
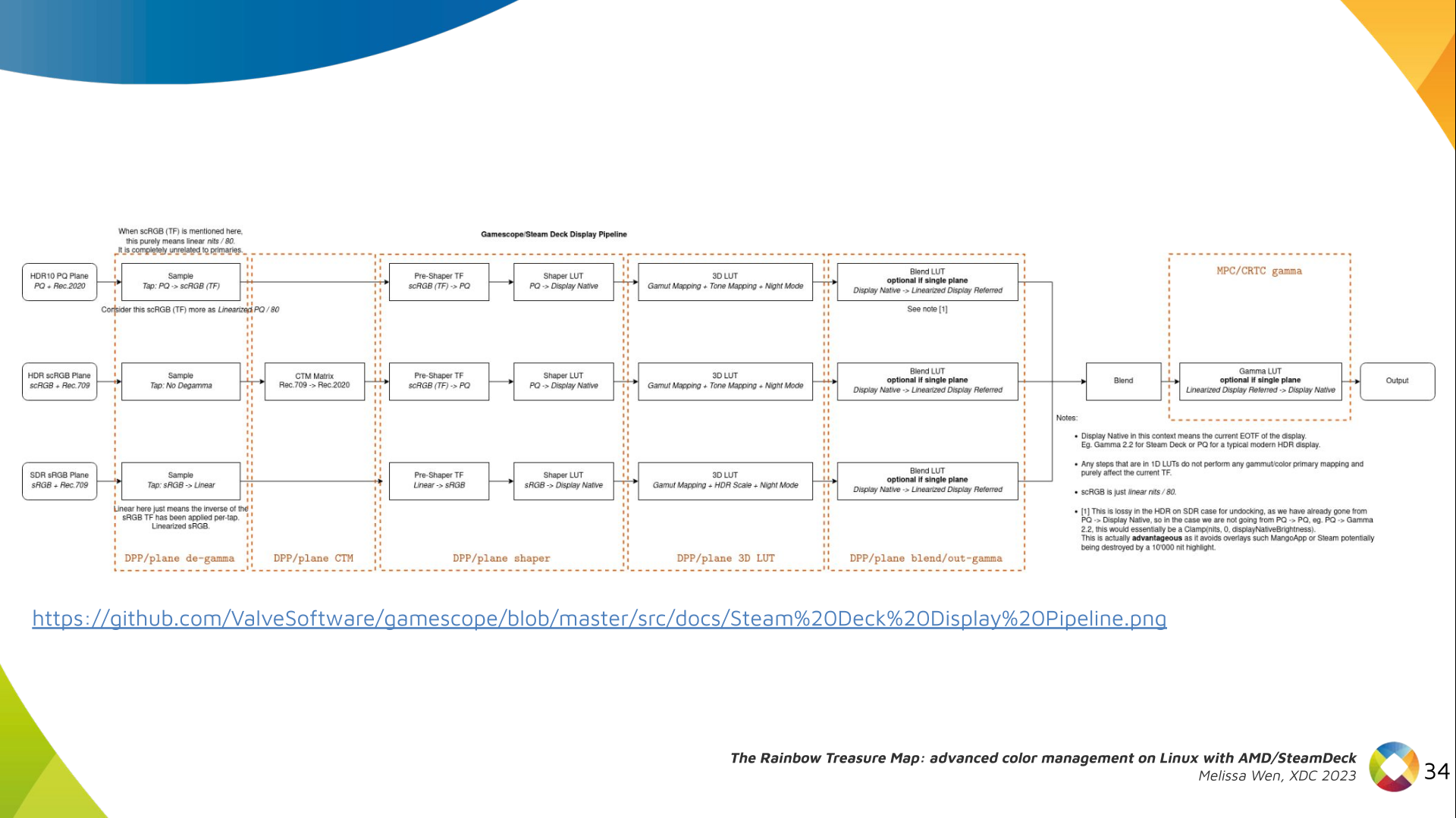
As a follow-up to yesterday's post detailing my
favourite works of fiction from 2022, today I'll be listing my favourite fictional works that are typically filed under classics.
Books that just missed the cut here include: E. M. Forster's
A Room with a View (1908) and his later
A Passage to India (1913), both gently nudged out by Forster's superb
Howard's End (see below). Giuseppe Tomasi di Lampedusa's
The Leopard (1958) also just missed out on a write-up here, but I can definitely recommend it to anyone interested in reading a modern Italian classic.
War and Peace (1867)
Leo Tolstoy
It's strange to think that there is almost no point in reviewing this novel: who hasn't heard of War and Peace? What more could possibly be said about it now? Still, when I was growing up, War and Peace was always the stereotypical example of the 'impossible book', and even start it was, at best, a pointless task, and an act of hubris at worst. And so there surely exists a parallel universe in which I never have and will never will read the book...
Nevertheless, let us try to set the scene. Book nine of the novel opens as follows:
On the twelfth of June, 1812, the forces of Western Europe crossed the Russian frontier and war began; that is, an event took place opposed to human reason and to human nature. Millions of men perpetrated against one another such innumerable crimes, frauds, treacheries, thefts, forgeries, issues of false money, burglaries, incendiarisms and murders as in whole centuries are not recorded in the annals of all the law courts of the world, but which those who committed them did not at the time regard as being crimes. What produced this extraordinary occurrence? What were its causes? [ ] The more we try to explain such events in history reasonably, the more unreasonable and incomprehensible they become to us.
Set against the backdrop of the Napoleonic Wars and Napoleon's invasion of Russia,
War and Peace follows the lives and fates of three aristocratic families: The Rostovs, The Bolkonskys and the Bezukhov's. These characters find themselves situated athwart (or against) history, and all this time, Napoleon is marching ever closer to Moscow. Still, Napoleon himself is essentially just a kind of wallpaper for a diverse set of personal stories touching on love, jealousy, hatred, retribution, naivety, nationalism, stupidity and much much more. As Elif Batuman wrote earlier this year, "
the whole premise of the book was that you couldn t explain war without recourse to domesticity and interpersonal relations."
The result is that Tolstoy has woven an incredibly intricate web that connects the war, noble families and the everyday Russian people to a degree that is surprising for a book started in 1865. Tolstoy's characters are probably timeless (especially the
picaresque adventures and constantly changing thoughts Pierre Bezukhov), and the reader who has any social experience will immediately recognise characters' thoughts and actions. Some of this is at a 'micro' interpersonal level: for instance, take this example from the elegant party that opens the novel:
Each visitor performed the ceremony of greeting this old aunt whom not one of them knew, not one of them wanted to know, and not one of them cared about. The aunt spoke to each of them in the same words, about their health and her own and the health of Her Majesty, who, thank God, was better today. And each visitor, though politeness prevented his showing impatience, left the old woman with a sense of relief at having performed a vexatious duty and did not return to her the whole evening.
But then, some of the focus of the observations are at the 'macro' level of the entire continent. This section about cities that feel themselves in danger might suffice as an example:
At the approach of danger, there are always two voices that speak with equal power in the human soul: one very reasonably tells a man to consider the nature of the danger and the means of escaping it; the other, still more reasonably, says that it is too depressing and painful to think of the danger, since it is not in man s power to foresee everything and avert the general course of events, and it is therefore better to disregard what is painful till it comes and to think about what is pleasant. In solitude, a man generally listens to the first voice, but in society to the second.
And finally, in his lengthy epilogues, Tolstoy offers us a dissertation on the behaviour of large organisations, much of it through engagingly witty analogies. These epilogues actually turn out to be an oblique and sarcastic commentary on the idiocy of governments and the madness of war in general. Indeed, the thorough dismantling of the
'great man' theory of history is a common theme throughout the book:
During the whole of that period [of 1812], Napoleon, who seems to us to have been the leader of all these movements as the figurehead of a ship may seem to a savage to guide the vessel acted like a child who, holding a couple of strings inside a carriage, thinks he is driving it.
[ ]
Why do [we] all speak of a military genius ? Is a man a genius who can order bread to be brought up at the right time and say who is to go to the right and who to the left? It is only because military men are invested with pomp and power and crowds of sychophants flatter power, attributing to it qualities of genius it does not possess.
Unlike some other readers, I especially enjoyed these diversions into the accounting and workings of history, as well as our narrow-minded way of trying to 'explain' things in a singular way:
When an apple has ripened and falls, why does it fall? Because of its attraction to the earth, because its stalk withers, because it is dried by the sun, because it grows heavier, because the wind shakes it, or because the boy standing below wants to eat it? Nothing is the cause. All this is only the coincidence of conditions in which all vital organic and elemental events occur. And the botanist who finds that the apple falls because the cellular tissue decays and so forth is equally right with the child who stands under the tree and says the apple fell because he wanted to eat it and prayed for it.
Given all of these serious asides, I was also not expecting this book to be quite so funny. At the risk of boring the reader with citations, take this sarcastic remark about the ineptness of medicine men:
After his liberation, [Pierre] fell ill and was laid up for three months. He had what the doctors termed 'bilious fever.' But despite the fact that the doctors treated him, bled him and gave him medicines to drink he recovered.
There is actually a multitude of remarks that are not entirely complimentary towards Russian medical practice, but they are usually deployed with an eye to the human element involved rather than simply to the detriment of a doctor's reputation "How would the count have borne his dearly loved daughter s illness had he not known that it was costing him a thousand rubles?"
Other elements of note include some stunning set literary pieces, such as
when Prince Andrei encounters a gnarly oak tree under two different circumstances in his life, and when
Nat sha's 'Russian' soul is awakened by the strains of a folk song on the
balalaika. Still, despite all of these micro- and macro-level happenings, for a long time I felt that something else was going on in
War and Peace. It was difficult to put into words precisely what it was until I came across this passage by E. M. Forster:
After one has read War and Peace for a bit, great chords begin to sound, and we cannot say exactly what struck them. They do not arise from the story [and] they do not come from the episodes nor yet from the characters. They come from the immense area of Russia, over which episodes and characters have been scattered, from the sum-total of bridges and frozen rivers, forests, roads, gardens and fields, which accumulate grandeur and sonority after we have passed them. Many novelists have the feeling for place, [but] very few have the sense of space, and the possession of it ranks high in Tolstoy s divine equipment. Space is the lord of War and Peace, not time.
'Space' indeed. Yes, potential readers should note the novel's great length, but the 365 chapters are actually remarkably short, so the sensation of reading it is not in the least overwhelming. And more importantly, once you become familiar with its
large cast of characters, it is really not a difficult book to follow, especially when compared to the other Russian classics. My only regret is that it has taken me so long to read this magnificent novel and that I might find it hard to find time to re-read it within the next few years.
Coming Up for Air (1939)
George Orwell
It wouldn't be a roundup of mine without at least one entry from George Orwell, and, this year, that place is occupied by a book I hadn't haven't read in almost two decades Still, the George Bowling of Coming Up for Air is a middle-aged insurance salesman who lives in a distinctly average English suburban row house with his nuclear family. One day, after winning some money on a bet, he goes back to the village where he grew up in order to fish in a pool he remembers from thirty years before.
Less important than the plot, however, is both the well-observed remarks and scathing criticisms that Bowling has of the town he has returned to, combined with an ominous sense of foreboding before the Second World War breaks out. At several times throughout the book, George's placid thoughts about his beloved carp pool are replaced by racing, anxious thoughts that overwhelm his inner peace:
War is coming. In 1941, they say. And there'll be plenty of broken crockery, and little houses ripped open like packing-cases, and the guts of the chartered accountant's clerk plastered over the piano that he's buying on the never-never. But what does that kind of thing matter, anyway? I'll tell you what my stay in Lower Binfield had taught me, and it was this. IT'S ALL GOING TO HAPPEN. All the things you've got at the back of your mind, the things you're terrified of, the things that you tell yourself are just a nightmare or only happen in foreign countries. The bombs, the food-queues, the rubber truncheons, the barbed wire, the coloured shirts, the slogans, the enormous faces, the machine-guns squirting out of bedroom windows. It's all going to happen. I know it - at any rate, I knew it then. There's no escape. Fight against it if you like, or look the other way and pretend not to notice, or grab your spanner and rush out to do a bit of face-smashing along with the others. But there's no way out. It's just something that's got to happen.
Already we can hear psychological madness that underpinned the Second World War. Indeed, there is no great story in
Coming Up For Air, no wonderfully empathetic characters and no revelations or catharsis, so it is impressive that I was held by the descriptions, observations and nostalgic remembrances about life in modern Lower Binfield, its residents, and how it has changed over the years. It turns out, of course, that George's beloved pool has been filled in with rubbish, and the village has been perverted by modernity beyond recognition. And to cap it off, the principal event of George's holiday in Lower Binfield is an accidental bombing by the British Royal Air Force.
Orwell is always good at descriptions of awful food, and this book is no exception:
The frankfurter had a rubber skin, of course, and my temporary teeth weren't much of a fit. I had to do a kind of sawing movement before I could get my teeth through the skin. And then suddenly pop! The thing burst in my mouth like a rotten pear. A sort of horrible soft stuff was oozing all over my tongue. But the taste! For a moment I just couldn't believe it. Then I rolled my tongue around it again and had another try. It was fish! A sausage, a thing calling itself a frankfurter, filled with fish! I got up and walked straight out without touching my coffee. God knows what that might have tasted of.
Many other tell-tale elements of Orwell's fictional writing are in attendance in this book as well, albeit worked out somewhat less successfully than elsewhere in his oeuvre. For example, the idea of a physical ailment also serving as a metaphor is present in George's false teeth, embodying his constant preoccupation with his ageing. (Readers may recall Winston Smith's varicose ulcer representing his repressed humanity in
Nineteen Eighty-Four). And, of course, we have a prematurely middle-aged protagonist who almost but not quite resembles Orwell himself.
Given this and a few other niggles (such as almost all the women being of the
typical Orwell 'nagging wife' type), it is not exactly Orwell's magnum opus. But it remains a fascinating historical snapshot of the feeling felt by a vast number of people just prior to the Second World War breaking out, as well as a captivating insight into how the process of nostalgia functions and operates.
Howards End (1910)
E. M. Forster
Howards End begins with the following sentence:
One may as well begin with Helen s letters to her sister.
In fact, "one may as well begin with" my own assumptions about this book instead. I was actually primed to consider
Howards End a much more 'Victorian' book: I had just finished Virginia Woolf's
Mrs Dalloway and had found her 1925 book at once rather 'modern' but also very much constrained by its time. I must have then unconsciously surmised that a book written 15 years before would be even more inscrutable, and, with its Victorian social mores added on as well,
Howards End would probably not undress itself so readily in front of the reader. No doubt there were also the usual expectations about 'the classics' as well.
So imagine my surprise when I realised just how inordinately affable and witty
Howards End turned out to be. It doesn't have that
Wildean shine of humour, of course, but it's a couple of fields over in the English countryside, perhaps abutting the more mordant social satires of the earlier George Orwell novels (see
Coming Up for Air above).
But now let us return to the story itself.
Howards End explores class warfare, conflict and the English character through a tale of three quite different families at the beginning of the twentieth century: the rich Wilcoxes; the gentle & idealistic Schlegels; and the lower-middle class Basts. As the
Bloomsbury Group Schlegel sisters desperately try to help the Basts and educate the rich but close-minded Wilcoxes, the three families are drawn ever closer and closer together.
Although the whole story does, I suppose, revolve around the house in the title (which is based on the
Forster's own childhood home),
Howards End is perhaps best described as a comedy of manners or a novel that shows up the hypocrisy of people and society. In fact, it is surprising how little of the story actually takes place in the eponymous house, with the overwhelming majority of the first half of the book taking place in London. But it is perhaps more illuminating to remark that the Howards End of the book is a house that the Wilcoxes who own it at the start of the novel do not really need or want.
What I particularly liked about
Howards End is how the main character's ideals alter as they age, and subsequently how they find their lives changing in different ways. Some of them find themselves better off at the end, others worse. And whilst it is also surprisingly funny, it still manages to trade in heavier social topics as well. This is apparent in the fact that, although the characters themselves are primarily in charge of their own destinies, their choices are still constrained by the changing world and shifting sense of morality around them.
This shouldn't be too surprising: after all, Forster's novel was published just four years before the Great War, a distinctly uncertain time. Not for nothing did Virginia Woolf herself later observe that "on or about December 1910, human character changed" and that "all human relations have shifted: those between masters and servants, husbands and wives, parents and children." This process can undoubtedly be seen rehearsed throughout Forster's
Howards End, and it's a credit to the author to be able to capture it so early on, if not even before it was widespread throughout Western Europe.
I was also particularly taken by Forster's fertile use of simile. An extremely apposite example can be found in the description Tibby Schlegel gives of his fellow Cambridge undergraduates. Here, Timmy doesn't want to besmirch his lofty idealisation of them with any banal specificities, and wishes that the idea of them remain as ideal
Platonic forms instead. Or, as Forster puts it, to Timmy it is if they are "pictures that must not walk out of their frames."
Wilde, at his most weakest, is 'just' style, but Forster often deploys his flair for a deeper effect. Indeed, when you get to the end of this section mentioning picture frames, you realise Forster has actually just smuggled into the story a failed attempt on Tibby's part to engineer an anonymous homosexual encounter with another undergraduate. It is a credit to Forster's sleight-of-hand that you don't quite notice what has just happened underneath you and that the books' reticence to honestly describe what has happened is thus structually analogus Tibby's reluctance to admit his desires to himself. Another layer to the character of Tibby (and the novel as a whole) is thereby introduced without the imposition of clumsy literary scaffolding. In a similar vein, I felt very clever noticing the arch reference to Debussy's
Pr lude l'apr s-midi d'un faune until I realised I just fell into the trap Forster set for the reader in that I had become even more like Tibby in his pseudo-scholarly views on classical music.
Finally, I enjoyed that each chapter commences with an ironic and self-conscious
bon mot about society which is only
slightly overblown for effect. Particularly amusing are the ironic asides on "women" that run through the book, ventriloquising the narrow-minded views of people like the Wilcoxes. The omniscient and amiable narrator of the book also recalls those ironically distant voiceovers from
various French New Wave films at times, yet Forster's narrator seems to have bigger concerns in his mordant asides: Forster seems to encourage some sympathy for all of the characters even the more contemptible ones at their worst moments.
Highly recommended, as are Forster's
A Room with a View (1908) and his slightly later
A Passage to India (1913).
The Good Soldier (1915)
Ford Madox Ford
The Good Soldier starts off fairly simply as the narrator's account of his and his wife's relationship with some old friends, including the eponymous 'Good Soldier' of the book's title. It's an experience to read the beginning of this novel, as, like any account of endless praise of someone you've never met or care about, the pages of approving remarks about them appear to be intended to wash over you.
Yet as the chapters of The Good Soldier go by, the account of the other characters in the book gets darker and darker. Although the author himself is uncritical of others' actions, your own critical faculties are slowgrly brought into play, and you gradully begin to question the narrator's retelling of events. Our narrator is an unreliable narrator in the strict sense of the term, but with the caveat that he is at least is telling us everything we need to know to come to our own conclusions.
