Melissa Wen: The Rainbow Treasure Map Talk: Advanced color management on Linux with AMD/Steam Deck.
Last week marked a major milestone for me:
the AMD driver-specific color management properties
reached the upstream linux-next!
And to celebrate, I m happy to share the
slides
notes from my 2023 XDC talk, The Rainbow Treasure Map along with the
individual recording that just
dropped last week on youtube talk about happy coincidences!
Steam Deck Rainbow: Treasure Map & Magic Frogs
While I may be bubbly and chatty in everyday life, the stage isn t exactly my
comfort zone (hallway talks are more my speed). But the journey of developing
the AMD color management properties was so full of discoveries that I simply
had to share the experience. Witnessing the fantastic work of Jeremy and Joshua
bring it all to life on the Steam Deck OLED was like uncovering magical
ingredients and whipping up something truly enchanting.
For XDC 2023, we split our Rainbow journey into two talks. My focus, The
Rainbow Treasure Map, explored the new color features we added to the Linux
kernel driver, diving deep into the hardware capabilities of AMD/Steam Deck.
Joshua then followed with The Rainbow Frogs and showed the breathtaking color
magic released on Gamescope thanks to the power unlocked by the kernel driver s
Steam Deck color properties.
Steam Deck Rainbow: Treasure Map & Magic Frogs
While I may be bubbly and chatty in everyday life, the stage isn t exactly my
comfort zone (hallway talks are more my speed). But the journey of developing
the AMD color management properties was so full of discoveries that I simply
had to share the experience. Witnessing the fantastic work of Jeremy and Joshua
bring it all to life on the Steam Deck OLED was like uncovering magical
ingredients and whipping up something truly enchanting.
For XDC 2023, we split our Rainbow journey into two talks. My focus, The
Rainbow Treasure Map, explored the new color features we added to the Linux
kernel driver, diving deep into the hardware capabilities of AMD/Steam Deck.
Joshua then followed with The Rainbow Frogs and showed the breathtaking color
magic released on Gamescope thanks to the power unlocked by the kernel driver s
Steam Deck color properties.
Packing a Rainbow into 15 Minutes
I had so much to tell, but a half-slot talk meant crafting a concise
presentation. To squeeze everything into 15 minutes (and calm my pre-talk
jitters a bit!), I drafted and practiced those slides and notes countless
times.
So grab your map, and let s embark on the Rainbow journey together!
 Intro: Hi, I m Melissa from Igalia and welcome to the Rainbow Treasure Map, a
talk about advanced color management on Linux with AMD/SteamDeck.
Intro: Hi, I m Melissa from Igalia and welcome to the Rainbow Treasure Map, a
talk about advanced color management on Linux with AMD/SteamDeck.
 Useful links: First of all, if you are not used to the topic, you may find
these links useful.
Useful links: First of all, if you are not used to the topic, you may find
these links useful.
- XDC 2022 - I m not an AMD expert, but - Melissa Wen
- XDC 2022 - Is HDR Harder? - Harry Wentland
- XDC 2022 Lightning - HDR Workshop Summary - Harry Wentland
- Color management and HDR documentation for FOSS graphics - Pekka Paalanen et al.
- Cinematic Color - 2012 SIGGRAPH course notes - Jeremy Selan
- AMD Driver-specific Properties for Color Management on Linux (Part 1) - Melissa Wen
 Context: When we talk about colors in the graphics chain, we should keep in
mind that we have a wide variety of source content colorimetry, a variety of
output display devices and also the internal processing. Users expect
consistent color reproduction across all these devices.
The userspace can use GPU-accelerated color management to get it. But this also
requires an interface with display kernel drivers that is currently missing
from the DRM/KMS framework.
Context: When we talk about colors in the graphics chain, we should keep in
mind that we have a wide variety of source content colorimetry, a variety of
output display devices and also the internal processing. Users expect
consistent color reproduction across all these devices.
The userspace can use GPU-accelerated color management to get it. But this also
requires an interface with display kernel drivers that is currently missing
from the DRM/KMS framework.
 Since April, I ve been bothering the DRM community by sending patchsets from
the work of me and Joshua to add driver-specific color properties to the AMD
display driver. In parallel, discussions on defining a generic color management
interface are still ongoing in the community. Moreover, we are still not clear
about the diversity of color capabilities among hardware vendors.
To bridge this gap, we defined a color pipeline for Gamescope that fits the
latest versions of AMD hardware. It delivers advanced color management features
for gamut mapping, HDR rendering, SDR on HDR, and HDR on SDR.
Since April, I ve been bothering the DRM community by sending patchsets from
the work of me and Joshua to add driver-specific color properties to the AMD
display driver. In parallel, discussions on defining a generic color management
interface are still ongoing in the community. Moreover, we are still not clear
about the diversity of color capabilities among hardware vendors.
To bridge this gap, we defined a color pipeline for Gamescope that fits the
latest versions of AMD hardware. It delivers advanced color management features
for gamut mapping, HDR rendering, SDR on HDR, and HDR on SDR.
 AMD/Steam Deck hardware: AMD frequently releases new GPU and APU generations.
Each generation comes with a DCN version with display hardware improvements.
Therefore, keep in mind that this work uses the AMD Steam Deck hardware and its
kernel driver. The Steam Deck is an APU with a DCN3.01 display driver, a DCN3
family.
It s important to have this information since newer AMD DCN drivers inherit
implementations from previous families but aldo each generation of AMD hardware
may introduce new color capabilities. Therefore I recommend you to familiarize
yourself with the hardware you are working on.
AMD/Steam Deck hardware: AMD frequently releases new GPU and APU generations.
Each generation comes with a DCN version with display hardware improvements.
Therefore, keep in mind that this work uses the AMD Steam Deck hardware and its
kernel driver. The Steam Deck is an APU with a DCN3.01 display driver, a DCN3
family.
It s important to have this information since newer AMD DCN drivers inherit
implementations from previous families but aldo each generation of AMD hardware
may introduce new color capabilities. Therefore I recommend you to familiarize
yourself with the hardware you are working on.
 The AMD display driver in the kernel space: It consists of three layers, (1)
the DRM/KMS framework, (2) the AMD Display Manager, and (3) the AMD Display
Core. We extended the color interface exposed to userspace by leveraging
existing DRM resources and connecting them using driver-specific functions for
color property management.
The AMD display driver in the kernel space: It consists of three layers, (1)
the DRM/KMS framework, (2) the AMD Display Manager, and (3) the AMD Display
Core. We extended the color interface exposed to userspace by leveraging
existing DRM resources and connecting them using driver-specific functions for
color property management.
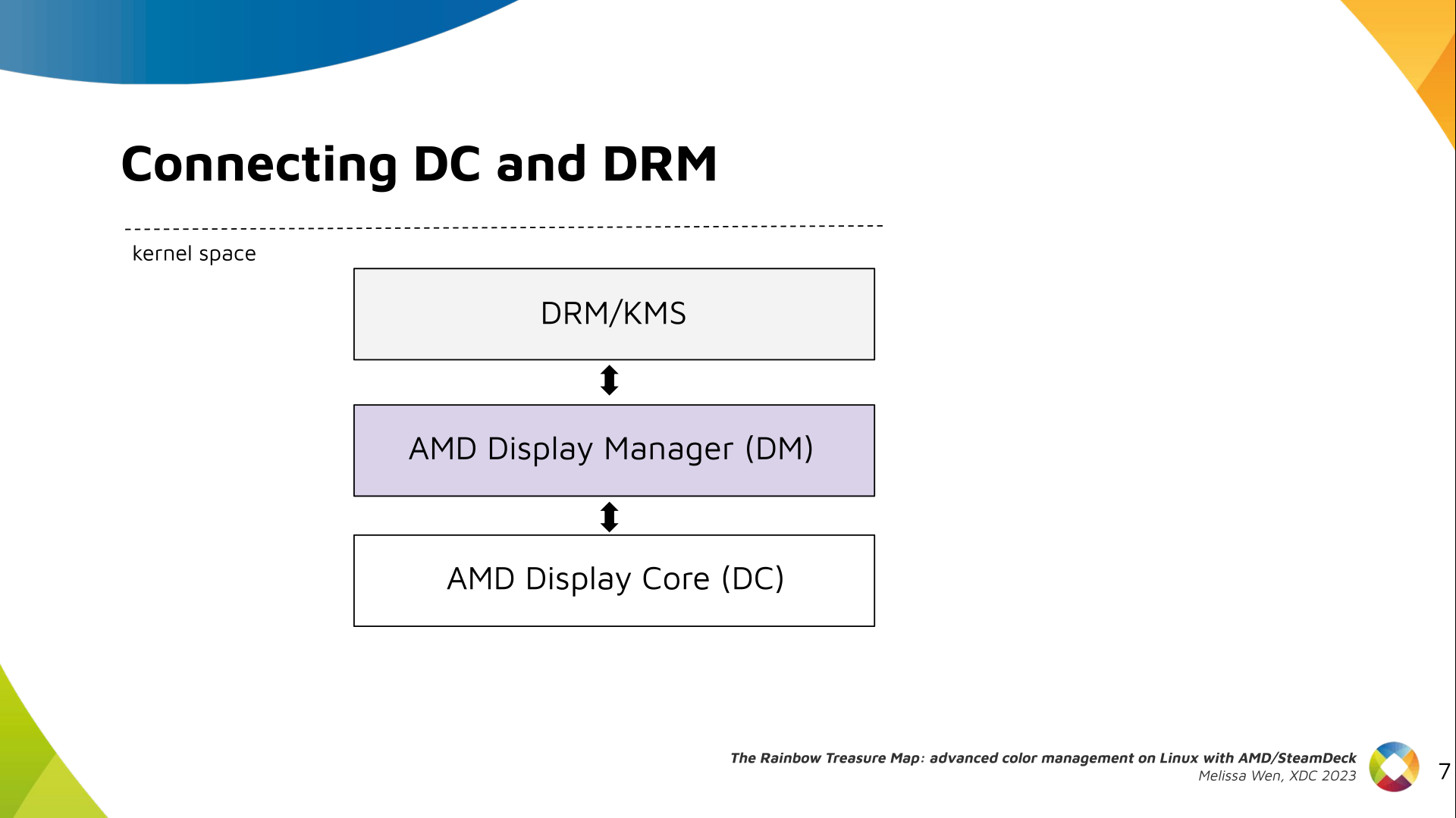 Bridging DC color capabilities and the DRM API required significant changes in
the color management of AMD Display Manager - the Linux-dependent part that
connects the AMD DC interface to the DRM/KMS framework.
Bridging DC color capabilities and the DRM API required significant changes in
the color management of AMD Display Manager - the Linux-dependent part that
connects the AMD DC interface to the DRM/KMS framework.
