With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up I d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. For now, we ll be using a custom ISO image, while waiting for the above-mentioned merge-proposal to be landed. Furthermore, as the Debian archive is going through major transitions builds of the unstable branch of d-i don t currently work. So I implemented a small backport, producing updated netcfg and netcfg-static for Bookworm, which can be used as localudebs/ during the d-i build.
Let s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
Now let s download the custom mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes, as mentioned above.
TODO: localudebs/
Next we ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
Finally, let s launch the installer using a custom preseed.cfg file, that will automatically install Netplan for us in the target system. A minimal preseed file could look like this:
For this demo, we re installing the full netplan.io package (incl. Python CLI), as the netplan-generator package was not yet split out as an independent binary in the Bookworm cycle. You can choose the preseed file from a set of different variants to test the different configurations:
We re using the custom linux kernel and initrd.gz here to be able to pass the PRESEED_URL as a parameter to the kernel s cmdline directly. Launching this VM should bring up the normal debian-installer in its netboot/gtk form:
Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
Done! After the installation finished you can reboot into your virgin Debian Bookworm system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was written by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
Finally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
In our case we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more join the discussion at Salsa:installer-team/netcfg and find us at GitHub:netplan.
I am upstream and Debian package maintainer of
python-debianbts, which is a Python library that allows for
querying Debian s Bug Tracking System (BTS). python-debianbts is used by
reportbug, the standard tool to report bugs in Debian, and therefore the glue
between the reportbug and the BTS.
debbugs, the software that powers Debian s BTS, provides a SOAP
interface for querying the BTS. Unfortunately, SOAP is not a very popular
protocol anymore, and I m facing the second migration to another underlying
SOAP library as they continue to become unmaintained over time. Zeep, the
library I m currently considering, requires a WSDL file in order to work
with a SOAP service, however, debbugs does not provide one. Since I m not
familiar with WSDL, I need help from someone who can create a WSDL file for
debbugs, so I can migrate python-debianbts away from pysimplesoap to zeep.
How did we get here?
Back in the olden days, reportbug was querying the BTS by parsing its HTML
output. While this worked, it tightly coupled the user-facing
presentation of the BTS with critical functionality of the bug reporting tool.
The setup was fragile, prone to breakage, and did not allow changing anything
in the BTS frontend for fear of breaking reportbug itself.
In 2007, I started to work on reportbug-ng, a user-friendly alternative
to reportbug, targeted at users not comfortable using the command line. Early
on, I decided to use the BTS SOAP interface instead of parsing HTML like
reportbug did. 2008, I extracted the code that dealt with the BTS into a
separate Python library, and after some collaboration with the reportbug
maintainers, reportbug adopted python-debianbts in 2011 and has used it ever
since.
2015, I was working on porting python-debianbts to Python 3.
During that process, it turned out that its major dependency, SoapPy was pretty
much unmaintained for years and blocking the Python3 transition. Thanks to the
help of Gaetano Guerriero, who ported python-debianbts to
pysimplesoap, the migration was unblocked and could proceed.
In 2024, almost ten years later, pysimplesoap seems to be unmaintained as well,
and I have to look again for alternatives. The most promising one right now
seems to be zeep. Unfortunately, zeep requires a WSDL file for working with
a SOAP service, which debbugs does not provide.
How can you help?
reportbug (and thus python-debianbts) is used by thousands of users and I have
a certain responsibility to keep things working properly. Since I simply don t
know enough about WSDL to create such a file for debbugs myself, I m looking
for someone who can help me with this task.
If you re familiar with SOAP, WSDL and optionally debbugs, please get in
touch with me. I don t speak Pearl, so I m not
really able to read debbugs code, but I do know some things about the SOAP
requests and replies due to my work on python-debianbts, so I m sure we can
work something out.
There is a WSDL file for a debbugs version used by GNU, but I
don t think it s official and it currently does not work with zeep. It may be a
good starting point, though.
The future of debbugs API
While we can probably continue to support debbugs SOAP interface for a while,
I don t think it s very sustainable in the long run. A simpler, well documented
REST API that returns JSON seems more appropriate nowadays. The queries and
replies that debbugs currently supports are simple enough to design a REST API
with JSON around it. The benefit would be less complex libraries on the client
side and probably easier maintainability on the server side as well. debbugs
maintainer seemed to be in agreement with this idea back in
2018. I created an attempt to define a new API
(HTML render), but somehow we got stuck and no progress has been
made since then. I m still happy to help shaping such an API for debbugs, but I
can t really implement anything in debbugs itself, as it is written in Perl,
which I m not familiar with.
Welcome to the March 2024 report from the Reproducible Builds project! In our reports, we attempt to outline what we have been up to over the past month, as well as mentioning some of the important things happening more generally in software supply-chain security. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Table of contents:
Arch Linux minimal container userland now 100% reproducible
In remarkable news, Reproducible builds developer kpcyrd reported that that the Arch Linux minimal container userland is now 100% reproducible after work by developers dvzv and Foxboron on the one remaining package. This represents a real world , widely-used Linux distribution being reproducible.
Their post, which kpcyrd suffixed with the question now what? , continues on to outline some potential next steps, including validating whether the container image itself could be reproduced bit-for-bit. The post, which was itself a followup for an Arch Linux update earlier in the month, generated a significant number of replies.
Validating Debian s build infrastructure after the XZ backdoor
From our mailing list this month, Vagrant Cascadian wrote about being asked about trying to perform concrete reproducibility checks for recent Debian security updates, in an attempt to gain some confidence about Debian s build infrastructure given that they performed builds in environments running the high-profile XZ vulnerability.
Vagrant reports (with some caveats):
So far, I have not found any reproducibility issues; everything I tested I was able to get to build bit-for-bit identical with what is in the
Debian archive.
That is to say, reproducibility testing permitted Vagrant and Debian to claim with some confidence that builds performed when this vulnerable version of XZ was installed were not interfered with.
Functional package managers (FPMs) and reproducible builds (R-B) are technologies and methodologies that are conceptually very different from the traditional software deployment model, and that have promising properties for software supply chain security. This thesis aims to evaluate the impact of FPMs and R-B on the security of the software supply chain and propose improvements to the FPM model to further improve trust in the open source supply chain. PDF
Julien s paper poses a number of research questions on how the model of distributions such as GNU Guix and NixOS can be leveraged to further improve the safety of the software supply chain , etc.
Software and source code identification with GNU Guix and reproducible builds
In a long line of commendably detailed blog posts, Ludovic Court s, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier have together published two interesting posts on the GNU Guix blog this month. In early March, Ludovic Court s, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier wrote about software and source code identification and how that might be performed using Guix, rhetorically posing the questions: What does it take to identify software ? How can we tell what software is running on a machine to determine, for example, what security vulnerabilities might affect it?
Later in the month, Ludovic Court s wrote a solo post describing adventures on the quest for long-term reproducible deployment. Ludovic s post touches on GNU Guix s aim to support time travel , the ability to reliably (and reproducibly) revert to an earlier point in time, employing the iconic image of Harold Lloyd hanging off the clock in Safety Last! (1925) to poetically illustrate both the slapstick nature of current modern technology and the gymnastics required to navigate hazards of our own making.
Two new Rust-based tools for post-processing determinism
Zbigniew J drzejewski-Szmek announced add-determinism, a work-in-progress reimplementation of the Reproducible Builds project s own strip-nondeterminism tool in the Rust programming language, intended to be used as a post-processor in RPM-based distributions such as Fedora
In addition, Yossi Kreinin published a blog post titled refix: fast, debuggable, reproducible builds that describes a tool that post-processes binaries in such a way that they are still debuggable with gdb, etc.. Yossi post details the motivation and techniques behind the (fast) performance of the tool.
Distribution work
In Debian this month, since the testing framework no longer varies the build path, James Addison performed a bulk downgrade of the bug severity for issues filed with a level of normal to a new level of wishlist. In addition, 28 reviews of Debian packages were added, 38 were updated and 23 were removed this month adding to ever-growing knowledge about identified issues. As part of this effort, a number of issue types were updated, including Chris Lamb adding a new ocaml_include_directories toolchain issue [] and James Addison adding a new filesystem_order_in_java_jar_manifest_mf_include_resource issue [] and updating the random_uuid_in_notebooks_generated_by_nbsphinx to reference a relevant discussion thread [].
In addition, Roland Clobus posted his 24th status update of reproducible Debian ISO images. Roland highlights that the images for Debian unstable often cannot be generated due to changes in that distribution related to the 64-bit time_t transition.
Lastly, Bernhard M. Wiedemann posted another monthly update for his reproducibility work in openSUSE.
Mailing list highlights
Elsewhere on our mailing list this month:
Website updates
There were made a number of improvements to our website this month, including:
Pol Dellaiera noticed the frequent need to correctly cite the website itself in academic work. To facilitate easier citation across multiple formats, Pol contributed a Citation File Format (CIF) file. As a result, an export in BibTeX format is now available in the Academic Publications section. Pol encourages community contributions to further refine the CITATION.cff file. Pol also added an substantial new section to the buy in page documenting the role of Software Bill of Materials (SBOMs) and ephemeral development environments. [][]
Bernhard M. Wiedemann added a new commandments page to the documentation [][] and fixed some incorrect YAML elsewhere on the site [].
Chris Lamb add three recent academic papers to the publications page of the website. []
Mattia Rizzolo and Holger Levsen collaborated to add Infomaniak as a sponsor of amd64 virtual machines. [][][]
Roland Clobus updated the stable outputs page, dropping version numbers from Python documentation pages [] and noting that Python s set data structure is also affected by the PYTHONHASHSEED functionality. []
Delta chat clients now reproducible
Delta Chat, an open source messaging application that can work over email, announced this month that the Rust-based core library underlying Delta chat application is now reproducible.
diffoscopediffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 259, 260 and 261 to Debian and made the following additional changes:
New features:
Add support for the zipdetails tool from the Perl distribution. Thanks to Fay Stegerman and Larry Doolittle et al. for the pointer and thread about this tool. []
Bug fixes:
Don t identify Redis database dumps as GNU R database files based simply on their filename. []
Add a missing call to File.recognizes so we actually perform the filename check for GNU R data files. []
Don t crash if we encounter an .rdb file without an equivalent .rdx file. (#1066991)
Correctly check for 7z being available and not lz4 when testing 7z. []
Prevent a traceback when comparing a contentful .pyc file with an empty one. []
Testsuite improvements:
Fix .epub tests after supporting the new zipdetails tool. []
Don t use parenthesis within test skipping messages, as PyTest adds its own parenthesis. []
Factor out Python version checking in test_zip.py. []
Skip some Zip-related tests under Python 3.10.14, as a potential regression may have been backported to the 3.10.x series. []
Actually test 7z support in the test_7z set of tests, not the lz4 functionality. (Closes: reproducible-builds/diffoscope#359). []
In addition, Fay Stegerman updated diffoscope s monkey patch for supporting the unusual Mozilla ZIP file format after Python s zipfile module changed to detect potentially insecure overlapping entries within .zip files. (#362)
Chris Lamb also updated the trydiffoscope command line client, dropping a build-dependency on the deprecated python3-distutils package to fix Debian bug #1065988 [], taking a moment to also refresh the packaging to the latest Debian standards []. Finally, Vagrant Cascadian submitted an update for diffoscope version 260 in GNU Guix. []
Upstream patches
This month, we wrote a large number of patches, including:
I don t have the hardware to test this firmware, but the build produces the same hashes for the firmware so it s safe to say that the firmware should keep working.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In March, an enormous number of changes were made by Holger Levsen:
Initial work to clean up a messy NetBSD-related script. [][]
Roland Clobus:
Show the installer log if the installer fails to build. []
Avoid the minus character (i.e. -) in a variable in order to allow for tags in openQA. []
Update the schedule of Debian live image builds. []
Vagrant Cascadian:
Maintenance on the virt* nodes is completed so bring them back online. []
Use the fully qualified domain name in configuration. []
Node maintenance was also performed by Holger Levsen, Mattia Rizzolo [][] and Vagrant Cascadian [][][][]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
tl;dr: Don t just apt install rustc cargo. Either do that and make sure to use only Rust libraries from your distro (with the tiresome config runes below); or, just use rustup.
Don t do the obvious thing; it s never what you want
Debian ships a Rust compiler, and a large number of Rust libraries.
But if you just do things the obvious default way, with apt install rustc cargo, you will end up using Debian s compiler but upstream libraries, directly and uncurated from crates.io.
This is not what you want. There are about two reasonable things to do, depending on your preferences.
Q. Download and run whatever code from the internet?
The key question is this:
Are you comfortable downloading code, directly from hundreds of upstream Rust package maintainers, and running it ?
That s what cargo does. It s one of the main things it s for. Debian s cargo behaves, in this respect, just like upstream s. Let me say that again:
Debian s cargo promiscuously downloads code from crates.io just like upstream cargo.
So if you use Debian s cargo in the most obvious way, you are still downloading and running all those random libraries. The only thing you re avoiding downloading is the Rust compiler itself, which is precisely the part that is most carefully maintained, and of least concern.
Debian s cargo can even download from crates.io when you re building official Debian source packages written in Rust: if you run dpkg-buildpackage, the downloading is suppressed; but a plain cargo build will try to obtain and use dependencies from the upstream ecosystem. ( Happily , if you do this, it s quite likely to bail out early due to version mismatches, before actually downloading anything.)
Option 1: WTF, no I don t want curl bash
OK, but then you must limit yourself to libraries available within Debian. Each Debian release provides a curated set. It may or may not be sufficient for your needs. Many capable programs can be written using the packages in Debian.
But any upstream Rust project that you encounter is likely to be a pain to get working, unless their maintainers specifically intend to support this. (This is fairly rare, and the Rust tooling doesn t make it easy.)
To go with this plan, apt install rustc cargo and put this in your configuration, in $HOME/.cargo/config.toml:
This causes cargo to look in /usr/share for dependencies, rather than downloading them from crates.io. You must then install the librust-FOO-dev packages for each of your dependencies, with apt.
This will allow you to write your own program in Rust, and build it using cargo build.
Option 2: Biting the curl bash bullet
If you want to build software that isn t specifically targeted at Debian s Rust you will probably need to use packages from crates.io, not from Debian.
If you re doing to do that, there is little point not using rustup to get the latest compiler. rustup s install rune is alarming, but cargo will be doing exactly the same kind of thing, only worse (because it trusts many more people) and more hidden.
So in this case: do run the curl bash install rune.
Hopefully the Rust project you are trying to build have shipped a Cargo.lock; that contains hashes of all the dependencies that they last used and tested. If you run cargo build --locked, cargo will only use those versions, which are hopefully OK.
And you can run cargo audit to see if there are any reported vulnerabilities or problems. But you ll have to bootstrap this with cargo install --locked cargo-audit; cargo-audit is from the RUSTSEC folks who do care about these kind of things, so hopefully running their code (and their dependencies) is fine. Note the --locked which is needed because cargo s default behaviour is wrong.
Privilege separation
This approach is rather alarming. For my personal use, I wrote a privsep tool which allows me to run all this upstream Rust code as a separate user.
That tool is nailing-cargo. It s not particularly well productised, or tested, but it does work for at least one person besides me. You may wish to try it out, or consider alternative arrangements. Bug reports and patches welcome.
OMG what a mess
Indeed. There are large number of technical and social factors at play.
cargo itself is deeply troubling, both in principle, and in detail. I often find myself severely disappointed with its maintainers decisions. In mitigation, much of the wider Rust upstream community does takes this kind of thing very seriously, and often makes good choices. RUSTSEC is one of the results.
Debian s technical arrangements for Rust packaging are quite dysfunctional, too: IMO the scheme is based on fundamentally wrong design principles. But, the Debian Rust packaging team is dynamic, constantly working the update treadmills; and the team is generally welcoming and helpful.
Sadly last time I explored the possibility, the Debian Rust Team didn t have the appetite for more fundamental changes to the workflow (including, for example, changes to dependency version handling). Significant improvements to upstream cargo s approach seem unlikely, too; we can only hope that eventually someone might manage to supplant it.
edited 2024-03-21 21:49 to add a cut tag
To achieve my aims regarding Convergence of mobile phone and PC [1] I need something a big bigger than the 4G of RAM that s in the PinePhone Pro [2]. The PinePhonePro was released at the end of 2021 but has a SoC that was first released in 2016. That SoC seems to compare well to the ones used in the Pixel and Pixel 2 phones that were released in the same time period so it s not a bad SoC, but it doesn t compare well to more recent Android devices and it also isn t a great fit for the non-Android things I want to do. Also the PinePhonePro and Librem5 have relatively short battery life so reusing Android functionality for power saving could provide a real benefit. So I want a phone designed for the mass market that I can use for running Debian.
PostmarketOS
One thing I m definitely not going to do is attempt a full port of Linux to a different platform or support of kernel etc. So I need to choose a device that already has support from a somewhat free Linux system. The PostmarketOS system is the first I considered, the PostmarketOS Wiki page of supported devices [3] was the first place I looked. The main supported devices are the PinePhone (not Pro) and the Librem5, both of which are under-powered. For the community devices there seems to be nothing that supports calls, SMS, mobile data, and USB-OTG and which also has 4G of RAM or more. If I skip USB-OTG (which presumably means I d have to get dock functionality via wifi not impossible but not great) then I m left with the SHIFT6mq which was never sold in Australia and the Xiomi POCO F1 which doesn t appear to be available on ebay.
LineageOS
The libhybris libraries are a compatibility layer between Android and glibc programs [4]. Which includes running Wayland with Android display drivers. So running a somewhat standard Linux desktop on top of an Android kernel should be possible. Here is a table of the LineageOS supported devices that seem to have a useful feature set and are available in Australia and which could be used for running Debian with firmware and drivers copied from Android. I only checked LineageOS as it seems to be the main free Android build.
I just bought a Note 9 with 128G of storage and 6G of RAM for $109 to try out Droidian, it has some screen burn but that s OK for a test system and if I end up using it seriously I ll just buy another that s in as-new condition. With no support for an external display I ll need to setup a software dock to do Convergence, but that s not a serious problem. If I end up making a Note 9 with Droidian my daily driver then I ll use the 512G/8G model for that and use the cheap one for testing.
Mobian
I should have checked the Mobian list first as it s the main Debian variant for phones.
