the Long Term Support project for Samba 4.17. You can find all the important details in that post, but we would like to highlight that it is thanks to our LTS sponsors that we are able to fund the work from our partner, Catalyst, towards improving the security support of Samba in Debian 12 (Bookworm).
Thanks to our sponsors
Sponsors that joined recently are in bold.
/usr-move, by Helmut Grohne
Much of the work was spent on handling interaction with time time64 transition
and sending patches for mitigating fallout. The set of packages relevant to
debootstrap is mostly converted and the patches for glibc and base-files
have been refined due to feedback from the upload to Ubuntu noble. Beyond this,
he sent patches for all remaining packages that cannot move their files with
dh-sequence-movetousr and packages using dpkg-divert in ways that dumat
would not recognize.
Upcoming improvements to Salsa CI, by Santiago Ruano Rinc n
Last month, Santiago Ruano Rinc n started the work on integrating sbuild into
the Salsa CI pipeline. Initially, Santiago used sbuild with the unshare
chroot mode. However, after discussion with josch, jochensp and helmut (thanks
to them!), it turns out that the unshare mode is not the most suitable for the
pipeline, since the level of isolation it provides is not needed, and some test
suites would fail (eg: krb5). Additionally, one of the requirements of the
build job is the use of ccache, since it is needed by some C/C++ large projects
to reduce the compilation time. In the preliminary work with unshare last
month, it was not possible to make ccache to work.
Finally, Santiago changed the chroot mode, and now has a couple of POC (cf:
1
and 2)
that rely on the schroot and sudo, respectively. And the good news is that
ccache is successfully used by sbuild with schroot!
The image here comes from an example of building grep. At the end of the
build, ccache -s shows the statistics of the cache that it used, and so a
little more than half of the calls of that job were cacheable. The most
important pieces are in place to finish the integration of sbuild into the
pipeline.
Other than that, Santiago also reviewed the very useful
merge request !346,
made by IOhannes zm lnig to autodetect the release from debian/changelog. As
agreed with IOhannes, Santiago is preparing a merge request to include the
release autodetection use case in the very own Salsa CI s CI.
Packaging simplemonitor, by Carles Pina i Estany
Carles started using simplemonitor in
2017, opened a
WNPP bug in 2022
and started packaging simplemonitor dependencies in October 2023. After
packaging five direct and indirect dependencies, Carles finally uploaded
simplemonitor to unstable in February.
During the packaging of simplemonitor, Carles reported
a few issues
to upstream. Some of these were to make the simplemonitor package build and run
tests reproducibly. A reproducibility issue was reprotest overriding the
timezone, which broke simplemonitor s tests. There have been discussions on
resolving this upstream in simplemonitor and
in reprotest,
too.
Carles also started upgrading or improving some of simplemonitor s dependencies.
Miscellaneous contributions
Stefano Rivera spent some time doing admin on debian.social infrastructure.
Including dealing with a spike of abuse on the Jitsi server.
Stefano started to prepare a new release of dh-python, including cleaning out
a lot of old Python 2.x related code. Thanks to Niels Thykier (outside
Freexian) for spear-heading this work.
DebConf 24 planning is beginning. Stefano discussed venues and finances with
the local team and remotely supported a site-visit by Nattie (outside
Freexian).
Also in the DebConf 24 context, Santiago took part in discussions and
preparations related to the Content Team.
A JIT bug was
reported against pypy3 in Debian Bookworm. Stefano bisected the upstream
history to find the patch (it was already resolved upstream) and released an
update to pypy3 in bookworm.
Enrico participated in /usr-merge discussions with Helmut.
Colin dug into a cluster of celery build failures and tracked the hardest bit
down to a Python 3.12 regression, now
fixed in unstable. celery should be back in testing once the 64-bit time_t
migration is out of the way.
Thorsten Alteholz uploaded a new upstream version of cpdb-libs. Unfortunately
upstream changed the naming of their release tags, so updating the watch file
was a bit demanding. Anyway this version 2.0 is a huge step towards
introduction of the new Common Print Dialog Backends.
Helmut send patches for 48 cross build failures.
Helmut changed debvm to use mkfs.ext4 instead of genext2fs.
Helmut sent a
debci MR
for improving collector robustness.
In preparation for DebConf 25, Santiago worked on the Brest Bid.
FTP master
This month I accepted 242 and rejected 42 packages. The overall number of packages that got accepted was 251.
This was just a short month and the weather outside was not really motivating. I hope it will be better in March.
Debian LTS
This was my hundred-sixteenth month that I did some work for the Debian LTS initiative, started by Raphael Hertzog at Freexian.
During my allocated time I uploaded:
[DLA 3739-1] libjwt security update for one CVE to fix some constant-time-for-execution-issue
[#1064551] Bookworm PU bug for libjwt; upload after approval
[DLA 3741-1] engrampa security update for one CVE to fix a path traversal issue with CPIO archives
[#1060186] Bookworm PU-bug for libde265 was flagged for acceptance
[#1056935] Bullseye PU-bug for libde265 was flagged for acceptance
I also started to work on qtbase-opensource-src (an update is needed for ELTS, so an LTS update seems to be appropriate as well, especially as there are postponed CVE).
Debian ELTS
This month was the sixty-seventth ELTS month. During my allocated time I uploaded:
[ELA-1047-1]bind9 security update for one CVE to fix an stack exhaustion issue in Jessie and Stretch
The upload of bind9 was a bit exciting, but all occuring issues with the new upload workflow could be quickly fixed by Helmut and the packages finally reached their destination. I wonder why it is always me who stumbles upon special cases? This month I also worked on the Jessie and Stretch updates for exim4. I also started to work on an update for qtbase-opensource-src in Stretch (and LTS and other releases as well).
Debian Printing
This month I uploaded new upstream versions of:
This work is generously funded by Freexian!
Debian Matomo
I started a new team debian-matomo-maintainers. Within this team all matomo related packages should be handled. PHP PEAR or PECL packages shall be still maintained in their corresponding teams.
This month I uploaded:
Welcome to the February 2024 report from the Reproducible Builds project! In our reports, we try to outline what we have been up to over the past month as well as mentioning some of the important things happening in software supply-chain security.
Reproducible Builds at FOSDEM 2024
Core Reproducible Builds developer Holger Levsen presented at the main track at FOSDEM on Saturday 3rd February this year in Brussels, Belgium. However, that wasn t the only talk related to Reproducible Builds.
However, please see our comprehensive FOSDEM 2024 news post for the full details and links.
