In my tubman setup, I started using ZFS on an old server
I had lying around. The machine is really old though (2011!) and it
"feels" pretty slow. I want to see how much of that is ZFS and how
much is the machine. Synthetic benchmarks show that ZFS may be slower
than mdadm in RAID-10 or RAID-6 configuration, so I want to confirm
that on a live workload: my workstation. Plus, I want easy, regular,
high performance backups (with send/receive snapshots) and there's no
way I'm going to use BTRFS because I find
it too confusing and unreliable.
So off we go.
Installation
Since this is a conversion (and not a new install), our procedure is
slightly different than the official documentation but otherwise
it's pretty much in the same spirit: we're going to use ZFS for
everything, including the root filesystem.
So, install the required packages, on the current system:
root@curie:/home/anarcat# sgdisk -p /dev/sdc
Disk /dev/sdc: 1953525168 sectors, 931.5 GiB
Model: ESD-S1C
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): [REDACTED]
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 1953525134
Partitions will be aligned on 16-sector boundaries
Total free space is 14 sectors (7.0 KiB)
Number Start (sector) End (sector) Size Code Name
1 48 2047 1000.0 KiB EF02
2 2048 1050623 512.0 MiB EF00
3 1050624 3147775 1024.0 MiB BF01
4 3147776 1953525134 930.0 GiB BF00
Unfortunately, we can't be sure of the sector size here, because the
USB controller is probably lying to us about it. Normally, this
smartctl command should tell us the sector size as well:
root@curie:~# smartctl -i /dev/sdb -qnoserial
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-14-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Black Mobile
Device Model: WDC WD10JPLX-00MBPT0
Firmware Version: 01.01H01
User Capacity: 1 000 204 886 016 bytes [1,00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 6
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue May 17 13:33:04 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Above is the example of the builtin HDD drive. But the SSD device
enclosed in that USB controller doesn't support SMART commands,
so we can't trust that it really has 512 bytes sectors.
This matters because we need to tweak the ashift value
correctly. We're going to go ahead the SSD drive has the common 4KB
settings, which means ashift=12.
Note here that we are not creating a separate partition for
swap. Swap on ZFS volumes (AKA "swap on ZVOL") can trigger lockups and
that issue is still not fixed upstream. Ubuntu recommends using a
separate partition for swap instead. But since this is "just" a
workstation, we're betting that we will not suffer from this problem,
after hearing a report from another Debian developer running this
setup on their workstation successfully.
We do not recommend this setup though. In fact, if I were to redo this
partition scheme, I would probably use LUKS encryption and setup a
dedicated swap partition, as I had problems with ZFS encryption as
well.
Creating pools
ZFS pools are somewhat like "volume groups" if you are familiar with
LVM, except they obviously also do things like RAID-10. (Even though
LVM can technically also do RAID, people typically use mdadm
instead.)
In any case, the guide suggests creating two different pools here:
one, in cleartext, for boot, and a separate, encrypted one, for the
rest. Technically, the boot partition is required because the Grub
bootloader only supports readonly ZFS pools, from what I
understand. But I'm a little out of my depth here and just following
the guide.
Boot pool creation
This creates the boot pool in readonly mode with features that grub
supports:
-O encryption=on -O keylocation=prompt -O keyformat=passphrase:
encryption, prompt for a password, default algorithm is
aes-256-gcm, explicit in the guide, made implicit here
-O acltype=posixacl -O xattr=sa: enable ACLs, with better
performance (not enabled by default)
-O dnodesize=auto: related to extended attributes, less
compatibility with other implementations
-O compression=zstd: enable zstd compression, can be
disabled/enabled by dataset to with zfs set compression=off
rpool/example
-O relatime=on: classic atime optimisation, another that could
be used on a busy server is atime=off
-O canmount=off: do not make the pool mount automatically with
mount -a?
-O mountpoint=/ -R /mnt: mount pool on / in the future, but
/mnt for now
Those settings are all available in zfsprops(8). Other flags are
defined in zpool-create(8). The reasoning behind them is also
explained in the upstream guide and some also in [the Debian
wiki][]. Those flags were actually not used:
-O normalization=formD: normalize file names on comparisons (not
storage), implies utf8only=on, which is a bad idea (and
effectively meant my first sync failed to copy some files,
including this folder from a supysonic checkout). and this
cannot be changed after the filesystem is created. bad, bad, bad.
Side note about single-disk pools
Also note that we're living dangerously here: single-disk ZFS pools
are rumoured to be more dangerous than not running ZFS at all. The
choice quote from this article is:
[...] any error can be detected, but cannot be corrected. This
sounds like an acceptable compromise, but its actually not. The
reason its not is that ZFS' metadata cannot be allowed to be
corrupted. If it is it is likely the zpool will be impossible to
mount (and will probably crash the system once the corruption is
found). So a couple of bad sectors in the right place will mean that
all data on the zpool will be lost. Not some, all. Also there's no
ZFS recovery tools, so you cannot recover any data on the drives.
Compared with (say) ext4, where a single disk error can recovered,
this is pretty bad. But we are ready to live with this with the idea
that we'll have hourly offline snapshots that we can easily recover
from. It's trade-off. Also, we're running this on a NVMe/M.2 drive
which typically just blinks out of existence completely, and doesn't
"bit rot" the way a HDD would.
Also, the FreeBSD handbook quick start doesn't have any warnings
about their first example, which is with a single disk. So I am
reassured at least.
Creating mount points
Next we create the actual filesystems, known as "datasets" which are
the things that get mounted on mountpoint and hold the actual files.
Note that it's unclear to me why those datasets are necessary, but
they seem common practice, also used in this FreeBSD
example. The OpenZFS guide mentions the Solaris upgrades and
Ubuntu's zsys that use that container for upgrades and rollbacks.
This blog post seems to explain a bit the layout behind the
installer.
this creates the actual boot and root filesystems:
Notice here a peculiarity: we must create rpool/var/lib to
create rpool/var/lib/docker otherwise we get this error:
cannot create 'rpool/var/lib/docker': parent does not exist
... and no, just creating /mnt/var/lib doesn't fix that
problem. In fact, it makes things even more confusing because an
existing directory shadows a mountpoint, which is the opposite of
how things normally work.
Also note that you will probably need to change storage driver in
Docker, see the zfs-driver documentation for details but,
basically, I did:
Now that we have everything setup and mounted, let's copy all files
over.
Copying files
This is a list of all the mounted filesystems
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
You can check that the list is correct with:
mount -l -t ext4,btrfs,vfat awk ' print $3 '
Note that we skip /srv as it's on a different disk.
On the first run, we had:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
16,831,437 100% 184.14MB/s 0:00:00 (xfr#101, to-chk=0/110)
syncing / to /mnt/...
