If you ve done anything in the Kubernetes space in recent years, you ve most likely come across the words Service Mesh . It s backed by a set of mature technologies that provides cross-cutting networking, security, infrastructure capabilities to be used by workloads running in Kubernetes in a manner that is transparent to the actual workload. This abstraction enables application developers to not worry about building in otherwise sophisticated capabilities for networking, routing, circuit-breaking and security, and simply rely on the services offered by the service mesh.In this post, I ll be covering Linkerd, which is an alternative to Istio. It has gone through a significant re-write when it transitioned from the JVM to a Go-based Control Plane and a Rust-based Data Plane a few years back and is now a part of the CNCF and is backed by Buoyant. It has proven itself widely for use in production workloads and has a healthy community and release cadence.It achieves this with a side-car container that communicates with a Linkerd control plane that allows central management of policy, telemetry, mutual TLS, traffic routing, shaping, retries, load balancing, circuit-breaking and other cross-cutting concerns before the traffic hits the container. This has made the task of implementing the application services much simpler as it is managed by container orchestrator and service mesh. I covered Istio in a prior post a few years back, and much of the content is still applicable for this post, if you d like to have a look.Here are the broad architectural components of Linkerd:The components are separated into the control plane and the data plane.The control plane components live in its own namespace and consists of a controller that the Linkerd CLI interacts with via the Kubernetes API. The destination service is used for service discovery, TLS identity, policy on access control for inter-service communication and service profile information on routing, retries, timeouts. The identity service acts as the Certificate Authority which responds to Certificate Signing Requests (CSRs) from proxies for initialization and for service-to-service encrypted traffic. The proxy injector is an admission webhook that injects the Linkerd proxy side car and the init container automatically into a pod when the linkerd.io/inject: enabled is available on the namespace or workload.On the data plane side are two components. First, the init container, which is responsible for automatically forwarding incoming and outgoing traffic through the Linkerd proxy via iptables rules. Second, the Linkerd proxy, which is a lightweight micro-proxy written in Rust, is the data plane itself.I will be walking you through the setup of Linkerd (2.12.2 at the time of writing) on a Kubernetes cluster.Let s see what s running on the cluster currently. This assumes you have a cluster running and kubectl is installed and available on the PATH.
On most systems, this should be sufficient to setup the CLI. You may need to restart your terminal to load the updated paths. If you have a non-standard configuration and linkerd is not found after the installation, add the following to your PATH to be able to find the cli:
export PATH=$PATH:~/.linkerd2/bin/
At this point, checking the version would give you the following:
$ linkerd version Client version: stable-2.12.2 Server version: unavailable
Setting up Linkerd Control PlaneBefore installing Linkerd on the cluster, run the following step to check the cluster for pre-requisites:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
pre-kubernetes-setup -------------------- control plane namespace does not already exist can create non-namespaced resources can create ServiceAccounts can create Services can create Deployments can create CronJobs can create ConfigMaps can create Secrets can read Secrets can read extension-apiserver-authentication configmap no clock skew detected
linkerd-version --------------- can determine the latest version cli is up-to-date
Status check results are
All the pre-requisites appear to be good right now, and so installation can proceed.The first step of the installation is to setup the Custom Resource Definitions (CRDs) that Linkerd requires. The linkerd cli only prints the resource YAMLs to standard output and does not create them directly in Kubernetes, so you would need to pipe the output to kubectl apply to create the resources in the cluster that you re working with.
$ linkerd install --crds kubectl apply -f - Rendering Linkerd CRDs... Next, run linkerd install kubectl apply -f - to install the control plane.
customresourcedefinition.apiextensions.k8s.io/authorizationpolicies.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/httproutes.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/meshtlsauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/networkauthentications.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serverauthorizations.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/servers.policy.linkerd.io created customresourcedefinition.apiextensions.k8s.io/serviceprofiles.linkerd.io created
Next, install the Linkerd control plane components in the same manner, this time without the crds switch:
$ linkerd install kubectl apply -f - namespace/linkerd created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-identity created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-identity created serviceaccount/linkerd-identity created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-destination created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-destination created serviceaccount/linkerd-destination created secret/linkerd-sp-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-sp-validator-webhook-config created secret/linkerd-policy-validator-k8s-tls created validatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-policy-validator-webhook-config created clusterrole.rbac.authorization.k8s.io/linkerd-policy created clusterrolebinding.rbac.authorization.k8s.io/linkerd-destination-policy created role.rbac.authorization.k8s.io/linkerd-heartbeat created rolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-heartbeat created clusterrolebinding.rbac.authorization.k8s.io/linkerd-heartbeat created serviceaccount/linkerd-heartbeat created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-proxy-injector created serviceaccount/linkerd-proxy-injector created secret/linkerd-proxy-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-proxy-injector-webhook-config created configmap/linkerd-config created secret/linkerd-identity-issuer created configmap/linkerd-identity-trust-roots created service/linkerd-identity created service/linkerd-identity-headless created deployment.apps/linkerd-identity created service/linkerd-dst created service/linkerd-dst-headless created service/linkerd-sp-validator created service/linkerd-policy created service/linkerd-policy-validator created deployment.apps/linkerd-destination created cronjob.batch/linkerd-heartbeat created deployment.apps/linkerd-proxy-injector created service/linkerd-proxy-injector created secret/linkerd-config-overrides created
Kubernetes will start spinning up the data plane components and you should see the following when you list the pods:
kubernetes-api -------------- can initialize the client can query the Kubernetes API
kubernetes-version ------------------ is running the minimum Kubernetes API version is running the minimum kubectl version
linkerd-existence ----------------- 'linkerd-config' config map exists heartbeat ServiceAccount exist control plane replica sets are ready no unschedulable pods control plane pods are ready cluster networks contains all pods cluster networks contains all services
linkerd-config -------------- control plane Namespace exists control plane ClusterRoles exist control plane ClusterRoleBindings exist control plane ServiceAccounts exist control plane CustomResourceDefinitions exist control plane MutatingWebhookConfigurations exist control plane ValidatingWebhookConfigurations exist proxy-init container runs as root user if docker container runtime is used
linkerd-identity ---------------- certificate config is valid trust anchors are using supported crypto algorithm trust anchors are within their validity period trust anchors are valid for at least 60 days issuer cert is using supported crypto algorithm issuer cert is within its validity period issuer cert is valid for at least 60 days issuer cert is issued by the trust anchor
linkerd-webhooks-and-apisvc-tls ------------------------------- proxy-injector webhook has valid cert proxy-injector cert is valid for at least 60 days sp-validator webhook has valid cert sp-validator cert is valid for at least 60 days policy-validator webhook has valid cert policy-validator cert is valid for at least 60 days
linkerd-version --------------- can determine the latest version cli is up-to-date
control-plane-version --------------------- can retrieve the control plane version control plane is up-to-date control plane and cli versions match
linkerd-control-plane-proxy --------------------------- control plane proxies are healthy control plane proxies are up-to-date control plane proxies and cli versions match
Status check results are
Everything looks good.Setting up the Viz ExtensionAt this point, the required components for the service mesh are setup, but let s also install the viz extension, which provides a good visualization capabilities that will come in handy subsequently. Once again, linkerd uses the same pattern for installing the extension.
$ linkerd viz install kubectl apply -f - namespace/linkerd-viz created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-metrics-api created serviceaccount/metrics-api created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-prometheus created serviceaccount/prometheus created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-admin created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-delegator created serviceaccount/tap created rolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-tap-auth-reader created secret/tap-k8s-tls created apiservice.apiregistration.k8s.io/v1alpha1.tap.linkerd.io created role.rbac.authorization.k8s.io/web created rolebinding.rbac.authorization.k8s.io/web created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-check created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-admin created clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-viz-web-api created serviceaccount/web created server.policy.linkerd.io/admin created authorizationpolicy.policy.linkerd.io/admin created networkauthentication.policy.linkerd.io/kubelet created server.policy.linkerd.io/proxy-admin created authorizationpolicy.policy.linkerd.io/proxy-admin created service/metrics-api created deployment.apps/metrics-api created server.policy.linkerd.io/metrics-api created authorizationpolicy.policy.linkerd.io/metrics-api created meshtlsauthentication.policy.linkerd.io/metrics-api-web created configmap/prometheus-config created service/prometheus created deployment.apps/prometheus created service/tap created deployment.apps/tap created server.policy.linkerd.io/tap-api created authorizationpolicy.policy.linkerd.io/tap created clusterrole.rbac.authorization.k8s.io/linkerd-tap-injector created clusterrolebinding.rbac.authorization.k8s.io/linkerd-tap-injector created serviceaccount/tap-injector created secret/tap-injector-k8s-tls created mutatingwebhookconfiguration.admissionregistration.k8s.io/linkerd-tap-injector-webhook-config created service/tap-injector created deployment.apps/tap-injector created server.policy.linkerd.io/tap-injector-webhook created authorizationpolicy.policy.linkerd.io/tap-injector created networkauthentication.policy.linkerd.io/kube-api-server created service/web created deployment.apps/web created serviceprofile.linkerd.io/metrics-api.linkerd-viz.svc.cluster.local created serviceprofile.linkerd.io/prometheus.linkerd-viz.svc.cluster.local created
A few seconds later, you should see the following in your pod list:
The viz components live in the linkerd-viz namespace.You can now checkout the viz dashboard:
$ linkerd viz dashboard Linkerd dashboard available at: http://localhost:50750 Grafana dashboard available at: http://localhost:50750/grafana Opening Linkerd dashboard in the default browser Opening in existing browser session.
The Meshed column indicates the workload that is currently integrated with the Linkerd control plane. As you can see, there are no application deployments right now that are running.Injecting the Linkerd Data Plane componentsThere are two ways to integrate Linkerd to the application containers:1 by manually injecting the Linkerd data plane components 2 by instructing Kubernetes to automatically inject the data plane componentsInject Linkerd data plane manuallyLet s try the first option. Below is a simple nginx-app that I will deploy into the cluster:
Back in the viz dashboard, I do see the workload deployed, but it isn t currently communicating with the Linkerd control plane, and so doesn t show any metrics, and the Meshed count is 0:Looking at the Pod s deployment YAML, I can see that it only includes the nginx container:
Let s directly inject the linkerd data plane into this running container. We do this by retrieving the YAML of the deployment, piping it to linkerd cli to inject the necessary components and then piping to kubectl apply the changed resources.
Back in the viz dashboard, the workload now is integrated into Linkerd control plane.Looking at the updated Pod definition, we see a number of changes that the linkerd has injected that allows it to integrate with the control plane. Let s have a look:
At this point, the necessary components are setup for you to explore Linkerd further. You can also try out the jaeger and multicluster extensions, similar to the process of installing and using the viz extension and try out their capabilities.Inject Linkerd data plane automaticallyIn this approach, we shall we how to instruct Kubernetes to automatically inject the Linkerd data plane to workloads at deployment time.We can achieve this by adding the linkerd.io/inject annotation to the deployment descriptor which causes the proxy injector admission hook to execute and inject linkerd data plane components automatically at the time of deployment.
This annotation can also be specified at the namespace level to affect all the workloads within the namespace. Note that any resources created before the annotation was added to the namespace will require a rollout restart to trigger the injection of the Linkerd components.Uninstalling LinkerdNow that we have walked through the installation and setup process of Linkerd, let s also cover how to remove it from the infrastructure and go back to the state prior to its installation.The first step would be to remove extensions, such as viz.
The Population Issue and its many facets
Another couple of weeks passed. A Lot of things happening, lots of anger and depression in folks due to handling in pandemic, but instead of blaming they are willing to blame everybody else including the population. Many of them want forced sterilization like what Sanjay Gandhi did during the Emergency (1975). I had to share So Long, My son . A very moving tale of two families of what happened to them during the one-child policy in China. I was so moved by it and couldn t believe that the Chinese censors allowed it to be produced, shot, edited, and then shared worldwide. It also won a couple of awards at the 69th Berlin Film Festival, silver bear for the best actor and the actress in that category. But more than the award, the theme, and the concept as well as the length of the movie which was astonishing. Over a 3 hr. something it paints a moving picture of love, loss, shame, relief, anger, and asking for forgiveness. All of which can be identified by any rational person with feelings worldwide.
Girl child
What was also interesting though was what it couldn t or wasn t able to talk about and that is the Chinese leftover men. In fact, a similar situation exists here in India, only it has been suppressed. This has been more pronounced more in Asia than in other places. One big thing in this is human trafficking and mostly women trafficking. For the Chinese male, that was happening on a large scale from all neighboring countries including India. This has been shared in media and everybody knows about it and yet people are silent. But this is not limited to just the Chinese, even Indians have been doing it. Even yesteryear actress Rupa Ganguly was caught red-handed but then later let off after formal questioning as she is from the ruling party. So much for justice.
What is and has been surprising at least for me is Rwanda which is in the top 10 of some of the best places in equal gender. It, along with other African countries have also been in news for putting quite a significant amount of percentage of GDP into public healthcare (between 20-10%), but that is a story for a bit later. People forget or want to forget that it was in Satara, a city in my own state where 220 girls changed their name from nakusha or unwanted to something else and that had become a piece of global news. One would think that after so many years, things would have changed, the only change that has happened is that now we have two ministries, The Ministry of Women and Child Development (MoWCD) and The Ministry of Health and Welfare (MoHFW). Sadly, in both cases, the ministries have been found wanting, Whether it was the high-profile Hathras case or even the routine cries of help which given by women on the twitter helpline. Sadly, neither of these ministries talks about POSH guidelines which came up after the 2012 gangrape case. For both these ministries, it should have been a pinned tweet. There is also the 1994 PCPNDT Act which although made in 1994, actually functioned in 2006, although what happens underground even today nobody knows .
On the global stage, about a decade ago, Stephen J. Dubner and Steven Levitt argued in their book Freakonomics how legalized abortion both made the coming population explosion as well as expected crime rates to be reduced. There was a huge pushback on the same from the conservatives and has become a matter of debate, perhaps something that the Conservatives wanted. Interestingly, it hasn t made them go back but go forward as can be seen from the Freakonomics site.
Climate Change
Another topic that came up for discussion was repeatedly climate change, but when I share Shell s own 1998 Confidential report titled Greenhouse effect all become strangely silent. The silence here is of two parts, there probably is a large swathe of Indians who haven t read the report and there may be a minority who have read it and know what already has been shared with U.S. Congress. The Conservative s argument has been for it is jobs and a weak we need to research more . There was a partial debunk of it on the TBD podcast by Matt Farell and his brother Sean Farell as to how quickly the energy companies are taking to the coming change.
Health Budget
Before going to Covid stories. I first wanted to talk about Health Budgets. From the last 7 years the Center s allocation for health has been between 0.34 to 0.8% per year. That amount barely covers the salaries to the staff, let alone any money for equipment or anything else. And here by allocation I mean, what is actually spent, not the one that is shared by GOI as part of budget proposal. In fact, an article on Wire gives a good breakdown of the numbers. Even those who are on the path of free markets describe India s health business model as a flawed one. See the Bloomberg Quint story on that. Now let me come to Rwanda. Why did I chose Rwanda, I could have chosen South Africa where I went for Debconf 2016, I chose because Rwanda s story is that much more inspiring. In many ways much more inspiring than that South Africa in many ways. Here is a country which for decades had one war or the other, culminating into the Rwanda Civil War which ended in 1994. And coincidentally, they gained independence on a similar timeline as South Africa ending Apartheid in 1994. What does the country do, when it gains its independence, it first puts most of its resources in the healthcare sector. The first few years at 20% of GDP, later than at 10% of GDP till everybody has universal medical coverage.
Coming back to the Bloomberg article I shared, the story does not go into the depth of beyond-expiry date medicines, spurious medicines and whatnot. Sadly, most media in India does not cover the deaths happening in rural areas and this I am talking about normal times. Today what is happening in rural areas is just pure madness. For last couple of days have been talking with people who are and have been covering rural areas. In many of those communities, there is vaccine hesitancy and why, because there have been whatsapp forwards sharing that if you go to a hospital you will die and your kidney or some other part of the body will be taken by the doctor. This does two things, it scares people into not going and getting vaccinated, at the same time they are prejudiced against science. This is politics of the lowest kind. And they do it so that they will be forced to go to temples or babas and what not and ask for solutions. And whether they work or not is immaterial, they get fixed and property and money is seized. Sadly, there are not many Indian movies of North which have tried to show it except for oh my god but even here it doesn t go the distance. A much more honest approach was done in Trance . I have never understood how the South Indian movies are able to do a more honest job of story-telling than what is done in Bollywood even though they do in 1/10th the budget that is needed in Bollywood. Although, have to say with OTT, some baggage has been shed but with the whole film certification rearing its ugly head through MEITY orders, it seems two steps backward instead of forward. The idea being simply to infantilize the citizens even more. That is a whole different ball-game which probably will require its own space.
