The Reproducible Builds project relies on several projects, supporters and sponsors for financial support, but they are also valued as ambassadors who spread the word about our project and the work that we do.
This is the
sixth instalment in a series featuring the projects, companies and individuals who support the Reproducible Builds project. We started this series by
featuring the Civil Infrastructure Platform project and followed this up with a
post about the Ford Foundation as well as a recent ones about
ARDC, the
Google Open Source Security Team (GOSST),
Jan Nieuwenhuizen on Bootstrappable Builds, GNU Mes and GNU Guix and
Hans-Christoph Steiner of the F-Droid project.
Today, however, we will be talking with
David A. Wheeler, the Director of Open Source Supply Chain Security at the
Linux Foundation.

Holger Levsen: Welcome, David, thanks for taking the time to talk with us today. First, could you briefly tell me about yourself?
David: Sure! I m David A. Wheeler and
I work for the
Linux Foundation as the Director of Open Source Supply Chain Security.
That just means that my job is to help open source software projects
improve their security, including its development, build, distribution,
and incorporation in larger works, all the way out to its eventual use by end-users.
In my copious free time I also teach at
George Mason University (GMU); in particular,
I teach a graduate course on how to design and implement secure software.
My background is technical. I have a Bachelor s in Electronics Engineering,
a Master s in Computer Science and a PhD in Information Technology.
My PhD dissertation is connected to reproducible builds.
My PhD dissertation was on countering the Trusting Trust attack, an attack
that subverts fundamental build system tools such as compilers.
The attack was discovered by Karger & Schell in the 1970s, and later
demonstrated & popularized by Ken Thompson.
In
my dissertation on trusting trust I showed that a process
called Diverse Double-Compiling (DDC) could detect trusting trust attacks.
That process is a specialized kind of reproducible build specifically designed
to detect trusting trust style attacks. In addition, countering the trusting trust
attack primarily becomes more important only when reproducible builds become
more common. Reproducible builds enable detection of
build-time subversions.
Most attackers wouldn t bother with a trusting trust attack if they could just
directly use a build-time subversion of the software they actually want to subvert.
Holger: Thanks for taking the time to introduce yourself to us. What do you think are the biggest challenges today in computing?
There are many big challenges in computing today. For example:
- Lack of resilience & capacity in chip fabrication. Fabs are extraordinarily expensive,
and at the high end continue to have technological advancement.
As a result, supply is failing to meet demand, and geopolitical issues raise further concerns.
We ve seen cars, gaming consoles and many other devices
unable to be delivered due to chip shortages. More fabs are
being built, and some politicians are raising concerns, but it s unclear
that current efforts will be enough.
- Lack of enough developers able to develop the software that people & organizations need.
Computers are far faster, and open source software has made software reuse
incredibly easy. However, organizations still struggle to automate
many tasks. The bottleneck is the lack of enough talented developers able to convert
ideas into working software. Low-code and no-code approaches help in specialized areas,
just like all previous automate the programmer efforts of the last 60 years, but
there s no reason to believe they will help enough.
- Large scale of software. Small systems are easier to develop & maintain, but today s
systems increasingly get bigger to meet users needs & are much harder to manage.
Even small embedded systems are often supported by huge back-end systems.
- Ending tail of Moore s law & rise of smartphones. Historically people would just wait a few years for their
software to speed up, but Moore s law is petering out, and smartphones are necessarily
limited by power & size limits. As a result, software developers
can t wait for the hardware to save their slow systems; they must redesign.
Switching to faster languages, or using multiple processors, is much more difficult than
waiting for performance problems to disappear.
- Continuous change in interfaces. Developers continuously find reasons to change
component interfaces: perhaps they re too inflexible, too hard to use, and so on.
But now that developers are reusing hundreds, thousands, or tens of thousands of components,
managing the continuous change of the reused components is challenging.
Package managers make updating easy but don t automatically handle interface changes.
