For a while now I wanted to have direct access to the
Signal database of messages and
channels of my Desktop edition of Signal. I prefer the enforced end
to end encryption of Signal these days for my communication with
friends and family, to increase the level of safety and privacy as
well as raising the cost of the mass surveillance government and
non-government entities practice these days. In August I came across
a nice
recipe
on how to use sqlcipher to extract statistics from the Signal
database explaining how to do this. Unfortunately this did not
work with the version of sqlcipher in Debian. The
sqlcipher
package is a "fork" of the sqlite package with added support for
encrypted databases. Sadly the current Debian maintainer
announced more than three
years ago that he did not have time to maintain sqlcipher, so it
seemed unlikely to be upgraded by the maintainer. I was reluctant to
take on the job myself, as I have very limited experience maintaining
shared libraries in Debian. After waiting and hoping for a few
months, I gave up the last week, and set out to update the package. In
the process I orphaned it to make it more obvious for the next person
looking at it that the package need proper maintenance.
The version in Debian was around five years old, and quite a lot of
changes had taken place upstream into the Debian maintenance git
repository. After spending a few days importing the new upstream
versions, realising that upstream did not care much for SONAME
versioning as I saw library symbols being both added and removed with
minor version number changes to the project, I concluded that I had to
do a SONAME bump of the library package to avoid surprising the
reverse dependencies. I even added a simple
autopkgtest script to ensure the package work as intended. Dug deep
into the hole of learning shared library maintenance, I set out a few
days ago to upload the new version to Debian experimental to see what
the quality assurance framework in Debian had to say about the result.
The feedback told me the pacakge was not too shabby, and yesterday I
uploaded the latest version to Debian unstable. It should enter
testing today or tomorrow, perhaps delayed by
a small library
transition.
Armed with a new version of sqlcipher, I can now have a look at the
SQL database in ~/.config/Signal/sql/db.sqlite. First, one need to
fetch the encryption key from the Signal configuration using this
simple JSON extraction command:
/usr/bin/jq -r '."key"' ~/.config/Signal/config.json