Three new reproducibility-related academic papers
A total of three separate scholarly papers related to Reproducible Builds have appeared this month:
Signing in Four Public Software Package Registries: Quantity, Quality, and Influencing Factors by Taylor R. Schorlemmer, Kelechi G. Kalu, Luke Chigges, Kyung Myung Ko, Eman Abdul-Muhd, Abu Ishgair, Saurabh Bagchi, Santiago Torres-Arias and James C. Davis (Purdue University, Indiana, USA) is concerned with the problem that:
Package maintainers can guarantee package authorship through software signing [but] it is unclear how common this practice is, and whether the resulting signatures are created properly. Prior work has provided raw data on signing practices, but measured single platforms, did not consider time, and did not provide insight on factors that may influence signing. We lack a comprehensive, multi-platform understanding of signing adoption and relevant factors. This study addresses this gap. (arXiv, full PDF)
[The] principle of reusability [ ] makes it harder to reproduce projects build environments, even though reproducibility of build environments is essential for collaboration, maintenance and component lifetime. In this work, we argue that functional package managers provide the tooling to make build environments reproducible in space and time, and we produce a preliminary evaluation to justify this claim.
This paper thus proposes an approach to automatically identify configuration options causing non-reproducibility of builds. It begins by building a set of builds in order to detect non-reproducible ones through binary comparison. We then develop automated techniques that combine statistical learning with symbolic reasoning to analyze over 20,000 configuration options. Our methods are designed to both detect options causing non-reproducibility, and remedy non-reproducible configurations, two tasks that are challenging and costly to perform manually. (HAL Portal, full PDF)
Distribution work
In Debian this month, 5 reviews of Debian packages were added, 22 were updated and 8 were removed this month adding to Debian s knowledge about identified issues. A number of issue types were updated as well. [ ][ ][ ][ ] In addition, Roland Clobus posted his 23rd update of the status of reproducible ISO images on our mailing list. In particular, Roland helpfully summarised that all major desktops build reproducibly with bullseye, bookworm, trixie and sid provided they are built for a second time within the same DAK run (i.e. [within] 6 hours) and that there will likely be further work at a MiniDebCamp in Hamburg. Furthermore, Roland also responded in-depth to a query about a previous report Fedora developer Zbigniew J drzejewski-Szmek announced a work-in-progress script called fedora-repro-build that attempts to reproduce an existing package within a koji build environment. Although the projects README file lists a number of fields will always or almost always vary and there is a non-zero list of other known issues, this is an excellent first step towards full Fedora reproducibility.
Jelle van der Waa introduced a new linter rule for Arch Linux packages in order to detect cache files leftover by the Sphinx documentation generator which are unreproducible by nature and should not be packaged. At the time of writing, 7 packages in the Arch repository are affected by this.
Elsewhere, Bernhard M. Wiedemann posted another monthly update for his work elsewhere in openSUSE.
diffoscopediffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 256, 257 and 258 to Debian and made the following additional changes:
Use a deterministic name instead of trusting gpg s use-embedded-filenames. Many thanks to Daniel Kahn Gillmor dkg@debian.org for reporting this issue and providing feedback. [][]
Don t error-out with a traceback if we encounter struct.unpack-related errors when parsing Python .pyc files. (#1064973). []
Don t try and compare rdb_expected_diff on non-GNU systems as %p formatting can vary, especially with respect to MacOS. []
Expand an older changelog entry with a CVE reference. []
Make test_zip black clean. []
In addition, James Addison contributed a patch to parse the headers from the diff(1) correctly [][] thanks! And lastly, Vagrant Cascadian pushed updates in GNU Guix for diffoscope to version 255, 256, and 258, and updated trydiffoscope to 67.0.6.
reprotestreprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian made a number of changes, including:
Create a (working) proof of concept for enabling a specific number of CPUs. [][]
Consistently use 398 days for time variation rather than choosing randomly and update README.rst to match. [][]
Support a new --vary=build_path.path option. [][][][]
Website updates
There were made a number of improvements to our website this month, including:
Chris Lamb:
Improve the relative sizing of headers. []
Re-order and punch up the introduction and documentation on the SOURCE_DATE_EPOCH page. []
Update SOURCE_DATE_EPOCH documentation re. datetime.datetime.fromtimestamp. Thanks, James Addison. []
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
Grant Jan-Benedict Glaw shell access to the Jenkins node. []
Enable debugging for NetBSD reproducibility testing. []
Use /usr/bin/du --apparent-size in the Jenkins shell monitor. []
Revert reproducible nodes: mark osuosl2 as down . []
Thanks again to Codethink, for they have doubled the RAM on our arm64 nodes. []
Only set /proc/$pid/oom_score_adj to -1000 if it has not already been done. []
Add the opemwrt-target-tegra and jtx task to the list of zombie jobs. [][]
Vagrant Cascadian also made the following changes:
Overhaul the handling of OpenSSH configuration files after updating from Debian bookworm. [][][]
Add two new armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [][] [][]
In addition, Alexander Couzens updated the OpenWrt configuration in order to replace the tegra target with mpc85xx [], Jan-Benedict Glaw updated the NetBSD build script to use a separate $TMPDIR to mitigate out of space issues on a tmpfs-backed /tmp [] and Zheng Junjie added a link to the GNU Guix tests [].
Lastly, node maintenance was performed by Holger Levsen [][][][][][] and Vagrant Cascadian [][][][].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Posted on March 7, 2024
Tags: madeof:atoms, FreeSoftWear
I was working on what looked like a good pattern for a pair of
jeans-shaped trousers, and I knew I wasn t happy with 200-ish g/m
cotton-linen for general use outside of deep summer, but I didn t have a
source for proper denim either (I had been low-key looking for it for a
long time).
Then one day I looked at an article I had saved about fabric shops that
sell technical fabric and while window-shopping on one I found that they
had a decent selection of denim in a decent weight.
I decided it was a sign, and decided to buy the two heaviest denim they
had: a 100% cotton, 355 g/m one
and a 97% cotton, 3% elastane at 385 g/m 1; the latter was a bit of compromise as I shouldn t really be
buying fabric adulterated with the Scourge of Humanity, but it was
heavier than the plain one, and I may be having a thing for tightly
fitting jeans, so this may be one of the very few woven fabric where I m
not morally opposed to its existence.
And, I d like to add, I resisted buying any of the very nice wools they
also seem to carry, other than just a couple of samples.
Since the shop only sold in 1 meter increments, and I needed about 1.5
meters for each pair of jeans, I decided to buy 3 meters per type, and
have enough to make a total of four pair of jeans. A bit more than I
strictly needed, maybe, but I was completely out of wearable day-to-day
trousers.
The shop sent everything very quickly, the courier took their time (oh,
well) but eventually delivered my fabric on a sunny enough day that I
could wash it and start as soon as possible on the first pair.
The pattern I did in linen was a bit too fitting, but I was afraid I had
widened it a bit too much, so I did the first pair in the 100% cotton
denim. Sewing them took me about a week of early mornings and late
afternoons, excluding the weekend, and my worries proved false: they
were mostly just fine.
The only bit that could have been a bit better is the waistband, which
is a tiny bit too wide on the back: it s designed to be so for comfort,
but the next time I should pull the elastic a bit more, so that it stays
closer to the body.
