Joachim Breitner: Convenient sandboxed development environment
 I like using one machine and setup for everything, from serious development work to hobby projects to managing my finances. This is very convenient, as often the lines between these are blurred. But it is also scary if I think of the large number of people who I have to trust to not want to extract all my personal data. Whenever I run a
I like using one machine and setup for everything, from serious development work to hobby projects to managing my finances. This is very convenient, as often the lines between these are blurred. But it is also scary if I think of the large number of people who I have to trust to not want to extract all my personal data. Whenever I run a cabal install, or a fun VSCode extension gets updated, or anything like that, I am running code that could be malicious or buggy.
In a way it is surprising and reassuring that, as far as I can tell, this commonly does not happen. Most open source developers out there seem to be nice and well-meaning, after all.
Convenient or it won t happen
Nevertheless I thought I should do something about this. The safest option would probably to use dedicated virtual machines for the development work, with very little interaction with my main system. But knowing me, that did not seem likely to happen, as it sounded like a fair amount of hassle. So I aimed for a viable compromise between security and convenient, and one that does not get too much in the way of my current habits.
For instance, it seems desirable to have the project files accessible from my unconstrained environment. This way, I could perform certain actions that need access to secret keys or tokens, but are (unlikely) to run code (e.g. git push, git pull from private repositories, gh pr create) from the outside , and the actual build environment can do without access to these secrets.
The user experience I thus want is a quick way to enter a development environment where I can do most of the things I need to do while programming (network access, running command line and GUI programs), with access to the current project, but without access to my actual /home directory.
I initially followed the blog post Application Isolation using NixOS Containers by Marcin Sucharski and got something working that mostly did what I wanted, but then a colleague pointed out that tools like firejail can achieve roughly the same with a less global setup. I tried to use firejail, but found it to be a bit too inflexible for my particular whims, so I ended up writing a small wrapper around the lower level sandboxing tool https://github.com/containers/bubblewrap.
Selective bubblewrapping
This script, called dev and included below, builds a new filesystem namespace with minimal /proc and /dev directories, it s own /tmp directories. It then binds-mound some directories to make the host s NixOS system available inside the container (/bin, /usr, the nix store including domain socket, stuff for OpenGL applications). My user s home directory is taken from ~/.dev-home and some configuration files are bind-mounted for convenient sharing. I intentionally don t share most of the configuration for example, a direnv enable in the dev environment should not affect the main environment. The X11 socket for graphical applications and the corresponding .Xauthority file is made available. And finally, if I run dev in a project directory, this project directory is bind mounted writable, and the current working directory is preserved.
The effect is that I can type dev on the command line to enter dev mode rather conveniently. I can run development tools, including graphical ones like VSCode, and especially the latter with its extensions is part of the sandbox. To do a git push I either exit the development environment (Ctrl-D) or open a separate terminal. Overall, the inconvenience of switching back and forth seems worth the extra protection.
Clearly, isn t going to hold against a determined and maybe targeted attacker (e.g. access to the X11 and the nix daemon socket can probably be used to escape easily). But I hope it will help against a compromised dev dependency that just deletes or exfiltrates data, like keys or passwords, from the usual places in $HOME.
Rough corners
There is more polishing that could be done.
- In particular, clicking on a link inside VSCode in the container will currently open Firefox inside the container, without access to my settings and cookies etc. Ideally, links would be opened in the Firefox running outside. This is a problem that has a solution in the world of applications that are sandboxed with Flatpak, and involves a bunch of moving parts (a xdg-desktop-portal user service, a filtering dbus proxy, exposing access to that proxy in the container). I experimented with that for a bit longer than I should have, but could not get it to work to satisfaction (even without a container involved, I could not get
xdg-desktop-portal to heed my default browser settings ). For now I will live with manually copying and pasting URLs, we ll see how long this lasts.
- With this setup (and unlike the NixOS container setup I tried first), the same applications are installed inside and outside. It might be useful to separate the set of installed programs: There is simply no point in running
evolution or firefox inside the container, and if I do not even have VSCode or cabal available outside, so that it s less likely that I forget to enter dev before using these tools.