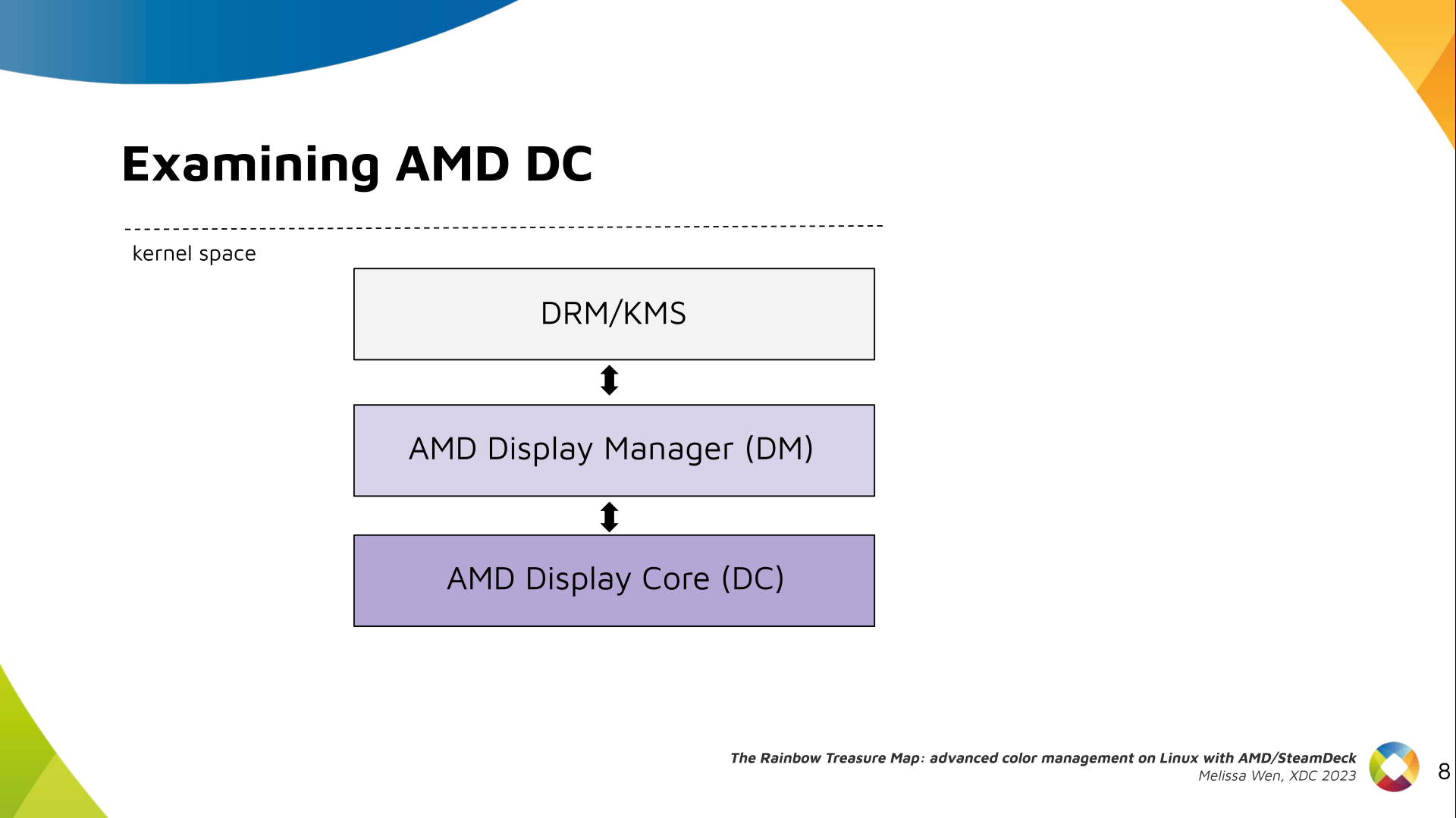 The AMD DC is the OS-agnostic layer. Its code is shared between platforms and
DCN versions. Examining this part helps us understand the AMD color pipeline
and hardware capabilities, since the machinery for hardware settings and
resource management are already there.
The AMD DC is the OS-agnostic layer. Its code is shared between platforms and
DCN versions. Examining this part helps us understand the AMD color pipeline
and hardware capabilities, since the machinery for hardware settings and
resource management are already there.
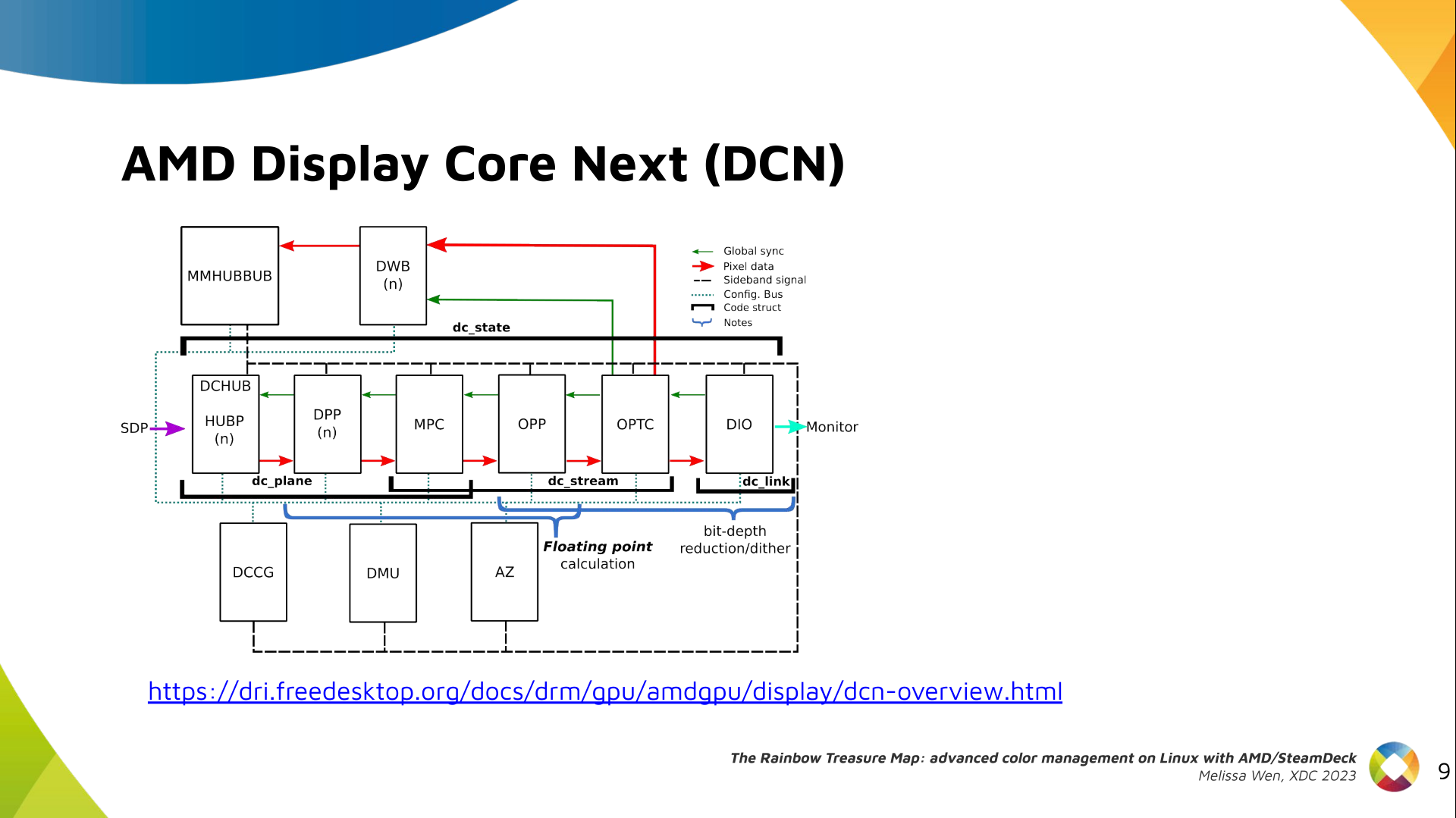 The newest architecture for AMD display hardware is the AMD Display Core Next.
The newest architecture for AMD display hardware is the AMD Display Core Next.
 In this architecture, two blocks have the capability to manage colors:
In this architecture, two blocks have the capability to manage colors:
- Display Pipe and Plane (DPP) - for pre-blending adjustments;
- Multiple Pipe/Plane Combined (MPC) - for post-blending color transformations.
Let s see what we have in the DRM API for pre-blending color management.
 DRM plane color properties:
This is the DRM color management API before blending.
Nothing!
Except two basic DRM plane properties:
DRM plane color properties:
This is the DRM color management API before blending.
Nothing!
Except two basic DRM plane properties: color_encoding and color_range for
the input colorspace conversion, that is not covered by this work.
 In case you re not familiar with AMD shared code, what we need to do is
basically draw a map and navigate there!
We have some DRM color properties after blending, but nothing before blending
yet. But much of the hardware programming was already implemented in the AMD DC
layer, thanks to the shared code.
In case you re not familiar with AMD shared code, what we need to do is
basically draw a map and navigate there!
We have some DRM color properties after blending, but nothing before blending
yet. But much of the hardware programming was already implemented in the AMD DC
layer, thanks to the shared code.
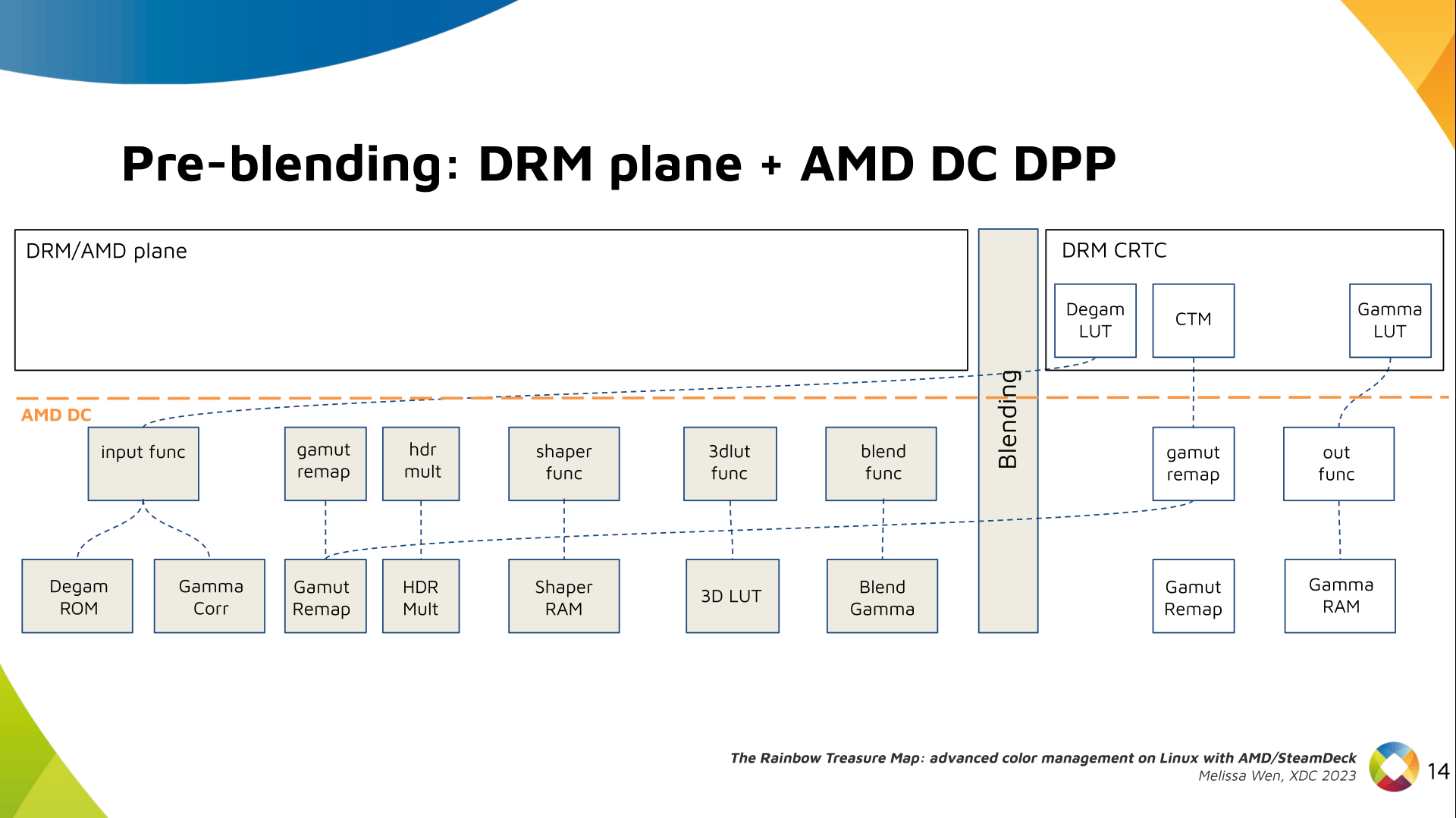 Still both the DRM interface and its connection to the shared code were
missing. That s when the search begins!