From the Mobian Devices list [16] the OnePlus 6T has 8G of RAM or more but isn t available in Australia and costs more than $400 when imported. The PocoPhone F1 doesn t seem to be available on ebay. The Shift6mq is made by a German company with similar aims to the Fairphone [17], it looks nice but costs E577 which is more than I want to spend and isn t on the officially supported list.
Smart Watches
The same issues apply to smart watches. AstereoidOS is a free smart phone OS designed for closed hardware [18]. I don t have time to get involved in this sort of thing though, I can t hack on every device I use.
Welcome to the February 2024 report from the Reproducible Builds project! In our reports, we try to outline what we have been up to over the past month as well as mentioning some of the important things happening in software supply-chain security.
Reproducible Builds at FOSDEM 2024
Core Reproducible Builds developer Holger Levsen presented at the main track at FOSDEM on Saturday 3rd February this year in Brussels, Belgium. However, that wasn t the only talk related to Reproducible Builds.
However, please see our comprehensive FOSDEM 2024 news post for the full details and links.
Three new reproducibility-related academic papers
A total of three separate scholarly papers related to Reproducible Builds have appeared this month:
Signing in Four Public Software Package Registries: Quantity, Quality, and Influencing Factors by Taylor R. Schorlemmer, Kelechi G. Kalu, Luke Chigges, Kyung Myung Ko, Eman Abdul-Muhd, Abu Ishgair, Saurabh Bagchi, Santiago Torres-Arias and James C. Davis (Purdue University, Indiana, USA) is concerned with the problem that:
Package maintainers can guarantee package authorship through software signing [but] it is unclear how common this practice is, and whether the resulting signatures are created properly. Prior work has provided raw data on signing practices, but measured single platforms, did not consider time, and did not provide insight on factors that may influence signing. We lack a comprehensive, multi-platform understanding of signing adoption and relevant factors. This study addresses this gap. (arXiv, full PDF)
[The] principle of reusability [ ] makes it harder to reproduce projects build environments, even though reproducibility of build environments is essential for collaboration, maintenance and component lifetime. In this work, we argue that functional package managers provide the tooling to make build environments reproducible in space and time, and we produce a preliminary evaluation to justify this claim.
This paper thus proposes an approach to automatically identify configuration options causing non-reproducibility of builds. It begins by building a set of builds in order to detect non-reproducible ones through binary comparison. We then develop automated techniques that combine statistical learning with symbolic reasoning to analyze over 20,000 configuration options. Our methods are designed to both detect options causing non-reproducibility, and remedy non-reproducible configurations, two tasks that are challenging and costly to perform manually. (HAL Portal, full PDF)
Distribution work
In Debian this month, 5 reviews of Debian packages were added, 22 were updated and 8 were removed this month adding to Debian s knowledge about identified issues. A number of issue types were updated as well. [ ][ ][ ][ ] In addition, Roland Clobus posted his 23rd update of the status of reproducible ISO images on our mailing list. In particular, Roland helpfully summarised that all major desktops build reproducibly with bullseye, bookworm, trixie and sid provided they are built for a second time within the same DAK run (i.e. [within] 6 hours) and that there will likely be further work at a MiniDebCamp in Hamburg. Furthermore, Roland also responded in-depth to a query about a previous report Fedora developer Zbigniew J drzejewski-Szmek announced a work-in-progress script called fedora-repro-build that attempts to reproduce an existing package within a koji build environment. Although the projects README file lists a number of fields will always or almost always vary and there is a non-zero list of other known issues, this is an excellent first step towards full Fedora reproducibility.
Jelle van der Waa introduced a new linter rule for Arch Linux packages in order to detect cache files leftover by the Sphinx documentation generator which are unreproducible by nature and should not be packaged. At the time of writing, 7 packages in the Arch repository are affected by this.
Elsewhere, Bernhard M. Wiedemann posted another monthly update for his work elsewhere in openSUSE.
diffoscopediffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 256, 257 and 258 to Debian and made the following additional changes:
Use a deterministic name instead of trusting gpg s use-embedded-filenames. Many thanks to Daniel Kahn Gillmor dkg@debian.org for reporting this issue and providing feedback. [][]
Don t error-out with a traceback if we encounter struct.unpack-related errors when parsing Python .pyc files. (#1064973). []
Don t try and compare rdb_expected_diff on non-GNU systems as %p formatting can vary, especially with respect to MacOS. []
Expand an older changelog entry with a CVE reference. []
Make test_zip black clean. []
In addition, James Addison contributed a patch to parse the headers from the diff(1) correctly [][] thanks! And lastly, Vagrant Cascadian pushed updates in GNU Guix for diffoscope to version 255, 256, and 258, and updated trydiffoscope to 67.0.6.
reprotestreprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian made a number of changes, including:
Create a (working) proof of concept for enabling a specific number of CPUs. [][]
Consistently use 398 days for time variation rather than choosing randomly and update README.rst to match. [][]
Support a new --vary=build_path.path option. [][][][]
Website updates
There were made a number of improvements to our website this month, including:
Chris Lamb:
Improve the relative sizing of headers. []
Re-order and punch up the introduction and documentation on the SOURCE_DATE_EPOCH page. []
Update SOURCE_DATE_EPOCH documentation re. datetime.datetime.fromtimestamp. Thanks, James Addison. []
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
Grant Jan-Benedict Glaw shell access to the Jenkins node. []
Enable debugging for NetBSD reproducibility testing. []
Use /usr/bin/du --apparent-size in the Jenkins shell monitor. []
Revert reproducible nodes: mark osuosl2 as down . []
Thanks again to Codethink, for they have doubled the RAM on our arm64 nodes. []
Only set /proc/$pid/oom_score_adj to -1000 if it has not already been done. []
Add the opemwrt-target-tegra and jtx task to the list of zombie jobs. [][]
Vagrant Cascadian also made the following changes:
Overhaul the handling of OpenSSH configuration files after updating from Debian bookworm. [][][]
Add two new armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [][] [][]
In addition, Alexander Couzens updated the OpenWrt configuration in order to replace the tegra target with mpc85xx [], Jan-Benedict Glaw updated the NetBSD build script to use a separate $TMPDIR to mitigate out of space issues on a tmpfs-backed /tmp [] and Zheng Junjie added a link to the GNU Guix tests [].
Lastly, node maintenance was performed by Holger Levsen [][][][][][] and Vagrant Cascadian [][][][].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Posted on March 7, 2024
Tags: madeof:atoms, FreeSoftWear
I was working on what looked like a good pattern for a pair of
jeans-shaped trousers, and I knew I wasn t happy with 200-ish g/m
cotton-linen for general use outside of deep summer, but I didn t have a
source for proper denim either (I had been low-key looking for it for a
long time).
Then one day I looked at an article I had saved about fabric shops that
sell technical fabric and while window-shopping on one I found that they
had a decent selection of denim in a decent weight.
I decided it was a sign, and decided to buy the two heaviest denim they
had: a 100% cotton, 355 g/m one
and a 97% cotton, 3% elastane at 385 g/m 1; the latter was a bit of compromise as I shouldn t really be
buying fabric adulterated with the Scourge of Humanity, but it was
heavier than the plain one, and I may be having a thing for tightly
fitting jeans, so this may be one of the very few woven fabric where I m
not morally opposed to its existence.
And, I d like to add, I resisted buying any of the very nice wools they
also seem to carry, other than just a couple of samples.
Since the shop only sold in 1 meter increments, and I needed about 1.5
meters for each pair of jeans, I decided to buy 3 meters per type, and
have enough to make a total of four pair of jeans. A bit more than I
strictly needed, maybe, but I was completely out of wearable day-to-day
trousers.
The shop sent everything very quickly, the courier took their time (oh,
well) but eventually delivered my fabric on a sunny enough day that I
could wash it and start as soon as possible on the first pair.
The pattern I did in linen was a bit too fitting, but I was afraid I had
widened it a bit too much, so I did the first pair in the 100% cotton
denim. Sewing them took me about a week of early mornings and late
afternoons, excluding the weekend, and my worries proved false: they
were mostly just fine.
The only bit that could have been a bit better is the waistband, which
is a tiny bit too wide on the back: it s designed to be so for comfort,
but the next time I should pull the elastic a bit more, so that it stays
closer to the body.
I wore those jeans daily for the rest of the week, and confirmed that
they were indeed comfortable and the pattern was ok, so on the next
Monday I started to cut the elastic denim.
I decided to cut and sew two pairs, assembly-line style, using the
shaped waistband for one of them and the straight one for the other one.
I started working on them on a Monday, and on that week I had a couple
of days when I just couldn t, plus I completely skipped sewing on the
weekend, but on Tuesday the next week one pair was ready and could be
worn, and the other one only needed small finishes.
And I have to say, I m really, really happy with the ones with a shaped
waistband in elastic denim, as they fit even better than the ones with a
straight waistband gathered with elastic. Cutting it requires more
fabric, but I think it s definitely worth it.
But it will be a problem for a later time: right now three pairs of
jeans are a good number to keep in rotation, and I hope I won t have to
sew jeans for myself for quite some time.
I think that the leftovers of plain denim will be used for a skirt or
something else, and as for the leftovers of elastic denim, well, there
aren t a lot left, but what else I did with them is the topic for
another post.
Thanks to the fact that they are all slightly different, I ve started to
keep track of the times when I wash each pair, and hopefully I will be
able to see whether the elastic denim is significantly less durable than
the regular, or the added weight compensates for it somewhat. I m not
sure I ll manage to remember about saving the data until they get worn,
but if I do it will be interesting to know.
Oh, and I say I ve finished working on jeans and everything, but I still
haven t sewn the belt loops to the third pair. And I m currently wearing
them. It s a sewist tradition, or something. :D
The links are to the shop for Italy; you can copy the
Codice prodotto and look for it on one of the shop version for
other countries (where they apply the right vat etc., but sadly they
don t allow to mix and match those settings and the language).
I first became aware of Ray Dalio when either he or his publisher
plastered advertisements for The Principles all over the San
Francisco 4th and King Caltrain station. If I recall correctly, there
were also constant radio commercials; it was a whole thing in 2017. My
brain is very good at tuning out advertisements, so my only thought at the
time was "some business guy wrote a self-help book." I think I vaguely
assumed he was a CEO of some traditional business, since that's usually
who writes heavily marketed books like this. I did not connect him with
hedge funds or Bridgewater, which I have a bad habit of confusing with
Blackwater.
The Principles turns out to be more of a laundered cult manual than
a self-help book. And therein lies a story.
Rob Copeland is currently with The New York Times, but for many
years he was the hedge fund reporter for The Wall Street Journal.
He covered, among other things, Bridgewater Associates, the enormous hedge
fund founded by Ray Dalio. The Fund is a biography of Ray Dalio
and a history of Bridgewater from its founding as a vehicle for Dalio's
advising business until 2022 when Dalio, after multiple false starts and
title shuffles, finally retired from running the company. (Maybe. Based
on the history recounted here, it wouldn't surprise me if he was back at
the helm by the time you read this.)
It is one of the wildest, creepiest, and most abusive business histories
that I have ever read.
It's probably worth mentioning, as Copeland does explicitly, that Ray
Dalio and Bridgewater hate this book and claim it's a pack of lies.
Copeland includes some of their denials (and many non-denials that sound
as good as confirmations to me) in footnotes that I found increasingly
amusing.
A lawyer for Dalio said he "treated all employees equally, giving
people at all levels the same respect and extending them the same
perks."
Uh-huh.
Anyway, I personally know nothing about Bridgewater other than what I
learned here and the occasional mention in Matt Levine's newsletter (which
is where I got the recommendation for this book). I have no independent
information whether anything Copeland describes here is true, but Copeland
provides the typical extensive list of notes and sourcing one expects in a
book like this, and Levine's comments indicated it's generally consistent
with Bridgewater's industry reputation. I think this book is true, but
since the clear implication is that the world's largest hedge fund was
primarily a deranged cult whose employees mostly spied on and rated each
other rather than doing any real investment work, I also have questions,
not all of which Copeland answers to my satisfaction. But more on that
later.
The center of this book are the Principles. These were an ever-changing
list of rules and maxims for how people should conduct themselves within
Bridgewater. Per Copeland, although Dalio later published a book by that
name, the version of the Principles that made it into the book was
sanitized and significantly edited down from the version used inside the
company. Dalio was constantly adding new ones and sometimes changing
them, but the common theme was radical, confrontational "honesty": never
being silent about problems, confronting people directly about anything
that they did wrong, and telling people all of their faults so that they
could "know themselves better."
If this sounds like textbook abusive behavior, you have the right idea.
This part Dalio admits to openly, describing Bridgewater as a firm that
isn't for everyone but that achieves great results because of this
culture. But the uncomfortably confrontational vibes are only the tip of
the iceberg of dysfunction. Here are just a few of the ways this played
out according to Copeland:
Dalio decided that everyone's opinions should be weighted by the
accuracy of their previous decisions, to create a "meritocracy," and
therefore hired people to build a social credit system in which people
could use an app to constantly rate all of their co-workers. This
almost immediately devolved into out-group bullying worthy of a high
school, with employees hurriedly down-rating and ostracizing any
co-worker that Dalio down-rated.
When an early version of the system uncovered two employees at
Bridgewater with more credibility than Dalio, Dalio had the system
rigged to ensure that he always had the highest ratings and was not
affected by other people's ratings.
Dalio became so obsessed with the principle of confronting problems
that he created a centralized log of problems at Bridgewater and
required employees find and report a quota of ten or twenty new issues
every week or have their bonus docked. He would then regularly pick
some issue out of the issue log, no matter how petty, and treat it
like a referendum on the worth of the person responsible for the
issue.
Dalio's favorite way of dealing with a problem was to put someone on
trial. This involved extensive investigations followed by a meeting
where Dalio would berate the person and harshly catalog their flaws,
often reducing them to tears or panic attacks, while smugly insisting
that having an emotional reaction to criticism was a personality flaw.
These meetings were then filmed and added to a library available to
all Bridgewater employees, often edited to remove Dalio's personal
abuse and to make the emotional reaction of the target look
disproportionate. The ones Dalio liked the best were shown to all new
employees as part of their training in the Principles.
One of the best ways to gain institutional power in Bridgewater was to
become sycophantically obsessed with the Principles and to be an eager
participant in Dalio's trials. The highest levels of Bridgewater
featured constant jockeying for power, often by trying to catch rivals
in violations of the Principles so that they would be put on trial.
In one of the common and all-too-disturbing connections between Wall
Street finance and the United States' dysfunctional government, James
Comey (yes, that James
Comey) ran internal security for Bridgewater for three years, meaning
that he was the one who pulled evidence from surveillance cameras for
Dalio to use to confront employees during his trials.
In case the cult vibes weren't strong enough already, Bridgewater
developed its own idiosyncratic language worthy of Scientology. The
trials were called "probings," firing someone was called "sorting" them,
and rating them was called "dotting," among many other
Bridgewater-specific terms. Needless to say, no one ever probed Dalio
himself. You will also be completely unsurprised to learn that Copeland
documents instances of sexual harassment and discrimination at
Bridgewater, including some by Dalio himself, although that seems to be a
relatively small part of the overall dysfunction. Dalio was happy to
publicly humiliate anyone regardless of gender.
If you're like me, at this point you're probably wondering how Bridgewater
continued operating for so long in this environment. (Per Copeland, since
Dalio's retirement in 2022, Bridgewater has drastically reduced the
cult-like behaviors, deleted its archive of probings, and de-emphasized the
Principles.) It was not actually a religious cult; it was a hedge fund
that has to provide investment services to huge, sophisticated clients,
and by all accounts it's a very successful one. Why did this bizarre
nightmare of a workplace not interfere with Bridgewater's business?
This, I think, is the weakest part of this book. Copeland makes a few
gestures at answering this question, but none of them are very satisfying.
First, it's clear from Copeland's account that almost none of the
employees of Bridgewater had any control over Bridgewater's investments.
Nearly everyone was working on other parts of the business (sales,
investor relations) or on cult-related obsessions. Investment decisions
(largely incorporated into algorithms) were made by a tiny core of people
and often by Dalio himself. Bridgewater also appears to not trade
frequently, unlike some other hedge funds, meaning that they probably stay
clear of the more labor-intensive high-frequency parts of the business.
Second, Bridgewater took off as a hedge fund just before the hedge fund
boom in the 1990s. It transformed from Dalio's personal consulting
business and investment newsletter to a hedge fund in 1990 (with an
earlier investment from the World Bank in 1987), and the 1990s were a very
good decade for hedge funds. Bridgewater, in part due to Dalio's
connections and effective marketing via his newsletter, became one of the
largest hedge funds in the world, which gave it a sort of institutional
momentum. No one was questioned for putting money into Bridgewater even
in years when it did poorly compared to its rivals.
Third, Dalio used the tried and true method of getting free publicity from
the financial press: constantly predict an upcoming downturn, and
aggressively take credit whenever you were right. From nearly the start
of his career, Dalio predicted economic downturns year after year.
Bridgewater did very well in the 2000 to 2003 downturn, and again during
the 2008 financial crisis. Dalio aggressively takes credit for predicting
both of those downturns and positioning Bridgewater correctly going into
them. This is correct; what he avoids mentioning is that he also
predicted downturns in every other year, the majority of which never
happened.
These points together create a bit of an answer, but they don't feel like
the whole picture and Copeland doesn't connect the pieces. It seems
possible that Dalio may simply be good at investing; he reads obsessively
and clearly enjoys thinking about markets, and being an abusive cult
leader doesn't take up all of his time. It's also true that to some
extent hedge funds are semi-free money machines, in that once you have a
sufficient quantity of money and political connections you gain access to
investment opportunities and mechanisms that are very likely to make money
and that the typical investor simply cannot access. Dalio is clearly good
at making personal connections, and invested a lot of effort into forming
close ties with tricky clients such as pools of Chinese money.
Perhaps the most compelling explanation isn't mentioned directly in this
book but instead comes from Matt Levine. Bridgewater touts its
algorithmic trading over humans making individual trades, and there is
some reason to believe that consistently applying an algorithm without
regard to human emotion is a solid trading strategy in at least some
investment areas. Levine has asked in his newsletter, tongue firmly in
cheek, whether the bizarre cult-like behavior and constant infighting is a
strategy to distract all the humans and keep them from messing with the
algorithm and thus making bad decisions.