It shouldn t be too hard to cargo-cult some of the NixOS Containers infrastructure to be able to have a separate system configuration that I can manage as part of my normal system configuration and make available to bubblewrap here.
So likely I will refine this some more over time. Or get tired of typing dev and going back to what I did before
The script
The dev script (at the time of writing)
#!/usr/bin/env bash
extra=()
if [[ "$PWD" == /home/jojo/build/* ]] [[ "$PWD" == /home/jojo/projekte/programming/* ]]
then
extra+=(--bind "$PWD" "$PWD" --chdir "$PWD")
fi
if [ -n "$1" ]
then
cmd=( "$@" )
else
cmd=( bash )
fi
# Caveats:
# * access to all of /etc
# * access to /nix/var/nix/daemon-socket/socket , and is trusted user (but needed to run nix)
# * access to X11
exec bwrap \
--unshare-all \
\
# blank slate \
--share-net \
--proc /proc \
--dev /dev \
--tmpfs /tmp \
--tmpfs /run/user/1000 \
\
# Needed for GLX applications, in paticular alacritty \
--dev-bind /dev/dri /dev/dri \
--ro-bind /sys/dev/char /sys/dev/char \
--ro-bind /sys/devices/pci0000:00 /sys/devices/pci0000:00 \
--ro-bind /run/opengl-driver /run/opengl-driver \
\
--ro-bind /bin /bin \
--ro-bind /usr /usr \
--ro-bind /run/current-system /run/current-system \
--ro-bind /nix /nix \
--ro-bind /etc /etc \
--ro-bind /run/systemd/resolve/stub-resolv.conf /run/systemd/resolve/stub-resolv.conf \
\
--bind ~/.dev-home /home/jojo \
--ro-bind ~/.config/alacritty ~/.config/alacritty \
--ro-bind ~/.config/nvim ~/.config/nvim \
--ro-bind ~/.local/share/nvim ~/.local/share/nvim \
--ro-bind ~/.bin ~/.bin \
\
--bind /tmp/.X11-unix/X0 /tmp/.X11-unix/X0 \
--bind ~/.Xauthority ~/.Xauthority \
--setenv DISPLAY :0 \
\
--setenv container dev \
"$ extra[@] " \
-- \
"$ cmd[@] "
dev and included below, builds a new filesystem namespace with minimal /proc and /dev directories, it s own /tmp directories. It then binds-mound some directories to make the host s NixOS system available inside the container (/bin, /usr, the nix store including domain socket, stuff for OpenGL applications). My user s home directory is taken from ~/.dev-home and some configuration files are bind-mounted for convenient sharing. I intentionally don t share most of the configuration for example, a direnv enable in the dev environment should not affect the main environment. The X11 socket for graphical applications and the corresponding .Xauthority file is made available. And finally, if I run dev in a project directory, this project directory is bind mounted writable, and the current working directory is preserved.
The effect is that I can type dev on the command line to enter dev mode rather conveniently. I can run development tools, including graphical ones like VSCode, and especially the latter with its extensions is part of the sandbox. To do a git push I either exit the development environment (Ctrl-D) or open a separate terminal. Overall, the inconvenience of switching back and forth seems worth the extra protection.
Clearly, isn t going to hold against a determined and maybe targeted attacker (e.g. access to the X11 and the nix daemon socket can probably be used to escape easily). But I hope it will help against a compromised dev dependency that just deletes or exfiltrates data, like keys or passwords, from the usual places in $HOME.
Rough corners
There is more polishing that could be done.
- In particular, clicking on a link inside VSCode in the container will currently open Firefox inside the container, without access to my settings and cookies etc. Ideally, links would be opened in the Firefox running outside. This is a problem that has a solution in the world of applications that are sandboxed with Flatpak, and involves a bunch of moving parts (a xdg-desktop-portal user service, a filtering dbus proxy, exposing access to that proxy in the container). I experimented with that for a bit longer than I should have, but could not get it to work to satisfaction (even without a container involved, I could not get
xdg-desktop-portal to heed my default browser settings ). For now I will live with manually copying and pasting URLs, we ll see how long this lasts.
