With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up I d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. For now, we ll be using a custom ISO image, while waiting for the above-mentioned merge-proposal to be landed. Furthermore, as the Debian archive is going through major transitions builds of the unstable branch of d-i don t currently work. So I implemented a small backport, producing updated netcfg and netcfg-static for Bookworm, which can be used as localudebs/ during the d-i build.
Let s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
Now let s download the custom mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes, as mentioned above.
TODO: localudebs/
Next we ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
Finally, let s launch the installer using a custom preseed.cfg file, that will automatically install Netplan for us in the target system. A minimal preseed file could look like this:
For this demo, we re installing the full netplan.io package (incl. Python CLI), as the netplan-generator package was not yet split out as an independent binary in the Bookworm cycle. You can choose the preseed file from a set of different variants to test the different configurations:
We re using the custom linux kernel and initrd.gz here to be able to pass the PRESEED_URL as a parameter to the kernel s cmdline directly. Launching this VM should bring up the normal debian-installer in its netboot/gtk form:
Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
Done! After the installation finished you can reboot into your virgin Debian Bookworm system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was written by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
Finally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
In our case we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more join the discussion at Salsa:installer-team/netcfg and find us at GitHub:netplan.
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
write build-ids to debian binary control files,
so that the build-id (more specifically, the ELF note
.note.gnu.build-id) wound up in the Debian apt archive metadata.
I ve always thought this was super cool, and seeing as how Michael Stapelberg
blogged
some great pointers around the ecosystem, including the fancy new debuginfod
service, and the
find-dbgsym-packages
helper, which uses these same headers, I don t think I m the only one.
At work I ve been using a lot of rust,
specifically, async rust using tokio. To try and work on
my style, and to dig deeper into the how and why of the decisions made in these
frameworks, I ve decided to hack up a project that I ve wanted to do ever
since 2015 write a debug filesystem. Let s get to it.
Back to the Future
Time to admit something. I really love Plan 9. It s
just so good. So many ideas from Plan 9 are just so prescient, and everything
just feels right. Not just right like, feels good like, correct. The
bit that I ve always liked the most is 9p, the network protocol for serving
a filesystem over a network. This leads to all sorts of fun programs, like the
Plan 9 ftp client being a 9p server you mount the ftp server and access
files like any other files. It s kinda like if fuse were more fully a part
of how the operating system worked, but fuse is all running client-side. With
9p there s a single client, and different servers that you can connect to,
which may be backed by a hard drive, remote resources over something like SFTP, FTP, HTTP or even purely synthetic.
The interesting (maybe sad?) part here is that 9p wound up outliving Plan 9
in terms of adoption 9p is in all sorts of places folks don t usually expect.
For instance, the Windows Subsystem for Linux uses the 9p protocol to share
files between Windows and Linux. ChromeOS uses it to share files with Crostini,
and qemu uses 9p (virtio-p9) to share files between guest and host. If you re
noticing a pattern here, you d be right; for some reason 9p is the go-to protocol
to exchange files between hypervisor and guest. Why? I have no idea, except maybe
due to being designed well, simple to implement, and it s a lot easier to validate the data being shared
and validate security boundaries. Simplicity has its value.
As a result, there s a lot of lingering 9p support kicking around. Turns out
Linux can even handle mounting 9p filesystems out of the box. This means that I
can deploy a filesystem to my LAN or my localhost by running a process on top
of a computer that needs nothing special, and mount it over the network on an
unmodified machine unlike fuse, where you d need client-specific software
to run in order to mount the directory. For instance, let s mount a 9p
filesystem running on my localhost machine, serving requests on 127.0.0.1:564
(tcp) that goes by the name mountpointname to /mnt.
Linux will mount away, and attach to the filesystem as the root user, and by default,
attach to that mountpoint again for each local user that attempts to use
it. Nifty, right? I think so. The server is able
to keep track of per-user access and authorization
along with the host OS.
WHEREIN I STYX WITH IT
Since I wanted to push myself a bit more with rust and tokio specifically,
I opted to implement the whole stack myself, without third party libraries on
the critical path where I could avoid it. The 9p protocol (sometimes called
Styx, the original name for it) is incredibly simple. It s a series of client
to server requests, which receive a server to client response. These are,
respectively, T messages, which transmit a request to the server, which
trigger an R message in response (Reply messages). These messages are
TLV payload
with a very straight forward structure so straight forward, in fact, that I
was able to implement a working server off nothing more than a handful of man
pages.
Later on after the basics worked, I found a more complete
spec page
that contains more information about the
unix specific variant
that I opted to use (9P2000.u rather than 9P2000) due to the level
of Linux specific support for the 9P2000.u variant over the 9P2000
protocol.
MR ROBOTO
The backend stack over at zoo is rust and tokio
running i/o for an HTTP and WebRTC server. I figured I d pick something
fairly similar to write my filesystem with, since 9P can be implemented
on basically anything with I/O. That means tokio tcp server bits, which
construct and use a 9p server, which has an idiomatic Rusty API that
partially abstracts the raw R and T messages, but not so much as to
cause issues with hiding implementation possibilities. At each abstraction
level, there s an escape hatch allowing someone to implement any of
the layers if required. I called this framework
arigato which can be found over on
docs.rs and
crates.io.
/// Simplified version of the arigato File trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.File.html
trait File
/// OpenFile is the type returned by this File via an Open call.
typeOpenFile: OpenFile;
/// Return the 9p Qid for this file. A file is the same if the Qid is
/// the same. A Qid contains information about the mode of the file,
/// version of the file, and a unique 64 bit identifier.
fnqid(&self) -> Qid;
/// Construct the 9p Stat struct with metadata about a file.
async fnstat(&self) -> FileResult<Stat>;
/// Attempt to update the file metadata.
async fnwstat(&mut self, s: &Stat) -> FileResult<()>;
/// Traverse the filesystem tree.
async fnwalk(&self, path: &[&str]) -> FileResult<(Option<Self>, Vec<Self>)>;
/// Request that a file's reference be removed from the file tree.
async fnunlink(&mut self) -> FileResult<()>;
/// Create a file at a specific location in the file tree.
async fncreate(
&mut self,
name: &str,
perm: u16,
ty: FileType,
mode: OpenMode,
extension: &str,
) -> FileResult<Self>;
/// Open the File, returning a handle to the open file, which handles
/// file i/o. This is split into a second type since it is genuinely
/// unrelated -- and the fact that a file is Open or Closed can be
/// handled by the arigato server for us.
async fnopen(&mut self, mode: OpenMode) -> FileResult<Self::OpenFile>;
/// Simplified version of the arigato OpenFile trait; this isn't actually
/// the same trait; there's some small cosmetic differences. The
/// actual trait can be found at:
///
/// https://docs.rs/arigato/latest/arigato/server/trait.OpenFile.html
trait OpenFile
/// iounit to report for this file. The iounit reported is used for Read
/// or Write operations to signal, if non-zero, the maximum size that is
/// guaranteed to be transferred atomically.
fniounit(&self) -> u32;
/// Read some number of bytes up to buf.len() from the provided
/// offset of the underlying file. The number of bytes read is
/// returned.
async fnread_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
/// Write some number of bytes up to buf.len() from the provided
/// offset of the underlying file. The number of bytes written
/// is returned.
fnwrite_at(
&mut self,
buf: &mut [u8],
offset: u64,
) -> FileResult<u32>;
Thanks, decade ago paultag!
Let s do it! Let s use arigato to implement a 9p filesystem we ll call
debugfs that will serve all the debug
files shipped according to the Packages metadata from the apt archive. We ll
fetch the Packages file and construct a filesystem based on the reported
Build-Id entries. For those who don t know much about how an apt repo
works, here s the 2-second crash course on what we re doing. The first is to
fetch the Packages file, which is specific to a binary architecture (such as
amd64, arm64 or riscv64). That architecture is specific to a
component (such as main, contrib or non-free). That component is
specific to a suite, such as stable, unstable or any of its aliases
(bullseye, bookworm, etc). Let s take a look at the Packages.xz file for
the unstable-debugsuite, maincomponent, for all amd64 binaries.
This will return the Debian-style
rfc2822-like headers,
which is an export of the metadata contained inside each .deb file which
apt (or other tools that can use the apt repo format) use to fetch
information about debs. Let s take a look at the debug headers for the
netlabel-tools package in unstable which is a package named
netlabel-tools-dbgsym in unstable-debug.
So here, we can parse the package headers in the Packages.xz file, and store,
for each Build-Id, the Filename where we can fetch the .deb at. Each
.deb contains a number of files but we re only really interested in the
files inside the .deb located at or under /usr/lib/debug/.build-id/,
which you can find in debugfs under
rfc822.rs. It s
crude, and very single-purpose, but I m feeling a bit lazy.
Who needs dpkg?!
For folks who haven t seen it yet, a .deb file is a special type of
.ar file, that contains (usually)
three files inside debian-binary, control.tar.xz and data.tar.xz.
The core of an .ar file is a fixed size (60 byte) entry header,
followed by the specified size number of bytes.
[8 byte .ar file magic]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
[60 byte entry header]
[N bytes of data]
...
First up was to implement a basic ar parser in
ar.rs. Before we get
into using it to parse a deb, as a quick diversion, let s break apart a .deb
file by hand something that is a bit of a rite of passage (or at least it
used to be? I m getting old) during the Debian nm (new member) process, to take
a look at where exactly the .debug file lives inside the .deb file.
$ ar x netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ ls
control.tar.xz debian-binary
data.tar.xz netlabel-tools-dbgsym_0.30.0-1+b1_amd64.deb
$ tar --list -f data.tar.xz grep '.debug$'
./usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
Since we know quite a bit about the structure of a .deb file, and I had to
implement support from scratch anyway, I opted to implement a (very!) basic
debfile parser using HTTP Range requests. HTTP Range requests, if supported by
the server (denoted by a accept-ranges: bytes HTTP header in response to an
HTTP HEAD request to that file) means that we can add a header such as
range: bytes=8-68 to specifically request that the returned GET body be the
byte range provided (in the above case, the bytes starting from byte offset 8
until byte offset 68). This means we can fetch just the ar file entry from
the .deb file until we get to the file inside the .deb we are interested in
(in our case, the data.tar.xz file) at which point we can request the body
of that file with a final range request. I wound up writing a struct to
handle a read_at-style API surface in
hrange.rs, which
we can pair with ar.rs above and start to find our data in the .deb remotely
without downloading and unpacking the .deb at all.
After we have the body of the data.tar.xz coming back through the HTTP
response, we get to pipe it through an xz decompressor (this kinda sucked in
Rust, since a tokioAsyncRead is not the same as an http Body response is
not the same as std::io::Read, is not the same as an async (or sync)
Iterator is not the same as what the xz2 crate expects; leading me to read
blocks of data to a buffer and stuff them through the decoder by looping over
the buffer for each lzma2 packet in a loop), and tarfile parser (similarly
troublesome). From there we get to iterate over all entries in the tarfile,
stopping when we reach our file of interest. Since we can t seek, but gdb
needs to, we ll pull it out of the stream into a Cursor<Vec<u8>> in-memory
and pass a handle to it back to the user.
From here on out its a matter of
gluing together a File traited struct
in debugfs, and serving the filesystem over TCP using arigato. Done
deal!
A quick diversion about compression
I was originally hoping to avoid transferring the whole tar file over the
network (and therefore also reading the whole debug file into ram, which
objectively sucks), but quickly hit issues with figuring out a way around
seeking around an xz file. What s interesting is xz has a great primitive
to solve this specific problem (specifically, use a block size that allows you
to seek to the block as close to your desired seek position just before it,
only discarding at most block size - 1 bytes), but data.tar.xz files
generated by dpkg appear to have a single mega-huge block for the whole file.
I don t know why I would have expected any different, in retrospect. That means
that this now devolves into the base case of How do I seek around an lzma2
compressed data stream ; which is a lot more complex of a question.
Thankfully, notoriously brilliant tianon was
nice enough to introduce me to Jon Johnson
who did something super similar adapted a technique to seek inside a
compressed gzip file, which lets his service
oci.dag.dev
seek through Docker container images super fast based on some prior work
such as soci-snapshotter, gztool, and
zran.c.
He also pulled this party trick off for apk based distros
over at apk.dag.dev, which seems apropos.
Jon was nice enough to publish a lot of his work on this specifically in a
central place under the name targz
on his GitHub, which has been a ton of fun to read through.
The gist is that, by dumping the decompressor s state (window of previous
bytes, in-memory data derived from the last N-1 bytes) at specific
checkpoints along with the compressed data stream offset in bytes and
decompressed offset in bytes, one can seek to that checkpoint in the compressed
stream and pick up where you left off creating a similar block mechanism
against the wishes of gzip. It means you d need to do an O(n) run over the
file, but every request after that will be sped up according to the number
of checkpoints you ve taken.
Given the complexity of xz and lzma2, I don t think this is possible
for me at the moment especially given most of the files I ll be requesting
will not be loaded from again especially when I can just cache the debug
header by Build-Id. I want to implement this (because I m generally curious
and Jon has a way of getting someone excited about compression schemes, which
is not a sentence I thought I d ever say out loud), but for now I m going to
move on without this optimization. Such a shame, since it kills a lot of the
work that went into seeking around the .deb file in the first place, given
the debian-binary and control.tar.gz members are so small.
