Russell Coker: The Shape of Computers
Introduction
There have been many experiments with the sizes of computers, some of which have stayed around and some have gone away. The trend has been to make computers smaller, the early computers had buildings for them. Recently for come classes computers have started becoming as small as could be reasonably desired. For example phones are thin enough that they can blow away in a strong breeze, smart watches are much the same size as the old fashioned watches they replace, and NUC type computers are as small as they need to be given the size of monitors etc that they connect to.
This means that further development in the size and shape of computers will largely be determined by human factors.
I think we need to consider how computers might be developed to better suit humans and how to write free software to make such computers usable without being constrained by corporate interests.
Those of us who are involved in developing OSs and applications need to consider how to adjust to the changes and ideally anticipate changes. While we can t anticipate the details of future devices we can easily predict general trends such as being smaller, higher resolution, etc.
Desktop/Laptop PCs
When home computers first came out it was standard to have the keyboard in the main box, the Apple ][ being the most well known example. This has lost popularity due to the demand to have multiple options for a light keyboard that can be moved for convenience combined with multiple options for the box part. But it still pops up occasionally such as the Raspberry Pi 400 [1] which succeeds due to having the computer part being small and light. I think this type of computer will remain a niche product. It could be used in a add a screen to make a laptop as opposed to the add a keyboard to a tablet to make a laptop model but a tablet without a keyboard is more useful than a non-server PC without a display.
The PC as box with connections for keyboard, display, etc has a long future ahead of it. But the sizes will probably decrease (they should have stopped making PC cases to fit CD/DVD drives at least 10 years ago). The NUC size is a useful option and I think that DVD drives will stop being used for software soon which will allow a range of smaller form factors.
The regular laptop is something that will remain useful, but the tablet with detachable keyboard devices could take a lot of that market. Full functionality for all tasks requires a keyboard because at the moment text editing with a touch screen is an unsolved problem in computer science [2].
The Lenovo Thinkpad X1 Fold [3] and related Lenovo products are very interesting. Advances in materials allow laptops to be thinner and lighter which leaves the screen size as a major limitation to portability. There is a conflict between desiring a large screen to see lots of content and wanting a small size to carry and making a device foldable is an obvious solution that has recently become possible. Making a foldable laptop drives a desire for not having a permanently attached keyboard which then makes a touch screen keyboard a requirement. So this means that user interfaces for PCs have to be adapted to work well on touch screens. The Think line seems to be continuing the history of innovation that it had when owned by IBM. There are also a range of other laptops that have two regular screens so they are essentially the same as the Thinkpad X1 Fold but with two separate screens instead of one folding one, prices are as low as $600US.
I think that the typical interfaces for desktop PCs (EG MS-Windows and KDE) don t work well for small devices and touch devices and the Android interface generally isn t a good match for desktop systems. We need to invent more options for this. This is not a criticism of KDE, I use it every day and it works well. But it s designed for use cases that don t match new hardware that is on sale. As an aside it would be nice if Lenovo gave samples of their newest gear to people who make significant contributions to GUIs. Give a few Thinkpad Fold devices to KDE people, a few to GNOME people, and a few others to people involved in Wayland development and see how that promotes software development and future sales.
We also need to adopt features from laptops and phones into desktop PCs. When voice recognition software was first released in the 90s it was for desktop PCs, it didn t take off largely because it wasn t very accurate (none of them recognised my voice). Now voice recognition in phones is very accurate and it s very common for desktop PCs to have a webcam or headset with a microphone so it s time for this to be re-visited. GPS support in laptops is obviously useful and can work via Wifi location, via a USB GPS device, or via wwan mobile phone hardware (even if not used for wwan networking). Another possibility is using the same software interfaces as used for GPS on laptops for a static definition of location for a desktop PC or server.
The Interesting New Things
Watch Like
The wrist-watch [4] has been a standard format for easy access to data when on the go since it s military use at the end of the 19th century when the practical benefits beat the supposed femininity of the watch. So it seems most likely that they will continue to be in widespread use in computerised form for the forseeable future. For comparison smart phones have been in widespread use as pocket watches for about 10 years.
The question is how will watch computers end up? Will we have Dick Tracy style watch phones that you speak into? Will it be the current smart watch functionality of using the watch to answer a call which goes to a bluetooth headset? Will smart watches end up taking over the functionality of the calculator watch [5] which was popular in the 80 s? With today s technology you could easily have a fully capable PC strapped to your forearm, would that be useful?
