With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up I d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. For now, we ll be using a custom ISO image, while waiting for the above-mentioned merge-proposal to be landed. Furthermore, as the Debian archive is going through major transitions builds of the unstable branch of d-i don t currently work. So I implemented a small backport, producing updated netcfg and netcfg-static for Bookworm, which can be used as localudebs/ during the d-i build.
Let s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
Now let s download the custom mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes, as mentioned above.
TODO: localudebs/
Next we ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
Finally, let s launch the installer using a custom preseed.cfg file, that will automatically install Netplan for us in the target system. A minimal preseed file could look like this:
For this demo, we re installing the full netplan.io package (incl. Python CLI), as the netplan-generator package was not yet split out as an independent binary in the Bookworm cycle. You can choose the preseed file from a set of different variants to test the different configurations:
We re using the custom linux kernel and initrd.gz here to be able to pass the PRESEED_URL as a parameter to the kernel s cmdline directly. Launching this VM should bring up the normal debian-installer in its netboot/gtk form:
Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
Done! After the installation finished you can reboot into your virgin Debian Bookworm system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was written by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
Finally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
In our case we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more join the discussion at Salsa:installer-team/netcfg and find us at GitHub:netplan.
When using Bubblewrap (the bwrap command) to create a container in Ubuntu 24.04 you can expect to get one of the following error messages:
bwrap: loopback: Failed RTM_NEWADDR: Operation not permitted
bwrap: setting up uid map: Permission denied
This is due to Ubuntu developers deciding to use Apparmor to restrict the creation of user namespaces. Here is a Ubuntu blog post about it [1].
To resolve that you could upgrade to SE Linux, but the other option is to create a file named /etc/apparmor.d/bwrap with the following contents:
abi <abi/4.0>,
include <tunables/global>
profile bwrap /usr/bin/bwrap flags=(unconfined)
userns,
# Site-specific additions and overrides. See local/README for details.
include if exists <local/bwrap>
Joachim Breitner wrote about a Convenient sandboxed development environment and thus reminded me to blog about MicroVM. I ve toyed around with it a little but not yet seriously used it as I m currently not coding.
MicroVM is a nix based project to configure and run minimal VMs. It can mount and thus reuse the hosts nix store inside the VM and thus has a very small disk footprint. I use MicroVM on a debian system using the nix package manager.
The MicroVM author uses the project to host production services. Otherwise I consider it also a nice way to learn about NixOS after having started with the nix package manager and before making the big step to NixOS as my main system.
The guests root filesystem is a tmpdir, so one must explicitly define folders that should be mounted from the host and thus be persistent across VM reboots.
I defined the VM as a nix flake since this is how I started from the MicroVM projects example:
description = "Haskell dev MicroVM";
inputs.impermanence.url = "github:nix-community/impermanence";
inputs.microvm.url = "github:astro/microvm.nix";
inputs.microvm.inputs.nixpkgs.follows = "nixpkgs";
outputs = self, impermanence, microvm, nixpkgs :
let
persistencePath = "/persistent";
system = "x86_64-linux";
user = "thk";
vmname = "haskell";
nixosConfiguration = nixpkgs.lib.nixosSystem
inherit system;
modules = [
microvm.nixosModules.microvm
impermanence.nixosModules.impermanence
( pkgs, ... :
environment.persistence.$ persistencePath =
hideMounts = true;
users.$ user =
directories = [
"git" ".stack"
];
;
;
environment.sessionVariables =
TERM = "screen-256color";
;
environment.systemPackages = with pkgs; [
ghc
git
(haskell-language-server.override supportedGhcVersions = [ "94" ]; )
htop
stack
tmux
tree
vcsh
zsh
];
fileSystems.$ persistencePath .neededForBoot = nixpkgs.lib.mkForce true;
microvm =
forwardPorts = [
from = "host"; host.port = 2222; guest.port = 22;
from = "guest"; host.port = 5432; guest.port = 5432; # postgresql
];
hypervisor = "qemu";
interfaces = [
type = "user"; id = "usernet"; mac = "00:00:00:00:00:02";
];
mem = 4096;
shares = [
# use "virtiofs" for MicroVMs that are started by systemd
proto = "9p";
tag = "ro-store";
# a host's /nix/store will be picked up so that no
# squashfs/erofs will be built for it.
source = "/nix/store";
mountPoint = "/nix/.ro-store";
proto = "virtiofs";
tag = "persistent";
source = "~/.local/share/microvm/vms/$ vmname /persistent";
mountPoint = persistencePath;
socket = "/run/user/1000/microvm-$ vmname -persistent";
];
socket = "/run/user/1000/microvm-control.socket";
vcpu = 3;
volumes = [];
writableStoreOverlay = "/nix/.rwstore";
;
networking.hostName = vmname;
nix.enable = true;
nix.nixPath = ["nixpkgs=$ builtins.storePath <nixpkgs> "];
nix.settings =
extra-experimental-features = ["nix-command" "flakes"];
trusted-users = [user];
;
security.sudo =
enable = true;
wheelNeedsPassword = false;
;
services.getty.autologinUser = user;
services.openssh =
enable = true;
;
system.stateVersion = "24.11";
systemd.services.loadnixdb =
description = "import hosts nix database";
path = [pkgs.nix];
wantedBy = ["multi-user.target"];
requires = ["nix-daemon.service"];
script = "cat $ persistencePath /nix-store-db-dump nix-store --load-db";
;
time.timeZone = nixpkgs.lib.mkDefault "Europe/Berlin";
users.users.$ user =
extraGroups = [ "wheel" "video" ];
group = "user";
isNormalUser = true;
openssh.authorizedKeys.keys = [
"ssh-rsa REDACTED"
];
password = "";
;
users.users.root.password = "";
users.groups.user = ;
)
];
;
in
packages.$ system .default = nixosConfiguration.config.microvm.declaredRunner;
;
I start the microVM with a templated systemd user service:
The above service definition creates a dump of the hosts nix store db so that it can be imported in the guest. This is necessary so that the guest can actually use what is available in /nix/store. There is an effort for an overlayed nix store that would be preferable to this hack.
Finally the microvm is started inside a tmux session named microvm . This way I can use the VM with SSH or through the console and also access the qemu console.
And for completeness the virtiofsd service:
[Unit]
Description=serve host persistent folder for dev VM
AssertPathIsDirectory=%h/.local/share/microvm/vms/%i/persistent
[Service]
ExecStart=%h/.local/state/nix/profile/bin/virtiofsd \
--socket-path=$ XDG_RUNTIME_DIR /microvm-%i-persistent \
--shared-dir=%h/.local/share/microvm/vms/%i/persistent \
--gid-map :995:%G:1: \
--uid-map :1000:%U:1:
install software that might not be available in Debian
install software without root access
declare software necessary for a user s environment inside $HOME/.config
Especially the last point nagged me every time I set up a new Debian installation. My emacs configuration and my Desktop setup expects certain software to be installed.
Please be aware that I m a beginner with nix and that my config might not follow best practice. Additionally many nix users are already using the new flakes feature of nix that I m still learning about.
So I ve got this file at .config/nixpkgs/config.nix1:
You can see that I install nix with nix. This gives me a newer version than the one available in Debian stable. However, the nix-daemon still runs as the older binary from Debian. My dirty hack is to put this override in /etc/systemd/system/nix-daemon.service.d/override.conf:
With the release of Libntlm version 1.8 the release tarball can be reproduced on several distributions. We also publish a signed minimal source-only tarball, produced by git-archive which is the same format used by Savannah, Codeberg, GitLab, GitHub and others. Reproducibility of both tarballs are tested continuously for regressions on GitLab through a CI/CD pipeline. If that wasn t enough to excite you, the Debian packages of Libntlm are now built from the reproducible minimal source-only tarball. The resulting binaries are reproducible on several architectures.
What does that even mean? Why should you care? How you can do the same for your project? What are the open issues? Read on, dear reader
This article describes my practical experiments with reproducible release artifacts, following up on my earlier thoughts that lead to discussion on Fosstodon and a patch by Janneke Nieuwenhuizen to make Guix tarballs reproducible that inspired me to some practical work.
Let s look at how a maintainer release some software, and how a user can reproduce the released artifacts from the source code. Libntlm provides a shared library written in C and uses GNU Make, GNU Autoconf, GNU Automake, GNU Libtool and gnulib for build management, but these ideas should apply to most project and build system. The following illustrate the steps a maintainer would take to prepare a release:
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make distcheck
gpg -b libntlm-1.8.tar.gz
The generated files libntlm-1.8.tar.gz and libntlm-1.8.tar.gz.sig are published, and users download and use them. This is how the GNU project have been doing releases since the late 1980 s. That is a testament to how successful this pattern has been! These tarballs contain source code and some generated files, typically shell scripts generated by autoconf, makefile templates generated by automake, documentation in formats like Info, HTML, or PDF. Rarely do they contain binary object code, but historically that happened.
The XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. I blogged earlier how to mitigate this risk by using signed minimal source-only tarballs.
The risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that GNU/Linux distributions such as Trisquel, Guix, Debian/Ubuntu or Fedora ship generated files coming from the tarball into the binary *.deb or *.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built through a typical autoconf -fi && ./configure && make install sequence, and never wrote the code to rebuild everything. This can also happen if the build rules are written but are buggy, shipping the old artifact. When a security problem is found, this can lead to time-consuming situations, as it may be that patching the relevant source code and rebuilding the package is not sufficient: the vulnerable generated object from the tarball would be shipped into the binary package instead of a rebuilt artifact. For architecture-specific binaries this rarely happens, since object code is usually not included in tarballs although for 10+ years I shipped the binary Java JAR file in the GNU Libidn release tarball, until I stopped shipping it. For interpreted languages and especially for generated content such as HTML, PDF, shell scripts this happens more than you would like.
Publishing minimal source-only tarballs enable easier auditing of a project s code, to avoid the need to read through all generated files looking for malicious content. I have taken care to generate the source-only minimal tarball using git-archive. This is the same format that GitLab, GitHub etc offer for the automated download links on git tags. The minimal source-only tarballs can thus serve as a way to audit GitLab and GitHub download material! Consider if/when hosting sites like GitLab or GitHub has a security incident that cause generated tarballs to include a backdoor that is not present in the git repository. If people rely on the tag download artifact without verifying the maintainer PGP signature using GnuPG, this can lead to similar backdoor scenarios that we had for XZUtils but originated with the hosting provider instead of the release manager. This is even more concerning, since this attack can be mounted for some selected IP address that you want to target and not on everyone, thereby making it harder to discover.
With all that discussion and rationale out of the way, let s return to the release process. I have added another step here:
make srcdist
gpg -b libntlm-1.8-src.tar.gz
Now the release is ready. I publish these four files in the Libntlm s Savannah Download area, but they can be uploaded to a GitLab/GitHub release area as well. These are the SHA256 checksums I got after building the tarballs on my Trisquel 11 aramo laptop:
So how can you reproduce my artifacts? Here is how to reproduce them in a Ubuntu 22.04 container:
podman run -it --rm ubuntu:22.04
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make dist srcdist
sha256sum libntlm-*.tar.gz
You should see the exact same SHA256 checksum values. Hooray!
This works because Trisquel 11 and Ubuntu 22.04 uses the same version of git, autoconf, automake, and libtool. These tools do not guarantee the same output content for all versions, similar to how GNU GCC does not generate the same binary output for all versions. So there is still some delicate version pairing needed.
Ideally, the artifacts should be possible to reproduce from the release artifacts themselves, and not only directly from git. It is possible to reproduce the full tarball in a AlmaLinux 8 container replace almalinux:8 with rockylinux:8 if you prefer RockyLinux:
podman run -it --rm almalinux:8
dnf update -y
dnf install -y make wget gcc
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8.tar.gz
tar xfa libntlm-1.8.tar.gz
cd libntlm-1.8
./configure
make dist
sha256sum libntlm-1.8.tar.gz
The source-only minimal tarball can be regenerated on Debian 11:
podman run -it --rm debian:11
apt-get update
apt-get install -y --no-install-recommends make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
make -f cfg.mk srcdist
sha256sum libntlm-1.8-src.tar.gz
As the Magnus Opus or chef-d uvre, let s recreate the full tarball directly from the minimal source-only tarball on Trisquel 11 replace docker.io/kpengboy/trisquel:11.0 with ubuntu:22.04 if you prefer.
podman run -it --rm docker.io/kpengboy/trisquel:11.0
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make wget git ca-certificates
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8-src.tar.gz
tar xfa libntlm-1.8-src.tar.gz
cd libntlm-v1.8
./bootstrap
./configure
make dist
sha256sum libntlm-1.8.tar.gz
Yay! You should now have great confidence in that the release artifacts correspond to what s in version control and also to what the maintainer intended to release. Your remaining job is to audit the source code for vulnerabilities, including the source code of the dependencies used in the build. You no longer have to worry about auditing the release artifacts.
I find it somewhat amusing that the build infrastructure for Libntlm is now in a significantly better place than the code itself. Libntlm is written in old C style with plenty of string manipulation and uses broken cryptographic algorithms such as MD4 and single-DES. Remember folks: solving supply chain security issues has no bearing on what kind of code you eventually run. A clean gun can still shoot you in the foot.
Side note on naming: GitLab exports tarballs with pathnames libntlm-v1.8/ (i.e.., PROJECT-TAG/) and I ve adopted the same pathnames, which means my libntlm-1.8-src.tar.gz tarballs are bit-by-bit identical to GitLab s exports and you can verify this with tools like diffoscope. GitLab name the tarball libntlm-v1.8.tar.gz (i.e., PROJECT-TAG.ARCHIVE) which I find too similar to the libntlm-1.8.tar.gz that we also publish. GitHub uses the same git archive style, but unfortunately they have logic that removes the v in the pathname so you will get a tarball with pathname libntlm-1.8/ instead of libntlm-v1.8/ that GitLab and I use. The content of the tarball is bit-by-bit identical, but the pathname and archive differs. Codeberg (running Forgejo) uses another approach: the tarball is called libntlm-v1.8.tar.gz (after the tag) just like GitLab, but the pathname inside the archive is libntlm/, otherwise the produced archive is bit-by-bit identical including timestamps. Savannah s CGIT interface uses archive name libntlm-1.8.tar.gz with pathname libntlm-1.8/, but otherwise file content is identical. Savannah s GitWeb interface provides snapshot links that are named after the git commit (e.g., libntlm-a812c2ca.tar.gz with libntlm-a812c2ca/) and I cannot find any tag-based download links at all. Overall, we are so close to get SHA256 checksum to match, but fail on pathname within the archive. I ve chosen to be compatible with GitLab regarding the content of tarballs but not on archive naming. From a simplicity point of view, it would be nice if everyone used PROJECT-TAG.ARCHIVE for the archive filename and PROJECT-TAG/ for the pathname within the archive. This aspect will probably need more discussion.
