Subsequent to
my previous use of American Fuzzy Lop (AFL) on the NetSurf bitmap image library I applied it to the
gif library which, after fixing the test runner, failed to produce any crashes but did result in a better test corpus improving coverage above 90%
I then turned my attention to the
SVG processing library. This was different to the bitmap libraries in that it required parsing a much lower density text format and performing operations on the resulting tree representation.
The test program for the SVG library needed some improvement but is very basic in operation. It takes the test SVG, parses it using libsvgtiny and then uses the parsed output to write out an
imagemagick mvg file.
The libsvg processing uses the
NetSurf DOM library which in turn uses an expat binding to parse the SVG XML text. To process this with AFL required instrumenting not only the XVG library but the DOM library. I did not initially understand this and my first run resulted in a "map coverage" indicating an issue. Helpfully the AFL docs do cover this so it was straightforward to rectify.
Once the test program was written and environment set up an AFL run was started and left to run. The next day I was somewhat alarmed to discover the fuzzer had made almost no progress and was running very slowly. I asked for help on the AFL mailing list and got a polite and helpful response, basically I needed to RTFM.
I must thank the members of the AFL mailing list for being so helpful and tolerating someone who ought to know better asking dumb questions.
After reading the fine manual I understood I needed to ensure all my test cases were as small as possible and further that the fuzzer needed a dictionary as a hint to the file format because the text file was of such low data density compared to binary formats.
I crafted an SVG dictionary based on the XML one, ensured all the seed SVG files were as small as possible and tried again. The immediate result was thousands of crashes, nothing like being savaged by a rabbit to cause a surprise.
Not being in possession of the appropriate holy hand grenade I resorted instead to GDB and electric fence. Unlike the bitmap library crashes memory bounds issues simply did not feature in the crashes.Instead they mainly centered around actual logic errors when constructing and traversing the data structures.
For example Daniel Silverstone
fixed an interesting bug where the XML parser binding would try and go "above" the root node in the tree if the source closed more tags than it opened which resulted in wild pointers and NULL references.
I found and squashed several others including
dealing with SVG which has no valid root element and
division by zero errors when things like colour gradients have no points.
I find it interesting that the type and texture of the crashes completely changed between the SVG and binary formats. Perhaps it is just the nature of the textural formats that causes this although it might be due to the techniques used to parse the formats.
Once all the immediately reproducible crashes were dealt with I performed a longer run. I used my monster system as previously described and ran the fuzzer for a whole week.
Summary stats
=============
Fuzzers alive : 10
Total run time : 68 days, 7 hours
Total execs : 9268 million
Cumulative speed : 15698 execs/sec
Pending paths : 0 faves, 2501 total
Pending per fuzzer : 0 faves, 250 total (on average)
Crashes found : 9 locally unique
After burning almost seventy days of processor time AFL found me another nine crashes and possibly more importantly a test corpus that generates over 90% coverage.
A useful tool that AFL provides is afl-cmin. This reduces the number of test files in a corpus to only those that are required to exercise all the code paths reached by the test set. In this case it reduced the number of files from 8242 to 2612
afl-cmin -i queue_all/ -o queue_cmin -- test_decode_svg @@ 1.0 /dev/null
corpus minimization tool for afl-fuzz by
[+] OK, 1447 tuples recorded.
[*] Obtaining traces for input files in 'queue_all/'...
Processing file 8242/8242...
[*] Sorting trace sets (this may take a while)...
[+] Found 23812 unique tuples across 8242 files.
[*] Finding best candidates for each tuple...
Processing file 8242/8242...
[*] Sorting candidate list (be patient)...
[*] Processing candidates and writing output files...
Processing tuple 23812/23812...
[+] Narrowed down to 2612 files, saved in 'queue_cmin'.
Additionally the actual information within the test files can be minimised with the afl-tmin tool. This must be run on each file individually and can take a relatively long time. Fortunately with
GNU parallel one can run many of these jobs simultaneously which merely required another three days of CPU time to process. The resulting test corpus weighs in at a svelte 15 Megabytes or so against the 25 Megabytes before minimisation.
The result is yet another NetSurf library significantly improved by the use of AFL both from finding and squashing crashing bugs and from having a greatly improved test corpus to allow future library changes with a high confidence there will not be any regressions.
 My plan for
My plan for 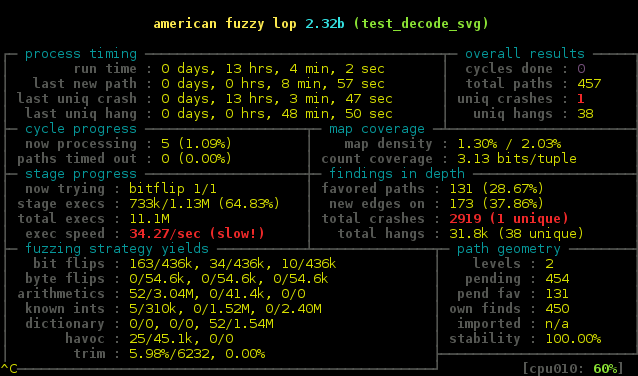




























 Ok, so following the trend, I created some time ago a new GPG
key, which I'm now transitioning too. I've set up a transition
document, available at
Ok, so following the trend, I created some time ago a new GPG
key, which I'm now transitioning too. I've set up a transition
document, available at