Welcome to the May 2023 report from the Reproducible Builds project
 In our reports, we outline the most important things that we have been up to over the past month. As always, if you are interested in contributing to the project, please visit our Contribute page on our website.
In our reports, we outline the most important things that we have been up to over the past month. As always, if you are interested in contributing to the project, please visit our Contribute page on our website.

Holger Levsen gave a talk at the 2023 edition of the
Debian Reunion Hamburg, a semi-informal meetup of Debian-related people in northern Germany. The
slides are available online.

In April, Holger Levsen gave a talk at
foss-north 2023 titled
Reproducible Builds, the first ten years. Last month, however, Holger s talk was covered in
a round-up of the conference on the Free Software Foundation Europe (FSFE) blog.

Pronnoy Goswami, Saksham Gupta, Zhiyuan Li, Na Meng and Daphne Yao from
Virginia Tech published a paper investigating the
Reproducibility of NPM Packages. The abstract includes:
When using open-source NPM packages, most developers download prebuilt packages on npmjs.com instead of building those packages from available source, and implicitly trust the downloaded packages. However, it is unknown whether the blindly trusted prebuilt NPM packages are reproducible (i.e., whether there is always a verifiable path from source code to any published NPM package). [ ] We downloaded versions/releases of 226 most popularly used NPM packages and then built each version with the available source on GitHub. Next, we applied a differencing tool to compare the versions we built against versions downloaded from NPM, and further inspected any reported difference.
The paper reports that among the 3,390 versions of the 226 packages, only 2,087 versions are reproducible, and furthermore that multiple factors contribute to the non-reproducibility including flexible versioning information in package.json file and the divergent behaviors between distinct versions of tools used in the build process. The paper concludes with insights for future verifiable build procedures.
Unfortunately, a PDF is not available publically yet, but a
Digital Object Identifier (DOI) is available on the
paper s IEEE page.

Elsewhere in academia, Betul Gokkaya, Leonardo Aniello and Basel Halak of the
School of Electronics and Computer Science at the
University of Southampton published a new paper containing a broad overview of attacks and comprehensive risk assessment for software supply chain security.
Their paper, titled
Software supply chain: review of attacks, risk assessment strategies and security controls, analyses the most common software supply-chain attacks by providing the latest trend of analyzed attack, and identifies the security risks for open-source and third-party software supply chains. Furthermore, their study introduces unique security controls to mitigate analyzed cyber-attacks and risks by linking them with real-life security incidence and attacks . (
arXiv.org,
PDF)
 NixOS
NixOS is now tracking two new reports at
reproducible.nixos.org. Aside from the collection of build-time dependencies of the minimal and Gnome installation ISOs, this page now also contains reports that are restricted to the artifacts that make it into the image. The minimal ISO is currently reproducible except for Python 3.10, which hopefully will be resolved with the coming update to Python version 3.11.
On
our rb-general mailing list this month:

David A. Wheeler
started a thread noting that the
OSSGadget project s oss-reproducible tool was measuring something related to but not the same as reproducible builds. Initially they had adopted the term semantically reproducible build term for what it measured, which they defined as being if its build results can be either recreated exactly (a bit for bit reproducible build), or if the differences between the release package and a rebuilt package are not expected to produce functional differences in normal cases. This
generated a significant number of replies, and several were concerned that people might confuse what they were measuring with reproducible builds . After discussion, the OSSGadget developers decided to
switch to the term semantically equivalent for what they measured in order to reduce the risk of confusion.
Vagrant Cascadian (
vagrantc) posted an update about
GCC, binutils, and Debian s build-essential set with some progress, some hope, and I daresay, some fears .
Lastly,
kpcyrd asked a question about
building a reproducible Linux kernel package for Arch Linux (
answered by Arnout Engelen). In the same, thread David A. Wheeler pointed out that the
Linux Kernel documentation has a chapter about Reproducible kernel builds now as well.

In Debian this month, nine reviews of Debian packages were added, 20 were updated and 6 were removed this month, all adding to
our knowledge about identified issues. In addition, Vagrant Cascadian added a link to the source code causing various
ecbuild issues. [
]

The
F-Droid project updated its Inclusion How-To with a
new section explaining why it considers reproducible builds to be best practice and hopes developers will support the team s efforts to make as many (new) apps reproducible as it reasonably can.
In
diffoscope development this month, version
242 was
uploaded to Debian unstable by Chris Lamb who also made the following changes:
- If
binwalk is not available, ensure the user knows they may be missing more info. [ ]
- Factor out generating a human-readable comment when missing a Python module. [ ]
In addition, Mattia Rizzolo documented how to (re)-produce a binary blob in the code [
] and Vagrant Cascadian updated the version of
diffoscope in
GNU Guix to 242 [
].
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Holger Levsen uploaded versions
0.7.24 and
0.7.25 to Debian
unstable which added support for
Tox versions 3 and 4 with help from Vagrant Cascadian [
][
][
]
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Alper Nebi Yasak:
-
Bernhard M. Wiedemann:
-
Chris Lamb:
-
Vagrant Cascadian:
In addition, Jason A. Donenfeld filed a bug (now fixed in the latest alpha version) in the Android issue tracker to report that generateLocaleConfig in Android Gradle Plugin version 8.1.0 generates XML files using non-deterministic ordering, breaking reproducible builds. [ ]
Testing framework
 The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In May, a number of changes were made by Holger Levsen:
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In May, a number of changes were made by Holger Levsen:
- Update the kernel configuration of
arm64 nodes only put required modules in the initrd to save space in the /boot partition. [ ]
- A huge number of changes to a new tool to document/track Jenkins node maintenance, including adding
--fetch, --help, --no-future and --verbose options [ ][ ][ ][ ] as well as adding a suite of new actions, such as apt-upgrade, command, deploy-git, rmstamp, etc. [ ][ ][ ][ ] in addition a significant amount of refactoring [ ][ ][ ][ ].
- Issue warnings if
apt has updates to install. [ ]
- Allow Jenkins to run apt get update in maintenance job. [ ]
- Installed
bind9-dnsutils on some Ubuntu 18.04 nodes. [ ][ ]
- Fixed the Jenkins shell monitor to correctly deal with little-used directories. [ ]
- Updated the node health check to warn when
apt upgrades are available. [ ]
- Performed some node maintenance. [ ]
In addition, Vagrant Cascadian added the nocheck, nopgo and nolto when building gcc-* and binutils packages [ ] as well as performed some node maintenance [ ][ ]. In addition, Roland Clobus updated the openQA configuration to specify longer timeouts and access to the developer mode [ ] and updated the URL used for reproducible Debian Live images [ ].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
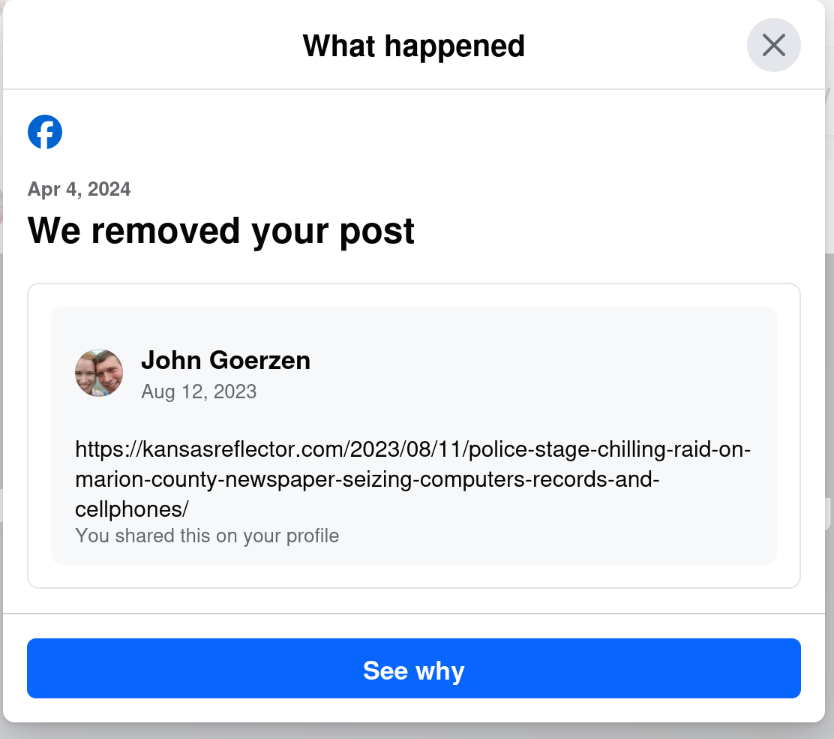 Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
Yes, that s right: today, April 6, I get a notification that they removed a post from August 12. The notification was dated April 4, but only showed up for me today.
I wonder why my post from August 12 was fine for nearly 8 months, and then all of a sudden, when the same website runs an article critical of Facebook, my 8-month-old post is a problem. Hmm.
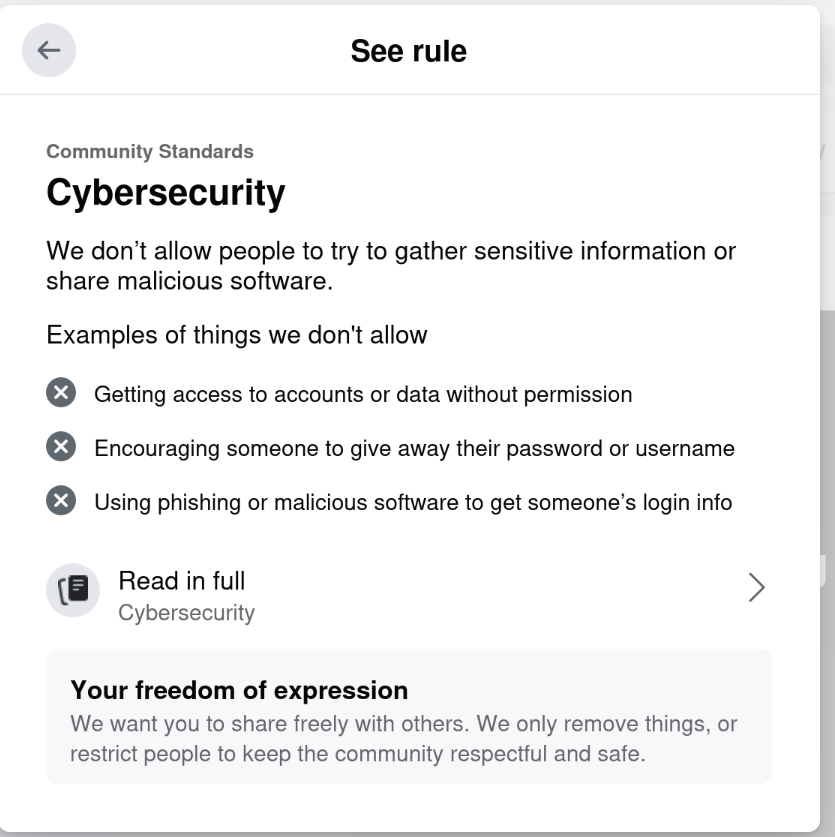 Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they
Riiiiiight. Cybersecurity.
This isn t even the first time they ve done this to me.
On September 11, 2021, they 
 The
The
 Debian Public Statement about the EU Cyber Resilience Act and the Product Liability Directive
The European Union is currently preparing a regulation "on horizontal
cybersecurity requirements for products with digital elements" known as the
Cyber Resilience Act (CRA). It is currently in the final "trilogue" phase of
the legislative process. The act includes a set of essential cybersecurity and
vulnerability handling requirements for manufacturers. It will require products
to be accompanied by information and instructions to the user. Manufacturers
will need to perform risk assessments and produce technical documentation and,
for critical components, have third-party audits conducted. Discovered security
issues will have to be reported to European authorities within 25 hours (1).
The CRA will be followed up by the Product Liability Directive (PLD) which will
introduce compulsory liability for software.
While a lot of these regulations seem reasonable, the Debian project believes
that there are grave problems for Free Software projects attached to them.
Therefore, the Debian project issues the following statement:
Debian Public Statement about the EU Cyber Resilience Act and the Product Liability Directive
The European Union is currently preparing a regulation "on horizontal
cybersecurity requirements for products with digital elements" known as the
Cyber Resilience Act (CRA). It is currently in the final "trilogue" phase of
the legislative process. The act includes a set of essential cybersecurity and
vulnerability handling requirements for manufacturers. It will require products
to be accompanied by information and instructions to the user. Manufacturers
will need to perform risk assessments and produce technical documentation and,
for critical components, have third-party audits conducted. Discovered security
issues will have to be reported to European authorities within 25 hours (1).
The CRA will be followed up by the Product Liability Directive (PLD) which will
introduce compulsory liability for software.
While a lot of these regulations seem reasonable, the Debian project believes
that there are grave problems for Free Software projects attached to them.
Therefore, the Debian project issues the following statement:







 On
On 
 (I wrote this up for an internal work post, but I figure it s worth sharing more publicly too.)
I spent last week at
(I wrote this up for an internal work post, but I figure it s worth sharing more publicly too.)
I spent last week at  O Debian Day em Macei 2023 foi realizado no audit rio do Senai em Macei com
apoio e realiza o do
O Debian Day em Macei 2023 foi realizado no audit rio do Senai em Macei com
apoio e realiza o do 











 . Internet shutdowns impact women
. Internet shutdowns impact women 


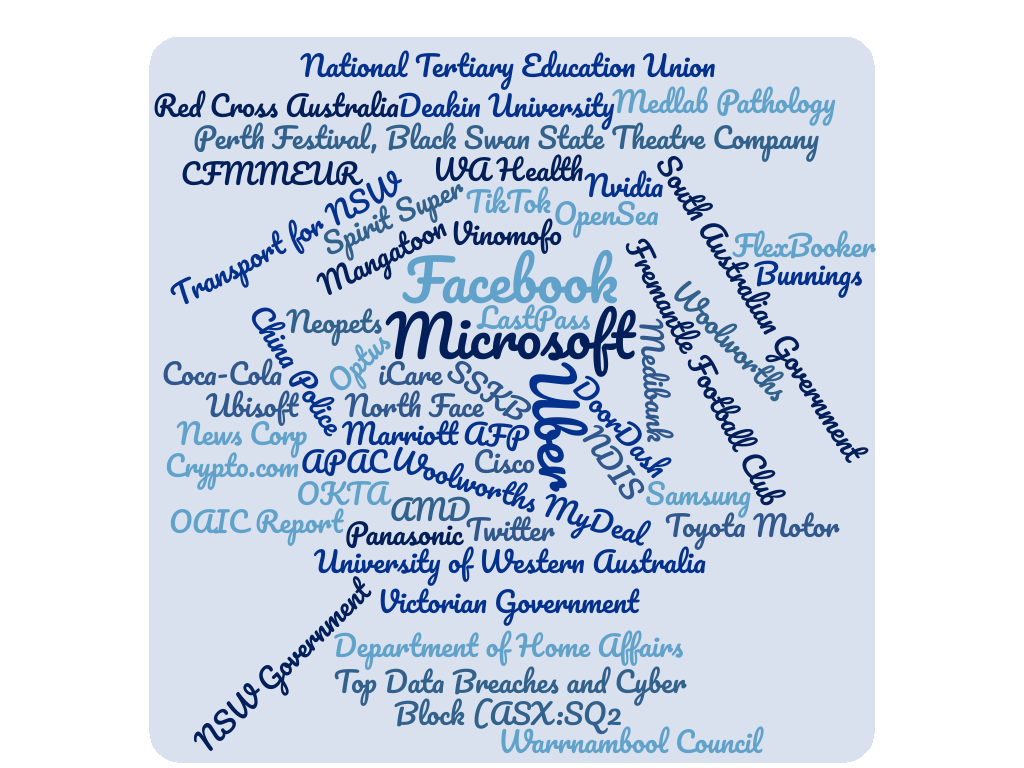 Just some of the organisations that leaked data in 2022
Just some of the organisations that leaked data in 2022
 Not very useful for a database
Not very useful for a database
 Indeed
Indeed
 Everyone who uses a database...
Everyone who uses a database...