Vaccine issues
One good news though is that Vaccination has started. But it has been a long story full of greed by none other than GOI (Government of India) or the ruling party BJP. Where should I start with. I probably should start with this excellent article done by Priyanka Pulla. It is interesting and fascinating to know how vaccines are made, at least one way which she shared. She also shared about the Cutter Incident which happened in the late 50 s. The response was on expected lines, character assassination of her and the newspaper they published but could not critique any of the points made by her. Not a single point that she didn t think about x or y. Interestingly enough, in January 2021 Bharati Biotech was supposed to be share phase 3 trial data but hasn t been put up in public domain till May 2021. In fact, there have been a few threads raised by both well-meaning Indians as well as others globally especially on twitter to which GOI/ICMR (Indian Council of Medical Research) is silent. Another interesting point to note is that Russia did say in its press release that it is possible that their vaccine may not be standard (read inactivation on their vaccines and another way is possible but would take time, again Brazil has objected, but India hasn t till date.)
What also has been interesting is the homegrown B.1.617 lineage or known as double mutant . This was first discovered from my own state, Maharashtra and then transported around the world. There is also B.1.618 which was found in West Bengal and is same or supposed to be similar to the one found in South Africa. This one is known as Triple mutant . About B.1.618 we don t know much other than knowing that it is much more easily transferable, much more infectious. Most countries have banned flights from India and I cannot fault them anyway. Hell, when even our diplomats do not care for procedures to be followed during the pandemic then how a common man is supposed to do. Of course, now for next month, Mr. Modi was supposed to go and now will not attend the G7 meeting. Whether, it is because he would have to face the press (the only Prime Minister and the only Indian Prime Minister who never has faced free press.) or because the Indian delegation has been disinvited, we would never know.
A good article which shares lots of lows with how things have been done in India has been an article by Arundhati Roy. And while the article in itself is excellent and shares a bit of the bitter truth but is still incomplete as so much has been happening. The problem is that the issue manifests in so many ways, it is difficult to hold on. As Arundhati shared, should we just look at figures and numbers and hold on, or should we look at individual ones, for e.g. the one shared in Outlook India. Or the one shared by Dr. Dipshika Ghosh who works in Covid ICU in some hospital
Dr. Dipika Ghosh sharing an incident in Covid Ward
Interestingly as well, while in the vaccine issue, Brazil Anvisa doesn t know what they are doing or the regulator just isn t knowledgeable etc. (statements by various people in GOI, when it comes to testing kits, the same is an approver.)
ICMR/DGCI approving internationally validated kits, Press release.
Twitter
In the midst of all this, one thing that many people have forgotten and seem to have forgotten that Twitter and other tools are used by only the elite. The reason why the whole thing has become serious now than in the first phase is because the elite of India have also fallen sick and dying which was not the case so much in the first phase. The population on Twitter is estimated to be around 30-34 million and people who are everyday around 20 odd million or so, which is what 2% of the Indian population which is estimated to be around 1.34 billion. The other 98% don t even know that there is something like twitter on which you can ask help. Twitter itself is exclusionary in many ways, with both the emoticons, the language and all sorts of things. There is a small subset who does use Twitter in regional languages, but they are too small to write anything about. The main language is English which does become a hindrance to lot of people.
Censorship
Censorship of Indians critical of Govt. mishandling has been non-stop. Even U.S. which usually doesn t interfere into India s internal politics was forced to make an exception. But of course, this has been on deaf ears. There is and was a good thread on Twitter by Gaurav Sabnis, a friend, fellow Puneite now settled in U.S. as a professor.
Gaurav on Trump-Biden on vaccination of their own citizens
Now just to surmise what has been happened in India and what has been happening in most of the countries around the world. Most of the countries have done centralization purchasing of the vaccine and then is distributed by the States, this is what we understand as co-operative federalism. While last year, GOI took a lot of money under the shady PM Cares fund for vaccine purchase, donations from well-meaning Indians as well as Industries and trade bodies. Then later, GOI said it would leave the states hanging and it is they who would have to buy vaccines from the manufacturers. This is again cheap politics. The idea behind it is simple, GOI knows that almost all the states are strapped for cash. This is not new news, this I have shared a couple of months back. The problem has been that for the last 6-8 months no GST meeting has taken place as shared by Punjab s Finance Minister Amarinder Singh. What will happen is that all the states will fight in-between themselves for the vaccine and most of them are now non-BJP Governments. The idea is let the states fight and somehow be on top. So, the pandemic, instead of being a public health issue has become something of on which politics has to played. The news on whatsapp by RW media is it s ok even if a million or two also die, as it is India is heavily populated. Although that argument vanishes for those who lose their dear and near ones. But that just isn t the issue, the issue goes much more deeper than that
Oxygen:12% Remedisivir:12% Sanitiser:12% Ventilator:12% PPE:18% Ambulances 28%
Now all the products above are essential medical equipment and should be declared as essential medical equipment and should have price controls on which GST is levied. In times of pandemic, should the center be profiting on those. States want to let go and even want the center to let go so that some relief is there to the public, while at the same time make them as essential medical equipment with price controls. But GOI doesn t want to. Leaders of opposition parties wrote open letters but no effect. What is sad to me is how Ambulances are being taxed at 28%. Are they luxury items or sin goods ? This also reminds of the recent discovery shared by Mr. Pappu Yadav in Bihar. You can see the color of ambulances as shared by Mr. Yadav, and the same news being shared by India TV news showing other ambulances. Also, the weak argument being made of not having enough drivers. Ideally, you should have 2-3 people, both 9-1-1 and Chicago Fire show 2 people in ambulance but a few times they have also shown to be flipped over. European seems to have three people in ambulance, also they are also much more disciplined as drivers, at least an opinion shared by an American expat.
Pappu Yadav, President Jan Adhikar Party, Bihar May 11, 2021
What is also interesting to note is GOI plays this game of Health is State subject and health is Central subject depending on its convenience. Last year, when it invoked the Epidemic and DMA Act it was a Central subject, now when bodies are flowing down the Ganges and pyres being lit everywhere, it becomes a State subject. But when and where money is involved, it again becomes a Central subject. The States are also understanding it, but they are fighting on too many fronts.
Snippets from Karnataka High Court hearing today, 13th March 2021
One of the good things is most of the High Courts have woken up. Many of the people on the RW think that the Courts are doing Judicial activism . And while there may be an iota of truth in it, the bitter truth is that many judges or relatives or their helpers have diagnosed and some have even died due to Covid. In face of the inevitable, what can they do. They are hauling up local Governments to make sure they are accountable while at the same time making sure that they get access to medical facilities. And I as a citizen don t see any wrong in that even if they are doing it for selfish reasons. Because, even if justice is being done for selfish reasons, if it does improve medical delivery systems for the masses, it is cool. If it means that the poor and everybody else are able to get vaccinations, oxygen and whatever they need, it is cool. Of course, we are still seeing reports of patients spending in the region of INR 50k and more for each day spent in hospital. But as there are no price controls, judges cannot do anything unless they want to make an enemy of the medical lobby in the country. A good story on medicines and what happens in rural areas, see no further than Laakhon mein ek.
Allahabad High Court hauling Uttar Pradesh Govt. for lack of Oxygen is equal to genocide, May 11, 2021
The censorship is not just related to takedown requests on twitter but nowadays also any articles which are critical of the GOI s handling. I have been seeing many articles which have shared facts and have been critical of GOI being taken down. Previously, we used to see 404 errors happen 7-10 years down the line and that was reasonable. Now we see that happen, days weeks or months. India seems to be turning more into China and North Korea and become more anti-science day-by-day
Fake websites
Before going into fake websites, let me start with a fake newspaper which was started by none other than the Gujarat CM Mr. Modi in 2005 .
Gujarat Satya Samachar 2005 launched by Mr. Modi.
And if this wasn t enough than on Feb 8, 2005, he had invoked Official Secrets Act
Mr. Modi invoking Official Secrets Act, Feb 8 2005 Gujarat Samachar
The headlines were In Modi s regime press freedom is in peril-Down with Modi s dictatorship. So this was a tried and tested technique. The above information was shared by Mr. Urvish Kothari, who incidentally also has his own youtube channel.
Now cut to 2021, and we have a slew of fake websites being done by the same party. In fact, it seems they started this right from 2011. A good article on BBC itself tells the story. Hell, Disinfo.eu which basically combats disinformation in EU has a whole pdf chronicling how BJP has been doing it. Some of the sites it shared are
Times of New York Manchester Times Times of Los Angeles Manhattan Post Washington Herald and many more.
The idea being take any site name which sounds similar to a brand name recognized by Indians and make fool of them. Of course, those of who use whois and other such tools can easily know what is happening. Two more were added to the list yesterday, Daily Guardian and Australia Today. There are of course, many features which tell them apart from genuine websites. Most of these are on shared hosting rather than dedicated hosting, most of these are bought either from Godaddy and Bluehost. While Bluehost used to be a class act once upon a time, both the above will do anything as long as they get money. Don t care whether it s a fake website or true. Capitalism at its finest or worst depending upon how you look at it. But most of these details are lost on people who do not know web servers, at all and instead think see it is from an exotic site, a foreign site and it chooses to have same ideas as me. Those who are corrupt or see politics as a tool to win at any cost will not see it as evil. And as a gentleman Raghav shared with me, it is so easy to fool us. An example he shared which I had forgotten. Peter England which used to be an Irish brand was bought by Aditya Birla group way back in 2000. But even today, when you go for Peter England, the way the packaging is done, the way the prices are, more often than not, people believe they are buying the Irish brand. While sharing this, there is so much of Naom Chomsky which comes to my mind again and again
Caste Issues
I had written about caste issues a few times on this blog. This again came to the fore as news came that a Hindu sect used forced labor from Dalit community to make a temple. This was also shared by the hill. In both, Mr. Joshi doesn t tell that if they were volunteers then why their passports have been taken forcibly, also I looked at both minimum wage prevailing in New Jersey as a state as well as wage given to those who are in the construction Industry. Even in minimum wage, they were giving $1 when the prevailing minimum wage for unskilled work is $12.00 and as Mr. Joshi shared that they are specialized artisans, then they should be paid between $23 $30 per hour. If this isn t exploitation, then I don t know what is.
And this is not the first instance, the first instance was perhaps the case against Cisco which was done by John Doe. While I had been busy with other things, it seems Cisco had put up both a demurrer petition and a petition to strike which the Court stayed. This seemed to all over again a type of apartheid practice, only this time applied to caste. The good thing is that the court stayed the petition.
Dr. Ambedkar s statement if Hindus migrate to other regions on earth, Indian caste would become a world problem given at Columbia University in 1916, seems to be proven right in today s time and sadly has aged well. But this is not just something which is there only in U.S. this is there in India even today, just couple of days back, a popular actress Munmun Dutta used a casteist slur and then later apologized giving the excuse that she didn t know Hindi. And this is patently false as she has been in the Bollywood industry for almost now 16-17 years. This again, was not an isolated incident. Seema Singh, a lecturer in IIT-Kharagpur abused students from SC, ST backgrounds and was later suspended. There is an SC/ST Atrocities Act but that has been diluted by this Govt. A bit on the background of Dr. Ambedkar can be found at a blog on Columbia website. As I have shared and asked before, how do we think, for what reason the Age of Englightenment or the Age of Reason happened. If I were a fat monk or a priest who was privileges, would I have let Age of Enlightenment happen. It broke religion or rather Church which was most powerful to not so powerful and that power was more distributed among all sort of thinkers, philosophers, tinkers, inventors and so on and so forth.
Situation going forward
I believe things are going to be far more complex and deadly before they get better. I had to share another term called Comorbidities which fortunately or unfortunately has also become part of twitter lexicon. While I have shared what it means, it simply means when you have an existing ailment or condition and then Coronavirus attacks you. The Virus will weaken you. The Vaccine in the best case just stops the damage, but the damage already done can t be reversed. There are people who advise and people who are taking steroids but that again has its own side-effects. And this is now, when we are in summer. I am afraid for those who have recovered, what will happen to them during the Monsoons. We know that the Virus attacks most the lungs and their quality of life will be affected. Even the immune system may have issues. We also know about the inflammation. And the grant that has been given to University of Dundee also has signs of worry, both for people like me (obese) as well as those who have heart issues already. In other news, my city which has been under partial lockdown since a month, has been extended for another couple of weeks. There are rumors that the same may continue till the year-end even if it means economics goes out of the window.There is possibility that in the next few months something like 2 million odd Indians could die
The above is a conversation between Karan Thapar and an Oxford Mathematician Dr. Murad Banaji who has shared that the under-counting of cases in India is huge. Even BBC shared an article on the scope of under-counting. Of course, those on the RW call of the evidence including the deaths and obituaries in newspapers as a narrative . And when asked that when deaths used to be in the 20 s or 30 s which has jumped to 200-300 deaths and this is just the middle class and above. The poor don t have the money to get wood and that is the reason you are seeing the bodies in Ganges whether in Buxar Bihar or Gajipur, Uttar Pradesh. The sights and visuals makes for sorry reading Pandit Ranjan Mishra son on his father s death due to unavailability of oxygen, Varanasi, Uttar Pradesh, 11th May 2021.
For those who don t know Pandit Ranjan Mishra was a renowned classical singer. More importantly, he was the first person to suggest Mr. Modi s name as a Prime Ministerial Candidate. If they couldn t fulfil his oxygen needs, then what can be expected for the normal public.
Conclusion
Sadly, this time I have no humorous piece to share, I can however share a documentary which was shared on Feluda . I have shared about Feluda or Prodosh Chandra Mitter a few times on this blog. He has been the answer of James Bond from India. I have shared previously about The Golden Fortress . An amazing piece of art by Satyajit Ray. I watched that documentary two-three times. I thought, mistakenly that I am the only fool or fan of Feluda in Pune to find out that there are people who are even more than me. There were so many facets both about Feluda and master craftsman Satyajit Ray that I was unaware about. I was just simply amazed. I even shared few of the tidbits with mum as well, although now she has been truly hooked to Korean dramas. The only solace from all the surrounding madness. So, if you have nothing to do, you can look up his books, read them and then see the movies. And my first recommendation would be the Golden Fortress. The only thing I would say, do not have high hopes. The movie is beautiful. It starts slow and then picks up speed, just like a train. So, till later.
Update The Mass surveillance part I could not do justice do hence removed it at the last moment. It actually needs its whole space, article. There is so much that the Govt. is doing under the guise of the pandemic that it is difficult to share it all in one article. As it is, the article is big
Sorry for not being on blog for sometime, the last few months have been brutal. While I am externally ok, because of the lockdown I sensed major hearing loss. First, I thought it may be a hallucination or something but as it persisted for days, I got myself checked and found out that I got 80% hearing loss in my right ear. How and why I don t know. Is this NIHL or some other kind of hearing loss is yet to be ascertained. I do live what is and used to be one of the busiest roads in the city, now for last few months not so much. On top of it, you have various other noises.
Tinnitus
I also experienced Tinnitus which again I perceived to be a hallucination but found it s not. I have no clue if my eiplepsy has anything to do with hearing loss or both are different. I did discover that while today we know that something like Tinnitus exists, just 10-15 years back, people might mistake it for madness. In a way it is madness because you are constantly hearing sound, music etc. 24 7 , that is enough to drive anybody mad.
During this brief period, did learn what an Otoscope is . I did get audiometry tests done but need to get at least a second or if possible also a third opinion but those will have to wait as the audio clinics are about 8-10 kms. away. In the open-close-open-close environment just makes it impossible to figure out the time, date and get it done. After that is done then probably get a hearing device, probably a Siemens Signia hearing aid. The hearing aids are damn expensive, almost 50k per piece and they probably have a lifetime of about 5-6 years, so it s a bit of a expensive proposition. I also need a second or/and third opinion on the audiometry profile so I know things are correct. All of these things are gonna take time.
Pandemic Situation in India and Testing
Coincidentally, was talking to couple of people about this. It is sad to see that we have the third highest number of covid cases at 1/10th the tests we are doing vis-a-vis U.S.A. According to statistical site ourworldindata , we seem to be testing 0.22 per thousand people compared to 2.28 people per thousand done by United States. Sadly it doesn t give the breakup of the tests, from what I read the PCR tests are better than the antibody tests, a primer shares the difference between the two tests. IIRC, the antibody tests are far cheaper than the swab tests but swab tests are far more accurate as it looks for the virus s genetic material (RNA) . Anyways coming to the numbers, U.S. has a population of roughly 35 crores taking a little bit liberty from numbers given at popclock . India meanwhile has 135 crore or almost four times the population of U.S. and the amount of testing done is 1/10th as shared above. Just goes to share where the GOI priorities lie . We are running out of beds, ventilators and whatever else there is. Whatever resources are there are being used for covid patients and they are being charged a bomb. I have couple of hospitals near my place and the cost of a bed in an isolation ward is upward of INR 100k and if you need a ventilator then add another 50k . And in moment of rarity, the differences between charges of private and public are zero. Meaning there is immense profiteering happening it seems in the medical world. Heck, even the Govt. is on the act where they are charging 18% GST on sanitizers. If this is not looting then I dunno what is.