I wore those jeans daily for the rest of the week, and confirmed that
they were indeed comfortable and the pattern was ok, so on the next
Monday I started to cut the elastic denim.
I decided to cut and sew two pairs, assembly-line style, using the
shaped waistband for one of them and the straight one for the other one.
I started working on them on a Monday, and on that week I had a couple
of days when I just couldn t, plus I completely skipped sewing on the
weekend, but on Tuesday the next week one pair was ready and could be
worn, and the other one only needed small finishes.
And I have to say, I m really, really happy with the ones with a shaped
waistband in elastic denim, as they fit even better than the ones with a
straight waistband gathered with elastic. Cutting it requires more
fabric, but I think it s definitely worth it.
But it will be a problem for a later time: right now three pairs of
jeans are a good number to keep in rotation, and I hope I won t have to
sew jeans for myself for quite some time.
I think that the leftovers of plain denim will be used for a skirt or
something else, and as for the leftovers of elastic denim, well, there
aren t a lot left, but what else I did with them is the topic for
another post.
Thanks to the fact that they are all slightly different, I ve started to
keep track of the times when I wash each pair, and hopefully I will be
able to see whether the elastic denim is significantly less durable than
the regular, or the added weight compensates for it somewhat. I m not
sure I ll manage to remember about saving the data until they get worn,
but if I do it will be interesting to know.
Oh, and I say I ve finished working on jeans and everything, but I still
haven t sewn the belt loops to the third pair. And I m currently wearing
them. It s a sewist tradition, or something. :D
The links are to the shop for Italy; you can copy the
Codice prodotto and look for it on one of the shop version for
other countries (where they apply the right vat etc., but sadly they
don t allow to mix and match those settings and the language).
I first became aware of Ray Dalio when either he or his publisher
plastered advertisements for The Principles all over the San
Francisco 4th and King Caltrain station. If I recall correctly, there
were also constant radio commercials; it was a whole thing in 2017. My
brain is very good at tuning out advertisements, so my only thought at the
time was "some business guy wrote a self-help book." I think I vaguely
assumed he was a CEO of some traditional business, since that's usually
who writes heavily marketed books like this. I did not connect him with
hedge funds or Bridgewater, which I have a bad habit of confusing with
Blackwater.
The Principles turns out to be more of a laundered cult manual than
a self-help book. And therein lies a story.
Rob Copeland is currently with The New York Times, but for many
years he was the hedge fund reporter for The Wall Street Journal.
He covered, among other things, Bridgewater Associates, the enormous hedge
fund founded by Ray Dalio. The Fund is a biography of Ray Dalio
and a history of Bridgewater from its founding as a vehicle for Dalio's
advising business until 2022 when Dalio, after multiple false starts and
title shuffles, finally retired from running the company. (Maybe. Based
on the history recounted here, it wouldn't surprise me if he was back at
the helm by the time you read this.)
It is one of the wildest, creepiest, and most abusive business histories
that I have ever read.
It's probably worth mentioning, as Copeland does explicitly, that Ray
Dalio and Bridgewater hate this book and claim it's a pack of lies.
Copeland includes some of their denials (and many non-denials that sound
as good as confirmations to me) in footnotes that I found increasingly
amusing.
A lawyer for Dalio said he "treated all employees equally, giving
people at all levels the same respect and extending them the same
perks."
Uh-huh.
Anyway, I personally know nothing about Bridgewater other than what I
learned here and the occasional mention in Matt Levine's newsletter (which
is where I got the recommendation for this book). I have no independent
information whether anything Copeland describes here is true, but Copeland
provides the typical extensive list of notes and sourcing one expects in a
book like this, and Levine's comments indicated it's generally consistent
with Bridgewater's industry reputation. I think this book is true, but
since the clear implication is that the world's largest hedge fund was
primarily a deranged cult whose employees mostly spied on and rated each
other rather than doing any real investment work, I also have questions,
not all of which Copeland answers to my satisfaction. But more on that
later.
The center of this book are the Principles. These were an ever-changing
list of rules and maxims for how people should conduct themselves within
Bridgewater. Per Copeland, although Dalio later published a book by that
name, the version of the Principles that made it into the book was
sanitized and significantly edited down from the version used inside the
company. Dalio was constantly adding new ones and sometimes changing
them, but the common theme was radical, confrontational "honesty": never
being silent about problems, confronting people directly about anything
that they did wrong, and telling people all of their faults so that they
could "know themselves better."
If this sounds like textbook abusive behavior, you have the right idea.
This part Dalio admits to openly, describing Bridgewater as a firm that
isn't for everyone but that achieves great results because of this
culture. But the uncomfortably confrontational vibes are only the tip of
the iceberg of dysfunction. Here are just a few of the ways this played
out according to Copeland:
Dalio decided that everyone's opinions should be weighted by the
accuracy of their previous decisions, to create a "meritocracy," and
therefore hired people to build a social credit system in which people
could use an app to constantly rate all of their co-workers. This
almost immediately devolved into out-group bullying worthy of a high
school, with employees hurriedly down-rating and ostracizing any
co-worker that Dalio down-rated.
When an early version of the system uncovered two employees at
Bridgewater with more credibility than Dalio, Dalio had the system
rigged to ensure that he always had the highest ratings and was not
affected by other people's ratings.
Dalio became so obsessed with the principle of confronting problems
that he created a centralized log of problems at Bridgewater and
required employees find and report a quota of ten or twenty new issues
every week or have their bonus docked. He would then regularly pick
some issue out of the issue log, no matter how petty, and treat it
like a referendum on the worth of the person responsible for the
issue.
Dalio's favorite way of dealing with a problem was to put someone on
trial. This involved extensive investigations followed by a meeting
where Dalio would berate the person and harshly catalog their flaws,
often reducing them to tears or panic attacks, while smugly insisting
that having an emotional reaction to criticism was a personality flaw.
These meetings were then filmed and added to a library available to
all Bridgewater employees, often edited to remove Dalio's personal
abuse and to make the emotional reaction of the target look
disproportionate. The ones Dalio liked the best were shown to all new
employees as part of their training in the Principles.
One of the best ways to gain institutional power in Bridgewater was to
become sycophantically obsessed with the Principles and to be an eager
participant in Dalio's trials. The highest levels of Bridgewater
featured constant jockeying for power, often by trying to catch rivals
in violations of the Principles so that they would be put on trial.
In one of the common and all-too-disturbing connections between Wall
Street finance and the United States' dysfunctional government, James
Comey (yes, that James
Comey) ran internal security for Bridgewater for three years, meaning
that he was the one who pulled evidence from surveillance cameras for
Dalio to use to confront employees during his trials.