I think this is mostly a self-inflicted problem most components could support old interfaces
(like the Linux kernel does) but because it s often not acknowledged as a problem, it s often not addressed.
- Security & privacy. Decades ago there were fewer computers and most computers weren t connected to a network.
Today things are different. Criminals have found many ways to attack computer systems to
make money, and nation-states have found many ways to attack computer systems for their own reasons.
Attackers now have very strong motivations to perform attacks.
Yet many developers aren t told how to develop software that resists attacks, nor
how to protect their supply chains. Operations try to monitor and recover from
attacks, but their job is difficult due to inadequately secure software that doesn t
support those monitoring & recovery efforts well either. The results are terrible security.
Holger: Do you think reproducible builds are an important part in secure computing today already?
David: Yes, but first let s put things in context.
Today, when attackers exploit software vulnerabilities, they re primarily
exploiting unintentional vulnerabilities that were created by the software
developers. There are a lot of efforts to counter this:
- Train & education developers in how to develop secure software.
The OpenSSF provides a free course on how to do that (full disclosure: I m the author).
Take that course or something like it!
- Add tools to your CI pipeline to detect potential vulnerabilities. Yes, they have false
positives and false negatives, so you have to also use your brain but that just means you
need to be smart about using tools, instead of not using them.
- Get projects & organizations to update the components they use,
since often the vulnerabilities are well-known publicly
(e.g., Equifax in 2017). Add some tools to your development process to warn you about
components with known vulnerabilities! GitHub & GitLab both provide tools to do this,
and there are many other tools.
- When starting new projects, try to use memory-safe languages. On average 70% of the
vulnerabilities in Chrome and in Microsoft are from memory safety problems; using a memory-safe
language eliminates most of them.
We re just starting to get better at this, which is good. However, attackers always
try to attack the easiest target. As our deployed software has started to be hardened
against attack, attackers have dramatically increased their attacks
on the software supply chain (
Sonatype found in 2022 that there s been a 742% increase year-over-year).
The software supply chain hasn t historically gotten much attention, making it the easy target.
There are simple supply chain attacks with simple solutions:
- In almost every year the top attack has been typosquatting. In typo squatting,
an attacker creates packages with almost the right name. This is an easy attack to
counter developers just need to double-check the name of a package before adding it.
But we aren t warning developers enough about it!
For more information, see papers such as the Backstabber s Knife Collection.
- Last year the top software supply chain attack was dependency confusion convincing
projects to use the wrong repo for a given package. There are simple solutions to this, such as
specifying the package source and/or requiring a cryptographic hash to match.
- Some attacks involve takeovers of developer accounts. In almost all cases, these are
caused by stolen passwords. Using a multi-factor authentication (MFA) token eliminates
stolen password attacks, which is why several
repositories are starting to require MFA tokens in some cases.
Unfortunately, attackers know there are other lines of attack.
One of the most dangerous is subverted build systems, as demonstrated by
the subversion of SolarWinds Orion system. In a subverted build system,
developers can review the software source code all day and see no problem,
because there
is no problem there. Instead, the process to convert source code
into the code people run, called the build system , is subverted by an attacker.
One solution for countering subverted build systems is to make the build systems harder
to attack. That s a good thing to do, but you can never be confident that it was good enough .
How can you be sure it s not subverted, if there s no way to know?
A stronger defense against subverted build systems is the idea of verified reproducible builds.
A build is reproducible if given the same source code, build environment and build instructions,
any party can recreate bit-by-bit identical copies of all specified artifacts.
A build is
verified if multiple different parties verify that they get the same result for that situation.
When you have a verified reproducible build, either all the parties colluded
(and you could always double-check it yourself), or the build process isn t subverted.
There is one last turtle: What if the build system tools or machines are subverted themselves?
This is not a common attack today, but it s important to know if we
can address them
when the time comes. The good news is that we
can address this.
For some situations reproducible builds can also counter such attacks.
