Did you hear the news?
Firefox development is moving from Mercurial to Git. While the decision is far from being mine, and I was barely involved in the small incremental changes that ultimately led to this decision, I feel I have to take at least some responsibility. And if you are one of those who would rather use Mercurial than Git, you may direct all your ire at me.
But let's take a step back and review the past 25 years leading to this decision. You'll forgive me for skipping some details and any possible inaccuracies. This is already a long post, while I could have been more thorough, even I think that would have been too much. This is also not an official Mozilla position, only my personal perception and recollection as someone who was involved at times, but mostly an observer from a distance.
From CVS to DVCS
From its
release in 1998, the Mozilla source code was kept in a CVS repository. If you're too young to know what
CVS is, let's just say it's an old school version control system, with its set of problems. Back then, it was mostly ubiquitous in the Open Source world, as far as I remember.
In the early 2000s, the
Subversion version control system gained some traction, solving some of the problems that came with CVS. Incidentally, Subversion was created by Jim Blandy, who now works at Mozilla on completely unrelated matters. In the same period, the Linux kernel development moved from CVS to
Bitkeeper, which was more suitable to the distributed nature of the Linux community. BitKeeper had its own problem, though: it was the opposite of Open Source, but for most pragmatic people, it wasn't a real concern because free access was provided. Until it became a problem: someone at
OSDL developed an alternative client to BitKeeper, and licenses of BitKeeper were rescinded for OSDL members, including Linus Torvalds (they were even prohibited from purchasing one).
Following this fiasco, in April 2005, two weeks from each other, both Git and Mercurial were born. The former was created by Linus Torvalds himself, while the latter was developed by Olivia Mackall, who was a Linux kernel developer back then. And because they both came out of the same community for the same needs, and the same shared experience with BitKeeper, they both were similar distributed version control systems.
Interestingly enough, several other DVCSes existed:
- SVK, a DVCS built on top of Subversion, allowing users to create local (offline) branches of remote Subversion repositories. It was also known for its powerful merging capabilities. I picked it at some point for my Debian work, mainly because I needed to interact with Subversion repositories.
- Arch (tla), later known as GNU arch. From what I remember, it was awful to use. You think Git is complex or confusing? Arch was way worse. It was forked as "Bazaar", but the fork was abandoned in favor of "Bazaar-NG", now known as "Bazaar" or "bzr", a much more user-friendly DVCS. The first release of Bzr actually precedes Git's by two weeks. I guess it was too new to be considered by Linus Torvalds for the Linux kernel needs.
- Monotone, which I don't know much about, but it was mentioned by Linus Torvalds two days before the initial Git commit of Git. As far as I know, it was too slow for the Linux kernel's needs. I'll note in passing that Monotone is the creation of Graydon Hoare, who also created Rust.
- Darcs, with its patch-based model, rather than the common snapshot-based model, allowed more flexible management of changes. This approach came, however, at the expense of performance.
In this landscape, the major difference Git was making at the time was that it was blazing fast. Almost incredibly so, at least on Linux systems. That was less true on other platforms (especially Windows). It was a game-changer for handling large codebases in a smooth manner.
Anyways, two years later, in 2007, Mozilla decided to move its source code not to Bzr, not to Git, not to Subversion (which, yes, was a contender), but to Mercurial. The decision "process" was laid down in two rather
colorful blog
posts. My memory is a bit fuzzy, but I don't recall that it was a particularly controversial choice. All of those DVCSes were still young, and there was no definite "winner" yet (GitHub hadn't even been founded). It made the most sense for Mozilla back then, mainly because the Git experience on Windows still wasn't there, and that mattered a lot for Mozilla, with its diverse platform support. As a contributor, I didn't think much of it, although to be fair, at the time, I was mostly consuming the source tarballs.
Personal preferences
Digging through my archives, I've unearthed a forgotten chapter: I did end up setting up both a Mercurial and a Git mirror of the Firefox source repository on alioth.debian.org. Alioth.debian.org was a
FusionForge-based collaboration system for Debian developers, similar to
SourceForge. It was the ancestor of
salsa.debian.org. I used those mirrors for the Debian packaging of Firefox (
cough cough Iceweasel). The Git mirror was created with
hg-fast-export, and the Mercurial mirror was only a necessary step in the process. By that time, I had converted my Subversion repositories to Git, and switched off SVK. Incidentally, I started contributing to Git around that time as well.
I apparently did this not too long after Mozilla switched to Mercurial. As a Linux user, I think I just wanted the speed that Mercurial was not providing. Not that Mercurial was
that slow, but the difference between a couple seconds and a couple hundred milliseconds was a significant enough difference in user experience for me to prefer Git (and Firefox was not the only thing I was using version control for)
Other people had also similarly created
their own mirror, or with
other tools. But none of them were "compatible": their commit hashes were different. Hg-git, used by the latter, was putting extra information in commit messages that would make the conversion differ, and hg-fast-export would just not be consistent with itself! My mirror is long gone, and those have not been updated in more than a decade.
I did end up using Mercurial, when I got
commit access to the Firefox source repository in April 2010. I still kept using Git for my Debian activities, but I now was also using Mercurial to push to the Mozilla servers. I joined Mozilla as a contractor a few months after that, and kept using Mercurial for a while, but as a, by then, long time Git user, it never really clicked for me. It turns out, the sentiment was shared by several at Mozilla.
Git incursion
In the early 2010s, GitHub was becoming ubiquitous, and the Git mindshare was getting large. Multiple projects at Mozilla were already entirely hosted on GitHub. As for the Firefox source code base, Mozilla back then was kind of a Wild West, and engineers being engineers, multiple people had been using Git, with their own inconvenient workflows involving a local Mercurial clone. The most popular set of scripts was
moz-git-tools, to incorporate changes in a local Git repository into the local Mercurial copy, to then send to Mozilla servers. In terms of the number of people doing that, though, I don't think it was a lot of people, probably a few handfuls. On my end, I was still keeping up with Mercurial.
I think at that time several engineers had their own unofficial Git mirrors on GitHub, and later on Ehsan Akhgari provided
another mirror, with a twist: it also contained the full CVS history, which the canonical Mercurial repository didn't have. This was particularly interesting for engineers who needed to do some code archeology and couldn't get past the 2007 cutoff of the Mercurial repository. I think that mirror ultimately became the official-looking, but really unofficial,
mozilla-central repository on GitHub. On a side note, a Mercurial repository containing the CVS history was also
later set up, but that didn't lead to something officially supported on the Mercurial side.
Some time around 2011~2012, I started to more seriously consider using Git for work myself, but wasn't satisfied with the workflows others had set up for themselves. I really didn't like the idea of wasting extra disk space keeping a Mercurial clone around while using a Git mirror. I wrote a Python script that would use Mercurial as a library to access a remote repository and produce a
git-fast-import stream. That would allow the creation of a git repository without a local Mercurial clone. It worked quite well, but it was not able to incrementally update. Other, more complete tools existed already, some of which I mentioned above. But as time was passing and the size and depth of the Mercurial repository was growing, these tools were showing their limits and were too slow for my taste, especially for the initial clone.
Boot to Git
In the same time frame, Mozilla
ventured in the Mobile OS sphere with Boot to Gecko, later known as Firefox OS. What does that have to do with version control? The needs of third party collaborators in the mobile space led to the creation of what is now the
gecko-dev repository on GitHub. As I remember it, it was challenging to create, but once it was there, Git users could just clone it and have a working, up-to-date local copy of the Firefox source code and its history... which they could already have, but this was the first officially supported way of doing so. Coincidentally, Ehsan's unofficial mirror was having trouble (to the point of
GitHub closing the repository) and was
ultimately shut down in December 2013.
