
Dear Debianites
This morning I decided to just start writing Bits from DPL and send
whatever I have by 18:00 local time. Here it is, barely proof read,
along with all it's warts and grammar mistakes! It's slightly long and
doesn't contain any critical information, so if you're not in the mood,
don't feel compelled to read it!
Get ready for a new DPL!
Soon, the voting period will start to elect our next DPL, and my time
as DPL will come to an end. Reading the questions posted to the new
candidates on
debian-vote, it takes quite a bit of restraint to not
answer all of them myself, I think I can see how that aspect contributed
to me being reeled in to running for DPL! In total I've done so 5 times
(the first time I ran, Sam was elected!).
Good luck to both
Andreas and
Sruthi, our current
DPL candidates! I've already started working on preparing handover, and
there's multiple request from teams that have came in recently that will
have to wait for the new term, so I hope they're both ready to hit the
ground running!
Things that I wish could have gone better
Communication
Recently, I saw a t-shirt that read:
Adulthood is saying, 'But after this week things will slow down a bit'
over and over until you die.
I can relate! With every task, crisis or deadline that appears, I think
that once this is over, I'll have some more breathing space to get back
to non-urgent, but important tasks. "Bits from the DPL" was something I
really wanted to get right this last term, and clearly failed
spectacularly. I have two long Bits from the DPL drafts that I never
finished, I tend to have prioritised problems of the day over
communication. With all the hindsight I have, I'm not sure which is
better to prioritise, I do rate communication and transparency very
highly and this is really the top thing that I wish I could've done
better over the last four years.
On that note, thanks to people who provided me with some kind words
when I've mentioned this to them before. They pointed out that there
are many other ways to communicate and be in touch with the community,
and they mentioned that they thought that I did a good job with that.
Since I'm still on communication, I think we can all learn to be more
effective at it, since it's really so important for the project. Every
time I publicly spoke about us spending more money, we got more
donations. People out there really like to see how we invest funds in
to Debian, instead of just making it heap up. DSA just spent a nice
chunk on money on hardware, but we don't have very good visibility on
it. It's one thing having it on a public line item in SPI's reporting,
but it would be much more exciting if DSA could provide a write-up on
all the cool hardware they're buying and what impact it would have on
developers, and post it somewhere prominent like debian-devel-announce,
Planet Debian or Bits from Debian (from the publicity team).
I don't want to single out DSA there, it's difficult and affects many
other teams. The Salsa CI team also spent a lot of resources (time and
money wise) to extend testing on AMD GPUs and other AMD hardware. It's
fantastic and interesting work, and really more people within the
project and in the outside world should know about it!
I'm not going to push my agendas to the next DPL, but I hope that they
continue to encourage people to write about their work, and hopefully
at some point we'll build enough excitement in doing so that it becomes
a more normal part of our daily work.
Founding Debian as a standalone entity
This was my number one goal for the project this last term, which was a
carried over item from my previous terms.
I'm tempted to write everything out here, including the problem
statement and our current predicaments, what kind of ground work needs
to happen, likely constitutional changes that need to happen, and the
nature of the GR that would be needed to make such a thing happen, but
if I start with that, I might not finish this mail.
In short, I 100% believe that this is still a very high ranking issue
for Debian, and perhaps after my term I'd be in a better position to
spend more time on this (hmm, is this an instance of "The grass is
always better on the other side", or "Next week will go better until I
die?"). Anyway, I'm willing to work with any future DPL on this, and
perhaps it can in itself be a delegation tasked to properly explore
all the options, and write up a report for the project that can lead to
a GR.
Overall, I'd rather have us take another few years and do this
properly, rather than rush into something that is again difficult to
change afterwards. So while I very much wish this could've been
achieved in the last term, I can't say that I have any regrets here
either.
My terms in a nutshell
COVID-19 and Debian 11 era
My first term in 2020 started just as the COVID-19 pandemic became
known to spread globally. It was a tough year for everyone, and Debian
wasn't immune against its effects either. Many of our contributors got
sick, some have lost loved ones (my father passed away in March 2020
just after I became DPL), some have lost their jobs (or other earners
in their household have) and the effects of social distancing took a
mental and even physical health toll on many. In Debian, we tend to do
really well when we get together in person to solve problems, and when
DebConf20 got cancelled in person, we understood that that was
necessary, but it was still more bad news in a year we had too much of
it already.
I can't remember if there was ever any kind of formal choice or
discussion about this at any time, but the DebConf video team just kind
of organically and spontaneously became the orga team for an online
DebConf, and that lead to our first ever completely online DebConf. This
was great on so many levels. We got to see each other's faces again,
even though it was on screen. We had some teams talk to each other face
to face for the first time in years, even though it was just on a Jitsi
call. It had a lasting cultural change in Debian, some teams still have
video meetings now, where they didn't do that before, and I think it's a
good supplement to our other methods of communication.