- With this setup (and unlike the NixOS container setup I tried first), the same applications are installed inside and outside. It might be useful to separate the set of installed programs: There is simply no point in running
evolution or firefox inside the container, and if I do not even have VSCode or cabal available outside, so that it s less likely that I forget to enter dev before using these tools.
It shouldn t be too hard to cargo-cult some of the NixOS Containers infrastructure to be able to have a separate system configuration that I can manage as part of my normal system configuration and make available to bubblewrap here.
So likely I will refine this some more over time. Or get tired of typing dev and going back to what I did before
The script
The dev script (at the time of writing)
#!/usr/bin/env bash
extra=()
if [[ "$PWD" == /home/jojo/build/* ]] [[ "$PWD" == /home/jojo/projekte/programming/* ]]
then
extra+=(--bind "$PWD" "$PWD" --chdir "$PWD")
fi
if [ -n "$1" ]
then
cmd=( "$@" )
else
cmd=( bash )
fi
# Caveats:
# * access to all of /etc
# * access to /nix/var/nix/daemon-socket/socket , and is trusted user (but needed to run nix)
# * access to X11
exec bwrap \
--unshare-all \
\
# blank slate \
--share-net \
--proc /proc \
--dev /dev \
--tmpfs /tmp \
--tmpfs /run/user/1000 \
\
# Needed for GLX applications, in paticular alacritty \
--dev-bind /dev/dri /dev/dri \
--ro-bind /sys/dev/char /sys/dev/char \
--ro-bind /sys/devices/pci0000:00 /sys/devices/pci0000:00 \
--ro-bind /run/opengl-driver /run/opengl-driver \
\
--ro-bind /bin /bin \
--ro-bind /usr /usr \
--ro-bind /run/current-system /run/current-system \
--ro-bind /nix /nix \
--ro-bind /etc /etc \
--ro-bind /run/systemd/resolve/stub-resolv.conf /run/systemd/resolve/stub-resolv.conf \
\
--bind ~/.dev-home /home/jojo \
--ro-bind ~/.config/alacritty ~/.config/alacritty \
--ro-bind ~/.config/nvim ~/.config/nvim \
--ro-bind ~/.local/share/nvim ~/.local/share/nvim \
--ro-bind ~/.bin ~/.bin \
\
--bind /tmp/.X11-unix/X0 /tmp/.X11-unix/X0 \
--bind ~/.Xauthority ~/.Xauthority \
--setenv DISPLAY :0 \
\
--setenv container dev \
"$ extra[@] " \
-- \
"$ cmd[@] "
xdg-desktop-portal to heed my default browser settings ). For now I will live with manually copying and pasting URLs, we ll see how long this lasts.evolution or firefox inside the container, and if I do not even have VSCode or cabal available outside, so that it s less likely that I forget to enter dev before using these tools.
It shouldn t be too hard to cargo-cult some of the NixOS Containers infrastructure to be able to have a separate system configuration that I can manage as part of my normal system configuration and make available to bubblewrap here.
