Award winning code
Me and
Yuwei had a fun day at
hhhmcr
(
#hhhmcr) and even managed to put
together a prototype that won the first prize \o/
We played with the
gmp24 dataset
kindly extracted from Twitter by
Michael Brunton-Spall
of the
Guardian into
a convenient JSON
dataset. The idea was to find ways of making it
easier to look at the data and making sense of it.
This is the story of what we did, including the code we wrote.
The original dataset has several JSON files, so the first task was to put them
all together:
#!/usr/bin/python
# Merge the JSON data
# (C) 2010 Enrico Zini <enrico@enricozini.org>
# License: WTFPL version 2 (http://sam.zoy.org/wtfpl/)
import simplejson
import os
res = []
for f in os.listdir("."):
if not f.startswith("gmp24"): continue
data = open(f).read().strip()
if data == "[]": continue
parsed = simplejson.loads(data)
res.extend(parsed)
print simplejson.dumps(res)
The results however were not ordered by date, as
GMP had to use several accounts to twit because
Twitter was putting Greather Manchester Police into
jail for generating
too much traffic. There would be quite a bit to write about that, but let's
stick to our work.
Here is code to sort the JSON data by time:
#!/usr/bin/python
# Sort the JSON data
# (C) 2010 Enrico Zini <enrico@enricozini.org>
# License: WTFPL version 2 (http://sam.zoy.org/wtfpl/)
import simplejson
import sys
import datetime as dt
all_recs = simplejson.load(sys.stdin)
all_recs.sort(key=lambda x: dt.datetime.strptime(x["created_at"], "%a %b %d %H:%M:%S +0000 %Y"))
simplejson.dump(all_recs, sys.stdout)
I then wanted to play with
Tf-idf for extracting the most
important words of every tweet:
#!/usr/bin/python
# tfifd - Annotate JSON elements with Tf-idf extracted keywords
#
# Copyright (C) 2010 Enrico Zini <enrico@enricozini.org>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import sys, math
import simplejson
import re
# Read all the twits
records = simplejson.load(sys.stdin)
# All the twits by ID
byid = dict(((x["id"], x) for x in records))
# Stopwords we ignore
stopwords = set(["by", "it", "and", "of", "in", "a", "to"])
# Tokenising engine
re_num = re.compile(r"^\d+$")
re_word = re.compile(r"(\w+)")
def tokenise(tweet):
"Extract tokens from a tweet"
for tok in tweet["text"].split():
tok = tok.strip().lower()
if re_num.match(tok): continue
mo = re_word.match(tok)
if not mo: continue
if mo.group(1) in stopwords: continue
yield mo.group(1)
# Extract tokens from tweets
tokenised = dict(((x["id"], list(tokenise(x))) for x in records))
# Aggregate token counts
aggregated =
for d in byid.iterkeys():
for t in tokenised[d]:
if t in aggregated:
aggregated[t] += 1
else:
aggregated[t] = 1
def tfidf(doc, tok):
"Compute TFIDF score of a token in a document"
return doc.count(tok) * math.log(float(len(byid)) / aggregated[tok])
# Annotate tweets with keywords
res = []
for name, tweet in byid.iteritems():
doc = tokenised[name]
keywords = sorted(set(doc), key=lambda tok: tfidf(doc, tok), reverse=True)[:5]
tweet["keywords"] = keywords
res.append(tweet)
simplejson.dump(res, sys.stdout)
I thought this was producing a nice summary of every tweet but nobody was
particularly interested, so we moved on to adding categories to tweet.
Thanks to
Yuwei who put together some useful keyword
sets, we managed to annotate each tweet with a place name (i.e. "Stockport"),
a social place name (i.e. "pub", "bank") and a social category (i.e. "man",
"woman", "landlord"...)
The code is simple; the biggest work in it was the dictionary of keywords:
#!/usr/bin/python
# categorise - Annotate JSON elements with categories
#
# Copyright (C) 2010 Enrico Zini <enrico@enricozini.org>
# Copyright (C) 2010 Yuwei Lin <yuwei@ylin.org>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import sys, math
import simplejson
import re
# Electoral wards from http://en.wikipedia.org/wiki/List_of_electoral_wards_in_Greater_Manchester
placenames = ["Altrincham", "Sale West",
"Altrincham", "Ashton upon Mersey", "Bowdon", "Broadheath", "Hale Barns", "Hale Central", "St Mary", "Timperley", "Village",
"Ashton-under-Lyne",
"Ashton Hurst", "Ashton St Michael", "Ashton Waterloo", "Droylsden East", "Droylsden West", "Failsworth East", "Failsworth West", "St Peter",
"Blackley", "Broughton",
"Broughton", "Charlestown", "Cheetham", "Crumpsall", "Harpurhey", "Higher Blackley", "Kersal",
"Bolton North East",
"Astley Bridge", "Bradshaw", "Breightmet", "Bromley Cross", "Crompton", "Halliwell", "Tonge with the Haulgh",
"Bolton South East",
"Farnworth", "Great Lever", "Harper Green", "Hulton", "Kearsley", "Little Lever", "Darcy Lever", "Rumworth",
"Bolton West",
"Atherton", "Heaton", "Lostock", "Horwich", "Blackrod", "Horwich North East", "Smithills", "Westhoughton North", "Chew Moor", "Westhoughton South",
"Bury North",
"Church", "East", "Elton", "Moorside", "North Manor", "Ramsbottom", "Redvales", "Tottington",
"Bury South",
"Besses", "Holyrood", "Pilkington Park", "Radcliffe East", "Radcliffe North", "Radcliffe West", "St Mary", "Sedgley", "Unsworth",
"Cheadle",
"Bramhall North", "Bramhall South", "Cheadle", "Gatley", "Cheadle Hulme North", "Cheadle Hulme South", "Heald Green", "Stepping Hill",
"Denton", "Reddish",
"Audenshaw", "Denton North East", "Denton South", "Denton West", "Dukinfield", "Reddish North", "Reddish South",
"Hazel Grove",
"Bredbury", "Woodley", "Bredbury Green", "Romiley", "Hazel Grove", "Marple North", "Marple South", "Offerton",
"Heywood", "Middleton",
"Bamford", "Castleton", "East Middleton", "Hopwood Hall", "Norden", "North Heywood", "North Middleton", "South Middleton", "West Heywood", "West Middleton",
"Leigh",
"Astley Mosley Common", "Atherleigh", "Golborne", "Lowton West", "Leigh East", "Leigh South", "Leigh West", "Lowton East", "Tyldesley",
"Makerfield",
"Abram", "Ashton", "Bryn", "Hindley", "Hindley Green", "Orrell", "Winstanley", "Worsley Mesnes",
"Manchester Central",
"Ancoats", "Clayton", "Ardwick", "Bradford", "City Centre", "Hulme", "Miles Platting", "Newton Heath", "Moss Side", "Moston",
"Manchester", "Gorton",
"Fallowfield", "Gorton North", "Gorton South", "Levenshulme", "Longsight", "Rusholme", "Whalley Range",
"Manchester", "Withington",
"Burnage", "Chorlton", "Chorlton Park", "Didsbury East", "Didsbury West", "Old Moat", "Withington",
"Oldham East", "Saddleworth",
"Alexandra", "Crompton", "Saddleworth North", "Saddleworth South", "Saddleworth West", "Lees", "St James", "St Mary", "Shaw", "Waterhead",
"Oldham West", "Royton",
"Chadderton Central", "Chadderton North", "Chadderton South", "Coldhurst", "Hollinwood", "Medlock Vale", "Royton North", "Royton South", "Werneth",
"Rochdale",
"Balderstone", "Kirkholt", "Central Rochdale", "Healey", "Kingsway", "Littleborough Lakeside", "Milkstone", "Deeplish", "Milnrow", "Newhey", "Smallbridge", "Firgrove", "Spotland", "Falinge", "Wardle", "West Littleborough",
"Salford", "Eccles",
"Claremont", "Eccles", "Irwell Riverside", "Langworthy", "Ordsall", "Pendlebury", "Swinton North", "Swinton South", "Weaste", "Seedley",
"Stalybridge", "Hyde",
"Dukinfield Stalybridge", "Hyde Godley", "Hyde Newton", "Hyde Werneth", "Longdendale", "Mossley", "Stalybridge North", "Stalybridge South",
"Stockport",
"Brinnington", "Central", "Davenport", "Cale Green", "Edgeley", "Cheadle Heath", "Heatons North", "Heatons South", "Manor",
