Freexian Collaborators: Debian Contributions: SSO Authentication for jitsi.debian.social, /usr-move updates, and more! (by Utkarsh Gupta)
 Contributing to Debian
is part of Freexian s mission. This article
covers the latest achievements of Freexian and their collaborators. All of this
is made possible by organizations subscribing to our
Long Term Support contracts and
consulting services.
P.S. We ve completed over a year of writing these blogs. If you have any
suggestions on how to make them better or what you d like us to cover, or any
other opinions/reviews you might have, et al, please let us know by dropping an
email to us. We d be
happy to hear your thoughts. :)
Contributing to Debian
is part of Freexian s mission. This article
covers the latest achievements of Freexian and their collaborators. All of this
is made possible by organizations subscribing to our
Long Term Support contracts and
consulting services.
P.S. We ve completed over a year of writing these blogs. If you have any
suggestions on how to make them better or what you d like us to cover, or any
other opinions/reviews you might have, et al, please let us know by dropping an
email to us. We d be
happy to hear your thoughts. :)
SSO Authentication for jitsi.debian.social, by Stefano Rivera
Debian.social s jitsi instance has been getting
some abuse by (non-Debian) people sharing sexually explicit content on the
service. After playing whack-a-mole with this for a month, and shutting the
instance off for another month, we opened it up again and the abuse immediately
re-started.
Stefano sat down and wrote an
SSO Implementation
that hooks into Jitsi s existing JWT SSO support. This requires everyone using
jitsi.debian.social to have a Salsa account.
With only a little bit of effort, we could change this in future, to only
require an account to open a room, and allow guests to join the call.
/usr-move, by Helmut Grohne
The biggest task this month was sending mitigation patches for all of the
/usr-move issues arising from package renames due to the 2038 transition. As a
result, we can now say that every affected package in unstable can either be
converted with dh-sequence-movetousr or has an open bug report. The package
set relevant to debootstrap except for the set that has to be uploaded
concurrently has been moved to /usr and is awaiting migration. The move of
coreutils happened to affect piuparts which hard codes the location of
/bin/sync and received multiple updates as a result.
Miscellaneous contributions
- Stefano Rivera uploaded a stable release update to python3.11 for bookworm,
fixing a use-after-free crash.
- Stefano uploaded a new version of python-html2text, and updated
python3-defaults to build with it.
- In support of Python 3.12, Stefano dropped distutils as a Build-Dependency
from a few packages, and uploaded a complex set of patches to python-mitogen.
- Stefano landed some merge requests to clean up dead code in dh-python,
removed the flit plugin, and uploaded it.
- Stefano uploaded new upstream versions of twisted, hatchling,
python-flexmock, python-authlib, python mitogen, python-pipx, and xonsh.
- Stefano requested removal of a few packages supporting the Opsis HDMI2USB
hardware that DebConf Video team used to use for HDMI capture, as they are
not being maintained upstream. They started to FTBFS, with recent sdcc
changes.
- DebConf 24 is getting ready to open registration, Stefano spent some time
fixing bugs in the website, caused by infrastructure updates.
- Stefano reviewed all the DebConf 23 travel reimbursements, filing requests
for more information from SPI where our records mismatched.
- Stefano spun up a Wafer website for the
Berlin 2024 mini DebConf.
- Roberto C. S nchez worked on facilitating the transfer of upstream
maintenance responsibility for the dormant Shorewall project to a new team
led by the current maintainer of the Shorewall packages in Debian.
- Colin Watson fixed build failures in celery-haystack-ng, db1-compat,
jsonpickle, libsdl-perl, kali, knews, openssh-ssh1,
python-json-log-formatter, python-typing-extensions, trn4, vigor, and
wcwidth. Some of these were related to the 64-bit time_t transition, since
that involved enabling
-Werror=implicit-function-declaration.
- Colin fixed an
off-by-one error in neovim,
which was already causing a build failure in Ubuntu and would eventually have
caused a build failure in Debian with stricter toolchain settings.
- Colin added an sshd@.service template to
openssh to help newer systemd versions make containers and VMs SSH-accessible
over AF_VSOCK sockets.
- Following the xz-utils backdoor, Colin
spent some time testing and discussing OpenSSH upstream s proposed
inline systemd notification patch,
since the current implementation via libsystemd was part of the attack vector
used by that backdoor.
