 My project
My project.
I m publishing my report earlier this week, because there was a lot to talk about. This week I started to make changes in the code going in the direction of what I want to do. I haven t started a final implementation, but I m studying about how what I want to do will affect the rest of the
Garbage Collection (GC). I noticed the code in
rts/sm/Sweep.c was simple and similar to what I m planning to do, so I started changing how it works.
Sweep in the
Glasgow Haskell Compiler (GHC) is done by a bitmap, which contains a bit for each word in a memory block, and is set to 1 when there s an object starting in the mapped area and 0 otherwise. When there s a block with no objects starting at it, that is, all bits of the bitmap are set to 0, the block is freed.
if (resid == 0)
freed++;
gen->n_old_blocks--;
if (prev == NULL)
gen->old_blocks = next;
else
prev->link = next;
freeGroup(bd);
The bits are analyzed in a group of
BITS_IN(W_), where
BITS_IN(W_) is the number of bits in a word.
for (i = 0; i < BLOCK_SIZE_W / BITS_IN(W_); i++)
if (bd->u.bitmap[i] != 0) resid++;
If more than of the groups are completely set to 0, the block is considered fragmented.
if (resid < (BLOCK_SIZE_W * 3) / (BITS_IN(W_) * 4))
fragd++;
bd->flags = BF_FRAGMENTED;
Immix, the GC algorithm I plan to implement in GHC, divides the blocks of memory in lines. My initial plan was to identify free lines. I decided to consider a the size of a line fixed in
BITS_IN(W_) words, because it will map to a word in the bitmap, and the code was already analyzing in groups of
BITS_IN(W_) words. This was very easy with the current code.
if (bd->u.bitmap[i] != 0) resid++;
else printf("DEBUG: line_found(%p)\n", bd->start + BITS_IN(W_) * i);
This worked, and showed some free lines. I m sure there are other ways of logging in GHC, but
printf was the simplest way I could thought of. I measured the occurrence of free lines using the
bernouilli program from
the NoFib benchmark suite, calling it with
500 +RTS -w, to make it uses sweep. In 782 calls to
GarbageCollect(),
sweep() was called 171 times, for 41704 blocks to be swept and found 230461 free lines. This gives us about 5.5 free lines per block, from the 8 lines in each block (on 64 bits systems).
The problem is that the bitmap is marked only in the start of the objects allocated, so even in a line that all bits are marked with 0 we can t assume that it s completely free, because there may be an object that starts in the previous line that is using the space of the line. Checking only for the previous line doesn t work either, because a big object can span several lines. What we can do here is a variation of conservative marking, as proposed in
the Immix paper, checking only the previous line and working only with objects smaller than a line.
To make sure I was working only with objects smaller than a line, I had to mark the blocks that contains medium objects and avoid them when seeking free lines. The block flags are defined in
includes/rts/storage/Block.h, so I included another flag in this file,
BF_MEDIUM.
/* Block contains objects evacuated during this GC */
#define BF_EVACUATED 1
/* Block is a large object */
#define BF_LARGE 2
/* Block is pinned */
#define BF_PINNED 4
/* Block is to be marked, not copied */
#define BF_MARKED 8
/* Block is free, and on the free list (TODO: is this used?) */
#define BF_FREE 16
/* Block is executable */
#define BF_EXEC 32
/* Block contains only a small amount of live data */
#define BF_FRAGMENTED 64
/* we know about this block (for finding leaks) */
#define BF_KNOWN 128
/* Block contains objects larger than a line */
#define BF_MEDIUM 256
The GHC GC is generational, there is, objects are allocated in a generation and, after a time, the ones that are still being used are moved the next generation. This idea assumes the death probability of younger objects is higher, so few objects are moved to the next generation. Sweep and Immix work only in the last generation so, to mark blocks with medium objects we have to check the size of the objects that are moved to the next generation.
This is done in the
copy_tag function of
rts/sm/Evac.c. I inserted a code that checks for the object size and marks the block when it s bigger than
BITS_IN(W_).