You'll often find comments on the interwebs about how GitHub has become unreliable since the Microsoft acquisition. I can't really comment on that, but if you think GitHub is unreliable now, rest assured that it was worse in its beginning. And its sustainability as a platform also wasn't a given, being a rather new player. So on top of having this official mirror on GitHub, Mozilla also ventured in setting up its own
Git server for greater control and reliability.
But the canonical repository was still the Mercurial one, and while Git users now had a supported mirror to pull from, they still had to somehow interact with Mercurial repositories, most notably for the
Try server.
Git slowly creeping in Firefox build tooling
Still in the same time frame, tooling around building Firefox
was improving drastically. For obvious reasons, when version control integration was needed in the tooling, Mercurial support was always a no-brainer.
The first explicit acknowledgement of a Git repository for the Firefox source code, other than the addition of the
.gitignore file, was
bug 774109. It added a script to install the prerequisites to build Firefox on macOS (still called OSX back then), and that would print a message inviting people to obtain a copy of the source code with either Mercurial or Git. That was a precursor to current
bootstrap.py, from September 2012.
Following that, as far as I can tell, the first real incursion of Git in the Firefox source tree tooling happened in
bug 965120. A few days earlier,
bug 952379 had added a
mach clang-format command that would apply
clang-format-diff to the output from
hg diff. Obviously, running
hg diff on a Git working tree didn't work, and
bug 965120 was filed, and support for Git was added there. That was in January 2014.
A year later, when the initial implementation of
mach artifact was added (which ultimately led to
artifact builds), Git users were an immediate thought. But while they were considered, it was not to support them, but to avoid actively breaking their workflows. Git support for
mach artifact was eventually added
14 months later, in March 2016.
From gecko-dev to git-cinnabar
Let's step back a little here, back to the end of 2014. My user experience with Mercurial had reached a level of dissatisfaction that was enough for me to decide to take that script from a couple years prior and make it work for incremental updates. That meant finding a way to store enough information locally to be able to reconstruct whatever the incremental updates would be relying on (guess why other tools hid a local Mercurial clone under hood). I got something working rather quickly, and after talking to a few people about this side project at the
Mozilla Portland All Hands and seeing their excitement, I published a
git-remote-hg initial prototype on the last day of the All Hands.
Within weeks, the prototype gained the ability to
directly push to Mercurial repositories, and a couple months later, was renamed to
git-cinnabar. At that point, as a Git user, instead of cloning the gecko-dev repository from GitHub and switching to a local Mercurial repository whenever you needed to push to a Mercurial repository (i.e. the aforementioned Try server, or, at the time, for reviews), you could just clone and push directly from/to Mercurial, all within Git. And it was fast too. You could get a full clone of mozilla-central in less than half an hour, when at the time, other similar tools would take more than 10 hours (needless to say, it's even worse now).
Another couple months later (we're now at the end of April 2015), git-cinnabar became able to start off a local clone of the gecko-dev repository, rather than clone from scratch, which could be time consuming. But because git-cinnabar and the tool that was updating gecko-dev weren't producing the same commits, this setup was cumbersome and not really recommended. For instance, if you pushed something to mozilla-central with git-cinnabar from a gecko-dev clone, it would come back with a different commit hash in gecko-dev, and you'd have to deal with the divergence.
Eventually, in April 2020, the scripts updating
gecko-dev were switched to git-cinnabar, making the use of gecko-dev alongside git-cinnabar a more viable option. Ironically(?), the switch occurred to ease collaboration with
KaiOS (you know, the mobile OS born from the ashes of Firefox OS). Well, okay, in all honesty, when the need of syncing in both directions between Git and Mercurial (we only had ever synced from Mercurial to Git) came up, I nudged Mozilla in the direction of git-cinnabar, which, in my (biased but still honest) opinion, was the more reliable option for two-way synchronization (we did have regular conversion problems with hg-git, nothing of the sort has happened since the switch).
One Firefox repository to rule them all
For reasons I don't know, Mozilla decided to use separate Mercurial repositories as "branches". With the switch to the
rapid release process in 2011, that meant one repository for nightly (mozilla-central), one for aurora, one for beta, and one for release. And with the addition of
Extended Support Releases in 2012, we now add a new ESR repository every year. Boot to Gecko also had its own branches, and so did Fennec (Firefox for Mobile, before Android). There are a
lot of them.
And then there are also
integration branches, where developer's work lands before being merged in mozilla-central (or backed out if it breaks things), always leaving mozilla-central in a (hopefully) good state. Only one of them remains in use today, though.
I can only suppose that the way Mercurial branches work was not deemed practical. It is worth noting, though, that Mercurial branches
are used in some cases, to branch off a dot-release when the next major release process has already started, so it's not a matter of not knowing the feature exists or some such.
In 2016, Gregory Szorc set up a
new repository that would contain them all (or at least most of them), which
eventually became what is now the
mozilla-unified repository. This would e.g. simplify switching between branches when necessary.
7 years later, for some reason, the other "branches" still exist, but most developers are expected to be using mozilla-unified. Mozilla's CI also
switched to using mozilla-unified as base repository.
Honestly, I'm not sure why the separate repositories are still the main entry point for pushes, rather than going directly to mozilla-unified, but it probably comes down to switching being work, and not being a top priority. Also, it probably doesn't help that working with multiple heads in Mercurial, even (especially?) with bookmarks, can be a source of confusion. To give an example, if you aren't careful, and do a plain clone of the mozilla-unified repository, you may not end up on the latest mozilla-central changeset, but rather, e.g. one from beta, or some other branch, depending which one was last updated.
Hosting is simple, right?
Put your repository on a server, install hgweb or gitweb, and that's it? Maybe that works for...
Mercurial itself, but that repository "only" has slightly over 50k changesets and less than 4k files. Mozilla-central has more than an order of magnitude more changesets (close to 700k) and two orders of magnitude more files (more than 700k if you count the deleted or moved files, 350k if you count the currently existing ones).
And remember, there are a lot of "duplicates" of this repository. And I didn't even mention
user repositories and
project branches.
Sure, it's a self-inflicted pain, and you'd think it could probably(?) be mitigated with
shared repositories. But consider the simple case of two repositories: mozilla-central and autoland. You make autoland use mozilla-central as a shared repository. Now, you push something new to autoland, it's stored in the autoland datastore. Eventually, you merge to mozilla-central. Congratulations, it's now in both datastores, and you'd need to clean-up autoland if you wanted to avoid the duplication.
Now, you'd think mozilla-unified would solve these issues, and it would... to some extent. Because that wouldn't cover user repositories and project branches briefly mentioned above, which in GitHub parlance would be considered as Forks. So you'd want a mega global datastore shared by all repositories, and repositories would need to only expose what they really contain. Does Mercurial support that? I don't think so (okay, I'll give you that: even if it doesn't, it could, but that's extra work). And since we're talking about a transition to Git, does Git support that? You may have read about how you can
link to a commit from a fork and make-pretend that it comes from the main repository on GitHub? At least, it shows a warning, now. That's essentially the architectural reason why. So the actual answer is that Git doesn't support it out of the box, but GitHub has some backend magic to handle it somehow (and hopefully, other things like Gitea, Girocco, Gitlab, etc. have something similar).
Now, to come back to the size of the repository. A repository is not a static file. It's a server with which you negotiate what you have against what it has that you want. Then the server bundles what you asked for based on what you said you have. Or in the opposite direction, you negotiate what you have that it doesn't, you send it, and the server incorporates what you sent it. Fortunately the latter is less frequent and requires authentication. But the former is more frequent and CPU intensive. Especially when pulling a large number of changesets, which, incidentally, cloning is.
"But there is a solution for clones" you might say, which is true. That's
clonebundles, which offload the CPU intensive part of cloning to a single job scheduled regularly. Guess who implemented it?