- Utkarsh reviewed and sponsored some Go packages for Lena Voytek and Rajudev.
- Utkarsh also helped Mitchell Dzurick with the adoption of pyparted package.
- Helmut sent 10 patches for cross build failures.
- Helmut partially fixed architecture cross bootstrap tooling to deal with
changes in
linux-libc-dev and the recent gcc-for-host changes and also
fixed a 64bit-time_t FTBFS in libtextwrap.
- Thorsten Alteholz uploaded several packages from debian-printing: cjet,
lprng, rlpr and epson-inkjet-printer-escpr were affected by the newly enabled
compiler switch -Werror=implicit-function-declaration. Besides fixing these
serious bugs, Thorsten also worked on other bugs and could fix one or the
other.
- Carles updated simplemonitor and python-ring-doorbell packages with new
upstream versions.
- Santiago is still working on the Salsa CI MRs to adapt the build jobs so they
can rely on sbuild. Current work includes
adapting the images used by the build job,
implementing the basic sbuild support the related jobs,
and adjusting the support for experimental and *-backports releases..
Additionally, Santiago reviewed some MR such as
Make timeout action explicit in the logs
and the subsequent
Implement conditional timeout verbosity,
and the batch of MRs included in
https://salsa.debian.org/salsa-ci-team/pipeline/-/merge_requests/482.
- Santiago also reviewed applications for the
improving Salsa CI in Debian
GSoC 2024 project. We received applications from four very talented
candidates. The selection process is currently ongoing. A huge thanks to all
of them!
- As part of the DebConf 24 organization, Santiago has taken part in the
Content team discussions.
dh-sequence-movetousr or has an open bug report. The package
set relevant to debootstrap except for the set that has to be uploaded
concurrently has been moved to /usr and is awaiting migration. The move of
coreutils happened to affect piuparts which hard codes the location of
/bin/sync and received multiple updates as a result.
Miscellaneous contributions
- Stefano Rivera uploaded a stable release update to python3.11 for bookworm,
fixing a use-after-free crash.
- Stefano uploaded a new version of python-html2text, and updated
python3-defaults to build with it.
- In support of Python 3.12, Stefano dropped distutils as a Build-Dependency
from a few packages, and uploaded a complex set of patches to python-mitogen.
- Stefano landed some merge requests to clean up dead code in dh-python,
removed the flit plugin, and uploaded it.
- Stefano uploaded new upstream versions of twisted, hatchling,
python-flexmock, python-authlib, python mitogen, python-pipx, and xonsh.
- Stefano requested removal of a few packages supporting the Opsis HDMI2USB
hardware that DebConf Video team used to use for HDMI capture, as they are
not being maintained upstream. They started to FTBFS, with recent sdcc
changes.
- DebConf 24 is getting ready to open registration, Stefano spent some time
fixing bugs in the website, caused by infrastructure updates.
- Stefano reviewed all the DebConf 23 travel reimbursements, filing requests
for more information from SPI where our records mismatched.
- Stefano spun up a Wafer website for the
Berlin 2024 mini DebConf.
- Roberto C. S nchez worked on facilitating the transfer of upstream
maintenance responsibility for the dormant Shorewall project to a new team
led by the current maintainer of the Shorewall packages in Debian.
- Colin Watson fixed build failures in celery-haystack-ng, db1-compat,
jsonpickle, libsdl-perl, kali, knews, openssh-ssh1,
python-json-log-formatter, python-typing-extensions, trn4, vigor, and
wcwidth. Some of these were related to the 64-bit time_t transition, since
that involved enabling
-Werror=implicit-function-declaration.
- Colin fixed an
off-by-one error in neovim,
which was already causing a build failure in Ubuntu and would eventually have
caused a build failure in Debian with stricter toolchain settings.
- Colin added an sshd@.service template to
openssh to help newer systemd versions make containers and VMs SSH-accessible
over AF_VSOCK sockets.
- Following the xz-utils backdoor, Colin
spent some time testing and discussing OpenSSH upstream s proposed
inline systemd notification patch,
since the current implementation via libsystemd was part of the attack vector
used by that backdoor.
- Utkarsh reviewed and sponsored some Go packages for Lena Voytek and Rajudev.
- Utkarsh also helped Mitchell Dzurick with the adoption of pyparted package.
