Version 0.0.17 of RcppSpdlog arrived
on CRAN overnight following and
has been uploaded to Debian. RcppSpdlog
bundles spdlog, a
wonderful header-only C++ logging library with all the bells and
whistles you would want that was written by Gabi Melman, and also includes fmt by Victor Zverovich. You can learn
more at the nice package
documention site.
This releases updates the code to the version 1.14 of spdlog which was release
yesterday.
The NEWS entry for this release follows.
It s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation s current status and some exciting upcoming changes.
Finances
As you may be aware, the GNOME Foundation has operated at a deficit (nonprofit speak for a loss ie spending more than we ve been raising each year) for over three years, essentially running the Foundation on reserves from some substantial donations received 4-5 years ago. The Foundation has a reserves policy which specifies a minimum amount of money we have to keep in our accounts. This is so that if there is a significant interruption to our usual income, we can preserve our core operations while we work on new funding sources. We ve now hit the buffers of this reserves policy, meaning the Board can t approve any more deficit budgets to keep spending at the same level we must increase our income.
One of the board s top priorities in hiring Holly was therefore her experience in communications and fundraising, and building broader and more diverse support for our mission and work. Her goals since joining as well as building her familiarity with the community and project have been to set up better financial controls and reporting, develop a strategic plan, and start fundraising. You may have noticed the Foundation being more cautious with spending this year, because Holly prepared a break-even budget for the Board to approve in October, so that we can steady the ship while we prepare and launch our new fundraising initiatives.
Strategy & Fundraising
The biggest prerequisite for fundraising is a clear strategy we need to explain what we re doing and why it s important, and use that to convince people to support our plans. I m very pleased to report that Holly has been working hard on this and meeting with many stakeholders across the community, and has prepared a detailed and insightful five year strategic plan. The plan defines the areas where the Foundation will prioritise, develop and fund initiatives to support and grow the GNOME project and community. The board has approved a draft version of this plan, and over the coming weeks Holly and the Foundation team will be sharing this plan and running a consultation process to gather feedback input from GNOME foundation and community members.
In parallel, Holly has been working on a fundraising plan to stabilise the Foundation, growing our revenue and ability to deliver on these plans. We will be launching a variety of fundraising activities over the coming months, including a development fund for people to directly support GNOME development, working with professional grant writers and managers to apply for government and private foundation funding opportunities, and building better communications to explain the importance of our work to corporate and individual donors.
Board Development
Another observation that Holly had since joining was that we had, by general nonprofit standards, a very small board of just 7 directors. While we do have some committees which have (very much appreciated!) volunteers from outside the board, our officers are usually appointed from within the board, and many board members end up serving on multiple committees and wearing several hats. It also means the number of perspectives on the board is limited and less representative of the diverse contributors and users that make up the GNOME community.
Holly has been working with the board and the governance committee to reduce how much we ask from individual board members, and improve representation from the community within the Foundation s governance. Firstly, the board has decided to increase its size from 7 to 9 members, effective from the upcoming elections this May & June, allowing more voices to be heard within the board discussions. After that, we re going to be working on opening up the board to more participants, creating non-voting officer seats to represent certain regions or interests from across the community, and take part in committees and board meetings. These new non-voting roles are likely to be appointed with some kind of application process, and we ll share details about these roles and how to be considered for them as we refine our plans over the coming year.
Elections
We re really excited to develop and share these plans and increase the ways that people can get involved in shaping the Foundation s strategy and how we raise and spend money to support and grow the GNOME community. This brings me to my final point, which is that we re in the run up to the annual board elections which take place in the run up to GUADEC. Because of the expansion of the board, and four directors coming to the end of their terms, we ll be electing 6 seats this election. It s really important to Holly and the board that we use this opportunity to bring some new voices to the table, leading by example in growing and better representing our community.
Allan wrote in the past about what the board does and what s expected from directors. As you can see we re working hard on reducing what we ask from each individual board member by increasing the number of directors, and bringing additional members in to committees and non-voting roles. If you re interested in seeing more diverse backgrounds and perspectives represented on the board, I would strongly encourage you consider standing for election and reach out to a board member to discuss their experience.
Thanks for reading! Until next time.
Best Wishes, Rob President, GNOME Foundation
(also posted to GNOME Discourse, please head there if you have any questions or comments)
I wrote a blog post The Shape of Computers [1] exploring ideas of how computers might evolve and how we can use them. One of the devices I mentioned was the Humane AI Pin, which has just been the recipient of one of the biggest roast reviews I ve ever seen [2], good work Marques Brownlee! As an aside I was once given a product to review which didn t work nearly as well as I think it should have worked so I sent an email to the developers saying sorry this product failed to work well so I can t say anything good about it and didn t publish a review.
One of the first things that caught my attention in the review is the note that the AI Pin doesn t connect to your phone. I think that everything should connect to everything else as a usability feature. For security we don t want so much connecting and it s quite reasonable to turn off various connections at appropriate times for security, the Librem5 is an example of how this can be done with hardware switches to disable Wifi etc. But to just not have connectivity is bad.
The next noteworthy thing is the external battery which also acts as a magnetic attachment from inside your shirt. So I guess it s using wireless charging through your shirt. A magnetically attached external battery would be a great feature for a phone, you could quickly swap a discharged battery for a fresh one and keep using it. When I tried to make the PinePhonePro my daily driver [3] I gave up and charging was one of the main reasons. One thing I learned from my experiment with the PinePhonePro is that the ratio of charge time to discharge time is sometimes more important than battery life and being able to quickly swap batteries without rebooting is a way of solving that. The reviewer of the AI Pin complains later in the video about battery life which seems to be partly due to wireless charging from the detachable battery and partly due to being physically small. It seems the phablet form factor is the smallest viable personal computer at this time.
The review glosses over what could be the regarded as the 2 worst issues of the device. It does everything via the cloud (where the cloud means a computer owned by someone I probably shouldn t trust ) and it records everything. Strange that it s not getting the hate the Google Glass got.
The user interface based on laser projection of menus on the palm of your hand is an interesting concept. I d rather have a Bluetooth attached tablet or something for operations that can t be conveniently done with voice. The reviewer harshly criticises the laser projection interface later in the video, maybe technology isn t yet adequate to implement this properly.
The first criticism of the device in the review part of the video is of the time taken to answer questions, especially when Internet connectivity is poor. His question who designed the Washington Monument took 8 seconds to start answering it in his demonstration. I asked the Alpaca LLM the same question running on 4 cores of a E5-2696 and it took 10 seconds to start answering and then printed the words at about speaking speed. So if we had a free software based AI device for this purpose it shouldn t be difficult to get local LLM computation with less delay than the Humane device by simply providing more compute power than 4 cores of a E5-2696v3. How does a 32 core 1.05GHz Mali G72 from 2017 (as used in the Galaxy Note 9) compare to 4 cores of a 2.3GHz Intel CPU from 2015? Passmark says that Intel CPU can do 48GFlop with all 18 cores so 4 cores can presumably do about 10GFlop which seems less than the claimed 20-32GFlop of the Mali G72. It seems that with the right software even older Android phones could give adequate performance for a local LLM. The Alpaca model I m testing with takes 4.2G of RAM to run which is usable in a Note 9 with 8G of RAM or a Pixel 8 Pro with 12G. A Pixel 8 Pro could have 4.2G of RAM reserved for a LLM and still have as much RAM for other purposes as my main laptop as of a few months ago. I consider the speed of Alpaca on my workstation to be acceptable but not great. If we can get FOSS phones running a LLM at that speed then I think it would be great for a first version we can always rely on newer and faster hardware becoming available.
Marques notes that the cause of some of the problems is likely due to a desire to make it a separate powerful product in the future and that if they gave it phone connectivity in the start they would have to remove that later on. I think that the real problem is that the profit motive is incompatible with good design. They want to have a product that s stand-alone and justifies the purchase price plus subscription and that means not making it a phone accessory . While I think that the best thing for the user is to allow it to talk to a phone, a PC, a car, and anything else the user wants. He compares it to the Apple Vision Pro which has the same issue of trying to be a stand-alone computer but not being properly capable of it.
