Antoine Beaupr : Using signal-cli to cancel your Signal account
For obscure reasons, I have found
myself with a phone number registered with Signal but without any
device associated with it.
This is the I lost my phone section in Signal support, which
rather unhelpfully tell you that, literally:
Disclaimer: no warranty or liability
Before following this guide, make sure you remember the
license of this website, which specifically has a
Section 5 Disclaimer of Warranties and Limitation of Liability.
If you follow this guide literally, you might actually get into
trouble.
You have been warned. All Cats Are Beautiful.
Until you have access to your phone number, there is nothing that can be done with Signal.To be fair, I guess that sort of makes sense: Signal relies heavily on phone numbers for identity. It's how you register to the service and how you recover after losing your phone number. If you have your PIN ready, you don't even change safety numbers! But my case is different: this phone number was a test number, associated with my tablet, because you can't link multiple Android device to the same phone number. And now that I brilliantly bricked that tablet, I just need to tell people to stop trying to contact me over that thing (which wasn't really working in the first place anyway because I wasn't using the tablet that much, but I digress). So. What do you do? You could follow the above "lost my phone" guide and get a new Android or iOS phone to register on Signal again, but that's pretty dumb: I don't want another phone, I already have one. Lo and behold, signal-cli to the rescue!
Disclaimer: no warranty or liability
Before following this guide, make sure you remember the
license of this website, which specifically has a
Section 5 Disclaimer of Warranties and Limitation of Liability.
If you follow this guide literally, you might actually get into
trouble.
You have been warned. All Cats Are Beautiful.
Installing in Docker
Because signal-cli is not packaged in Debian (but really should
be), I need to bend over backwards to install it. The installation
instructions suggest building from source (what is this,
GentooBSD?) or installing binary files (what is this,
Debiandows?), that's all so last millennium. I want something fresh
and fancy, so I went with the extremely legit Docker registry ran
by the not-shady-at-all gitlab.com/packaging group which is
suspiciously not owned by any GitLab.com person I know of.
This is surely perfectly safe.
(Insert long digression on supply chain security here and how Podman
is so much superior to Docker. Feel free to dive deep into how
RedHat sold out to the nazis or how this is just me
ranting about something I don't understand, again. I'm not going to
do all the work for you.)
Anyway.
The magic command is:
mkdir .config/signal-cli
podman pull registry.gitlab.com/packaging/signal-cli/signal-cli-jre:latest
# lightly hit computer with magic supply chain verification wand
alias signal-cli="podman run --rm --publish 7583:7583 --volume .config/signal-cli:/var/lib/signal-cli --tmpfs /tmp:exec registry.gitlab.com/packaging/signal-cli/signal-cli-jre:latest --config /var/lib/signal-cli"
At this point, you have a signal-cli alias that should more or less
behave as per upstream documentation. Note that it sets up a
network service on port 7583 which is unnecessary because you likely
won't be using signal-cli's "daemon mode" here, this is a one-shot
thing. But I'll probably be reusing those instructions later on, so I
figured it might be a safe addition. Besides, it's what the
instructions told me to do so I'm blindly slamming my head in the
bash pipe, as trained.
Also, you're going to have the signal-cli configuration persist in
~/.config/signal-cli there. Again, totally unnecessary.
Re-registering the number
Back to our original plan of canceling our Signal account. The next
step is, of course, to register with Signal.
Yes, this is a little counter-intuitive and you'd think there would
be a "I want off this boat" button on https://signal.org
that would do this for you, but hey, I guess that's only reserved for
elite hackers who want to screw people over, I mean close
their accounts. Mere mortals don't get access to such beauties.
Update: a friend reminded me there used to be such a page at
https://signal.org/signal/unregister/ but it's mysteriously gone
from the web, but still available on the wayback machine
although surely that doesn't work anymore. Untested.
