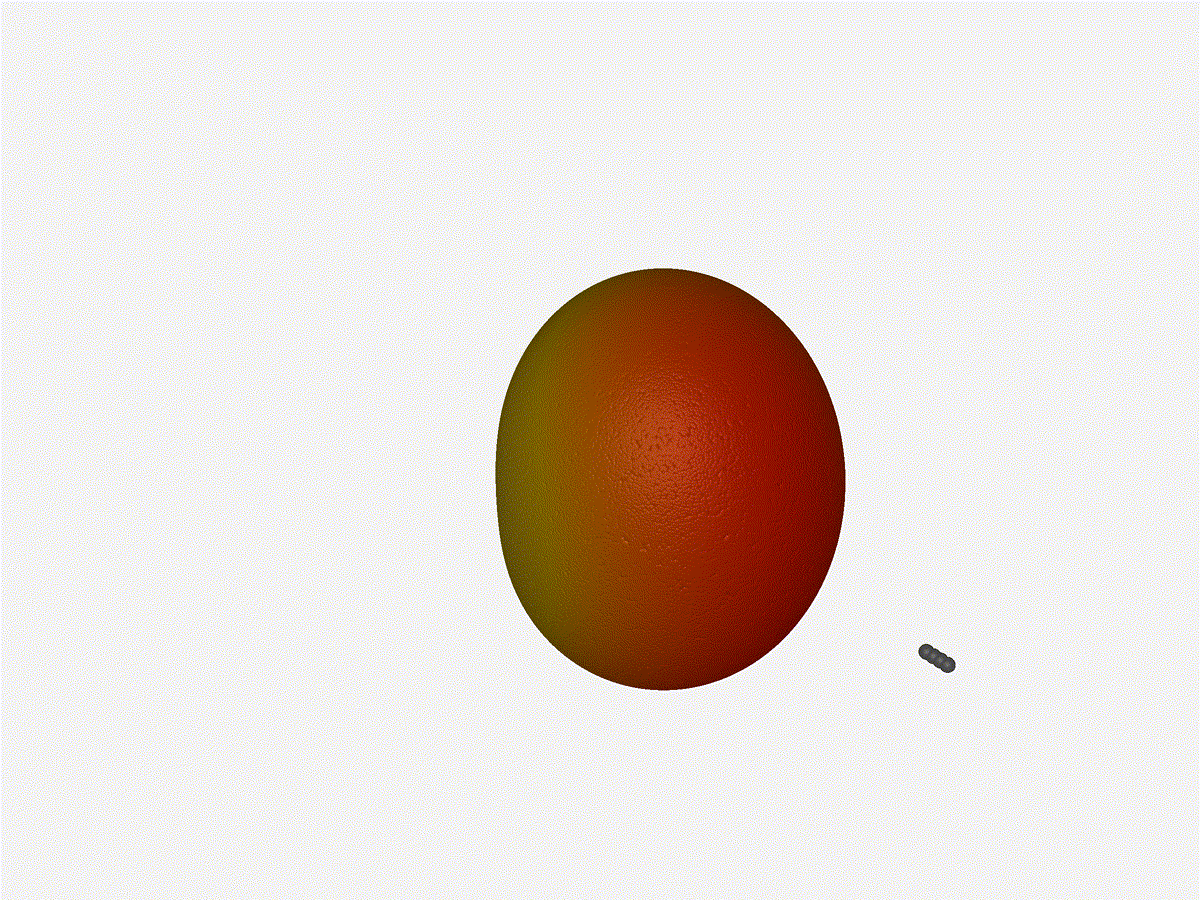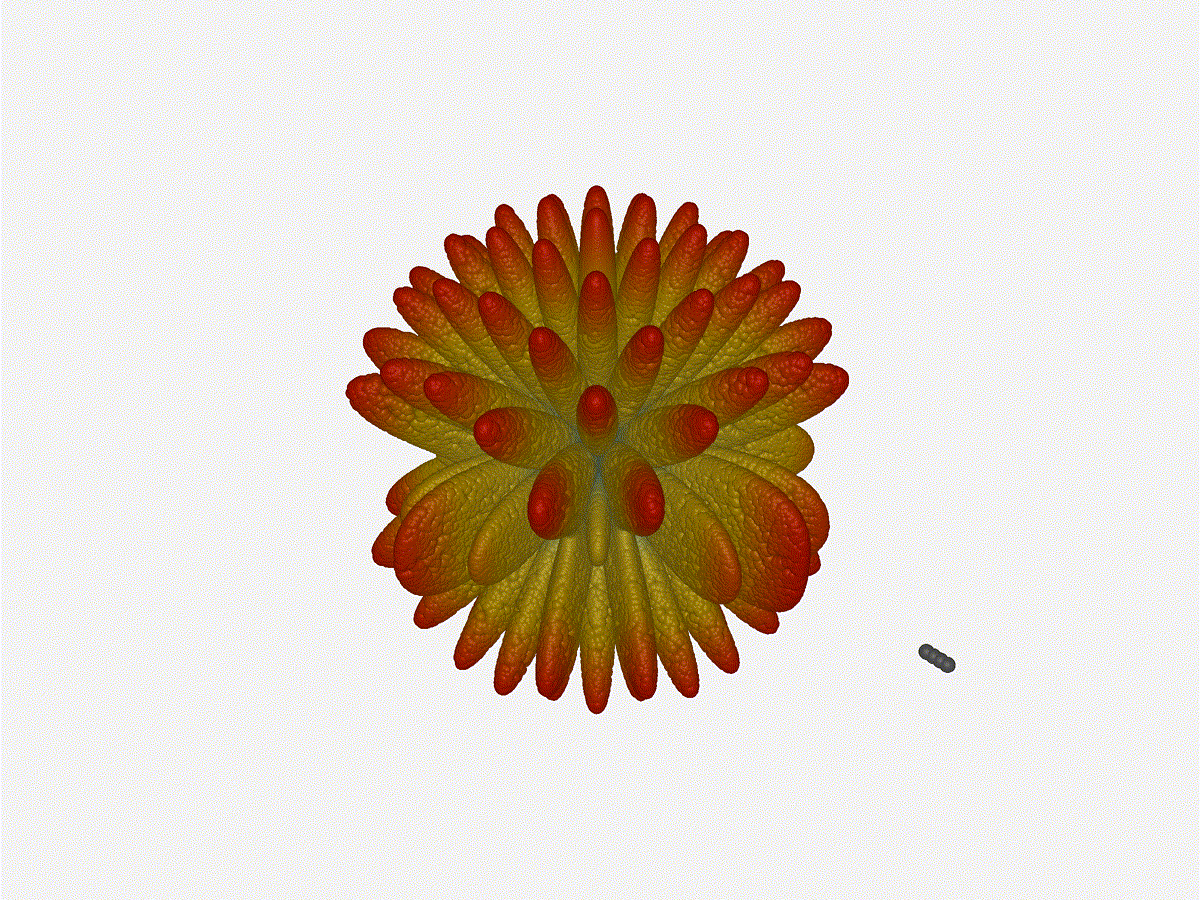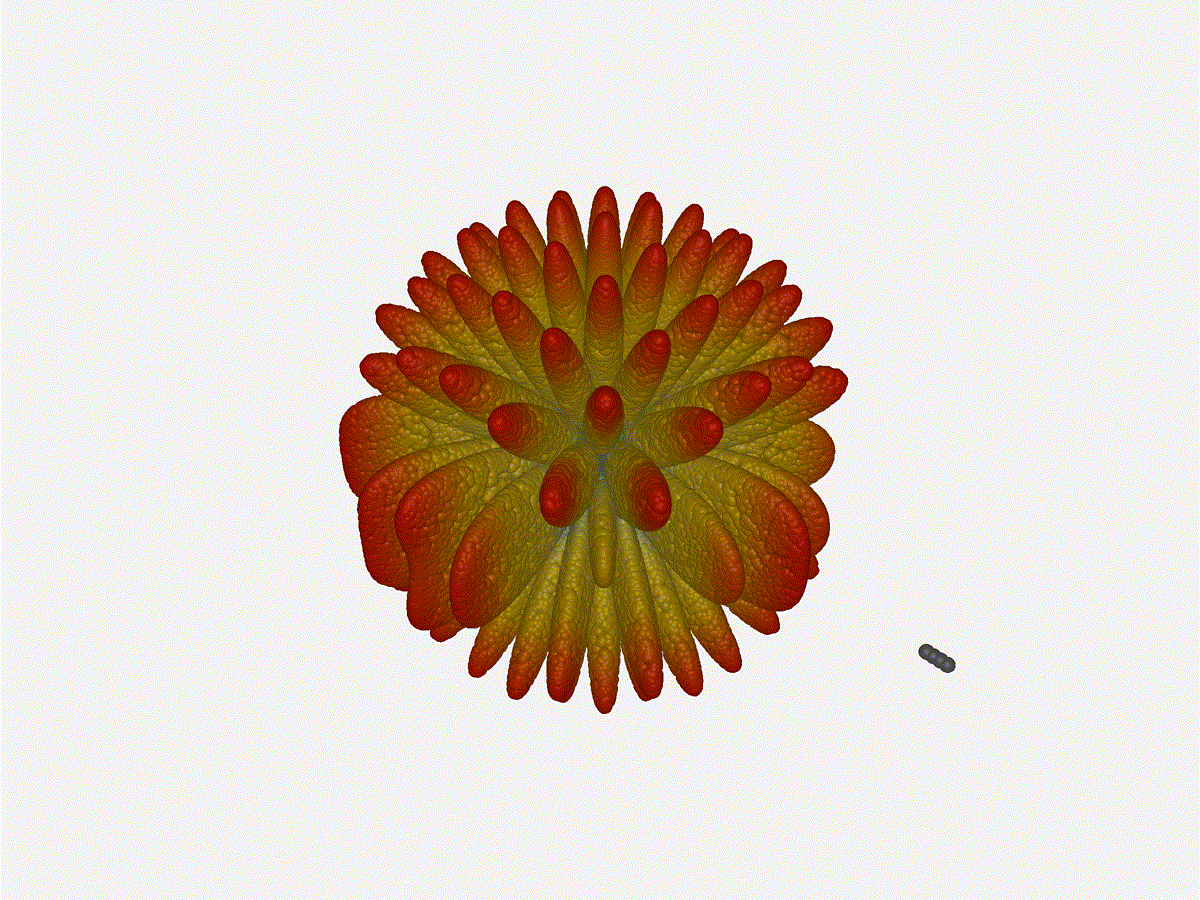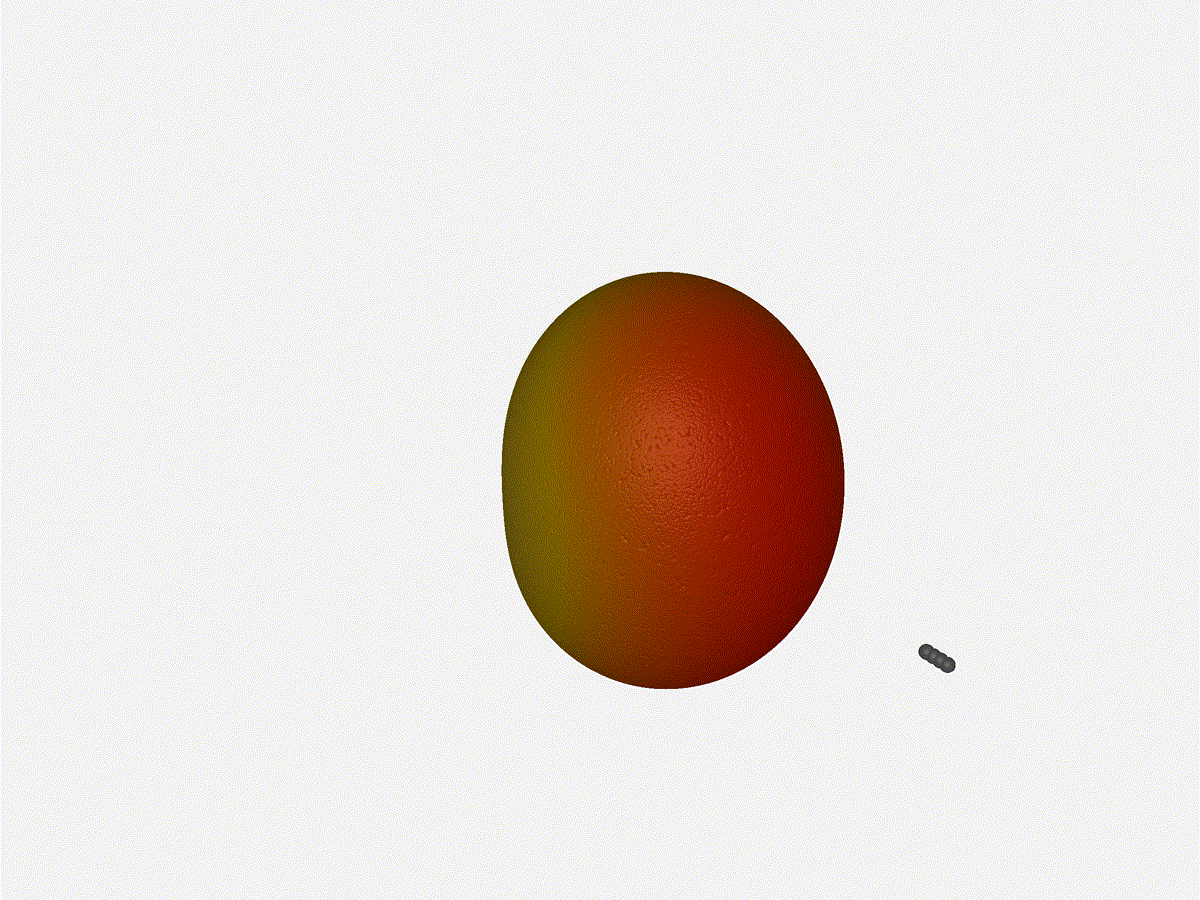In my previous blog post
Providing online reference documentation for debputy,
I made a point about how
debhelper documentation was suboptimal on account
of being static rather than online. The thing is that
debhelper is not alone
in this problem space, even if it is a major contributor to the number of
packaging files you have to to know about.
If we look at the "competition" here such as Fedora and Arch Linux, they tend to only
have one packaging file. While most Debian people will tell you a long list of cons
about having one packaging file (such a Fedora's spec file being 3+ domain specific
languages "mashed" into one file), one major advantage is that there is only
"the one packaging file". You only need to remember where to find the documentation
for one file, which is great when you are running on wetware with limited storage
capacity.
Which means as a newbie, you can dedicate less mental resources to tracking multiple
files and how they interact and more effort understanding the "one file" at hand.
I started by asking myself how can we in Debian make the packaging stack more
accessible to newcomers? Spoiler alert, I dug myself into rabbit hole and ended up
somewhere else than where I thought I was going.
I started by wanting to scan the debian directory and annotate all files that I
could with documentation links. The logic was that if
debputy could do that
for you, then you could spend more mental effort elsewhere. So I combined
debputy's packager provided files detection with a static list of files and
I quickly had a good starting point for
debputy-based packages.
Adding (non-static) dpkg and debhelper files to the mix
Now, I could have closed the topic here and said "Look, I did
debputy files
plus couple of super common files". But I decided to take it a bit further. I added
support for handling some
dpkg files like packager provided files (such as
debian/substvars and
debian/symbols). But even then, we all know that
debhelper is the big hurdle and a major part of the omission...