Assuming the result from that command is 'secretkey', which is a
hexadecimal number representing the key used to encrypt the database.
Next, one can now connect to the database and inject the encryption
key for access via SQL to fetch information from the database. Here
is an example dumping the database structure:
% sqlcipher ~/.config/Signal/sql/db.sqlite
sqlite> PRAGMA key = "x'secretkey'";
sqlite> .schema
CREATE TABLE sqlite_stat1(tbl,idx,stat);
CREATE TABLE conversations(
id STRING PRIMARY KEY ASC,
json TEXT,
active_at INTEGER,
type STRING,
members TEXT,
name TEXT,
profileName TEXT
, profileFamilyName TEXT, profileFullName TEXT, e164 TEXT, serviceId TEXT, groupId TEXT, profileLastFetchedAt INTEGER);
CREATE TABLE identityKeys(
id STRING PRIMARY KEY ASC,
json TEXT
);
CREATE TABLE items(
id STRING PRIMARY KEY ASC,
json TEXT
);
CREATE TABLE sessions(
id TEXT PRIMARY KEY,
conversationId TEXT,
json TEXT
, ourServiceId STRING, serviceId STRING);
CREATE TABLE attachment_downloads(
id STRING primary key,
timestamp INTEGER,
pending INTEGER,
json TEXT
);
CREATE TABLE sticker_packs(
id TEXT PRIMARY KEY,
key TEXT NOT NULL,
author STRING,
coverStickerId INTEGER,
createdAt INTEGER,
downloadAttempts INTEGER,
installedAt INTEGER,
lastUsed INTEGER,
status STRING,
stickerCount INTEGER,
title STRING
, attemptedStatus STRING, position INTEGER DEFAULT 0 NOT NULL, storageID STRING, storageVersion INTEGER, storageUnknownFields BLOB, storageNeedsSync
INTEGER DEFAULT 0 NOT NULL);
CREATE TABLE stickers(
id INTEGER NOT NULL,
packId TEXT NOT NULL,
emoji STRING,
height INTEGER,
isCoverOnly INTEGER,
lastUsed INTEGER,
path STRING,
width INTEGER,
PRIMARY KEY (id, packId),
CONSTRAINT stickers_fk
FOREIGN KEY (packId)
REFERENCES sticker_packs(id)
ON DELETE CASCADE
);
CREATE TABLE sticker_references(
messageId STRING,
packId TEXT,
CONSTRAINT sticker_references_fk
FOREIGN KEY(packId)
REFERENCES sticker_packs(id)
ON DELETE CASCADE
);
CREATE TABLE emojis(
shortName TEXT PRIMARY KEY,
lastUsage INTEGER
);
CREATE TABLE messages(
rowid INTEGER PRIMARY KEY ASC,
id STRING UNIQUE,
json TEXT,
readStatus INTEGER,
expires_at INTEGER,
sent_at INTEGER,
schemaVersion INTEGER,
conversationId STRING,
received_at INTEGER,
source STRING,
hasAttachments INTEGER,
hasFileAttachments INTEGER,
hasVisualMediaAttachments INTEGER,
expireTimer INTEGER,
expirationStartTimestamp INTEGER,
type STRING,
body TEXT,
messageTimer INTEGER,
messageTimerStart INTEGER,
messageTimerExpiresAt INTEGER,
isErased INTEGER,
