
Over the years, I have had many different blogs. I mainly use them to post updates regarding my work in the FOSS community, with most of these relating to Ubuntu/Debian. My most recent blog was a Wordpress instance I ran on a VPS provided by a friend. This worked pretty well, but for various reasons, I no longer have access to that box.
Earlier today, I started thinking about launching a new blog. The first problem I had to overcome was deciding where to host it. Many of the groups I am involved with provide members with a
~/public_html directory that can be used to host simple HTML+Javascript+CSS websites. However, most of these sites do not have the ability to use PHP, CGI, or access databases. I realized rather quickly that if I were to find a blogging platform that I could run from a
~/public_html directory on one of those machines, I would never have the problem of not having a host for my blog ever again. There is a near infinite number of free web hosts that can handle simple HTML sites.
One key feature of any blog is the ability for readers to subscribe to it. Usually, the blogging platform handles automatically updating the feed when a new post is published. However, my simple HTML blog would not be able to do that. Since I knew I did not want to manually update the feeds, I started looking for a way to generate the feed locally on my personal machine and then push it to the remote site that is hosting my blog.
About this time, I started compiling a list of features I would need to make this blogging platform usable. In no particular order, they included:
- Produce a blog that only uses HTML, CSS, and Javascript that can be run from a ~/public_html directory
- Output an RSS feed for the site and per-tag RSS feeds that people can subscribe to
- Display an index of the most recent blog posts and allow people to browse an archive of older posts
- Allow formatting blog posts through HTML or Markdown
- Be maintainable in a VCS
After some searching, I found an application developed by Steve Kemp called
Chronicle. Chronicle supports all of the features I described plus many more. It is also very quick and easy to setup. If you are running Debian, Chronicle is available from the
repositories.
Start by installing Chronicle. Note that these steps should all be done on your personal machine, not the machine that is going to host your blog.
sudo apt-get install chronicle
There are a few other packages that you can install to extend the functionality of Chronicle
sudo apt-get install memcached libcache-memcached-perl libhtml-calendarmonthsimple-perl libtext-vimcolor-perl libtext-markdown-perl
Next, create a few folders to hold our blog. We will store our raw blog posts in
~/blog/input and have the generated HTML versions go in
~/blog/output.
mkdir -p ~/blog/ input,output
Now, we need to configure some preferences. We will base our preferences on the global configuration file shipped with the package.
cp /etc/chroniclerc ~/.chroniclerc
Open up the new
~/.chroniclerc file in your favorite editor. It is pretty well commented, but I will still explain the changes I made.
input is the path to where your blog posts can be found. These are the raw blog posts, not the generated HTML versions of the posts. In our example, this should be set to
~/blog/input.
pattern tells Chronicle which files in the
input directory are blog posts. We will use a
.txt extension to denote these files. Therefore, set
pattern to
*.txt.
output is the directory where Chronicle should store the generated HTML versions of the blog posts. This should be
~/blog/output
theme-dir is the directory that holds all of the themes. Chronicle ships with a couple of sample themes that you can use. Set this to
/usr/share/chronicle/themes
theme is the name of the theme you want to use. We will just use the default them, so set this to
default
entry-count specifies how many blog posts should be displayed on the HTML index page for the blog. I like to keep this fairly small, so I set mine to
10.
rss-count is similar to
entry-count, but it specifies the number of blog posts to include in the RSS feed. I also set this to
10
format specifies the format used in the raw blog posts. I write mine in
markdown, but
multimarkdown,
textile, and
html are also supported.
Since most
~/public_html directories do not support CGI. We will disable comments by setting
no-comments to
1
suffix gets appended to the filenames of all of the generated blog posts. Set this to
.html
url_prefix is the first part of the URL for the blog. If the index.html file for the blog is going to be available at http://example.com/blog/ , set this to *http://example.com/~user/blog/
blog_title is whatever you want your blog to be called. The title is displayed at the top of the site. Set it to something like
Your Name's Blog
post-build is a very useful setting. It allows us to have Chronicle perform some action after it finishes running. We will use this to copy our blog to the remote host's public_html directory. Set this field to something like
scp -r output/* user@example.com:~/public_html/blog. You will probably want to setup SSH so that you do not need to enter a password each time.
Finally,
date-archive-path will allow you to get the nice year/month directories to sort your posts. Set this to
1.
Your final
~/.chroniclerc should look something like this:
input = ~/blog
pattern = *.txt
output = ~/blog/output
theme-dir = /usr/share/chronicle/themes
theme = default
entry-count = 10
rss-count = 10
format = markdown
no-comments = 1
suffix = .html
url_prefix = http://example.com/~user/blog/
blog_title = Your Name's Blog
post-build = scp -r output/* user2@example.com:~/public_html/blog
date-archive-path = 1
You are now ready to start writing your first blog post. Open up
~/blog/MyFirstBlogPost.txt in your favorite text editor. Modify it to look like this:
Title: My First Blog Post
Tags: MyTag
Date: October 29, 2012
This is my **first** blog post.
Notice the metadata stored at the top? This is required for every post. Chronicle uses it to figure out the post title, tags, and date. It has some logic to try and guess this information if missing, but it is probably safest if you specify it. The empty line between the metadata and the post content is also required.
Remember, we configured Chronicle to treat these as Markdown files, so feel free to utilize any Markdown formatting you wish. Finally, run
chronicle from a terminal. If all goes well, it should generate your blog and copy the files to the remote host. You can now go to http://example.com/~user/blog to view it.
One final suggestion would be to store the entire blog in a git repository. This will allow you to utilize all of the features of a VCS, such as reverting any accidental changes or allowing multiple people to collaborate on a blog post at the same time.
 On Thursday, October 22, 2015, Ubuntu 15.10 (Wily Werewolf) was released. To celebrate, some San Francisco members of the Ubuntu California LoCo Team held a small release party. Yelp was gracious enough to host the event and provide us with food and drinks. Canonical also sent us a box of swag for the event. Unfortunately, it did not arrive in time. Luckily, James Ouyang had some extra goodies from a previous event for us to hand out. Despite having a rather small turnout for the event, it was still a fun night. Several people borrowed the USB flash drives I had setup with Ubuntu, Kubuntu, and Xubuntu 15.10 in order to install Ubuntu on their machines. Other people were happy to play around with the new release in a virtual machine on my computer. Overall, it was a good night. Hopefully, we can put together an even better and larger release party for Ubuntu 16.04 LTS.
On Thursday, October 22, 2015, Ubuntu 15.10 (Wily Werewolf) was released. To celebrate, some San Francisco members of the Ubuntu California LoCo Team held a small release party. Yelp was gracious enough to host the event and provide us with food and drinks. Canonical also sent us a box of swag for the event. Unfortunately, it did not arrive in time. Luckily, James Ouyang had some extra goodies from a previous event for us to hand out. Despite having a rather small turnout for the event, it was still a fun night. Several people borrowed the USB flash drives I had setup with Ubuntu, Kubuntu, and Xubuntu 15.10 in order to install Ubuntu on their machines. Other people were happy to play around with the new release in a virtual machine on my computer. Overall, it was a good night. Hopefully, we can put together an even better and larger release party for Ubuntu 16.04 LTS.
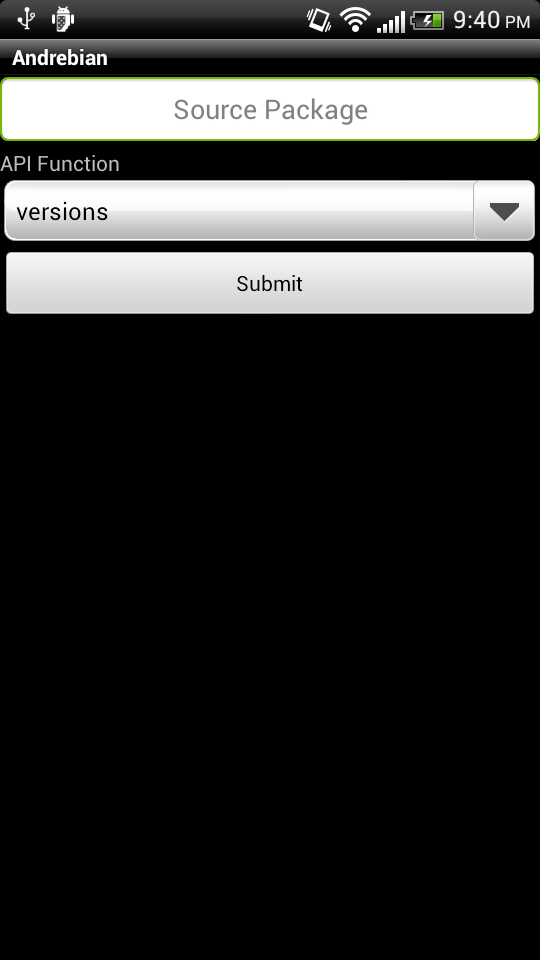
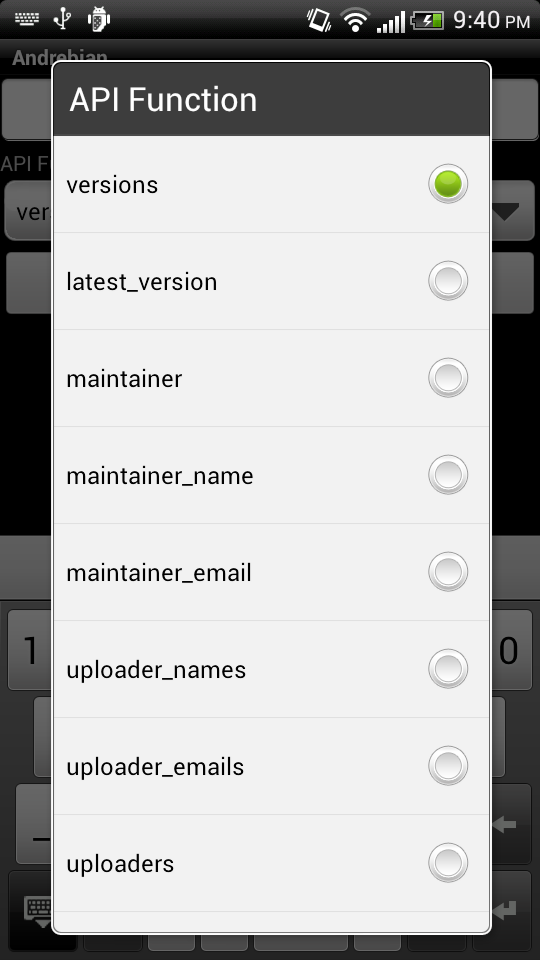
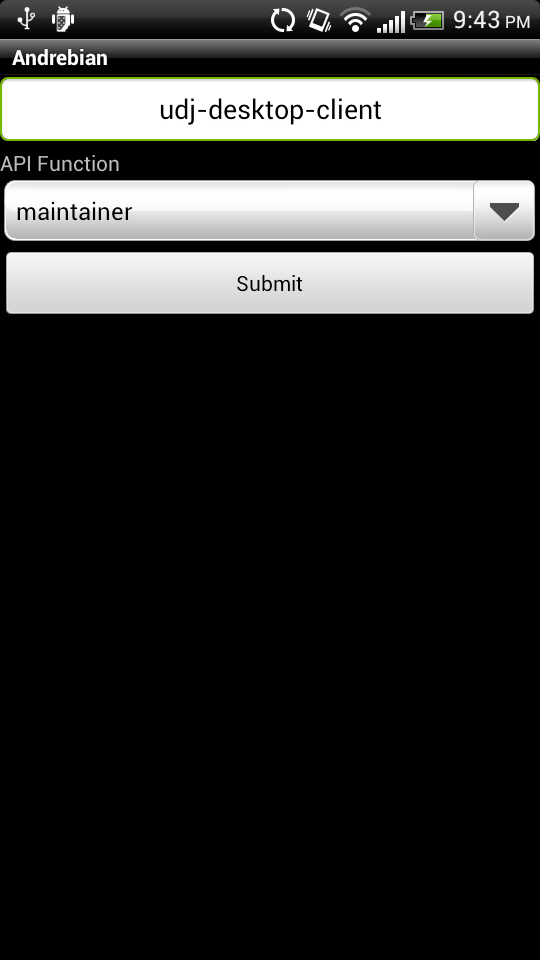
 If you have any feature suggestions, questions, or comments, feel free to send me an email (nhandler@debian.org). The source code for the Android application is currently not available, but I plan to put it up in a git repository sometime in the near future. The source code for the Python script that provides a REST API to access the PTS and BTS SOAP interface is available on
If you have any feature suggestions, questions, or comments, feel free to send me an email (nhandler@debian.org). The source code for the Android application is currently not available, but I plan to put it up in a git repository sometime in the near future. The source code for the Python script that provides a REST API to access the PTS and BTS SOAP interface is available on  after having used
after having used  As a followup to my toy over at
As a followup to my toy over at 






{kind=link}