Copeland leaves this question unsettled. Instead, one comes away from
this book with a clear vision of the most dysfunctional workplace I have
ever heard of, and an endless litany of bizarre events each more
astonishing than the last. If you like watching train wrecks, this is the
book for you. The only drawback is that, unlike other entries in this
genre such as Bad Blood or
Billion Dollar Loser, Bridgewater is a
wildly successful company, so you don't get the schadenfreude of seeing a
house of cards collapse. You do, however, get a helpful mental model to
apply to the next person who tries to talk to you about "radical honesty"
and "idea meritocracy."
The flaw in this book is that the existence of an organization like
Bridgewater is pointing to systematic flaws in how our society works,
which Copeland is largely uninterested in interrogating. "How could this
have happened?" is a rather large question to leave unanswered. The sheer
outrageousness of Dalio's behavior also gets a bit tiring by the end of
the book, when you've seen the patterns and are hearing about the fourth
variation. But this is still an astonishing book, and a worthy entry in
the genre of capitalism disasters.
Rating: 7 out of 10
Posted on February 19, 2024
Tags: madeof:atoms, craft:sewing, FreeSoftWear
CW for body size change mentions
Just like the corset, I also needed a new pair of jeans.
Back when my body size changed drastically of course my jeans no longer
fit. While I was waiting for my size to stabilize I kept wearing them
with a somewhat tight belt, but it was ugly and somewhat uncomfortable.
When I had stopped changing a lot I tried to buy new ones in the same
model, and found out that I was too thin for the menswear jeans of that
shop. I could have gone back to wearing women s jeans, but I didn t want
to have to deal with the crappy fabric and short pockets, so I basically
spent a few years wearing mostly skirts, and oversized jeans when I
really needed trousers.
Meanwhile, I had drafted a jeans pattern for my SO, which we had
planned to make in technical fabric, but ended up being made in a
cotton-wool mystery mix for winter and in linen-cotton for summer, and
the technical fabric version was no longer needed (yay for natural
fibres!)
It was clear what the solution to my jeans problems would have been, I
just had to stop getting distracted by other projects and draft a new
pattern using a womanswear block instead of a menswear one.
Which, in January 2024 I finally did, and I believe it took a bit less
time than the previous one, even if it had all of the same fiddly
pieces.
I already had a cut of the same cotton-linen I had used for my SO,
except in black, and used it to make the pair this post is about.
The parametric pattern is of course online, as #FreeSoftWear, at the
usual place.
This time it was faster, since I didn t have to write step-by-step
instructions, as they are exactly the same as the other pattern.
Making also went smoothly, and the result was fitting. Very fitting. A
big too fitting, and the standard bum adjustment of the back was just
enough for what apparently still qualifies as a big bum, so I adjusted
the pattern to be able to add a custom amount of ease in a few places.
But at least I had a pair of jeans-shaped trousers that fit!
Except, at 200 g/m I can t say that fabric is the proper weight for a
pair of trousers, and I may have looked around online1 for
some denim, and, well, it s 2024, so my no-fabric-buy 2023 has not been
broken, right?
Let us just say that there may be other jeans-related posts in the near
future.
I had already asked years ago for denim at my local fabric
shops, but they don t have the proper, sturdy, type I was looking
for.
In October 2023, I departed from the Wikimedia Foundation, the non-profit organization
behind well-known projects like Wikipedia and others, to join Spryker.
However, in January 2024 Spryker conducted a round of layoffs reportedly due to budget and business reasons.
I was among those affected, being let go just three months after joining the company.
Fortunately, the Wikimedia Cloud Services team, where I previously worked, was still seeking to backfill my
position, so I reached out to them. They graciously welcomed me back as a Senior Site Reliability Engineer,
in the same team and position as before.
Although this three-month career detour wasn t the outcome I initially envisioned, I found it to be a valuable experience.
During this time, I gained knowledge in a new tech stack, based on AWS, and discovered new engineering methodologies.
Additionally, I had the opportunity to meet some wonderful individuals. I believe I have emerged stronger from this experience.
Returning to the Wikimedia Foundation is truly motivating. It feels privileged to be part of this mature organization,
its community, and movement, with its inspiring mission and values.
In addition, I m hoping that this also means I can once again dedicate a bit more attention to my FLOSS activities,
such as my duties within the Debian project.
My email address is back online: aborrero@wikimedia.org.
You can find me again in the IRC libera.chat server, in the usual wikimedia channels, nick arturo.
Welcome to the January 2024 report from the Reproducible Builds project. In these reports we outline the most important things that we have been up to over the past month. If you are interested in contributing to the project, please visit our Contribute page on our website.
How we executed a critical supply chain attack on PyTorch
John Stawinski and Adnan Khan published a lengthy blog post detailing how they executed a supply-chain attack against PyTorch, a popular machine learning platform used by titans like Google, Meta, Boeing, and Lockheed Martin :
Our exploit path resulted in the ability to upload malicious PyTorch releases to GitHub, upload releases to [Amazon Web Services], potentially add code to the main repository branch, backdoor PyTorch dependencies the list goes on. In short, it was bad. Quite bad.
The attack pivoted on PyTorch s use of self-hosted runners as well as submitting a pull request to address a trivial typo in the project s README file to gain access to repository secrets and API keys that could subsequently be used for malicious purposes.
New Arch Linux forensic filesystem tool
On our mailing list this month, long-time Reproducible Builds developer kpcyrdannounced a new tool designed to forensically analyse Arch Linux filesystem images.
Called archlinux-userland-fs-cmp, the tool is supposed to be used from a rescue image (any Linux) with an Arch install mounted to, [for example], /mnt. Crucially, however, at no point is any file from the mounted filesystem eval d or otherwise executed. Parsers are written in a memory safe language.
More information about the tool can be found on their announcement message, as well as on the tool s homepage. A GIF of the tool in action is also available.
Issues with our SOURCE_DATE_EPOCH code?
Chris Lamb started a thread on our mailing list summarising some potential problems with the source code snippet the Reproducible Builds project has been using to parse the SOURCE_DATE_EPOCH environment variable:
I m not 100% sure who originally wrote this code, but it was probably sometime in the ~2015 era, and it must be in a huge number of codebases by now.
Anyway, Alejandro Colomar was working on the shadow security tool and pinged me regarding some potential issues with the code. You can see this conversation here.
Chris ends his message with a request that those with intimate or low-level knowledge of time_t, C types, overflows and the various parsing libraries in the C standard library (etc.) contribute with further info.
Distribution updates
In Debian this month, Roland Clobus posted another detailed update of the status of reproducible ISO images on our mailing list. In particular, Roland helpfully summarised that all major desktops build reproducibly with bullseye, bookworm, trixie and sid provided they are built for a second time within the same DAK run (i.e. [within] 6 hours) . Additionally 7 of the 8 bookworm images from the official download link build reproducibly at any later time.
In addition to this, three reviews of Debian packages were added, 17 were updated and 15 were removed this month adding to our knowledge about identified issues.
Elsewhere, Bernhard posted another monthly update for his work elsewhere in openSUSE.
Community updates
There were made a number of improvements to our website, including Bernhard M. Wiedemann fixing a number of typos of the term nondeterministic . [] and Jan Zerebecki adding a substantial and highly welcome section to our page about SOURCE_DATE_EPOCH to document its interaction with distribution rebuilds. [].
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 254 and 255 to Debian but focusing on triaging and/or merging code from other contributors. This included adding support for comparing eXtensible ARchive (.XAR/.PKG) files courtesy of Seth Michael Larson [][], as well considerable work from Vekhir in order to fix compatibility between various and subtle incompatible versions of the progressbar libraries in Python [][][][]. Thanks!
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In January, a number of changes were made by Holger Levsen:
Limit the execution of chroot-installation jobs to a maximum of 4 concurrent runs. [][]
Significant amounts of node maintenance was performed by Holger Levsen (eg. [][][][][][][] etc.) and Vagrant Cascadian (eg. [][][][][][][][]). Indeed, Vagrant Cascadian handled an extended power outage for the network running the Debian armhf architecture test infrastructure. This provided the incentive to replace the UPS batteries and consolidate infrastructure to reduce future UPS load. []
Elsewhere in our infrastructure, however, Holger Levsen also adjusted the email configuration for @reproducible-builds.org to deal with a new SMTP email attack. []
Upstream patches
The Reproducible Builds project tries to detects, dissects and fix as many (currently) unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
Separate to this, Vagrant Cascadian followed up with the relevant maintainers when reproducibility fixes were not included in newly-uploaded versions of the mm-common package in Debian this was quickly fixed, however. []
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Inspired by a Mastodon
post by Fran oise Conil,
who investigated the current popularity of build backends used in
pyproject.toml files, I wanted to investigate how the popularity of build
backends used in pyproject.toml files evolved over the years since the
introduction of PEP-0517 in 2015.
Getting the data
Tom Forbes provides a huge
dataset that contains information
about every file within every release uploaded to PyPI. To
get the current dataset, we can use:
This will download approximately 30GB of parquet files, providing detailed
information about each file included in a PyPI upload, including:
project name, version and release date
file path, size and line count
hash of the file
The dataset does not contain the actual files themselves though, more on that
in a moment.
Querying the dataset using duckdb
We can now use duckdb to query the parquet files directly. Let s look into
the schema first:
From all files mentioned in the dataset, we only care about pyproject.toml
files that are in the project s root directory. Since we ll still have to
download the actual files, we need to get the path and the repository to
construct the corresponding URL to the mirror that contains all files in a
bunch of huge git repositories. Some files are not available on the mirrors; to
skip these, we only take files where the skip_reason is empty. We also care
about the timestamp of the upload (uploaded_on) and the hash to avoid
processing identical files twice:
This query runs for a few minutes on my laptop and returns ~1.2M rows.
Getting the actual files
Using the repository and path, we can now construct an URL from which we
can fetch the actual file for further processing:
We can download the individual pyproject.toml files and parse them to read
the build-backend into a dictionary mapping the file-hash to the build
backend. Downloads on GitHub are rate-limited, so downloading 1.2M files
will take a couple of days. By skipping files with a hash we ve already
processed, we can avoid downloading the same file more than once, cutting the
required downloads by circa 50%.
Results
Assuming the data is complete and my analysis is sound, these are the findings:
There is a surprising amount of build backends in use, but the overall amount
of uploads per build backend decreases quickly, with a long tail of single
uploads:
We pick only the top 4 build backends, and group the remaining ones (including
PDM and Maturin) into other so they are accounted for as well.
The following plot shows the relative distribution of build backends over time.
Each bin represents a time span of 28 days. I chose 28 days to reduce visual
clutter. Within each bin, the height of the bars corresponds to the relative
proportion of uploads during that time interval:
Looking at the right side of the plot, we see the current distribution. It
confirms Fran oise s findings about the current popularity of build
backends:
Setuptools: ~50%
Poetry: ~33%
Hatch: ~10%
Flit: ~3%
Other: ~4%
Between 2018 and 2020 the graph exhibits significant fluctuations, due to the
relatively low amount uploads utizing pyproject.toml files. During that early
period, Flit started as the most popular build backend, but was eventually
displaced by Setuptools and Poetry.
Between 2020 and 2020, the overall usage of pyproject.toml files increased
significantly. By the end of 2022, the share of Setuptools peaked at 70%.
After 2020, other build backends experienced a gradual rise in popularity.
Amongh these, Hatch emerged as a notable contender, steadily gaining
traction and ultimately stabilizing at 10%.
We can also look into the absolute distribution of build backends over time:
The plot shows that Setuptools has the strongest growth trajectory, surpassing
all other build backends. Poetry and Hatch are growing at a comparable rate,
but since Hatch started roughly 4 years after Poetry, it s lagging behind in
popularity. Despite not being among the most widely used backends anymore, Flit
maintains a steady and consistent growth pattern, indicating its enduring
relevance in the Python packaging landscape.
The script for downloading and analyzing the data can be found in my GitHub
repository. It contains the results of the duckb query (so you
don t have to download the full dataset) and the pickled dictionary, mapping
the file hashes to the build backends, saving you days for downloading and
analyzing the pyproject.toml files yourself.
Interested in future updates? Follow me on mastodon at
@paul@soylent.green. Posts about
hz.tools will be tagged
#hztools.
If you're on the Fediverse, I'd very much appreciate boosts on
my toot!
While working on hz.tools, I started to move my beamforming
code from 2-D (meaning, beamforming to some specific angle on the X-Y plane for
waves on the X-Y plane) to 3-D. I ll have more to say about that once I get
around to publishing the code as soon as I m sure it s not completely wrong,
but in the meantime I decided to write a simple simulator to visually
check the beamformer against the textbooks. The results were pretty rad,
so I figured I d throw together a post since it s interesting all on its
own outside of beamforming as a general topic.
I figured I d write this in Rust, since I ve been using Rust as my primary
language over at zoo, and it s a good chance
to learn the language better.
This post has some large GIFs
It make take a little bit to load depending
on your internet connection. Sorry about that, I'm not clever enough to
do better without doing tons of complex engineering work. They may be
choppy while they load or something. I tried to compress an ensmall them,
so if they're loaded but fuzzy, click on them to load a slightly larger
version.
This post won t cover the basics of how
phased arrays work
or the specifics of calculating the phase offsets for each antenna,
but I ll dig into how I wrote a simple simulator and how I wound up
checking my phase offsets to generate the renders below.
Assumptions
I didn t want to build a general purpose RF simulator, anything particularly
generic, or something that would solve for any more than the things right
in front of me. To do this as simply (and quickly all this code took about
a day to write, including the beamforming math) I had to reduce the
amount of work in front of me.
Given that I was concerend with visualizing what the antenna pattern would look
like in 3-D given some antenna geometry, operating frequency and configured
beam, I made the following assumptions:
All anetnnas are perfectly isotropic they receive a signal that is
exactly the same strength no matter what direction the signal originates
from.
There s a single point-source isotropic emitter in the far-field (I modeled
this as being 1 million meters away 1000 kilometers) of the antenna system.
There is no noise, multipath, loss or distortion in the signal as it travels
through space.
Antennas will never interfere with each other.
2-D Polar Plots
The last time I wrote something like this,
I generated 2-D GIFs which show a radiation pattern, not unlike the
polar plots you d see on a microphone.
These are handy because it lets you visualize what the directionality of
the antenna looks like, as well as in what direction emissions are
captured, and in what directions emissions are nulled out. You can see
these plots
on spec sheets for antennas in both 2-D and 3-D form.
Now, let s port the 2-D approach to 3-D and see how well it works out.
Writing the 3-D simulator
As an EM wave travels through free space, the place at which you sample
the wave controls that phase you observe at each time-step. This means,
assuming perfectly synchronized clocks, a transmitter and receiver exactly
one RF wavelength apart will observe a signal in-phase, but a transmitter
and receiver a half wavelength apart will observe a signal 180 degrees
out of phase.
This means that if we take the distance between our point-source and
antenna element, divide it by the wavelength, we can use the fractional
part of the resulting number to determine the phase observed. If we
multiply that number (in the range of 0 to just under 1) by
tau, we can generate a complex number by taking the
cos and sin of the multiplied phase (in the range of 0 to tau), assuming
the transmitter is emitting a carrier wave at a static amplitude and all
clocks are in perfect sync.
At this point, given some synthetic transmission point and each antenna, we
know what the expected complex sample would be at each antenna. At this point,
we can adjust the phase of each antenna according to the beamforming
phase offset configuration, and add up every sample in order to determine
what the entire system would collectively produce a sample as.
let beamformed_phases: Vec<Complex>= ...;
let magnitude = beamformed_phases
.iter()
.zip(observed_phases.iter())
.map((beamformed, observed) observed * beamformed)
.reduce(acc, el acc + el)
.unwrap()
.abs();
Armed with this information, it s straight forward to generate some number
of (Azimuth, Elevation) points to sample, generate a transmission point
far away in that direction, resolve what the resulting Complex sample would be,
take its magnitude, and use that to create an (x, y, z) point at
(azimuth, elevation, magnitude). The color attached two that point is
based on its distance from (0, 0, 0). I opted to use the
Life Aquatic
table for this one.
After this process is complete, I have a
point cloud of
((x, y, z), (r, g, b)) points. I wrote a small program using
kiss3d to render point cloud using tons of
small spheres, and write out the frames to a set of PNGs, which get compiled
into a GIF.
Now for the fun part, let s take a look at some radiation patterns!
1x4 Phased Array
The first configuration is a phased array where all the elements are
in perfect alignment on the y and z axis, and separated by some
offset in the x axis. This configuration can sweep 180 degrees (not
the full 360), but can t be steared in elevation at all.
Let s take a look at what this looks like for a well constructed
1x4 phased array:
And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
Nice. Looks perfect. When pointing forward at (0, 0), we d expect to see a
torus, which we do. As we sweep between 0 and 360, astute observers will notice
the pattern is mirrored along the axis of the antennas, when the beam is facing
forward to 0 degrees, it ll also receive at 180 degrees just as strong. There s
a small sidelobe that forms when it s configured along the array, but
it also becomes the most directional, and the sidelobes remain fairly small.
Long compared to the wavelength (1 )
Let s try again, but rather than spacing each antenna of a wavelength
apart, let s see about spacing each antenna 1 of a wavelength apart instead.
The main lobe is a lot more narrow (not a bad thing!), but some significant
sidelobes have formed (not ideal). This can cause a lot of confusion when doing
things that require a lot of directional resolution unless they re compensated
for.
Going from ( to 5 )
The last model begs the question - what do things look like when you separate
the antennas from each other but without moving the beam? Let s simulate moving
our antennas but not adjusting the configured beam or operating frequency.
Very cool. As the spacing becomes longer in relation to the operating frequency,
we can see the sidelobes start to form out of the end of the antenna system.
2x2 Phased Array
The second configuration I want to try is a phased array where the elements
are in perfect alignment on the z axis, and separated by a fixed offset
in either the x or y axis by their neighbor, forming a square when
viewed along the x/y axis.
Let s take a look at what this looks like for a well constructed
2x2 phased array:
Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
Sweet. Heck yeah. The array is quite directional in the configured direction,
and can even sweep a little bit in elevation, a definite improvement
from the 1x4 above.
Long compared to the wavelength (1 )
Let s do the same thing as the 1x4 and take a look at what happens when the
distance between elements is long compared to the frequency of operation
say, 1 of a wavelength apart? What happens to the sidelobes given this
spacing when the frequency of operation is much different than the physical
geometry?
