Crash on full sync
The first thing that happened on a full sync is this crash:
Copy message from RemoteAnarcat:junk:
ERROR: Copying message 30624 [acc: Anarcat]
decoding with 'X-EUC-TW' codec failed (AttributeError: 'memoryview' object has no attribute 'decode')
Thread 'Copy message from RemoteAnarcat:junk' terminated with exception:
Traceback (most recent call last):
File "/usr/share/offlineimap3/offlineimap/imaputil.py", line 406, in utf7m_decode
for c in binary.decode():
AttributeError: 'memoryview' object has no attribute 'decode'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/share/offlineimap3/offlineimap/threadutil.py", line 146, in run
Thread.run(self)
File "/usr/lib/python3.9/threading.py", line 892, in run
self._target(*self._args, **self._kwargs)
File "/usr/share/offlineimap3/offlineimap/folder/Base.py", line 802, in copymessageto
message = self.getmessage(uid)
File "/usr/share/offlineimap3/offlineimap/folder/IMAP.py", line 342, in getmessage
data = self._fetch_from_imap(str(uid), self.retrycount)
File "/usr/share/offlineimap3/offlineimap/folder/IMAP.py", line 908, in _fetch_from_imap
ndata1 = self.parser['8bit-RFC'].parsebytes(data[0][1])
File "/usr/lib/python3.9/email/parser.py", line 123, in parsebytes
return self.parser.parsestr(text, headersonly)
File "/usr/lib/python3.9/email/parser.py", line 67, in parsestr
return self.parse(StringIO(text), headersonly=headersonly)
File "/usr/lib/python3.9/email/parser.py", line 56, in parse
feedparser.feed(data)
File "/usr/lib/python3.9/email/feedparser.py", line 176, in feed
self._call_parse()
File "/usr/lib/python3.9/email/feedparser.py", line 180, in _call_parse
self._parse()
File "/usr/lib/python3.9/email/feedparser.py", line 385, in _parsegen
for retval in self._parsegen():
File "/usr/lib/python3.9/email/feedparser.py", line 298, in _parsegen
for retval in self._parsegen():
File "/usr/lib/python3.9/email/feedparser.py", line 385, in _parsegen
for retval in self._parsegen():
File "/usr/lib/python3.9/email/feedparser.py", line 256, in _parsegen
if self._cur.get_content_type() == 'message/delivery-status':
File "/usr/lib/python3.9/email/message.py", line 578, in get_content_type
value = self.get('content-type', missing)
File "/usr/lib/python3.9/email/message.py", line 471, in get
return self.policy.header_fetch_parse(k, v)
File "/usr/lib/python3.9/email/policy.py", line 163, in header_fetch_parse
return self.header_factory(name, value)
File "/usr/lib/python3.9/email/headerregistry.py", line 601, in __call__
return self[name](name, value)
File "/usr/lib/python3.9/email/headerregistry.py", line 196, in __new__
cls.parse(value, kwds)
File "/usr/lib/python3.9/email/headerregistry.py", line 445, in parse
kwds['parse_tree'] = parse_tree = cls.value_parser(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 2675, in parse_content_type_header
ctype.append(parse_mime_parameters(value[1:]))
File "/usr/lib/python3.9/email/_header_value_parser.py", line 2569, in parse_mime_parameters
token, value = get_parameter(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 2492, in get_parameter
token, value = get_value(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 2403, in get_value
token, value = get_quoted_string(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 1294, in get_quoted_string
token, value = get_bare_quoted_string(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 1223, in get_bare_quoted_string
token, value = get_encoded_word(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 1064, in get_encoded_word
text, charset, lang, defects = _ew.decode('=?' + tok + '?=')
File "/usr/lib/python3.9/email/_encoded_words.py", line 181, in decode
string = bstring.decode(charset)
AttributeError: decoding with 'X-EUC-TW' codec failed (AttributeError: 'memoryview' object has no attribute 'decode')
Last 1 debug messages logged for Copy message from RemoteAnarcat:junk prior to exception:
thread: Register new thread 'Copy message from RemoteAnarcat:junk' (account 'Anarcat')
ERROR: Exceptions occurred during the run!