As the book unfolds further, the narrator's compromised credibility seems to infuse every element of the novel even the 'Good' of the book's title starts to seem like a minor dishonesty, perhaps serving as the inspiration for the irony embedded in the title of The 'Great' Gatsby. Much more effectively, however, the narrator's fixations, distractions and manner of speaking feel very much part of his dissimulation. It sometimes feels like he is unconsciously skirting over the crucial elements in his tale, exactly like one does in real life when recounting a story containing incriminating ingredients. Indeed, just how much the narrator is conscious of his own concealment is just one part of what makes this such an interesting book: Ford Madox Ford has gifted us with enough ambiguity that it is also possible that even the narrator cannot find it within himself to understand the events of the story he is narrating.
It was initially hard to believe that such a carefully crafted analysis of a small group of characters could have been written so long ago, and despite being fairly easy to read, The Good Soldier is an almost infinitely subtle book even the jokes are of the subtle kind and will likely get a re-read within the next few years.
Anna Karenina (1878)
Leo Tolstoy
There are many similar themes running through War and Peace (reviewed above) and Anna Karenina. Unrequited love; a young man struggling to find a purpose in life; a loving family; an overwhelming love of nature and countless fascinating observations about the minuti of Russian society. Indeed, rather than primarily being about the eponymous Anna, Anna Karenina provides a vast panorama of contemporary life in Russia and of humanity in general.
Nevertheless, our Anna is a sophisticated woman who abandons her empty existence as the wife of government official Alexei Karenin, a colourless man who has little personality of his own, and she turns to a certain Count Vronsky in order to fulfil her passionate nature. Needless to say, this results in tragic consequences as their (admittedly somewhat qualified) desire to live together crashes against the rocks of reality and Russian society.