In case the cult vibes weren't strong enough already, Bridgewater
developed its own idiosyncratic language worthy of Scientology. The
trials were called "probings," firing someone was called "sorting" them,
and rating them was called "dotting," among many other
Bridgewater-specific terms. Needless to say, no one ever probed Dalio
himself. You will also be completely unsurprised to learn that Copeland
documents instances of sexual harassment and discrimination at
Bridgewater, including some by Dalio himself, although that seems to be a
relatively small part of the overall dysfunction. Dalio was happy to
publicly humiliate anyone regardless of gender.
If you're like me, at this point you're probably wondering how Bridgewater
continued operating for so long in this environment. (Per Copeland, since
Dalio's retirement in 2022, Bridgewater has drastically reduced the
cult-like behaviors, deleted its archive of probings, and de-emphasized the
Principles.) It was not actually a religious cult; it was a hedge fund
that has to provide investment services to huge, sophisticated clients,
and by all accounts it's a very successful one. Why did this bizarre
nightmare of a workplace not interfere with Bridgewater's business?
This, I think, is the weakest part of this book. Copeland makes a few
gestures at answering this question, but none of them are very satisfying.
First, it's clear from Copeland's account that almost none of the
employees of Bridgewater had any control over Bridgewater's investments.
Nearly everyone was working on other parts of the business (sales,
investor relations) or on cult-related obsessions. Investment decisions
(largely incorporated into algorithms) were made by a tiny core of people
and often by Dalio himself. Bridgewater also appears to not trade
frequently, unlike some other hedge funds, meaning that they probably stay
clear of the more labor-intensive high-frequency parts of the business.
Second, Bridgewater took off as a hedge fund just before the hedge fund
boom in the 1990s. It transformed from Dalio's personal consulting
business and investment newsletter to a hedge fund in 1990 (with an
earlier investment from the World Bank in 1987), and the 1990s were a very
good decade for hedge funds. Bridgewater, in part due to Dalio's
connections and effective marketing via his newsletter, became one of the
largest hedge funds in the world, which gave it a sort of institutional
momentum. No one was questioned for putting money into Bridgewater even
in years when it did poorly compared to its rivals.
Third, Dalio used the tried and true method of getting free publicity from
the financial press: constantly predict an upcoming downturn, and
aggressively take credit whenever you were right. From nearly the start
of his career, Dalio predicted economic downturns year after year.
Bridgewater did very well in the 2000 to 2003 downturn, and again during
the 2008 financial crisis. Dalio aggressively takes credit for predicting
both of those downturns and positioning Bridgewater correctly going into
them. This is correct; what he avoids mentioning is that he also
predicted downturns in every other year, the majority of which never
happened.
These points together create a bit of an answer, but they don't feel like
the whole picture and Copeland doesn't connect the pieces. It seems
possible that Dalio may simply be good at investing; he reads obsessively
and clearly enjoys thinking about markets, and being an abusive cult
leader doesn't take up all of his time. It's also true that to some
extent hedge funds are semi-free money machines, in that once you have a
sufficient quantity of money and political connections you gain access to
investment opportunities and mechanisms that are very likely to make money
and that the typical investor simply cannot access. Dalio is clearly good
at making personal connections, and invested a lot of effort into forming
close ties with tricky clients such as pools of Chinese money.
Perhaps the most compelling explanation isn't mentioned directly in this
book but instead comes from Matt Levine. Bridgewater touts its
algorithmic trading over humans making individual trades, and there is
some reason to believe that consistently applying an algorithm without
regard to human emotion is a solid trading strategy in at least some
investment areas. Levine has asked in his newsletter, tongue firmly in
cheek, whether the bizarre cult-like behavior and constant infighting is a
strategy to distract all the humans and keep them from messing with the
algorithm and thus making bad decisions.
Copeland leaves this question unsettled. Instead, one comes away from
this book with a clear vision of the most dysfunctional workplace I have
ever heard of, and an endless litany of bizarre events each more
astonishing than the last. If you like watching train wrecks, this is the
book for you. The only drawback is that, unlike other entries in this
genre such as Bad Blood or
Billion Dollar Loser, Bridgewater is a
wildly successful company, so you don't get the schadenfreude of seeing a
house of cards collapse. You do, however, get a helpful mental model to
apply to the next person who tries to talk to you about "radical honesty"
and "idea meritocracy."
The flaw in this book is that the existence of an organization like
Bridgewater is pointing to systematic flaws in how our society works,
which Copeland is largely uninterested in interrogating. "How could this
have happened?" is a rather large question to leave unanswered. The sheer
outrageousness of Dalio's behavior also gets a bit tiring by the end of
the book, when you've seen the patterns and are hearing about the fourth
variation. But this is still an astonishing book, and a worthy entry in
the genre of capitalism disasters.
Rating: 7 out of 10
This is my third update on writing a language server for Debian packaging files, which
aims at providing a better developer experience for Debian packagers.
Lets go over what have done since the last report.
Semantic token support
I have added support for what the Language Server Protocol (LSP) call semantic tokens. These
are used to provide the editor insights into tokens of interest for users. Allegedly,
this is what editors would use for syntax highlighting as well.
Unfortunately, eglot (emacs) does not support semantic tokens, so I was not able to test
this. There is a 3-year old PR for supporting with the last update being ~3 month basically
saying "Please sign the Copyright Assignment". I pinged the GitHub issue in the hopes it will
get unstuck.
For good measure, I also checked if I could try it via neovim. Before installing, I read
the neovim docs, which helpfully listed the features supported. Sadly, I did not spot
semantic tokens among those and parked from there.
That was a bit of a bummer, but I left the feature in for now. If you have an LSP capable
editor that supports semantic tokens, let me know how it works for you! :)
Spellchecking
Finally, I implemented something Otto was missing! :)
This stared with Paul Wise reminding me that there were Python binding for the hunspell
spellchecker. This enabled me to get started with a quick prototype that spellchecked the
Description fields in debian/control. I also added spellchecking of comments while
I was add it.
The spellchecker runs with the standard en_US dictionary from hunspell-en-us, which
does not have a lot of technical terms in it. Much less any of the Debian specific slang.
I spend considerable time providing a "built-in" wordlist for technical and Debian specific
slang to overcome this. I also made a "wordlist" for known Debian people that the
spellchecker did not recognise. Said wordlist is fairly short as a proof of concept, and
I fully expect it to be community maintained if the language server becomes a success.
My second problem was performance. As I had suspected that spellchecking was not the
fastest thing in the world. Therefore, I added a very small language server for the
debian/changelog, which only supports spellchecking the textual part. Even for a
small changelog of a 1000 lines, the spellchecking takes about 5 seconds, which
confirmed my suspicion. With every change you do, the existing diagnostics hangs around
for 5 seconds before being updated. Notably, in emacs, it seems that diagnostics
gets translated into an absolute character offset, so all diagnostics after the change
gets misplaced for every character you type.
Now, there is little I could do to speed up hunspell. But I can, as always, cheat.
