The Reproducible Builds project relies on several projects, supporters and sponsors for financial support, but they are also valued as ambassadors who spread the word about our project and the work that we do.
The Reproducible Builds project relies on several projects, supporters and sponsors for financial support, but they are also valued as ambassadors who spread the word about our project and the work that we do.
This is the
seventh instalment in a series featuring the projects, companies and individuals who support the Reproducible Builds project. We started this series by
featuring the Civil Infrastructure Platform project, and followed this up with a
post about the Ford Foundation as well as recent ones about
ARDC, the
Google Open Source Security Team (GOSST),
Bootstrappable Builds,
the F-Droid project and
David A. Wheeler.
Today, however, we will be talking with
Simon Butler, an associate senior lecturer in the School of
Informatics at the
University of Sk vde, where he undertakes research in software engineering that focuses on IoT and open source software, and contributes to the teaching of computer science to undergraduates.
Chris: For those who have not heard of it before, can you tell us more about the School of Informatics at Sk vde University?
Simon: Certainly, but I may be a little long-winded. Sk vde is a city in the area between the two large lakes in southern Sweden. The city is a busy place. Sk vde is home to the regional hospital, some of Volvo s manufacturing facilities, two regiments of the Swedish defence force, a lot of businesses in the
Swedish computer games industry, other tech companies and more.

The University of Sk vde is relatively small. Sweden s large land area and low population density mean that regional centres such as Sk vde are important and local universities support businesses by training new staff and supporting innovation.
The School of Informatics has two divisions. One focuses on teaching and researching computer games. The other division encompasses a wider range of teaching and research, including computer science, web development, computer security, network administration, data science and so on.

Chris: You recently
had a open-access paper published in Software Quality Journal. Could you tell us a little bit more about it and perhaps briefly summarise its key findings?
Simon: The paper is one output of a collaborative research project with six Swedish businesses that use open source software. There are two parts to the paper. The first consists of an analysis of what the group of businesses in the project know about Reproducible Builds (R-Bs), their experiences with R-Bs and their perception of the value of R-Bs to the businesses. The second part is an interview study with business practitioners and others with experience and expertise in R-Bs.
We set out to try to understand the extent to which software-intensive businesses were aware of R-Bs, the technical and business reasons they were or were not using R-Bs and to document the business and technical use cases for R-Bs. The key findings were that businesses are aware of R-Bs, and some are using R-Bs as part of their day-to-day development process. Some of the uses for R-Bs we found were not previously documented. We also found that businesses understood the value R-Bs have as part of engineering and software quality processes. They are also aware of the costs of implementing R-Bs and that R-Bs are an intangible value proposition - in other words, businesses can add value through process improvement by using R-Bs. But, that, currently at least, R-Bs are not a selling point for software or products.
Chris: You performed a large number of interviews in order to prepare your paper. What was the most surprising response to you?
Simon: Most surprising is a good question. Everybody I spoke to brought something new to my understanding of R-Bs, and many responses surprised me. The interviewees that surprised me most were I01 and I02 (interviews were anonymised and interviewees were assigned numeric identities).
I02 described the sceptical perspective that there is a viable, pragmatic alternative to R-Bs - verifiable builds - which I was aware of before undertaking the research. The company had developed a sufficiently robust system for their needs and worked well. With a large archive of software used in production, they couldn t justify the cost of retrofitting a different solution that might only offer small advantages over the existing system.
Doesn t really sound too surprising, but the interview was one of the first I did on this topic, and I was very focused on the value of, and need for, trust in a system that motivated the R-B. The solution used by the company requires trust, but they seem to have established sufficient trust for their needs by securing their build systems to the extent that they are more or less tamper-proof.