"Stretford", "Urmston",
"Bucklow-St Martins", "Clifford", "Davyhulme East", "Davyhulme West", "Flixton", "Gorse Hill", "Longford", "Stretford", "Urmston",
"Wigan",
"Aspull New Springs Whelley", "Douglas", "Ince", "Pemberton", "Shevington with Lower Ground", "Standish with Langtree", "Wigan Central", "Wigan West",
"Worsley", "Eccles South",
"Barton", "Boothstown", "Ellenbrook", "Cadishead", "Irlam", "Little Hulton", "Walkden North", "Walkden South", "Winton", "Worsley",
"Wythenshawe", "Sale East",
"Baguley", "Brooklands", "Northenden", "Priory", "Sale Moor", "Sharston", "Woodhouse Park"]
# Manual coding from Yuwei
placenames.extend(["City centre", "Tameside", "Oldham", "Bury", "Bolton",
"Trafford", "Pendleton", "New Moston", "Denton", "Eccles", "Leigh", "Benchill",
"Prestwich", "Sale", "Kearsley", ])
placenames.extend(["Trafford", "Bolton", "Stockport", "Levenshulme", "Gorton",
"Tameside", "Blackley", "City centre", "Airport", "South Manchester",
"Rochdale", "Chorlton", "Uppermill", "Castleton", "Stalybridge", "Ashton",
"Chadderton", "Bury", "Ancoats", "Whalley Range", "West Yorkshire",
"Fallowfield", "New Moston", "Denton", "Stretford", "Eccles", "Pendleton",
"Leigh", "Altrincham", "Sale", "Prestwich", "Kearsley", "Hulme", "Withington",
"Moss Side", "Milnrow", "outskirt of Manchester City Centre", "Newton Heath",
"Wythenshawe", "Mancunian Way", "M60", "A6", "Droylesden", "M56", "Timperley",
"Higher Ince", "Clayton", "Higher Blackley", "Lowton", "Droylsden",
"Partington", "Cheetham Hill", "Benchill", "Longsight", "Didsbury",
"Westhoughton"])
# Social categories from Yuwei
soccat = ["man", "woman", "men", "women", "youth", "teenager", "elderly",
"patient", "taxi driver", "neighbour", "male", "tenant", "landlord", "child",
"children", "immigrant", "female", "workmen", "boy", "girl", "foster parents",
"next of kin"]
for i in range(100):
soccat.append("%d-year-old" % i)
soccat.append("%d-years-old" % i)
# Types of social locations from Yuwei
socloc = ["car park", "park", "pub", "club", "shop", "premises", "bus stop",
"property", "credit card", "supermarket", "garden", "phone box", "theatre",
"toilet", "building site", "Crown court", "hard shoulder", "telephone kiosk",
"hotel", "restaurant", "cafe", "petrol station", "bank", "school",
"university"]
extras = "placename": placenames, "soccat": soccat, "socloc": socloc
# Normalise keyword lists
for k, v in extras.iteritems():
# Remove duplicates
v = list(set(v))
# Sort by length
v.sort(key=lambda x:len(x), reverse=True)
# Add keywords
def add_categories(tweet):
text = tweet["text"].lower()
for field, categories in extras.iteritems():
for cat in categories:
if cat.lower() in text:
tweet[field] = cat
break
return tweet
# Read all the twits
records = (add_categories(x) for x in simplejson.load(sys.stdin))
simplejson.dump(list(records), sys.stdout)
All these scripts form a nice processing chain: each script takes a list of
JSON records, adds some bit and passes it on.
In order to see what we have so far, here is a simple script to convert the
JSON twits to CSV so they can be viewed in a spreadsheet:
#!/usr/bin/python
# Convert the JSON twits to CSV
# (C) 2010 Enrico Zini <enrico@enricozini.org>
# License: WTFPL version 2 (http://sam.zoy.org/wtfpl/)
import simplejson
import sys
import csv
rows = ["id", "created_at", "text", "keywords", "placename"]
writer = csv.writer(sys.stdout)
for rec in simplejson.load(sys.stdin):
rec["keywords"] = " ".join(rec["keywords"])
rec["placename"] = rec.get("placename", "")
writer.writerow([rec[row] for row in rows])
At this point we were coming up with lots of questions: "were there more
reports on women or men?", "which place had most incidents?", "what were the
incidents involving animals?"... Time to bring
Xapian
into play.