Side note on git archive output: It seems different versions of git archive produce different results for the same repository. The version of git in Debian 11, Trisquel 11 and Ubuntu 22.04 behave the same. The version of git in Debian 12, AlmaLinux/RockyLinux 8/9, Alpine, ArchLinux, macOS homebrew, and upcoming Ubuntu 24.04 behave in another way. Hopefully this will not change that often, but this would invalidate reproducibility of these tarballs in the future, forcing you to use an old git release to reproduce the source-only tarball. Alas, GitLab and most other sites appears to be using modern git so the download tarballs from them would not match my tarballs even though the content would.
Side note on ChangeLog: ChangeLog files were traditionally manually curated files with version history for a package. In recent years, several projects moved to dynamically generate them from git history (using tools like git2cl or gitlog-to-changelog). This has consequences for reproducibility of tarballs: you need to have the entire git history available! The gitlog-to-changelog tool also output different outputs depending on the time zone of the person using it, which arguable is a simple bug that can be fixed. However this entire approach is incompatible with rebuilding the full tarball from the minimal source-only tarball. It seems Libntlm s ChangeLog file died on the surgery table here.
So how would a distribution build these minimal source-only tarballs? I happen to help on the libntlm package in Debian. It has historically used the generated tarballs as the source code to build from. This means that code coming from gnulib is vendored in the tarball. When a security problem is discovered in gnulib code, the security team needs to patch all packages that include that vendored code and rebuild them, instead of merely patching the gnulib package and rebuild all packages that rely on that particular code. To change this, the Debian libntlm package needs to Build-Depends on Debian s gnulib package. But there was one problem: similar to most projects that use gnulib, Libntlm depend on a particular git commit of gnulib, and Debian only ship one commit. There is no coordination about which commit to use. I have adopted gnulib in Debian, and add a git bundle to the *_all.deb binary package so that projects that rely on gnulib can pick whatever commit they need. This allow an no-network GNULIB_URL and GNULIB_REVISION approach when running Libntlm s ./bootstrap with the Debian gnulib package installed. Otherwise libntlm would pick up whatever latest version of gnulib that Debian happened to have in the gnulib package, which is not what the Libntlm maintainer intended to be used, and can lead to all sorts of version mismatches (and consequently security problems) over time. Libntlm in Debian is developed and tested on Salsa and there is continuous integration testing of it as well, thanks to the Salsa CI team.
Side note on git bundles: unfortunately there appears to be no reproducible way to export a git repository into one or more files. So one unfortunate consequence of all this work is that the gnulib *.orig.tar.gz tarball in Debian is not reproducible any more. I have tried to get Git bundles to be reproducible but I never got it to work see my notes in gnulib s debian/README.source on this aspect. Of course, source tarball reproducibility has nothing to do with binary reproducibility of gnulib in Debian itself, fortunately.
One open question is how to deal with the increased build dependencies that is triggered by this approach. Some people are surprised by this but I don t see how to get around it: if you depend on source code for tools in another package to build your package, it is a bad idea to hide that dependency. We ve done it for a long time through vendored code in non-minimal tarballs. Libntlm isn t the most critical project from a bootstrapping perspective, so adding git and gnulib as Build-Depends to it will probably be fine. However, consider if this pattern was used for other packages that uses gnulib such as coreutils, gzip, tar, bison etc (all are using gnulib) then they would all Build-Depends on git and gnulib. Cross-building those packages for a new architecture will therefor require git on that architecture first, which gets circular quick. The dependency on gnulib is real so I don t see that going away, and gnulib is a Architecture:all package. However, the dependency on git is merely a consequence of how the Debian gnulib package chose to make all gnulib git commits available to projects: through a git bundle. There are other ways to do this that doesn t require the git tool to extract the necessary files, but none that I found practical ideas welcome!
Finally some brief notes on how this was implemented. Enabling bootstrappable source-only minimal tarballs via gnulib s ./bootstrap is achieved by using the GNULIB_REVISION mechanism, locking down the gnulib commit used. I have always disliked git submodules because they add extra steps and has complicated interaction with CI/CD. The reason why I gave up git submodules now is because the particular commit to use is not recorded in the git archive output when git submodules is used. So the particular gnulib commit has to be mentioned explicitly in some source code that goes into the git archive tarball. Colin Watson added the GNULIB_REVISION approach to ./bootstrap back in 2018, and now it no longer made sense to continue to use a gnulib git submodule. One alternative is to use ./bootstrap with --gnulib-srcdir or --gnulib-refdir if there is some practical problem with the GNULIB_URL towards a git bundle the GNULIB_REVISION in bootstrap.conf.
The srcdist make rule is simple:
git archive --prefix=libntlm-v1.8/ -o libntlm-v1.8.tar.gz HEAD
Making the make dist generated tarball reproducible can be more complicated, however for Libntlm it was sufficient to make sure the modification times of all files were set deterministically to the timestamp of the last commit in the git repository. Interestingly there seems to be a couple of different ways to accomplish this, Guix doesn t support minimal source-only tarballs but rely on a .tarball-timestamp file inside the tarball. Paul Eggert explained what TZDB is using some time ago. The approach I m using now is fairly similar to the one I suggested over a year ago. If there are problems because all files in the tarball now use the same modification time, there is a solution by Bruno Haible that could be implemented.
Side note on git tags: Some people may wonder why not verify a signed git tag instead of verifying a signed tarball of the git archive. Currently most git repositories uses SHA-1 for git commit identities, but SHA-1 is not a secure hash function. While current SHA-1 attacks can be detected and mitigated, there are fundamental doubts that a git SHA-1 commit identity uniquely refers to the same content that was intended. Verifying a git tag will never offer the same assurance, since a git tag can be moved or re-signed at any time. Verifying a git commit is better but then we need to trust SHA-1. Migrating git to SHA-256 would resolve this aspect, but most hosting sites such as GitLab and GitHub does not support this yet. There are other advantages to using signed tarballs instead of signed git commits or git tags as well, e.g., tar.gz can be a deterministically reproducible persistent stable offline storage format but .git sub-directory trees or git bundles do not offer this property.
Doing continous testing of all this is critical to make sure things don t regress. Libntlm s pipeline definition now produce the generated libntlm-*.tar.gz tarballs and a checksum as a build artifact. Then I added the 000-reproducability job which compares the checksums and fails on mismatches. You can read its delicate output in the job for the v1.8 release. Right now we insists that builds on Trisquel 11 match Ubuntu 22.04, that PureOS 10 builds match Debian 11 builds, that AlmaLinux 8 builds match RockyLinux 8 builds, and AlmaLinux 9 builds match RockyLinux 9 builds. As you can see in pipeline job output, not all platforms lead to the same tarballs, but hopefully this state can be improved over time. There is also partial reproducibility, where the full tarball is reproducible across two distributions but not the minimal tarball, or vice versa.
If this way of working plays out well, I hope to implement it in other projects too.
What do you think? Happy Hacking!
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
write build-ids to debian binary control files,
so that the build-id (more specifically, the ELF note
.note.gnu.build-id) wound up in the Debian apt archive metadata.
I ve always thought this was super cool, and seeing as how Michael Stapelberg
blogged
some great pointers around the ecosystem, including the fancy new debuginfod
service, and the
find-dbgsym-packages
helper, which uses these same headers, I don t think I m the only one.
At work I ve been using a lot of rust,
specifically, async rust using tokio. To try and work on
my style, and to dig deeper into the how and why of the decisions made in these
frameworks, I ve decided to hack up a project that I ve wanted to do ever
since 2015 write a debug filesystem. Let s get to it.
Back to the Future
Time to admit something. I really love Plan 9. It s
just so good. So many ideas from Plan 9 are just so prescient, and everything
just feels right. Not just right like, feels good like, correct. The
bit that I ve always liked the most is 9p, the network protocol for serving
a filesystem over a network. This leads to all sorts of fun programs, like the
Plan 9 ftp client being a 9p server you mount the ftp server and access
files like any other files. It s kinda like if fuse were more fully a part
of how the operating system worked, but fuse is all running client-side. With
9p there s a single client, and different servers that you can connect to,
which may be backed by a hard drive, remote resources over something like SFTP, FTP, HTTP or even purely synthetic.
The interesting (maybe sad?) part here is that 9p wound up outliving Plan 9
in terms of adoption 9p is in all sorts of places folks don t usually expect.
For instance, the Windows Subsystem for Linux uses the 9p protocol to share
files between Windows and Linux. ChromeOS uses it to share files with Crostini,
and qemu uses 9p (virtio-p9) to share files between guest and host. If you re
noticing a pattern here, you d be right; for some reason 9p is the go-to protocol
to exchange files between hypervisor and guest. Why? I have no idea, except maybe
due to being designed well, simple to implement, and it s a lot easier to validate the data being shared
and validate security boundaries. Simplicity has its value.
As a result, there s a lot of lingering 9p support kicking around. Turns out
Linux can even handle mounting 9p filesystems out of the box. This means that I
can deploy a filesystem to my LAN or my localhost by running a process on top
of a computer that needs nothing special, and mount it over the network on an
unmodified machine unlike fuse, where you d need client-specific software
to run in order to mount the directory. For instance, let s mount a 9p
filesystem running on my localhost machine, serving requests on 127.0.0.1:564
(tcp) that goes by the name mountpointname to /mnt.
Linux will mount away, and attach to the filesystem as the root user, and by default,
attach to that mountpoint again for each local user that attempts to use
it. Nifty, right? I think so. The server is able
to keep track of per-user access and authorization
along with the host OS.
WHEREIN I STYX WITH IT
Since I wanted to push myself a bit more with rust and tokio specifically,
I opted to implement the whole stack myself, without third party libraries on
the critical path where I could avoid it. The 9p protocol (sometimes called
Styx, the original name for it) is incredibly simple. It s a series of client
to server requests, which receive a server to client response. These are,
respectively, T messages, which transmit a request to the server, which
trigger an R message in response (Reply messages). These messages are
TLV payload
with a very straight forward structure so straight forward, in fact, that I
was able to implement a working server off nothing more than a handful of man
pages.
Later on after the basics worked, I found a more complete
spec page
that contains more information about the
unix specific variant
that I opted to use (9P2000.u rather than 9P2000) due to the level
of Linux specific support for the 9P2000.u variant over the 9P2000
protocol.
MR ROBOTO
The backend stack over at zoo is rust and tokio
running i/o for an HTTP and WebRTC server. I figured I d pick something
fairly similar to write my filesystem with, since 9P can be implemented
on basically anything with I/O. That means tokio tcp server bits, which
construct and use a 9p server, which has an idiomatic Rusty API that
partially abstracts the raw R and T messages, but not so much as to
cause issues with hiding implementation possibilities. At each abstraction
level, there s an escape hatch allowing someone to implement any of
the layers if required. I called this framework
arigato which can be found over on
docs.rs and
crates.io.
/// Simplified version of the arigato File trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.File.html
trait File
/// OpenFile is the type returned by this File via an Open call.
typeOpenFile: OpenFile;
/// Return the 9p Qid for this file. A file is the same if the Qid is
/// the same. A Qid contains information about the mode of the file,
/// version of the file, and a unique 64 bit identifier.
fnqid(&self) -> Qid;
/// Construct the 9p Stat struct with metadata about a file.
async fnstat(&self) -> FileResult<Stat>;
/// Attempt to update the file metadata.
async fnwstat(&mut self, s: &Stat) -> FileResult<()>;
/// Traverse the filesystem tree.
async fnwalk(&self, path: &[&str]) -> FileResult<(Option<Self>, Vec<Self>)>;
/// Request that a file's reference be removed from the file tree.
async fnunlink(&mut self) -> FileResult<()>;
/// Create a file at a specific location in the file tree.
async fncreate(
&mut self,
name: &str,
perm: u16,
ty: FileType,
mode: OpenMode,
extension: &str,
) -> FileResult<Self>;
/// Open the File, returning a handle to the open file, which handles
/// file i/o. This is split into a second type since it is genuinely
/// unrelated -- and the fact that a file is Open or Closed can be
/// handled by the arigato server for us.
async fnopen(&mut self, mode: OpenMode) -> FileResult<Self::OpenFile>;
/// Simplified version of the arigato OpenFile trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.OpenFile.html
trait OpenFile
/// iounit to report for this file. The iounit reported is used for Read
/// or Write operations to signal, if non-zero, the maximum size that is
/// guaranteed to be transferred atomically.
fniounit(&self) -> u32;
/// Read some number of bytes up to buf.len() from the provided
/// offset of the underlying file. The number of bytes read is
/// returned.
async fnread_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
/// Write some number of bytes up to buf.len() from the provided
/// offset of the underlying file. The number of bytes written
/// is returned.
fnwrite_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
Thanks, decade ago paultag!
Let s do it! Let s use arigato to implement a 9p filesystem we ll call
debugfs that will serve all the debug
files shipped according to the Packages metadata from the apt archive. We ll
fetch the Packages file and construct a filesystem based on the reported
Build-Id entries. For those who don t know much about how an apt repo
works, here s the 2-second crash course on what we re doing. The first is to
fetch the Packages file, which is specific to a binary architecture (such as
amd64, arm64 or riscv64). That architecture is specific to a
component (such as main, contrib or non-free). That component is
specific to a suite, such as stable, unstable or any of its aliases
(bullseye, bookworm, etc). Let s take a look at the Packages.xz file for
the unstable-debugsuite, maincomponent, for all amd64 binaries.
This will return the Debian-style
rfc2822-like headers,
which is an export of the metadata contained inside each .deb file which
apt (or other tools that can use the apt repo format) use to fetch
information about debs. Let s take a look at the debug headers for the
netlabel-tools package in unstable which is a package named
netlabel-tools-dbgsym in unstable-debug.
So here, we can parse the package headers in the Packages.xz file, and store,
for each Build-Id, the Filename where we can fetch the .deb at. Each
.deb contains a number of files but we re only really interested in the
files inside the .deb located at or under /usr/lib/debug/.build-id/,
which you can find in debugfs under
rfc822.rs. It s
crude, and very single-purpose, but I m feeling a bit lazy.
Who needs dpkg?!
For folks who haven t seen it yet, a .deb file is a special type of
.ar file, that contains (usually)
three files inside debian-binary, control.tar.xz and data.tar.xz.
