Matthew Garrett: Digital forgeries are hard
 Closing arguments in the trial between various people and Craig Wright over whether he's Satoshi Nakamoto are wrapping up today, amongst a bewildering array of presented evidence. But one utterly astonishing aspect of this lawsuit is that expert witnesses for both sides agreed that much of the digital evidence provided by Craig Wright was unreliable in one way or another, generally including indications that it wasn't produced at the point in time it claimed to be. And it's fascinating reading through the subtle (and, in some cases, not so subtle) ways that that's revealed.
Closing arguments in the trial between various people and Craig Wright over whether he's Satoshi Nakamoto are wrapping up today, amongst a bewildering array of presented evidence. But one utterly astonishing aspect of this lawsuit is that expert witnesses for both sides agreed that much of the digital evidence provided by Craig Wright was unreliable in one way or another, generally including indications that it wasn't produced at the point in time it claimed to be. And it's fascinating reading through the subtle (and, in some cases, not so subtle) ways that that's revealed.One of the pieces of evidence entered is screenshots of data from Mind Your Own Business, a business management product that's been around for some time. Craig Wright relied on screenshots of various entries from this product to support his claims around having controlled meaningful number of bitcoin before he was publicly linked to being Satoshi. If these were authentic then they'd be strong evidence linking him to the mining of coins before Bitcoin's public availability. Unfortunately the screenshots themselves weren't contemporary - the metadata shows them being created in 2020. This wouldn't fundamentally be a problem (it's entirely reasonable to create new screenshots of old material), as long as it's possible to establish that the material shown in the screenshots was created at that point. Sadly, well.
One part of the disclosed information was an email that contained a zip file that contained a raw database in the format used by MYOB. Importing that into the tool allowed an audit record to be extracted - this record showed that the relevant entries had been added to the database in 2020, shortly before the screenshots were created. This was, obviously, not strong evidence that Craig had held Bitcoin in 2009. This evidence was reported, and was responded to with a couple of additional databases that had an audit trail that was consistent with the dates in the records in question. Well, partially. The audit record included session data, showing an administrator logging into the data base in 2011 and then, uh, logging out in 2023, which is rather more consistent with someone changing their system clock to 2011 to create an entry, and switching it back to present day before logging out. In addition, the audit log included fields that didn't exist in versions of the product released before 2016, strongly suggesting that the entries dated 2009-2011 were created in software released after 2016. And even worse, the order of insertions into the database didn't line up with calendar time - an entry dated before another entry may appear in the database afterwards, indicating that it was created later. But even more obvious? The database schema used for these old entries corresponded to a version of the software released in 2023.
This is all consistent with the idea that these records were created after the fact and backdated to 2009-2011, and that after this evidence was made available further evidence was created and backdated to obfuscate that. In an unusual turn of events, during the trial Craig Wright introduced further evidence in the form of a chain of emails to his former lawyers that indicated he had provided them with login details to his MYOB instance in 2019 - before the metadata associated with the screenshots. The implication isn't entirely clear, but it suggests that either they had an opportunity to examine this data before the metadata suggests it was created, or that they faked the data? So, well, the obvious thing happened, and his former lawyers were asked whether they received these emails. The chain consisted of three emails, two of which they confirmed they'd received. And they received a third email in the chain, but it was different to the one entered in evidence. And, uh, weirdly, they'd received a copy of the email that was submitted - but they'd received it a few days earlier. In 2024.
And again, the forensic evidence is helpful here! It turns out that the email client used associates a timestamp with any attachments, which in this case included an image in the email footer - and the mysterious time travelling email had a timestamp in 2024, not 2019. This was created by the client, so was consistent with the email having been sent in 2024, not being sent in 2019 and somehow getting stuck somewhere before delivery. The date header indicates 2019, as do encoded timestamps in the MIME headers - consistent with the mail being sent by a computer with the clock set to 2019.