28,019,293,280 94% 47.63MB/s 0:09:21 (xfr#703710, ir-chk=6748/839220)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,267,990 98% 50.71MB/s 0:10:40 (xfr#736577, to-chk=0/867732)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
24,456,268,098 98% 68.03MB/s 0:05:42 (xfr#159867, ir-chk=6875/172377)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/B3AB0CDA9C4454B3C1197E5A22669DF8EE849D90"
199,762,528,125 93% 74.82MB/s 0:42:26 (xfr#1437846, ir-chk=1018/1983979)rsync: [generator] recv_generator: mkdir "/mnt/home/anarcat/dist/supysonic/tests/assets/\#346" failed: Invalid or incomplete multibyte or wide character (84)
*** Skipping any contents from this failed directory ***
315,384,723,978 96% 76.82MB/s 1:05:15 (xfr#2256473, to-chk=0/2993950)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Note the failure to transfer that supysonic file? It turns out they
had a weird filename in their source tree, since then removed,
but still it showed how the utf8only feature might not be such a bad
idea. At this point, the procedure was restarted all the way back to
"Creating pools", after unmounting all ZFS filesystems (umount
/mnt/run /mnt/boot/efi && umount -t zfs -a) and destroying the pool,
which, surprisingly, doesn't require any confirmation (zpool destroy
rpool).
The second run was cleaner:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/110)
syncing / to /mnt/...
28,019,033,070 97% 42.03MB/s 0:10:35 (xfr#703671, ir-chk=1093/833515)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,807,102 98% 44.84MB/s 0:12:04 (xfr#736580, to-chk=0/867723)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
IO error encountered -- skipping file deletion
24,043,086,450 96% 62.03MB/s 0:06:09 (xfr#151819, ir-chk=15117/172571)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/4C1FDBFEA976FF924D062FB990B24B897A77B84B"
315,423,626,507 96% 67.09MB/s 1:14:43 (xfr#2256845, to-chk=0/2994364)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Also note the transfer speed: we seem capped at 76MB/s, or
608Mbit/s. This is not as fast as I was expecting: the USB connection
seems to be at around 5Gbps:
anarcat@curie:~$ lsusb -tv head -4
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/6p, 5000M
ID 1d6b:0003 Linux Foundation 3.0 root hub
__ Port 1: Dev 4, If 0, Class=Mass Storage, Driver=uas, 5000M
ID 0b05:1932 ASUSTek Computer, Inc.
So it shouldn't cap at that speed. It's possible the USB adapter is
failing to give me the full speed though. It's not the M.2 SSD drive
either, as that has a ~500MB/s bandwidth, acccording to its spec.
At this point, we're about ready to do the final configuration. We
drop to single user mode and do the rest of the procedure. That used
to be shutdown now, but it seems like the systemd switch broke that,
so now you can reboot into grub and pick the "recovery"
option. Alternatively, you might try systemctl rescue, as I found
out.
I also wanted to copy the drive over to another new NVMe drive, but
that failed: it looks like the USB controller I have doesn't work with
older, non-NVME drives.
Boot configuration
Now we need to enter the new system to rebuild the boot loader and
initrd and so on.
First, we bind mounts and chroot into the ZFS disk:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
Next we add an extra service that imports the bpool on boot, to make
sure it survives a zpool.cache destruction:
I had to trim down /etc/fstab and /etc/crypttab to only contain
references to the legacy filesystems (/srv is still BTRFS!).
If we don't already have a tmpfs defined in /etc/fstab:
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
test
read I/O
read IOPS
write I/O
write IOPS
rand4k4g1x
39.27
10052
212.15
54310
rand4k4g1x--fsync=1
39.29
10057
2.73
699
rand64k256m16x
1297.00
20751
1068.57
17097
rand64k256m16x--fsync=1
1290.90
20654
353.82
5661
rand1m16g1x
315.15
315
563.77
563
rand1m16g1x--fsync=1
345.88
345
157.01
157
Peaks are at about 20k IOPS and ~1.3GiB/s read, 1GiB/s write in the
64KB blocks with 16 jobs.
Slowest is the random 4k block sync write at an abysmal 3MB/s and 700
IOPS The 1MB read/write tests have lower IOPS, but that is expected.
Rescue test, ZFS
This test was also performed in rescue mode.
Raw numbers, from the ?job-curie-zfs.log, converted to MiB/s and
manually merged:
test
read I/O
read IOPS
write I/O
write IOPS
rand4k4g1x
77.20
19763
27.13
6944
rand4k4g1x--fsync=1
76.16
19495
6.53
1673
rand64k256m16x
1882.40
30118
70.58
1129
rand64k256m16x--fsync=1
1865.13
29842
71.98
1151
rand1m16g1x
921.62
921
102.21
102
rand1m16g1x--fsync=1
908.37
908
64.30
64
Peaks are at 1.8GiB/s read, also in the 64k job like above, but much
faster. The write is, as expected, much slower at 70MiB/s (compared
to 1GiB/s!), but it should be noted the sync write doesn't degrade
performance compared to async writes (although it's still below the
LVM 300MB/s).
Conclusions
Really, ZFS has trouble performing in all write conditions. The
random 4k sync write test is the only place where ZFS outperforms
LVM in writes, and barely (7MiB/s vs 3MiB/s). Everywhere else, writes
are much slower, sometimes by an order of magnitude.
And before some ZFS zealot jumps in talking about the SLOG or some
other cache that could be added to improved performance, I'll remind
you that those numbers are on a bare bones NVMe drive, pretty much as
fast storage as you can find on this machine. Adding another NVMe
drive as a cache probably will not improve write performance here.
Still, those are very different results than the tests performed by
Salter which shows ZFS beating traditional configurations in all
categories but uncached 4k reads (not writes!). That said, those tests
are very different from the tests I performed here, where I test
writes on a single disk, not a RAID array, which might explain the
discrepancy.
Also, note that neither LVM or ZFS manage to reach the 2400MB/s read
and 1750MB/s write performance specification. ZFS does manage to reach
82% of the read performance (1973MB/s) and LVM 64% of the write
performance (1120MB/s). LVM hits 57% of the read performance and ZFS
hits barely 6% of the write performance.
Overall, I'm a bit disappointed in the ZFS write performance here, I
must say. Maybe I need to tweak the record size or some other ZFS
voodoo, but I'll note that I didn't have to do any such configuration
on the other side to kick ZFS in the pants...
Real world experience
This section document not synthetic backups, but actual real world
workloads, comparing before and after I switched my workstation to
ZFS.
Docker performance
I had the feeling that running some git hook (which was firing a
Docker container) was "slower" somehow. It seems that, at runtime, ZFS
backends are significant slower than their overlayfs/ext4 equivalent:
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:53 curie dockerd[1723]: time="2022-05-16T14:42:53.087219426-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 pid=151170
May 16 14:42:53 curie systemd[1]: Started libcontainer container af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.
May 16 14:42:54 curie systemd[1]: docker-af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.scope: Succeeded.
May 16 14:42:54 curie dockerd[1723]: time="2022-05-16T14:42:54.047297800-04:00" level=info msg="shim disconnected" id=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10
May 16 14:42:54 curie dockerd[998]: time="2022-05-16T14:42:54.051365015-04:00" level=info msg="ignoring event" container=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 16 14:42:54 curie systemd[2444]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[2444]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
Translating this:
container setup: ~1 second
container runtime: ~1 second
container teardown: ~1 second
total runtime: 2-3 seconds
Obviously, those timestamps are not quite accurate enough to make
precise measurements...