Mozilla. But that only covers the cloning part. We actually had laid the ground to support
offloading large incremental updates and split clones, but that never materialized. Even with all that, that still leaves you with a server that can display file contents, diffs, blames, provide zip archives of a revision, and more, all of which are CPU intensive in their own way.
And these endpoints are regularly abused, and cause extra load to your servers, yes plural, because of course a single server won't handle the load for the number of users of your big repositories. And because your endpoints are abused,
you have to close some of them. And I'm not mentioning the Try repository with its tens of thousands of heads, which brings its own sets of problems (and it would have even more heads if we didn't fake-merge them once in a while).
Of course, all the above applies to Git (and it only gained
support for something akin to clonebundles last year). So, when the Firefox OS project was stopped, there wasn't much motivation to continue supporting our own Git server, Mercurial still being the official point of entry, and
git.mozilla.org was shut down in 2016.
The growing difficulty of maintaining the status quo
Slowly, but steadily in more recent years, as new tooling was added that needed some input from the source code manager, support for Git was more and more consistently added. But at the same time, as people left for other endeavors and weren't necessarily replaced, or more recently with
layoffs, resources allocated to such tooling have been spread thin.
Meanwhile, the repository growth didn't take a break, and the Try repository was becoming an increasing pain, with push times quite often exceeding 10 minutes. The ongoing work to
move Try pushes to Lando will hide the problem under the rug, but the underlying problem will still exist (although the last version of Mercurial seems to have improved things).
On the flip side, more and more people have been relying on Git for Firefox development, to my own surprise, as I didn't really push for that to happen. It just happened organically, by ways of git-cinnabar existing, providing a compelling experience to those who prefer Git, and, I guess, word of mouth. I was genuinely surprised when I recently heard the use of Git among
moz-phab users had surpassed a third. I did, however, occasionally orient people who struggled with Mercurial and said they were more familiar with Git, towards git-cinnabar. I suspect there's a somewhat large number of people who never realized Git was a viable option.
But that, on its own, can come with its own challenges: if you use git-cinnabar without being backed by gecko-dev, you'll have a hard time sharing your branches on GitHub, because you can't push to a fork of gecko-dev without pushing your entire local repository, as they have different commit histories. And switching to gecko-dev when you weren't already using it requires some extra work to rebase all your local branches from the old commit history to the new one.
Clone times with git-cinnabar have also started to go a little out of hand in the past few years, but this was mitigated in a similar manner as with the Mercurial cloning problem: with static files that are refreshed regularly. Ironically, that made
cloning with git-cinnabar faster than cloning with Mercurial. But generating those static files is increasingly time-consuming. As of writing, generating those for mozilla-unified takes close to 7 hours. I was predicting clone times over 10 hours "in 5 years" in a
post from 4 years ago, I wasn't too far off. With exponential growth, it could still happen, although to be fair, CPUs have improved since. I will explore the performance aspect in a subsequent blog post, alongside the upcoming release of git-cinnabar 0.7.0-b1. I don't even want to check how long it now takes with hg-git or git-remote-hg (they were already taking more than a day when git-cinnabar was taking a couple hours).
I suppose it's about time that I clarify that git-cinnabar has always been a side-project. It hasn't been part of my duties at Mozilla, and the extent to which Mozilla supports git-cinnabar is in the form of
taskcluster workers on the
community instance for both git-cinnabar CI and generating those clone bundles. Consequently, that makes the above git-cinnabar specific issues a Me problem, rather than a Mozilla problem.
Taking the leap
I can't talk for the people who made the proposal to move to Git, nor for the people who put a green light on it. But I can at least give my perspective.
Developers have regularly asked why Mozilla was still using Mercurial, but I think it was the first time that a formal proposal was laid out. And it came from the Engineering Workflow team, responsible for issue tracking, code reviews, source control, build and more.
It's easy to say "Mozilla should have chosen Git in the first place", but back in 2007, GitHub wasn't there, Bitbucket wasn't there, and all the available options were rather new (especially compared to the then 21 years-old CVS). I think Mozilla made the right choice, all things considered. Had they waited a couple years, the story might have been different.
You might say that Mozilla stayed with Mercurial for so long because of the
sunk cost fallacy. I don't think that's true either. But after the
biggest Mercurial repository hosting service turned off Mercurial support, and the
main contributor to Mercurial going their own way, it's hard to ignore that the landscape has evolved.
And the problems that we regularly encounter with the Mercurial servers are not going to get any better as the repository continues to grow. As far as I know, all the Mercurial repositories bigger than Mozilla's are... not using Mercurial. Google has its own closed-source server, and Facebook has another of its own, and
it's not really public either. With resources spread thin, I don't expect Mozilla to be able to continue supporting a Mercurial server indefinitely (although I guess
Octobus could be contracted to give a hand, but is that sustainable?).
Mozilla, being a champion of Open Source, also doesn't live in a silo. At some point, you have to meet your contributors where they are. And the Open Source world is now majoritarily using Git. I'm sure the vast majority of new hires at Mozilla in the past, say, 5 years, know Git and have had to learn Mercurial (although they arguably didn't need to). Even within Mozilla, with thousands(!) of repositories on GitHub, Firefox is now actually the exception rather than the norm. I should even actually say Desktop Firefox, because even Mobile Firefox lives on GitHub (although
Fenix is moving back in together with Desktop Firefox, and the timing is such that that will probably happen before Firefox moves to Git).
Heck, even
Microsoft moved to Git!
With a significant developer base already using Git thanks to git-cinnabar, and all the constraints and problems I mentioned previously, it actually seems natural that a transition (finally) happens. However, had git-cinnabar or something similarly viable not existed, I don't think Mozilla would be in a position to take this decision. On one hand, it probably wouldn't be in the current situation of having to support both Git and Mercurial in the tooling around Firefox, nor the resource constraints related to that. But on the other hand, it would be farther from supporting Git and being able to make the switch in order to address all the other problems.
But... GitHub?
I hope I made a compelling case that hosting is not as simple as it can seem, at the scale of the Firefox repository. It's also not Mozilla's main focus. Mozilla has enough on its plate with the migration of existing infrastructure that does rely on Mercurial to understandably not want to figure out the hosting part, especially with limited resources, and with the mixed experience hosting both Mercurial and git has been so far.
After all, GitHub couldn't even display things like the
contributors' graph on gecko-dev until recently, and hosting is literally their job! They still drop the ball on large blames (thankfully we have
searchfox for those).
Where does that leave us?
Gitlab? For those criticizing GitHub for being proprietary, that's probably not open enough.
Cloud Source Repositories? "But GitHub is Microsoft" is a complaint I've read a lot after the announcement. Do you think Google hosting would have appealed to these people?
Bitbucket? I'm kind of surprised it wasn't in the list of providers that were considered, but I'm also kind of glad it wasn't (and I'll leave it at that).
I think the only relatively big hosting provider that could have made the people criticizing the choice of GitHub happy is
Codeberg, but I hadn't even heard of it before it was mentioned in response to Mozilla's announcement. But really, with literal thousands of Mozilla repositories already on GitHub, with literal
tens of millions repositories on the platform overall, the pragmatic in me can't deny that it's an attractive option (and I can't stress enough that I wasn't remotely close to the room where the discussion about what choice to make happened).
"But it's a slippery slope". I can see that being a real concern. LLVM also
moved its repository to GitHub (from a (I think) self-hosted Subversion server), and ended up
moving off Bugzilla and Phabricator to GitHub issues and PRs four years later. As an occasional contributor to LLVM, I hate this move. I hate the GitHub review UI with a passion.
