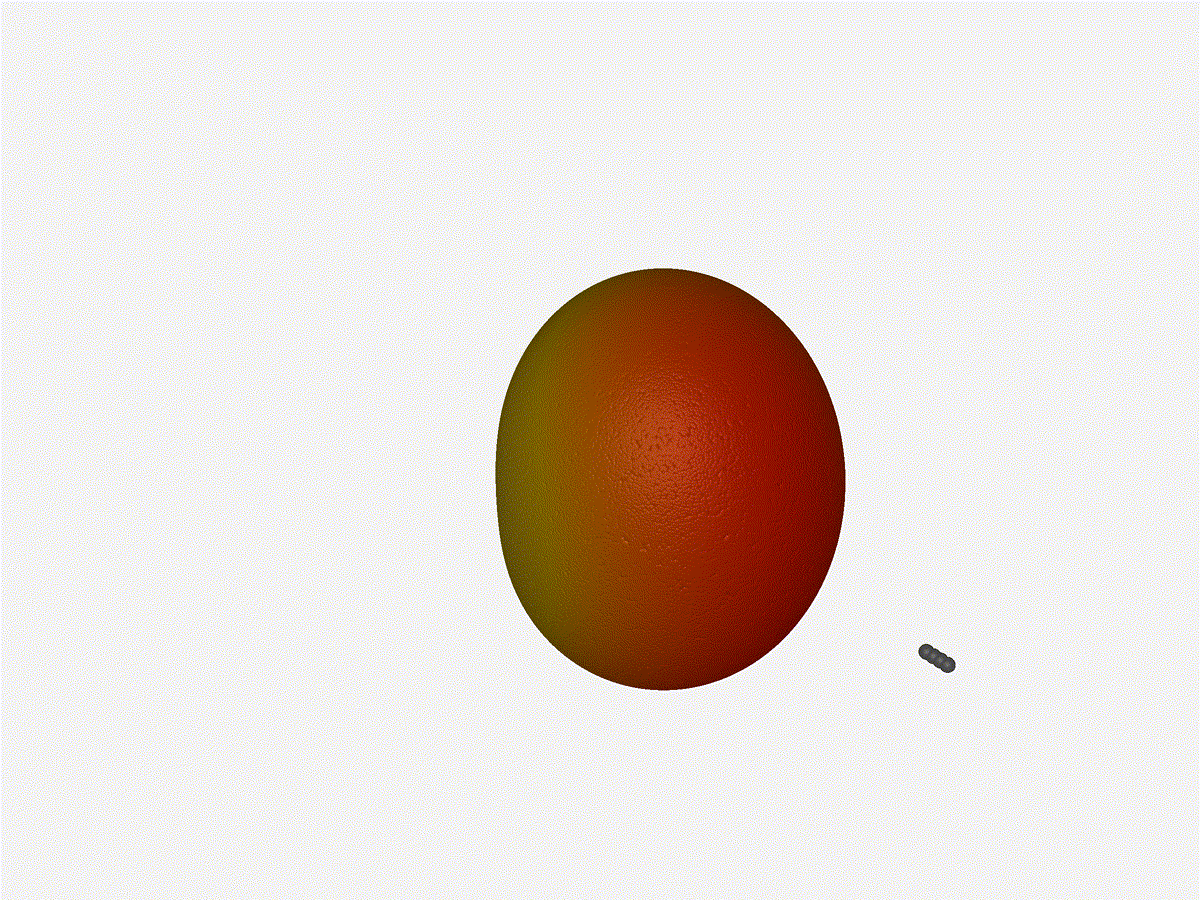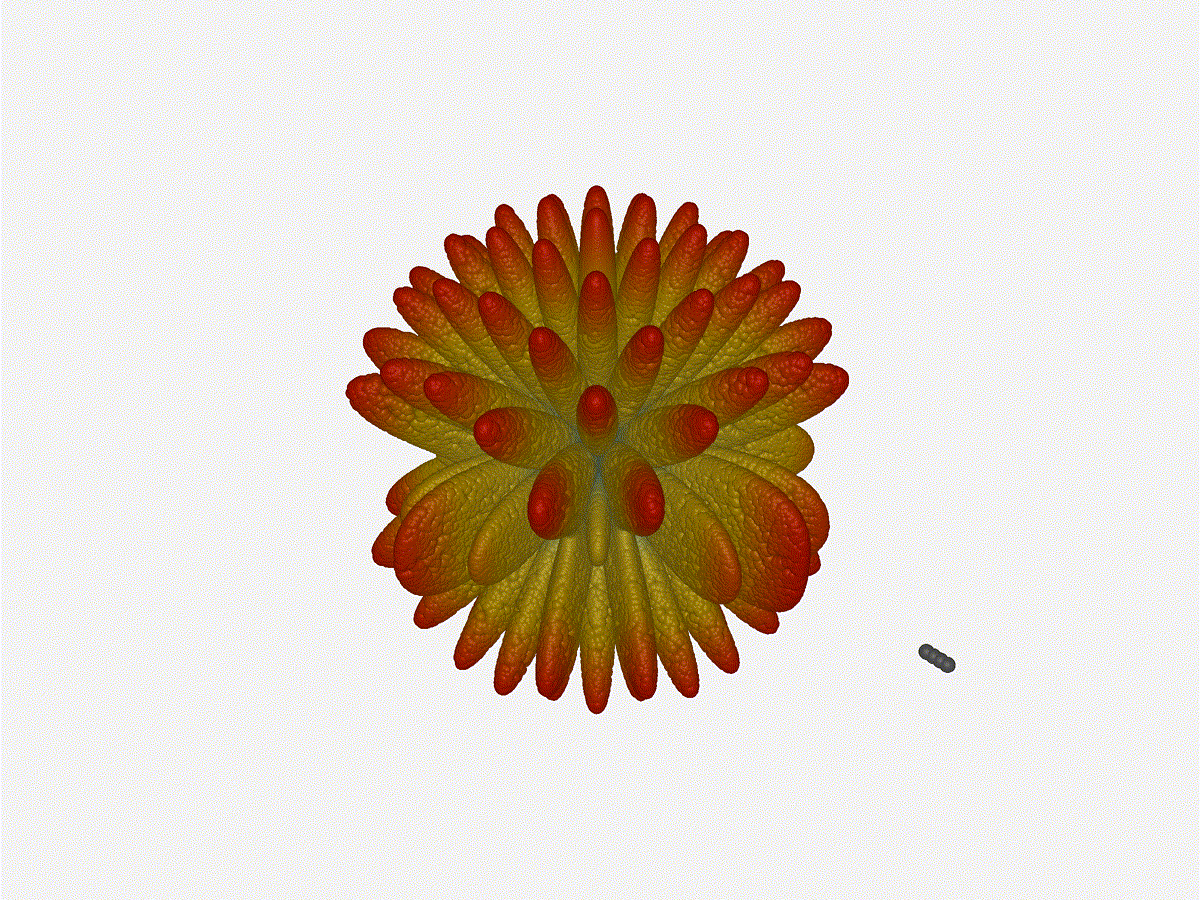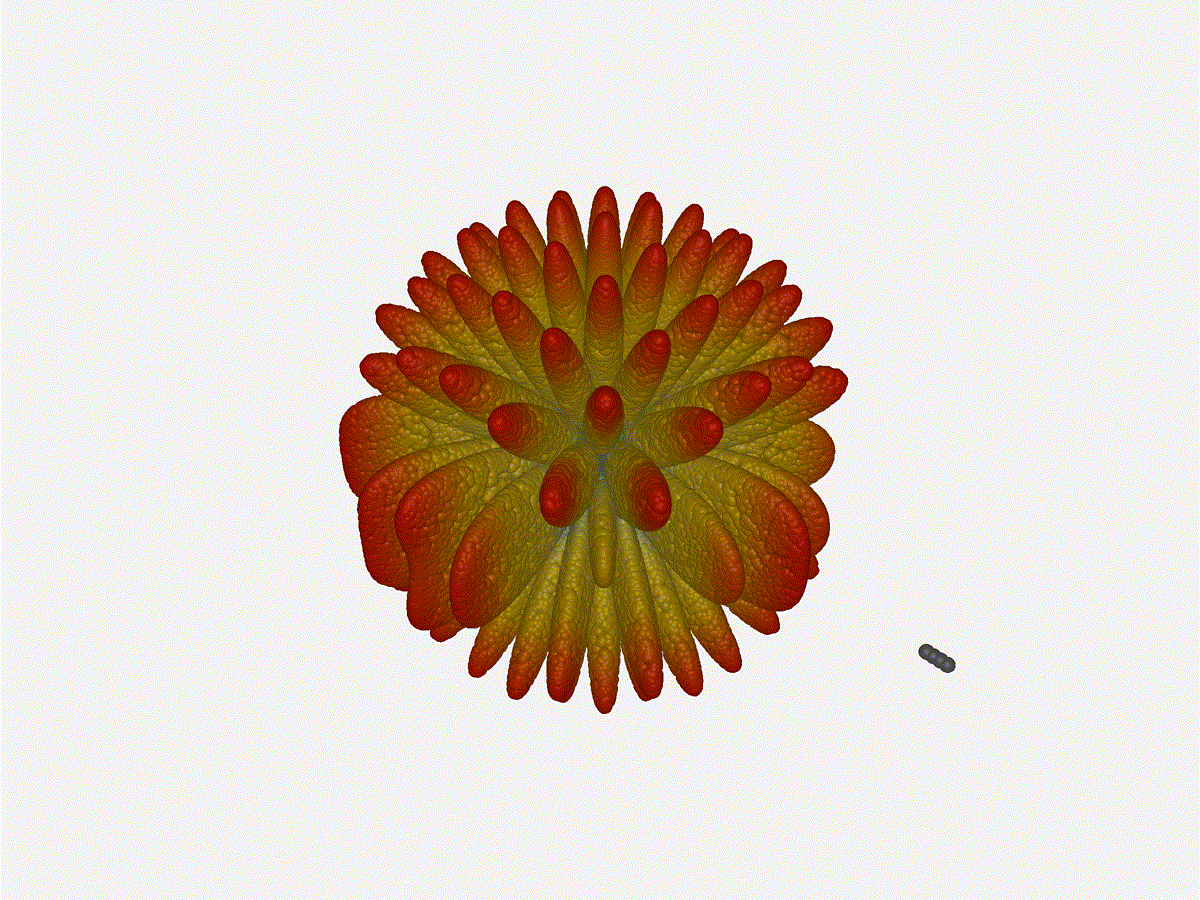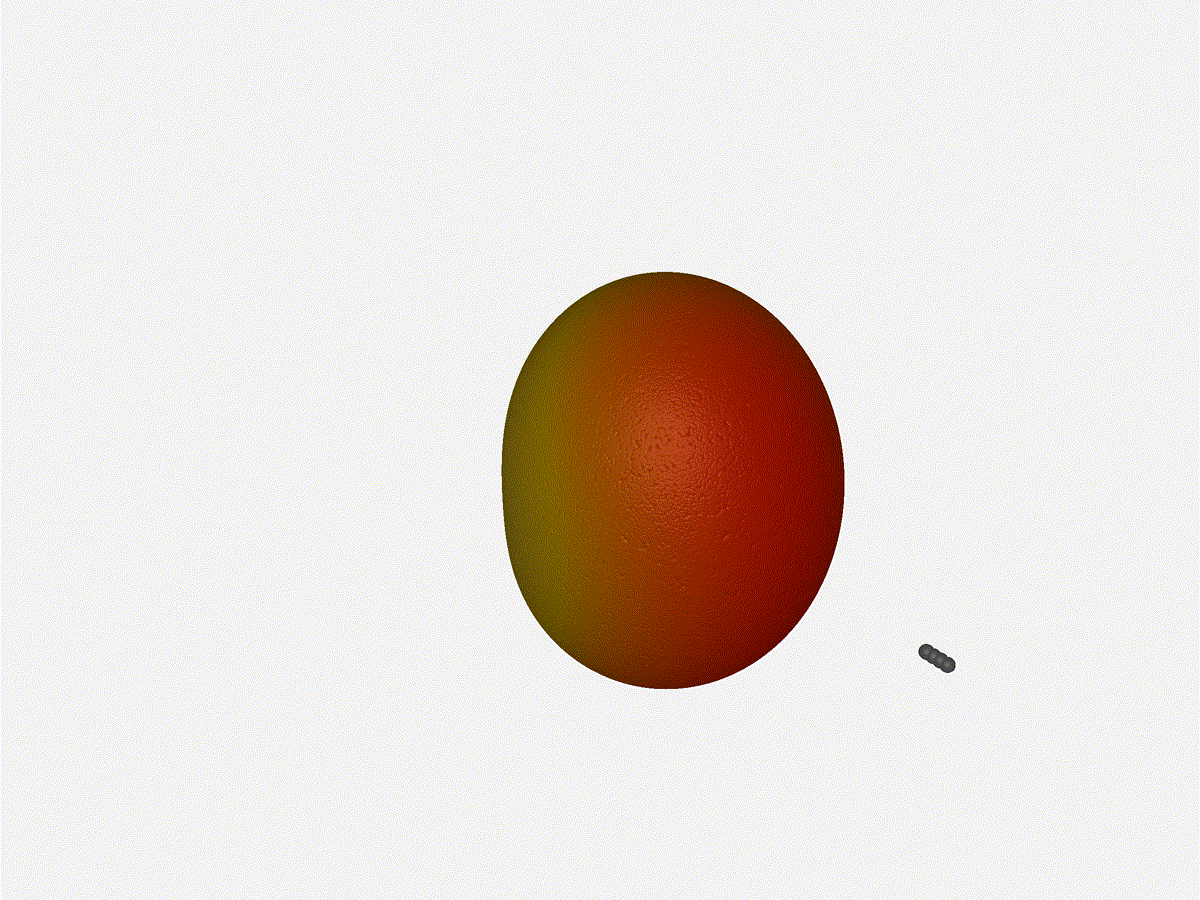With the
release of Libntlm version 1.8 the release tarball can be reproduced on several distributions. We also publish a signed minimal source-only tarball, produced by
git-archive which is the same format used by
Savannah,
Codeberg,
GitLab,
GitHub and others. Reproducibility of both tarballs are tested
continuously for regressions on GitLab through a CI/CD pipeline. If that wasn t enough to excite you, the
Debian packages of Libntlm are now built from the reproducible minimal source-only tarball. The resulting binaries are
hopefully reproducible on several architectures.
What does that even mean? Why should you care? How you can do the same for your project? What are the open issues? Read on, dear reader
This article describes my practical experiments with reproducible release artifacts, following up on
my earlier thoughts that lead to
discussion on Fosstodon and a
patch by Janneke Nieuwenhuizen to make Guix tarballs reproducible that inspired me to some practical work.
Let s look at how a maintainer release some software, and how a user can reproduce the released artifacts from the source code. Libntlm provides a shared library written in C and uses
GNU Make,
GNU Autoconf,
GNU Automake,
GNU Libtool and
gnulib for build management, but these ideas should apply to most project and build system. The following illustrate the steps a maintainer would take to prepare a release:
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make distcheck
gpg -b libntlm-1.8.tar.gz
The generated files
libntlm-1.8.tar.gz and
libntlm-1.8.tar.gz.sig are published, and users download and use them. This is how