Phone Like
Folding phones (originally popularised as Star Trek Tricorders) seem likely to have a long future ahead of them. Engineering technology has only recently developed to the stage of allowing them to work the way people would hope them to work (a folding screen with no gaps). Phones and tablets with multiple folds are coming out now [6]. This will allow phones to take much of the market share that tablets used to have while tablets and laptops merge at the high end. I ve previously written about Convergence between phones and desktop computers [7], the increased capabilities of phones adds to the case for Convergence.
Folding phones also provide new possibilities for the OS. The Oppo OnePlus Open and the Google Pixel Fold both have a UI based around using the two halves of the folding screen for separate data at some times. I think that the current user interfaces for desktop PCs don t properly take advantage of multiple monitors and the possibilities raised by folding phones only adds to the lack. My pet peeve with multiple monitor setups is when they don t make it obvious which monitor has keyboard focus so you send a CTRL-W or ALT-F4 to the wrong screen by mistake, it s a problem that also happens on a single screen but is worse with multiple screens. There are rumours of phones described as three fold (where three means the number of segments with two folds between them), it will be interesting to see how that goes.
Will phones go the same way as PCs in terms of having a separation between the compute bit and the input device? It s quite possible to have a compute device in the phone form factor inside a secure pocket which talks via Bluetooth to another device with a display and speakers. Then you could change your phone between a phone-size display and a tablet sized display easily and when using your phone a thief would not be able to easily steal the compute bit (which has passwords etc). Could the watch part of the phone (strapped to your wrist and difficult to steal) be the active part and have a tablet size device as an external display? There are already announcements of smart watches with up to 1GB of RAM (same as the Samsung Galaxy S3), that s enough for a lot of phone functionality.
The Rabbit R1 [8] and the Humane AI Pin [9] have some interesting possibilities for AI speech interfaces. Could that take over some of the current phone use? It seems that visually impaired people have been doing badly in the trend towards touch screen phones so an option of a voice interface phone would be a good option for them. As an aside I hope some people are working on AI stuff for FOSS devices.
Laptop Like
One interesting PC variant I just discovered is the Higole 2 Pro portable battery operated Windows PC with 5.5 touch screen [10]. It looks too thick to fit in the same pockets as current phones but is still very portable. The version with built in battery is $AU423 which is in the usual price range for low end laptops and tablets. I don t think this is the future of computing, but it is something that is usable today while we wait for foldable devices to take over.
The recent release of the Apple Vision Pro [11] has driven interest in 3D and head mounted computers. I think this could be a useful peripheral for a laptop or phone but it won t be part of a primary computing environment. In 2011 I wrote about the possibility of using augmented reality technology for providing a desktop computing environment [12]. I wonder how a Vision Pro would work for that on a train or passenger jet.
Another interesting thing that s on offer is a laptop with 7 touch screen beside the keyboard [13]. It seems that someone just looked at what parts are available cheaply in China (due to being parts of more popular devices) and what could fit together. I think a keyboard should be central to the monitor for serious typing, but there may be useful corner cases where typing isn t that common and a touch-screen display is of use. Developing a range of strange hardware and then seeing which ones get adopted is a good thing and an advantage of Ali Express and Temu.
Useful Hardware for Developing These Things
I recently bought a second hand Thinkpad X1 Yoga Gen3 for $359 which has stylus support [14], and it s generally a great little laptop in every other way. There s a common failure case of that model where touch support for fingers breaks but the stylus still works which allows it to be used for testing touch screen functionality while making it cheap.
The PineTime is a nice smart watch from Pine64 which is designed to be open [15]. I am quite happy with it but haven t done much with it yet (apart from wearing it every day and getting alerts etc from Android). At $50 when delivered to Australia it s significantly more expensive than most smart watches with similar features but still a lot cheaper than the high end ones. Also the Raspberry Pi Watch [16] is interesting too.
The PinePhonePro is an OK phone made to open standards but it s hardware isn t as good as Android phones released in the same year [17]. I ve got some useful stuff done on mine, but the battery life is a major issue and the screen resolution is low. The Librem 5 phone from Purism has a better hardware design for security with switches to disable functionality [18], but it s even slower than the PinePhonePro. These are good devices for test and development but not ones that many people would be excited to use every day.
Wwan hardware (for accessing the phone network) in M.2 form factor can be obtained for free if you have access to old/broken laptops. Such devices start at about $35 if you want to buy one. USB GPS devices also start at about $35 so probably not worth getting if you can get a wwan device that does GPS as well.
What We Must Do
Debian appears to have some voice input software in the pocketsphinx package but no documentation on how it s to be used. This would be a good thing to document, I spent 15 mins looking at it and couldn t get it going.
To take advantage of the hardware features in phones we need software support and we ideally don t want free software to lag too far behind proprietary software which IMHO means the typical Android setup for phones/tablets.
Support for changing screen resolution is already there as is support for touch screens. Support for adapting the GUI to changed screen size is something that needs to be done even today s hardware of connecting a small laptop to an external monitor doesn t have the ideal functionality for changing the UI. There also seem to be some limitations in touch screen support with multiple screens, I haven t investigated this properly yet, it definitely doesn t work in an expected manner in Ubuntu 22.04 and I haven t yet tested the combinations on Debian/Unstable.
ML is becoming a big thing and it has some interesting use cases for small devices where a smart device can compensate for limited input options. There s a lot of work that needs to be done in this area and we are limited by the fact that we can t just rip off the work of other people for use as training data in the way that corporations do.
Security is more important for devices that are at high risk of theft. The vast majority of free software installations are way behind Android in terms of security and we need to address that. I have some ideas for improvement but there is always a conflict between security and usability and while Android is usable for it s own special apps it s not usable in a I want to run applications that use any files from any other applicationsin any way I want sense. My post about Sandboxing Phone apps is relevant for people who are interested in this [19]. We also need to extend security models to cope with things like ok google type functionality which has the potential to be a bug and the emerging class of LLM based attacks.
I will write more posts about these thing.
Please write comments mentioning FOSS hardware and software projects that address these issues and also documentation for such things.
- [1] https://www.raspberrypi.com/products/raspberry-pi-400/
- [2] https://jenson.org/text/
- [3] http://tinyurl.com/27lrakl6
- [4] https://en.wikipedia.org/wiki/Watch
- [5] https://en.wikipedia.org/wiki/Calculator_watch
- [6] http://tinyurl.com/27gb7zrq
- [7] https://etbe.coker.com.au/2023/05/29/considering-convergence/
- [8] http://tinyurl.com/yuurhkvm
- [9] http://tinyurl.com/ytmw42bt
- [10] https://www.aliexpress.com/store/1103322555
- [11] https://en.wikipedia.org/wiki/Apple_Vision_Pro
- [12] https://etbe.coker.com.au/2011/10/28/desktop-augmented-reality/
- [13] https://www.aliexpress.com/item/1005005999353358.html
- [14] https://etbe.coker.com.au/2024/01/29/thinkpad-x1-yoga-gen3/
- [15] https://etbe.coker.com.au/2023/10/21/more-about-pinetime/
- [16] http://tinyurl.com/24myjjqn
- [17] https://etbe.coker.com.au/2023/10/11/pinephone-status/
- [18] https://etbe.coker.com.au/2022/03/19/more-librem5/
- [19] https://etbe.coker.com.au/2023/07/08/sandboxing-phone-apps/
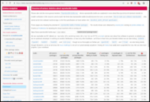
 This post describes how I m using
This post describes how I m using







 Dormitory room in Zostel Ernakulam, Kochi.
Dormitory room in Zostel Ernakulam, Kochi.
 Beds in Zostel Ernakulam, Kochi.
Beds in Zostel Ernakulam, Kochi.
 Onam sadya menu from Brindhavan restaurant.
Onam sadya menu from Brindhavan restaurant.
 Sadya lined up for serving
Sadya lined up for serving
 Sadya thali served on banana leaf.
Sadya thali served on banana leaf.
 We were treated with such views during the Wayanad trip.
We were treated with such views during the Wayanad trip.
 A road in Rippon.
A road in Rippon.
 Entry to Kanthanpara Falls.
Entry to Kanthanpara Falls.
 Kanthanpara Falls.
Kanthanpara Falls.
 A view of Zostel Wayanad.
A view of Zostel Wayanad.
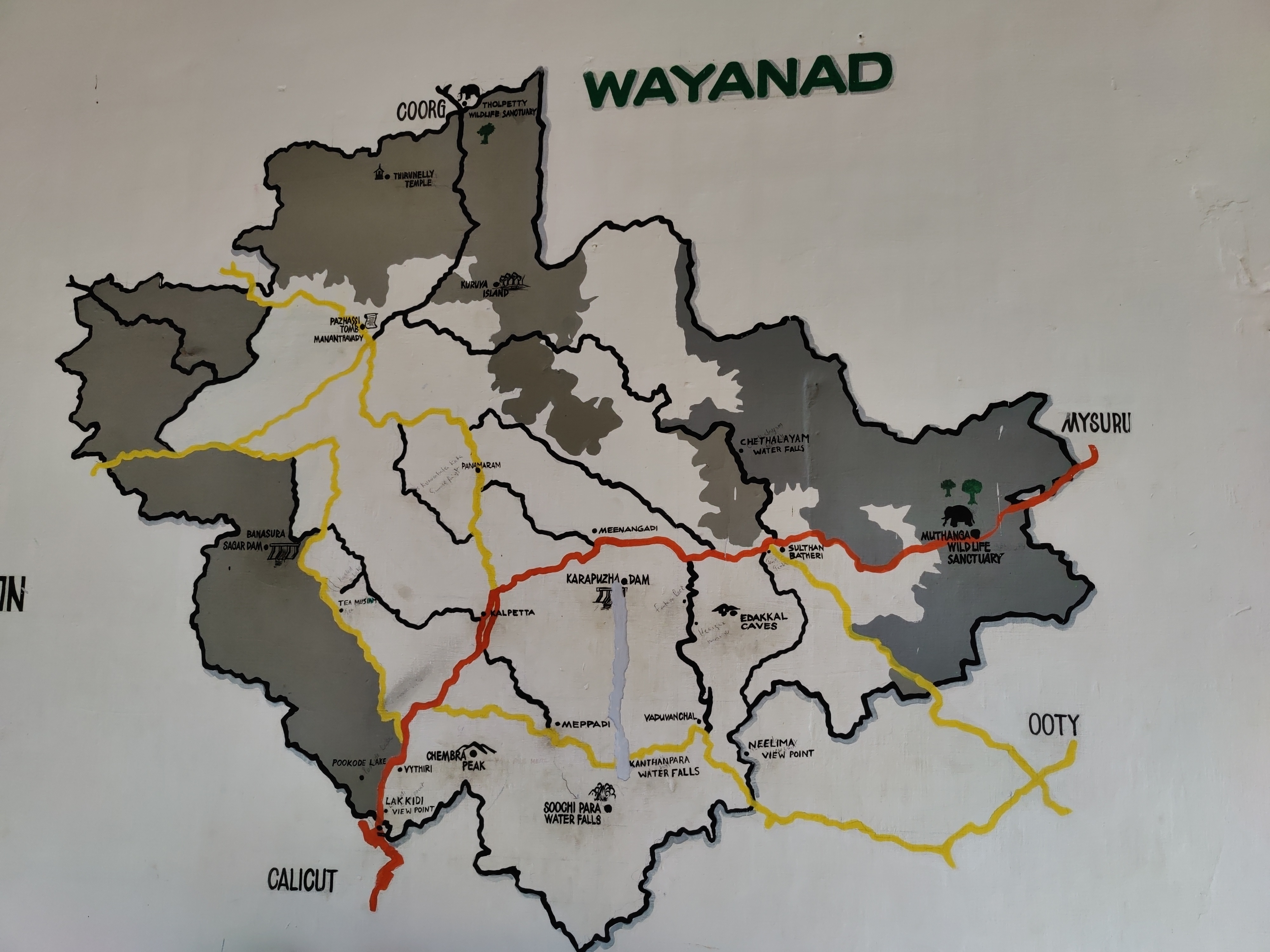 A map of Wayanad showing tourist places.
A map of Wayanad showing tourist places.
 A view from inside the Zostel Wayanad property.
A view from inside the Zostel Wayanad property.
 Terrain during trekking towards the Chembra peak.
Terrain during trekking towards the Chembra peak.
 Heart-shaped lake at the Chembra peak.
Heart-shaped lake at the Chembra peak.
 Me at the heart-shaped lake.
Me at the heart-shaped lake.
 Views from the top of the Chembra peak.
Views from the top of the Chembra peak.
 View of another peak from the heart-shaped lake.
View of another peak from the heart-shaped lake.

