 This post was originally published in the Wikimedia Tech blog, authored by
Arturo Borrero Gonzalez.
This post was originally published in the Wikimedia Tech blog, authored by
Arturo Borrero Gonzalez.
NFS is a central piece of infrastructure that is essential to services like Toolforge.
Recently, the Cloud Services team at Wikimedia had been reviewing how we do NFS.
The current situation
NFS is a central piece of technology for some of the services that the
Wikimedia Cloud Services team offers to the community. We have several shares that power
different use cases:
Toolforge user home directories live on NFS, and
Cloud VPS users can also access dumps using this protocol. The current setup involves
several physical hardware servers, with about 20TB of storage, offering shares over 10G links to
the cloud. For the system to be more fault-tolerant, we duplicate each share for redundancy using
DRBD.
Running NFS on dedicated hardware servers has traditionally offered us advantages: mostly on the
performance and the capacity fields.
As time has passed, we have been enumerating more and more reasons to review how we do NFS. For
one, the current setup is in violation of some of
our internal rules regarding realm separation.
Additionally, we had been longing for additional flexibility managing our servers: we wanted to use
virtual machines managed by
Openstack Nova. The DRBD-based high-availability system
required mostly a hand-crafted procedure for failover/failback. There s also some scalability
concerns as NFS is easy to grow up, but not to grow horizontally, and of course, we have to be able
to keep the tenancy setup while doing so, something that NFS does by using LDAP/Unix users and may
get complicated too when growing. In general, the servers have become too big to fail , clearly
technical debt, and it has taken us years to decide on taking on the task to rethink the
architecture. It s worth mentioning that in an ideal world, we wouldn t depend on NFS, but the
truth is that it will still be a central piece of infrastructure for years to come in services like
Toolforge.
Over a series of brainstorming meetings, the WMCS team evaluated the situation and sorted out the
many moving parts. The team managed to boil down the potential service future to two competing
options:
- Adopt and introduce a new Openstack component into our cloud: Manila this was the right choice
if we were interested in a general NFS as a service offering for our Cloud VPS users.
- Put the data on Cinder volumes and serve NFS from a couple of virtual machines created by hand
this was the right choice if we wanted something that required low effort to engineer and adopt.
Then we decided to research both options in parallel. For a number of reasons, the evaluation was
timeboxed to three weeks. Both ideas had a couple of points in common: the NFS data would be stored
on our
Ceph farm via Cinder volumes, and we would rely on Ceph reliability to avoid using DRBD.
Another open topic was how to back up data from Ceph, to store our important bits in more than one
basket. We will get to the back up topic later.
The manila experiment
The Wikimedia Foundation was an early adopter of some Openstack components (
Nova,
Glance,
Designate,
Horizon), but
Manila was never
evaluated for usage until now. Our approach for this experiment was to closely follow the upstream
guidelines. We read the documentation and tried to understand the different setups you can build
with Manila. As we often feel with other Openstack components, the documentation doesn t perfectly
describe how to introduce a given component in your particular local setup. Here we use an
admin-controller flat-topology Neutron network. This network is shared by all tenants (or projects)
in our Openstack deployment. Also, Manila can use many
different driver backends, for
things like NetApps or CephFS that we don t use , yet. After some research, the
generic driver was the one that seemed to better fit our use case. The generic driver
leverages Nova virtual machines instances plus Cinder volume to create and manage the shares. In
general, Manila supports two operational modes, whether it should create/destroy the share servers
(i.e, the virtual machine instances) or not. This option is called driver_handles_share_server (or
DHSS) and takes a boolean value.
We were interested in trying with DHSS=true, to really benefit from the potential of the setup.
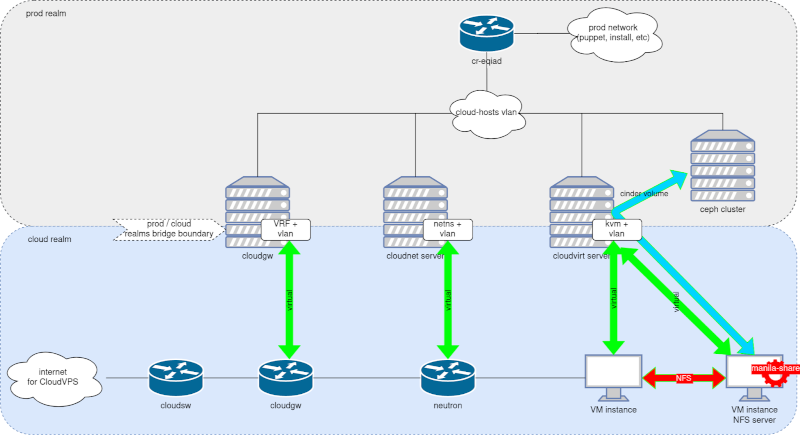 NFS idea 6, original image in Wikitech
NFS idea 6, original image in Wikitech
So, after sorting all these variables, we moved on with our initial testing. We built a PoC setup
as depicted in the diagram above, with the manila-share component running in a virtual machine
inside the cloud. The PoC led to us reporting several bugs upstream:
In some cases we tried to address these bugs ourselves:
It s worth mentioning that the upstream community was extra-welcoming to us, and we re thankful for
that. However, at the end of our three-week period, our Manila setup still wasn t working as
expected. Your experience may change with other drivers perhaps the ZFSonLinux or the CephFS ones.
In general, we were having trouble making the setup work as expected, so we decided to abandon this
approach in favor of the other option we were considering at the beginning.
Simple virtual machine serving NFS
The alternative was to create a Nova virtual machine instance by hand and to configure it using
puppet. We have been investing in an
automation framework lately, so the idea is to
not actually create the server by hand. Anyway, the data would be decoupled from the instance into
Cinder volumes, which led us to the question we left for later: How should we back up those
terabytes of important information? Just to be clear, the backup problem was independent of the above
options; with Manila we would still have had to solve the same challenge. We would like to see our
data be backed up somewhere else other than in Ceph. And that s exactly where we are at right now.
We ve been exploring
different backup strategies and will finally use the Cinder backup
API.
Conclusion
The iteration will end with the dedicated NFS hardware servers being stopped, and the shares being
served from within the cloud. The migration will take some time to happen because we will check and
double-check that everything works as expected (including from the performance point of view)
before making definitive changes. We already have some plans to make sure our users experience as
little service impact as possible. The most troublesome shares will be those related to Toolforge.
At some point we will need to disallow writes to the NFS share, rsync the data out of the hardware
servers into the Cinder volumes, point the NFS clients to the new virtual machines, and then enable
writes again. The main Toolforge share has about 8TB of data, so this will take a while.
We will have more updates in the future. Who knows, perhaps our next-next iteration, in a couple of
years, will see us adopting Openstack Manila for good.
Featured image credit:
File:(from break water) Manila Skyline panoramio.jpg,
ewol,
CC BY-SA 3.0
This post was originally published in the Wikimedia Tech blog, authored
by Arturo Borrero Gonzalez.


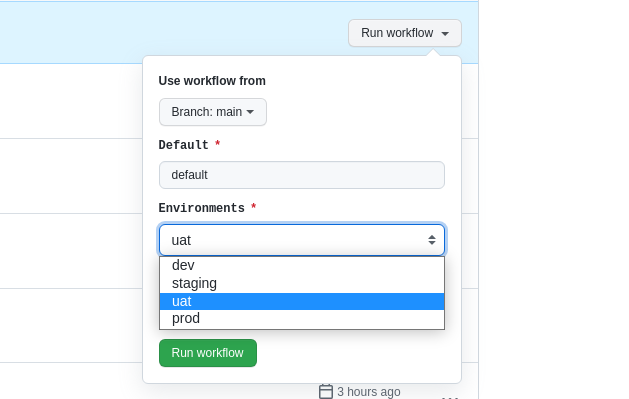
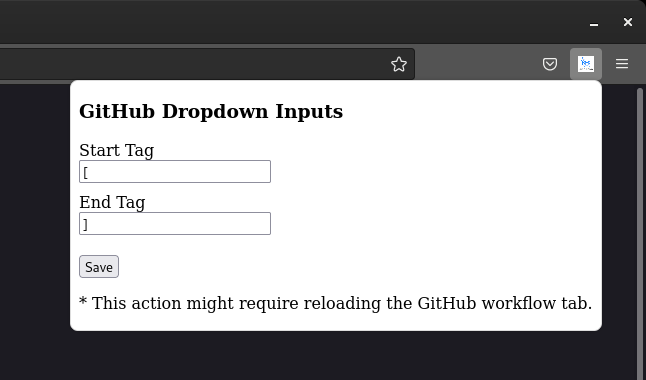
 So I decided to create a solution for this, always thinking about simplicity and in a way that makes it easy to get this missing functionality. I started by creating an input array pattern using
So I decided to create a solution for this, always thinking about simplicity and in a way that makes it easy to get this missing functionality. I started by creating an input array pattern using 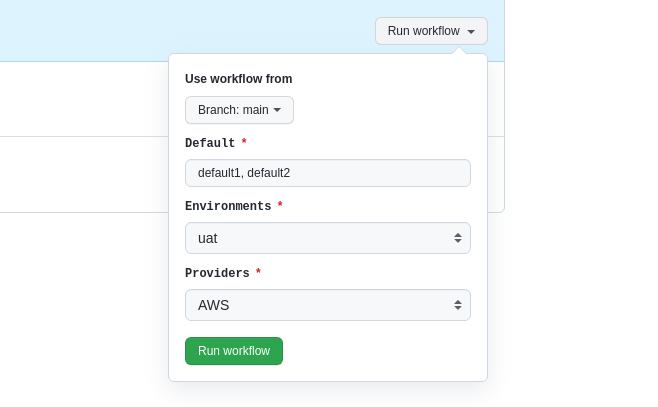
 What happened in the
What happened in the 

.png){kind=link}
_Manila_Skyline_-_panoramio.jpg){kind=link}
{kind=link}