The
dev script (at the time of writing)
#!/usr/bin/env bash
extra=()
if [[ "$PWD" == /home/jojo/build/* ]] [[ "$PWD" == /home/jojo/projekte/programming/* ]]
then
extra+=(--bind "$PWD" "$PWD" --chdir "$PWD")
fi
if [ -n "$1" ]
then
cmd=( "$@" )
else
cmd=( bash )
fi
# Caveats:
# * access to all of /etc
# * access to /nix/var/nix/daemon-socket/socket , and is trusted user (but needed to run nix)
# * access to X11
exec bwrap \
--unshare-all \
\
# blank slate \
--share-net \
--proc /proc \
--dev /dev \
--tmpfs /tmp \
--tmpfs /run/user/1000 \
\
# Needed for GLX applications, in paticular alacritty \
--dev-bind /dev/dri /dev/dri \
--ro-bind /sys/dev/char /sys/dev/char \
--ro-bind /sys/devices/pci0000:00 /sys/devices/pci0000:00 \
--ro-bind /run/opengl-driver /run/opengl-driver \
\
--ro-bind /bin /bin \
--ro-bind /usr /usr \
--ro-bind /run/current-system /run/current-system \
--ro-bind /nix /nix \
--ro-bind /etc /etc \
--ro-bind /run/systemd/resolve/stub-resolv.conf /run/systemd/resolve/stub-resolv.conf \
\
--bind ~/.dev-home /home/jojo \
--ro-bind ~/.config/alacritty ~/.config/alacritty \
--ro-bind ~/.config/nvim ~/.config/nvim \
--ro-bind ~/.local/share/nvim ~/.local/share/nvim \
--ro-bind ~/.bin ~/.bin \
\
--bind /tmp/.X11-unix/X0 /tmp/.X11-unix/X0 \
--bind ~/.Xauthority ~/.Xauthority \
--setenv DISPLAY :0 \
\
--setenv container dev \
"$ extra[@] " \
-- \
"$ cmd[@] "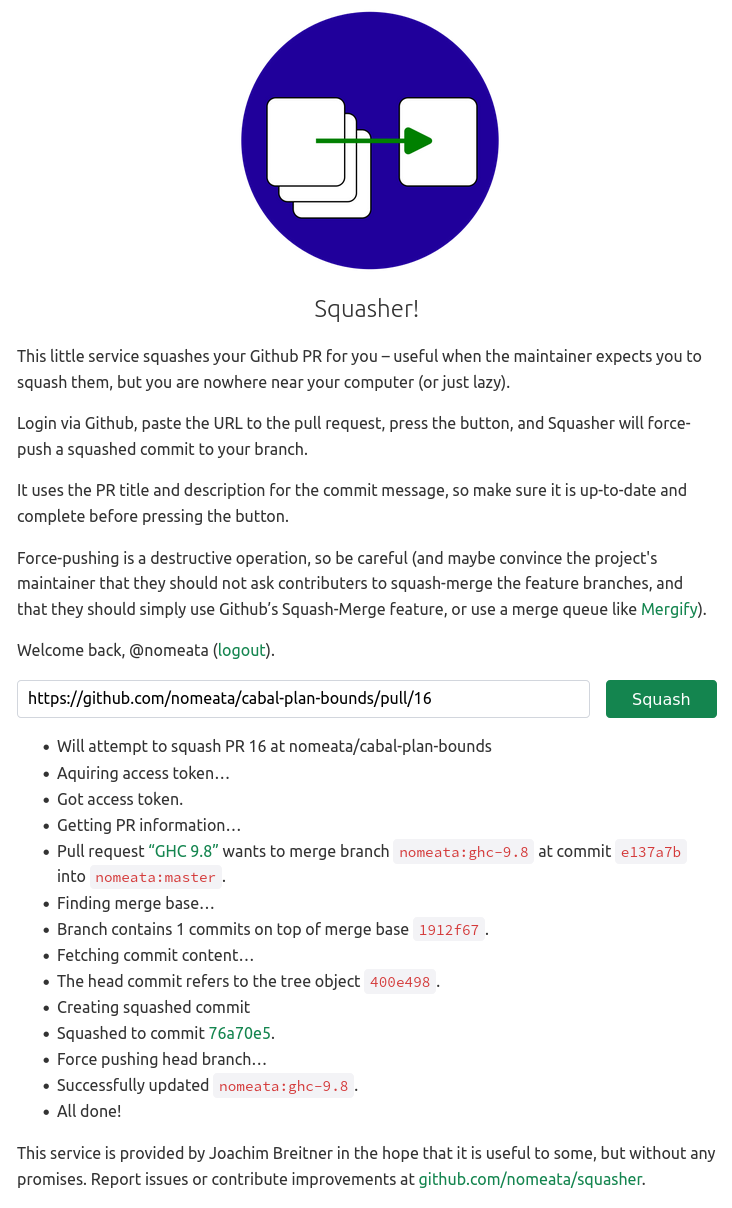 Squasher in action
Squasher in action


 Microsoft Minesweeper
Microsoft Minesweeper
 Norman Ramsey shows a formula
Norman Ramsey shows a formula
 Our most favorite camp spot
Our most favorite camp spot
 The IDE
The IDE
 A chatbot
A chatbot