The other big surprise for me was I01 s use of R-Bs to support the verification of system configuration in a system with multiple embedded components at boot time. It s such an obvious application of R-Bs, and exactly the kind of response I hoped to get from interviewees. However, it is another instance of a solution where trust is only one factor. In the first instance, the developer is using R-Bs to establish trust in the toolchain. There is also the second application that the developer can use a set of R-Bs to establish that deployed system consists of compatible components. While this might not sound too significant, there appear to be some important potential applications. One that came to mind immediately is a problem with firmware updates on nodes in IoT systems where the node needs to update quickly with limited downtime and without failure. The node also needs to be able to roll back any update proposed by a server if there are conflicts with the current configuration or if any tests on the node fail. Perhaps the chances of failure could be reduced, if a node can instead negotiate with a server to determine a safe path to migrate from its current configuration to a working configuration with the upgraded components the central system requires? Another potential application appears to be in the configuration management of AI systems, where decisions need to be explainable. A means of specifying validated configurations of training data, models and deployed systems might, perhaps, be leveraged to prevent invalid or broken configurations from being deployed in production.
Chris: One of your findings was that reproducible builds were perceived to be good engineering practice . To what extent do you believe cultural forces affect the adoption or rejection of a given technology or practice?
Simon: To a large extent. People s decisions are informed by cultural norms, and business decisions are made by people acting collectively. Of course, decision-making, including assessments of risk and usefulness, is mediated by individual positions on the continuum from conformity to non-conformity, as well as individual and in-group norms. Whether a business will consider a given technology for adoption will depend on cultural forces. The decision to adopt may well be made on the grounds of cost and benefits.
Chris: Another conclusion implied by your research is that businesses are often dealing with software deployment lifespans (eg. 20+ years) that differ from widely from those of the typical hobbyist programmer. To what degree do you think this temporal mismatch is a problem for both groups?
Simon: This is a fascinating question. Long-term software maintenance is a requirement in some industries because of the working lifespans of the products and legal requirements to maintain the products for a fixed period. For some other industries, it is less of a problem. Consequently, I would tend to divide developers into those who have been exposed to long-term maintenance problems and those who have not. Although, more professional than hobbyist developers will have been exposed to the problem. Nonetheless, there are areas, such as music software, where there are also long-term maintenance challenges for data formats and software.
Chris: Based on your research, what would you say are the biggest blockers for the adoption of reproducible builds within business ? And, based on this, would you have any advice or recommendations for the broader reproducible builds ecosystem?
Simon: From the research, the main blocker appears to be cost. Not an absolute cost, but there is an overhead to introducing R-Bs. Businesses (and thus business managers) need to understand the business case for R-Bs.

Making decision-makers in businesses aware of R-Bs and that they are valuable will take time. Advocacy at multiple levels appears to be the way forward and this is being done. I would recommend being persistent while being patient and to keep talking about reproducible builds. The work done in Linux distributions raises awareness of R-Bs amongst developers. Guix, NixOS and Software Heritage are all providing practical solutions and getting attention - I ve been seeing progressively more mentions of all three during the last couple of years. Increased awareness amongst developers should lead to more interest within companies. There is also research money being assigned to supply chain security and R-B s. The
CHAINS project at KTH in Stockholm is one example of a strategic research project. There may be others that I m not aware of. The policy-level advocacy is slowly getting results in some countries, and where CISA leads, others may follow.
Chris: Was there a particular reason you alighted on the question of the adoption of reproducible builds in business? Do you think there s any truth behind the shopworn stereotype of hacker types neglecting the resources that business might be able to offer?
Simon: Much of the motivation for the research came from the contrast between the visibility of R-Bs in open source projects and the relative invisibility of R-Bs in industry. Where companies are known to be using R-Bs (e.g. Google, etc.) there is no fuss, no hype. They were not selling R-Bs as a solution; instead the documentation is very matter-of-fact that R-Bs are part of a customer-facing process in their cloud solutions.
An obvious question for me was that if some people use R-B s in software development, why doesn t everybody? There are limits to the tooling for some programming languages that mean R-Bs are difficult or impossible. But where creating an R-B is practical, why are they not used more widely?
So, to your second question. There is another factor, which seems to be more about a lack of communication rather than neglecting opportunities. Businesses may not always be willing to discuss their development processes and innovations. Though I do think the increasing number of conferences (big and small) for software practitioners is helping to facilitate more communication and greater exchange of ideas.