To register an account with signal-cli, you first need to pass a
CAPTCHA. Those are the funky images generated by deep neural
networks that try to fool humans into thinking other neural networks
can't break them, and generally annoy the hell out of people. This
will generate a URL that looks like:
signalcaptcha://signal-hcaptcha.$UUID.registration.$THIRTYTWOKILOBYTESOFGARBAGE
Yes, it's a very long URL. Yes, you need the entire thing.
The URL is hidden behind the Open Signal link, you can right-click
on the link to copy it or, if you want to feel like it's 1988
again, use view-source: or butterflies or something.
You will also need the phone number you want to unregister here,
obviously. We're going to take a not quite random phone number as an
example, +18002677468.
Don't do this at home kids! Use the actual number and don't
copy-paste examples from random websites!
So the actual command you need to run now is:
signal-cli -a +18002677468 register --captcha signalcaptcha://signal-hcaptcha.$UUID.registration.$THIRTYTWOKILOBYTESOFGARBAGE
To confirm the registration, Signal will send a text message (SMS) to
that phone number with a verification code. (Fun fact: it's actually
Twilio relaying that message for Signal and that is... not
great.)
If you don't have access to SMS on that number, you can try again with
the --voice option, which will do the same thing with a actual phone
call. I wish it would say "Ok boomer" when it calls, but it doesn't.
If you don't have access to either, you're screwed. You may be able to
port your phone number to another provider to gain control of the
phone number again that said, but at that point it's a whole different
ball game.
With any luck now you've received the verification code. You use it with:
signal-cli -a +18002677468 verify 131213
If you want to make sure this worked, you can try writing to another
not random number at all, it should Just Work:
signal-cli -a +18002677468 send -mtest +18005778477
This is almost without any warning on the other end too, which says
something amazing about Signal's usability and something horrible
about its security.
Unregistering the number
Now we get to the final conclusion, the climax. Can you feel it? I'll
try to refrain from further rants, I promise.
It's pretty simple and fast, just call:
signal-cli -a +18002677468 unregister
That's it! Your peers will now see an "Invite to Signal" button
instead of a text field to send a text message.
Cleanup
Optionally, cleanup the mess you left on this computer:
rm -r ~/.config/signal-cli
podman image rm registry.gitlab.com/packaging/signal-cli/signal-cli-jre
(Insert long digression on supply chain security here and how Podman is so much superior to Docker. Feel free to dive deep into how RedHat sold out to the nazis or how this is just me ranting about something I don't understand, again. I'm not going to do all the work for you.)Anyway. The magic command is:
mkdir .config/signal-cli
podman pull registry.gitlab.com/packaging/signal-cli/signal-cli-jre:latest
# lightly hit computer with magic supply chain verification wand
alias signal-cli="podman run --rm --publish 7583:7583 --volume .config/signal-cli:/var/lib/signal-cli --tmpfs /tmp:exec registry.gitlab.com/packaging/signal-cli/signal-cli-jre:latest --config /var/lib/signal-cli"
signal-cli alias that should more or less
behave as per upstream documentation. Note that it sets up a
network service on port 7583 which is unnecessary because you likely
won't be using signal-cli's "daemon mode" here, this is a one-shot
thing. But I'll probably be reusing those instructions later on, so I
figured it might be a safe addition. Besides, it's what the
instructions told me to do so I'm blindly slamming my head in the
bash pipe, as trained.
Also, you're going to have the signal-cli configuration persist in
~/.config/signal-cli there. Again, totally unnecessary.
Re-registering the number
Back to our original plan of canceling our Signal account. The next
step is, of course, to register with Signal.
Yes, this is a little counter-intuitive and you'd think there would
be a "I want off this boat" button on https://signal.org
that would do this for you, but hey, I guess that's only reserved for
elite hackers who want to screw people over, I mean close
their accounts. Mere mortals don't get access to such beauties.