Mesmerising. This is my favorate render. The sidelobes are very fun to
watch come in and out of existence. It looks absolutely other-worldly.
Going from ( to 5 )
Finally, for completeness' sake, what do things look like when you separate the
antennas from each other just as we did with the 1x4? Let s simulate moving our
antennas but not adjusting the configured beam or operating frequency.
Very very cool. The sidelobes wind up turning the very blobby cardioid into
an electromagnetic dog toy. I think we ve proven to ourselves that using
a phased array much outside its designed frequency of operation seems like
a real bad idea.
Future Work
Now that I have a system to test things out, I m a bit more confident that
my beamforming code is close to right! I d love to push that code over
the line and blog about it, since it s a really interesting topic on its own.
Once I m sure the code involved isn t full of lies, I ll put it up on the
hztools org, and post about it here and on
mastodon.
Now that I m freelancing, I need to
actually track my time, which is something I ve had the luxury of not having
to do before. That meant something of a rethink of the way I ve been
keeping track of my to-do list. Up to now that was a combination of things
like the bug lists for the projects I m working on at the moment, whatever
task tracking system Canonical was using at the moment (Jira when I left),
and a giant flat text file in which I recorded logbook-style notes of what
I d done each day plus a few extra notes at the bottom to remind myself of
particularly urgent tasks. I could have started manually adding times to
each logbook entry, but ugh, let s not.
In general, I had the following goals (which were a bit reminiscent of my
address book):
free software throughout
storage under my control
ability to annotate tasks with URLs (especially bugs and merge requests)
lightweight time tracking (I m OK with having to explicitly tell it when
I start and stop tasks)
ability to drive everything from the command line
decent filtering so I don t have to look at my entire to-do list all the time
ability to easily generate billing information for multiple clients
optionally, integration with Android (mainly so I can tick off personal
tasks like change bedroom lightbulb or whatever that don t involve
being near a computer)
I didn t do an elaborate evaluation of multiple options, because I m not
trying to come up with the best possible solution for a client here. Also,
there are a bazillion to-do list trackers out there and if I tried to
evaluate them all I d never do anything else. I just wanted something that
works well enough for me.
Since it came up on
Mastodon: a bunch
of people swear by Org mode, which I know can do at
least some of this sort of thing. However, I don t use Emacs and don t plan
to use Emacs. nvim-orgmode does
have some support for time tracking, but when I ve tried vim-based
versions of Org mode in the past I ve found they haven t really fitted my
brain very well.
Taskwarrior and Timewarrior
One of the other Freexian collaborators mentioned
Taskwarrior and
Timewarrior, so I had a look at those.
The basic idea of Taskwarrior is that you have a task command that tracks
each task as a blob of JSON and provides subcommands to let you add, modify,
and remove tasks with a minimum of friction. task add adds a task, and
you can add metadata like project:Personal (I always make sure every task
has a project, for ease of filtering). Just running task shows you a task
list sorted by Taskwarrior s idea of urgency, with an ID for each task, and
there are various other reports with different filtering and verbosity.
task <id> annotate lets you attach more information to a task. task <id>
done marks it as done. So far so good, so a redacted version of my to-do
list looks like this:
Once I got comfortable with it, this was already a big improvement. I
haven t bothered to learn all the filtering gadgets yet, but it was easy
enough to see that I could do something like task all project:Personal and
it d show me both pending and completed tasks in that project, and that all
the data was stored in ~/.task - though I have to say that there are
enough reporting bells and whistles that I haven t needed to poke around
manually. In combination with the regular backups that I do anyway (you do
too, right?), this gave me enough confidence to abandon my previous
text-file logbook approach.
Next was time tracking. Timewarrior integrates with Taskwarrior, albeit in
an only semi-packaged way, and
it was easy enough to set that up. Now I can do:
$task25start
Startingtask00a9516f'Write blog post about task tracking'.
Started1task.
Note:'"Write blog post about task tracking"'isanewtag.
TrackingColumbiform"Write blog post about task tracking"Started2024-01-10T11:28:38
Current38Total0:00:00
Youhavemoreurgenttasks.
Project'Columbiform'is25%complete(3of4tasksremaining).
When I stop work on something, I do task active to find the ID, then task
<id> stop. Timewarrior does the tedious stopwatch business for me, and I
can manually enter times if I forget to start/stop a task. Then the really
useful bit: I can do something like timew summary :month <name-of-client>
and it tells me how much to bill that client for this month. Perfect.
I also started using VIT to simplify
the day-to-day flow a little, which means I m normally just using one or two
keystrokes rather than typing longer commands. That isn t really necessary
from my point of view, but it does save some time.
Android integration
I left Android integration for a bit later since it wasn t essential. When
I got round to it, I have to say that it felt a bit clumsy, but it did
eventually work.
The first step was to set up a
taskserver. Most
of the setup procedure was OK, but I wanted to use Let s Encrypt to minimize
the amount of messing around with CAs I had to do. Getting this to work
involved hitting things with sticks a bit, and there s still a local CA
involved for client certificates. What I ended up with was a certbot
setup with the webroot authenticator and a custom deploy hook as follows
(with cert_name replaced by a DNS name in my house domain):
Then I could set taskd.ca on my laptop to
/usr/share/ca-certificates/mozilla/ISRG_Root_X1.crt and otherwise follow
the client setup instructions, run task sync init to get things started,
and then task sync every so often to sync changes between my laptop and
the taskserver.
I used TaskWarrior
Mobile
as the client. I have to say I wouldn t want to use that client as my
primary task tracking interface: the setup procedure is clunky even beyond
the necessity of copying a client certificate around, it expects you to give
it a .taskrc rather than having a proper settings interface for that, and
it only seems to let you add a task if you specify a due date for it. It
also lacks Timewarrior integration, so I can only really use it when I don t
care about time tracking, e.g. personal tasks. But that s really all I
need, so it meets my minimum requirements.
Next?
Considering this is literally the first thing I tried, I have to say I m
pretty happy with it. There are a bunch of optional extras I haven t tried
yet, but in general it kind of has the vim nature for me: if I need
something it s very likely to exist or easy enough to build, but the
features I don t use don t get in my way.
I wouldn t recommend any of this to somebody who didn t already spend most
of their time in a terminal - but I do. I m glad people have gone to all
the effort to build this so I didn t have to.
The Faithless is the second book in a political fantasy series that
seems likely to be a trilogy. It is a direct sequel to
The Unbroken, which you should read
first. As usual, Orbit made it unnecessarily hard to get re-immersed in
the world by refusing to provide memory aids for readers who read books as
they come out instead of only when the series is complete, but this is not
the fault of Clark or the book and you've heard me rant about this before.
The Unbroken was set in Qaz l (not-Algeria). The Faithless,
as readers of the first book might guess from the title, is set in
Balladaire (not-France). This is the palace intrigue book. Princess Luca
is fighting for her throne against her uncle, the regent. Touraine is
trying to represent her people. Whether and to what extent those
interests are aligned is much of the meat of this book.
Normally I enjoy palace intrigue novels for the competence porn: watching
someone navigate a complex political situation with skill and cunning, or
upend the entire system by building unlikely coalitions or using
unexpected routes to power. If you are similar, be warned that this is
not what you're going to get. Touraine is a fish out of water with no
idea how to navigate the Balladairan court, and does not magically become
an expert in the course of this novel. Luca has the knowledge, but she's
unsure, conflicted, and largely out-maneuvered. That means you will have
to brace for some painful scenes of some of the worst people apparently
getting what they want.
Despite that, I could not put this down. It was infuriating, frustrating,
and a much slower burn than I prefer, but the layers of complex
motivations that Clark builds up provided a different sort of payoff.
Two books in, the shape of this series is becoming clearer. This series
is about empire and colonialism, but with considerably more complexity
than fantasy normally brings to that topic. Power does not loosen its
grasp easily, and it has numerous tools for subtle punishment after
apparent upstart victories. Righteous causes rarely call banners to your
side; instead, they create opportunities for other people to maneuver to
their own advantage. Touraine has some amount of power now, but it's far
from obvious how to use it. Her life's training tells her that exercising
power will only cause trouble, and her enemies are more than happy to
reinforce that message at every opportunity.
Most notable to me is Clark's bitingly honest portrayal of the supposed
allies within the colonial power. It is clear that Luca is attempting to
take the most ethical actions as she defines them, but it's remarkable how
those efforts inevitably imply that Touraine should help Luca now in
exchange for Luca's tenuous and less-defined possible future aid. This is
not even a lie; it may be an accurate summary of Balladairan politics.
And yet, somehow what Balladaire needs always matters more than the needs
of their abused colony.
Underscoring this, Clark introduces another faction in the form of a
populist movement against the Balladairan monarchy. The details of that
setup in another fantasy novel would make them allies of the Qaz l. Here,
as is so often the case in real life, a substantial portion of the
populists are even more xenophobic and racist than the nobility. There
are no easy alliances.
The trump card that Qaz l holds is magic. They have it, and (for reasons
explored in The Unbroken) Balladaire needs it, although that is a
position held by Luca's faction and not by her uncle. But even Luca wants
to reduce that magic to a manageable technology, like any other element of
the Balladairan state. She wants to understand it, harness it, and bring
it under local control. Touraine, trained by Balladaire and facing
Balladairan political problems, has the same tendency. The magic, at
least in this book, refuses not in the flashy, rebellious way that it
would in most fantasy, but in a frustrating and incomprehensible lack of
predictable or convenient rules. I think this will feel like a plot
device to some readers, and that is to some extent true, but I think I see
glimmers of Clark setting up a conflict of world views that will play out
in the third book.
I think some people are going to bounce off this book. It's frustrating,
enraging, at times melodramatic, and does not offer the cathartic payoff
typically offered in fantasy novels of this type. Usually these are
things I would be complaining about as well. And yet, I found it
satisfyingly challenging, engrossing, and memorable. I spent a lot of the
book yelling "just kill him already" at the characters, but I think one of
Clark's points is that overcoming colonial relationships requires a lot
more than just killing one evil man. The characters profoundly fail to
execute some clever and victorious strategy. Instead, as in the first
book, they muddle through, making the best choice that they can see in
each moment, making lots of mistakes, and paying heavy prices. It's
realistic in a way that has nothing to do with blood or violence or
grittiness. (Although I did appreciate having the thin thread of Pruett's
story and its highly satisfying conclusion.)
This is also a slow-burn romance, and there too I think opinions will
differ. Touraine and Luca keep circling back to the same arguments and
the same frustrations, and there were times that this felt repetitive. It
also adds a lot of personal drama to the politics in a way that
occasionally made me dubious. But here too, I think Clark is partly using
the romance to illustrate the deeper political points.
Luca is often insufferable, cruel and ambitious in ways she doesn't
realize, and only vaguely able to understand the Qaz l perspective; in
short, she's the pragmatic centrist reformer. I am dubious that her
ethics would lead her to anything other than endless compromise without
Touraine to push her. To Luca's credit, she also realizes that and wants
to be a better person, but struggles to have the courage to act on it.
Touraine both does and does not want to manipulate her; she wants Luca's
help (and more), but it's not clear Luca will give it under acceptable
terms, or even understand how much she's demanding. It's that
foundational conflict that turns the romance into a slow burn by pushing
them apart. Apparently I have more patience for this type of on-again,
off-again relationship than one based on artificial miscommunication.
The more I noticed the political subtext, the more engaging I found the
romance on the surface.
I picked this up because I'd read several books about black characters
written by white authors, and while there was nothing that wrong with
those books, the politics felt a little too reductionist and simplified.
I wanted a book that was going to force me out of comfortable political
assumptions. The Faithless did exactly what I was looking for, and
I am definitely here for the rest of the series. In that sense,
recommended, although do not go into this book hoping for adroit court
maneuvering and competence porn.
Followed by The Sovereign, which does not yet have a release date.
Content warnings: Child death, attempted cultural genocide.
Rating: 7 out of 10
Posted on January 7, 2024
Tags: madeof:atoms, craft:sewing, period:victorian, FreeSoftWear
CW for body size change mentions
I needed a corset, badly.
Years ago I had a chance to have my measurements taken by a former
professional corset maker and then a lesson in how to draft an underbust
corset, and that lead to me learning how nice wearing a well-fitted
corset feels.
Later I tried to extend that pattern up for a midbust corset, with
success.
And then my body changed suddenly, and I was no longer able to wear
either of those, and after a while I started missing them.
Since my body was still changing (if no longer drastically so), and I
didn t want to use expensive materials for something that had a risk of
not fitting after too little time, I decided to start by making myself a
summer lightweight corset in aida cloth and plastic boning (for which I
had already bought materials). It fitted, but not as well as the first
two ones, and I ve worn it quite a bit.
I still wanted back the feeling of wearing a comfy, heavy contraption of
coutil and steel, however.
After a lot of procrastination I redrafted a new pattern, scrapped
everything, tried again, had my measurements taken by a dressmaker
[#dressmaker], put them in the draft, cut a first mock-up in cheap
cotton, fixed the position of a seam, did a second mock-up in denim
[#jeans] from an old pair of jeans, and then cut into the cheap
herringbone coutil I was planning to use.
And that s when I went to see which one of the busks in my stash would
work, and realized that I had used a wrong vertical measurement and the
front of the corset was way too long for a midbust corset.
Luckily I also had a few longer busks, I basted one to the denim mock up
and tried to wear it for a few hours, to see if it was too long to be
comfortable. It was just a bit, on the bottom, which could be easily
fixed with the Power Tools1.
Except, the more I looked at it the more doing this felt wrong: what I
needed most was a midbust corset, not an overbust one, which is what
this was starting to be.
I could have trimmed it down, but I knew that I also wanted this corset
to be a wearable mockup for the pattern, to refine it and have it
available for more corsets. And I still had more than half of the cheap
coutil I was using, so I decided to redo the pattern and cut new panels.
And this is where the or two comes in: I m not going to waste the
overbust panels: I had been wanting to learn some techniques to make
corsets with a fashion fabric layer, rather than just a single layer of
coutil, and this looks like an excellent opportunity for that, together
with a piece of purple silk that I know I have in the stash. This will
happen later, however, first I m giving priority to the underbust.
Anyway, a second set of panels was cut, all the seam lines marked with
tailor tacks, and I started sewing by inserting the busk.
And then realized that the pre-made boning channel tape I had was too
narrow for the 10 mm spiral steel I had plenty of. And that the 25 mm
twill tape was also too narrow for a double boning channel.
On the other hand, the 18 mm twill tape I had used for the waist tape
was good for a single channel, so I decided to put a single bone on each
seam, and then add another piece of boning in the middle of each panel.
Since I m making external channels, making them in self fabric would
have probably looked better, but I no longer had enough fabric, because
of the cutting mishap, and anyway this is going to be a strictly
underwear only corset, so it s not a big deal.
Once the boning channel situation was taken care of, everything else
proceeded quite smoothly and I was able to finish the corset during the
Christmas break, enlisting again my SO to take care of the flat steel
boning while I cut the spiral steels myself with wire cutters.
I could have been a bit more precise with the binding, as it doesn t
align precisely at the front edge, but then again, it s underwear,
nobody other than me and everybody who reads this post is going to see
it and I was in a hurry to see it finished. I will be more careful with
the next one.
I also think that I haven t been careful enough when pressing the seams
and applying the tape, and I ve lost about a cm of width per part, so
I m using a lacing gap that is a bit wider than I planned for, but that
may change as the corset gets worn, and is still within tolerance.
Also, on the morning after I had finished the corset I woke up and
realized that I had forgotten to add garter tabs at the bottom edge.
I don t know whether I will ever use them, but I wanted the option, so
maybe I ll try to add them later on, especially if I can do it without
undoing the binding.
The next step would have been flossing, which I proceeded to postpone
until I ve worn the corset for a while: not because there is any reason
for it, but because I still don t know how I want to do it :)
What was left was finishing and uploading the pattern and instructions,
that are now on my sewing pattern website
as #FreeSoftWear, and finally I could post this on the blog.
i.e. by asking my SO to cut and sand it, because I m lazy
and I hate doing that part :D
At the end of the last part of this,
we got a Home Assistant OS installation that contains in itself a Firefly III instance and that
contains all the current financial information. They are communicating and calculating predictions
for me.
The only part that I was not 100% happy with was accounting of cash transactions. You see payments
in cash are mostly made away from computer and sometimes even in areas without a mobile Internet
connection. And all Firefly III apps that I tried failed at the task of creating a new transaction
when offline. Even the one recommended Telegram bot from Firefly III page used a dialog-based
approach for creating even a simplest transaction. Issue asking for a one-shot transaction creation
option stands as unresolved.
Theoretically it would have been best if I could simply contribute that feature to that particular
Telegram bot ... but it's written in Javascript. By mapping the API onto tasks somehow. After about
4 hours I still could not figure out where in the code anything actually happens. It all looked like
just sugar or spagetty. Connectors on connectors on mappers.
So I did the real open-source thing and just wrote my own tool.
firefly3_telegram_oneshot is a maximally simple
Telegram bot based on python-telegram-bot library.
So what does it do? The primary usage for me is to simply send a message to the bot at any time with
text like "23.2 coffee and cake" and when the message eventually reaches the bot, it then should
create a new transaction from my "cash" account to "Unknown" account in amount of 23.20 and
description "coffee and cake".
That is the key. Everything else in the bot is comfort.
For example "/undo" command deletes the last transaction in cash account (presumably added by error)
and "/last" shows which transaction the "/undo" would delete.
And to help with expense categorisation one can also do a message like "6.1 beer, dest=Edeka, cat=alcohol"
that would search for a destination account that would fuzzy match to "Edeka" (a supermarket in Germany)
and add the transation to the category fuzzy matched to "alcohol", like "Shopping - alcoholic drinks".
And to make that fuzzy matching more reliable I also added "/cat something" and "/dest something" commands
that would show which category or destination account would be matched with a given string.
All of that in around 250 lines of Python code and executed by a 17 line Dockerfile (via the Portainer
on my Home Assistant OS). One remaining function that could be nice is creating a category or destination
account on request (for example when the first character of the supplied string is "+").
I am really plesantly surprised about how much can be done with how little code using the above Python
library. And you never need to have any open incoming ports anywhere to runs such bots, so the attack
surface for such bot-based service is much tighter.
All in all the system works and works well. The only exception is that for my particual bank there is
still no automatic way of extracting data about credit card transactions. For those I still have to manually
log into the Internet bank, export a CSV file and then feed that into the Firefly III importer. Annoying.