isViewOnce INTEGER,
sourceServiceId TEXT, serverGuid STRING NULL, sourceDevice INTEGER, storyId STRING, isStory INTEGER
GENERATED ALWAYS AS (type IS 'story'), isChangeCreatedByUs INTEGER NOT NULL DEFAULT 0, isTimerChangeFromSync INTEGER
GENERATED ALWAYS AS (
json_extract(json, '$.expirationTimerUpdate.fromSync') IS 1
), seenStatus NUMBER default 0, storyDistributionListId STRING, expiresAt INT
GENERATED ALWAYS
AS (ifnull(
expirationStartTimestamp + (expireTimer * 1000),
9007199254740991
)), shouldAffectActivity INTEGER
GENERATED ALWAYS AS (
type IS NULL
OR
type NOT IN (
'change-number-notification',
'contact-removed-notification',
'conversation-merge',
'group-v1-migration',
'keychange',
'message-history-unsynced',
'profile-change',
'story',
'universal-timer-notification',
'verified-change'
)
), shouldAffectPreview INTEGER
GENERATED ALWAYS AS (
type IS NULL
OR
type NOT IN (
'change-number-notification',
'contact-removed-notification',
'conversation-merge',
'group-v1-migration',
'keychange',
'message-history-unsynced',
'profile-change',
'story',
'universal-timer-notification',
'verified-change'
)
), isUserInitiatedMessage INTEGER
GENERATED ALWAYS AS (
type IS NULL
OR
type NOT IN (
'change-number-notification',
'contact-removed-notification',
'conversation-merge',
'group-v1-migration',
'group-v2-change',
'keychange',
'message-history-unsynced',
'profile-change',
'story',
'universal-timer-notification',
'verified-change'
)
), mentionsMe INTEGER NOT NULL DEFAULT 0, isGroupLeaveEvent INTEGER
GENERATED ALWAYS AS (
type IS 'group-v2-change' AND
json_array_length(json_extract(json, '$.groupV2Change.details')) IS 1 AND
json_extract(json, '$.groupV2Change.details[0].type') IS 'member-remove' AND
json_extract(json, '$.groupV2Change.from') IS NOT NULL AND
json_extract(json, '$.groupV2Change.from') IS json_extract(json, '$.groupV2Change.details[0].aci')
), isGroupLeaveEventFromOther INTEGER
GENERATED ALWAYS AS (
isGroupLeaveEvent IS 1
AND
isChangeCreatedByUs IS 0
), callId TEXT
GENERATED ALWAYS AS (
json_extract(json, '$.callId')
));
CREATE TABLE sqlite_stat4(tbl,idx,neq,nlt,ndlt,sample);
CREATE TABLE jobs(
id TEXT PRIMARY KEY,
queueType TEXT STRING NOT NULL,
timestamp INTEGER NOT NULL,
data STRING TEXT
);
CREATE TABLE reactions(
conversationId STRING,
emoji STRING,
fromId STRING,
messageReceivedAt INTEGER,
targetAuthorAci STRING,
targetTimestamp INTEGER,
unread INTEGER
, messageId STRING);
CREATE TABLE senderKeys(
id TEXT PRIMARY KEY NOT NULL,
senderId TEXT NOT NULL,