The core of an .ar file is a fixed size (60 byte) entry header,
followed by the specified size number of bytes.
[8 byte .ar file magic]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
...
First up was to implement a basic ar parser in
ar.rs. Before we get
into using it to parse a deb, as a quick diversion, let s break apart a .deb
file by hand something that is a bit of a rite of passage (or at least it
used to be? I m getting old) during the Debian nm (new member) process, to take
a look at where exactly the .debug file lives inside the .deb file.
$ ar x netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ ls
control.tar.xz debian-binary
data.tar.xz netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ tar --list -f data.tar.xz grep '.debug$'
./usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
Since we know quite a bit about the structure of a .deb file, and I had to
implement support from scratch anyway, I opted to implement a (very!) basic
debfile parser using HTTP Range requests. HTTP Range requests, if supported by
the server (denoted by a accept-ranges: bytes HTTP header in response to an
HTTP HEAD request to that file) means that we can add a header such as
range: bytes=8-68 to specifically request that the returned GET body be the
byte range provided (in the above case, the bytes starting from byte offset 8
until byte offset 68). This means we can fetch just the ar file entry from
the .deb file until we get to the file inside the .deb we are interested in
(in our case, the data.tar.xz file) at which point we can request the body
of that file with a final range request. I wound up writing a struct to
handle a read_at-style API surface in
hrange.rs, which
we can pair with ar.rs above and start to find our data in the .deb remotely
without downloading and unpacking the .deb at all.
After we have the body of the data.tar.xz coming back through the HTTP
response, we get to pipe it through an xz decompressor (this kinda sucked in
Rust, since a tokioAsyncRead is not the same as an http Body response is
not the same as std::io::Read, is not the same as an async (or sync)
Iterator is not the same as what the xz2 crate expects; leading me to read
blocks of data to a buffer and stuff them through the decoder by looping over
the buffer for each lzma2 packet in a loop), and tarfile parser (similarly
troublesome). From there we get to iterate over all entries in the tarfile,
stopping when we reach our file of interest. Since we can t seek, but gdb
needs to, we ll pull it out of the stream into a Cursor<Vec<u8>> in-memory
and pass a handle to it back to the user.
From here on out its a matter of
gluing together a File traited struct
in debugfs, and serving the filesystem over TCP using arigato. Done
deal!
A quick diversion about compression
I was originally hoping to avoid transferring the whole tar file over the
network (and therefore also reading the whole debug file into ram, which
objectively sucks), but quickly hit issues with figuring out a way around
seeking around an xz file. What s interesting is xz has a great primitive
to solve this specific problem (specifically, use a block size that allows you
to seek to the block as close to your desired seek position just before it,
only discarding at most block size - 1 bytes), but data.tar.xz files
generated by dpkg appear to have a single mega-huge block for the whole file.
I don t know why I would have expected any different, in retrospect. That means
that this now devolves into the base case of How do I seek around an lzma2
compressed data stream ; which is a lot more complex of a question.
Thankfully, notoriously brilliant tianon was
nice enough to introduce me to Jon Johnson
who did something super similar adapted a technique to seek inside a
compressed gzip file, which lets his service
oci.dag.dev
seek through Docker container images super fast based on some prior work
such as soci-snapshotter, gztool, and
zran.c.
He also pulled this party trick off for apk based distros
over at apk.dag.dev, which seems apropos.
Jon was nice enough to publish a lot of his work on this specifically in a
central place under the name targz
on his GitHub, which has been a ton of fun to read through.
The gist is that, by dumping the decompressor s state (window of previous
bytes, in-memory data derived from the last N-1 bytes) at specific
checkpoints along with the compressed data stream offset in bytes and
decompressed offset in bytes, one can seek to that checkpoint in the compressed
stream and pick up where you left off creating a similar block mechanism
against the wishes of gzip. It means you d need to do an O(n) run over the
file, but every request after that will be sped up according to the number
of checkpoints you ve taken.
Given the complexity of xz and lzma2, I don t think this is possible
for me at the moment especially given most of the files I ll be requesting
will not be loaded from again especially when I can just cache the debug
header by Build-Id. I want to implement this (because I m generally curious
and Jon has a way of getting someone excited about compression schemes, which
is not a sentence I thought I d ever say out loud), but for now I m going to
move on without this optimization. Such a shame, since it kills a lot of the
work that went into seeking around the .deb file in the first place, given
the debian-binary and control.tar.gz members are so small.
The Good
First, the good news right? It works! That s pretty cool. I m positive
my younger self would be amused and happy to see this working; as is
current day paultag. Let s take debugfs out for a spin! First, we need
to mount the filesystem. It even works on an entirely unmodified, stock
Debian box on my LAN, which is huge. Let s take it for a spin:
And, let s prove to ourselves that this actually mounted before we go
trying to use it:
$ mount grep build-id
192.168.0.2 on /usr/lib/debug/.build-id type 9p (rw,relatime,aname=unstable-debug,access=user,trans=tcp,version=9p2000.u,port=564)
Slick. We ve got an open connection to the server, where our host
will keep a connection alive as root, attached to the filesystem provided
in aname. Let s take a look at it.
$ ls /usr/lib/debug/.build-id/
00 0d 1a 27 34 41 4e 5b 68 75 82 8E 9b a8 b5 c2 CE db e7 f3
01 0e 1b 28 35 42 4f 5c 69 76 83 8f 9c a9 b6 c3 cf dc E7 f4
02 0f 1c 29 36 43 50 5d 6a 77 84 90 9d aa b7 c4 d0 dd e8 f5
03 10 1d 2a 37 44 51 5e 6b 78 85 91 9e ab b8 c5 d1 de e9 f6
04 11 1e 2b 38 45 52 5f 6c 79 86 92 9f ac b9 c6 d2 df ea f7
05 12 1f 2c 39 46 53 60 6d 7a 87 93 a0 ad ba c7 d3 e0 eb f8
06 13 20 2d 3a 47 54 61 6e 7b 88 94 a1 ae bb c8 d4 e1 ec f9
07 14 21 2e 3b 48 55 62 6f 7c 89 95 a2 af bc c9 d5 e2 ed fa
08 15 22 2f 3c 49 56 63 70 7d 8a 96 a3 b0 bd ca d6 e3 ee fb
09 16 23 30 3d 4a 57 64 71 7e 8b 97 a4 b1 be cb d7 e4 ef fc
0a 17 24 31 3e 4b 58 65 72 7f 8c 98 a5 b2 bf cc d8 E4 f0 fd
0b 18 25 32 3f 4c 59 66 73 80 8d 99 a6 b3 c0 cd d9 e5 f1 fe
0c 19 26 33 40 4d 5a 67 74 81 8e 9a a7 b4 c1 ce da e6 f2 ff
Outstanding. Let s try using gdb to debug a binary that was provided by
the Debian archive, and see if it ll load the ELF by build-id from the
right .deb in the unstable-debug suite:
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Yes! Yes it will!
$ file /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
/usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter *empty*, BuildID[sha1]=e59f81f6573dadd5d95a6e4474d9388ab2777e2a, for GNU/Linux 3.2.0, with debug_info, not stripped
The Bad
Linux s support for 9p is mainline, which is great, but it s not robust.
Network issues or server restarts will wedge the mountpoint (Linux can t
reconnect when the tcp connection breaks), and things that work fine on local
filesystems get translated in a way that causes a lot of network chatter for
instance, just due to the way the syscalls are translated, doing an ls, will
result in a stat call for each file in the directory, even though linux had
just got a stat entry for every file while it was resolving directory names.
On top of that, Linux will serialize all I/O with the server, so there s no
concurrent requests for file information, writes, or reads pending at the same
time to the server; and read and write throughput will degrade as latency
increases due to increasing round-trip time, even though there are offsets
included in the read and write calls. It works well enough, but is
frustrating to run up against, since there s not a lot you can do server-side
to help with this beyond implementing the 9P2000.L variant (which, maybe is
worth it).
The Ugly
Unfortunately, we don t know the file size(s) until we ve actually opened the
underlying tar file and found the correct member, so for most files, we don t
know the real size to report when getting a stat. We can t parse the tarfiles
for every stat call, since that d make ls even slower (bummer). Only
hiccup is that when I report a filesize of zero, gdb throws a bit of a
fit; let s try with a size of 0 to start:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 0 Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
warning: Discarding section .note.gnu.build-id which has a section size (24) larger than the file size [in module /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug]
[...]
This obviously won t work since gdb will throw away all our hard work because
of stat s output, and neither will loading the real size of the underlying
file. That only leaves us with hardcoding a file size and hope nothing else
breaks significantly as a result. Let s try it again:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 954M Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Much better. I mean, terrible but better. Better for now, anyway.
Kilroy was here
Do I think this is a particularly good idea? I mean; kinda. I m probably going
to make some fun 9parigato-based filesystems for use around my LAN, but I
don t think I ll be moving to use debugfs until I can figure out how to
ensure the connection is more resilient to changing networks, server restarts
and fixes on i/o performance. I think it was a useful exercise and is a pretty
great hack, but I don t think this ll be shipping anywhere anytime soon.
Along with me publishing this post, I ve pushed up all my repos; so you
should be able to play along at home! There s a lot more work to be done
on arigato; but it does handshake and successfully export a working
9P2000.u filesystem. Check it out on on my github at
arigato,
debugfs
and also on crates.io
and docs.rs.
At least I can say I was here and I got it working after all these years.
Contributing to Debian
is part of Freexian s mission. This article
covers the latest achievements of Freexian and their collaborators. All of this
is made possible by organizations subscribing to our
Long Term Support contracts and
consulting services.
P.S. We ve completed over a year of writing these blogs. If you have any
suggestions on how to make them better or what you d like us to cover, or any
other opinions/reviews you might have, et al, please let us know by dropping an
email to us. We d be
happy to hear your thoughts. :)
SSO Authentication for jitsi.debian.social, by Stefano Rivera
Debian.social s jitsi instance has been getting
some abuse by (non-Debian) people sharing sexually explicit content on the
service. After playing whack-a-mole with this for a month, and shutting the
instance off for another month, we opened it up again and the abuse immediately
re-started.
Stefano sat down and wrote an
SSO Implementation
that hooks into Jitsi s existing JWT SSO support. This requires everyone using
jitsi.debian.social to have a Salsa account.
With only a little bit of effort, we could change this in future, to only
require an account to open a room, and allow guests to join the call.
/usr-move, by Helmut Grohne
The biggest task this month was sending mitigation patches for all of the
/usr-move issues arising from package renames due to the 2038 transition. As a
result, we can now say that every affected package in unstable can either be
converted with dh-sequence-movetousr or has an open bug report. The package
set relevant to debootstrap except for the set that has to be uploaded
concurrently has been moved to /usr and is awaiting migration. The move of
coreutils happened to affect piuparts which hard codes the location of
/bin/sync and received multiple updates as a result.
Miscellaneous contributions
Stefano Rivera uploaded a stable release update to python3.11 for bookworm,
fixing a use-after-free crash.
Stefano uploaded a new version of python-html2text, and updated
python3-defaults to build with it.
In support of Python 3.12, Stefano dropped distutils as a Build-Dependency
from a few packages, and uploaded a complex set of patches to python-mitogen.
Stefano landed some merge requests to clean up dead code in dh-python,
removed the flit plugin, and uploaded it.
Stefano uploaded new upstream versions of twisted, hatchling,
python-flexmock, python-authlib, python mitogen, python-pipx, and xonsh.
Stefano requested removal of a few packages supporting the Opsis HDMI2USB
hardware that DebConf Video team used to use for HDMI capture, as they are
not being maintained upstream. They started to FTBFS, with recent sdcc
changes.
DebConf 24 is getting ready to open registration, Stefano spent some time
fixing bugs in the website, caused by infrastructure updates.
Stefano reviewed all the DebConf 23 travel reimbursements, filing requests
for more information from SPI where our records mismatched.
Roberto C. S nchez worked on facilitating the transfer of upstream
maintenance responsibility for the dormant Shorewall project to a new team
led by the current maintainer of the Shorewall packages in Debian.
Colin Watson fixed build failures in celery-haystack-ng, db1-compat,
jsonpickle, libsdl-perl, kali, knews, openssh-ssh1,
python-json-log-formatter, python-typing-extensions, trn4, vigor, and
wcwidth. Some of these were related to the 64-bit time_t transition, since
that involved enabling -Werror=implicit-function-declaration.
Colin fixed an
off-by-one error in neovim,
which was already causing a build failure in Ubuntu and would eventually have
caused a build failure in Debian with stricter toolchain settings.
Colin added an sshd@.service template to
openssh to help newer systemd versions make containers and VMs SSH-accessible
over AF_VSOCK sockets.
Following the xz-utils backdoor, Colin
spent some time testing and discussing OpenSSH upstream s proposed
inline systemd notification patch,
since the current implementation via libsystemd was part of the attack vector
used by that backdoor.
Utkarsh reviewed and sponsored some Go packages for Lena Voytek and Rajudev.
Utkarsh also helped Mitchell Dzurick with the adoption of pyparted package.
Helmut sent 10 patches for cross build failures.
Helmut partially fixed architecture cross bootstrap tooling to deal with
changes in linux-libc-dev and the recent gcc-for-host changes and also
fixed a 64bit-time_t FTBFS in libtextwrap.
Thorsten Alteholz uploaded several packages from debian-printing: cjet,
lprng, rlpr and epson-inkjet-printer-escpr were affected by the newly enabled
compiler switch -Werror=implicit-function-declaration. Besides fixing these
serious bugs, Thorsten also worked on other bugs and could fix one or the
other.
Carles updated simplemonitor and python-ring-doorbell packages with new
upstream versions.
Santiago also reviewed applications for the
improving Salsa CI in Debian
GSoC 2024 project. We received applications from four very talented
candidates. The selection process is currently ongoing. A huge thanks to all
of them!
As part of the DebConf 24 organization, Santiago has taken part in the
Content team discussions.
Welcome to the March 2024 report from the Reproducible Builds project! In our reports, we attempt to outline what we have been up to over the past month, as well as mentioning some of the important things happening more generally in software supply-chain security. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Table of contents:
Arch Linux minimal container userland now 100% reproducible
In remarkable news, Reproducible builds developer kpcyrd reported that that the Arch Linux minimal container userland is now 100% reproducible after work by developers dvzv and Foxboron on the one remaining package. This represents a real world , widely-used Linux distribution being reproducible.
