
We re coming closer to the
Debian/stretch stable release and similar to what we had with
#newinwheezy and
#newinjessie it s time for #newinstretch!
Hideki Yamane already started the game by blogging about
GitHub s Icon font, fonts-octicons and Arturo Borrero Gonzalez wrote a nice article about
nftables in Debian/stretch.
One package that isn t new but its tools are used by many of us is
util-linux, providing many essential system utilities. We have util-linux v2.25.2 in Debian/jessie and in Debian/stretch there will be util-linux >=v2.29.2. There are many new options available and we also have a few new tools available.
Tools that have been taken over from other packages
- last: used to be shipped via sysvinit-utils in Debian/jessie
- lastb: used to be shipped via sysvinit-utils in Debian/jessie
- mesg: used to be shipped via sysvinit-utils in Debian/jessie
- mountpoint: used to be shipped via initscripts in Debian/jessie
- sulogin: used to be shipped via sysvinit-utils in Debian/jessie
New tools
- lsipc: show information on IPC facilities, e.g.:
root@ff2713f55b36:/# lsipc
RESOURCE DESCRIPTION LIMIT USED USE%
MSGMNI Number of message queues 32000 0 0.00%
MSGMAX Max size of message (bytes) 8192 - -
MSGMNB Default max size of queue (bytes) 16384 - -
SHMMNI Shared memory segments 4096 0 0.00%
SHMALL Shared memory pages 18446744073692774399 0 0.00%
SHMMAX Max size of shared memory segment (bytes) 18446744073692774399 - -
SHMMIN Min size of shared memory segment (bytes) 1 - -
SEMMNI Number of semaphore identifiers 32000 0 0.00%
SEMMNS Total number of semaphores 1024000000 0 0.00%
SEMMSL Max semaphores per semaphore set. 32000 - -
SEMOPM Max number of operations per semop(2) 500 - -
SEMVMX Semaphore max value 32767 - -
lslogins: display information about known users in the system, e.g.:
root@ff2713f55b36:/# lslogins
UID USER PROC PWD-LOCK PWD-DENY LAST-LOGIN GECOS
0 root 2 0 1 root
1 daemon 0 0 1 daemon
2 bin 0 0 1 bin
3 sys 0 0 1 sys
4 sync 0 0 1 sync
5 games 0 0 1 games
6 man 0 0 1 man
7 lp 0 0 1 lp
8 mail 0 0 1 mail
9 news 0 0 1 news
10 uucp 0 0 1 uucp
13 proxy 0 0 1 proxy
33 www-data 0 0 1 www-data
34 backup 0 0 1 backup
38 list 0 0 1 Mailing List Manager
39 irc 0 0 1 ircd
41 gnats 0 0 1 Gnats Bug-Reporting System (admin)
100 _apt 0 0 1
65534 nobody 0 0 1 nobody
lsns: list system namespaces, e.g.:
root@ff2713f55b36:/# lsns
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 2 1 root bash
4026531837 user 2 1 root bash
4026532473 mnt 2 1 root bash
4026532474 uts 2 1 root bash
4026532475 ipc 2 1 root bash
4026532476 pid 2 1 root bash
4026532478 net 2 1 root bash
setpriv: run a program with different privilege settings
zramctl: tool to quickly set up zram device parameters, to reset zram devices, and to query the status of used zram devices
New features/options
addpart (show or change the real-time scheduling attributes of a process):
--reload reload prompts on running agetty instances
blkdiscard (discard the content of sectors on a device):
-p, --step <num> size of the discard iterations within the offset
-z, --zeroout zero-fill rather than discard
chrt (show or change the real-time scheduling attributes of a process):
-d, --deadline set policy to SCHED_DEADLINE
-T, --sched-runtime <ns> runtime parameter for DEADLINE
-P, --sched-period <ns> period parameter for DEADLINE
-D, --sched-deadline <ns> deadline parameter for DEADLINE
fdformat (do a low-level formatting of a floppy disk):
-f, --from <N> start at the track N (default 0)
-t, --to <N> stop at the track N
-r, --repair <N> try to repair tracks failed during the verification (max N retries)
fdisk (display or manipulate a disk partition table):
-B, --protect-boot don't erase bootbits when creating a new label
-o, --output <list> output columns
--bytes print SIZE in bytes rather than in human readable format
-w, --wipe <mode> wipe signatures (auto, always or never)
-W, --wipe-partitions <mode> wipe signatures from new partitions (auto, always or never)
New available columns (for -o):
gpt: Device Start End Sectors Size Type Type-UUID Attrs Name UUID
dos: Device Start End Sectors Cylinders Size Type Id Attrs Boot End-C/H/S Start-C/H/S
