There are plenty of times where it is nice to have Linux transmit things out a radio. One obvious example is the digital communication modes, where software acts as a sort of modem. A prominent example of this in Debian is
fldigi.
Sometimes, it is nice to transmit voice instead of a digital signal. This is called voice keying. When operating a contest, for instance, a person might call CQ over and over, with just some brief gaps.
Most people that interface a radio with a computer use a sound card interface of some sort. The more modern of these have a simple USB cable that connects to the computer and acts as a USB sound card. So, at a certain level, all that you have to do is play sound out a specific device.
But it s not quite so easy, because there is one other wrinkle: you have to engage the radio s transmitter. This is obviously not something that is part of typical sound card APIs. There are all sorts of ways to do it, ranging from dedicated serial or parallel port circuits involving asserting voltage on certain pins, to voice-activated (VOX) circuits.
I have used two of these interfaces: the basic
Signalink USB and the more powerful
RigExpert TI-5. The Signalink USB integrates a VOX circuit and provides cabling to engage the transmitter when VOX is tripped. The TI-5, on the other hand, emulates three USB serial ports, and if you raise RTS on one of them, it will keep the transmitter engaged as long as RTS is high. This is a more accurate and precise approach.
VOX-based voice keying with the Signalink USB
But let s first look at the Signalink USB case. The problem here is that its VOX circuit is really tuned for digital transmissions, which tend to be either really loud or completely silent. Human speech rises and falls in volume, and it tends to rapidly assert and drop PTT (Push-To-Talk, the name for the control that engages the radio s transmitter) when used with VOX.
The solution I hit on was to add a constant, loud tone to the transmitted audio, but one which is outside the range of frequencies that the radio will transmit (which is usually no higher than 3kHz). This can be done using sox and aplay, the ALSA player. Here s my script to call cq with Signalink USB:
#!/bin/bash
# NOTE: use alsamixer and set playback gain to 99
set -e
playcmd ()
sox -V0 -m "$1" \
" sox -V0 -r 44100 $1 -t wav -c 1 - synth sine 20000 gain -1" \
-t wav - \
aplay -q -D default:CARD=CODEC
DELAY=$ 1:-1.5
echo -n "Started at: "
date
STARTTIME= date +%s
while true; do
printf "\r"
echo -n $(( ( date +%s -$STARTTIME) / 60))
printf "m/$ DELAY s: TRANSMIT"
playcmd ~/audio/cq/cq.wav
printf "\r"
echo -n $(( ( date +%s -$STARTTIME) / 60))
printf "m/$ DELAY s: off "
sleep $DELAY
done
Run this, and it will continuously play your message, with a 1.5s gap in between during which the transmitter is not keyed.
The screen will look like this:
Started at: Fri Aug 24 21:17:47 CDT 2012
2m/1.5s: off
The 2m is how long it s been going this time, and the 1.5s shows the configured gap.
The sox commands are really two nested ones. The -m causes sox to merge the .wav file in $1 with the 20kHz sine wave being generated, and the entire thing is piped to the ALSA player.
Tweaks for RigExpert TI-5
This is actually a much simpler case. We just replace playcmd as follows:
playcmd ()
~/bin/raiserts /dev/ttyUSB1 'aplay -q -D default:CARD=CODEC' < "$1"
Where raiserts is a program that simply keeps RTS asserted on the serial port while the given command executes. Here's its source, which I modified a bit from a program I found online:
/* modified from
* https://www.linuxquestions.org/questions/programming-9/manually-controlling-rts-cts-326590/
* */
#include <stdio.h>
#include <stdlib.h>
#include <termios.h>
#include <unistd.h>
#include <sys>ioctl.h>
#include <sys< sys="">types.h>
#include <sys>stat.h>
#include <fcntl.h>
static struct termios oldterminfo;
void closeserial(int fd)
tcsetattr(fd, TCSANOW, &oldterminfo);
if (close(fd) < 0)
perror("closeserial()");
int openserial(char *devicename)
int fd;
struct termios attr;
if ((fd = open(devicename, O_RDWR)) == -1)
perror("openserial(): open()");
return 0;
if (tcgetattr(fd, &oldterminfo) == -1)
perror("openserial(): tcgetattr()");
return 0;
attr = oldterminfo;
attr.c_cflag = CRTSCTS CLOCAL;
attr.c_oflag = 0;
if (tcflush(fd, TCIOFLUSH) == -1)
perror("openserial(): tcflush()");
return 0;
if (tcsetattr(fd, TCSANOW, &attr) == -1)
perror("initserial(): tcsetattr()");
return 0;
return fd;
int setRTS(int fd, int level)
int status;
if (ioctl(fd, TIOCMGET, &status) == -1)
perror("setRTS(): TIOCMGET");
return 0;
status &= ~TIOCM_DTR; </sys>* ALWAYS clear DTR */
if (level)
status = TIOCM_RTS;
else
status &= ~TIOCM_RTS;
if (ioctl(fd, TIOCMSET, &status) == -1)
perror("setRTS(): TIOCMSET");
return 0;
return 1;
int main(int argc, char *argv[])
int fd, retval;
char *serialdev;
if (argc < 3)
printf("Syntax: raiserts /dev/ttyname 'command to run while RTS held'\n");
return 5;
serialdev = argv[1];
fd = openserial(serialdev);
if (!fd)
fprintf(stderr, "Error while initializing %s.\n", serialdev);
return 1;
setRTS(fd, 1);
retval = system(argv[2]);
setRTS(fd, 0);
closeserial(fd);
return retval;
This compiles to an executable less than 10K in size. I love it when that happens.
So these examples support voice keying both with VOX circuits and with serial-controlled PTT. raiserts.c could be trivially modified to control other serial pins as well, should you have an interface which uses different ones.
 syncoid to TrueNAS In my homelab, I have 2 NAS systems:
Linux (Debian) TrueNAS Core (based on FreeBSD) On my Linux box, I use Jim Salter s sanoid to periodically take snapshots of my ZFS pool. I also want to have a proper backup of the whole pool, so I use syncoid to transfer those snapshots to another machine. Sanoid itself is responsible only for taking new snapshots and pruning old ones you no longer care about.
syncoid to TrueNAS In my homelab, I have 2 NAS systems:
Linux (Debian) TrueNAS Core (based on FreeBSD) On my Linux box, I use Jim Salter s sanoid to periodically take snapshots of my ZFS pool. I also want to have a proper backup of the whole pool, so I use syncoid to transfer those snapshots to another machine. Sanoid itself is responsible only for taking new snapshots and pruning old ones you no longer care about.
 Every month or two keyring-maint gets a comment about how a key update we say we ve performed hasn t actually made it to the active keyring, or a query about why the keyring is so out of date, or told that although a key has been sent to the HKP interface and that is showing the update as received it isn t working when trying to upload to the Debian archive. It s frustrating to have to deal with these queries, but the confusion is understandable. There are multiple public interfaces to the Debian keyrings and they re not all equal. This post attempts to explain the interactions between them, and how I go about working with them as part of the keyring-maint team.
First, a diagram to show the different interfaces to the keyring and how they connect to each other:
Every month or two keyring-maint gets a comment about how a key update we say we ve performed hasn t actually made it to the active keyring, or a query about why the keyring is so out of date, or told that although a key has been sent to the HKP interface and that is showing the update as received it isn t working when trying to upload to the Debian archive. It s frustrating to have to deal with these queries, but the confusion is understandable. There are multiple public interfaces to the Debian keyrings and they re not all equal. This post attempts to explain the interactions between them, and how I go about working with them as part of the keyring-maint team.
First, a diagram to show the different interfaces to the keyring and how they connect to each other:
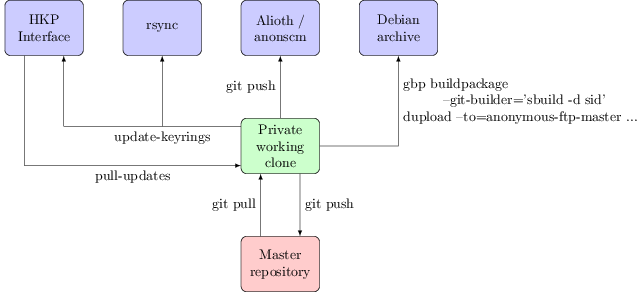
 The idea is simply to have one coherent place with pointers to all the stuff we have and provide, without repeating nor replacing other documentation.
The idea is simply to have one coherent place with pointers to all the stuff we have and provide, without repeating nor replacing other documentation. I just finished reading
I just finished reading  Tim and my mother are both neonatologists at the Golisano Children's Hospital inside the University of Rochester.
Earlier today, they had this conversation:
Tim and my mother are both neonatologists at the Golisano Children's Hospital inside the University of Rochester.
Earlier today, they had this conversation:
 I am following closely this
I am following closely this  Long weekend of travel and family, and now we're back on our way to
Long weekend of travel and family, and now we're back on our way to {kind=link}
{kind=link}
{kind=link}