In another previous blog post (
A new Debian package helper: debputy),
I made a point about how
debputy could list all auxiliary files while
debhelper could not. This was exactly the kind of feature that I would need
for this feature, if this feature was to cover
debhelper. Now, I also
remarked in that blog post that I was not willing to maintain such a list.
Also, I may have ranted about static documentation being unhelpful for
debhelper as it excludes third-party provided tooling.
Fortunately, a recent update to
dh_assistant had provided some basic
plumbing for loading
dh sequences. This meant that getting a list of
all relevant commands for a source package was a lot easier than it used
to be. Once you have a list of commands, it would be possible to check
all of them for
dh's
NOOP PROMISE hints. In these hints, a command
can assert it does nothing if a given
pkgfile is not present. This
lead to the new
dh_assistant list-guessed-dh-config-files command
that will list all declared
pkgfiles and which helpers listed them.
With this combined feature set in place,
debputy could call
dh_assistant to get a list of
pkgfiles, pretend they were packager
provided files and annotate those along with manpage for the relevant
debhelper command. The exciting thing about letting
debpputy
resolve the
pkgfiles is that
debputy will resolve "named" files
automatically (
debhelper tools will only do so when
--name is
passed), so it is much more likely to detect named
pkgfiles
correctly too. Side note: I am going to ignore the elephant in the room
for now, which is
dh_installsystemd and its
package@.service files
and the wide-spread use of
debian/foo.service where there is no
package called
foo. For the latter case, the "proper" name would
be
debian/pkg.foo.service.
With the new
dh_assistant feature done and added to
debputy,
debputy could now detect the ubiquitous
debian/install file.
Excellent. But less great was that the very common
debian/docs
file was not. Turns out that
dh_installdocs cannot
be skipped by
dh, so it cannot have
NOOP PROMISE hints. Meh...
Well,
dh_assistant could learn about a new
INTROSPECTABLE marker
in addition to the
NOOP PROMISE and then I could sprinkle that into
a few commands. Indeed that worked and meant that
debian/postinst
(etc.) are now also detectable.
At this point,
debputy would be able to identify a wide range of
debhelper related configuration files in
debian/ and at least
associate each of them with one or more commands.
Nice, surely, this would be a good place to stop, right...?
Adding more metadata to the files
The
debhelper detected files only had a command name and manpage
URI to that command. It would be nice if we could contextualize this
a bit more.
Like is this file installed into the package as is like
debian/pam
or is it a file list to be processed like
debian/install. To make
this distinction, I could add the most common
debhelper file types
to my static list and then merge the result together.
Except, I do not want to maintain a full list in
debputy.
Fortunately,
debputy has a quite extensible plugin infrastructure,
so added a new plugin feature to provide this kind of detail and
now I can outsource the problem! I split my definitions into two and
placed the generic ones in the
debputy-documentation plugin and
moved the
debhelper related ones to
debhelper-documentation.
Additionally, third-party
dh addons could provide their own
debputy plugin to add context to their configuration files.
So, this gave birth file categories and configuration features, which
described each file on different fronts. As an example,
debian/gbp.conf could be tagged as a
maint-config to signal
that it is not directly related to the package build but more of a
tool or style preference file. On the other hand,
debian/install
and
debian/debputy.manifest would both be tagged as a
pkg-helper-config. Files like
debian/pam were
tagged as
ppf-file for packager provided file and so on.
I mentioned configuration features above and those were added
because, I have had a beef with
debhelper's "standard"
configuration file format as read by
filearray and
filedoublearray. They are often considered simple to
understand, but it is hard to know how a tool will actually read
the file. As an example, consider the following:
- Will the debhelper use filearray, filedoublearray
or none of them to read the file? This topic has about 2
bits of entropy.
- Will the config file be executed if it is marked executable
assuming you are using the right compat level? If it is
executable, does dh-exec allow renaming for this file?
This topic adds 1 or 2 bit of entropy depending on the
context.
- Will the config file be subject to glob expansions? This
topic sounds like a boolean but is a complicated mess.
The globs can be handled either by debhelper as it
parses the file for you. In this case, the globs are
applied to every token. However, this is not what
dh_install does. Here the last token on each line
is supposed to be a directory and therefore not subject
to globs. Therefore, dh_install does the globbing
itself afterwards but only on part of the tokens. So
that is about 2 bits of entropy more. Actually, it gets
worse...
- If the file is executed, debhelper will refuse to
expand globs in the output of the command, which was
a deliberate design choice by the original
debhelper maintainer took when he introduced the
feature in debhelper/8.9.12. Except, dh_install
feature interacts with the design choice and does
enable glob expansion in the tool output, because it
does so manually after its filedoublearray call.
So these "simple" files have way too many combinations of
how they can be interpreted. I figured it would be helpful
if
debputy could highlight these difference, so I added
support for those as well.
Accordingly,
debian/install is tagged with multiple
tags including
dh-executable-config and
dh-glob-after-execute. Then, I added a datatable of
these tags, so it would be easy for people to look up what
they meant.
Ok, this seems like a closed deal, right...?
Context, context, context
However, the dh-executable-config tag among other are
only applicable in compat 9 or later. It does not seem
newbie friendly if you are told that this feature exist,
but then have to read in the extended description that
that it actually does not apply to your package.