 QNAP TS-453mini product photo
QNAP TS-453mini product photo The logo for QNAP HappyGet 2 and Blizzard s StarCraft 2 side by side
The logo for QNAP HappyGet 2 and Blizzard s StarCraft 2 side by side Thermalright AXP120-X67, AMD Ryzen 5 PRO 5650GE, ASRock Rack X570D4I-2T, all assembled and running on a flat surface
Thermalright AXP120-X67, AMD Ryzen 5 PRO 5650GE, ASRock Rack X570D4I-2T, all assembled and running on a flat surface Memtest86 showing test progress, taken from IPMI remote control window
Memtest86 showing test progress, taken from IPMI remote control window Screenshot of PCIe 16x slot bifurcation options in UEFI settings, taken from IPMI remote control window
Screenshot of PCIe 16x slot bifurcation options in UEFI settings, taken from IPMI remote control window Internal image of Silverstone CS280 NAS build. Image stolen from
Internal image of Silverstone CS280 NAS build. Image stolen from  Internal image of Silverstone CS280 NAS build. Image stolen from
Internal image of Silverstone CS280 NAS build. Image stolen from  NAS build in Silverstone SUGO 14, mid build, panels removed
NAS build in Silverstone SUGO 14, mid build, panels removed Silverstone SUGO 14 from the front, with hot swap bay installed
Silverstone SUGO 14 from the front, with hot swap bay installed Storage SSD loaded into hot swap sled
Storage SSD loaded into hot swap sled TrueNAS Dashboard screenshot in browser window
TrueNAS Dashboard screenshot in browser window The final system, powered up
The final system, powered up
 Daniel Knowles Carmageddon: How Cars Make Life Worse and What to
Do About It is an entertaining, lucid, and well-written manifesto
(to borrow a term from the author) aiming to get us all thinking a bit
more about what cars do to society, and how to move on to a better
outcome for all.
The book alternates between historical context and background, lived
experience (as the author is a foreign correspondent who had the
opportunity to travel), and researched content. It is refreshingly free
of formalities (no endless footnotes or endnotes with references, though
I would have liked occassional references but hey we all went to school
long enough to do a bit of research given a pointer or two). I learned
or relearned a few things as I was for example somewhat unaware of the
air pollution (micro-particle) impact stemming from tires and brake
abrasions for which electronic vehicles do zilch, and for which the
auto-obesity of ever larger and heavier cars is making things
much worse. And some terms (even when re-used by Knowles) are clever
such bionic duckweed. But now you need to read the book to
catch up on it.
Overall, the book argues its case rather well. The author brings
sufficient evidence to make the formal guilty charge quite convincing.
It is also recent having come out just months ago, making current
figures even more relevant.
I forget the exact circumstance but I think I came across the author
in the context of our joint obsession with both Chicago and cycling (as
there may have been a link from a related social media post) and/or the
fact that I followed some of his colleagues at The Economist on
social media. Either way, the number of Chicago and MidWest references
made for some additional fun when reading the book over a the last few
days. And for me another highlight was the ode to Tokyo which I
wholeheartedly agree with: on my second trip to Japan I spent a spare
day cycling across the city as the AirBnB host kindly gave me access to
his bicycles. Great weather, polite drivers, moderate traffic, and just
wicked good infrastructure made me wonder why I did not see more
cyclists.
I have little to criticize beyond the lack of any references. The
repeated insistence on reminding us that Knowles comes from Birmingham
gets a little old by the fifth or sixth repetition. It is all a wee bit
anglo- or UK-centric. It obviously has a bit on France, Paris,
and all the recent success of Anne Hidalgo (who, when I was in graduate
school in France, was still a TV person rather than the very successful
mayor she is now) but then does not mention the immense (and well known)
success of the French train system which lead to a recent dictum to no
longer allow intra-Frace air travel if train rides of under 2 1/2 hours
are available which is rather remarkable. (Though in fairness that may
have been enacted once the book was finished.)
Lastly, the book appears to have
Daniel Knowles Carmageddon: How Cars Make Life Worse and What to
Do About It is an entertaining, lucid, and well-written manifesto
(to borrow a term from the author) aiming to get us all thinking a bit
more about what cars do to society, and how to move on to a better
outcome for all.