This script reads all the JSON tweets and builds a Xapian index with them:
#!/usr/bin/python
# toxapian - Index JSON tweets in Xapian
#
# Copyright (C) 2010 Enrico Zini <enrico@enricozini.org>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import simplejson
import sys
import os, os.path
import xapian
DBNAME = sys.argv[1]
db = xapian.WritableDatabase(DBNAME, xapian.DB_CREATE_OR_OPEN)
stemmer = xapian.Stem("english")
indexer = xapian.TermGenerator()
indexer.set_stemmer(stemmer)
indexer.set_database(db)
data = simplejson.load(sys.stdin)
for rec in data:
doc = xapian.Document()
doc.set_data(str(rec["id"]))
indexer.set_document(doc)
indexer.index_text_without_positions(rec["text"])
# Index categories as categories
if "placename" in rec:
doc.add_boolean_term("XP" + rec["placename"].lower())
if "soccat" in rec:
doc.add_boolean_term("XS" + rec["soccat"].lower())
if "socloc" in rec:
doc.add_boolean_term("XL" + rec["socloc"].lower())
db.add_document(doc)
db.flush()
# Also save the whole dataset so we know where to find it later if we want to
# show the details of an entry
simplejson.dump(data, open(os.path.join(DBNAME, "all.json"), "w"))
And this is a simple command line tool to query to the database:
#!/usr/bin/python
# xgrep - Command line tool to query the GMP24 tweet Xapian database
#
# Copyright (C) 2010 Enrico Zini <enrico@enricozini.org>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import simplejson
import sys
import os, os.path
import xapian
DBNAME = sys.argv[1]
db = xapian.Database(DBNAME)
stem = xapian.Stem("english")
qp = xapian.QueryParser()
qp.set_default_op(xapian.Query.OP_AND)
qp.set_database(db)
qp.set_stemmer(stem)
qp.set_stemming_strategy(xapian.QueryParser.STEM_SOME)
qp.add_boolean_prefix("place", "XP")
qp.add_boolean_prefix("soc", "XS")
qp.add_boolean_prefix("loc", "XL")
query = qp.parse_query(sys.argv[2],
xapian.QueryParser.FLAG_BOOLEAN
xapian.QueryParser.FLAG_LOVEHATE
xapian.QueryParser.FLAG_BOOLEAN_ANY_CASE
xapian.QueryParser.FLAG_WILDCARD
xapian.QueryParser.FLAG_PURE_NOT
xapian.QueryParser.FLAG_SPELLING_CORRECTION
xapian.QueryParser.FLAG_AUTO_SYNONYMS)
enquire = xapian.Enquire(db)
enquire.set_query(query)
count = 40
matches = enquire.get_mset(0, count)
estimated = matches.get_matches_estimated()
print "%d/%d results" % (matches.size(), estimated)
data = dict((str(x["id"]), x) for x in simplejson.load(open(os.path.join(DBNAME, "all.json"))))
for m in matches:
rec = data[m.document.get_data()]
print rec["text"]
print "%d/%d results" % (matches.size(), matches.get_matches_estimated())
total = db.get_doccount()
estimated = matches.get_matches_estimated()
print "%d results over %d documents, %d%%" % (estimated, total, estimated * 100 / total)
Neat! Now that we have a proper index that supports all sort of cool things,
like stemming, tag clouds, full text search with complex queries, lookup of
similar documents, suggest keywords and so on, it was just fair to put together
a web service to share it with other people at the event.
It helped that I had already written similar code for
apt-xapian-index and
dde before.
Here is the server, quickly built on
bottle. The very last line starts
the server and it is where you can configure the listening interface and port.