Parallel to Anna's narrative, though, Konstantin Levin serves as the novel's alter-protagonist. In contrast to Anna, Levin is a socially awkward individual who straddles many schools of thought within Russia at the time: he is neither a free-thinker (nor heavy-drinker) like his brother Nikolai, and neither is he a bookish intellectual like his half-brother Serge. In short, Levin is his own man, and it is generally agreed by commentators that he is Tolstoy's surrogate within the novel. Levin tends to come to his own version of an idea, and he would rather find his own way than adopt any prefabricated view, even if confusion and muddle is the eventual result. In a roughly isomorphic fashion then, he resembles Anna in this particular sense, whose story is a counterpart to Levin's in their respective searches for happiness and self-actualisation.
Whilst many of the passionate and exciting passages are told on Anna's side of the story (I'm thinking horse race in particular, as thrilling as anything in cinema ), many of the broader political thoughts about the nature of the working classes are expressed on Levin's side instead. These are stirring and engaging in their own way, though, such as when he joins his peasants to mow the field and seems to enter the nineteenth-century version of 'flow':
The longer Levin mowed, the more often he felt those moments of oblivion during which it was no longer his arms that swung the scythe, but the scythe itself that lent motion to his whole body, full of life and conscious of itself, and, as if by magic, without a thought of it, the work got rightly and neatly done on its own. These were the most blissful moments.
Overall, Tolstoy poses no didactic moral message towards any of the characters in
Anna Karenina, and merely invites us to watch rather than judge. (Still, there is a hilarious section that is scathing of contemporary classical music, presaging many of the ideas found in Tolstoy's 1897
What is Art?). In addition, just like the earlier
War and Peace, the novel is run through with a number of uncannily accurate observations about daily life:
Anna smiled, as one smiles at the weaknesses of people one loves, and, putting her arm under his, accompanied him to the door of the study.