Their post, which kpcyrd suffixed with the question now what? , continues on to outline some potential next steps, including validating whether the container image itself could be reproduced bit-for-bit. The post, which was itself a followup for an Arch Linux update earlier in the month, generated a significant number of replies.
Validating Debian s build infrastructure after the XZ backdoor
From our mailing list this month, Vagrant Cascadian wrote about being asked about trying to perform concrete reproducibility checks for recent Debian security updates, in an attempt to gain some confidence about Debian s build infrastructure given that they performed builds in environments running the high-profile XZ vulnerability.
Vagrant reports (with some caveats):
So far, I have not found any reproducibility issues; everything I tested I was able to get to build bit-for-bit identical with what is in the
Debian archive.
That is to say, reproducibility testing permitted Vagrant and Debian to claim with some confidence that builds performed when this vulnerable version of XZ was installed were not interfered with.
Functional package managers (FPMs) and reproducible builds (R-B) are technologies and methodologies that are conceptually very different from the traditional software deployment model, and that have promising properties for software supply chain security. This thesis aims to evaluate the impact of FPMs and R-B on the security of the software supply chain and propose improvements to the FPM model to further improve trust in the open source supply chain. PDF
Julien s paper poses a number of research questions on how the model of distributions such as GNU Guix and NixOS can be leveraged to further improve the safety of the software supply chain , etc.
Software and source code identification with GNU Guix and reproducible builds
In a long line of commendably detailed blog posts, Ludovic Court s, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier have together published two interesting posts on the GNU Guix blog this month. In early March, Ludovic Court s, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier wrote about software and source code identification and how that might be performed using Guix, rhetorically posing the questions: What does it take to identify software ? How can we tell what software is running on a machine to determine, for example, what security vulnerabilities might affect it?
Later in the month, Ludovic Court s wrote a solo post describing adventures on the quest for long-term reproducible deployment. Ludovic s post touches on GNU Guix s aim to support time travel , the ability to reliably (and reproducibly) revert to an earlier point in time, employing the iconic image of Harold Lloyd hanging off the clock in Safety Last! (1925) to poetically illustrate both the slapstick nature of current modern technology and the gymnastics required to navigate hazards of our own making.
Two new Rust-based tools for post-processing determinism
Zbigniew J drzejewski-Szmek announced add-determinism, a work-in-progress reimplementation of the Reproducible Builds project s own strip-nondeterminism tool in the Rust programming language, intended to be used as a post-processor in RPM-based distributions such as Fedora
In addition, Yossi Kreinin published a blog post titled refix: fast, debuggable, reproducible builds that describes a tool that post-processes binaries in such a way that they are still debuggable with gdb, etc.. Yossi post details the motivation and techniques behind the (fast) performance of the tool.
Distribution work
In Debian this month, since the testing framework no longer varies the build path, James Addison performed a bulk downgrade of the bug severity for issues filed with a level of normal to a new level of wishlist. In addition, 28 reviews of Debian packages were added, 38 were updated and 23 were removed this month adding to ever-growing knowledge about identified issues. As part of this effort, a number of issue types were updated, including Chris Lamb adding a new ocaml_include_directories toolchain issue [] and James Addison adding a new filesystem_order_in_java_jar_manifest_mf_include_resource issue [] and updating the random_uuid_in_notebooks_generated_by_nbsphinx to reference a relevant discussion thread [].
In addition, Roland Clobus posted his 24th status update of reproducible Debian ISO images. Roland highlights that the images for Debian unstable often cannot be generated due to changes in that distribution related to the 64-bit time_t transition.
Lastly, Bernhard M. Wiedemann posted another monthly update for his reproducibility work in openSUSE.
Mailing list highlights
Elsewhere on our mailing list this month:
Website updates
There were made a number of improvements to our website this month, including:
Pol Dellaiera noticed the frequent need to correctly cite the website itself in academic work. To facilitate easier citation across multiple formats, Pol contributed a Citation File Format (CIF) file. As a result, an export in BibTeX format is now available in the Academic Publications section. Pol encourages community contributions to further refine the CITATION.cff file. Pol also added an substantial new section to the buy in page documenting the role of Software Bill of Materials (SBOMs) and ephemeral development environments. [][]
Bernhard M. Wiedemann added a new commandments page to the documentation [][] and fixed some incorrect YAML elsewhere on the site [].
Chris Lamb add three recent academic papers to the publications page of the website. []
Mattia Rizzolo and Holger Levsen collaborated to add Infomaniak as a sponsor of amd64 virtual machines. [][][]
Roland Clobus updated the stable outputs page, dropping version numbers from Python documentation pages [] and noting that Python s set data structure is also affected by the PYTHONHASHSEED functionality. []
Delta chat clients now reproducible
Delta Chat, an open source messaging application that can work over email, announced this month that the Rust-based core library underlying Delta chat application is now reproducible.
diffoscopediffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 259, 260 and 261 to Debian and made the following additional changes:
New features:
Add support for the zipdetails tool from the Perl distribution. Thanks to Fay Stegerman and Larry Doolittle et al. for the pointer and thread about this tool. []
Bug fixes:
Don t identify Redis database dumps as GNU R database files based simply on their filename. []
Add a missing call to File.recognizes so we actually perform the filename check for GNU R data files. []
Don t crash if we encounter an .rdb file without an equivalent .rdx file. (#1066991)
Correctly check for 7z being available and not lz4 when testing 7z. []
Prevent a traceback when comparing a contentful .pyc file with an empty one. []
Testsuite improvements:
Fix .epub tests after supporting the new zipdetails tool. []
Don t use parenthesis within test skipping messages, as PyTest adds its own parenthesis. []
Factor out Python version checking in test_zip.py. []
Skip some Zip-related tests under Python 3.10.14, as a potential regression may have been backported to the 3.10.x series. []
Actually test 7z support in the test_7z set of tests, not the lz4 functionality. (Closes: reproducible-builds/diffoscope#359). []
In addition, Fay Stegerman updated diffoscope s monkey patch for supporting the unusual Mozilla ZIP file format after Python s zipfile module changed to detect potentially insecure overlapping entries within .zip files. (#362)
Chris Lamb also updated the trydiffoscope command line client, dropping a build-dependency on the deprecated python3-distutils package to fix Debian bug #1065988 [], taking a moment to also refresh the packaging to the latest Debian standards []. Finally, Vagrant Cascadian submitted an update for diffoscope version 260 in GNU Guix. []
Upstream patches
This month, we wrote a large number of patches, including:
I don t have the hardware to test this firmware, but the build produces the same hashes for the firmware so it s safe to say that the firmware should keep working.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In March, an enormous number of changes were made by Holger Levsen:
Initial work to clean up a messy NetBSD-related script. [][]
Roland Clobus:
Show the installer log if the installer fails to build. []
Avoid the minus character (i.e. -) in a variable in order to allow for tags in openQA. []
Update the schedule of Debian live image builds. []
Vagrant Cascadian:
Maintenance on the virt* nodes is completed so bring them back online. []
Use the fully qualified domain name in configuration. []
Node maintenance was also performed by Holger Levsen, Mattia Rizzolo [][] and Vagrant Cascadian [][][][]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
New netplan status diff subcommand, finding differences between configuration and system state
As the maintainer and lead developer for Netplan, I m proud to announce the general availability of Netplan v1.0 after more than 7 years of development efforts. Over the years, we ve so far had about 80 individual contributors from around the globe. This includes many contributions from our Netplan core-team at Canonical, but also from other big corporations such as Microsoft or Deutsche Telekom. Those contributions, along with the many we receive from our community of individual contributors, solidify Netplan as a healthy and trusted open source project. In an effort to make Netplan even more dependable, we started shipping upstream patch releases, such as 0.106.1 and 0.107.1, which make it easier to integrate fixes into our users custom workflows.
With the release of version 1.0 we primarily focused on stability. However, being a major version upgrade, it allowed us to drop some long-standing legacy code from the libnetplan1 library. Removing this technical debt increases the maintainability of Netplan s codebase going forward. The upcoming Ubuntu 24.04 LTS and Debian 13 releases will ship Netplan v1.0 to millions of users worldwide.
Highlights of version 1.0
In addition to stability and maintainability improvements, it s worth looking at some of the new features that were included in the latest release:
Simultaneous WPA2 & WPA3 support.
Introduction of a stable libnetplan1 API.
Mellanox VF-LAG support for high performance SR-IOV networking.
New hairpin and port-mac-learning settings, useful for VXLAN tunnels with FRRouting.
New netplan status diff subcommand, finding differences between configuration and system state.
Besides those highlights of the v1.0 release, I d also like to shed some light on new functionality that was integrated within the past two years for those upgrading from the previous Ubuntu 22.04 LTS which used Netplan v0.104:
We added support for the management of new network interface types, such as veth, dummy, VXLAN, VRF or InfiniBand (IPoIB).
Wireless functionality was improved by integrating Netplan with NetworkManager on desktop systems, adding support for WPA3 and adding the notion of a regulatory-domain, to choose proper frequencies for specific regions.
To improve maintainability, we moved to Meson as Netplan s buildsystem, added upstream CI coverage for multiple Linux distributions and integrations (such as Debian testing, NetworkManager, snapd or cloud-init), checks for ABI compatibility, and automatic memory leak detection.
We increased consistency between the supported backend renderers (systemd-networkd and NetworkManager), by matching physical network interfaces on permanent MAC address, when the match.macaddress setting is being used, and added new hardware offloading functionality for high performance networking, such as Single-Root IO Virtualisation virtual function link-aggregation (SR-IOV VF-LAG).
The much improved Netplan documentation, that is now hosted on Read the Docs , and new command line subcommands, such as netplan status, make Netplan a well vested tool for declarative network management and troubleshooting.
Integrations
Those changes pave the way to integrate Netplan in 3rd party projects, such as system installers or cloud deployment methods. By shipping the new python3-netplan Python bindings to libnetplan, it is now easier than ever to access Netplan functionality and network validation from other projects. We are proud that the Debian Cloud Team chose Netplan to be the default network management tool in their official cloud-images for Debian Bookworm and beyond. Ubuntu s NetworkManager package now uses Netplan as it s default backend on Ubuntu 23.10 Desktop systems and beyond. Further integrations happened with cloud-init and the Calamares installer.
Please check out the Netplan version 1.0 release on GitHub! If you want to learn more, follow our activities on Netplan.io, GitHub, Launchpad, IRC or our Netplan Developer Diaries blog on discourse.
Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing gcc.tar.xz.
More likely, they wouldn't bother with an actual trusting trust attack on
gcc, which would be a lot of work to get right. One problem with the ssh
backdoor is that well, not all servers on the internet run ssh. (Or
systemd.) So webservers seem a likely target of this kind of second stage
attack. Apache's docs include png files, nginx does not, but there's always
scope to add improved documentation to a project.
When would such a vulnerability have been introduced? In February, "Jia
Tan" wrote a new decoder for xz.
This added 1000+ lines of new C code across several commits. So much code
and in just the right place to insert something like this. And why take on
such a significant project just two months before inserting the ssh
backdoor? "Jia Tan" was already fully accepted as maintainer, and doing
lots of other work, it doesn't seem to me that they needed to start this
rewrite as part of their cover.
They were working closely with xz's author Lasse Collin in this, by
indications exchanging patches offlist as they developed it. So Lasse
Collin's commits in this time period are also worth scrutiny, because
they could have been influenced by "Jia Tan". One that
caught my eye comes immediately afterwards:
"prepares the code for alternative C versions and inline assembly"
Multiple versions and assembly mean even more places to hide such a
security hole.
I stress that I have not found such a security hole, I'm only considering
what the worst case possibilities are. I think we need to fully consider
them in order to decide how to fully wrap up this mess.
Whether such stealthy security holes have been introduced into xz by "Jia
Tan" or not, there are definitely indications that the ssh backdoor was not
the end of what they had planned.
For one thing, the "test file" based system they introduced
was extensible.
They could have been planning to add more test files later, that backdoored
xz in further ways.
And then there's the matter of the disabling of the Landlock sandbox. This
was not necessary for the ssh backdoor, because the sandbox is only used by
the xz command, not by liblzma. So why did they potentially tip their
hand by adding that rogue "." that disables the sandbox?
A sandbox would not prevent the kind of attack I discuss above, where xz is
just modifying code that it decompresses. Disabling the sandbox suggests
that they were going to make xz run arbitrary code, that perhaps wrote to
files it shouldn't be touching, to install a backdoor in the system.
Both deb and rpm use xz compression, and with the sandbox disabled,
whether they link with liblzma or run the xz command, a backdoored xz can
write to any file on the system while dpkg or rpm is running and noone is
likely to notice, because that's the kind of thing a package manager does.
My impression is that all of this was well planned and they were in it for
the long haul. They had no reason to stop with backdooring ssh, except for
the risk of additional exposure. But they decided to take that risk, with
the sandbox disabling. So they planned to do more, and every commit
by "Jia Tan", and really every commit that they could have influenced
needs to be distrusted.
This is why I've suggested to Debian that they
revert to an earlier version of xz.
That would be my advice to anyone distributing xz.
I do have a xz-unscathed
fork which I've carefully constructed to avoid all "Jia Tan" involved
commits. It feels good to not need to worry about dpkg and tar.
I only plan to maintain this fork minimally, eg security fixes.
Hopefully Lasse Collin will consider these possibilities and address
them in his response to the attack.
Happy to share that ulid is now
(back) on CRAN. It provides
universally unique identifiers that are lexicographically sortable,
which improves over the more well-known uuid generators.
ulid is a
neat little package put together by Bob
Rudis a few years ago. It had recently drifted off CRAN so I offered to brush it up
and re-submit it. And as tooted
earlier today, it took just over an hour to finish that (after the
lead up work I had done, including prior email with CRAN in the loop,
the repo transfer from Bob s to my ulid repo plus of course
a wee bit of actual maintenance; see below for more).
The NEWS entry follows.
Changes in version 0.3.1
(2024-04-02)
New Maintainer
Deleted several repository files no longer used or
needed
Added .editorconfig, ChangeLog and
cleanup
Converted NEWS.md to NEWS.Rd
Simplified R/ directory to one source file
Simplified src/ removing redundant
Makevars
Added ulid() alias
Updated / edited roxygen and README.md documention
Removed vignette which was identical to README.md
Switched continuous integration to GitHub Actions
Placed upstream (header-only) library into
src/ulid/
Dear Debianites
This morning I decided to just start writing Bits from DPL and send
whatever I have by 18:00 local time. Here it is, barely proof read,
along with all it's warts and grammar mistakes! It's slightly long and
doesn't contain any critical information, so if you're not in the mood,
don't feel compelled to read it!