#!/usr/bin/python
# xserve - Make the GMP24 tweet Xapian database available on the web
#
# Copyright (C) 2010 Enrico Zini <enrico@enricozini.org>
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
import bottle
from bottle import route, post
from cStringIO import StringIO
import cPickle as pickle
import simplejson
import sys
import os, os.path
import xapian
import urllib
import math
bottle.debug(True)
DBNAME = sys.argv[1]
QUERYLOG = os.path.join(DBNAME, "queries.txt")
data = dict((str(x["id"]), x) for x in simplejson.load(open(os.path.join(DBNAME, "all.json"))))
prefixes = "place": "XP", "soc": "XS", "loc": "XL"
prefix_desc = "place": "Place name", "soc": "Social category", "loc": "Social location"
db = xapian.Database(DBNAME)
stem = xapian.Stem("english")
qp = xapian.QueryParser()
qp.set_default_op(xapian.Query.OP_AND)
qp.set_database(db)
qp.set_stemmer(stem)
qp.set_stemming_strategy(xapian.QueryParser.STEM_SOME)
for k, v in prefixes.iteritems():
qp.add_boolean_prefix(k, v)
def make_query(qstring):
return qp.parse_query(qstring,
xapian.QueryParser.FLAG_BOOLEAN
xapian.QueryParser.FLAG_LOVEHATE
xapian.QueryParser.FLAG_BOOLEAN_ANY_CASE
xapian.QueryParser.FLAG_WILDCARD
xapian.QueryParser.FLAG_PURE_NOT
xapian.QueryParser.FLAG_SPELLING_CORRECTION
xapian.QueryParser.FLAG_AUTO_SYNONYMS)
@route("/")
def index():
query = urllib.unquote_plus(bottle.request.GET.get("q", ""))
out = StringIO()
print >>out, '''
<html>
<head>
<title>Query</title>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.4.2/jquery.min.js"></script>
<script type="text/javascript">
$(function()
$("#queryfield")[0].focus()
)
</script>
</head>
<body>
<h1>Search</h1>
<form method="POST" action="/query">
Keywords: <input type="text" name="query" value="%s" id="queryfield">
<input type="submit">
<a href="http://xapian.org/docs/queryparser.html">Help</a>
</form>''' % query
print >>out, '''
<p>Example: "car place:wigan"</p>
<p>Available prefixes:</p>
<ul>
'''
for pfx in prefixes.keys():
print >>out, "<li><a href='/catinfo/%s'>%s - %s</a></li>" % (pfx, pfx, prefix_desc[pfx])
print >>out, '''
</ul>
'''
oldqueries = []
if os.path.exists(QUERYLOG):
total = db.get_doccount()
fd = open(QUERYLOG, "r")
while True:
try:
q = pickle.load(fd)
except EOFError:
break
oldqueries.append(q)
fd.close()
def print_query(q):
count = q["count"]
print >>out, "<li><a href='/query?query=%s'>%s (%d/%d %.2f%%)</a></li>" % (urllib.quote_plus(q["q"]), q["q"], count, total, count * 100.0 / total)
print >>out, "<p>Last 10 queries:</p><ul>"
for q in oldqueries[:-10:-1]:
print_query(q)
print >>out, "</ul>"
# Remove duplicates
oldqueries = dict(((x["q"], x) for x in oldqueries)).values()
print >>out, "<table>"
print >>out, "<tr><th>10 queries with most results</th><th>10 queries with least results</th></tr>"
print >>out, "<tr><td>"
print >>out, "<ul>"
oldqueries.sort(key=lambda x:x["count"], reverse=True)
for q in oldqueries[:10]:
print_query(q)
print >>out, "</ul>"
print >>out, "</td><td>"
print >>out, "<ul>"
nonempty = [x for x in oldqueries if x["count"] > 0]
nonempty.sort(key=lambda x:x["count"])
for q in nonempty[:10]:
print_query(q)
print >>out, "</ul>"
print >>out, "</td></tr>"
print >>out, "</table>"
print >>out, '''
</body>
</html>'''
return out.getvalue()
@route("/query")
@route("/query/")
@post("/query")
@post("/query/")
def query():
query = bottle.request.POST.get("query", bottle.request.GET.get("query", ""))
enquire = xapian.Enquire(db)
enquire.set_query(make_query(query))
count = 40
matches = enquire.get_mset(0, count)
estimated = matches.get_matches_estimated()
total = db.get_doccount()
out = StringIO()
print >>out, '''
<html>
<head><title>Results</title></head>
<body>
<h1>Results for "<b>%s</b>"</h1>
''' % query
if estimated == 0:
print >>out, "No results found."