After I switched to ZFS:
mai 30 15:31:39 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:39 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:40 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:40 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:41 curie dockerd[3199]: time="2022-05-30T15:31:41.551403693-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 pid=141080
mai 30 15:31:41 curie systemd[1]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[5287]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[1]: Started libcontainer container 42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.
mai 30 15:31:45 curie systemd[1]: docker-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.scope: Succeeded.
mai 30 15:31:45 curie dockerd[3199]: time="2022-05-30T15:31:45.883019128-04:00" level=info msg="shim disconnected" id=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142
mai 30 15:31:45 curie dockerd[1726]: time="2022-05-30T15:31:45.883064491-04:00" level=info msg="ignoring event" container=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
mai 30 15:31:45 curie systemd[1]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
That's double or triple the run time, from 2 seconds to 6
seconds. Most of the time is spent in run time, inside the
container. Here's the breakdown:
container setup: ~2 seconds
container run: ~4 seconds
container teardown: ~1 second
total run time: about ~6-7 seconds
That's a two- to three-fold increase! Clearly something is going on
here that I should tweak. It's possible that code path is less
optimized in Docker. I also worry about podman, but apparently it
also supports ZFS backends. Possibly it would perform better, but
at this stage I wouldn't have a good comparison: maybe it would have
performed better on non-ZFS as well...
Interactivity
While doing the offsite backups (below), the system became somewhat
"sluggish". I felt everything was slow, and I estimate it introduced
~50ms latency in any input device.
Arguably, those are all USB and the external drive was connected
through USB, but I suspect the ZFS drivers are not as well tuned with
the scheduler as the regular filesystem drivers...
Recovery procedures
For test purposes, I unmounted all systems during the procedure:
umount /mnt/boot/efi /mnt/boot/run
umount -a -t zfs
zpool export -a
And disconnected the drive, to see how I would recover this system
from another Linux system in case of a total motherboard failure.
To import an existing pool, plug the device, then import the pool with
an alternate root, so it doesn't mount over your existing filesystems,
then you mount the root filesystem and all the others:
zpool import -l -a -R /mnt &&
zfs mount rpool/ROOT/debian &&
zfs mount -a &&
mount /dev/sdc2 /mnt/boot/efi &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
Offsite backup
Part of the goal of using ZFS is to simplify and harden backups. I
wanted to experiment with shorter recovery times specifically both
point in time recovery objective and recovery time objective
and faster incremental backups.
This is, therefore, part of my backup services.
This section documents how an external NVMe enclosure was setup in a
pool to mirror the datasets from my workstation.
The final setup should include syncoid copying datasets to the backup
server regularly, but I haven't finished that configuration yet.
Partitioning
The above partitioning procedure used sgdisk, but I couldn't figure
out how to do this with sgdisk, so this uses sfdisk to dump the
partition from the first disk to an external, identical drive:
First sync
I used syncoid to copy all pools over to the external device. syncoid
is a thing that's part of the sanoid project which is
specifically designed to sync snapshots between pool, typically over
SSH links but it can also operate locally.
The sanoid command had a --readonly argument to simulate changes,
but syncoid didn't so I tried to fix that with an upstream PR.
It seems it would be better to do this by hand, but this was much
easier. The full first sync was:
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
Funny how the CRITICAL ERROR doesn't actually stop syncoid and it
just carries on merrily doing when it's telling you it's "cowardly
refusing to destroy your existing target"... Maybe that's because my pull
request broke something though...
During the transfer, the computer was very sluggish: everything feels
like it has ~30-50ms latency extra:
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
I wonder how much of that is due to syncoid, particularly because I
often saw mbuffer and pv in there which are not strictly necessary
to do those kind of operations, as far as I understand.
Once that's done, export the pools to disconnect the drive:
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcosv1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
When I first moved from being a technical consultant to a manager of other consultants, I took a 5-day course Managing Technical Teams a bootstrap for managing people within organisations, but with a particular focus on technical people. We do have some particular quirks, after all
Two elements of that course keep coming to mind when doing Debian work, and they both relate to how teams fit together and get stuff done.
Tuckman s four stages model
In the mid-1960s Bruce W. Tuckman developed a four-stage descriptive model of the stages a project team goes through in its lifetime. They are:
Forming: the team comes together and its members are typically motivated and excited, but they often also feel anxiety or uncertainty about how the team will operate and their place within it.
Storming: initial enthusiasm can give way to frustration or disagreement about goals, roles, expectations and responsibilities. Team members are establishing trust, power and status. This is the most critical stage.
Norming: team members take responsibility and share a common goal. They tolerate the whims and fancies of others, sometimes at the expense of conflict and sharing controversial ideas.
Performing: team members are confident, motivated and knowledgeable. They work towards the team s common goal. The team is high-achieving.
Resolved disagreements and personality clashes result in greater intimacy, and a spirit of co-operation emerges.
Teams need to understand these stages because a team can regress to earlier stages when its composition or goals change. A new member, the departure of an existing member, changes in supervisor or leadership style can all lead a team to regress to the storming stage and fail to perform for a time.
When you see a team member say this, as I observed in an IRC channel recently, you know the team is performing:
nice teamwork these busy days Seen on IRC in the channel of a performing team
Tuckman s model describes a team s performance overall, but how can team members establish what they can contribute and how can they go doing so confidently and effectively?
Belbin s Team Roles
The types of behaviour in which people engage are infinite. But the range of useful behaviours, which make an effective contribution to team performance, is finite. These behaviours are grouped into a set number of related clusters, to which the term Team Role is applied. Belbin, R M. Team Roles at Work. Oxford: Butterworth-Heinemann, 2010
Dr Meredith Belbin s thesis, based on nearly ten years research during the 1970s and 1980s, is that each team has a number of roles which need to be filled at various times, but they re not innate characteristics of the people filling them. People may have attributes which make them more or less suited to each role, and they can consciously take up a role if they recognise its need in the team at a particular time.
Belbin s nine team roles are:
Resource investigator (people): outgoing; enthusiastic; has lots of contacts knows someone who might know someone who knows how to solve a problem. Associated weaknessses: over-optimism, enthusiasm wanes quickly
Co-ordinator (people): mature; confident; identifies talent; clarifies goals and delegates effectively. Associated weaknesses: may be seen as manipulative; offloads own share of work.
Shaper (action): challenging; dynamic; has drive. Describes what they want and when they want it. Associated weaknesses: prone to provocation; offends others feelings.
Monitor/evaluator (thinking): sees all options, judges accurately. Best given data and options and asked which the team should choose. Associated weaknesses: lacks drive; can be overly critical.
Teamworker (people): takes care of things behind the scenes; spots a problem and deals with it quietly without fuss. Averts friction. Associated weaknesses: indecisive; avoids confrontation.
Implementer (action): turns ideas into actions and organises work. Allowable weaknesses: somewhat inflexible; slow to respond to new possibilities.
Completer finisher (action): searches out errors; polishes and perfects. Despite the name, may never actually consider something finished . Associated weaknesses: inclined to worry; reluctant to delegate.
