My descent began with a user
reporting a bug and I fear I am still on my way down.
The bug was simple enough, a windows bitmap file caused NetSurf to crash. Pretty quickly this was tracked down to the libnsbmp library attempting to decode the file. As to why we have a heavily used library for bitmaps? I am afraid they are part of every
icon file and many websites still have
favicons using that format.
Some time with a hex editor and the file format specification soon showed that the image in question was malformed and had a bad offset header entry. So I was faced with two issues, firstly that the decoder crashed when presented with badly encoded data and secondly that it failed to deal with incorrect header data.
This is typical of bug reports from real users, the obvious issues have already been encountered by the developers and unit tests formed to prevent them, what remains is harder to produce. After a debugging session with Valgrind and electric fence I discovered the crash was actually caused by running off the front of an allocated block due to an incorrect bounds check. Fixing the
bounds check was simple enough as was
working round the bad header value and after
adding a unit test for the issue I almost moved on.
Almost...
We already used the
bitmap test suite of images to check the library decode which was giving us a good 75% or so line coverage (I long ago added
coverage testing to our CI system) but I wondered if there was a test set that might increase the coverage and perhaps exercise some more of the bounds checking code. A bit of searching turned up the
american fuzzy lop (AFL) projects
synthetic corpora of bmp and ico images.
After checking with the AFL authors that the images were usable in our project I
added them to our test corpus and discovered a whole heap of trouble. After fixing more bounds checks and signed issues I finally had a library I was pretty sure was solid with over 85% test coverage.
Then I had the idea of actually running AFL on the library. I had been avoiding this because my previous experimentation with other fuzzing utilities had been utter frustration and very poor return on investment of time. Following the quick start guide looked straightforward enough so I thought I would spend a short amount of time and maybe I would learn a useful tool.
I downloaded the AFL source and built it with a simple make which was an encouraging start. The library was compiled in debug mode with AFL instrumentation simply by changing the compiler and linker environment variables.
$ LD=afl-gcc CC=afl-gcc AFL_HARDEN=1 make VARIANT=debug test
afl-cc 2.32b by <lcamtuf@google.com>
afl-cc 2.32b by <lcamtuf@google.com>
COMPILE: src/libnsbmp.c
afl-cc 2.32b by <lcamtuf@google.com>
afl-as 2.32b by <lcamtuf@google.com>
[+] Instrumented 751 locations (64-bit, hardened mode, ratio 100%).
AR: build-x86_64-linux-gnu-x86_64-linux-gnu-debug-lib-static/libnsbmp.a
COMPILE: test/decode_bmp.c
afl-cc 2.32b by <lcamtuf@google.com>
afl-as 2.32b by <lcamtuf@google.com>
[+] Instrumented 52 locations (64-bit, hardened mode, ratio 100%).
LINK: build-x86_64-linux-gnu-x86_64-linux-gnu-debug-lib-static/test_decode_bmp
afl-cc 2.32b by <lcamtuf@google.com>
COMPILE: test/decode_ico.c
afl-cc 2.32b by <lcamtuf@google.com>
afl-as 2.32b by <lcamtuf@google.com>
[+] Instrumented 65 locations (64-bit, hardened mode, ratio 100%).
LINK: build-x86_64-linux-gnu-x86_64-linux-gnu-debug-lib-static/test_decode_ico
afl-cc 2.32b by <lcamtuf@google.com>
Test bitmap decode
Tests:606 Pass:606 Error:0
Test icon decode
Tests:392 Pass:392 Error:0
TEST: Testing complete
I stuffed the AFL build directory on the end of my PATH, created a directory for the output and ran afl-fuzz
afl-fuzz -i test/bmp -o findings_dir -- ./build-x86_64-linux-gnu-x86_64-linux-gnu-debug-lib-static/test_decode_bmp @@ /dev/null
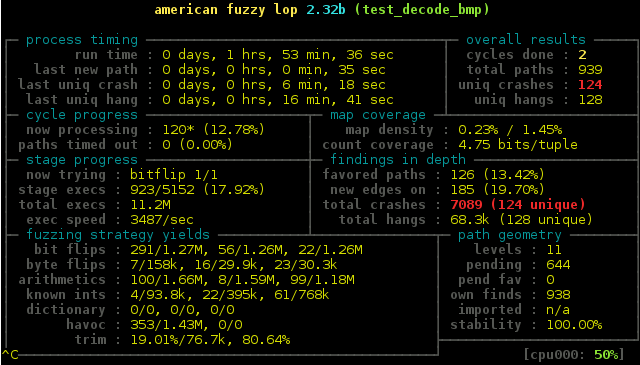
The result was immediate and not a little worrying, within seconds there were crashes and lots of them! Over the next couple of hours I watched as the unique crash total climbed into the triple digits.
I was forced to abort the run at this point as, despite clear warnings in the AFL documentation of the demands of the tool, my laptop was clearly not cut out to do this kind of work and had become distressingly hot.
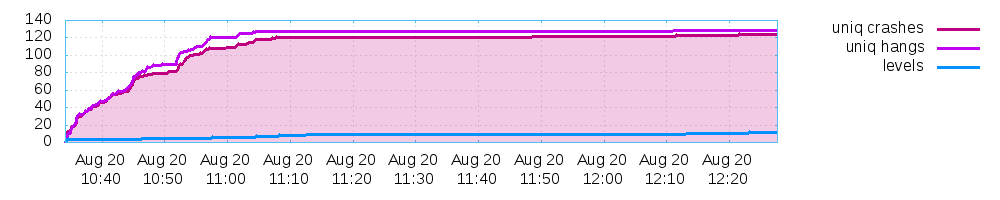
AFL has a visualisation tool so you can see what kind of progress it is making which produced a graph that showed just how fast it managed to produce crashes and how much the return plateaus after just a few cycles. Although it was finding a new unique crash every ten minutes or so when aborted.
I dove in to analyse the crashes and it immediately became obvious the main issue was caused when the test tool attempted allocations of absurdly large bitmaps. The browser itself uses a heuristic to determine the maximum image size based on used memory and several other values. I simply applied an upper bound of 48 megabytes per decoded image which fits easily within the fuzzers default heap limit of 50 megabytes.
The main source of "hangs" also came from large allocations so once the test was fixed afl-fuzz was re-run with a timeout parameter set to 100ms. This time after several minutes no crashes and only a single hang were found which came as a great relief, at which point my laptop had a hard shutdown due to thermal event!
Once the laptop cooled down I spooled up a more appropriate system to perform this kind of work a 24way 2.1GHz Xeon system. A Debian Jessie guest vm with 20 processors and 20 gigabytes of memory was created and the build replicated and instrumented.
To fully utilise this system the next test run would utilise AFL in parallel mode. In this mode there is a single "master" running all the deterministic checks and many "secondary" instances performing random tweaks.
If I have one tiny annoyance with AFL, it is that breeding and feeding a herd of rabbits by hand is annoying and something I would like to see a convenience utility for.
The warren was left overnight with 19 instances and by morning had generated crashes again. This time though the crashes actually appeared to be real failures.
$ afl-whatsup sync_dir/
Summary stats
=============
Fuzzers alive : 19
Total run time : 5 days, 12 hours
Total execs : 214 million
Cumulative speed : 8317 execs/sec
Pending paths : 0 faves, 542 total
Pending per fuzzer : 0 faves, 28 total (on average)
Crashes found : 554 locally unique
All the crashing test cases are available and a simple file command immediately showed that all the crashing test files had one thing in common the height of the image was -2147483648 This seemingly odd number is actually meaningful to a programmer, it is the largest negative number which can be stored in a 32bit integer (INT32_MIN) I immediately examined the source code that processes the height in the image header.
if ((width <= 0) (height == 0))
return BMP_DATA_ERROR;
if (height < 0)
bmp->reversed = true;
height = -height;
The bug is where the height is made a positive number and results in height being set to 0 after the existing check for zero and results in a crash later in execution. A
simple fix was applied and test case added removing the crash and any possible future failure due to this.
Another AFL run has been started and after a few hours has yet to find a crash or non false positive hang so it looks like if there are any more crashes to find they are much harder to uncover.
Main lessons learned are:
- AFL is an easy to use and immensely powerful and effective tool. State of the art has taken a massive step forward.
- The test harness is part of the test! make sure it does not behave in a poor manner and cause issues itself.
- Even a library with extensive test coverage and real world users can benefit from this technique. But it remains to be seen how quickly the rate of return will reduce after the initial fixes.
- Use the right tool for the job! Ensure you head the warnings in the manual as AFL uses a lot of resources including CPU, disc and memory.
I will of course be debugging any new crashes that occur and perhaps turning my sights to all the projects other unit tested libraries. I will also be investigating the generation of our own custom test corpus from AFL to replace the demo set, this will hopefully increase our unit test coverage even further.
Overall this has been my first successful use of a fuzzing tool and a very positive experience. I would wholeheartedly recommend using AFL to find errors and perhaps even integrate as part of a CI system.

 Over roughly the last year and a half I have been participating as a reviewer in
ACM s Computing Reviews, and have even
been honored as a Featured
Reviewer.
Given I have long enjoyed reading friends reviews of their reading material
(particularly, hats off to the very active Russ
Allbery, who both beats all of my
frequency expectations (I could never sustain the rythm he reads to!) and holds
documented records for his >20 years as a book reader, with far more clarity and
readability than I can aim for!), I decided to explicitly share my reviews via
this blog, as the audience is somewhat congruent; I will also link here some
reviews that were not approved for publication, clearly marking them so.
I will probably work on wrangling my Jekyll site
to display an (auto-)updated page and RSS feed for the reviews. In the meantime,
the reviews I have published are:
Over roughly the last year and a half I have been participating as a reviewer in
ACM s Computing Reviews, and have even
been honored as a Featured
Reviewer.
Given I have long enjoyed reading friends reviews of their reading material
(particularly, hats off to the very active Russ
Allbery, who both beats all of my
frequency expectations (I could never sustain the rythm he reads to!) and holds
documented records for his >20 years as a book reader, with far more clarity and
readability than I can aim for!), I decided to explicitly share my reviews via
this blog, as the audience is somewhat congruent; I will also link here some
reviews that were not approved for publication, clearly marking them so.
I will probably work on wrangling my Jekyll site
to display an (auto-)updated page and RSS feed for the reviews. In the meantime,
the reviews I have published are:















 On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the
On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the  On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in
On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in  Previously:
Previously: 

 Whilst there is an in-depth report forthcoming, the
Whilst there is an in-depth report forthcoming, the 

 Since some time everybody (read developer) want to run his new
Since some time everybody (read developer) want to run his new 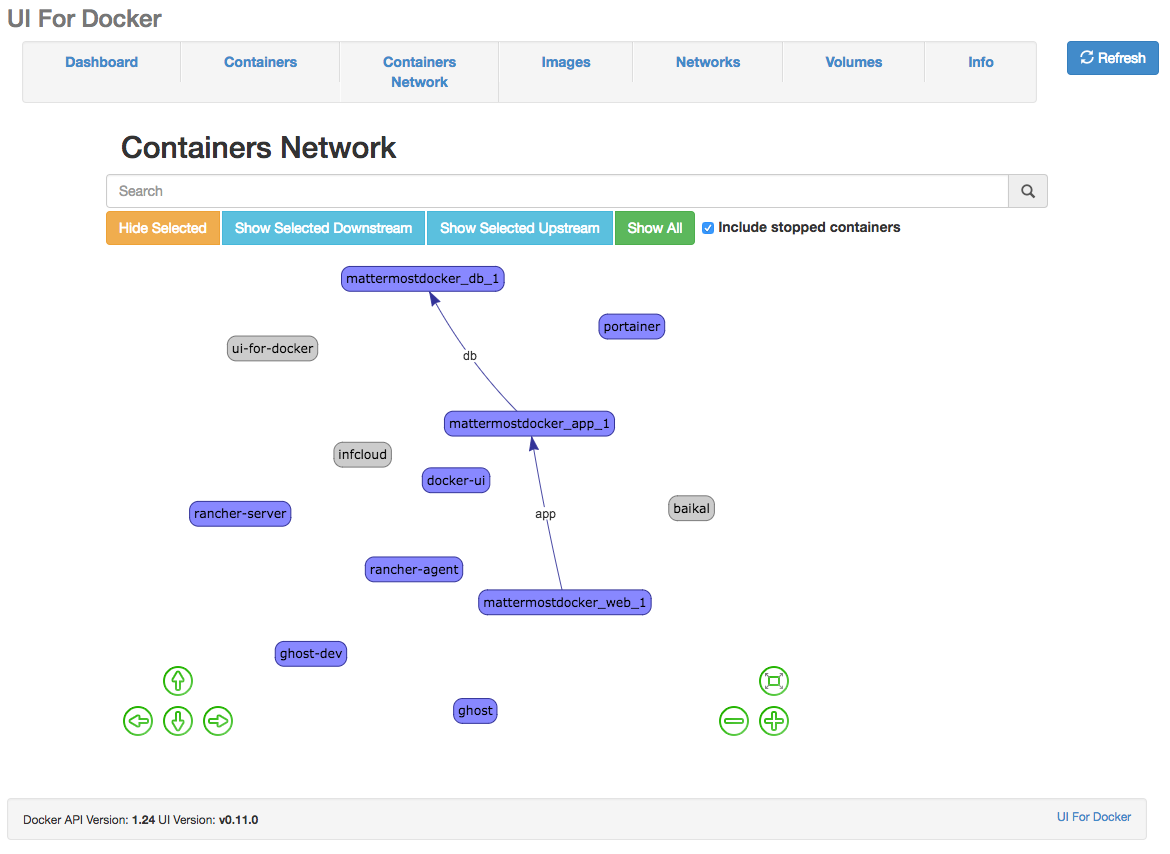
 For the use cases, we are facing,
For the use cases, we are facing,