distributionId TEXT NOT NULL,
data BLOB NOT NULL,
lastUpdatedDate NUMBER NOT NULL
);
CREATE TABLE unprocessed(
id STRING PRIMARY KEY ASC,
timestamp INTEGER,
version INTEGER,
attempts INTEGER,
envelope TEXT,
decrypted TEXT,
source TEXT,
serverTimestamp INTEGER,
sourceServiceId STRING
, serverGuid STRING NULL, sourceDevice INTEGER, receivedAtCounter INTEGER, urgent INTEGER, story INTEGER);
CREATE TABLE sendLogPayloads(
id INTEGER PRIMARY KEY ASC,
timestamp INTEGER NOT NULL,
contentHint INTEGER NOT NULL,
proto BLOB NOT NULL
, urgent INTEGER, hasPniSignatureMessage INTEGER DEFAULT 0 NOT NULL);
CREATE TABLE sendLogRecipients(
payloadId INTEGER NOT NULL,
recipientServiceId STRING NOT NULL,
deviceId INTEGER NOT NULL,
PRIMARY KEY (payloadId, recipientServiceId, deviceId),
CONSTRAINT sendLogRecipientsForeignKey
FOREIGN KEY (payloadId)
REFERENCES sendLogPayloads(id)
ON DELETE CASCADE
);
CREATE TABLE sendLogMessageIds(
payloadId INTEGER NOT NULL,
messageId STRING NOT NULL,
PRIMARY KEY (payloadId, messageId),
CONSTRAINT sendLogMessageIdsForeignKey
FOREIGN KEY (payloadId)
REFERENCES sendLogPayloads(id)
ON DELETE CASCADE
);
CREATE TABLE preKeys(
id STRING PRIMARY KEY ASC,
json TEXT
, ourServiceId NUMBER
GENERATED ALWAYS AS (json_extract(json, '$.ourServiceId')));
CREATE TABLE signedPreKeys(
id STRING PRIMARY KEY ASC,
json TEXT
, ourServiceId NUMBER
GENERATED ALWAYS AS (json_extract(json, '$.ourServiceId')));
CREATE TABLE badges(
id TEXT PRIMARY KEY,
category TEXT NOT NULL,
name TEXT NOT NULL,
descriptionTemplate TEXT NOT NULL
);
CREATE TABLE badgeImageFiles(
badgeId TEXT REFERENCES badges(id)
ON DELETE CASCADE
ON UPDATE CASCADE,
'order' INTEGER NOT NULL,
url TEXT NOT NULL,
localPath TEXT,
theme TEXT NOT NULL
);
CREATE TABLE storyReads (
authorId STRING NOT NULL,
conversationId STRING NOT NULL,
storyId STRING NOT NULL,
storyReadDate NUMBER NOT NULL,
PRIMARY KEY (authorId, storyId)
);
CREATE TABLE storyDistributions(
id STRING PRIMARY KEY NOT NULL,
name TEXT,
senderKeyInfoJson STRING
, deletedAtTimestamp INTEGER, allowsReplies INTEGER, isBlockList INTEGER, storageID STRING, storageVersion INTEGER, storageUnknownFields BLOB, storageNeedsSync INTEGER);
CREATE TABLE storyDistributionMembers(
listId STRING NOT NULL REFERENCES storyDistributions(id)
ON DELETE CASCADE
ON UPDATE CASCADE,
serviceId STRING NOT NULL,
PRIMARY KEY (listId, serviceId)
);
CREATE TABLE uninstalled_sticker_packs (
id STRING NOT NULL PRIMARY KEY,
uninstalledAt NUMBER NOT NULL,
storageID STRING,
storageVersion NUMBER,
