
All but about four hours of my Debian contributions this month were
sponsored by
Freexian. (I ended up going a bit over my 20% billing limit this month.)
You can also support my work directly via
Liberapay.
man-db and friends
I released
libpipeline
1.5.8 and
man-db 2.13.0.
Since autopkgtests are great for making sure we spot regressions caused by
changes in dependencies, I added one to man-db that runs the upstream tests
against the installed package. This required some preparatory work
upstream, but otherwise was surprisingly easy to do.
OpenSSH
I fixed the various 9.8 regressions I mentioned
last
month: socket activation, libssh2, and
Twisted. There were a few other regressions reported too:
TCP wrappers
support,
openssh-server-udeb,
and
xinetd were all broken by changes
related to the listener/per-session binary split, and I fixed all of those.
Once all that had made it through to testing, I finally uploaded the first
stage of my
plan to split out GSS-API
support: there
are now
openssh-client-gssapi and
openssh-server-gssapi packages in
unstable, and if you use either
GSS-
API authentication or key exchange then
you should install the corresponding package in order for upgrades to
trixie+1 to work correctly. I ll write a release note once this has reached testing.
Multiple identical results from getaddrinfo
I expect this is really a bug in a chroot creation script somewhere, but I
haven t been able to track down what s causing it yet. My sbuild chroots,
and apparently Lucas Nussbaum s as well, have an
/etc/hosts that looks
like this:
$ cat /var/lib/schroot/chroots/sid-amd64/etc/hosts
127.0.0.1 localhost
127.0.1.1 [...]
127.0.0.1 localhost ip6-localhost ip6-loopback
The last line clearly ought to be
::1 rather than
127.0.0.1; but things
mostly work anyway, since most code doesn t really care which protocol it
uses to talk to localhost. However, a few things try to set up test
listeners by calling
getaddrinfo("localhost", ...) and binding a socket
for each result. This goes wrong if there are duplicates in the resulting
list, and the test output is typically very confusing: it looks just like
what you d see if a test isn t tearing down its resources correctly, which
is a much more common thing for a test suite to get wrong, so it took me a
while to spot the problem.
I ran into this in both python-asyncssh
(
#1052788,
upstream
PR) and Ruby
(
ruby3.1/#1069399,
ruby3.2/#1064685,
ruby3.3/#1077462,
upstream
PR). The latter took a while
since Ruby isn t one of my languages, but hey, I ve tackled
much harder
side quests. I
NMUed ruby3.1 for this since it was showing up as a blocker for openssl
testing migration, but haven t done the other active versions (yet, anyway).
OpenSSL vs. cryptography
I tend to care about openssl migrating to testing promptly, since openssh
uploads have a habit of getting stuck on it otherwise.
Debian s OpenSSL packaging recently split out some legacy code (cryptography
that s no longer considered a good idea to use, but that s sometimes needed
for compatibility) to an
openssl-legacy-provider package, and added a
Recommends on it. Most users install Recommends, but package build
processes don t; and the Python
cryptography package requires this code
unless you set the
CRYPTOGRAPHY_OPENSSL_NO_LEGACY=1 environment variable,
which caused a bunch of packages that build-depend on it to fail to build.
After playing whack-a-mole setting that environment variable in a few
packages build process, I decided I didn t want to be caught in the middle
here and filed an
upstream
issue to see if I could
get Debian s OpenSSL team and cryptography s upstream talking to each other
directly. There was some moderately spirited discussion and the issue
remains open, but for the time being the OpenSSL team has
effectively
reverted the
change
so it s no longer a pressing problem.
GCC 14 regressions
Continuing from
last month, I fixed build
failures in
pccts (
NMU) and
trn4.
Python team
I upgraded alembic, automat, gunicorn, incremental, referencing, pympler
(fixing
compatibility with Python >=
3.10), python-aiohttp, python-asyncssh
(fixing
CVE-2023-46445,
CVE-2023-46446, and
CVE-2023-48795), python-avro,
python-multidict (fixing a
build failure with GCC
14), python-tokenize-rt, python-zipp,
pyupgrade, twisted (fixing
CVE-2024-41671
and
CVE-2024-41810), zope.exceptions,
zope.interface, zope.proxy, zope.security, and zope.testrunner to new
upstream versions. In the process, I added myself to
Uploaders for
zope.interface; I m reasonably comfortable with the Zope Toolkit and I seem
to be gradually picking up much of its maintenance in Debian.
A few of these required their own bits of yak-shaving:
I improved some
Multi-Arch: foreign tagging
(
python-importlib-metadata,
python-typing-extensions,
python-zipp).
I fixed build failures in
pipenv,
python-stdlib-list,
psycopg3, and
sen, and fixed autopkgtest failures in
autoimport
(
upstream PR),
python-semantic-release
and
rstcheck.
Upstream for zope.file (not in Debian) filed an issue about a
test failure
with Python 3.12,
which I tracked down to a
Python 3.12 compatibility
PR in zope.security.
I made python-nacl build reproducibly (
upstream
PR).
I moved aliased files from
/ to
/usr in timekpr-next
(
#1073722).
Installer team
I applied a patch from Ubuntu to make os-prober support building with the
noudeb profile (
#983325).
 Another short status update of what happened on my side last
month. One larger blocks are the Phosh 0.45 release, also reviews
took a considerable amount of time. From the fun side debugging bananui and coming up with a fix in
phoc as well as setting up a small GSM network using osmocom to test more Cell Broadcast thingies were likely the most fun parts.
phosh
Another short status update of what happened on my side last
month. One larger blocks are the Phosh 0.45 release, also reviews
took a considerable amount of time. From the fun side debugging bananui and coming up with a fix in
phoc as well as setting up a small GSM network using osmocom to test more Cell Broadcast thingies were likely the most fun parts.
phosh























 The theme
The theme 





 A new release of the
A new release of the 









 Kudos to everybody involved!
Kudos to everybody involved! 
 I am using
I am using 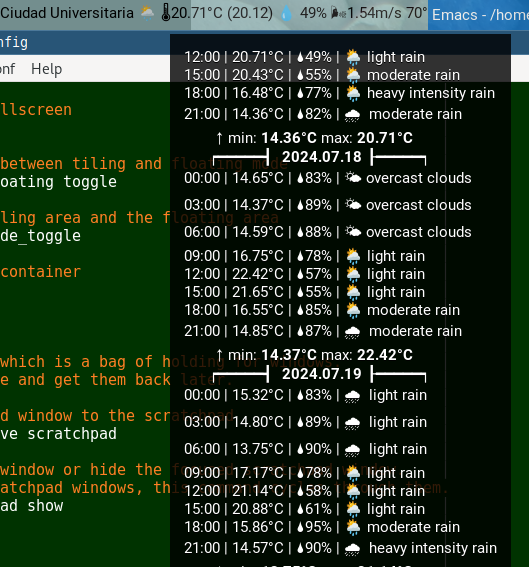 Do note that it seems OpenWeather will return the name of the closest available
meteorology station with (most?) recent data for my home, I often get Ciudad
Universitaria, but sometimes Coyoac n or even San ngel Inn.
Do note that it seems OpenWeather will return the name of the closest available
meteorology station with (most?) recent data for my home, I often get Ciudad
Universitaria, but sometimes Coyoac n or even San ngel Inn.











