In this blog post, I will cover how
debputy parses its manifest and the
conceptual improvements I did to make parsing of the manifest easier.
All instructions to
debputy are provided via the
debian/debputy.manifest file and
said manifest is written in the YAML format. After the YAML parser has read the
basic file structure,
debputy does another pass over the data to extract the
information from the basic structure. As an example, the following YAML file:
manifest-version: "0.1"
installations:
- install:
source: foo
dest-dir: usr/bin
would be transformed by the YAML parser into a structure resembling:
"manifest-version": "0.1",
"installations": [
"install":
"source": "foo",
"dest-dir": "usr/bin",
]
This structure is then what
debputy does a pass on to translate this into
an even higher level format where the
"install" part is translated into
an
InstallRule.
In the original prototype of
debputy, I would hand-write functions to extract
the data that should be transformed into the internal in-memory high level format.
However, it was quite tedious. Especially because I wanted to catch every possible
error condition and report "You are missing the required field X at Y" rather
than the opaque
KeyError: X message that would have been the default.
Beyond being tedious, it was also quite error prone. As an example, in
debputy/0.1.4 I added support for the
install rule and you should allegedly
have been able to add a
dest-dir: or an
as: inside it. Except I crewed up the
code and
debputy was attempting to look up these keywords from a dict that
could never have them.
Hand-writing these parsers were so annoying that it demotivated me from making
manifest related changes to
debputy simply because I did not want to code
the parsing logic. When I got this realization, I figured I had to solve this
problem better.
While reflecting on this, I also considered that I eventually wanted plugins
to be able to add vocabulary to the manifest. If the API was "provide a
callback to extract the details of whatever the user provided here", then the
result would be bad.
- Most plugins would probably throw KeyError: X or ValueError style
errors for quite a while. Worst case, they would end on my table because
the user would have a hard time telling where debputy ends and where
the plugins starts. "Best" case, I would teach debputy to say "This
poor error message was brought to you by plugin foo. Go complain to
them". Either way, it would be a bad user experience.
- This even assumes plugin providers would actually bother writing manifest
parsing code. If it is that difficult, then just providing a custom file
in debian might tempt plugin providers and that would undermine the idea
of having the manifest be the sole input for debputy.
So beyond me being unsatisfied with the current situation, it was also clear
to me that I needed to come up with a better solution if I wanted externally
provided plugins for
debputy. To put a bit more perspective on what I
expected from the end result:
- It had to cover as many parsing errors as possible. An error case this
code would handle for you, would be an error where I could ensure it
sufficient degree of detail and context for the user.
- It should be type-safe / provide typing support such that IDEs/mypy could
help you when you work on the parsed result.
- It had to support "normalization" of the input, such as
# User provides
- install: "foo"
# Which is normalized into:
- install:
source: "foo"
4) It must be simple to tell debputy what input you expected.
At this point, I remembered that I had seen a Python (PYPI) package where
you could give it a
TypedDict and an arbitrary input (Sadly, I do not
remember the name). The package would then validate the said input against the
TypedDict. If the match was successful, you would get the result back
casted as the
TypedDict. If the match was unsuccessful, the code would
raise an error for you. Conceptually, this seemed to be a good starting
point for where I wanted to be.
Then I looked a bit on the normalization requirement (point 3).
What is really going on here is that you have two "schemas" for the input.
One is what the programmer will see (the normalized form) and the other is
what the user can input (the manifest form). The problem is providing an
automatic normalization from the user input to the simplified programmer
structure. To expand a bit on the following example:
# User provides
- install: "foo"
# Which is normalized into:
- install:
source: "foo"
Given that
install has the attributes
source,
sources,
dest-dir,
as,
into, and
when, how exactly would you automatically normalize
"foo" (str) into
source: "foo"? Even if the code filtered by "type" for these
attributes, you would end up with at least
source,
dest-dir, and
as
as candidates. Turns out that
TypedDict actually got this covered. But
the Python package was not going in this direction, so I parked it here and
started looking into doing my own.
At this point, I had a general idea of what I wanted. When defining an extension
to the manifest, the plugin would provide
debputy with one or two
definitions of
TypedDict. The first one would be the "parsed" or "target" format, which
would be the normalized form that plugin provider wanted to work on. For this
example, lets look at an earlier version of the
install-examples rule:
# Example input matching this typed dict.
#
# "source": ["foo"]
# "into": ["pkg"]
#
class InstallExamplesTargetFormat(TypedDict):
# Which source files to install (dest-dir is fixed)
sources: List[str]
# Which package(s) that should have these files installed.
into: NotRequired[List[str]]
In this form, the
install-examples has two attributes - both are list of
strings. On the flip side, what the user can input would look something like
this:
# Example input matching this typed dict.
#
# "source": "foo"
# "into": "pkg"
#
#
class InstallExamplesManifestFormat(TypedDict):
# Note that sources here is split into source (str) vs. sources (List[str])
sources: NotRequired[List[str]]
source: NotRequired[str]
# We allow the user to write into: foo in addition to into: [foo]
into: Union[str, List[str]]
FullInstallExamplesManifestFormat = Union[
InstallExamplesManifestFormat,
List[str],
str,
]
The idea was that the plugin provider would use these two definitions to tell
debputy how to parse
install-examples. Pseudo-registration code could
look something like:
def _handler(
normalized_form: InstallExamplesTargetFormat,
) -> InstallRule:
... # Do something with the normalized form and return an InstallRule.
concept_debputy_api.add_install_rule(
keyword="install-examples",
target_form=InstallExamplesTargetFormat,
manifest_form=FullInstallExamplesManifestFormat,
handler=_handler,
)
This was my conceptual target and while the current actual API ended up being slightly different,
the core concept remains the same.
From concept to basic implementation
Building this code is kind like swallowing an elephant. There was no way I would just sit down
and write it from one end to the other. So the first prototype of this did not have all the
features it has now.
Spoiler warning, these next couple of sections will contain some Python typing details.
When reading this, it might be helpful to know things such as
Union[str, List[str]] being
the Python type for either a
str (string) or a
List[str] (list of strings). If typing
makes your head spin, these sections might less interesting for you.
To build this required a lot of playing around with Python's introspection and
typing APIs. My very first draft only had one "schema" (the normalized form) and
had the following features:
- Read TypedDict.__required_attributes__ and TypedDict.__optional_attributes__ to
determine which attributes where present and which were required. This was used for
reporting errors when the input did not match.
- Read the types of the provided TypedDict, strip the Required / NotRequired
markers and use basic isinstance checks based on the resulting type for str and
List[str]. Again, used for reporting errors when the input did not match.
This prototype did not take a long (I remember it being within a day) and worked surprisingly
well though with some poor error messages here and there. Now came the first challenge,
adding the manifest format schema plus relevant normalization rules. The very first
normalization I did was transforming
into: Union[str, List[str]] into
into: List[str].
At that time,
source was not a separate attribute. Instead,
sources was a
Union[str, List[str]], so it was the only normalization I needed for all my
use-cases at the time.
There are two problems when writing a normalization. First is determining what the "source"
type is, what the target type is and how they relate. The second is providing a runtime
rule for normalizing from the manifest format into the target format. Keeping it simple,
the runtime normalizer for
Union[str, List[str]] -> List[str] was written as:
def normalize_into_list(x: Union[str, List[str]]) -> List[str]:
return x if isinstance(x, list) else [x]
This basic form basically works for all types (assuming none of the types will have
List[List[...]]).
The logic for determining when this rule is applicable is slightly more involved. My current code
is about 100 lines of Python code that would probably lose most of the casual readers.
For the interested, you are looking for _union_narrowing in declarative_parser.py
With this, when the manifest format had
Union[str, List[str]] and the target format
had
List[str] the generated parser would silently map a string into a list of strings
for the plugin provider.
But with that in place, I had covered the basics of what I needed to get started. I was
quite excited about this milestone of having my first keyword parsed without handwriting
the parser logic (at the expense of writing a more generic parse-generator framework).
Adding the first parse hint
With the basic implementation done, I looked at what to do next. As mentioned, at the time
sources in the manifest format was
Union[str, List[str]] and I considered to split
into a
source: str and a
sources: List[str] on the manifest side while keeping
the normalized form as
sources: List[str]. I ended up committing to this change and
that meant I had to solve the problem getting my parser generator to understand the
situation:
# Map from
class InstallExamplesManifestFormat(TypedDict):
# Note that sources here is split into source (str) vs. sources (List[str])
sources: NotRequired[List[str]]
source: NotRequired[str]
# We allow the user to write into: foo in addition to into: [foo]
into: Union[str, List[str]]
# ... into
class InstallExamplesTargetFormat(TypedDict):
# Which source files to install (dest-dir is fixed)
sources: List[str]
# Which package(s) that should have these files installed.
into: NotRequired[List[str]]
There are two related problems to solve here:
- How will the parser generator understand that source should be normalized
and then mapped into sources?
- Once that is solved, the parser generator has to understand that while source
and sources are declared as NotRequired, they are part of a exactly one of
rule (since sources in the target form is Required). This mainly came down
to extra book keeping and an extra layer of validation once the previous step is solved.
While working on all of this type introspection for Python, I had noted the
Annotated[X, ...]
type. It is basically a fake type that enables you to attach metadata into the type system.
A very random example:
# For all intents and purposes, foo is a string despite all the Annotated stuff.
foo: Annotated[str, "hello world"] = "my string here"
The exciting thing is that you can put arbitrary details into the type field and read it
out again in your introspection code. Which meant, I could add "parse hints" into the type.
Some "quick" prototyping later (a day or so), I got the following to work:
# Map from
#
# "source": "foo" # (or "sources": ["foo"])
# "into": "pkg"
#
class InstallExamplesManifestFormat(TypedDict):
# Note that sources here is split into source (str) vs. sources (List[str])
sources: NotRequired[List[str]]
source: NotRequired[
Annotated[
str,
DebputyParseHint.target_attribute("sources")
]
]
# We allow the user to write into: foo in addition to into: [foo]
into: Union[str, List[str]]
# ... into
#
# "source": ["foo"]
# "into": ["pkg"]
#
class InstallExamplesTargetFormat(TypedDict):
# Which source files to install (dest-dir is fixed)
sources: List[str]
# Which package(s) that should have these files installed.
into: NotRequired[List[str]]
Without me (as a plugin provider) writing a line of code, I can have
debputy rename
or "merge" attributes from the manifest form into the normalized form. Obviously, this
required me (as the
debputy maintainer) to write a lot code so other me and future
plugin providers did not have to write it.
High level typing
At this point, basic normalization between one mapping to another mapping form worked.
But one thing irked me with these install rules. The
into was a list of strings
when the parser handed them over to me. However, I needed to map them to the actual
BinaryPackage (for technical reasons). While I felt I was careful with my manual
mapping, I knew this was exactly the kind of case where a busy programmer would skip
the "is this a known package name" check and some user would typo their package
resulting in an opaque
KeyError: foo.
Side note: "Some user" was me today and I was super glad to see
debputy tell me
that I had typoed a package name (I would have been more happy if I had remembered to
use
debputy check-manifest, so I did not have to wait through the upstream part
of the build that happened before
debhelper passed control to
debputy...)
I thought adding this feature would be simple enough. It basically needs two things:
- Conversion table where the parser generator can tell that BinaryPackage requires
an input of str and a callback to map from str to BinaryPackage.