storageUnknownFields BLOB,
storageNeedsSync INTEGER NOT NULL
);
CREATE TABLE groupCallRingCancellations(
ringId INTEGER PRIMARY KEY,
createdAt INTEGER NOT NULL
);
CREATE TABLE IF NOT EXISTS 'messages_fts_data'(id INTEGER PRIMARY KEY, block BLOB);
CREATE TABLE IF NOT EXISTS 'messages_fts_idx'(segid, term, pgno, PRIMARY KEY(segid, term)) WITHOUT ROWID;
CREATE TABLE IF NOT EXISTS 'messages_fts_content'(id INTEGER PRIMARY KEY, c0);
CREATE TABLE IF NOT EXISTS 'messages_fts_docsize'(id INTEGER PRIMARY KEY, sz BLOB);
CREATE TABLE IF NOT EXISTS 'messages_fts_config'(k PRIMARY KEY, v) WITHOUT ROWID;
CREATE TABLE edited_messages(
messageId STRING REFERENCES messages(id)
ON DELETE CASCADE,
sentAt INTEGER,
readStatus INTEGER
, conversationId STRING);
CREATE TABLE mentions (
messageId REFERENCES messages(id) ON DELETE CASCADE,
mentionAci STRING,
start INTEGER,
length INTEGER
);
CREATE TABLE kyberPreKeys(
id STRING PRIMARY KEY NOT NULL,
json TEXT NOT NULL, ourServiceId NUMBER
GENERATED ALWAYS AS (json_extract(json, '$.ourServiceId')));
CREATE TABLE callsHistory (
callId TEXT PRIMARY KEY,
peerId TEXT NOT NULL, -- conversation id (legacy) uuid groupId roomId
ringerId TEXT DEFAULT NULL, -- ringer uuid
mode TEXT NOT NULL, -- enum "Direct" "Group"
type TEXT NOT NULL, -- enum "Audio" "Video" "Group"
direction TEXT NOT NULL, -- enum "Incoming" "Outgoing
-- Direct: enum "Pending" "Missed" "Accepted" "Deleted"
-- Group: enum "GenericGroupCall" "OutgoingRing" "Ringing" "Joined" "Missed" "Declined" "Accepted" "Deleted"
status TEXT NOT NULL,
timestamp INTEGER NOT NULL,
UNIQUE (callId, peerId) ON CONFLICT FAIL
);
[ dropped all indexes to save space in this blog post ]
CREATE TRIGGER messages_on_view_once_update AFTER UPDATE ON messages
WHEN
new.body IS NOT NULL AND new.isViewOnce = 1
BEGIN
DELETE FROM messages_fts WHERE rowid = old.rowid;
END;
CREATE TRIGGER messages_on_insert AFTER INSERT ON messages
WHEN new.isViewOnce IS NOT 1 AND new.storyId IS NULL
BEGIN
INSERT INTO messages_fts
(rowid, body)
VALUES
(new.rowid, new.body);
END;
CREATE TRIGGER messages_on_delete AFTER DELETE ON messages BEGIN
DELETE FROM messages_fts WHERE rowid = old.rowid;
DELETE FROM sendLogPayloads WHERE id IN (
SELECT payloadId FROM sendLogMessageIds
WHERE messageId = old.id
);
DELETE FROM reactions WHERE rowid IN (
SELECT rowid FROM reactions
WHERE messageId = old.id
);
DELETE FROM storyReads WHERE storyId = old.storyId;
END;
CREATE VIRTUAL TABLE messages_fts USING fts5(
body,
tokenize = 'signal_tokenizer'
);