the GNU project have been doing releases since the late 1980 s. That is a testament to how successful this pattern has been! These tarballs contain source code and some generated files, typically shell scripts generated by autoconf, makefile templates generated by automake, documentation in formats like
Info, HTML, or PDF. Rarely do they contain binary object code, but historically that happened.
The
XZUtils incident illustrate that tarballs with files that are not included in the git archive offer an opportunity to disguise malicious backdoors. I
blogged earlier how to mitigate this risk by using signed minimal source-only tarballs.
The risk of hiding malware is not the only motivation to publish signed minimal source-only tarballs. With pre-generated content in tarballs, there is a risk that
GNU/Linux distributions such as
Trisquel,
Guix,
Debian/
Ubuntu or
Fedora ship generated files coming from the tarball into the binary
*.deb or
*.rpm package file. Typically the person packaging the upstream project never realized that some installed artifacts was not re-built through a typical
autoconf -fi && ./configure && make install sequence, and never wrote the code to rebuild everything. This can also happen if the build rules are written but are buggy, shipping the old artifact. When a security problem is found, this can lead to time-consuming situations, as it may be that patching the relevant source code and rebuilding the package is not sufficient: the vulnerable generated object from the tarball would be shipped into the binary package instead of a rebuilt artifact. For architecture-specific binaries this rarely happens, since object code is usually not included in tarballs although for 10+ years I shipped the binary Java JAR file in the
GNU Libidn release tarball, until I
stopped shipping it. For interpreted languages and especially for generated content such as HTML, PDF, shell scripts this happens more than you would like.
Publishing minimal source-only tarballs enable easier auditing of a project s code, to avoid the need to read through all generated files looking for malicious content. I have taken care to generate the source-only minimal tarball using
git-archive. This is the same format that GitLab, GitHub etc offer for the automated download links on git tags. The minimal source-only tarballs can thus serve as a way to audit GitLab and GitHub download material! Consider if/when hosting sites like GitLab or GitHub has a security incident that cause generated tarballs to include a backdoor that is not present in the git repository. If people rely on the tag download artifact without verifying the maintainer PGP signature using
GnuPG, this can lead to similar backdoor scenarios that we had for XZUtils but originated with the hosting provider instead of the release manager. This is even more concerning, since this attack can be mounted for some selected IP address that you want to target and not on everyone, thereby making it harder to discover.
With all that discussion and rationale out of the way, let s return to the release process. I have added another step here:
make srcdist
gpg -b libntlm-1.8-src.tar.gz
Now the release is ready. I publish these four files in the
Libntlm s Savannah Download area, but they can be uploaded to a GitLab/GitHub release area as well. These are the SHA256 checksums I got after building the tarballs on my
Trisquel 11 aramo laptop:
91de864224913b9493c7a6cec2890e6eded3610d34c3d983132823de348ec2ca libntlm-1.8-src.tar.gz
ce6569a47a21173ba69c990965f73eb82d9a093eb871f935ab64ee13df47fda1 libntlm-1.8.tar.gz
So how can you reproduce my artifacts? Here is how to reproduce them in a Ubuntu 22.04 container:
podman run -it --rm ubuntu:22.04
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
./bootstrap
./configure
make dist srcdist
sha256sum libntlm-*.tar.gz
You should see the exact same SHA256 checksum values. Hooray!
This works because Trisquel 11 and Ubuntu 22.04 uses the same version of git, autoconf, automake, and libtool. These tools do not guarantee the same output content for all versions, similar to how
GNU GCC does not generate the same binary output for all versions. So there is still some delicate version pairing needed.
Ideally, the artifacts should be possible to reproduce from the release artifacts themselves, and not only directly from git. It is possible to reproduce the full tarball in a
AlmaLinux 8 container replace
almalinux:8 with
rockylinux:8 if you prefer
RockyLinux:
podman run -it --rm almalinux:8
dnf update -y
dnf install -y make wget gcc
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8.tar.gz
tar xfa libntlm-1.8.tar.gz
cd libntlm-1.8
./configure
make dist
sha256sum libntlm-1.8.tar.gz
The source-only minimal tarball can be regenerated on
Debian 11:
podman run -it --rm debian:11
apt-get update
apt-get install -y --no-install-recommends make git ca-certificates
git clone https://gitlab.com/gsasl/libntlm.git
cd libntlm
git checkout v1.8
make -f cfg.mk srcdist
sha256sum libntlm-1.8-src.tar.gz
As the Magnus Opus or chef-d uvre, let s recreate the full tarball directly from the minimal source-only tarball on Trisquel 11 replace
docker.io/kpengboy/trisquel:11.0 with
ubuntu:22.04 if you prefer.
podman run -it --rm docker.io/kpengboy/trisquel:11.0
apt-get update
apt-get install -y --no-install-recommends autoconf automake libtool make wget git ca-certificates
wget https://download.savannah.nongnu.org/releases/libntlm/libntlm-1.8-src.tar.gz
tar xfa libntlm-1.8-src.tar.gz
cd libntlm-v1.8
./bootstrap
./configure
make dist
sha256sum libntlm-1.8.tar.gz
Yay! You should now have great confidence in that the release artifacts correspond to what s in version control and also to what the maintainer intended to release. Your remaining job is to audit the source code for vulnerabilities, including the source code of the dependencies used in the build. You no longer have to worry about auditing the release artifacts.
I find it somewhat amusing that the build infrastructure for Libntlm is now in a significantly better place than the code itself. Libntlm is written in old C style with plenty of string manipulation and uses broken cryptographic algorithms such as
MD4 and
single-DES. Remember folks: solving supply chain security issues has no bearing on what kind of code you eventually run. A clean gun can still shoot you in the foot.
Side note on naming: GitLab exports tarballs with pathnames
libntlm-v1.8/ (i.e..,
PROJECT-TAG/) and I ve adopted the same pathnames, which means my
libntlm-1.8-src.tar.gz tarballs are bit-by-bit identical to GitLab s exports and you can verify this with tools like
diffoscope. GitLab name the tarball
libntlm-v1.8.tar.gz (i.e.,
PROJECT-TAG.ARCHIVE) which I find too similar to the
libntlm-1.8.tar.gz that we also publish. GitHub uses the same git archive style, but unfortunately they have logic that removes the v in the pathname so you will get a tarball with pathname
libntlm-1.8/ instead of
libntlm-v1.8/ that GitLab and I use. The content of the tarball is bit-by-bit identical, but the pathname and archive differs. Codeberg (running
Forgejo) uses another approach: the tarball is called
libntlm-v1.8.tar.gz (after the tag) just like GitLab, but the pathname inside the archive is
libntlm/, otherwise the produced archive is bit-by-bit identical including timestamps.
Savannah s CGIT interface uses archive name
libntlm-1.8.tar.gz with pathname
libntlm-1.8/, but otherwise file content is identical. Savannah s
GitWeb interface provides snapshot links that are named after the git commit (e.g.,
libntlm-a812c2ca.tar.gz with
libntlm-a812c2ca/) and I cannot find any tag-based download links at all. Overall, we are so close to get SHA256 checksum to match, but fail on pathname within the archive. I ve chosen to be compatible with GitLab regarding the content of tarballs but not on archive naming. From a simplicity point of view, it would be nice if everyone used
PROJECT-TAG.ARCHIVE for the archive filename and
PROJECT-TAG/ for the pathname within the archive. This aspect will probably need more discussion.
Side note on git archive output: It seems different versions of
git archive produce different results for the same repository. The version of git in Debian 11, Trisquel 11 and Ubuntu 22.04 behave the same. The version of git in Debian 12, AlmaLinux/RockyLinux 8/9, Alpine, ArchLinux, macOS homebrew, and upcoming Ubuntu 24.04 behave in another way. Hopefully this will not change that often, but this would invalidate reproducibility of these tarballs in the future, forcing you to use an old git release to reproduce the source-only tarball. Alas, GitLab and most other sites appears to be using modern git so the download tarballs from them would not match my tarballs even though the content would.
Side note on ChangeLog:
ChangeLog files were traditionally manually curated files with version history for a package. In recent years, several projects moved to dynamically generate them from git history (using tools like
git2cl or
gitlog-to-changelog). This has consequences for reproducibility of tarballs: you need to have the entire git history available! The
gitlog-to-changelog tool also output
different outputs depending on the time zone of the person using it, which arguable is a simple bug that can be fixed. However this entire approach is incompatible with rebuilding the full tarball from the minimal source-only tarball. It seems
Libntlm s ChangeLog file died on the
surgery table here.
So how would a distribution build these minimal source-only tarballs? I happen to help on the
libntlm package in Debian. It has historically used the generated tarballs as the source code to build from. This means that code coming from gnulib is vendored in the tarball. When a security problem is discovered in gnulib code, the security team needs to patch all packages that include that vendored code and rebuild them, instead of merely patching the gnulib package and rebuild all packages that rely on that particular code. To change this, the Debian libntlm package needs to Build-Depends on
Debian s gnulib package. But there was one problem: similar to most projects that use gnulib, Libntlm depend on a particular git commit of gnulib, and Debian only ship one commit. There is no coordination about which commit to use. I
have adopted gnulib in Debian, and add a
git bundle to the
*_all.deb binary package so that projects that rely on gnulib can pick whatever commit they need. This allow an
no-network GNULIB_URL and GNULIB_REVISION approach when running Libntlm s ./bootstrap with the Debian gnulib package installed. Otherwise libntlm would pick up whatever latest version of gnulib that Debian happened to have in the gnulib package, which is not what the Libntlm maintainer intended to be used, and can lead to all sorts of version mismatches (and consequently security problems) over time.
Libntlm in Debian is developed and tested on Salsa and there is
continuous integration testing of it as well, thanks to the
Salsa CI team.
Side note on git bundles: unfortunately there appears to be no reproducible way to export a git repository into one or more files. So one unfortunate consequence of all this work is that the gnulib
*.orig.tar.gz tarball in Debian is not reproducible any more. I have
tried to get Git bundles to be reproducible but I never got it to work see my notes in
gnulib s debian/README.source on this aspect. Of course, source tarball reproducibility has nothing to do with binary
reproducibility of gnulib in Debian itself, fortunately.
One open question is how to deal with the increased build dependencies that is triggered by this approach. Some
people are surprised by this but I don t see how to get around it: if you depend on source code for tools in another package to build your package, it is a bad idea to hide that dependency. We ve done it for a long time through vendored code in non-minimal tarballs. Libntlm isn t the most critical project from a bootstrapping perspective, so adding git and gnulib as
Build-Depends to it will probably be fine. However, consider if this pattern was used for other packages that uses gnulib such as
coreutils,
gzip,
tar,
bison etc (all are using gnulib) then they would all
Build-Depends on git and gnulib. Cross-building those packages for a new architecture will therefor require git on that architecture first, which gets circular quick. The dependency on gnulib is real so I don t see that going away, and gnulib is a
Architecture:all package. However, the dependency on git is merely a consequence of how the Debian gnulib package chose to make all gnulib git commits available to projects: through a git bundle. There are other ways to do this that doesn t require the git tool to extract the necessary files, but none that I found practical ideas welcome!
Finally some brief notes on how this was implemented. Enabling bootstrappable source-only minimal tarballs via gnulib s
./bootstrap is achieved by using the
GNULIB_REVISION mechanism, locking down the gnulib commit used. I have always disliked git submodules because they add extra steps and has complicated interaction with CI/CD. The reason why I
gave up git submodules now is because the particular commit to use is not recorded in the
git archive output when git submodules is used. So the particular gnulib commit has to be mentioned explicitly in some source code that goes into the git archive tarball.
Colin Watson added the GNULIB_REVISION approach to
./bootstrap back in 2018, and now it no longer made sense to continue to use a gnulib git submodule. One alternative is to use
./bootstrap with
--gnulib-srcdir or
--gnulib-refdir if there is some practical problem with the
GNULIB_URL towards a git bundle the
GNULIB_REVISION in
bootstrap.conf.
The
srcdist make rule is simple:
git archive --prefix=libntlm-v1.8/ -o libntlm-v1.8.tar.gz HEAD
Making the
make dist generated tarball reproducible can be more complicated, however for Libntlm it was sufficient to make sure the
modification times of all files were set deterministically to the timestamp of the last commit in the git repository. Interestingly there seems to be a couple of different ways to accomplish this, Guix doesn t support minimal source-only tarballs but
rely on a .tarball-timestamp file inside the tarball. Paul Eggert
explained what TZDB is using some time ago. The
approach I m using now is fairly similar to the
one I suggested over a year ago. If there are problems because all files in the tarball now use the same modification time, there is
a solution by Bruno Haible that could be implemented.
Side note on git tags: Some people may wonder why not verify a signed git tag instead of verifying a signed tarball of the git archive. Currently most git repositories uses SHA-1 for git commit identities, but
SHA-1 is not a secure hash function. While current SHA-1 attacks can be detected and mitigated, there are fundamental doubts that a git SHA-1 commit identity uniquely refers to the same content that was intended. Verifying a git tag will never offer the same assurance, since a git tag can be moved or re-signed at any time. Verifying a git commit is better but then we need to trust SHA-1. Migrating
git to SHA-256 would resolve this aspect, but most hosting sites such as GitLab and GitHub does not support this yet. There are other advantages to using signed tarballs instead of signed git commits or git tags as well, e.g.,
tar.gz can be a deterministically reproducible persistent stable offline storage format but
.git sub-directory trees or
git bundles do not offer this property.
Doing continous testing of all this is critical to make sure things don t regress.
Libntlm s pipeline definition now produce the generated
libntlm-*.tar.gz tarballs and a checksum as a build artifact. Then I added the
000-reproducability job which compares the checksums and fails on mismatches. You can read its
delicate output in the job for the v1.8 release. Right now we insists that builds on Trisquel 11 match Ubuntu 22.04, that PureOS 10 builds match Debian 11 builds, that AlmaLinux 8 builds match RockyLinux 8 builds, and AlmaLinux 9 builds match RockyLinux 9 builds. As you can see in pipeline job output, not all platforms lead to the same tarballs, but hopefully this state can be improved over time. There is also partial reproducibility, where the full tarball is reproducible across two distributions but not the minimal tarball, or vice versa.
If this way of working plays out well, I hope to implement it in other projects too.
What do you think? Happy Hacking!
 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
 Getting the
Getting the  Now that we are back from our six month period in Argentina, we
decided to adopt a kitten, to bring more diversity into our
lives. Perhaps this little girl will teach us to think outside the
box!
Now that we are back from our six month period in Argentina, we
decided to adopt a kitten, to bring more diversity into our
lives. Perhaps this little girl will teach us to think outside the
box!



 Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the
Those of you who haven t been in IT for far, far too long might not know that next month will be the 16th(!) anniversary of the 
 They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze
They're called The Usual Suspects for a reason, but sometimes, it really is Keyser S ze

 A welcome sign at Bangkok's Suvarnabhumi airport.
A welcome sign at Bangkok's Suvarnabhumi airport.
 Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
Bus from Suvarnabhumi Airport to Jomtien Beach in Pattaya.
 Road near Jomtien beach in Pattaya
Road near Jomtien beach in Pattaya
 Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
Photo of a songthaew in Pattaya. There are shared songthaews which run along Jomtien Second road and takes 10 bath to anywhere on the route.
 Jomtien Beach in Pattaya.
Jomtien Beach in Pattaya.
 A welcome sign at Pattaya Floating market.
A welcome sign at Pattaya Floating market.
 This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
This Korean Vegetasty noodles pack was yummy and was available at many 7-Eleven stores.
 Wat Arun temple stamps your hand upon entry
Wat Arun temple stamps your hand upon entry
 Wat Arun temple
Wat Arun temple
 Khao San Road
Khao San Road
 A food stall at Khao San Road
A food stall at Khao San Road
 Chao Phraya Express Boat
Chao Phraya Express Boat
 Banana with yellow flesh
Banana with yellow flesh
 Fruits at a stall in Bangkok
Fruits at a stall in Bangkok
 Trimmed pineapples from Thailand.
Trimmed pineapples from Thailand.
 Corn in Bangkok.
Corn in Bangkok.
 A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
A board showing coffee menu at a 7-Eleven store along with rates in Pattaya.
 In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
In this section of 7-Eleven, you can buy a premix coffee and mix it with hot water provided at the store to prepare.
 Red wine being served in Air India
Red wine being served in Air India
 Release 0.6.35 of the
Release 0.6.35 of the 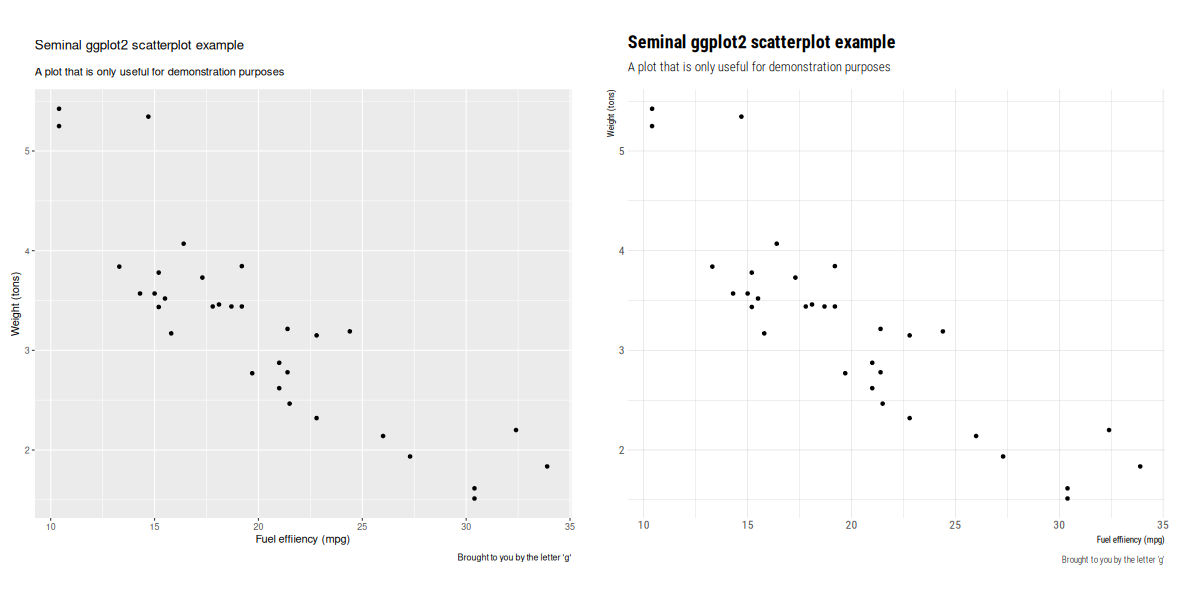 This version mostly just updates to the newest releases of
This version mostly just updates to the newest releases of  Two months into my
Two months into my  Mee Goreng, a dish made of noodles in Malaysia.
Mee Goreng, a dish made of noodles in Malaysia.
 Me at Petronas Towers.
Me at Petronas Towers.
 Photo with Malaysians.
Photo with Malaysians.


 Insert obligatory "not THAT data" comment here
Insert obligatory "not THAT data" comment here
 If you don't know who Professor Julius Sumner Miller is, I highly recommend
If you don't know who Professor Julius Sumner Miller is, I highly recommend  No thanks, Bender, I'm busy tonight
No thanks, Bender, I'm busy tonight
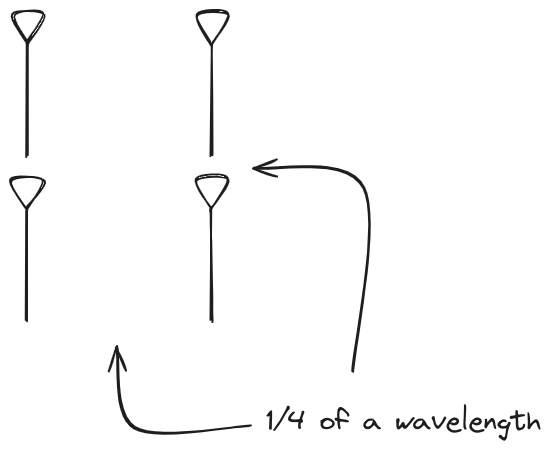
 And now let s take a look at the renders as we play with the configuration of
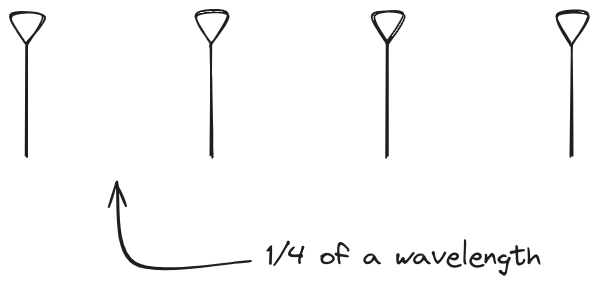
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
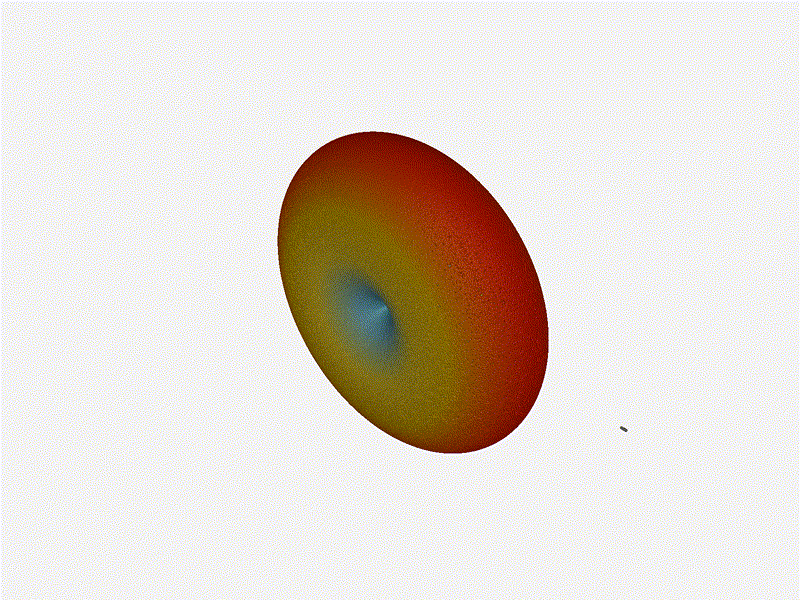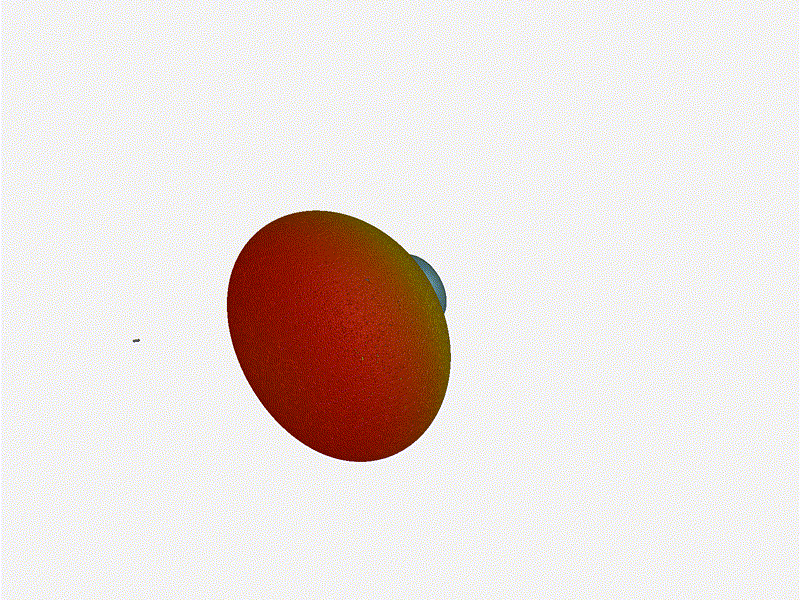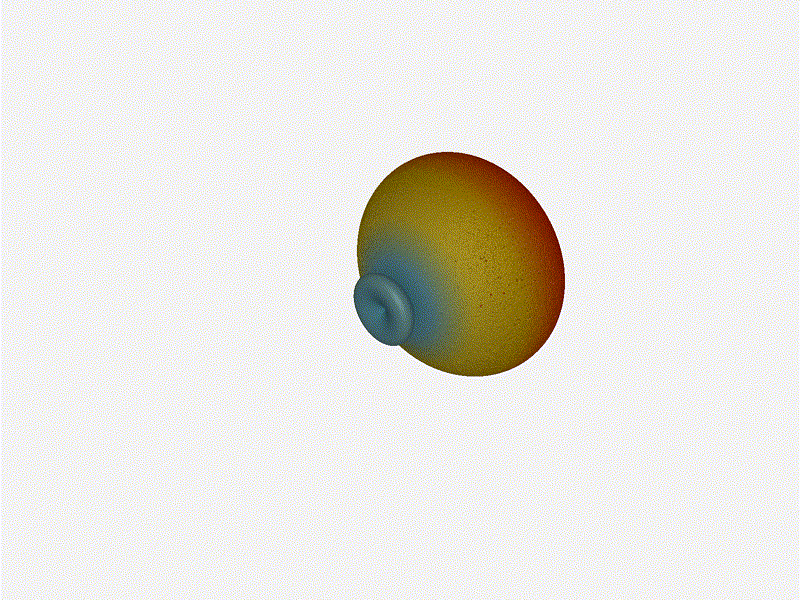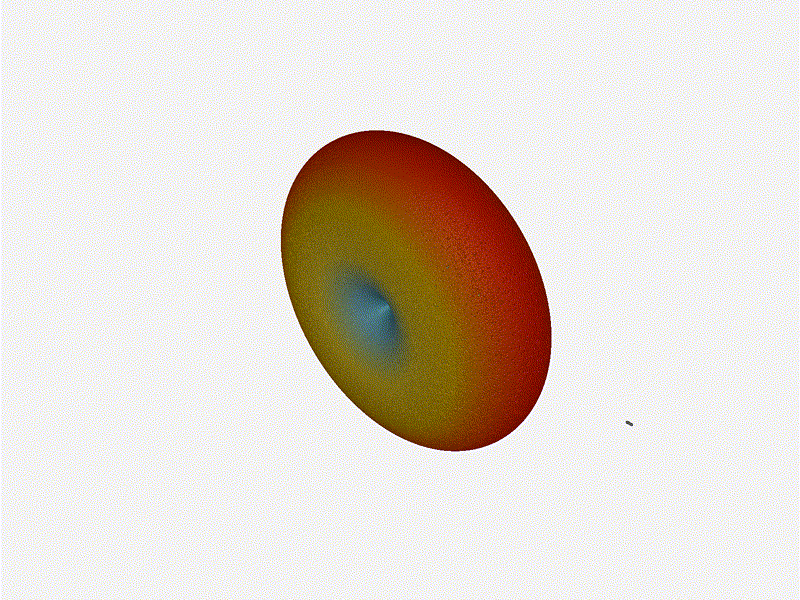
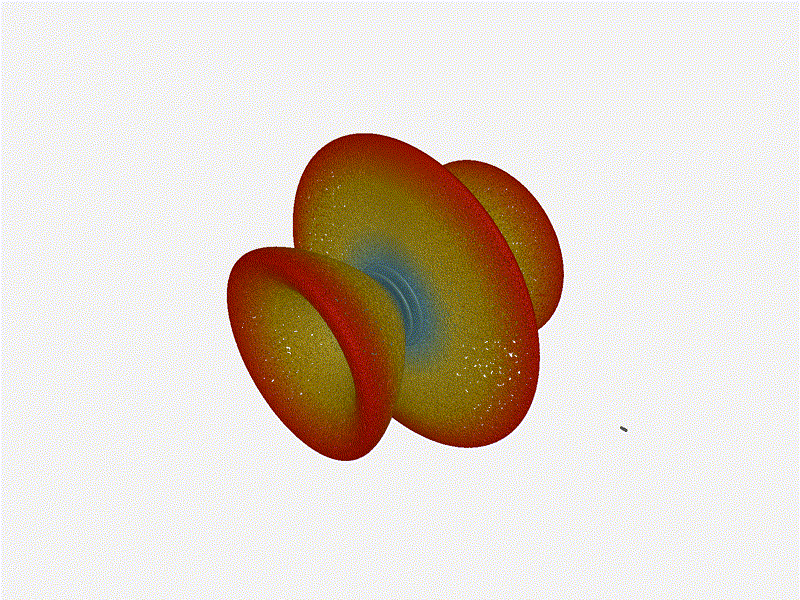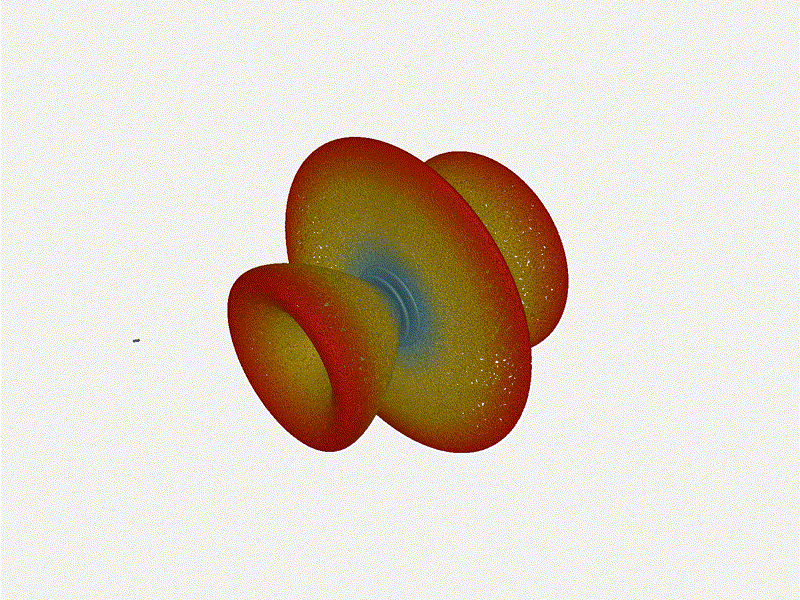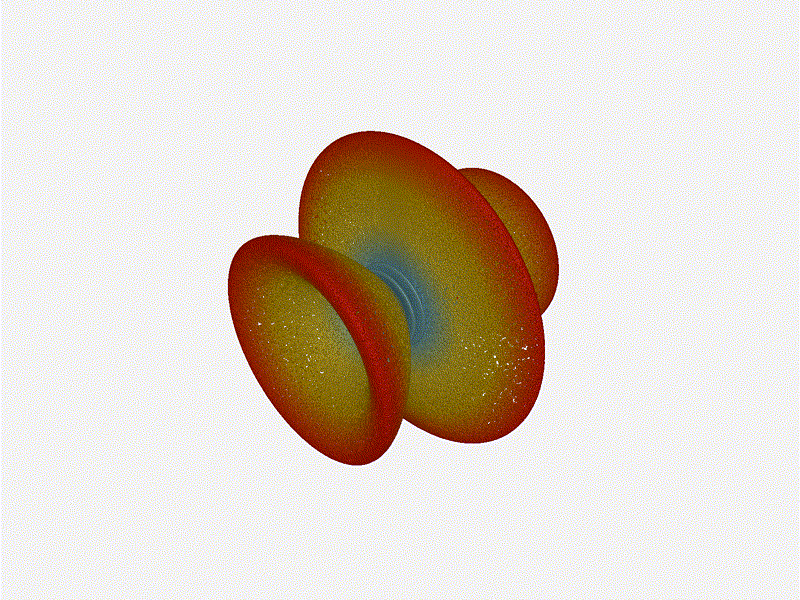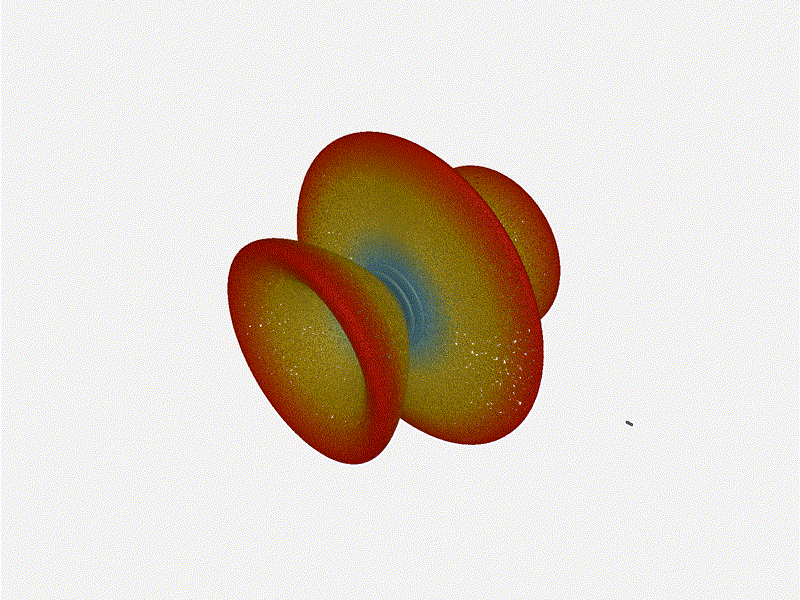

 Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.