(That is probably lie. I think the conversion table came later, but honestly I do
remember and I am not digging into the git history for this one)
- At runtime, said callback needed access to the list of known packages, so it could
resolve the provided string.
It was not super difficult given the existing infrastructure, but it did take some hours
of coding and debugging. Additionally, I added a parse hint to support making the
into conditional based on whether it was a single binary package. With this done,
you could now write something like:
# Map from
class InstallExamplesManifestFormat(TypedDict):
# Note that sources here is split into source (str) vs. sources (List[str])
sources: NotRequired[List[str]]
source: NotRequired[
Annotated[
str,
DebputyParseHint.target_attribute("sources")
]
]
# We allow the user to write into: foo in addition to into: [foo]
into: Union[BinaryPackage, List[BinaryPackage]]
# ... into
class InstallExamplesTargetFormat(TypedDict):
# Which source files to install (dest-dir is fixed)
sources: List[str]
# Which package(s) that should have these files installed.
into: NotRequired[
Annotated[
List[BinaryPackage],
DebputyParseHint.required_when_multi_binary()
]
]
Code-wise, I still had to check for
into being absent and providing a default for that
case (that is still true in the current codebase - I will hopefully fix that eventually). But
I now had less room for mistakes and a standardized error message when you misspell the package
name, which was a plus.
The added side-effect - Introspection
A lovely side-effect of all the parsing logic being provided to
debputy in a declarative
form was that the generated parser snippets had fields containing all expected attributes
with their types, which attributes were required, etc. This meant that adding an
introspection feature where you can ask
debputy "What does an
install rule look like?"
was quite easy. The code base already knew all of this, so the "hard" part was resolving the
input the to concrete rule and then rendering it to the user.
I added this feature recently along with the ability to provide online documentation for
parser rules. I covered that in more details in my blog post
Providing online reference documentation for debputy
in case you are interested. :)
Wrapping it up
This was a short insight into how
debputy parses your input. With this declarative
technique:
- The parser engine handles most of the error reporting meaning users get most of the errors
in a standard format without the plugin provider having to spend any effort on it.
There will be some effort in more complex cases. But the common cases are done for you.
- It is easy to provide flexibility to users while avoiding having to write code to normalize
the user input into a simplified programmer oriented format.
- The parser handles mapping from basic types into higher forms for you. These days, we have
high level types like FileSystemMode (either an octal or a symbolic mode), different
kind of file system matches depending on whether globs should be performed, etc. These
types includes their own validation and parsing rules that debputy handles for you.
- Introspection and support for providing online reference documentation. Also, debputy
checks that the provided attribute documentation covers all the attributes in the manifest
form. If you add a new attribute, debputy will remind you if you forget to document
it as well. :)
In this way everybody wins. Yes, writing this parser generator code was more enjoyable than
writing the ad-hoc manual parsers it replaced. :)
 I am upstream and
I am upstream and  The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The Project Leader is the official representative of The Debian Project tasked with
managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last
The Debian Project Developers will shortly vote for a new Debian Project Leader
known as the DPL.
The Project Leader is the official representative of The Debian Project tasked with
managing the overall project, its vision, direction, and finances.
The DPL is also responsible for the selection of Delegates, defining areas of
responsibility within the project, the coordination of Developers, and making
decisions required for the project.
Our outgoing and present DPL Jonathan Carter served 4 terms, from 2020
through 2024. Jonathan shared his last 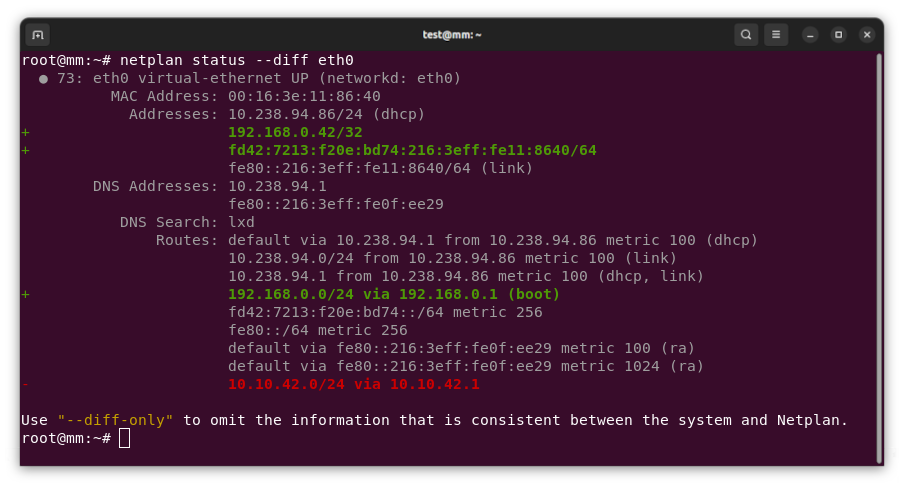
 I had reported this to Ansible a year ago (2023-02-23), but it seems this is considered expected behavior, so I am posting it here now.
TL;DR
Don't ever consume any data you got from an inventory if there is a chance somebody untrusted touched it.
Inventory plugins
I had reported this to Ansible a year ago (2023-02-23), but it seems this is considered expected behavior, so I am posting it here now.
TL;DR
Don't ever consume any data you got from an inventory if there is a chance somebody untrusted touched it.
Inventory plugins
 A short status update what happened last month. Work in progress is marked as WiP:
GNOME Calls
A short status update what happened last month. Work in progress is marked as WiP:
GNOME Calls
 If you ve perused the
If you ve perused the  Insert obligatory "not THAT data" comment here
Insert obligatory "not THAT data" comment here
 If you don't know who Professor Julius Sumner Miller is, I highly recommend
If you don't know who Professor Julius Sumner Miller is, I highly recommend  No thanks, Bender, I'm busy tonight
No thanks, Bender, I'm busy tonight



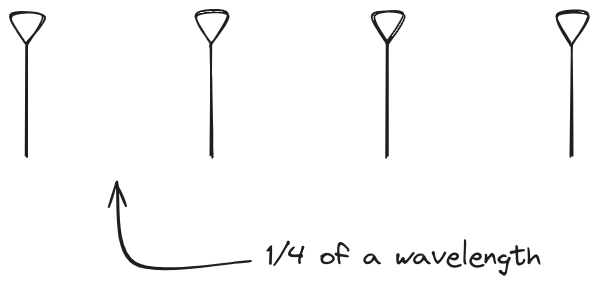 And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
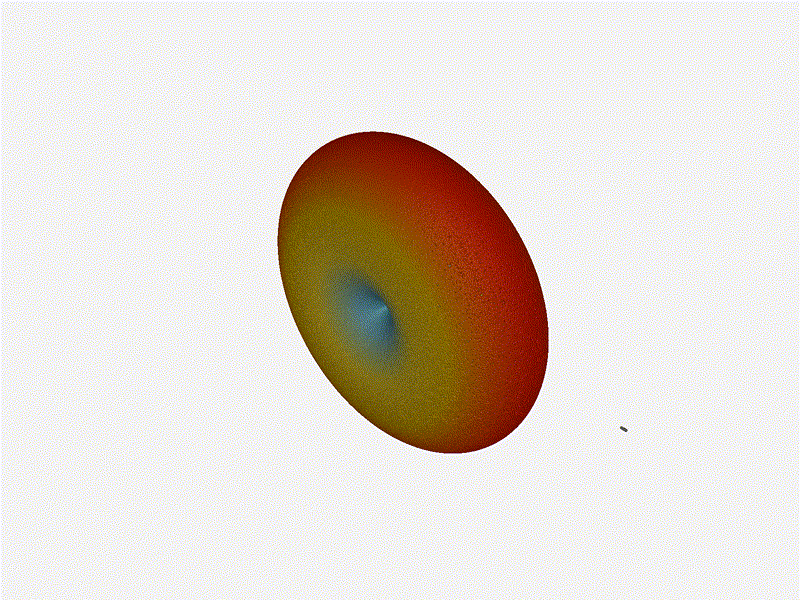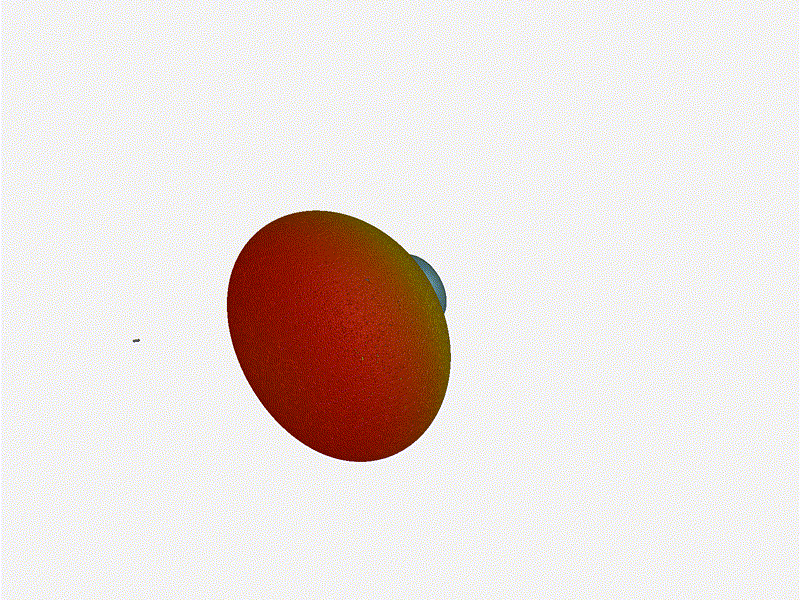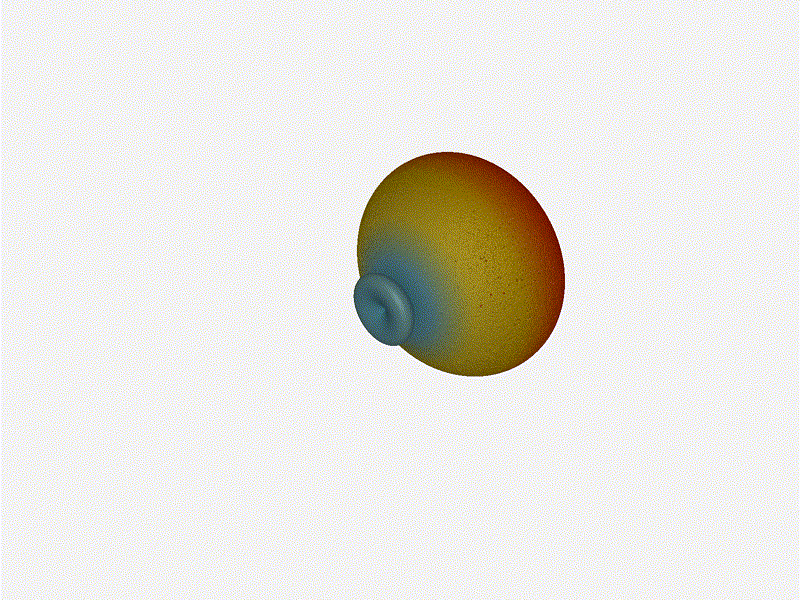