ERROR: Copying message 30624 [acc: Anarcat]
decoding with 'X-EUC-TW' codec failed (AttributeError: 'memoryview' object has no attribute 'decode')
Traceback:
File "/usr/share/offlineimap3/offlineimap/folder/Base.py", line 802, in copymessageto
message = self.getmessage(uid)
File "/usr/share/offlineimap3/offlineimap/folder/IMAP.py", line 342, in getmessage
data = self._fetch_from_imap(str(uid), self.retrycount)
File "/usr/share/offlineimap3/offlineimap/folder/IMAP.py", line 908, in _fetch_from_imap
ndata1 = self.parser['8bit-RFC'].parsebytes(data[0][1])
File "/usr/lib/python3.9/email/parser.py", line 123, in parsebytes
return self.parser.parsestr(text, headersonly)
File "/usr/lib/python3.9/email/parser.py", line 67, in parsestr
return self.parse(StringIO(text), headersonly=headersonly)
File "/usr/lib/python3.9/email/parser.py", line 56, in parse
feedparser.feed(data)
File "/usr/lib/python3.9/email/feedparser.py", line 176, in feed
self._call_parse()
File "/usr/lib/python3.9/email/feedparser.py", line 180, in _call_parse
self._parse()
File "/usr/lib/python3.9/email/feedparser.py", line 385, in _parsegen
for retval in self._parsegen():
File "/usr/lib/python3.9/email/feedparser.py", line 298, in _parsegen
for retval in self._parsegen():
File "/usr/lib/python3.9/email/feedparser.py", line 385, in _parsegen
for retval in self._parsegen():
File "/usr/lib/python3.9/email/feedparser.py", line 256, in _parsegen
if self._cur.get_content_type() == 'message/delivery-status':
File "/usr/lib/python3.9/email/message.py", line 578, in get_content_type
value = self.get('content-type', missing)
File "/usr/lib/python3.9/email/message.py", line 471, in get
return self.policy.header_fetch_parse(k, v)
File "/usr/lib/python3.9/email/policy.py", line 163, in header_fetch_parse
return self.header_factory(name, value)
File "/usr/lib/python3.9/email/headerregistry.py", line 601, in __call__
return self[name](name, value)
File "/usr/lib/python3.9/email/headerregistry.py", line 196, in __new__
cls.parse(value, kwds)
File "/usr/lib/python3.9/email/headerregistry.py", line 445, in parse
kwds['parse_tree'] = parse_tree = cls.value_parser(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 2675, in parse_content_type_header
ctype.append(parse_mime_parameters(value[1:]))
File "/usr/lib/python3.9/email/_header_value_parser.py", line 2569, in parse_mime_parameters
token, value = get_parameter(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 2492, in get_parameter
token, value = get_value(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 2403, in get_value
token, value = get_quoted_string(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 1294, in get_quoted_string
token, value = get_bare_quoted_string(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 1223, in get_bare_quoted_string
token, value = get_encoded_word(value)
File "/usr/lib/python3.9/email/_header_value_parser.py", line 1064, in get_encoded_word
text, charset, lang, defects = _ew.decode('=?' + tok + '?=')
File "/usr/lib/python3.9/email/_encoded_words.py", line 181, in decode
string = bstring.decode(charset)
Folder junk [acc: Anarcat]:
Copy message UID 30626 (29008/49310) RemoteAnarcat:junk -> LocalAnarcat:junk
Command exited with non-zero status 100
5252.91user 535.86system 3:21:00elapsed 47%CPU (0avgtext+0avgdata 846304maxresident)k
96344inputs+26563792outputs (1189major+2155815minor)pagefaults 0swaps
That only transferred about 8GB of mail, which gives us a transfer
rate of 5.3Mbit/s, more than 5 times slower than mbsync. This bug is
possibly limited to the bullseye version of offlineimap3 (the
lovely 0.0~git20210225.1e7ef9e+dfsg-4), while the current sid
version (the equally gorgeous 0.0~git20211018.e64c254+dfsg-1) seems
unaffected.
 A few days ago CISPE, a trade association of European cloud providers, published a press release complaining about the new VMware licensing scheme and asking for regulators and legislators to intervene.
But VMware does not have a monopoly on virtualization software: I think that asking regulators to interfere is unnecessary and unwise, unless, of course, they wish to question the entire foundations of copyright. Which, on the other hand, could be an intriguing position that I would support...
I believe that over-reliance on a single supplier is a typical enterprise risk: in the past decade some companies have invested in developing their own virtualization infrastructure using free software, while others have decided to rely entirely on a single proprietary software vendor.