The way diagnostics work in the LSP is that the server listens to a set of notifications
like "document opened" or "document changed". In a response to that, the LSP can start
its diagnostics scanning of the document and eventually publish all the diagnostics to
the editor. The spec is quite clear that the server owns the diagnostics and the
diagnostics are sent as a "notification" (that is, fire-and-forgot). Accordingly, there
is nothing that prevents the server from publishing diagnostics multiple times for a
single trigger. The only requirement is that the server publishes the accumulated
diagnostics in every publish (that is, no delta updating).
Leveraging this, I had the language server for debian/changelog scan the document and
publish once for approximately every 25 typos (diagnostics) spotted. This means you quickly
get your first result and that clears the obsolete diagnostics. Thereafter, you get
frequent updates to the remainder of the document if you do not perform any further changes.
That is, up to a predefined max of typos, so we do not overload the client for longer
changelogs. If you do any changes, it resets and starts over.
The only bit missing was dealing with concurrency. By default, a pygls language server
is single threaded. It is not great if the language server hangs for 5 seconds everytime
you type anything. Fortunately, pygls has builtin support for asyncio and threaded
handlers. For now, I did an async handler that await after each line and setup some
manual detection to stop an obsolete diagnostics run. This means the server will fairly
quickly abandon an obsolete run.
Also, as a side-effect of working on the spellchecking, I fixed multiple typos in the
changelog of debputy. :)
Follow up on the "What next?" from my previous update