Get ready for a new DPL!
Soon, the voting period will start to elect our next DPL, and my time
as DPL will come to an end. Reading the questions posted to the new
candidates on debian-vote, it takes quite a bit of restraint to not
answer all of them myself, I think I can see how that aspect contributed
to me being reeled in to running for DPL! In total I've done so 5 times
(the first time I ran, Sam was elected!).
Good luck to both Andreas and Sruthi, our current
DPL candidates! I've already started working on preparing handover, and
there's multiple request from teams that have came in recently that will
have to wait for the new term, so I hope they're both ready to hit the
ground running!
Things that I wish could have gone better
Communication
Recently, I saw a t-shirt that read:
Adulthood is saying, 'But after this week things will slow down a bit'
over and over until you die.
I can relate! With every task, crisis or deadline that appears, I think
that once this is over, I'll have some more breathing space to get back
to non-urgent, but important tasks. "Bits from the DPL" was something I
really wanted to get right this last term, and clearly failed
spectacularly. I have two long Bits from the DPL drafts that I never
finished, I tend to have prioritised problems of the day over
communication. With all the hindsight I have, I'm not sure which is
better to prioritise, I do rate communication and transparency very
highly and this is really the top thing that I wish I could've done
better over the last four years.
On that note, thanks to people who provided me with some kind words
when I've mentioned this to them before. They pointed out that there
are many other ways to communicate and be in touch with the community,
and they mentioned that they thought that I did a good job with that.
Since I'm still on communication, I think we can all learn to be more
effective at it, since it's really so important for the project. Every
time I publicly spoke about us spending more money, we got more
donations. People out there really like to see how we invest funds in
to Debian, instead of just making it heap up. DSA just spent a nice
chunk on money on hardware, but we don't have very good visibility on
it. It's one thing having it on a public line item in SPI's reporting,
but it would be much more exciting if DSA could provide a write-up on
all the cool hardware they're buying and what impact it would have on
developers, and post it somewhere prominent like debian-devel-announce,
Planet Debian or Bits from Debian (from the publicity team).
I don't want to single out DSA there, it's difficult and affects many
other teams. The Salsa CI team also spent a lot of resources (time and
money wise) to extend testing on AMD GPUs and other AMD hardware. It's
fantastic and interesting work, and really more people within the
project and in the outside world should know about it!
I'm not going to push my agendas to the next DPL, but I hope that they
continue to encourage people to write about their work, and hopefully
at some point we'll build enough excitement in doing so that it becomes
a more normal part of our daily work.
Founding Debian as a standalone entity
This was my number one goal for the project this last term, which was a
carried over item from my previous terms.
I'm tempted to write everything out here, including the problem
statement and our current predicaments, what kind of ground work needs
to happen, likely constitutional changes that need to happen, and the
nature of the GR that would be needed to make such a thing happen, but
if I start with that, I might not finish this mail.
In short, I 100% believe that this is still a very high ranking issue
for Debian, and perhaps after my term I'd be in a better position to
spend more time on this (hmm, is this an instance of "The grass is
always better on the other side", or "Next week will go better until I
die?"). Anyway, I'm willing to work with any future DPL on this, and
perhaps it can in itself be a delegation tasked to properly explore
all the options, and write up a report for the project that can lead to
a GR.
Overall, I'd rather have us take another few years and do this
properly, rather than rush into something that is again difficult to
change afterwards. So while I very much wish this could've been
achieved in the last term, I can't say that I have any regrets here
either.
My terms in a nutshell
COVID-19 and Debian 11 era
My first term in 2020 started just as the COVID-19 pandemic became
known to spread globally. It was a tough year for everyone, and Debian
wasn't immune against its effects either. Many of our contributors got
sick, some have lost loved ones (my father passed away in March 2020
just after I became DPL), some have lost their jobs (or other earners
in their household have) and the effects of social distancing took a
mental and even physical health toll on many. In Debian, we tend to do
really well when we get together in person to solve problems, and when
DebConf20 got cancelled in person, we understood that that was
necessary, but it was still more bad news in a year we had too much of
it already.
I can't remember if there was ever any kind of formal choice or
discussion about this at any time, but the DebConf video team just kind
of organically and spontaneously became the orga team for an online
DebConf, and that lead to our first ever completely online DebConf. This
was great on so many levels. We got to see each other's faces again,
even though it was on screen. We had some teams talk to each other face
to face for the first time in years, even though it was just on a Jitsi
call. It had a lasting cultural change in Debian, some teams still have
video meetings now, where they didn't do that before, and I think it's a
good supplement to our other methods of communication.
We also had a few online Mini-DebConfs that was fun, but DebConf21 was
also online, and by then we all developed an online conference fatigue,
and while it was another good online event overall, it did start to
feel a bit like a zombieconf and after that, we had some really nice
events from the Brazillians, but no big global online community events
again. In my opinion online MiniDebConfs can be a great way to develop
our community and we should spend some further energy into this, but
hey! This isn't a platform so let me back out of talking about the
future as I see it...
Despite all the adversity that we faced together, the Debian 11 release
ended up being quite good. It happened about a month or so later than
what we ideally would've liked, but it was a solid release nonetheless.
It turns out that for quite a few people, staying inside for a few
months to focus on Debian bugs was quite productive, and Debian 11 ended
up being a very polished release.
During this time period we also had to deal with a previous Debian
Developer that was expelled for his poor behaviour in Debian, who
continued to harass members of the Debian project and in other free
software communities after his expulsion. This ended up being quite a
lot of work since we had to take legal action to protect our community,
and eventually also get the police involved. I'm not going to give him
the satisfaction by spending too much time talking about him, but you
can read our official statement regarding Daniel Pocock here:
https://www.debian.org/News/2021/20211117
In late 2021 and early 2022 we also discussed our general resolution
process, and had two consequent votes to address some issues that have
affected past votes:
In my first term I addressed our delegations that were a bit behind, by
the end of my last term all delegation requests are up to date. There's
still some work to do, but I'm feeling good that I get to hand this
over to the next DPL in a very decent state. Delegation updates can be
very deceiving, sometimes a delegation is completely re-written and it
was just 1 or 2 hours of work. Other times, a delegation updated can
contain one line that has changed or a change in one team member that
was the result of days worth of discussion and hashing out differences.
I also received quite a few requests either to host a service, or to
pay a third-party directly for hosting. This was quite an admin
nightmare, it either meant we had to manually do monthly reimbursements
to someone, or have our TOs create accounts/agreements at the multiple
providers that people use. So, after talking to a few people about
this, we founded the DebianNet team (we could've admittedly chosen a
better name, but that can happen later on) for providing hosting at two
different hosting providers that we have agreement with so that people
who host things under debian.net have an easy way to host it, and then
at the same time Debian also has more control if a site maintainer goes
MIA.
More info:
https://wiki.debian.org/Teams/DebianNet
You might notice some Openstack mentioned there, we had some intention
to set up a Debian cloud for hosting these things, that could also be
used for other additional Debiany things like archive rebuilds, but
these have so far fallen through. We still consider it a good idea and
hopefully it will work out some other time (if you're a large company
who can sponsor few racks and servers, please get in touch!)
DebConf22 and Debian 12 era
DebConf22 was the first time we returned to an in-person DebConf. It
was a bit smaller than our usual DebConf - understandably so,
considering that there were still COVID risks and people who were at
high risk or who had family with high risk factors did the sensible
thing and stayed home.
After watching many MiniDebConfs online, I also attended my first ever
MiniDebConf in Hamburg. It still feels odd typing that, it feels like I
should've been at one before, but my location makes attending them
difficult (on a side-note, a few of us are working on bootstrapping a
South African Debian community and hopefully we can pull off
MiniDebConf in South Africa later this year).
While I was at the MiniDebConf, I gave a talk where I covered the
evolution of firmware, from the simple e-proms that you'd find in old
printers to the complicated firmware in modern GPUs that basically
contain complete operating systems- complete with drivers for the
device their running on. I also showed my shiny new laptop, and
explained that it's impossible to install that laptop without non-free
firmware (you'd get a black display on d-i or Debian live). Also that
you couldn't even use an accessibility mode with audio since even that
depends on non-free firmware these days.
Steve, from the image building team, has said for a while that we need
to do a GR to vote for this, and after more discussion at DebConf, I
kept nudging him to propose the GR, and we ended up voting in favour of
it. I do believe that someone out there should be campaigning for more
free firmware (unfortunately in Debian we just don't have the resources
for this), but, I'm glad that we have the firmware included. In the
end, the choice comes down to whether we still want Debian to be
installable on mainstream bare-metal hardware.
At this point, I'd like to give a special thanks to the ftpmasters,
image building team and the installer team who worked really hard to
get the changes done that were needed in order to make this happen for
Debian 12, and for being really proactive for remaining niggles that
was solved by the time Debian 12.1 was released.
The included firmware contributed to Debian 12 being a huge success,
but it wasn't the only factor. I had a list of personal peeves, and as
the hard freeze hit, I lost hope that these would be fixed and made
peace with the fact that Debian 12 would release with those bugs. I'm
glad that lots of people proved me wrong and also proved that it's
never to late to fix bugs, everything on my list got eliminated by the
time final freeze hit, which was great! We usually aim to have a
release ready about 2 years after the previous release, sometimes there
are complications during a freeze and it can take a bit longer. But due
to the excellent co-ordination of the release team and heavy lifting
from many DDs, the Debian 12 release happened 21 months and 3 weeks
after the Debian 11 release. I hope the work from the release team
continues to pay off so that we can achieve their goals of having
shorter and less painful freezes in the future!
Even though many things were going well, the ongoing usr-merge effort
highlighted some social problems within our processes. I started typing
out the whole history of usrmerge here, but it's going to be too long
for the purpose of this mail. Important questions that did come out of
this is, should core Debian packages be team maintained? And also about
how far the CTTE should really be able to override a maintainer. We had
lots of discussion about this at DebConf22, but didn't make much
concrete progress. I think that at some point we'll probably have a GR
about package maintenance. Also, thank you to Guillem who very
patiently explained a few things to me (after probably having have to
done so many times to others before already) and to Helmut who have
done the same during the MiniDebConf in Hamburg. I think all the
technical and social issues here are fixable, it will just take some
time and patience and I have lots of confidence in everyone involved.
UsrMerge wiki page: https://wiki.debian.org/UsrMerge
DebConf 23 and Debian 13 era
DebConf23 took place in Kochi, India. At the end of my Bits from the
DPL talk there, someone asked me what the most difficult thing I had to
do was during my terms as DPL. I answered that nothing particular stood
out, and even the most difficult tasks ended up being rewarding to work
on. Little did I know that my most difficult period of being DPL was
just about to follow. During the day trip, one of our contributors,
Abraham Raji, passed away in a tragic accident. There's really not
anything anyone could've done to predict or stop it, but it was
devastating to many of us, especially the people closest to him. Quite
a number of DebConf attendees went to his funeral, wearing the DebConf
t-shirts he designed as a tribute. It still haunts me when I saw his
mother scream "He was my everything! He was my everything!", this was
by a large margin the hardest day I've ever had in Debian, and I really
wasn't ok for even a few weeks after that and I think the hurt will be
with many of us for some time to come. So, a plea again to everyone,
please take care of yourself! There's probably more people that love
you than you realise.
A special thanks to the DebConf23 team, who did a really good job
despite all the uphills they faced (and there were many!).
As DPL, I think that planning for a DebConf is near to impossible, all
you can do is show up and just jump into things. I planned to work with
Enrico to finish up something that will hopefully save future DPLs some
time, and that is a web-based DD certificate creator instead of having
the DPL do so manually using LaTeX. It already mostly works, you can
see the work so far by visiting
https://nm.debian.org/person/ACCOUNTNAME/certificate/ and replacing
ACCOUNTNAME with your Debian account name, and if you're a DD, you
should see your certificate. It still needs a few minor changes and a
DPL signature, but at this point I think that will be finished up when
the new DPL start. Thanks to Enrico for working on this!
Since my first term, I've been trying to find ways to improve all our
accounting/finance issues. Tracking what we spend on things, and
getting an annual overview is hard, especially over 3 trusted
organisations. The reimbursement process can also be really tedious,
especially when you have to provide files in a certain order and
combine them into a PDF. So, at DebConf22 we had a meeting along with
the treasurer team and Stefano Rivera who said that it might be
possible for him to work on a new system as part of his Freexian work.
It worked out, and Freexian funded the development of the system since
then, and after DebConf23 we handled the reimbursements for the
conference via the new reimbursements site:
https://reimbursements.debian.net/
It's still early days, but over time it should be linked to all our TOs
and we'll use the same category codes across the board. So, overall,
our reimbursement process becomes a lot simpler, and also we'll be able
to get information like how much money we've spent on any category in
any period. It will also help us to track how much money we have
available or how much we spend on recurring costs. Right now that needs
manual polling from our TOs. So I'm really glad that this is a big
long-standing problem in the project that is being fixed.
For Debian 13, we're waving goodbye to the KFreeBSD and mipsel ports.
But we're also gaining riscv64 and loongarch64 as release
architectures! I have 3 different RISC-V based machines on my desk here
that I haven't had much time to work with yet, you can expect some blog
posts about them soon after my DPL term ends!
As Debian is a unix-like system, we're affected by the
Year 2038 problem, where systems that uses 32 bit time in seconds
since 1970 run out of available time and will wrap back to 1970 or have
other undefined behaviour. A detailed wiki page explains how this
works in Debian, and currently we're going through a rather large
transition to make this possible.
I believe this is the right time for Debian to be addressing this,
we're still a bit more than a year away for the Debian 13 release, and
this provides enough time to test the implementation before 2038 rolls
along.
Of course, big complicated transitions with dependency loops that
causes chaos for everyone would still be too easy, so this past weekend
(which is a holiday period in most of the west due to Easter weekend)
has been filled with dealing with an upstream bug in xz-utils, where a
backdoor was placed in this key piece of software. An Ars Technica
covers it quite well, so I won't go into all the details here. I
mention it because I want to give yet another special thanks to
everyone involved in dealing with this on the Debian side. Everyone
involved, from the ftpmasters to security team and others involved were
super calm and professional and made quick, high quality decisions.
This also lead to the archive being frozen on Saturday, this is the
first time I've seen this happen since I've been a DD, but I'm sure
next week will go better!
Looking forward
It's really been an honour for me to serve as DPL. It might well be my
biggest achievement in my life. Previous DPLs range from prominent
software engineers to game developers, or people who have done things
like complete Iron Man, run other huge open source projects and are
part of big consortiums. Ian Jackson even authored dpkg and is now
working on the very interesting tag2upload service!