Chris: Has your personal view of reproducible builds changed since before you embarked on writing this paper?
Simon: Absolutely! In the early stages of the research, I was interested in questions of trust and how R-Bs were applied to resolve build and supply chain security problems. As the research developed, however, I started to see there were benefits to the use of R-Bs that were less obvious and that, in some cases, an R-B can have more than a single application.
Chris: Finally, do you have any plans to do future research touching on reproducible builds?
Simon: Yes, definitely. There are a set of problems that interest me. One already mentioned is the use of reproducible builds with AI systems. Interpretable or explainable AI (XAI) is a necessity, and I think that R-Bs can be used to support traceability in the configuration and testing of both deployed systems and systems used during model training and evaluation.
I would also like to return to a problem discussed briefly in the article, which is to develop a deeper understanding of the elements involved in the application of R-Bs that can be used to support reasoning about existing and potential applications of R-Bs. For example, R-Bs can be used to establish trust for different groups of individuals at different times, say, between remote developers prior to the release of software and by users after release. One question is whether
when an R-B is used might be a significant factor. Another group of questions concerns the ways in which trust (of some sort) propagates among users of an R-B. There is an example in the paper of a company that rebuilds Debian reproducibly for security reasons and is then able to collaborate on software projects where software is built reproducibly with other companies that use public distributions of Debian.

Chris: Many thanks for this interview, Simon. If someone wanted to get in touch or learn more about you and your colleagues at the School of Informatics, where might they go?
Thank you for the opportunity. It has been a pleasure to reflect a little more widely on the research!
Personally, you can find out about my work
on my official homepage and on
my personal site. The software systems research group (SSRG)
has a website, and the
University of Sk vde s English language pages are also available.
Chris: Many thanks for this interview, Simon!
For more information about the Reproducible Builds project, please see our website at
reproducible-builds.org. If you are interested in
ensuring the ongoing security of the software that underpins our civilisation
and wish to sponsor the Reproducible Builds project, please reach out to the
project by emailing
contact@reproducible-builds.org.
 Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I d share it as a tale of how huh, that s weird can be a powerful threat-hunting tool but only if you ve got the time to keep pulling at the thread.
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the disclosure of what was, at the time, a fairly earth-shattering revelation: that for about 18 months, the Debian OpenSSL package was generating entirely predictable private keys.
The recent xz-stential threat (thanks to @nixCraft for making me aware of that one), has got me thinking about my own serendipitous interaction with a major vulnerability.
Given that the statute of limitations has (probably) run out, I thought I d share it as a tale of how huh, that s weird can be a powerful threat-hunting tool but only if you ve got the time to keep pulling at the thread.

 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze



 The Emacs part is superceded by
The Emacs part is superceded by  Attribution of source code has been limited to comments, but a deeper
embedding of attribution into code is possible. When an embedded
attribution is removed or is incorrect, the code should no longer work.
I've developed a way to do this in Haskell that is lightweight to add, but
requires more work to remove than seems worthwhile for someone who is
training an LLM on my code. And when it's not removed, it invites LLM
hallucinations of broken code.
I'm embedding attribution by defining a function like this in a module,
which uses an
Attribution of source code has been limited to comments, but a deeper
embedding of attribution into code is possible. When an embedded
attribution is removed or is incorrect, the code should no longer work.
I've developed a way to do this in Haskell that is lightweight to add, but
requires more work to remove than seems worthwhile for someone who is
training an LLM on my code. And when it's not removed, it invites LLM
hallucinations of broken code.
I'm embedding attribution by defining a function like this in a module,
which uses an 







 Work involves supporting Windows (there's a lot of specialised hardware design software that's only supported under Windows, so this isn't really avoidable), but also involves git, so I've been working on extending our support for hardware-backed SSH certificates to Windows and trying to glue that into git. In theory this doesn't sound like a hard problem, but in practice oh good heavens.
Work involves supporting Windows (there's a lot of specialised hardware design software that's only supported under Windows, so this isn't really avoidable), but also involves git, so I've been working on extending our support for hardware-backed SSH certificates to Windows and trying to glue that into git. In theory this doesn't sound like a hard problem, but in practice oh good heavens.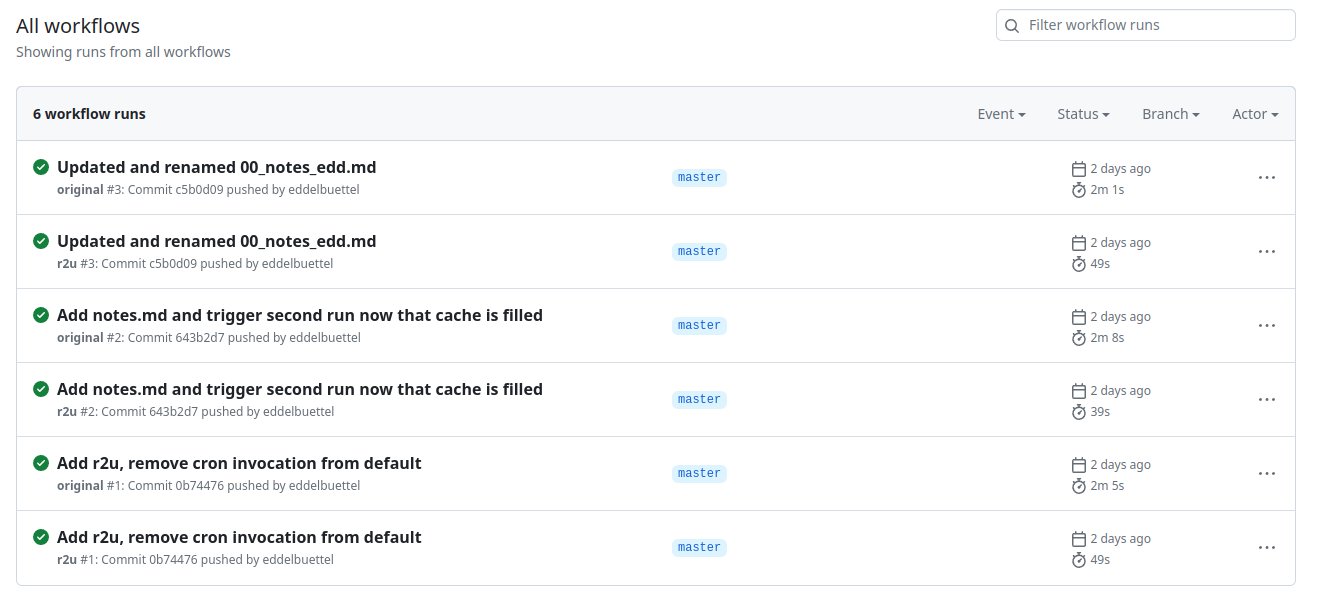 Turns out maybe not so much (yet ?). As the
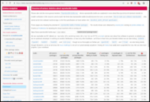
Turns out maybe not so much (yet ?). As the  Now, this is of course entirely possibly that not all possible venues
for speedups were exploited in how the action setup was setup. If so,
please file an issue at the
Now, this is of course entirely possibly that not all possible venues
for speedups were exploited in how the action setup was setup. If so,
please file an issue at the  The first time you do this, it will open up a new browser tab where
your Codespace is being instantiated. This first-time instantiation
will take a few minutes (feel free to click View logs to see how
things are progressing) so please be patient. Once built, your Codespace
will deploy almost immediately when you use it again in the future.
The first time you do this, it will open up a new browser tab where
your Codespace is being instantiated. This first-time instantiation
will take a few minutes (feel free to click View logs to see how
things are progressing) so please be patient. Once built, your Codespace
will deploy almost immediately when you use it again in the future.