Specialist (thinking): knows or can acquire a wealth of things on a subject. Associated weaknesses: narrow focus; overwhelmes others with depth of knowledge.
(adapted from https://www.belbin.com/media/3471/belbin-team-role-descriptions-2022.pdf)
A well-balanced team, Belbin asserts, isn t comprised of multiples of nine individuals who fit into one of these roles permanently. Rather, it has a number of people who are comfortable to wear some of these hats as the need arises. It s even useful to use the team roles as language: for example, someone playing a shaper might say the way we ve always done this is holding us back , to which a co-ordinator s could respond Steve, Joanna put on your Plant hats and find some new ideas. Talk to Susan and see if she knows someone who s tackled this before. Present the options to Nigel and he ll help evaluate which ones might work for us.
Teams in Debian
There are all sort of teams in Debian those which are formally brought into operation by the DPL or the constitution; package maintenance teams; public relations teams; non-technical content teams; special interest teams; and a whole heap of others. Teams can be formal and informal, fleeting or long-lived, two people working together or dozens.
But they all have in common the Tuckman stages of their development and the Belbin team roles they need to fill to flourish. At some stage in their existence, they will all experience new or departing team members and a period of re-forming, norming and storming perhaps fleetingly, perhaps not. And at some stage they will all need someone to step into a team role, play the part and get the team one step further towards their goals.
Footnote
Belbin Associates, the company Meredith Belbin established to promote and continue his work, offers a personalised report with guidance about which roles team members show the strongest preferences for, and how to make best use of them in various settings. They re quick to complete and can also take into account observers , i.e. how others see a team member. All my technical staff go through this process blind shortly after they start, so as not to bias their input, and then we discuss the roles and their report in detail as a one-to-one.
There are some teams in Debian for which this process and discussion as a group activity could be invaluable. I have no particular affiliation with Belbin Associates other than having used the reports and the language of team roles for a number of years. If there s sufficient interest for a BoF session at the next DebConf, I could probably be persuaded to lead it.
Photo by Josh Calabrese on Unsplash
Today ist May, 1st. In about two weeks on May, 15th WhatsApp will put their changed Terms of Service into action and when you don t accept their rules you won t be able to use WhatsApp any longer.
Early this year there was already a strong movement away from WhatsApp towards other solutions. Mainly to Signal, but also some other services like the Fediverse gained some new users. And also XMPP got their fair share of new users.
So, what to do about the WhatsApp ToS change then? Shall we go all to Signal? Surely not. Signal is another vendor lock-in silo. It s centralistic and recent development plans want to implement some crypto payment system. Even Bruce Schneier thinks that this is a bad idea.
Other alternatives often named include Matrix/Element or XMPP. Today, Don di Dislessia in the (german) Fediverse asked about power consumption of the Fediverse incl. Matrix and XMPP and how much renewable energy is being used. Of course this is no easy answer to this question, but I tried my best at least for my own server.
Here are my findings and conclusions
Power
screenshot showing power consumption of server
Currently my server in the colocation is using about 93W in average with 6c Xeon E5-2630L, 128 GB RAM, 4x 2 TB WD Red + 1 Samsung 960pro NVMe. The server is 7 years old. When I started with that server the power consumption was about 75W, but back then there were far less users on the server. So, 20W more over the past year
Users
I m running my Friendica node on Nerdica.net since 2013. Over the years it became one of the largest Friendica servers in the Fediverse, for some time it was the largest one. It has currently like 700 total users and 180 monthly active users. My Mastodon instance on Nerdculture.de has about 1000 total users and about 300 monthly active users.
Since last year I also run a Matrix-Synapse server. Although I invited my family I m in fact the only active user on that server and have joined some channels.
My XMPP server is even older than my Friendica node. For long time I had like maybe 20 users. Now I setup a new website and added some domains like hookipa.net and xmpp.social the user count increased and currently I have like 130 users on those two domains and maybe like 50 monthly active users. Also note that all my Friendica and Mastodon users can use XMPP with their accounts, but won t be counted the same way as on native users on ejabberd, because the auth backend is different.
So, let s assume I do have like 2000 total users and 500 monthly active users.
CPU, Database Sizes and Disk I/O
Let s have a look about how many resources are being used by those users.
Database Sizes:
Friendica (MariaDB): 31 GB for 700 users
Mastodon (PostgreSQL): 15 GB for 1000 users
Matrix-Synapse (PostgreSQL): 5 GB for 1 user
XMPP (PostgreSQL): 0.4 GB for 200 users
CPU times according to xentop:
Webserver VM (Matrix, Friendica & Mastodon): 13410130 s / 130%
XMPP VM: 944275 s / 5.4%
Friendica does use the largest database and causes most disk I/O on NVMe, but it s difficult to differentiate between the load between the web apps on the webserver. So, let s have a quick look on an simple metric:
Number of lines in webserver logfile:
Friendica: 11575 lines
Matrix: 8174 lines
Mastodon: 3212 lines
These metrics correlate to some degree with the database I/O load, at least for Friendica. If you take into account the number of users, things look quite different.
Conclusion
Overall, and my personal impression, is that Matrix is really bad in regards of resource usage. Given that I m the only active user it uses exceptionally many resources. When you also consider that Matrix is using a distributed database for its chat rooms, you can assume that the resource usage is multiplied across the network, making things even worse.
Friendica is using a large database and many disk accesses, but has a fairly large user base, so it seems ok, but of course should be improved.
Mastodon seems to be quite good, considering the database size, the number of log lines and the user count.
XMPP turns out to be the most efficient contestant in this comparison: it uses much less CPU cycles and database disk I/O.
Of course, Mastdon/Friendica are different services than XMPP or Matrix. So, coming back to the initial question about alternatives to WhatsApp, the answer for me is: you should prefer XMPP over Matrix alone for reasons of saving resources and thus reducing power consumption. Less power consumption also means a smaller ecological footprint and fewer CO2 emissions for your communication with your family and friends.
XMPP is surely not the perfect replacement for WhatsApp, but I think it is the best thing to recommend. As said above, I don t think that Signal is an viable option. It s just another proprierary silo with all the problems that come with it. Matrix is a resource hog and not a messenger but a MS Teams replacement. Element as the main Matrix client is laggy and not multi-account/multi-server capable. Other Matrix clients do support multiple accounts but are not as feature-complete as Element. In the end the Matrix ecosystem will suffer from the same issues as XMPP did already a decade ago. But XMPP has learned to deal with it.
Also XMPP is proceeding fast in the last years and it has solved many problems many people are still complaining about. Sure, there still some open issues. The situation on IOS is still not as good as on Android with Conversations, but it is fairly close to it.
There are many efforts to improve XMPP. There is Quicksy IM, which is a service that will use your phone number as Jabber ID/JID and is thus comparable to Signal which uses phone numbers as well as unique identifier. But Quicksy is compatible with XMPP standards. Snikket is another new XMPP ecosystem aiming at smaller groups hosting their own server by simply installing a Docker container and setup some basic SRV records in the DNS. Or there is Mailcow, a Docker based mailserver setup that added XMPP server in their setup as well, so you can have the same mail and XMPP address. Snikket even got EU based funding for implementing XMPP Account Portability which also will improve the decentralization even further. Additionally XMPP helps vaccination in Canada and USA with vaxbot by Monal.