- Helmut sent 10 patches for cross build failures.
- Helmut partially fixed architecture cross bootstrap tooling to deal with
changes in
linux-libc-dev and the recent gcc-for-host changes and also
fixed a 64bit-time_t FTBFS in libtextwrap.
- Thorsten Alteholz uploaded several packages from debian-printing: cjet,
lprng, rlpr and epson-inkjet-printer-escpr were affected by the newly enabled
compiler switch -Werror=implicit-function-declaration. Besides fixing these
serious bugs, Thorsten also worked on other bugs and could fix one or the
other.
- Carles updated simplemonitor and python-ring-doorbell packages with new
upstream versions.
- Santiago is still working on the Salsa CI MRs to adapt the build jobs so they
can rely on sbuild. Current work includes
adapting the images used by the build job,
implementing the basic sbuild support the related jobs,
and adjusting the support for experimental and *-backports releases..
Additionally, Santiago reviewed some MR such as
Make timeout action explicit in the logs
and the subsequent
Implement conditional timeout verbosity,
and the batch of MRs included in
https://salsa.debian.org/salsa-ci-team/pipeline/-/merge_requests/482.
- Santiago also reviewed applications for the
improving Salsa CI in Debian
GSoC 2024 project. We received applications from four very talented
candidates. The selection process is currently ongoing. A huge thanks to all
of them!
- As part of the DebConf 24 organization, Santiago has taken part in the
Content team discussions.
-Werror=implicit-function-declaration.linux-libc-dev and the recent gcc-for-host changes and also
fixed a 64bit-time_t FTBFS in libtextwrap.Additionally, Santiago reviewed some MR such as Make timeout action explicit in the logs and the subsequent Implement conditional timeout verbosity, and the batch of MRs included in https://salsa.debian.org/salsa-ci-team/pipeline/-/merge_requests/482.
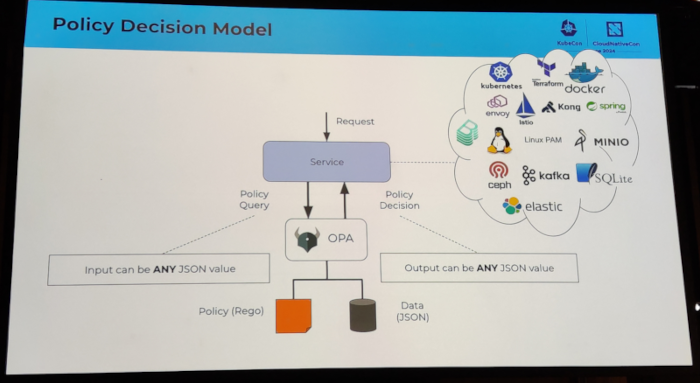 I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
I attended several sessions related to authentication topics. I discovered the keycloak software, which looks very
promising. I also attended an Oauth2 session which I had a hard time following, because I clearly missed some additional
knowledge about how Oauth2 works internally.
I also attended a couple of sessions that ended up being a vendor sales talk.
See also:
 I very recently missed some semantics for limiting the number of open connections per namespace, see
I very recently missed some semantics for limiting the number of open connections per namespace, see 













 In light of the recent
In light of the recent  I realize it s a bit late to start publicly organizing this, but better late
than never I m happy some Debian people I have directly contacted have
already expressed interest. So, lets make this public!
I realize it s a bit late to start publicly organizing this, but better late
than never I m happy some Debian people I have directly contacted have
already expressed interest. So, lets make this public!
 For all interested people who are reasonably close to central Argentina, or can
be persuaded to come here in a month s time You are all welcome!
It seems I managed to convince my good friend Mart n Bayo (some Debian people
will remember him, as he was present in DebConf19 in Curitiba, Brazil) to get
some facilities for us to have a nice Debian get-together in Central Argentina.
For all interested people who are reasonably close to central Argentina, or can
be persuaded to come here in a month s time You are all welcome!
It seems I managed to convince my good friend Mart n Bayo (some Debian people
will remember him, as he was present in DebConf19 in Curitiba, Brazil) to get
some facilities for us to have a nice Debian get-together in Central Argentina.