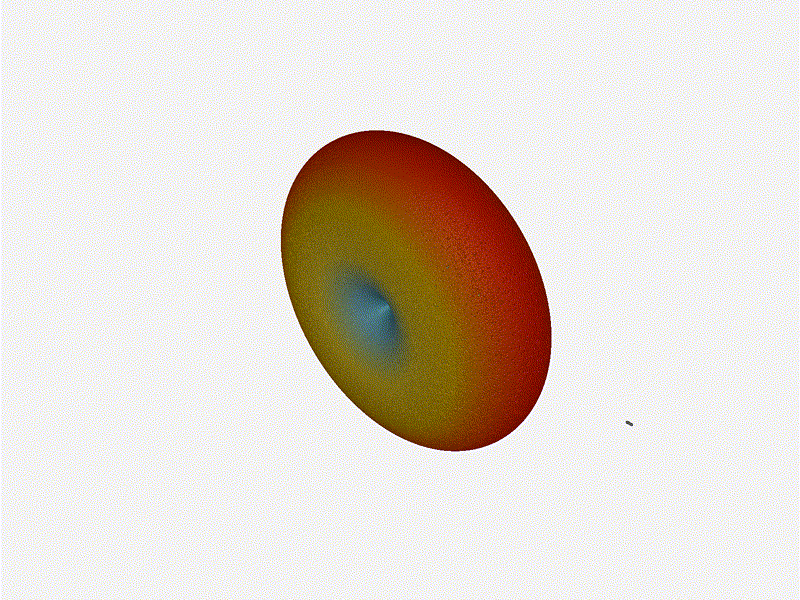
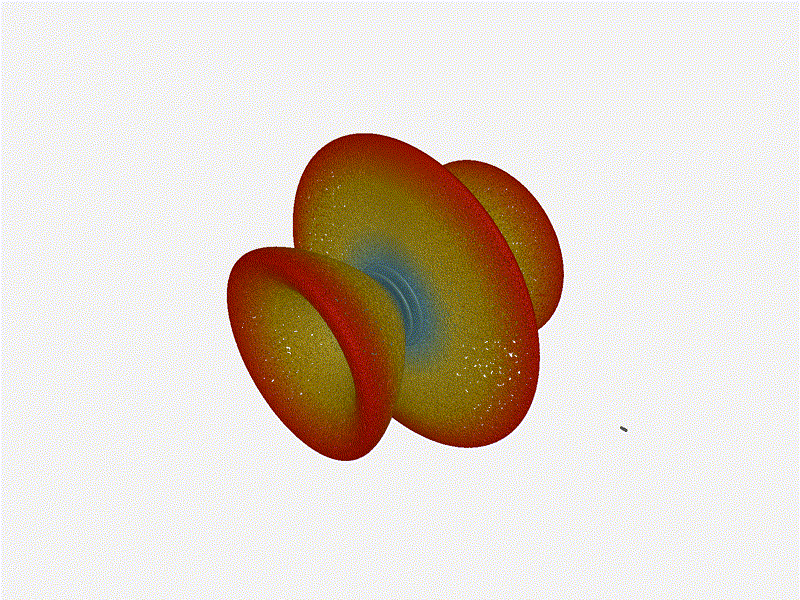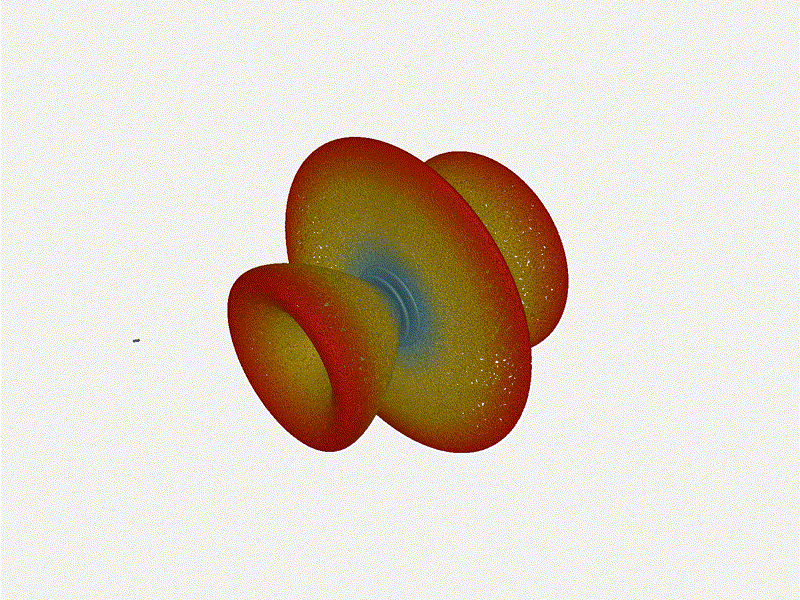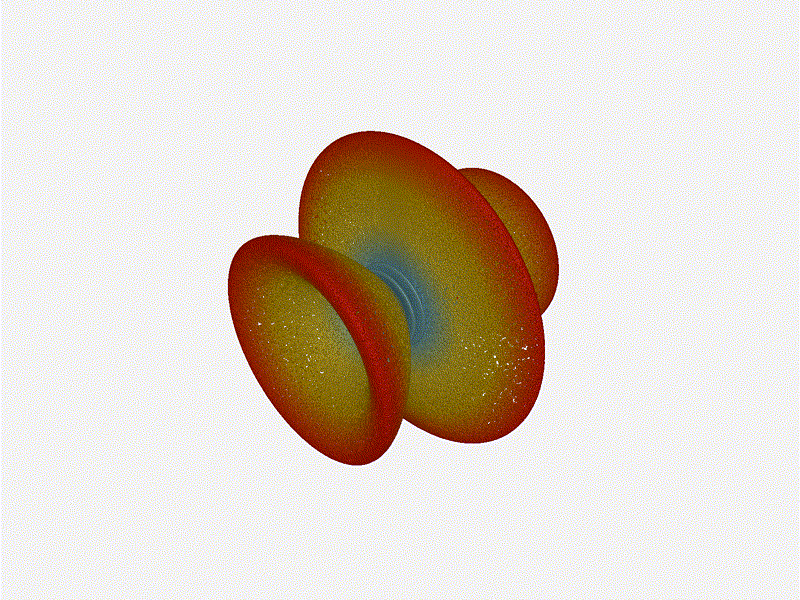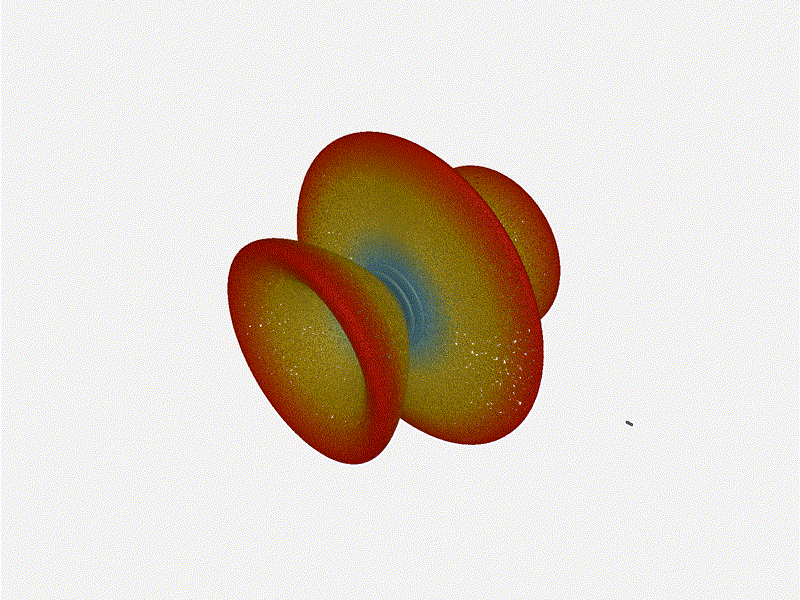