... as well as the usual sprinkling of Tolstoy's sardonic humour ("No one is pleased with his fortune, but everyone is pleased with his wit.").
Fyodor Dostoyevsky, the other titan of Russian literature, once described
Anna Karenina as a "flawless work of art," and if you re only going to read one Tolstoy novel in your life, it should probably be this one.
 In light of the recent
In light of the recent  I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
But this also creates problems: By switching to Wayland compositors, we are already forcing a lot of porting work onto toolkit developers and application developers. This is annoying, but just work that has to be done. It becomes frustrating though if Wayland provides toolkits with absolutely no way to reach their goal in any reasonable way. For Nate s Photoshop analogy: Of course Linux does not break Photoshop, it is Adobe s responsibility to port it. But what if Linux was missing a crucial syscall that Photoshop needed for proper functionality and Adobe couldn t port it without that? In that case it becomes much less clear on who is to blame for Photoshop not being available.
A lot of Wayland protocol work is focused on the environment and design, while applications and work to port them often is considered less. I think this happens because the overlap between application developers and developers of the desktop environments is not necessarily large, and the overlap with people willing to engage with Wayland upstream is even smaller. The combination of Windows developers porting apps to Linux and having involvement with toolkits or Wayland is pretty much nonexistent. So they have less of a voice.
I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
But this also creates problems: By switching to Wayland compositors, we are already forcing a lot of porting work onto toolkit developers and application developers. This is annoying, but just work that has to be done. It becomes frustrating though if Wayland provides toolkits with absolutely no way to reach their goal in any reasonable way. For Nate s Photoshop analogy: Of course Linux does not break Photoshop, it is Adobe s responsibility to port it. But what if Linux was missing a crucial syscall that Photoshop needed for proper functionality and Adobe couldn t port it without that? In that case it becomes much less clear on who is to blame for Photoshop not being available.
A lot of Wayland protocol work is focused on the environment and design, while applications and work to port them often is considered less. I think this happens because the overlap between application developers and developers of the desktop environments is not necessarily large, and the overlap with people willing to engage with Wayland upstream is even smaller. The combination of Windows developers porting apps to Linux and having involvement with toolkits or Wayland is pretty much nonexistent. So they have less of a voice.

 I will also bring my two protocol MRs to their conclusion for sure, because as application developers we need clarity on what the platform (either all desktops or even just a few) supports and will or will not support in future. And the only way to get something good done is by contribution and friendly discussion.
I will also bring my two protocol MRs to their conclusion for sure, because as application developers we need clarity on what the platform (either all desktops or even just a few) supports and will or will not support in future. And the only way to get something good done is by contribution and friendly discussion.









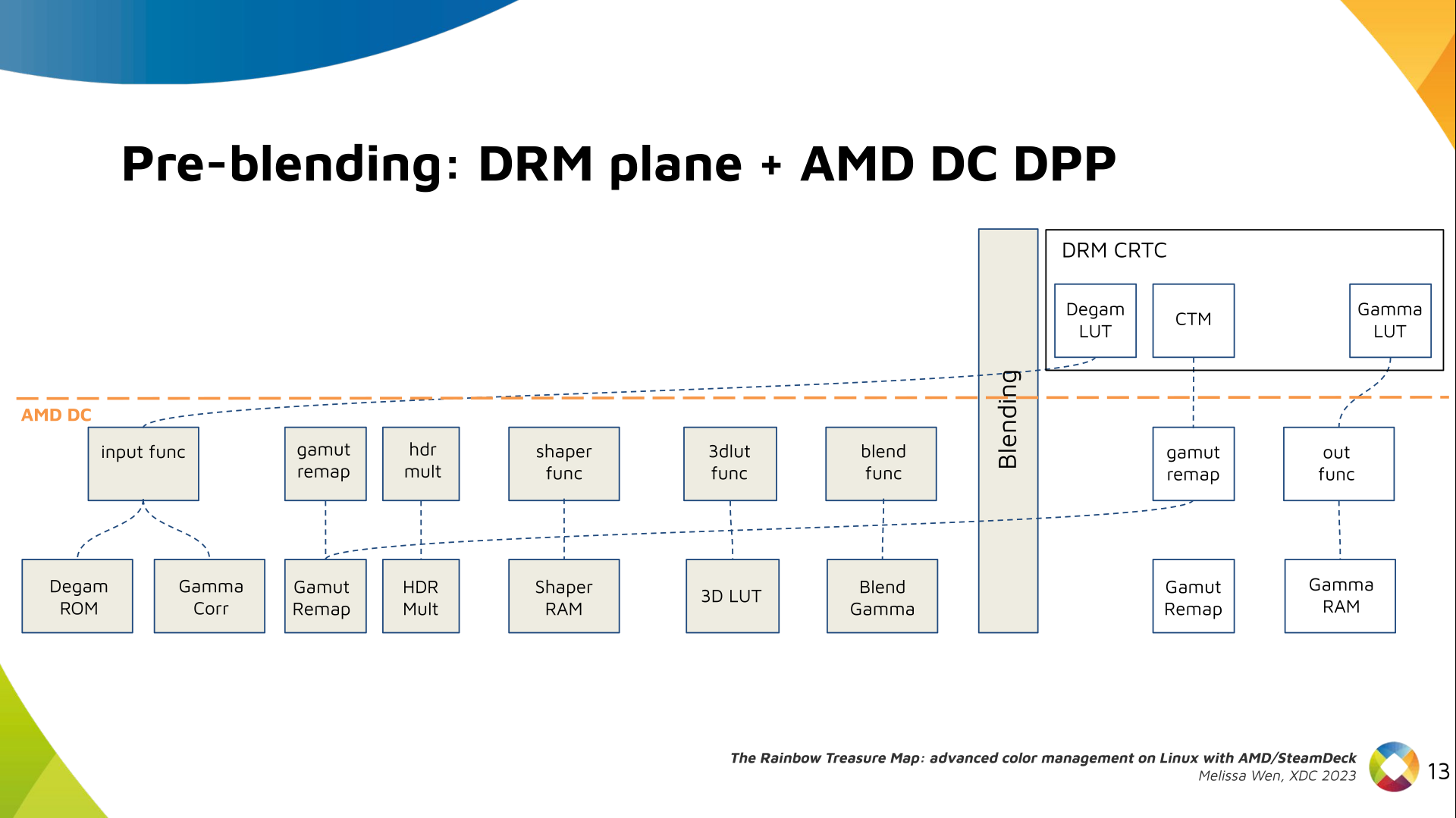
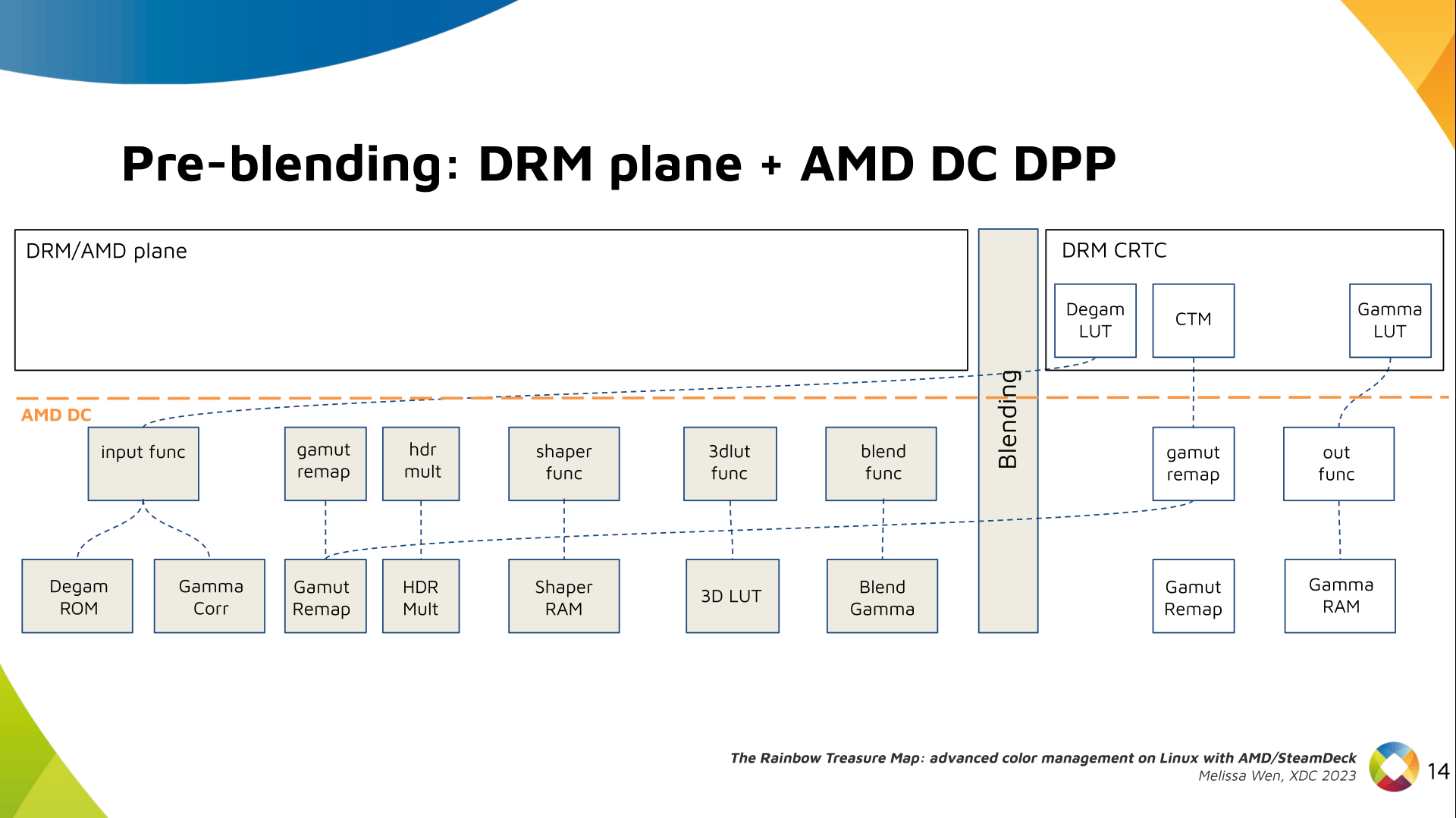
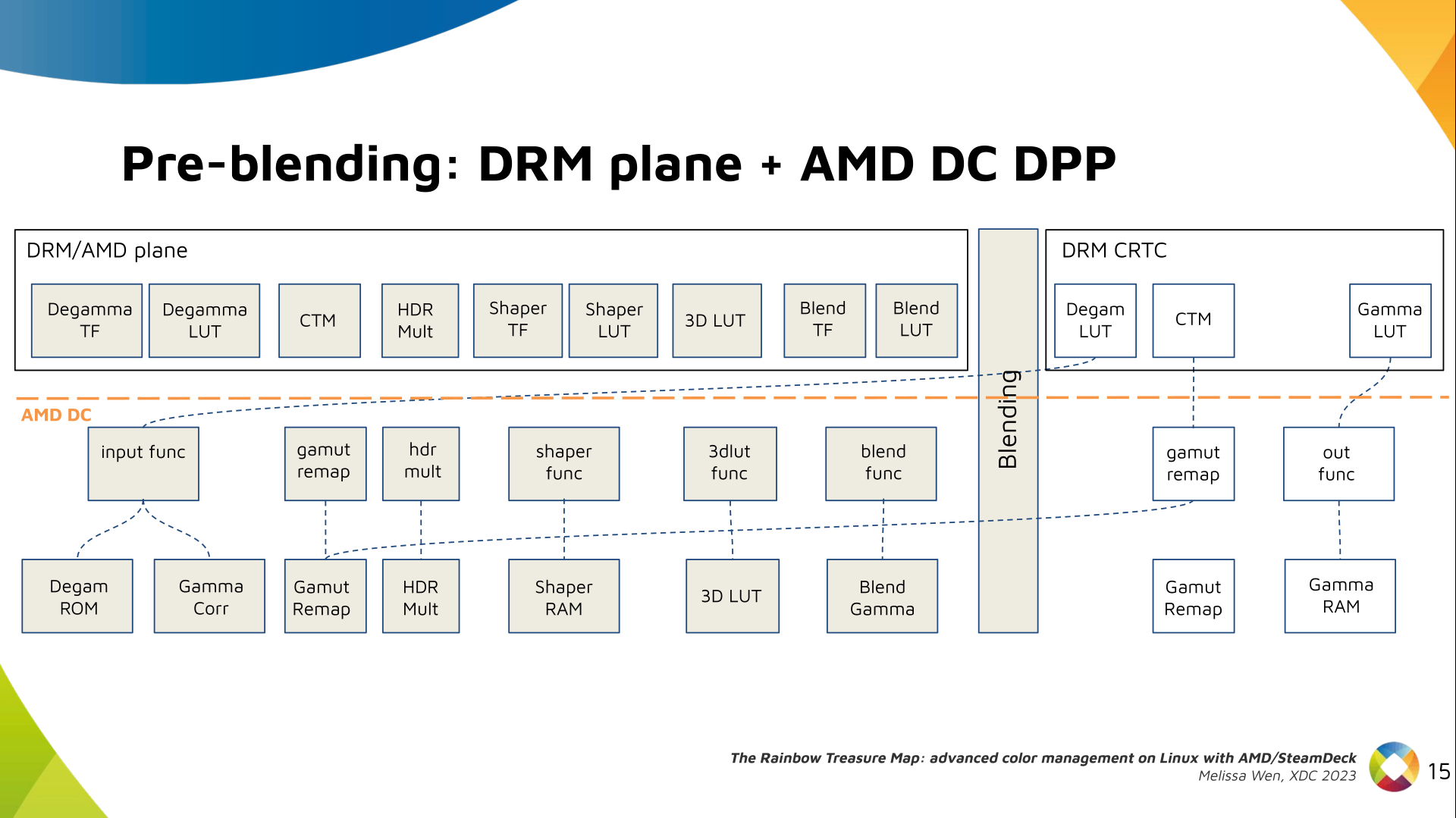
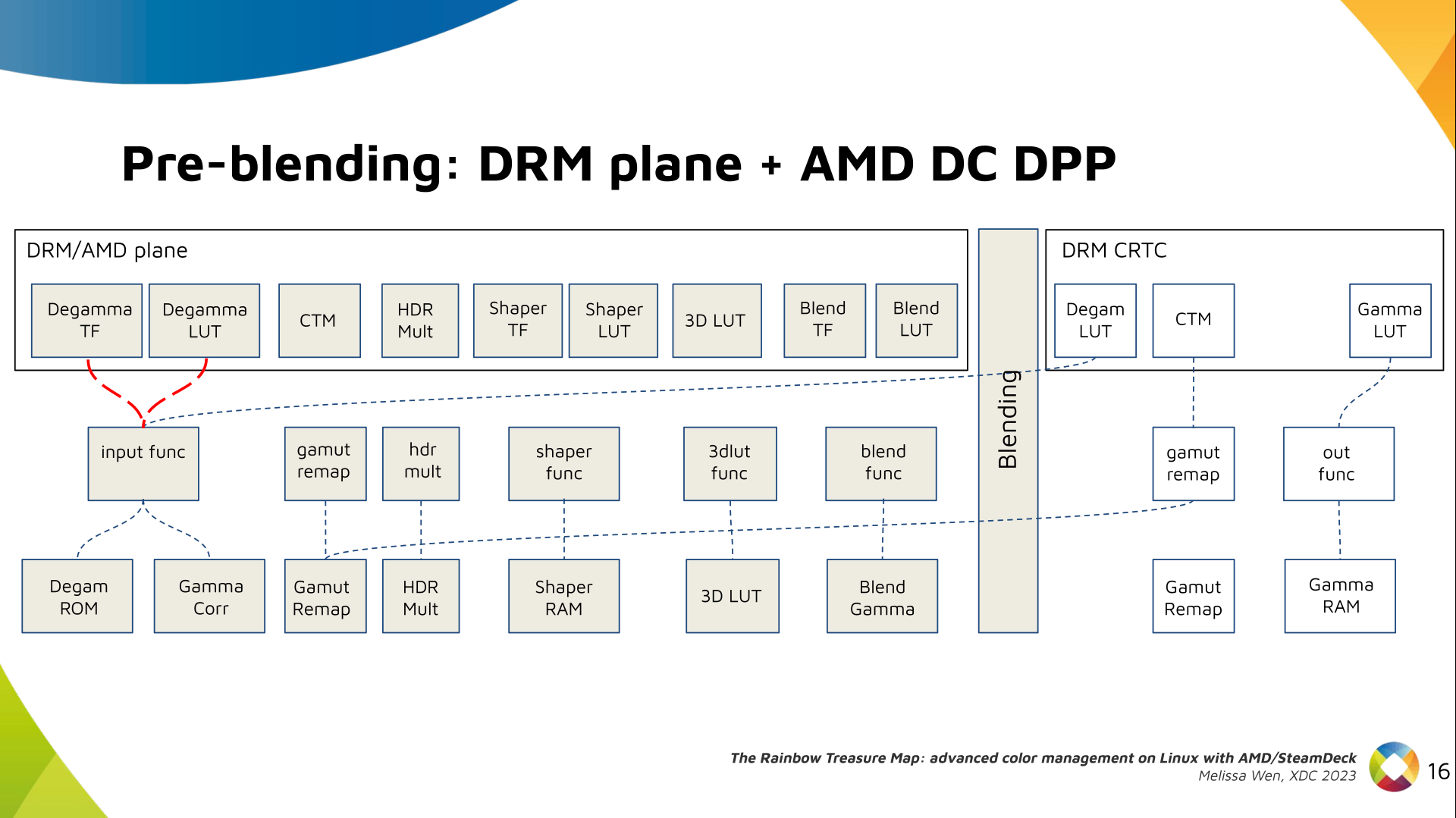

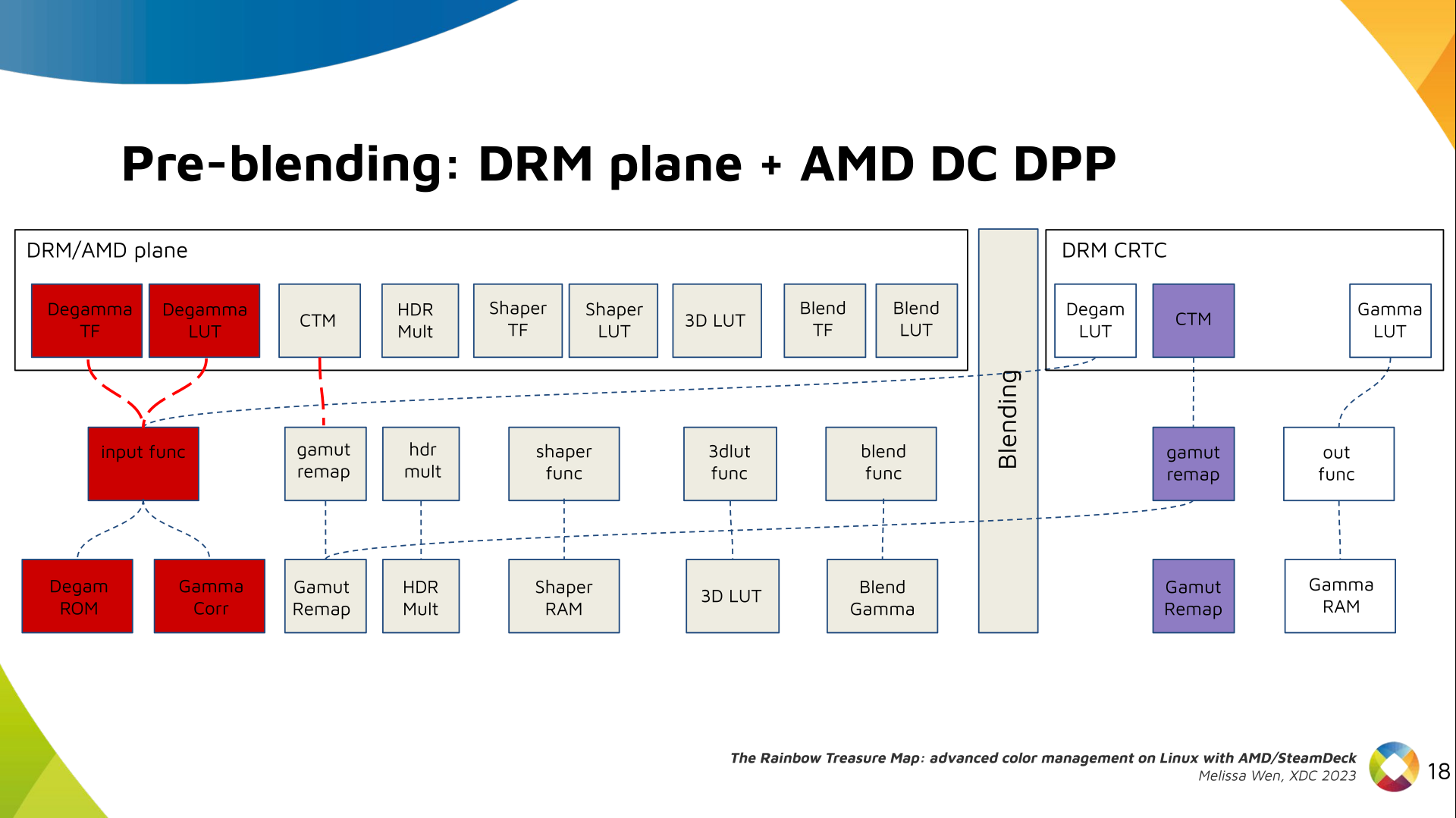

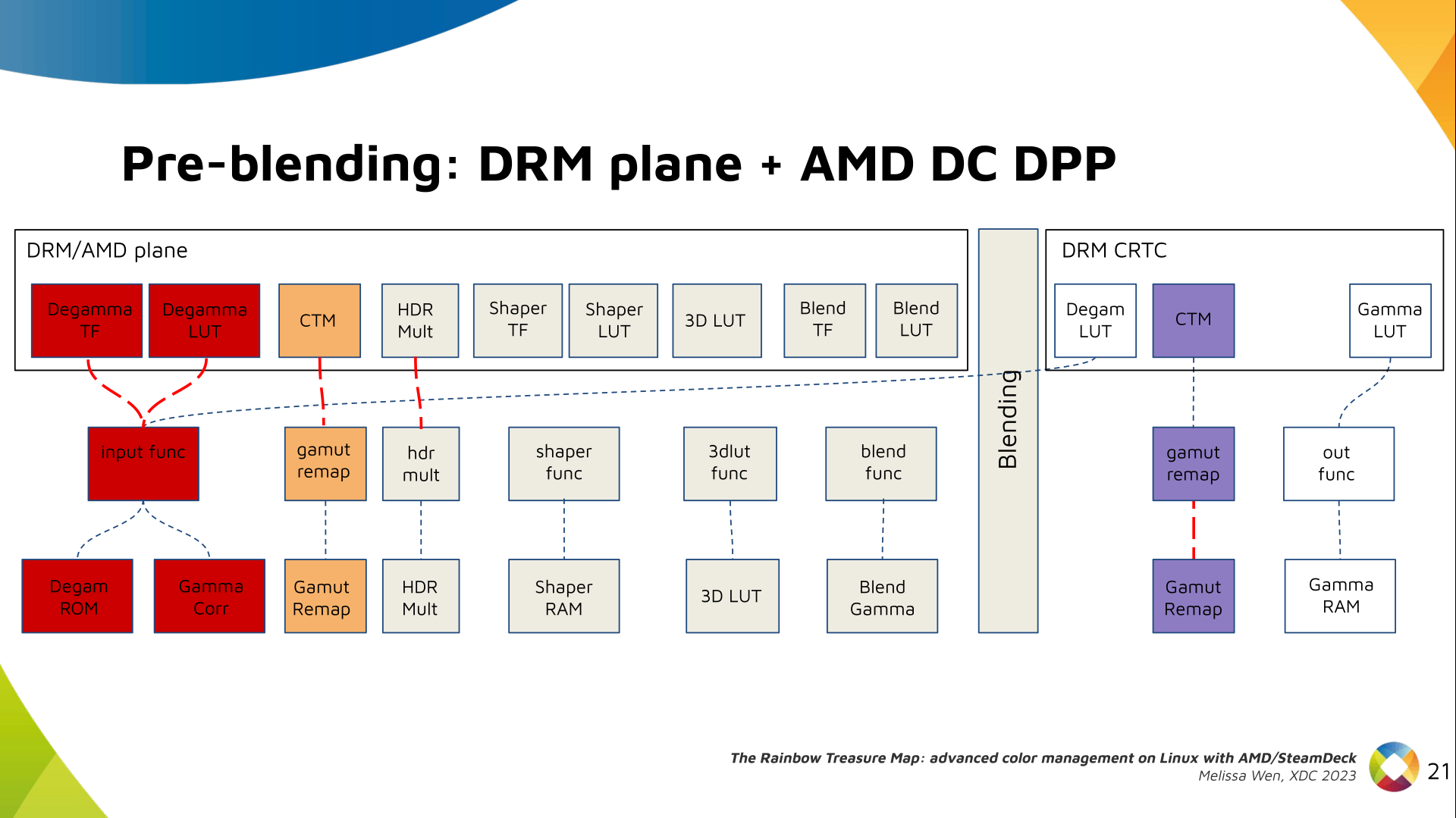

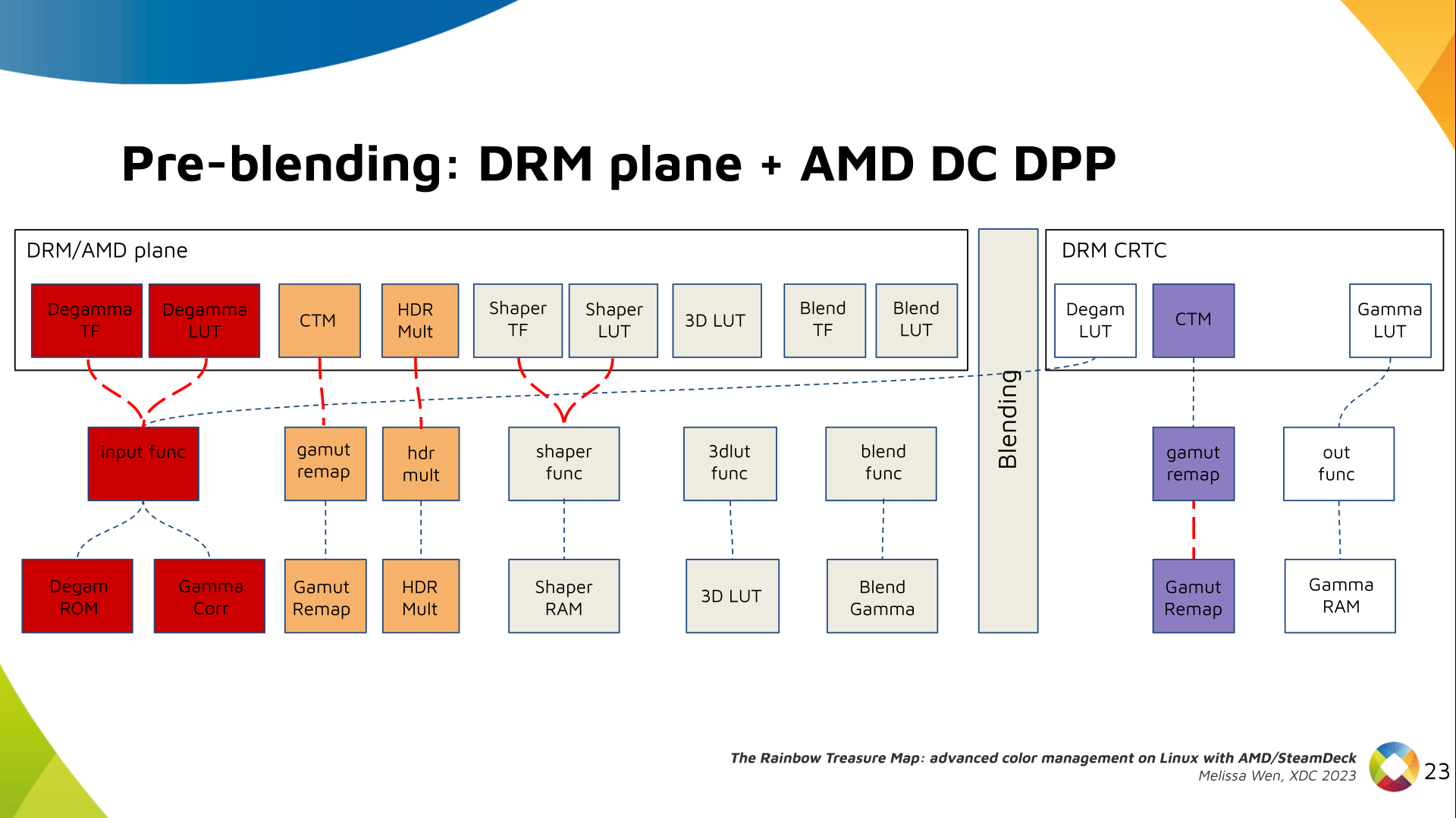

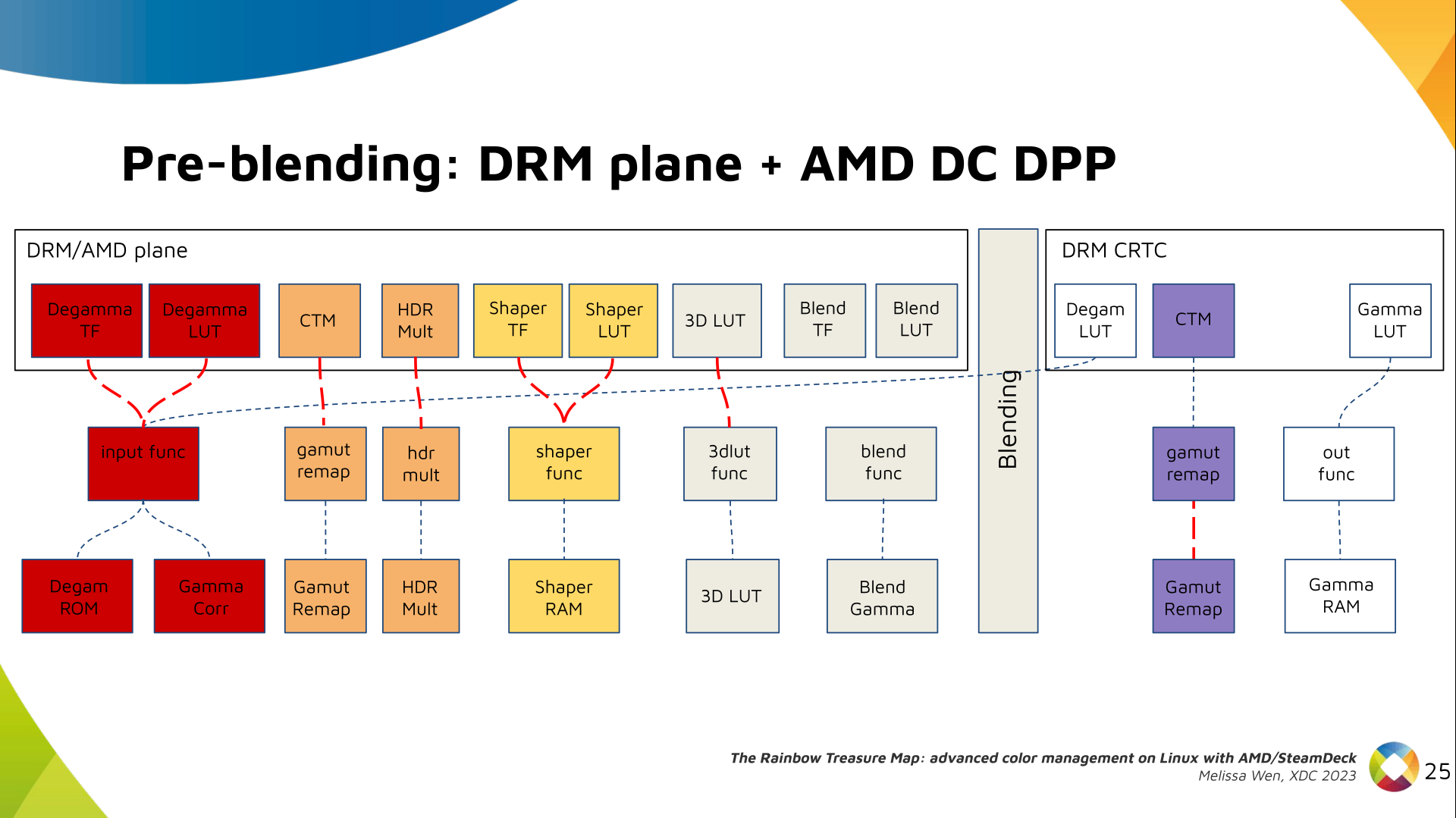

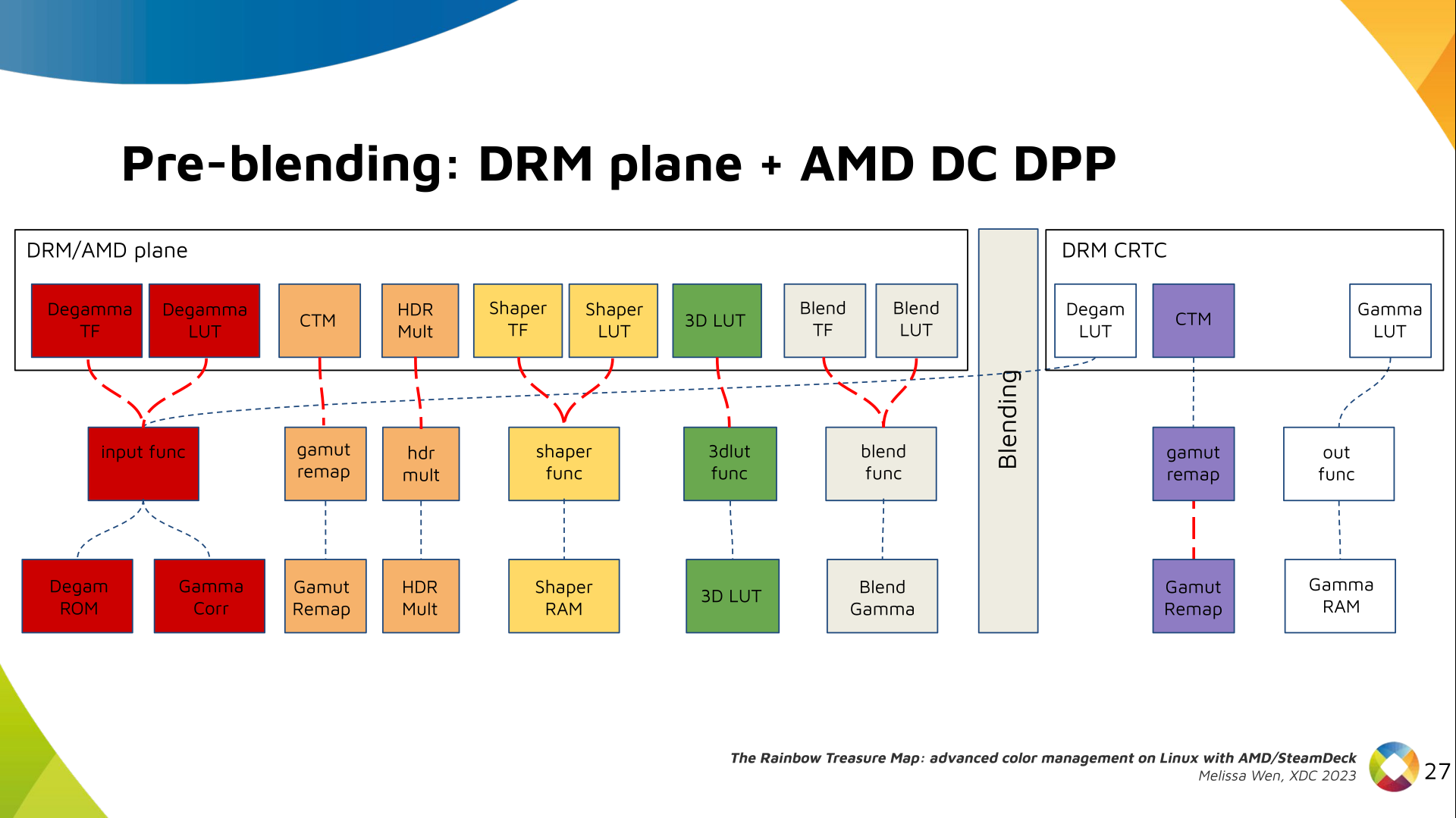

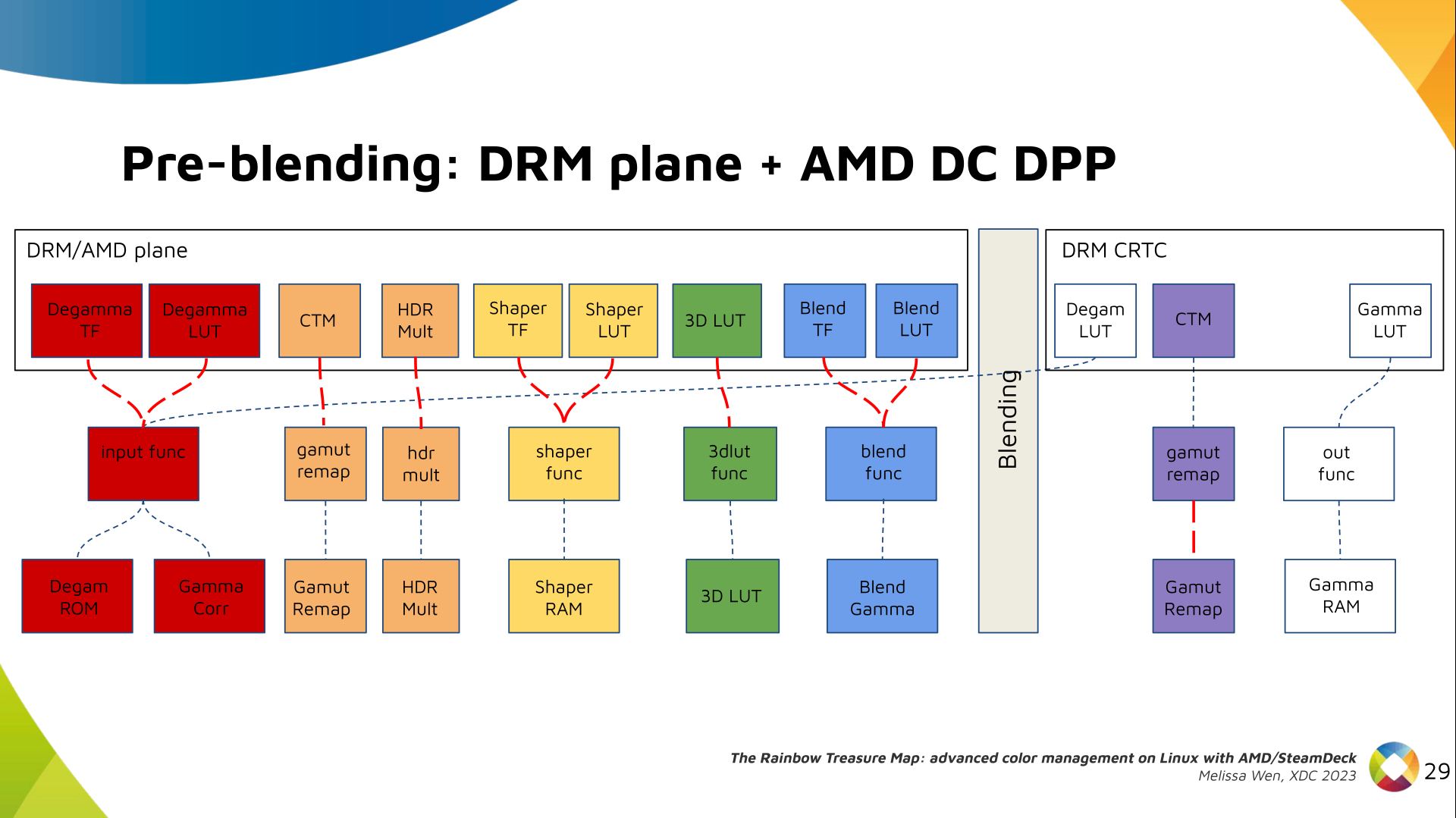
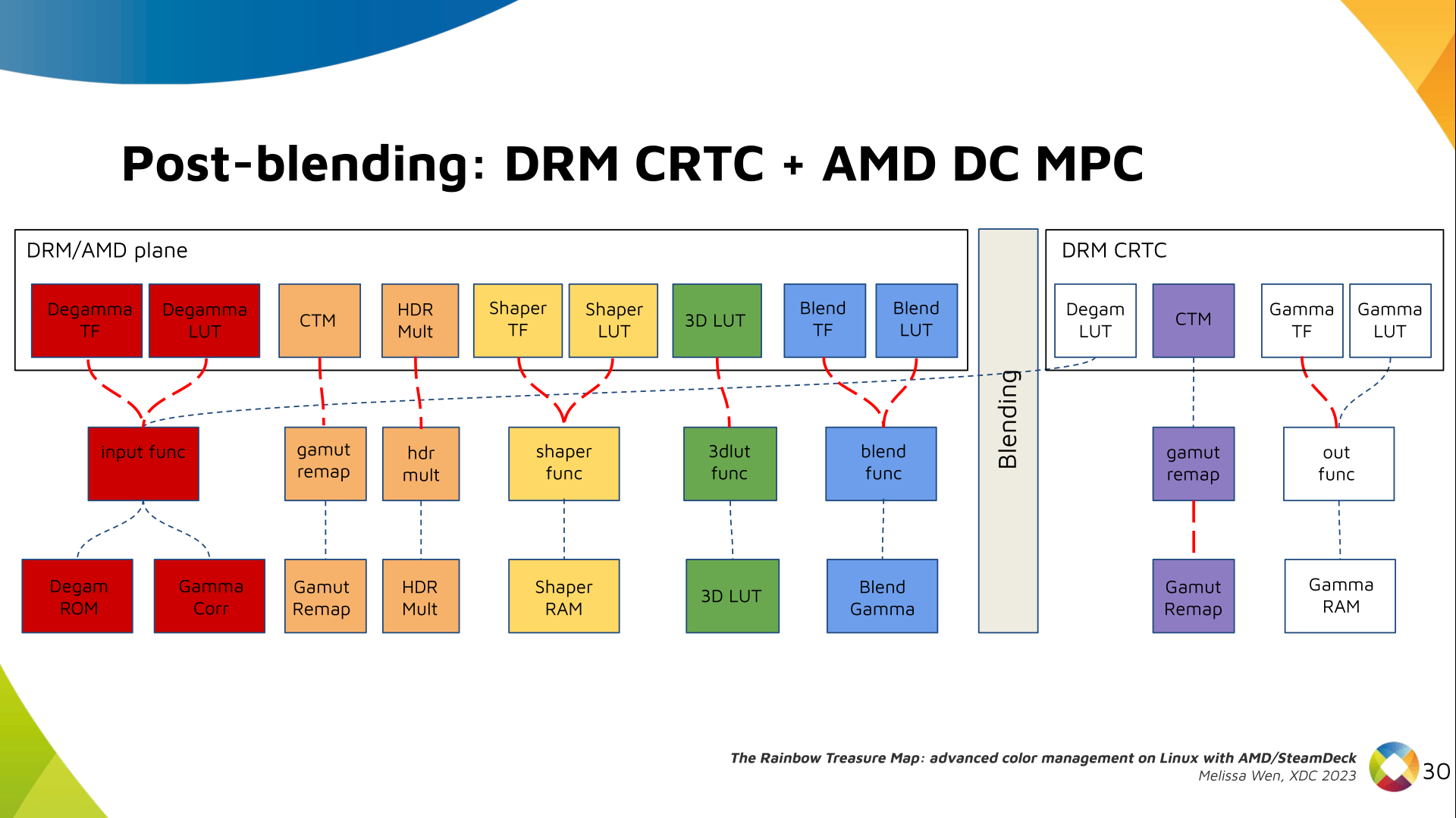

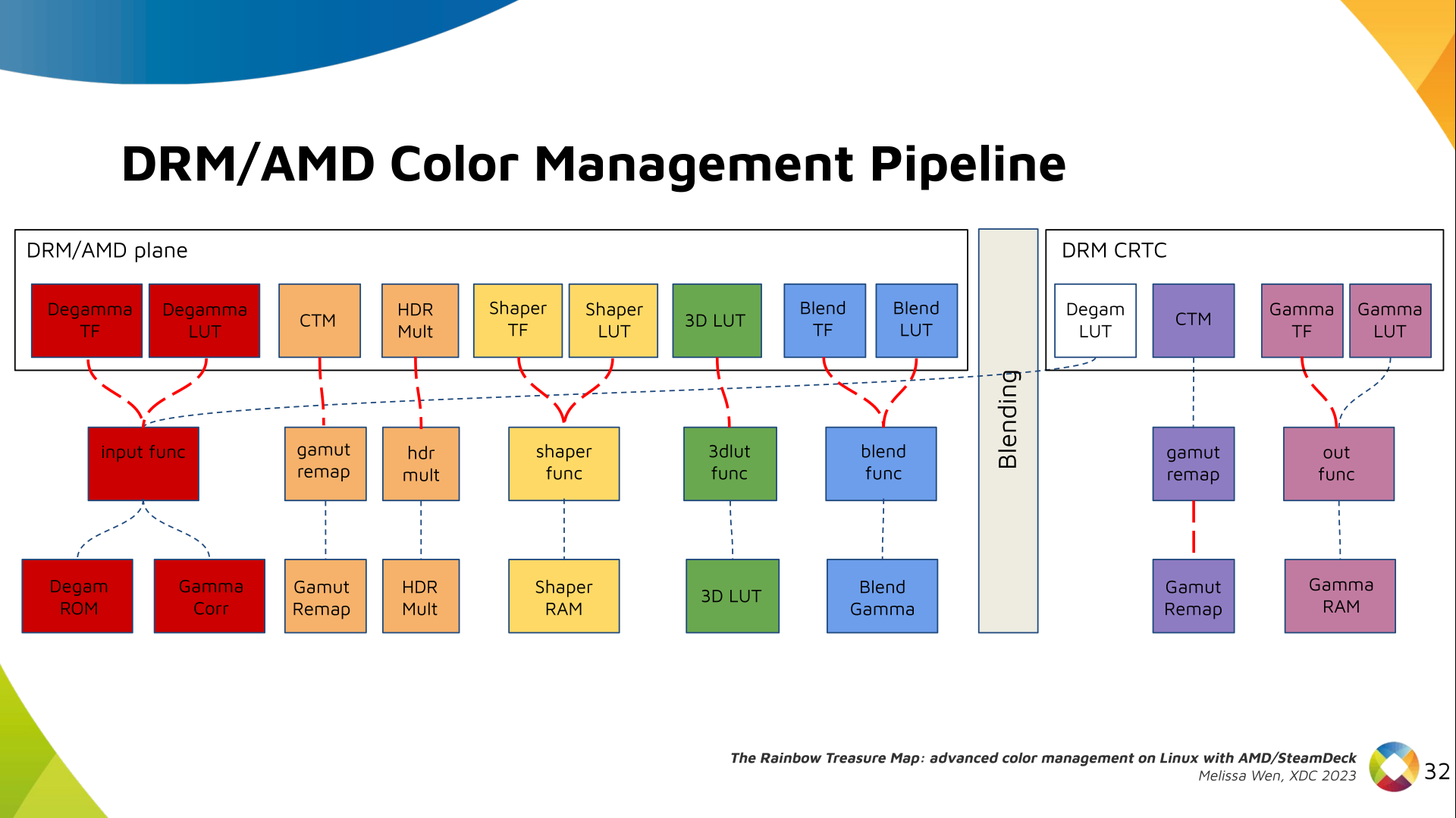

 I've never been a fan of IoT devices for obvious reasons: not only do they tend
to be excellent at being expensive vendor locked-in machines, but far too often,
they also end up turning into e-waste after a short amount of time.
Manufacturers can go out of business or simply decide to