Be smart and use ecofriendly infrastructure.
Self-handicapping is a cognitive strategy by which people avoid effort in the hopes of keeping potential failure from hurting self-esteem.[1] It was first theorized by Edward E. Jones and Steven Berglas,[2] according to whom self-handicaps are obstacles created, or claimed, by the individual in anticipation of failing performance.[3]
Learned Helplessness is behaviour exhibited by a subject after enduring repeated aversive stimuli beyond their control. It was initially thought to be caused from the subject's acceptance of their powerlessness: discontinuing attempts to escape or avoid the aversive stimulus, even when such alternatives are unambiguously presented. Upon exhibiting such behavior, the subject was said to have acquired learned helplessness.[1][2] Over the past few decades, neuroscience has provided insight into learned helplessness and shown that the original theory actually had it backwards: the brain's default state is to assume that control is not present, and the presence of "helpfulness" is what is actually learned.[3]
Confession time: I started making these posts (eons ago) because a close
friend did as well, and I enjoyed reading them. But the main reason why I
continue is because the primary way I have to keep track of the books I've
bought and avoid duplicates is, well, grep on these posts.
I should come up with a non-bullshit way of doing this, but time to do
more elegant things is in short supply, and, well, it's my blog. So I'm
boring all of you who read this in various places with my internal
bookkeeping. I do try to at least add a bit of commentary.
This one will be more tedious than most since it includes five separate
Humble Bundles, which
increases the volume a lot. (I just realized I'd forgotten to record
those purchases from the past several months.)
First, the individual books I bought directly:
Ilona Andrews Sweep in Peace (sff)
Ilona Andrews One Fell Sweep (sff)
Steven Brust Vallista (sff)
Nicky Drayden The Prey of Gods (sff)
Meg Elison The Book of the Unnamed Midwife (sff)
Pat Green Night Moves (nonfiction)
Ann Leckie Provenance (sff)
Seanan McGuire Once Broken Faith (sff)
Seanan McGuire The Brightest Fell (sff)
K. Arsenault Rivera The Tiger's Daughter (sff)
Matthew Walker Why We Sleep (nonfiction)
Some new books by favorite authors, a few new releases I heard good things
about, and two (Night Moves and Why We Sleep) from
references in on-line articles that impressed me.
The books from security bundles (this is mostly work reading, assuming
I'll get to any of it), including a blockchain bundle:
Wil Allsop Unauthorised Access (nonfiction)
Ross Anderson Security Engineering (nonfiction)
Chris Anley, et al. The Shellcoder's Handbook (nonfiction)
Conrad Barsky & Chris Wilmer Bitcoin for the Befuddled
(nonfiction)
Imran Bashir Mastering Blockchain (nonfiction)
Richard Bejtlich The Practice of Network Security
(nonfiction)
Kariappa Bheemaiah The Blockchain Alternative (nonfiction)
Violet Blue Smart Girl's Guide to Privacy (nonfiction)
Richard Caetano Learning Bitcoin (nonfiction)
Nick Cano Game Hacking (nonfiction)
Bruce Dang, et al. Practical Reverse Engineering (nonfiction)
Chris Dannen Introducing Ethereum and Solidity (nonfiction)
Daniel Drescher Blockchain Basics (nonfiction)
Chris Eagle The IDA Pro Book, 2nd Edition (nonfiction)
Nikolay Elenkov Android Security Internals (nonfiction)
Jon Erickson Hacking, 2nd Edition (nonfiction)
Pedro Franco Understanding Bitcoin (nonfiction)
Christopher Hadnagy Social Engineering (nonfiction)
Peter N.M. Hansteen The Book of PF (nonfiction)
Brian Kelly The Bitcoin Big Bang (nonfiction)
David Kennedy, et al. Metasploit (nonfiction)
Manul Laphroaig (ed.) PoC GTFO (nonfiction)
Michael Hale Ligh, et al. The Art of Memory Forensics
(nonfiction)
Michael Hale Ligh, et al. Malware Analyst's Cookbook
(nonfiction)
Michael W. Lucas Absolute OpenBSD, 2nd Edition (nonfiction)
Bruce Nikkel Practical Forensic Imaging (nonfiction)
Sean-Philip Oriyano CEHv9 (nonfiction)
Kevin D. Mitnick The Art of Deception (nonfiction)
Narayan Prusty Building Blockchain Projects (nonfiction)
Prypto Bitcoin for Dummies (nonfiction)
Chris Sanders Practical Packet Analysis, 3rd Edition
(nonfiction)
Bruce Schneier Applied Cryptography (nonfiction)
Adam Shostack Threat Modeling (nonfiction)
Craig Smith The Car Hacker's Handbook (nonfiction)
Dafydd Stuttard & Marcus Pinto The Web Application Hacker's
Handbook (nonfiction)
Albert Szmigielski Bitcoin Essentials (nonfiction)
David Thiel iOS Application Security (nonfiction)
Georgia Weidman Penetration Testing (nonfiction)
Finally, the two SF bundles:
Buzz Aldrin & John Barnes Encounter with Tiber (sff)
Poul Anderson Orion Shall Rise (sff)
Greg Bear The Forge of God (sff)
Octavia E. Butler Dawn (sff)
William C. Dietz Steelheart (sff)
J.L. Doty A Choice of Treasons (sff)
Harlan Ellison The City on the Edge of Forever (sff)
Toh Enjoe Self-Reference ENGINE (sff)
David Feintuch Midshipman's Hope (sff)
Alan Dean Foster Icerigger (sff)
Alan Dean Foster Mission to Moulokin (sff)
Alan Dean Foster The Deluge Drivers (sff)
Taiyo Fujii Orbital Cloud (sff)
Hideo Furukawa Belka, Why Don't You Bark? (sff)
Haikasoru (ed.) Saiensu Fikushon 2016 (sff anthology)
Joe Haldeman All My Sins Remembered (sff)
Jyouji Hayashi The Ouroboros Wave (sff)
Sergei Lukyanenko The Genome (sff)
Chohei Kambayashi Good Luck, Yukikaze (sff)
Chohei Kambayashi Yukikaze (sff)
Sakyo Komatsu Virus (sff)
Miyuki Miyabe The Book of Heroes (sff)
Kazuki Sakuraba Red Girls (sff)
Robert Silverberg Across a Billion Years (sff)
Allen Steele Orbital Decay (sff)
Bruce Sterling Schismatrix Plus (sff)
Michael Swanwick Vacuum Flowers (sff)
Yoshiki Tanaka Legend of the Galactic Heroes, Volume 1: Dawn
(sff)
Yoshiki Tanaka Legend of the Galactic Heroes, Volume 2: Ambition
(sff)
Yoshiki Tanaka Legend of the Galactic Heroes, Volume 3: Endurance
(sff)
Tow Ubukata Mardock Scramble (sff)
Sayuri Ueda The Cage of Zeus (sff)
Sean Williams & Shane Dix Echoes of Earth (sff)
Hiroshi Yamamoto MM9 (sff)
Timothy Zahn Blackcollar (sff)
Phew. Okay, all caught up, and hopefully won't have to dump something
like this again in the near future. Also, more books than I have any
actual time to read, but what else is new.