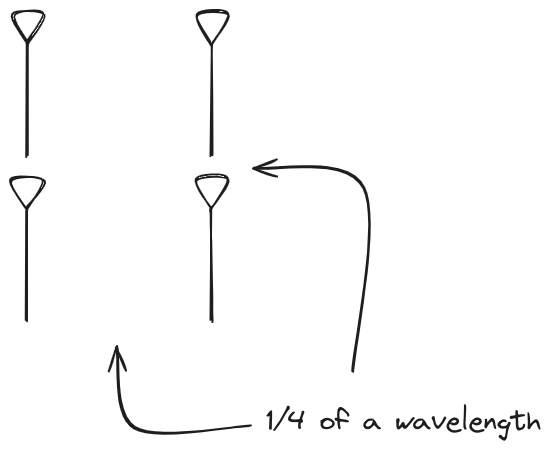 Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
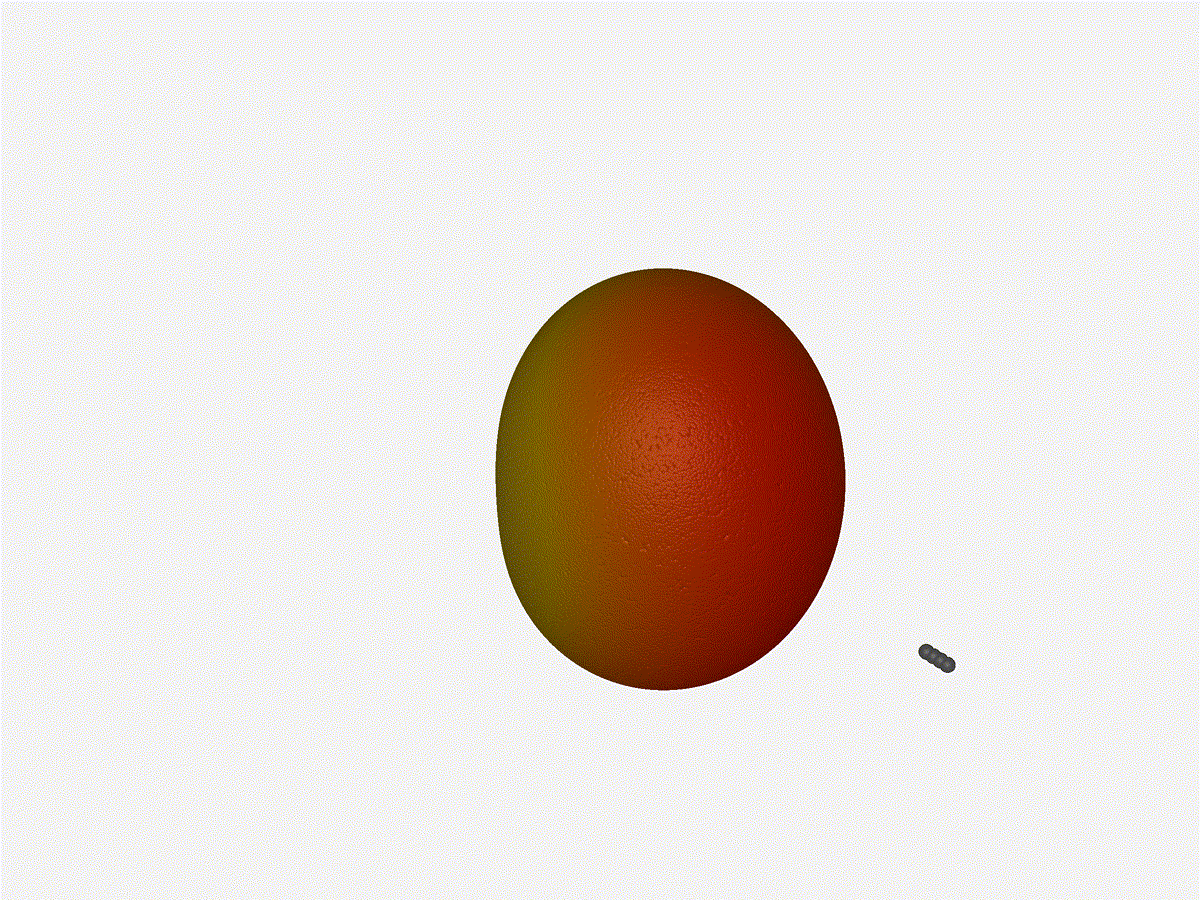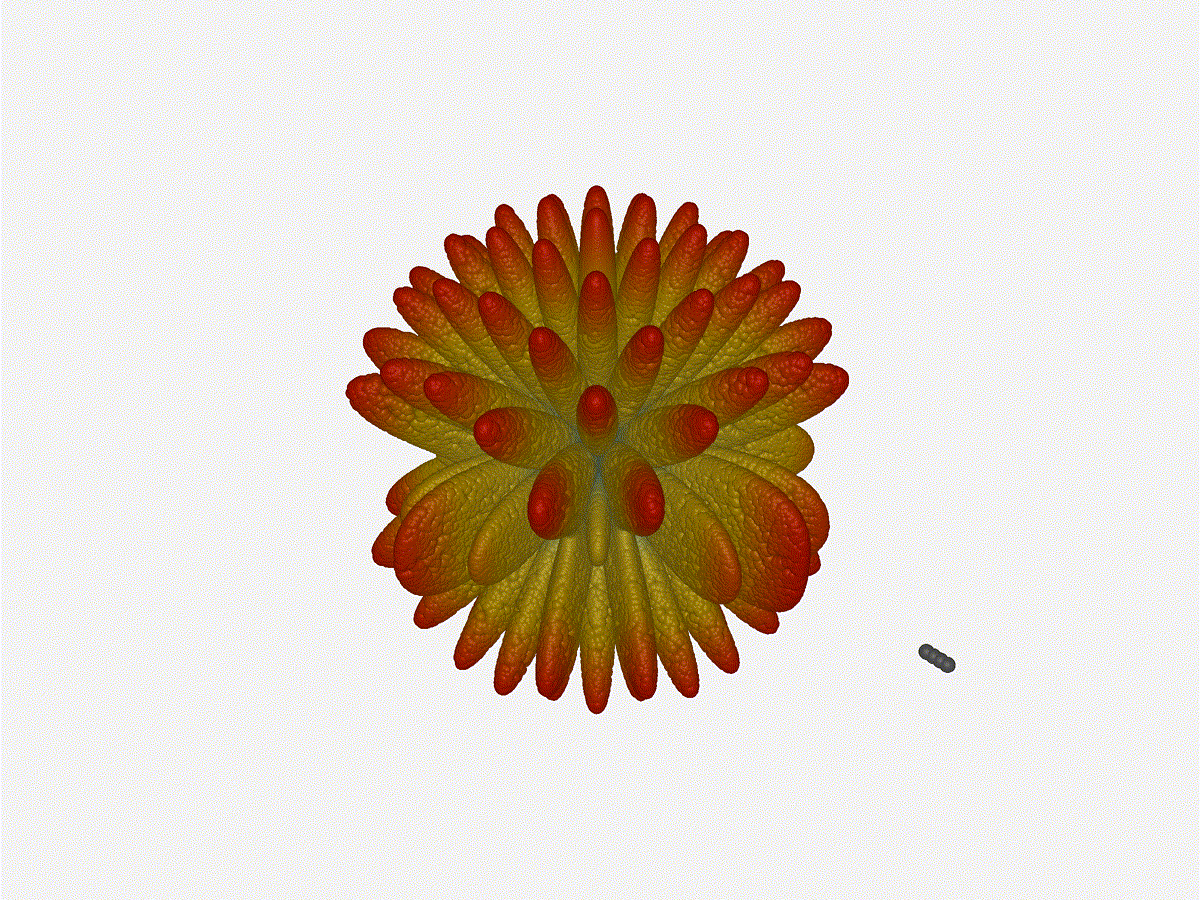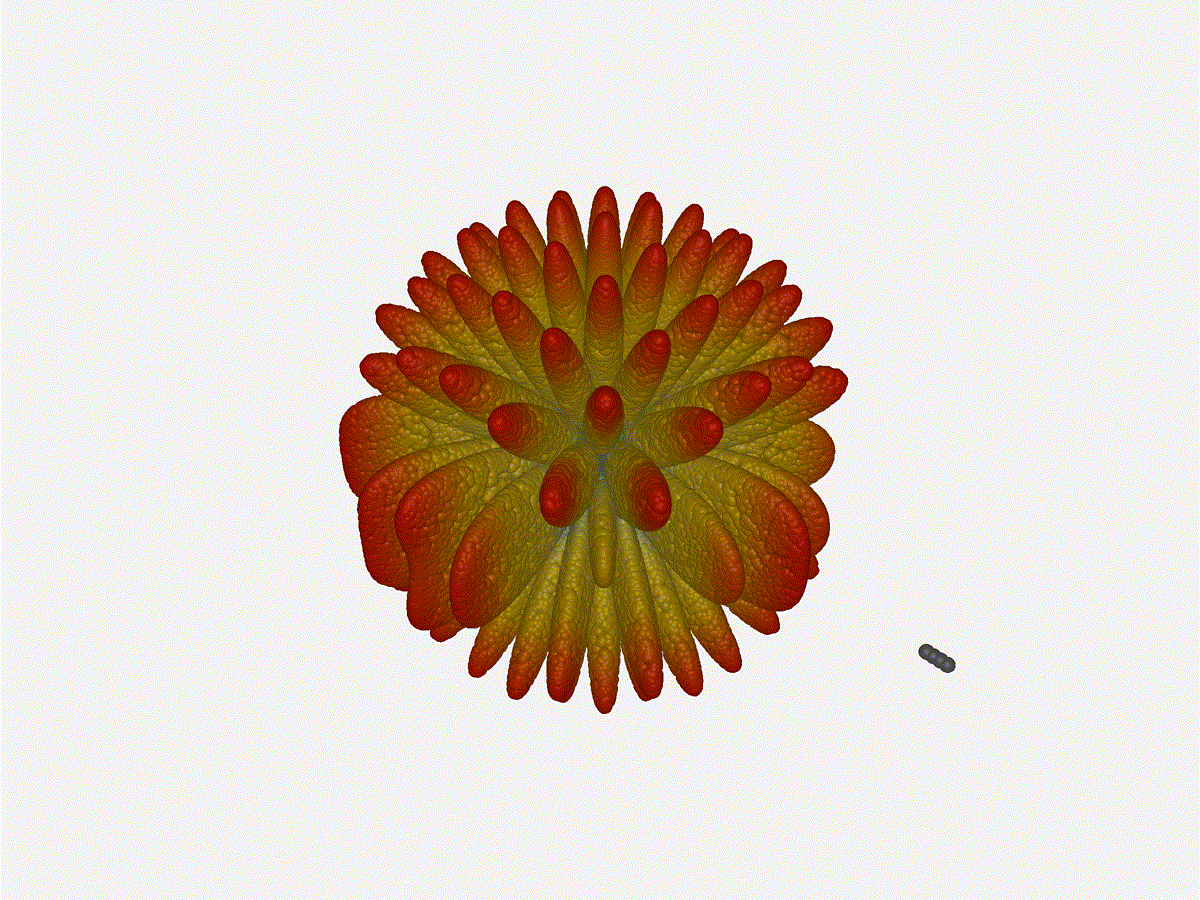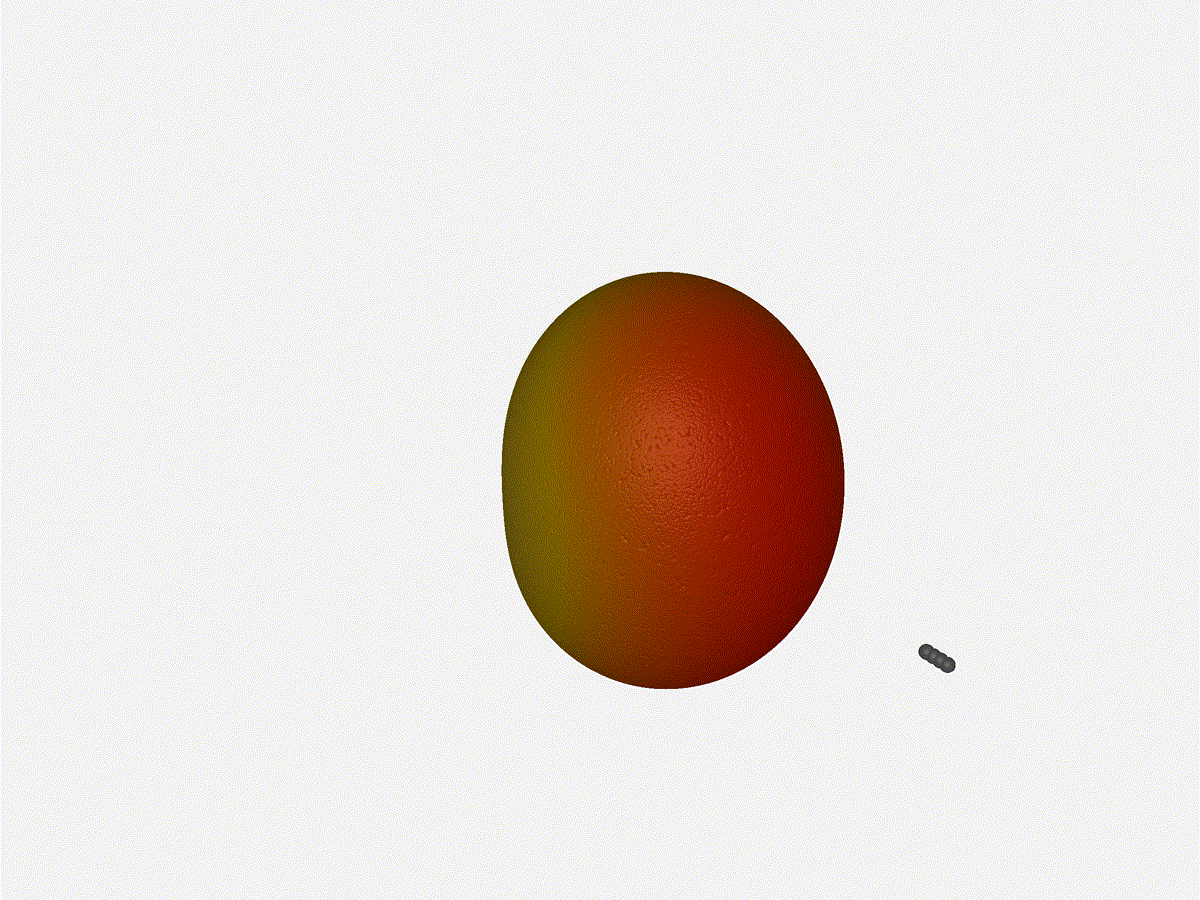
 Apparently I got an
Apparently I got an 