I've never been a fan of IoT devices for obvious reasons: not only do they tend
to be excellent at being expensive vendor locked-in machines, but far too often,
they also end up turning into e-waste after a short amount of time.
Manufacturers can go out of business or simply decide to 

 No per odo de 25 a 27 de maio, Bras lia foi palco da
No per odo de 25 a 27 de maio, Bras lia foi palco da
 Atividades
A programa o da MiniDebConf foi intensa e diversificada. Nos dias 25 e 26
(quinta e sexta-feira), tivemos palestras, debates, oficinas e muitas atividades
pr ticas. J no dia 27 (s bado), ocorreu o Hacking Day, um momento especial em
que os(as) colaboradores(as) do Debian se reuniram para trabalhar em conjunto em
v rios aspectos do projeto. Essa foi a vers o brasileira da Debcamp, tradi o
pr via DebConf. Nesse dia, priorizamos as atividades pr ticas de contribui o
ao projeto, como empacotamento de softwares, tradu es, assinaturas de chaves,
install fest e a Bug Squashing Party.
Atividades
A programa o da MiniDebConf foi intensa e diversificada. Nos dias 25 e 26
(quinta e sexta-feira), tivemos palestras, debates, oficinas e muitas atividades
pr ticas. J no dia 27 (s bado), ocorreu o Hacking Day, um momento especial em
que os(as) colaboradores(as) do Debian se reuniram para trabalhar em conjunto em
v rios aspectos do projeto. Essa foi a vers o brasileira da Debcamp, tradi o
pr via DebConf. Nesse dia, priorizamos as atividades pr ticas de contribui o
ao projeto, como empacotamento de softwares, tradu es, assinaturas de chaves,
install fest e a Bug Squashing Party.

 N meros da edi o
Os n meros do evento impressionam e demonstram o envolvimento da comunidade com
o Debian. Tivemos 236 inscritos(as), 20 palestras submetidas, 14 volunt rios(as)
e 125 check-ins realizados. Al m disso, nas atividades pr ticas, tivemos
resultados significativos, como 7 novas instala es do Debian GNU/Linux, a
atualiza o de 18 pacotes no reposit rio oficial do projeto Debian pelos
participantes e a inclus o de 7 novos contribuidores na equipe de tradu o.
Destacamos tamb m a participa o da comunidade de forma remota, por meio de
transmiss es ao vivo. Os dados anal ticos revelam que nosso site obteve 7.058
visualiza es no total, com 2.079 visualiza es na p gina principal (que contava
com o apoio de nossos patrocinadores), 3.042 visualiza es na p gina de
programa o e 104 visualiza es na p gina de patrocinadores. Registramos 922
usu rios(as) nicos durante o evento.
No
N meros da edi o
Os n meros do evento impressionam e demonstram o envolvimento da comunidade com
o Debian. Tivemos 236 inscritos(as), 20 palestras submetidas, 14 volunt rios(as)
e 125 check-ins realizados. Al m disso, nas atividades pr ticas, tivemos
resultados significativos, como 7 novas instala es do Debian GNU/Linux, a
atualiza o de 18 pacotes no reposit rio oficial do projeto Debian pelos
participantes e a inclus o de 7 novos contribuidores na equipe de tradu o.
Destacamos tamb m a participa o da comunidade de forma remota, por meio de
transmiss es ao vivo. Os dados anal ticos revelam que nosso site obteve 7.058
visualiza es no total, com 2.079 visualiza es na p gina principal (que contava
com o apoio de nossos patrocinadores), 3.042 visualiza es na p gina de
programa o e 104 visualiza es na p gina de patrocinadores. Registramos 922
usu rios(as) nicos durante o evento.
No  Fotos e v deos
Para revivermos os melhores momentos do evento, temos dispon veis fotos e v deos.
As fotos podem ser acessadas em:
Fotos e v deos
Para revivermos os melhores momentos do evento, temos dispon veis fotos e v deos.
As fotos podem ser acessadas em:  A MiniDebConf Bras lia 2023 foi um marco para a comunidade Debian, demonstrando
o poder da colabora o e do Software Livre. Esperamos que todas e todos tenham
desfrutado desse encontro enriquecedor e que continuem participando ativamente
das pr ximas iniciativas do Projeto Debian. Juntos, podemos fazer a diferen a!
A MiniDebConf Bras lia 2023 foi um marco para a comunidade Debian, demonstrando
o poder da colabora o e do Software Livre. Esperamos que todas e todos tenham
desfrutado desse encontro enriquecedor e que continuem participando ativamente
das pr ximas iniciativas do Projeto Debian. Juntos, podemos fazer a diferen a!










 As the President of the GNOME Foundation Board of Directors, I m really pleased to see the
As the President of the GNOME Foundation Board of Directors, I m really pleased to see the 

{kind=link}