An earlier article showed that
private key storage is an important problem to solve in any
cryptographic system and established keycards as a good way to store
private key material offline. But which keycard should we use? This
article examines the form factor, openness, and performance of four
keycards to try to help readers choose the one that will fit their
needs.
I have personally been using a YubiKey NEO, since a 2015
announcement
on GitHub promoting two-factor authentication. I was also able to hook
up my SSH authentication key into the YubiKey's 2048 bit RSA slot. It
seemed natural to move the other subkeys onto the keycard, provided that
performance was sufficient. The mail client that I use,
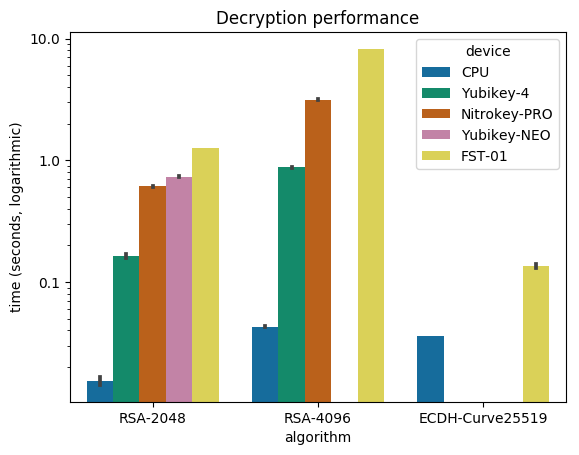
(Notmuch), blocks when decrypting messages,
which could be a serious problems on large email threads from encrypted
mailing lists.
So I built a test harness and got access to some more keycards: I bought
a FST-01 from its creator,
Yutaka Niibe, at the last DebConf and Nitrokey donated a Nitrokey
Pro. I also
bought a YubiKey 4
when I got the NEO. There are of course other keycards out there, but
those are the ones I could get my hands on. You'll notice none of those
keycards have a physical keypad to enter passwords, so they are all
vulnerable to keyloggers that could extract the key's PIN. Keep in mind,
however, that even with the PIN, an attacker could only ask the keycard
to decrypt or sign material but not extract the key that is protected by
the card's firmware.
Form factor
The four keycards have similar form factors: they all connect to a
standard USB port, although both YubiKey keycards have a capacitive
button by which the user triggers two-factor authentication and the
YubiKey 4 can also require a button
press
to confirm private key use. The YubiKeys feel sturdier than the other
two. The NEO has withstood two years of punishment in my pockets along
with the rest of my "real" keyring and there is only minimal wear on the
keycard in the picture. It's also thinner so it fits well on the
keyring.
The FST-01 stands out from the other two with its minimal design. Out of
the box, the FST-01 comes without a case, so the circuitry is exposed.
This is deliberate: one of its goals is to be as transparent as
possible, both in terms of software and hardware design and you
definitely get that feeling at the physical level. Unfortunately, that
does mean it feels more brittle than other models: I wouldn't carry it
in my pocket all the time, although there is a
case
that may protect the key a little better, but it does not provide an
easy way to hook it into a keyring. In the group picture above, the
FST-01 is the pink plastic thing, which is a rubbery casing I received
along with the device when I got it.
Notice how the USB connectors of the YubiKeys differ from the other two:
while the FST-01 and the Nitrokey have standard USB connectors, the
YubiKey has only a "half-connector", which is what makes it thinner than
the other two. The "Nano" form factor takes this even further and almost
disappears in the USB port. Unfortunately, this arrangement means the
YubiKey NEO often comes loose and falls out of the USB port, especially
when connected to a laptop. On my workstation, however, it usually stays
put even with my whole keyring hanging off of it. I suspect this adds
more strain to the host's USB port but that's a tradeoff I've lived with
without any noticeable wear so far. Finally, the NEO has this peculiar
feature of supporting NFC for certain operations, as LWN previously
covered, but I haven't used that
feature yet.
The Nitrokey Pro looks like a normal USB key, in contrast with the other
two devices. It does feel a little brittle when compared with the
YubiKey, although only time will tell how much of a beating it can take.
It has a small ring in the case so it is possible to carry it directly
on your keyring, but I would be worried the cap would come off
eventually. Nitrokey devices are also two times thicker than the Yubico
models which makes them less convenient to carry around on keyrings.
Open and closed designs
The FST-01 is as open as hardware comes, down to the PCB design
available as KiCad files in this Git
repository. The
software running on the card is the
Gnuk firmware that implements the
OpenPGP card protocol, but you can
also get it with firmware implementing a true random number generator
(TRNG) called
NeuG
(pronounced "noisy"); the device is
programmable through a
standard Serial Wire
Debug (SWD) port. The
Nitrokey Start model also runs the Gnuk firmware. However, the Nitrokey
website announces only ECC and RSA 2048-bit
support for the Start, while the FST-01 also supports RSA-4096.
Nitrokey's founder Jan Suhr, in a private email, explained that this is
because "Gnuk doesn't support RSA-3072 or larger at a reasonable speed".
Its devices (the Pro, Start, and HSM models) use a similar chip to the
FST-01: the STM32F103
microcontroller.
Nitrokey also publishes its hardware designs, on
GitHub, which shows the Pro is basically a
fork of the FST-01, according to the
ChangeLog.
I opened the case to confirm it was using the STM MCU, something I
should warn you against; I broke one of the pins holding it together
when opening it so now it's even more fragile. But at least, I was able
to confirm it was built using the STM32F103TBU6 MCU, like the FST-01.
But this is where the comparison ends: on the back side, we find a SIM
card reader that holds the OpenPGP
card that, in turn, holds
the private key material and does the cryptographic operations. So, in
effect, the Nitrokey Pro is really a evolution of the original OpenPGP
card readers.
Nitrokey confirmed the OpenPGP card featured in the Pro is the same as
the one shipped by
the Free Software Foundation Europe (FSFE): the
BasicCard built by ZeitControl. Those cards,
however, are covered by NDAs and the firmware is only partially open
source.
This makes the Nitrokey Pro less open than the FST-01, but that's an
inevitable tradeoff when choosing a design based on the OpenPGP cards,
which Suhr described to me as "pretty proprietary". There are other
keycards out there, however, for example the
SLJ52GDL150-150k
smartcard suggested by
Debian developer Yves-Alexis Perez, which he prefers as it is certified
by French and German authorities. In that blog post, he also said he was
experimenting with the GPL-licensed OpenPGP
applet implemented by the French
ANSSI.
But the YubiKey devices are even further away in the closed-design
direction. Both the hardware designs and firmware are proprietary. The
YubiKey NEO, for example, cannot be upgraded at all, even though it is
based on an open firmware. According to Yubico's
FAQ,
this is due to "best security practices": "There is a 'no upgrade'
policy for our devices since nothing, including malware, can write to
the firmware."
I find this decision questionable in a context where security updates
are often more important than trying to design a bulletproof design,
which may simply be impossible. And the YubiKey NEO did suffer from
critical security
issue
that allowed attackers to bypass the PIN protection on the card, which
raises the question of the actual protection of the private key material
on those cards. According to Niibe, "some OpenPGP cards store the
private key unencrypted. It is a common attitude for many smartcard
implementations", which was confirmed by Suhr: "the private key is
protected by hardware mechanisms which prevent its extraction and
misuse". He is referring to the use of tamper
resistance.
After that security issue, there was no other option for YubiKey NEO
users than to get a new keycard (for free, thankfully) from Yubico,
which also meant discarding the private key material on the key. For
OpenPGP keys, this may mean having to bootstrap the web of trust from
scratch if the keycard was responsible for the main certification key.
But at least the NEO is running free software based on the OpenPGP card
applet and the
source is still available on
GitHub. The YubiKey 4, on the
other hand, is now closed
source,
which was controversial when the new model was announced last year. It
led the main Linux Foundation system administrator, Konstantin
Ryabitsev, to withdraw his
endorsement
of Yubico products. In response, Yubico argued that this approach was
essential to the security of its
devices,
which are now based on "a secure chip, which has built-in
countermeasures to mitigate a long list of attacks". In particular, it
claims that:
A commercial-grade AVR or ARM controller is unfit to be used in a
security product. In most cases, these controllers are easy to attack,
from breaking in via a debug/JTAG/TAP port to probing memory contents.
Various forms of fault injection and side-channel analysis are
possible, sometimes allowing for a complete key recovery in a
shockingly short period of time.
While I understand those concerns, they eventually come down to the
trust you have in an organization. Not only do we have to trust Yubico,
but also hardware manufacturers and designs they have chosen. Every step
in the hidden supply chain is then trusted to make correct technical
decisions and not introduce any backdoors.
History, unfortunately, is not on Yubico's side: Snowden revealed the
example of RSA security
accepting what renowned cryptographer Bruce Schneier described as a
"bribe"
from the NSA to weaken its ECC implementation, by using the presumably
backdoored Dual_EC_DRBG
algorithm. What makes Yubico or its suppliers so different from RSA
Security? Remember that RSA Security used to be an adamant opponent to
the degradation of encryption standards, campaigning against the
Clipper chip in the first
crypto wars.
Even if we trust the Yubico supply chain, how can we trust a closed
design using what basically amounts to security through obscurity?
Publicly auditable designs are an important tradition in cryptography,
and that principle shouldn't stop when software is frozen into silicon.
In fact, a critical vulnerability called
ROCA
disclosed recently affects closed "smartcards" like the
YubiKey 4
and allows full private key recovery from the public key if the key was
generated on a vulnerable keycard. When speaking with Ars
Technica,
the researchers outlined the importance of open designs and questioned
the reliability of certification:
Our work highlights the dangers of keeping the design secret and the
implementation closed-source, even if both are thoroughly analyzed and
certified by experts. The lack of public information causes a delay in
the discovery of flaws (and hinders the process of checking for them),
thereby increasing the number of already deployed and affected devices
at the time of detection.
This issue with open hardware designs seems to be recurring topic of
conversation on the Gnuk mailing
list. For
example, there was a
discussion
in September 2017 regarding possible hardware vulnerabilities in the STM
MCU that would allow extraction of encrypted key material from the key.
Niibe referred to a
talk
presented at the WOOT 17
workshop, where Johannes Obermaier and Stefan Tatschner, from the
Fraunhofer Institute, demonstrated attacks against the STMF0 family
MCUs. It is still unclear if those attacks also apply to the older STMF1
design used in the FST-01, however. Furthermore, extracted private key
material is still protected by user passphrase, but the Gnuk uses a weak
key derivation function, so brute-forcing attacks may be possible.
Fortunately, there is work in progress to
make GnuPG hash the passphrase before sending it to the keycard, which
should make such attacks harder if not completely pointless.
When asked about the Yubico claims in a private email, Niibe did
recognize that "it is true that there are more weak points in general
purpose implementations than special implementations". During the last
DebConf in Montreal, Niibe
explained:
If you don't trust me, you should not buy from me. Source code
availability is only a single factor: someone can maliciously replace
the firmware to enable advanced attacks.
Niibe recommends to "build the firmware yourself", also saying the
design of the FST-01 uses normal hardware that "everyone can replicate".
Those advantages are hard to deny for a cryptographic system: using more
generic components makes it harder for hostile parties to mount targeted
attacks.
A counter-argument here is that it can be difficult for a regular user
to audit such designs, let alone physically build the device from
scratch but, in a mailing list discussion, Debian developer Ian Jackson
explained
that:
You don't need to be able to validate it personally. The thing spooks
most hate is discovery. Backdooring supposedly-free hardware is harder
(more costly) because it comes with greater risk of discovery.
To put it concretely: if they backdoor all of them, someone (not
necessarily you) might notice. (Backdooring only yours involves
messing with the shipping arrangements and so on, and supposes that
you specifically are of interest.)
Since that, as far as we know, the STM microcontrollers are not
backdoored, I would tend to favor those devices instead of proprietary
ones, as such a backdoor would be more easily detectable than in a
closed design. Even though physical attacks may be possible against
those microcontrollers, in the end, if an attacker has physical access
to a keycard, I consider the key compromised, even if it has the best
chip on the market. In our email exchange, Niibe argued that "when a
token is lost, it is better to revoke keys, even if the token is
considered secure enough". So like any other device, physical compromise
of tokens may mean compromise of the key and should trigger
key-revocation procedures.
Algorithms and performance
To establish reliable performance results, I wrote a benchmark program
naively called crypto-bench
that could produce comparable results between the different keys. The
program takes each algorithm/keycard combination and runs 1000
decryptions of a 16-byte file (one AES-128 block) using GnuPG, after
priming it to get the password cached. I assume the overhead of GnuPG
calls to be negligible, as it should be the same across all tokens, so
comparisons are possible. AES encryption is constant across all tests as
it is always performed on the host and fast enough to be irrelevant in
the tests.
I used the following:
Intel(R) Core(TM) i3-6100U CPU @ 2.30GHz running Debian 9
("stretch"/stable amd64), using GnuPG 2.1.18-6 (from the stable
Debian package)
Nitrokey Pro 0.8 (latest firmware)
FST-01, running Gnuk version 1.2.5 (latest firmware)
I ran crypto-bench for each keycard, which resulted in the following:
Algorithm
Device
Mean time (s)
ECDH-Curve25519
CPU
0.036
FST-01
0.135
RSA-2048
CPU
0.016
YubiKey-4
0.162
Nitrokey-Pro
0.610
YubiKey-NEO
0.736
FST-01
1.265
RSA-4096
CPU
0.043
YubiKey-4
0.875
Nitrokey-Pro
3.150
FST-01
8.218
There we see the performance of the four keycards I tested, compared
with the same operations done without a keycard: the "CPU" device. That
provides the baseline time of GnuPG decrypting the file. The first
obvious observation is that using a keycard is slower: in the best
scenario (FST-01 + ECC) we see a four-fold slowdown, but in the worst
case (also FST-01, but RSA-4096), we see a catastrophic 200-fold
slowdown. When I
presented
the results on the Gnuk mailing list, GnuPG developer Werner Koch
confirmed those "numbers are as expected":
With a crypto chip RSA is much faster. By design the Gnuk can't be as
fast - it is just a simple MCU. However, using Curve25519 Gnuk is
really fast.