The Good
First, the good news right? It works! That s pretty cool. I m positive
my younger self would be amused and happy to see this working; as is
current day paultag. Let s take debugfs out for a spin! First, we need
to mount the filesystem. It even works on an entirely unmodified, stock
Debian box on my LAN, which is huge. Let s take it for a spin:
And, let s prove to ourselves that this actually mounted before we go
trying to use it:
$ mount grep build-id
192.168.0.2 on /usr/lib/debug/.build-id type 9p (rw,relatime,aname=unstable-debug,access=user,trans=tcp,version=9p2000.u,port=564)
Slick. We ve got an open connection to the server, where our host
will keep a connection alive as root, attached to the filesystem provided
in aname. Let s take a look at it.
$ ls /usr/lib/debug/.build-id/
00 0d 1a 27 34 41 4e 5b 68 75 82 8E 9b a8 b5 c2 CE db e7 f3
01 0e 1b 28 35 42 4f 5c 69 76 83 8f 9c a9 b6 c3 cf dc E7 f4
02 0f 1c 29 36 43 50 5d 6a 77 84 90 9d aa b7 c4 d0 dd e8 f5
03 10 1d 2a 37 44 51 5e 6b 78 85 91 9e ab b8 c5 d1 de e9 f6
04 11 1e 2b 38 45 52 5f 6c 79 86 92 9f ac b9 c6 d2 df ea f7
05 12 1f 2c 39 46 53 60 6d 7a 87 93 a0 ad ba c7 d3 e0 eb f8
06 13 20 2d 3a 47 54 61 6e 7b 88 94 a1 ae bb c8 d4 e1 ec f9
07 14 21 2e 3b 48 55 62 6f 7c 89 95 a2 af bc c9 d5 e2 ed fa
08 15 22 2f 3c 49 56 63 70 7d 8a 96 a3 b0 bd ca d6 e3 ee fb
09 16 23 30 3d 4a 57 64 71 7e 8b 97 a4 b1 be cb d7 e4 ef fc
0a 17 24 31 3e 4b 58 65 72 7f 8c 98 a5 b2 bf cc d8 E4 f0 fd
0b 18 25 32 3f 4c 59 66 73 80 8d 99 a6 b3 c0 cd d9 e5 f1 fe
0c 19 26 33 40 4d 5a 67 74 81 8e 9a a7 b4 c1 ce da e6 f2 ff
Outstanding. Let s try using gdb to debug a binary that was provided by
the Debian archive, and see if it ll load the ELF by build-id from the
right .deb in the unstable-debug suite:
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Yes! Yes it will!
$ file /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
/usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter *empty*, BuildID[sha1]=e59f81f6573dadd5d95a6e4474d9388ab2777e2a, for GNU/Linux 3.2.0, with debug_info, not stripped
The Bad
Linux s support for 9p is mainline, which is great, but it s not robust.
Network issues or server restarts will wedge the mountpoint (Linux can t
reconnect when the tcp connection breaks), and things that work fine on local
filesystems get translated in a way that causes a lot of network chatter for
instance, just due to the way the syscalls are translated, doing an ls, will
result in a stat call for each file in the directory, even though linux had
just got a stat entry for every file while it was resolving directory names.
On top of that, Linux will serialize all I/O with the server, so there s no
concurrent requests for file information, writes, or reads pending at the same
time to the server; and read and write throughput will degrade as latency
increases due to increasing round-trip time, even though there are offsets
included in the read and write calls. It works well enough, but is
frustrating to run up against, since there s not a lot you can do server-side
to help with this beyond implementing the 9P2000.L variant (which, maybe is
worth it).
The Ugly
Unfortunately, we don t know the file size(s) until we ve actually opened the
underlying tar file and found the correct member, so for most files, we don t
know the real size to report when getting a stat. We can t parse the tarfiles
for every stat call, since that d make ls even slower (bummer). Only
hiccup is that when I report a filesize of zero, gdb throws a bit of a
fit; let s try with a size of 0 to start:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 0 Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
warning: Discarding section .note.gnu.build-id which has a section size (24) larger than the file size [in module /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug]
[...]
This obviously won t work since gdb will throw away all our hard work because
of stat s output, and neither will loading the real size of the underlying
file. That only leaves us with hardcoding a file size and hope nothing else
breaks significantly as a result. Let s try it again:
$ ls -lah /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
-r--r--r-- 1 root root 954M Dec 31 1969 /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug
$ gdb -q /usr/sbin/netlabelctl
Reading symbols from /usr/sbin/netlabelctl...
Reading symbols from /usr/lib/debug/.build-id/e5/9f81f6573dadd5d95a6e4474d9388ab2777e2a.debug...
(gdb)
Much better. I mean, terrible but better. Better for now, anyway.
Kilroy was here
Do I think this is a particularly good idea? I mean; kinda. I m probably going
to make some fun 9parigato-based filesystems for use around my LAN, but I
don t think I ll be moving to use debugfs until I can figure out how to
ensure the connection is more resilient to changing networks, server restarts
and fixes on i/o performance. I think it was a useful exercise and is a pretty
great hack, but I don t think this ll be shipping anywhere anytime soon.
Along with me publishing this post, I ve pushed up all my repos; so you
should be able to play along at home! There s a lot more work to be done
on arigato; but it does handshake and successfully export a working
9P2000.u filesystem. Check it out on on my github at
arigato,
debugfs
and also on crates.io
and docs.rs.
At least I can say I was here and I got it working after all these years.
Contributing to Debian
is part of Freexian s mission. This article
covers the latest achievements of Freexian and their collaborators. All of this
is made possible by organizations subscribing to our
Long Term Support contracts and
consulting services.
P.S. We ve completed over a year of writing these blogs. If you have any
suggestions on how to make them better or what you d like us to cover, or any
other opinions/reviews you might have, et al, please let us know by dropping an
email to us. We d be
happy to hear your thoughts. :)
SSO Authentication for jitsi.debian.social, by Stefano Rivera
Debian.social s jitsi instance has been getting
some abuse by (non-Debian) people sharing sexually explicit content on the
service. After playing whack-a-mole with this for a month, and shutting the
instance off for another month, we opened it up again and the abuse immediately
re-started.
Stefano sat down and wrote an
SSO Implementation
that hooks into Jitsi s existing JWT SSO support. This requires everyone using
jitsi.debian.social to have a Salsa account.
With only a little bit of effort, we could change this in future, to only
require an account to open a room, and allow guests to join the call.
/usr-move, by Helmut Grohne
The biggest task this month was sending mitigation patches for all of the
/usr-move issues arising from package renames due to the 2038 transition. As a
result, we can now say that every affected package in unstable can either be
converted with dh-sequence-movetousr or has an open bug report. The package
set relevant to debootstrap except for the set that has to be uploaded
concurrently has been moved to /usr and is awaiting migration. The move of
coreutils happened to affect piuparts which hard codes the location of
/bin/sync and received multiple updates as a result.
Miscellaneous contributions
Stefano Rivera uploaded a stable release update to python3.11 for bookworm,
fixing a use-after-free crash.
Stefano uploaded a new version of python-html2text, and updated
python3-defaults to build with it.
In support of Python 3.12, Stefano dropped distutils as a Build-Dependency
from a few packages, and uploaded a complex set of patches to python-mitogen.
Stefano landed some merge requests to clean up dead code in dh-python,
removed the flit plugin, and uploaded it.
Stefano uploaded new upstream versions of twisted, hatchling,
python-flexmock, python-authlib, python mitogen, python-pipx, and xonsh.
Stefano requested removal of a few packages supporting the Opsis HDMI2USB
hardware that DebConf Video team used to use for HDMI capture, as they are
not being maintained upstream. They started to FTBFS, with recent sdcc
changes.
DebConf 24 is getting ready to open registration, Stefano spent some time
fixing bugs in the website, caused by infrastructure updates.
Stefano reviewed all the DebConf 23 travel reimbursements, filing requests
for more information from SPI where our records mismatched.
Roberto C. S nchez worked on facilitating the transfer of upstream
maintenance responsibility for the dormant Shorewall project to a new team
led by the current maintainer of the Shorewall packages in Debian.
Colin Watson fixed build failures in celery-haystack-ng, db1-compat,
jsonpickle, libsdl-perl, kali, knews, openssh-ssh1,
python-json-log-formatter, python-typing-extensions, trn4, vigor, and
wcwidth. Some of these were related to the 64-bit time_t transition, since
that involved enabling -Werror=implicit-function-declaration.
Colin fixed an
off-by-one error in neovim,
which was already causing a build failure in Ubuntu and would eventually have
caused a build failure in Debian with stricter toolchain settings.
Colin added an sshd@.service template to
openssh to help newer systemd versions make containers and VMs SSH-accessible
over AF_VSOCK sockets.
Following the xz-utils backdoor, Colin
spent some time testing and discussing OpenSSH upstream s proposed
inline systemd notification patch,
since the current implementation via libsystemd was part of the attack vector
used by that backdoor.
Utkarsh reviewed and sponsored some Go packages for Lena Voytek and Rajudev.
Utkarsh also helped Mitchell Dzurick with the adoption of pyparted package.
Helmut sent 10 patches for cross build failures.
Helmut partially fixed architecture cross bootstrap tooling to deal with
changes in linux-libc-dev and the recent gcc-for-host changes and also
fixed a 64bit-time_t FTBFS in libtextwrap.
Thorsten Alteholz uploaded several packages from debian-printing: cjet,
lprng, rlpr and epson-inkjet-printer-escpr were affected by the newly enabled
compiler switch -Werror=implicit-function-declaration. Besides fixing these
serious bugs, Thorsten also worked on other bugs and could fix one or the
other.
Carles updated simplemonitor and python-ring-doorbell packages with new
upstream versions.
Santiago also reviewed applications for the
improving Salsa CI in Debian
GSoC 2024 project. We received applications from four very talented
candidates. The selection process is currently ongoing. A huge thanks to all
of them!
As part of the DebConf 24 organization, Santiago has taken part in the
Content team discussions.
I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to Openreach FTTP, provided by Aquiss, but I worry about what happens if there s a cable cut somewhere or some other long lasting problem. Worst case I could tether to my work phone, or try to find some local coworking space to use while things get sorted, but I felt like arranging a backup option was a wise move.
Step 1 turned out to be sorting out recursive DNS. It s been many moons since I had to deal with running DNS in a production setting, and I ve mostly done my best to avoid doing it at home too. dnsmasq has done a decent job at providing for my needs over the years, covering DHCP, DNS (+ tftp for my test device network). However I just let it forward to my ISP s nameservers, which means if that link goes down it ll no longer be able to resolve anything outside the house.
One option would have been to either point to a different recursive DNS server (Cloudfare s 1.1.1.1 or Google s Public DNS being the common choices), but I ve no desire to share my lookup information with them. As another approach I could have done some sort of failover of resolv.conf when the primary network went down, but then I would have to get into moving files around based on networking status and that felt a bit clunky.
So I decided to finally setup a proper local recursive DNS server, which is something I ve kinda meant to do for a while but never had sufficient reason to look into. Last time I did this I did it with BIND 9 but there are more options these days, and I decided to go with unbound, which is primarily focused on recursive DNS.
One extra wrinkle, pointed out by Lars, is that having dynamic name information from DHCP hosts is exceptionally convenient. I ve kept dnsmasq as the local DHCP server, so I wanted to be able to forward local queries there.
I m doing all of this on my RB5009, running Debian. Installing unbound was a simple matter of apt install unbound. I needed 2 pieces of configuration over the default, one to enable recursive serving for the house networks, and one to enable forwarding of queries for the local domain to dnsmasq. I originally had specified the wildcard address for listening, but this caused problems with the fact my router has many interfaces and would sometimes respond from a different address than the request had come in on.
/etc/unbound/unbound.conf.d/network-resolver.conf
server:
domain-insecure: "example.org"
do-not-query-localhost: no
forward-zone:
name: "example.org"
forward-addr: 127.0.0.1@5353
I then had to configure dnsmasq to not listen on port 53 (so unbound could), respond to requests on the loopback interface (I have dnsmasq restricted to only explicitly listed interfaces), and to hand out unbound as the appropriate nameserver in DHCP requests - once dnsmasq is not listening on port 53 it no longer does this by default.
/etc/dnsmasq.d/behind-unbound
With these minor changes in place I now have local recursive DNS being handled by unbound, without losing dynamic local DNS for DHCP hosts. As an added bonus I now get 10/10 on Test IPv6 - previously I was getting dinged on the ability for my DNS server to resolve purely IPv6 reachable addresses.
Next step, actually sorting out a backup link.
Welcome to the March 2024 report from the Reproducible Builds project! In our reports, we attempt to outline what we have been up to over the past month, as well as mentioning some of the important things happening more generally in software supply-chain security. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Table of contents:
Arch Linux minimal container userland now 100% reproducible
In remarkable news, Reproducible builds developer kpcyrd reported that that the Arch Linux minimal container userland is now 100% reproducible after work by developers dvzv and Foxboron on the one remaining package. This represents a real world , widely-used Linux distribution being reproducible.
Their post, which kpcyrd suffixed with the question now what? , continues on to outline some potential next steps, including validating whether the container image itself could be reproduced bit-for-bit. The post, which was itself a followup for an Arch Linux update earlier in the month, generated a significant number of replies.
Validating Debian s build infrastructure after the XZ backdoor
From our mailing list this month, Vagrant Cascadian wrote about being asked about trying to perform concrete reproducibility checks for recent Debian security updates, in an attempt to gain some confidence about Debian s build infrastructure given that they performed builds in environments running the high-profile XZ vulnerability.
Vagrant reports (with some caveats):
So far, I have not found any reproducibility issues; everything I tested I was able to get to build bit-for-bit identical with what is in the
Debian archive.
That is to say, reproducibility testing permitted Vagrant and Debian to claim with some confidence that builds performed when this vulnerable version of XZ was installed were not interfered with.
Functional package managers (FPMs) and reproducible builds (R-B) are technologies and methodologies that are conceptually very different from the traditional software deployment model, and that have promising properties for software supply chain security. This thesis aims to evaluate the impact of FPMs and R-B on the security of the software supply chain and propose improvements to the FPM model to further improve trust in the open source supply chain. PDF
Julien s paper poses a number of research questions on how the model of distributions such as GNU Guix and NixOS can be leveraged to further improve the safety of the software supply chain , etc.
Software and source code identification with GNU Guix and reproducible builds
In a long line of commendably detailed blog posts, Ludovic Court s, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier have together published two interesting posts on the GNU Guix blog this month. In early March, Ludovic Court s, Maxim Cournoyer, Jan Nieuwenhuizen and Simon Tournier wrote about software and source code identification and how that might be performed using Guix, rhetorically posing the questions: What does it take to identify software ? How can we tell what software is running on a machine to determine, for example, what security vulnerabilities might affect it?
Later in the month, Ludovic Court s wrote a solo post describing adventures on the quest for long-term reproducible deployment. Ludovic s post touches on GNU Guix s aim to support time travel , the ability to reliably (and reproducibly) revert to an earlier point in time, employing the iconic image of Harold Lloyd hanging off the clock in Safety Last! (1925) to poetically illustrate both the slapstick nature of current modern technology and the gymnastics required to navigate hazards of our own making.
Two new Rust-based tools for post-processing determinism
Zbigniew J drzejewski-Szmek announced add-determinism, a work-in-progress reimplementation of the Reproducible Builds project s own strip-nondeterminism tool in the Rust programming language, intended to be used as a post-processor in RPM-based distributions such as Fedora
In addition, Yossi Kreinin published a blog post titled refix: fast, debuggable, reproducible builds that describes a tool that post-processes binaries in such a way that they are still debuggable with gdb, etc.. Yossi post details the motivation and techniques behind the (fast) performance of the tool.
Distribution work
In Debian this month, since the testing framework no longer varies the build path, James Addison performed a bulk downgrade of the bug severity for issues filed with a level of normal to a new level of wishlist. In addition, 28 reviews of Debian packages were added, 38 were updated and 23 were removed this month adding to ever-growing knowledge about identified issues. As part of this effort, a number of issue types were updated, including Chris Lamb adding a new ocaml_include_directories toolchain issue [] and James Addison adding a new filesystem_order_in_java_jar_manifest_mf_include_resource issue [] and updating the random_uuid_in_notebooks_generated_by_nbsphinx to reference a relevant discussion thread [].
In addition, Roland Clobus posted his 24th status update of reproducible Debian ISO images. Roland highlights that the images for Debian unstable often cannot be generated due to changes in that distribution related to the 64-bit time_t transition.
Lastly, Bernhard M. Wiedemann posted another monthly update for his reproducibility work in openSUSE.
Mailing list highlights
Elsewhere on our mailing list this month:
Website updates
There were made a number of improvements to our website this month, including:
Pol Dellaiera noticed the frequent need to correctly cite the website itself in academic work. To facilitate easier citation across multiple formats, Pol contributed a Citation File Format (CIF) file. As a result, an export in BibTeX format is now available in the Academic Publications section. Pol encourages community contributions to further refine the CITATION.cff file. Pol also added an substantial new section to the buy in page documenting the role of Software Bill of Materials (SBOMs) and ephemeral development environments. [][]
Bernhard M. Wiedemann added a new commandments page to the documentation [][] and fixed some incorrect YAML elsewhere on the site [].
Chris Lamb add three recent academic papers to the publications page of the website. []
Mattia Rizzolo and Holger Levsen collaborated to add Infomaniak as a sponsor of amd64 virtual machines. [][][]
Roland Clobus updated the stable outputs page, dropping version numbers from Python documentation pages [] and noting that Python s set data structure is also affected by the PYTHONHASHSEED functionality. []
Delta chat clients now reproducible
Delta Chat, an open source messaging application that can work over email, announced this month that the Rust-based core library underlying Delta chat application is now reproducible.
diffoscopediffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 259, 260 and 261 to Debian and made the following additional changes:
New features:
Add support for the zipdetails tool from the Perl distribution. Thanks to Fay Stegerman and Larry Doolittle et al. for the pointer and thread about this tool. []
Bug fixes:
Don t identify Redis database dumps as GNU R database files based simply on their filename. []
Add a missing call to File.recognizes so we actually perform the filename check for GNU R data files. []
Don t crash if we encounter an .rdb file without an equivalent .rdx file. (#1066991)
Correctly check for 7z being available and not lz4 when testing 7z. []
Prevent a traceback when comparing a contentful .pyc file with an empty one. []
Testsuite improvements:
Fix .epub tests after supporting the new zipdetails tool. []
Don t use parenthesis within test skipping messages, as PyTest adds its own parenthesis. []
Factor out Python version checking in test_zip.py. []
Skip some Zip-related tests under Python 3.10.14, as a potential regression may have been backported to the 3.10.x series. []
Actually test 7z support in the test_7z set of tests, not the lz4 functionality. (Closes: reproducible-builds/diffoscope#359). []
In addition, Fay Stegerman updated diffoscope s monkey patch for supporting the unusual Mozilla ZIP file format after Python s zipfile module changed to detect potentially insecure overlapping entries within .zip files. (#362)
Chris Lamb also updated the trydiffoscope command line client, dropping a build-dependency on the deprecated python3-distutils package to fix Debian bug #1065988 [], taking a moment to also refresh the packaging to the latest Debian standards []. Finally, Vagrant Cascadian submitted an update for diffoscope version 260 in GNU Guix. []
Upstream patches
This month, we wrote a large number of patches, including:
I don t have the hardware to test this firmware, but the build produces the same hashes for the firmware so it s safe to say that the firmware should keep working.
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework running primarily at tests.reproducible-builds.org in order to check packages and other artifacts for reproducibility.
In March, an enormous number of changes were made by Holger Levsen:
Initial work to clean up a messy NetBSD-related script. [][]
Roland Clobus:
Show the installer log if the installer fails to build. []
Avoid the minus character (i.e. -) in a variable in order to allow for tags in openQA. []
Update the schedule of Debian live image builds. []
Vagrant Cascadian:
Maintenance on the virt* nodes is completed so bring them back online. []
Use the fully qualified domain name in configuration. []
Node maintenance was also performed by Holger Levsen, Mattia Rizzolo [][] and Vagrant Cascadian [][][][]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I d share it as a tale of how huh, that s weird can be a powerful threat-hunting tool but only if you ve got the time to keep pulling at the thread.
Prelude to an Adventure
Our story begins back in March 2008.
I was working at Engine Yard (EY), a now largely-forgotten Rails-focused hosting company, which pioneered several advances in Rails application deployment.
Probably EY s greatest claim to lasting fame is that they helped launch a little code hosting platform you might have heard of, by providing them free infrastructure when they were little more than a glimmer in the Internet s eye.
I am, of course, talking about everyone s favourite Microsoft product: GitHub.
Since GitHub was in the right place, at the right time, with a compelling product offering, they quickly started to gain traction, and grow their userbase.
With growth comes challenges, amongst them the one we re focusing on today: SSH login times.
Then, as now, GitHub provided SSH access to the git repos they hosted, by SSHing to git@github.com with publickey authentication.
They were using the standard way that everyone manages SSH keys: the ~/.ssh/authorized_keys file, and that became a problem as the number of keys started to grow.
The way that SSH uses this file is that, when a user connects and asks for publickey authentication, SSH opens the ~/.ssh/authorized_keys file and scans all of the keys listed in it, looking for a key which matches the key that the user presented.
This linear search is normally not a huge problem, because nobody in their right mind puts more than a few keys in their ~/.ssh/authorized_keys, right?
Of course, as a popular, rapidly-growing service, GitHub was gaining users at a fair clip, to the point that the one big file that stored all the SSH keys was starting to visibly impact SSH login times.
This problem was also not going to get any better by itself.
Something Had To Be Done.
EY management was keen on making sure GitHub ran well, and so despite it not really being a hosting problem, they were willing to help fix this problem.
For some reason, the late, great, Ezra Zygmuntowitz pointed GitHub in my direction, and let me take the time to really get into the problem with the GitHub team.
After examining a variety of different possible solutions, we came to the conclusion that the least-worst option was to patch OpenSSH to lookup keys in a MySQL database, indexed on the key fingerprint.
We didn t take this decision on a whim it wasn t a case of yeah, sure, let s just hack around with OpenSSH, what could possibly go wrong? .
We knew it was potentially catastrophic if things went sideways, so you can imagine how much worse the other options available were.
Ensuring that this wouldn t compromise security was a lot of the effort that went into the change.
In the end, though, we rolled it out in early April, and lo! SSH logins were fast, and we were pretty sure we wouldn t have to worry about this problem for a long time to come.
Normally, you d think patching OpenSSH to make mass SSH logins super fast would be a good story on its own.
But no, this is just the opening scene.
Chekov s Gun Makes its Appearance
Fast forward a little under a month, to the first few days of May 2008.
I get a message from one of the GitHub team, saying that somehow users were able to access other users repos over SSH.
Naturally, as we d recently rolled out the OpenSSH patch, which touched this very thing, the code I d written was suspect number one, so I was called in to help.
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
Eventually, after more than a little debugging, we discovered that, somehow, there were two users with keys that had the same key fingerprint.
This absolutely shouldn t happen it s a bit like winning the lottery twice in a row1 unless the users had somehow shared their keys with each other, of course.
Still, it was worth investigating, just in case it was a web application bug, so the GitHub team reached out to the users impacted, to try and figure out what was going on.
The users professed no knowledge of each other, neither admitted to publicising their key, and couldn t offer any explanation as to how the other person could possibly have gotten their key.
Then things went from weird to what the ? .
Because another pair of users showed up, sharing a key fingerprint but it was a different shared key fingerprint.
The odds now have gone from winning the lottery multiple times in a row to as close to this literally cannot happen as makes no difference.
Once we were really, really confident that the OpenSSH patch wasn t the cause of the problem, my involvement in the problem basically ended.
I wasn t a GitHub employee, and EY had plenty of other customers who needed my help, so I wasn t able to stay deeply involved in the on-going investigation of The Mystery of the Duplicate Keys.
However, the GitHub team did keep talking to the users involved, and managed to determine the only apparent common factor was that all the users claimed to be using Debian or Ubuntu systems, which was where their SSH keys would have been generated.
That was as far as the investigation had really gotten, when along came May 13, 2008.
Chekov s Gun Goes Off
With the publication of DSA-1571-1, everything suddenly became clear.
Through a well-meaning but ultimately disasterous cleanup of OpenSSL s randomness generation code, the Debian maintainer had inadvertently reduced the number of possible keys that could be generated by a given user from bazillions to a little over 32,000.
With so many people signing up to GitHub some of them no doubt following best practice and freshly generating a separate key it s unsurprising that some collisions occurred.
You can imagine the sense of oooooooh, so that s what s going on! that rippled out once the issue was understood.
I was mostly glad that we had conclusive evidence that my OpenSSH patch wasn t at fault, little knowing how much more contact I was to have with Debian weak keys in the future, running a huge store of known-compromised keys and using them to find misbehaving Certificate Authorities, amongst other things.
Lessons Learned
While I ve not found a description of exactly when and how Luciano Bello discovered the vulnerability that became CVE-2008-0166, I presume he first came across it some time before it was disclosed likely before GitHub tripped over it.
The stable Debian release that included the vulnerable code had been released a year earlier, so there was plenty of time for Luciano to have discovered key collisions and go hmm, I wonder what s going on here? , then keep digging until the solution presented itself.
The thought hmm, that s odd , followed by intense investigation, leading to the discovery of a major flaw is also what ultimately brought down the recent XZ backdoor.
The critical part of that sequence is the ability to do that intense investigation, though.
When I reflect on my brush with the Debian weak keys vulnerability, what sticks out to me is the fact that I didn t do the deep investigation.
I wonder if Luciano hadn t found it, how long it might have been before it was found.
The GitHub team would have continued investigating, presumably, and perhaps they (or I) would have eventually dug deep enough to find it.
But we were all super busy myself, working support tickets at EY, and GitHub feverishly building features and fighting the fires in their rapidly-growing service.
As it was, Luciano was able to take the time to dig in and find out what was happening, but just like the XZ backdoor, I feel like we, as an industry, got a bit lucky that someone with the skills, time, and energy was on hand at the right time to make a huge difference.
It s a luxury to be able to take the time to really dig into a problem, and it s a luxury that most of us rarely have.
Perhaps an understated takeaway is that somehow we all need to wrestle back some time to follow our hunches and really dig into the things that make us go hmm .
Support My Hunches
If you d like to help me be able to do intense investigations of mysterious software phenomena, you can shout me a refreshing beverage on ko-fi.
the odds are actually probably more like winning the lottery about twenty times in a row.
The numbers involved are staggeringly huge, so it s easiest to just approximate it as really, really unlikely .
It is, sadly, not entirely surprising that Facebook is censoring articles critical of Meta.
The Kansas Reflector published an artical about Meta censoring environmental articles about climate change deeming them too controversial .
Facebook then censored the article about Facebook censorship, and then after an independent site published a copy of the climate change article, Facebook censored it too.
The CNN story says Facebook apologized and said it was a mistake and was fixing it.
Color me skeptical, because today I saw this:
Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they removed my post about the social network Mastodon (click that link for screenshot). A post that, incidentally, had been made 10 months prior to being removed.
While they ultimately reversed themselves, I subsequently wrote Facebook s Blocking Decisions Are Deliberate Including Their Censorship of Mastodon.