STATIC_INLINE GNUC_ATTR_HOT void
copy_tag(StgClosure **p, const StgInfoTable *info,
StgClosure *src, nat size, generation *gen, StgWord tag)
StgPtr to, from;
nat i;
to = alloc_for_copy(size,gen);
if(size > 8)
Bdescr(to)->flags = BF_MEDIUM;
So I updated the code in
rts/sm/Sweep.c to only inspect for free lines in blocks without BF_MEDIUM mark.
if (bd->u.bitmap[i] != 0) resid++;
else if(!(bd->flags & BF_MEDIUM))
printf("DEBUG: line_found(%p)\n", bd->start + BITS_IN(W_) * i);
This also worked. Now, in the 32012 blocks there were 189015 free lines, found in the same number of GCs, making about 5.9 free lines per block. We considered only blocks with small objects, but we didn t ignore the first line of each group of free lines. This can be achieved by checking if the previous line was also free.
if (bd->u.bitmap[i] != 0) resid++;
else if(!(bd->flags & BF_MEDIUM) && i > 0 && bd->u.bitmap[i] == 0)
printf("DEBUG: line_found(%p)\n", bd->start + BITS_IN(W_) * i);
Now, from the 32239 blocks, 165547 free lines were found, giving 5.1 free lines per block. But there are more things to improve. If the whole block is free, we want to free it, instead of marking it s lines as free. So it s better to mark the lines after we know that the blocks are not completely free. So I left the code that checks the bitmap as it was, and included a line check only for blocks that are not completely free. At this point, I also associated the fragmentation test with blocks with medium objects, because in blocks of small objects we plan to allocate in free lines, so fragmentation is not a (big) issue.
if (resid < (BLOCK_SIZE_W * 3) / (BITS_IN(W_) * 4) &&
(bd->flags & BF_MEDIUM))
fragd++;
printf("DEBUG: BF_FRAGMENTED\n");
bd->flags = BF_FRAGMENTED;
else if(!(bd->flags & BF_MEDIUM))
for(i = 1; i < BLOCK_SIZE_W / BITS_IN(W_); i++)
if(bd->u.bitmap[i] == 0 && bd->u.bitmap[i - 1] == 0)
printf("DEBUG: line_found(%p)\n", bd->start + BITS_IN(W_) * i);
The total ammount of blocks increased dramatically: the blocks that become fragmented and were not called again in sweep made a huge difference. From the 345143 blocks, 1633268 free lines were found, or about 4.7 free lines per block. 9434 blocks were free, so, from the remaining blocks, we have about 4.9 free lines per block.
Something we ll need then is a way to access these lines latter. The simplest way I thought to achieve it is constructing a list of lines, in each the first word of each free line is a pointer to the next free line, and the first word of the last free line is 0. It s useful to keep reporting the lines to stdout, so that we can then follow the list and check if we went to the same lines.
if(bd->u.bitmap[i] == 0 && bd->u.bitmap[i - 1] == 0)
StgPtr start = bd->start + BITS_IN(W_) * i;
printf("DEBUG: line_found(%p)\n", start);
if(line_first == NULL)
line_first = start;
if(line_last != NULL)
*line_last = (StgWord) start;
line_last = start;
*line_last = 0;
for(line_last = line_first; line_last; line_last = (StgPtr) *line_last)
fprintf(stderr, "DEBUG: line_found(%p)\n", line_last);
I printed the inclusion of the lines on the list to
stdout, and the walking on the list in stderr, so that it d be easy to diff. There was no difference between the lists.
There re another improvements that can be made, like using a list of groups of free lines, but I think it ll be better to think about this after studying how the allocation in the free lines will be done. That s where I m going to now.
There are some minor things I learned, and thought they worth blogging. The current GHC uses three strategies for collecting the last generation: copying, mark-compact and mark-sweep. Copying is the default until the memory reaches 30% of the maximum heap size; after that, mark-compact is used. Sweep can be chosen by a
Real Time System (RTS) flag,
-w. To use mark-compact always, the flag is
-c.
I ve been submitting small patches to the
cvs-ghc mailling list, mostly about outdated comments. Most of them were accepted, except for one which contained a lot of commentary, and that indeed was not completely correct. I corrected it and resend to the list, but the message is waiting for approval because the message header matched a filter rule. I believe this is because I replied the message generated from
darcs.
There s a very useful ghc option, specially for testing the compiler, because in this case you need to rebuild the source, even when there re no changes in it. It s
-fforce-recomp, and it makes only sense when used with
--make.







 Hello folks!
We recently received a case letting us know that Dataproc 2.1.1 was unable to write to a BigQuery table with a column of type JSON. Although the BigQuery connector for Spark has had support for JSON columns since 0.28.0, the Dataproc images on the 2.1 line still cannot create tables with JSON columns or write to existing tables with JSON columns.
The customer has graciously granted permission to share the code we developed to allow this operation. So if you are interested in working with JSON column tables on Dataproc 2.1 please continue reading!
Use the following gcloud command to create your single-node dataproc cluster:
Hello folks!
We recently received a case letting us know that Dataproc 2.1.1 was unable to write to a BigQuery table with a column of type JSON. Although the BigQuery connector for Spark has had support for JSON columns since 0.28.0, the Dataproc images on the 2.1 line still cannot create tables with JSON columns or write to existing tables with JSON columns.