If there s a loop (that is, a compiler is used to generate itself), that s called the trusting trust attack,
and that is more challenging. Thankfully, the trusting trust attack has been known about for
decades and there are known solutions. The diverse double-compiling (DDC) process that
I explained in my PhD dissertation, as well as the bootstrappable builds process, can
both counter trusting trust attacks in the software space. So there is no reason to lose hope:
there is a bottom turtle , as it were.
Holger: Thankfully, this has all slowly started to change and supply chain issues are now widely discussed, as evident by efforts like
Securing the Software Supply Chain: Recommended Practices Guide for Developers
which you shared
on our mailing list. In there, Reproducible Builds are mentioned as recommended advanced practice, which is both pretty cool (we ve come a long way!), but to me it also sounds like this will take another decade until it s become standard normal procedure. Do you agree on that timeline?
David: I don t think there will be any particular timeframe. Different projects and
ecosystems will move at different speeds. I wouldn t be surprised if it
took a decade or so for them to become relatively common there are
good reasons for that.
Today the most common kinds of attacks based on software
vulnerabilities still involve unintentional vulnerabilities in operational systems.
Attackers are starting to apply supply chain attacks, but the top such attacks
today are typosquatting (creating packages with similar names) and
dependency confusion) (convincing projects to download packages from the wrong
repositories).
Reproducible builds don t counter those kinds of attacks, they
counter subverted builds. It s important to eventually have verified
reproducible builds, but understandably other issues are currently getting
prioritized first.
That said, reproducible builds are important long term.
Many people are working on countering unintentional vulnerabilities
and the most common kinds of supply chain attacks.
As these other threats are countered, attackers will increasingly target
build systems. Attackers always go for the weakest link.
We will eventually need verified reproducible builds in many situations, and
it ll take a while to get build systems able to widely perform reproducible builds,
so we need to start that work now. That s true for anything where you know
you ll need it but it will take a long time to get ready you need to start now.
Holger: What are your suggestions to accelerate adoption?
David: Reproducible builds need to be:
- Easy (ideally automatic). Tools need to be modified so that reproducible builds
are the default or at least easier to do.
- Transparent to projects & potential users. Many projects have no idea that their results aren t
reproducible, and many potential users of the project don t know either.
That information needs to be obvious. I ve proposed that the OpenSSF
Dashboard SIG try to reproduce builds, for at least some packages, to make it
more obvious to everyone when a project isn t reproducible. I don t know if that
will happen in that particular case, but the point is to help people learn that information
as soon as possible.
- Deployed.
Experiments are great, but experiments showing that a project could be reproducible
are inadequate. We need the projects that people use to be reproducible.
I think there s a snowball effect. Once many projects packages are reproducible,
it will be easier to convince other projects to make their packages reproducible.
I also think there should be some prioritization. If a package is in wide use
(e.g., part of minimum set of packages for a widely-used Linux distribution or
framework), its reproducibility should be a special focus. If a package is vital for
supporting some societally important critical infrastructure (e.g., running dams),
it should also be considered important. You can then work on the
ones that are less important over time.
Holger: How is the
Best Practices Badge going? How many projects are participating and how many are missing?
David: It s going very well. You can
see some automatically-generated statistics, showing we have over 5,000 projects, adding more than 1/day on average.
We have more than 900 projects that have earned at least the passing badge level.
Holger: How many of the projects participating in the Best Practices badge engaging with reproducible builds?
David: As of this writing there are 168 projects that report meeting the reproducible builds criterion.
That s a relatively small percentage of projects. However, note that this criterion (labelled
build_reproducible)
is only required for the gold badge. It s not required for the passing or silver level badge.
Currently we ve been strategically focused on getting projects to at least earn a passing badge,
and less on earning silver or gold badges.
We would
love for all projects to get earn a silver or gold badge, of course, but
our theory is that projects that can t even earn a passing badge present the most risk to their users.
That said, there are some projects we especially want to see implementing higher badge levels.
Those include projects that are very widely used, so that
vulnerabilities in them can impact many systems.
Examples of such projects include the Linux kernel and curl.
In addition, some projects are used within
systems where it s important to society that they not have serious security vulnerabilities.
Examples include projects used by
chemical manufacturers, financial systems and weapons.
We definitely encourage any of those kinds of projects to earn higher badge levels.
Holger: Many thanks for this interview, David, and for all of your work at the Linux Foundation and elsewhere!

For more information about the Reproducible Builds project, please see our website at
reproducible-builds.org. If you are interested in
ensuring the ongoing security of the software that underpins our civilisation
and wish to sponsor the Reproducible Builds project, please reach out to the
project by emailing
contact@reproducible-builds.org.
 Debian is running a "vcswatch"
service that keeps track of the status of all packaging repositories that have a
Vcs-Git
(and other VCSes) header set and shows which repos might need a package upload to push pending changes out.
Naturally, this is a lot of data and the scratch partition on qa.debian.org
had to be expanded several times, up to 300 GB in the last iteration.
Attempts to reduce that size using shallow clones (git clone --depth=50)
did not result more than a few percent of space saved. Running git gc on
all repos helps a bit, but is tedious and as Debian is growing, the repos are
still growing both in size and number. I ended up blocking all repos with
checkouts larger than a gigabyte, and still the only cure was expanding the
disk, or to lower the blocking threshold.
Since we only need a tiny bit of info from the repositories, namely the content
of debian/changelog and a few other files from debian/, plus
the number of commits since the last tag on the packaging branch, it made sense
to try to get the info without fetching a full repo clone. The question if we
could grab that solely using the GitLab API at salsa.debian.org was never
really answered. But then, in #1032623,
G bor N meth suggested the use of
git clone --filter blob:none.
As things go, this sat unattended in the bug report for almost a year until the
next "disk full" event made me give it a try.
The blob:none filter makes git clone omit all files, fetching only commit and
tree information. Any blob (file content) needed at git run time is
transparently fetched from the upstream repository, and stored locally. It
turned out to be a game-changer. The (largish) repositories I tried it on
shrank to 1/100 of the original size.
Poking around I figured we could even do better by using tree:0 as
filter. This additionally omits all trees from the git clone, again only
fetching the information at run time when needed. Some of the larger repos I
tried it on shrank to 1/1000 of their original size.
I deployed the new option on qa.debian.org and scheduled all repositories to
fetch a new clone on the next scan:
Debian is running a "vcswatch"
service that keeps track of the status of all packaging repositories that have a
Vcs-Git
(and other VCSes) header set and shows which repos might need a package upload to push pending changes out.
Naturally, this is a lot of data and the scratch partition on qa.debian.org
had to be expanded several times, up to 300 GB in the last iteration.
Attempts to reduce that size using shallow clones (git clone --depth=50)
did not result more than a few percent of space saved. Running git gc on
all repos helps a bit, but is tedious and as Debian is growing, the repos are
still growing both in size and number. I ended up blocking all repos with
checkouts larger than a gigabyte, and still the only cure was expanding the
disk, or to lower the blocking threshold.
Since we only need a tiny bit of info from the repositories, namely the content
of debian/changelog and a few other files from debian/, plus
the number of commits since the last tag on the packaging branch, it made sense
to try to get the info without fetching a full repo clone. The question if we
could grab that solely using the GitLab API at salsa.debian.org was never
really answered. But then, in #1032623,
G bor N meth suggested the use of
git clone --filter blob:none.
As things go, this sat unattended in the bug report for almost a year until the
next "disk full" event made me give it a try.
The blob:none filter makes git clone omit all files, fetching only commit and
tree information. Any blob (file content) needed at git run time is
transparently fetched from the upstream repository, and stored locally. It
turned out to be a game-changer. The (largish) repositories I tried it on
shrank to 1/100 of the original size.
Poking around I figured we could even do better by using tree:0 as
filter. This additionally omits all trees from the git clone, again only
fetching the information at run time when needed. Some of the larger repos I
tried it on shrank to 1/1000 of their original size.