That this same pattern has played out a second time again with something that is a very slight challenege to Facebook seems to validate my conclusion. Facebook lets all sort of hateful garbage infest their site, but anything about climate change or their own censorship gets removed, and this pattern persists for years.
There s a reason I prefer Mastodon these days. You can find me there as @jgoerzen@floss.social.
So. I ve written this blog post. And then I m going to post it to Facebook. Let s see if they try to censor me for a third time. Bring it, Facebook.
Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing gcc.tar.xz.
More likely, they wouldn't bother with an actual trusting trust attack on
gcc, which would be a lot of work to get right. One problem with the ssh
backdoor is that well, not all servers on the internet run ssh. (Or
systemd.) So webservers seem a likely target of this kind of second stage
attack. Apache's docs include png files, nginx does not, but there's always
scope to add improved documentation to a project.
When would such a vulnerability have been introduced? In February, "Jia
Tan" wrote a new decoder for xz.
This added 1000+ lines of new C code across several commits. So much code
and in just the right place to insert something like this. And why take on
such a significant project just two months before inserting the ssh
backdoor? "Jia Tan" was already fully accepted as maintainer, and doing
lots of other work, it doesn't seem to me that they needed to start this
rewrite as part of their cover.
They were working closely with xz's author Lasse Collin in this, by
indications exchanging patches offlist as they developed it. So Lasse
Collin's commits in this time period are also worth scrutiny, because
they could have been influenced by "Jia Tan". One that
caught my eye comes immediately afterwards:
"prepares the code for alternative C versions and inline assembly"
Multiple versions and assembly mean even more places to hide such a
security hole.
I stress that I have not found such a security hole, I'm only considering
what the worst case possibilities are. I think we need to fully consider
them in order to decide how to fully wrap up this mess.
Whether such stealthy security holes have been introduced into xz by "Jia
Tan" or not, there are definitely indications that the ssh backdoor was not
the end of what they had planned.
For one thing, the "test file" based system they introduced
was extensible.
They could have been planning to add more test files later, that backdoored
xz in further ways.
And then there's the matter of the disabling of the Landlock sandbox. This
was not necessary for the ssh backdoor, because the sandbox is only used by
the xz command, not by liblzma. So why did they potentially tip their
hand by adding that rogue "." that disables the sandbox?
A sandbox would not prevent the kind of attack I discuss above, where xz is
just modifying code that it decompresses. Disabling the sandbox suggests
that they were going to make xz run arbitrary code, that perhaps wrote to
files it shouldn't be touching, to install a backdoor in the system.
Both deb and rpm use xz compression, and with the sandbox disabled,
whether they link with liblzma or run the xz command, a backdoored xz can
write to any file on the system while dpkg or rpm is running and noone is
likely to notice, because that's the kind of thing a package manager does.
My impression is that all of this was well planned and they were in it for
the long haul. They had no reason to stop with backdooring ssh, except for
the risk of additional exposure. But they decided to take that risk, with
the sandbox disabling. So they planned to do more, and every commit
by "Jia Tan", and really every commit that they could have influenced
needs to be distrusted.
This is why I've suggested to Debian that they
revert to an earlier version of xz.
That would be my advice to anyone distributing xz.
I do have a xz-unscathed
fork which I've carefully constructed to avoid all "Jia Tan" involved
commits. It feels good to not need to worry about dpkg and tar.
I only plan to maintain this fork minimally, eg security fixes.
Hopefully Lasse Collin will consider these possibilities and address
them in his response to the attack.
While the work to analyze the xz backdoor is in progress, several ideas have been suggested to improve the software supply chain ecosystem. Some of those ideas are good, some of the ideas are at best irrelevant and harmless, and some suggestions are plain bad. I d like to attempt to formalize two ideas, which have been discussed before, but the context in which they can be appreciated have not been as clear as it is today.
Reproducible tarballs. The idea is that published source tarballs should be possible to reproduce independently somehow, and that this should be continuously tested and verified preferrably as part of the upstream project continuous integration system (e.g., GitHub action or GitLab pipeline). While nominally this looks easy to achieve, there are some complex matters in this, for example: what timestamps to use for files in the tarball? I ve brought up this aspect before.
Minimal source tarballs without generated vendor files. Most GNU Autoconf/Automake-based tarballs pre-generated files which are important for bootstrapping on exotic systems that does not have the required dependencies. For the bootstrapping story to succeed, this approach is important to support. However it has become clear that this practice raise significant costs and risks. Most modern GNU/Linux distributions have all the required dependencies and actually prefers to re-build everything from source code. These pre-generated extra files introduce uncertainty to that process.
My strawman proposal to improve things is to define new tarball format *-src.tar.gz with at least the following properties:
The tarball should allow users to build the project, which is the entire purpose of all this. This means that at least all source code for the project has to be included.
The tarballs should be signed, for example with PGP or minisign.
The tarball should be possible to reproduce bit-by-bit by a third party using upstream s version controlled sources and a pointer to which revision was used (e.g., git tag or git commit).
The tarball should not require an Internet connection to download things.
Corollary: every external dependency either has to be explicitly documented as such (e.g., gcc and GnuTLS), or included in the tarball.
Observation: This means including all *.pogettext translations which are normally downloaded when building from version controlled sources.
The tarball should contain everything required to build the project from source using as much externally released versioned tooling as possible. This is the minimal property lacking today.
Corollary: This means including a vendored copy of OpenSSL or libz is not acceptable: link to them as external projects.
Open question: How about non-released external tooling such as gnulib or autoconf archive macros? This is a bit more delicate: most distributions either just package one current version of gnulib or autoconf archive, not previous versions. While this could change, and distributions could package the gnulib git repository (up to some current version) and the autoconf archive git repository and packages were set up to extract the version they need (gnulib s ./bootstrap already supports this via the gnulib-refdir parameter), this is not normally in place.
Suggested Corollary: The tarball should contain content from git submodule s such as gnulib and the necessary Autoconf archive M4 macros required by the project.
Similar to how the GNU project specify the ./configure interface we need a documented interface for how to bootstrap the project. I suggest to use the already well established idiom of running ./bootstrap to set up the package to later be able to be built via ./configure. Of course, some projects are not using the autotool ./configure interface and will not follow this aspect either, but like most build systems that compete with autotools have instructions on how to build the project, they should document similar interfaces for bootstrapping the source tarball to allow building.
If tarballs that achieve the above goals were available from popular upstream projects, distributions could more easily use them instead of current tarballs that include pre-generated content. The advantage would be that the build process is not tainted by unnecessary files. We need to develop tools for maintainers to create these tarballs, similar to make dist that generate today s foo-1.2.3.tar.gz files.
I think one common argument against this approach will be: Why bother with all that, and just use git-archive outputs? Or avoid the entire tarball approach and move directly towards version controlled check outs and referring to upstream releases as git URL and commit tag or id. One problem with this is that SHA-1 is broken, so placing trust in a SHA-1 identifier is simply not secure. Another counter-argument is that this optimize for packagers benefits at the cost of upstream maintainers: most upstream maintainers do not want to store gettext *.po translations in their source code repository. A compromise between the needs of maintainers and packagers is useful, so this *-src.tar.gz tarball approach is the indirection we need to solve that. Update: In my experiment with source-only tarballs for Libntlm I actually did use git-archive output.
What do you think?
Closing arguments in the trial between various people and Craig Wright over whether he's Satoshi Nakamoto are wrapping up today, amongst a bewildering array of presented evidence. But one utterly astonishing aspect of this lawsuit is that expert witnesses for both sides agreed that much of the digital evidence provided by Craig Wright was unreliable in one way or another, generally including indications that it wasn't produced at the point in time it claimed to be. And it's fascinating reading through the subtle (and, in some cases, not so subtle) ways that that's revealed.
One of the pieces of evidence entered is screenshots of data from Mind Your Own Business, a business management product that's been around for some time. Craig Wright relied on screenshots of various entries from this product to support his claims around having controlled meaningful number of bitcoin before he was publicly linked to being Satoshi. If these were authentic then they'd be strong evidence linking him to the mining of coins before Bitcoin's public availability. Unfortunately the screenshots themselves weren't contemporary - the metadata shows them being created in 2020. This wouldn't fundamentally be a problem (it's entirely reasonable to create new screenshots of old material), as long as it's possible to establish that the material shown in the screenshots was created at that point. Sadly, well.
One part of the disclosed information was an email that contained a zip file that contained a raw database in the format used by MYOB. Importing that into the tool allowed an audit record to be extracted - this record showed that the relevant entries had been added to the database in 2020, shortly before the screenshots were created. This was, obviously, not strong evidence that Craig had held Bitcoin in 2009. This evidence was reported, and was responded to with a couple of additional databases that had an audit trail that was consistent with the dates in the records in question. Well, partially. The audit record included session data, showing an administrator logging into the data base in 2011 and then, uh, logging out in 2023, which is rather more consistent with someone changing their system clock to 2011 to create an entry, and switching it back to present day before logging out. In addition, the audit log included fields that didn't exist in versions of the product released before 2016, strongly suggesting that the entries dated 2009-2011 were created in software released after 2016. And even worse, the order of insertions into the database didn't line up with calendar time - an entry dated before another entry may appear in the database afterwards, indicating that it was created later. But even more obvious? The database schema used for these old entries corresponded to a version of the software released in 2023.
This is all consistent with the idea that these records were created after the fact and backdated to 2009-2011, and that after this evidence was made available further evidence was created and backdated to obfuscate that. In an unusual turn of events, during the trial Craig Wright introduced further evidence in the form of a chain of emails to his former lawyers that indicated he had provided them with login details to his MYOB instance in 2019 - before the metadata associated with the screenshots. The implication isn't entirely clear, but it suggests that either they had an opportunity to examine this data before the metadata suggests it was created, or that they faked the data? So, well, the obvious thing happened, and his former lawyers were asked whether they received these emails. The chain consisted of three emails, two of which they confirmed they'd received. And they received a third email in the chain, but it was different to the one entered in evidence. And, uh, weirdly, they'd received a copy of the email that was submitted - but they'd received it a few days earlier. In 2024.
And again, the forensic evidence is helpful here! It turns out that the email client used associates a timestamp with any attachments, which in this case included an image in the email footer - and the mysterious time travelling email had a timestamp in 2024, not 2019. This was created by the client, so was consistent with the email having been sent in 2024, not being sent in 2019 and somehow getting stuck somewhere before delivery. The date header indicates 2019, as do encoded timestamps in the MIME headers - consistent with the mail being sent by a computer with the clock set to 2019.
But there's a very weird difference between the copy of the email that was submitted in evidence and the copy that was located afterwards! The first included a header inserted by gmail that included a 2019 timestamp, while the latter had a 2024 timestamp. Is there a way to determine which of these could be the truth? It turns out there is! The format of that header changed in 2022, and the version in the email is the new version. The version with the 2019 timestamp is anachronistic - the format simply doesn't match the header that gmail would have introduced in 2019, suggesting that an email sent in 2022 or later was modified to include a timestamp of 2019.
This is by no means the only indication that Craig Wright's evidence may be misleading (there's the whole argument that the Bitcoin white paper was written in LaTeX when general consensus is that it's written in OpenOffice, given that's what the metadata claims), but it's a lovely example of a more general issue.
Our technology chains are complicated. So many moving parts end up influencing the content of the data we generate, and those parts develop over time. It's fantastically difficult to generate an artifact now that precisely corresponds to how it would look in the past, even if we go to the effort of installing an old OS on an old PC and setting the clock appropriately (are you sure you're going to be able to mimic an entirely period appropriate patch level?). Even the version of the font you use in a document may indicate it's anachronistic. I'm pretty good at computers and I no longer have any belief I could fake an old document.
(References: this Dropbox, under "Expert reports", "Patrick Madden". Initial MYOB data is in "Appendix PM7", further analysis is in "Appendix PM42", email analysis is "Sixth Expert Report of Mr Patrick Madden")
Welcome to the February 2024 report from the Reproducible Builds project! In our reports, we try to outline what we have been up to over the past month as well as mentioning some of the important things happening in software supply-chain security.
Reproducible Builds at FOSDEM 2024
Core Reproducible Builds developer Holger Levsen presented at the main track at FOSDEM on Saturday 3rd February this year in Brussels, Belgium. However, that wasn t the only talk related to Reproducible Builds.
However, please see our comprehensive FOSDEM 2024 news post for the full details and links.
Three new reproducibility-related academic papers
A total of three separate scholarly papers related to Reproducible Builds have appeared this month:
Signing in Four Public Software Package Registries: Quantity, Quality, and Influencing Factors by Taylor R. Schorlemmer, Kelechi G. Kalu, Luke Chigges, Kyung Myung Ko, Eman Abdul-Muhd, Abu Ishgair, Saurabh Bagchi, Santiago Torres-Arias and James C. Davis (Purdue University, Indiana, USA) is concerned with the problem that:
Package maintainers can guarantee package authorship through software signing [but] it is unclear how common this practice is, and whether the resulting signatures are created properly. Prior work has provided raw data on signing practices, but measured single platforms, did not consider time, and did not provide insight on factors that may influence signing. We lack a comprehensive, multi-platform understanding of signing adoption and relevant factors. This study addresses this gap. (arXiv, full PDF)
[The] principle of reusability [ ] makes it harder to reproduce projects build environments, even though reproducibility of build environments is essential for collaboration, maintenance and component lifetime. In this work, we argue that functional package managers provide the tooling to make build environments reproducible in space and time, and we produce a preliminary evaluation to justify this claim.