CREATE TRIGGER messages_on_update AFTER UPDATE ON messages
WHEN
(new.body IS NULL OR old.body IS NOT new.body) AND
new.isViewOnce IS NOT 1 AND new.storyId IS NULL
BEGIN
DELETE FROM messages_fts WHERE rowid = old.rowid;
INSERT INTO messages_fts
(rowid, body)
VALUES
(new.rowid, new.body);
END;
CREATE TRIGGER messages_on_insert_insert_mentions AFTER INSERT ON messages
BEGIN
INSERT INTO mentions (messageId, mentionAci, start, length)
SELECT messages.id, bodyRanges.value ->> 'mentionAci' as mentionAci,
bodyRanges.value ->> 'start' as start,
bodyRanges.value ->> 'length' as length
FROM messages, json_each(messages.json ->> 'bodyRanges') as bodyRanges
WHERE bodyRanges.value ->> 'mentionAci' IS NOT NULL
AND messages.id = new.id;
END;
CREATE TRIGGER messages_on_update_update_mentions AFTER UPDATE ON messages
BEGIN
DELETE FROM mentions WHERE messageId = new.id;
INSERT INTO mentions (messageId, mentionAci, start, length)
SELECT messages.id, bodyRanges.value ->> 'mentionAci' as mentionAci,
bodyRanges.value ->> 'start' as start,
bodyRanges.value ->> 'length' as length
FROM messages, json_each(messages.json ->> 'bodyRanges') as bodyRanges
WHERE bodyRanges.value ->> 'mentionAci' IS NOT NULL
AND messages.id = new.id;
END;
sqlite>
Finally I have the tool needed to inspect and process Signal
messages that I need, without using the vendor provided client. Now
on to transforming it to a more useful format.
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
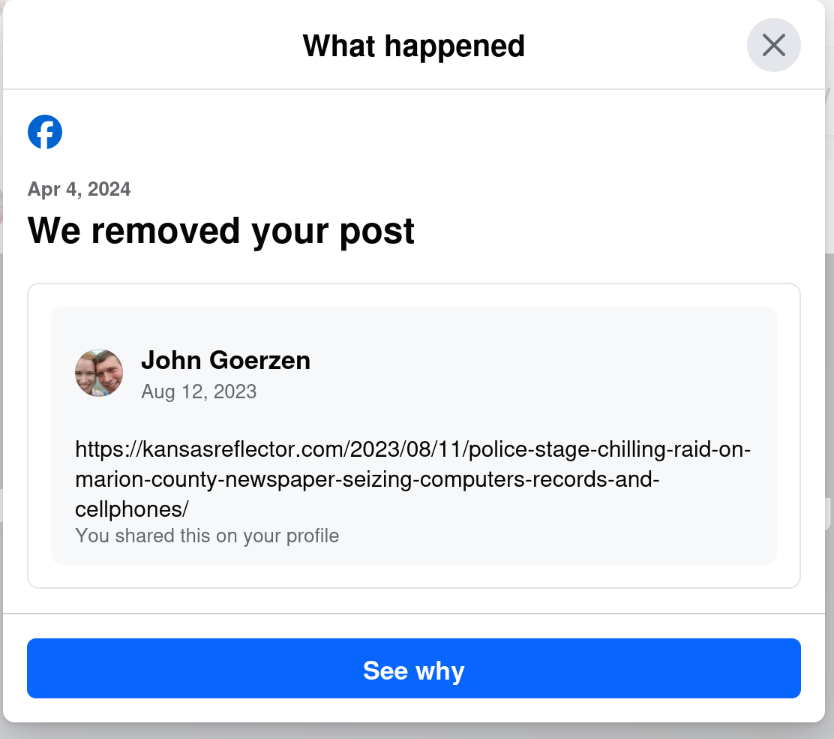 Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
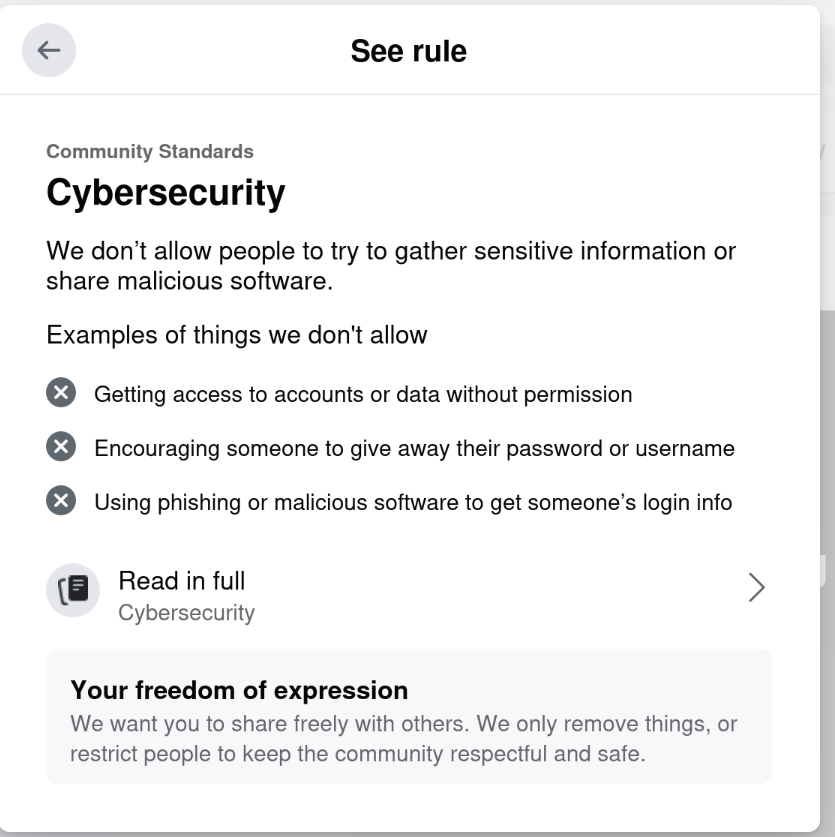 Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they
Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they 

 After making my
After making my 






















































































 Dormitory room in Zostel Ernakulam, Kochi.
Dormitory room in Zostel Ernakulam, Kochi.
 Beds in Zostel Ernakulam, Kochi.
Beds in Zostel Ernakulam, Kochi.
 Onam sadya menu from Brindhavan restaurant.
Onam sadya menu from Brindhavan restaurant.
 Sadya lined up for serving
Sadya lined up for serving
 Sadya thali served on banana leaf.
Sadya thali served on banana leaf.
 We were treated with such views during the Wayanad trip.
We were treated with such views during the Wayanad trip.
 A road in Rippon.
A road in Rippon.
 Entry to Kanthanpara Falls.
Entry to Kanthanpara Falls.
 Kanthanpara Falls.
Kanthanpara Falls.
 A view of Zostel Wayanad.
A view of Zostel Wayanad.