The book alternates between historical context and background, lived
experience (as the author is a foreign correspondent who had the
opportunity to travel), and researched content. It is refreshingly free
of formalities (no endless footnotes or endnotes with references, though
I would have liked occassional references but hey we all went to school
long enough to do a bit of research given a pointer or two). I learned
or relearned a few things as I was for example somewhat unaware of the
air pollution (micro-particle) impact stemming from tires and brake
abrasions for which electronic vehicles do zilch, and for which the
auto-obesity of ever larger and heavier cars is making things
much worse. And some terms (even when re-used by Knowles) are clever
such bionic duckweed. But now you need to read the book to
catch up on it.
Overall, the book argues its case rather well. The author brings
sufficient evidence to make the formal guilty charge quite convincing.
It is also recent having come out just months ago, making current
figures even more relevant.
I forget the exact circumstance but I think I came across the author
in the context of our joint obsession with both Chicago and cycling (as
there may have been a link from a related social media post) and/or the
fact that I followed some of his colleagues at The Economist on
social media. Either way, the number of Chicago and MidWest references
made for some additional fun when reading the book over a the last few
days. And for me another highlight was the ode to Tokyo which I
wholeheartedly agree with: on my second trip to Japan I spent a spare
day cycling across the city as the AirBnB host kindly gave me access to
his bicycles. Great weather, polite drivers, moderate traffic, and just
wicked good infrastructure made me wonder why I did not see more
cyclists.
I have little to criticize beyond the lack of any references. The
repeated insistence on reminding us that Knowles comes from Birmingham
gets a little old by the fifth or sixth repetition. It is all a wee bit
anglo- or UK-centric. It obviously has a bit on France, Paris,
and all the recent success of Anne Hidalgo (who, when I was in graduate
school in France, was still a TV person rather than the very successful
mayor she is now) but then does not mention the immense (and well known)
success of the French train system which lead to a recent dictum to no
longer allow intra-Frace air travel if train rides of under 2 1/2 hours
are available which is rather remarkable. (Though in fairness that may
have been enacted once the book was finished.)
Lastly, the book appears to have 
 A real sad state of affairs
A real sad state of affairs 
















 US-11604662-B2
US-11604662-B2 Two weeks ago, I had the chance to go see Cory Doctorow at my local independent
bookstore, in Montr al. He was there to present his latest essay, co-written
with Rebecca Giblin
Two weeks ago, I had the chance to go see Cory Doctorow at my local independent
bookstore, in Montr al. He was there to present his latest essay, co-written
with Rebecca Giblin Although Doctorow is known for his strong political stances, I have to say I'm
quite surprised by the quality of the research Giblin and he did for this book.
They both show a pretty advanced understanding of the market dynamics they look
at, and even though most of the solutions they propose aren't new or
groundbreaking, they manage to be convincing and clear.
That is to say, you certainly don't need to be an economist to understand or
enjoy this book :)
As I have mentioned before, the book heavily criticises monopolies, but also
monopsonies a market structure that has only one buyer (instead of one
seller). I find this quite interesting, as whereas people are often familiar
with the concept of monopolies, monopsonies are frequently overlooked.
The classic example of a monopsony is a labor market with a single employer:
there is a multitude of workers trying to sell their labor power, but in the
end, working conditions are dictated by the sole employer, who gets to decide
who has a job and who hasn't. Mining towns are good real-world examples of
monopsonies.
In the book, the authors argue most of the contemporary work produced by
creative workers (especially musicians and writers) is sold to monopsonies and
Although Doctorow is known for his strong political stances, I have to say I'm
quite surprised by the quality of the research Giblin and he did for this book.
They both show a pretty advanced understanding of the market dynamics they look
at, and even though most of the solutions they propose aren't new or
groundbreaking, they manage to be convincing and clear.
That is to say, you certainly don't need to be an economist to understand or
enjoy this book :)
As I have mentioned before, the book heavily criticises monopolies, but also
monopsonies a market structure that has only one buyer (instead of one
seller). I find this quite interesting, as whereas people are often familiar
with the concept of monopolies, monopsonies are frequently overlooked.
The classic example of a monopsony is a labor market with a single employer:
there is a multitude of workers trying to sell their labor power, but in the
end, working conditions are dictated by the sole employer, who gets to decide
who has a job and who hasn't. Mining towns are good real-world examples of
monopsonies.
In the book, the authors argue most of the contemporary work produced by
creative workers (especially musicians and writers) is sold to monopsonies and