This paper thus proposes an approach to automatically identify configuration options causing non-reproducibility of builds. It begins by building a set of builds in order to detect non-reproducible ones through binary comparison. We then develop automated techniques that combine statistical learning with symbolic reasoning to analyze over 20,000 configuration options. Our methods are designed to both detect options causing non-reproducibility, and remedy non-reproducible configurations, two tasks that are challenging and costly to perform manually. (HAL Portal, full PDF)
Distribution work
In Debian this month, 5 reviews of Debian packages were added, 22 were updated and 8 were removed this month adding to Debian s knowledge about identified issues. A number of issue types were updated as well. [ ][ ][ ][ ] In addition, Roland Clobus posted his 23rd update of the status of reproducible ISO images on our mailing list. In particular, Roland helpfully summarised that all major desktops build reproducibly with bullseye, bookworm, trixie and sid provided they are built for a second time within the same DAK run (i.e. [within] 6 hours) and that there will likely be further work at a MiniDebCamp in Hamburg. Furthermore, Roland also responded in-depth to a query about a previous report Fedora developer Zbigniew J drzejewski-Szmek announced a work-in-progress script called fedora-repro-build that attempts to reproduce an existing package within a koji build environment. Although the projects README file lists a number of fields will always or almost always vary and there is a non-zero list of other known issues, this is an excellent first step towards full Fedora reproducibility.
Jelle van der Waa introduced a new linter rule for Arch Linux packages in order to detect cache files leftover by the Sphinx documentation generator which are unreproducible by nature and should not be packaged. At the time of writing, 7 packages in the Arch repository are affected by this.
Elsewhere, Bernhard M. Wiedemann posted another monthly update for his work elsewhere in openSUSE.
diffoscopediffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 256, 257 and 258 to Debian and made the following additional changes:
Use a deterministic name instead of trusting gpg s use-embedded-filenames. Many thanks to Daniel Kahn Gillmor dkg@debian.org for reporting this issue and providing feedback. [][]
Don t error-out with a traceback if we encounter struct.unpack-related errors when parsing Python .pyc files. (#1064973). []
Don t try and compare rdb_expected_diff on non-GNU systems as %p formatting can vary, especially with respect to MacOS. []
Expand an older changelog entry with a CVE reference. []
Make test_zip black clean. []
In addition, James Addison contributed a patch to parse the headers from the diff(1) correctly [][] thanks! And lastly, Vagrant Cascadian pushed updates in GNU Guix for diffoscope to version 255, 256, and 258, and updated trydiffoscope to 67.0.6.
reprotestreprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian made a number of changes, including:
Create a (working) proof of concept for enabling a specific number of CPUs. [][]
Consistently use 398 days for time variation rather than choosing randomly and update README.rst to match. [][]
Support a new --vary=build_path.path option. [][][][]
Website updates
There were made a number of improvements to our website this month, including:
Chris Lamb:
Improve the relative sizing of headers. []
Re-order and punch up the introduction and documentation on the SOURCE_DATE_EPOCH page. []
Update SOURCE_DATE_EPOCH documentation re. datetime.datetime.fromtimestamp. Thanks, James Addison. []
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
Grant Jan-Benedict Glaw shell access to the Jenkins node. []
Enable debugging for NetBSD reproducibility testing. []
Use /usr/bin/du --apparent-size in the Jenkins shell monitor. []
Revert reproducible nodes: mark osuosl2 as down . []
Thanks again to Codethink, for they have doubled the RAM on our arm64 nodes. []
Only set /proc/$pid/oom_score_adj to -1000 if it has not already been done. []
Add the opemwrt-target-tegra and jtx task to the list of zombie jobs. [][]
Vagrant Cascadian also made the following changes:
Overhaul the handling of OpenSSH configuration files after updating from Debian bookworm. [][][]
Add two new armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [][] [][]
In addition, Alexander Couzens updated the OpenWrt configuration in order to replace the tegra target with mpc85xx [], Jan-Benedict Glaw updated the NetBSD build script to use a separate $TMPDIR to mitigate out of space issues on a tmpfs-backed /tmp [] and Zheng Junjie added a link to the GNU Guix tests [].
Lastly, node maintenance was performed by Holger Levsen [][][][][][] and Vagrant Cascadian [][][][].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Intro
Since 2019, I have traveled to Brussels at the beginning of the year to join FOSDEM, considered the largest and most important Free Software event in Europe. The 2024 edition was the fourth in-person edition in a row that I joined (2021 and 2022 did not happen due to COVID-19) and always with the financial help of Debian, which kindly paid my flight tickets after receiving my request asking for help to travel and approved by the Debian leader.
In 2020 I wrote several posts with a very complete report of the days I spent in Brussels. But in 2023 I didn t write anything, and becayse last year and this year I coordinated a room dedicated to translations of Free Software and Open Source projects, I m going to take the opportunity to write about these two years and how it was my experience.
After my first trip to FOSDEM, I started to think that I could join in a more active way than just a regular attendee, so I had the desire to propose a talk to one of the rooms. But then I thought that instead of proposing a tal, I could organize a room for talks :-) and with the topic translations which is something that I m very interested in, because it s been a few years since I ve been helping to translate the Debian for Portuguese.
Joining FOSDEM 2023
In the second half of 2022 I did some research and saw that there had never been a room dedicated to translations, so when the FOSDEM organization opened the call to receive room proposals (called DevRoom) for the 2023 edition, I sent a proposal to a translation room and it was accepted!
After the room was confirmed, the next step was for me, as room coordinator, to publicize the call for talk proposals. I spent a few weeks hoping to find out if I would receive a good number of proposals or if it would be a failure. But to my happiness, I received eight proposals and I had to select six to schedule the room programming schedule due to time constraints .
FOSDEM 2023 took place from February 4th to 5th and the translation devroom was scheduled on the second day in the afternoon.
The talks held in the room were these below, and in each of them you can watch the recording video.
And on the first day of FOSDEM I was at the Debian stand selling the t-shirts that I had taken from Brazil. People from France were also there selling other products and it was cool to interact with people who visited the booth to buy and/or talk about Debian.
Joining FOSDEM 2024
The 2023 result motivated me to propose the translation devroom again when the FOSDEM 2024 organization opened the call for rooms . I was waiting to find out if the FOSDEM organization would accept a room on this topic for the second year in a row and to my delight, my proposal was accepted again :-)
This time I received 11 proposals! And again due to time constraints, I had to select six to schedule the room schedule grid.
FOSDEM 2024 took place from February 3rd to 4th and the translation devroom was scheduled for the second day again, but this time in the morning.
The talks held in the room were these below, and in each of them you can watch the recording video.
This time I didn t help at the Debian stand because I couldn t bring t-shirts to sell from Brazil. So I just stopped by and talked to some people who were there like some DDs. But I volunteered for a few hours to operate the streaming camera in one of the main rooms.
Conclusion
The topics of the talks in these two years were quite diverse, and all the lectures were really very good. In the 12 talks we can see how translations happen in some projects such as KDE, PostgreSQL, Debian and Mattermost. We had the presentation of tools such as LibreTranslate, Weblate, scripts, AI, data model. And also reports on the work carried out by communities in Africa, China and Indonesia.
The rooms were full for some talks, a little more empty for others, but I was very satisfied with the final result of these two years.
I leave my special thanks to Jonathan Carter, Debian Leader who approved my flight tickets requests so that I could join FOSDEM 2023 and 2024. This help was essential to make my trip to Brussels because flight tickets are not cheap at all.
I would also like to thank my wife Jandira, who has been my travel partner :-)
As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.
The diffoscope maintainers are pleased to announce the release of diffoscope
version 259. This version includes the following changes:
[ Chris Lamb ]
* Don't error-out with a traceback if we encounter "struct.unpack"-related
errors when parsing .pyc files. (Closes: #1064973)
* Fix compatibility with PyTest 8.0. (Closes: reproducible-builds/diffoscope#365)
* Don't try and compare rdb_expected_diff on non-GNU systems as %p formatting
can vary. (Re: reproducible-builds/diffoscope#364)
I ve been using Pyblosxom here for nearly 17 years, but have become
increasingly dissatisfied with having to write HTML instead of
Markdown.
Today I looked at upgrading my web server and discovered that
Pyblosxom was removed from Debian after Debian 10, presumably because
it wasn t updated for Python 3.
I keep hearing about Jekyll as a static site generator for blogs, so I
finally investigated how to use that and how to convert my existing
entries. Fortunately it supports both HTML and Markdown (and probably
other) input formats, so this was mostly a matter of converting
metadata.
I have my own crappy script for drafting, publishing, and listing
blog entries, which also needed a bit of work to update, but that is
now done.
If all has gone to plan, you should be seeing just one new entry in
the feed but all permalinks to older entries still working.
I first became aware of Ray Dalio when either he or his publisher
plastered advertisements for The Principles all over the San
Francisco 4th and King Caltrain station. If I recall correctly, there
were also constant radio commercials; it was a whole thing in 2017. My
brain is very good at tuning out advertisements, so my only thought at the
time was "some business guy wrote a self-help book." I think I vaguely
assumed he was a CEO of some traditional business, since that's usually
who writes heavily marketed books like this. I did not connect him with
hedge funds or Bridgewater, which I have a bad habit of confusing with
Blackwater.
The Principles turns out to be more of a laundered cult manual than
a self-help book. And therein lies a story.
Rob Copeland is currently with The New York Times, but for many
years he was the hedge fund reporter for The Wall Street Journal.
He covered, among other things, Bridgewater Associates, the enormous hedge
fund founded by Ray Dalio. The Fund is a biography of Ray Dalio
and a history of Bridgewater from its founding as a vehicle for Dalio's
advising business until 2022 when Dalio, after multiple false starts and
title shuffles, finally retired from running the company. (Maybe. Based
on the history recounted here, it wouldn't surprise me if he was back at
the helm by the time you read this.)
It is one of the wildest, creepiest, and most abusive business histories
that I have ever read.
It's probably worth mentioning, as Copeland does explicitly, that Ray
Dalio and Bridgewater hate this book and claim it's a pack of lies.
Copeland includes some of their denials (and many non-denials that sound
as good as confirmations to me) in footnotes that I found increasingly
amusing.
A lawyer for Dalio said he "treated all employees equally, giving
people at all levels the same respect and extending them the same
perks."
Uh-huh.
Anyway, I personally know nothing about Bridgewater other than what I
learned here and the occasional mention in Matt Levine's newsletter (which
is where I got the recommendation for this book). I have no independent
information whether anything Copeland describes here is true, but Copeland
provides the typical extensive list of notes and sourcing one expects in a
book like this, and Levine's comments indicated it's generally consistent
with Bridgewater's industry reputation. I think this book is true, but
since the clear implication is that the world's largest hedge fund was
primarily a deranged cult whose employees mostly spied on and rated each
other rather than doing any real investment work, I also have questions,
not all of which Copeland answers to my satisfaction. But more on that
later.
The center of this book are the Principles. These were an ever-changing
list of rules and maxims for how people should conduct themselves within
Bridgewater. Per Copeland, although Dalio later published a book by that
name, the version of the Principles that made it into the book was
sanitized and significantly edited down from the version used inside the
company. Dalio was constantly adding new ones and sometimes changing
them, but the common theme was radical, confrontational "honesty": never
being silent about problems, confronting people directly about anything
that they did wrong, and telling people all of their faults so that they
could "know themselves better."
If this sounds like textbook abusive behavior, you have the right idea.
This part Dalio admits to openly, describing Bridgewater as a firm that
isn't for everyone but that achieves great results because of this
culture. But the uncomfortably confrontational vibes are only the tip of
the iceberg of dysfunction. Here are just a few of the ways this played
out according to Copeland:
Dalio decided that everyone's opinions should be weighted by the
accuracy of their previous decisions, to create a "meritocracy," and
therefore hired people to build a social credit system in which people
could use an app to constantly rate all of their co-workers. This
almost immediately devolved into out-group bullying worthy of a high
school, with employees hurriedly down-rating and ostracizing any
co-worker that Dalio down-rated.
When an early version of the system uncovered two employees at
Bridgewater with more credibility than Dalio, Dalio had the system
rigged to ensure that he always had the highest ratings and was not
affected by other people's ratings.
Dalio became so obsessed with the principle of confronting problems
that he created a centralized log of problems at Bridgewater and
required employees find and report a quota of ten or twenty new issues
every week or have their bonus docked. He would then regularly pick
some issue out of the issue log, no matter how petty, and treat it
like a referendum on the worth of the person responsible for the
issue.
Dalio's favorite way of dealing with a problem was to put someone on
trial. This involved extensive investigations followed by a meeting
where Dalio would berate the person and harshly catalog their flaws,
often reducing them to tears or panic attacks, while smugly insisting
that having an emotional reaction to criticism was a personality flaw.
These meetings were then filmed and added to a library available to
all Bridgewater employees, often edited to remove Dalio's personal
abuse and to make the emotional reaction of the target look
disproportionate. The ones Dalio liked the best were shown to all new
employees as part of their training in the Principles.
One of the best ways to gain institutional power in Bridgewater was to
become sycophantically obsessed with the Principles and to be an eager
participant in Dalio's trials. The highest levels of Bridgewater
featured constant jockeying for power, often by trying to catch rivals
in violations of the Principles so that they would be put on trial.
In one of the common and all-too-disturbing connections between Wall
Street finance and the United States' dysfunctional government, James
Comey (yes, that James
Comey) ran internal security for Bridgewater for three years, meaning
that he was the one who pulled evidence from surveillance cameras for
Dalio to use to confront employees during his trials.