Still both the DRM interface and its connection to the shared code were
missing. That s when the search begins!
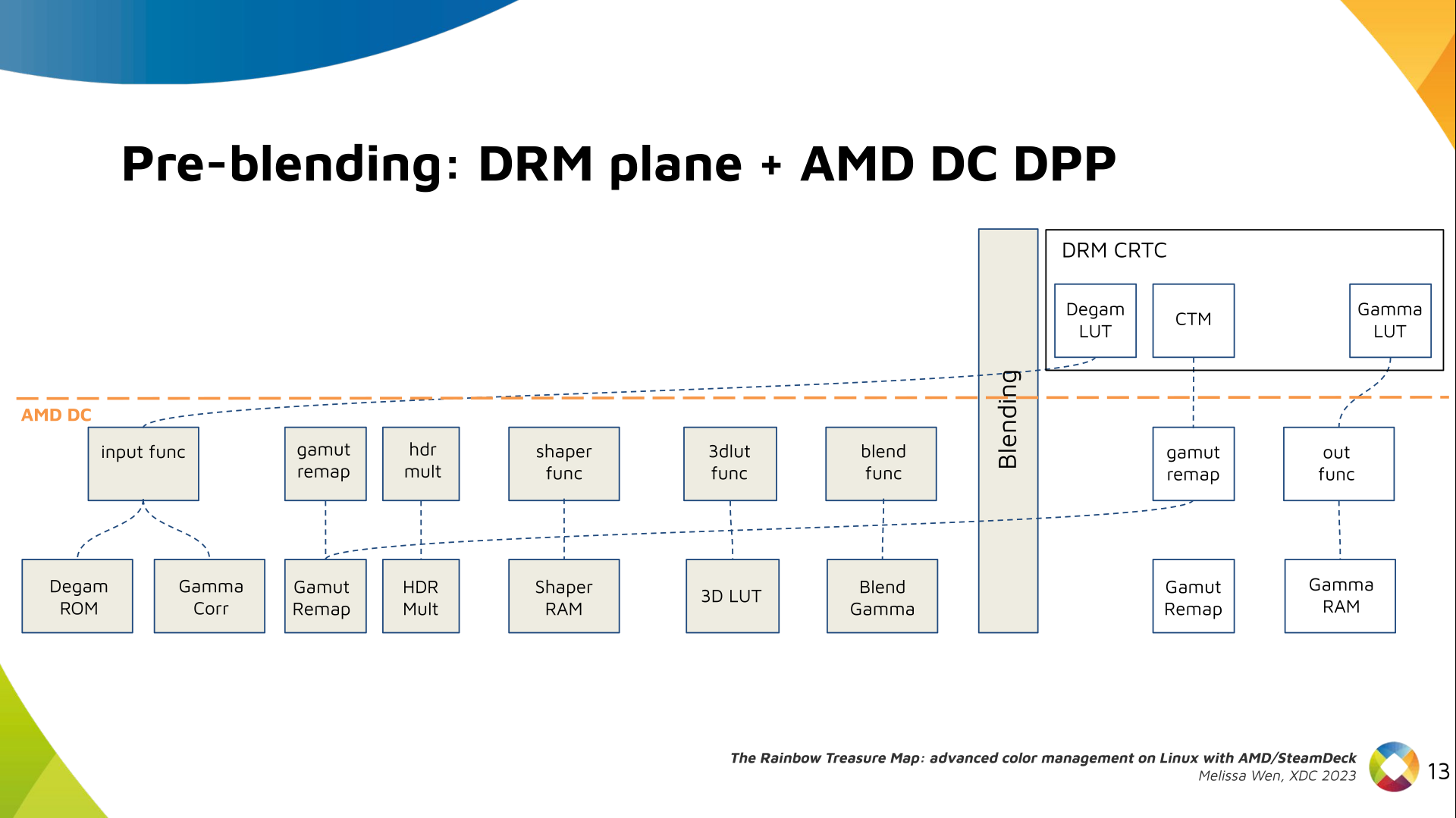
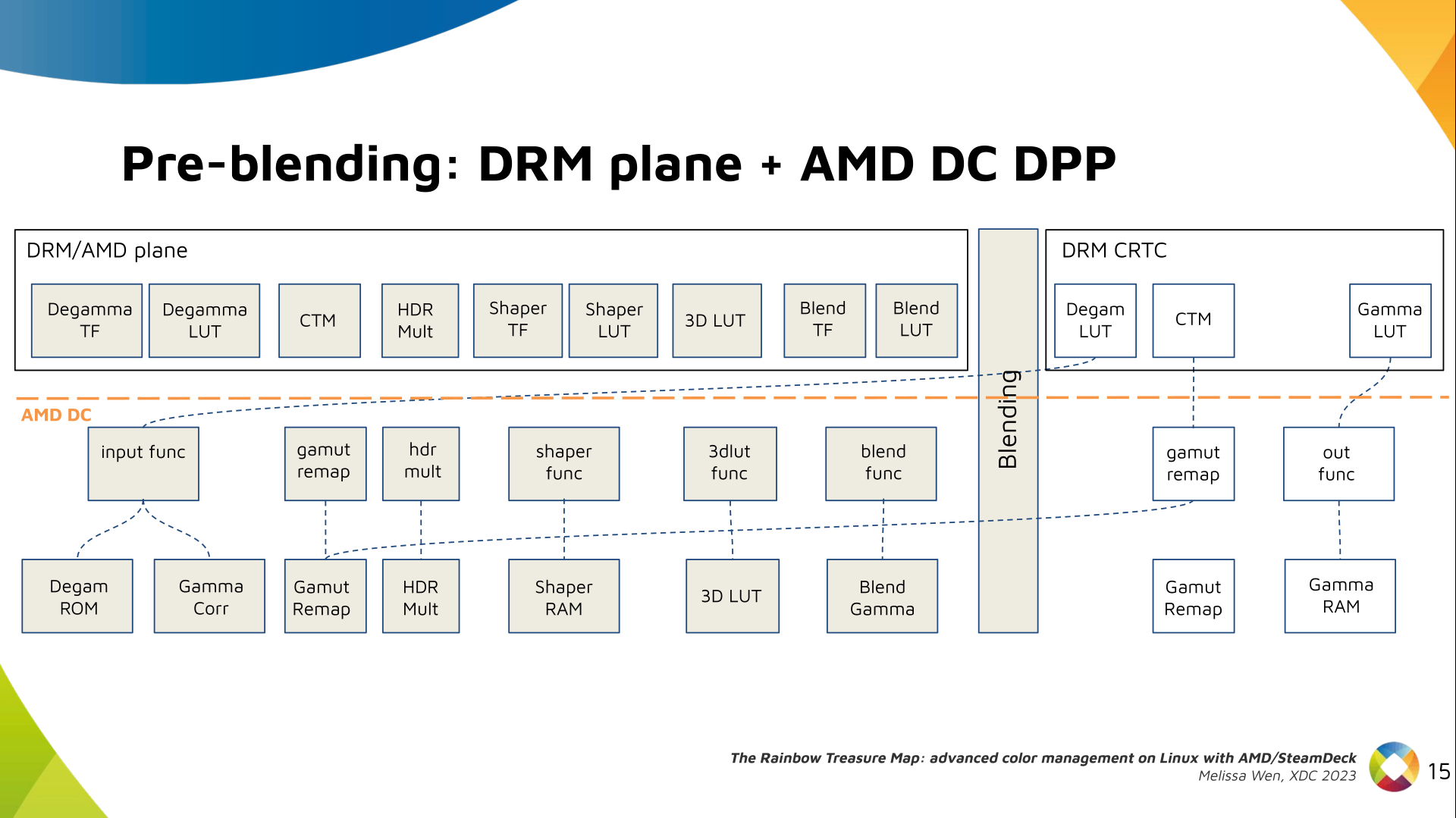 AMD driver-specific color pipeline:
Looking at the color capabilities of the hardware, we arrive at this initial
set of properties. The path wasn t exactly like that. We had many iterations
and discoveries until reached to this pipeline.
AMD driver-specific color pipeline:
Looking at the color capabilities of the hardware, we arrive at this initial
set of properties. The path wasn t exactly like that. We had many iterations
and discoveries until reached to this pipeline.