The customer has graciously granted permission to share the code we developed to allow this operation. So if you are interested in working with JSON column tables on Dataproc 2.1 please continue reading!
Use the following gcloud command to create your single-node dataproc cluster:

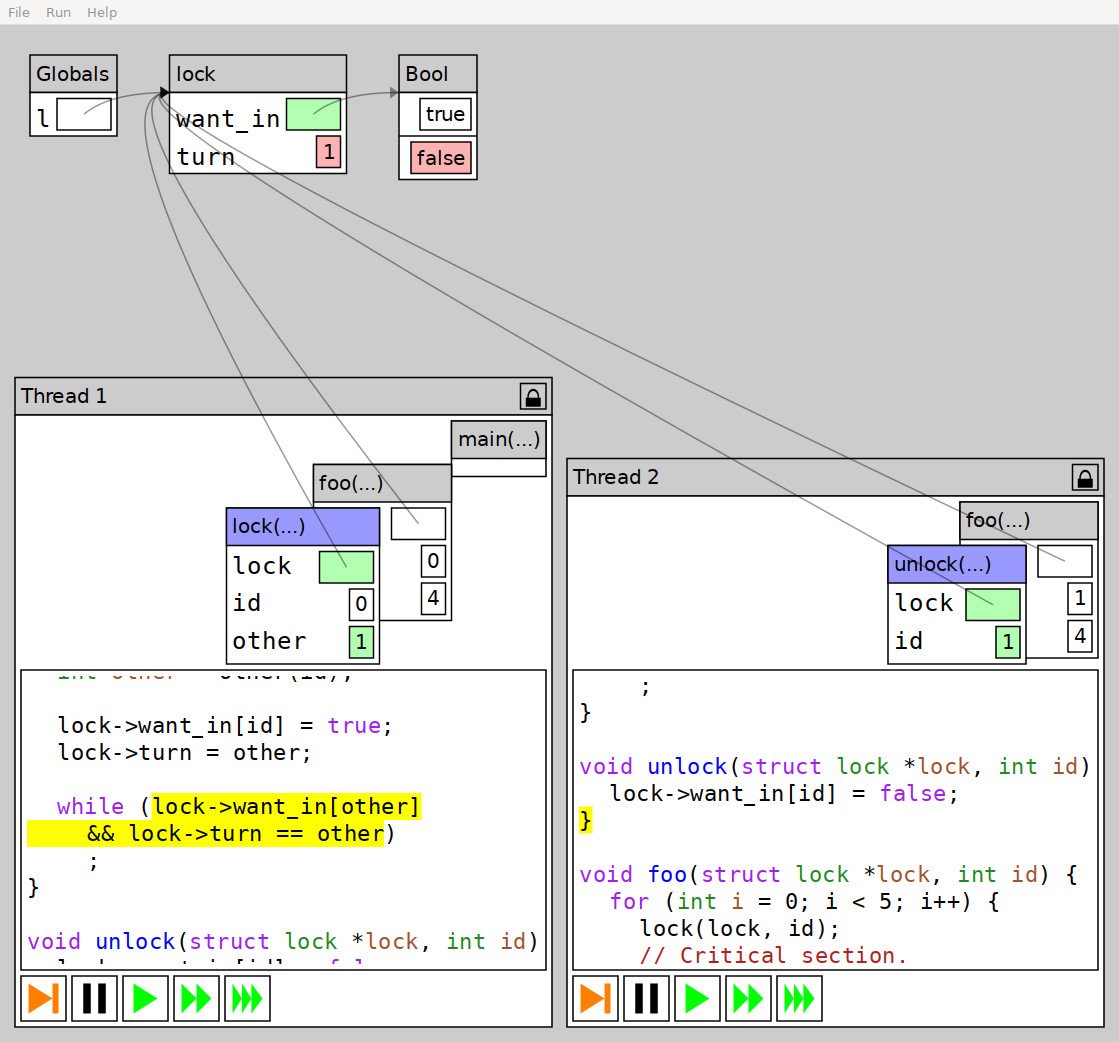
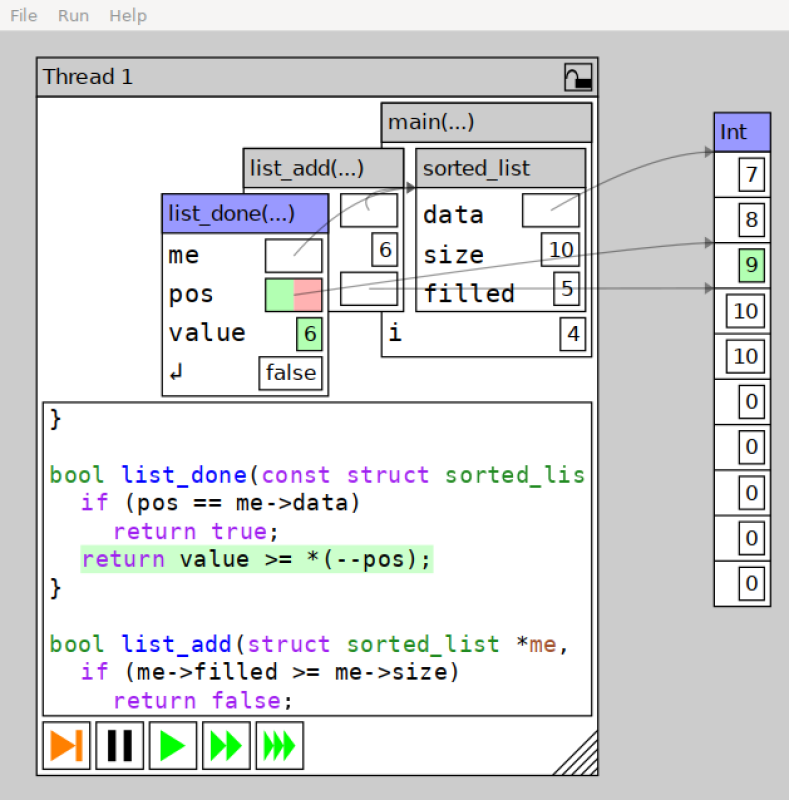
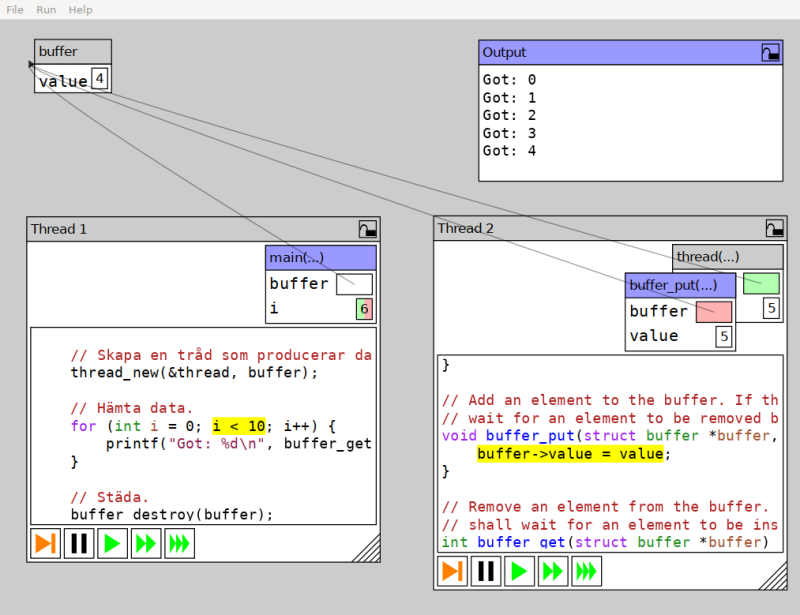
 So, what is this Storm thing? Filip promptly informed me that
Progvis is not just a pedagogical tool Or rather, that it is part
of something bigger. Progvis is a program built using
So, what is this Storm thing? Filip promptly informed me that
Progvis is not just a pedagogical tool Or rather, that it is part
of something bigger. Progvis is a program built using 

 Here s a short preview of our latest accepted paper (to appear at
Here s a short preview of our latest accepted paper (to appear at  Sometimes one stumbles upon artists by accident and immediately falls in love with them. A link to a video from
Sometimes one stumbles upon artists by accident and immediately falls in love with them. A link to a video from  I use
I use 





















 A common way to debug a network server is to use 'telnet' or 'nc' to
connect to the server and issue some commands in the protocol to verify
whether everything is working correctly. That obviously only works for
ASCII protocols (as opposed to binary protocols), and it obviously also
only works if you're not using any encryption.
But that doesn't mean you can't test an encrypted protocol in a
similar way, thanks to openssl's s_client:
A common way to debug a network server is to use 'telnet' or 'nc' to
connect to the server and issue some commands in the protocol to verify
whether everything is working correctly. That obviously only works for
ASCII protocols (as opposed to binary protocols), and it obviously also
only works if you're not using any encryption.
But that doesn't mean you can't test an encrypted protocol in a
similar way, thanks to openssl's s_client: