
It s been quite a few months since the most recent updates about Flathub last year. We ve been busy behind the scenes, so I d like to share what we ve been up to at Flathub and why and what s coming up from us this year. I want to focus on:
- Where Flathub is today as a strong ecosystem with 2,000 apps
- Our progress on evolving Flathub from a build service to an app store
- The economic barrier to growing the ecosystem, and its consequences
- What s next to overcome our challenges with focused initiatives
Today
Flathub is going strong: we offer 2,000 apps from over 1,500 collaborators on GitHub. We re averaging 700,000 app downloads a day, with 898 million HTTP requests totalling 88.3 TB served by our CDN each day (thank you Fastly!). Flatpak has, in my opinion, solved the largest technical issue which has held back the mainstream growth and acceptance of Linux on the desktop (or other personal computing devices) for the past 25 years: namely, the difficulty for app developers to publish their work in a way that makes it easy for people to discover, download (or sideload, for people in challenging connectivity environments), install and use. Flathub builds on that to help users discover the work of app developers and helps that work reach users in a timely manner.
Initial results of this disintermediation are promising: even with its modest size so far, Flathub has hundreds of apps that I have never, ever heard of before and that s even considering I ve been working in the Linux desktop space for nearly 20 years and spent many of those staring at the contents of
dselect (showing my age a little) or GNOME Software, attending conferences, and reading blog posts, news articles, and forums. I am also heartened to see that many of our OS distributor partners have recognised that this model is hugely complementary and additive to the indispensable work they are doing to bring the Linux desktop to end users, and that having more apps available to your users is a value-add allowing you to focus on your core offering and not a zero-sum game that should motivate infighting.
Ongoing Progress
Getting Flathub into its current state has been a long ongoing process. Here s what we ve been up to behind the scenes:
Development
Last year, we concluded our first engagement with Codethink to build features into the Flathub web app to move from a build service to an app store. That includes accounts for users and developers, payment processing via Stripe, and the ability for developers to manage upload tokens for the apps they control. In parallel, James Westman has been working on app verification and the corresponding features in flat-manager to ensure app metadata accurately reflects verification and pricing, and to provide authentication for paying users for app downloads when the developer enables it. Only verified developers will be able to make direct uploads or access payment settings for their apps.
Legal
So far, the GNOME Foundation has acted as an incubator and legal host for Flathub even though it s not purely a GNOME product or initiative. Distributing software to end users along with processing and forwarding payments and donations also has a different legal profile in terms of risk exposure and nonprofit compliance than the current activities of the GNOME Foundation. Consequently, we plan to establish an independent legal entity to own and operate Flathub which reduces risk for the GNOME Foundation, better reflects the independent and cross-desktop interests of Flathub, and provides flexibility in the future should we need to change the structure.
We re currently in the process of reviewing legal advice to ensure we have the right structure in place before moving forward.
Governance
As Flathub is something we want to set outside of the existing Linux desktop and distribution space and ensure we represent and serve the widest community of Linux users and developers we ve been working on a governance model that ensures that there is transparency and trust in who is making decisions, and why. We have set up a working group with myself and Mart n Abente Lahaye from GNOME, Aleix Pol Gonzalez, Neofytos Kolokotronis, and Timoth e Ravier from KDE, and Jorge Castro flying the flag for the Flathub community. Thanks also to Neil McGovern and Nick Richards who were also more involved in the process earlier on.
We don t want to get held up here creating something complex with memberships and elections, so at first we re going to come up with a simple/balanced way to appoint people into a board that makes key decisions about Flathub and iterate from there.
Funding
We have received one grant for 2023 of $100K from
Endless Network which will go towards the infrastructure, legal, and operations costs of running Flathub and setting up the structure described above. (Full disclosure: Endless Network is the umbrella organisation which also funds my employer, Endless OS Foundation.) I am hoping to grow the available funding to $250K for this year in order to cover the next round of development on the software, prepare for higher operations costs (e.g., accounting gets more complex), and bring in a second full-time staff member in addition to Bart omiej Piotrowski to handle enquiries, reviews, documentation, and partner outreach.
We re currently in discussions with
NLnet about funding further software development, but have been unfortunately turned down for a grant from the
Plaintext Group for this year; this Schmidt Futures project around OSS sustainability is not currently issuing grants in 2023. However, we continue to work on other funding opportunities.