Example of Medical Bills people have to pay.
China, Nepal & Diplomacy
While everybody today knows how China has intruded and captured quite a part of Ladakh, this wasn t the case when they started in April. That time Ajai Shukla had shared this with the top defence personnel but nothing came of it. Then on May 30th he broke/shared the news with the rest of the world and was immediately branded anti-national, person on Chinese payroll and what not. This is when he and Pravin Sawnhey of Force Magazine had both been warning of the same from last year itself. Pravin, has a youtube channel and had been warning India against Chinese intentions from 2015 and even before that. He had warned repeatedly that our obsession with the Pakistan border meant that we were taking eyes of the border with China which spans almost 2300 odd kms. going all the way to Arunachal Pradesh. A good map which shows the conflict can be found at dw.com which I am sharing/reproducing below India-China Border Areas Copyright DW.com 2020
Note:- I am sharing a neutral party s rendering of the border disputes or somebody who doesn t have much at stake as the two countries have so that things could be looked at little objectively.
The Prime Minister on the other hand, made the comment which made galvanising a made-up word into verb . It means to go without coming in. In fact, several news sites shared the statement told by the Prime Minister and the majority of people were shocked. In fact, there had been reports that he gave the current CDS, General Rawat, a person of his own choosing, a peace of his mind. But what lead to this confrontation in the first place ? I think many pieces are part of that puzzle, one of the pieces are surely the cutting of defense budget for the last 6 years, Even this year, if you look at the budget slashes done in the earlier part of the year when he shared how HAL had to raise loans from the market to pay salaries of its own people. Later he shared how the Govt. was planning to slash the defence budget. Interestingly, he had also shared some of the reasons which reaffirm that it is the only the Govt. which can solve some of the issues/conundrum
First, it must recognize that our firms competing for global orders are up against rivals that are being supported by their home governments with tax and export incentives and infrastructure that almost invariably surpasses India s. Our government must provide its aerospace firms with a level playing field, if not a competitive advantage. The greatest deterrent to growth our companies face is the high cost of capital and lack of access to funds. In several cases, Indian MSMEs have had to turn down offers to build components and assemblies for global OEM supply chains simply because the cost of capital to create the shop floor and train the personnel was too high. This resulted in a loss of business and a missed opportunity for creating jobs and skills. To overcome this, the government could create a sector specific A&D Fund to provide low cost capital quickly to enable our MSMEs to grab fleeting business opportunities. Ajai Shukla, blogpost 13th March 2020 .
And then reporting on 11th May 2020 itself, CDS Gen. Rawat himself commented on saving the budget, they were in poor taste but still he shared what he thought about it. So, at the end of it one part of the story. The other part of the story probably lies in India s relations with its neighbors and lack of numbers in diplomats and diplomacy. So let me cover both the things one by one .
Diplomats, lack of numbers and hence the hands we are dealth with
When Mr. Modi started his first term, he used the term Maximum Governance, Minimum Government but sadly cut those places where it indeed needs more people, one of which is diplomacy. A slightly dated 2012 article/opinion shared writes that India needs to engage with the rest of the world and do with higher number. Cut to 2020 and the numbers more or less remain the same . What Mr. Modi tried to do is instead of using diplomats, he tried to use his charm and hugopolicy for lack of a better term. 6 years later, here we are. After 200 trips abroad, not a single trade agreement to show what he done. I could go on but both time and energy are not on my side hence now switching to Nepal
Nepal, once friend, now enemy ?
Nepal had been a friend of India for 70 odd years, what changed in the last few years that it changed from friend to enemy ? There had been two incidents in recent memory that changed the status quo. The first is the 2015 Nepal blockade . Now one could argue it either way but the truth is that Nepal understood that it is heavily dependent on India hence as any sovereign country would do in its interest it also started courting China for imports so there is some balance.
The second one though is one of our own making. On December 16, 2014 RBI allowed Nepali citizens to have cash upto INR 25,000/- . Then in 2016 when demonetization was announced, they said that people could exchange only upto INR 4,500/- which was far below the limit shared above. And btw, before people start blaming just RBI for the decision, FEMA decisions are taken jointly by the finance ministry (FE) as well as ministry of external affairs (MEA) . So without them knowing the decision could not have been taken when announcing it. The result of lowering of demonetization is what made Nepal move more into Chinese hands and this has been shared by number of people in numerous articles in different websites. The wire interview with the vice-chairman of Niti Ayog is pretty interesting. The argument that Nepal show give an estimate of how much old money is there falls flat when in demonetization itself, it was thought of that around 30-40% was black money and would not be returned but by RBI s own admissions all 99.3% of the money was returned. Perhaps they should have consulted Prof. Arun Kumar of JNU who has extensivelywritten and studied the topic before doing that fool-hardy step. It is the reason that since then, an economy which was searing at 9% has been contracting ever since, I could give a dozen articles stating that, but for the moment, just one will suffice. The slowing economy and the sharp divisions between people based on either outlook, religion or whatever also encouraged China to attack us. This year is not good for India. The only thing I hope Indians and people all over do is just maintain physical distances, masks and somehow survive till middle of next year without getting infected when probably most of the vaccine candidates have been trialed, results are in and we have a ready vaccine. I do hope that at least for once, ICMR shares data even after the vaccine is approved, whichever vaccine. Till later.
Because posting private keys on the Internet is a bad idea, some
people like to redact their private keys, so that it looks kinda-sorta like a private key,
but it isn t actually giving away anything secret. Unfortunately, due to the way that
private keys are represented, it is easy to redact a key in such a way that it
doesn t actually redact anything at all. RSA private keys are particularly bad at this,
but the problem can (potentially) apply to other keys as well.
I ll show you a bit of Inside Baseball with key formats, and then demonstrate the practical
implications. Finally, we ll go through a practical worked example from an actual not-really-redacted
key I recently stumbled across in my travels.
The Private Lives of Private Keys
Here is what a typical private key looks like, when you come across it:
Obviously, there s some hidden meaning in there computers don t encrypt
things by shouting BEGIN RSA PRIVATE KEY! , after all. What is between the
BEGIN/END lines above is, in fact, a
base64-encoded
DER format
ASN.1 structure representing a PKCS#1 private
key.
In simple terms, it s a list of numbers very important numbers. The list
of numbers is, in order:
A version number (0);
The public modulus , commonly referred to as n ;
The public exponent , or e (which is almost always 65,537, for various unimportant reasons);
The private exponent , or d ;
The two private primes , or p and q ;
Two exponents, which are known as dmp1 and dmq1 ; and
A coefficient, known as iqmp .
Why Is This a Problem?
The thing is, only three of those numbers are actually required in a private
key. The rest, whilst useful to allow the RSA encryption and decryption to be
more efficient, aren t necessary. The three absolutely required values are
e, p, and q.
Of the other numbers, most of them are at least about the same size as each
of p and q. So of the total data in an RSA key, less than a quarter of the
data is required. Let me show you with the above toy key, by breaking it
down piece by piece1:
MGI DER for this is a sequence
CAQ version (0)
CxjdTmecltJEz2PLMpS4BXn
AgMBAAe
ECEDKtuwD17gpagnASq1zQTYd
ECCQDVTYVsjjF7IQp
IJANUYZsIjRsR3q
AgkAkahDUXL0RSdmp1
ECCB78r2SnsJC9dmq1
AghaOK3FsKoELg==iqmp
Remember that in order to reconstruct all of these values, all I need are
e, p, and q and e is pretty much always 65,537. So I could redact
almost all of this key, and still give all the important, private bits of this
key. Let me show you:
Now, I doubt that anyone is going to redact a key precisely like
this but then again, this isn t a typical RSA key. They usually
look a lot more like this:
People typically redact keys by deleting whole lines, and usually replacing them
with [...] and the like. But only about 345 of those 1588 characters
(excluding the header and footer) are required to construct the entire key.
You can redact about 4/5ths of that giant blob of stuff, and your private parts
(or at least, those of your key) are still left uncomfortably exposed.
But Wait! There s More!
Remember how I said that everything in the key other than e, p,
and q could be derived from those three numbers? Let s talk about one
of those numbers: n.
This is known as the public modulus (because, along with e, it is also
present in the public key). It is very easy to calculate: n = p * q. It
is also very early in the key (the second number, in fact).
Since n = p * q, it follows that q = n / p. Thus, as long
as the key is intact up to p, you can derive q by simple division.
Real World Redaction
At this point, I d like to introduce an acquaintance of mine: Mr. Johan Finn.
He is the proud owner of the GitHub repo johanfinn/scripts.
For a while, his repo contained a script that contained a poorly-redacted private
key. He since deleted it, by making a new commit, but of course because
git never really deletes anything, it s
still available.
Of course, Mr. Finn may delete the repo, or force-push a new history without
that commit, so here is the redacted private key, with a bit of the surrounding
shell script, for our illustrative pleasure:
Now, if you try to reconstruct this key by removing the obvious garbage
lines (the ones that are all repeated characters, some of which aren t even valid
base64 characters), it still isn t a key at least, openssl pkey
doesn t want anything to do with it. The key is very much still in there,
though, as we shall soon see.
Using a gem I wrote and a quick bit of
Ruby, we can extract a complete private key. The irb session looks something
like this:
What I ve done, in case you don t speak Ruby, is take the two chunks of
plausible-looking base64 data, chuck them together into a variable named b64,
unbase64 it into a variable named der, pass that into a new DerParse
instance, and then walk the DER value tree until I got all the values I need.
Interestingly, the q value actually traverses the split in the two chunks,
which means that there s always the possibility that there are lines missing
from the key. However, since p and q are supposed to be prime, we can
sanity check them to see if corruption is likely to have occurred:
Excellent! The chances of a corrupted file producing valid-but-incorrect prime
numbers isn t huge, so we can be fairly confident that we ve got the real p
and q. Now, with the help of another one of my
creations we can use e, p,
and q to create a fully-operational battle key:
and there you have it. One fairly redacted-looking private key brought back
to life by maths and far too much free time.
Sorry Mr. Finn, I hope you re not still using that key on anything
Internet-facing.
What About Other Key Types?
EC keys are very different beasts, but they have much the same problems as RSA
keys. A typical EC key contains both private and public data, and the public
portion is twice the size so only about 1/3 of the data in the key is
private material. It is quite plausible that you can redact an EC key and
leave all the actually private bits exposed.
What Do We Do About It?
In short: don t ever try and redact real private keys. For documentation purposes,
just put KEY GOES HERE in the appropriate spot, or something like that. Store your
secrets somewhere that isn t a public (or even private!) git repo.
Generating a dummy private key and sticking it in there isn t a great idea,
for different reasons: people have this odd habit of reusing demo keys in
real
life.
There s no need to encourage that sort of thing.
Technically the pieces aren t 100% aligned with the underlying DER, because of how base64 works.
I felt it was easier to understand if I stuck to chopping up the base64, rather than
decoding into DER and then chopping up the DER.
There have been lot of stories about Coronavirus and with it a lot of political blame-game has been happening. The first step that India took of a lockdown is and was a good step but without having a plan as to how especially the poor and the needy and especially the huge migrant population that India has (internal migration) be affected by it. A 2019 World Economic Forum shares the stats. as 139 million people. That is a huge amount of people and there are a variety of both push and pull factors which has displaced these huge number of people. While there have been attempts in the past and probably will continue in future they will be hampered unless we have trust-worthy data which is where there is lots that need to be done. In the recent few years, both the primary and secondary data has generated lot of controversies within India as well as abroad so no point in rehashing all of that. Even the definition of who is a migrant needs to be well-established just as who is a farmer . The simplest lucanae in the later is those who have land are known as farmers but the tenant farmers and their wives are not added as farmers hence the true numbers are never known. Is this an India-specific problem or similar definition issues are there in the rest of the world I don t know.
How our Policies fail to reach the poor and the vulnerable
The sad part is most policies in India are made in castles in the air . An interview by the wire shares the conundrum of those who are affected and the policies which are enacted for them (it s a youtube video, sorry)
If one with an open and fresh mind sees the interview it is clear that why there was a huge reverse migration from Indian cities to villages. The poor and marginalized has always seen the Indian state as an extortive force so it doesn t make sense for them to be in the cities. The Prime Minister s annoucement of food for 3 months was a clear indication for the migrant population that for 3 months they will have no work. Faced with such a scenario, the best option for them was to return to their native places. While videos of huge number of migrants were shown of Delhi, this was the scenario of most states and cities, including Pune, my own city . Another interesting point which was made is most of the policies will need the migrants to be back in the villages. Most of these are tied to the accounts which are opened in villages, so even if they want to have the benefits they will have to migrate to villages in order to use them. Of course, everybody in India knows how leaky the administration is. The late Shri Rajiv Gandhi had famously and infamously remarked once how leaky the Public Distribution system and such systems are. It s only 10 paise out of rupee which reaches the poor. And he said this about 30 years ago. There have been numerous reports of both IPS (Indian Police Services) reforms and IAS (Indian Administrative Services) reforms over the years, many of the committee reports have been in public domain and in fact was part of the election manifesto of the ruling party in 2014 but no movement has happened on that part. The only thing which has happened is people from the ruling party have been appointed on various posts which is same as earlier governments.
I was discussing with a friend who is a contractor and builder about the construction labour issues which were pointed in the report and if it is true that many a times the migrant labour is not counted. While he shared a number of cases where he knew, a more recent case in public memory was when some labourers died while building Amanora mall which is perhaps one of largest malls in India. There were few accidents while constructing the mall. Apparently, the insurance money which should have gone to the migrant laborer was taken by somebody close to the developers who were building the mall. I have a friend in who lives in Jharkhand who is a labour officer. She has shared with me so many stories of how the labourers are exploited. Keep in mind she has been a labor officer appointed by the state and her salary is paid by the state. So she always has to maintain a balance of ensuring worker s rights and the interests of the state, private entities etc. which are usually in cahoots with the state and it is possible that lot of times the State wins over the worker s rights. Again, as a labour officer, she doesn t have that much power and when she was new to the work, she was often frustrated but as she remarked few months back, she has started taking it easy (routinized) as anyways it wasn t helping her in any good way. Also there have been plenty of cases of labor officers being murdered so its easier to understand why one tries to retain some sanity while doing their job.
The Indian response and the World Response
The Indian response has been the lockdown and very limited testing. We seem to be following the pattern of UK and U.S. which had been slow to respond and slow to testing. In the past Kerala showed the way but this time even that is not enough. At the end of the day we need to test, test and test just as shared by the WHO chairman. India is trying to create its own cheap test kits with ICMR approval, for e.g. a firm from my own city Pune MyLab has been given approval. We will know how good or bad they are only after they have been field-tested. For ventilators we have asked Mahindra and Mahindra even though there are companies like Allied Medical and others who have exported to EU and others which the Govt. is still taking time to think through. This is similar to how in UK some companies who are with the Govt. but who have no experience in making ventilators are been given orders while those who have experience and were exporting to Germany and other countries are not been given orders. The playbook is errily similar. In India, we don t have the infrastructure for any new patients, period. Heck only a couple of states have done something proper for the anganwadi workers. In fact, last year there were massive strikes by anganwadi workers all over India but only NDTV showed a bit of it along with some of the news channels from South India. Most mainstream channels chose to ignore it.
On the world stage, some of the other countries and how they have responded perhaps need sharing. For e.g. I didn t know that Cuba had so many doctors and the politics between it and Brazil. Or the interesting stats. shared by Andreas Backhaus which seems to show how distributed the issue (age-wise) is rather than just a few groups as has been told in Indian media. What was surprising for me is the 20-29 age group which has not been shared so much in the Indian media which is the bulk of our population. The HBR article also makes a few key points which I hope both the general public and policymakers both in India as well as elsewhere take note of.
What is worrying though that people can be infected twice or more as seems to be from Singapore or China and elsewhere. I have read enough of Robin Cook and Michael Crichton books to be aware that viruses can do whatever. They will over time mutate, how things will happen then is anybody s guess. What I found interesting is the world economic forum article which hypothesis that it may be two viruses which got together as well as research paper from journal from poteome research which has recently been published. The biggest myth flying around is that summer will halt or kill the spread which even some of my friends have been victim of . While a part of me wants to believe them, a simple scientific fact has been viruses have probably been around us and evolved over time, just like we have. In fact, there have been cases of people dying due to common cold and other things. Viruses are so prevalent it s unbelivable. What is and was interesting to note is that bat-borne viruses as well as pangolin viruses had been theorized and shared by Chinese researchers going all the way back to 90 s . The problem is even if we killed all the bats in the world, some other virus will take its place for sure. One of the ideas I had, dunno if it s feasible or not that at least in places like Airports, we should have some sort of screenings and a labs working on virology. Of course, this will mean more expenses for flying passengers but for public health and safety maybe it would worth doing so. In any case, virologists should have a field day cataloging various viruses and would make it harder for viruses to spread as fast as this one has. The virus spread also showed a lack of leadership in most of our leaders who didn t react fast enough. While one hopes people do learn from this, I am afraid the whole thing is far from over. These are unprecedented times and hope that all are maintaining social distancing and going out only when needed.
While the adoption of OpenPGP by the general
population is marginal at best, it is a critical component for the
security community and particularly for Linux distributions. For
example, every package uploaded into Debian is verified by the central
repository using the maintainer's OpenPGP keys and the repository itself
is, in turn, signed using a separate key. If upstream packages also use
such signatures, this creates a complete trust path from the original
upstream developer to users. Beyond that, pull requests for the Linux
kernel are verified using signatures as well. Therefore, the stakes are
high: a compromise of the release key, or even of a single maintainer's
key, could enable devastating attacks against many machines.
That has led the Debian community to develop a good grasp of best
practices for cryptographic signatures (which are typically handled
using GNU Privacy Guard, also known as GnuPG or
GPG). For example, weak (less than 2048 bits) and
vulnerable PGPv3 keys were
removed from
the keyring in 2015, and there is a strong culture of cross-signing keys
between Debian members at in-person meetings. Yet even Debian developers
(DDs) do not seem to have established practices on how to actually store
critical private key material, as we can see in this
discussion
on the debian-project mailing list. That email boiled down to a simple
request: can I have a "key dongles for dummies" tutorial? Key dongles,
or keycards as we'll call them here, are small devices that allow users
to store keys on an offline device and provide one possible solution for
protecting private key material. In this article, I hope to use my
experience in this domain to clarify the issue of how to store those
precious private keys that, if compromised, could enable arbitrary code
execution on millions of machines all over the world.
Why store keys offline?
Before we go into details about storing keys offline, it may be useful
to do a small reminder of how the OpenPGP
standard works. OpenPGP keys are
made of a main public/private key pair, the certification key, used to
sign user identifiers and subkeys. My public key, shown below, has the
usual main certification/signature key (marked SC) but also an
encryption subkey (marked E), a separate signature key (S), and two
authentication keys (marked A) which I use as RSA keys to log into
servers using SSH, thanks to the
Monkeysphere project.
pub rsa4096/792152527B75921E 2009-05-29 [SC] [expires: 2018-04-19]
8DC901CE64146C048AD50FBB792152527B75921E
uid [ultimate] Antoine Beaupr <anarcat@anarc.at>
uid [ultimate] Antoine Beaupr <anarcat@koumbit.org>
uid [ultimate] Antoine Beaupr <anarcat@orangeseeds.org>
uid [ultimate] Antoine Beaupr <anarcat@debian.org>
sub rsa2048/B7F648FED2DF2587 2012-07-18 [A]
sub rsa2048/604E4B3EEE02855A 2012-07-20 [A]
sub rsa4096/A51D5B109C5A5581 2009-05-29 [E]
sub rsa2048/3EA1DDDDB261D97B 2017-08-23 [S]
All the subkeys (sub) and identities (uid) are bound by the main
certification key using cryptographic self-signatures. So while an
attacker stealing a private subkey can spoof signatures in my name or
authenticate to other servers, that key can always be revoked by the
main certification key. But if the certification key gets stolen, all
bets are off: the attacker can create or revoke identities or subkeys as
they wish. In a catastrophic scenario, an attacker could even steal the
key and remove your copies, taking complete control of the key, without
any possibility of recovery. Incidentally, this is why it is so
important to generate a revocation certificate and store it offline.
So by moving the certification key offline, we reduce the attack surface
on the OpenPGP trust chain: day-to-day keys (e.g. email encryption or
signature) can stay online but if they get stolen, the certification key
can revoke those keys without having to revoke the main certification
key as well. Note that a stolen encryption key is a different problem:
even if we revoke the encryption subkey, this will only affect future
encrypted messages. Previous messages will be readable by the attacker
with the stolen subkey even if that subkey gets revoked, so the benefits
of revoking encryption certificates are more limited.
Common strategies for offline key storage
Considering the security tradeoffs, some propose storing those critical
keys offline to reduce those threats. But where exactly? In an attempt
to answer that question, Jonathan McDowell, a member of the Debian
keyring maintenance team,
said that there are three
options:
use an external LUKS-encrypted volume, an air-gapped system, or a
keycard.
Full-disk encryption like LUKS adds an extra layer of security by hiding
the content of the key from an attacker. Even though private keyrings
are usually protected by a passphrase, they are easily identifiable as a
keyring. But when a volume is fully encrypted, it's not immediately
obvious to an attacker there is private key material on the device.
According
to Sean Whitton, another advantage of LUKS over plain GnuPG keyring
encryption is that you can pass the --iter-time argument when creating
a LUKS partition to increase key-derivation delay, which makes
brute-forcing much harder. Indeed, GnuPG 2.x doesn't
have a run-time option to configure the
key-derivation algorithm, although a
patch was introduced recently to make the
delay configurable at compile time in gpg-agent, which is now
responsible for all secret key operations.
The downside of external volumes is complexity: GnuPG makes it difficult
to extract secrets out of its keyring, which makes the first setup
tricky and error-prone. This is easier in the 2.x series thanks to the
new storage system and the associated keygrip files, but it still
requires arcane knowledge of GPG internals. It is also inconvenient to
use secret keys stored outside your main keyring when you actually do
need to use them, as GPG doesn't know where to find those keys anymore.
Another option is to set up a separate air-gapped system to perform
certification operations. An example is the PGP clean
room project,
which is a live system based on Debian and designed by DD Daniel Pocock
to operate an OpenPGP and X.509 certificate authority using commodity
hardware. The basic principle is to store the secrets on a different
machine that is never connected to the network and, therefore, not
exposed to attacks, at least in theory. I have personally discarded that
approach because I feel air-gapped systems provide a false sense of
security: data eventually does need to come in and out of the system,
somehow, even if only to propagate signatures out of the system, which
exposes the system to attacks.
System updates are similarly problematic: to keep the system secure,
timely security updates need to be deployed to the air-gapped system. A
common use pattern is to share data through USB keys, which introduce a
vulnerability where attacks like
BadUSB can infect the air-gapped
system. From there, there is a multitude of exotic ways of exfiltrating
the data using
LEDs,
infrared
cameras,
or the good old
TEMPEST
attack. I therefore concluded the complexity tradeoffs of an air-gapped
system are not worth it. Furthermore, the workflow for air-gapped
systems is complex: even though PGP clean room went a long way, it's
still lacking even simple scripts that allow signing or transferring
keys, which is a problem shared by the external LUKS storage approach.
Keycard advantages
The approach I have chosen is to use a cryptographic keycard: an
external device, usually connected through the USB port, that stores the
private key material and performs critical cryptographic operations on
the behalf of the host. For example, the FST-01
keycard can perform RSA and
ECC public-key decryption without ever exposing the private key material
to the host. In effect, a keycard is a miniature computer that performs
restricted computations for another host. Keycards usually support
multiple "slots" to store subkeys. The OpenPGP standard specifies there
are three subkeys available by default: for signature, authentication,
and encryption. Finally, keycards can have an actual physical keypad to
enter passwords so a potential keylogger cannot capture them, although
the keycards I have access to do not feature such a keypad.
We could easily draw a parallel between keycards and an air-gapped
system; in effect, a keycard is a miniaturized air-gapped computer and
suffers from similar problems. An attacker can intercept data on the
host system and attack the device in the same way, if not more easily,
because a keycard is actually "online" (i.e. clearly not air-gapped)
when connected. The advantage over a fully-fledged air-gapped computer,
however, is that the keycard implements only a restricted set of
operations. So it is easier to create an open hardware and software
design that is audited and verified, which is much harder to accomplish
for a general-purpose computer.
Like air-gapped systems, keycards address the scenario where an attacker
wants to get the private key material. While an attacker could fool the
keycard into signing or decrypting some data, this is possible only
while the key is physically connected, and the keycard software will
prompt the user for a password before doing the operation, though the
keycard can cache the password for some time. In effect, it thwarts
offline attacks: to brute-force the key's password, the attacker needs
to be on the target system and try to guess the keycard's password,
which will lock itself after a limited number of tries. It also provides
for a clean and standard interface to store keys offline: a single GnuPG
command moves private key material to a keycard (the keytocard command
in the --edit-key interface), whereas moving private key material to a
LUKS-encrypted device or air-gapped computer is more complex.
Keycards are also useful if you operate on multiple computers. A common
problem when using GnuPG on multiple machines is how to safely copy and
synchronize private key material among different devices, which
introduces new security problems. Indeed, a "good rule of thumb in a
forensics lab",
according
to Robert J. Hansen on the GnuPG mailing list, is to "store the minimum
personal data possible on your systems". Keycards provide the best of
both worlds here: you can use your private key on multiple computers
without actually storing it in multiple places. In fact, Mike Gerwitz
went as far as
saying:
For users that need their GPG key on multiple boxes, I consider a
smartcard to be essential. Otherwise, the user is just furthering her
risk of compromise.
Keycard tradeoffs
As Gerwitz hinted, there are multiple downsides to using a keycard,
however. Another DD, Wouter Verhelst clearly
expressed
the tradeoffs:
Smartcards are useful. They ensure that the private half of your key
is never on any hard disk or other general storage device, and
therefore that it cannot possibly be stolen (because there's only one
possible copy of it).
Smartcards are a pain in the ass. They ensure that the private half of
your key is never on any hard disk or other general storage device but
instead sits in your wallet, so whenever you need to access it, you
need to grab your wallet to be able to do so, which takes more effort
than just firing up GnuPG. If your laptop doesn't have a builtin
cardreader, you also need to fish the reader from your backpack or
wherever, etc.
"Smartcards" here refer to older OpenPGP
cards that relied on the
IEC 7816 smartcard
connectors and therefore
needed a specially-built smartcard reader. Newer keycards simply use a
standard USB connector. In any case, it's true that having an external
device introduces new issues: attackers can steal your keycard, you can
simply lose it, or wash it with your dirty laundry. A laptop or a
computer can also be lost, of course, but it is much easier to lose a
small USB keycard than a full laptop and I have yet to hear of someone
shoving a full laptop into a washing machine. When you lose your
keycard, unless a separate revocation certificate is available
somewhere, you lose complete control of the key, which is catastrophic.
But, even if you revoke the lost key, you need to create a new one,
which involves rebuilding the web of trust for the key a rather
expensive operation as it usually requires meeting other OpenPGP users
in person to exchange fingerprints.
You should therefore think about how to back up the certification key,
which is a problem that already exists for online keys; of course,
everyone has a revocation certificates and backups of their OpenPGP
keys... right? In the keycard scenario, backups may be multiple keycards
distributed geographically.
Note that, contrary to an air-gapped system, a key generated on a
keycard cannot be backed up, by design. For subkeys, this is not a
problem as they do not need to be backed up (except encryption keys).
But, for a certification key, this means users need to generate the key
on the host and transfer it to the keycard, which means the host is
expected to have enough entropy to generate cryptographic-strength
random numbers, for example. Also consider the possibility of combining
different approaches: you could, for example, use a keycard for
day-to-day operation, but keep a backup of the certification key on a
LUKS-encrypted offline volume.
Keycards introduce a new element into the trust chain: you need to trust
the keycard manufacturer to not have any hostile code in the key's
firmware or hardware. In addition, you need to trust that the
implementation is correct. Keycards are harder to update: the firmware
may be deliberately inaccessible to the host for security reasons or may
require special software to manipulate. Keycards may be slower than the
CPU in performing certain operations because they are small embedded
microcontrollers with limited computing power.
Finally, keycards may encourage users to trust multiple machines with
their secrets, which works against the "minimum personal data"
principle. A completely different approach called the trusted physical
console
(TPC) does the opposite: instead of trying to get private key material
onto all of those machines, just have them on a single machine that is
used for everything. Unlike a keycard, the TPC is an actual computer,
say a laptop, which has the advantage of needing no special procedure to
manage keys. The downside is, of course, that you actually need to carry
that laptop everywhere you go, which may be problematic, especially in
some corporate environments that restrict bringing your own devices.
Quick keycard "howto"
Getting keys onto a keycard is easy enough:
Use the key command to select the first subkey, then copy it to
the keycard (you can also use the addcardkey command to just
generate a new subkey directly on the keycard):
gpg> key 1
gpg> keytocard
If you want to move the subkey, use the save command, which will
remove the local copy of the private key, so the keycard will be the
only copy of the secret key. Otherwise use the quit command to
save the key on the keycard, but keep the secret key in your normal
keyring; answer "n" to "save changes?" and "y" to "quit without
saving?" . This way the keycard is a backup of your secret key.
Once you are satisfied with the results, repeat steps 1 through 4
with your normal keyring (unset $GNUPGHOME)
When a key is moved to a keycard, --list-secret-keys will show it as
sec> (or ssb> for subkeys) instead of the usual sec keyword. If
the key is completely missing (for example, if you moved it to a LUKS
container), the # sign is used instead. If you need to use a key from
a keycard backup, you simply do gpg --card-edit with the key plugged
in, then type the fetch command at the prompt to fetch the public key
that corresponds to the private key on the keycard (which stays on the
keycard). This is the same procedure as the one to use the secret key
on another
computer.
Conclusion
There are already informal OpenPGP best-practices
guides
out there and some recommend storing keys offline, but they rarely
explain what exactly that means. Storing your primary secret key offline
is important in dealing with possible compromises and we examined the
main ways of doing so: either with an air-gapped system, LUKS-encrypted
keyring, or by using keycards. Each approach has its own tradeoffs, but
I recommend getting familiar with keycards if you use multiple computers
and want a standardized interface with minimal configuration trouble.
And of course, those approaches can be combined. This
tutorial,
for example, uses a keycard on an air-gapped computer, which neatly
resolves the question of how to transmit signatures between the
air-gapped system and the world. It is definitely not for the faint of
heart, however.
Once one has decided to use a keycard, the next order of business is to
choose a specific device. That choice will be addressed in a followup
article, where I will look at performance, physical design, and other
considerations.
While the adoption of OpenPGP by the general
population is marginal at best, it is a critical component for the
security community and particularly for Linux distributions. For
example, every package uploaded into Debian is verified by the central
repository using the maintainer's OpenPGP keys and the repository itself
is, in turn, signed using a separate key. If upstream packages also use
such signatures, this creates a complete trust path from the original
upstream developer to users. Beyond that, pull requests for the Linux
kernel are verified using signatures as well. Therefore, the stakes are
high: a compromise of the release key, or even of a single maintainer's
key, could enable devastating attacks against many machines.
That has led the Debian community to develop a good grasp of best
practices for cryptographic signatures (which are typically handled
using GNU Privacy Guard, also known as GnuPG or
GPG). For example, weak (less than 2048 bits) and
vulnerable PGPv3 keys were
removed from
the keyring in 2015, and there is a strong culture of cross-signing keys
between Debian members at in-person meetings. Yet even Debian developers
(DDs) do not seem to have established practices on how to actually store
critical private key material, as we can see in this
discussion
on the debian-project mailing list. That email boiled down to a simple
request: can I have a "key dongles for dummies" tutorial? Key dongles,
or keycards as we'll call them here, are small devices that allow users
to store keys on an offline device and provide one possible solution for
protecting private key material. In this article, I hope to use my
experience in this domain to clarify the issue of how to store those
precious private keys that, if compromised, could enable arbitrary code
execution on millions of machines all over the world.
Why store keys offline?
Before we go into details about storing keys offline, it may be useful
to do a small reminder of how the OpenPGP
standard works. OpenPGP keys are
made of a main public/private key pair, the certification key, used to
sign user identifiers and subkeys. My public key, shown below, has the
usual main certification/signature key (marked SC) but also an
encryption subkey (marked E), a separate signature key (S), and two
authentication keys (marked A) which I use as RSA keys to log into
servers using SSH, thanks to the
Monkeysphere project.
pub rsa4096/792152527B75921E 2009-05-29 [SC] [expires: 2018-04-19]
8DC901CE64146C048AD50FBB792152527B75921E
uid [ultimate] Antoine Beaupr <anarcat@anarc.at>
uid [ultimate] Antoine Beaupr <anarcat@koumbit.org>
uid [ultimate] Antoine Beaupr <anarcat@orangeseeds.org>
uid [ultimate] Antoine Beaupr <anarcat@debian.org>
sub rsa2048/B7F648FED2DF2587 2012-07-18 [A]
sub rsa2048/604E4B3EEE02855A 2012-07-20 [A]
sub rsa4096/A51D5B109C5A5581 2009-05-29 [E]
sub rsa2048/3EA1DDDDB261D97B 2017-08-23 [S]
All the subkeys (sub) and identities (uid) are bound by the main
certification key using cryptographic self-signatures. So while an
attacker stealing a private subkey can spoof signatures in my name or
authenticate to other servers, that key can always be revoked by the
main certification key. But if the certification key gets stolen, all
bets are off: the attacker can create or revoke identities or subkeys as
they wish. In a catastrophic scenario, an attacker could even steal the
key and remove your copies, taking complete control of the key, without
any possibility of recovery. Incidentally, this is why it is so
important to generate a revocation certificate and store it offline.
So by moving the certification key offline, we reduce the attack surface
on the OpenPGP trust chain: day-to-day keys (e.g. email encryption or
signature) can stay online but if they get stolen, the certification key
can revoke those keys without having to revoke the main certification
key as well. Note that a stolen encryption key is a different problem:
even if we revoke the encryption subkey, this will only affect future
encrypted messages. Previous messages will be readable by the attacker
with the stolen subkey even if that subkey gets revoked, so the benefits
of revoking encryption certificates are more limited.
Common strategies for offline key storage
Considering the security tradeoffs, some propose storing those critical
keys offline to reduce those threats. But where exactly? In an attempt
to answer that question, Jonathan McDowell, a member of the Debian
keyring maintenance team,
said that there are three
options:
use an external LUKS-encrypted volume, an air-gapped system, or a
keycard.
Full-disk encryption like LUKS adds an extra layer of security by hiding
the content of the key from an attacker. Even though private keyrings
are usually protected by a passphrase, they are easily identifiable as a
keyring. But when a volume is fully encrypted, it's not immediately
obvious to an attacker there is private key material on the device.
According
to Sean Whitton, another advantage of LUKS over plain GnuPG keyring
encryption is that you can pass the --iter-time argument when creating
a LUKS partition to increase key-derivation delay, which makes
brute-forcing much harder. Indeed, GnuPG 2.x doesn't
have a run-time option to configure the
key-derivation algorithm, although a
patch was introduced recently to make the
delay configurable at compile time in gpg-agent, which is now
responsible for all secret key operations.
The downside of external volumes is complexity: GnuPG makes it difficult
to extract secrets out of its keyring, which makes the first setup
tricky and error-prone. This is easier in the 2.x series thanks to the
new storage system and the associated keygrip files, but it still
requires arcane knowledge of GPG internals. It is also inconvenient to
use secret keys stored outside your main keyring when you actually do
need to use them, as GPG doesn't know where to find those keys anymore.
Another option is to set up a separate air-gapped system to perform
certification operations. An example is the PGP clean
room project,
which is a live system based on Debian and designed by DD Daniel Pocock
to operate an OpenPGP and X.509 certificate authority using commodity
hardware. The basic principle is to store the secrets on a different
machine that is never connected to the network and, therefore, not
exposed to attacks, at least in theory. I have personally discarded that
approach because I feel air-gapped systems provide a false sense of
security: data eventually does need to come in and out of the system,
somehow, even if only to propagate signatures out of the system, which
exposes the system to attacks.
System updates are similarly problematic: to keep the system secure,
timely security updates need to be deployed to the air-gapped system. A
common use pattern is to share data through USB keys, which introduce a
vulnerability where attacks like
BadUSB can infect the air-gapped
system. From there, there is a multitude of exotic ways of exfiltrating
the data using
LEDs,
infrared
cameras,
or the good old
TEMPEST
attack. I therefore concluded the complexity tradeoffs of an air-gapped
system are not worth it. Furthermore, the workflow for air-gapped
systems is complex: even though PGP clean room went a long way, it's
still lacking even simple scripts that allow signing or transferring
keys, which is a problem shared by the external LUKS storage approach.
Keycard advantages
The approach I have chosen is to use a cryptographic keycard: an
external device, usually connected through the USB port, that stores the
private key material and performs critical cryptographic operations on
the behalf of the host. For example, the FST-01
keycard can perform RSA and
ECC public-key decryption without ever exposing the private key material
to the host. In effect, a keycard is a miniature computer that performs
restricted computations for another host. Keycards usually support
multiple "slots" to store subkeys. The OpenPGP standard specifies there
are three subkeys available by default: for signature, authentication,
and encryption. Finally, keycards can have an actual physical keypad to
enter passwords so a potential keylogger cannot capture them, although
the keycards I have access to do not feature such a keypad.
We could easily draw a parallel between keycards and an air-gapped
system; in effect, a keycard is a miniaturized air-gapped computer and
suffers from similar problems. An attacker can intercept data on the
host system and attack the device in the same way, if not more easily,
because a keycard is actually "online" (i.e. clearly not air-gapped)
when connected. The advantage over a fully-fledged air-gapped computer,
however, is that the keycard implements only a restricted set of
operations. So it is easier to create an open hardware and software
design that is audited and verified, which is much harder to accomplish
for a general-purpose computer.
Like air-gapped systems, keycards address the scenario where an attacker
wants to get the private key material. While an attacker could fool the
keycard into signing or decrypting some data, this is possible only
while the key is physically connected, and the keycard software will
prompt the user for a password before doing the operation, though the
keycard can cache the password for some time. In effect, it thwarts
offline attacks: to brute-force the key's password, the attacker needs
to be on the target system and try to guess the keycard's password,
which will lock itself after a limited number of tries. It also provides
for a clean and standard interface to store keys offline: a single GnuPG
command moves private key material to a keycard (the keytocard command
in the --edit-key interface), whereas moving private key material to a
LUKS-encrypted device or air-gapped computer is more complex.
Keycards are also useful if you operate on multiple computers. A common
problem when using GnuPG on multiple machines is how to safely copy and
synchronize private key material among different devices, which
introduces new security problems. Indeed, a "good rule of thumb in a
forensics lab",
according
to Robert J. Hansen on the GnuPG mailing list, is to "store the minimum
personal data possible on your systems". Keycards provide the best of
both worlds here: you can use your private key on multiple computers
without actually storing it in multiple places. In fact, Mike Gerwitz
went as far as
saying:
For users that need their GPG key on multiple boxes, I consider a
smartcard to be essential. Otherwise, the user is just furthering her
risk of compromise.
Keycard tradeoffs
As Gerwitz hinted, there are multiple downsides to using a keycard,
however. Another DD, Wouter Verhelst clearly
expressed
the tradeoffs:
Smartcards are useful. They ensure that the private half of your key
is never on any hard disk or other general storage device, and
therefore that it cannot possibly be stolen (because there's only one
possible copy of it).
Smartcards are a pain in the ass. They ensure that the private half of
your key is never on any hard disk or other general storage device but
instead sits in your wallet, so whenever you need to access it, you
need to grab your wallet to be able to do so, which takes more effort
than just firing up GnuPG. If your laptop doesn't have a builtin
cardreader, you also need to fish the reader from your backpack or
wherever, etc.
"Smartcards" here refer to older OpenPGP
cards that relied on the
IEC 7816 smartcard
connectors and therefore
needed a specially-built smartcard reader. Newer keycards simply use a
standard USB connector. In any case, it's true that having an external
device introduces new issues: attackers can steal your keycard, you can
simply lose it, or wash it with your dirty laundry. A laptop or a
computer can also be lost, of course, but it is much easier to lose a
small USB keycard than a full laptop and I have yet to hear of someone
shoving a full laptop into a washing machine. When you lose your
keycard, unless a separate revocation certificate is available
somewhere, you lose complete control of the key, which is catastrophic.
But, even if you revoke the lost key, you need to create a new one,
which involves rebuilding the web of trust for the key a rather
expensive operation as it usually requires meeting other OpenPGP users
in person to exchange fingerprints.
You should therefore think about how to back up the certification key,
which is a problem that already exists for online keys; of course,
everyone has a revocation certificates and backups of their OpenPGP
keys... right? In the keycard scenario, backups may be multiple keycards
distributed geographically.
Note that, contrary to an air-gapped system, a key generated on a
keycard cannot be backed up, by design. For subkeys, this is not a
problem as they do not need to be backed up (except encryption keys).
But, for a certification key, this means users need to generate the key
on the host and transfer it to the keycard, which means the host is
expected to have enough entropy to generate cryptographic-strength
random numbers, for example. Also consider the possibility of combining
different approaches: you could, for example, use a keycard for
day-to-day operation, but keep a backup of the certification key on a
LUKS-encrypted offline volume.
Keycards introduce a new element into the trust chain: you need to trust
the keycard manufacturer to not have any hostile code in the key's
firmware or hardware. In addition, you need to trust that the
implementation is correct. Keycards are harder to update: the firmware
may be deliberately inaccessible to the host for security reasons or may
require special software to manipulate. Keycards may be slower than the
CPU in performing certain operations because they are small embedded
microcontrollers with limited computing power.
Finally, keycards may encourage users to trust multiple machines with
their secrets, which works against the "minimum personal data"
principle. A completely different approach called the trusted physical
console
(TPC) does the opposite: instead of trying to get private key material
onto all of those machines, just have them on a single machine that is
used for everything. Unlike a keycard, the TPC is an actual computer,
say a laptop, which has the advantage of needing no special procedure to
manage keys. The downside is, of course, that you actually need to carry
that laptop everywhere you go, which may be problematic, especially in
some corporate environments that restrict bringing your own devices.
Quick keycard "howto"
Getting keys onto a keycard is easy enough:
Use the key command to select the first subkey, then copy it to
the keycard (you can also use the addcardkey command to just
generate a new subkey directly on the keycard):
gpg> key 1
gpg> keytocard
If you want to move the subkey, use the save command, which will
remove the local copy of the private key, so the keycard will be the
only copy of the secret key. Otherwise use the quit command to
save the key on the keycard, but keep the secret key in your normal
keyring; answer "n" to "save changes?" and "y" to "quit without
saving?" . This way the keycard is a backup of your secret key.
Once you are satisfied with the results, repeat steps 1 through 4
with your normal keyring (unset $GNUPGHOME)
When a key is moved to a keycard, --list-secret-keys will show it as
sec> (or ssb> for subkeys) instead of the usual sec keyword. If
the key is completely missing (for example, if you moved it to a LUKS
container), the # sign is used instead. If you need to use a key from
a keycard backup, you simply do gpg --card-edit with the key plugged
in, then type the fetch command at the prompt to fetch the public key
that corresponds to the private key on the keycard (which stays on the
keycard). This is the same procedure as the one to use the secret key
on another
computer.
Conclusion
There are already informal OpenPGP best-practices
guides
out there and some recommend storing keys offline, but they rarely
explain what exactly that means. Storing your primary secret key offline
is important in dealing with possible compromises and we examined the
main ways of doing so: either with an air-gapped system, LUKS-encrypted
keyring, or by using keycards. Each approach has its own tradeoffs, but
I recommend getting familiar with keycards if you use multiple computers
and want a standardized interface with minimal configuration trouble.
And of course, those approaches can be combined. This
tutorial,
for example, uses a keycard on an air-gapped computer, which neatly
resolves the question of how to transmit signatures between the
air-gapped system and the world. It is definitely not for the faint of
heart, however.
Once one has decided to use a keycard, the next order of business is to
choose a specific device. That choice will be addressed in a followup
article, where I will look at performance, physical design, and other
considerations.
Yesterday, I was giving a talk at the The South SF Bay Haskell User Group about how implementing lock-step simulation is trivial in Haskell and how Chris Smith and me are using this to make CodeWorld even more attractive to students. I gave the talk before, at Compose::Conference in New York City earlier this year, so I felt well prepared. On the flight to the West Coast I slightly extended the slides, and as I was too cheap to buy in-flight WiFi, I tested them only locally.
So I arrived at the offices of Target1 in Sunnyvale, got on the WiFi, uploaded my slides, which are in fact one large interactive CodeWorld program, and tried to run it. But I got a type error
Turns out that the API of CodeWorld was changed just the day before:
commit 054c811b494746ec7304c3d495675046727ab114
Author: Chris Smith <cdsmith@gmail.com>
Date: Wed Jun 21 23:53:53 2017 +0000
Change dilated to take one parameter.
Function is nearly unused, so I'm not concerned about breakage.
This new version better aligns with standard educational usage,
in which "dilation" means uniform scaling. Taken as a separate
operation, it commutes with rotation, and preserves similarity
of shapes, neither of which is true of scaling in general.
Ok, that was quick to fix, and the CodeWorld server started to compile my code, and compiled, and aborted. It turned out that my program, presumably the larges CodeWorld interaction out there, hit the time limit of the compiler.
Luckily, Chris Smith just arrived at the venue, and he emergency-bumped the compiler time limit. The program compiled and I could start my presentation.
Unfortunately, the biggest blunder was still awaiting for me. I came to the slide where two instances of pong are played over a simulated network, and my point was that the two instances are perfectly in sync. Unfortunately, they were not. I guess it did support my point that lock-step simulation can easily go wrong, but it really left me out in the rain there, and I could not explain it I did not modify this code since New York, and there it worked flawless2. In the end, I could save my face a bit by running the real pong game against an attendee over the network, and no desynchronisation could be observed there.
Today I dug into it and it took me a while, and it turned out that the problem was not in CodeWorld, or the lock-step simulation code discussed in our paper about it, but in the code in my presentation that simulated the delayed network messages; in some instances it would deliver the UI events in different order to the two simulated players, and hence cause them do something different. Phew.
Yes, the retail giant. Turns out that they have a small but enthusiastic Haskell-using group in their IT department.
I hope the video is going to be online soon, then you can check for yourself.
Looking into self-financing
Before I begin, I should mention that I started tracking my time
working on free software more systematically. I spend a lot of time on
the computer, as regular readers of this blog might
remember so I wanted to know exactly how
much time was paid vs free work. I was already using org-mode's
time clock system to keep track of my work hours, so I just
extended this to my regular free software contributions, which also
helps in writing those reports.
It turns out that over 60% of my computer time is spent working on
free software. That's huge! I was expecting something more along the
range of 20 to 40% of my time. So I started thinking about ways of
financing this work. I created a Patreon page but I'm hesitant
into launching such a campaign: the only thing worse than "no patreon
page" is "a patreon page with failed goals and no one financing
it". So before starting such an effort, I'd like to get a feeling of
what other people's experience with it are. I know that joeyh is
close to achieving his goals, but I can't compare with the guy that
invented git-annex or debhelper, so I'm concerned I wouldn't be able
to raise the same level of funding.
So any advice you have, feel free to contact me in private or in the
comments. If you would be ready to fund my work, I'd love to know
about it, obviously, but I guess I wouldn't get real numbers until I
actually open up such a page...
Now, onto the regular report.
Wallabako
I spent a good chunk of time completing most of the things I had in
mind for Wallabako, which I mentioned quickly in the previous
report. Wallabako
is now much easier to installed, with clearer instructions, an easier
to use configuration file, more reliable synchronization and read
status propagation. As usual the Wallabako README file has all the
details.
I've also looked at better integration with Koreader, the free
software e-reader that forms the basis of
the okreader free software distribution which has been able to
port Debian to the Kobo e-readers, a project I am really excited
about. This project has the potential of supporting Kobo readers
beyond the lifetime that upstream grants it and removes a lot of
proprietary software and spyware that ships with the Kobo readers. So
I have made a few contributions to okreader
and also on koreader, the ebook reader okreader is based on.
Stressant
I rewrote stressant, my simple burn-in and
stress-testing tool. After struggling in turn
with Debirf, live-build, vmdebootstrap and even FAI, I
just figured maybe it wasn't the best idea to try and reinvent that
particular wheel: instead of reinventing how to build yet
another Debian system build tool, maybe I should just reuse what's
already there.
It turns out there's a well known, succesful and fairly complete
recovery system called Grml. It is a Debian Derivative, so all
I needed to do was to stop procrastinating and actually write the
actual stressant tool instead of just creating a distribution with a
bunch of random tools shipped in. This allowed me to focus on which
tools were the best to stress test different components. This
selection ended up being:
fio can also be used to overwrite disk drives with the proper
options (--overwrite and --size=100%), although grml also ships
with nwipe for wiping old spinning disks and hdparm to
do a secure erase of SSD disks (whatever that's worth).
Stressant still needs to be shipped with grml for this transition
to be complete. In the meantime, I was able to configure the excellent
public Gitlab CI service to provide ISO images with Stressant
built-in as a stopgap measure. I also need to figure out a way to
automate starting stressant from a boot menu to automate deployments
on a larger scale, although because I have little need for the feature
at this moment in time, this will likely wait for a sponsor to show up
for this to be implemented.
Still, stressant has useful features like the capability of sending
logs by email using a fresh new implementation of the
Python SMTPHandler (BufferedSMTPHandler) which waits for
logging to complete before sending a single email. Another interesting
piece of code in there is the NegateActionargparse handler
that enables the use of "toggle flags" (e.g. --flag /
--no-flag). I'm so happy with the code that I figure I could just
share it here directly:
classNegateAction(argparse.Action):'''add a toggle flag to argparse this is similar to 'store_true' or 'store_false', but allows arguments prefixed with --no to disable the default. the default is set depending on the first argument - if it starts with the negative form (define by default as '--no'), the default is False, otherwise True. '''
negative ='--no'def__init__(self, option_strings, *args, **kwargs):'''set default depending on the first argument'''
default =not option_strings[0].startswith(self.negative)super(NegateAction, self).__init__(option_strings, *args,
default=default, nargs=0, **kwargs)def__call__(self, parser, ns, values, option):'''set the truth value depending on whether it starts with the negative form'''setattr(ns, self.dest,not option.startswith(self.negative))
Short and sweet. I wonder why stuff like this is not in the standard
library yet - maybe just because no one bothered yet? It'd be great to
get feedback of more experienced Pythonistas on this one.
I hope that my work on Stressant is complete. I get zero funding for
this work, and have little use for it myself: I manage only a few
machines and such a tool really shines when you regularly put new
hardware online, which is (fortunately?) not my case anymore. I'd be
happy, of course, to accompany organisations and people that wish to
further develop and use such a tool.
A short demo of stressant as well as detailed description of how
it works is of course available in its README file.
Standard third party repositories
After looking
at improvements for the grml repository instructions, I realized
there was no real "best practices" document on how to configure an Apt
repository. Sure, there are tools like reprepro and
others, but those hardly qualify as policy: they are very flexible and
there are lots of ways to create insecure repositories
or curl sh style instructions, which we of course generally want
to avoid.
While the larger problem of Unstrusted Debian packages remain
generally unsolved (e.g. when you install any.deb file, it can
get root on your system), it seemed to me one critical part of this
problem was how to add a random third-party repository to your machine
while limiting, as much as possible, what possible attackers could
do with such a repository. In other words, to solve the more general
problem of insecure .deb files, we also need to solve the
distribution problem, otherwise fixing the .deb files themselves
will be useless.
This lead to the creation of standardized repository instructions
that define:
how to distribute the repository's public signing key (ie. over
HTTPS)
how to name suites and components (e.g. use stable and main
unless you have a good reason, and explain yourself)
how to distribute keys (e.g. with a derive-archive-keyring
package)
I've seen so many third party repositories get this wrong. For
example, a lot of repositories recommend this type of command to
intialize the OpenPGP trust path:
curl http://example.com/key.asc apt-key add -
This has the following problems:
the key is transfered in plaintext and can easily be manipulated by
an active attacker (e.g. a router on your path to the server or a
neighbor in a Wifi cafe)
the key is added to the main trust root, which allows the key to
authentify as the real Debian archive, therefore giving it all
rights over all packages
since it's part of the global archive, it's difficult for a package
to remove/add the key when a key rollover is necessary (and
repositories generally don't provide a deriv-archive-keyring to
do that process anyways)
An example of this are the Docker install instructions that, at
least, manage to do this over HTTPS. Some other repositories don't
even bother teaching people about the proper way of adding
those keys. We settled for:
That location was explicitly chosen to be out of the main trust
directory, so that it needs to be explicitly added to the sources.list
as well:
deb [signed-by=/usr/share/keyrings/deriv-archive-keyring.gpg] https://deriv.example.net/debian/ stable main
Similarly, we highly recommend users setup "apt pinning" to restrict
what a given repository can do. Since pinning is so confusing, most
people don't actually bother even configuring it and I have yet to see
a single repo advise its users to configure those preferences, which
are essential to limit what a repository can do. To keep configuration
simple, we recommend this:
And the priority should probably be set to 1 unless you want to
allow automatic upgrades.
It is my hope that this design will get more traction in the years to
come and become a de-facto standard that will be a key part in safely
adding third party repositories. There is obviously much more work to
be done to improve security when installing untrusted .deb files,
and I encourage Debian developers to consider contributing to the
UntrustedDebs discussions and particularly to the
Teams/Dpkg/Spec/DeclarativePackaging work.
Signal R&D
I spent a significant amount of time this month struggling with
the Signal project on my phone. I'm still ambivalent on Signal:
it's a centralized designed, too dependent on phone numbers, but I
must admit they get a lot of things right and it's the only
free-software platform that allows for easy-to-use, multi-platform
videoconferencing that my family can use.
I've been following Signal for a while: up until now, I had been using
the LibreSignal rebuild of the official client, as it is
distributed on a F-Droid repository. Because I try to avoid Google
(proprietary) software on my phone, it's basically the only way I
could even install Signal. Unfortunately, the repository is out of
date and introduces another point of trust in the distribution
model: now you not only need to trust the Signal authors to do the
right thing, you also need to trust that F-Droid repo not to inject
nasty code on your phone. I've therefore started a discussion
about how Signal could be distributed outside of the Google Play
Store. I'd like to think it's one of the things that led the Signal
people to distribute an official copy of Signal outside of the
playstore.
After much struggling, I was able to upgrade to this official client
and will be able to upgrade easily by just downloading the APK. (Do
note that I ended up reinstalling and re-registering Signal, which
unfortunately changed my secret keys.)
I do hope Signal enters F-Droid one day, but it could take a while
because it still doesn't work without Google services
and barely works with MicroG, the free software alternative to
the Google services clients. Moxie also set a list of requirements
like crash reporting and statistics that need to be implemented on
F-Droid's side before he agrees to the deployment, so this could take
a while.
I've also participated in the, ahem, discussion on the JWZ blog
regarding a supposed vulnerability in Signal where it would leak
previously unknown phone numbers to third parties. I reviewed the
way the phone number is uploaded and, while it's possible to create a
rainbow table of phone numbers (which are hashed with a truncated
SHA-1 checksum), I couldn't verify the claims of other participants in
the thread. For me, Signal still does the right thing with contacts,
although I do question the way "read status" notifications get
transmitted, but that belong in another bug report / blog post.
Debian Long Term Support (LTS)
It's been more than a year working on Debian LTS, started by
Raphael Hertzog at Freexian. I didn't work much in February so I
had a lot of hours to catchup with, and was unfortunately unable to do
so, partly because I was busy with other projects, and partly because
my colleagues are doing a great job at resolving the most important
issues.
So one my concerns this month was finding work. It seemed that all the
hard packages were either taken (e.g. my usual favorites, tiff and
imagemagick, we done by others) or just too challenging (e.g. I don't
feel quite comfortable tackling the LTS branch of the Linux kernel
yet).
I spent quite a bit of time trying to figure out what was wrong with
pcre3, only to realise the "32" in the report was not about the
architecture, but about the character width. Because of thise, I
marked 4 CVEs (CVE-2017-7186, CVE-2017-7244, CVE-2017-7245, CVE-2017-7246) as "not-affected", since the
32-bith character support wasn't enabled in wheezy (or jessie, for
that matter). I still spent some time trying to reproduce the issues,
which require a compiler with an AddressSanitizer, something that
was introduced in both Clang and GCC after Wheezy was released, which
makes reproducing this fairly complicated...
This allowed me to experiment more with Vagrant, however, and I have
provided the Debian cloud team with a 32-bit Vagrant box that was
merged in shortly after, although it doesn't show up yet in
the official list of Debian images.
Then I looked at the apparmor situation (CVE-2017-6507),
Debian bug #858768). That was one tricky bug as well, since it's not a
security issue in apparmor per se, but more an issue with things that
assume a certain behavior from apparmor. I have concluded that Wheezy
was not affected because there are no assumptions of proper isolation
there - which are provided only starting from LXC 1.0 - and Docker is
not in Wheezy. I also couldn't reproduce the issue on Jessie, but, as
it turns out, the issue was sysvinit-specific, which is why I couldn't
reproduce it under the default systemd configuration shipped with
Jessie.
I also looked at the various binutilssecurity issues: as I reported on the mailing list, I didn't see anything serious
enough in there to warrant a a security release and followed the lead
of both the stable and Red Hat security teams by marking this
"no-dsa". I similiarly reviewed the mp3spltsecurity issues (specifically CVE-2017-5666) and was fairly puzzled by that issue, which seems
to be triggered only the same address sanitization extensions than PCRE, although there was
some pretty wild interplay with debugging flags in there. All in all,
it seems we can't reproduce that issue in wheezy, but I do not feel
confident enough in the results to push that issue aside for now.
I finally uploaded the pending graphicsmagickissue (DLA-547-2), a regression
update to fix a crash that was introduced in the previous release
(DLA-547-1, mistakenly named DLA-574-1). Hopefully that release should clear up some of the
confusion and fix the regression.
I also released DLA-879-1 for the CVE-2017-6369 in
firebird2.5 which was an interesting experiment:
I couldn't reproduce the issue in a local VM. After following
the Ubuntu setup tutorial, as I wasn't too familiar with the
Firebird database until now (hint: the default username and password
is sysdba/masterkey), I ended up assuming we were vulnerable and
just backporting the patch after seeing the jessie folks push out a
release just in case.
I also looked at updating the ca-certificates package to
deal with the pending WoSign/Startcom
removal: I made an explicit list of the CAs that need to be removed
after reviewing the Mozilla list. I also sent a patch for an unrelated
issue where ca-certificates is writing to /usr/local (!!) in Debian bug #843722.
I have also done some "meta" work in starting a discussion about fixing the
missing DLA links in the tracker, as you will notice all of the
above links lead to nowhere. Thanks to pabs, there are now some
links but unfortunately there are about 500
DLAs missing from the website. We also discussed ways to Debian bug #859123,
something which is currently a manual process. This is now in the
hands of the excellent webmaster
team.
I have also filed a few missing security bugs (Debian bug #859135,
Debian bug #859136), partly because I wanted to help the security
team. But it turned out that I felt the script needed some
improvements, so I submitted a patch to improve the script so it is easier to
run.
Other projects
As usual, there's the usual mixed bags of chaos:
basic maintenance on
the Linkchecker
project, including particularly a set
of
community guidelines which
I'd like to standardize as well
raised a red flag on the security of the Weechat project by
reporting that most users are not aware that Weechat relays provide
arbitrary remote code execution to clients, upstream thinks users
are to blame, issue still opened
I got a new computer and wondered... How can I test it? One of those
innocent questions that brings hours and hours of work and
questionning...
A new desktop: Intel NUC devices
After reading up on Jeff Atwood's blog and especially his article
on the scooter computer, I have discovered a whole range of small
computers that could answer my need for a faster machine in my office
at a low price tag and without taking up too much of my precious desk
space. After what now seems like a
too short review I ended up buying a new
Intel NUC device from NCIX.com, along with 16GB of RAM and
an amazing 500GB M.2 hard drive for around 750$. I am very happy
with the machine. It's very quiet and takes up zero space on my desk
as I was able to screw it to the back of my screen. You can see my
review of the hardware compatibility and installation report in the
Debian wiki.
I wish I had taken more time to review the possible alternatives - for
example I found out about the amazing Airtop PC recently and,
although that specific brand is a bit too expensive, the space of
small computers is far and wide and deserves a more thorough review
than just finding the NUC by accident while shopping for laptops on
System76.com...
Reviving the Stressant project
But this, and Atwood's Is Your Computer Stable? article, got me
thinking about how to test new computers. It's one thing to build a
machine and fire it up, but how do you know everything is actually
really working? It is common practice to do a basic stress test or
burn-in when you get a new machine in the industry - how do you
proceed with such tests?
Back in the days when I was working at Koumbit, I wrote a tool
exactly for that purpose called Stressant. Since I am the main
author of the project and I didn't see much activity on it since I
left, I felt it would be a good idea to bring it under my personal
wing again, and I have therefore moved it to my Gitlab where I
hope to bring it back to life. Parts of the project's rationale are
explained in an "Intent To Package" the "breakin" tool
(Debian bug #707178), which, after closer examination, ended up
turning into a complete rewrite.
The homepage has a bit more information about how the tool works and
its objectives, but generally, the idea is to have a live CD or USB
stick that you can just plugin into a machine to run a battery of
automated tests (memtest86, bonnie++, stress-ng and disk wiping, for
example) or allow for interactive rescue missions on broken
machines. At Koumbit, we had Debirf-based live images that we could
boot off the network fairly easily that we would use for various
purposes, although nothing was automated yet. The tool is based on
Debian, but since it starts from boot, it should be runnable on any
computer.
I was able to bring the project back to life, to a certain extent, by
switching to vmdebootstrap instead of debirf for builds, but
that removed netboot support. Also, I hope that Gitlab could
provide with an autobuilder for the images, but unfortunately there's
a bug in Docker that makes it impossible to mount loop images in
Docker images (which makes it impossible to build Docker in Docker,
apparently).
Should I start yet another project?
So there's still a lot of work to do in this project to get it off the
ground. I am still a bit hesitant in getting into this, however, for a
few reasons:
It's yet another volunteer job - which I am trying to reduce for
health and obvious economic reasons. That's a purely personal
reason and there isn't much you can do about it.
I am not sure the project is useful. It's one thing to build a
tool that can do basic tests on a machine - I can probably just
build an live image for myself that will do everything I need -
it's another completely different thing to build something that
will scale to multiple machines and be useful for more various use
cases and users.
(A variation of #1 is how everything and everyone is moving to the
cloud. It's become a common argument that you shouldn't run your own
metal these days, and we seem to be fighting an uphill economic battle
when we run our own datacenters, rack or even physical servers these
days. I still think it's essential to have some connexion to metal to be
autonomous in our communications, but I'm worried that focusing on such
a project is another of my precious dead entreprises... )
Part #2 is obviously where you people come in. Here's a few
questions I'd like to have feedback on:
(How) do you perform stress-testing of your machines before putting
them in production (or when you find issues you suspect to be
hardware-related)?
Would a tool like breakin or stressant be useful in your environment?
Which tools do you use now for such purposes?
Would you contribute to such a project? How?
Do you think there is room for such a project in the existing
ecology of projects) or should I contribute to an existing project?
Any feedback here would be, of course, greatly appreciated.
Here is my monthly update covering what I have been doing in the free software world (previous month):
Fixed a number of instances in the Django web development framework where methods had mutable defaults arguments such as lists or dictionaries. (#7253)
Made a large number of improvements to travis.debian.net, my hosted service for projects that host their Debian packaging on GitHub to use the Travis CI continuous integration platform to test builds on every update:
Worked with Evgeni Golov to run autopkgtest and autodep8 tests after builds. (#23, #24 & #25)
Ensured that all remote branches are created locally so that packages that specify options such as pristine_tar=True in debian/gbp.conf work as expected. (commit)
Fixed an issue where checking out other branches did not reliably not work due to Travis cloning the repository with --depth=50. (#21)
Submitted a pull request for the Handbrake video transcoder to make the build reproducible. (#320)
Updated the configuration for my OpenWRT-based router (a device I use as a range extender and to save tedious reconfiguration of all my wifi devices in new locales) to enter a "fallback" mode if it cannot connect to the client network. This works around a longstanding "wontfix" upstream issue. (diff)
Whilst anyone can inspect the source code of free software for malicious flaws, most Linux distributions provide binary (or "compiled") packages to end users.
The motivation behind the Reproducible Builds effort is to allow verification that no flaws have been introduced either maliciously and accidentally during this compilation process by promising identical binary packages are always generated from a given source.
My work in the Reproducible Builds project was also covered in our weekly reports #71, #72, #71 & #74.
I made the following improvements to our tools:
diffoscope
diffoscope is our "diff on steroids" that will not only recursively unpack archives but will transform binary formats into human-readable forms in order to compare them.
Added a global Progress object to track the status of the comparison process allowing for graphical and machine-readable status indicators. I also blogged about this feature in more detail.
Moved the global Config object to a more Pythonic "singleton" pattern and ensured that constraints are checked on every change.
disorderfs
disorderfs is our FUSE filesystem that deliberately introduces nondeterminism into the results of system calls such as readdir(3).
Display the "disordered" behaviour we intend to show on startup. (#837689)
Support relative paths in command-line parameters (previously only absolute paths were permitted).
strip-nondeterminism
strip-nondeterminism is our tool to remove specific information from a completed build.
Fix an issue where temporary files were being left on the filesystem and add a test to avoid similar issues in future. (#836670)
Print an error if the file to normalise does not exist. (#800159)
Testsuite improvements:
Set the timezone in tests to avoid a FTBFS and add a File::StripNondeterminism::init method to the API to to set tzset everywhere. (#837382)
"Smoke test" the strip-nondeterminism(1) and dh_strip_nondeterminism(1) scripts to prevent syntax regressions.
Add a testcase for .jar file ordering and normalisation.
Check the stripping process before comparing file attributes to make it less confusing on failure.
Move to a lookup table for descriptions of stat(1) indices and use that for nicer failure messages.
Don't uselessly test whether the inode number has changed.
Run perlcritic across the codebase and adopt some of its prescriptions including explicitly using oct(..) for integers with leading zeroes, avoiding mixing high and low-precedence booleans, ensuring subroutines end with a return statement, etc.
3.2.3-2 Call ulimit -n 65536 by default from SysVinit scripts to normalise the behaviour with systemd. I also bumped the Debian package epoch as the "2:" prefix made it look like we are shipping version 2.x. I additionaly backported this upload to Debian Jessie.
3.2.4-1 New upstream release, add missing -ldl for dladdr(3) & add missing dependency on lsb-base.
Move to "minimal" debhelper style, making the build reproducible. (#777446 & #792991)
Reorder linker command options to build with --as-needed (#729726) and add hardening flags.
Move to machine-readable copyright file, add missing #DEBHELPER# tokens to postinst and prerm scripts, tidy descriptions & other debian/control fields and other smaller changes.
I sponsored the upload of 5 packages from other developers:
I'm using grub version 2.02~beta2-2. I want to make a USB stick that's capable of booting Intel architecture EFI machines, both 64-bit (x86_64) and 32-bit (ia32). I'm starting from a USB stick which is attached to a running debian system as /dev/sdX. I have nothing that i care about on that USB stick, and all data on it will be destroyed by this process. I'm also going to try to make it bootable for traditional Intel BIOS machines, since that seems handy.I'm documenting what I did here, in case it's useful to other people. Set up the USB stick's partition table:
parted /dev/sdX -- mktable gpt
parted /dev/sdX -- mkpart biosgrub fat32 1MiB 4MiB
parted /dev/sdX -- mkpart efi fat32 4MiB -1
parted /dev/sdX -- set 1 bios_grub on
parted /dev/sdX -- set 2 esp on
After this, my 1GiB USB stick looks like:
0 root@foo:~# parted /dev/sdX -- print
Model: USB FLASH DRIVE (scsi)
Disk /dev/sdX: 1032MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 4194kB 3146kB fat32 biosgrub bios_grub
2 4194kB 1031MB 1027MB efi boot, esp
0 root@foo:~#
make a filesystem and mount it temporarily at /mnt:
mkfs -t vfat -n GRUB /dev/sdX2
mount /dev/sdX2 /mnt
ensure we have the binaries needed, and add three grub targets for the different platforms:
since people keep talking to me about my RC bug fixing activities, I thought
it might be time again for a short report. to be honest, I mostly stopped my
almost daily work at some point in december, partly because the overall
number of RC bugs affecting both testing &
unstable is quite low (& therefore the number of
easy-to-fix bugs), due to the auto-removal policy of the release team
(kudos!). but I still kept track about RC bugs I worked on, &
here's the list; as you can see, mostly pkg-perl bugs
#711430 src:libcgi-cookie-splitter-perl: "libcgi-cookie-splitter-perl: FTBFS with perl 5.18: test failures" add patch from CPAN RT (pkg-perl)
#711436 src:libdbix-abstract-perl: "libdbix-abstract-perl: FTBFS with perl 5.18: test failures" upload new upstream release (pkg-perl)
#711444 src:libgraph-readwrite-perl: "libgraph-readwrite-perl: FTBFS with perl 5.18: test failure" upload new upstream release (pkg-perl)
#711620 src:libthread-queue-any-perl: "libthread-queue-any-perl: FTBFS with perl 5.18: test failures" upload new upstream release (pkg-perl)
#724137 src:libschedule-cron-perl: "libschedule-cron-perl: FTBFS: Tests failures" upload new upstream release
#725570 src:pgfincore: "build postgresql-9.3 extension only" send improved debdiff to the bug, thanks to Martin Pitt
#731794 libanyevent-perl: "FBFTS: AnyEvent fails t/81_hosts.t on system with OpenDNS" upload new upstream release prepared by Xavier Guimard (pkg-perl)
#733364 src:libjxp-java: "libjxp-java: FTBFS: [javac] / PKGBUILDDIR /src/java/org/onemind/jxp/servlet/JxpServlet.java:29: error: package javax.servlet does not exist" add missing build dependency (pkg-java)
#733379 src:libonemind-commons-java-java: "libonemind-commons-java-java: FTBFS: [javac] / PKGBUILDDIR /src/java/org/onemind/commons/java/util/ServletUtils.java:28: error: package javax.servlet does not exist" add missing build dependency (pkg-java)
#735367 bti: "bti: stopped working after SSL/TLS traffic restriction, due to obsolete URL" upload new upstream release
#735823 src:libgtk3-perl: "libgtk3-perl: FTBFS: Tests failures" set HOME for tests (pkg-perl)
#736275 libmarc-xml-perl: "libmarc-xml-perl: CVE-2014-1626: XML External Entity privilege escalation" upload new upstream release (pkg-perl)
#736718 libalien-sdl-perl: "libalien-sdl-perl: depends on libtiff4 which is going away" fix dependencies (pkg-perl)
#736820 libnet-frame-perl: "libnet-frame-perl: package seems to depend on things that are not packaged" upload new upstream release prepared by Daniel Lintott (pkg-perl)
#738431 src:latex-make: "latex-make: FTBFS: Font T1/cmr/m/n/10=ecrm1000 at 10.0pt not loadable: Metric (TFM) file not found" propose patch, then fixed by maintainer
#739144 src:librpc-xml-perl: "librpc-xml-perl: FTBFS: Test failure" upload new upstream release (pkg-perl)
ps: the how-can-i-help package is a nice tool for finding RC
bugs in packages you care about. install it if you haven't so far!
An interesting question popped up in my Twitter stream today is there an Android alternative to Apple configurator (for iPhone, iPad and iPod Touch) that allows to create a bunch of identical Apple devices with some added configurations and applications. The best I could come up with is not as polished, but on the other hand much more powerful option Nandroid backup and restore (also known as ClockworkMod Recovery backup).
To do this, you need a source phone and a bunch of destination phones. On the source phone a ClockworkMod Recovery (CWR) must be installed (either via a root or via a bootloader unlock). On the destination phones you will either need to also install ClockworkMod Recovery or unlock the bootloader to allow the Fastboot tool to work.
So the procedure then goes as follows:
1. Unlock the bootloader on the source phone (search for device specific info on how to do that)
2. Use fastboot flash recovery filename.img to write a device-specific version of CWR to the recovery partition of the device (the phone must be in fastboot mode at that point)
3. Do whatever customisations you want to the source phone at this point. You can use custorm ROMs, install whatever applications, do whatever configuration, but I would suggest keeping everything in phone memory so you don t have to flash the SD card as well.
4. Reboot the source phone into CWR mode, use the backup option to create a full backup.
5. The backup will now be in the SD card of the source device. Copy that to the computer that you will use for creating copies.
For each destination phone:
6. Unlock the bootloader of the destination phone
7. Reboot the phone in the fastboot mode, connect it via USB to the copying computer
8. Flash all partitions from the backup using fastboot flash ... commands, skip flashing the recovery partition if you don t want CMR on the destination device
9. Re-lock the bootloader (with fastboot oem lock)
And you are done!
All the phones must be of the same model. And that model must support unlocking bootloader for this to work.
I prefer this method, because this way it is possible to create an end device without root, with a locked bootloader and without CWR thus providing some security as unlocking the bootloader wipes the device, so without specific hacking an attacker can not easily get access to system data on such device. It is also possible to do this with devices that do not have an boot unlock if there is a way to root the original firmware which allows to install CWR and go on from there, but that is significantly more complicated and time-consuming, so using devices with an ability to unlock the bootloader is much preferable.
However, before you go to all that trouble, it might be worth to consider if maybe for your particular use case it would be enough with the two commands from Android SDK adb install ... and adb push ... to install applications or individual files on devices or adb backup AppName and adb restore ... to backup and restore one or more individual applications with all their settings. These options have the benefit of that they will work across different device models and that they do not wipe other data or applications from the devices.
As I could not immediately find a better way or even a detailed guide how to do this, I decided to write this post, so it would be easier for other people to find this information. If you know a better way, please do mention it in the comments section!
jrollins and i recently did a bunch of cleanup work on debirf, with the result that debirf 0.30 can now build all the shipped example profiles without error (well, as long as debootstrap --variant=fakechroot is working properly -- apprently that's not the case for fakechroot 2.9 in squeeze right now, which is why i've uploaded a backport of 2.14). To try to avoid getting into a broken state again, we set up an autobuilder to create the images from the three example profiles (minimal, rescue, and xkiosk) for amd64 systems. The logs for these builds are published (with changes) nightly at:
git://debirf.cmrg.net/debirf-autobuilder-logs
But even better, we are also publishing the auto-generated debirf images themselves. So, for example, if you've got an amd64-capable machine with a decent amount of RAM (512MiB is easily enough), you can download a rescue kernel and image into /boot/debirf/, add a stanza to your bootloader, and be able to reboot to it cleanly, without having to sort out the debirf image creation process yourself. We're also providing ISOs so people who still use optical media don't have to format their own. Please be sure to verify the checksums of the files you download. The checksums themselves are signed by the OpenPGP key for Debirf Autobuilder <debirf@cmrg.net>, which i've certified and published to the keyserver network. What's next? It would be nice to have auto-built images for i386 and other architectures. And if someone has a good idea for a new example profile that we should also be auto-building, please submit a bug to the BTS so we can try to sort it out.Tags: debirf
I've changed jobs recently and after 5 years of not having to work with a Windows system I am having all sorts of adaptation-to-Windows problems at the new job.
First I just had to have the usual X-mouse behaviour and so I installed True X-Mouse Gizmo for Windows. This provides focus under mouse, middle click paste after select (not perfect, but it works), right click to push to bottom the window.
Second I had to have a virtual desktop, so I installed Microsoft's Virtual Desktop Manager from the PowerToys page. I tried another virtual desktop manager before using MSVDM, but I found it too clumsy so I switched to MSVDM which I knew from way back when I used Windows the last time. Good, now I can have my applications organised the way I am used to. UPDATE: I gave up on MSVDM in favour of Virtual Dimension since I wasn't able to send a particular window to the intended desktop unless I had in the taskbar all apps visible (Shared Desktop option). I might try other suggestions (Virtual Dimension does not have a way to send a window directly to a specific desktop, but just to the neighbours of the current one.)
Third, I had to make Caps Lock work as Ctrl. I just can't go back to an inferior setup. I found information on this page and ended up at this page from where I got a zip file with various registry keys which allow the deactivation of caps, or turning it into another Ctrl.
Fourth, I am used to write with diacritics in Romanian with the secondary layout of the standard (SR 13392:2004), so I rushed to Cristian Secar 's page for the keyboard driver since on XP the Romanian layout is retarded (some history in which some arbitrary German guy decided y and z had to be switched on Romanian keyboards and some other similarly weird stuff). Since the installation, my keyboard behaves according to this layout:
Things started to look well, but I soon was reminded that Outlook is an idiotic mailer since it doesn't require a confirmation on send, not even if you didn't set a subject. And this is problematic since sending the mail is done via Alt+S, so if the current layer is NOT Romanian, when I want to type (s with a comma below), a fairly common character in Romanian words, you end up looking like an idiot on the recipient side since they receive an incomplete mail. Remember, no confirmation AND no default spell checking before send. Yay!
At my second such accidental mail sending (of which the last two were sent to the same person), I decided to see if this can't be fixed. I initially looked for changing the short cut, but I couldn't find it (I might be inept at finding things in Windows, remember, I haven't touched Windows systems in the last 5 years) but I found another workaround and decided it's good enough to share with other people that might hit the problem.
Just setup a delay rule following these steps. 1. Go to Tools....Rules Wizard 2. Click 'New' Rule 3. Select "Check messages after sending" 4. Click Next on "Which conditions you want to Check?" dialog. 5. Press yes to "This Rule will be applied to every message" message box 6. In the "What do you want to do with message?" dialog, Select "Defer delivery by a number of minutes" 7. Select your favourite number of minutes.... I usually select 2 mins. 8. Select Finish. and close the Rules Wizard.
Now everytime you send an email it will sit in your outbox for specified number of minutes. If you ever wanted to change it, delete it etc, You have sufficient time to do it :)
I used 3 minutes for the delay. At least now I can prevent looking retarded in front of people... more than necessary :D .
Oh, and Windows' clock display is retarded. It shows, by default, the hour and minutes, but there's no way to change that in a sane way. If you want the date, you must hover over the clock and it shows it, but the day of week is missing. Great job! You can see that information, too, but you have to drag the toolbar to be 2 or even 3 rows high (here it requires 2, but I've seen people saying they needed 3) to get that information, too. Great! One has to choose between wasting desktop real estate and having access to useful information. Or you could install an independent application for the clock... retarded. I am not making this shit up.
I recently added a solid-state drive to my desktop computer to take advantage of the performance boost rumored to come with these drives. For reliability reasons, I've always tried to use software RAID1 to avoid having to reinstall my machine from backups should a hard drive fail. While this strategy is fairly cheap with regular hard drives, it's not really workable with SSD drives which are still an order of magnitude more expensive.
The strategy I settled on is this one:
continue to have all partitions (/, /home and /data) on my RAID1 hard drives,
put another copy of the root partition (/) on the SSD drive, and
leave my /tmp and swap partitions in RAID0 arrays on my rotational hard drives to reduce the number of writes on the SSD.
This setup has the benefit of using a very small SSD to speed up the main partition while keeping all important data on the larger mirrored drives.
Resetting the SSDThe first thing I did, given that I purchased a second-hand drive, was to completely erase the drive and mark all sectors as empty using an ATA secure erase. Because SSDs have a tendency to get slower as data is added to them, it is necessary to clear the drive in a way that will let the controller know that every byte is now free to be used again.
Partitioning the SSDOnce the drive is empty, it's time to create partitions on it. I'm not sure how important it is to align the partitions to the SSD erase block size on newer drives, but I decided to follow Ted Ts'o's instructions anyways.
Another thing I did is leave 20% of the drive unpartitioned. I've often read that SSDs are faster the more free space they have so I figured that limiting myself to 80% of the drive should help the drive maintain its peak performance over time. In fact, I've heard that extra unused unpartitionable space is one of the main differences between the value and extreme series of Intel SSDs. I'd love to see an official confirmation of this from Intel of course!
Keeping the RAID1 array in sync with the SSDOnce I added the solid-state drive to my computer and copied my root partition on it, I adjusted my fstab and grub settings to boot from that drive. I also setup the following cron job (running twice daily) to keep a copy of my root partition on the old RAID1 drives (mounted on /mnt):
Given the impending
deprecation of
vservers, I've decided
to make the switch to KVM on my
laptop. Although lxc is a
closer approximation to vservers, I decided to go with KVM due to it's support
in Virtual Machine Manager.
My first step was to confirm that my CPU would support kvm:
egrep -o "svm vmx" /proc/cpuinfo
If that command outputs either svm or vmx (depending on whether you have Intel
or AMD hardware) then your CPU supports virtualization.
I'm working on a host machine called chicken, which has a logical volume called
vg_chicken0. All vservers on chicken operate on a root filesystem that is
backed by their own logical volume.
In this post, I'll describe the steps to convert the vserver hobo (which
operates on a filesystem mounted on the host in /var/lib/vservers/hobo and
is backed by the logical volume called vg_chicken0-hobo_root).
Both chicken and hobo are running debian squeeze.
vservers don't have a kernel installed or grub. KVM virtual servers need both.
I was hoping I could simply enter the vserver, install both a kernal and grub
and be ready to go. However, grub installation will fail miserably because grub
can't figure out how to install on the underlying disk (which is hidden from the
vserver).
Next, I tried launching a kvm instance, passing a
debirf generated ISO with the -c
(cdrom) option. However, grub recognized that it was being installed onto a
device that did not have a partition table (the logical volume was directly
formatted with a file system).
So, since I had disk space to spare, I created a new logical volume:
I then added a gpt
partition table (why not prepare for the coming 2TB disks?) and created two
partitions. One partition for grub2 and one for everything else:
parted /dev/mapper/vg_chicken0-hobo_root_new mklabel gpt
parted /dev/mapper/vg_chicken0-hobo_root_new unit s mkpart biosboot 2048 4095
parted /dev/mapper/vg_chicken0-hobo_root_new set 1 bios_grub on
parted /dev/mapper/vg_chicken0-hobo_root_new unit s mkpart primary 4096
When prompted for the end of the last partition, choose: -1 and accept the adjustment.
I had to eyeball cat /proc/partitions to figure out which dm device was the
second partition (dm-19).
I then created a file system:
mkfs -t ext3 /dev/dm-19
Mounted it:
mount /dev/dm-19 /mnt
And rsync'ed the data:
rsync -a /var/lib/vservers/hobo/ /mnt/
With the data in place, I chroot'ed and installed the packages I needed. When prompted, I chose not to install grub to the disk, because I wanted to wait until I had an environment in which the proper disk would be available to grub as it will when the virtual server boots (see below):
And I removed it from /etc/fstab.
Next, I created a new kvm virtual server, using the disk /dev/mapper/vg_chicken0-hobo_root and passing a debirf cd image with -c:
virt-install --name hobo --ram 512 --disk /dev/mapper/vgchicken0-hoboroot -c /usr/local/share/debian/ISOs/debirf-rescuesqueeze2.6.32-5-vserver-amd64.iso
After logging in, I installed grub2 (aptitude update; aptitude install grub2) and then I installed grub:
mount /dev/sda2 /mnt/
grub-install --no-floppy --root-directory=/mnt /dev/sda
After running grub-install, edit /mnt/boot/grub/device.map so it reads:
(hd0) /dev/sda
Then, rerun grub-install command.
I tried generating the grub.cfg file, but got an error message indicating that
grub-probe would not detect the device providing / (because I was running on a
ram file system from debirf).
I added the following to /mnt/etc/fstab:
This is the story of a weirdly unfriendly/non-compliant IMAP server, and some nice interactions that arose from a debugging session around it. Over the holidays, i got to do some computer/network debugging for friends and family. One old friend (I'll call him Fred) had a series of problems i managed to help work through, but was ultimately basically stumped based on the weird behavior of an IMAP server. Here's the details (names of the innocent and guilty have been changed), just in case it helps other folks in at least diagnosing similar situations. the diagnosis The initial symptom was that Fred's computer was "very slow". Sadly, this was a Windows machine, so my list of tricks for diagnosing sluggishness is limited. I went through a series of questions, uninstalling things, etc, until we figured it would be better to just have him do his usual work while i watched, kibitzing on what seemed acceptable and what seemed slow. Quite soon, we hit a very specific failure: Fred's Thunderbird installation (version 2, FWIW) was sometimes hanging for a very long period of time during message retrieval. This was not exhaustion of the CPU, disk, RAM, or other local resource. It was pure network delay, and it was a frequent (if unpredictable) frustrating hiccup in his workflow. One thought i had was Thunderbird's per-server max_cached_connections setting, which can sometimes cause a TB instance to hang if a remote server thinks Thunderbird is being too aggressive. After sorting out why Thunderbird was resetting the values after we'd set them to 0 (grr, thanks for the confusing UI, folks!), we set it to 1, but still had the same occasional, lengthy (about 2 minutes) hang when transfering messages between folders (including the trash folder!), or when reading new messages. Sending mail was quite fast, except for occasional (similarly lengthy) hangs writing the copy to the sent folder. So IMAP was the problem (not SMTP), and the 2-minute timeouts smelled like an issue with the networking layer to me. At this point, i busted out wireshark, the trusty packet sniffer, which fortunately works as well on Windows as it does on GNU/Linux. Since Fred was doing his IMAP traffic in the clear, i could actually see when and where in the IMAP session the hang was happening. (BTW, Fred's IMAP traffic is no longer in the clear: after all this happened, i switched him to IMAPS (IMAP wrapped in a TLS session), because although the IMAP server in question actually supports the STARTTLS directive, it fails to advertise it in response to the CAPABILITIES query, so Thunderbird refuses to try it. arrgh.) The basic sequence of Thunderbird's side of an initial IMAP conversation (using plain authentication, anyway) looks something like this:
What i found with this server was that if i issued commands 1 through 5, and then left the connection idle for over 5 minutes, then the next command (even if it was just a 6 NOOP or 6 LOGOUT) would cause the IMAP server to issue a TCP reset. No IMAP error message or anything, just a failure at the TCP level. But a nice, fast, responsive failure -- any IMAP client could recover nicely from that by just immediately opening a new connection. I don't mind busy servers killing inactive connections after a reasonable timeout. If it was just this, though, Thunderbird should have continued to be responsive. the deep weirdness But if i issued commands 1 through 6 in rapid succession (the only difference is that extra 6 UID fetch 1:* (FLAGS) command), and then let the connection idle for 5 minutes, then sent the next command: no response of any kind would come from the remote server (not even a TCP ACK or TCP RST). In this circumstance, my client OS's TCP stack would re-send the data repeatedly (staggered at appropriate intervals), until finally the client-side TCP timeout would trigger, and the OS would report the failure to the app, which could turn around and do a simple connection restart to finish up the desired operation. This was the underlying situation causing Fred's Thunderbird client to hang. In both cases above (with or without the 6th command), the magic window for the idle cutoff was a little more than 300 seconds (5 minutes) of idleness. If the client issued a NOOP at 4 minutes, 45 seconds from the last NOOP, it could keep a connection active indefinitely. Furthermore, i could replicate the exact same behavior when i used IMAPS -- the state of the IMAP session itself was somehow modifying the TCP session behavior characteristics, whether it was wrapped in a TLS tunnel or not. One interesting thing about this set of data is that it rules out most common problems in the network connectivity between the two machines. Since none of the hops between the two endpoints know anything about the IMAP state (especially under TLS), and some of the failures are reported properly (e.g. the TCP RST in the 5-command scenario), it's probably safe to say that the various routers, NAT devices, and such were not themselves responsible for the failures. So what's going on on that IMAP server? The service itself does not announce the flavor of IMAP server, though it does respond to a successful login with You are so in, and to a logout with IMAP server logging out, mate. A bit of digging on the 'net suggests that they are running a perdition IMAP proxy. (clearly written by an Aussie, mate!) But why does it not advertise its STARTTLS capability, even though it is capable? And why do some idle connections end up timing out without so much as an RST, when other idle connections give at least a clean break at the TCP level? Is there something about issuing the UID command that causes perdition to hand off the connection to some other service, which in turn doesn't do proper TCP error handling? I don't really know anything about the internals of perdition, so i'm just guessing here. the workaround I ultimately recommended to Fred to reduce the number of cached connections to 1, and to set Thunderbird's interval to check for new mail down to 4 minutes. Hopefully, this will keep his one connection active enough that nothing will timeout, and will keep the interference to his workflow to a minimum. It's an unsatisfactory solution to me, because the behavior of the remote server still seems so non-standard. However, i don't have any sort of control over the remote server, so there's not too much i can do to provide a real fix (other than point the server admins (and perdition developers?) at this writeup). I don't even know the types of backend server that their perdition proxy is balancing between, so i'm pretty lost for better diagnostics even, let alone a real resolution. some notes I couldn't have figured out the exact details listed above just using Thunderbird on Windows. Fortunately, i had a machine with a decent OS available, and was able to cobble together a fake IMAP client from a couple files (imapstart contained the lines above, and imapfinish contained 8 LOGOUT), bash, and socat. Here's the bash snippet i used as a fake IMAP client:
To do the test under IMAPS, i just replaced TCP4:imap.fubar.example.net:143 with OPENSSL:imap.fubar.example.net:993. And of course, i had wireshark handy on the GNU/Linux machine as well, so i could analyze the generated packets over there. One thing to note about user empowerment: Fred isn't a tech geek, but he can be curious about the technology he relies on if the situation is right. He was with me through the whole process, didn't get antsy, and never tried to get me to "just fix it" while he did something else. I like that, and wish i got to have that kind of interaction more (though i certainly don't begrudge people the time if they do need to get other things done). I was nervous about breaking out wireshark and scaring him off with it, but it turned out it actually was a good conversation starter about what was actually happening on the network, and how IP and TCP traffic worked. Giving a crash course like that in a quarter of an hour, i can't expect him to retain any concrete specifics, of course. But i think the process was useful in de-mystifying how computers talk to each other somewhat. It's not magic, there are just a lot of finicky pieces that need to fit together a certain way. And Wireshark turned out to be a really nice window into that process, especially when it displays packets during a real-time capture. I usually prefer to do packet captures with tcpdump and analyze them as a non-privileged user afterward for security reasons. But in this case, i felt the positives of user engagement (how often do you get to show someone how their machine actually works?) far outweighed the risks. As an added bonus, it also helped Fred really understand what i meant when i said that it was a bad idea to use IMAP in the clear. He could actually see his username and password in the network traffic! This might be worth keeping in mind as an idea for a demonstration for workshops or hacklabs for folks who are curious about networking -- do a live packet capture of the local network, project it, and just start asking questions about it. Wireshark contains such a wealth of obscure packet dissectors (and today's heterogenous public/open networks are so remarkably chatty and filled with weird stuff) that you're bound to run into things that most (or all!) people in the room don't know about, so it could be a good learning activity for groups of all skill levels. Tags: debugging, imap, perdition, wireshark
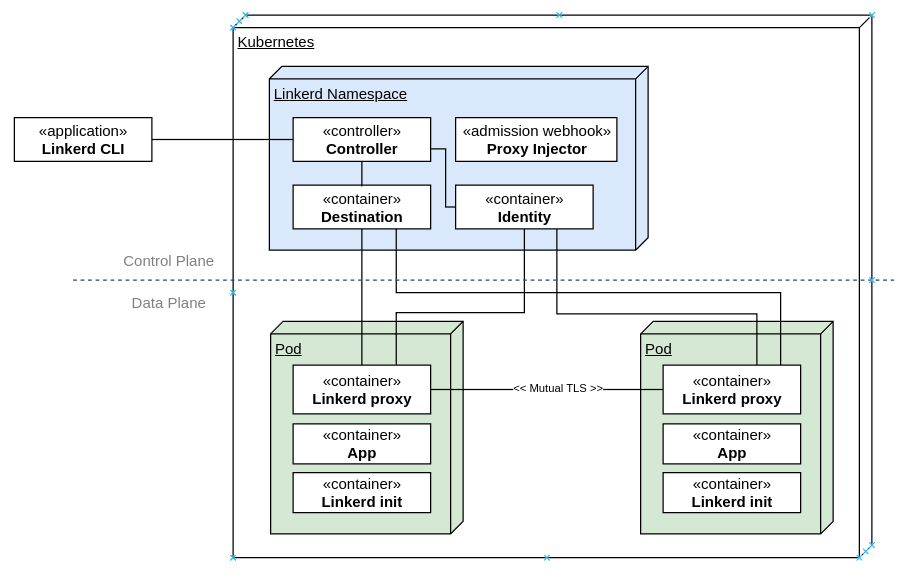
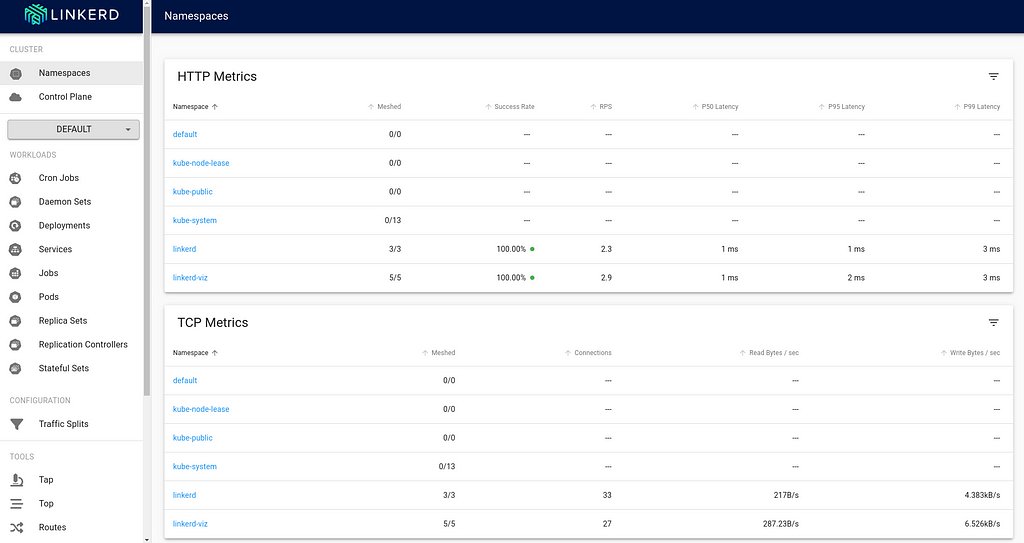
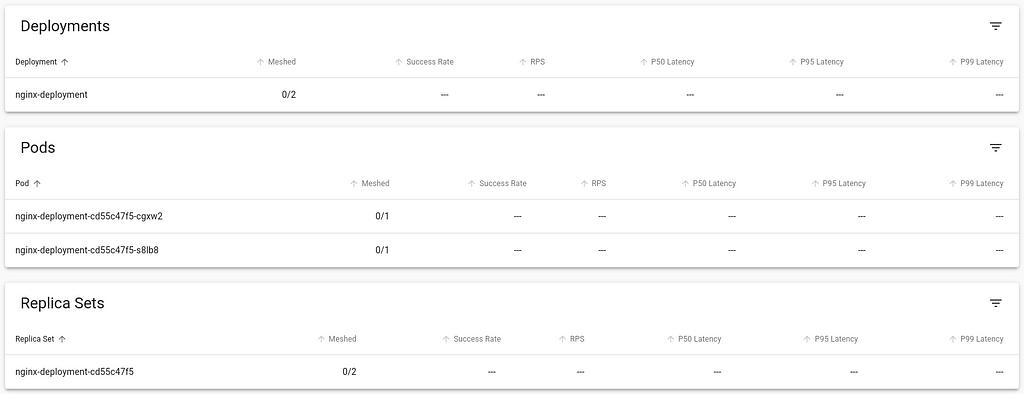
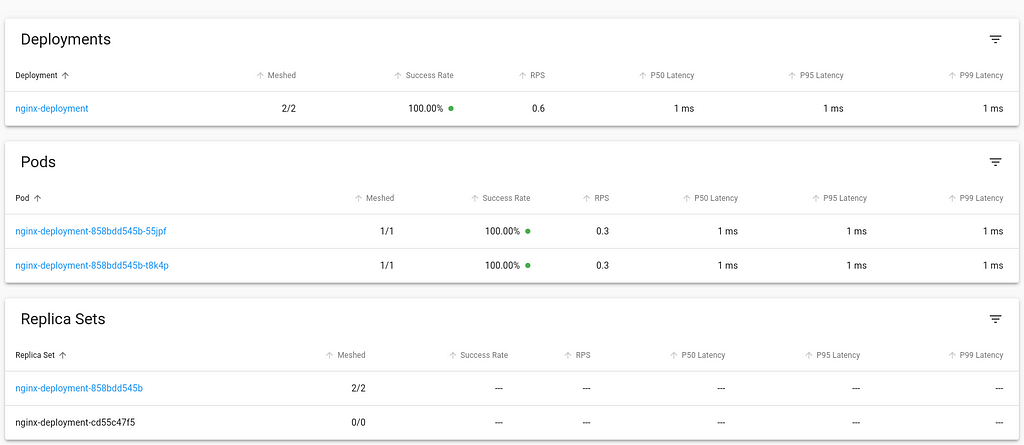

 .
On the global stage, about a decade ago, Stephen J. Dubner and Steven Levitt argued in their book
.
On the global stage, about a decade ago, Stephen J. Dubner and Steven Levitt argued in their book 


 Pappu Yadav, President Jan Adhikar Party, Bihar May 11, 2021
Pappu Yadav, President Jan Adhikar Party, Bihar May 11, 2021





 Example of Medical Bills people have to pay.
Example of Medical Bills people have to pay.  India-China Border Areas Copyright DW.com 2020
India-China Border Areas Copyright DW.com 2020  Because
Because  Yesterday, I was giving a
Yesterday, I was giving a  Here is my monthly update covering what I have been doing in the free software world (
Here is my monthly update covering what I have been doing in the free software world (
 I'm using
I'm using  since people keep talking to me about my RC bug fixing activities, I thought
it might be time again for a short report. to be honest, I mostly stopped my
almost daily work at some point in december, partly because the overall
number of RC bugs affecting both
since people keep talking to me about my RC bug fixing activities, I thought
it might be time again for a short report. to be honest, I mostly stopped my
almost daily work at some point in december, partly because the overall
number of RC bugs affecting both 




 An interesting question popped up in my Twitter stream today is there an Android alternative to
An interesting question popped up in my Twitter stream today is there an Android alternative to  I've changed jobs recently and after 5 years of not having to work with a Windows system I am having all sorts of adaptation-to-Windows problems at the new job.
I've changed jobs recently and after 5 years of not having to work with a Windows system I am having all sorts of adaptation-to-Windows problems at the new job.
 I recently added a
I recently added a