One of the benefits that Marques cites for the AI Pin is the ability to capture voice notes. Dictaphones have been around for over 100 years and very few people have bought them, not even in the 80s when they became cheap. While almost everyone can occasionally benefit from being able to make a note of an idea when it s not convenient to write it down there are few people who need it enough to carry a separate device, not even if that device is tiny. But a phone as a general purpose computing device with microphone can easily be adapted to such things. One possibility would be to program a phone to start a voice note when the volume up and down buttons are pressed at the same time or when some other condition is met. Another possibility is to have a phone have a hotkey function that varies by what you are doing, EG if bushwalking have the hotkey be to take a photo or if on a flight have it be taking a voice note. On the Mobile Apps page on the Debian wiki I created a section for categories of apps that I think we need [4]. In that section I added the following list:
Voice input for dictation
Voice assistant like Google/Apple
Voice output
Full operation for visually impaired people
One thing I really like about the AI Pin is that it has the potential to become a really good computing and personal assistant device for visually impaired people funded by people with full vision who want to legally control a computer while driving etc. I have some concerns about the potential uses of the AI Pin while driving (as Marques stated an aim to do), but if it replaces the use of regular phones while driving it will make things less bad.
Marques concludes his video by warning against buying a product based on the promise of what it can be in future. I bought the Librem5 on exactly that promise, the difference is that I have the source and the ability to help make the promise come true. My aim is to spend thousands of dollars on test hardware and thousands of hours of development time to help make FOSS phones a product that most people can use at low price with little effort.
Another interesting review of the pin is by Mrwhostheboss [5], one of his examples is of asking the pin for advice about a chair but without him knowing the pin selected a different chair in the room. He compares this to using Google s apps on a phone and seeing which item the app has selected. He also said that he doesn t want to make an order based on speech he wants to review a page of information about it. I suspect that the design of the pin had too much input from people accustomed to asking a corporate travel office to find them a flight and not enough from people who look through the details of the results of flight booking services trying to save an extra $20. Some people might say if you need to save $20 on a flight then a $24/month subscription computing service isn t for you , I reject that argument. I can afford lots of computing services because I try to get the best deal on every moderately expensive thing I pay for. Another point that Mrwhostheboss makes is regarding secret SMS, you probably wouldn t want to speak a SMS you are sending to your SO while waiting for a train. He makes it clear that changing between phone and pin while sharing resources (IE not having a separate phone number and separate data store) is a desired feature.
The most insightful point Mrwhostheboss made was when he suggested that if the pin had come out before the smartphone then things might have all gone differently, but now anything that s developed has to be based around the expectations of phone use. This is something we need to keep in mind when developing FOSS software, there s lots of different ways that things could be done but we need to meet the expectations of users if we want our software to be used by many people.
I previously wrote a blog post titled Considering Convergence [6] about the possible ways of using a phone as a laptop. While I still believe what I wrote there I m now considering the possibility of ease of movement of work in progress as a way of addressing some of the same issues. I ve written a blog post about Convergence vs Transferrence [7].
I previously wrote a blog post titled Considering Convergence [1] about the possible ways of using a phone as a laptop. While I still believe what I wrote there I m now considering the possibility of ease of movement of work in progress as a way of addressing some of the same issues.
Currently the expected use is that if you have web pages open on Chrome on Android it s possible to instruct Chrome on the desktop to open the same page if both instances of Chrome are signed in to the same GMail account. It s also possible to view the Chrome history with CTRL-H, select tabs from other devices and load things that were loaded on other devices some time ago. This is very minimal support for moving work between devices and I think we can do better.
Firstly for web browsing the Chrome functionality is barely adequate. It requires having a heavyweight login process on all browsers that includes sharing stored passwords etc which isn t desirable. There are many cases where moving work is desired without sharing such things, one example is using a personal device to research something for work. Also the Chrome method of sending web pages is slow and unreliable and the viewing history method gets all closed tabs when the common case is get the currently open tabs from one browser window without wanting the dozens of web pages that turned out not to be interesting and were closed. This could be done with browser plugins to allow functionality similar to KDE Connect for sending tabs and also the option of emailing a list of URLs or a JSON file that could be processed by a browser plugin on the receiving end. I can send email between my home and work addresses faster than the Chrome share to another device function can send a URL.
For documents we need a way of transferring files. One possibility is to go the Chromebook route and have it all stored on the web. This means that you rely on a web based document editing system and the FOSS versions are difficult to manage. Using Google Docs or Sharepoint for everything is not something I consider an acceptable option. Also for laptop use being able to run without Internet access is a good thing.
There are a range of distributed filesystems that have been used for various purposes. I don t think any of them cater to the use case of having a phone/laptop and a desktop PC (or maybe multiple PCs) using the same files.
For a technical user it would be an option to have a script that connects to a peer system (IE another computer with the same accounts and access control decisions) and rsync a directory of working files and the shell history, and then opens a shell with the HISTFILE variable, current directory, and optionally some user environment variables set to match. But this wouldn t be the most convenient thing even for technical users.
For programs that are integrated into the desktop environment it s possible for them to be restarted on login if they were active when the user logged out. The session tracking for that has about 1/4 the functionality needed for requesting a list of open files from the application, closing the application, transferring the files, and opening it somewhere else. I think that this would be a good feature to add to the XDG setup.
The model of having programs and data attached to one computer or one network server that terminals of some sort connect to worked well when computers were big and expensive. But computers continue to get smaller and cheaper so we need to think of a document based use of computers to allow things to be easily transferred as convenient. With convenience being important so the hacks of rsync scripts that can work for technical users won t work for most people.
A new minor release 0.4.22 of RQuantLib
arrived at CRAN earlier today,
and has been uploaded to Debian.
QuantLib is a rather
comprehensice free/open-source library for quantitative
finance. RQuantLib
connects (some parts of) it to the R environment and language, and has
been part of CRAN for more than
twenty years (!!) as it was one of the first packages I uploaded
there.
This release of RQuantLib
updates to QuantLib version 1.34
which was just released yesterday, and deprecates use of an access point
/ type for price/yield conversion for bonds. We also made two minor
earlier changes.
Changes in RQuantLib version 0.4.22 (2024-04-25)
Small code cleanup removing duplicate R code
Small improvements to C++ compilation flags
Robustify internal version comparison to accommodate RC
releases
Nine days ago, I started migrating orphaned Debian packages with no
version control system listed in debian/control of the source to git.
At the time there were 438 such packages. Now there are 391,
according to the UDD. In reality it is slightly less, as there is a
delay between uploads and UDD updates. In the nine days since, I have
thus been able to work my way through ten percent of the packages. I
am starting to run out of steam, and hope someone else will also help
brushing some dust of these packages. Here is a recipe how to do it.
I start by picking a random package by querying the UDD for a list of
10 random packages from the set of remaining packages:
PGPASSWORD="udd-mirror" psql --port=5432 --host=udd-mirror.debian.net \
--username=udd-mirror udd -c "select source from sources \
where release = 'sid' and (vcs_url ilike '%anonscm.debian.org%' \
OR vcs_browser ilike '%anonscm.debian.org%' or vcs_url IS NULL \
OR vcs_browser IS NULL) AND maintainer ilike '%packages@qa.debian.org%' \
order by random() limit 10;"
Next, I visit http://salsa.debian.org/debian and search for the
package name, to ensure no git repository already exist. If it does,
I clone it and try to get it to an uploadable state, and add the Vcs-*
entries in d/control to make the repository more widely known. These
packages are a minority, so I will not cover that use case here.
For packages without an existing git repository, I run the
following script debian-snap-to-salsa to prepare a git
repository with the existing packaging.
#!/bin/sh
#
# See also https://bugs.debian.org/804722#31
set -e
# Move to this Standards-Version.
SV_LATEST=4.7.0
PKG="$1"
if [ -z "$PKG" ]; then
echo "usage: $0 "
exit 1
fi
if [ -e "$ PKG -salsa" ]; then
echo "error: $ PKG -salsa already exist, aborting."
exit 1
fi
if [ -z "ALLOWFAILURE" ] ; then
ALLOWFAILURE=false
fi
# Fetch every snapshotted source package. Manually loop until all
# transfers succeed, as 'gbp import-dscs --debsnap' do not fail on
# download failures.
until debsnap --force -v $PKG $ALLOWFAILURE ; do sleep 1; done
mkdir $ PKG -salsa; cd $ PKG -salsa
git init
# Specify branches to override any debian/gbp.conf file present in the
# source package.
gbp import-dscs --debian-branch=master --upstream-branch=upstream \
--pristine-tar ../source-$PKG/*.dsc
# Add Vcs pointing to Salsa Debian project (must be manually created
# and pushed to).
if ! grep -q ^Vcs- debian/control ; then
awk "BEGIN s=1 /^\$/ if (s==1) print \"Vcs-Browser: https://salsa.debian.org/debian/$PKG\"; print \"Vcs-Git: https://salsa.debian.org/debian/$PKG.git\" ; s=0 print " < debian/control > debian/control.new && mv debian/control.new debian/control
git commit -m "Updated vcs in d/control to Salsa." debian/control
fi
# Tell gbp to enforce the use of pristine-tar.
inifile +inifile debian/gbp.conf +create +section DEFAULT +key pristine-tar +value True
git add debian/gbp.conf
git commit -m "Added d/gbp.conf to enforce the use of pristine-tar." debian/gbp.conf
# Update to latest Standards-Version.
SV="$(grep ^Standards-Version: debian/control awk ' print $2 ')"
if [ $SV_LATEST != $SV ]; then
sed -i "s/\(Standards-Version: \)\(.*\)/\1$SV_LATEST/" debian/control
git commit -m "Updated Standards-Version from $SV to $SV_LATEST." debian/control
fi
if grep -q pkg-config debian/control; then
sed -i s/pkg-config/pkgconf/ debian/control
git commit -m "Replaced obsolete pkg-config build dependency with pkgconf." debian/control
fi
if grep -q libncurses5-dev debian/control; then
sed -i s/libncurses5-dev/libncurses-dev/ debian/control
git commit -m "Replaced obsolete libncurses5-dev build dependency with libncurses-dev." debian/control
fi
Some times the debsnap script fail to download some of the versions.
In those cases I investigate, and if I decide the failing versions
will not be missed, I call it using ALLOWFAILURE=true to ignore the
problem and create the git repository anyway.
With the git repository in place, I do a test build (gbp
buildpackage) to ensure the build is actually working. If it does not
I pick a different package, or if the build failure is trivial to fix,
I fix it before continuing. At this stage I revisit
http://salsa.debian.org/debian and create the project under this group
for the package. I then follow the instructions to publish the local
git repository. Here is from a recent example:
With a working build, I have a look at the build rules if I want to
remove some more dust. I normally try to move to debhelper compat
level 13, which involves removing debian/compat and modifying
debian/control to build depend on debhelper-compat (=13). I also test
with 'Rules-Requires-Root: no' in debian/control and verify in
debian/rules that hardening is enabled, and include all of these if
the package still build. If it fail to build with level 13, I try
with 12, 11, 10 and so on until I find a level where it build, as I do
not want to spend a lot of time fixing build issues.
Some times, when I feel inspired, I make sure debian/copyright is
converted to the machine readable format, often by starting with
'debhelper -cc' and then cleaning up the autogenerated content until
it matches realities. If I feel like it, I might also clean up
non-dh-based debian/rules files to use the short style dh build
rules.
Once I have removed all the dust I care to process for the package,
I run 'gbp dch' to generate a debian/changelog entry based on the
commits done so far, run 'dch -r' to switch from 'UNRELEASED' to
'unstable' and get an editor to make sure the 'QA upload' marker is in
place and that all long commit descriptions are wrapped into sensible
lengths, run 'debcommit --release -a' to commit and tag the new
debian/changelog entry, run 'debuild -S' to build a source only
package, and 'dput ../perl-byacc_2.0-10_source.changes' to do the
upload. During the entire process, and many times per step, I run
'debuild' to verify the changes done still work. I also some times
verify the set of built files using 'find debian' to see if I can spot
any problems (like no file in usr/bin any more or empty package). I
also try to fix all lintian issues reported at the end of each
'debuild' run.
If I find Debian specific patches, I try to ensure their metadata
is fairly up to date and some times I even try to reach out to
upstream, to make the upstream project aware of the patches. Most of
my emails bounce, so the success rate is low. For projects with no
Homepage entry in debian/control I try to track down one, and for
packages with no debian/watch file I try to create one. But at least
for some of the packages I have been unable to find a functioning
upstream, and must skip both of these.
If I could handle ten percent in nine days, twenty people could
complete the rest in less then five days. I use approximately twenty
minutes per package, when I have twenty minutes spare time to spend.
Perhaps you got twenty minutes to spare too?
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
With local recursive DNS and a 5G modem in place the next thing was to work on some sort of automatic failover when the primary FTTP connection failed. My wife works from home too and I sometimes travel so I wanted to make sure things didn t require me to be around to kick them into switch the link in use.
First, let s talk about what I didn t do. One choice to try and ensure as seamless a failover as possible would be to get a VM somewhere out there. I d then run Wireguard tunnels over both the FTTP + 5G links to the VM, and run some sort of routing protocol (RIP, OSPF?) over the links. Set preferences such that the FTTP is preferred, NAT v4 to the VM IP, and choose somewhere that gave me a v6 range I could just use directly.
This has the advantage that I m actively checking link quality to the outside work, rather than just to the next hop. It also means, if the failover detection is fast enough, that existing sessions stay up rather than needing re-established.
The downsides are increased complexity, adding another point of potential failure (the VM + provider), the impact on connection quality (even with a decent endpoint it s an extra hop and latency), and finally the increased cost involved.
I can cope with having to reconnect my SSH sessions in the event of a failure, and I d rather be sure I can make full use of the FTTP connection, so I didn t go this route. I chose to rely on local link failure detection to provide the signal for failover, and a set of policy routing on top of that to make things a bit more seamless.
Local link failure turns out to be fairly easy. My FTTP is a PPPoE configuration, so in /etc/ppp/peers/aquiss I have:
Which gives me a failover of ~ 5s if the link goes down.
I m operating the 5G modem in bridge rather than router mode, which means I get the actual IP from the 5G network via DHCP. The DHCP lease the modem hands out is under a minute, and in the event of a network failure it only hands out a 192.168.254.x IP to talk to its web interface. As the 5G modem is the last resort path I choose not to do anything special with this, but the information is at least there if I need it.
To allow both interfaces to be up and the FTTP to be preferred I m simply using route metrics. For the PPP configuration that s:
There s a wrinkle in that pppd will not replace an existing default route, so I ve created /etc/ppp/ip-up.d/default-route to ensure it s added:
#!/bin/bash
[ "$PPP_IFACE" = "pppoe-wan" ] exit 0
# Ensure we add a default route; pppd will not do so if we have
# a lower pref route out the 5G modem
ip route add default dev pppoe-wan metric 100 true
Additionally, in /etc/dhcp/dhclient.conf I ve disabled asking for any server details (DNS, NTP, etc) - I have internal setups for the servers I want, and don t want to be trying to select things over the 5G link by default.
However, what I do want is to be able to access the 5G modem web interface and explicitly route some traffic out that link (e.g. so I can add it to my smokeping tests). For that I need some source based routing.
First step, add a 5g table to /etc/iproute2/rt_tables:
16 5g
Then I ended up with the following in /etc/dhcp/dhclient-exit-hooks.d/modem-interface-route, which is more complex than I d like but seems to do what I want:
#!/bin/sh
case "$reason" in
BOUND RENEW REBIND REBOOT)
# Check if we've actually changed IP address
if [ -z "$old_ip_address" ]
[ "$old_ip_address" != "$new_ip_address" ]
[ "$reason" = "BOUND" ] [ "$reason" = "REBOOT" ]; then
if [ ! -z "$old_ip_address" ]; then
ip rule del from $old_ip_address lookup 5g
fi
ip rule add from $new_ip_address lookup 5g
ip route add default dev sfp.31 table 5g true
ip route add 192.168.254.1 dev sfp.31 2>/dev/null true
fi
;;
EXPIRE)
if [ ! -z "$old_ip_address" ]; then
ip rule del from $old_ip_address lookup 5g
fi
;;
*)
;;
esac
What does all that aim to do? We want to ensure traffic directed to the 5G WAN address goes out the 5G modem, so I can SSH into it even when the main link is up. So we add a rule directing traffic from that IP to hit the 5g routing table, and a default route in that table which uses the 5G link. There s no configuration for the FTTP connection in that table, so if the 5G link is down the traffic gets dropped, which is what we want. We also configure 192.168.254.1 to go out the link to the modem, as that s where the web interface lives.
I also have a curl callout (curl --interface sfp.31 to ensure it goes out the 5G link) after the routes are configured to set dynamic DNS with Mythic Beasts, which helps with knowing where to connect back to. I seem to see IP address changes on the 5G link every couple of days at least.
Additionally, I have an entry in the interfaces configuration carving out the top set of the netblock my smokeping server is in:
up ip rule add from 192.0.2.224/27 lookup 5g
My smokeping /etc/smokeping/config.d/Probes file then looks like:
which allows me to use probe = FPing5G for targets to test them over the 5G link.
That mostly covers the functionality I want for a backup link. There s one piece that isn t quite solved, however, IPv6, which can wait for another post.
I've been enjoying Biosphere as the soundtrack to my recent "concentrated work" spells.
Knives by Biosphere
I remember seeing their name on playlists of yester-year:
axioms, bluemars1, and (still
a going concern) soma.fm's drone
zone.
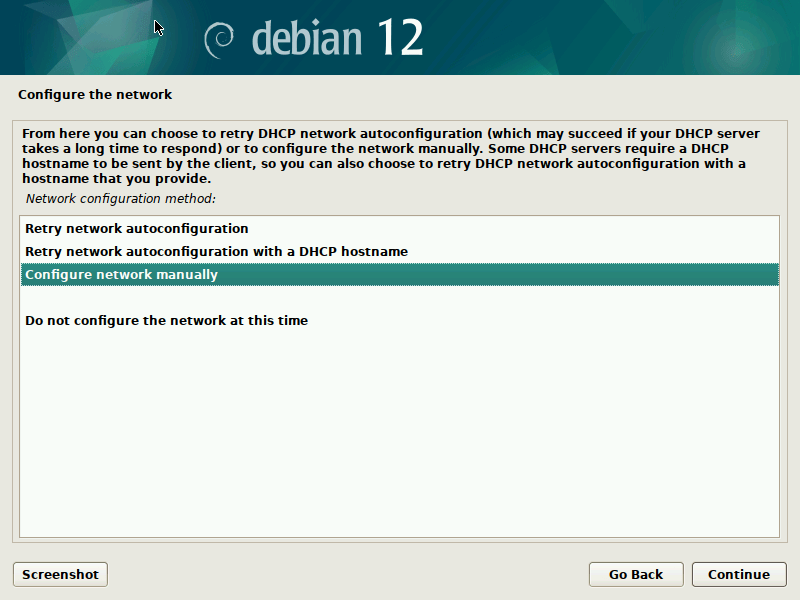
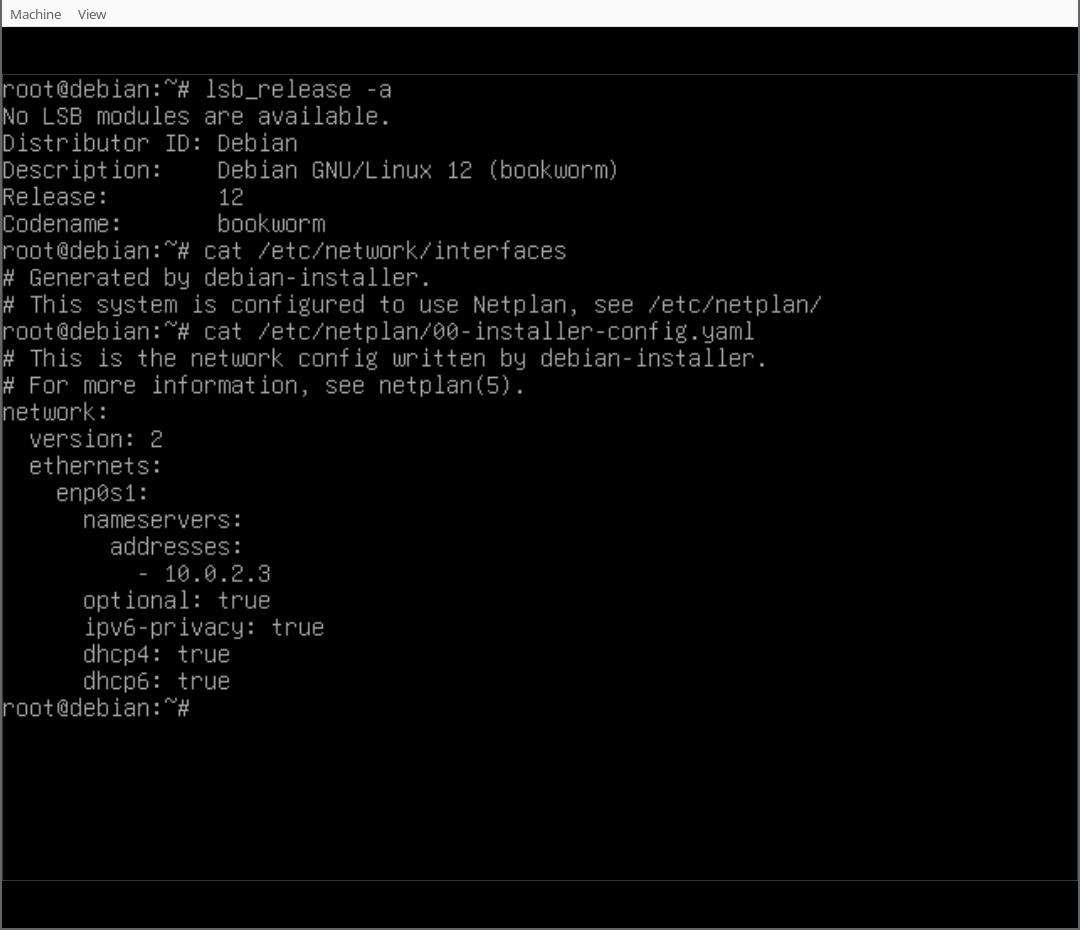
With the work that has been done in the debian-installer/netcfg merge-proposal !9 it is possible to install a standard Debian system, using the normal Debian-Installer (d-i) mini.iso images, that will come pre-installed with Netplan and all network configuration structured in /etc/netplan/.
In this write-up I d like to run you through a list of commands for experiencing the Netplan enabled installation process first-hand. For now, we ll be using a custom ISO image, while waiting for the above-mentioned merge-proposal to be landed. Furthermore, as the Debian archive is going through major transitions builds of the unstable branch of d-i don t currently work. So I implemented a small backport, producing updated netcfg and netcfg-static for Bookworm, which can be used as localudebs/ during the d-i build.
Let s start with preparing a working directory and installing the software dependencies for our virtualized Debian system:
Now let s download the custom mini.iso, linux kernel image and initrd.gz containing the Netplan enablement changes, as mentioned above.
TODO: localudebs/
Next we ll prepare a VM, by copying the EFI firmware files, preparing some persistent EFIVARs file, to boot from FS0:\EFI\debian\grubx64.efi, and create a virtual disk for our machine:
Finally, let s launch the installer using a custom preseed.cfg file, that will automatically install Netplan for us in the target system. A minimal preseed file could look like this:
For this demo, we re installing the full netplan.io package (incl. Python CLI), as the netplan-generator package was not yet split out as an independent binary in the Bookworm cycle. You can choose the preseed file from a set of different variants to test the different configurations:
We re using the custom linux kernel and initrd.gz here to be able to pass the PRESEED_URL as a parameter to the kernel s cmdline directly. Launching this VM should bring up the normal debian-installer in its netboot/gtk form:
Now you can click through the normal Debian-Installer process, using mostly default settings. Optionally, you could play around with the networking settings, to see how those get translated to /etc/netplan/ in the target system.
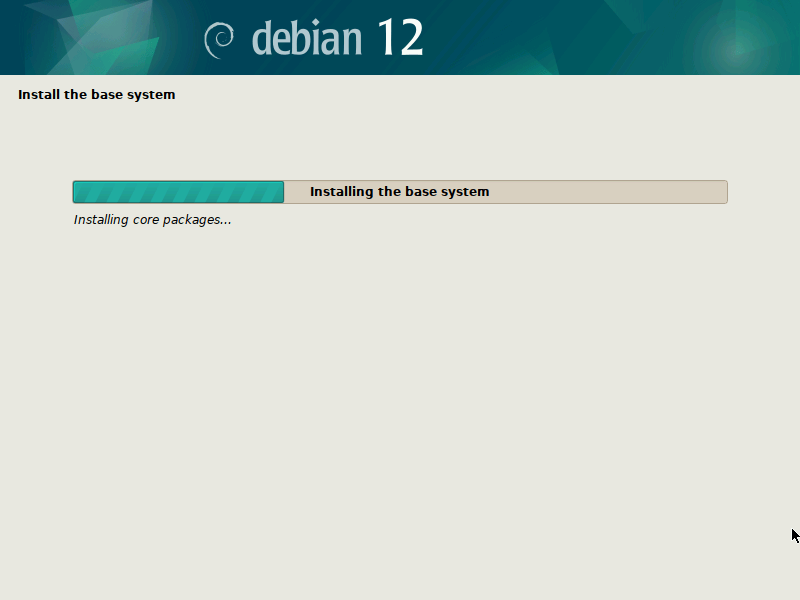
After you confirmed your partitioning changes, the base system gets installed. I suggest not to select any additional components, like desktop environments, to speed up the process.
During the final step of the installation (finish-install.d/55netcfg-copy-config) d-i will detect that Netplan was installed in the target system (due to the preseed file provided) and opt to write its network configuration to /etc/netplan/ instead of /etc/network/interfaces or /etc/NetworkManager/system-connections/.
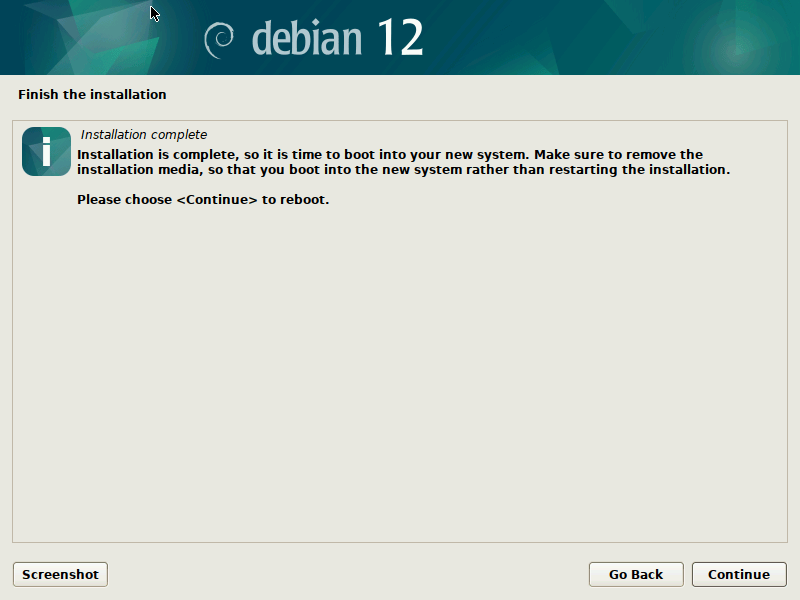
Done! After the installation finished you can reboot into your virgin Debian Bookworm system.
To do that, quit the current Qemu process, by pressing Ctrl+C and make sure to copy over the EFIVARS.fd file that was written by grub during the installation, so Qemu can find the new system. Then reboot into the new system, not using the mini.iso image any more:
Finally, you can play around with your Netplan enabled Debian system! As you will find, /etc/network/interfaces exists but is empty, it could still be used (optionally/additionally). Netplan was configured in /etc/netplan/ according to the settings given during the d-i installation process.
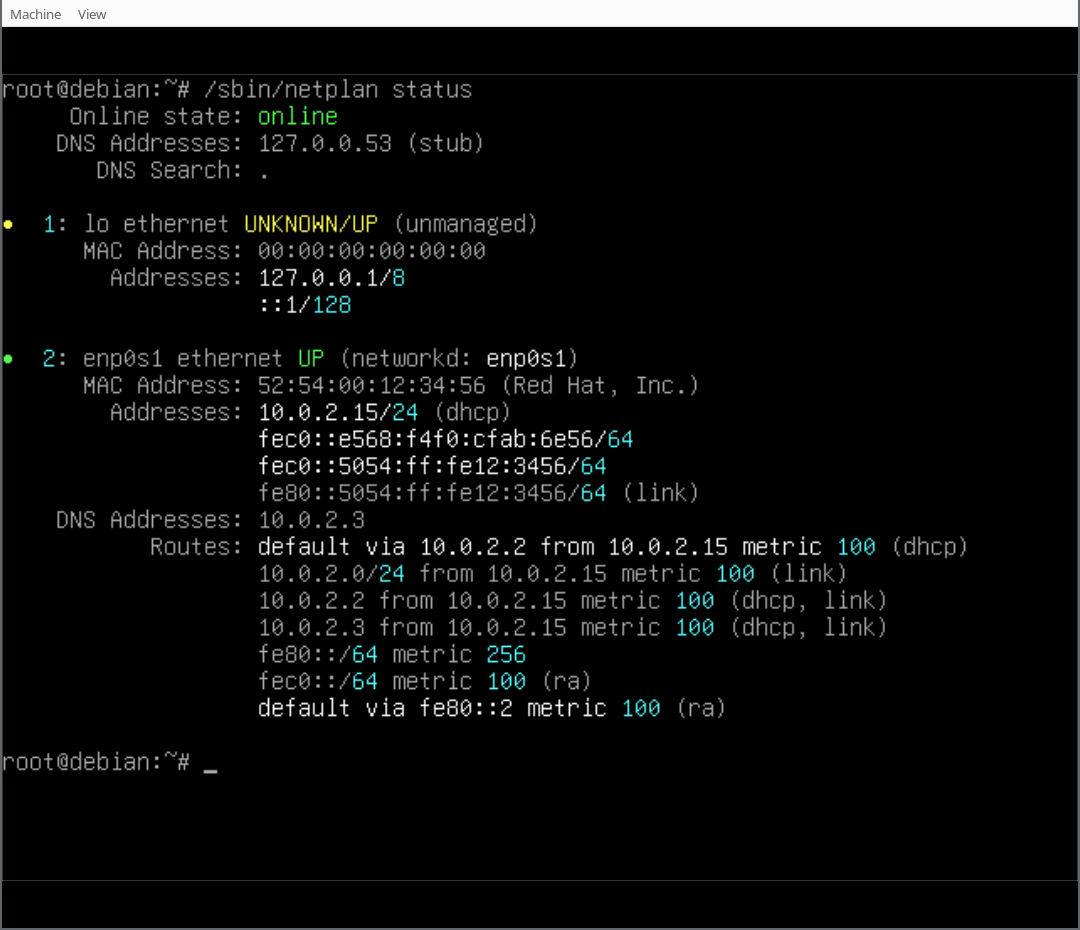
In our case we also installed the Netplan CLI, so we can play around with some of its features, like netplan status:
Thank you for following along the Netplan enabled Debian installation process and happy hacking! If you want to learn more join the discussion at Salsa:installer-team/netcfg and find us at GitHub:netplan.
Nation is a stand-alone young adult fantasy novel. It was
published in the gap between Discworld novels Making Money and Unseen
Academicals.
Nation starts with a plague. The Russian influenza has ravaged
Britain, including the royal family. The next in line to the throne is
off on a remote island and must be retrieved and crowned as soon as
possible, or an obscure provision in Magna Carta will cause no end of
trouble. The Cutty Wren is sent on this mission, carrying the
Gentlemen of Last Resort.
Then comes the tsunami.
In the midst of fire raining from the sky and a wave like no one has ever
seen, Captain Roberts tied himself to the wheel of the Sweet Judy
and steered it as best he could, straight into an island. The sole
survivor of the shipwreck: one Ermintrude Fanshaw, daughter of the
governor of some British island possessions. Oh, and a parrot.
Mau was on the Boys' Island when the tsunami came, going through his rite
of passage into manhood. He was to return to the Nation the next morning
and receive his tattoos and his adult soul. He survived in a canoe. No
one else in the Nation did.
Terry Pratchett considered Nation to be his best book. It is not
his best book, at least in my opinion; it's firmly below the top tier of
Discworld novels, let alone Night Watch.
It is, however, an interesting and enjoyable book that tackles gods and
religion with a sledgehammer rather than a knife.
It's also very, very dark and utterly depressing at the start, despite a
few glimmers of Pratchett's humor. Mau is the main protagonist at first,
and the book opens with everyone he cares about dying. This is the place
where I thought Pratchett diverged the most from his Discworld style: in
Discworld, I think most of that would have been off-screen, but here we
follow Mau through the realization, the devastation, the disassociation,
the burials at sea, the thoughts of suicide, and the complete upheaval of
everything he thought he was or was about to become. I found the start of
this book difficult to get through. The immediate transition into
potentially tragic misunderstandings between Mau and Daphne (as Ermintrude
names herself once there is no one to tell her not to) didn't help.
As I got farther into the book, though, I warmed to it. The best parts
early on are Daphne's baffled but scientific attempts to understand Mau's
culture and her place in it. More survivors arrive, and they start to
assemble a community, anchored in large part by Mau's stubborn
determination to do what's right even though he's lost all of his
moorings. That community eventually re-establishes contact with the rest
of the world and the opening plot about the British monarchy, but not
before Daphne has been changed profoundly by being part of it.
I think Pratchett worked hard at keeping Mau's culture at the center of
the story. It's notable that the community that reforms over the course
of the book essentially follows the patterns of Mau's lost Nation and
incorporates Daphne into it, rather than (as is so often the case) the
other way around. The plot itself is fiercely anti-colonial in a way that
mostly worked. Still, though, it's a quasi-Pacific-island culture written
by a white British man, and I had some qualms.
Pratchett quite rightfully makes it clear in the afterward that this is an
alternate world and Mau's culture is not a real Pacific island culture.
However, that also means that its starkly gender-essentialist nature was a
free choice, rather than one based on some specific culture, and I found
that choice somewhat off-putting. The religious rituals are all gendered,
the dwelling places are gendered, and one's entire life course in Mau's
world seems based on binary classification as a man or a woman. Based on
Pratchett's other books, I assume this was more an unfortunate default
than a deliberate choice, but it's still a choice he could have avoided.
The end of this book wrestles directly with the relative worth of Mau's
culture versus that of the British. I liked most of this, but the twists
that Pratchett adds to avoid the colonialist results we saw in our world
stumble partly into the trap of making Mau's culture valuable by British
standards. (I'm being a bit vague here to avoid spoilers.) I think it is
very hard to base this book on a different set of priorities and still
bring the largely UK, US, and western European audience along, so I don't
blame Pratchett for failing to do it, but I'm a bit sad that the world
still revolved around a British axis.
This felt quite similar to Discworld to me in its overall sensibilities,
but with the roles of moral philosophy and humor reversed. Discworld
novels usually start with some larger-than-life characters and an absurd
plot, and then the moral philosophy sneaks up behind you when you're not
looking and hits you over the head. Nation starts with the moral
philosophy: Mau wrestles with his gods and the problem of evil in a way
that reminded me of Job, except with a far different pantheon and rather
less tolerance for divine excuses on the part of the protagonist. It's
the humor, instead, that sneaks up on you and makes you laugh when the
plot is a bit too much. But the mix arrives at much the same place: the
absurd hand-in-hand with the profound, and all seen from an angle that
makes it a bit easier to understand.
I'm not sure I would recommend Nation as a good place to start with
Pratchett. I felt like I benefited from having read a lot of Discworld
to build up my willingness to trust where Pratchett was going. But it has
the quality of writing of late Discworld without the (arguable) need to
read 25 books to understand all of the backstory. Regardless,
recommended, and you'll never hear Twinkle Twinkle Little Star in
quite the same way again.
Rating: 8 out of 10
The XKCD comic Code Quality [1] inspired me to test out emoji in source. I really should have done this years ago when that XKCD was first published.
The following code compiles in gcc and runs in the way that anyone who wants to write such code would want it to run. The hover text in the XKCD comic is correct. You could have a style guide for such programming, store error messages in the doctor and nurse emoji for example.
#include <stdio.h>
int main()
int = 1, = 2;
printf(" =%d, =%d\n", , );
return 0;
To get this to display correctly in Debian you need to install the fonts-noto-color-emoji package (used by the KDE emoji picker that runs when you press Windows-. among other things) and restart programs that use emoji. The Konsole terminal emulator will probably need it s profile settings changed to work with this if you ran Konsole before installing fonts-noto-color-emoji. The Kitty terminal emulator works if you restart it after installing fonts-noto-color-emoji.
This web page gives a list of HTML codes for emoji [2]. If I start writing real code with emoji variable names then I ll have to update my source to HTML conversion script (which handles <>" and repeated spaces) to convert emoji.
I spent a couple of hours on this and I think it s worth it. I have filed several Debian bug reports about improvements needed to issues related to emoji.
When using Bubblewrap (the bwrap command) to create a container in Ubuntu 24.04 you can expect to get one of the following error messages:
bwrap: loopback: Failed RTM_NEWADDR: Operation not permitted
bwrap: setting up uid map: Permission denied
This is due to Ubuntu developers deciding to use Apparmor to restrict the creation of user namespaces. Here is a Ubuntu blog post about it [1].
To resolve that you could upgrade to SE Linux, but the other option is to create a file named /etc/apparmor.d/bwrap with the following contents:
abi <abi/4.0>,
include <tunables/global>
profile bwrap /usr/bin/bwrap flags=(unconfined)
userns,
# Site-specific additions and overrides. See local/README for details.
include if exists <local/bwrap>
The voting period for the Debian Project Leader election has ended. Please join
us in congratulating Andreas Tille as the new Debian Project Leader.
The new term for the project leader started on 2024-04-21.
369 of 1,010 Debian Developers voted using the Condorcet method.
More information about the results of the voting are available on the Debian Project Leader Elections 2024 page.
Many thanks all of our Developers for voting.
Version 3.3 brings in new features, including reverse Laplace transforms and fits, pH fits, commands for picking points from a dataset, averaging points with the same X value, or perform singular value decomposition.
In addition to these new features, many previous commands were improved, like the addition of a bandcut filter in FFT filtering, better handling of the loading of files produced by QSoas itself, and a button to interrupt the processing of scripts.
There are a lot of other new features, improvements and so on, look for the full list there.
About QSoas QSoas is a powerful open source data analysis program that focuses on flexibility and powerful fitting capacities. It is released under the GNU General Public License. It is described in Fourmond, Anal. Chem., 2016, 88 (10), pp 5050 5052. Current version is 3.3. You can download for free its source code or precompiled versions for MacOS and Windows there. Alternatively, you can clone from the GitHub repository.
The Stars, Like Dust is usually listed as the first book in
Asimov's lesser-known Galactic Empire Trilogy since it takes place before
Pebble in the Sky. Pebble in the
Sky was published first, though, so I count it as the second book. It is
very early science fiction with a few mystery overtones.
Buying books produces about 5% of the pleasure of reading them while
taking much less than 5% of the time. There was a time in my life when I
thoroughly enjoyed methodically working through a used book store, list in
hand, tracking down cheap copies to fill in holes in series. This means
that I own a lot of books that I thought at some point that I would want
to read but never got around to, often because, at the time, I was feeling
completionist about some series or piece of world-building. From time to
time, I get the urge to try to read some of them.
Sometimes this is a poor use of my time.
The Galactic Empire series is from Asimov's first science fiction period,
after the Foundation series but contemporaneous with their
collection into novels. They're set long, long before Foundation,
but after humans have inhabited numerous star systems and Earth has become
something of a backwater. That process is just starting in The
Stars, Like Dust: Earth is still somewhere where an upper-class son might
be sent for an education, but it has been devastated by nuclear wars and
is well on its way to becoming an inward-looking relic on the edge of
galactic society.
Biron Farrill is the son of the Lord Rancher of Widemos, a wealthy noble
whose world is one of those conquered by the Tyranni. In many other SF
novels, the Tyranni would be an alien race; here, it's a hierarchical and
authoritarian human civilization. The book opens with Biron discovering a
radiation bomb planted in his dorm room. Shortly after, he learns that
his father had been arrested. One of his fellow students claims to be on
Biron's side against the Tyranni and gives him false papers to travel to
Rhodia, a wealthy world run by a Tyranni sycophant.
Like most books of this era, The Stars, Like Dust is a short novel
full of plot twists. Unlike some of its contemporaries, it's not devoid
of characterization, but I might have liked it better if it were. Biron
behaves like an obnoxious teenager when he's not being an arrogant ass.
There is a female character who does a few plot-relevant things and at no
point is sexually assaulted, so I'll give Asimov that much, but the gender
stereotypes are ironclad and there is an entire subplot focused on what I
can only describe as seduction via petty jealousy.
The writing... well, let me quote a typical passage:
There was no way of telling when the threshold would be reached.
Perhaps not for hours, and perhaps the next moment. Biron remained
standing helplessly, flashlight held loosely in his damp hands. Half
an hour before, the visiphone had awakened him, and he had been at
peace then. Now he knew he was going to die.
Biron didn't want to die, but he was penned in hopelessly, and there
was no place to hide.
Needless to say, Biron doesn't die. Even if your tolerance for pulp
melodrama is high, 192 small-print pages of this sort of thing is
wearying.
Like a lot of Asimov plots, The Stars, Like Dust has some of the
shape of a mystery novel. Biron, with the aid of some newfound companions
on Rhodia, learns of a secret rebellion against the Tyranni and attempts
to track down its base to join them. There are false leads, disguised
identities, clues that are difficult to interpret, and similar classic
mystery trappings, all covered with a patina of early 1950s imaginary
science. To me, it felt constructed and artificial in ways that made the
strings Asimov was pulling obvious. I don't know if someone who likes
mystery construction would feel differently about it.
The worst part of the plot thankfully doesn't come up much. We learn
early in the story that Biron was on Earth to search for a long-lost
document believed to be vital to defeating the Tyranni. The nature of
that document is revealed on the final page, so I won't spoil it, but if
you try to think of the stupidest possible document someone could have
built this plot around, I suspect you will only need one guess. (In
Asimov's defense, he blamed Galaxy editor H.L. Gold for persuading
him to include this plot, and disavowed it a few years later.)
The Stars, Like Dust is one of the worst books I have ever read.
The characters are overwrought, the politics are slapdash and build on
broad stereotypes, the romantic subplot is dire and plays out mainly via
Biron egregiously manipulating his petulant love interest, and the writing
is annoying. Sometimes pulp fiction makes up for those common flaws
through larger-than-life feats of daring, sweeping visions of future
societies, and ever-escalating stakes. There is little to none of that
here. Asimov instead provides tedious political maneuvering among a class
of elitist bankers and land owners who consider themselves natural
leaders. The only places where the power structures of this future
government make sense are where Asimov blatantly steals them from either
the Roman Empire or the Doge of Venice.
The one thing this book has going for it the thing, apart from
bloody-minded completionism, that kept me reading is that the technology
is hilariously weird in that way that only 1940s and 1950s science fiction
can be. The characters have access to communication via some sort of
interstellar telepathy (messages coded to a specific person's "brain
waves") and can travel between stars through hyperspace jumps, but each
jump is manually calculated by referring to the pilot's (paper!) volumes of
the Standard Galactic Ephemeris. Communication between ships (via
"etheric radio") requires manually aiming a radio beam at the area in
space where one thinks the other ship is. It's an unintentionally
entertaining combination of technology that now looks absurdly primitive
and science that is so advanced and hand-waved that it's obviously made
up.
I also have to give Asimov some points for using spherical coordinates.
It's a small thing, but the coordinate systems in most SF novels and TV
shows are obviously not fit for purpose.
I spent about a month and a half of this year barely reading, and while
some of that is because I finally tackled a few projects I'd been putting
off for years, a lot of it was because of this book. It was only 192
pages, and I'm still curious about the glue between Asimov's
Foundation and Robot series, both of which I devoured as a
teenager. But every time I picked it up to finally finish it and start
another book, I made it about ten pages and then couldn't take any more.
Learn from my error: don't try this at home, or at least give up if the
same thing starts happening to you.
Followed by The Currents of Space.
Rating: 2 out of 10
I am upstream and Debian package maintainer of
python-debianbts, which is a Python library that allows for
querying Debian s Bug Tracking System (BTS). python-debianbts is used by
reportbug, the standard tool to report bugs in Debian, and therefore the glue
between the reportbug and the BTS.
debbugs, the software that powers Debian s BTS, provides a SOAP
interface for querying the BTS. Unfortunately, SOAP is not a very popular
protocol anymore, and I m facing the second migration to another underlying
SOAP library as they continue to become unmaintained over time. Zeep, the
library I m currently considering, requires a WSDL file in order to work
with a SOAP service, however, debbugs does not provide one. Since I m not
familiar with WSDL, I need help from someone who can create a WSDL file for
debbugs, so I can migrate python-debianbts away from pysimplesoap to zeep.
How did we get here?
Back in the olden days, reportbug was querying the BTS by parsing its HTML
output. While this worked, it tightly coupled the user-facing
presentation of the BTS with critical functionality of the bug reporting tool.
The setup was fragile, prone to breakage, and did not allow changing anything
in the BTS frontend for fear of breaking reportbug itself.
In 2007, I started to work on reportbug-ng, a user-friendly alternative
to reportbug, targeted at users not comfortable using the command line. Early
on, I decided to use the BTS SOAP interface instead of parsing HTML like
reportbug did. 2008, I extracted the code that dealt with the BTS into a
separate Python library, and after some collaboration with the reportbug
maintainers, reportbug adopted python-debianbts in 2011 and has used it ever
since.
2015, I was working on porting python-debianbts to Python 3.
During that process, it turned out that its major dependency, SoapPy was pretty
much unmaintained for years and blocking the Python3 transition. Thanks to the
help of Gaetano Guerriero, who ported python-debianbts to
pysimplesoap, the migration was unblocked and could proceed.
In 2024, almost ten years later, pysimplesoap seems to be unmaintained as well,
and I have to look again for alternatives. The most promising one right now
seems to be zeep. Unfortunately, zeep requires a WSDL file for working with
a SOAP service, which debbugs does not provide.
How can you help?
reportbug (and thus python-debianbts) is used by thousands of users and I have
a certain responsibility to keep things working properly. Since I simply don t
know enough about WSDL to create such a file for debbugs myself, I m looking
for someone who can help me with this task.
If you re familiar with SOAP, WSDL and optionally debbugs, please get in
touch with me. I don t speak Pearl, so I m not
really able to read debbugs code, but I do know some things about the SOAP
requests and replies due to my work on python-debianbts, so I m sure we can
work something out.
There is a WSDL file for a debbugs version used by GNU, but I
don t think it s official and it currently does not work with zeep. It may be a
good starting point, though.
The future of debbugs API
While we can probably continue to support debbugs SOAP interface for a while,
I don t think it s very sustainable in the long run. A simpler, well documented
REST API that returns JSON seems more appropriate nowadays. The queries and
replies that debbugs currently supports are simple enough to design a REST API
with JSON around it. The benefit would be less complex libraries on the client
side and probably easier maintainability on the server side as well. debbugs
maintainer seemed to be in agreement with this idea back in
2018. I created an attempt to define a new API
(HTML render), but somehow we got stuck and no progress has been
made since then. I m still happy to help shaping such an API for debbugs, but I
can t really implement anything in debbugs itself, as it is written in Perl,
which I m not familiar with.
Time really flies when you are really busy you have fun! Our Montr al
Debian User Group met on Sunday March 31st and I only just found the time to
write our report :)
This time around, 9 of us we met at EfficiOS's offices1 to
chat, hang out and work on Debian and other stuff!
Here is what we did:
pollo:
did some clerical work for the DebConf videoteam
tried to book a plane ticket for DC24
triaged #1067620 (dependency problem with whipper)
Pictures
Here are pictures of the event. Well, one picture (thanks Tassia!) of the event
itself and another one of the crisp Italian lager I drank at the bar after the
event :)
Maintainers, amongst other things, of the great LTTng.
The diffoscope maintainers are pleased to announce the release of diffoscope
version 265. This version includes the following changes:
[ Chris Lamb ]
* Ensure that tests with ">=" version constraints actually print the
corresponding tool name. (Closes: reproducible-builds/diffoscope#370)
* Prevent odt2txt tests from always being skipped due to an impossibly new
version requirement. (Closes: reproducible-builds/diffoscope#369)
* Avoid nested parens-in-parens when printing "skipping " messages
in the testsuite.
Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they ve kicked me off Go Roam, so I ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don t expect to use all of the data allowance, but I didn t want to have to worry about unexpected excess charges.
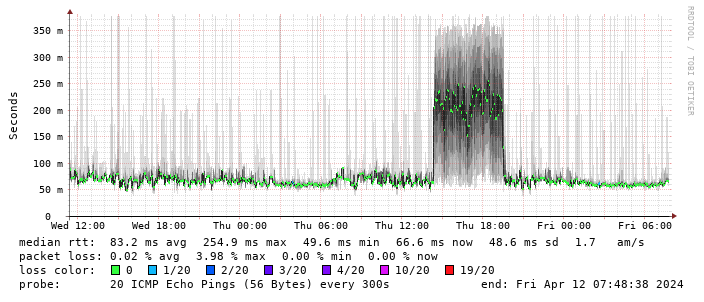
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
(There s a handy zte.js script to allow doing this from the device web interface.)
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
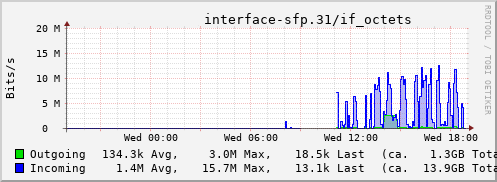
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
Joachim Breitner wrote about a Convenient sandboxed development environment and thus reminded me to blog about MicroVM. I ve toyed around with it a little but not yet seriously used it as I m currently not coding.
MicroVM is a nix based project to configure and run minimal VMs. It can mount and thus reuse the hosts nix store inside the VM and thus has a very small disk footprint. I use MicroVM on a debian system using the nix package manager.
The MicroVM author uses the project to host production services. Otherwise I consider it also a nice way to learn about NixOS after having started with the nix package manager and before making the big step to NixOS as my main system.
The guests root filesystem is a tmpdir, so one must explicitly define folders that should be mounted from the host and thus be persistent across VM reboots.
I defined the VM as a nix flake since this is how I started from the MicroVM projects example:
description = "Haskell dev MicroVM";
inputs.impermanence.url = "github:nix-community/impermanence";
inputs.microvm.url = "github:astro/microvm.nix";
inputs.microvm.inputs.nixpkgs.follows = "nixpkgs";
outputs = self, impermanence, microvm, nixpkgs :
let
persistencePath = "/persistent";
system = "x86_64-linux";
user = "thk";
vmname = "haskell";
nixosConfiguration = nixpkgs.lib.nixosSystem
inherit system;
modules = [
microvm.nixosModules.microvm
impermanence.nixosModules.impermanence
( pkgs, ... :
environment.persistence.$ persistencePath =
hideMounts = true;
users.$ user =
directories = [
"git" ".stack"
];
;
;
environment.sessionVariables =
TERM = "screen-256color";
;
environment.systemPackages = with pkgs; [
ghc
git
(haskell-language-server.override supportedGhcVersions = [ "94" ]; )
htop
stack
tmux
tree
vcsh
zsh
];
fileSystems.$ persistencePath .neededForBoot = nixpkgs.lib.mkForce true;
microvm =
forwardPorts = [
from = "host"; host.port = 2222; guest.port = 22;
from = "guest"; host.port = 5432; guest.port = 5432; # postgresql
];
hypervisor = "qemu";
interfaces = [
type = "user"; id = "usernet"; mac = "00:00:00:00:00:02";
];
mem = 4096;
shares = [
# use "virtiofs" for MicroVMs that are started by systemd
proto = "9p";
tag = "ro-store";
# a host's /nix/store will be picked up so that no
# squashfs/erofs will be built for it.
source = "/nix/store";
mountPoint = "/nix/.ro-store";
proto = "virtiofs";
tag = "persistent";
source = "~/.local/share/microvm/vms/$ vmname /persistent";
mountPoint = persistencePath;
socket = "/run/user/1000/microvm-$ vmname -persistent";
];
socket = "/run/user/1000/microvm-control.socket";
vcpu = 3;
volumes = [];
writableStoreOverlay = "/nix/.rwstore";
;
networking.hostName = vmname;
nix.enable = true;
nix.nixPath = ["nixpkgs=$ builtins.storePath <nixpkgs> "];
nix.settings =
extra-experimental-features = ["nix-command" "flakes"];
trusted-users = [user];
;
security.sudo =
enable = true;
wheelNeedsPassword = false;
;
services.getty.autologinUser = user;
services.openssh =
enable = true;
;
system.stateVersion = "24.11";
systemd.services.loadnixdb =
description = "import hosts nix database";
path = [pkgs.nix];
wantedBy = ["multi-user.target"];
requires = ["nix-daemon.service"];
script = "cat $ persistencePath /nix-store-db-dump nix-store --load-db";
;
time.timeZone = nixpkgs.lib.mkDefault "Europe/Berlin";
users.users.$ user =
extraGroups = [ "wheel" "video" ];
group = "user";
isNormalUser = true;
openssh.authorizedKeys.keys = [
"ssh-rsa REDACTED"
];
password = "";
;
users.users.root.password = "";
users.groups.user = ;
)
];
;
in
packages.$ system .default = nixosConfiguration.config.microvm.declaredRunner;
;
I start the microVM with a templated systemd user service:
The above service definition creates a dump of the hosts nix store db so that it can be imported in the guest. This is necessary so that the guest can actually use what is available in /nix/store. There is an effort for an overlayed nix store that would be preferable to this hack.
Finally the microvm is started inside a tmux session named microvm . This way I can use the VM with SSH or through the console and also access the qemu console.
And for completeness the virtiofsd service:
[Unit]
Description=serve host persistent folder for dev VM
AssertPathIsDirectory=%h/.local/share/microvm/vms/%i/persistent
[Service]
ExecStart=%h/.local/state/nix/profile/bin/virtiofsd \
--socket-path=$ XDG_RUNTIME_DIR /microvm-%i-persistent \
--shared-dir=%h/.local/share/microvm/vms/%i/persistent \
--gid-map :995:%G:1: \
--uid-map :1000:%U:1:
 Version 0.0.17 of RcppSpdlog arrived
on CRAN overnight following and
has been uploaded to Debian. RcppSpdlog
bundles spdlog, a
wonderful header-only C++ logging library with all the bells and
whistles you would want that was written by Gabi Melman, and also includes fmt by Victor Zverovich. You can learn
more at the nice package
documention site.
This releases updates the code to the version 1.14 of spdlog which was release
yesterday.
The NEWS entry for this release follows.
Version 0.0.17 of RcppSpdlog arrived
on CRAN overnight following and
has been uploaded to Debian. RcppSpdlog
bundles spdlog, a
wonderful header-only C++ logging library with all the bells and
whistles you would want that was written by Gabi Melman, and also includes fmt by Victor Zverovich. You can learn
more at the nice package
documention site.
This releases updates the code to the version 1.14 of spdlog which was release
yesterday.
The NEWS entry for this release follows.
 It s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation s current status and some exciting upcoming changes.
It s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation s current status and some exciting upcoming changes.
 With
With  I've been enjoying Biosphere as the soundtrack to my recent "concentrated work" spells.
I've been enjoying Biosphere as the soundtrack to my recent "concentrated work" spells.
 The voting period for the Debian Project Leader election has ended. Please join
us in congratulating Andreas Tille as the new Debian Project Leader.
The new term for the project leader started on 2024-04-21.
369 of 1,010 Debian Developers voted using the
The voting period for the Debian Project Leader election has ended. Please join
us in congratulating Andreas Tille as the new Debian Project Leader.
The new term for the project leader started on 2024-04-21.
369 of 1,010 Debian Developers voted using the  I am upstream and
I am upstream and  Time really flies when
Time really flies when 

 (There s a handy
(There s a handy 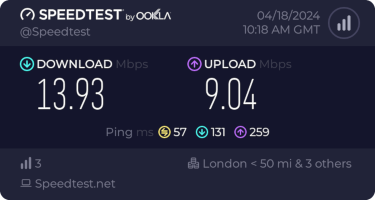 This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
