
pg_dirtyread
Earlier this week, I updated
pg_dirtyread
to work with
PostgreSQL 14.
pg_dirtyread is a PostgreSQL extension that allows reading "dead" rows from
tables, i.e. rows that have already been deleted, or updated. Of course that
works only if the table has not been cleaned-up yet by a VACUUM command or
autovacuum, which is PostgreSQL's garbage collection machinery.
Here's an example of pg_dirtyread in action:
# create table foo (id int, t text);
CREATE TABLE
# insert into foo values (1, 'Doc1');
INSERT 0 1
# insert into foo values (2, 'Doc2');
INSERT 0 1
# insert into foo values (3, 'Doc3');
INSERT 0 1
# select * from foo;
id t
1 Doc1
2 Doc2
3 Doc3
(3 rows)
# delete from foo where id < 3;
DELETE 2
# select * from foo;
id t
3 Doc3
(1 row)
Oops! The first two documents have disappeared.
Now let's use pg_dirtyread to look at the table:
# create extension pg_dirtyread;
CREATE EXTENSION
# select * from pg_dirtyread('foo') t(id int, t text);
id t
1 Doc1
2 Doc2
3 Doc3
All three documents are still there, but only one of them is visible.
pg_dirtyread can also show PostgreSQL's system colums with the row location and
visibility information. For the first two documents, xmax is set, which means
the row has been deleted:
# select * from pg_dirtyread('foo') t(ctid tid, xmin xid, xmax xid, id int, t text);
ctid xmin xmax id t
(0,1) 1577 1580 1 Doc1
(0,2) 1578 1580 2 Doc2
(0,3) 1579 0 3 Doc3
(3 rows)
Undelete
Caveat:
I'm not promising any of the ideas quoted below will actually work in
practice. There are a few caveats and a good portion of intricate knowledge
about the PostgreSQL internals might be required to succeed properly. Consider
consulting your favorite PostgreSQL support channel for advice if you need to
recover data on any production system. Don't try this at work.
I always had plans to extend pg_dirtyread to include some "undelete" command to
make deleted rows reappear, but never got around to trying that. But rows can already be
restored by using the output of pg_dirtyread itself:
# insert into foo select * from pg_dirtyread('foo') t(id int, t text) where id = 1;
This is not a true "undelete", though - it just inserts new rows from the data
read from the table.
pg_surgery
Enter
pg_surgery,
which is a new PostgreSQL extension supplied with PostgreSQL 14. It contains
two functions to "perform surgery on a damaged relation". As a side-effect,
they can also make delete tuples reappear.
As I discovered now, one of the functions, heap_force_freeze(), works nicely
with pg_dirtyread. It takes a list of ctids (row locations) that it marks
"frozen", but at the same time as "not deleted".
Let's apply it to our test table, using the ctids that pg_dirtyread can read:
# create extension pg_surgery;
CREATE EXTENSION
# select heap_force_freeze('foo', array_agg(ctid))
from pg_dirtyread('foo') t(ctid tid, xmin xid, xmax xid, id int, t text) where id = 1;
heap_force_freeze
(1 row)
Et voil , our deleted document is back:
# select * from foo;
id t
1 Doc1
3 Doc3
(2 rows)
# select * from pg_dirtyread('foo') t(ctid tid, xmin xid, xmax xid, id int, t text);
ctid xmin xmax id t
(0,1) 2 0 1 Doc1
(0,2) 1578 1580 2 Doc2
(0,3) 1579 0 3 Doc3
(3 rows)
Disclaimer
Most importantly, none of the above methods will work if the data you just
deleted has already been purged by VACUUM or autovacuum. These actively zero
out reclaimed space. Restore from backup to get your data back.
Since both pg_dirtyread and pg_surgery operate outside the normal PostgreSQL
MVCC machinery, it's easy to create corrupt data using them. This includes
duplicated rows, duplicated primary key values, indexes being out of sync with
tables, broken foreign key constraints, and others.
You have been warned.
pg_dirtyread does not work (yet) if the deleted rows contain any
toasted
values. Possible other approaches include using
pageinspect
and
pg_filedump
to retrieve the ctids of deleted rows.
Please make sure you have working backups and don't need any of the above.
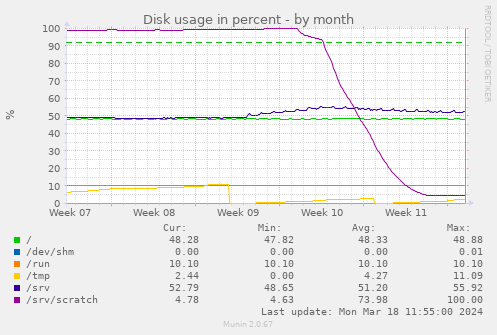 The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.









 About a year ago I bought a new workstation computer for myself at
home. It s a
About a year ago I bought a new workstation computer for myself at
home. It s a  I'm very pleased to say that the
I'm very pleased to say that the 
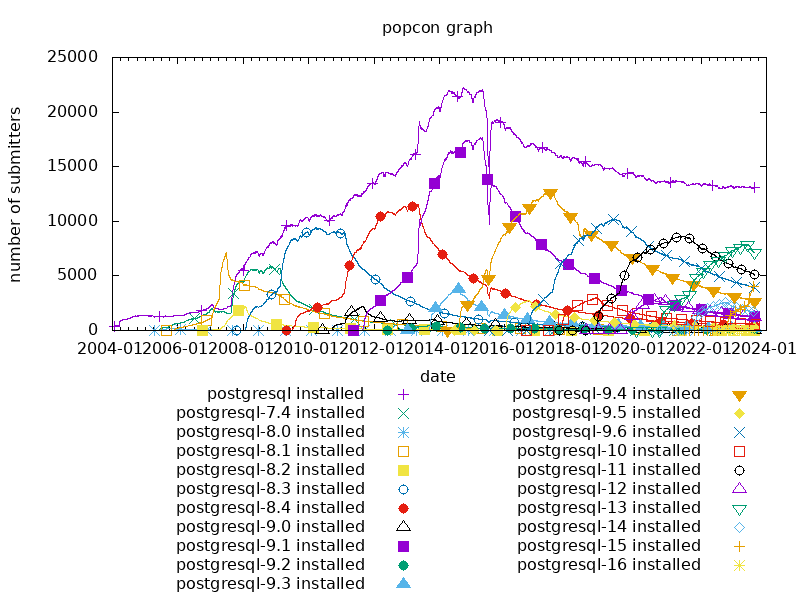
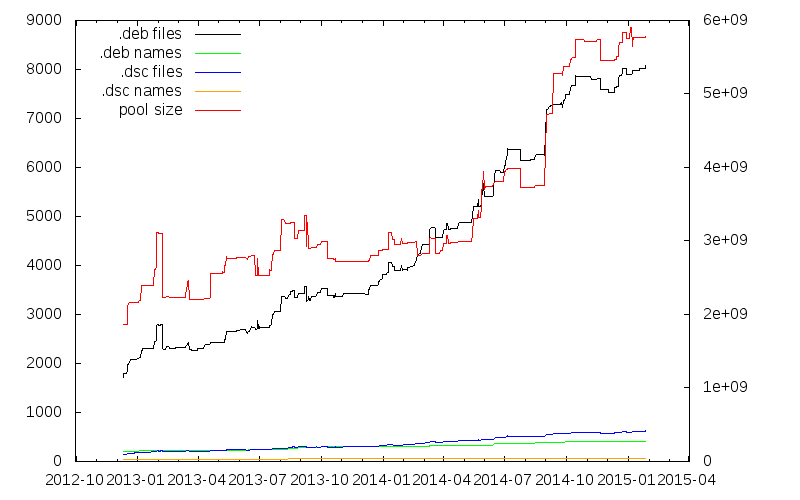 The yellow line at the very bottom is the number of different source package
names, currently 71. From that, a somewhat larger number of actual source
packages that include the "pgdgXX" version suffixes targeting the various
distributions we have is built (blue). The number of different binary package
names (green) is in about the same range. The dimension explosion then happens
for the actual number of binary packages (black, almost 8000) targeting all
distributions and architectures.
The red line is the total size of the pool/ directory, currently a bit less
than 6GB.
(The graphs sometimes decrease when packages in the -testing distributions are
promoted to the live distributions and the old live packages get removed.)
The yellow line at the very bottom is the number of different source package
names, currently 71. From that, a somewhat larger number of actual source
packages that include the "pgdgXX" version suffixes targeting the various
distributions we have is built (blue). The number of different binary package
names (green) is in about the same range. The dimension explosion then happens
for the actual number of binary packages (black, almost 8000) targeting all
distributions and architectures.
The red line is the total size of the pool/ directory, currently a bit less
than 6GB.
(The graphs sometimes decrease when packages in the -testing distributions are
promoted to the live distributions and the old live packages get removed.)