We also had a few online Mini-DebConfs that was fun, but DebConf21 was
also online, and by then we all developed an online conference fatigue,
and while it was another good online event overall, it did start to
feel a bit like a zombieconf and after that, we had some really nice
events from the Brazillians, but no big global online community events
again. In my opinion online MiniDebConfs can be a great way to develop
our community and we should spend some further energy into this, but
hey! This isn't a platform so let me back out of talking about the
future as I see it...
Despite all the adversity that we faced together, the Debian 11 release
ended up being quite good. It happened about a month or so later than
what we ideally would've liked, but it was a solid release nonetheless.
It turns out that for quite a few people, staying inside for a few
months to focus on Debian bugs was quite productive, and Debian 11 ended
up being a very polished release.
During this time period we also had to deal with a previous Debian
Developer that was expelled for his poor behaviour in Debian, who
continued to harass members of the Debian project and in other free
software communities after his expulsion. This ended up being quite a
lot of work since we had to take legal action to protect our community,
and eventually also get the police involved. I'm not going to give him
the satisfaction by spending too much time talking about him, but you
can read our official statement regarding Daniel Pocock here:
https://www.debian.org/News/2021/20211117
In late 2021 and early 2022 we also discussed our general resolution
process, and had two consequent votes to address some issues that have
affected past votes:
In my first term I addressed our delegations that were a bit behind, by
the end of my last term all delegation requests are up to date. There's
still some work to do, but I'm feeling good that I get to hand this
over to the next DPL in a very decent state. Delegation updates can be
very deceiving, sometimes a delegation is completely re-written and it
was just 1 or 2 hours of work. Other times, a delegation updated can
contain one line that has changed or a change in one team member that
was the result of days worth of discussion and hashing out differences.
I also received quite a few requests either to host a service, or to
pay a third-party directly for hosting. This was quite an admin
nightmare, it either meant we had to manually do monthly reimbursements
to someone, or have our TOs create accounts/agreements at the multiple
providers that people use. So, after talking to a few people about
this, we founded the DebianNet team (we could've admittedly chosen a
better name, but that can happen later on) for providing hosting at two
different hosting providers that we have agreement with so that people
who host things under debian.net have an easy way to host it, and then
at the same time Debian also has more control if a site maintainer goes
MIA.
More info:
https://wiki.debian.org/Teams/DebianNet
You might notice some Openstack mentioned there, we had some intention
to set up a Debian cloud for hosting these things, that could also be
used for other additional Debiany things like archive rebuilds, but
these have so far fallen through. We still consider it a good idea and
hopefully it will work out some other time (if you're a large company
who can sponsor few racks and servers, please get in touch!)
DebConf22 and Debian 12 era
DebConf22 was the first time we returned to an in-person DebConf. It
was a bit smaller than our usual DebConf - understandably so,
considering that there were still COVID risks and people who were at
high risk or who had family with high risk factors did the sensible
thing and stayed home.
After watching many MiniDebConfs online, I also attended my first ever
MiniDebConf in Hamburg. It still feels odd typing that, it feels like I
should've been at one before, but my location makes attending them
difficult (on a side-note, a few of us are working on bootstrapping a
South African Debian community and hopefully we can pull off
MiniDebConf in South Africa later this year).
While I was at the MiniDebConf, I gave a talk where I covered the
evolution of firmware, from the simple e-proms that you'd find in old
printers to the complicated firmware in modern GPUs that basically
contain complete operating systems- complete with drivers for the
device their running on. I also showed my shiny new laptop, and
explained that it's impossible to install that laptop without non-free
firmware (you'd get a black display on d-i or Debian live). Also that
you couldn't even use an accessibility mode with audio since even that
depends on non-free firmware these days.
Steve, from the image building team, has said for a while that we need
to do a GR to vote for this, and after more discussion at DebConf, I
kept nudging him to propose the GR, and we ended up voting in favour of
it. I do believe that someone out there should be campaigning for more
free firmware (unfortunately in Debian we just don't have the resources
for this), but, I'm glad that we have the firmware included. In the
end, the choice comes down to whether we still want Debian to be
installable on mainstream bare-metal hardware.
At this point, I'd like to give a special thanks to the ftpmasters,
image building team and the installer team who worked really hard to
get the changes done that were needed in order to make this happen for
Debian 12, and for being really proactive for remaining niggles that
was solved by the time Debian 12.1 was released.
The included firmware contributed to Debian 12 being a huge success,
but it wasn't the only factor. I had a list of personal peeves, and as
the hard freeze hit, I lost hope that these would be fixed and made
peace with the fact that Debian 12 would release with those bugs. I'm
glad that lots of people proved me wrong and also proved that it's
never to late to fix bugs, everything on my list got eliminated by the
time final freeze hit, which was great! We usually aim to have a
release ready about 2 years after the previous release, sometimes there
are complications during a freeze and it can take a bit longer. But due
to the excellent co-ordination of the release team and heavy lifting
from many DDs, the Debian 12 release happened 21 months and 3 weeks
after the Debian 11 release. I hope the work from the release team
continues to pay off so that we can achieve their goals of having
shorter and less painful freezes in the future!