And I am not really motivated to try to hack my bank :D
Has this been useful to any of you? Any ideas to expand or improve what I have? Just find me as "aigarius" on
any social media and speak up :)
I needed to migrate an existing system to an Hetzner cloud VPS. While it is
possible to attach KVM consoles and custom ISO images to dedicated servers, i
didn t find any way to do so with regular cloud instances.
For system migrations i usually use REAR,
which has never failed me. (and also has saved my ass during recovery multiple
times). It s an awesome utility!
It s possible to do this using the Hetzner recovery console too, but using REAR
is very convenient here, because it handles things like re-creating the
partition layout and network settings automatically!
The steps are:
Create bootable REAR rescue image on the source system.
Register a target system in Hetzner Cloud with at least the same disk size as the source system.
Boot the REAR image s initrd and kernel from the running VPS system using kexec
Make the REAR recovery console accessible via SSH (or use Hetzners console).
Let REAR do its magic and re-partition the system.
Restore the system data to the freshly partitioned disks
Let REAR handle the bootloader and network re-configuration.
Example
To create a rescue image on the source system:
apt install rear
echo OUTPUT=ISO > /etc/rear/local.conf
rear mkrescue -v[..]
Wrote ISO image: /var/lib/rear/output/rear-debian12.iso (185M)
My source system had a 128 GB disk, so i registered an instance on Hetzner
cloud with greater disk size to make things easier:
Now copy the ISO image to the newly created instance and extract
its data:
Note down the current gateway configuration, this is required later
on to make the REAR recovery console reachable via SSH:
root@testme:~# ip route
default via 172.31.1.1 dev eth0
172.31.1.1 dev eth0 scope link
Reboot the running VPS instance into the REAR recovery image using somewhat
the same kernel cmdline:
root@testme:~# cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-6.1.0-13-amd64 root=UUID=5174a81e-5897-47ca-8fe4-9cd19dc678c4 ro consoleblank=0 systemd.show_status=true console=tty1 console=ttyS0
kexec --initrd /tmp/initrd.cgz --command-line="consoleblank=0 systemd.show_status=true console=tty1 console=ttyS0" /tmp/kernel
Connection to 49.13.193.226 closed by remote host.
Connection to 49.13.193.226 closed
Now watch the system on the Console booting into the REAR system:
Login the recovery console (root without password) and fix its default route to
make it reachable:
ip addr
[..]
2: enp1s0
..
$ ip route add 172.31.1.1 dev enp1s0
$ ip route add default via 172.31.1.1
ping 49.13.193.226
64 bytes from 49.13.193.226: icmp_seq=83 ttl=52 time=27.7 ms
The network configuration might differ, the source system in this example used
DHCP, as the target does. If REAR detects changed static network configuration
it guides you through the setup pretty nicely.
Login via SSH (REAR will store your ssh public keys in the image) and start the
recovery process, follow the steps as suggested by REAR:
ssh -l root 49.13.193.226
Welcome to Relax-and-Recover. Run "rear recover" to restore your system !
RESCUE debian12:~ # rear recover
Relax-and-Recover 2.7 / Git
Running rear recover (PID 673 date 2024-01-04 19:20:22)
Using log file: /var/log/rear/rear-debian12.log
Running workflow recover within the ReaR rescue/recovery system
Will do driver migration (recreating initramfs/initrd)
Comparing disks
Device vda does not exist (manual configuration needed)
Switching to manual disk layout configuration (GiB sizes rounded down to integer)
/dev/vda had size 137438953472 (128 GiB) but it does no longer exist
/dev/sda was not used on the original system and has now 163842097152 (152 GiB)
Original disk /dev/vda does not exist (with same size)in the target system
Using /dev/sda (the only available of the disks)for recreating /dev/vda
Current disk mapping table (source=> target):
/dev/vda => /dev/sda
Confirm or edit the disk mapping
1) Confirm disk mapping and continue'rear recover'[..]
User confirmed recreated disk layout
[..]
This step re-recreates your original disk layout and mounts it to /mnt/local/
(this example uses a pretty lame layout, but usually REAR will handle things
like lvm/btrfs just nicely):
mount
/dev/sda3 on /mnt/local type ext4 (rw,relatime,errors=remount-ro)
/dev/sda1 on /mnt/local/boot type ext4 (rw,relatime)
Now clone your source systems data to /mnt/local/ with whatever utility you
like to use and exit the recovery step. After confirming everything went well,
REAR will setup the bootloader (and all other config details like fstab entries
and adjusted network configuration) for you as required:
rear> exit
Did you restore the backup to /mnt/local ? Are you ready to continue recovery ? yes
User confirmed restored files
Updated initramfs with new drivers for this system.
Skip installing GRUB Legacy boot loader because GRUB 2 is installed (grub-probe or grub2-probe exist).
Installing GRUB2 boot loader...
Determining where to install GRUB2 (no GRUB2_INSTALL_DEVICES specified)
Found possible boot disk /dev/sda - installing GRUB2 there
Finished 'recover'. The target system is mounted at '/mnt/local'.
Exiting rear recover (PID 7103) and its descendant processes ...
Running exit tasks
Now reboot the recovery console and watch it boot into your target
systems configuration:
Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
I ve been getting annoyed with Raspberry Pi OS (Raspbian) for years now. It s a fork of Debian, but manages to omit some of the most useful things. So I ve decided to migrate all of my Pis to run pure Debian. These are my reasons:
Raspberry Pi OS has, for years now, specified that there is no upgrade path. That is, to get to a newer major release, it s a reinstall. While I have sometimes worked around this, for a device that is frequently installed in hard-to-reach locations, this is even more important than usual. It s common for me to upgrade machines for a decade or more across Debian releases and there s no reason that it should be so much more difficult with Raspbian.
As I noted in Consider Security First, the security situation for Raspberry Pi OS isn t as good as it is with Debian.
Raspbian lags behind Debian often times by 6 months or more for major releases, and days or weeks for bug fixes and security patches.
Raspbian uses a custom kernel without initramfs support
It turns out it is actually possible to do an in-place migration from Raspberry Pi OS bullseye to Debian bookworm. Here I will describe how. Even if you don t have a Raspberry Pi, this might still be instructive on how Raspbian and Debian packages work.
WARNINGS
Before continuing, back up your system. This process isn t for the neophyte and it is entirely possible to mess up your boot device to the point that you have to do a fresh install to get your Pi to boot. This isn t a supported process at all.
Architecture Confusion
Debian has three ARM-based architectures:
armel, for the lowest-end 32-bit ARM devices without hardware floating point support
armhf, for the higher-end 32-bit ARM devices with hardware float (hence hf )
arm64, for 64-bit ARM devices (which all have hardware float)
Although the Raspberry Pi 0 and 1 do support hardware float, they lack support for other CPU features that Debian s armhf architecture assumes. Therefore, the Raspberry Pi 0 and 1 could only run Debian s armel architecture.
Raspberry Pi 3 and above are capable of running 64-bit, and can run both armhf and arm64.
Prior to the release of the Raspberry Pi 5 / Raspbian bookworm, Raspbian only shipped the armhf architecture. Well, it was an architecture they called armhf, but it was different from Debian s armhf in that everything was recompiled to work with the more limited set of features on the earlier Raspberry Pi boards. It was really somewhere between Debian s armel and armhf archs. You could run Debian armel on those, but it would run more slowly, due to doing floating point calculations without hardware support. Debian s raspi FAQ goes into this a bit.
What I am going to describe here is going from Raspbian armhf to Debian armhf with a 64-bit kernel. Therefore, it will only work with Raspberry Pi 3 and above. It may theoretically be possible to take a Raspberry Pi 2 to Debian armhf with a 32-bit kernel, but I haven t tried this and it may be more difficult. I have seen conflicting information on whether armhf really works on a Pi 2. (If you do try it on a Pi 2, ignore everything about arm64 and 64-bit kernels below, and just go with the linux-image-armmp-lpae kernel per the ARMMP page)
There is another wrinkle: Debian doesn t support running 32-bit ARM kernels on 64-bit ARM CPUs, though it does support running a 32-bit userland on them. So we will wind up with a system with kernel packages from arm64 and everything else from armhf. This is a perfectly valid configuration as the arm64 like x86_64 is multiarch (that is, the CPU can natively execute both the 32-bit and 64-bit instructions).
(It is theoretically possible to crossgrade a system from 32-bit to 64-bit userland, but that felt like a rather heavy lift for dubious benefit on a Pi; nevertheless, if you want to make this process even more complicated, refer to the CrossGrading page.)
Prerequisites and Limitations
In addition to the need for a Raspberry Pi 3 or above in order for this to work, there are a few other things to mention.
If you are using the GPIO features of the Pi, I don t know if those work with Debian.
I think Raspberry Pi OS modified the desktop environment more than other components. All of my Pis are headless, so I don t know if this process will work if you use a desktop environment.
I am assuming you are booting from a MicroSD card as is typical in the Raspberry Pi world. The Pi s firmware looks for a FAT partition (MBR type 0x0c) and looks within it for boot information. Depending on how long ago you first installed an OS on your Pi, your /boot may be too small for Debian. Use df -h /boot to see how big it is. I recommend 200MB at minimum. If your /boot is smaller than that, stop now (or use some other system to shrink your root filesystem and rearrange your partitions; I ve done this, but it s outside the scope of this article.)
You need to have stable power. Once you begin this process, your pi will mostly be left in a non-bootable state until you finish. (You did make a backup, right?)
Basic idea
The basic idea here is that since bookworm has almost entirely newer packages then bullseye, we can just switch over to it and let the Debian packages replace the Raspbian ones as they are upgraded. Well, it s not quite that easy, but that s the main idea.
Preparation
First, make a backup. Even an image of your MicroSD card might be nice. OK, I think I ve said that enough now.
It would be a good idea to have a HDMI cable (with the appropriate size of connector for your particular Pi board) and a HDMI display handy so you can troubleshoot any bootup issues with a console.
Preparation: access
The Raspberry Pi OS by default sets up a user named pi that can use sudo to gain root without a password. I think this is an insecure practice, but assuming you haven t changed it, you will need to ensure it still works once you move to Debian. Raspberry Pi OS had a patch in their sudo package to enable it, and that will be removed when Debian s sudo package is installed. So, put this in /etc/sudoers.d/010_picompat:
pi ALL=(ALL) NOPASSWD: ALL
Also, there may be no password set for the root account. It would be a good idea to set one; it makes it easier to log in at the console. Use the passwd command as root to do so.
Preparation: bluetooth
Debian doesn t correctly identify the Bluetooth hardware address. You can save it off to a file by running hcitool dev > /root/bluetooth-from-raspbian.txt. I don t use Bluetooth, but this should let you develop a script to bring it up properly.
Package first steps
From here on, we are making modifications to the system that can leave it in a non-bootable state.
Examine /etc/apt/sources.list and all the files in /etc/apt/sources.list.d. Most likely you will want to delete or comment out all lines in all files there. Replace them with something like:
deb http://deb.debian.org/debian/ bookworm main non-free-firmware contrib non-free
deb http://security.debian.org/debian-security bookworm-security main non-free-firmware contrib non-free
deb https://deb.debian.org/debian bookworm-backports main non-free-firmware contrib non-free
(you might leave off contrib and non-free depending on your needs)
Now, we re going to tell it that we ll support arm64 packages:
dpkg --add-architecture arm64
And finally, download the bookworm package lists:
apt-get update
If there are any errors from that command, fix them and don t proceed until you have a clean run of apt-get update.
Moving /boot to /boot/firmware
The boot FAT partition I mentioned above is mounted at /boot by Raspberry Pi OS, but Debian s scripts assume it will be at /boot/firmware. We need to fix this. First:
umount /boot
mkdir /boot/firmware
Now, edit fstab and change the reference to /boot to be to /boot/firmware. Now:
mount -v /boot/firmware
cd /boot/firmware
mv -vi * ..
This mounts the filesystem at the new location, and moves all its contents back to where apt believes it should be. Debian s packages will populate /boot/firmware later.
Installing the first packages
Now we start by installing the first of the needed packages. Eventually we will wind up with roughly the same set Debian uses.
If you get errors relating to firmware-brcm80211 from any commands, run that install firmware-brcm80211 command and then proceed. There are a few packages that Raspbian marked as newer than the version in bookworm (whether or not they really are), and that s one of them.
Configuring the bootloader
We need to configure a few things in /etc/default/raspi-firmware before proceeding. Edit that file.
First, uncomment (or add) a line like this:
KERNEL_ARCH="arm64"
Next, in /boot/cmdline.txt you can find your old Raspbian boot command line. It will say something like:
root=PARTUUID=...
Save off the bit starting with PARTUUID. Back in /etc/default/raspi-firmware, set a line like this:
ROOTPART=PARTUUID=abcdef00
(substituting your real value for abcdef00).
This is necessary because the microSD card device name often changes from /dev/mmcblk0 to /dev/mmcblk1 when switching to Debian s kernel. raspi-firmware will encode the current device name in /boot/firmware/cmdline.txt by default, which will be wrong once you boot into Debian s kernel. The PARTUUID approach lets it work regardless of the device name.
Resolving firmware package version issues
If it gives an error about the installed version of a package, you may need to force it to the bookworm version. For me, this often happened with firmware-atheros, firmware-libertas, and firmware-realtek.
Here s how to resolve it, with firmware-realtek as an example:
apt list '?narrow(?installed, ?not(?origin(Debian)))'
Deal with them; mostly you will need to force the installation of a bookworm version using the procedure in the section Resolving firmware package version issues above (even if it s not for a firmware package). For non-firmware packages, you might possibly want to add --mark-auto to your apt-get install command line to allow the package to be autoremoved later if the things depending on it go away.
If you aren t going to use Bluetooth, I recommend apt-get --purge remove bluez as well. Sometimes it can hang at boot if you don t fix it up as described above.
Set up networking
We ll be switching to the Debian method of networking, so we ll create some files in /etc/network/interfaces.d. First, eth0 should look like this:
allow-hotplug eth0
iface eth0 inet dhcp
iface eth0 inet6 auto
Raspbian is inconsistent about using eth0/wlan0 or renamed interface. Run ifconfig or ip addr. If you see a long-named interface such as enx<something> or wlp<something>, copy the eth0 file to the one named after the enx interface, or the wlan0 file to the one named after the wlp interface, and edit the internal references to eth0/wlan0 in this new file to name the long interface name.
If using wifi, verify that your SSIDs and passwords are in /etc/wpa_supplicant/wpa_supplicant.conf. It should have lines like:
network=
ssid="NetworkName"
psk="passwordHere"
(This is where Raspberry Pi OS put them).
Deal with DHCP
Raspberry Pi OS used dhcpcd, whereas bookworm normally uses isc-dhcp-client. Verify the system is in the correct state:
Set up LEDs
To set up the LEDs to trigger on MicroSD activity as they did with Raspbian, follow the Debian instructions. Run apt-get install sysfsutils. Then put this in a file at /etc/sysfs.d/local-raspi-leds.conf:
Prepare for boot
To make sure all the /boot/firmware files are updated, run update-initramfs -u. Verify that root in /boot/firmware/cmdline.txt references the PARTUUID as appropriate. Verify that /boot/firmware/config.txt contains the lines arm_64bit=1 and upstream_kernel=1. If not, go back to the section on modifying /etc/default/raspi-firmware and fix it up.
The moment arrives
Cross your fingers and try rebooting into your Debian system:
reboot
For some reason, I found that the first boot into Debian seems to hang for 30-60 seconds during bootstrap. I m not sure why; don t panic if that happens. It may be necessary to power cycle the Pi for this boot.
Troubleshooting
If things don t work out, hook up the Pi to a HDMI display and see what s up. If I anticipated a particular problem, I would have documented it here (a lot of the things I documented here are because I ran into them!) So I can t give specific advice other than to watch boot messages on the console. If you don t even get kernel messages going, then there is some problem with your partition table or /boot/firmware FAT partition. Otherwise, you ve at least got the kernel going and can troubleshoot like usual from there.
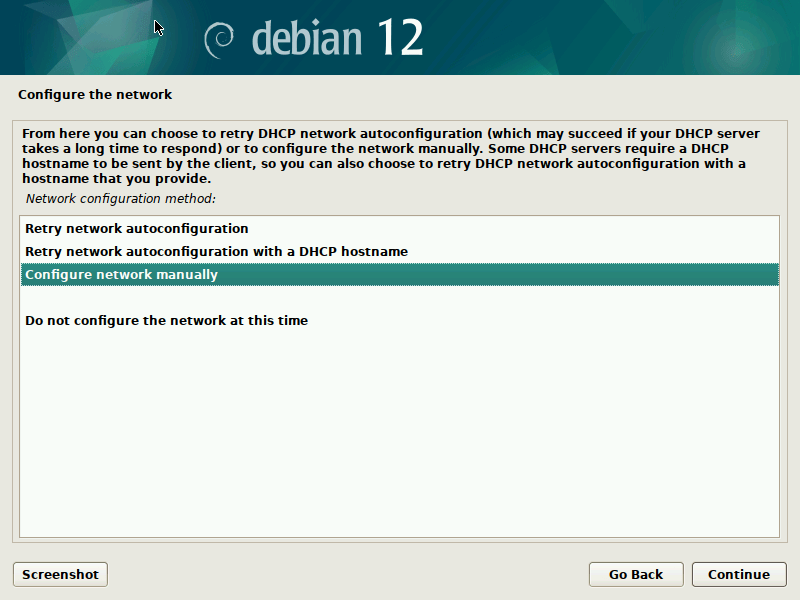
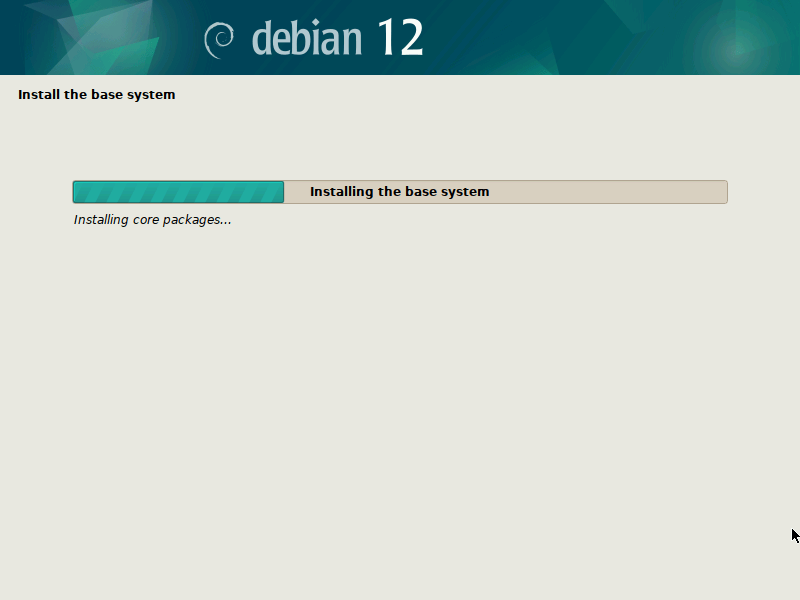
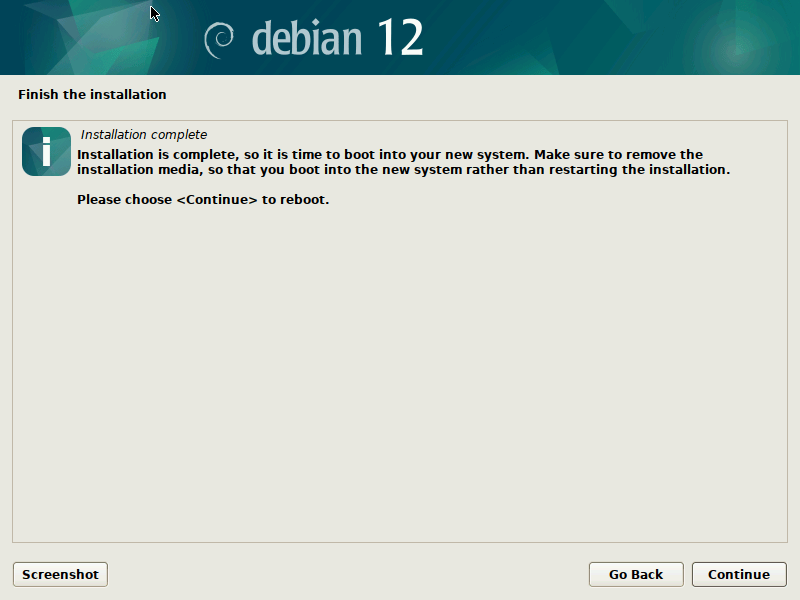
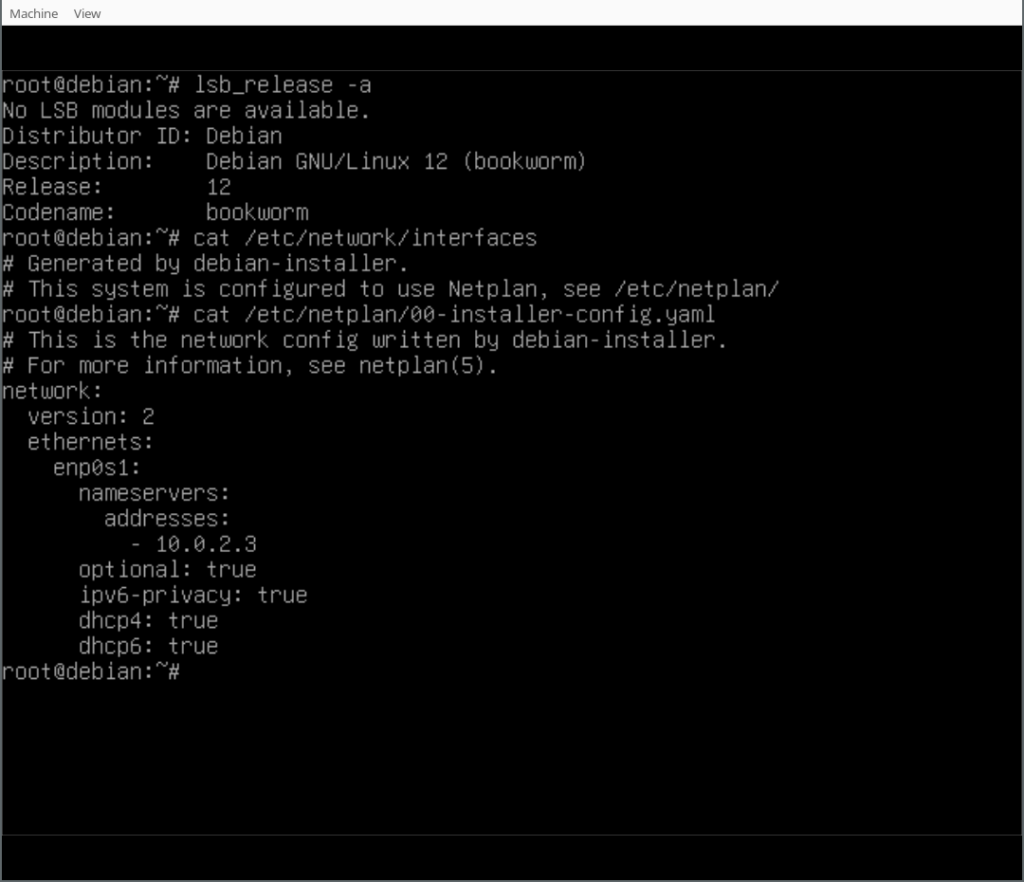
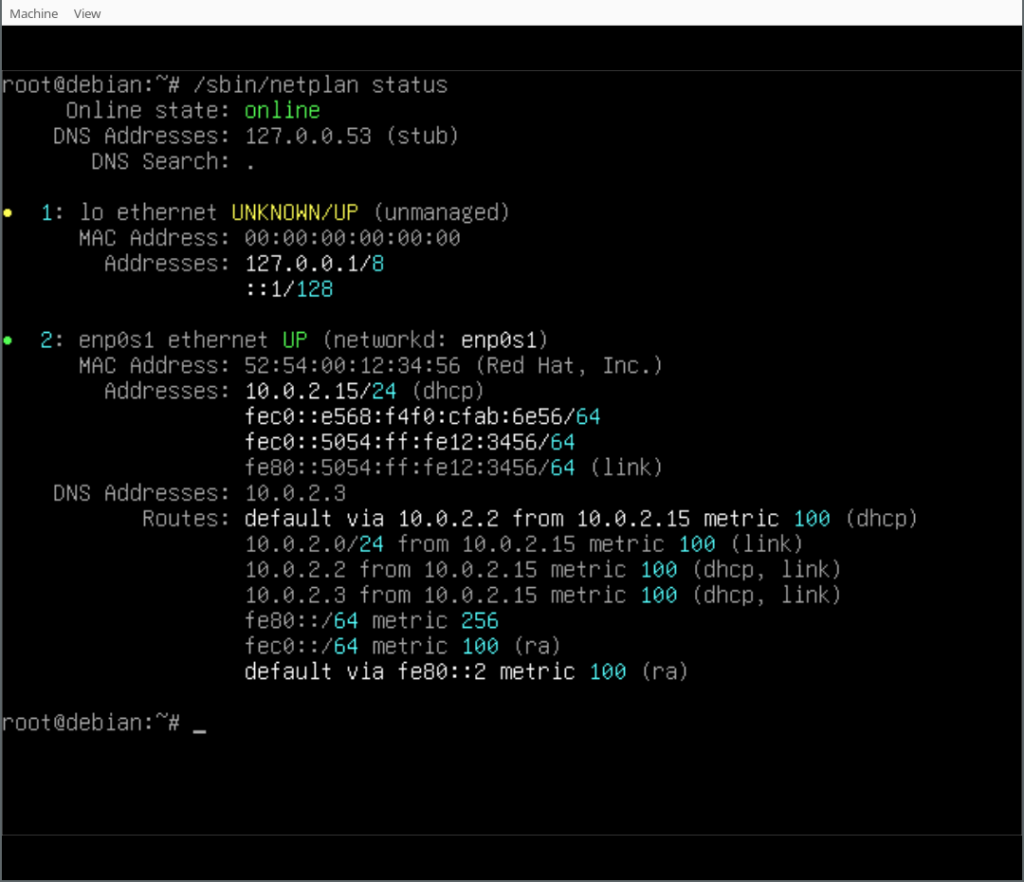
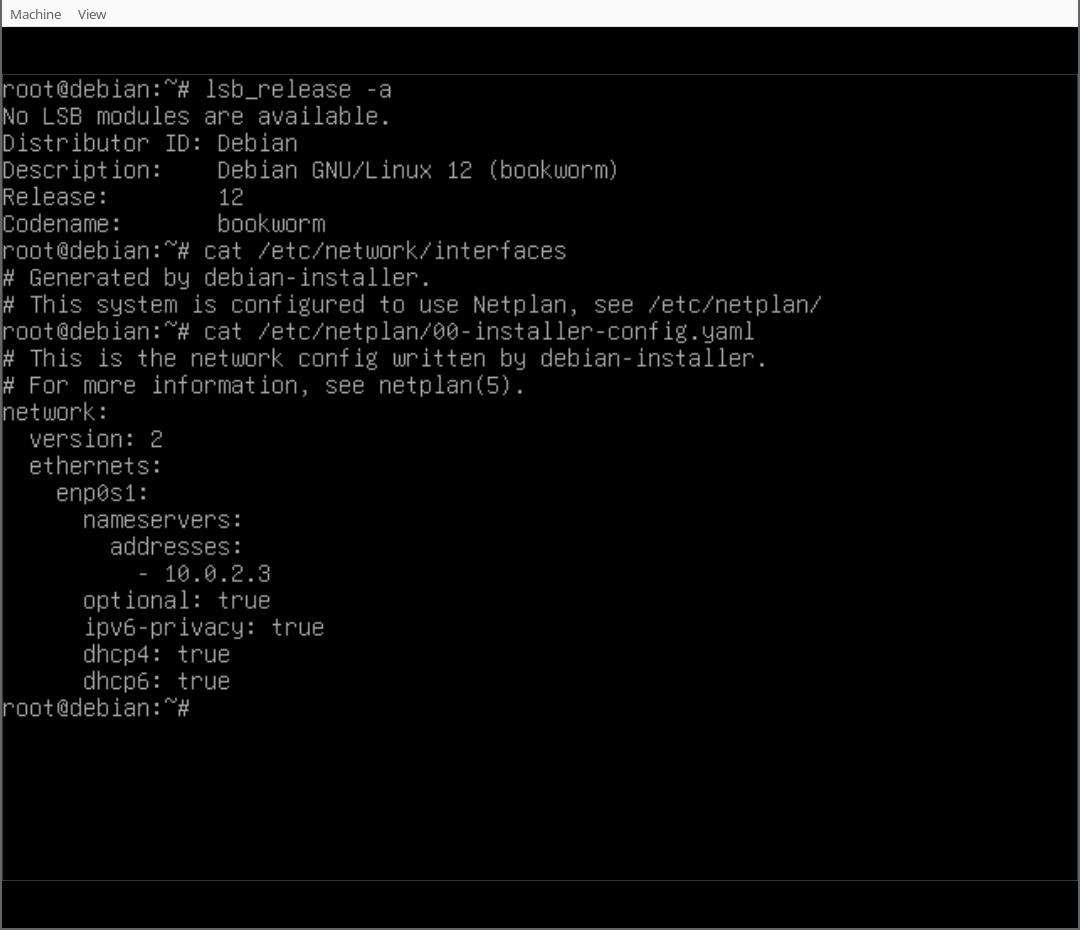
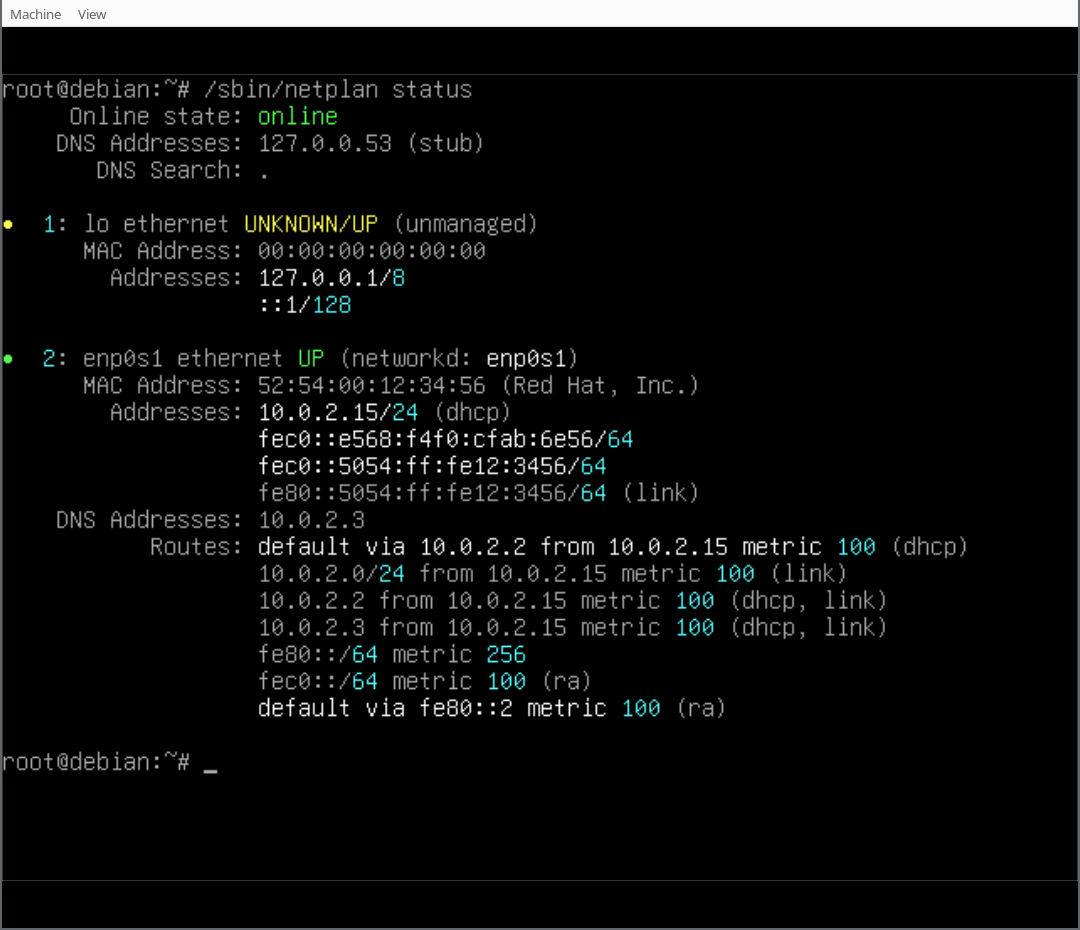
 I am upstream and
I am upstream and 























 I was working on what looked like a good pattern for a pair of
jeans-shaped trousers, and I knew I wasn t happy with 200-ish g/m
cotton-linen for general use outside of deep summer, but I didn t have a
source for proper denim either (I had been low-key looking for it for a
long time).
Then one day I looked at an article I had saved about fabric shops that
sell technical fabric and while window-shopping on one I found that they
had a decent selection of denim in a decent weight.
I decided it was a sign, and decided to buy the two heaviest denim they
had: a
I was working on what looked like a good pattern for a pair of
jeans-shaped trousers, and I knew I wasn t happy with 200-ish g/m
cotton-linen for general use outside of deep summer, but I didn t have a
source for proper denim either (I had been low-key looking for it for a
long time).
Then one day I looked at an article I had saved about fabric shops that
sell technical fabric and while window-shopping on one I found that they
had a decent selection of denim in a decent weight.
I decided it was a sign, and decided to buy the two heaviest denim they
had: a  The shop sent everything very quickly, the courier took their time (oh,
well) but eventually delivered my fabric on a sunny enough day that I
could wash it and start as soon as possible on the first pair.
The pattern I did in linen was a bit too fitting, but I was afraid I had
widened it a bit too much, so I did the first pair in the 100% cotton
denim. Sewing them took me about a week of early mornings and late
afternoons, excluding the weekend, and my worries proved false: they
were mostly just fine.
The only bit that could have been a bit better is the waistband, which
is a tiny bit too wide on the back: it s designed to be so for comfort,
but the next time I should pull the elastic a bit more, so that it stays
closer to the body.
The shop sent everything very quickly, the courier took their time (oh,
well) but eventually delivered my fabric on a sunny enough day that I
could wash it and start as soon as possible on the first pair.
The pattern I did in linen was a bit too fitting, but I was afraid I had
widened it a bit too much, so I did the first pair in the 100% cotton
denim. Sewing them took me about a week of early mornings and late
afternoons, excluding the weekend, and my worries proved false: they
were mostly just fine.
The only bit that could have been a bit better is the waistband, which
is a tiny bit too wide on the back: it s designed to be so for comfort,
but the next time I should pull the elastic a bit more, so that it stays
closer to the body.
 I wore those jeans daily for the rest of the week, and confirmed that
they were indeed comfortable and the pattern was ok, so on the next
Monday I started to cut the elastic denim.
I decided to cut and sew two pairs, assembly-line style, using the
shaped waistband for one of them and the straight one for the other one.
I started working on them on a Monday, and on that week I had a couple
of days when I just couldn t, plus I completely skipped sewing on the
weekend, but on Tuesday the next week one pair was ready and could be
worn, and the other one only needed small finishes.
I wore those jeans daily for the rest of the week, and confirmed that
they were indeed comfortable and the pattern was ok, so on the next
Monday I started to cut the elastic denim.
I decided to cut and sew two pairs, assembly-line style, using the
shaped waistband for one of them and the straight one for the other one.
I started working on them on a Monday, and on that week I had a couple
of days when I just couldn t, plus I completely skipped sewing on the
weekend, but on Tuesday the next week one pair was ready and could be
worn, and the other one only needed small finishes.
 And I have to say, I m really, really happy with the ones with a shaped
waistband in elastic denim, as they fit even better than the ones with a
straight waistband gathered with elastic. Cutting it requires more
fabric, but I think it s definitely worth it.
But it will be a problem for a later time: right now three pairs of
jeans are a good number to keep in rotation, and I hope I won t have to
sew jeans for myself for quite some time.
And I have to say, I m really, really happy with the ones with a shaped
waistband in elastic denim, as they fit even better than the ones with a
straight waistband gathered with elastic. Cutting it requires more
fabric, but I think it s definitely worth it.
But it will be a problem for a later time: right now three pairs of
jeans are a good number to keep in rotation, and I hope I won t have to
sew jeans for myself for quite some time.
 I think that the leftovers of plain denim will be used for a skirt or
something else, and as for the leftovers of elastic denim, well, there
aren t a lot left, but what else I did with them is the topic for
another post.
Thanks to the fact that they are all slightly different, I ve started to
keep track of the times when I wash each pair, and hopefully I will be
able to see whether the elastic denim is significantly less durable than
the regular, or the added weight compensates for it somewhat. I m not
sure I ll manage to remember about saving the data until they get worn,
but if I do it will be interesting to know.
Oh, and I say I ve finished working on jeans and everything, but I still
haven t sewn the belt loops to the third pair. And I m currently wearing
them. It s a sewist tradition, or something. :D
I think that the leftovers of plain denim will be used for a skirt or
something else, and as for the leftovers of elastic denim, well, there
aren t a lot left, but what else I did with them is the topic for
another post.
Thanks to the fact that they are all slightly different, I ve started to
keep track of the times when I wash each pair, and hopefully I will be
able to see whether the elastic denim is significantly less durable than
the regular, or the added weight compensates for it somewhat. I m not
sure I ll manage to remember about saving the data until they get worn,
but if I do it will be interesting to know.
Oh, and I say I ve finished working on jeans and everything, but I still
haven t sewn the belt loops to the third pair. And I m currently wearing
them. It s a sewist tradition, or something. :D
 Just like the corset, I also needed a new pair of jeans.
Back when my body size changed drastically of course my jeans no longer
fit. While I was waiting for my size to stabilize I kept wearing them
with a somewhat tight belt, but it was ugly and somewhat uncomfortable.
When I had stopped changing a lot I tried to buy new ones in the same
model, and found out that I was too thin for the menswear jeans of that
shop. I could have gone back to wearing women s jeans, but I didn t want
to have to deal with the crappy fabric and short pockets, so I basically
spent a few years wearing mostly skirts, and oversized jeans when I
really needed trousers.
Meanwhile, I had drafted a
Just like the corset, I also needed a new pair of jeans.
Back when my body size changed drastically of course my jeans no longer
fit. While I was waiting for my size to stabilize I kept wearing them
with a somewhat tight belt, but it was ugly and somewhat uncomfortable.
When I had stopped changing a lot I tried to buy new ones in the same
model, and found out that I was too thin for the menswear jeans of that
shop. I could have gone back to wearing women s jeans, but I didn t want
to have to deal with the crappy fabric and short pockets, so I basically
spent a few years wearing mostly skirts, and oversized jeans when I
really needed trousers.
Meanwhile, I had drafted a  Making also went smoothly, and the result was fitting. Very fitting. A
big too fitting, and the standard bum adjustment of the back was just
enough for what apparently still qualifies as a big bum, so I adjusted
the pattern to be able to add a custom amount of ease in a few places.
But at least I had a pair of jeans-shaped trousers that fit!
Except, at 200 g/m I can t say that fabric is the proper weight for a
pair of trousers, and I may have looked around online
Making also went smoothly, and the result was fitting. Very fitting. A
big too fitting, and the standard bum adjustment of the back was just
enough for what apparently still qualifies as a big bum, so I adjusted
the pattern to be able to add a custom amount of ease in a few places.
But at least I had a pair of jeans-shaped trousers that fit!
Except, at 200 g/m I can t say that fabric is the proper weight for a
pair of trousers, and I may have looked around online









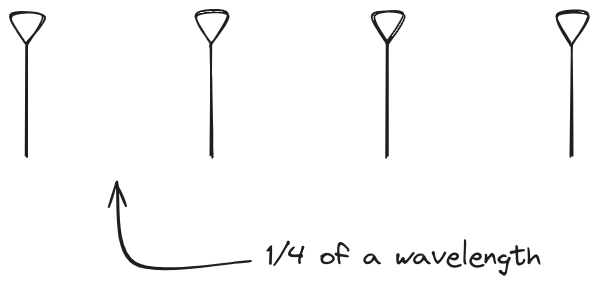 And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
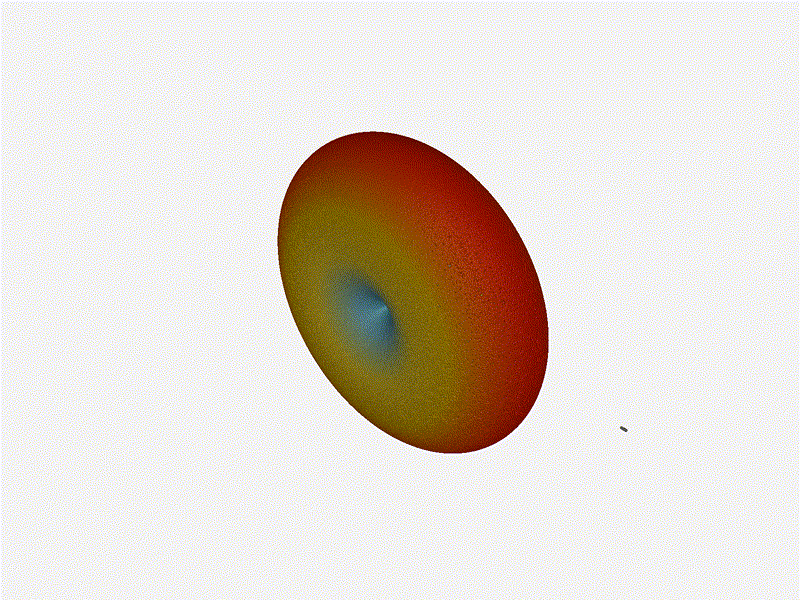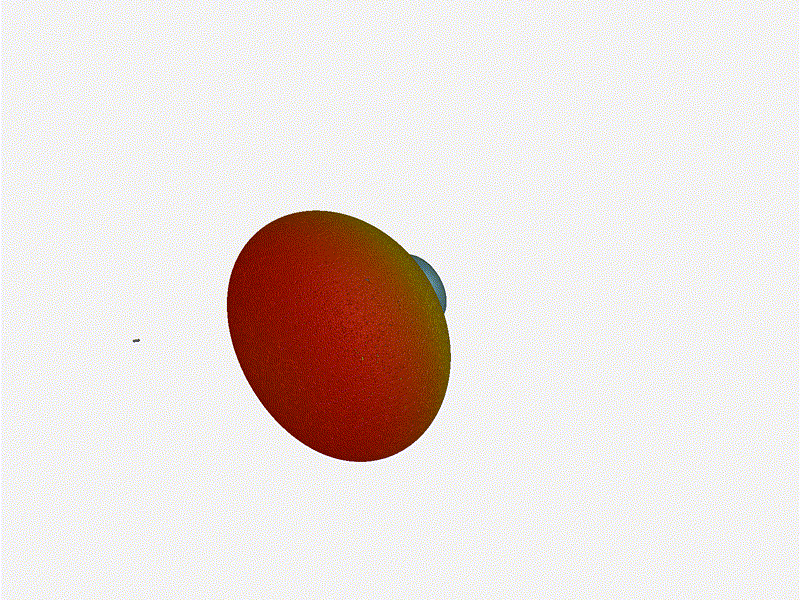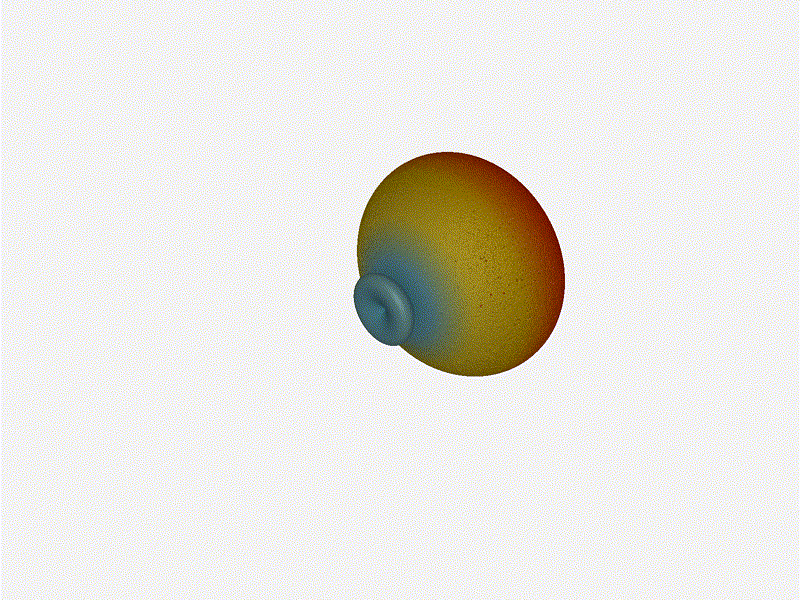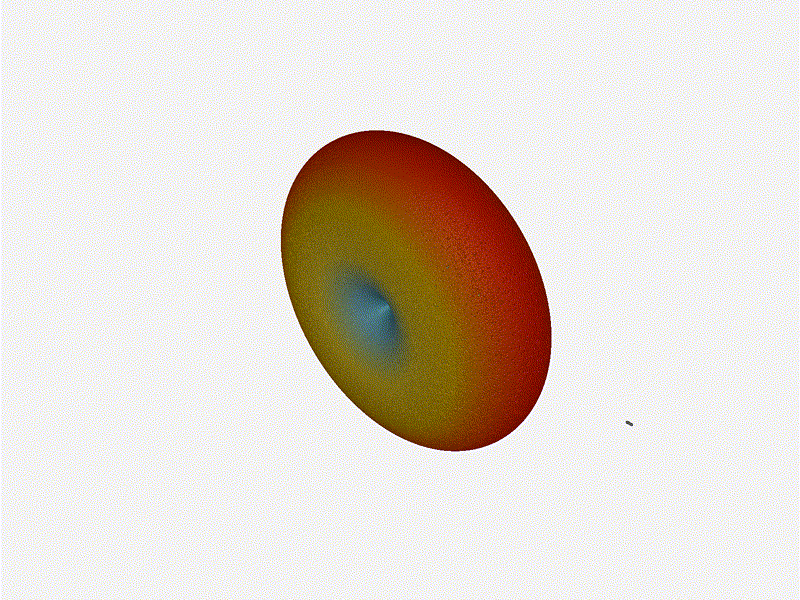
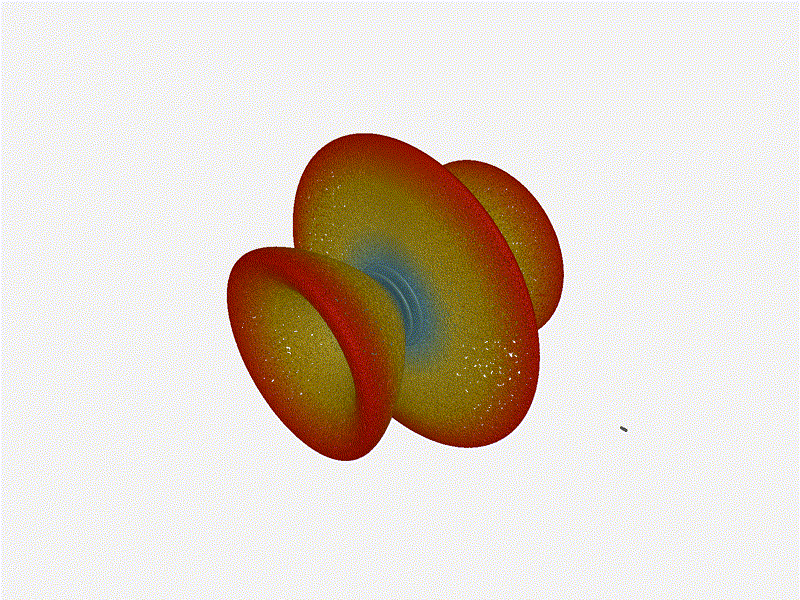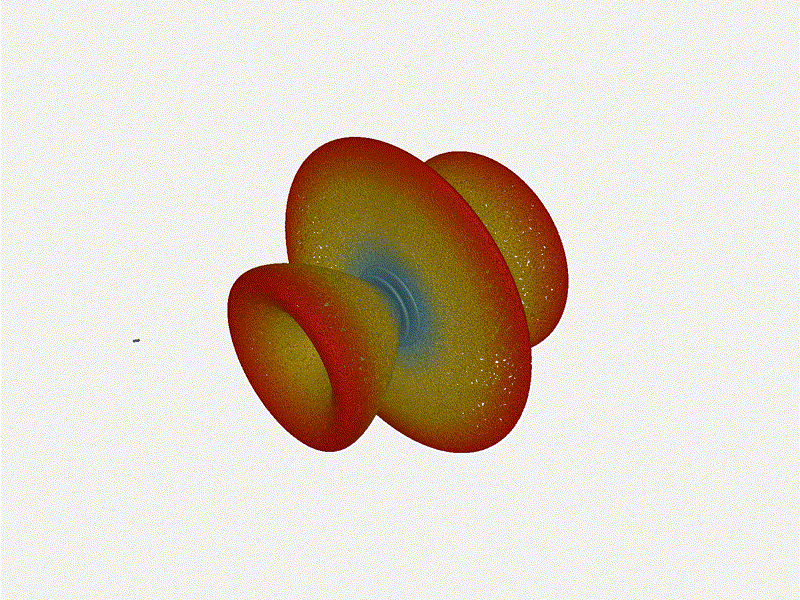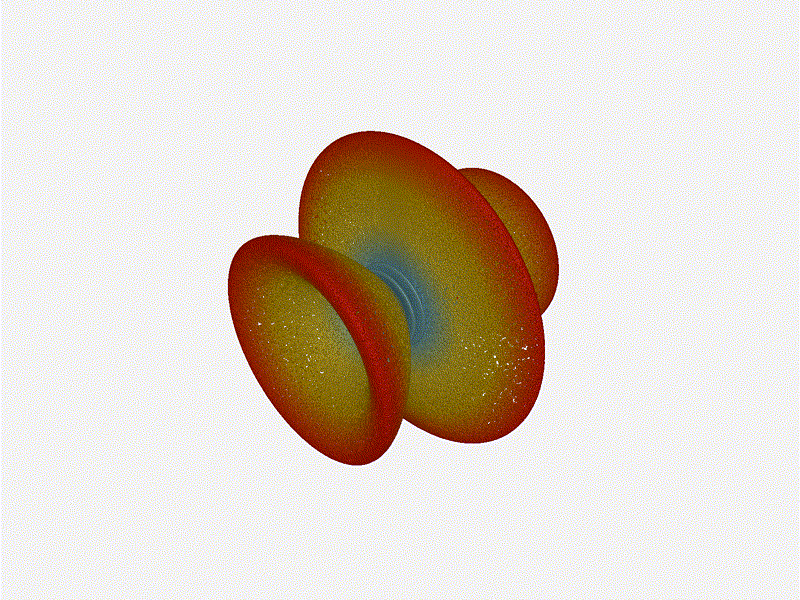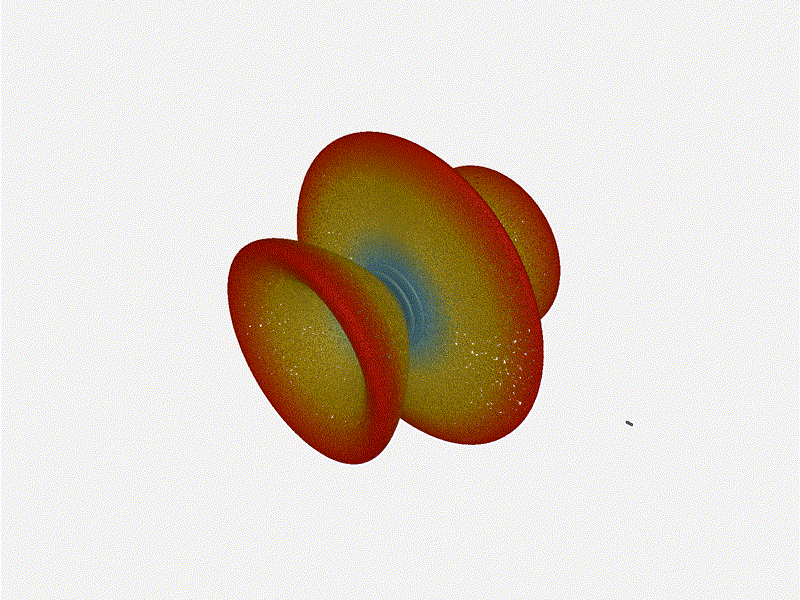

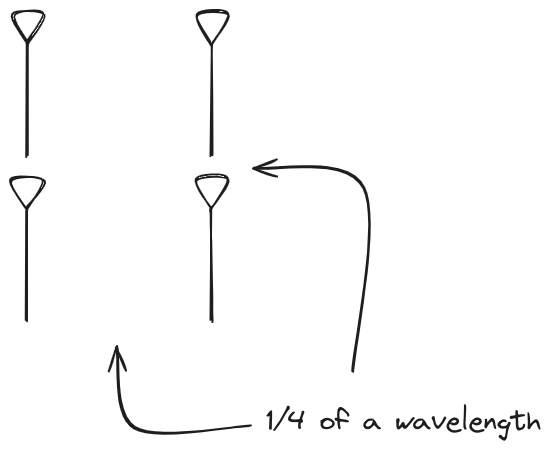 Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
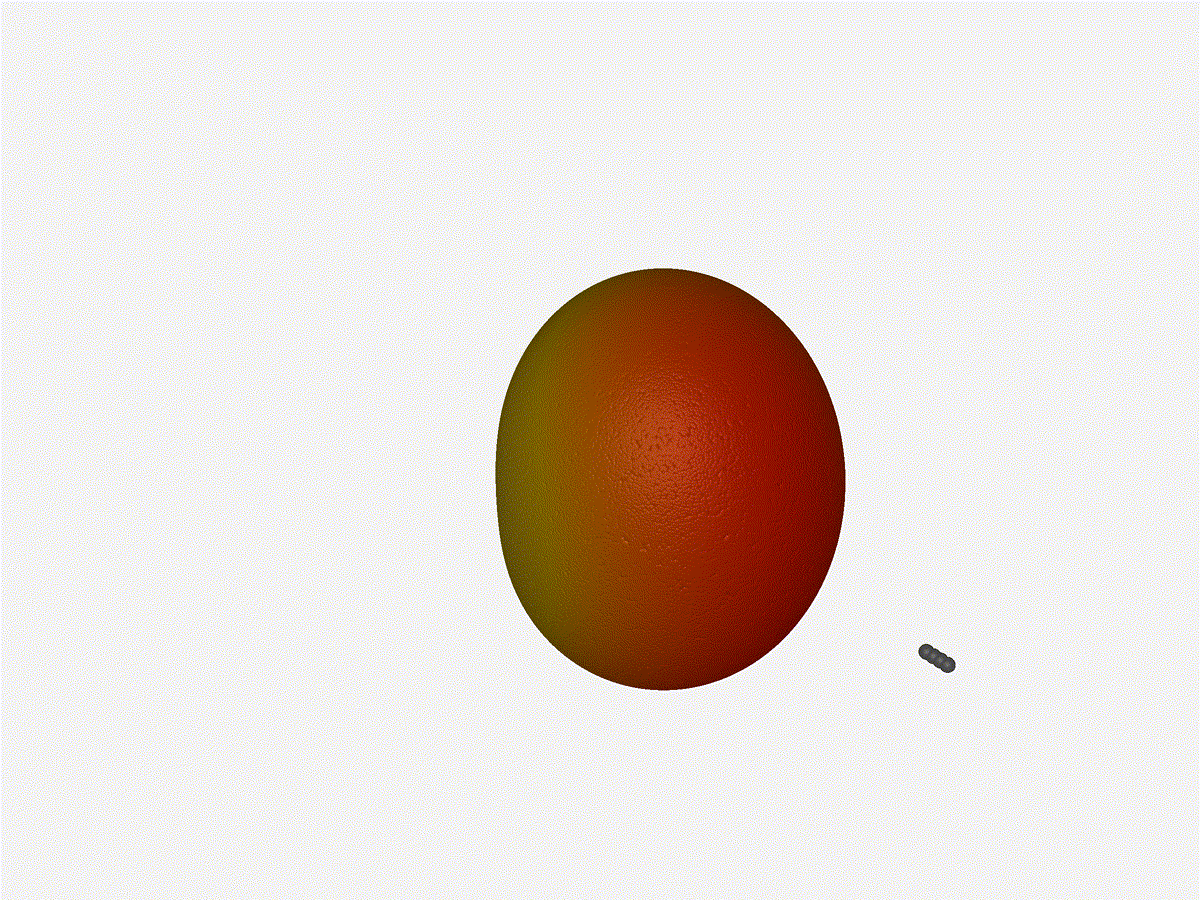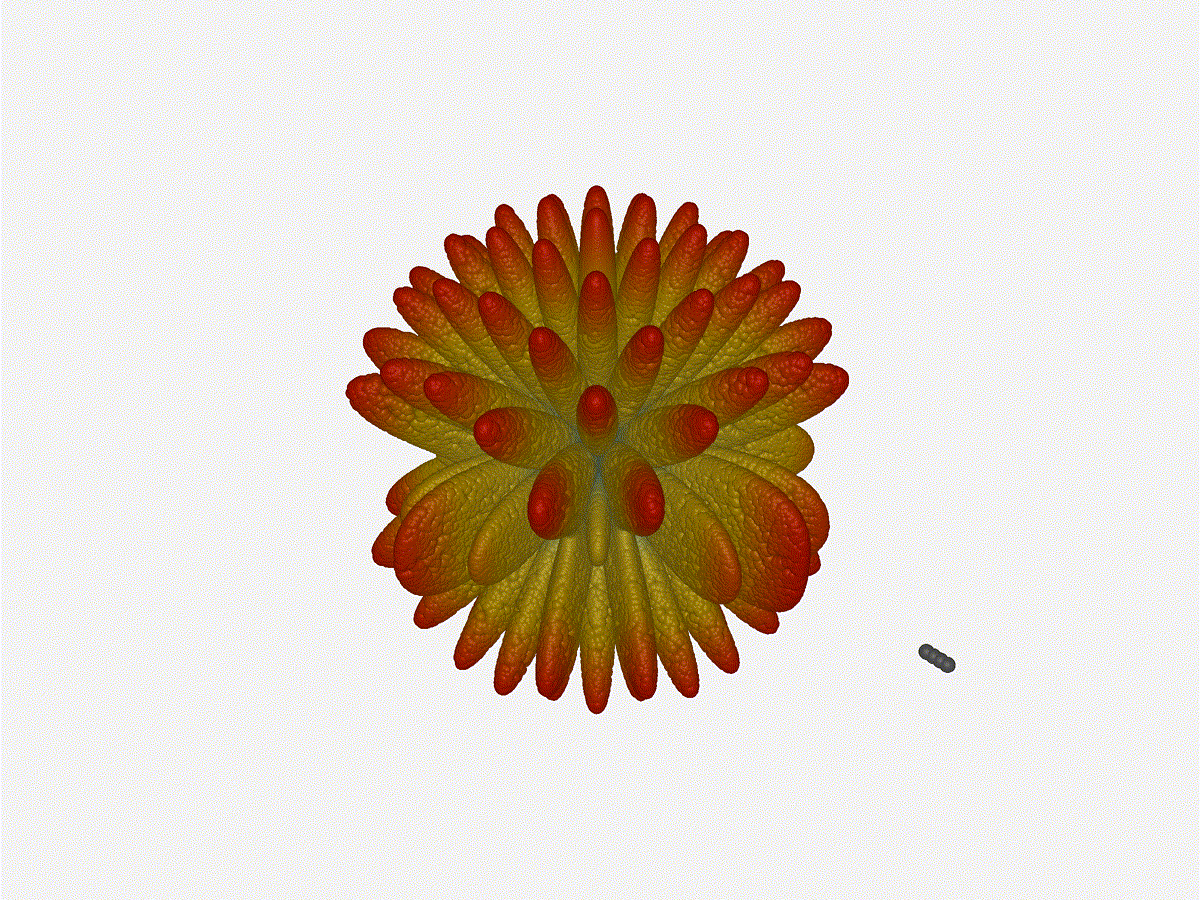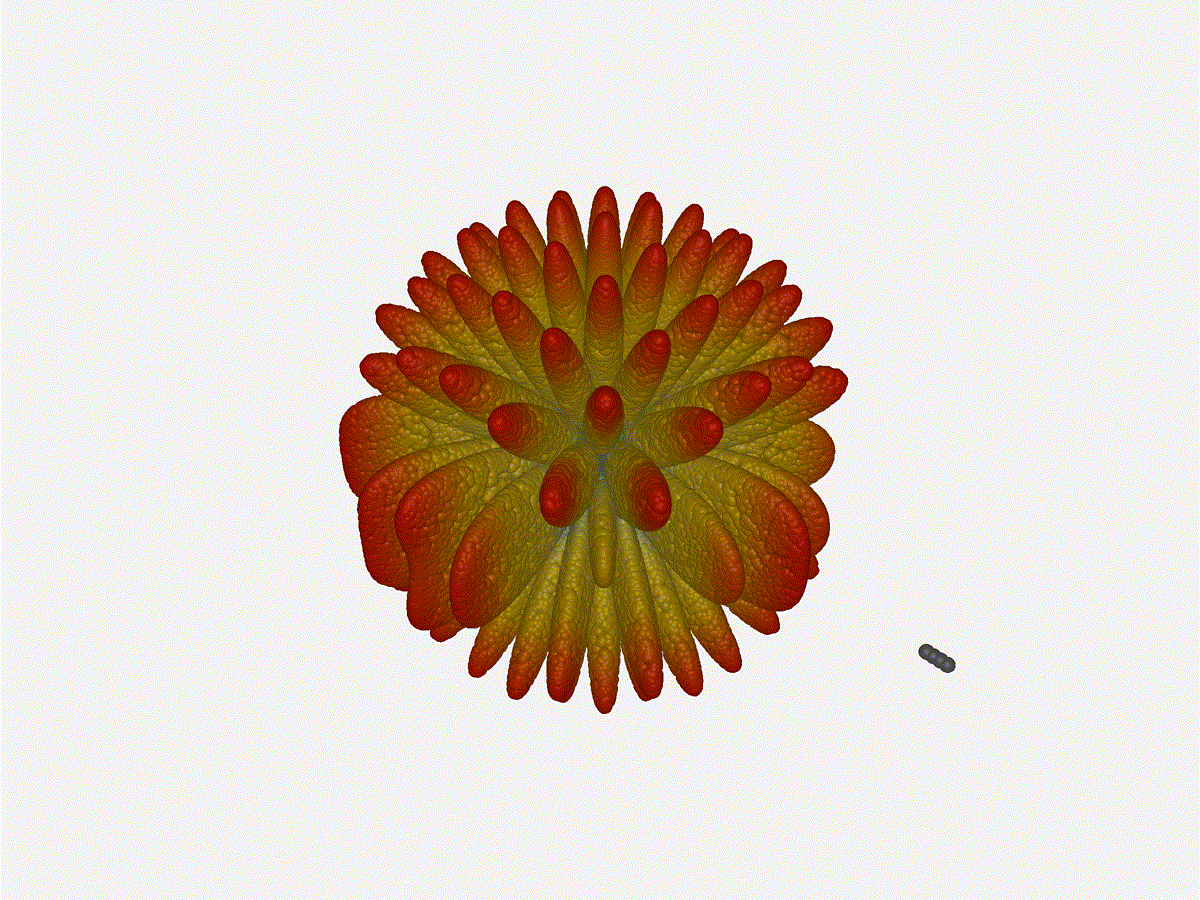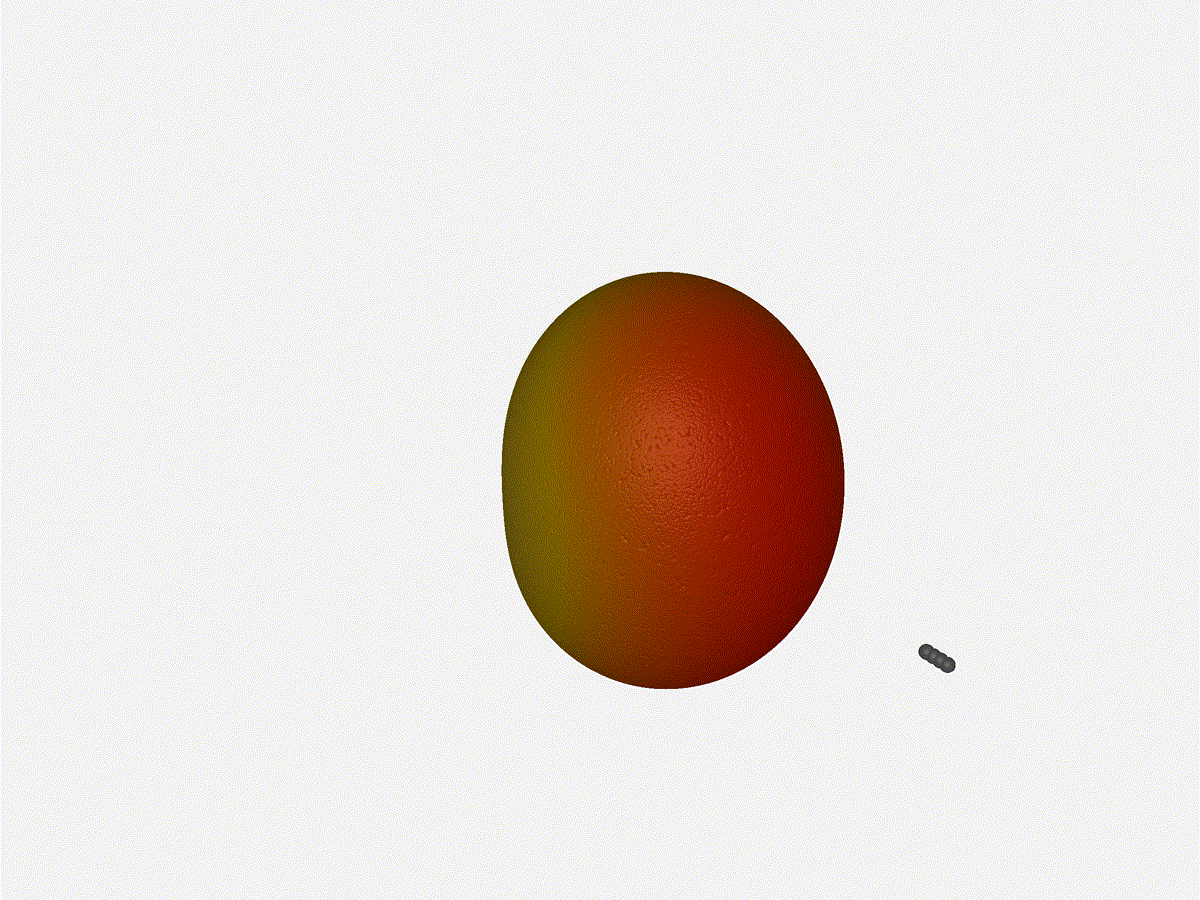
 Now that I m
Now that I m  CW for body size change mentions
I needed a corset, badly.
Years ago I had a chance to have my measurements taken by a former
professional corset maker and then a lesson in how to draft an underbust
corset, and that lead to me learning how nice wearing a well-fitted
corset feels.
Later I tried to extend that pattern up for a midbust corset, with
success.
And then my body changed suddenly, and I was no longer able to wear
either of those, and after a while I started missing them.
Since my body was still changing (if no longer drastically so), and I
didn t want to use expensive materials for something that had a risk of
not fitting after too little time, I decided to start by making myself a
summer lightweight corset in aida cloth and plastic boning (for which I