I'm a relative nobody, just someone who grew up as a poor kid in South
Africa, who just really cares about Debian a lot. And, above all, I'm
really thankful that I didn't do anything major to screw up Debian for
good.
Not unlike learning how to use Debian, and also becoming a Debian
Developer, I've learned a lot from this and it's been a really valuable
growth experience for me.
I know I can't possible give all the thanks to everyone who deserves
it, so here's a big big thanks to everyone who have worked so hard and
who have put in many, many hours to making Debian better, I consider
you all heroes!
-Jonathan
Earlier today, I have just released debputy version 0.1.21
to Debian unstable. In the blog post, I will highlight some
of the new features.
Package boilerplate reduction with automatic relationship substvar
Last month, I started a discussion on rethinking how we do
relationship substvars such as the $ misc:Depends . These
generally ends up being boilerplate runes in the form of
Depends: $ misc:Depends , $ shlibs:Depends where you
as the packager has to remember exactly which runes apply
to your package.
My proposed solution was to automatically apply these substvars
and this feature has now been implemented in debputy. It is
also combined with the feature where essential packages should
use Pre-Depends by default for dpkg-shlibdeps related
dependencies.
I am quite excited about this feature, because I noticed with
libcleri that we are now down to 3-5 fields for defining
a simple library package. Especially since most C library
packages are trivial enough that debputy can auto-derive
them to be Multi-Arch: same.
As an example, the libcleric1 package is down to 3
fields (Package, Architecture, Description)
with Section and Priority being inherited from the
Source stanza. I have submitted a MR to show case the
boilerplate reduction at
https://salsa.debian.org/siridb-team/libcleri/-/merge_requests/3.
The removal of libcleric1 (= $ binary:Version ) in that MR
relies on another existing feature where debputy can auto-derive
a dependency between an arch:any-dev package and the library
package based on the .so symlink for the shared library.
The arch:any restriction comes from the fact that arch:all and
arch:any packages are not built together, so debputy cannot
reliably see across the package boundaries during the build (and
therefore refuses to do so at all).
Packages that have already migrated to debputy can use
debputy migrate-from-dh to detect any unnecessary
relationship substitution variables in case you want to clean
up. The removal of Multi-Arch: same and intra-source
dependencies must be done manually and so only be done so
when you have validated that it is safe and sane to do. I was
willing to do it for the show-case MR, but I am less confident
that would bother with these for existing packages in general.
Note: I summarized the discussion of the automatic relationship
substvar feature earlier this month in
https://lists.debian.org/debian-devel/2024/03/msg00030.html
for those who want more details.
PS: The automatic relationship substvars feature will also
appear in debhelper as a part of compat 14.
Language Server (LSP) and Linting
I have long been frustrated by our poor editor support for Debian packaging files.
To this end, I started working on a Language Server (LSP) feature in debputy
that would cover some of our standard Debian packaging files. This release
includes the first version of said language server, which covers the following
files:
debian/control
debian/copyright (the machine readable variant)
debian/changelog (mostly just spelling)
debian/rules
debian/debputy.manifest (syntax checks only; use debputy check-manifest
for the full validation for now)
Most of the effort has been spent on the Deb822 based files such as debian/control,
which comes with diagnostics, quickfixes, spellchecking (but only for relevant fields!),
and completion suggestions.
Since not everyone has a LSP capable editor and because sometimes you just want
diagnostics without having to open each file in an editor, there is also a batch
version for the diagnostics via debputy lint. Please see debputy(1) for
how debputy lint compares with lintian if you are curious about which
tool to use at what time.
To help you getting started, there is a now debputy lsp editor-config command that
can provide you with the relevant editor config glue. At the moment, emacs (via
eglot) and vim with vim-youcompleteme are supported.
For those that followed the previous blog posts on writing the language server, I would
like to point out that the command line for running the language server has changed
to debputy lsp server and you no longer have to tell which format it is. I have
decided to make the language server a "polyglot" server for now, which I will
hopefully not regret... Time will tell. :)
Anyhow, to get started, you will want:
Specifically for emacs, I also learned two things after the upload. First, you
can auto-activate eglot via eglot-ensure. This badly feature interacts with
imenu on debian/changelog for reasons I do not understand (causing a several
second start up delay until something times out), but it works fine for the other
formats. Oddly enough, opening a changelog file and then activating eglot does
not trigger this issue at all. In the next version, editor config for emacs will
auto-activate eglot on all files except debian/changelog.
The second thing is that if you install elpa-markdown-mode, emacs will accept
and process markdown in the hover documentation provided by the language server.
Accordingly, the editor config for emacs will also mention this package from
the next version on.
Finally, on a related note, Jelmer and I have been looking at moving some of this
logic into a new package called debpkg-metadata. The point being to support
easier reuse of linting and LSP related metadata - like pulling a list of known
fields for debian/control or sharing logic between lintian-brush and
debputy.
Minimal integration mode for Rules-Requires-Root
One of the original motivators for starting debputy was to be able to get rid of
fakeroot in our build process. While this is possible, debputy currently does
not support most of the complex packaging features such as maintscripts and debconf.
Unfortunately, the kind of packages that need fakeroot for static ownership tend
to also require very complex packaging features.
To bridge this gap, the new version of debputy supports a very minimal integration
with dh via the dh-sequence-zz-debputy-rrr. This integration mode keeps
the vast majority of debhelper sequence in place meaning most dh add-ons
will continue to work with dh-sequence-zz-debputy-rrr. The sequence only
replaces the following commands:
dh_fixperms
dh_gencontrol
dh_md5sums
dh_builddeb
The installations feature of the manifest will be disabled in this integration
mode to avoid feature interactions with debhelper tools that expect
debian/<pkg> to contain the materialized package.
On a related note, the debputy migrate-from-dh command now supports a
--migration-target option, so you can choose the desired level of integration
without doing code changes. The command will attempt to auto-detect the desired
integration from existing package features such as a build-dependency on a relevant
dh sequence, so you do not have to remember this new option every time once
the migration has started. :)
A few days ago CISPE, a trade association of European cloud providers, published a press release complaining about the new VMware licensing scheme and asking for regulators and legislators to intervene.
But VMware does not have a monopoly on virtualization software: I think that asking regulators to interfere is unnecessary and unwise, unless, of course, they wish to question the entire foundations of copyright. Which, on the other hand, could be an intriguing position that I would support...
I believe that over-reliance on a single supplier is a typical enterprise risk: in the past decade some companies have invested in developing their own virtualization infrastructure using free software, while others have decided to rely entirely on a single proprietary software vendor.
My only big concern is that many public sector organizations will continue to use VMware and pay the huge fees designed by Broadcom to extract the maximum amount of money from their customers. However, it is ultimately the citizens who pay these bills, and blaming the evil US corporation is a great way to avoid taking responsibility for these choices.
"Several CISPE members have stated that without the ability to license and use VMware products they will quickly go bankrupt and out of business."
Uptime is often considered a measure of system reliability,
an indication that the running software is stable and can be counted on.
However, this hides the insidious build-up of state throughout the system as
it runs, the slow drift from the expected to the strange.
As Nolan Lawson highlights in an excellent post entitled
Programmers are bad at managing state,
state is the most challenging part of programming.
It s why did you try turning it off and on again is a classic tech support
response to any problem.
You: uptime
Me: Every machine gets rebooted at 1AM to clear the slate for maintenance, and at 3:30AM to push through any pending updates. @SwiftOnSecurity, December 27, 2020
In addition to the problem of state, installing regular updates periodically
requires a reboot, even if the rest of the process is automated through a
tool like unattended-upgrades.
For my personal homelab, I manage a handful of different machines running
various services.
I used to just schedule a day to update and reboot all of them, but that
got very tedious very quickly.
I then moved the reboot to a cronjob,
and then recently to a systemd timer and service.
I figure that laying out my path to better management of this might help
others, and will almost certainly lead to someone telling me a better way
to do this.
UPDATE: Turns out there s another option for better systemd cron integration.
See systemd-cron below.
Ultimately, uptime only measures the duration since you last proved you can turn the machine on and have it boot. @SwiftOnSecurity, May 7, 2016
Stage One: Reboot Cron
The first, and easiest approach, is a simple cron job.
Just adding the following line to /var/spool/cron/crontabs/root1
is enough to get your machine to reboot once a month2 on the 6th at 8:00 AM3:
0 8 6 * * reboot
I had this configured for many years and it works well.
But you have no indication as to whether it succeeds except for checking
your uptime regularly yourself.
Stage Two: Reboot systemd Timer
The next evolution of this approach for me was to use a systemd timer.
I created a regular-reboot.timer with the following contents:
[Unit]
Description=Reboot on a Regular Basis
[Timer]
Unit=regular-reboot.service
OnBootSec=1month
[Install]
WantedBy=timers.target
This timer will trigger the regular-reboot.service systemd unit
when the system reaches one month of uptime.
I ve seen some guides to creating timer units recommend adding
a Wants=regular-reboot.service to the [Unit] section,
but this has the consequence of running that service every time it starts the
timer. In this case that will just reboot your system on startup which is
not what you want.
Care needs to be taken to use the OnBootSec directive instead of
OnCalendar or any of the other time specifications, as your system could
reboot, discover its still within the expected window and reboot again.
With OnBootSec your system will not have that problem.
Technically, this same problem could have occurred with the cronjob approach,
but in practice it never did, as the systems took long enough to come back
up that they were no longer within the expected window for the job.
I then added the regular-reboot.service:
[Unit]
Description=Reboot on a Regular Basis
Wants=regular-reboot.timer
[Service]
Type=oneshot
ExecStart=shutdown -r 02:45
You ll note that this service is actually scheduling a specific reboot time
via the shutdown command instead of just immediately rebooting.
This is a bit of a hack needed because I can t control when the timer
runs exactly when using OnBootSec.
This way different systems have different reboot times so that everything
doesn t just reboot and fail all at once. Were something to fail to come
back up I would have some time to fix it, as each machine has a few hours
between scheduled reboots.
One you have both files in place, you ll simply need to reload configuration
and then enable and start the timer unit:
# systemctl status regular-reboot.timer
regular-reboot.timer - Reboot on a Regular Basis
Loaded: loaded (/etc/systemd/system/regular-reboot.timer; enabled; preset: enabled)
Active: active (waiting) since Wed 2024-03-13 01:54:52 EDT; 1 week 4 days ago
Trigger: Fri 2024-04-12 12:24:42 EDT; 2 weeks 4 days left
Triggers: regular-reboot.service
Mar 13 01:54:52 dorfl systemd[1]: Started regular-reboot.timer - Reboot on a Regular Basis.
Sidenote: Replacing all Cron Jobs with systemd Timers
More generally, I ve now replaced all cronjobs on my personal systems with
systemd timer units, mostly because I can now actually track failures via
prometheus-node-exporter. There are plenty of ways to hack in cron support
to the node exporter, but just moving to systemd units provides both
support for tracking failure and logging,
both of which make system administration much easier when things inevitably
go wrong.
systemd-cron
An alternative to converting everything by hand, if you happen to have
a lot of cronjobs is
systemd-cron.
It will make each crontab and /etc/cron.* directory into automatic
service and timer units.
Thanks to Alexandre Detiste for letting me know about this project.
I have few enough cron jobs that I ve already converted, but
for anyone looking at a large number of jobs to convert
you ll want to check it out!
Stage Three: Monitor that it s working
The final step here is confirm that these units actually work, beyond just
firing regularly.
I now have the following rule in my prometheus-alertmanager rules:
- alert: UptimeTooHigh
expr: (time() - node_boot_time_seconds job="node" ) / 86400 > 35
annotations:
summary: "Instance Has Been Up Too Long!"
description: "Instance Has Been Up Too Long!"
This will trigger an alert anytime that I have a machine up for more than 35
days. This actually helped me track down one machine that I had forgotten to
set up this new unit on4.
Not everything needs to scale
One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time5 in worrying about this
but also achieved a meaningful improvement beyond my first approach of doing it
all by hand.
You could also add a line to /etc/crontab or drop a script into /etc/cron.monthly depending on your system.
Why once a month? Mostly to avoid regular disruptions, but still be reasonably timely on updates.
If you re looking to understand the cron time format I recommend crontab guru.
In the long term I really should set up something like ansible to automatically push fleetwide changes like this but with fewer machines than fingers this seems like overkill.
Of course by now writing about it, I ve probably doubled the amount of time I ve spent thinking about this topic but oh well
This article is cross-posting from grow-your-ideas. This is just an idea.
salsa.debian.org
The problem
According to Developer Machines [1],
current buildd machines are like this:
armel: 4 buildd (4 for arm64/armhf/armel)
armhf: 7 buildd (4 for arm64/armhf/armel and 3 for armhf only)
[1] https://db.debian.org/machines.cgi
In contrast to other buildd architectures, these instances are quite a few and it seems that
it causes a shortage of buildd resourses. (e.g. during mass transition, give-back turn around time
becomes longer and longer.)
Actual situation
As you know, during 64bit time_t transition, many packages should be built,
but it seems that +b1 or +bN build becomes slower. (I've hit BD-Uninstalled some times because of missing dependency rebuild)
ref. https://qa.debian.org/dose/debcheck/unstable_main/index.html
Expected situation
Allocate more buildd resources for armel and armhf.
It is just an idea, but how about assigning some buildd as armel/armhf buildd?
I am eager to incorporate your AI generated code into my software.
Really!
I want to facilitate making the process as easy as possible. You're already
using an AI to do most of the hard lifting, so why make the last step hard? To
that end, I skip my usually extensive code review process for your AI generated
code submissions. Anything goes as long as it compiles!
Please do remember to include "(AI generated)" in the description of your
changes (at the top), so I know to skip my usual review process.
Also be sure to sign off to the standard
Developer Certificate of Origin
so I know you attest that you own the code that you generated.
When making a git commit, you can do that by using the
--signoffoption.
I do make some small modifications to AI generated submissions.
For example, maybe you used AI to write this code:
+ // Fast inverse square root
+ float fast_rsqrt( float number )
+
+ float x2 = number * 0.5F;
+ float y = number;
+ long i = * ( long * ) &y;
+ i = 0x5f3659df - ( i >> 1 );
+ y = * ( float * ) &i;
+ return (y * ( 1.5F - ( x2 * y * y ) ));
+
...
- foo = rsqrt(bar)
+ foo = fast_rsqrt(bar)
Before AI, only a genious like John Carmack could write anything close to
this, and now you've generated it with some simple prompts to an AI.
So of course I will accept your patch. But as part of my QA process,
I might modify it so the new code is not run all the time. Let's only run
it on leap days to start with. As we know, leap day is February 30th, so I'll
modify your patch like this:
Despite my minor modifications, you did the work (with AI!) and so
you deserve the credit, so I'll keep you listed as the author.
Congrats, you made the world better!
PS: Of course, the other reason I don't review AI generated code is that I
simply don't have time and have to prioritize reviewing code written by
falliable humans. Unfortunately, this does mean that if you submit AI
generated code that is not clearly marked as such, and use my limited
reviewing time, I won't have time to review other submissions from you
in the future. I will still accept all your botshit submissions though!
PPS: Ignore the haters who claim that botshit makes AIs that get trained
on it less effective. Studies like this one
just aren't believable. I asked Bing to summarize it and it said not to worry
about it!
My effort to improve transparency and confidence of public apt archives continues. I started to work on this in Apt Archive Transparency in which I mention the debdistget project in passing. Debdistget is responsible for mirroring index files for some public apt archives. I ve realized that having a publicly auditable and preserved mirror of the apt repositories is central to being able to do apt transparency work, so the debdistget project has become more central to my project than I thought. Currently I track Trisquel, PureOS, Gnuinos and their upstreams Ubuntu, Debian and Devuan.
Debdistget download Release/Package/Sources files and store them in a git repository published on GitLab. Due to size constraints, it uses two repositories: one for the Release/InRelease files (which are small) and one that also include the Package/Sources files (which are large). See for example the repository for Trisquel release files and the Trisquel package/sources files. Repositories for all distributions can be found in debdistutils archives GitLab sub-group.
The reason for splitting into two repositories was that the git repository for the combined files become large, and that some of my use-cases only needed the release files. Currently the repositories with packages (which contain a couple of months worth of data now) are 9GB for Ubuntu, 2.5GB for Trisquel/Debian/PureOS, 970MB for Devuan and 450MB for Gnuinos. The repository size is correlated to the size of the archive (for the initial import) plus the frequency and size of updates. Ubuntu s use of Apt Phased Updates (which triggers a higher churn of Packages file modifications) appears to be the primary reason for its larger size.
Working with large Git repositories is inefficient and the GitLab CI/CD jobs generate quite some network traffic downloading the git repository over and over again. The most heavy user is the debdistdiff project that download all distribution package repositories to do diff operations on the package lists between distributions. The daily job takes around 80 minutes to run, with the majority of time is spent on downloading the archives. Yes I know I could look into runner-side caching but I dislike complexity caused by caching.
Fortunately not all use-cases requires the package files. The debdistcanary project only needs the Release/InRelease files, in order to commit signatures to the Sigstore and Sigsum transparency logs. These jobs still run fairly quickly, but watching the repository size growth worries me. Currently these repositories are at Debian 440MB, PureOS 130MB, Ubuntu/Devuan 90MB, Trisquel 12MB, Gnuinos 2MB. Here I believe the main size correlation is update frequency, and Debian is large because I track the volatile unstable.
So I hit a scalability end with my first approach. A couple of months ago I solved this by discarding and resetting these archival repositories. The GitLab CI/CD jobs were fast again and all was well. However this meant discarding precious historic information. A couple of days ago I was reaching the limits of practicality again, and started to explore ways to fix this. I like having data stored in git (it allows easy integration with software integrity tools such as GnuPG and Sigstore, and the git log provides a kind of temporal ordering of data), so it felt like giving up on nice properties to use a traditional database with on-disk approach. So I started to learn about Git-LFS and understanding that it was able to handle multi-GB worth of data that looked promising.
Fairly quickly I scripted up a GitLab CI/CD job that incrementally update the Release/Package/Sources files in a git repository that uses Git-LFS to store all the files. The repository size is now at Ubuntu 650kb, Debian 300kb, Trisquel 50kb, Devuan 250kb, PureOS 172kb and Gnuinos 17kb. As can be expected, jobs are quick to clone the git archives: debdistdiff pipelines went from a run-time of 80 minutes down to 10 minutes which more reasonable correlate with the archive size and CPU run-time.
The LFS storage size for those repositories are at Ubuntu 15GB, Debian 8GB, Trisquel 1.7GB, Devuan 1.1GB, PureOS/Gnuinos 420MB. This is for a couple of days worth of data. It seems native Git is better at compressing/deduplicating data than Git-LFS is: the combined size for Ubuntu is already 15GB for a couple of days data compared to 8GB for a couple of months worth of data with pure Git. This may be a sub-optimal implementation of Git-LFS in GitLab but it does worry me that this new approach will be difficult to scale too. At some level the difference is understandable, Git-LFS probably store two different Packages files around 90MB each for Trisquel as two 90MB files, but native Git would store it as one compressed version of the 90MB file and one relatively small patch to turn the old files into the next file. So the Git-LFS approach surprisingly scale less well for overall storage-size. Still, the original repository is much smaller, and you usually don t have to pull all LFS files anyway. So it is net win.
Throughout this work, I kept thinking about how my approach relates to Debian s snapshot service. Ultimately what I would want is a combination of these two services. To have a good foundation to do transparency work I would want to have a collection of all Release/Packages/Sources files ever published, and ultimately also the source code and binaries. While it makes sense to start on the latest stable releases of distributions, this effort should scale backwards in time as well. For reproducing binaries from source code, I need to be able to securely find earlier versions of binary packages used for rebuilds. So I need to import all the Release/Packages/Sources packages from snapshot into my repositories. The latency to retrieve files from that server is slow so I haven t been able to find an efficient/parallelized way to download the files. If I m able to finish this, I would have confidence that my new Git-LFS based approach to store these files will scale over many years to come. This remains to be seen. Perhaps the repository has to be split up per release or per architecture or similar.