Update: a friend reminded me there used to be such a page at
https://signal.org/signal/unregister/ but it's mysteriously gone
from the web, but still available on the wayback machine
although surely that doesn't work anymore. Untested.
To register an account with signal-cli, you first need to pass a
CAPTCHA. Those are the funky images generated by deep neural
networks that try to fool humans into thinking other neural networks
can't break them, and generally annoy the hell out of people. This
will generate a URL that looks like:
signalcaptcha://signal-hcaptcha.$UUID.registration.$THIRTYTWOKILOBYTESOFGARBAGE
Yes, it's a very long URL. Yes, you need the entire thing.
The URL is hidden behind the Open Signal link, you can right-click
on the link to copy it or, if you want to feel like it's 1988
again, use view-source: or butterflies or something.
You will also need the phone number you want to unregister here,
obviously. We're going to take a not quite random phone number as an
example, +18002677468.
Don't do this at home kids! Use the actual number and don't
copy-paste examples from random websites!
So the actual command you need to run now is:
signal-cli -a +18002677468 register --captcha signalcaptcha://signal-hcaptcha.$UUID.registration.$THIRTYTWOKILOBYTESOFGARBAGE
To confirm the registration, Signal will send a text message (SMS) to
that phone number with a verification code. (Fun fact: it's actually
Twilio relaying that message for Signal and that is... not
great.)
If you don't have access to SMS on that number, you can try again with
the --voice option, which will do the same thing with a actual phone
call. I wish it would say "Ok boomer" when it calls, but it doesn't.
If you don't have access to either, you're screwed. You may be able to
port your phone number to another provider to gain control of the
phone number again that said, but at that point it's a whole different
ball game.
With any luck now you've received the verification code. You use it with:
signal-cli -a +18002677468 verify 131213
If you want to make sure this worked, you can try writing to another
not random number at all, it should Just Work:
signal-cli -a +18002677468 send -mtest +18005778477
This is almost without any warning on the other end too, which says
something amazing about Signal's usability and something horrible
about its security.
Unregistering the number
Now we get to the final conclusion, the climax. Can you feel it? I'll
try to refrain from further rants, I promise.
It's pretty simple and fast, just call:
signal-cli -a +18002677468 unregister
That's it! Your peers will now see an "Invite to Signal" button
instead of a text field to send a text message.
Cleanup
Optionally, cleanup the mess you left on this computer:
rm -r ~/.config/signal-cli
podman image rm registry.gitlab.com/packaging/signal-cli/signal-cli-jre
signalcaptcha://signal-hcaptcha.$UUID.registration.$THIRTYTWOKILOBYTESOFGARBAGE
signal-cli -a +18002677468 register --captcha signalcaptcha://signal-hcaptcha.$UUID.registration.$THIRTYTWOKILOBYTESOFGARBAGE
signal-cli -a +18002677468 verify 131213
signal-cli -a +18002677468 send -mtest +18005778477
signal-cli -a +18002677468 unregister
Cleanup
Optionally, cleanup the mess you left on this computer:
rm -r ~/.config/signal-cli
podman image rm registry.gitlab.com/packaging/signal-cli/signal-cli-jre
rm -r ~/.config/signal-cli
podman image rm registry.gitlab.com/packaging/signal-cli/signal-cli-jre
 I realised this week that my recent efforts to improve how Consfigurator makes
the fork(2) system call have also created a way to install executables to
remote systems which will execute arbitrary Common Lisp code. Distributing
precompiled programs using free software implementations of the Common Lisp
standard tends to be more of a hassle than with a lot of other high level
programming languages. Executables will often be hundreds of megabytes in
size even if your codebase is just a few megabytes, because the whole
interactive Common Lisp environment gets bundled along with your program s
code. Commercial Common Lisp implementations manage to do better, as I
understand it, by knowing how to shake out unused code paths. Consfigurator s
new mechanism uploads only changed source code, which might only be kilobytes
in size, and updates the executable on the remote system. So it should be
useful for deploying Common Lisp-powered web services, and the like.
Here s how it works. When you use Consfigurator you define an ASDF system
analagous to a Python package or Perl distribution called your consfig .
This defines HOST objects to represent the machines that you ll use
Consfigurator to manage, and any custom properties, functions those properties
call, etc.. An ASDF system can depend upon other systems; for example, every
consfig depends upon Consfigurator itself. When you execute Consfigurator
deployments, Consfigurator uploads the source code of any ASDF systems that
have changed since you last deployed this host, starts up Lisp on the remote
machine, and loads up all the systems. Now the remote Lisp image is in a
similarly clean state to when you ve just started up Lisp on your laptop and
loaded up the libraries you re going to use. Only then are the actual
deployment instructions are sent on stdin.
What I ve done this week is insert an extra step for the remote Lisp image in
between loading up all the ASDF systems and reading the deployment from stdin:
the image calls fork(2) and establishes a pipe to communicate with the child
process. The child process can be sent Lisp forms to evaluate, but for each
Lisp form it receives it will actually fork again, and have its child
process evaluate the form. Thus, going into the deployment, the original
remote Lisp image has the capability to have arbitrary Lisp forms evaluated in
a context in which all that has happened is that a statically defined set of
ASDF systems has been loaded the child processes never see the full
deployment instructions sent on stdin. Further, the child process responsible
for actually evaluating the Lisp form received from the first process first
forks off another child process and sets up its own control pipe, such that it
too has the capacbility to have arbitrary Lisp forms evaluated in a cleanly
loaded context, no matter what else it might put in its memory in the
meantime. (Things are set up such that the child processes responsible for
actually evaluating the Lisp forms never see the Lisp forms received for
evaluation by other child processes, either.)
So suppose now we have an ASDF system
I realised this week that my recent efforts to improve how Consfigurator makes
the fork(2) system call have also created a way to install executables to
remote systems which will execute arbitrary Common Lisp code. Distributing
precompiled programs using free software implementations of the Common Lisp
standard tends to be more of a hassle than with a lot of other high level
programming languages. Executables will often be hundreds of megabytes in
size even if your codebase is just a few megabytes, because the whole
interactive Common Lisp environment gets bundled along with your program s
code. Commercial Common Lisp implementations manage to do better, as I
understand it, by knowing how to shake out unused code paths. Consfigurator s
new mechanism uploads only changed source code, which might only be kilobytes
in size, and updates the executable on the remote system. So it should be
useful for deploying Common Lisp-powered web services, and the like.
Here s how it works. When you use Consfigurator you define an ASDF system
analagous to a Python package or Perl distribution called your consfig .
This defines HOST objects to represent the machines that you ll use
Consfigurator to manage, and any custom properties, functions those properties
call, etc.. An ASDF system can depend upon other systems; for example, every
consfig depends upon Consfigurator itself. When you execute Consfigurator
deployments, Consfigurator uploads the source code of any ASDF systems that
have changed since you last deployed this host, starts up Lisp on the remote
machine, and loads up all the systems. Now the remote Lisp image is in a
similarly clean state to when you ve just started up Lisp on your laptop and
loaded up the libraries you re going to use. Only then are the actual
deployment instructions are sent on stdin.
What I ve done this week is insert an extra step for the remote Lisp image in
between loading up all the ASDF systems and reading the deployment from stdin:
the image calls fork(2) and establishes a pipe to communicate with the child
process. The child process can be sent Lisp forms to evaluate, but for each
Lisp form it receives it will actually fork again, and have its child
process evaluate the form. Thus, going into the deployment, the original
remote Lisp image has the capability to have arbitrary Lisp forms evaluated in
a context in which all that has happened is that a statically defined set of
ASDF systems has been loaded the child processes never see the full
deployment instructions sent on stdin. Further, the child process responsible
for actually evaluating the Lisp form received from the first process first
forks off another child process and sets up its own control pipe, such that it
too has the capacbility to have arbitrary Lisp forms evaluated in a cleanly
loaded context, no matter what else it might put in its memory in the
meantime. (Things are set up such that the child processes responsible for
actually evaluating the Lisp forms never see the Lisp forms received for
evaluation by other child processes, either.)
So suppose now we have an ASDF system 
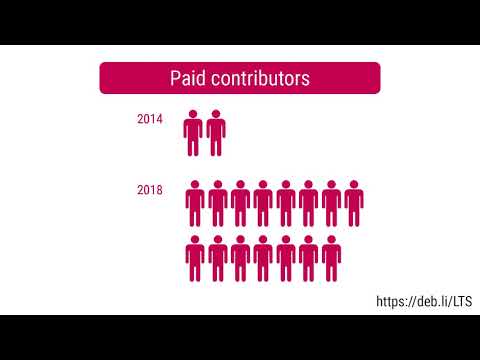
 Here is my monthly update covering what I have been doing in the free software world during April 2020 (
Here is my monthly update covering what I have been doing in the free software world during April 2020 (









 Today I was wondering about converting a pdf made from scan of a book
into djvu, hopefully to reduce the size, without too much loss of
quality. My initial experiments with
Today I was wondering about converting a pdf made from scan of a book
into djvu, hopefully to reduce the size, without too much loss of
quality. My initial experiments with

 probably just not as default.
I do agree
probably just not as default.
I do agree 
 In fact, the "risk" of using only 2048 rather than 4096 bits in the smartcard may well be far outweighed by the benefits of hardware security (especially if a smartcard reader with pin-pad is used)
My own conclusion is that 2048 is not a dead duck and using this key length remains a valid decision and is very likely to remain so for the next 5 years at least.
In fact, the "risk" of using only 2048 rather than 4096 bits in the smartcard may well be far outweighed by the benefits of hardware security (especially if a smartcard reader with pin-pad is used)
My own conclusion is that 2048 is not a dead duck and using this key length remains a valid decision and is very likely to remain so for the next 5 years at least.  Imagine you had an excellent successful Kickstarter campaign, and during
it a lot of people asked for an Android port to be made of the software.
Which is written in Haskell. No problem, you'd think -- the user interface
can be written as a local webapp, which will be nicely platform agnostic
and so make it easy to port. Also, it's easy to promise a lot of stuff
during a Kickstarter campaign. Keeps the graph going up. What could go
wrong?
So, rather later you realize there is no Haskell compiler for Android. At
all. But surely there will be eventually. And so you go off and build the
webapp. Since Yesod seems to be the pinnacle of type-safe Haskell web
frameworks, you use it. Hmm, there's this Template Haskell stuff that it
uses a lot, but it only makes compiles a little slow, and the result is
cool, so why not.
Then, about half-way through the project, it seems time to get around
to this Android port. And, amazingly, a
Imagine you had an excellent successful Kickstarter campaign, and during
it a lot of people asked for an Android port to be made of the software.
Which is written in Haskell. No problem, you'd think -- the user interface
can be written as a local webapp, which will be nicely platform agnostic
and so make it easy to port. Also, it's easy to promise a lot of stuff
during a Kickstarter campaign. Keeps the graph going up. What could go
wrong?
So, rather later you realize there is no Haskell compiler for Android. At
all. But surely there will be eventually. And so you go off and build the
webapp. Since Yesod seems to be the pinnacle of type-safe Haskell web
frameworks, you use it. Hmm, there's this Template Haskell stuff that it
uses a lot, but it only makes compiles a little slow, and the result is
cool, so why not.
Then, about half-way through the project, it seems time to get around
to this Android port. And, amazingly, a
 I bricked a Samsung laptop today. Unlike most of the reported cases of Samsung laptops refusing to boot, I never booted Linux on it - all experimentation was performed under Windows. It seems that the bug we've been seeing is simultaneously simpler in some ways and more complicated in others than we'd previously realised.
I bricked a Samsung laptop today. Unlike most of the reported cases of Samsung laptops refusing to boot, I never booted Linux on it - all experimentation was performed under Windows. It seems that the bug we've been seeing is simultaneously simpler in some ways and more complicated in others than we'd previously realised.







 So, on July 31st 2011, it was exactly 10 years since I am a Debian
developer. What happened in the meantime? What lead me to this? What
turned this unskilled dude into a sometimes quite visible contributor
of one of the major free software projects?
If you're interested in that, please read on. Otherwise, well, this is
just yet another "bubulle talks about self" post and you can skip it.
Well, first of all, how did I end up being a DD?
And first of firsts, how did I end up not being a random user of
Windows, playing games on his desktop computer at work?
I am not a computer scientist, an "informaticien" as we sometimes say
in French (most often, what people who are not in computing stuff
say...thinking that all folks working more or less closely to
computers know everything about them).
I graduated with a PhD in
Materials science, in 1989 after conducting a research on "Influence
of Yttrium Oxide dispersion on the strength of titanium alloys", at
Onera, a French public research institution for aerospace and defence.
I was then hired, still at Onera (where I'm still working, 25 years
after starting my PhD work) to lead the Mechanical Testing Laboratory in the
Materials Science department.
So, my lab had many big machines
designed to conduct creep and fatigue tests often at interestingly
high temperatures such as 2000 C, on samples of various
materials that are used in aircrafts structures, engines, etc. or in
various space thingies (remember Herm s, the european shuttle?) or in
various "things that fly but just one way and you shouldn't be there
when they land".
So, we had computers handling data acquisition for these tests. So I
became involved with designing data acquisition setups, or even
programming data acquisition programs (one of mine, written in Forth,
ran all Onera creep tests until 2004 and successfully passed Y2K
because I knew that 2000 was a leap year. It could even pass 2100 as I
knew this is not a leap year..:-)
One day, I had to buy a modem in order to communicate with out italian
counterpart (CIRA) and exchange tests results. Then I had to learn how
modems work in MS-Dos(yeah...). Then, I discovered "online"
resources...indeed more that strange world that was then called "BBS"
(Bulletin Board Systems), those mysterious things ran by some happy
few who were using modems at their home place to communicate in
"forums" and everything related to technology.
PC-Board, Remote
Access, Fidonet, etc. became familiar to me these days, back in
1988-1990. So familiar that I ended up running my own BBS at home,
killing our phone bills and using very sophisticated techniques such as
US Robotics "High Speed Transfer" modems that could be used at
19200bps asymetrical for very high speed transfers of kilobytes and
kilobytes of useless MS-Dos "freeware" and "shareware".
Indeed, my
very first BBS didn't even have one of these: it was using a cheaper
V.22bis modem operating at 2400bps. I was waiting for my order of a
sophisticated HST modem to arrive from USA through obscure import
channels meant to circumvent the French telephone company regulations
that were forbidding the use of "unapproved" systems, in order to
protect the famous French Telephone System from interferences brought
by Bad American Material.
Bubulle System was born.
During those years, I discovered very interesting things: computers can
run together once you draw a wire between them. That's called Local
Area Network and you can even transfer data at 1Mbps between two
computers, assuming you don't forget to put terminating resistors at
the end of the line on these funny 10-baseT connectors at the back of
your home-assembled PC that was using 2MB of RAM (bought for very
cheap through the help of an American friend who was in touch with
some Chinese folks who were selling 256kb RAM sticks for half the
retail price....assuming you want to drive in a mysterious storing
place close to Charles de Gaulle airport or Eurodisney).
Hello Gordon. Yes, I know, we're still friends on Facebook and you're
probably still using that weird programming language which you were,
IIRC, the only person in the world to use.
2MB, that should be enough for barely anything, including running
*multitasking* software where, miracle, I could run two tasks at the
same time on my one and only PC at home. Miracle, I don't have to
shutdown my BBS if I want to read forums on my friends BBS. Yay for
Desqview/386! Multitasking for dummies
Still, I have to build one of these "networks" at home. Elizabeth
won't like that as it means one more box (home-made of course) in our
living room and some more wires. And why the hell is it running 24/7?
So that friends can visit the BBS, darling... And I can even
communicate with them: I write a message, I get an answer the day
after and so on. In one full week, we can have a great conversation
that would have taken *minutes* to have in the real life. Isn't this
the miracle of technlogy?
And, yes, this is a good reason for having
phone bills raising up to 500 Francs/month: people can "exchange"
programs through my BBS, that horrible white box running in the living
room. Often, these programs are written for free and some of them are
even given with "source code", which allows people to *modify* them.
And that even makes friends, you know? Imagine that some day we have
to move from one house to another: then I can just call out "who
wants to help bubulle moving?", and probably a dozen of (sometimes
scary but always nice and polite...and sometimes even showered) geeks
will pop up and happily carry boxes full of my vinyl LP collection all
day long. An entire world of friends.
"bubulle", you say, dear? What's that? That's my nickname. It was
invented by one of these friends, a really strange guy named Ren
Cougnenc who wrote this "free software" program anmed BBTH, which
allows you to use modems to connect to BBS, and even to those many
"Minitel" BBS we have in France, thanks to our wonderful world-leading
technology using V.23 communication.
Many people know me as "bubulle" because, you know, Perrier water has
bubbles and Ren likes Gaston Lagaffe fish companion who he named "bubulle".
Ren , I love you. You chose to leave this world back in 1998. We'll no
longer have our "p'tits midis" in Antony where you were showing me the
marvels of what's coming in next episode.
All this was around 1988 and about 1992, doing all these mysterious
things at home (between Jean-Baptiste and Sophie's diapers) while
still working with data acquisition MS-Dos machines at work.
How did this end up being a Debian Developer? You'll know in the next
episode..:-)
So, on July 31st 2011, it was exactly 10 years since I am a Debian
developer. What happened in the meantime? What lead me to this? What
turned this unskilled dude into a sometimes quite visible contributor
of one of the major free software projects?
If you're interested in that, please read on. Otherwise, well, this is
just yet another "bubulle talks about self" post and you can skip it.
Well, first of all, how did I end up being a DD?
And first of firsts, how did I end up not being a random user of
Windows, playing games on his desktop computer at work?
I am not a computer scientist, an "informaticien" as we sometimes say
in French (most often, what people who are not in computing stuff
say...thinking that all folks working more or less closely to
computers know everything about them).
I graduated with a PhD in
Materials science, in 1989 after conducting a research on "Influence
of Yttrium Oxide dispersion on the strength of titanium alloys", at
Onera, a French public research institution for aerospace and defence.
I was then hired, still at Onera (where I'm still working, 25 years
after starting my PhD work) to lead the Mechanical Testing Laboratory in the
Materials Science department.
So, my lab had many big machines
designed to conduct creep and fatigue tests often at interestingly
high temperatures such as 2000 C, on samples of various
materials that are used in aircrafts structures, engines, etc. or in
various space thingies (remember Herm s, the european shuttle?) or in
various "things that fly but just one way and you shouldn't be there
when they land".
So, we had computers handling data acquisition for these tests. So I
became involved with designing data acquisition setups, or even
programming data acquisition programs (one of mine, written in Forth,
ran all Onera creep tests until 2004 and successfully passed Y2K
because I knew that 2000 was a leap year. It could even pass 2100 as I
knew this is not a leap year..:-)
One day, I had to buy a modem in order to communicate with out italian
counterpart (CIRA) and exchange tests results. Then I had to learn how
modems work in MS-Dos(yeah...). Then, I discovered "online"
resources...indeed more that strange world that was then called "BBS"
(Bulletin Board Systems), those mysterious things ran by some happy
few who were using modems at their home place to communicate in
"forums" and everything related to technology.
PC-Board, Remote
Access, Fidonet, etc. became familiar to me these days, back in
1988-1990. So familiar that I ended up running my own BBS at home,
killing our phone bills and using very sophisticated techniques such as
US Robotics "High Speed Transfer" modems that could be used at
19200bps asymetrical for very high speed transfers of kilobytes and
kilobytes of useless MS-Dos "freeware" and "shareware".
Indeed, my
very first BBS didn't even have one of these: it was using a cheaper
V.22bis modem operating at 2400bps. I was waiting for my order of a
sophisticated HST modem to arrive from USA through obscure import
channels meant to circumvent the French telephone company regulations
that were forbidding the use of "unapproved" systems, in order to
protect the famous French Telephone System from interferences brought
by Bad American Material.
Bubulle System was born.
During those years, I discovered very interesting things: computers can
run together once you draw a wire between them. That's called Local
Area Network and you can even transfer data at 1Mbps between two
computers, assuming you don't forget to put terminating resistors at
the end of the line on these funny 10-baseT connectors at the back of
your home-assembled PC that was using 2MB of RAM (bought for very
cheap through the help of an American friend who was in touch with
some Chinese folks who were selling 256kb RAM sticks for half the
retail price....assuming you want to drive in a mysterious storing
place close to Charles de Gaulle airport or Eurodisney).
Hello Gordon. Yes, I know, we're still friends on Facebook and you're
probably still using that weird programming language which you were,
IIRC, the only person in the world to use.
2MB, that should be enough for barely anything, including running
*multitasking* software where, miracle, I could run two tasks at the
same time on my one and only PC at home. Miracle, I don't have to
shutdown my BBS if I want to read forums on my friends BBS. Yay for
Desqview/386! Multitasking for dummies
Still, I have to build one of these "networks" at home. Elizabeth
won't like that as it means one more box (home-made of course) in our
living room and some more wires. And why the hell is it running 24/7?
So that friends can visit the BBS, darling... And I can even
communicate with them: I write a message, I get an answer the day
after and so on. In one full week, we can have a great conversation
that would have taken *minutes* to have in the real life. Isn't this
the miracle of technlogy?
And, yes, this is a good reason for having
phone bills raising up to 500 Francs/month: people can "exchange"
programs through my BBS, that horrible white box running in the living
room. Often, these programs are written for free and some of them are
even given with "source code", which allows people to *modify* them.
And that even makes friends, you know? Imagine that some day we have
to move from one house to another: then I can just call out "who
wants to help bubulle moving?", and probably a dozen of (sometimes
scary but always nice and polite...and sometimes even showered) geeks
will pop up and happily carry boxes full of my vinyl LP collection all
day long. An entire world of friends.
"bubulle", you say, dear? What's that? That's my nickname. It was
invented by one of these friends, a really strange guy named Ren
Cougnenc who wrote this "free software" program anmed BBTH, which
allows you to use modems to connect to BBS, and even to those many
"Minitel" BBS we have in France, thanks to our wonderful world-leading
technology using V.23 communication.
Many people know me as "bubulle" because, you know, Perrier water has
bubbles and Ren likes Gaston Lagaffe fish companion who he named "bubulle".
Ren , I love you. You chose to leave this world back in 1998. We'll no
longer have our "p'tits midis" in Antony where you were showing me the
marvels of what's coming in next episode.
All this was around 1988 and about 1992, doing all these mysterious
things at home (between Jean-Baptiste and Sophie's diapers) while
still working with data acquisition MS-Dos machines at work.
How did this end up being a Debian Developer? You'll know in the next
episode..:-)
 I spent most of last week working on
I spent most of last week working on