But there's a very weird difference between the copy of the email that was submitted in evidence and the copy that was located afterwards! The first included a header inserted by gmail that included a 2019 timestamp, while the latter had a 2024 timestamp. Is there a way to determine which of these could be the truth? It turns out there is! The format of that header changed in 2022, and the version in the email is the new version. The version with the 2019 timestamp is anachronistic - the format simply doesn't match the header that gmail would have introduced in 2019, suggesting that an email sent in 2022 or later was modified to include a timestamp of 2019.
This is by no means the only indication that Craig Wright's evidence may be misleading (there's the whole argument that the Bitcoin white paper was written in LaTeX when general consensus is that it's written in OpenOffice, given that's what the metadata claims), but it's a lovely example of a more general issue.
Our technology chains are complicated. So many moving parts end up influencing the content of the data we generate, and those parts develop over time. It's fantastically difficult to generate an artifact now that precisely corresponds to how it would look in the past, even if we go to the effort of installing an old OS on an old PC and setting the clock appropriately (are you sure you're going to be able to mimic an entirely period appropriate patch level?). Even the version of the font you use in a document may indicate it's anachronistic. I'm pretty good at computers and I no longer have any belief I could fake an old document.
(References: this Dropbox, under "Expert reports", "Patrick Madden". Initial MYOB data is in "Appendix PM7", further analysis is in "Appendix PM42", email analysis is "Sixth Expert Report of Mr Patrick Madden")
 Perl REGEX Problems courtesy of XKCD
Perl REGEX Problems courtesy of XKCD Grafana console showing the use of the label_replace function
Grafana console showing the use of the label_replace function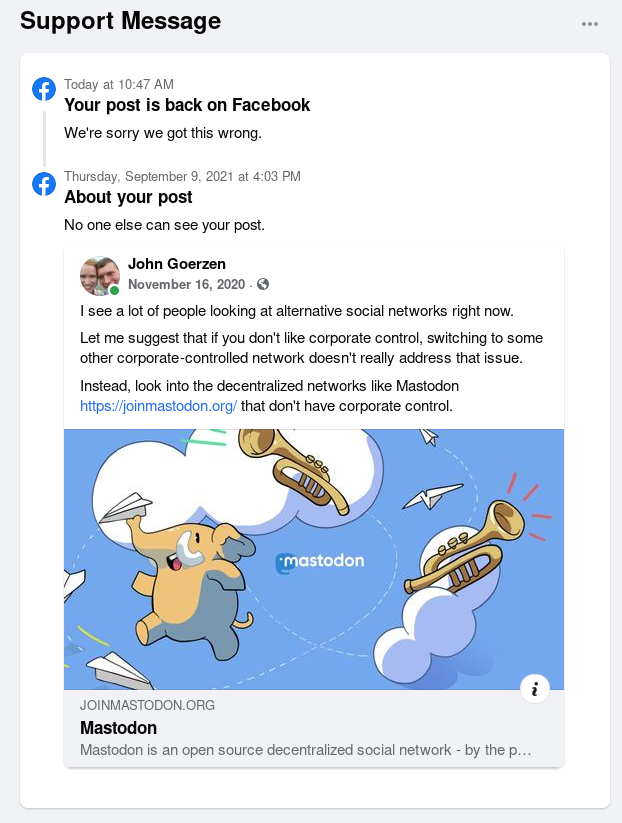 We also don t know if this reversal was human or algorithmic, but that still is beside the point.
The point is, Facebook intentionally chooses to surface and promote those things that drive engagement, regardless of quality.
Clearly many have wondered if tens of thousands of people have died unnecessary deaths over COVID as a result. One whistleblower says
We also don t know if this reversal was human or algorithmic, but that still is beside the point.
The point is, Facebook intentionally chooses to surface and promote those things that drive engagement, regardless of quality.
Clearly many have wondered if tens of thousands of people have died unnecessary deaths over COVID as a result. One whistleblower says