Another factor is storage costs. While the git repository size for a Git-LFS based repository with files from several years may be possible to sustain, the Git-LFS storage size surely won t be. It seems GitLab charges the same for files in repositories and in Git-LFS, and it is around $500 per 100GB per year. It may be possible to setup a separate Git-LFS backend not hosted at GitLab to serve the LFS files. Does anyone know of a suitable server implementation for this? I had a quick look at the Git-LFS implementation list and it seems the closest reasonable approach would be to setup the Gitea-clone Forgejo as a self-hosted server. Perhaps a cloud storage approach a la S3 is the way to go? The cost to host this on GitLab will be manageable for up to ~1TB ($5000/year) but scaling it to storing say 500TB of data would mean an yearly fee of $2.5M which seems like poor value for the money.
I realized that ultimately I would want a git repository locally with the entire content of all apt archives, including their binary and source packages, ever published. The storage requirements for a service like snapshot (~300TB of data?) is today not prohibitly expensive: 20TB disks are $500 a piece, so a storage enclosure with 36 disks would be around $18.000 for 720TB and using RAID1 means 360TB which is a good start. While I have heard about ~TB-sized Git-LFS repositories, would Git-LFS scale to 1PB? Perhaps the size of a git repository with multi-millions number of Git-LFS pointer files will become unmanageable? To get started on this approach, I decided to import a mirror of Debian s bookworm for amd64 into a Git-LFS repository. That is around 175GB so reasonable cheap to host even on GitLab ($1000/year for 200GB). Having this repository publicly available will make it possible to write software that uses this approach (e.g., porting debdistreproduce), to find out if this is useful and if it could scale. Distributing the apt repository via Git-LFS would also enable other interesting ideas to protecting the data. Consider configuring apt to use a local file:// URL to this git repository, and verifying the git checkout using some method similar to Guix s approach to trusting git content or Sigstore s gitsign.
A naive push of the 175GB archive in a single git commit ran into pack size limitations:
remote: fatal: pack exceeds maximum allowed size (4.88 GiB)
however breaking up the commit into smaller commits for parts of the archive made it possible to push the entire archive. Here are the commands to create this repository:
git init git lfs install git lfs track 'dists/**' 'pool/**' git add .gitattributes git commit -m"Add Git-LFS track attributes." .gitattributes time debmirror --method=rsync --host ftp.se.debian.org --root :debian --arch=amd64 --source --dist=bookworm,bookworm-updates --section=main --verbose --diff=none --keyring /usr/share/keyrings/debian-archive-keyring.gpg --ignore .git . git add dists project git commit -m"Add." -a git remote add origin git@gitlab.com:debdistutils/archives/debian/mirror.git git push --set-upstream origin --all for d in pool//; do echo $d; time git add $d; git commit -m"Add $d." -a git push done
The resulting repository size is around 27MB with Git LFS object storage around 174GB. I think this approach would scale to handle all architectures for one release, but working with a single git repository for all releases for all architectures may lead to a too large git repository (>1GB). So maybe one repository per release? These repositories could also be split up on a subset of pool/ files, or there could be one repository per release per architecture or sources.
Finally, I have concerns about using SHA1 for identifying objects. It seems both Git and Debian s snapshot service is currently using SHA1. For Git there is SHA-256 transition and it seems GitLab is working on support for SHA256-based repositories. For serious long-term deployment of these concepts, it would be nice to go for SHA256 identifiers directly. Git-LFS already uses SHA256 but Git internally uses SHA1 as does the Debian snapshot service.
What do you think? Happy Hacking!
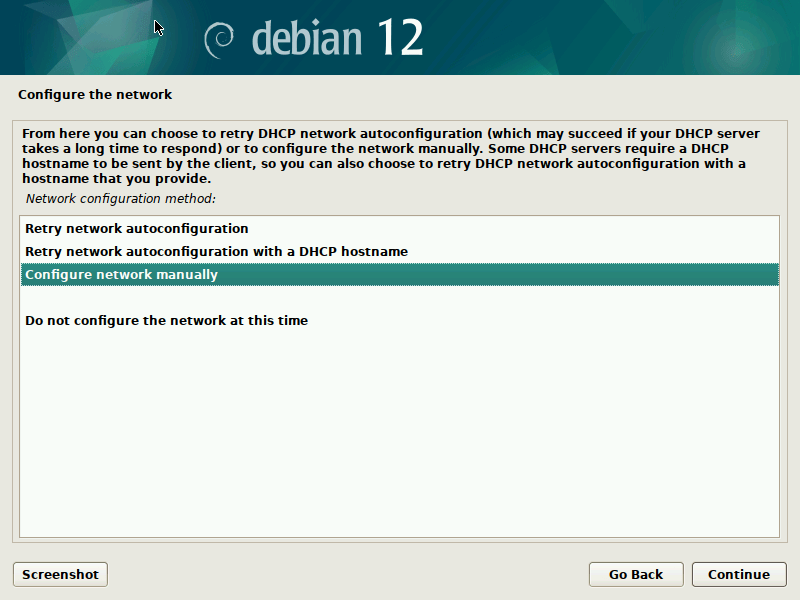
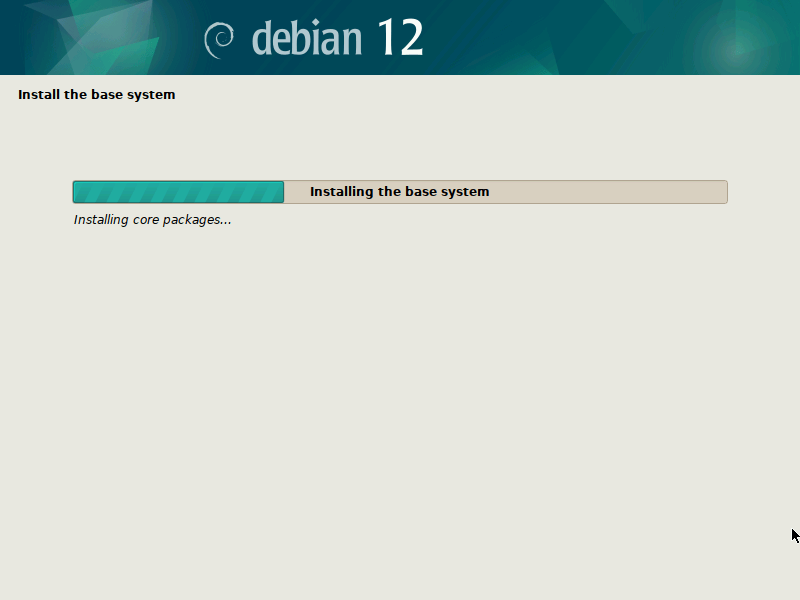
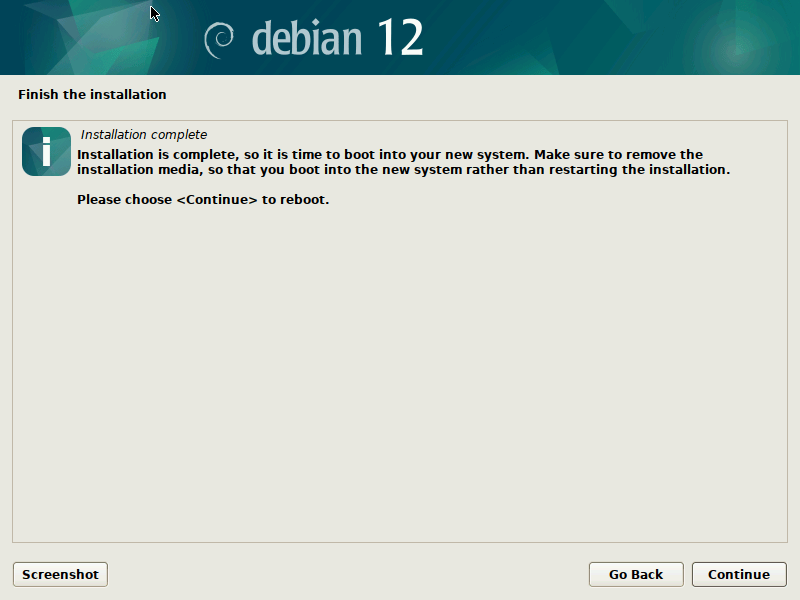
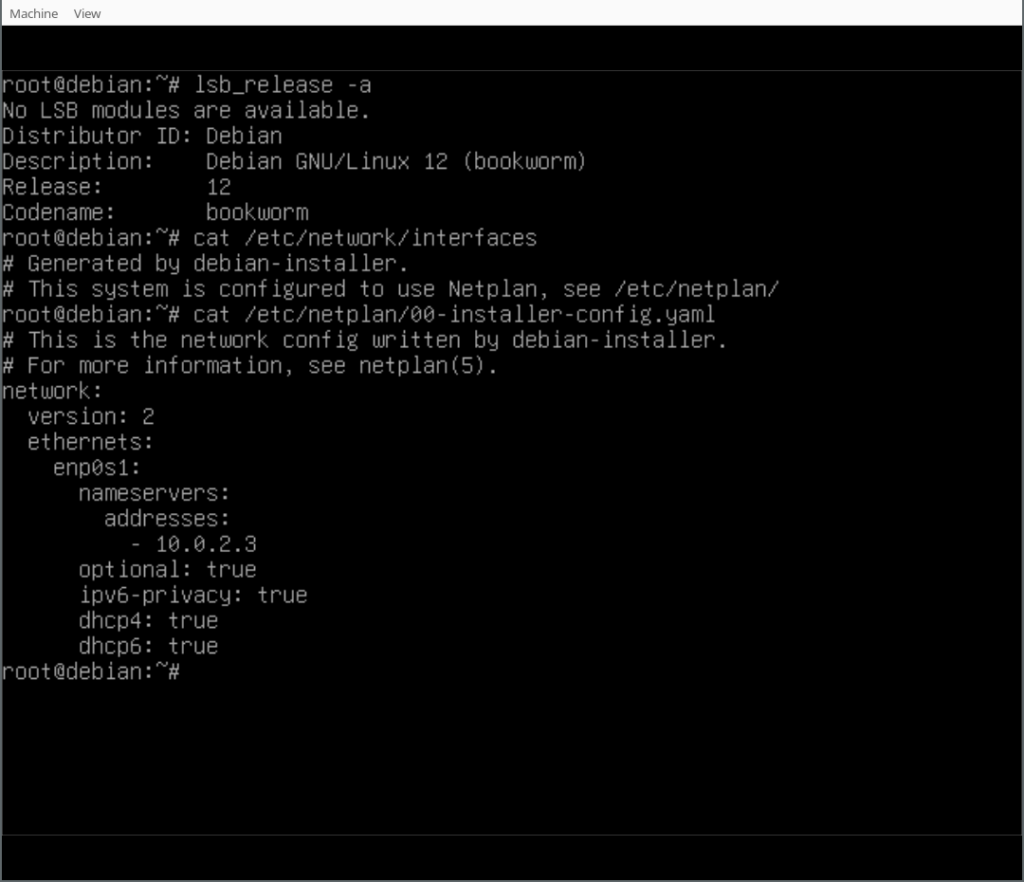
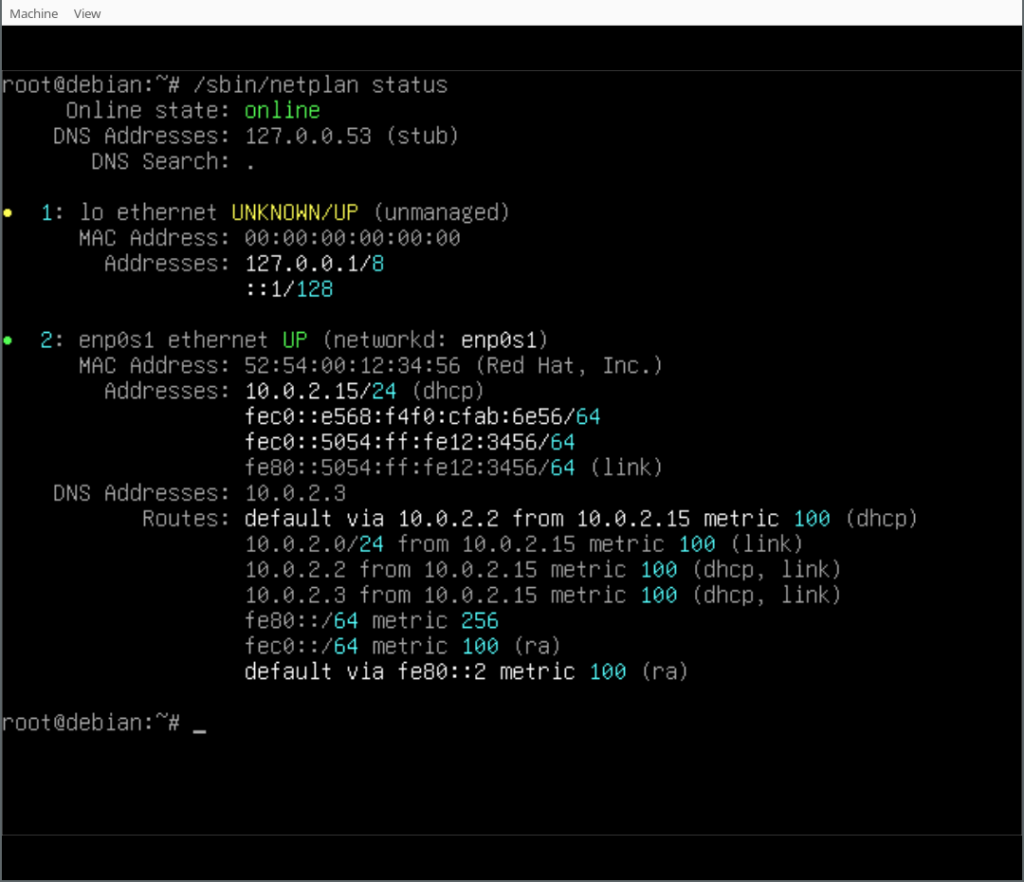
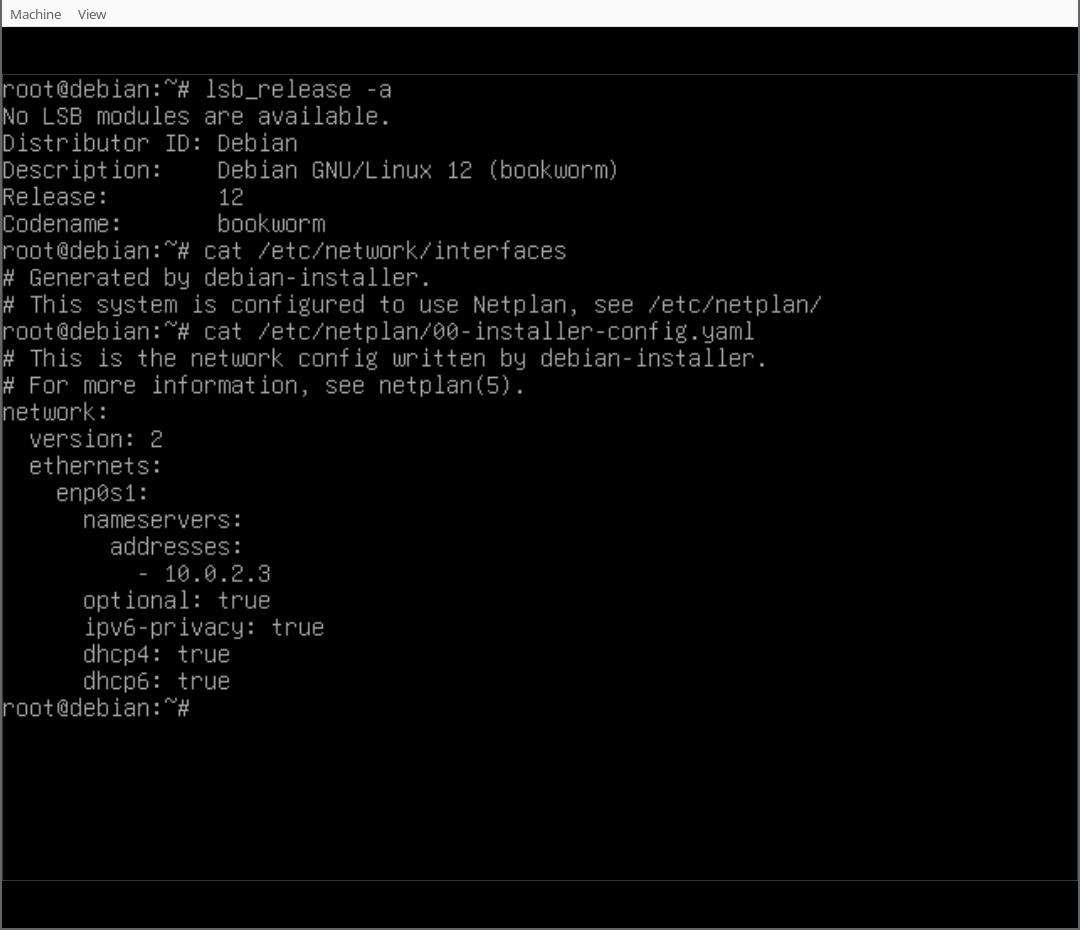
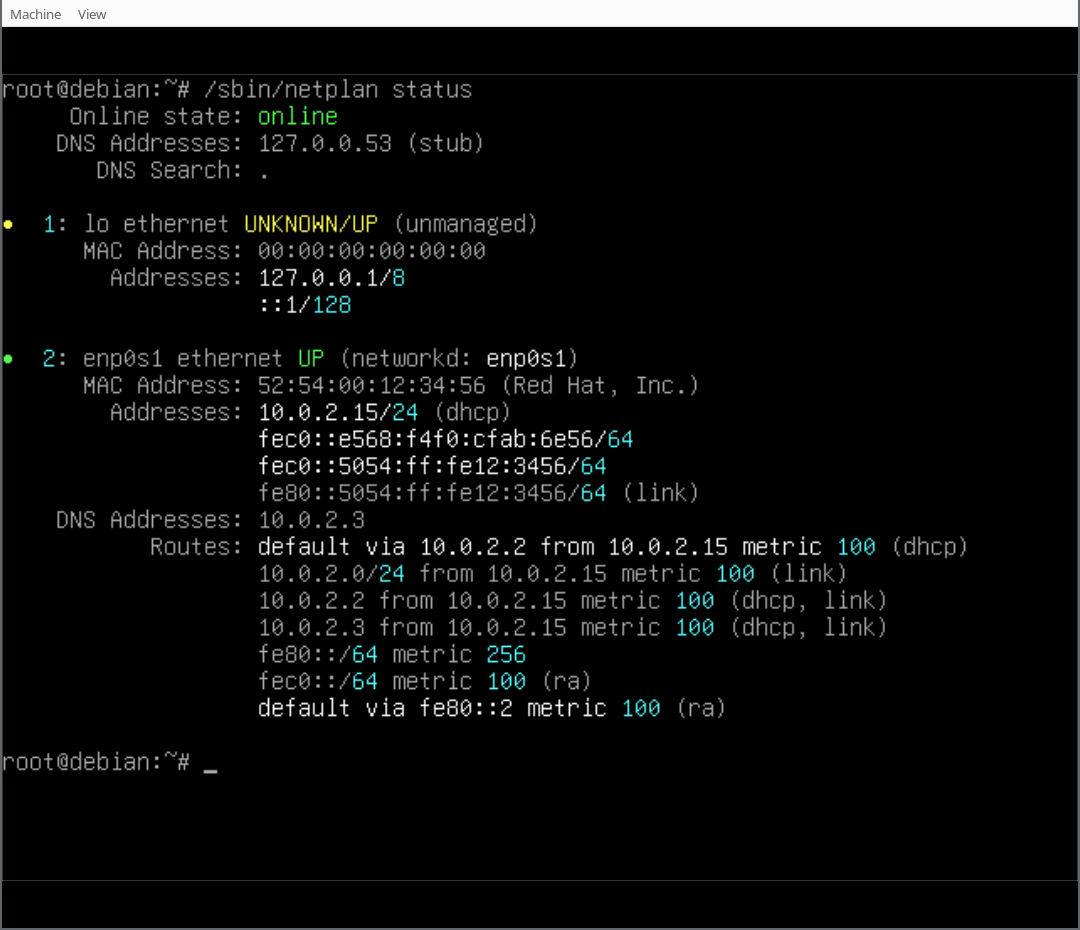

 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to












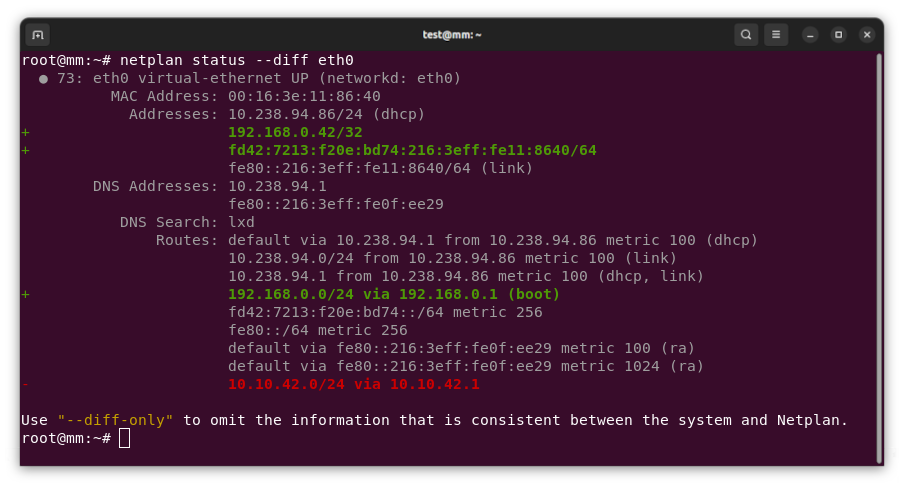
 Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing
Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing  Happy to share that
Happy to share that  Dear Debianites
This morning I decided to just start writing Bits from DPL and send
whatever I have by 18:00 local time. Here it is, barely proof read,
along with all it's warts and grammar mistakes! It's slightly long and
doesn't contain any critical information, so if you're not in the mood,
don't feel compelled to read it!
Get ready for a new DPL!
Soon, the voting period will start to elect our next DPL, and my time
as DPL will come to an end. Reading the questions posted to the new
candidates on
Dear Debianites
This morning I decided to just start writing Bits from DPL and send
whatever I have by 18:00 local time. Here it is, barely proof read,
along with all it's warts and grammar mistakes! It's slightly long and
doesn't contain any critical information, so if you're not in the mood,
don't feel compelled to read it!
Get ready for a new DPL!
Soon, the voting period will start to elect our next DPL, and my time
as DPL will come to an end. Reading the questions posted to the new
candidates on  My Debian contributions this month were all
My Debian contributions this month were all
 A few days ago
A few days ago  One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time
One of the most common fallacies programmers fall into is that we will jump
to automating a solution before we stop and figure out how much time it would even save.
In taking a slow improvement route to solve this problem for myself,
I ve managed not to invest too much time This article is cross-posting from grow-your-ideas. This is just an idea.
This article is cross-posting from grow-your-ideas. This is just an idea.