In case the cult vibes weren't strong enough already, Bridgewater
developed its own idiosyncratic language worthy of Scientology. The
trials were called "probings," firing someone was called "sorting" them,
and rating them was called "dotting," among many other
Bridgewater-specific terms. Needless to say, no one ever probed Dalio
himself. You will also be completely unsurprised to learn that Copeland
documents instances of sexual harassment and discrimination at
Bridgewater, including some by Dalio himself, although that seems to be a
relatively small part of the overall dysfunction. Dalio was happy to
publicly humiliate anyone regardless of gender.
If you're like me, at this point you're probably wondering how Bridgewater
continued operating for so long in this environment. (Per Copeland, since
Dalio's retirement in 2022, Bridgewater has drastically reduced the
cult-like behaviors, deleted its archive of probings, and de-emphasized the
Principles.) It was not actually a religious cult; it was a hedge fund
that has to provide investment services to huge, sophisticated clients,
and by all accounts it's a very successful one. Why did this bizarre
nightmare of a workplace not interfere with Bridgewater's business?
This, I think, is the weakest part of this book. Copeland makes a few
gestures at answering this question, but none of them are very satisfying.
First, it's clear from Copeland's account that almost none of the
employees of Bridgewater had any control over Bridgewater's investments.
Nearly everyone was working on other parts of the business (sales,
investor relations) or on cult-related obsessions. Investment decisions
(largely incorporated into algorithms) were made by a tiny core of people
and often by Dalio himself. Bridgewater also appears to not trade
frequently, unlike some other hedge funds, meaning that they probably stay
clear of the more labor-intensive high-frequency parts of the business.
Second, Bridgewater took off as a hedge fund just before the hedge fund
boom in the 1990s. It transformed from Dalio's personal consulting
business and investment newsletter to a hedge fund in 1990 (with an
earlier investment from the World Bank in 1987), and the 1990s were a very
good decade for hedge funds. Bridgewater, in part due to Dalio's
connections and effective marketing via his newsletter, became one of the
largest hedge funds in the world, which gave it a sort of institutional
momentum. No one was questioned for putting money into Bridgewater even
in years when it did poorly compared to its rivals.
Third, Dalio used the tried and true method of getting free publicity from
the financial press: constantly predict an upcoming downturn, and
aggressively take credit whenever you were right. From nearly the start
of his career, Dalio predicted economic downturns year after year.
Bridgewater did very well in the 2000 to 2003 downturn, and again during
the 2008 financial crisis. Dalio aggressively takes credit for predicting
both of those downturns and positioning Bridgewater correctly going into
them. This is correct; what he avoids mentioning is that he also
predicted downturns in every other year, the majority of which never
happened.
These points together create a bit of an answer, but they don't feel like
the whole picture and Copeland doesn't connect the pieces. It seems
possible that Dalio may simply be good at investing; he reads obsessively
and clearly enjoys thinking about markets, and being an abusive cult
leader doesn't take up all of his time. It's also true that to some
extent hedge funds are semi-free money machines, in that once you have a
sufficient quantity of money and political connections you gain access to
investment opportunities and mechanisms that are very likely to make money
and that the typical investor simply cannot access. Dalio is clearly good
at making personal connections, and invested a lot of effort into forming
close ties with tricky clients such as pools of Chinese money.
Perhaps the most compelling explanation isn't mentioned directly in this
book but instead comes from Matt Levine. Bridgewater touts its
algorithmic trading over humans making individual trades, and there is
some reason to believe that consistently applying an algorithm without
regard to human emotion is a solid trading strategy in at least some
investment areas. Levine has asked in his newsletter, tongue firmly in
cheek, whether the bizarre cult-like behavior and constant infighting is a
strategy to distract all the humans and keep them from messing with the
algorithm and thus making bad decisions.
Copeland leaves this question unsettled. Instead, one comes away from
this book with a clear vision of the most dysfunctional workplace I have
ever heard of, and an endless litany of bizarre events each more
astonishing than the last. If you like watching train wrecks, this is the
book for you. The only drawback is that, unlike other entries in this
genre such as Bad Blood or
Billion Dollar Loser, Bridgewater is a
wildly successful company, so you don't get the schadenfreude of seeing a
house of cards collapse. You do, however, get a helpful mental model to
apply to the next person who tries to talk to you about "radical honesty"
and "idea meritocracy."
The flaw in this book is that the existence of an organization like
Bridgewater is pointing to systematic flaws in how our society works,
which Copeland is largely uninterested in interrogating. "How could this
have happened?" is a rather large question to leave unanswered. The sheer
outrageousness of Dalio's behavior also gets a bit tiring by the end of
the book, when you've seen the patterns and are hearing about the fourth
variation. But this is still an astonishing book, and a worthy entry in
the genre of capitalism disasters.
Rating: 7 out of 10
I have spent some more time on improving my language server for debian/control. Today,
I managed to provide the following features:
The X- style prefixes for field names are now understood and handled. This means
the language server now considers XC-Package-Type the same as Package-Type.
More diagnostics:
Fields without values now trigger an error marker
Duplicated fields now trigger an error marker
Fields used in the wrong paragraph now trigger an error marker
Typos in field names or values now trigger a warning marker. For field names,
X- style prefixes are stripped before typo detection is done.
The value of the Section field is now validated against a dataset of known sections
and trigger a warning marker if not known.
The "on-save trim end of line whitespace" now works. I had a logic bug in the server
side code that made it submit "no change" edits to the editor.
The language server now provides "hover" documentation for field names. There is a small
screenshot of this below. Sadly, emacs does not support markdown or, if it does, it
does not announce the support for markdown. For now, all the documentation is always in
markdown format and the language server will tag it as either markdown or plaintext
depending on the announced support.
The language server now provides quick fixes for some of the more trivial problems such
as deprecated fields or typos of fields and values.
Added more known fields including the XS-Autobuild field for non-free packages
along with a link to the relevant devref section in its hover doc.
This covers basically all my known omissions from last update except spellchecking of the
Description field.
Spellchecking
Personally, I feel spellchecking would be a very welcome addition to the current feature set.
However, reviewing my options, it seems that most of the spellchecking python libraries out
there are not packaged for Debian, or at least not other the name I assumed they would be.
The alternative is to pipe the spellchecking to another program like aspell list. I did not
test this fully, but aspell list does seem to do some input buffering that I cannot easily
default (at least not in the shell). Though, either way, the logic for this will not be trivial
and aspell list does not seem to include the corrections either. So best case, you would get
typo markers but no suggestions for what you should have typed. Not ideal.
Additionally, I am also concerned with the performance for this feature. For d/control, it
will be a trivial matter in practice. However, I would be reusing this for d/changelog which
is 99% free text with plenty of room for typos. For a regular linter, some slowness is
acceptable as it is basically a batch tool. However, for a language server, this potentially
translates into latency for your edits and that gets annoying.
While it is definitely on my long term todo list, I am a bit afraid that it can easily become
a time sink. Admittedly, this does annoy me, because I wanted to cross off at least one of
Otto's requested features soon.
On wrap-and-sort support
The other obvious request from Otto would be to automate wrap-and-sort formatting. Here,
the problem is that "we" in Debian do not agree on the one true formatting of
debian/control. In fact, I am fairly certain we do not even agree on whether we should
all use wrap-and-sort. This implies we need a style configuration.
However, if we have a style configuration per person, then you get style "ping-pong" for
packages where the co-maintainers do not all have the same style configuration. Additionally,
it is very likely that you are a member of multiple packaging teams or groups that all have
their own unique style. Ergo, only having a personal config file is doomed to fail.
The only "sane" option here that I can think of is to have or support "per package" style
configuration. Something that would be committed to git, so the tooling would automatically
pick up the configuration. Obviously, that is not fun for large packaging teams where you
have to maintain one file per package if you want a consistent style across all packages.
But it beats "style ping-pong" any day of the week.
Note that I am perfectly open to having a personal configuration file as a fallback for when
the "per package" configuration file is absent.
The second problem is the question of which format to use and what to name this file.
Since file formats and naming has never been controversial at all, this will obviously be
the easy part of this problem. But the file should be parsable by both wrap-and-sort
and the language server, so you get the same result regardless of which tool you use. If
we do not ensure this, then we still have the style ping-pong problem as people use
different tools.
This also seems like time sink with no end. So, what next then...?
What next?
On the language server front, I will have a look at its support for providing semantic
hints to the editors that might be used for syntax highlighting. While I think most
common Debian editors have built syntax highlighting already, I would like this language
server to stand on its own. I would like us to be in a situation where we do not have
implement yet another editor extension for Debian packaging files. At least not for
editors that support the LSP spec.
On a different front, I have an idea for how we go about relationship related substvars.
It is not directly related to this language server, except I got triggered by the language
server "missing" a diagnostic for reminding people to add the magic
Depends: $ misc:Depends [, $ shlibs:Depends ] boilerplate. The magic boilerplate that
you have to write even though we really should just fix this at a tooling level instead.
Energy permitting, I will formulate a proposal for that and send it to debian-devel.
Beyond that, I think I might start adding support for another file. I also need to wrap
up my python-debian branch, so I can get the position support into the Debian
soon, which would remove one papercut for using this language server.
Finally, it might be interesting to see if I can extract a "batch-linter" version of
the diagnostics and related quickfix features. If nothing else, the "linter" variant
would enable many of you to get a "mini-Lintian" without having to do a package
build first.
About a month ago, Otto Kek l inen asked for editor extensions for debian related
files on the debian-devel mailing list. In that thread, I concluded that what we
were missing was a "Language Server" (LSP) for our packaging files.
Last week, I started a prototype for such a LSP for the debian/control file as
a starting point based on the pygls
library. The initial prototype worked and I could do very basic diagnostics plus
completion suggestion for field names.
Current features
I got 4 basic features implemented, though I have only been able to test two of them in
emacs.
Diagnostics or linting of basic issues.
Completion suggestions for all known field names that I could think of and values for
some fields.
Folding ranges (untested). This feature enables the editor to "fold" multiple lines.
It is often used with multi-line comments and that is the feature currently supported.
On save, trim trailing whitespace at the end of lines (untested). Might not be
registered correctly on the server end.
Despite its very limited feature set, I feel editing debian/control in emacs is
now a much more pleasant experience.
Coming back to the features that Otto requested, the above covers a grand total of zero.
Sorry, Otto. It is not you, it is me.
Completion suggestions
For completion, all known fields are completed. Place the cursor at the start of the line
or in a partially written out field name and trigger the completion in your editor. In my
case, I can type R-R-R and trigger the completion and the editor will automatically
replace it with Rules-Requires-Root as the only applicable match. Your milage may
vary since I delegate most of the filtering to the editor, meaning the editor has the
final say about whether your input matches anything.
The only filtering done on the server side is that the server prunes out fields already used
in the paragraph, so you are not presented with the option to repeat an already used field,
which would be an error. Admittedly, not an error the language server detects at the moment,
but other tools will.
When completing field, if the field only has one non-default value such as Essential
which can be either no (the default, but you should not use it) or yes, then the
completion suggestion will complete the field along with its value.
This is mostly only applicable for "yes/no" fields such as Essential and Protected.
But it does also trigger for Package-Type at the moment.
As for completing values, here the language server can complete the value for simple fields
such as "yes/no" fields, Multi-Arch, Package-Type and Priority. I intend to add
support for Section as well - maybe also Architecture.
Diagnostics
On the diagnostic front, I have added multiple diagnostics:
An error marker for syntax errors.
An error marker for missing a mandatory field like Package or Architecture.
This also includes Standards-Version, which is admittedly mandatory by policy rather
than tooling falling part.
An error marker for adding Multi-Arch: same to an Architecture: all package.
Error marker for providing an unknown value to a field with a set of known values.
As an example, writing foo in Multi-Arch would trigger this one.
Warning marker for using deprecated fields such as DM-Upload-Allowed, or when
setting a field to its default value for fields like Essential. The latter rule
only applies to selected fields and notably Multi-Arch: no does not trigger a
warning.
Info level marker if a field like Priority duplicates the value of the Source
paragraph.
Notable omission at this time:
No errors are raised if a field does not have a value.
No errors are raised if a field is duplicated inside a paragraph.
No errors are used if a field is used in the wrong paragraph.
No spellchecking of the Description field.
No understanding that Foo and X[CBS]-Foo are related. As an example,
XC-Package-Type is completely ignored despite being the old name for Package-Type.
Quick fixes to solve these problems... :)
Trying it out
If you want to try, it is sadly a bit more involved due to things not being uploaded
or merged yet. Also, be advised that I will regularly rebase my git branches as I
revise the code.
The setup:
Build and install the deb of the main branch of pygls from https://salsa.debian.org/debian/pygls
The package is in NEW and hopefully this step will soon just be a regular apt install.
Configure your editor to run debputy lsp debian/control as the language server
for debian/control. This is depends on your editor. I figured out how to do it
for emacs (see below). I also found a guide for neovim at https://neovim.io/doc/user/lsp.
Note that debputy can be run from any directory here. The debian/control is a
reference to the file format and not a concrete file in this case.
Obviously, the setup should get easier over time. The first three bullet points should
eventually get resolved by merges and upload meaning you end up with an apt install
command instead of them.
For the editor part, I would obviously love it if we can add snippets for editors to make
the automatically pick up the language server when the relevant file is installed.
Using the debputy LSP in emacs
The guide I found so far relies on eglot. The guide below assumes you have the
elpa-dpkg-dev-el package installed for the debian-control-mode. Though it should
be a trivially matter to replace debian-control-mode with a different mode if you
use a different mode for your debian/control file.
In your emacs init file (such as ~/.emacs or ~/.emacs.d/init.el), you add the
follow blob.
Once you open the debian/control file in emacs, you can type M-x eglot to
activate the language server. Not sure why that manual step is needed and if someone
knows how to automate it such that eglot activates automatically on opening
debian/control, please let me know.
For testing completions, I often have to manually activate them (with C-M-i or
M-xcomplete-symbol). Though, it is a bit unclear to me whether this is an
emacs setting that I have not toggled or something I need to do on the language server
side.
From here
As next steps, I will probably look into fixing some of the "known missing" items under
diagnostics. The quick fix would be a considerable improvement to assisting users.
In the not so distant future, I will probably start to look at supporting other files
such as debian/changelog or look into supporting configuration, so I can cover
formatting features like wrap-and-sort.
I am also very much open to how we can provide integrations for this feature into
editors by default. I will probably create a separate binary package for specifically
this feature that pulls all relevant dependencies that would be able to provide editor
integrations as well.
We have a cabin out in the forest, and when I say "out in the forest" I mean "in a national forest subject to regulation by the US Forest Service" which means there's an extremely thick book describing the things we're allowed to do and (somewhat longer) not allowed to do. It's also down in the bottom of a valley surrounded by tall trees (the whole "forest" bit). There used to be AT&T copper but all that infrastructure burned down in a big fire back in 2021 and AT&T no longer supply new copper links, and Starlink isn't viable because of the whole "bottom of a valley surrounded by tall trees" thing along with regulations that prohibit us from putting up a big pole with a dish on top. Thankfully there's LTE towers nearby, so I'm simply using cellular data. Unfortunately my provider rate limits connections to video streaming services in order to push them down to roughly SD resolution. The easy workaround is just to VPN back to somewhere else, which in my case is just a Wireguard link back to San Francisco.
This worked perfectly for most things, but some streaming services simply wouldn't work at all. Attempting to load the video would just spin forever. Running tcpdump at the local end of the VPN endpoint showed a connection being established, some packets being exchanged, and then nothing. The remote service appeared to just stop sending packets. Tcpdumping the remote end of the VPN showed the same thing. It wasn't until I looked at the traffic on the VPN endpoint's external interface that things began to become clear.
This probably needs some background. Most network infrastructure has a maximum allowable packet size, which is referred to as the Maximum Transmission Unit or MTU. For ethernet this defaults to 1500 bytes, and these days most links are able to handle packets of at least this size, so it's pretty typical to just assume that you'll be able to send a 1500 byte packet. But what's important to remember is that that doesn't mean you have 1500 bytes of packet payload - that 1500 bytes includes whatever protocol level headers are on there. For TCP/IP you're typically looking at spending around 40 bytes on the headers, leaving somewhere around 1460 bytes of usable payload. And if you're using a VPN, things get annoying. In this case the original packet becomes the payload of a new packet, which means it needs another set of TCP (or UDP) and IP headers, and probably also some VPN header. This still all needs to fit inside the MTU of the link the VPN packet is being sent over, so if the MTU of that is 1500, the effective MTU of the VPN interface has to be lower. For Wireguard, this works out to an effective MTU of 1420 bytes. That means simply sending a 1500 byte packet over a Wireguard (or any other VPN) link won't work - adding the additional headers gives you a total packet size of over 1500 bytes, and that won't fit into the underlying link's MTU of 1500.
And yet, things work. But how? Faced with a packet that's too big to fit into a link, there are two choices - break the packet up into multiple smaller packets ("fragmentation") or tell whoever's sending the packet to send smaller packets. Fragmentation seems like the obvious answer, so I'd encourage you to read Valerie Aurora's article on how fragmentation is more complicated than you think. tl;dr - if you can avoid fragmentation then you're going to have a better life. You can explicitly indicate that you don't want your packets to be fragmented by setting the Don't Fragment bit in your IP header, and then when your packet hits a link where your packet exceeds the link MTU it'll send back a packet telling the remote that it's too big, what the actual MTU is, and the remote will resend a smaller packet. This avoids all the hassle of handling fragments in exchange for the cost of a retransmit the first time the MTU is exceeded. It also typically works these days, which wasn't always the case - people had a nasty habit of dropping the ICMP packets telling the remote that the packet was too big, which broke everything.
What I saw when I tcpdumped on the remote VPN endpoint's external interface was that the connection was getting established, and then a 1500 byte packet would arrive (this is kind of the behaviour you'd expect for video - the connection handshaking involves a bunch of relatively small packets, and then once you start sending the video stream itself you start sending packets that are as large as possible in order to minimise overhead). This 1500 byte packet wouldn't fit down the Wireguard link, so the endpoint sent back an ICMP packet to the remote telling it to send smaller packets. The remote should then have sent a new, smaller packet - instead, about a second after sending the first 1500 byte packet, it sent that same 1500 byte packet. This is consistent with it ignoring the ICMP notification and just behaving as if the packet had been dropped.
All the services that were failing were failing in identical ways, and all were using Fastly as their CDN. I complained about this on social media and then somehow ended up in contact with the engineering team responsible for this sort of thing - I sent them a packet dump of the failure, they were able to reproduce it, and it got fixed. Hurray!
(Between me identifying the problem and it getting fixed I was able to work around it. The TCP header includes a Maximum Segment Size (MSS) field, which indicates the maximum size of the payload for this connection. iptables allows you to rewrite this, so on the VPN endpoint I simply rewrote the MSS to be small enough that the packets would fit inside the Wireguard MTU. This isn't a complete fix since it's done at the TCP level rather than the IP level - so any large UDP packets would still end up breaking)
I've no idea what the underlying issue was, and at the client end the failure was entirely opaque: the remote simply stopped sending me packets. The only reason I was able to debug this at all was because I controlled the other end of the VPN as well, and even then I wouldn't have been able to do anything about it other than being in the fortuitous situation of someone able to do something about it seeing my post. How many people go through their lives dealing with things just being broken and having no idea why, and how do we fix that?
(Edit: thanks to this comment, it sounds like the underlying issue was a kernel bug that Fastly developed a fix for - under certain configurations, the kernel fails to associate the MTU update with the egress interface and so it continues sending overly large packets)
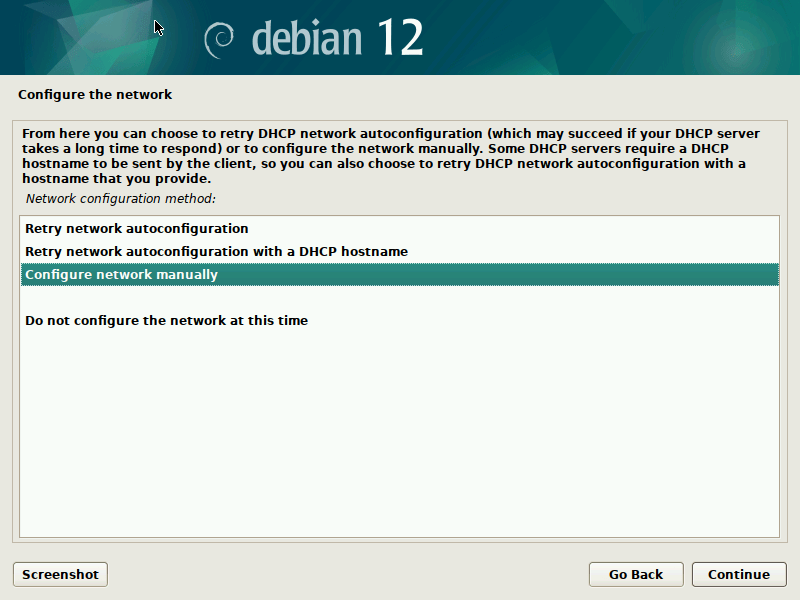
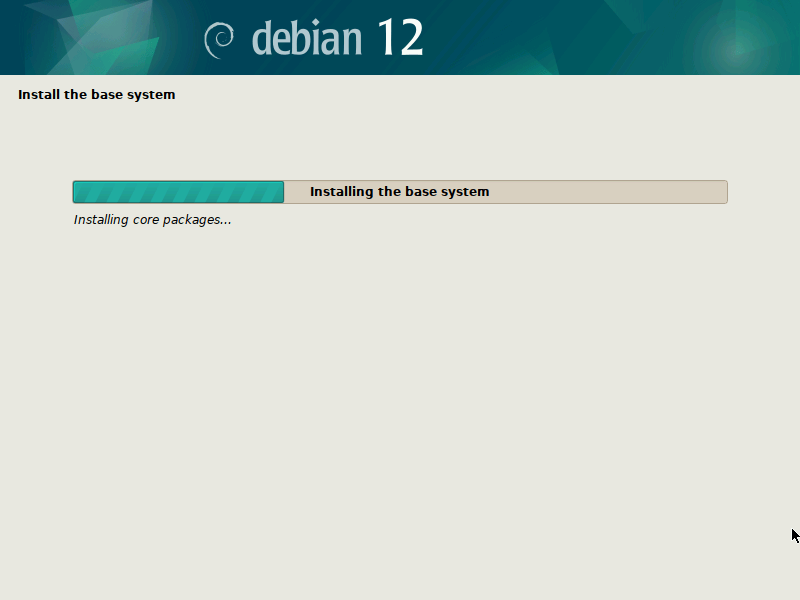
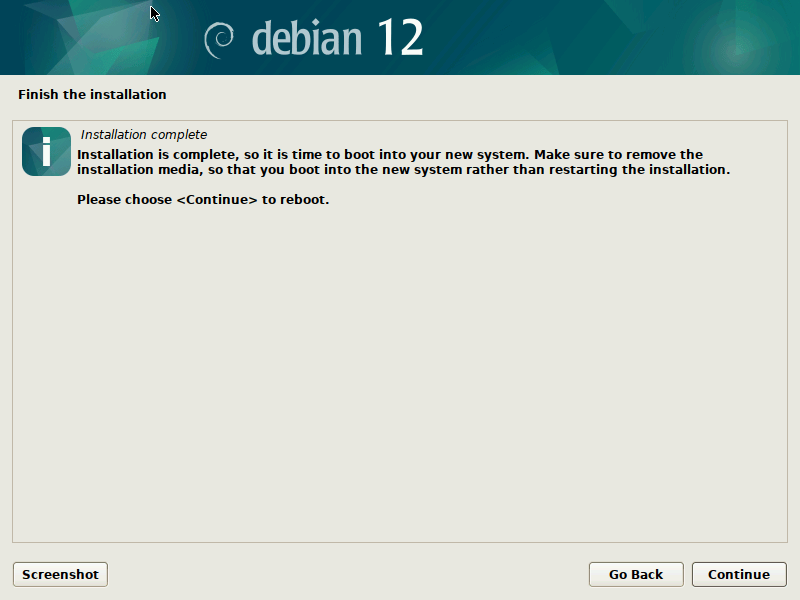
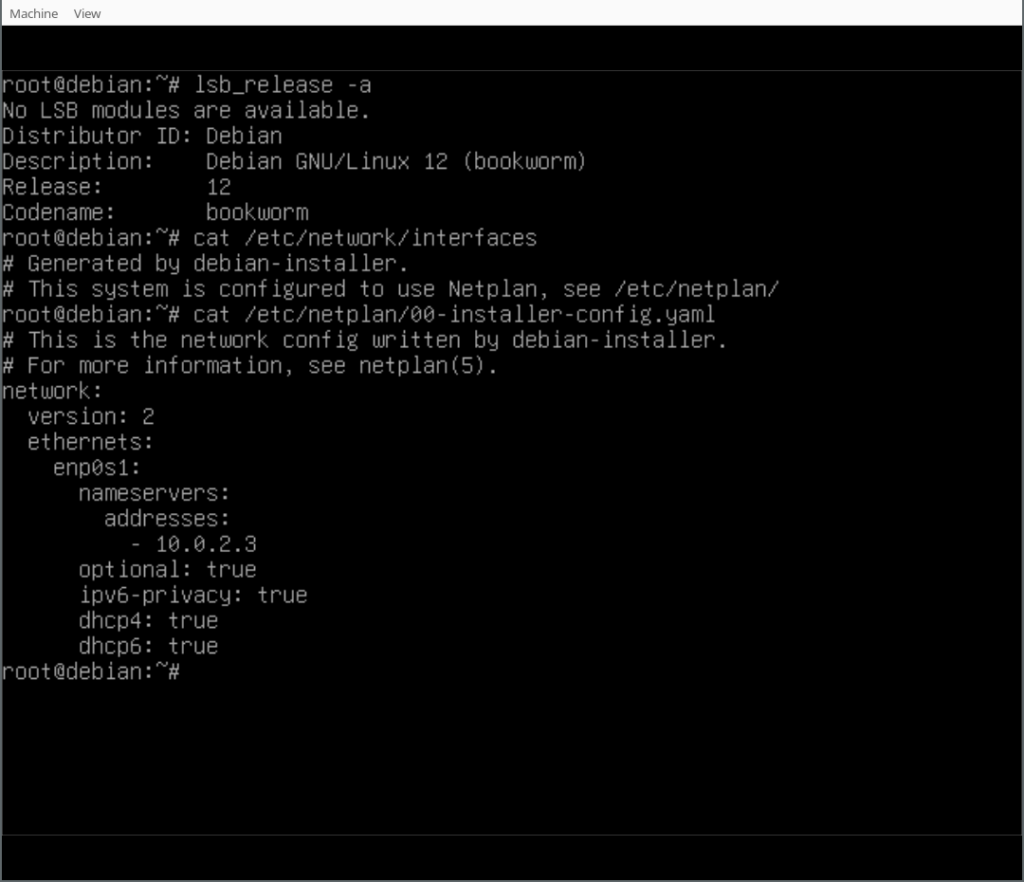
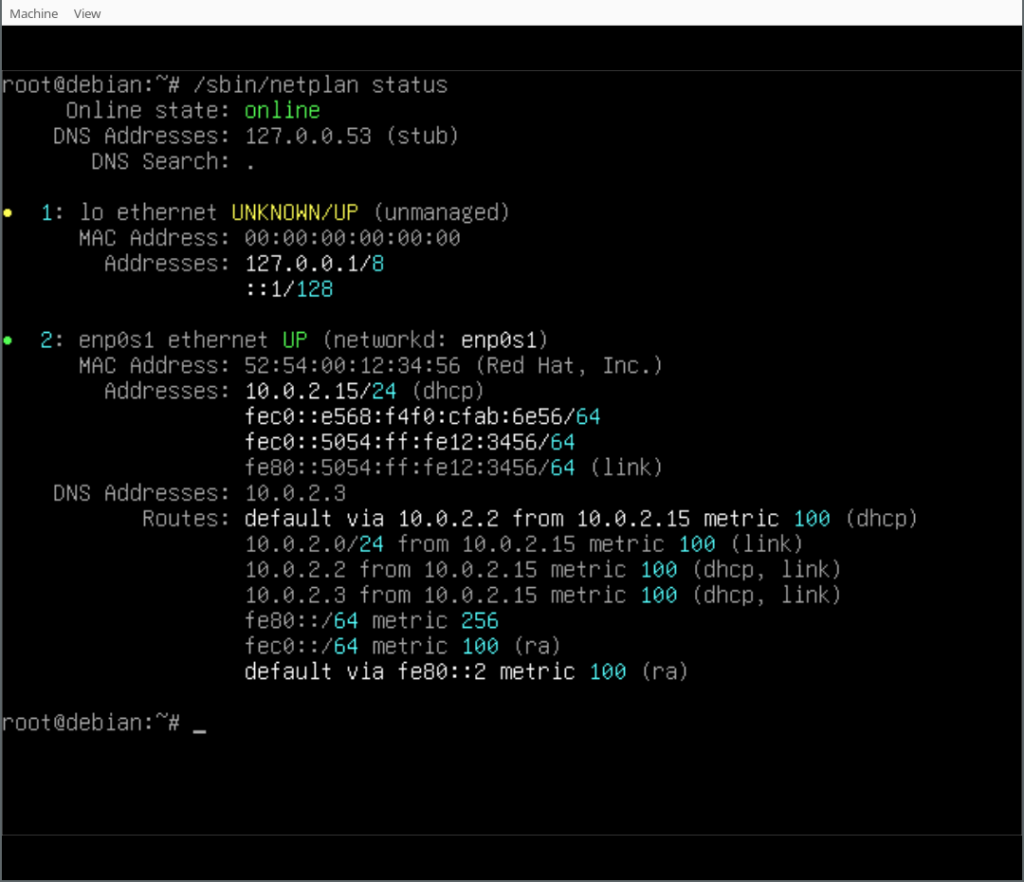
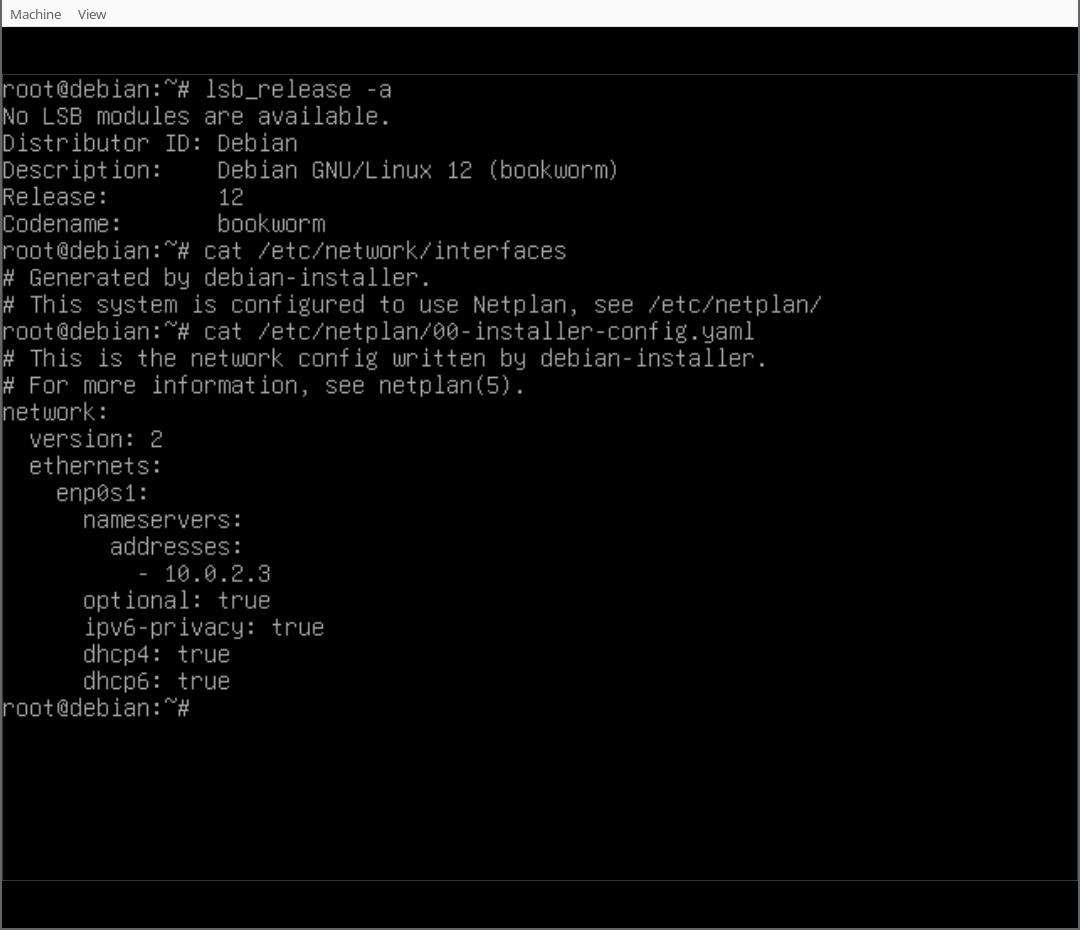
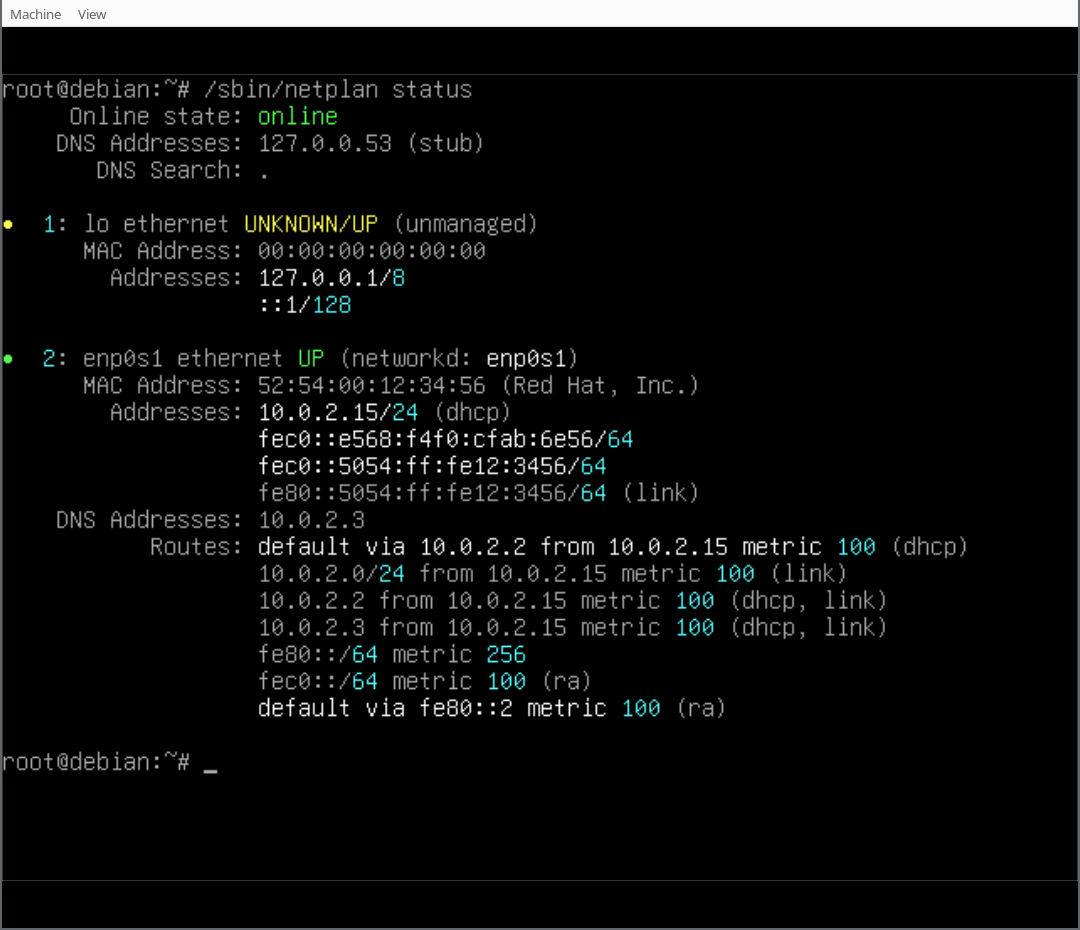
 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to

 I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to
I work from home these days, and my nearest office is over 100 miles away, 3 hours door to door if I travel by train (and, to be honest, probably not a lot faster given rush hour traffic if I drive). So I m reliant on a functional internet connection in order to be able to work. I m lucky to have access to 










 Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the 
 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze

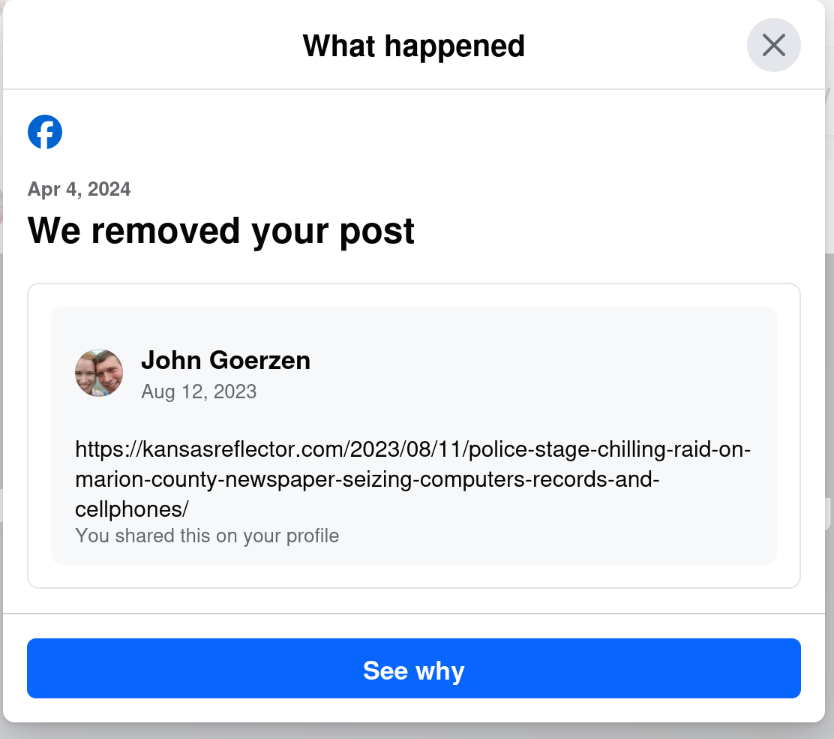 Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
 Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they
Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they  Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing
Was the ssh backdoor the only goal that "Jia Tan" was pursuing
with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete,
because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was
calculated and malicious, then we have to think about the full threat
surface of using xz. This quickly gets into nightmare scenarios of the
"trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that
can be exploited by the xz file it's decompressing? This would let the
attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing  My Debian contributions this month were all
My Debian contributions this month were all
 Closing arguments in the trial between various people and
Closing arguments in the trial between various people and 













 The talks held in the room were these below, and in each of them you can watch the recording video.
The talks held in the room were these below, and in each of them you can watch the recording video.




 As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.
As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.
 I ve been using Pyblosxom here for nearly 17 years, but have become
increasingly dissatisfied with having to write HTML instead of
Markdown.
Today I looked at upgrading my web server and discovered that
Pyblosxom was removed from Debian after Debian 10, presumably because
it wasn t updated for Python 3.
I keep hearing about Jekyll as a static site generator for blogs, so I
finally investigated how to use that and how to convert my existing
entries. Fortunately it supports both HTML and Markdown (and probably
other) input formats, so this was mostly a matter of converting
metadata.
I have my own crappy script for drafting, publishing, and listing
blog entries, which also needed a bit of work to update, but that is
now done.
If all has gone to plan, you should be seeing just one new entry in
the feed but all permalinks to older entries still working.
I ve been using Pyblosxom here for nearly 17 years, but have become
increasingly dissatisfied with having to write HTML instead of
Markdown.
Today I looked at upgrading my web server and discovered that
Pyblosxom was removed from Debian after Debian 10, presumably because
it wasn t updated for Python 3.
I keep hearing about Jekyll as a static site generator for blogs, so I
finally investigated how to use that and how to convert my existing
entries. Fortunately it supports both HTML and Markdown (and probably
other) input formats, so this was mostly a matter of converting
metadata.
I have my own crappy script for drafting, publishing, and listing
blog entries, which also needed a bit of work to update, but that is
now done.
If all has gone to plan, you should be seeing just one new entry in
the feed but all permalinks to older entries still working.