In my previous update, I mentioned I had to finish up my python-debian changes to
support getting the location of a token in a deb822 file. That was done, the MR
is now filed, and is pending review. Hopefully, it will be merged and uploaded soon. :)
I also submitted my proposal for a different way of handling relationship substvars to
debian-devel. So far, it seems to have received only positive feedback. I hope it stays
that way and we will have this feature soon. Guillem proposed to move some of this into
dpkg, which might delay my plans a bit. However, it might be for the better in the
long run, so I will wait a bit to see what happens on that front. :)
As noted above, I managed to add debian/changelog as a support format for the
language server. Even if it only does spellchecking and trimming of trailing newlines
on save, it technically is a new format and therefore cross that item off my list. :D
Unfortunately, I did not manage to write a linter variant that does not involve using
an LSP-capable editor. So that is still pending. Instead, I submitted an MR against
elpa-dpkg-dev-el to have it recognize all the fields that the debian/control
LSP knows about at this time to offset the lack of semantic token support in
eglot.
From here...
My sprinting on this topic will soon come to an end, so I have to a bit more careful
now with what tasks I open!
I think I will narrow my focus to providing a batch linting interface. Ideally, with
an auto-fix for some of the more mechanical issues, where this is little doubt about
the answer.
Additionally, I think the spellchecking will need a bit more maturing. My current
code still trips on naming patterns that are "clearly" verbatim or code references
like things written in CamelCase or SCREAMING_SNAKE_CASE. That gets annoying
really quickly. It also trips on a lot of commands like dpkg-gencontrol, but that
is harder to fix since it could have been a real word. I think those will have to be
fixed people using quotes around the commands. Maybe the most popular ones will end
up in the wordlist.
Beyond that, I will play it by ear if I have any time left. :)
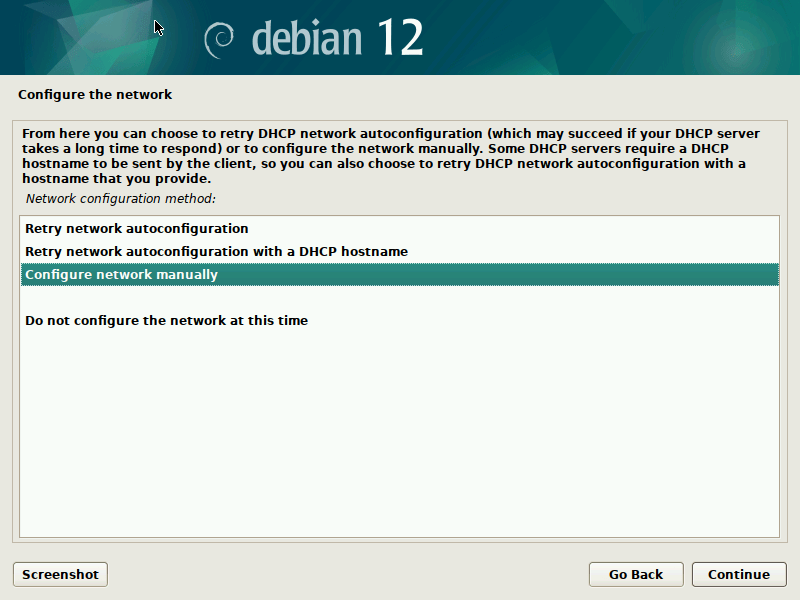
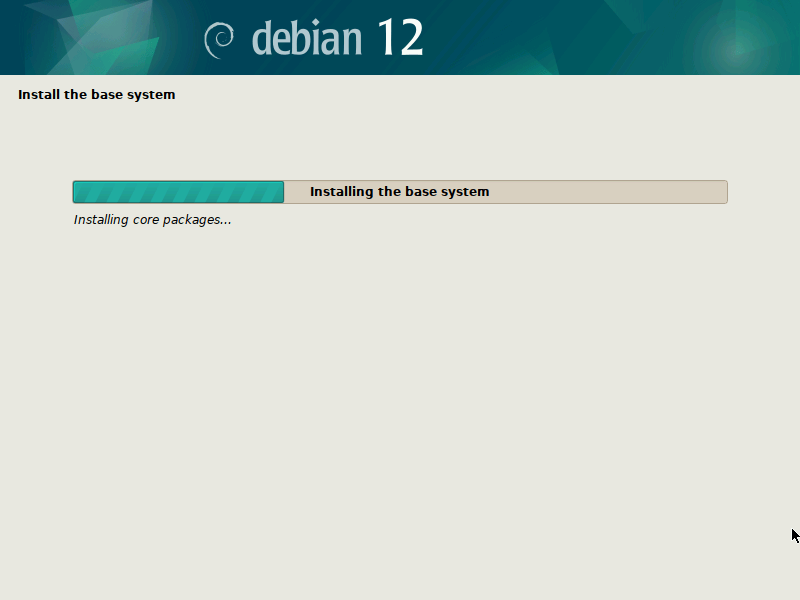
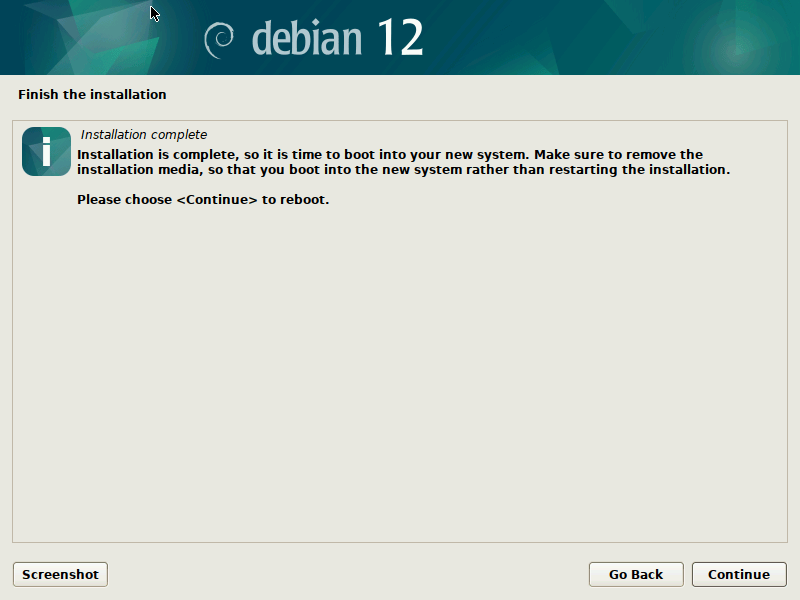
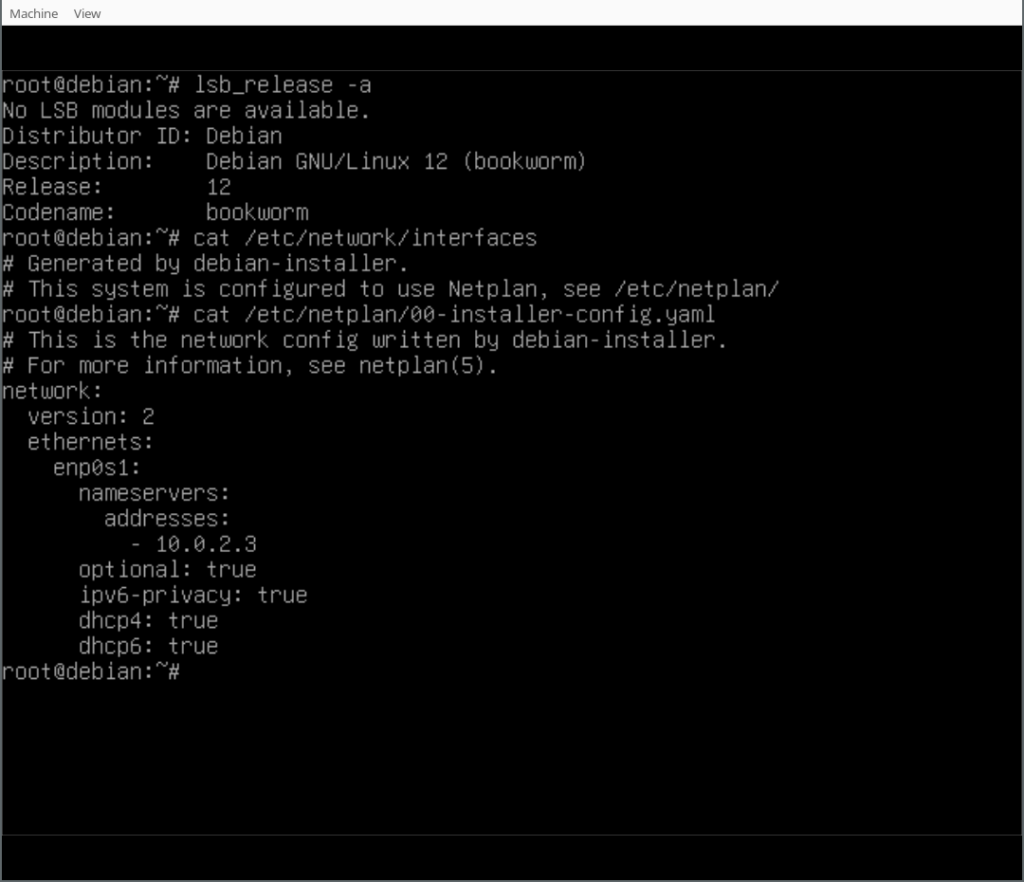
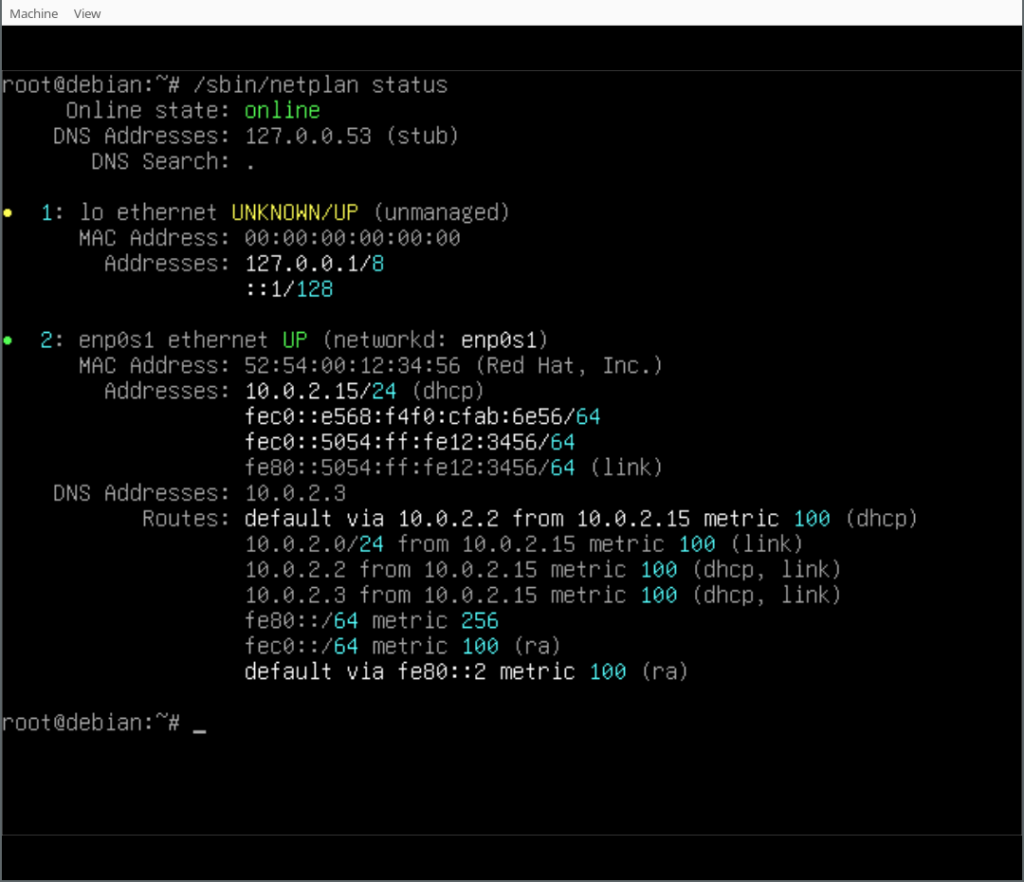
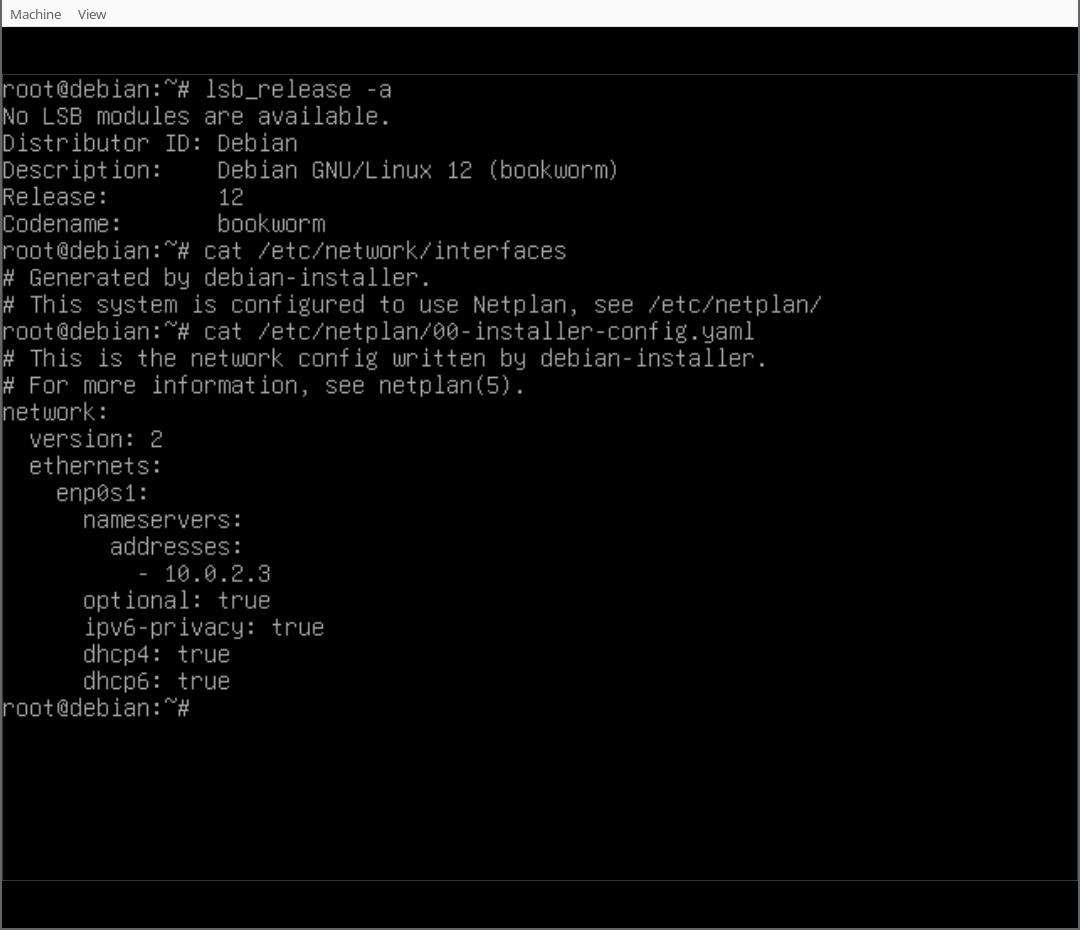
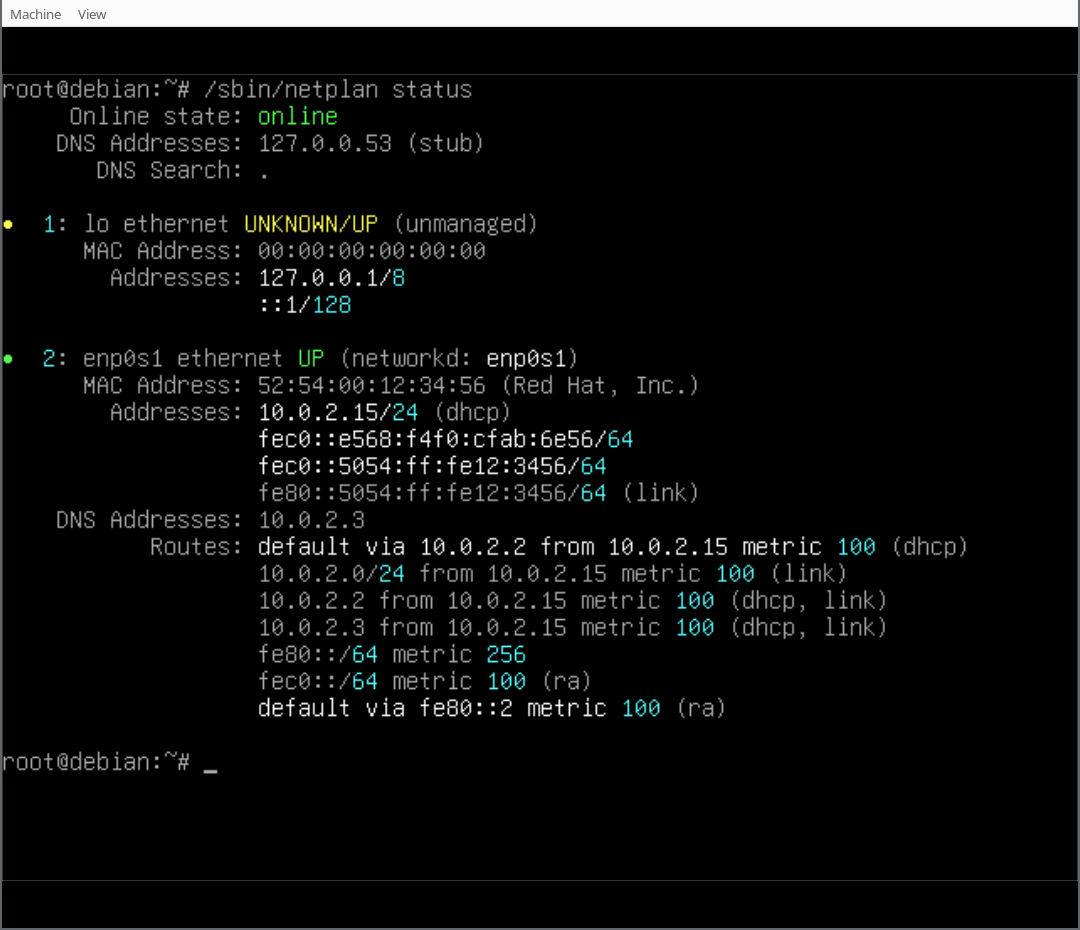


 I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to
I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to  Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the 
 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze

 The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The DPL is the official representative of representative of The Debian Project tasked with managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last
The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The DPL is the official representative of representative of The Debian Project tasked with managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last 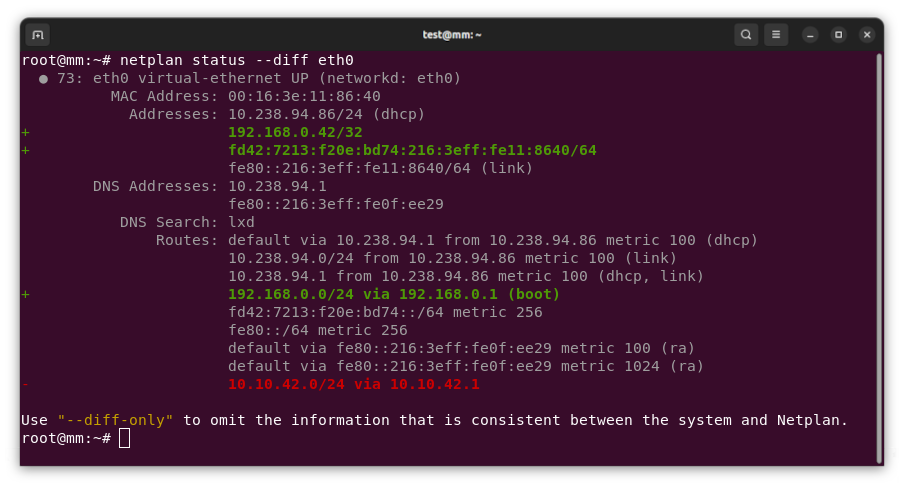

 The twentyfirst release of
The twentyfirst release of  Closing arguments in the trial between various people and
Closing arguments in the trial between various people and  The image here comes from an example of building
The image here comes from an example of building 












 I was working on what looked like a good pattern for a pair of
jeans-shaped trousers, and I knew I wasn t happy with 200-ish g/m
cotton-linen for general use outside of deep summer, but I didn t have a
source for proper denim either (I had been low-key looking for it for a
long time).
Then one day I looked at an article I had saved about fabric shops that
sell technical fabric and while window-shopping on one I found that they
had a decent selection of denim in a decent weight.
I decided it was a sign, and decided to buy the two heaviest denim they
had: a
I was working on what looked like a good pattern for a pair of
jeans-shaped trousers, and I knew I wasn t happy with 200-ish g/m
cotton-linen for general use outside of deep summer, but I didn t have a
source for proper denim either (I had been low-key looking for it for a
long time).
Then one day I looked at an article I had saved about fabric shops that
sell technical fabric and while window-shopping on one I found that they
had a decent selection of denim in a decent weight.
I decided it was a sign, and decided to buy the two heaviest denim they
had: a  The shop sent everything very quickly, the courier took their time (oh,
well) but eventually delivered my fabric on a sunny enough day that I
could wash it and start as soon as possible on the first pair.
The pattern I did in linen was a bit too fitting, but I was afraid I had
widened it a bit too much, so I did the first pair in the 100% cotton
denim. Sewing them took me about a week of early mornings and late
afternoons, excluding the weekend, and my worries proved false: they
were mostly just fine.
The only bit that could have been a bit better is the waistband, which
is a tiny bit too wide on the back: it s designed to be so for comfort,
but the next time I should pull the elastic a bit more, so that it stays
closer to the body.
The shop sent everything very quickly, the courier took their time (oh,
well) but eventually delivered my fabric on a sunny enough day that I
could wash it and start as soon as possible on the first pair.
The pattern I did in linen was a bit too fitting, but I was afraid I had
widened it a bit too much, so I did the first pair in the 100% cotton
denim. Sewing them took me about a week of early mornings and late
afternoons, excluding the weekend, and my worries proved false: they
were mostly just fine.
The only bit that could have been a bit better is the waistband, which
is a tiny bit too wide on the back: it s designed to be so for comfort,
but the next time I should pull the elastic a bit more, so that it stays
closer to the body.
 I wore those jeans daily for the rest of the week, and confirmed that
they were indeed comfortable and the pattern was ok, so on the next
Monday I started to cut the elastic denim.
I decided to cut and sew two pairs, assembly-line style, using the
shaped waistband for one of them and the straight one for the other one.
I started working on them on a Monday, and on that week I had a couple
of days when I just couldn t, plus I completely skipped sewing on the
weekend, but on Tuesday the next week one pair was ready and could be
worn, and the other one only needed small finishes.
I wore those jeans daily for the rest of the week, and confirmed that
they were indeed comfortable and the pattern was ok, so on the next
Monday I started to cut the elastic denim.
I decided to cut and sew two pairs, assembly-line style, using the
shaped waistband for one of them and the straight one for the other one.
I started working on them on a Monday, and on that week I had a couple
of days when I just couldn t, plus I completely skipped sewing on the
weekend, but on Tuesday the next week one pair was ready and could be
worn, and the other one only needed small finishes.
 And I have to say, I m really, really happy with the ones with a shaped
waistband in elastic denim, as they fit even better than the ones with a
straight waistband gathered with elastic. Cutting it requires more
fabric, but I think it s definitely worth it.
But it will be a problem for a later time: right now three pairs of
jeans are a good number to keep in rotation, and I hope I won t have to
sew jeans for myself for quite some time.
And I have to say, I m really, really happy with the ones with a shaped
waistband in elastic denim, as they fit even better than the ones with a
straight waistband gathered with elastic. Cutting it requires more
fabric, but I think it s definitely worth it.
But it will be a problem for a later time: right now three pairs of
jeans are a good number to keep in rotation, and I hope I won t have to
sew jeans for myself for quite some time.
 I think that the leftovers of plain denim will be used for a skirt or
something else, and as for the leftovers of elastic denim, well, there
aren t a lot left, but what else I did with them is the topic for
another post.
Thanks to the fact that they are all slightly different, I ve started to
keep track of the times when I wash each pair, and hopefully I will be
able to see whether the elastic denim is significantly less durable than
the regular, or the added weight compensates for it somewhat. I m not
sure I ll manage to remember about saving the data until they get worn,
but if I do it will be interesting to know.
Oh, and I say I ve finished working on jeans and everything, but I still
haven t sewn the belt loops to the third pair. And I m currently wearing
them. It s a sewist tradition, or something. :D
I think that the leftovers of plain denim will be used for a skirt or
something else, and as for the leftovers of elastic denim, well, there
aren t a lot left, but what else I did with them is the topic for
another post.
Thanks to the fact that they are all slightly different, I ve started to
keep track of the times when I wash each pair, and hopefully I will be
able to see whether the elastic denim is significantly less durable than
the regular, or the added weight compensates for it somewhat. I m not
sure I ll manage to remember about saving the data until they get worn,
but if I do it will be interesting to know.
Oh, and I say I ve finished working on jeans and everything, but I still
haven t sewn the belt loops to the third pair. And I m currently wearing
them. It s a sewist tradition, or something. :D