Remaining Barriers
My personal hypothesis is that our largest remaining barrier to Linux desktop scale and impact is economic. On competing platforms mobile or desktop a developer can offer their work for sale via an app store or direct download with payment or subscription within hours of making a release. While we have taken the time to first download time down from months to days with Flathub, as a community we continue to have a challenging relationship with money. Some creators are lucky enough to have a full-time job within the FLOSS space, while a few superstar developers are able to nurture some level of financial support by investing time in building a following through streaming, Patreon, Kickstarter, or similar. However, a large proportion of us have to make do with the main payback from our labours being a stream of bug reports on GitHub interspersed with occasional conciliatory beers at FOSDEM (other beverages and events are available).
The first and most obvious consequence is that if there is no financial payback for participating in developing apps for the free and open source desktop, we will lose many people in the process despite the amazing achievements of those who have brought us to where we are today. As a result, we ll have far fewer developers and apps. If we can t offer access to a growing base of users or the opportunity to offer something of monetary value to them, the reward in terms of adoption and possible payment will be very small. Developers would be forgiven for taking their time and attention elsewhere. With fewer apps, our platform has less to entice and retain prospective users.
The second consequence is that this also represents a significant hurdle for diverse and inclusive participation. We essentially require that somebody is in a position of privilege and comfort that they have internet, power, time, and income not to mention childcare, etc. to spare so that they can take part. If that s not the case for somebody, we are leaving them shut out from our community before they even have a chance to start. My belief is that free and open source software represents a better way for people to access computing, and there are billions of people in the world we should hope to reach with our work. But if the mechanism for participation ensures their voices and needs are never represented in our community of creators, we are significantly less likely to understand and meet those needs.
While these are
my thoughts, you ll notice a strong theme to this year will be leading a consultation process to ensure that we are including, understanding and reflecting the needs of our different communities app creators, OS distributors and Linux users as I don t believe that our initiative will be successful without ensuring mutual benefit and shared success. Ultimately, no matter how beautiful, performant, or featureful the latest versions of the Plasma or GNOME desktops are, or how slick the newly rewritten installer is from your favourite distribution, all of the projects making up the Linux desktop ecosystem are subdividing between ourselves an absolutely tiny market share of the global market of personal computers. To make a bigger mark on the world, as a community, we need to get out more.
What s Next?
After identifying our major barriers to overcome, we ve planned a number of focused initiatives and restructuring this year:
Phased Deployment
We re working on deploying the work we have been doing over the past year, starting first with launching the
new Flathub web experience as well as
the rebrand that Jakub has been talking about on his blog. This also will finally launch the verification features so we can distinguish those apps which are uploaded by their developers.
In parallel, we ll also be able to turn on the Flatpak repo subsets that enable users to select only verified and/or FLOSS apps in the Flatpak CLI or their desktop s app center UI.
Consultation
We would like to make sure that the voices of app creators, OS distributors, and Linux users are reflected in our plans for 2023 and beyond. We will be launching this in the form of Flathub Focus Groups at the Linux App Summit in Brno in May 2023, followed up with surveys and other opportunities for online participation. We see our role as interconnecting communities and want to be sure that we remain transparent and accountable to those we are seeking to empower with our work.
Whilst we are being bold and ambitious with what we are trying to create for the Linux desktop community, we also want to make sure we provide the right forums to listen to the FLOSS community and prioritise our work accordingly.
Advisory Board
As we build the Flathub organisation up in 2023, we re also planning to expand its governance by creating an Advisory Board. We will establish an ongoing forum with different stakeholders around Flathub: OS vendors, hardware integrators, app developers and user representatives to help us create the Flathub that supports and promotes our mutually shared interests in a strong and healthy Linux desktop community.
Direct Uploads
Direct app uploads are close to ready, and they enable exciting stuff like allowing Electron apps to be built outside of flatpak-builder, or driving automatic Flathub uploads from GitHub actions or GitLab CI flows; however, we need to think a little about how we encourage these to be used. Even with its frustrations, our current Buildbot ensures that the build logs and source versions of each app on Flathub are captured, and that the apps are built on all supported architectures. (Is 2023 when we add RISC-V? Reach out if you d like to help!). If we hand upload tokens out to any developer, even if the majority of apps are open source, we will go from this relatively structured situation to something a lot more unstructured and we fear many apps will be available on only 64-bit Intel/AMD machines.
My sketch here is that we need to establish some best practices around how to integrate Flathub uploads into popular CI systems, encouraging best practices so that we promote the properties of transparency and reproducibility that we don t want to lose. If anyone is a CI wizard and would like to work with us as a thought partner about how we can achieve this make it more flexible where and how build tasks can be hosted, but not lose these cross-platform and inspectability properties we d love to hear from you.
Donations and Payments
Once the work around legal and governance reaches a decent point, we will be in the position to move ahead with our Stripe setup and switch on the third big new feature in the Flathub web app. At present, we have already implemented support for one-off payments either as donations or a required purchase. We would like to go further than that, in line with what we were describing earlier about helping developers sustainably work on apps for our ecosystem: we would also like to enable developers to offer subscriptions. This will allow us to create a relationship between users and creators that funds
ongoing work rather than
what we already have.
Security
For Flathub to succeed, we need to make sure that as we grow, we continue to be a platform that can give users confidence in the quality and security of the apps we offer. To that end, we are planning to set up infrastructure to help ensure developers are shipping the best products they possibly can to users. For example, we d like to set up automated linting and security scanning on the Flathub back-end to help developers avoid bad practices, unnecessary sandbox permissions, outdated dependencies, etc. and to keep users informed and as secure as possible.
Sponsorship
Fundraising is a forever task as is running such a big and growing service. We hope that one day, we can cover our costs through some modest fees built into our payments but until we reach that point, we re going to be seeking a combination of grant funding and sponsorship to keep our roadmap moving. Our hope is very much that we can encourage different organisations that buy into our vision and will benefit from Flathub to help us support it and ensure we can deliver on our goals. If you have any suggestions of who might like to support Flathub, we would be very appreciative if you could reach out and get us in touch.
Finally, Thank You!
Thanks to you all for reading this far and supporting the work of Flathub, and also to our major sponsors and donors without whom Flathub could not exist:
GNOME Foundation,
KDE e.V.,
Mythic Beasts,
Endless Network,
Fastly, and
Equinix Metal via the
CNCF Community Cluster. Thanks also to the tireless work of the
Freedesktop SDK community to give us the runtime platform most Flatpaks depend on, particularly Seppo Yli-Olli,
Codethink and others.
I wanted to also give my personal thanks to a handful of dedicated people who keep Flathub working as a service and as a community: Bart omiej Piotrowski is keeping the infrastructure working essentially single-handedly (in his spare time from keeping everything running at GNOME); Kolja Lampe and Bart built the new web app and backend API for Flathub which all of the new functionality has been built on, and Filippe LeMarchand maintains the checker bot which helps keeps all of the Flatpaks up to date.
And finally, all of the submissions to Flathub are reviewed to ensure quality, consistency and security by a small dedicated team of reviewers, with a huge amount of work from Hubert Figui re and Bart to keep the submissions flowing. Thanks to everyone named or unnamed for building this vision of the future of the Linux desktop together with us.
(originally posted to Flathub Discourse, head there if you have any questions or comments)
 As well as the collection and distribution of
As well as the collection and distribution of  Read all parts of the series
Read all parts of the series
 And here s what he explains about his drawing:
And here s what he explains about his drawing:
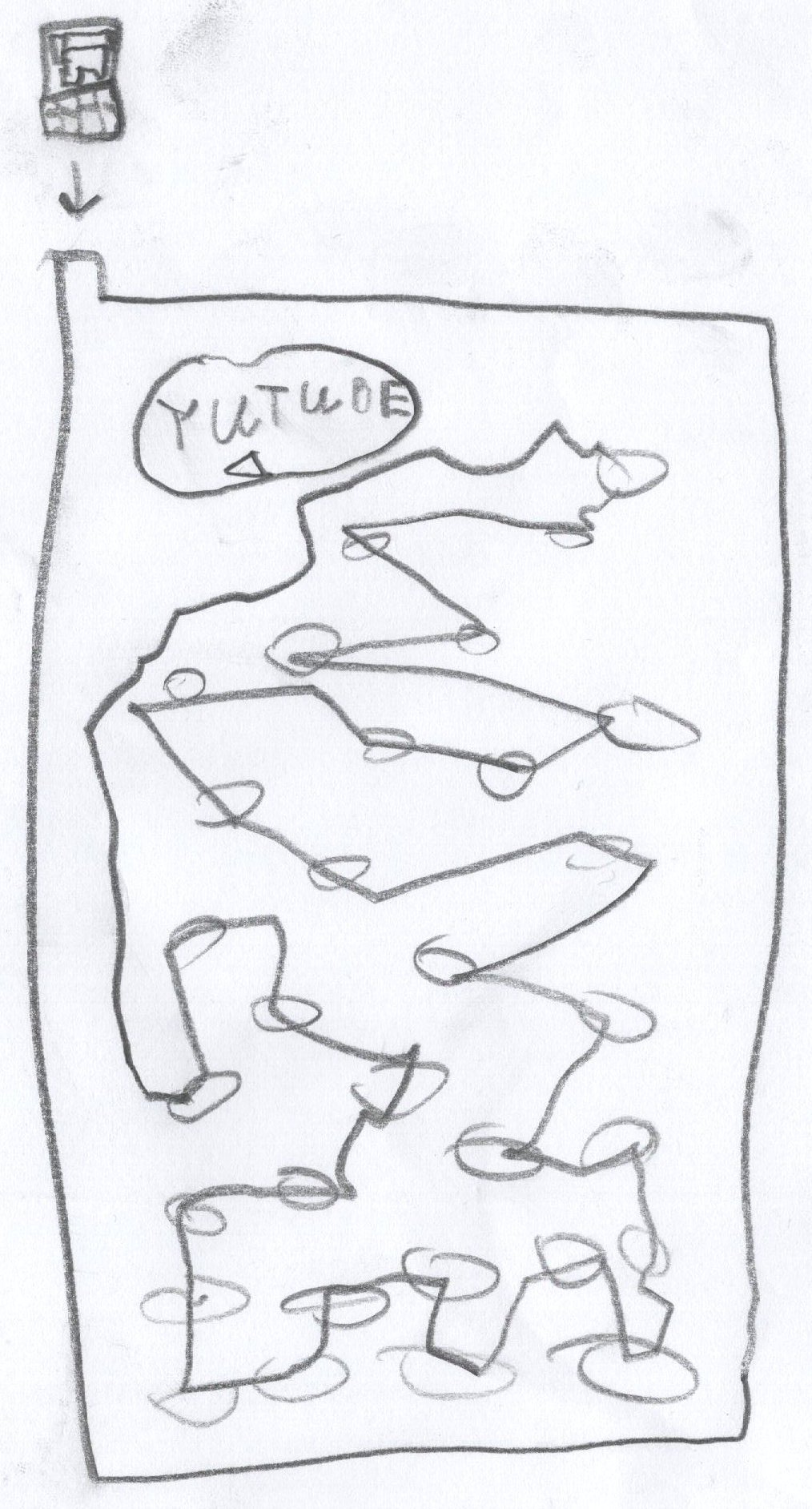
 In their drawing we see a Youtube prank channel on a screen, an external
trackpad on the right (likely it s not a touch screen), and headphones.
Notice how there is no keyboard, or maybe it s folded away.
If you could ask a nice and friendly dragon anything you d like to
learn about the internet, what would it be?
In their drawing we see a Youtube prank channel on a screen, an external
trackpad on the right (likely it s not a touch screen), and headphones.
Notice how there is no keyboard, or maybe it s folded away.
If you could ask a nice and friendly dragon anything you d like to
learn about the internet, what would it be?
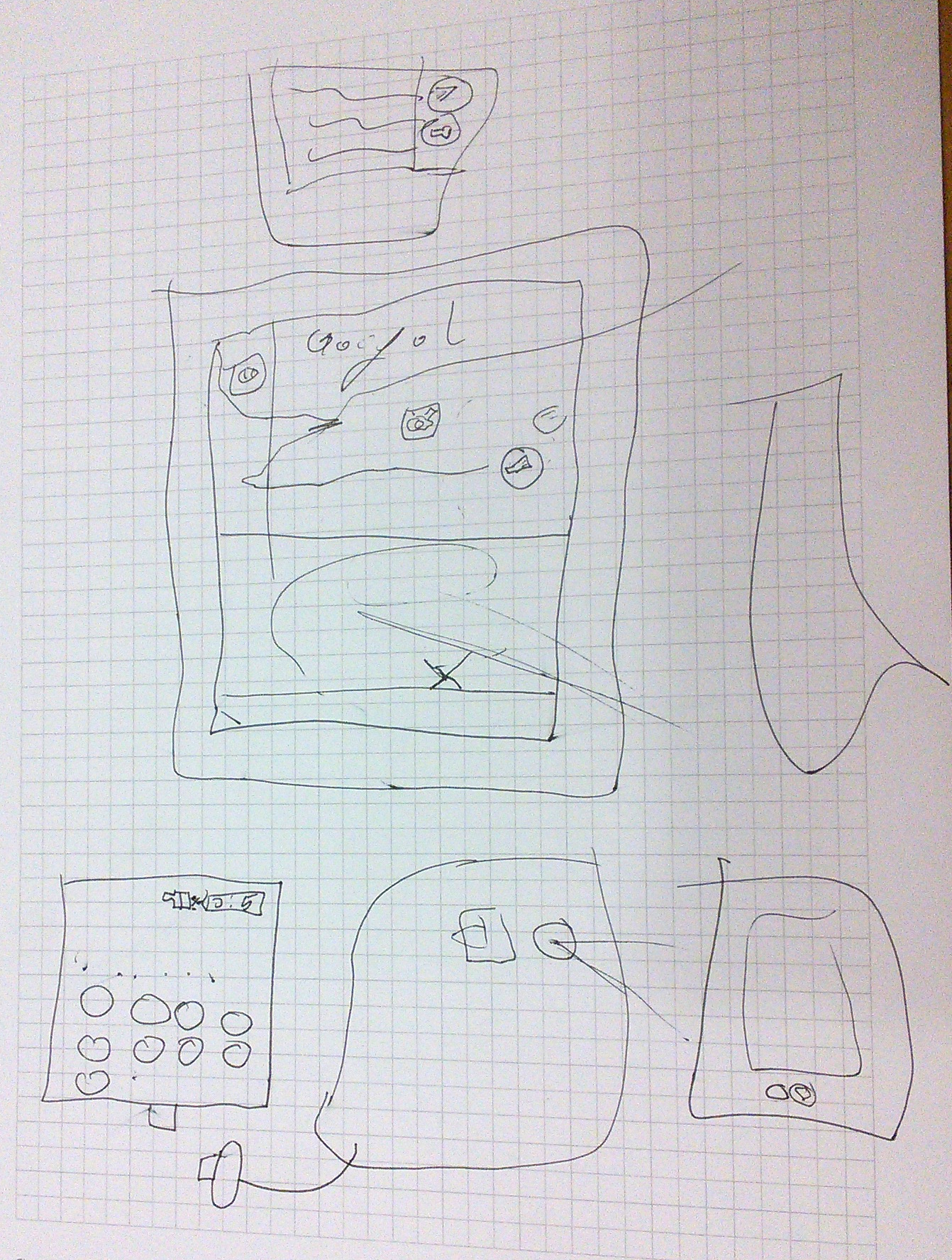 In her drawing, we see again Google - it s clearly everywhere - and also
the interfaces for calling and texting someone.
To explain what the internet is, besides the fact that one
can use it for calling and listening to music, she says:
In her drawing, we see again Google - it s clearly everywhere - and also
the interfaces for calling and texting someone.
To explain what the internet is, besides the fact that one
can use it for calling and listening to music, she says:
 When I asked if he knew what actually happens between the device and a
website he visits, he put forth the hypothesis of the existence of some
kind of
When I asked if he knew what actually happens between the device and a
website he visits, he put forth the hypothesis of the existence of some
kind of
 Now, I think it's safe to assume this program is dead and buried, and
anyways I'm running
Now, I think it's safe to assume this program is dead and buried, and
anyways I'm running  For multi-monitor setups,
For multi-monitor setups,  A new release 0.4.20 of
A new release 0.4.20 of  Attribution of source code has been limited to comments, but a deeper
embedding of attribution into code is possible. When an embedded
attribution is removed or is incorrect, the code should no longer work.
I've developed a way to do this in Haskell that is lightweight to add, but
requires more work to remove than seems worthwhile for someone who is
training an LLM on my code. And when it's not removed, it invites LLM
hallucinations of broken code.
I'm embedding attribution by defining a function like this in a module,
which uses an
Attribution of source code has been limited to comments, but a deeper
embedding of attribution into code is possible. When an embedded
attribution is removed or is incorrect, the code should no longer work.
I've developed a way to do this in Haskell that is lightweight to add, but
requires more work to remove than seems worthwhile for someone who is
training an LLM on my code. And when it's not removed, it invites LLM
hallucinations of broken code.
I'm embedding attribution by defining a function like this in a module,
which uses an 


 The seventeenth release of
The seventeenth release of 