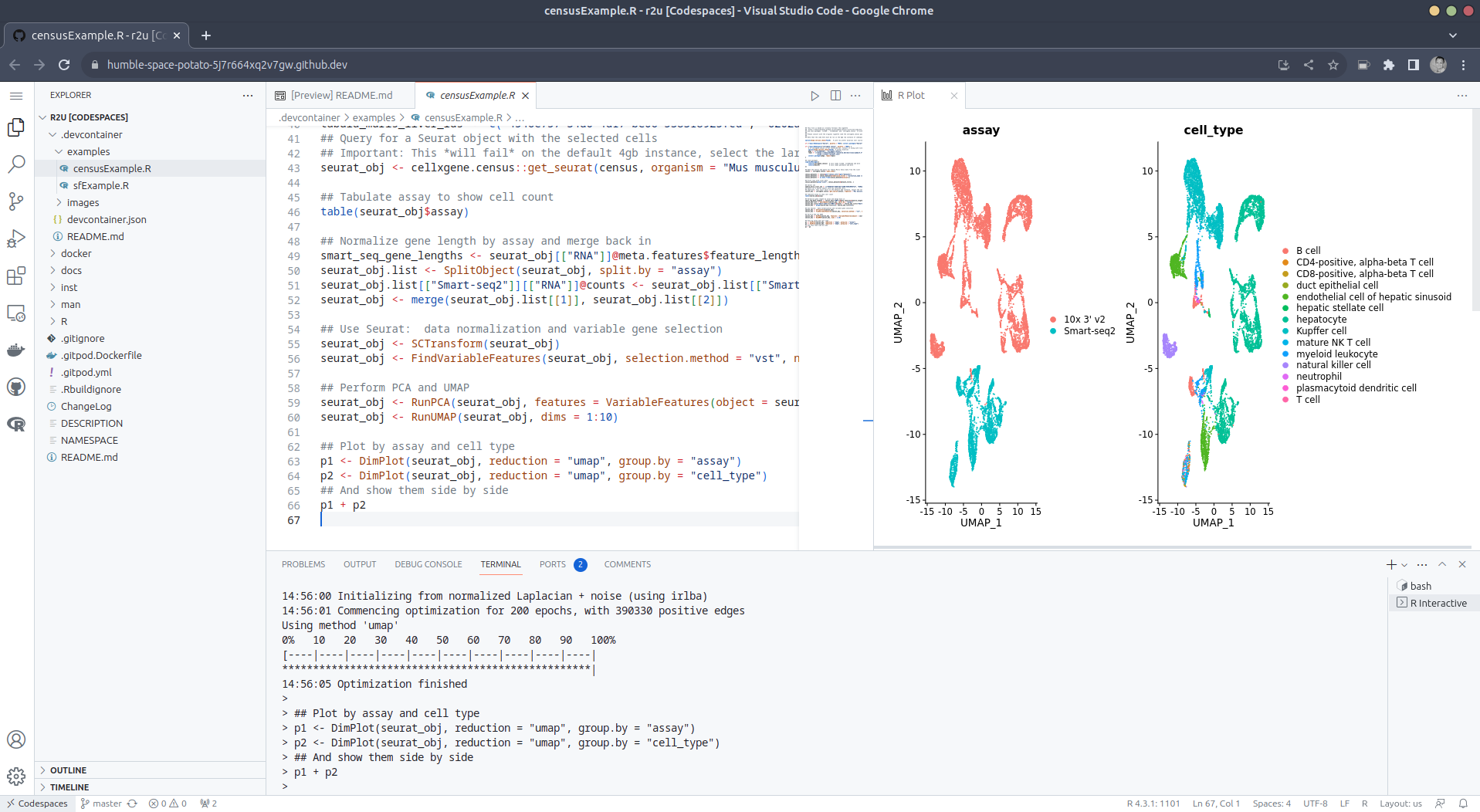
 After the VS Code editor opens up in your browser, feel free to open
up the
After the VS Code editor opens up in your browser, feel free to open
up the  (Both example screenshots reflect the initial
(Both example screenshots reflect the initial