This problem seems fixable. Thanks to dh_assistant, it is
easy to figure out which compat level the package is using.
Then tweak some metadata to enable per compat level rules.
With that tags like dh-executable-config only appears
for packages using compat 9 or later.
Also, debputy should be able to tell you where packager
provided files like debian/pam are installed. We already
have the logic for packager provided files that debputy
supports and I am already using debputy engine for
detecting the files. If only the plugin provided metadata gave
me the install pattern, debputy would be able tell you
where this file goes in the package. Indeed, a bit of tweaking
later and setting install-pattern to
usr/lib/pam.d/ name , debputy presented me with the
correct install-path with the package name placing the
name placeholder.
Now, I have been using debian/pam as an example, because
debian/pam is installed into usr/lib/pam.d in compat
14. But in earlier compat levels, it was installed into
etc/pam.d. Well, I already had an infrastructure for doing
compat file tags. Off we go to add install-pattern to the
complat level infrastructure and now changing the compat level
would change the path. Great. (Bug warning: The value is
off-by-one in the current version of debhelper. This is
fixed in git)
Also, while we are in this install-pattern business, a
number of debhelper config files causes files to be
installed into a fixed directory. Like debian/docs which
causes file to be installed into /usr/share/docs/ package .
Surely, we can expand that as well and provide that bit of
context too... and done. (Bug warning: The code currently does
not account for the main documentation package context)
It is rather common pattern for people to do debian/foo.in
files, because they want to custom generation of
debian/foo. Which means if you have debian/foo you get
"Oh, let me tell you about debian/foo ". Then you rename it
to debian/foo.in and the result is "debian/foo.in is a
total mystery to me!". That is suboptimal, so lets detect those
as well as if they were the original file but add a tag saying
that they are a generate template and which file we suspect it
generates.
Finally, if you use debputy, almost all of the standard
debhelper commands are removed from the sequence, since
debputy replaces them. It would be weird if these commands
still contributed configuration files when they are not actually
going to be invoked. This mostly happened naturally due to the
way the underlying dh_assistant command works. However,
any file mentioned by the debhelper-documentation plugin
would still appear unfortunately. So off I went to filter
the list of known configuration files against which dh_
commands that dh_assistant thought would be used for this
package.
Wrapping it up
I was several layers into this and had to dig myself out.
I have ended up with a lot of data and metadata. But it
was quite difficult for me to arrange the output in a user
friendly manner.
However, all this data did seem like it would be useful any
tool that wants to understand more about the package.
So to get out of the rabbit hole, I for now
wrapped all of this into JSON and now we have a
debputy tool-support annotate-debian-directory
command that might be useful for other tools.
To try it out, you can try the following demo:
In another day, I will figure out how to structure this output so it is
useful for non-machine consumers. Suggestions are welcome. :)
Limitations of the approach
As a closing remark, I should probably remind people that this feature relies
heavily on declarative features. These include:
- When determining which commands are relevant, using Build-Depends: dh-sequence-foo
is much more reliable than configuring it via the Turing complete configuration we call
debian/rules.
- When debhelper commands use NOOP promise hints, dh_assistant can
"see" the config files listed those hints, meaning the file will at least
be detected. For new introspectable hint and the debputy plugin, it is probably
better to wait until the dust settles a bit before adding any of those.
You can help yourself and others to better results by using the declarative way rather
than using
debian/rules, which is the bane of all introspection!
 Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they ve kicked me off Go Roam, so I ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don t expect to use all of the data allowance, but I didn t want to have to worry about unexpected excess charges.
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they ve kicked me off Go Roam, so I ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don t expect to use all of the data allowance, but I didn t want to have to worry about unexpected excess charges.
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
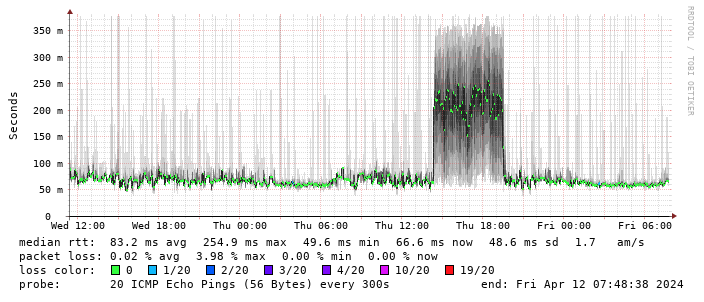 (There s a handy zte.js script to allow doing this from the device web interface.)
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
(There s a handy zte.js script to allow doing this from the device web interface.)
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
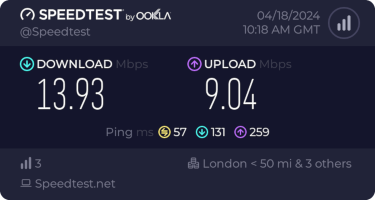 This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
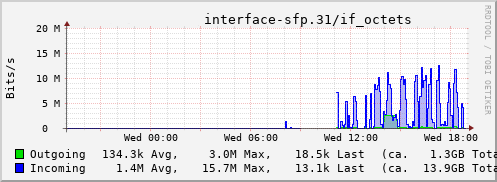 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
 On Mastodon, the
On Mastodon, the
 Closing arguments in the trial between various people and
Closing arguments in the trial between various people and  My brain is currently suffering from an overload caused by grading student
assignments.