else:
# Give as results the first 30 documents; also use them as the key
# ones to use to compute relevant terms
rset = xapian.RSet()
for m in enquire.get_mset(0, 30):
rset.add_document(m.document.get_docid())
# Compute the tag cloud
class NonTagFilter(xapian.ExpandDecider):
def __call__(self, term):
return not term[0].isupper() and not term[0].isdigit()
cloud = []
maxscore = None
for res in enquire.get_eset(40, rset, NonTagFilter()):
# Normalise the score in the interval [0, 1]
weight = math.log(res.weight)
if maxscore == None: maxscore = weight
tag = res.term
cloud.append([tag, float(weight) / maxscore])
max_weight = cloud[0][1]
min_weight = cloud[-1][1]
cloud.sort(key=lambda x:x[0])
def mklink(query, term):
return "/query?query=%s" % urllib.quote_plus(query + " and " + term)
print >>out, "<h2>Tag cloud</h2>"
print >>out, "<blockquote>"
for term, weight in cloud:
size = 100 + 100.0 * (weight - min_weight) / (max_weight - min_weight)
print >>out, "<a href='%s' style='font-size:%d%%; color:brown;'>%s</a>" % (mklink(query, term), size, term)
print >>out, "</blockquote>"
print >>out, "<h2>Results</h2>"
print >>out, "<p><a href='/'>Search again</a></p>"
print >>out, "<p>%d results over %d documents, %.2f%%</p>" % (estimated, total, estimated * 100.0 / total)
print >>out, "<p>%d/%d results</p>" % (matches.size(), estimated)
print >>out, "<ul>"
for m in matches:
rec = data[m.document.get_data()]
print >>out, "<li><a href='/item/%s'>%s</a></li>" % (rec["id"], rec["text"])
print >>out, "</ul>"
fd = open(QUERYLOG, "a")
qinfo = dict(q=query, count=estimated)
pickle.dump(qinfo, fd)
fd.close()
print >>out, '''
<a href="/">Search again</a>
</body>
</html>'''
return out.getvalue()
@route("/item/:id")
@route("/item/:id/")
def show(id):
rec = data[id]
out = StringIO()
print >>out, '''
<html>
<head><title>Result %s</title></head>
<body>
<h1>Raw JSON record for twit %s</h1>
<pre>''' % (rec["id"], rec["id"])
print >>out, simplejson.dumps(rec, indent=" ")
print >>out, '''
</pre>
</body>
</html>'''
return out.getvalue()
@route("/catinfo/:name")
@route("/catinfo/:name/")
def catinfo(name):
prefix = prefixes[name]
out = StringIO()
print >>out, '''
<html>
<head><title>Values for %s</title></head>
<body>
''' % name
terms = [(x.term[len(prefix):], db.get_termfreq(x.term)) for x in db.allterms(prefix)]
terms.sort(key=lambda x:x[1], reverse=True)
freq_min = terms[0][1]
freq_max = terms[-1][1]
def mklink(name, term):
return "/query?query=%s" % urllib.quote_plus(name + ":" + term)
# Build tag cloud
print >>out, "<h1>Tag cloud</h1>"
print >>out, "<blockquote>"
for term, freq in sorted(terms[:20], key=lambda x:x[0]):
size = 100 + 100.0 * (freq - freq_min) / (freq_max - freq_min)
print >>out, "<a href='%s' style='font-size:%d%%; color:brown;'>%s</a>" % (mklink(name, term), size, term)
print >>out, "</blockquote>"
print >>out, "<h1>All terms</h1>"
print >>out, "<table>"
print >>out, "<tr><th>Occurrences</th><th>Name</th></tr>"
for term, freq in terms:
print >>out, "<tr><td>%d</td><td><a href='/query?query=%s'>%s</a></td></tr>" % (freq, urllib.quote_plus(name + ":" + term), term)
print >>out, "</table>"
print >>out, '''
</body>
</html>'''
return out.getvalue()
# Change here for bind host and port
bottle.run(host="0.0.0.0", port=8024)
...and then we presented our work and ended up winning the contest.
This was the story of how we wrote this set of award winning code.
 This post should have marked the beginning of my yearly roundups of the favourite books and movies I read and watched in 2023.
However, due to coming down with a nasty bout of flu recently and other sundry commitments, I wasn't able to undertake writing the necessary four or five blog posts In lieu of this, however, I will simply present my (unordered and unadorned) highlights for now. Do get in touch if this (or any of my previous posts) have spurred you into picking something up yourself
This post should have marked the beginning of my yearly roundups of the favourite books and movies I read and watched in 2023.
However, due to coming down with a nasty bout of flu recently and other sundry commitments, I wasn't able to undertake writing the necessary four or five blog posts In lieu of this, however, I will simply present my (unordered and unadorned) highlights for now. Do get in touch if this (or any of my previous posts) have spurred you into picking something up yourself
 Peter Watts: Blindsight (2006)
Peter Watts: Blindsight (2006) Reymer Banham: Los Angeles: The Architecture of Four Ecologies (2006)
Reymer Banham: Los Angeles: The Architecture of Four Ecologies (2006) Joanne McNeil: Lurking: How a Person Became a User (2020)
Joanne McNeil: Lurking: How a Person Became a User (2020) J. L. Carr: A Month in the Country (1980)
J. L. Carr: A Month in the Country (1980) Hilary Mantel: A Memoir of My Former Self: A Life in Writing (2023)
Hilary Mantel: A Memoir of My Former Self: A Life in Writing (2023) Adam Higginbotham: Midnight in Chernobyl (2019)
Adam Higginbotham: Midnight in Chernobyl (2019) Tony Judt: Postwar: A History of Europe Since 1945 (2005)
Tony Judt: Postwar: A History of Europe Since 1945 (2005) Tony Judt: Reappraisals: Reflections on the Forgotten Twentieth Century (2008)
Tony Judt: Reappraisals: Reflections on the Forgotten Twentieth Century (2008) Peter Apps: Show Me the Bodies: How We Let Grenfell Happen (2021)
Peter Apps: Show Me the Bodies: How We Let Grenfell Happen (2021) Joan Didion: Slouching Towards Bethlehem (1968)
Joan Didion: Slouching Towards Bethlehem (1968) Erik Larson: The Devil in the White City (2003)
Erik Larson: The Devil in the White City (2003) The following contributors got their Debian Developer accounts in the last two months:
The following contributors got their Debian Developer accounts in the last two months:








 We have this PostgreSQL server with plenty of RAM that is still using some of
its swap over the day (up to 600MB). Then suddenly everything is swapped in
again.
We have this PostgreSQL server with plenty of RAM that is still using some of
its swap over the day (up to 600MB). Then suddenly everything is swapped in
again.
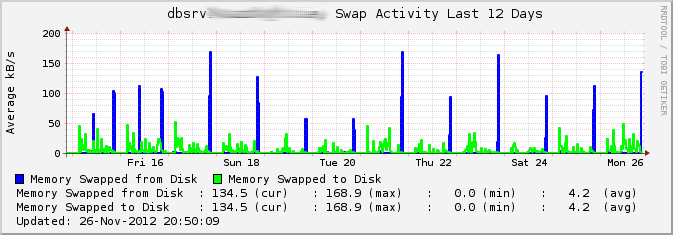 It turned out the reason is there are two clusters running, and the second one
isn't used as heavily as the first one. Disk I/O activity of the first cluster
slowly evicts pages from the second shared buffers cache to swap, and then the
daily pg_dump run reads them back every evening.
I was not aware of an easy way to get numbers for "amount of SysV shared memory
swapped to disk", but some googling led to shmctl(2):
It turned out the reason is there are two clusters running, and the second one
isn't used as heavily as the first one. Disk I/O activity of the first cluster
slowly evicts pages from the second shared buffers cache to swap, and then the
daily pg_dump run reads them back every evening.
I was not aware of an easy way to get numbers for "amount of SysV shared memory
swapped to disk", but some googling led to shmctl(2):
 With a
With a  Bastien
Bastien  I got
I got  And here are the three blogger friends I can think of who aren't too uptight and full of themselves to post a picture of a hand-drawn bunny:
And here are the three blogger friends I can think of who aren't too uptight and full of themselves to post a picture of a hand-drawn bunny:
 A common way to debug a network server is to use 'telnet' or 'nc' to
connect to the server and issue some commands in the protocol to verify
whether everything is working correctly. That obviously only works for
ASCII protocols (as opposed to binary protocols), and it obviously also
only works if you're not using any encryption.
But that doesn't mean you can't test an encrypted protocol in a
similar way, thanks to openssl's s_client:
A common way to debug a network server is to use 'telnet' or 'nc' to
connect to the server and issue some commands in the protocol to verify
whether everything is working correctly. That obviously only works for
ASCII protocols (as opposed to binary protocols), and it obviously also
only works if you're not using any encryption.
But that doesn't mean you can't test an encrypted protocol in a
similar way, thanks to openssl's s_client: