
I m one of the few folks left who run and maintain mail servers. Recently I had major troubles receiving mails from the mail servers used by a bank, and when
asking my favourite search engine, I m clearly
not the only
one who
ran into such
an issue. Actually, I should have checked off the issue and not become a customer at that bank, but the tech nerd in me couldn t resist getting to the bottom of the problem. Since I got it working and this might be useful for others, here we are. :)
I was trying to get an online banking account set up, but the corresponding account creation mail didn t arrive me, at all. Looking at my mail server logs, my postfix mail server didn t accept the mail due to:
postfix/smtpd[3319640]: warning: TLS library problem: error:1417A0C1:SSL routines:tls_post_process_client_hello:no shared cipher:../ssl/statem/statem_srvr.c:2283:
postfix/smtpd[3319640]: lost connection after STARTTLS from mx01.arz.at[193.110.182.61]
Huh, what s going on here?! Let s increase the TLS loglevel (setting
smtpd_tls_loglevel = 2) and retry. But how can I retry receiving yet another mail? Luckily, on the registration website of the bank there was a URL available, that let me request a one-time password. This triggered another mail, so I did that and managed to grab this in the logs:
postfix/smtpd[3320018]: initializing the server-side TLS engine
postfix/tlsmgr[3320020]: open smtpd TLS cache btree:/var/lib/postfix/smtpd_scache
postfix/tlsmgr[3320020]: tlsmgr_cache_run_event: start TLS smtpd session cache cleanup
postfix/smtpd[3320018]: connect from mx01.arz.at[193.110.182.61]
postfix/smtpd[3320018]: setting up TLS connection from mx01.arz.at[193.110.182.61]
postfix/smtpd[3320018]: mx01.arz.at[193.110.182.61]: TLS cipher list "aNULL:-aNULL:HIGH:MEDIUM:+RC4:@STRENGTH"
postfix/smtpd[3320018]: SSL_accept:before SSL initialization
postfix/smtpd[3320018]: SSL_accept:before SSL initialization
postfix/smtpd[3320018]: SSL3 alert write:fatal:handshake failure
postfix/smtpd[3320018]: SSL_accept:error in error
postfix/smtpd[3320018]: SSL_accept error from mx01.arz.at[193.110.182.61]: -1
postfix/smtpd[3320018]: warning: TLS library problem: error:1417A0C1:SSL routines:tls_post_process_client_hello:no shared cipher:../ssl/statem/statem_srvr.c:2283:
postfix/smtpd[3320018]: lost connection after STARTTLS from mx01.arz.at[193.110.182.61]
postfix/smtpd[3320018]: disconnect from mx01.arz.at[193.110.182.61] ehlo=1 starttls=0/1 commands=1/2
postfix/smtpd[3320018]: connect from mx01.arz.at[193.110.182.61]
postfix/smtpd[3320018]: disconnect from mx01.arz.at[193.110.182.61] ehlo=1 quit=1 commands=2
Ok, so this
TLS cipher list aNULL:-aNULL:HIGH:MEDIUM:+RC4:@STRENGTH looked like the
tls_medium_cipherlist setting in postfix, but which ciphers
might we expect? Let s see what their SMTP server would speak to us:
% testssl --cipher-per-proto -t=smtp mx01.arz.at:25
[...]
Hexcode Cipher Suite Name (OpenSSL) KeyExch. Encryption Bits Cipher Suite Name (IANA/RFC)
-----------------------------------------------------------------------------------------------------------------------------
SSLv2
SSLv3
TLS 1
TLS 1.1
TLS 1.2
xc030 ECDHE-RSA-AES256-GCM-SHA384 ECDH 256 AESGCM 256 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
xc028 ECDHE-RSA-AES256-SHA384 ECDH 256 AES 256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384
xc014 ECDHE-RSA-AES256-SHA ECDH 256 AES 256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
x9d AES256-GCM-SHA384 RSA AESGCM 256 TLS_RSA_WITH_AES_256_GCM_SHA384
x3d AES256-SHA256 RSA AES 256 TLS_RSA_WITH_AES_256_CBC_SHA256
x35 AES256-SHA RSA AES 256 TLS_RSA_WITH_AES_256_CBC_SHA
xc02f ECDHE-RSA-AES128-GCM-SHA256 ECDH 256 AESGCM 128 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
xc027 ECDHE-RSA-AES128-SHA256 ECDH 256 AES 128 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
xc013 ECDHE-RSA-AES128-SHA ECDH 256 AES 128 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
x9c AES128-GCM-SHA256 RSA AESGCM 128 TLS_RSA_WITH_AES_128_GCM_SHA256
x3c AES128-SHA256 RSA AES 128 TLS_RSA_WITH_AES_128_CBC_SHA256
x2f AES128-SHA RSA AES 128 TLS_RSA_WITH_AES_128_CBC_SHA
TLS 1.3
Looks like a very small subset of ciphers, and they don t seem to be talking TLS v1.3 at all? Not great. :(
A nice web service to verify the situation from another point of view is
checktls, which also confirmed this:
[000.705] <-- 220 2.0.0 Ready to start TLS
[000.705] STARTTLS command works on this server
[001.260] Connection converted to SSL
SSLVersion in use: TLSv1_2
Cipher in use: ECDHE-RSA-AES256-GCM-SHA384
Perfect Forward Secrecy: yes
Session Algorithm in use: Curve P-256 DHE(256 bits)
Certificate #1 of 3 (sent by MX):
Cert VALIDATED: ok
Cert Hostname VERIFIED (mx01.arz.at = *.arz.at DNS:*.arz.at DNS:arz.at)
[...]
[001.517] TLS successfully started on this server
I got distracted by some other work, and when coming back to this problem, the one-time password procedure no longer worked, as the password reset URL was no longer valid. :( I managed to find the underlying URL, and with some web developer tools tinkering I could still use the website to let me trigger sending further one-time password mails, phew.
Let s continue, so
my mail server was running Debian/bullseye with postfix v3.5.18-0+deb11u1 and openssl v1.1.1n-0+deb11u5, let s see what it offers:
% testssl --cipher-per-proto -t=smtp mail.example.com:25
[...]
Hexcode Cipher Suite Name (OpenSSL) KeyExch. Encryption Bits Cipher Suite Name (IANA/RFC)
-----------------------------------------------------------------------------------------------------------------------------
SSLv2
SSLv3
TLS 1
xc00a ECDHE-ECDSA-AES256-SHA ECDH 253 AES 256 TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
xc019 AECDH-AES256-SHA ECDH 253 AES 256 TLS_ECDH_anon_WITH_AES_256_CBC_SHA
x3a ADH-AES256-SHA DH 2048 AES 256 TLS_DH_anon_WITH_AES_256_CBC_SHA
x89 ADH-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DH_anon_WITH_CAMELLIA_256_CBC_SHA
xc009 ECDHE-ECDSA-AES128-SHA ECDH 253 AES 128 TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
xc018 AECDH-AES128-SHA ECDH 253 AES 128 TLS_ECDH_anon_WITH_AES_128_CBC_SHA
x34 ADH-AES128-SHA DH 2048 AES 128 TLS_DH_anon_WITH_AES_128_CBC_SHA
x9b ADH-SEED-SHA DH 2048 SEED 128 TLS_DH_anon_WITH_SEED_CBC_SHA
x46 ADH-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DH_anon_WITH_CAMELLIA_128_CBC_SHA
TLS 1.1
xc00a ECDHE-ECDSA-AES256-SHA ECDH 253 AES 256 TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
xc019 AECDH-AES256-SHA ECDH 253 AES 256 TLS_ECDH_anon_WITH_AES_256_CBC_SHA
x3a ADH-AES256-SHA DH 2048 AES 256 TLS_DH_anon_WITH_AES_256_CBC_SHA
x89 ADH-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DH_anon_WITH_CAMELLIA_256_CBC_SHA
xc009 ECDHE-ECDSA-AES128-SHA ECDH 253 AES 128 TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
xc018 AECDH-AES128-SHA ECDH 253 AES 128 TLS_ECDH_anon_WITH_AES_128_CBC_SHA
x34 ADH-AES128-SHA DH 2048 AES 128 TLS_DH_anon_WITH_AES_128_CBC_SHA
x9b ADH-SEED-SHA DH 2048 SEED 128 TLS_DH_anon_WITH_SEED_CBC_SHA
x46 ADH-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DH_anon_WITH_CAMELLIA_128_CBC_SHA
TLS 1.2
xc02c ECDHE-ECDSA-AES256-GCM-SHA384 ECDH 253 AESGCM 256 TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
xc024 ECDHE-ECDSA-AES256-SHA384 ECDH 253 AES 256 TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384
xc00a ECDHE-ECDSA-AES256-SHA ECDH 253 AES 256 TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA
xcca9 ECDHE-ECDSA-CHACHA20-POLY1305 ECDH 253 ChaCha20 256 TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256
xc0af ECDHE-ECDSA-AES256-CCM8 ECDH 253 AESCCM8 256 TLS_ECDHE_ECDSA_WITH_AES_256_CCM_8
xc0ad ECDHE-ECDSA-AES256-CCM ECDH 253 AESCCM 256 TLS_ECDHE_ECDSA_WITH_AES_256_CCM
xc073 ECDHE-ECDSA-CAMELLIA256-SHA384 ECDH 253 Camellia 256 TLS_ECDHE_ECDSA_WITH_CAMELLIA_256_CBC_SHA384
xc019 AECDH-AES256-SHA ECDH 253 AES 256 TLS_ECDH_anon_WITH_AES_256_CBC_SHA
xa7 ADH-AES256-GCM-SHA384 DH 2048 AESGCM 256 TLS_DH_anon_WITH_AES_256_GCM_SHA384
x6d ADH-AES256-SHA256 DH 2048 AES 256 TLS_DH_anon_WITH_AES_256_CBC_SHA256
x3a ADH-AES256-SHA DH 2048 AES 256 TLS_DH_anon_WITH_AES_256_CBC_SHA
xc5 ADH-CAMELLIA256-SHA256 DH 2048 Camellia 256 TLS_DH_anon_WITH_CAMELLIA_256_CBC_SHA256
x89 ADH-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DH_anon_WITH_CAMELLIA_256_CBC_SHA
xc05d ECDHE-ECDSA-ARIA256-GCM-SHA384 ECDH 253 ARIAGCM 256 TLS_ECDHE_ECDSA_WITH_ARIA_256_GCM_SHA384
xc02b ECDHE-ECDSA-AES128-GCM-SHA256 ECDH 253 AESGCM 128 TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
xc023 ECDHE-ECDSA-AES128-SHA256 ECDH 253 AES 128 TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256
xc009 ECDHE-ECDSA-AES128-SHA ECDH 253 AES 128 TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA
xc0ae ECDHE-ECDSA-AES128-CCM8 ECDH 253 AESCCM8 128 TLS_ECDHE_ECDSA_WITH_AES_128_CCM_8
xc0ac ECDHE-ECDSA-AES128-CCM ECDH 253 AESCCM 128 TLS_ECDHE_ECDSA_WITH_AES_128_CCM
xc072 ECDHE-ECDSA-CAMELLIA128-SHA256 ECDH 253 Camellia 128 TLS_ECDHE_ECDSA_WITH_CAMELLIA_128_CBC_SHA256
xc018 AECDH-AES128-SHA ECDH 253 AES 128 TLS_ECDH_anon_WITH_AES_128_CBC_SHA
xa6 ADH-AES128-GCM-SHA256 DH 2048 AESGCM 128 TLS_DH_anon_WITH_AES_128_GCM_SHA256
x6c ADH-AES128-SHA256 DH 2048 AES 128 TLS_DH_anon_WITH_AES_128_CBC_SHA256
x34 ADH-AES128-SHA DH 2048 AES 128 TLS_DH_anon_WITH_AES_128_CBC_SHA
xbf ADH-CAMELLIA128-SHA256 DH 2048 Camellia 128 TLS_DH_anon_WITH_CAMELLIA_128_CBC_SHA256
x9b ADH-SEED-SHA DH 2048 SEED 128 TLS_DH_anon_WITH_SEED_CBC_SHA
x46 ADH-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DH_anon_WITH_CAMELLIA_128_CBC_SHA
xc05c ECDHE-ECDSA-ARIA128-GCM-SHA256 ECDH 253 ARIAGCM 128 TLS_ECDHE_ECDSA_WITH_ARIA_128_GCM_SHA256
TLS 1.3
x1302 TLS_AES_256_GCM_SHA384 ECDH 253 AESGCM 256 TLS_AES_256_GCM_SHA384
x1303 TLS_CHACHA20_POLY1305_SHA256 ECDH 253 ChaCha20 256 TLS_CHACHA20_POLY1305_SHA256
x1301 TLS_AES_128_GCM_SHA256 ECDH 253 AESGCM 128 TLS_AES_128_GCM_SHA256
Not so bad, but sadly no overlap with any of the ciphers that mx01.arz.at offers.
What about disabling STARTTLS for the mx01.arz.at (+ mx02.arz.at being another one used by the relevant domain) mail servers when talking to mine? Let s try that:
% sudo postconf -nf smtpd_discard_ehlo_keyword_address_maps
smtpd_discard_ehlo_keyword_address_maps =
hash:/etc/postfix/smtpd_discard_ehlo_keywords
% cat /etc/postfix/smtpd_discard_ehlo_keywords
# *disable* starttls for mx01.arz.at / mx02.arz.at:
193.110.182.61 starttls
193.110.182.62 starttls
But the remote mail server doesn t seem to send mails without TLS:
postfix/smtpd[4151799]: connect from mx01.arz.at[193.110.182.61]
postfix/smtpd[4151799]: discarding EHLO keywords: STARTTLS
postfix/smtpd[4151799]: disconnect from mx01.arz.at[193.110.182.61] ehlo=1 quit=1 commands=2
Let s verify this further, but without fiddling with the main mail server too much. We can add a dedicated service to postfix (see
serverfault), and run it in verbose mode, to get more detailled logging:
% sudo postconf -Mf
[...]
10025 inet n - - - - smtpd
-o syslog_name=postfix/smtpd/badstarttls
-o smtpd_tls_security_level=none
-o smtpd_helo_required=yes
-o smtpd_helo_restrictions=pcre:/etc/postfix/helo_badstarttls_allow,reject
-v
[...]
% cat /etc/postfix/helo_badstarttls_allow
/mx01.arz.at/ OK
/mx02.arz.at/ OK
/193.110.182.61/ OK
/193.110.182.62/ OK
We redirect the traffic from mx01.arz.at + mx02.arz.at towards our new postfix service, listening on port 10025:
% sudo iptables -t nat -A PREROUTING -p tcp -s 193.110.182.61 --dport 25 -j REDIRECT --to-port 10025
% sudo iptables -t nat -A PREROUTING -p tcp -s 193.110.182.62 --dport 25 -j REDIRECT --to-port 10025
With this setup we get very detailed logging, and it seems to confirm our suspicion that the mail server doesn t want to talk unencrypted with us:
[...]
postfix/smtpd/badstarttls/smtpd[3491900]: connect from mx01.arz.at[193.110.182.61]
[...]
postfix/smtpd/badstarttls/smtpd[3491901]: disconnect from mx01.arz.at[193.110.182.61] ehlo=1 quit=1 commands=2
postfix/smtpd/badstarttls/smtpd[3491901]: master_notify: status 1
postfix/smtpd/badstarttls/smtpd[3491901]: connection closed
[...]
Let s step back and revert those changes, back to our original postfix setup. Might the problem be related to our Let s Encrypt certificate? Let s see what we have:
% echo QUIT openssl s_client -connect mail.example.com:25 -starttls
[...]
issuer=C = US, O = Let's Encrypt, CN = R3
---
No client certificate CA names sent
Peer signing digest: SHA384
Peer signature type: ECDSA
Server Temp Key: X25519, 253 bits
---
SSL handshake has read 4455 bytes and written 427 bytes
Verification: OK
---
New, TLSv1.3, Cipher is TLS_AES_256_GCM_SHA384
Server public key is 384 bit
[...]
We have an ECDSA based certificate, what about switching to RSA instead? Thanks to the wonderful
dehydrated, this is as easy as:
% echo KEY_ALGO=rsa > certs/mail.example.com/config
% ./dehydrated -c --domain mail.example.com --force
% sudo systemctl reload postfix
With switching to RSA type key we get:
% echo QUIT openssl s_client -connect mail.example.com:25 -starttls smtp
CONNECTED(00000003)
[...]
issuer=C = US, O = Let's Encrypt, CN = R3
---
No client certificate CA names sent
Peer signing digest: SHA256
Peer signature type: RSA-PSS
Server Temp Key: X25519, 253 bits
---
SSL handshake has read 5295 bytes and written 427 bytes
Verification: OK
---
New, TLSv1.3, Cipher is TLS_AES_256_GCM_SHA384
Server public key is 4096 bit
Which ciphers do we offer now? Let s check:
% testssl --cipher-per-proto -t=smtp mail.example.com:25
[...]
Hexcode Cipher Suite Name (OpenSSL) KeyExch. Encryption Bits Cipher Suite Name (IANA/RFC)
-----------------------------------------------------------------------------------------------------------------------------
SSLv2
SSLv3
TLS 1
xc014 ECDHE-RSA-AES256-SHA ECDH 253 AES 256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
x39 DHE-RSA-AES256-SHA DH 2048 AES 256 TLS_DHE_RSA_WITH_AES_256_CBC_SHA
x88 DHE-RSA-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DHE_RSA_WITH_CAMELLIA_256_CBC_SHA
xc019 AECDH-AES256-SHA ECDH 253 AES 256 TLS_ECDH_anon_WITH_AES_256_CBC_SHA
x3a ADH-AES256-SHA DH 2048 AES 256 TLS_DH_anon_WITH_AES_256_CBC_SHA
x89 ADH-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DH_anon_WITH_CAMELLIA_256_CBC_SHA
x35 AES256-SHA RSA AES 256 TLS_RSA_WITH_AES_256_CBC_SHA
x84 CAMELLIA256-SHA RSA Camellia 256 TLS_RSA_WITH_CAMELLIA_256_CBC_SHA
xc013 ECDHE-RSA-AES128-SHA ECDH 253 AES 128 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
x33 DHE-RSA-AES128-SHA DH 2048 AES 128 TLS_DHE_RSA_WITH_AES_128_CBC_SHA
x9a DHE-RSA-SEED-SHA DH 2048 SEED 128 TLS_DHE_RSA_WITH_SEED_CBC_SHA
x45 DHE-RSA-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DHE_RSA_WITH_CAMELLIA_128_CBC_SHA
xc018 AECDH-AES128-SHA ECDH 253 AES 128 TLS_ECDH_anon_WITH_AES_128_CBC_SHA
x34 ADH-AES128-SHA DH 2048 AES 128 TLS_DH_anon_WITH_AES_128_CBC_SHA
x9b ADH-SEED-SHA DH 2048 SEED 128 TLS_DH_anon_WITH_SEED_CBC_SHA
x46 ADH-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DH_anon_WITH_CAMELLIA_128_CBC_SHA
x2f AES128-SHA RSA AES 128 TLS_RSA_WITH_AES_128_CBC_SHA
x96 SEED-SHA RSA SEED 128 TLS_RSA_WITH_SEED_CBC_SHA
x41 CAMELLIA128-SHA RSA Camellia 128 TLS_RSA_WITH_CAMELLIA_128_CBC_SHA
TLS 1.1
xc014 ECDHE-RSA-AES256-SHA ECDH 253 AES 256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
x39 DHE-RSA-AES256-SHA DH 2048 AES 256 TLS_DHE_RSA_WITH_AES_256_CBC_SHA
x88 DHE-RSA-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DHE_RSA_WITH_CAMELLIA_256_CBC_SHA
xc019 AECDH-AES256-SHA ECDH 253 AES 256 TLS_ECDH_anon_WITH_AES_256_CBC_SHA
x3a ADH-AES256-SHA DH 2048 AES 256 TLS_DH_anon_WITH_AES_256_CBC_SHA
x89 ADH-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DH_anon_WITH_CAMELLIA_256_CBC_SHA
x35 AES256-SHA RSA AES 256 TLS_RSA_WITH_AES_256_CBC_SHA
x84 CAMELLIA256-SHA RSA Camellia 256 TLS_RSA_WITH_CAMELLIA_256_CBC_SHA
xc013 ECDHE-RSA-AES128-SHA ECDH 253 AES 128 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
x33 DHE-RSA-AES128-SHA DH 2048 AES 128 TLS_DHE_RSA_WITH_AES_128_CBC_SHA
x9a DHE-RSA-SEED-SHA DH 2048 SEED 128 TLS_DHE_RSA_WITH_SEED_CBC_SHA
x45 DHE-RSA-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DHE_RSA_WITH_CAMELLIA_128_CBC_SHA
xc018 AECDH-AES128-SHA ECDH 253 AES 128 TLS_ECDH_anon_WITH_AES_128_CBC_SHA
x34 ADH-AES128-SHA DH 2048 AES 128 TLS_DH_anon_WITH_AES_128_CBC_SHA
x9b ADH-SEED-SHA DH 2048 SEED 128 TLS_DH_anon_WITH_SEED_CBC_SHA
x46 ADH-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DH_anon_WITH_CAMELLIA_128_CBC_SHA
x2f AES128-SHA RSA AES 128 TLS_RSA_WITH_AES_128_CBC_SHA
x96 SEED-SHA RSA SEED 128 TLS_RSA_WITH_SEED_CBC_SHA
x41 CAMELLIA128-SHA RSA Camellia 128 TLS_RSA_WITH_CAMELLIA_128_CBC_SHA
TLS 1.2
xc030 ECDHE-RSA-AES256-GCM-SHA384 ECDH 253 AESGCM 256 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
xc028 ECDHE-RSA-AES256-SHA384 ECDH 253 AES 256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384
xc014 ECDHE-RSA-AES256-SHA ECDH 253 AES 256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
x9f DHE-RSA-AES256-GCM-SHA384 DH 2048 AESGCM 256 TLS_DHE_RSA_WITH_AES_256_GCM_SHA384
xcca8 ECDHE-RSA-CHACHA20-POLY1305 ECDH 253 ChaCha20 256 TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xccaa DHE-RSA-CHACHA20-POLY1305 DH 2048 ChaCha20 256 TLS_DHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xc0a3 DHE-RSA-AES256-CCM8 DH 2048 AESCCM8 256 TLS_DHE_RSA_WITH_AES_256_CCM_8
xc09f DHE-RSA-AES256-CCM DH 2048 AESCCM 256 TLS_DHE_RSA_WITH_AES_256_CCM
x6b DHE-RSA-AES256-SHA256 DH 2048 AES 256 TLS_DHE_RSA_WITH_AES_256_CBC_SHA256
x39 DHE-RSA-AES256-SHA DH 2048 AES 256 TLS_DHE_RSA_WITH_AES_256_CBC_SHA
xc077 ECDHE-RSA-CAMELLIA256-SHA384 ECDH 253 Camellia 256 TLS_ECDHE_RSA_WITH_CAMELLIA_256_CBC_SHA384
xc4 DHE-RSA-CAMELLIA256-SHA256 DH 2048 Camellia 256 TLS_DHE_RSA_WITH_CAMELLIA_256_CBC_SHA256
x88 DHE-RSA-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DHE_RSA_WITH_CAMELLIA_256_CBC_SHA
xc019 AECDH-AES256-SHA ECDH 253 AES 256 TLS_ECDH_anon_WITH_AES_256_CBC_SHA
xa7 ADH-AES256-GCM-SHA384 DH 2048 AESGCM 256 TLS_DH_anon_WITH_AES_256_GCM_SHA384
x6d ADH-AES256-SHA256 DH 2048 AES 256 TLS_DH_anon_WITH_AES_256_CBC_SHA256
x3a ADH-AES256-SHA DH 2048 AES 256 TLS_DH_anon_WITH_AES_256_CBC_SHA
xc5 ADH-CAMELLIA256-SHA256 DH 2048 Camellia 256 TLS_DH_anon_WITH_CAMELLIA_256_CBC_SHA256
x89 ADH-CAMELLIA256-SHA DH 2048 Camellia 256 TLS_DH_anon_WITH_CAMELLIA_256_CBC_SHA
x9d AES256-GCM-SHA384 RSA AESGCM 256 TLS_RSA_WITH_AES_256_GCM_SHA384
xc0a1 AES256-CCM8 RSA AESCCM8 256 TLS_RSA_WITH_AES_256_CCM_8
xc09d AES256-CCM RSA AESCCM 256 TLS_RSA_WITH_AES_256_CCM
x3d AES256-SHA256 RSA AES 256 TLS_RSA_WITH_AES_256_CBC_SHA256
x35 AES256-SHA RSA AES 256 TLS_RSA_WITH_AES_256_CBC_SHA
xc0 CAMELLIA256-SHA256 RSA Camellia 256 TLS_RSA_WITH_CAMELLIA_256_CBC_SHA256
x84 CAMELLIA256-SHA RSA Camellia 256 TLS_RSA_WITH_CAMELLIA_256_CBC_SHA
xc051 ARIA256-GCM-SHA384 RSA ARIAGCM 256 TLS_RSA_WITH_ARIA_256_GCM_SHA384
xc053 DHE-RSA-ARIA256-GCM-SHA384 DH 2048 ARIAGCM 256 TLS_DHE_RSA_WITH_ARIA_256_GCM_SHA384
xc061 ECDHE-ARIA256-GCM-SHA384 ECDH 253 ARIAGCM 256 TLS_ECDHE_RSA_WITH_ARIA_256_GCM_SHA384
xc02f ECDHE-RSA-AES128-GCM-SHA256 ECDH 253 AESGCM 128 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
xc027 ECDHE-RSA-AES128-SHA256 ECDH 253 AES 128 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
xc013 ECDHE-RSA-AES128-SHA ECDH 253 AES 128 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
x9e DHE-RSA-AES128-GCM-SHA256 DH 2048 AESGCM 128 TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
xc0a2 DHE-RSA-AES128-CCM8 DH 2048 AESCCM8 128 TLS_DHE_RSA_WITH_AES_128_CCM_8
xc09e DHE-RSA-AES128-CCM DH 2048 AESCCM 128 TLS_DHE_RSA_WITH_AES_128_CCM
xc0a0 AES128-CCM8 RSA AESCCM8 128 TLS_RSA_WITH_AES_128_CCM_8
xc09c AES128-CCM RSA AESCCM 128 TLS_RSA_WITH_AES_128_CCM
x67 DHE-RSA-AES128-SHA256 DH 2048 AES 128 TLS_DHE_RSA_WITH_AES_128_CBC_SHA256
x33 DHE-RSA-AES128-SHA DH 2048 AES 128 TLS_DHE_RSA_WITH_AES_128_CBC_SHA
xc076 ECDHE-RSA-CAMELLIA128-SHA256 ECDH 253 Camellia 128 TLS_ECDHE_RSA_WITH_CAMELLIA_128_CBC_SHA256
xbe DHE-RSA-CAMELLIA128-SHA256 DH 2048 Camellia 128 TLS_DHE_RSA_WITH_CAMELLIA_128_CBC_SHA256
x9a DHE-RSA-SEED-SHA DH 2048 SEED 128 TLS_DHE_RSA_WITH_SEED_CBC_SHA
x45 DHE-RSA-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DHE_RSA_WITH_CAMELLIA_128_CBC_SHA
xc018 AECDH-AES128-SHA ECDH 253 AES 128 TLS_ECDH_anon_WITH_AES_128_CBC_SHA
xa6 ADH-AES128-GCM-SHA256 DH 2048 AESGCM 128 TLS_DH_anon_WITH_AES_128_GCM_SHA256
x6c ADH-AES128-SHA256 DH 2048 AES 128 TLS_DH_anon_WITH_AES_128_CBC_SHA256
x34 ADH-AES128-SHA DH 2048 AES 128 TLS_DH_anon_WITH_AES_128_CBC_SHA
xbf ADH-CAMELLIA128-SHA256 DH 2048 Camellia 128 TLS_DH_anon_WITH_CAMELLIA_128_CBC_SHA256
x9b ADH-SEED-SHA DH 2048 SEED 128 TLS_DH_anon_WITH_SEED_CBC_SHA
x46 ADH-CAMELLIA128-SHA DH 2048 Camellia 128 TLS_DH_anon_WITH_CAMELLIA_128_CBC_SHA
x9c AES128-GCM-SHA256 RSA AESGCM 128 TLS_RSA_WITH_AES_128_GCM_SHA256
x3c AES128-SHA256 RSA AES 128 TLS_RSA_WITH_AES_128_CBC_SHA256
x2f AES128-SHA RSA AES 128 TLS_RSA_WITH_AES_128_CBC_SHA
xba CAMELLIA128-SHA256 RSA Camellia 128 TLS_RSA_WITH_CAMELLIA_128_CBC_SHA256
x96 SEED-SHA RSA SEED 128 TLS_RSA_WITH_SEED_CBC_SHA
x41 CAMELLIA128-SHA RSA Camellia 128 TLS_RSA_WITH_CAMELLIA_128_CBC_SHA
xc050 ARIA128-GCM-SHA256 RSA ARIAGCM 128 TLS_RSA_WITH_ARIA_128_GCM_SHA256
xc052 DHE-RSA-ARIA128-GCM-SHA256 DH 2048 ARIAGCM 128 TLS_DHE_RSA_WITH_ARIA_128_GCM_SHA256
xc060 ECDHE-ARIA128-GCM-SHA256 ECDH 253 ARIAGCM 128 TLS_ECDHE_RSA_WITH_ARIA_128_GCM_SHA256
TLS 1.3
x1302 TLS_AES_256_GCM_SHA384 ECDH 253 AESGCM 256 TLS_AES_256_GCM_SHA384
x1303 TLS_CHACHA20_POLY1305_SHA256 ECDH 253 ChaCha20 256 TLS_CHACHA20_POLY1305_SHA256
x1301 TLS_AES_128_GCM_SHA256 ECDH 253 AESGCM 128 TLS_AES_128_GCM_SHA256
With switching our SSL certificate to RSA, we gained around 51 new cipher options, amongst them being ones that also mx01.arz.at claimed to support.
FTR, the result from above is what you get with the default settings for postfix v3.5.18, being:
smtpd_tls_ciphers = medium
smtpd_tls_mandatory_ciphers = medium
smtpd_tls_mandatory_exclude_ciphers =
smtpd_tls_mandatory_protocols = !SSLv2, !SSLv3
But the delay between triggering the password reset mail and getting a mail server connect was getting bigger and bigger. Therefore while waiting for the next mail to arrive, I decided to capture the network traffic, to be able to look further into this if it should continue to be failing:
% sudo tshark -n -i eth0 -s 65535 -w arz.pcap -f "host 193.110.182.61 or host 193.110.182.62"
A few hours later the mail server connected again, and the mail went through!
postfix/smtpd[4162835]: connect from mx01.arz.at[193.110.182.61]
postfix/smtpd[4162835]: Anonymous TLS connection established from mx01.arz.at[193.110.182.61]: TLSv1.2 with cipher ECDHE-RSA-AES256-GCM-SHA384 (256/256 bits)
postfix/smtpd[4162835]: E50D6401E6: client=mx01.arz.at[193.110.182.61]
postfix/smtpd[4162835]: disconnect from mx01.arz.at[193.110.182.61] ehlo=2 starttls=1 mail=1 rcpt=1 data=1 quit=1 commands=7
Now also having the captured network traffic, we can check the details there:
[...]
% tshark -o smtp.decryption:true -r arz.pcap
1 0.000000000 193.110.182.61 203.0.113.42 TCP 74 24699 25 [SYN] Seq=0 Win=29200 Len=0 MSS=1460 SACK_PERM=1 TSval=2261106119 TSecr=0 WS=128
2 0.000042827 203.0.113.42 193.110.182.61 TCP 74 25 24699 [SYN, ACK] Seq=0 Ack=1 Win=65160 Len=0 MSS=1460 SACK_PERM=1 TSval=3233422181 TSecr=2261106119 WS=128
3 0.020719269 193.110.182.61 203.0.113.42 TCP 66 24699 25 [ACK] Seq=1 Ack=1 Win=29312 Len=0 TSval=2261106139 TSecr=3233422181
4 0.022883259 203.0.113.42 193.110.182.61 SMTP 96 S: 220 mail.example.com ESMTP
5 0.043682626 193.110.182.61 203.0.113.42 TCP 66 24699 25 [ACK] Seq=1 Ack=31 Win=29312 Len=0 TSval=2261106162 TSecr=3233422203
6 0.043799047 193.110.182.61 203.0.113.42 SMTP 84 C: EHLO mx01.arz.at
7 0.043811363 203.0.113.42 193.110.182.61 TCP 66 25 24699 [ACK] Seq=31 Ack=19 Win=65280 Len=0 TSval=3233422224 TSecr=2261106162
8 0.043898412 203.0.113.42 193.110.182.61 SMTP 253 S: 250-mail.example.com PIPELINING SIZE 20240000 VRFY ETRN AUTH PLAIN AUTH=PLAIN ENHANCEDSTATUSCODES 8BITMIME DSN SMTPUTF8 CHUNKING
9 0.064625499 193.110.182.61 203.0.113.42 SMTP 72 C: QUIT
10 0.064750257 203.0.113.42 193.110.182.61 SMTP 81 S: 221 2.0.0 Bye
11 0.064760200 203.0.113.42 193.110.182.61 TCP 66 25 24699 [FIN, ACK] Seq=233 Ack=25 Win=65280 Len=0 TSval=3233422245 TSecr=2261106183
12 0.085573715 193.110.182.61 203.0.113.42 TCP 66 24699 25 [FIN, ACK] Seq=25 Ack=234 Win=30336 Len=0 TSval=2261106204 TSecr=3233422245
13 0.085610229 203.0.113.42 193.110.182.61 TCP 66 25 24699 [ACK] Seq=234 Ack=26 Win=65280 Len=0 TSval=3233422266 TSecr=2261106204
14 1799.888108373 193.110.182.61 203.0.113.42 TCP 74 10330 25 [SYN] Seq=0 Win=29200 Len=0 MSS=1460 SACK_PERM=1 TSval=2262906007 TSecr=0 WS=128
15 1799.888161311 203.0.113.42 193.110.182.61 TCP 74 25 10330 [SYN, ACK] Seq=0 Ack=1 Win=65160 Len=0 MSS=1460 SACK_PERM=1 TSval=3235222069 TSecr=2262906007 WS=128
16 1799.909030335 193.110.182.61 203.0.113.42 TCP 66 10330 25 [ACK] Seq=1 Ack=1 Win=29312 Len=0 TSval=2262906028 TSecr=3235222069
17 1799.956621011 203.0.113.42 193.110.182.61 SMTP 96 S: 220 mail.example.com ESMTP
18 1799.977229656 193.110.182.61 203.0.113.42 TCP 66 10330 25 [ACK] Seq=1 Ack=31 Win=29312 Len=0 TSval=2262906096 TSecr=3235222137
19 1799.977229698 193.110.182.61 203.0.113.42 SMTP 84 C: EHLO mx01.arz.at
20 1799.977266759 203.0.113.42 193.110.182.61 TCP 66 25 10330 [ACK] Seq=31 Ack=19 Win=65280 Len=0 TSval=3235222158 TSecr=2262906096
21 1799.977351663 203.0.113.42 193.110.182.61 SMTP 267 S: 250-mail.example.com PIPELINING SIZE 20240000 VRFY ETRN STARTTLS AUTH PLAIN AUTH=PLAIN ENHANCEDSTATUSCODES 8BITMIME DSN SMTPUTF8 CHUNKING
22 1800.011494861 193.110.182.61 203.0.113.42 SMTP 76 C: STARTTLS
23 1800.011589267 203.0.113.42 193.110.182.61 SMTP 96 S: 220 2.0.0 Ready to start TLS
24 1800.032812294 193.110.182.61 203.0.113.42 TLSv1 223 Client Hello
25 1800.032987264 203.0.113.42 193.110.182.61 TLSv1.2 2962 Server Hello
26 1800.032995513 203.0.113.42 193.110.182.61 TCP 1266 25 10330 [PSH, ACK] Seq=3158 Ack=186 Win=65152 Len=1200 TSval=3235222214 TSecr=2262906151 [TCP segment of a reassembled PDU]
27 1800.053546755 193.110.182.61 203.0.113.42 TCP 66 10330 25 [ACK] Seq=186 Ack=3158 Win=36096 Len=0 TSval=2262906172 TSecr=3235222214
28 1800.092852469 193.110.182.61 203.0.113.42 TCP 66 10330 25 [ACK] Seq=186 Ack=4358 Win=39040 Len=0 TSval=2262906212 TSecr=3235222214
29 1800.092892905 203.0.113.42 193.110.182.61 TLSv1.2 900 Certificate, Server Key Exchange, Server Hello Done
30 1800.113546769 193.110.182.61 203.0.113.42 TCP 66 10330 25 [ACK] Seq=186 Ack=5192 Win=41856 Len=0 TSval=2262906232 TSecr=3235222273
31 1800.114763363 193.110.182.61 203.0.113.42 TLSv1.2 192 Client Key Exchange, Change Cipher Spec, Encrypted Handshake Message
32 1800.115000416 203.0.113.42 193.110.182.61 TLSv1.2 117 Change Cipher Spec, Encrypted Handshake Message
33 1800.136070200 193.110.182.61 203.0.113.42 TLSv1.2 113 Application Data
34 1800.136155526 203.0.113.42 193.110.182.61 TLSv1.2 282 Application Data
35 1800.158854473 193.110.182.61 203.0.113.42 TLSv1.2 162 Application Data
36 1800.159254794 203.0.113.42 193.110.182.61 TLSv1.2 109 Application Data
37 1800.180286407 193.110.182.61 203.0.113.42 TLSv1.2 144 Application Data
38 1800.223005960 203.0.113.42 193.110.182.61 TCP 66 25 10330 [ACK] Seq=5502 Ack=533 Win=65152 Len=0 TSval=3235222404 TSecr=2262906299
39 1802.230300244 203.0.113.42 193.110.182.61 TLSv1.2 146 Application Data
40 1802.251994333 193.110.182.61 203.0.113.42 TCP 2962 [TCP segment of a reassembled PDU]
41 1802.252034015 203.0.113.42 193.110.182.61 TCP 66 25 10330 [ACK] Seq=5582 Ack=3429 Win=63616 Len=0 TSval=3235224433 TSecr=2262908371
42 1802.252279083 193.110.182.61 203.0.113.42 TLSv1.2 1295 Application Data
43 1802.252288316 203.0.113.42 193.110.182.61 TCP 66 25 10330 [ACK] Seq=5582 Ack=4658 Win=64128 Len=0 TSval=3235224433 TSecr=2262908371
44 1802.272816060 193.110.182.61 203.0.113.42 TLSv1.2 833 Application Data, Application Data
45 1802.272827542 203.0.113.42 193.110.182.61 TCP 66 25 10330 [ACK] Seq=5582 Ack=5425 Win=64128 Len=0 TSval=3235224453 TSecr=2262908392
46 1802.338807683 203.0.113.42 193.110.182.61 TLSv1.2 131 Application Data
47 1802.398968611 193.110.182.61 203.0.113.42 TCP 66 10330 25 [ACK] Seq=5425 Ack=5647 Win=44800 Len=0 TSval=2262908518 TSecr=3235224519
48 1863.257457500 193.110.182.61 203.0.113.42 TLSv1.2 101 Application Data
49 1863.257495688 203.0.113.42 193.110.182.61 TCP 66 25 10330 [ACK] Seq=5647 Ack=5460 Win=64128 Len=0 TSval=3235285438 TSecr=2262969376
50 1863.257654942 203.0.113.42 193.110.182.61 TLSv1.2 110 Application Data
51 1863.257721010 203.0.113.42 193.110.182.61 TLSv1.2 97 Encrypted Alert
52 1863.278242216 193.110.182.61 203.0.113.42 TCP 66 10330 25 [ACK] Seq=5460 Ack=5691 Win=44800 Len=0 TSval=2262969397 TSecr=3235285438
53 1863.278464176 193.110.182.61 203.0.113.42 TCP 66 10330 25 [RST, ACK] Seq=5460 Ack=5723 Win=44800 Len=0 TSval=2262969397 TSecr=3235285438
% tshark -O tls -r arz.pcap
[...]
Transport Layer Security
TLSv1 Record Layer: Handshake Protocol: Client Hello
Content Type: Handshake (22)
Version: TLS 1.0 (0x0301)
Length: 152
Handshake Protocol: Client Hello
Handshake Type: Client Hello (1)
Length: 148
Version: TLS 1.2 (0x0303)
Random: 4575d1e7c93c09a564edc00b8b56ea6f5d826f8cfe78eb980c451a70a9c5123f
GMT Unix Time: Dec 5, 2006 21:09:11.000000000 CET
Random Bytes: c93c09a564edc00b8b56ea6f5d826f8cfe78eb980c451a70a9c5123f
Session ID Length: 0
Cipher Suites Length: 26
Cipher Suites (13 suites)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (0xc02f)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384 (0xc028)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256 (0xc027)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA (0xc014)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA (0xc013)
Cipher Suite: TLS_RSA_WITH_AES_256_GCM_SHA384 (0x009d)
Cipher Suite: TLS_RSA_WITH_AES_128_GCM_SHA256 (0x009c)
Cipher Suite: TLS_RSA_WITH_AES_256_CBC_SHA256 (0x003d)
Cipher Suite: TLS_RSA_WITH_AES_128_CBC_SHA256 (0x003c)
Cipher Suite: TLS_RSA_WITH_AES_256_CBC_SHA (0x0035)
Cipher Suite: TLS_RSA_WITH_AES_128_CBC_SHA (0x002f)
Cipher Suite: TLS_EMPTY_RENEGOTIATION_INFO_SCSV (0x00ff)
[...]
Transport Layer Security
TLSv1.2 Record Layer: Handshake Protocol: Server Hello
Content Type: Handshake (22)
Version: TLS 1.2 (0x0303)
Length: 89
Handshake Protocol: Server Hello
Handshake Type: Server Hello (2)
Length: 85
Version: TLS 1.2 (0x0303)
Random: cf2ed24e3300e95e5f56023bf8b4e5904b862bb2ed8a5796444f574e47524401
GMT Unix Time: Feb 23, 2080 23:16:46.000000000 CET
Random Bytes: 3300e95e5f56023bf8b4e5904b862bb2ed8a5796444f574e47524401
Session ID Length: 32
Session ID: 63d041b126ecebf857d685abd9d4593c46a3672e1ad76228f3eacf2164f86fb9
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
[...]
In this network dump we see what cipher suites are offered, and the
TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 here is the Cipher Suite Name in IANA/RFC speak. Whis corresponds to the
ECDHE-RSA-AES256-GCM-SHA384 in openssl speak (see Mozilla s
Mozilla s cipher suite correspondence table), which we also saw in the postfix log.
Mission accomplished! :)
Now, if we re interested in avoiding certain ciphers and increase security level, we can e.g. get rid of the SEED, CAMELLIA and all anonymous ciphers, and could accept only TLS v1.2 + v1.3, by further adjusting postfix s main.cf:
smtpd_tls_ciphers = high
smtpd_tls_exclude_ciphers = aNULL CAMELLIA
smtpd_tls_mandatory_ciphers = high
smtpd_tls_mandatory_protocols = TLSv1.2 TLSv1.3
smtpd_tls_protocols = TLSv1.2 TLSv1.3
Which would then gives us:
% testssl --cipher-per-proto -t=smtp mail.example.com:25
[...]
Hexcode Cipher Suite Name (OpenSSL) KeyExch. Encryption Bits Cipher Suite Name (IANA/RFC)
-----------------------------------------------------------------------------------------------------------------------------
SSLv2
SSLv3
TLS 1
TLS 1.1
TLS 1.2
xc030 ECDHE-RSA-AES256-GCM-SHA384 ECDH 253 AESGCM 256 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
xc028 ECDHE-RSA-AES256-SHA384 ECDH 253 AES 256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384
xc014 ECDHE-RSA-AES256-SHA ECDH 253 AES 256 TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
x9f DHE-RSA-AES256-GCM-SHA384 DH 2048 AESGCM 256 TLS_DHE_RSA_WITH_AES_256_GCM_SHA384
xcca8 ECDHE-RSA-CHACHA20-POLY1305 ECDH 253 ChaCha20 256 TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xccaa DHE-RSA-CHACHA20-POLY1305 DH 2048 ChaCha20 256 TLS_DHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xc0a3 DHE-RSA-AES256-CCM8 DH 2048 AESCCM8 256 TLS_DHE_RSA_WITH_AES_256_CCM_8
xc09f DHE-RSA-AES256-CCM DH 2048 AESCCM 256 TLS_DHE_RSA_WITH_AES_256_CCM
x6b DHE-RSA-AES256-SHA256 DH 2048 AES 256 TLS_DHE_RSA_WITH_AES_256_CBC_SHA256
x39 DHE-RSA-AES256-SHA DH 2048 AES 256 TLS_DHE_RSA_WITH_AES_256_CBC_SHA
x9d AES256-GCM-SHA384 RSA AESGCM 256 TLS_RSA_WITH_AES_256_GCM_SHA384
xc0a1 AES256-CCM8 RSA AESCCM8 256 TLS_RSA_WITH_AES_256_CCM_8
xc09d AES256-CCM RSA AESCCM 256 TLS_RSA_WITH_AES_256_CCM
x3d AES256-SHA256 RSA AES 256 TLS_RSA_WITH_AES_256_CBC_SHA256
x35 AES256-SHA RSA AES 256 TLS_RSA_WITH_AES_256_CBC_SHA
xc051 ARIA256-GCM-SHA384 RSA ARIAGCM 256 TLS_RSA_WITH_ARIA_256_GCM_SHA384
xc053 DHE-RSA-ARIA256-GCM-SHA384 DH 2048 ARIAGCM 256 TLS_DHE_RSA_WITH_ARIA_256_GCM_SHA384
xc061 ECDHE-ARIA256-GCM-SHA384 ECDH 253 ARIAGCM 256 TLS_ECDHE_RSA_WITH_ARIA_256_GCM_SHA384
xc02f ECDHE-RSA-AES128-GCM-SHA256 ECDH 253 AESGCM 128 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
xc027 ECDHE-RSA-AES128-SHA256 ECDH 253 AES 128 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256
xc013 ECDHE-RSA-AES128-SHA ECDH 253 AES 128 TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA
x9e DHE-RSA-AES128-GCM-SHA256 DH 2048 AESGCM 128 TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
xc0a2 DHE-RSA-AES128-CCM8 DH 2048 AESCCM8 128 TLS_DHE_RSA_WITH_AES_128_CCM_8
xc09e DHE-RSA-AES128-CCM DH 2048 AESCCM 128 TLS_DHE_RSA_WITH_AES_128_CCM
xc0a0 AES128-CCM8 RSA AESCCM8 128 TLS_RSA_WITH_AES_128_CCM_8
xc09c AES128-CCM RSA AESCCM 128 TLS_RSA_WITH_AES_128_CCM
x67 DHE-RSA-AES128-SHA256 DH 2048 AES 128 TLS_DHE_RSA_WITH_AES_128_CBC_SHA256
x33 DHE-RSA-AES128-SHA DH 2048 AES 128 TLS_DHE_RSA_WITH_AES_128_CBC_SHA
x9c AES128-GCM-SHA256 RSA AESGCM 128 TLS_RSA_WITH_AES_128_GCM_SHA256
x3c AES128-SHA256 RSA AES 128 TLS_RSA_WITH_AES_128_CBC_SHA256
x2f AES128-SHA RSA AES 128 TLS_RSA_WITH_AES_128_CBC_SHA
xc050 ARIA128-GCM-SHA256 RSA ARIAGCM 128 TLS_RSA_WITH_ARIA_128_GCM_SHA256
xc052 DHE-RSA-ARIA128-GCM-SHA256 DH 2048 ARIAGCM 128 TLS_DHE_RSA_WITH_ARIA_128_GCM_SHA256
xc060 ECDHE-ARIA128-GCM-SHA256 ECDH 253 ARIAGCM 128 TLS_ECDHE_RSA_WITH_ARIA_128_GCM_SHA256
TLS 1.3
x1302 TLS_AES_256_GCM_SHA384 ECDH 253 AESGCM 256 TLS_AES_256_GCM_SHA384
x1303 TLS_CHACHA20_POLY1305_SHA256 ECDH 253 ChaCha20 256 TLS_CHACHA20_POLY1305_SHA256
x1301 TLS_AES_128_GCM_SHA256 ECDH 253 AESGCM 128 TLS_AES_128_GCM_SHA256
Don t forget to also adjust the
smpt_tls_* accordingly (for your sending side). For further information see
the Postfix TLS Support documentation. Also check out options like
tls_ssl_options (setting it to e.g.
NO_COMPRESSION) and
tls_preempt_cipherlist (setting it to
yes would prefer the servers order of ciphers over clients).
Conclusions:
- no matter what you change in your mail server settings, be aware that the type of your SSL certificate also matters for what ciphers are offered and used
- there are mail servers out there that don t support SSL certificates with ECDSA, using RSA for those ensure better compatibility (nowadays postfix supports parallel usage of ECDSA and RSA keys BTW, check out the smtpd_tls_eccert_file + smtpd_tls_eckey_file options)
- testssl is a very useful tool, especially with its cipher-per-proto -t=smtp option to check SMTP servers
- if you re uncertain what s going on, consider capturing network data (tshark/tcpdump/ are your friends)
- review your postfix configuration and logs every now and then :)
 A few days ago
A few days ago 












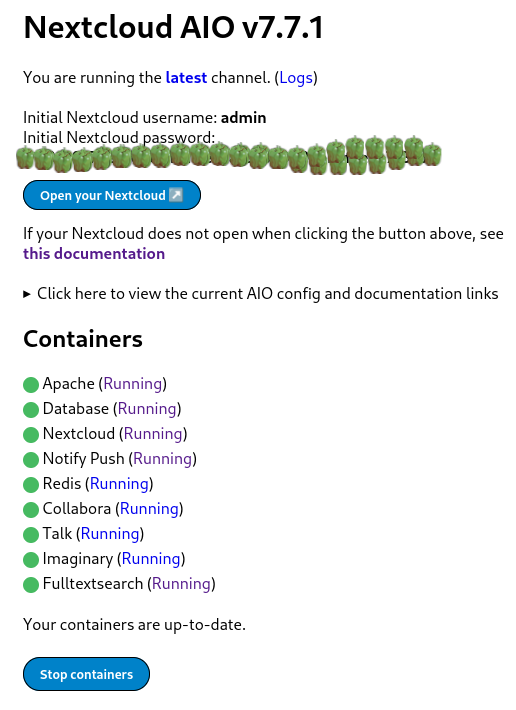
 Nextcloud is a popular self-hosted solution for file sync and share as well as cloud apps such as document editing, chat and talk, calendar, photo gallery etc. This guide will walk you through setting up Nextcloud AIO using Docker Compose. This blog post would not be possible without immense help from Sahil Dhiman a.k.a.
Nextcloud is a popular self-hosted solution for file sync and share as well as cloud apps such as document editing, chat and talk, calendar, photo gallery etc. This guide will walk you through setting up Nextcloud AIO using Docker Compose. This blog post would not be possible without immense help from Sahil Dhiman a.k.a. 


 Attribution of source code has been limited to comments, but a deeper
embedding of attribution into code is possible. When an embedded
attribution is removed or is incorrect, the code should no longer work.
I've developed a way to do this in Haskell that is lightweight to add, but
requires more work to remove than seems worthwhile for someone who is
training an LLM on my code. And when it's not removed, it invites LLM
hallucinations of broken code.
I'm embedding attribution by defining a function like this in a module,
which uses an
Attribution of source code has been limited to comments, but a deeper
embedding of attribution into code is possible. When an embedded
attribution is removed or is incorrect, the code should no longer work.
I've developed a way to do this in Haskell that is lightweight to add, but
requires more work to remove than seems worthwhile for someone who is
training an LLM on my code. And when it's not removed, it invites LLM
hallucinations of broken code.
I'm embedding attribution by defining a function like this in a module,
which uses an  There is a bit of context that needs to be shared before I get to this and would be a long one. For reasons known and unknown, I have a lot of sudden electricity outages. Not just me, all those who are on my line. A discussion with a lineman revealed that around 200+ families and businesses are on the same line and when for whatever reason the electricity goes for all. Even some of the traffic lights don t work. This affects software more than hardware or in some cases, both. And more specifically HDD s are vulnerable. I had bought an APC unit several years for precisely this, but over period of time it just couldn t function and trips also when the electricity goes out. It s been 6-7 years so can t even ask customer service to fix the issue and from whatever discussions I have had with APC personnel, the only meaningful difference is to buy a new unit but even then not sure this is an issue that can be resolved, even with that.
That comes to the issue that happens once in a while where the system fsck is unable to repair /home and you need to use an external pen drive for the same. This is my how my hdd stacks up
There is a bit of context that needs to be shared before I get to this and would be a long one. For reasons known and unknown, I have a lot of sudden electricity outages. Not just me, all those who are on my line. A discussion with a lineman revealed that around 200+ families and businesses are on the same line and when for whatever reason the electricity goes for all. Even some of the traffic lights don t work. This affects software more than hardware or in some cases, both. And more specifically HDD s are vulnerable. I had bought an APC unit several years for precisely this, but over period of time it just couldn t function and trips also when the electricity goes out. It s been 6-7 years so can t even ask customer service to fix the issue and from whatever discussions I have had with APC personnel, the only meaningful difference is to buy a new unit but even then not sure this is an issue that can be resolved, even with that.
That comes to the issue that happens once in a while where the system fsck is unable to repair /home and you need to use an external pen drive for the same. This is my how my hdd stacks up  The main argument as have shared before is that Indian Govt. thinks we need our home grown CPU and while I have no issues with that, as shared before except for RISC-V there is no other space where India could look into doing that. Especially after the Chip Act, Biden has made that any new fabs or any new thing in chip fabrication will only be shared with
The main argument as have shared before is that Indian Govt. thinks we need our home grown CPU and while I have no issues with that, as shared before except for RISC-V there is no other space where India could look into doing that. Especially after the Chip Act, Biden has made that any new fabs or any new thing in chip fabrication will only be shared with 
 . Backups certainly make a lot of sense, especially
. Backups certainly make a lot of sense, especially 

](https://jmtd.net/log/zarchscape/carpet_90s.jpg)

 I have had the pleasure to have Poha in many ways. One of my favorite ones is when people have actually put tadka on top of Poha. You do everything else but in a slight reverse order. The tadka has all the spices mixed and is concentrated and is put on top of Poha and then mixed. Done right, it tastes out of this world. For those who might not have had the Indian culinary experience, most of which is actually borrowed from the Mughals, you are in for a treat.
One of the other things I would suggest to people is to ask people where there can get five types of rice. This is a specialty of South India and a sort of street food. I know where you can get it Hyderabad, Bangalore, Chennai but not in Kerala, although am dead sure there is, just somehow have missed it. If asked, am sure the Kerala team should be able to guide.
That s all for now, feeling hungry, having dinner as have been sharing about cooking.
I have had the pleasure to have Poha in many ways. One of my favorite ones is when people have actually put tadka on top of Poha. You do everything else but in a slight reverse order. The tadka has all the spices mixed and is concentrated and is put on top of Poha and then mixed. Done right, it tastes out of this world. For those who might not have had the Indian culinary experience, most of which is actually borrowed from the Mughals, you are in for a treat.
One of the other things I would suggest to people is to ask people where there can get five types of rice. This is a specialty of South India and a sort of street food. I know where you can get it Hyderabad, Bangalore, Chennai but not in Kerala, although am dead sure there is, just somehow have missed it. If asked, am sure the Kerala team should be able to guide.
That s all for now, feeling hungry, having dinner as have been sharing about cooking.
 When I travel for a few days I don t usually
When I travel for a few days I don t usually For the soles I may have gone a bit overboard with the vibram claw, but:
For the soles I may have gone a bit overboard with the vibram claw, but:
 As for the finished weight, at 235 g for the pair I thought I could do better, but apparently shoes are considered ultralight if they are around 500 g? Using just one layer of mesh rather than two would probably help, but it would have required a few changes to the pattern, and anyway I don t really to carry them around all day.
As for the finished weight, at 235 g for the pair I thought I could do better, but apparently shoes are considered ultralight if they are around 500 g? Using just one layer of mesh rather than two would probably help, but it would have required a few changes to the pattern, and anyway I don t really to carry them around all day.
 I ve also added a loop of fabric (polycotton) to the centre back to be able to hang the slippers to the backpack when wet or dirty; a bit of narrow webbing may have been better, but I didn t have any in my stash.
The
I ve also added a loop of fabric (polycotton) to the centre back to be able to hang the slippers to the backpack when wet or dirty; a bit of narrow webbing may have been better, but I didn t have any in my stash.
The 