At least, right now, GitHub PRs are not a viable option for Mozilla, for their lack of support for security related PRs, and the more general shortcomings in the review UI. That doesn't mean things won't change in the future, but let's not get too far ahead of ourselves. The move to Git has just been announced, and the migration has not even begun yet. Just because Mozilla is moving the Firefox repository to GitHub doesn't mean it's locked in forever or that all the eggs are going to be thrown into one basket. If bridges need to be crossed in the future, we'll see then.
So, what's next?
The
official announcement said we're not expecting the migration to really begin until six months from now. I'll swim against the current here, and say this: the earlier you can switch to git, the earlier you'll find out what works and what doesn't work for you, whether you already know Git or not.
While there is not one unique workflow, here's what I would recommend anyone who wants to take the leap off Mercurial right now:
-
Make sure git is installed. Chances are you already have it.
-
Install
git-cinnabar where mach bootstrap would install it.
$ mkdir -p ~/.mozbuild/git-cinnabar
$ cd ~/.mozbuild/git-cinnabar
$ curl -sOL https://raw.githubusercontent.com/glandium/git-cinnabar/master/download.py
$ python3 download.py && rm download.py
-
Add
git-cinnabar to your PATH. Make sure to also set that wherever you keep your PATH up-to-date (.bashrc or wherever else).
$ PATH=$PATH:$HOME/.mozbuild/git-cinnabar
-
Enter your mozilla-central or mozilla-unified Mercurial working copy, we'll do an in-place conversion, so that you don't need to move your mozconfigs, objdirs and what not.
-
Initialize the git repository from GitHub.
$ git init
$ git remote add origin https://github.com/mozilla/gecko-dev
$ git remote update origin
-
Switch to a Mercurial remote.
$ git remote set-url origin hg::https://hg.mozilla.org/mozilla-unified
$ git config --local remote.origin.cinnabar-refs bookmarks
$ git remote update origin --prune
-
Fetch your local Mercurial heads.
$ git -c cinnabar.refs=heads fetch hg::$PWD refs/heads/default/*:refs/heads/hg/*
This will create a bunch of hg/<sha1> local branches, not all relevant to you (some come from old branches on mozilla-central). Note that if you're using Mercurial MQ, this will not pull your queues, as they don't exist as heads in the Mercurial repo. You'd need to apply your queues one by one and run the command above for each of them.
Or, if you have bookmarks for your local Mercurial work, you can use this instead:
$ git -c cinnabar.refs=bookmarks fetch hg::$PWD refs/heads/*:refs/heads/hg/*
This will create hg/<bookmark_name> branches.
-
Now, make git know what commit your working tree is on.
$ git reset $(git cinnabar hg2git $(hg log -r . -T ' node '))
This will take a little moment because Git is going to scan all the files in the tree for the first time. On the other hand, it won't touch their content or timestamps, so if you had a build around, it will still be valid, and mach build won't rebuild anything it doesn't have to.
As there is no one-size-fits-all workflow, I won't tell you how to organize yourself from there. I'll just say this: if you know the Mercurial sha1s of your previous local work, you can create branches for them with:
$ git branch <branch_name> $(git cinnabar hg2git <hg_sha1>)
At this point, you should have everything available on the Git side, and you can remove the
.hg directory. Or move it into some empty directory somewhere else, just in case. But don't leave it here, it will only confuse the tooling. Artifact builds WILL be confused, though, and you'll have to
./mach configure before being able to do anything. You may also hit
bug 1865299 if your working tree is older than this post.
If you have any problem or question, you can ping me on
#git-cinnabar or
#git on Matrix. I'll put the instructions above somewhere on wiki.mozilla.org, and we can collaboratively iterate on them.
Now, what the announcement didn't say is that the Git repository WILL NOT be gecko-dev, doesn't exist yet, and WON'T BE COMPATIBLE (trust me, it'll be for the better). Why did I make you do all the above, you ask? Because that won't be a problem. I'll have you covered, I promise. The upcoming release of git-cinnabar 0.7.0-b1 will have a way to smoothly switch between gecko-dev and the future repository (incidentally, that will also allow to switch from a pure git-cinnabar clone to a gecko-dev one, for the git-cinnabar users who have kept reading this far).
What about git-cinnabar?
With Mercurial going the way of the dodo at Mozilla, my own need for git-cinnabar will vanish. Legitimately, this begs the question whether it will still be maintained.
I can't answer for sure. I don't have a crystal ball. However, the needs of the transition itself will motivate me to finish some long-standing things (like finalizing the support for pushing merges, which is currently behind an experimental flag) or implement some missing features (support for creating Mercurial branches).
Git-cinnabar started as a Python script, it grew a sidekick implemented in C, which then incorporated some Rust, which then cannibalized the Python script and took its place. It is now close to 90% Rust, and 10% C (if you don't count the code from Git that is statically linked to it), and has sort of become my Rust playground (it's also, I must admit, a mess, because of its history, but it's getting better). So the day to day use with Mercurial is not my sole motivation to keep developing it. If it were, it would stay stagnant, because all the features I need are there, and the speed is not all that bad, although I know it could be better. Arguably, though, git-cinnabar has been relatively stagnant feature-wise, because all the features I need are there.
So, no, I don't expect git-cinnabar to die along Mercurial use at Mozilla, but I can't really promise anything either.
Final words
That was a long post. But there was a lot of ground to cover. And I still skipped over a bunch of things. I hope I didn't bore you to death. If I did and you're still reading... what's wrong with you? ;)
So this is the end of Mercurial at Mozilla.
So long, and thanks for all the fish. But this is also the beginning of a transition that is not easy, and that will not be without hiccups, I'm sure. So fasten your seatbelts (plural), and welcome the change.
To circle back to the clickbait title, did I really kill Mercurial at Mozilla? Of course not. But it's like I stumbled upon a few sparks and tossed a can of gasoline on them. I didn't start the fire, but I sure made it into a proper bonfire... and now it has turned into a wildfire.
And who knows? 15 years from now, someone else might be looking back at how Mozilla picked Git at the wrong time, and that, had we waited a little longer, we would have picked some yet to come new horse. But hey, that's the tech cycle for you.
 Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they ve kicked me off Go Roam, so I ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don t expect to use all of the data allowance, but I didn t want to have to worry about unexpected excess charges.
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
Having setup recursive DNS it was time to actually sort out a backup internet connection. I live in a Virgin Media area, but I still haven t forgiven them for my terrible Virgin experiences when moving here. Plus it involves a bigger contractual commitment. There are no altnets locally (though I m watching youfibre who have already rolled out in a few Belfast exchanges), so I decided to go for a 5G modem. That gives some flexibility, and is a bit easier to get up and running.
I started by purchasing a ZTE MC7010. This had the advantage of being reasonably cheap off eBay, not having any wifi functionality I would just have to disable (it s going to plug it into the same router the FTTP connection terminates on), being outdoor mountable should I decide to go that way, and, finally, being powered via PoE.
For now this device sits on the window sill in my study, which is at the top of the house. I printed a table stand for it which mostly does the job (though not as well with a normal, rather than flat, network cable). The router lives downstairs, so I ve extended a dedicated VLAN through the study switch, down to the core switch and out to the router. The PoE study switch can only do GigE, not 2.5Gb/s, but at present that s far from the limiting factor on the speed of the connection.
The device is 3 branded, and, as it happens, I ve ended up with a 3 SIM in it. Up until recently my personal phone was with them, but they ve kicked me off Go Roam, so I ve moved. Going with 3 for the backup connection provides some slight extra measure of resiliency; we now have devices on all 4 major UK networks in the house. The SIM is a preloaded data only SIM good for a year; I don t expect to use all of the data allowance, but I didn t want to have to worry about unexpected excess charges.
Performance turns out to be disappointing; I end up locking the device to 4G as the 5G signal is marginal - leaving it enabled results in constantly switching between 4G + 5G and a significant extra latency. The smokeping graph below shows a brief period where I removed the 4G lock and allowed 5G:
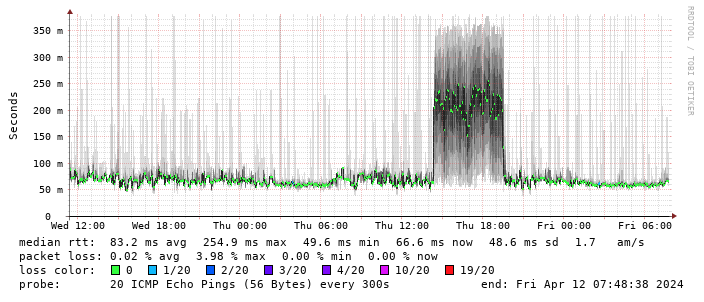 (There s a handy zte.js script to allow doing this from the device web interface.)
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
(There s a handy zte.js script to allow doing this from the device web interface.)
I get about 10Mb/s sustained downloads out of it. EE/Vodafone did not lead to significantly better results, so for now I m accepting it is what it is. I tried relocating the device to another part of the house (a little tricky while still providing switch-based PoE, but I have an injector), without much improvement. Equally pinning the 4G to certain bands provided a short term improvement (I got up to 40-50Mb/s sustained), but not reliably so.
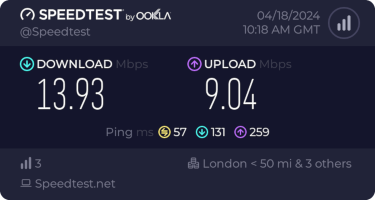 This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
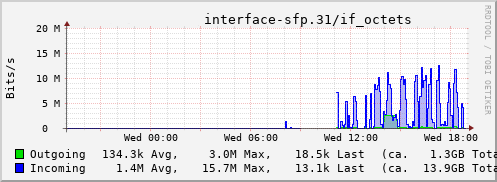 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
 Happy to share that
Happy to share that 
 And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
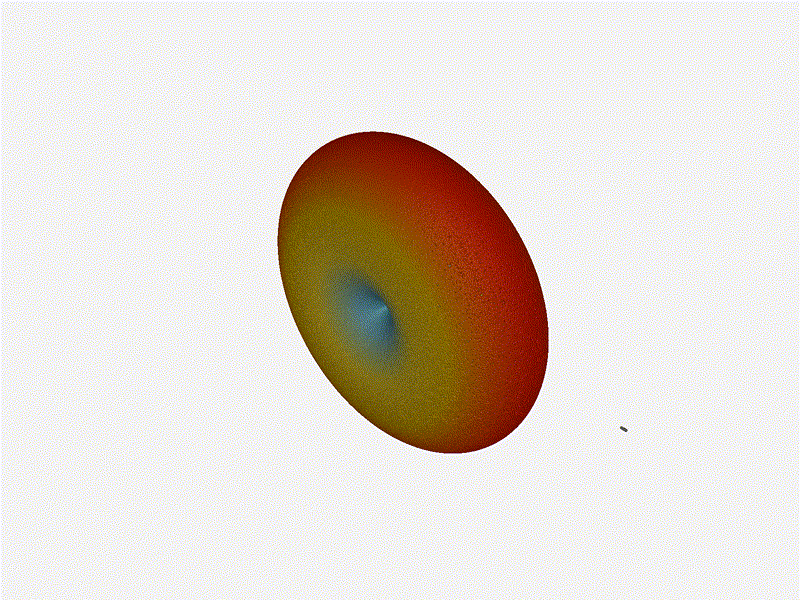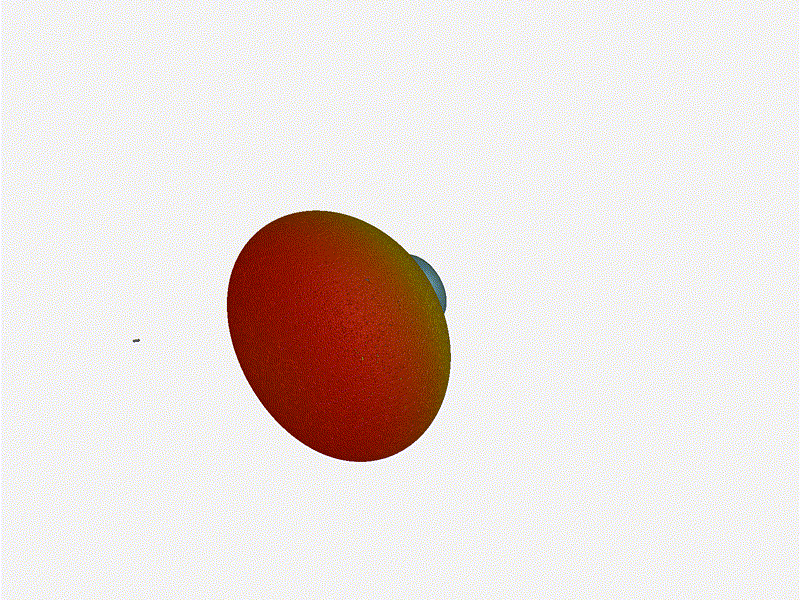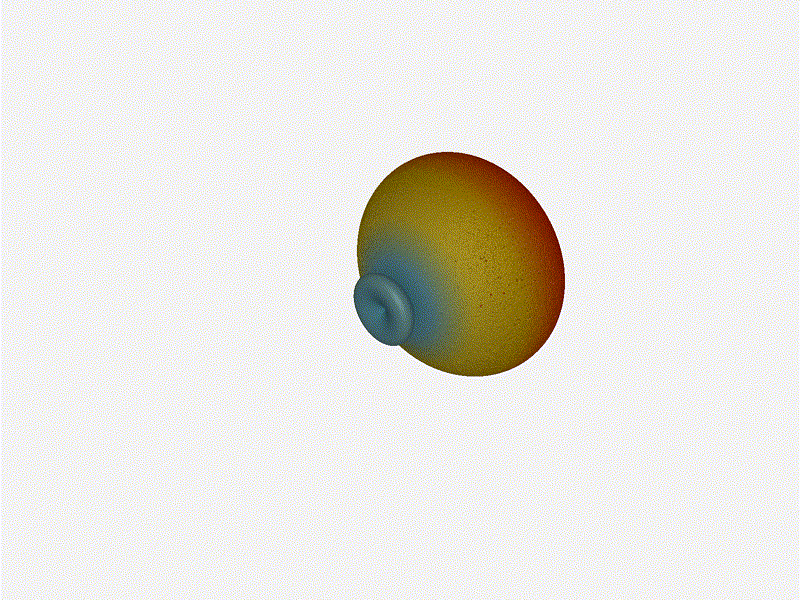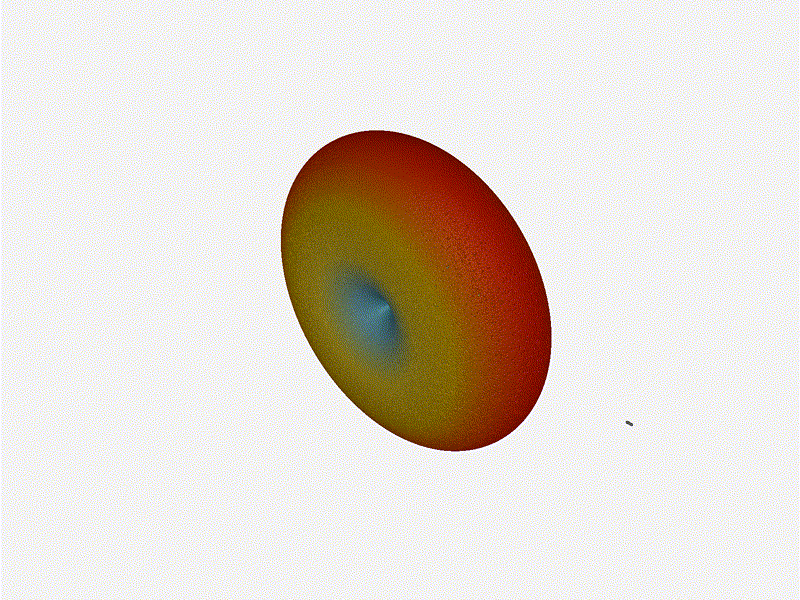
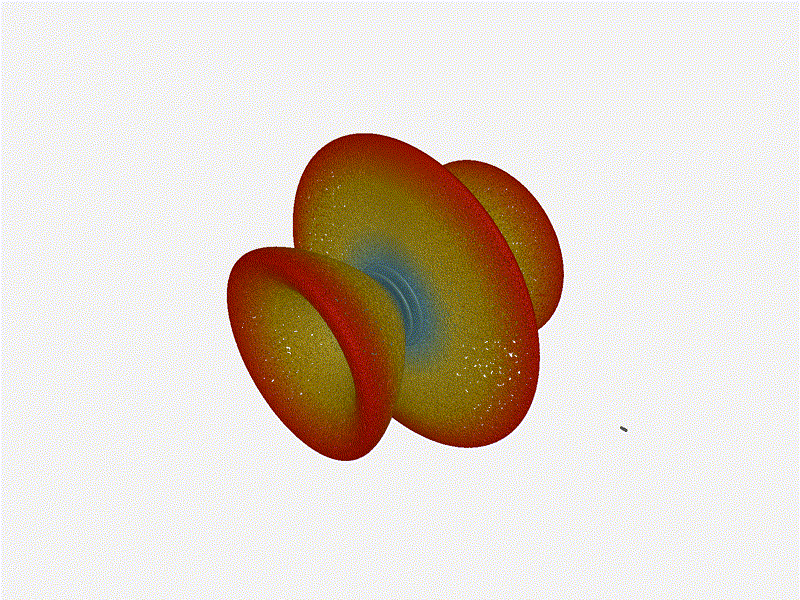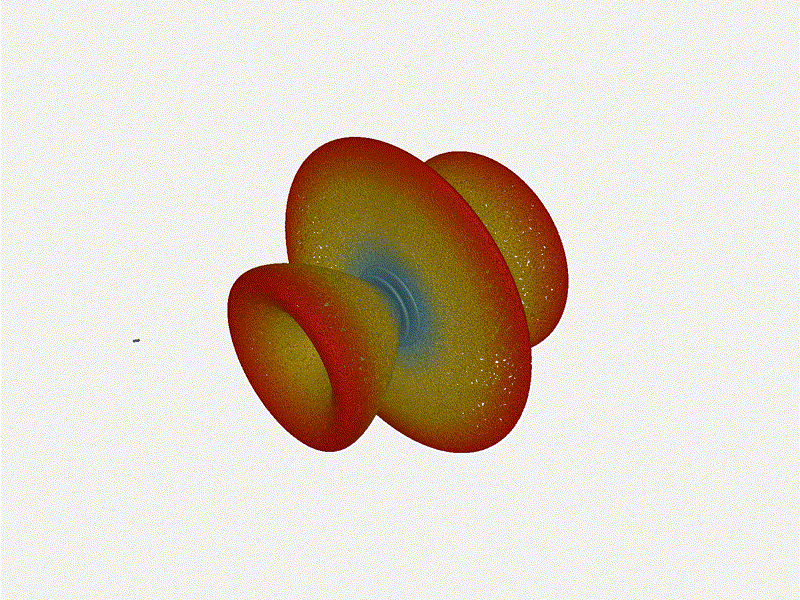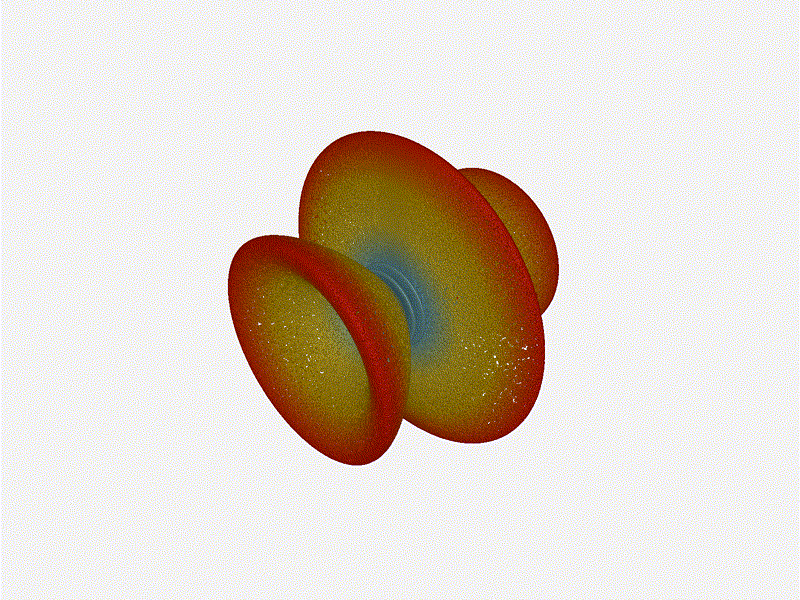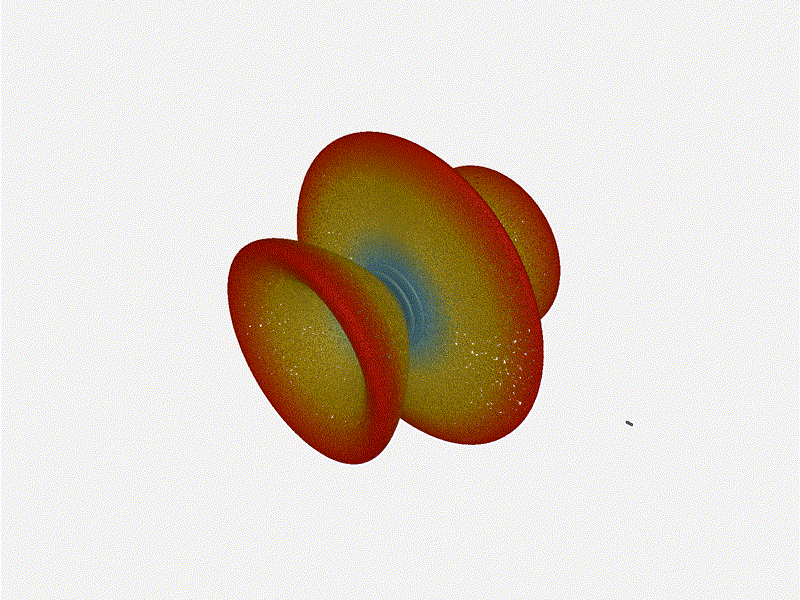

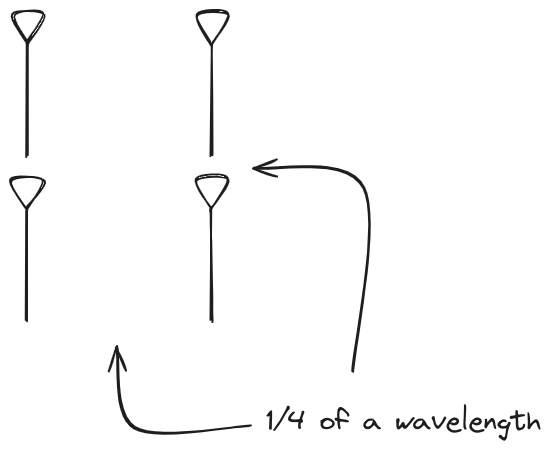 Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
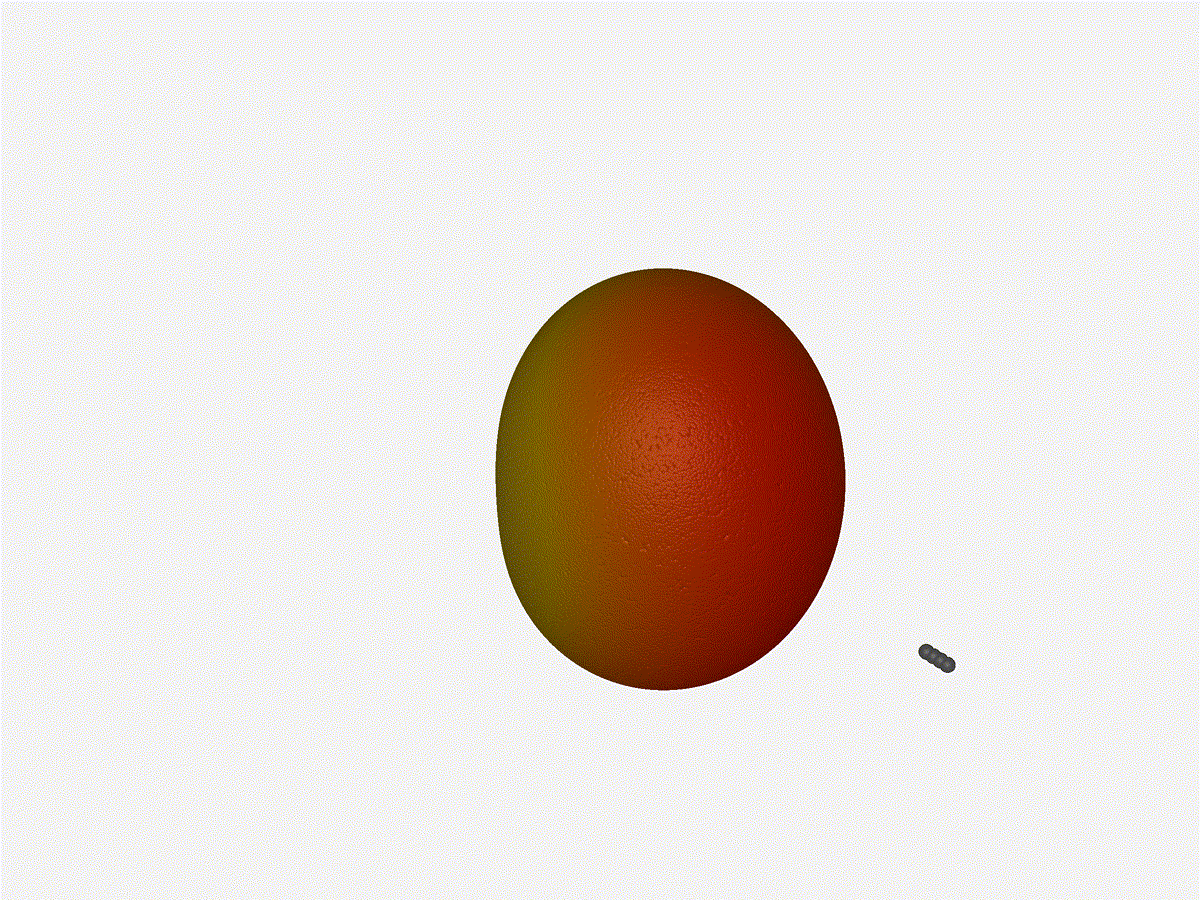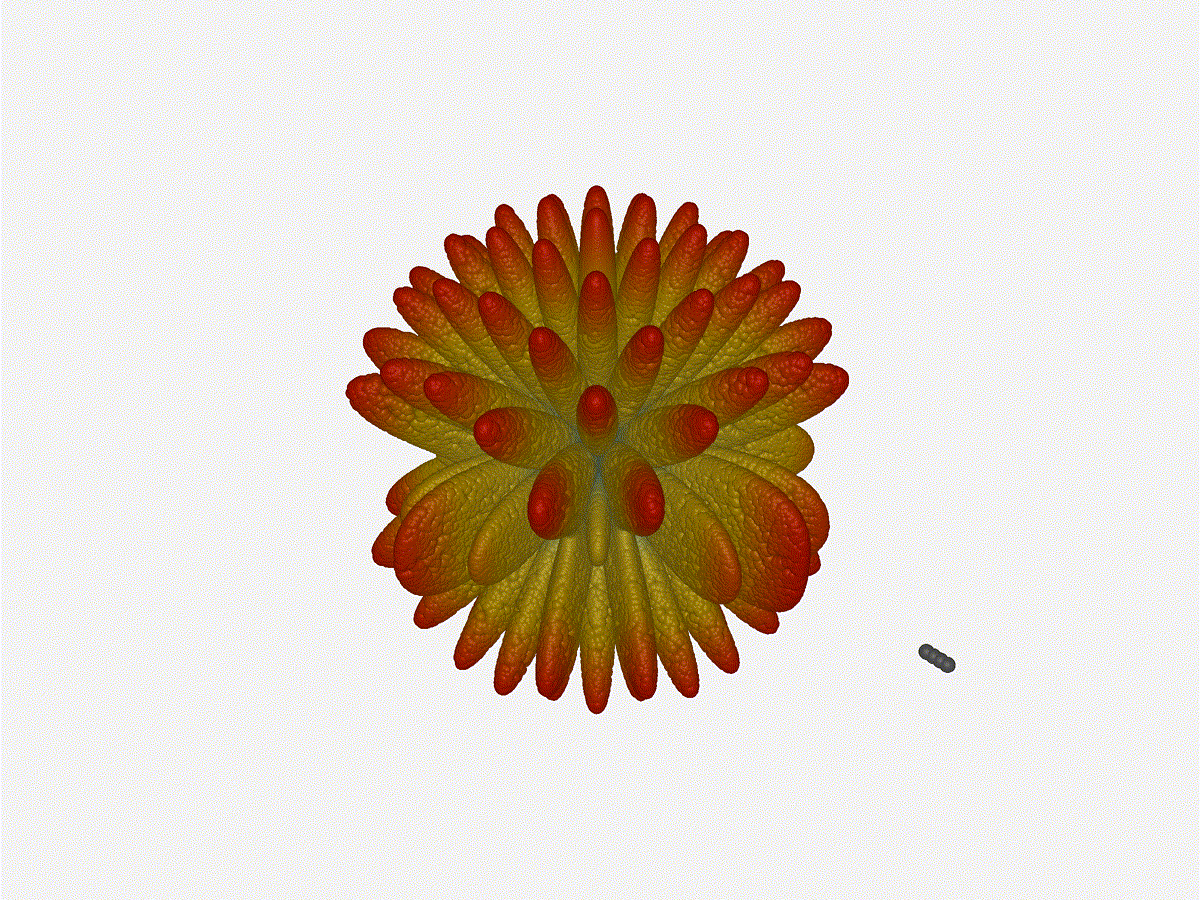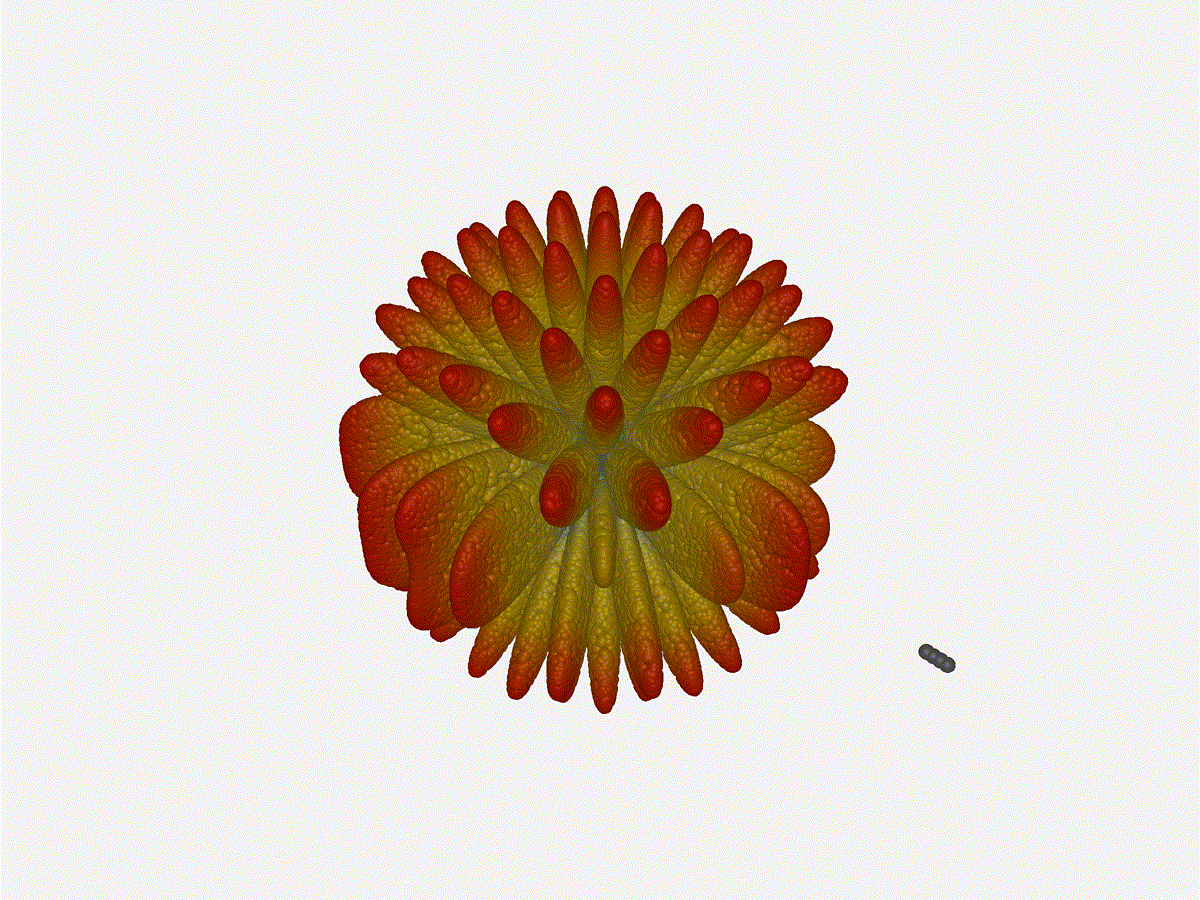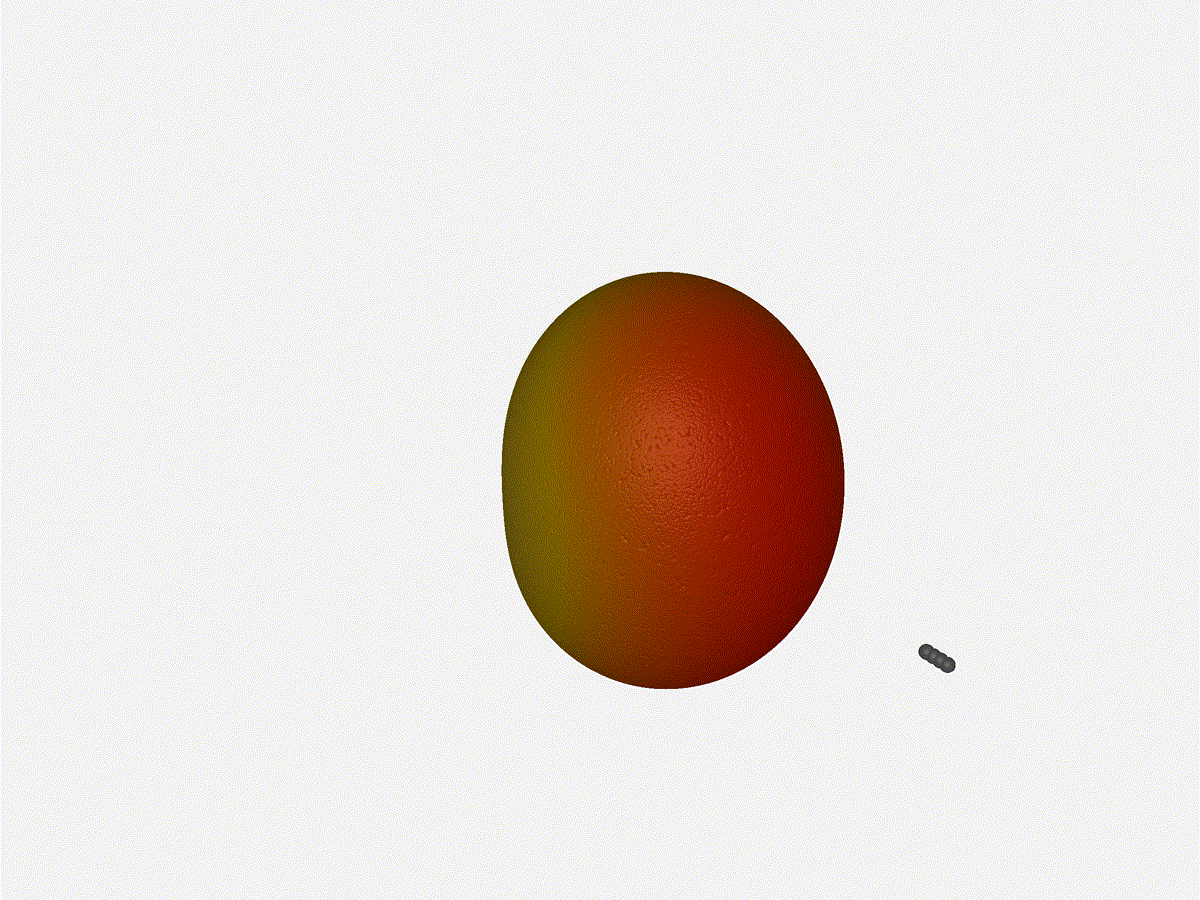













 As is traditional for the UK August Bank Holiday weekend I made my way to Cambridge for the Debian UK BBQ. As was pointed out we ve been doing this for more than 20 years now, and it s always good to catch up with old friends and meet new folk.
Thanks to
As is traditional for the UK August Bank Holiday weekend I made my way to Cambridge for the Debian UK BBQ. As was pointed out we ve been doing this for more than 20 years now, and it s always good to catch up with old friends and meet new folk.
Thanks to  It's August Bank Holiday Weekend, we're in Cambridge. It must be
the Debian
UK
It's August Bank Holiday Weekend, we're in Cambridge. It must be
the Debian
UK  Back in June 2018,
Back in June 2018,  So This is basically a call for adoption for the Raspberry Debian images
building service. I do intend to stick around and try to help. It s not only me
(although I m responsible for the build itself) we have a nice and healthy
group of Debian people hanging out in the
So This is basically a call for adoption for the Raspberry Debian images
building service. I do intend to stick around and try to help. It s not only me
(although I m responsible for the build itself) we have a nice and healthy
group of Debian people hanging out in the