In search of a somewhat productive way to procrastinate, I thought I
would share a small script I wrote sometime in 2023 to facilitate my grading
work.
I use Moodle for all the classes I teach and students use it to hand me out
their papers. When I'm ready to grade them, I download the ZIP archive Moodle
provides containing all their PDF files and comment them
My brain is currently suffering from an overload caused by grading student
assignments.
In search of a somewhat productive way to procrastinate, I thought I
would share a small script I wrote sometime in 2023 to facilitate my grading
work.
I use Moodle for all the classes I teach and students use it to hand me out
their papers. When I'm ready to grade them, I download the ZIP archive Moodle
provides containing all their PDF files and comment them  Thrilled to share that a new version of
Thrilled to share that a new version of  The key idea of
The key idea of 
 Update 28.02.2024 19:45 CET: There is now a blog entry at
Update 28.02.2024 19:45 CET: There is now a blog entry at  How can I not have done one of these for Propaganda already?
How can I not have done one of these for Propaganda already?

 If you ve perused the
If you ve perused the  Insert obligatory "not THAT data" comment here
Insert obligatory "not THAT data" comment here
 If you don't know who Professor Julius Sumner Miller is, I highly recommend
If you don't know who Professor Julius Sumner Miller is, I highly recommend  No thanks, Bender, I'm busy tonight
No thanks, Bender, I'm busy tonight

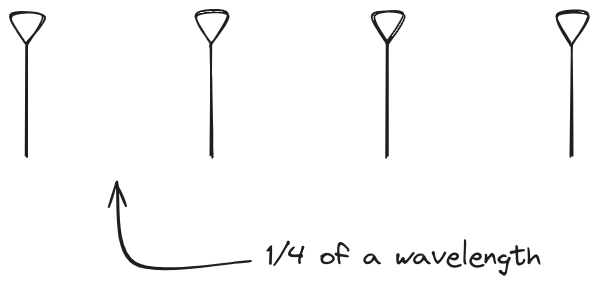 And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
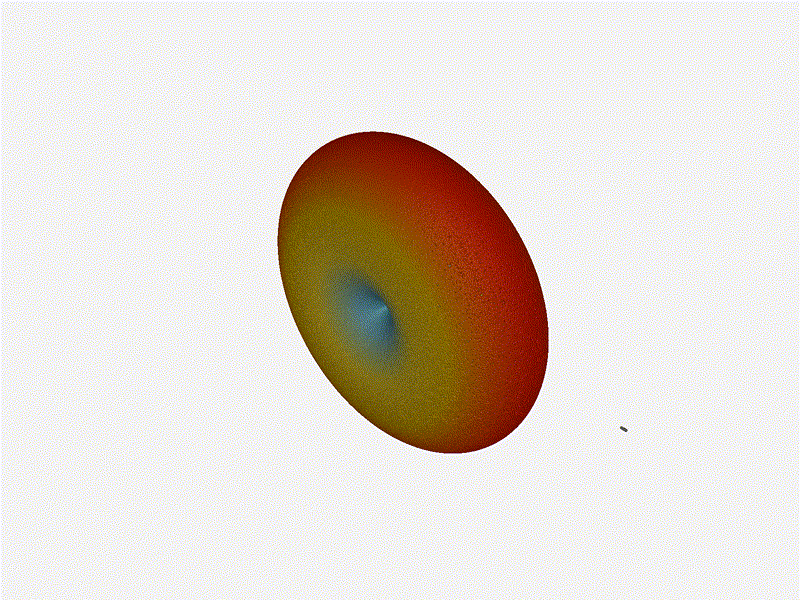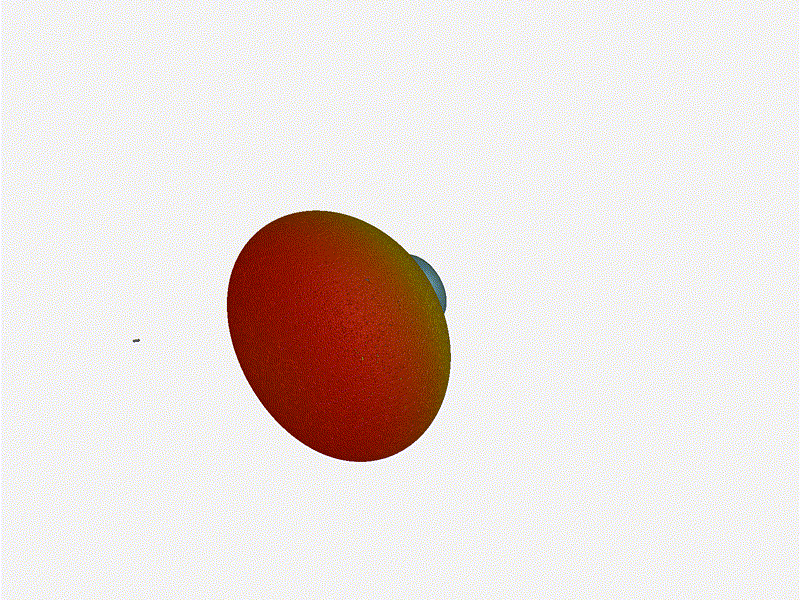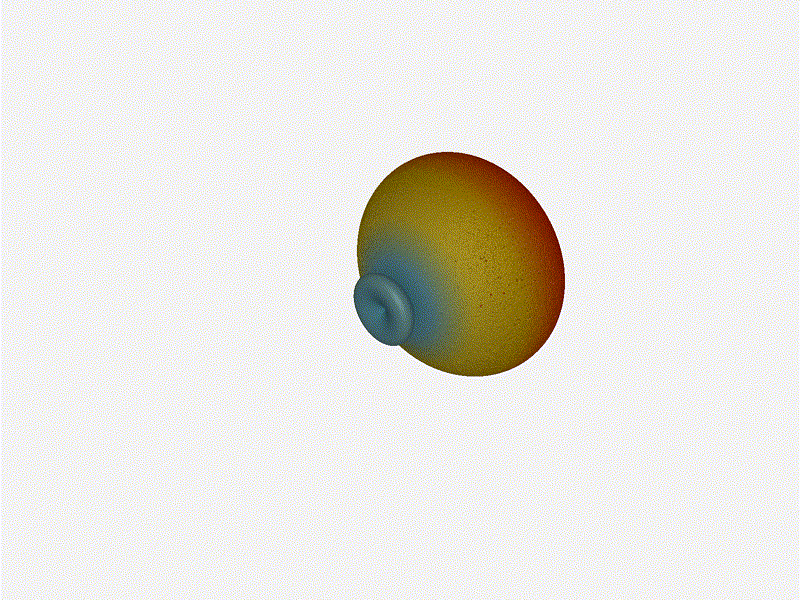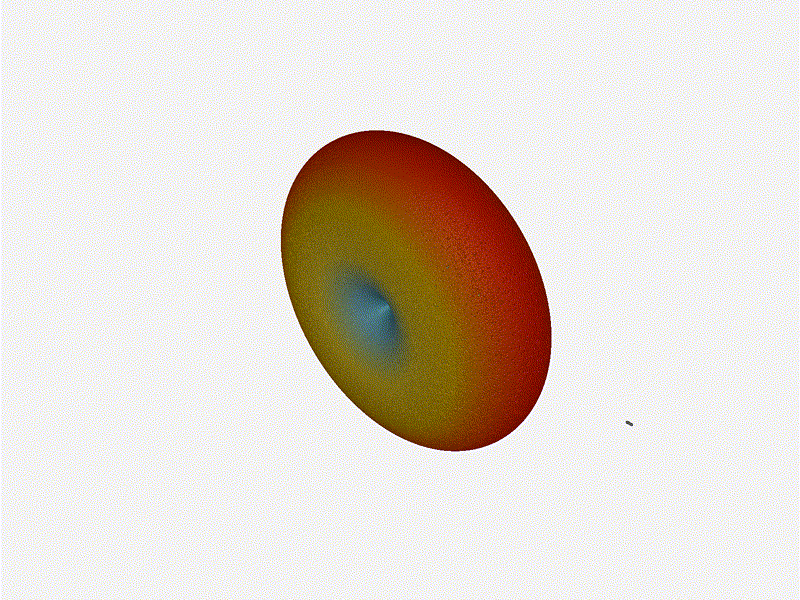
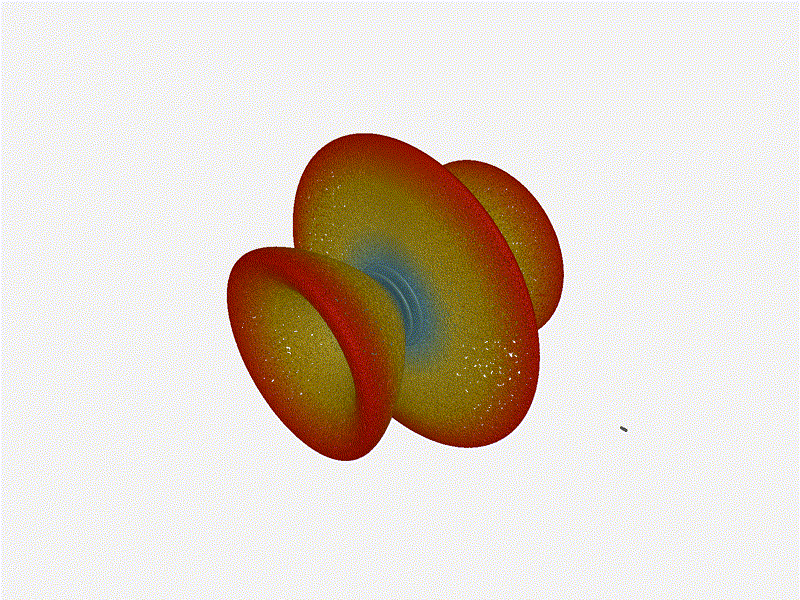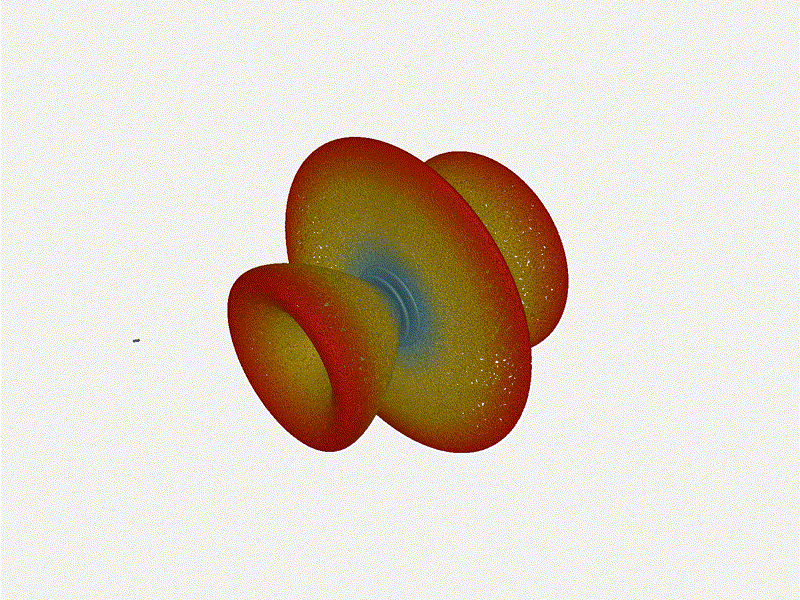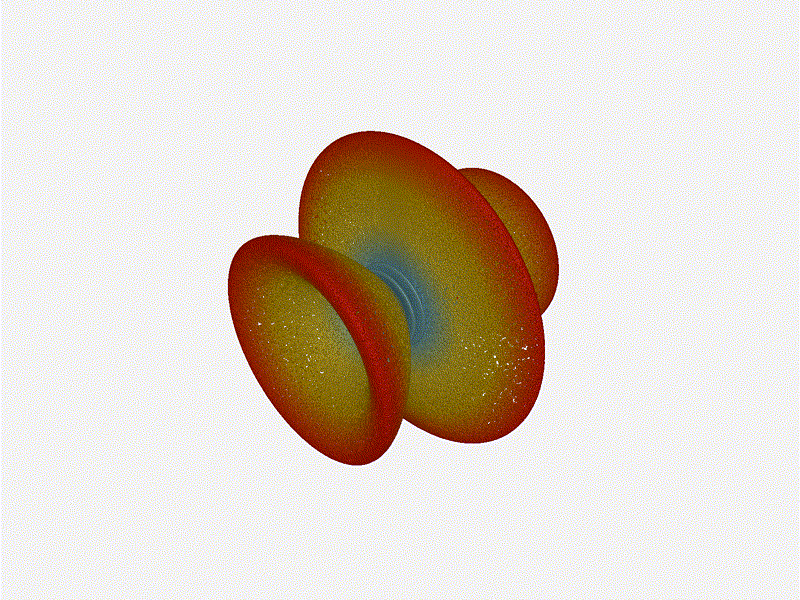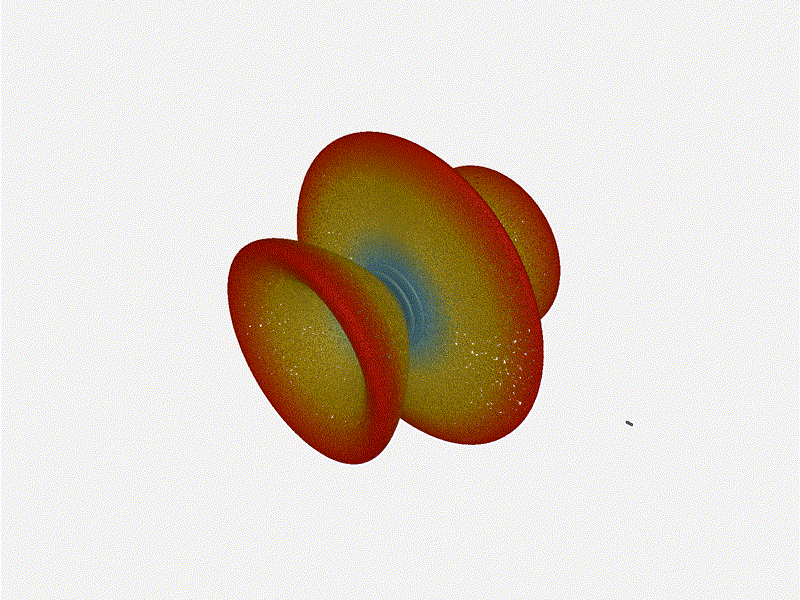

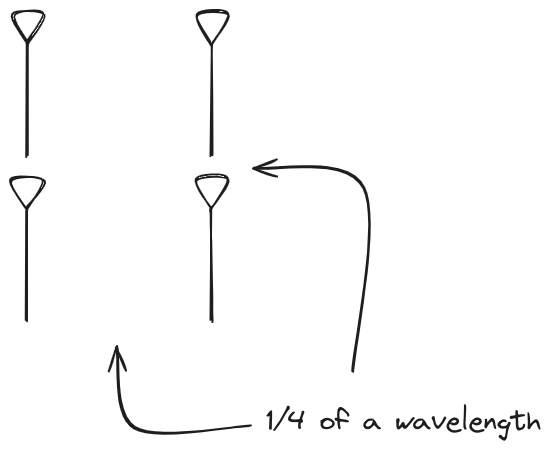 Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.