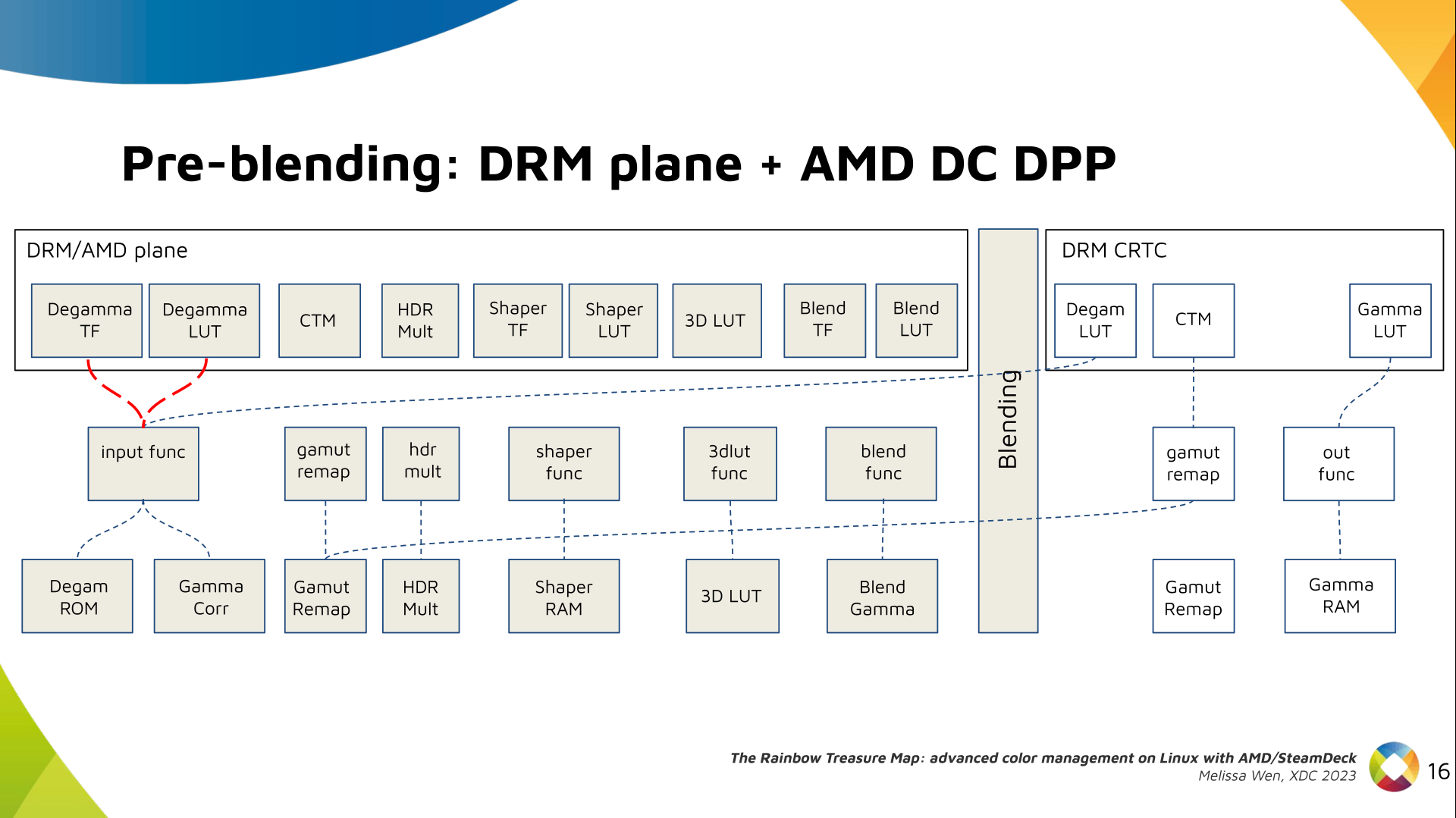 The Plane Degamma is our first driver-specific property before blending. It s
used to linearize the color space from encoded values to light linear values.
The Plane Degamma is our first driver-specific property before blending. It s
used to linearize the color space from encoded values to light linear values.
 We can use a pre-defined transfer function or a user lookup table (in short,
LUT) to linearize the color space.
Pre-defined transfer functions for plane degamma are hardcoded curves that go
to a specific hardware block called DPP Degamma ROM. It supports the following
transfer functions: sRGB EOTF, BT.709 inverse OETF, PQ EOTF, and pure power
curves Gamma 2.2, Gamma 2.4 and Gamma 2.6.
We also have a one-dimensional LUT. This 1D LUT has four thousand ninety six
(4096) entries, the usual 1D LUT size in the DRM/KMS. It s an array of
We can use a pre-defined transfer function or a user lookup table (in short,
LUT) to linearize the color space.
Pre-defined transfer functions for plane degamma are hardcoded curves that go
to a specific hardware block called DPP Degamma ROM. It supports the following
transfer functions: sRGB EOTF, BT.709 inverse OETF, PQ EOTF, and pure power
curves Gamma 2.2, Gamma 2.4 and Gamma 2.6.
We also have a one-dimensional LUT. This 1D LUT has four thousand ninety six
(4096) entries, the usual 1D LUT size in the DRM/KMS. It s an array of
drm_color_lut that goes to the DPP Gamma Correction block.
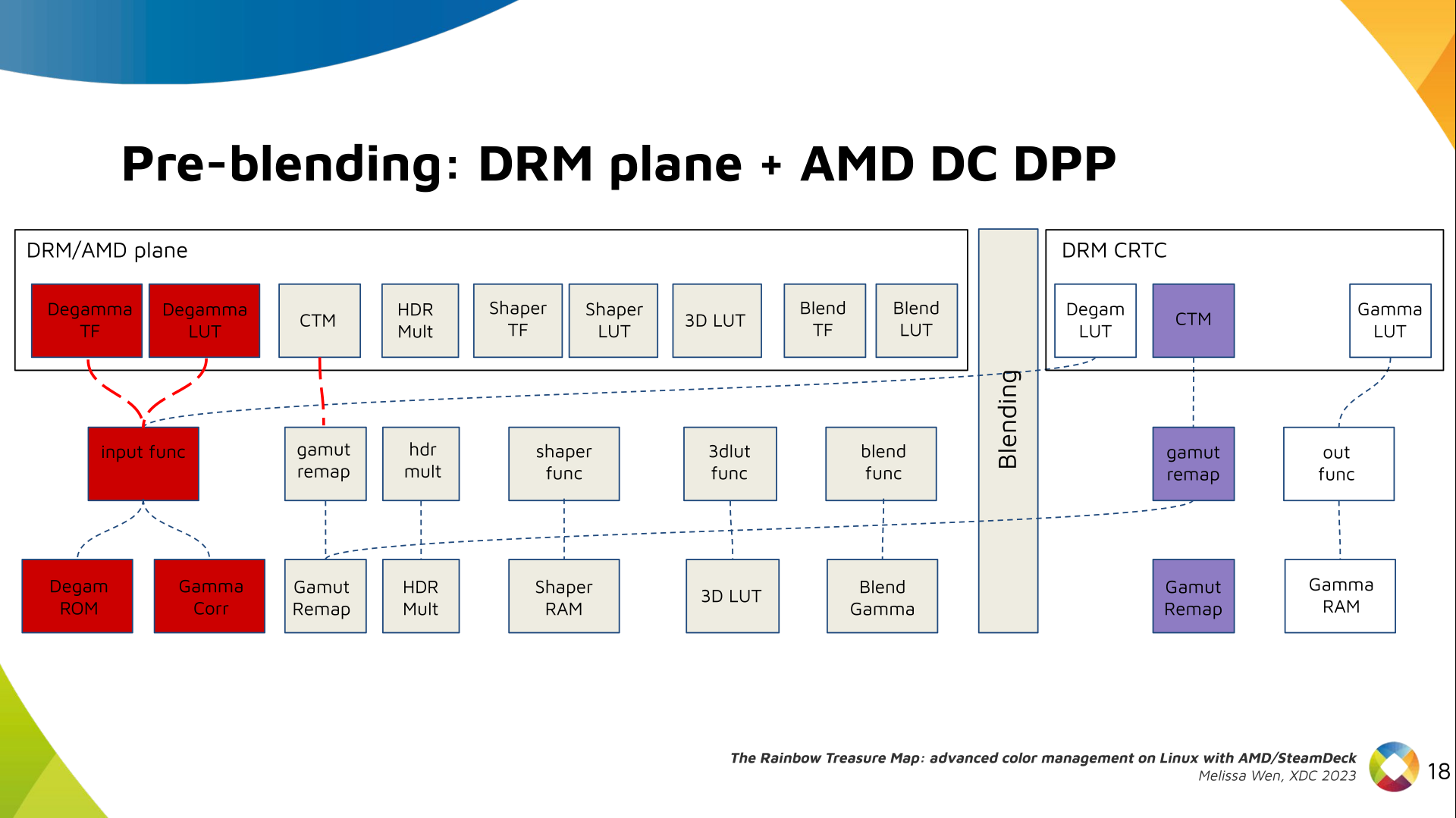 We also have now a color transformation matrix (CTM) for color space
conversion.
We also have now a color transformation matrix (CTM) for color space
conversion.
 It s a 3x4 matrix of fixed points that goes to the DPP Gamut Remap Block.
Both pre- and post-blending matrices were previously gone to the same color
block. We worked on detaching them to clear both paths.
Now each CTM goes on its own way.
It s a 3x4 matrix of fixed points that goes to the DPP Gamut Remap Block.
Both pre- and post-blending matrices were previously gone to the same color
block. We worked on detaching them to clear both paths.
Now each CTM goes on its own way.
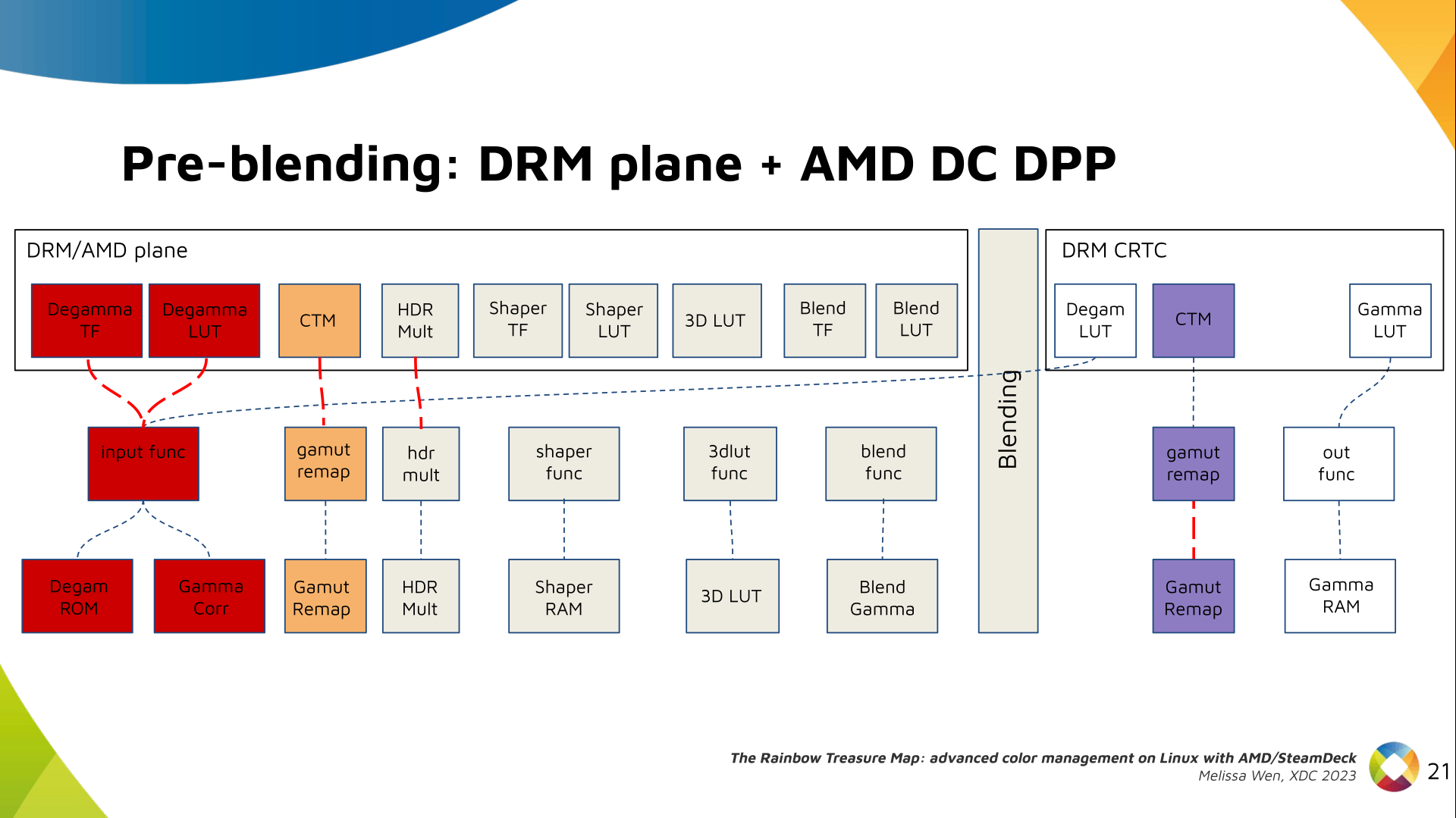 Next, the HDR Multiplier. HDR Multiplier is a factor applied to the color
values of an image to increase their overall brightness.
Next, the HDR Multiplier. HDR Multiplier is a factor applied to the color
values of an image to increase their overall brightness.
 This is useful for converting images from a standard dynamic range (SDR) to a
high dynamic range (HDR). As it can range beyond [0.0, 1.0] subsequent
transforms need to use the PQ(HDR) transfer functions.
This is useful for converting images from a standard dynamic range (SDR) to a
high dynamic range (HDR). As it can range beyond [0.0, 1.0] subsequent
transforms need to use the PQ(HDR) transfer functions.
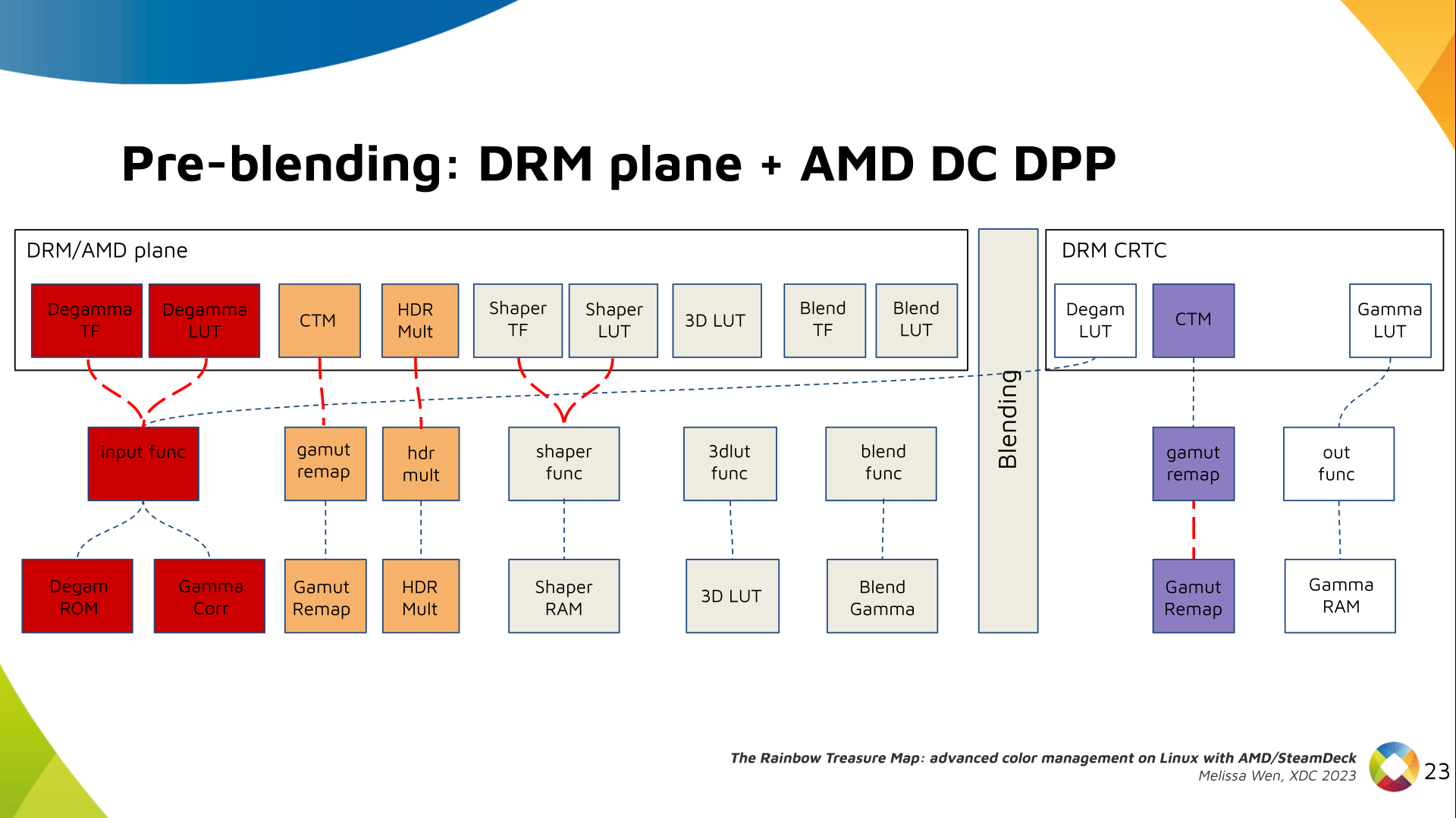 And we need a 3D LUT. But 3D LUT has a limited number of entries in each
dimension, so we want to use it in a colorspace that is optimized for human
vision. It means in a non-linear space. To deliver it, userspace may need one
1D LUT before 3D LUT to delinearize content and another one after to linearize
content again for blending.
And we need a 3D LUT. But 3D LUT has a limited number of entries in each
dimension, so we want to use it in a colorspace that is optimized for human
vision. It means in a non-linear space. To deliver it, userspace may need one
1D LUT before 3D LUT to delinearize content and another one after to linearize
content again for blending.
 The pre-3D-LUT curve is called Shaper curve. Unlike Degamma TF, there are no
hardcoded curves for shaper TF, but we can use the AMD color module in the
driver to build the following shaper curves from pre-defined coefficients. The
color module combines the TF and the user LUT values into the LUT that goes to
the DPP Shaper RAM block.
The pre-3D-LUT curve is called Shaper curve. Unlike Degamma TF, there are no
hardcoded curves for shaper TF, but we can use the AMD color module in the
driver to build the following shaper curves from pre-defined coefficients. The
color module combines the TF and the user LUT values into the LUT that goes to
the DPP Shaper RAM block.
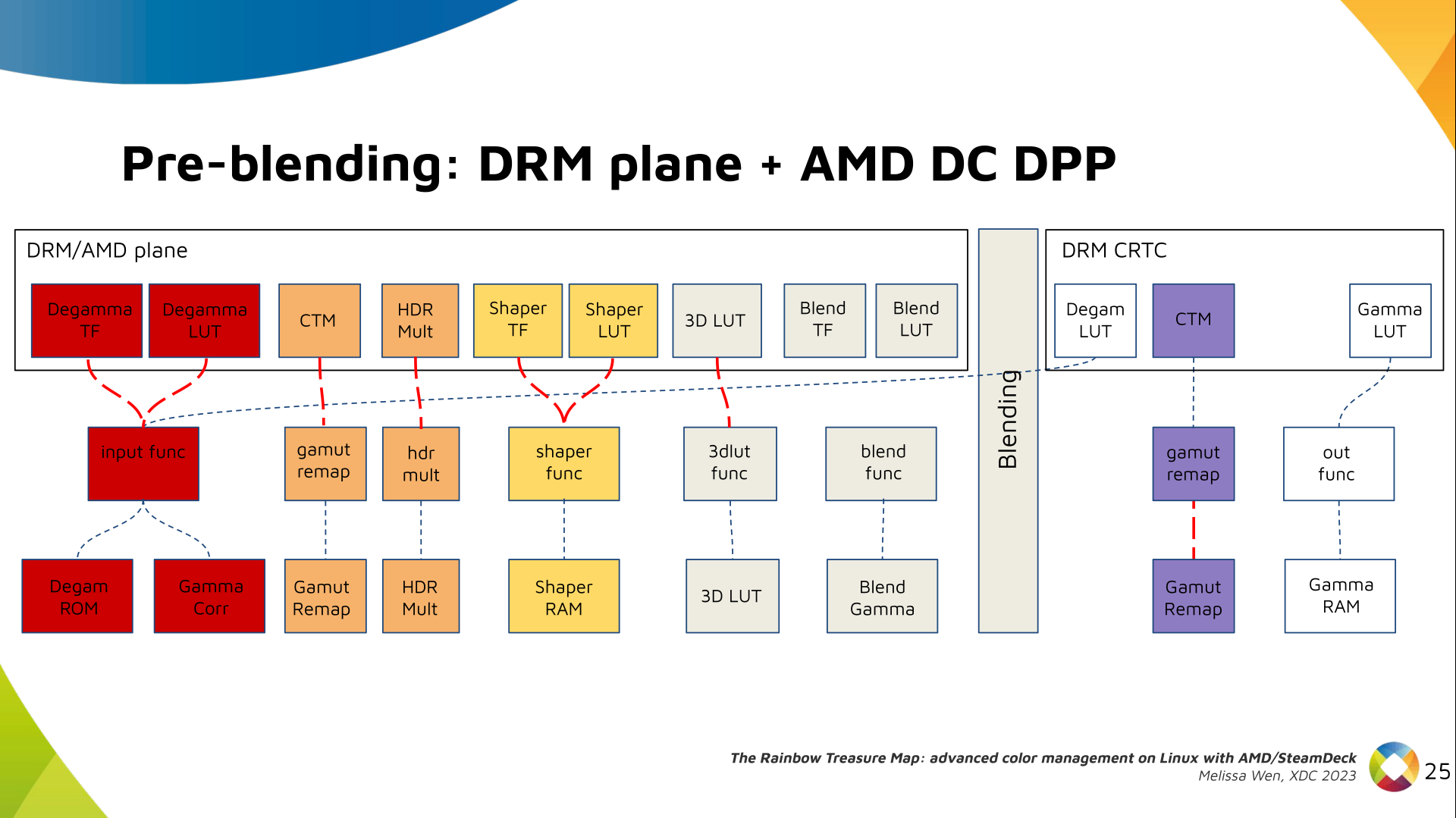 Finally, our rockstar, the 3D LUT. 3D LUT is perfect for complex color
transformations and adjustments between color channels.
Finally, our rockstar, the 3D LUT. 3D LUT is perfect for complex color
transformations and adjustments between color channels.
 3D LUT is also more complex to manage and requires more computational
resources, as a consequence, its number of entries is usually limited. To
overcome this restriction, the array contains samples from the approximated
function and values between samples are estimated by tetrahedral interpolation.
AMD supports 17 and 9 as the size of a single-dimension. Blue is the outermost
dimension, red the innermost.
3D LUT is also more complex to manage and requires more computational
resources, as a consequence, its number of entries is usually limited. To
overcome this restriction, the array contains samples from the approximated
function and values between samples are estimated by tetrahedral interpolation.
AMD supports 17 and 9 as the size of a single-dimension. Blue is the outermost
dimension, red the innermost.
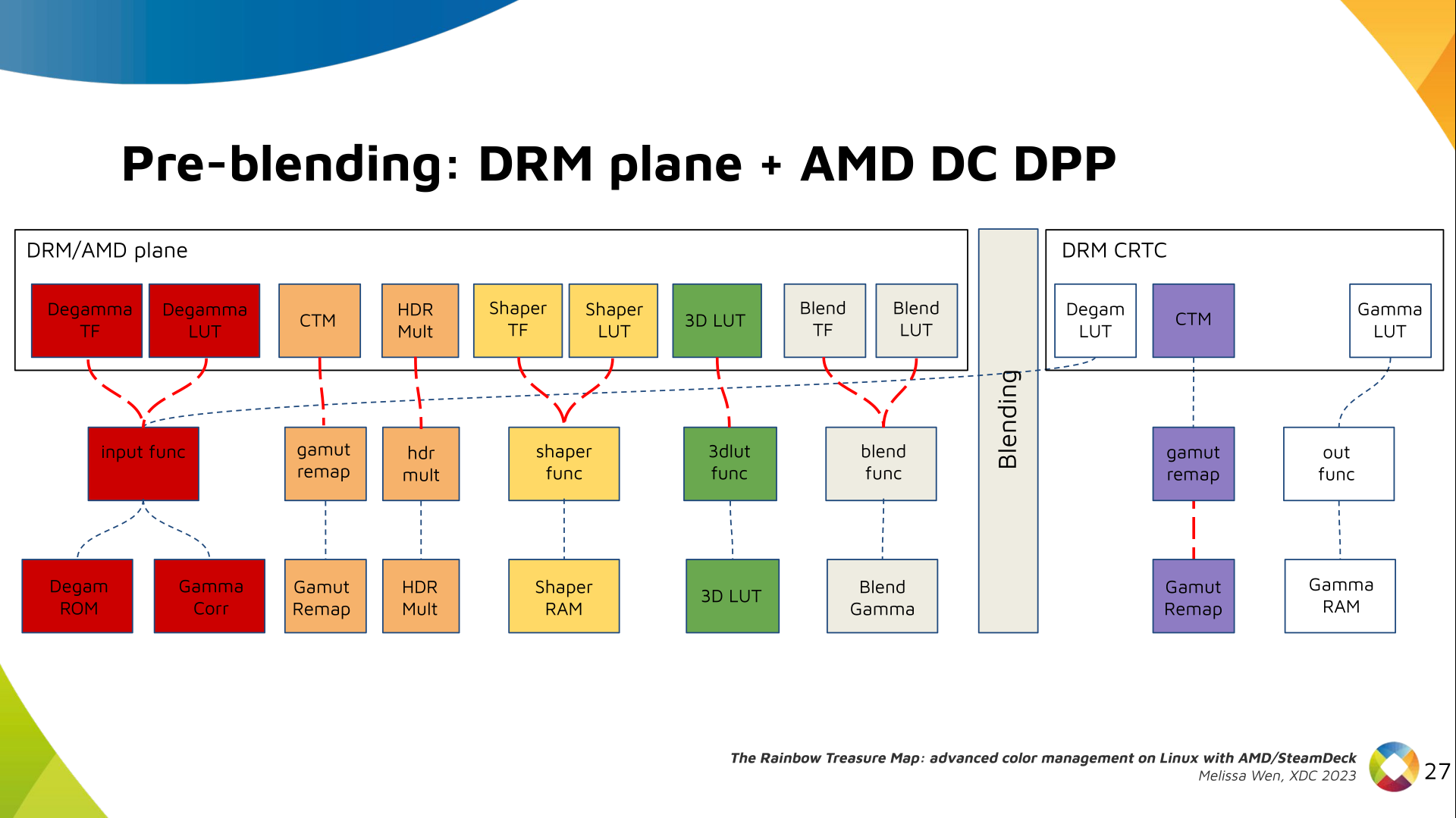 As mentioned, we need a post-3D-LUT curve to linearize the color space before
blending. This is done by Blend TF and LUT.
As mentioned, we need a post-3D-LUT curve to linearize the color space before
blending. This is done by Blend TF and LUT.
 Similar to shaper TF, there are no hardcoded curves for Blend TF. The
pre-defined curves are the same as the Degamma block, but calculated by the
color module. The resulting LUT goes to the DPP Blend RAM block.
Similar to shaper TF, there are no hardcoded curves for Blend TF. The
pre-defined curves are the same as the Degamma block, but calculated by the
color module. The resulting LUT goes to the DPP Blend RAM block.
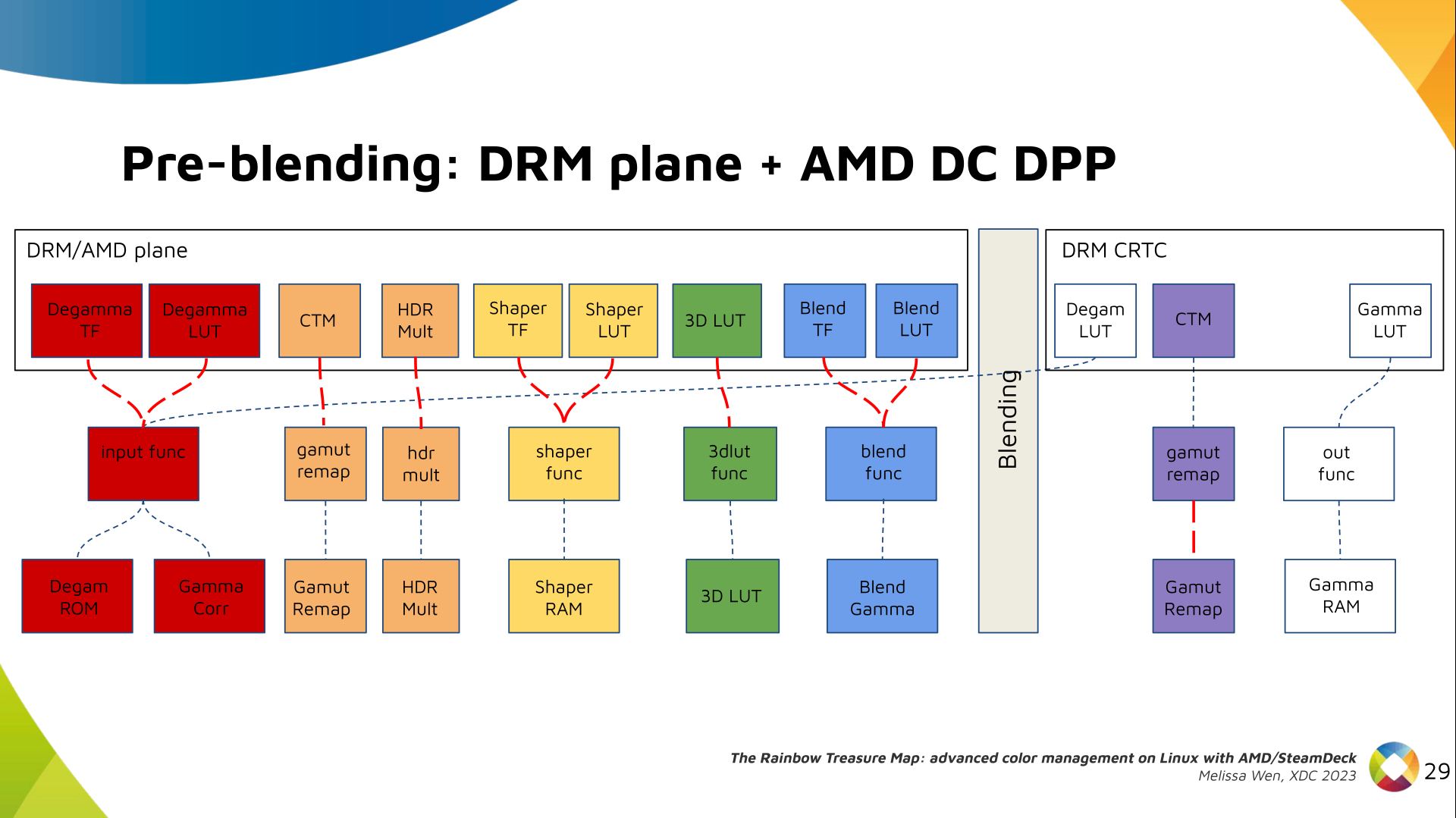 Now we have everything connected before blending. As a conflict between plane
and CRTC Degamma was inevitable, our approach doesn t accept that both are set
at the same time.
Now we have everything connected before blending. As a conflict between plane
and CRTC Degamma was inevitable, our approach doesn t accept that both are set
at the same time.
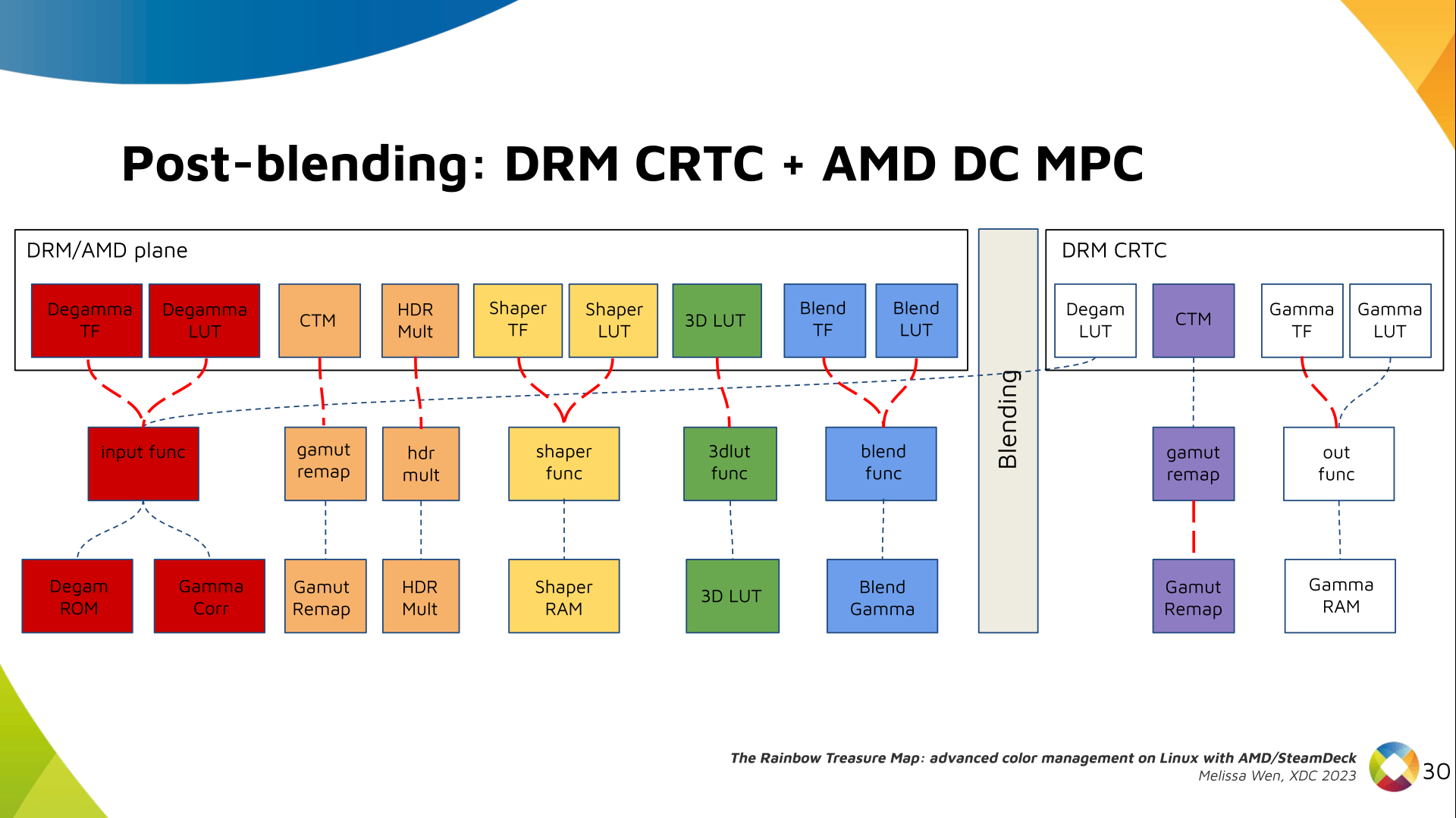 We also optimized the conversion of the framebuffer to wire encoding by adding
support to pre-defined CRTC Gamma TF.
We also optimized the conversion of the framebuffer to wire encoding by adding
support to pre-defined CRTC Gamma TF.
 Again, there are no hardcoded curves and TF and LUT are combined by the AMD
color module. The same types of shaper curves are supported. The resulting LUT
goes to the MPC Gamma RAM block.
Again, there are no hardcoded curves and TF and LUT are combined by the AMD
color module. The same types of shaper curves are supported. The resulting LUT
goes to the MPC Gamma RAM block.
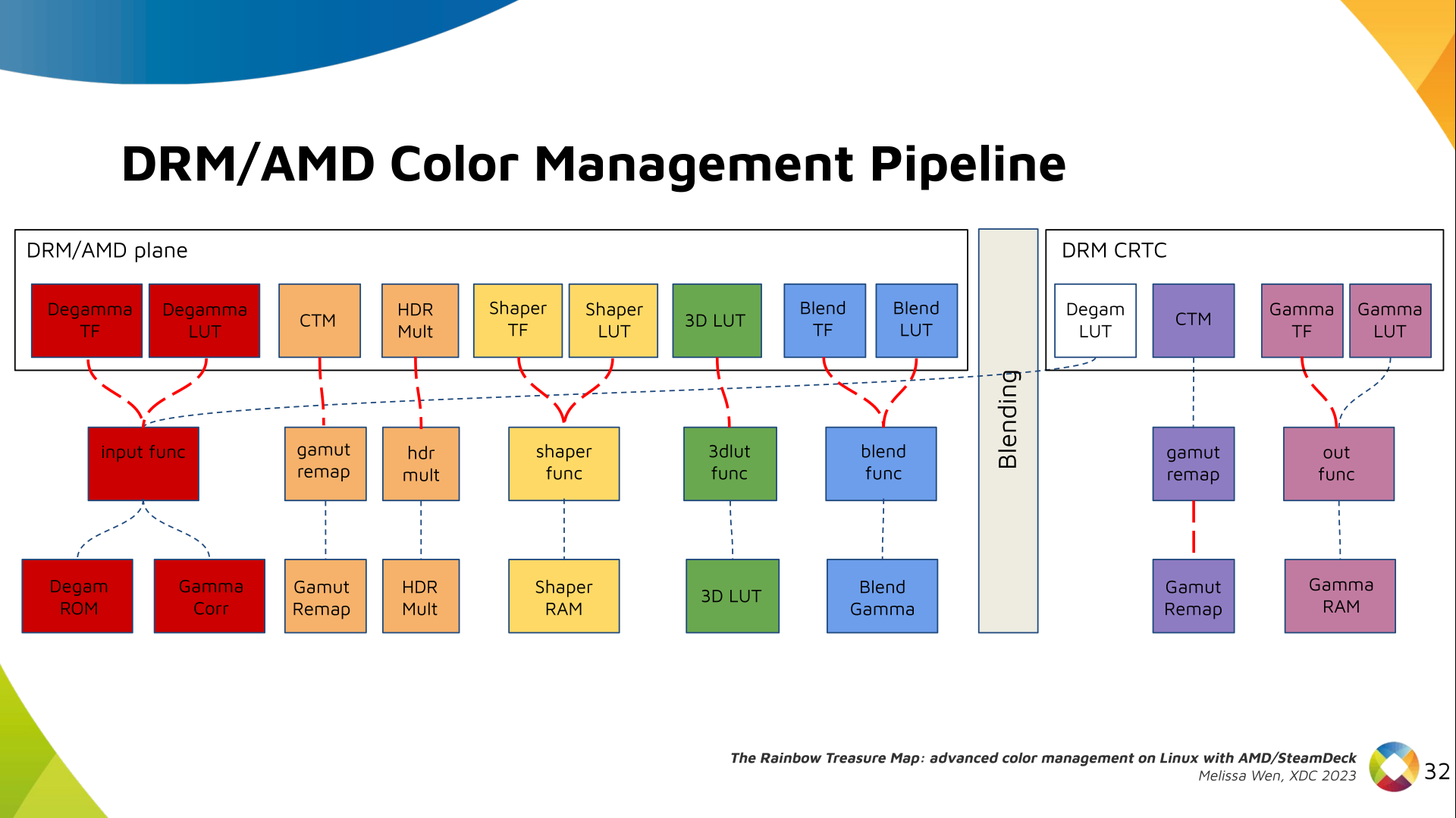 Finally, we arrived in the final version of DRM/AMD driver-specific color
management pipeline. With this knowledge, you re ready to better enjoy the
rainbow treasure of AMD display hardware and the world of graphics computing.
Finally, we arrived in the final version of DRM/AMD driver-specific color
management pipeline. With this knowledge, you re ready to better enjoy the
rainbow treasure of AMD display hardware and the world of graphics computing.
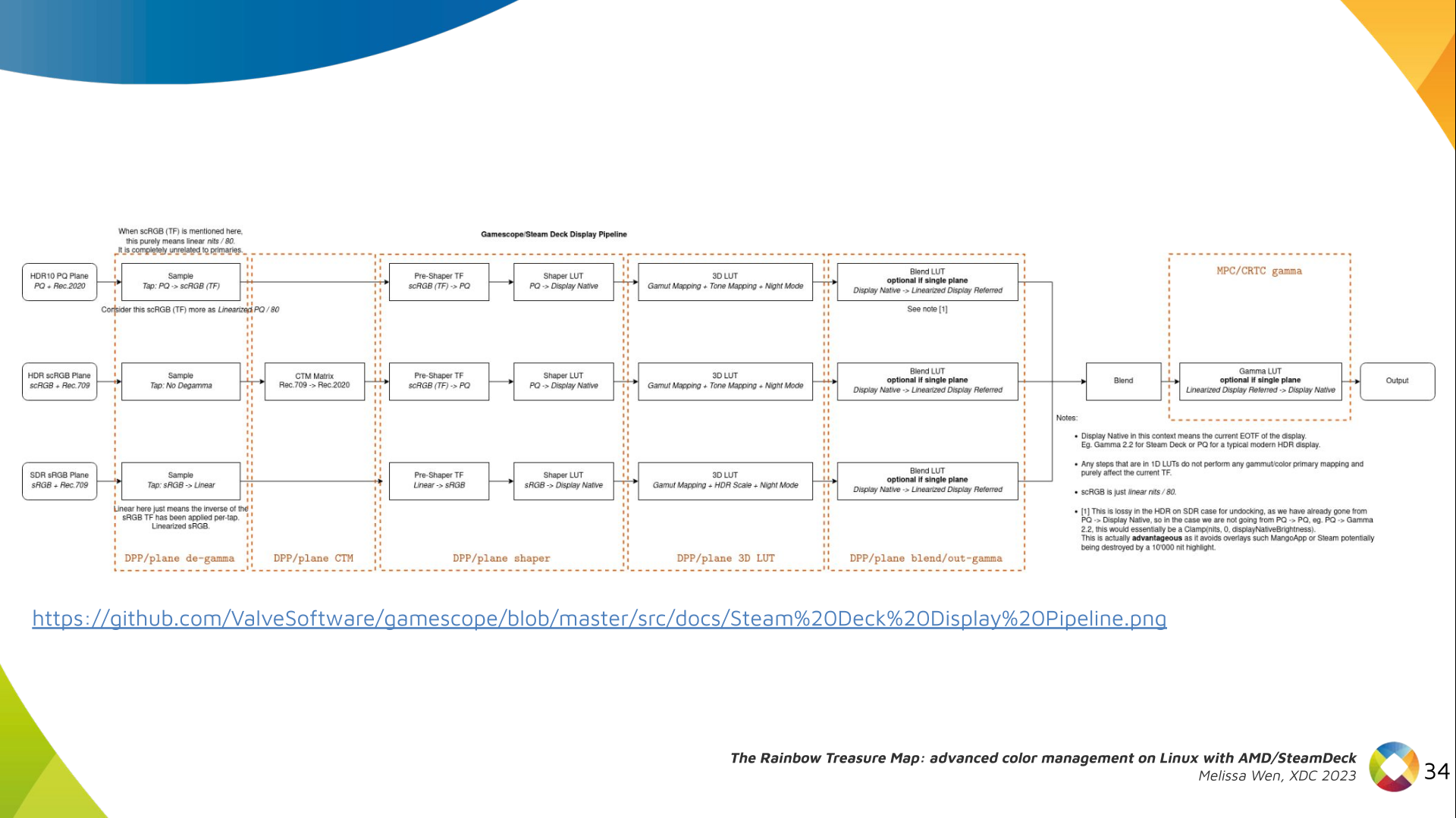 With this work, Gamescope/Steam Deck embraces the color capabilities of the AMD
GPU. We highlight here how we map the Gamescope color pipeline to each AMD
color block.
With this work, Gamescope/Steam Deck embraces the color capabilities of the AMD
GPU. We highlight here how we map the Gamescope color pipeline to each AMD
color block.
 Future works:
The search for the rainbow treasure is not over! The Linux DRM subsystem
contains many hidden treasures from different vendors. We want more complex
color transformations and adjustments available on Linux. We also want to
expose all GPU color capabilities from all hardware vendors to the Linux
userspace.
Thanks Joshua and Harry for this joint work and the Linux DRI community for all feedback and reviews.
The amazing part of this work comes in the next talk with Joshua and The Rainbow Frogs!
Any questions?
Future works:
The search for the rainbow treasure is not over! The Linux DRM subsystem
contains many hidden treasures from different vendors. We want more complex
color transformations and adjustments available on Linux. We also want to
expose all GPU color capabilities from all hardware vendors to the Linux
userspace.
Thanks Joshua and Harry for this joint work and the Linux DRI community for all feedback and reviews.
The amazing part of this work comes in the next talk with Joshua and The Rainbow Frogs!
Any questions?
References:
Intro: Hi, I m Melissa from Igalia and welcome to the Rainbow Treasure Map, a
talk about advanced color management on Linux with AMD/SteamDeck.
Useful links: First of all, if you are not used to the topic, you may find
these links useful.
- XDC 2022 - I m not an AMD expert, but - Melissa Wen
- XDC 2022 - Is HDR Harder? - Harry Wentland
- XDC 2022 Lightning - HDR Workshop Summary - Harry Wentland
- Color management and HDR documentation for FOSS graphics - Pekka Paalanen et al.
- Cinematic Color - 2012 SIGGRAPH course notes - Jeremy Selan
- AMD Driver-specific Properties for Color Management on Linux (Part 1) - Melissa Wen
Context: When we talk about colors in the graphics chain, we should keep in
mind that we have a wide variety of source content colorimetry, a variety of
output display devices and also the internal processing. Users expect
consistent color reproduction across all these devices.
The userspace can use GPU-accelerated color management to get it. But this also
requires an interface with display kernel drivers that is currently missing
from the DRM/KMS framework.
Since April, I ve been bothering the DRM community by sending patchsets from
the work of me and Joshua to add driver-specific color properties to the AMD
display driver. In parallel, discussions on defining a generic color management
interface are still ongoing in the community. Moreover, we are still not clear
about the diversity of color capabilities among hardware vendors.
To bridge this gap, we defined a color pipeline for Gamescope that fits the
latest versions of AMD hardware. It delivers advanced color management features
for gamut mapping, HDR rendering, SDR on HDR, and HDR on SDR.
AMD/Steam Deck hardware: AMD frequently releases new GPU and APU generations.
Each generation comes with a DCN version with display hardware improvements.
Therefore, keep in mind that this work uses the AMD Steam Deck hardware and its
kernel driver. The Steam Deck is an APU with a DCN3.01 display driver, a DCN3
family.
It s important to have this information since newer AMD DCN drivers inherit
implementations from previous families but aldo each generation of AMD hardware
may introduce new color capabilities. Therefore I recommend you to familiarize
yourself with the hardware you are working on.
The AMD display driver in the kernel space: It consists of three layers, (1)
the DRM/KMS framework, (2) the AMD Display Manager, and (3) the AMD Display
Core. We extended the color interface exposed to userspace by leveraging
existing DRM resources and connecting them using driver-specific functions for
color property management.
Bridging DC color capabilities and the DRM API required significant changes in
the color management of AMD Display Manager - the Linux-dependent part that
connects the AMD DC interface to the DRM/KMS framework.
The AMD DC is the OS-agnostic layer. Its code is shared between platforms and
DCN versions. Examining this part helps us understand the AMD color pipeline
and hardware capabilities, since the machinery for hardware settings and
resource management are already there.
The newest architecture for AMD display hardware is the AMD Display Core Next.
In this architecture, two blocks have the capability to manage colors:
- Display Pipe and Plane (DPP) - for pre-blending adjustments;
- Multiple Pipe/Plane Combined (MPC) - for post-blending color transformations.
DRM plane color properties:
This is the DRM color management API before blending.
Nothing!
Except two basic DRM plane properties: color_encoding and color_range for
the input colorspace conversion, that is not covered by this work.
In case you re not familiar with AMD shared code, what we need to do is
basically draw a map and navigate there!
We have some DRM color properties after blending, but nothing before blending
yet. But much of the hardware programming was already implemented in the AMD DC
layer, thanks to the shared code.
Still both the DRM interface and its connection to the shared code were
missing. That s when the search begins!
AMD driver-specific color pipeline:
Looking at the color capabilities of the hardware, we arrive at this initial
set of properties. The path wasn t exactly like that. We had many iterations
and discoveries until reached to this pipeline.
The Plane Degamma is our first driver-specific property before blending. It s
used to linearize the color space from encoded values to light linear values.
We can use a pre-defined transfer function or a user lookup table (in short,
LUT) to linearize the color space.
Pre-defined transfer functions for plane degamma are hardcoded curves that go
to a specific hardware block called DPP Degamma ROM. It supports the following
transfer functions: sRGB EOTF, BT.709 inverse OETF, PQ EOTF, and pure power
curves Gamma 2.2, Gamma 2.4 and Gamma 2.6.
We also have a one-dimensional LUT. This 1D LUT has four thousand ninety six
(4096) entries, the usual 1D LUT size in the DRM/KMS. It s an array of
drm_color_lut that goes to the DPP Gamma Correction block.
We also have now a color transformation matrix (CTM) for color space
conversion.
It s a 3x4 matrix of fixed points that goes to the DPP Gamut Remap Block.
Both pre- and post-blending matrices were previously gone to the same color
block. We worked on detaching them to clear both paths.
Now each CTM goes on its own way.
Next, the HDR Multiplier. HDR Multiplier is a factor applied to the color
values of an image to increase their overall brightness.
This is useful for converting images from a standard dynamic range (SDR) to a
high dynamic range (HDR). As it can range beyond [0.0, 1.0] subsequent
transforms need to use the PQ(HDR) transfer functions.
And we need a 3D LUT. But 3D LUT has a limited number of entries in each
dimension, so we want to use it in a colorspace that is optimized for human
vision. It means in a non-linear space. To deliver it, userspace may need one
1D LUT before 3D LUT to delinearize content and another one after to linearize
content again for blending.
The pre-3D-LUT curve is called Shaper curve. Unlike Degamma TF, there are no
hardcoded curves for shaper TF, but we can use the AMD color module in the
driver to build the following shaper curves from pre-defined coefficients. The
color module combines the TF and the user LUT values into the LUT that goes to
the DPP Shaper RAM block.
Finally, our rockstar, the 3D LUT. 3D LUT is perfect for complex color
transformations and adjustments between color channels.
3D LUT is also more complex to manage and requires more computational
resources, as a consequence, its number of entries is usually limited. To
overcome this restriction, the array contains samples from the approximated
function and values between samples are estimated by tetrahedral interpolation.
AMD supports 17 and 9 as the size of a single-dimension. Blue is the outermost
dimension, red the innermost.
As mentioned, we need a post-3D-LUT curve to linearize the color space before
blending. This is done by Blend TF and LUT.
Similar to shaper TF, there are no hardcoded curves for Blend TF. The
pre-defined curves are the same as the Degamma block, but calculated by the
color module. The resulting LUT goes to the DPP Blend RAM block.
Now we have everything connected before blending. As a conflict between plane
and CRTC Degamma was inevitable, our approach doesn t accept that both are set
at the same time.
We also optimized the conversion of the framebuffer to wire encoding by adding
support to pre-defined CRTC Gamma TF.
Again, there are no hardcoded curves and TF and LUT are combined by the AMD
color module. The same types of shaper curves are supported. The resulting LUT
goes to the MPC Gamma RAM block.
Finally, we arrived in the final version of DRM/AMD driver-specific color
management pipeline. With this knowledge, you re ready to better enjoy the
rainbow treasure of AMD display hardware and the world of graphics computing.
With this work, Gamescope/Steam Deck embraces the color capabilities of the AMD
GPU. We highlight here how we map the Gamescope color pipeline to each AMD
color block.
Future works:
The search for the rainbow treasure is not over! The Linux DRM subsystem
contains many hidden treasures from different vendors. We want more complex
color transformations and adjustments available on Linux. We also want to
expose all GPU color capabilities from all hardware vendors to the Linux
userspace.
Thanks Joshua and Harry for this joint work and the Linux DRI community for all feedback and reviews.
The amazing part of this work comes in the next talk with Joshua and The Rainbow Frogs!
Any questions?
References:


 The DRM/KMS framework provides the atomic API for color management through KMS
properties represented by
The DRM/KMS framework provides the atomic API for color management through KMS
properties represented by 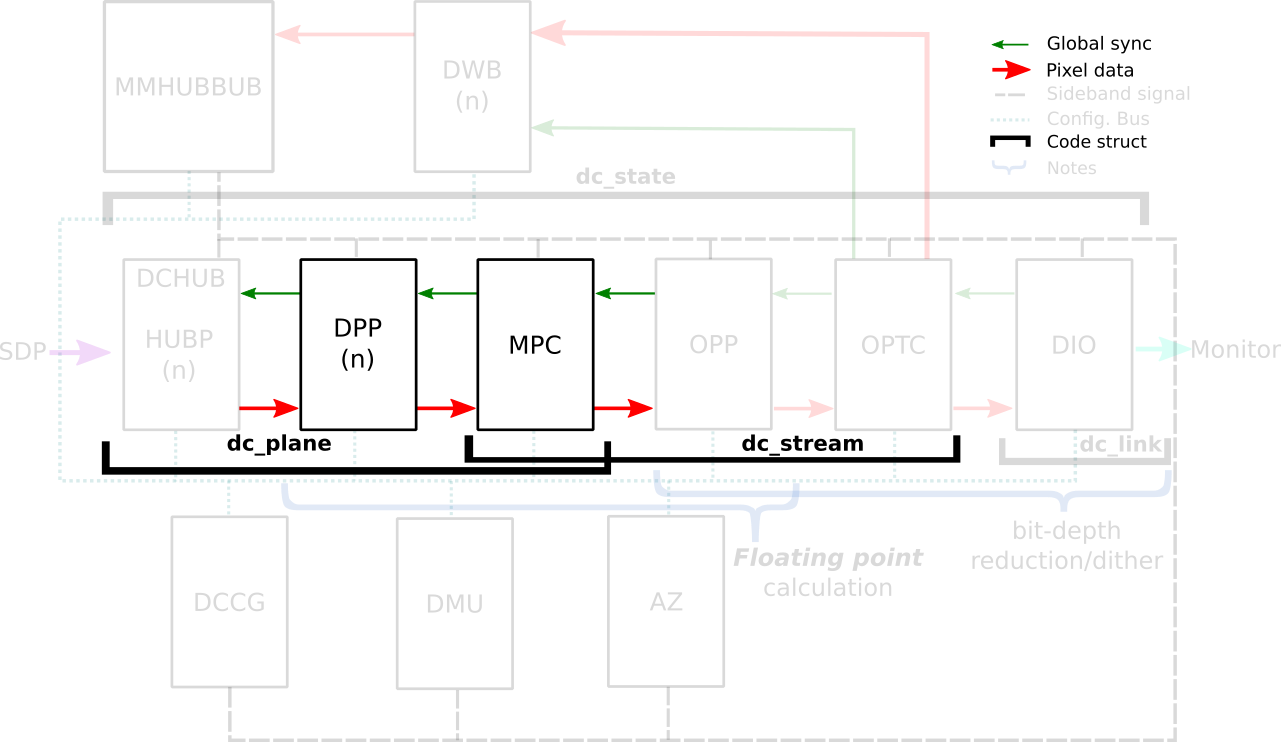



 A good six years ago I
A good six years ago I  The code uses a few standard finance packages for R (with most of them maintained by
The code uses a few standard finance packages for R (with most of them maintained by  Comments and further enhancements welcome!
Comments and further enhancements welcome!
 This week's lesson on the
This week's lesson on the 
 nevertheless, it's time to continue the series. The
nevertheless, it's time to continue the series. The 
{kind=link}