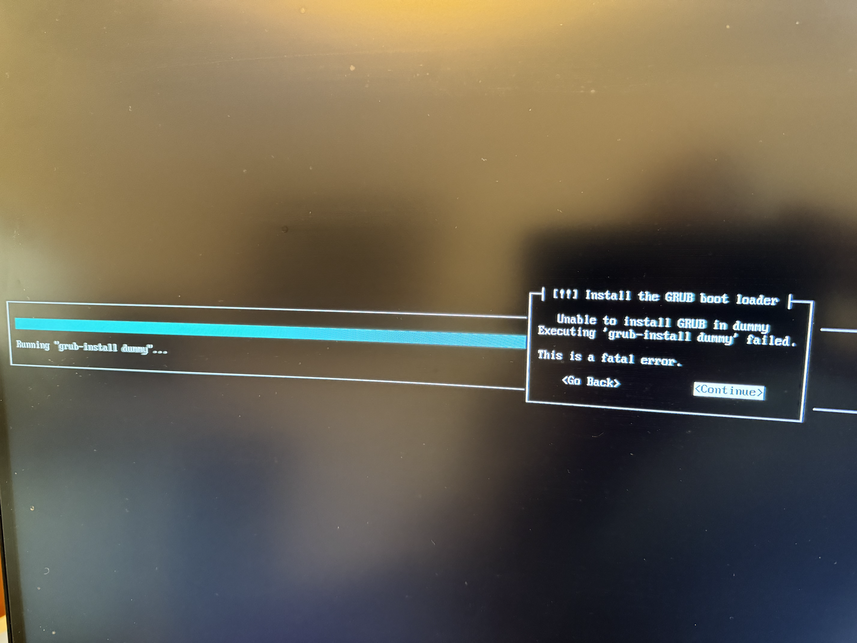
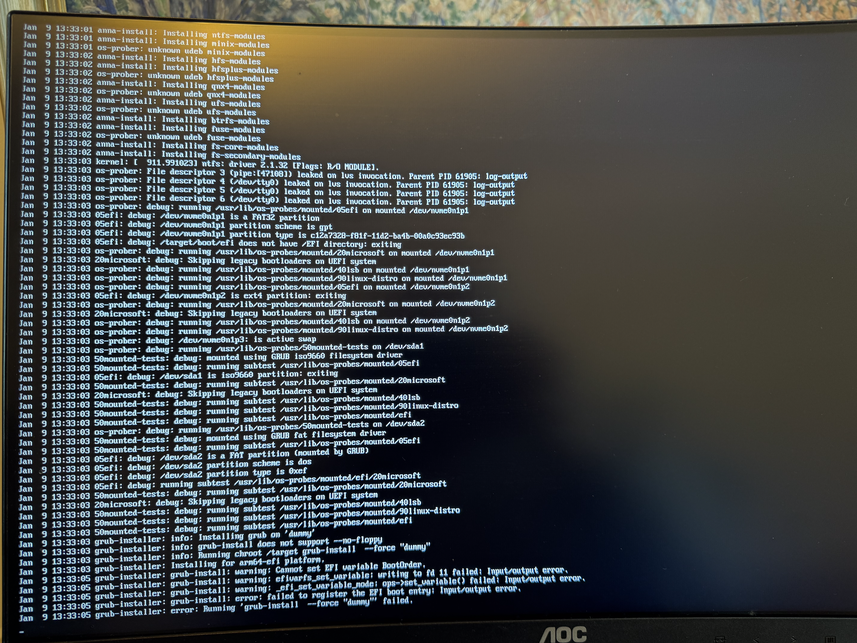
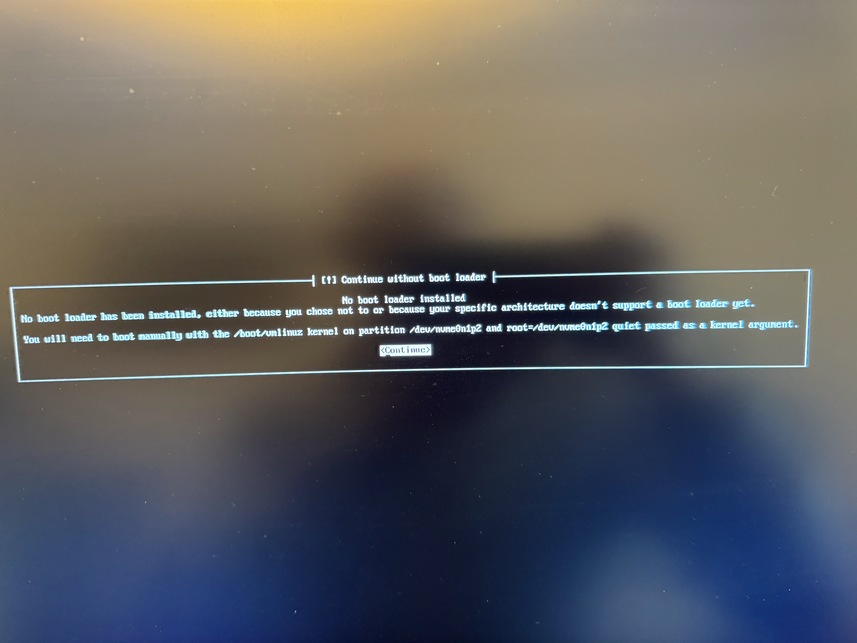
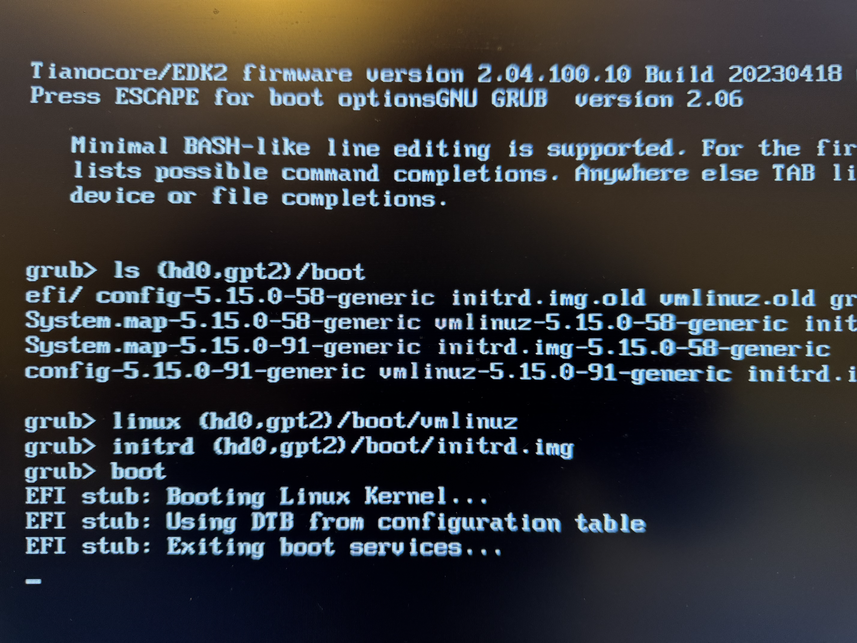
 Now copy the ISO image to the newly created instance and extract
its data:
Now copy the ISO image to the newly created instance and extract
its data:
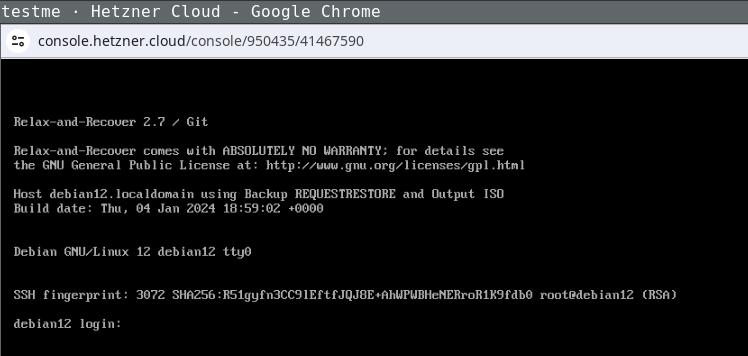 Login the recovery console (root without password) and fix its default route to
make it reachable:
Login the recovery console (root without password) and fix its default route to
make it reachable:
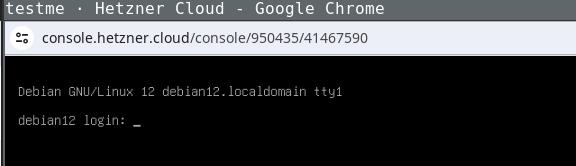 Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
 Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.
Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.







 Check it out
Check it out 