bsd: Slice Start End Sectors Cylinders Size Type Bsize Cpg Fsize
sgi: Device Start End Sectors Cylinders Size Type Id Attrs
sun: Device Start End Sectors Cylinders Size Type Id Flags
findmnt (find a (mounted) filesystem):
-J, --json use JSON output format
-M, --mountpoint <dir> the mountpoint directory
-x, --verify verify mount table content (default is fstab)
--verbose print more details
flock (manage file locks from shell scripts):
-F, --no-fork execute command without forking
--verbose increase verbosity
getty (open a terminal and set its mode):
--reload reload prompts on running agetty instances
hwclock (query or set the hardware clock):
--get read hardware clock and print drift corrected result
--update-drift update drift factor in /etc/adjtime (requires --set or --systohc)
ldattach (attach a line discipline to a serial line):
-c, --intro-command <string> intro sent before ldattach
-p, --pause <seconds> pause between intro and ldattach
logger (enter messages into the system log):
-e, --skip-empty do not log empty lines when processing files
--no-act do everything except the write the log
--octet-count use rfc6587 octet counting
-S, --size <size> maximum size for a single message
--rfc3164 use the obsolete BSD syslog protocol
--rfc5424[=<snip>] use the syslog protocol (the default for remote);
<snip> can be notime, or notq, and/or nohost
--sd-id <id> rfc5424 structured data ID
--sd-param <data> rfc5424 structured data name=value
--msgid <msgid> set rfc5424 message id field
--socket-errors[=<on off auto>] print connection errors when using Unix sockets
losetup (set up and control loop devices):
-L, --nooverlap avoid possible conflict between devices
--direct-io[=<on off>] open backing file with O_DIRECT
-J, --json use JSON --list output format
New available --list column:
DIO access backing file with direct-io
lsblk (list information about block devices):
-J, --json use JSON output format
New available columns (for --output):
HOTPLUG removable or hotplug device (usb, pcmcia, ...)
SUBSYSTEMS de-duplicated chain of subsystems
lscpu (display information about the CPU architecture):
-y, --physical print physical instead of logical IDs
New available column:
DRAWER logical drawer number
lslocks (list local system locks):
-J, --json use JSON output format
-i, --noinaccessible ignore locks without read permissions
nsenter (run a program with namespaces of other processes):
-C, --cgroup[=<file>] enter cgroup namespace
--preserve-credentials do not touch uids or gids
-Z, --follow-context set SELinux context according to --target PID
rtcwake (enter a system sleep state until a specified wakeup time):
--date <timestamp> date time of timestamp to wake
--list-modes list available modes
-r, --reorder <dev> fix partitions order (by start offset)
sfdisk (display or manipulate a disk partition table):
New Commands:
-J, --json <dev> dump partition table in JSON format
-F, --list-free [<dev> ...] list unpartitioned free areas of each device
-r, --reorder <dev> fix partitions order (by start offset)
--delete <dev> [<part> ...] delete all or specified partitions
--part-label <dev> <part> [<str>] print or change partition label
--part-type <dev> <part> [<type>] print or change partition type
--part-uuid <dev> <part> [<uuid>] print or change partition uuid
--part-attrs <dev> <part> [<str>] print or change partition attributes
New Options:
-a, --append append partitions to existing partition table
-b, --backup backup partition table sectors (see -O)
--bytes print SIZE in bytes rather than in human readable format
--move-data[=<typescript>] move partition data after relocation (requires -N)
--color[=<when>] colorize output (auto, always or never)
colors are enabled by default
-N, --partno <num> specify partition number
-n, --no-act do everything except write to device
--no-tell-kernel do not tell kernel about changes
-O, --backup-file <path> override default backup file name
-o, --output <list> output columns
-w, --wipe <mode> wipe signatures (auto, always or never)
-W, --wipe-partitions <mode> wipe signatures from new partitions (auto, always or never)
-X, --label <name> specify label type (dos, gpt, ...)
-Y, --label-nested <name> specify nested label type (dos, bsd)
Available columns (for -o):
gpt: Device Start End Sectors Size Type Type-UUID Attrs Name UUID
dos: Device Start End Sectors Cylinders Size Type Id Attrs Boot End-C/H/S Start-C/H/S
bsd: Slice Start End Sectors Cylinders Size Type Bsize Cpg Fsize
sgi: Device Start End Sectors Cylinders Size Type Id Attrs
sun: Device Start End Sectors Cylinders Size Type Id Flags
swapon (enable devices and files for paging and swapping):
-o, --options <list> comma-separated list of swap options
New available columns (for --show):
UUID swap uuid
LABEL swap label
unshare (run a program with some namespaces unshared from the parent):
-C, --cgroup[=<file>] unshare cgroup namespace
--propagation slave shared private unchanged modify mount propagation in mount namespace
-s, --setgroups allow deny control the setgroups syscall in user namespaces
Deprecated / removed options
sfdisk (display or manipulate a disk partition table):
-c, --id change or print partition Id
--change-id change Id
--print-id print Id
-C, --cylinders <number> set the number of cylinders to use
-H, --heads <number> set the number of heads to use
-S, --sectors <number> set the number of sectors to use
-G, --show-pt-geometry deprecated, alias to --show-geometry
-L, --Linux deprecated, only for backward compatibility
-u, --unit S deprecated, only sector unit is supported









 I wanted to look back at what changed in phosh in 2022 and figured I
could share it with you. I'll be focusing on things very close to the
mobile shell, for a broader overview see
I wanted to look back at what changed in phosh in 2022 and figured I
could share it with you. I'll be focusing on things very close to the
mobile shell, for a broader overview see 
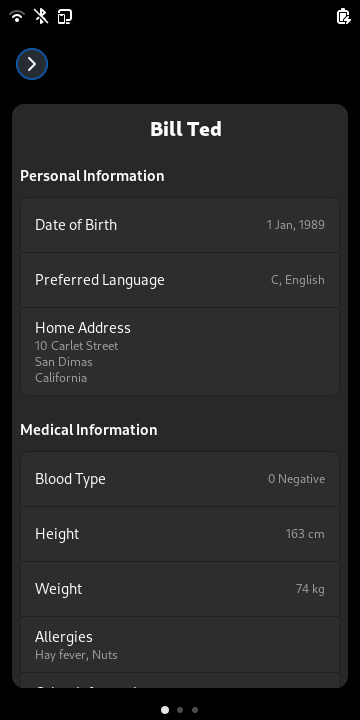
 We also added the possibility to have custom widgets via loadable
plugins on the lock screen so the user can decide which information
should be available. We currently ship plugins to show
We also added the possibility to have custom widgets via loadable
plugins on the lock screen so the user can decide which information
should be available. We currently ship plugins to show
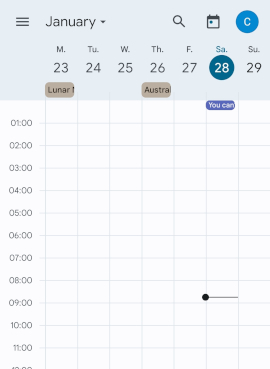
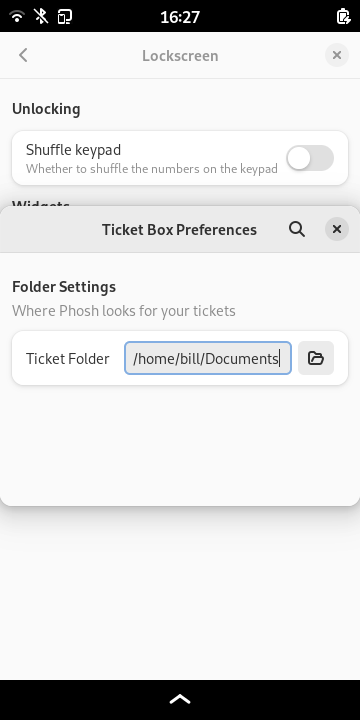 Speaking of configurability: Scale-to-fit settings (to work around
applications that don't fit the screen) and haptic/led feedback are
now configurable without resorting to the command line:
Speaking of configurability: Scale-to-fit settings (to work around
applications that don't fit the screen) and haptic/led feedback are
now configurable without resorting to the command line:
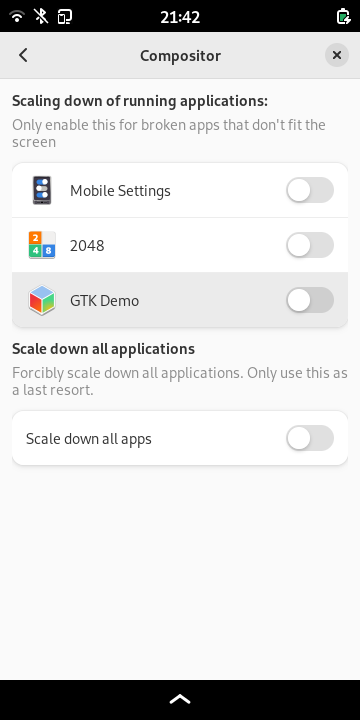
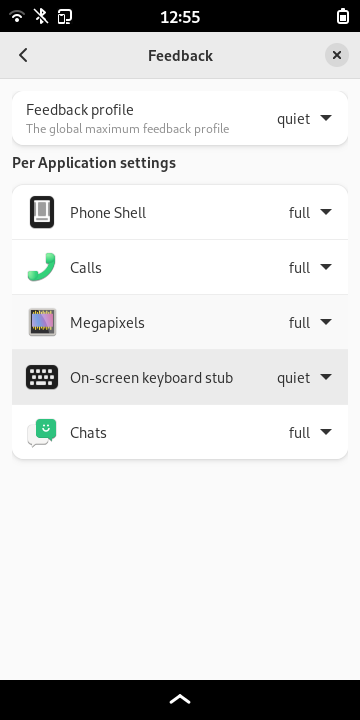 We can also have device specific settings which helps to temporarily
accumulate special workaround without affecting other phones.
Other user visible features include the ability to shuffle the digits
on the lockscreen's keypad, a VPN quick settings, improved screenshot
support and automatic high contrast theme switching when in bright
sunlight (based on ambient sensor readings) as shown
We can also have device specific settings which helps to temporarily
accumulate special workaround without affecting other phones.
Other user visible features include the ability to shuffle the digits
on the lockscreen's keypad, a VPN quick settings, improved screenshot
support and automatic high contrast theme switching when in bright
sunlight (based on ambient sensor readings) as shown  That's it for 2022. If you want to get involved into phosh testing, development
or documentation then just drop by in the
That's it for 2022. If you want to get involved into phosh testing, development
or documentation then just drop by in the 
 This has ended up longer than I expected. I ll write up posts about some of the individual steps with some more details at some point, but this is an overview of the yak shaving I engaged in. The TL;DR is:
This has ended up longer than I expected. I ll write up posts about some of the individual steps with some more details at some point, but this is an overview of the yak shaving I engaged in. The TL;DR is:
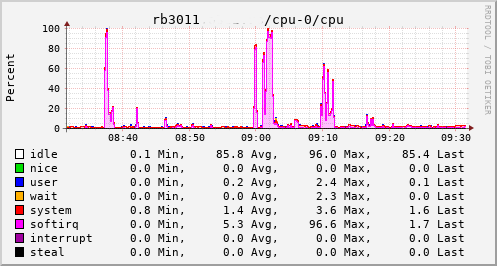 This provided an opportunity to see just what the RB3011 could actually manage. In the configuration I had it turned out to be not much more than the 80Mb/s speeds I had previously seen. The upload jumped from a solid 20Mb/s to 75Mb/s, so I knew the regrade had actually happened. Looking at CPU utilisation clearly showed the problem; softirqs were using almost 100% of a CPU core.
Now, the way the hardware is setup on the RB3011 is that there are two separate 5 port switches, each connected back to the CPU via a separate GigE interface. For various reasons I had everything on a single switch, which meant that all traffic was boomeranging in and out of the same CPU interface. The IPQ8064 has dual cores, so I thought I d try moving the external connection to the other switch. That puts it on its own GigE CPU interface, which then allows binding the interrupts to a different CPU core. That helps; throughput to the outside world hits 140Mb/s+. Still a long way from the expected max, but proof we just need more grunt.
This provided an opportunity to see just what the RB3011 could actually manage. In the configuration I had it turned out to be not much more than the 80Mb/s speeds I had previously seen. The upload jumped from a solid 20Mb/s to 75Mb/s, so I knew the regrade had actually happened. Looking at CPU utilisation clearly showed the problem; softirqs were using almost 100% of a CPU core.
Now, the way the hardware is setup on the RB3011 is that there are two separate 5 port switches, each connected back to the CPU via a separate GigE interface. For various reasons I had everything on a single switch, which meant that all traffic was boomeranging in and out of the same CPU interface. The IPQ8064 has dual cores, so I thought I d try moving the external connection to the other switch. That puts it on its own GigE CPU interface, which then allows binding the interrupts to a different CPU core. That helps; throughput to the outside world hits 140Mb/s+. Still a long way from the expected max, but proof we just need more grunt.
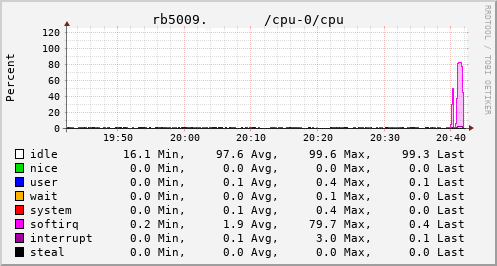 Which brings us to this past weekend, when, having worked out all the other bits, I tried the squashfs root image again on the RB3011. Success! The home automation bits connected to it, the link to the outside world came up, everything seemed happy. So I double checked my bootloader bits on the RB5009, brought it down to the comms room and plugged it in instead. And, modulo my failing to update the nftables config to allow it to do forwarding, it all came up ok. Some testing with iperf3 internally got a nice 912Mb/s sustained between subnets, and some less scientific testing with wget + speedtest-cli saw speeds of over 460Mb/s to the outside world.
Time from ordering the router until it was in service? Just under 8 weeks
Which brings us to this past weekend, when, having worked out all the other bits, I tried the squashfs root image again on the RB3011. Success! The home automation bits connected to it, the link to the outside world came up, everything seemed happy. So I double checked my bootloader bits on the RB5009, brought it down to the comms room and plugged it in instead. And, modulo my failing to update the nftables config to allow it to do forwarding, it all came up ok. Some testing with iperf3 internally got a nice 912Mb/s sustained between subnets, and some less scientific testing with wget + speedtest-cli saw speeds of over 460Mb/s to the outside world.
Time from ordering the router until it was in service? Just under 8 weeks








 Added memory to ACER Chromebox CXI3 (fizz/sion).
Got 2 16GB SO-DIMMs and installed them. I could not find correct information on how to open this box on the internet. They seem to be explaining similar boxes from HP or ASUS which seem to have simpler procedure to opening.
I had to ply out out the 4 rubber pieces at the bottom, and then open the 4 screws.
Then I could ply open the front and back panel by applying force where the screws were.
In the front panel there's two more shorter screws that needs to be opened; after taking out the two screws (that's 4+2),
I could open the box into two pieces. Be careful they are connected, I think there's audio cable.
After opening you can access the memory chips. Pull the metal piece open on left and right hand side of the memory chip so that it raises. Make sure the metal pieces latch closed when you insert the new memory, that should signify memory is in place. I didn't do that at the beginning and the machine didn't boot.
So far so good. No longer using zram.
Added memory to ACER Chromebox CXI3 (fizz/sion).
Got 2 16GB SO-DIMMs and installed them. I could not find correct information on how to open this box on the internet. They seem to be explaining similar boxes from HP or ASUS which seem to have simpler procedure to opening.
I had to ply out out the 4 rubber pieces at the bottom, and then open the 4 screws.
Then I could ply open the front and back panel by applying force where the screws were.
In the front panel there's two more shorter screws that needs to be opened; after taking out the two screws (that's 4+2),
I could open the box into two pieces. Be careful they are connected, I think there's audio cable.
After opening you can access the memory chips. Pull the metal piece open on left and right hand side of the memory chip so that it raises. Make sure the metal pieces latch closed when you insert the new memory, that should signify memory is in place. I didn't do that at the beginning and the machine didn't boot.
So far so good. No longer using zram.
 In the light of WhatsApp s recent move to
In the light of WhatsApp s recent move to  A new minor release 0.2.9 of
A new minor release 0.2.9 of  Over the past few weeks things have been pretty hectic. Since I'm not working at the moment I'm mostly doing childcare instead. I need a break, now and again, so I've been sending our child to p iv koti two days a week with him home the rest of the time.
I love taking care of the child, because he's seriously awesome, but it's a hell of a lot of work when most of our usual escapes are unavailable. For example we can't go to the (awesome)
Over the past few weeks things have been pretty hectic. Since I'm not working at the moment I'm mostly doing childcare instead. I need a break, now and again, so I've been sending our child to p iv koti two days a week with him home the rest of the time.
I love taking care of the child, because he's seriously awesome, but it's a hell of a lot of work when most of our usual escapes are unavailable. For example we can't go to the (awesome)