And yes, the FST-01 is really fast at doing ECC, but it's also the only
keycard that handles ECC in my tests; the Nitrokey Start and Nitrokey
HSM should support it as well, but I haven't been able to test those
devices. Also note that the YubiKey NEO doesn't support RSA-4096 at all,
so we can only compare RSA-2048 across keycards. We should note,
however, that ECC is slower than RSA on the CPU, which suggests the
Gnuk ECC implementation used by the FST-01 is exceptionally fast.
In
discussions
about improving the performance of the FST-01, Niibe estimated the user
tolerance threshold to be "2 seconds decryption time". In a new
design
using the STM32L432 microcontroller, Aurelien Jarno was able to bring
the numbers for RSA-2048 decryption from 1.27s down to 0.65s, and for
RSA-4096, from 8.22s down to 3.87s seconds. RSA-4096 is still beyond the
two-second threshold, but at least it brings the FST-01 close to the
YubiKey NEO and Nitrokey Pro performance levels.
We should also underline the superior performance of the YubiKey 4:
whatever that thing is doing, it's doing it faster than anyone else. It
does RSA-4096 faster than the FST-01 does RSA-2048, and almost as fast
as the Nitrokey Pro does RSA-2048. We should also note that the Nitrokey
Pro also fails to cross the two-second threshold for RSA-4096
decryption.
For me, the FST-01's stellar performance with ECC outshines the other
devices. Maybe it says more about the efficiency of the algorithm than
the FST-01 or Gnuk's design, but it's definitely an interesting avenue
for people who want to deploy those modern algorithms. So, in terms of
performance, it is clear that both the YubiKey 4 and the FST-01 take the
prize in their own areas (RSA and ECC, respectively).
Conclusion
In the above presentation, I have evaluated four cryptographic keycards
for use with various OpenPGP operations. What the results show is that
the only efficient way of storing a 4096-bit encryption key on a keycard
would be to use the YubiKey 4. Unfortunately, I do not feel we should
put our trust in such closed designs so I would argue you should either
stick with 2048-bit encryption subkeys or keep the keys on disk.
Considering that losing such a key would be catastrophic, this might be
a good approach anyway. You should also consider switching to ECC
encryption: even though it may not be supported everywhere, GnuPG
supports having multiple encryption subkeys on a keyring: if one
algorithm is unsupported (e.g. GnuPG 1.4 doesn't support ECC), it will
fall back to a supported algorithm (e.g. RSA). Do not forget your
previously encrypted material doesn't magically re-encrypt itself using
your new encryption subkey, however.
For authentication and signing keys, speed is not such an issue, so I
would warmly recommend either the Nitrokey Pro or Start, or the FST-01,
depending on whether you want to start experimenting with ECC
algorithms. Availability also seems to be an issue for the FST-01. While
you can generally get the device when you meet Niibe in person for a few
bucks (I bought mine for around \$30 Canadian), the Seeed online
shop says the device is out of
stock
at the time of this writing, even though Jonathan McDowell
said
that may be inaccurate in a debian-project discussion. Nevertheless,
this issue may make the Nitrokey devices more attractive. When deciding
on using the Pro or Start, Suhr offered the following advice:
In practice smart card security has been proven to work well (at least
if you use a decent smart card). Therefore the Nitrokey Pro should be
used for high security cases. If you don't trust the smart card or if
Nitrokey Start is just sufficient for you, you can choose that one.
This is why we offer both models.
So far, I have created a signing subkey and moved that and my
authentication key to the YubiKey NEO, because it's a device I
physically trust to keep itself together in my pockets and I was already
using it. It has served me well so far, especially with its extra
features like U2F and
HOTP
support, which I use frequently. Those features are also available on
the Nitrokey Pro, so that may be an alternative if I lose the YubiKey. I
will probably move my main certification key to the FST-01 and a
LUKS-encrypted USB disk, to keep that certification key offline but
backed up on two different devices. As for the encryption key, I'll wait
for keycard performance to improve, or simply switch my whole keyring to
ECC and use the FST-01 or Nitrokey Start for that purpose.
[The author would like to thank Nitrokey for providing hardware for
testing.]
This article first appeared in the Linux Weekly News.
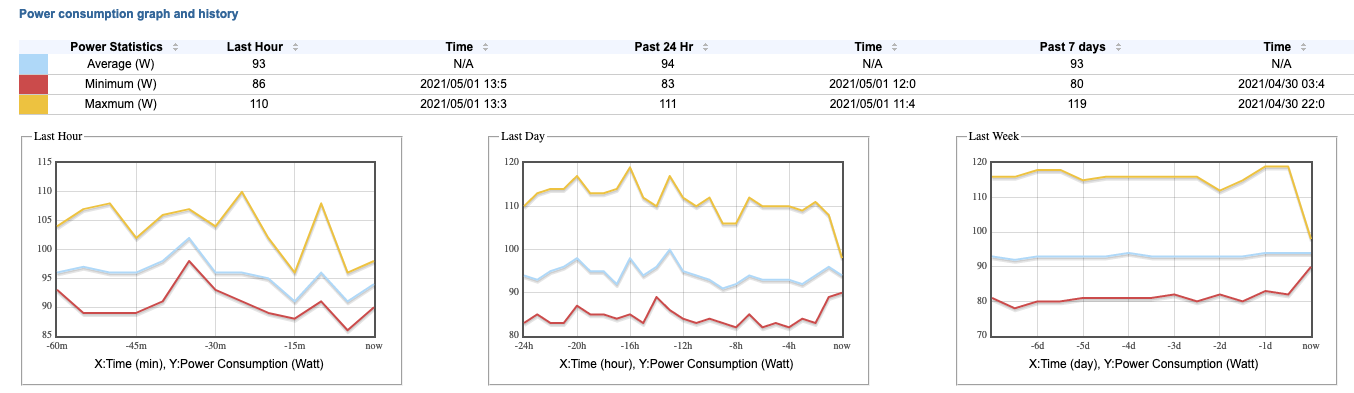 screenshot showing power consumption of server
screenshot showing power consumption of server Halloween is here, time to upload a new set of scary packages of TeX Live. About a month has passed, so there is the usual big stream up updates. There was actually an intermediate release to get out some urgent fixes, but I never reported the news here. So here are the accumulated changes and updates.
Halloween is here, time to upload a new set of scary packages of TeX Live. About a month has passed, so there is the usual big stream up updates. There was actually an intermediate release to get out some urgent fixes, but I never reported the news here. So here are the accumulated changes and updates.
 My favorite this time is
My favorite this time is