My only big concern is that many public sector organizations will continue to use VMware and pay the huge fees designed by Broadcom to extract the maximum amount of money from their customers. However, it is ultimately the citizens who pay these bills, and blaming the evil US corporation is a great way to avoid taking responsibility for these choices.
A few days ago CISPE, a trade association of European cloud providers, published a press release complaining about the new VMware licensing scheme and asking for regulators and legislators to intervene.
But VMware does not have a monopoly on virtualization software: I think that asking regulators to interfere is unnecessary and unwise, unless, of course, they wish to question the entire foundations of copyright. Which, on the other hand, could be an intriguing position that I would support...
I believe that over-reliance on a single supplier is a typical enterprise risk: in the past decade some companies have invested in developing their own virtualization infrastructure using free software, while others have decided to rely entirely on a single proprietary software vendor.
My only big concern is that many public sector organizations will continue to use VMware and pay the huge fees designed by Broadcom to extract the maximum amount of money from their customers. However, it is ultimately the citizens who pay these bills, and blaming the evil US corporation is a great way to avoid taking responsibility for these choices.
 Em 2023 o tradicional
Em 2023 o tradicional 
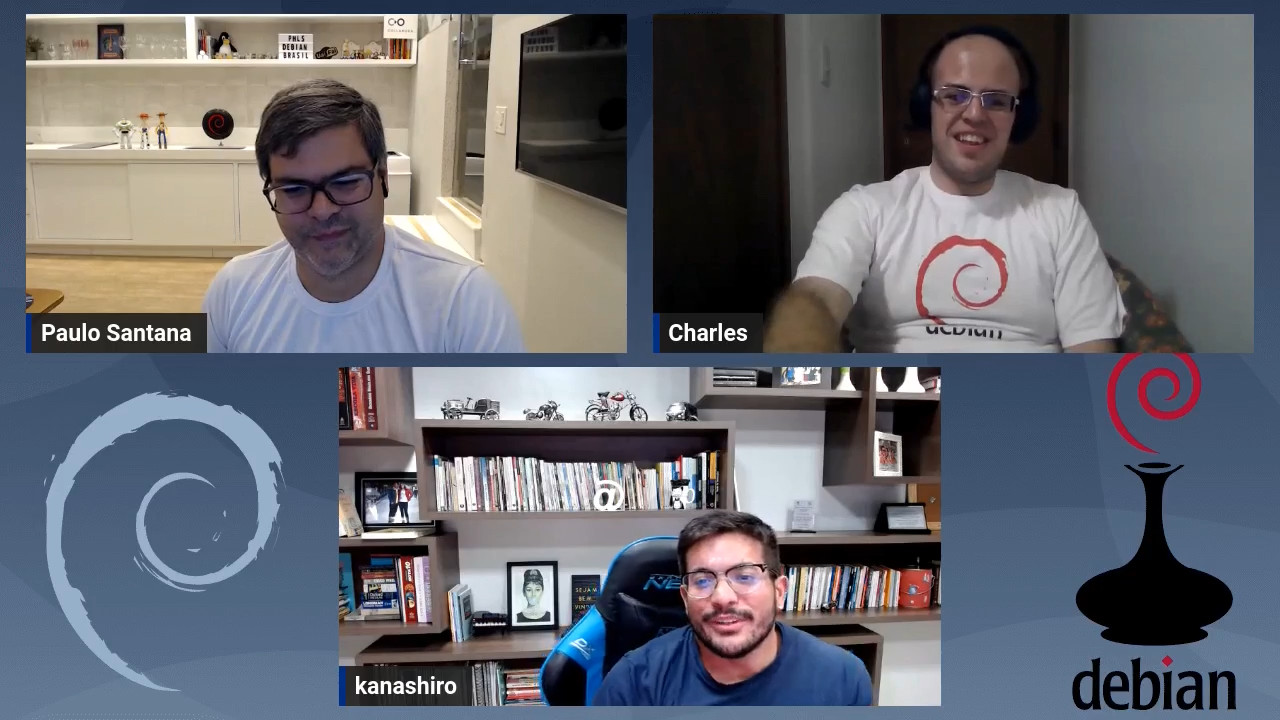
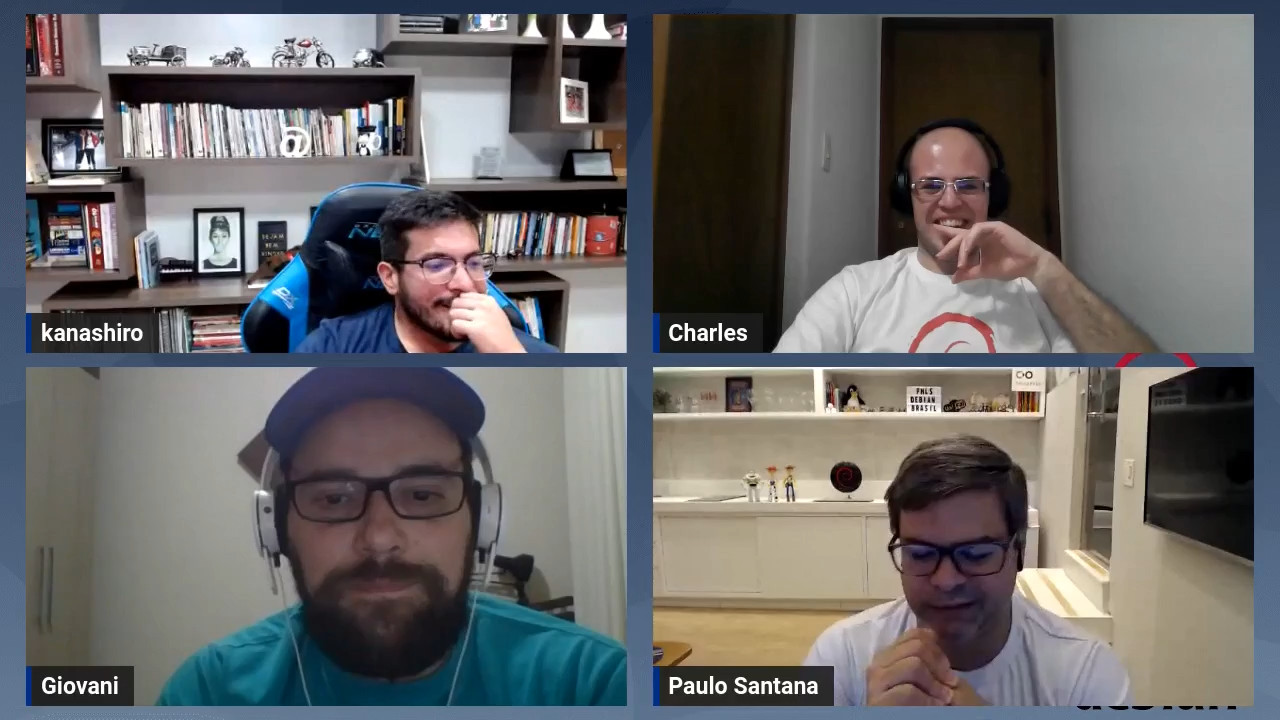

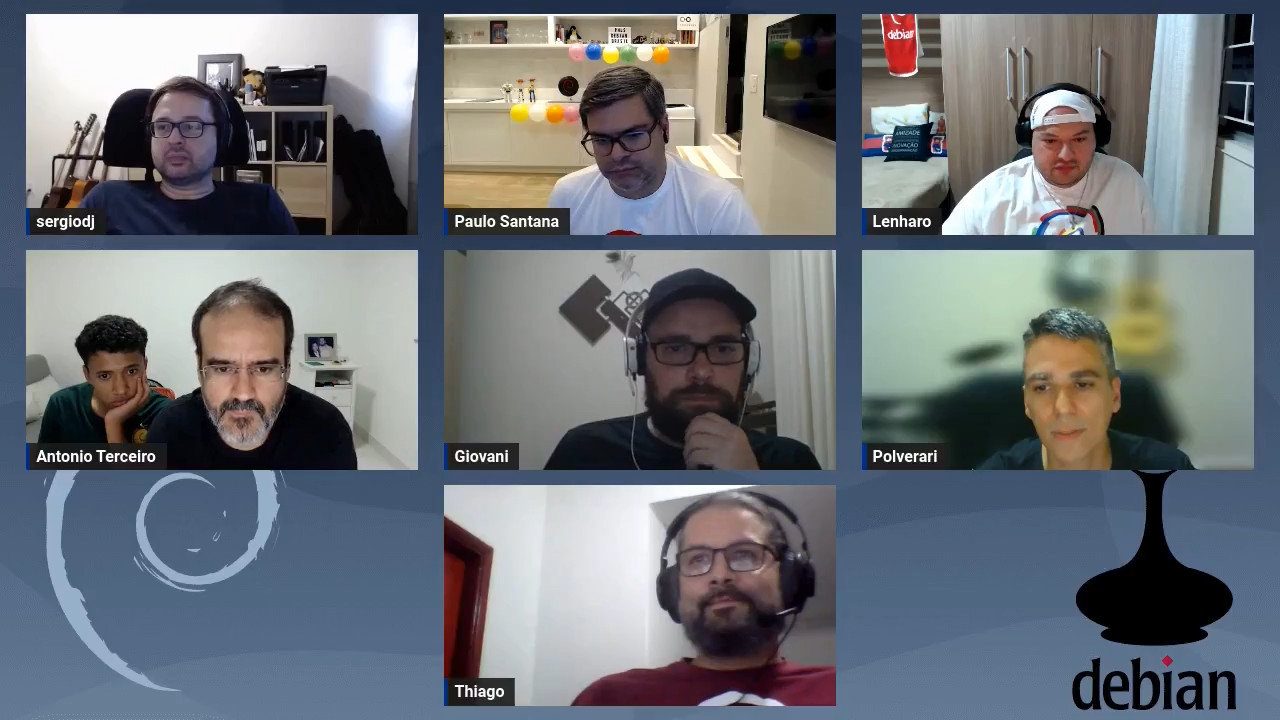
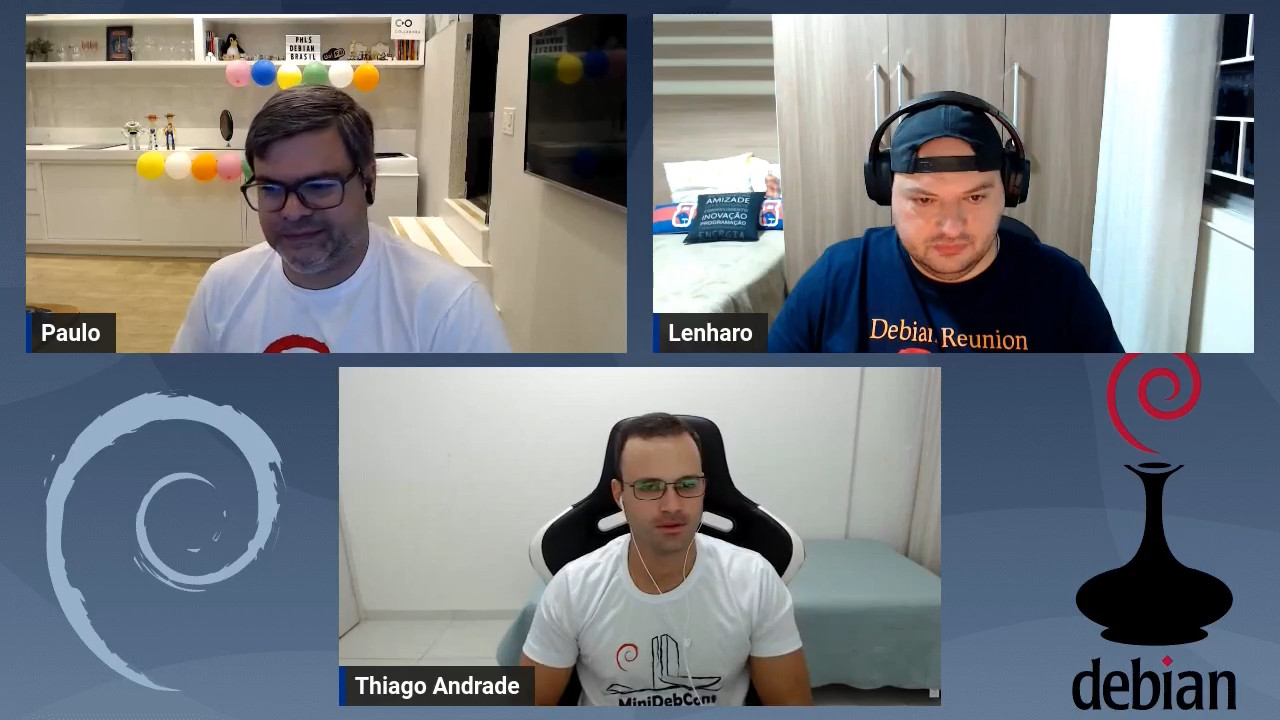
 No per odo de 25 a 27 de maio, Bras lia foi palco da
No per odo de 25 a 27 de maio, Bras lia foi palco da
 Atividades
A programa o da MiniDebConf foi intensa e diversificada. Nos dias 25 e 26
(quinta e sexta-feira), tivemos palestras, debates, oficinas e muitas atividades
pr ticas. J no dia 27 (s bado), ocorreu o Hacking Day, um momento especial em
que os(as) colaboradores(as) do Debian se reuniram para trabalhar em conjunto em
v rios aspectos do projeto. Essa foi a vers o brasileira da Debcamp, tradi o
pr via DebConf. Nesse dia, priorizamos as atividades pr ticas de contribui o
ao projeto, como empacotamento de softwares, tradu es, assinaturas de chaves,
install fest e a Bug Squashing Party.
Atividades
A programa o da MiniDebConf foi intensa e diversificada. Nos dias 25 e 26
(quinta e sexta-feira), tivemos palestras, debates, oficinas e muitas atividades
pr ticas. J no dia 27 (s bado), ocorreu o Hacking Day, um momento especial em
que os(as) colaboradores(as) do Debian se reuniram para trabalhar em conjunto em
v rios aspectos do projeto. Essa foi a vers o brasileira da Debcamp, tradi o
pr via DebConf. Nesse dia, priorizamos as atividades pr ticas de contribui o
ao projeto, como empacotamento de softwares, tradu es, assinaturas de chaves,
install fest e a Bug Squashing Party.

 N meros da edi o
Os n meros do evento impressionam e demonstram o envolvimento da comunidade com
o Debian. Tivemos 236 inscritos(as), 20 palestras submetidas, 14 volunt rios(as)
e 125 check-ins realizados. Al m disso, nas atividades pr ticas, tivemos
resultados significativos, como 7 novas instala es do Debian GNU/Linux, a
atualiza o de 18 pacotes no reposit rio oficial do projeto Debian pelos
participantes e a inclus o de 7 novos contribuidores na equipe de tradu o.
Destacamos tamb m a participa o da comunidade de forma remota, por meio de
transmiss es ao vivo. Os dados anal ticos revelam que nosso site obteve 7.058
visualiza es no total, com 2.079 visualiza es na p gina principal (que contava
com o apoio de nossos patrocinadores), 3.042 visualiza es na p gina de
programa o e 104 visualiza es na p gina de patrocinadores. Registramos 922
usu rios(as) nicos durante o evento.
No
N meros da edi o
Os n meros do evento impressionam e demonstram o envolvimento da comunidade com
o Debian. Tivemos 236 inscritos(as), 20 palestras submetidas, 14 volunt rios(as)
e 125 check-ins realizados. Al m disso, nas atividades pr ticas, tivemos
resultados significativos, como 7 novas instala es do Debian GNU/Linux, a
atualiza o de 18 pacotes no reposit rio oficial do projeto Debian pelos
participantes e a inclus o de 7 novos contribuidores na equipe de tradu o.
Destacamos tamb m a participa o da comunidade de forma remota, por meio de
transmiss es ao vivo. Os dados anal ticos revelam que nosso site obteve 7.058
visualiza es no total, com 2.079 visualiza es na p gina principal (que contava
com o apoio de nossos patrocinadores), 3.042 visualiza es na p gina de
programa o e 104 visualiza es na p gina de patrocinadores. Registramos 922
usu rios(as) nicos durante o evento.
No  Fotos e v deos
Para revivermos os melhores momentos do evento, temos dispon veis fotos e v deos.
As fotos podem ser acessadas em:
Fotos e v deos
Para revivermos os melhores momentos do evento, temos dispon veis fotos e v deos.
As fotos podem ser acessadas em:  A MiniDebConf Bras lia 2023 foi um marco para a comunidade Debian, demonstrando
o poder da colabora o e do Software Livre. Esperamos que todas e todos tenham
desfrutado desse encontro enriquecedor e que continuem participando ativamente
das pr ximas iniciativas do Projeto Debian. Juntos, podemos fazer a diferen a!
A MiniDebConf Bras lia 2023 foi um marco para a comunidade Debian, demonstrando
o poder da colabora o e do Software Livre. Esperamos que todas e todos tenham
desfrutado desse encontro enriquecedor e que continuem participando ativamente
das pr ximas iniciativas do Projeto Debian. Juntos, podemos fazer a diferen a!

 The following contributors got their Debian Developer accounts in the last two months:
The following contributors got their Debian Developer accounts in the last two months: