Reproducible Builds: Reproducible Builds in February 2024
 Welcome to the February 2024 report from the Reproducible Builds project! In our reports, we try to outline what we have been up to over the past month as well as mentioning some of the important things happening in software supply-chain security.
Welcome to the February 2024 report from the Reproducible Builds project! In our reports, we try to outline what we have been up to over the past month as well as mentioning some of the important things happening in software supply-chain security.
Reproducible Builds at FOSDEM 2024
 Core Reproducible Builds developer Holger Levsen presented at the main track at FOSDEM on Saturday 3rd February this year in Brussels, Belgium. However, that wasn t the only talk related to Reproducible Builds.
However, please see our comprehensive FOSDEM 2024 news post for the full details and links.
Core Reproducible Builds developer Holger Levsen presented at the main track at FOSDEM on Saturday 3rd February this year in Brussels, Belgium. However, that wasn t the only talk related to Reproducible Builds.
However, please see our comprehensive FOSDEM 2024 news post for the full details and links.
Maintainer Perspectives on Open Source Software Security
 Bernhard M. Wiedemann spotted that a recent report entitled Maintainer Perspectives on Open Source Software Security written by Stephen Hendrick and Ashwin Ramaswami of the Linux Foundation sports an infographic which mentions that 56% of [polled] projects support reproducible builds .
Bernhard M. Wiedemann spotted that a recent report entitled Maintainer Perspectives on Open Source Software Security written by Stephen Hendrick and Ashwin Ramaswami of the Linux Foundation sports an infographic which mentions that 56% of [polled] projects support reproducible builds .
Three new reproducibility-related academic papers
A total of three separate scholarly papers related to Reproducible Builds have appeared this month:
 Signing in Four Public Software Package Registries: Quantity, Quality, and Influencing Factors by Taylor R. Schorlemmer, Kelechi G. Kalu, Luke Chigges, Kyung Myung Ko, Eman Abdul-Muhd, Abu Ishgair, Saurabh Bagchi, Santiago Torres-Arias and James C. Davis (Purdue University, Indiana, USA) is concerned with the problem that:
Signing in Four Public Software Package Registries: Quantity, Quality, and Influencing Factors by Taylor R. Schorlemmer, Kelechi G. Kalu, Luke Chigges, Kyung Myung Ko, Eman Abdul-Muhd, Abu Ishgair, Saurabh Bagchi, Santiago Torres-Arias and James C. Davis (Purdue University, Indiana, USA) is concerned with the problem that:
Package maintainers can guarantee package authorship through software signing [but] it is unclear how common this practice is, and whether the resulting signatures are created properly. Prior work has provided raw data on signing practices, but measured single platforms, did not consider time, and did not provide insight on factors that may influence signing. We lack a comprehensive, multi-platform understanding of signing adoption and relevant factors. This study addresses this gap. (arXiv, full PDF)
 Reproducibility of Build Environments through Space and Time by Julien Malka, Stefano Zacchiroli and Th o Zimmermann (Institut Polytechnique de Paris, France) addresses:
Reproducibility of Build Environments through Space and Time by Julien Malka, Stefano Zacchiroli and Th o Zimmermann (Institut Polytechnique de Paris, France) addresses:
[The] principle of reusability [ ] makes it harder to reproduce projects build environments, even though reproducibility of build environments is essential for collaboration, maintenance and component lifetime. In this work, we argue that functional package managers provide the tooling to make build environments reproducible in space and time, and we produce a preliminary evaluation to justify this claim.
The abstract continues with the claim that Using historical data, we show that we are able to reproduce build environments of about 7 million Nix packages, and to rebuild 99.94% of the 14 thousand packages from a 6-year-old Nixpkgs revision. (arXiv, full PDF)
 Options Matter: Documenting and Fixing Non-Reproducible Builds in Highly-Configurable Systems by Georges Aaron Randrianaina, Djamel Eddine Khelladi, Olivier Zendra and Mathieu Acher (Inria centre at Rennes University, France):
Options Matter: Documenting and Fixing Non-Reproducible Builds in Highly-Configurable Systems by Georges Aaron Randrianaina, Djamel Eddine Khelladi, Olivier Zendra and Mathieu Acher (Inria centre at Rennes University, France):
This paper thus proposes an approach to automatically identify configuration options causing non-reproducibility of builds. It begins by building a set of builds in order to detect non-reproducible ones through binary comparison. We then develop automated techniques that combine statistical learning with symbolic reasoning to analyze over 20,000 configuration options. Our methods are designed to both detect options causing non-reproducibility, and remedy non-reproducible configurations, two tasks that are challenging and costly to perform manually. (HAL Portal, full PDF)
Mailing list highlights
From our mailing list this month:
-
User cen posted a query asking How to verify a package by rebuilding it locally on Debian which received a followup from Vagrant Cascadian.
-
James Addison asked Two questions about build-path reproducibility in Debian regarding the differences in the testing performed by Debian s GitLab continuous integration (CI) pipeline and the Debian-specific testing performed by the Reproducible Builds project itself, and followed this with a separate but related question regarding misconfigured reprotest configurations.
Distribution work
 In Debian this month, 5 reviews of Debian packages were added, 22 were updated and 8 were removed this month adding to Debian s knowledge about identified issues. A number of issue types were updated as well. [ ][ ][ ][ ] In addition, Roland Clobus posted his 23rd update of the status of reproducible ISO images on our mailing list. In particular, Roland helpfully summarised that all major desktops build reproducibly with bullseye, bookworm, trixie and sid provided they are built for a second time within the same DAK run (i.e. [within] 6 hours) and that there will likely be further work at a MiniDebCamp in Hamburg. Furthermore, Roland also responded in-depth to a query about a previous report
In Debian this month, 5 reviews of Debian packages were added, 22 were updated and 8 were removed this month adding to Debian s knowledge about identified issues. A number of issue types were updated as well. [ ][ ][ ][ ] In addition, Roland Clobus posted his 23rd update of the status of reproducible ISO images on our mailing list. In particular, Roland helpfully summarised that all major desktops build reproducibly with bullseye, bookworm, trixie and sid provided they are built for a second time within the same DAK run (i.e. [within] 6 hours) and that there will likely be further work at a MiniDebCamp in Hamburg. Furthermore, Roland also responded in-depth to a query about a previous report
 Fedora developer Zbigniew J drzejewski-Szmek announced a work-in-progress script called
Fedora developer Zbigniew J drzejewski-Szmek announced a work-in-progress script called fedora-repro-build that attempts to reproduce an existing package within a koji build environment. Although the projects README file lists a number of fields will always or almost always vary and there is a non-zero list of other known issues, this is an excellent first step towards full Fedora reproducibility.
 Jelle van der Waa introduced a new linter rule for Arch Linux packages in order to detect cache files leftover by the Sphinx documentation generator which are unreproducible by nature and should not be packaged. At the time of writing, 7 packages in the Arch repository are affected by this.
Jelle van der Waa introduced a new linter rule for Arch Linux packages in order to detect cache files leftover by the Sphinx documentation generator which are unreproducible by nature and should not be packaged. At the time of writing, 7 packages in the Arch repository are affected by this.
 Elsewhere, Bernhard M. Wiedemann posted another monthly update for his work elsewhere in openSUSE.
Elsewhere, Bernhard M. Wiedemann posted another monthly update for his work elsewhere in openSUSE.
diffoscope
 diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 256, 257 and 258 to Debian and made the following additional changes:
- Use a deterministic name instead of trusting
gpg s use-embedded-filenames. Many thanks to Daniel Kahn Gillmor dkg@debian.org for reporting this issue and providing feedback. [ ][ ]
- Don t error-out with a traceback if we encounter
struct.unpack-related errors when parsing Python .pyc files. (#1064973). [ ]
- Don t try and compare
rdb_expected_diff on non-GNU systems as %p formatting can vary, especially with respect to MacOS. [ ]
- Fix compatibility with
pytest 8.0. [ ]
- Temporarily fix support for Python 3.11.8. [ ]
- Use the
7zip package (over p7zip-full) after a Debian package transition. (#1063559). [ ]
- Bump the minimum Black source code reformatter requirement to 24.1.1+. [ ]
- Expand an older changelog entry with a CVE reference. [ ]
- Make
test_zip black clean. [ ]
In addition, James Addison contributed a patch to parse the headers from the diff(1) correctly [ ][ ] thanks! And lastly, Vagrant Cascadian pushed updates in GNU Guix for diffoscope to version 255, 256, and 258, and updated trydiffoscope to 67.0.6.
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian made a number of changes, including:
- Create a (working) proof of concept for enabling a specific number of CPUs. [ ][ ]
- Consistently use 398 days for time variation rather than choosing randomly and update
README.rst to match. [ ][ ]
- Support a new
--vary=build_path.path option. [ ][ ][ ][ ]
Website updates
 There were made a number of improvements to our website this month, including:
There were made a number of improvements to our website this month, including:
-
Chris Lamb:
- Improve the relative sizing of headers. [ ]
- Re-order and punch up the introduction and documentation on the
SOURCE_DATE_EPOCH page. [ ]
- Update
SOURCE_DATE_EPOCH documentation re. datetime.datetime.fromtimestamp. Thanks, James Addison. [ ]
- Add a post about Reproducible Builds at FOSDEM 2024. [ ]
-
Holger Levsen:
- Update the GNU Guix page to include their reproducibility QA page. [ ]
- Add Sune Vuorela and Jan-Benedict Glaw to our contributors list. [ ][ ]
-
Mattia Rizzolo:
- Add Sovereign Tech Fund s logo to our sponsors. [ ]
- Update our sponsors list. [ ]
Reproducibility testing framework
 The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Other changes:
- Grant Jan-Benedict Glaw shell access to the Jenkins node. [ ]
- Enable debugging for NetBSD reproducibility testing. [ ]
- Use
/usr/bin/du --apparent-size in the Jenkins shell monitor. [ ]
- Revert reproducible nodes: mark osuosl2 as down . [ ]
- Thanks again to Codethink, for they have doubled the RAM on our
arm64 nodes. [ ]
- Only set
/proc/$pid/oom_score_adj to -1000 if it has not already been done. [ ]
- Add the
opemwrt-target-tegra and jtx task to the list of zombie jobs. [ ][ ]
Vagrant Cascadian also made the following changes:
- Overhaul the handling of OpenSSH configuration files after updating from Debian bookworm. [ ][ ][ ]
- Add two new
armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [ ][ ] [ ][ ]
In addition, Alexander Couzens updated the OpenWrt configuration in order to replace the tegra target with mpc85xx [ ], Jan-Benedict Glaw updated the NetBSD build script to use a separate $TMPDIR to mitigate out of space issues on a tmpfs-backed /tmp [ ] and Zheng Junjie added a link to the GNU Guix tests [ ].
Lastly, node maintenance was performed by Holger Levsen [ ][ ][ ][ ][ ][ ] and Vagrant Cascadian [ ][ ][ ][ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Philip Rinn:
gimagereader (date)
-
Bernhard M. Wiedemann:
grass (date-related issue)grub2 (filesystem ordering issue)latex2html (drop a non-deterministic log)mhvtl (tar)obs (build-tool issue)ollama (GZip embedding the modification time)presenterm (filesystem-ordering issue)qt6-quick3d (parallelism)
-
Chris Lamb:
-
James Addison:
- #1064519 filed against
flask-limiter.
python-parsl-doc (disable dynamic argument evaluation by Sphinx autodoc extension)python3-pytest-repeat (remove entry_points.txt creation that varied by shell)python3-selinux (remove packaged direct_url.json file that embeds build path)python3-sepolicy (remove packaged direct_url.json file that embeds build path)- #1064575 filed against
pyswarms.
- #1064638 filed against
python-x2go.
snapd (fix timestamp header in packaged manual-page)zzzeeksphinx (existing RB patch forwarded and merged (with modifications))
-
Johannes Schauer Marin Rodrigues:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
Bernhard M. Wiedemann spotted that a recent report entitled Maintainer Perspectives on Open Source Software Security written by Stephen Hendrick and Ashwin Ramaswami of the Linux Foundation sports an infographic which mentions that 56% of [polled] projects support reproducible builds .
Three new reproducibility-related academic papers
A total of three separate scholarly papers related to Reproducible Builds have appeared this month:
Signing in Four Public Software Package Registries: Quantity, Quality, and Influencing Factors by Taylor R. Schorlemmer, Kelechi G. Kalu, Luke Chigges, Kyung Myung Ko, Eman Abdul-Muhd, Abu Ishgair, Saurabh Bagchi, Santiago Torres-Arias and James C. Davis (Purdue University, Indiana, USA) is concerned with the problem that:
Package maintainers can guarantee package authorship through software signing [but] it is unclear how common this practice is, and whether the resulting signatures are created properly. Prior work has provided raw data on signing practices, but measured single platforms, did not consider time, and did not provide insight on factors that may influence signing. We lack a comprehensive, multi-platform understanding of signing adoption and relevant factors. This study addresses this gap. (arXiv, full PDF)
Reproducibility of Build Environments through Space and Time by Julien Malka, Stefano Zacchiroli and Th o Zimmermann (Institut Polytechnique de Paris, France) addresses:
[The] principle of reusability [ ] makes it harder to reproduce projects build environments, even though reproducibility of build environments is essential for collaboration, maintenance and component lifetime. In this work, we argue that functional package managers provide the tooling to make build environments reproducible in space and time, and we produce a preliminary evaluation to justify this claim.
The abstract continues with the claim that Using historical data, we show that we are able to reproduce build environments of about 7 million Nix packages, and to rebuild 99.94% of the 14 thousand packages from a 6-year-old Nixpkgs revision. (arXiv, full PDF)
Options Matter: Documenting and Fixing Non-Reproducible Builds in Highly-Configurable Systems by Georges Aaron Randrianaina, Djamel Eddine Khelladi, Olivier Zendra and Mathieu Acher (Inria centre at Rennes University, France):
This paper thus proposes an approach to automatically identify configuration options causing non-reproducibility of builds. It begins by building a set of builds in order to detect non-reproducible ones through binary comparison. We then develop automated techniques that combine statistical learning with symbolic reasoning to analyze over 20,000 configuration options. Our methods are designed to both detect options causing non-reproducibility, and remedy non-reproducible configurations, two tasks that are challenging and costly to perform manually. (HAL Portal, full PDF)
Mailing list highlights
From our mailing list this month:
-
User cen posted a query asking How to verify a package by rebuilding it locally on Debian which received a followup from Vagrant Cascadian.
-
James Addison asked Two questions about build-path reproducibility in Debian regarding the differences in the testing performed by Debian s GitLab continuous integration (CI) pipeline and the Debian-specific testing performed by the Reproducible Builds project itself, and followed this with a separate but related question regarding misconfigured reprotest configurations.
Distribution work
In Debian this month, 5 reviews of Debian packages were added, 22 were updated and 8 were removed this month adding to Debian s knowledge about identified issues. A number of issue types were updated as well. [ ][ ][ ][ ] In addition, Roland Clobus posted his 23rd update of the status of reproducible ISO images on our mailing list. In particular, Roland helpfully summarised that all major desktops build reproducibly with bullseye, bookworm, trixie and sid provided they are built for a second time within the same DAK run (i.e. [within] 6 hours) and that there will likely be further work at a MiniDebCamp in Hamburg. Furthermore, Roland also responded in-depth to a query about a previous report
Fedora developer Zbigniew J drzejewski-Szmek announced a work-in-progress script called fedora-repro-build that attempts to reproduce an existing package within a koji build environment. Although the projects README file lists a number of fields will always or almost always vary and there is a non-zero list of other known issues, this is an excellent first step towards full Fedora reproducibility.
Jelle van der Waa introduced a new linter rule for Arch Linux packages in order to detect cache files leftover by the Sphinx documentation generator which are unreproducible by nature and should not be packaged. At the time of writing, 7 packages in the Arch repository are affected by this.
Elsewhere, Bernhard M. Wiedemann posted another monthly update for his work elsewhere in openSUSE.
diffoscope
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 256, 257 and 258 to Debian and made the following additional changes:
- Use a deterministic name instead of trusting
gpg s use-embedded-filenames. Many thanks to Daniel Kahn Gillmor dkg@debian.org for reporting this issue and providing feedback. [ ][ ]
- Don t error-out with a traceback if we encounter
struct.unpack-related errors when parsing Python .pyc files. (#1064973). [ ]
- Don t try and compare
rdb_expected_diff on non-GNU systems as %p formatting can vary, especially with respect to MacOS. [ ]
- Fix compatibility with
pytest 8.0. [ ]
- Temporarily fix support for Python 3.11.8. [ ]
- Use the
7zip package (over p7zip-full) after a Debian package transition. (#1063559). [ ]
- Bump the minimum Black source code reformatter requirement to 24.1.1+. [ ]
- Expand an older changelog entry with a CVE reference. [ ]
- Make
test_zip black clean. [ ]
In addition, James Addison contributed a patch to parse the headers from the diff(1) correctly [ ][ ] thanks! And lastly, Vagrant Cascadian pushed updates in GNU Guix for diffoscope to version 255, 256, and 258, and updated trydiffoscope to 67.0.6.
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian made a number of changes, including:
- Create a (working) proof of concept for enabling a specific number of CPUs. [ ][ ]
- Consistently use 398 days for time variation rather than choosing randomly and update
README.rst to match. [ ][ ]
- Support a new
--vary=build_path.path option. [ ][ ][ ][ ]
Website updates
There were made a number of improvements to our website this month, including:
-
Chris Lamb:
- Improve the relative sizing of headers. [ ]
- Re-order and punch up the introduction and documentation on the
SOURCE_DATE_EPOCH page. [ ]
- Update
SOURCE_DATE_EPOCH documentation re. datetime.datetime.fromtimestamp. Thanks, James Addison. [ ]
- Add a post about Reproducible Builds at FOSDEM 2024. [ ]
-
Holger Levsen:
- Update the GNU Guix page to include their reproducibility QA page. [ ]
- Add Sune Vuorela and Jan-Benedict Glaw to our contributors list. [ ][ ]
-
Mattia Rizzolo:
- Add Sovereign Tech Fund s logo to our sponsors. [ ]
- Update our sponsors list. [ ]
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Other changes:
- Grant Jan-Benedict Glaw shell access to the Jenkins node. [ ]
- Enable debugging for NetBSD reproducibility testing. [ ]
- Use
/usr/bin/du --apparent-size in the Jenkins shell monitor. [ ]
- Revert reproducible nodes: mark osuosl2 as down . [ ]
- Thanks again to Codethink, for they have doubled the RAM on our
arm64 nodes. [ ]
- Only set
/proc/$pid/oom_score_adj to -1000 if it has not already been done. [ ]
- Add the
opemwrt-target-tegra and jtx task to the list of zombie jobs. [ ][ ]
Vagrant Cascadian also made the following changes:
- Overhaul the handling of OpenSSH configuration files after updating from Debian bookworm. [ ][ ][ ]
- Add two new
armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [ ][ ] [ ][ ]
In addition, Alexander Couzens updated the OpenWrt configuration in order to replace the tegra target with mpc85xx [ ], Jan-Benedict Glaw updated the NetBSD build script to use a separate $TMPDIR to mitigate out of space issues on a tmpfs-backed /tmp [ ] and Zheng Junjie added a link to the GNU Guix tests [ ].
Lastly, node maintenance was performed by Holger Levsen [ ][ ][ ][ ][ ][ ] and Vagrant Cascadian [ ][ ][ ][ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Philip Rinn:
gimagereader (date)
-
Bernhard M. Wiedemann:
grass (date-related issue)grub2 (filesystem ordering issue)latex2html (drop a non-deterministic log)mhvtl (tar)obs (build-tool issue)ollama (GZip embedding the modification time)presenterm (filesystem-ordering issue)qt6-quick3d (parallelism)
-
Chris Lamb:
-
James Addison:
- #1064519 filed against
flask-limiter.
python-parsl-doc (disable dynamic argument evaluation by Sphinx autodoc extension)python3-pytest-repeat (remove entry_points.txt creation that varied by shell)python3-selinux (remove packaged direct_url.json file that embeds build path)python3-sepolicy (remove packaged direct_url.json file that embeds build path)- #1064575 filed against
pyswarms.
- #1064638 filed against
python-x2go.
snapd (fix timestamp header in packaged manual-page)zzzeeksphinx (existing RB patch forwarded and merged (with modifications))
-
Johannes Schauer Marin Rodrigues:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
- User cen posted a query asking How to verify a package by rebuilding it locally on Debian which received a followup from Vagrant Cascadian.
- James Addison asked Two questions about build-path reproducibility in Debian regarding the differences in the testing performed by Debian s GitLab continuous integration (CI) pipeline and the Debian-specific testing performed by the Reproducible Builds project itself, and followed this with a separate but related question regarding misconfigured reprotest configurations.
Distribution work
In Debian this month, 5 reviews of Debian packages were added, 22 were updated and 8 were removed this month adding to Debian s knowledge about identified issues. A number of issue types were updated as well. [ ][ ][ ][ ] In addition, Roland Clobus posted his 23rd update of the status of reproducible ISO images on our mailing list. In particular, Roland helpfully summarised that all major desktops build reproducibly with bullseye, bookworm, trixie and sid provided they are built for a second time within the same DAK run (i.e. [within] 6 hours) and that there will likely be further work at a MiniDebCamp in Hamburg. Furthermore, Roland also responded in-depth to a query about a previous report
Fedora developer Zbigniew J drzejewski-Szmek announced a work-in-progress script called fedora-repro-build that attempts to reproduce an existing package within a koji build environment. Although the projects README file lists a number of fields will always or almost always vary and there is a non-zero list of other known issues, this is an excellent first step towards full Fedora reproducibility.
Jelle van der Waa introduced a new linter rule for Arch Linux packages in order to detect cache files leftover by the Sphinx documentation generator which are unreproducible by nature and should not be packaged. At the time of writing, 7 packages in the Arch repository are affected by this.
Elsewhere, Bernhard M. Wiedemann posted another monthly update for his work elsewhere in openSUSE.
diffoscope
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 256, 257 and 258 to Debian and made the following additional changes:
- Use a deterministic name instead of trusting
gpg s use-embedded-filenames. Many thanks to Daniel Kahn Gillmor dkg@debian.org for reporting this issue and providing feedback. [ ][ ]
- Don t error-out with a traceback if we encounter
struct.unpack-related errors when parsing Python .pyc files. (#1064973). [ ]
- Don t try and compare
rdb_expected_diff on non-GNU systems as %p formatting can vary, especially with respect to MacOS. [ ]
- Fix compatibility with
pytest 8.0. [ ]
- Temporarily fix support for Python 3.11.8. [ ]
- Use the
7zip package (over p7zip-full) after a Debian package transition. (#1063559). [ ]
- Bump the minimum Black source code reformatter requirement to 24.1.1+. [ ]
- Expand an older changelog entry with a CVE reference. [ ]
- Make
test_zip black clean. [ ]
In addition, James Addison contributed a patch to parse the headers from the diff(1) correctly [ ][ ] thanks! And lastly, Vagrant Cascadian pushed updates in GNU Guix for diffoscope to version 255, 256, and 258, and updated trydiffoscope to 67.0.6.
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian made a number of changes, including:
- Create a (working) proof of concept for enabling a specific number of CPUs. [ ][ ]
- Consistently use 398 days for time variation rather than choosing randomly and update
README.rst to match. [ ][ ]
- Support a new
--vary=build_path.path option. [ ][ ][ ][ ]
Website updates
There were made a number of improvements to our website this month, including:
-
Chris Lamb:
- Improve the relative sizing of headers. [ ]
- Re-order and punch up the introduction and documentation on the
SOURCE_DATE_EPOCH page. [ ]
- Update
SOURCE_DATE_EPOCH documentation re. datetime.datetime.fromtimestamp. Thanks, James Addison. [ ]
- Add a post about Reproducible Builds at FOSDEM 2024. [ ]
-
Holger Levsen:
- Update the GNU Guix page to include their reproducibility QA page. [ ]
- Add Sune Vuorela and Jan-Benedict Glaw to our contributors list. [ ][ ]
-
Mattia Rizzolo:
- Add Sovereign Tech Fund s logo to our sponsors. [ ]
- Update our sponsors list. [ ]
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Other changes:
- Grant Jan-Benedict Glaw shell access to the Jenkins node. [ ]
- Enable debugging for NetBSD reproducibility testing. [ ]
- Use
/usr/bin/du --apparent-size in the Jenkins shell monitor. [ ]
- Revert reproducible nodes: mark osuosl2 as down . [ ]
- Thanks again to Codethink, for they have doubled the RAM on our
arm64 nodes. [ ]
- Only set
/proc/$pid/oom_score_adj to -1000 if it has not already been done. [ ]
- Add the
opemwrt-target-tegra and jtx task to the list of zombie jobs. [ ][ ]
Vagrant Cascadian also made the following changes:
- Overhaul the handling of OpenSSH configuration files after updating from Debian bookworm. [ ][ ][ ]
- Add two new
armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [ ][ ] [ ][ ]
In addition, Alexander Couzens updated the OpenWrt configuration in order to replace the tegra target with mpc85xx [ ], Jan-Benedict Glaw updated the NetBSD build script to use a separate $TMPDIR to mitigate out of space issues on a tmpfs-backed /tmp [ ] and Zheng Junjie added a link to the GNU Guix tests [ ].
Lastly, node maintenance was performed by Holger Levsen [ ][ ][ ][ ][ ][ ] and Vagrant Cascadian [ ][ ][ ][ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Philip Rinn:
gimagereader (date)
-
Bernhard M. Wiedemann:
grass (date-related issue)grub2 (filesystem ordering issue)latex2html (drop a non-deterministic log)mhvtl (tar)obs (build-tool issue)ollama (GZip embedding the modification time)presenterm (filesystem-ordering issue)qt6-quick3d (parallelism)
-
Chris Lamb:
-
James Addison:
- #1064519 filed against
flask-limiter.
python-parsl-doc (disable dynamic argument evaluation by Sphinx autodoc extension)python3-pytest-repeat (remove entry_points.txt creation that varied by shell)python3-selinux (remove packaged direct_url.json file that embeds build path)python3-sepolicy (remove packaged direct_url.json file that embeds build path)- #1064575 filed against
pyswarms.
- #1064638 filed against
python-x2go.
snapd (fix timestamp header in packaged manual-page)zzzeeksphinx (existing RB patch forwarded and merged (with modifications))
-
Johannes Schauer Marin Rodrigues:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made a number of changes such as uploading versions 256, 257 and 258 to Debian and made the following additional changes:
- Use a deterministic name instead of trusting
gpgs use-embedded-filenames. Many thanks to Daniel Kahn Gillmor dkg@debian.org for reporting this issue and providing feedback. [ ][ ] - Don t error-out with a traceback if we encounter
struct.unpack-related errors when parsing Python.pycfiles. (#1064973). [ ] - Don t try and compare
rdb_expected_diffon non-GNU systems as%pformatting can vary, especially with respect to MacOS. [ ] - Fix compatibility with
pytest8.0. [ ] - Temporarily fix support for Python 3.11.8. [ ]
- Use the
7zippackage (overp7zip-full) after a Debian package transition. (#1063559). [ ] - Bump the minimum Black source code reformatter requirement to 24.1.1+. [ ]
- Expand an older changelog entry with a CVE reference. [ ]
- Make
test_zipblack clean. [ ]
diff(1) correctly [ ][ ] thanks! And lastly, Vagrant Cascadian pushed updates in GNU Guix for diffoscope to version 255, 256, and 258, and updated trydiffoscope to 67.0.6.
reprotest
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian made a number of changes, including:
- Create a (working) proof of concept for enabling a specific number of CPUs. [ ][ ]
- Consistently use 398 days for time variation rather than choosing randomly and update
README.rst to match. [ ][ ]
- Support a new
--vary=build_path.path option. [ ][ ][ ][ ]
Website updates
There were made a number of improvements to our website this month, including:
-
Chris Lamb:
- Improve the relative sizing of headers. [ ]
- Re-order and punch up the introduction and documentation on the
SOURCE_DATE_EPOCH page. [ ]
- Update
SOURCE_DATE_EPOCH documentation re. datetime.datetime.fromtimestamp. Thanks, James Addison. [ ]
- Add a post about Reproducible Builds at FOSDEM 2024. [ ]
-
Holger Levsen:
- Update the GNU Guix page to include their reproducibility QA page. [ ]
- Add Sune Vuorela and Jan-Benedict Glaw to our contributors list. [ ][ ]
-
Mattia Rizzolo:
- Add Sovereign Tech Fund s logo to our sponsors. [ ]
- Update our sponsors list. [ ]
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Other changes:
- Grant Jan-Benedict Glaw shell access to the Jenkins node. [ ]
- Enable debugging for NetBSD reproducibility testing. [ ]
- Use
/usr/bin/du --apparent-size in the Jenkins shell monitor. [ ]
- Revert reproducible nodes: mark osuosl2 as down . [ ]
- Thanks again to Codethink, for they have doubled the RAM on our
arm64 nodes. [ ]
- Only set
/proc/$pid/oom_score_adj to -1000 if it has not already been done. [ ]
- Add the
opemwrt-target-tegra and jtx task to the list of zombie jobs. [ ][ ]
Vagrant Cascadian also made the following changes:
- Overhaul the handling of OpenSSH configuration files after updating from Debian bookworm. [ ][ ][ ]
- Add two new
armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [ ][ ] [ ][ ]
In addition, Alexander Couzens updated the OpenWrt configuration in order to replace the tegra target with mpc85xx [ ], Jan-Benedict Glaw updated the NetBSD build script to use a separate $TMPDIR to mitigate out of space issues on a tmpfs-backed /tmp [ ] and Zheng Junjie added a link to the GNU Guix tests [ ].
Lastly, node maintenance was performed by Holger Levsen [ ][ ][ ][ ][ ][ ] and Vagrant Cascadian [ ][ ][ ][ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Philip Rinn:
gimagereader (date)
-
Bernhard M. Wiedemann:
grass (date-related issue)grub2 (filesystem ordering issue)latex2html (drop a non-deterministic log)mhvtl (tar)obs (build-tool issue)ollama (GZip embedding the modification time)presenterm (filesystem-ordering issue)qt6-quick3d (parallelism)
-
Chris Lamb:
-
James Addison:
- #1064519 filed against
flask-limiter.
python-parsl-doc (disable dynamic argument evaluation by Sphinx autodoc extension)python3-pytest-repeat (remove entry_points.txt creation that varied by shell)python3-selinux (remove packaged direct_url.json file that embeds build path)python3-sepolicy (remove packaged direct_url.json file that embeds build path)- #1064575 filed against
pyswarms.
- #1064638 filed against
python-x2go.
snapd (fix timestamp header in packaged manual-page)zzzeeksphinx (existing RB patch forwarded and merged (with modifications))
-
Johannes Schauer Marin Rodrigues:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
README.rst to match. [ ][ ]--vary=build_path.path option. [ ][ ][ ][ ]
There were made a number of improvements to our website this month, including:
-
Chris Lamb:
- Improve the relative sizing of headers. [ ]
- Re-order and punch up the introduction and documentation on the
SOURCE_DATE_EPOCHpage. [ ] - Update
SOURCE_DATE_EPOCHdocumentation re.datetime.datetime.fromtimestamp. Thanks, James Addison. [ ] - Add a post about Reproducible Builds at FOSDEM 2024. [ ]
-
Holger Levsen:
- Update the GNU Guix page to include their reproducibility QA page. [ ]
- Add Sune Vuorela and Jan-Benedict Glaw to our contributors list. [ ][ ]
-
Mattia Rizzolo:
- Add Sovereign Tech Fund s logo to our sponsors. [ ]
- Update our sponsors list. [ ]
Reproducibility testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In February, a number of changes were made by Holger Levsen:
-
Debian-related changes:
-
Other changes:
- Grant Jan-Benedict Glaw shell access to the Jenkins node. [ ]
- Enable debugging for NetBSD reproducibility testing. [ ]
- Use
/usr/bin/du --apparent-size in the Jenkins shell monitor. [ ]
- Revert reproducible nodes: mark osuosl2 as down . [ ]
- Thanks again to Codethink, for they have doubled the RAM on our
arm64 nodes. [ ]
- Only set
/proc/$pid/oom_score_adj to -1000 if it has not already been done. [ ]
- Add the
opemwrt-target-tegra and jtx task to the list of zombie jobs. [ ][ ]
Vagrant Cascadian also made the following changes:
- Overhaul the handling of OpenSSH configuration files after updating from Debian bookworm. [ ][ ][ ]
- Add two new
armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [ ][ ] [ ][ ]
In addition, Alexander Couzens updated the OpenWrt configuration in order to replace the tegra target with mpc85xx [ ], Jan-Benedict Glaw updated the NetBSD build script to use a separate $TMPDIR to mitigate out of space issues on a tmpfs-backed /tmp [ ] and Zheng Junjie added a link to the GNU Guix tests [ ].
Lastly, node maintenance was performed by Holger Levsen [ ][ ][ ][ ][ ][ ] and Vagrant Cascadian [ ][ ][ ][ ].
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Philip Rinn:
gimagereader (date)
-
Bernhard M. Wiedemann:
grass (date-related issue)grub2 (filesystem ordering issue)latex2html (drop a non-deterministic log)mhvtl (tar)obs (build-tool issue)ollama (GZip embedding the modification time)presenterm (filesystem-ordering issue)qt6-quick3d (parallelism)
-
Chris Lamb:
-
James Addison:
- #1064519 filed against
flask-limiter.
python-parsl-doc (disable dynamic argument evaluation by Sphinx autodoc extension)python3-pytest-repeat (remove entry_points.txt creation that varied by shell)python3-selinux (remove packaged direct_url.json file that embeds build path)python3-sepolicy (remove packaged direct_url.json file that embeds build path)- #1064575 filed against
pyswarms.
- #1064638 filed against
python-x2go.
snapd (fix timestamp header in packaged manual-page)zzzeeksphinx (existing RB patch forwarded and merged (with modifications))
-
Johannes Schauer Marin Rodrigues:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Twitter: @ReproBuilds
-
Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org
- Grant Jan-Benedict Glaw shell access to the Jenkins node. [ ]
- Enable debugging for NetBSD reproducibility testing. [ ]
- Use
/usr/bin/du --apparent-sizein the Jenkins shell monitor. [ ] - Revert reproducible nodes: mark osuosl2 as down . [ ]
- Thanks again to Codethink, for they have doubled the RAM on our
arm64nodes. [ ] - Only set
/proc/$pid/oom_score_adjto -1000 if it has not already been done. [ ] - Add the
opemwrt-target-tegraandjtxtask to the list of zombie jobs. [ ][ ]
armhf architecture build nodes, virt32z and virt64z, and insert them into the Munin monitoring. [ ][ ] [ ][ ]-
Philip Rinn:
gimagereader(date)
-
Bernhard M. Wiedemann:
grass(date-related issue)grub2(filesystem ordering issue)latex2html(drop a non-deterministic log)mhvtl(tar)obs(build-tool issue)ollama(GZip embedding the modification time)presenterm(filesystem-ordering issue)qt6-quick3d(parallelism)
- Chris Lamb:
-
James Addison:
- #1064519 filed against
flask-limiter. python-parsl-doc(disable dynamic argument evaluation by Sphinxautodocextension)python3-pytest-repeat(removeentry_points.txtcreation that varied by shell)python3-selinux(remove packageddirect_url.jsonfile that embeds build path)python3-sepolicy(remove packageddirect_url.jsonfile that embeds build path)- #1064575 filed against
pyswarms. - #1064638 filed against
python-x2go. snapd(fix timestamp header in packaged manual-page)zzzeeksphinx(existing RB patch forwarded and merged (with modifications))
- #1064519 filed against
- Johannes Schauer Marin Rodrigues:
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-buildsonirc.oftc.net. - Twitter: @ReproBuilds
- Mastodon: @reproducible_builds@fosstodon.org
-
Mailing list:
rb-general@lists.reproducible-builds.org

 Yesterday I tagged a new version of onak, my OpenPGP compatible keyserver. I d spent a bit of time during
Yesterday I tagged a new version of onak, my OpenPGP compatible keyserver. I d spent a bit of time during  Reduce the size of your c: partition to the smallest it can be and then turn off windows with the understanding that you will never boot this system on the iron ever again.
Reduce the size of your c: partition to the smallest it can be and then turn off windows with the understanding that you will never boot this system on the iron ever again. To find the literal path names of your detected drives you can run fdisk -l. Pay attention to the names of the partitions and the sizes of the drives to help determine which is which.
Once you have a shell in the netinst installer, you should maybe be able to run a command like the following. This will duplicate the disk located at if (in file) to the disk located at of (out file) while showing progress as the status.
To find the literal path names of your detected drives you can run fdisk -l. Pay attention to the names of the partitions and the sizes of the drives to help determine which is which.
Once you have a shell in the netinst installer, you should maybe be able to run a command like the following. This will duplicate the disk located at if (in file) to the disk located at of (out file) while showing progress as the status.
 In the New VM window, select Import existing disk image
In the New VM window, select Import existing disk image 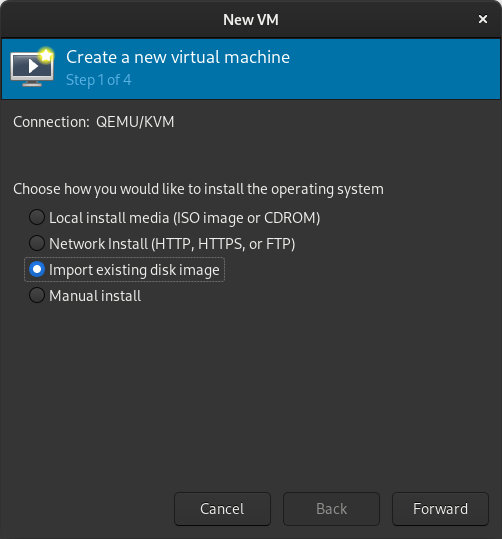 When prompted for the path to the image, use the one we created with sudo qemu-img convert above.
When prompted for the path to the image, use the one we created with sudo qemu-img convert above.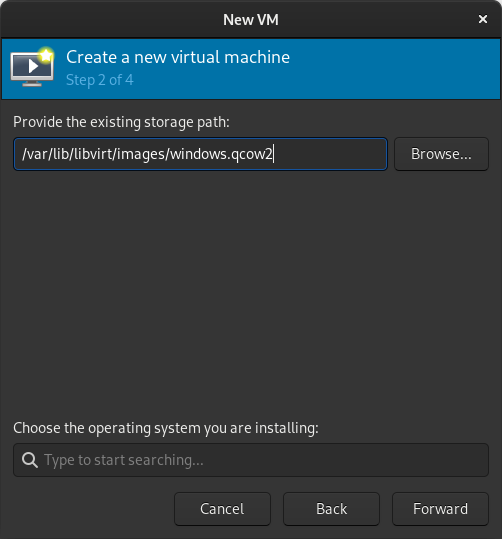 Select the version of Windows you want.
Select the version of Windows you want.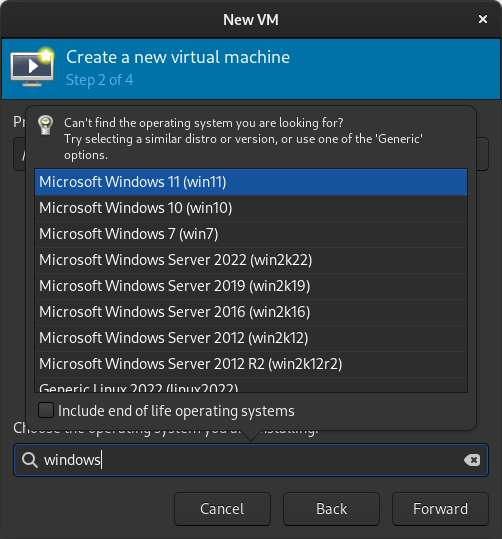 Select memory and CPUs to allocate to the VM.
Select memory and CPUs to allocate to the VM.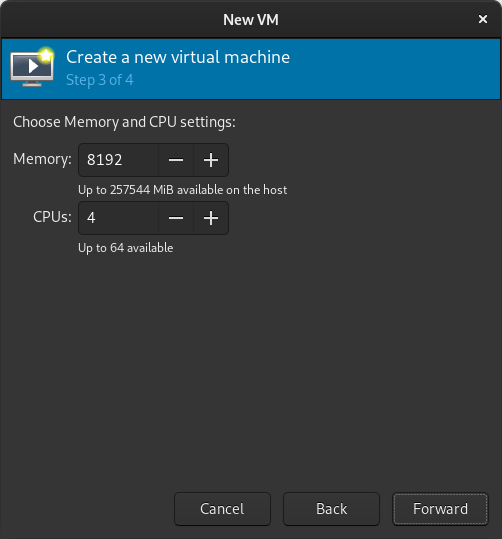 Tick the Customize configuration before install box
Tick the Customize configuration before install box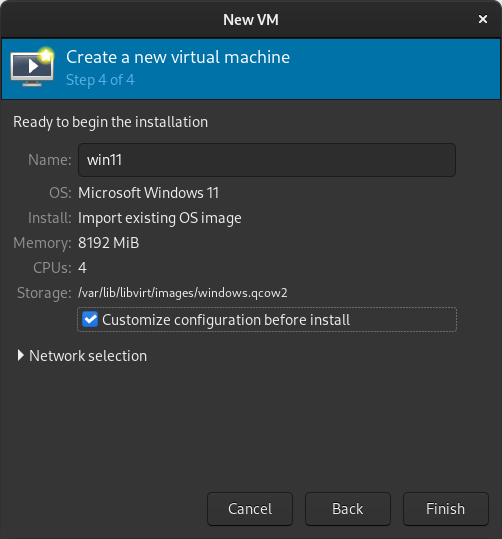 If you re prompted to enable the default network, do so now.
If you re prompted to enable the default network, do so now.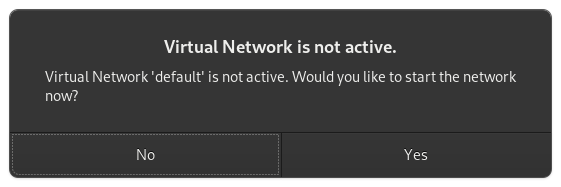 The default hardware layout should probably suffice. Get it as close to the underlying hardware as it is convenient to do. But Windows is pretty lenient these days about virtualizing licensed windows instances so long as they re not running in more than one place at a time.
The default hardware layout should probably suffice. Get it as close to the underlying hardware as it is convenient to do. But Windows is pretty lenient these days about virtualizing licensed windows instances so long as they re not running in more than one place at a time.
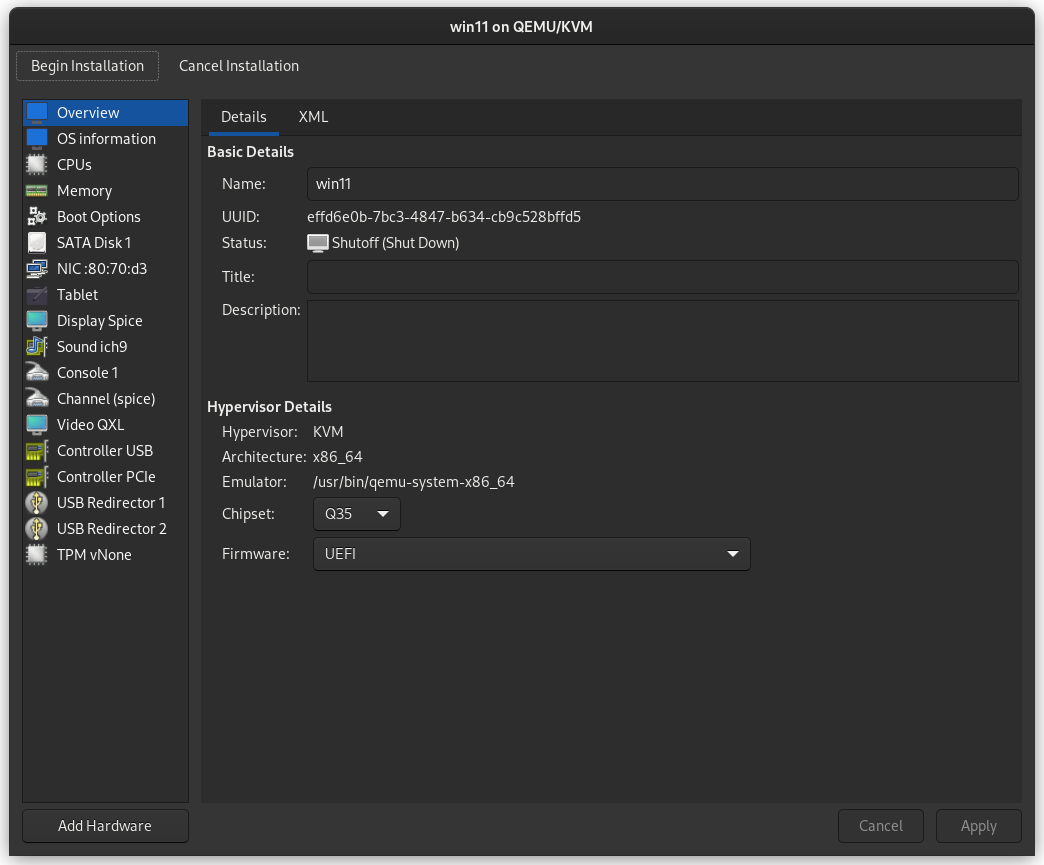 Good luck! Leave comments if you have questions.
Good luck! Leave comments if you have questions.
 I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is:
I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is: 
 Although it was a much larger step when I made a similar announcement
Although it was a much larger step when I made a similar announcement

 Completely forgot to mention this earlier in the year, but delighted to say that in just under 4 weeks I ll be attending DebConf 17 in Montr al. Looking forward to seeing a bunch of fine folk there!
Outbound:
Completely forgot to mention this earlier in the year, but delighted to say that in just under 4 weeks I ll be attending DebConf 17 in Montr al. Looking forward to seeing a bunch of fine folk there!
Outbound:
 Here is my monthly update covering what I have been doing in the free software world (
Here is my monthly update covering what I have been doing in the free software world ({kind=link}