had already bought materials). It fitted, but not as well as the first
two ones, and I ve worn it quite a bit.
I still wanted back the feeling of wearing a comfy, heavy contraption of
coutil and steel, however.
After a lot of procrastination I redrafted a new pattern, scrapped
everything, tried again, had my measurements taken by a dressmaker
[#dressmaker], put them in the draft, cut a first mock-up in cheap
cotton, fixed the position of a seam, did a second mock-up in denim
[#jeans] from an old pair of jeans, and then cut into the cheap
herringbone coutil I was planning to use.
And that s when I went to see which one of the busks in my stash would
work, and realized that I had used a wrong vertical measurement and the
front of the corset was way too long for a midbust corset.
CW for body size change mentions
I needed a corset, badly.
Years ago I had a chance to have my measurements taken by a former
professional corset maker and then a lesson in how to draft an underbust
corset, and that lead to me learning how nice wearing a well-fitted
corset feels.
Later I tried to extend that pattern up for a midbust corset, with
success.
And then my body changed suddenly, and I was no longer able to wear
either of those, and after a while I started missing them.
Since my body was still changing (if no longer drastically so), and I
didn t want to use expensive materials for something that had a risk of
not fitting after too little time, I decided to start by making myself a
summer lightweight corset in aida cloth and plastic boning (for which I
had already bought materials). It fitted, but not as well as the first
two ones, and I ve worn it quite a bit.
I still wanted back the feeling of wearing a comfy, heavy contraption of
coutil and steel, however.
After a lot of procrastination I redrafted a new pattern, scrapped
everything, tried again, had my measurements taken by a dressmaker
[#dressmaker], put them in the draft, cut a first mock-up in cheap
cotton, fixed the position of a seam, did a second mock-up in denim
[#jeans] from an old pair of jeans, and then cut into the cheap
herringbone coutil I was planning to use.
And that s when I went to see which one of the busks in my stash would
work, and realized that I had used a wrong vertical measurement and the
front of the corset was way too long for a midbust corset.
 Luckily I also had a few longer busks, I basted one to the denim mock up
and tried to wear it for a few hours, to see if it was too long to be
comfortable. It was just a bit, on the bottom, which could be easily
fixed with the Power Tools
Luckily I also had a few longer busks, I basted one to the denim mock up
and tried to wear it for a few hours, to see if it was too long to be
comfortable. It was just a bit, on the bottom, which could be easily
fixed with the Power Tools I could have been a bit more precise with the binding, as it doesn t
align precisely at the front edge, but then again, it s underwear,
nobody other than me and everybody who reads this post is going to see
it and I was in a hurry to see it finished. I will be more careful with
the next one.
I could have been a bit more precise with the binding, as it doesn t
align precisely at the front edge, but then again, it s underwear,
nobody other than me and everybody who reads this post is going to see
it and I was in a hurry to see it finished. I will be more careful with
the next one.
 I also think that I haven t been careful enough when pressing the seams
and applying the tape, and I ve lost about a cm of width per part, so
I m using a lacing gap that is a bit wider than I planned for, but that
may change as the corset gets worn, and is still within tolerance.
Also, on the morning after I had finished the corset I woke up and
realized that I had forgotten to add garter tabs at the bottom edge.
I don t know whether I will ever use them, but I wanted the option, so
maybe I ll try to add them later on, especially if I can do it without
undoing the binding.
The next step would have been flossing, which I proceeded to postpone
until I ve worn the corset for a while: not because there is any reason
for it, but because I still don t know how I want to do it :)
What was left was finishing and uploading the
I also think that I haven t been careful enough when pressing the seams
and applying the tape, and I ve lost about a cm of width per part, so
I m using a lacing gap that is a bit wider than I planned for, but that
may change as the corset gets worn, and is still within tolerance.
Also, on the morning after I had finished the corset I woke up and
realized that I had forgotten to add garter tabs at the bottom edge.
I don t know whether I will ever use them, but I wanted the option, so
maybe I ll try to add them later on, especially if I can do it without
undoing the binding.
The next step would have been flossing, which I proceeded to postpone
until I ve worn the corset for a while: not because there is any reason
for it, but because I still don t know how I want to do it :)
What was left was finishing and uploading the 
 Now copy the ISO image to the newly created instance and extract
its data:
Now copy the ISO image to the newly created instance and extract
its data:
 Login the recovery console (root without password) and fix its default route to
make it reachable:
Login the recovery console (root without password) and fix its default route to
make it reachable:
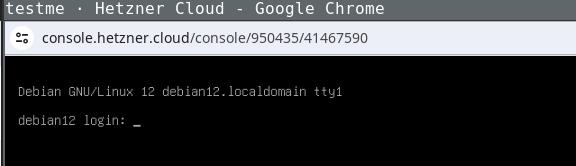 Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.
Being able to use this procedure for complete disaster recovery within Hetzner
cloud VPS (using off-site backups) gives me a better feeling, too.