Even though many things were going well, the ongoing usr-merge effort
highlighted some social problems within our processes. I started typing
out the whole history of usrmerge here, but it's going to be too long
for the purpose of this mail. Important questions that did come out of
this is, should core Debian packages be team maintained? And also about
how far the CTTE should really be able to override a maintainer. We had
lots of discussion about this at DebConf22, but didn't make much
concrete progress. I think that at some point we'll probably have a GR
about package maintenance. Also, thank you to Guillem who very
patiently explained a few things to me (after probably having have to
done so many times to others before already) and to Helmut who have
done the same during the MiniDebConf in Hamburg. I think all the
technical and social issues here are fixable, it will just take some
time and patience and I have lots of confidence in everyone involved.
UsrMerge wiki page:
https://wiki.debian.org/UsrMerge
DebConf 23 and Debian 13 era
DebConf23 took place in Kochi, India. At the end of my Bits from the
DPL talk there, someone asked me what the most difficult thing I had to
do was during my terms as DPL. I answered that nothing particular stood
out, and even the most difficult tasks ended up being rewarding to work
on. Little did I know that my most difficult period of being DPL was
just about to follow. During the day trip, one of our contributors,
Abraham Raji, passed away in a tragic accident. There's really not
anything anyone could've done to predict or stop it, but it was
devastating to many of us, especially the people closest to him. Quite
a number of DebConf attendees went to his funeral, wearing the DebConf
t-shirts he designed as a tribute. It still haunts me when I saw his
mother scream "He was my everything! He was my everything!", this was
by a large margin the hardest day I've ever had in Debian, and I really
wasn't ok for even a few weeks after that and I think the hurt will be
with many of us for some time to come. So, a plea again to everyone,
please take care of yourself! There's probably more people that love
you than you realise.
A special thanks to the DebConf23 team, who did a really good job
despite all the uphills they faced (and there were many!).
As DPL, I think that planning for a DebConf is near to impossible, all
you can do is show up and just jump into things. I planned to work with
Enrico to finish up something that will hopefully save future DPLs some
time, and that is a web-based DD certificate creator instead of having
the DPL do so manually using LaTeX. It already mostly works, you can
see the work so far by visiting
https://nm.debian.org/person/ACCOUNTNAME/certificate/ and replacing
ACCOUNTNAME with your Debian account name, and if you're a DD, you
should see your certificate. It still needs a few minor changes and a
DPL signature, but at this point I think that will be finished up when
the new DPL start. Thanks to Enrico for working on this!
Since my first term, I've been trying to find ways to improve all our
accounting/finance issues. Tracking what we spend on things, and
getting an annual overview is hard, especially over 3 trusted
organisations. The reimbursement process can also be really tedious,
especially when you have to provide files in a certain order and
combine them into a PDF. So, at DebConf22 we had a meeting along with
the treasurer team and Stefano Rivera who said that it might be
possible for him to work on a new system as part of his Freexian work.
It worked out, and Freexian funded the development of the system since
then, and after DebConf23 we handled the reimbursements for the
conference via the new reimbursements site:
https://reimbursements.debian.net/
It's still early days, but over time it should be linked to all our TOs
and we'll use the same category codes across the board. So, overall,
our reimbursement process becomes a lot simpler, and also we'll be able
to get information like how much money we've spent on any category in
any period. It will also help us to track how much money we have
available or how much we spend on recurring costs. Right now that needs
manual polling from our TOs. So I'm really glad that this is a big
long-standing problem in the project that is being fixed.
For Debian 13, we're waving goodbye to the KFreeBSD and mipsel ports.
But we're also gaining riscv64 and loongarch64 as release
architectures! I have 3 different RISC-V based machines on my desk here
that I haven't had much time to work with yet, you can expect some blog
posts about them soon after my DPL term ends!
As Debian is a unix-like system, we're affected by the
Year 2038 problem, where systems that uses 32 bit time in seconds
since 1970 run out of available time and will wrap back to 1970 or have
other undefined behaviour. A detailed
wiki page explains how this
works in Debian, and currently we're going through a rather large
transition to make this possible.
I believe this is the right time for Debian to be addressing this,
we're still a bit more than a year away for the Debian 13 release, and
this provides enough time to test the implementation before 2038 rolls
along.
Of course, big complicated transitions with dependency loops that
causes chaos for everyone would still be too easy, so this past weekend
(which is a holiday period in most of the west due to Easter weekend)
has been filled with dealing with an upstream bug in xz-utils, where a
backdoor was placed in this key piece of software. An
Ars Technica
covers it quite well, so I won't go into all the details here. I
mention it because I want to give yet another special thanks to
everyone involved in dealing with this on the Debian side. Everyone
involved, from the ftpmasters to security team and others involved were
super calm and professional and made quick, high quality decisions.
This also lead to the archive being frozen on Saturday, this is the
first time I've seen this happen since I've been a DD, but I'm sure
next week will go better!
Looking forward
It's really been an honour for me to serve as DPL. It might well be my
biggest achievement in my life. Previous DPLs range from prominent
software engineers to game developers, or people who have done things
like complete Iron Man, run other huge open source projects and are
part of big consortiums. Ian Jackson even authored dpkg and is now
working on the very interesting
tag2upload service!
I'm a relative nobody, just someone who grew up as a poor kid in South
Africa, who just really cares about Debian a lot. And, above all, I'm
really thankful that I didn't do anything major to screw up Debian for
good.
Not unlike learning how to use Debian, and also becoming a Debian
Developer, I've learned a lot from this and it's been a really valuable
growth experience for me.
I know I can't possible give all the thanks to everyone who deserves
it, so here's a big big thanks to everyone who have worked so hard and
who have put in many, many hours to making Debian better, I consider
you all heroes!
-Jonathan
 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to












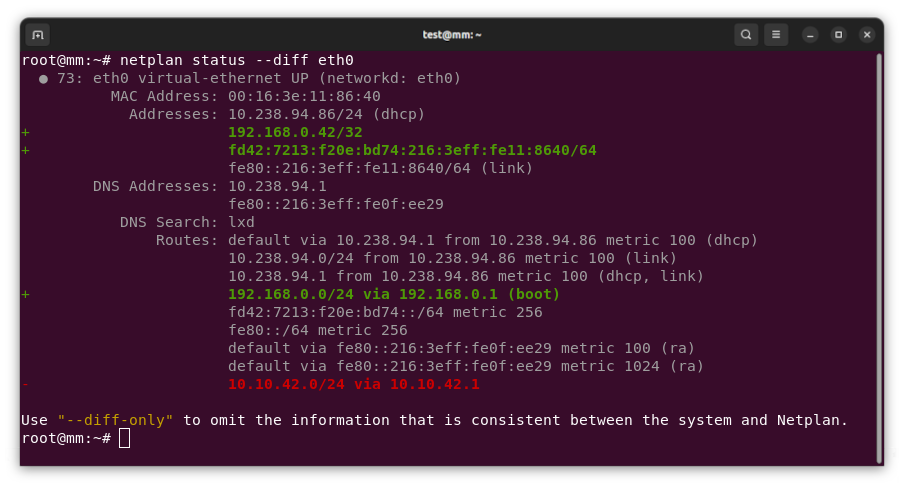
 Debian is running a "
Debian is running a "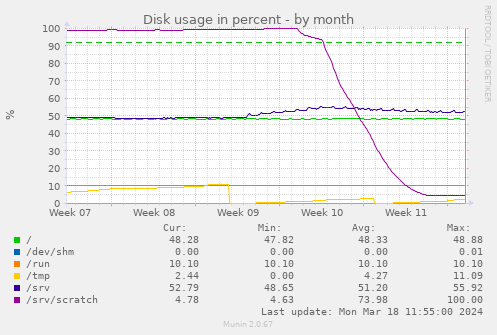 The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
The initial dip from 100% to 95% is my first "what happens if we block repos
> 500 MB" attempt. Over the week after that, the git filter clones reduce the
overall disk consumption from almost 300 GB to 15 GB, a 1/20. Some
repos shrank from GBs to below a MB.
Perhaps I should make all my git clones use one of the filters.
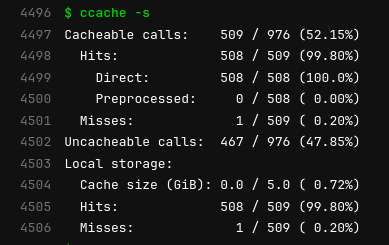 The image here comes from an example of building
The image here comes from an example of building 














 The talks held in the room were these below, and in each of them you can watch the recording video.
The talks held in the room were these below, and in each of them you can watch the recording video.




 As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.
As there has been an increase in the number of proposals received, I believe that interest in the translations devroom is growing. So I intend to send the devroom proposal to FOSDEM 2025, and if it is accepted, wait for the future Debian Leader to approve helping me with the flight tickets again. We ll see.

 While we couldn t go with 6 on our upcoming LTS release, I do recommend
While we couldn t go with 6 on our upcoming LTS release, I do recommend  Witch Wells AZ Sunset
Witch Wells AZ Sunset