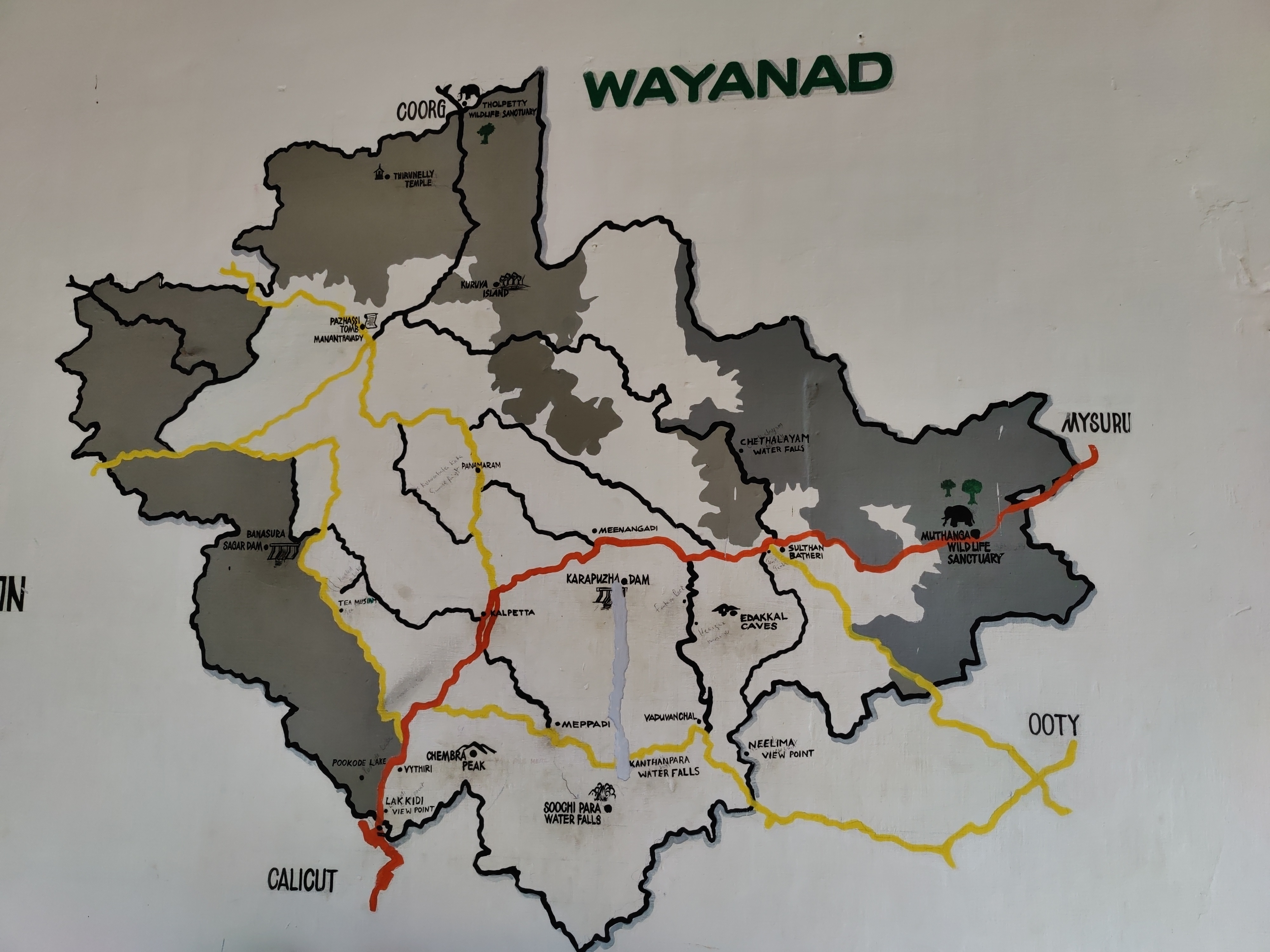 A map of Wayanad showing tourist places.
A map of Wayanad showing tourist places.
 A view from inside the Zostel Wayanad property.
A view from inside the Zostel Wayanad property.
 Terrain during trekking towards the Chembra peak.
Terrain during trekking towards the Chembra peak.
 Heart-shaped lake at the Chembra peak.
Heart-shaped lake at the Chembra peak.
 Me at the heart-shaped lake.
Me at the heart-shaped lake.
 Views from the top of the Chembra peak.
Views from the top of the Chembra peak.
 View of another peak from the heart-shaped lake.
View of another peak from the heart-shaped lake.