I deployed the new option on qa.debian.org and scheduled all repositories to
fetch a new clone on the next scan:
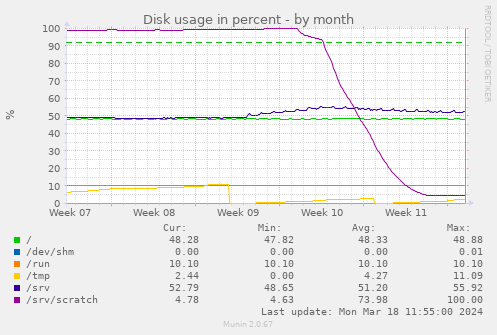 The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
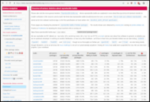
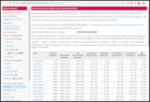
 The following contributors got their Debian Developer accounts in the last two months:
The following contributors got their Debian Developer accounts in the last two months:













 Very few highly-anticipated movies appear in January and February, as the bigger releases are timed so they can be considered for the
Very few highly-anticipated movies appear in January and February, as the bigger releases are timed so they can be considered for the  In 2022 I read 34 books (-19% on last year).
In 2021 roughly a quarter of the books I read were written by women. I was
determined to push that ratio in 2022, so I made an effort to try and only
read books by women. I knew that I wouldn't manage that, but by trying to, I
did get the ratio up to 58% (by page count).
I'm not sure what will happen in 2023. My to-read pile has some back-pressure
from books by male authors I postponed reading in 2022 (in particular new works
by Christopher Priest and Adam Roberts). It's possible the ratio will swing
back the other way, which would mean it would not be worth repeating the
experiment. At least if the ratio is the point of the exercise. But perhaps it
isn't: perhaps the useful outcome is more qualitative than quantitative.
I tried to read some new (to me) authors. I really enjoyed Shirley Jackson (The
Haunting of Hill House, We Have Always Lived In The Castle). I Struggled with
Angela Carter's Heroes and Villains although
I plan to return to her other work, in particular, The Bloody Chamber. I
also got through Donna Tartt's The Secret History on the recommendation of a
friend. I had to push through the first 15% or so but it turned out to be worth
it.
In 2022 I read 34 books (-19% on last year).
In 2021 roughly a quarter of the books I read were written by women. I was
determined to push that ratio in 2022, so I made an effort to try and only
read books by women. I knew that I wouldn't manage that, but by trying to, I
did get the ratio up to 58% (by page count).
I'm not sure what will happen in 2023. My to-read pile has some back-pressure
from books by male authors I postponed reading in 2022 (in particular new works
by Christopher Priest and Adam Roberts). It's possible the ratio will swing
back the other way, which would mean it would not be worth repeating the
experiment. At least if the ratio is the point of the exercise. But perhaps it
isn't: perhaps the useful outcome is more qualitative than quantitative.
I tried to read some new (to me) authors. I really enjoyed Shirley Jackson (The
Haunting of Hill House, We Have Always Lived In The Castle). I Struggled with
Angela Carter's Heroes and Villains although
I plan to return to her other work, in particular, The Bloody Chamber. I
also got through Donna Tartt's The Secret History on the recommendation of a
friend. I had to push through the first 15% or so but it turned out to be worth
it.




















 One of the huge benefits of
One of the huge benefits of 














 Hans: One key difference to the Google Play Store is that F-Droid does not ship proprietary software by default. All apps shipped from
Hans: One key difference to the Google Play Store is that F-Droid does not ship proprietary software by default. All apps shipped from 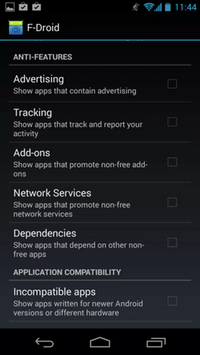
 Previously:
Previously: 



{kind=link}