Hello everyone! I am very excited to report about the awesome progress we made with Tanglu, the new Debian-based Linux-Distribution.

First of all, some off-topic info: I don t feel comfortable with posting too much Tanglu stuff to Planet-KDE, as this is often not KDE-related. So, in future Planet-KDE won t get Tanglu information, unless it is KDE-related

You might want to take a look at
Planet-Tanglu for (much) more information.
So, what happened during the last weeks? Because I haven t had lectures, I nearly worked full-time on Tanglu, setting up most of the infrastructure we need. (this will change with the next week, where I have lectures again, and I also have work to do on other projects, not just Tanglu ^^) Also, we already have an awesome community of translators, designers and developers. Thanks to them, the
Tanglu-Website is now translated to 6 languages, more are in the pipeline and will be merged later. Also, a new website based on the Django framework is in progress.
The Logo-Contest
We ve run a logo-contest, to find a new and official Tanglu logo, as the previous logo draft was too close to the Debian logo (I asked the trademark people at Debian). More than 30 valid votes (you had to be subscribed to a Tanglu Mailinglist) were received for 7 logo proposals, and we now have a final logo:

I like it very much
Fun with dak
I decided to use dak, the Debian Archive Kit, to handle the Tanglu archive. Choosing dak over smaller and easy-to-use solutions had multiple reasons, the main reason is that dak is way more flexible than the smaller solution (like reprepro or min-dak) and able to handle the large archive of Tanglu. Also, dak is lightning fast. And I would have been involved with dak sooner or later anyway, because I will implement the DEP-11 extension to the Debian Archive later (making the archive application-friendly).

Working with dak is not exactly fun. The documentation is not that awesome, and dak contains many hardcoded stuff for Debian, e.g. it often expects the unstable suite to be present. Also, running dak on Debian Wheezy turned out to be a problem, as the Python module apt_pkg changed the API and dak naturally had problems with that. But with the great help of some Debian ftpmasters (
many thanks to that!), dak is now working for Tanglu, managing the whole archive. There are still some quirks which need to be fixed, but the archive is in an usable state, accepting and integrating packages.
The work on dak is also great for Debian: I resolved many issues with non-Debian dak installations, and made many parts of dak Wheezy-proof. Also, I added a few functions which might also be useful for Debian itself. All patches have of course been submitted to upstream-dak.
Wanna-build and buildds

This is also nearly finished
Wanna-build, the software which manages all buildds for an archive, is a bit complicated to use. I still have some issues with it, but it does it s job so far. (need to talk to the Debian wanna-build admins for help, e.g. wanna-build seems to be unable to handle arch:all-only packages, also, build logs are only submitted in parts)
The status of Tanglu builds can be viewed at the provisoric
Buildd-Status pages.
Setting up a working buildd is also a tricky thing, it involves patching sbuild to escape
bug #696841 and applying various workarounds to make the buildd work and upload packages correctly. I will write instructions how to set-up and maintain a buildd soon. At time, we have only one i386 buildd up and running, but more servers (in numbers: 3) are prepared and need to be turned into buildds.
After working on Wanna-build and dak, I fully understand why Canonical developed Launchpad and it s Soyuz module for Ubuntu. But I think we might be able to achieve something similar, using just the tools Debian already uses (maybe a little less confortable than LP, but setting up an own LP instance would have been much more trouble).
Debian archive import
The import of packages from the Debian archive has finished. Importing the archive resulted in many issues and some odd findings (I didn t know that there are packages in the archive which didn t receive an upload since 2004!), but it has finally finished, and the archive is in a consistent state at time. To have a continuous package import from Debian while a distribution is in development, we need some changes to wanna-build, which will hopefully be possible.
Online package search
The
Online-Package-Search is (after resolving many issues, who expected that?

) up and running. You can search for any package there. Some issues are remaining, e.g. the file-contents-listing doesn t work, and changelog support is broken, but the basic functionality is there.
Tanglu Bugtracker
We now also have a bugtracker which is based on the Trac software. The
Tanglu-Bugtracker is automatically synced with the Tanglu archive, meaning that you find all packages in Trac to report bugs against them. The dak will automatically update new packages every day. Trac still needs a few confort-adjustments, e.g. submitting replies via email or tracking package versions.
Tanglu base system

The Tanglu metapackages have been published in a first alpha version. We will support
GNOME-3 and
KDE4, as long as this is possible (= enough people working on the packaging). The Tanglu packages will also depend on systemd, which we will need in GNOME anyway, and which also allows some great new features in KDE.
Side-effect of using systemd is at least for the start that Tanglu boots a bit slow, because we haven t done any systemd adjustments, and because systemd is very old. We will have to wait for the systemd and udev maintainers to merge the packages and release a new version first, before this will improve. (I don t want to do this downstream in Tanglu, because I don t know the plans for that at Debian (I only know the information Tollef Fog Heen & Co. provided at FOSDEM))
The community
The community really surprised me! We got an incredible amount of great feedback on Tanglu, and most of the people liked the idea of Tanglu. I think we are one of the less-flamed new distributions ever started
. Also, without the very active community, kickstarting Tanglu would not have been possible. My guess was that we might be able to have something running next year. Now, with the community help, I see a chance for a release in October
The only thing people complained about was the name of the distribution. And to be really honest, I am not too happy with the name. But finding a name was an incredibe difficult process (finding something all parties liked), and Tanglu was a good compromise. Tanglu has absolutely no meaning, it was taken because it sounded interesting. The name was created by combining the Brazilian Tangerine (Clementine) and the German Iglu (igloo). I also dont think the name matters that much, and I am more interested in the system itself than the name of it. Also, companies produce a lot of incredibly weird names, Tanglu is relatively harmless compared to that
.
In general, thanks to everyone participating in Tanglu! You are driving the project forward!
The first (planned) release
I hereby announce the name of the first Tanglu release, 1.1
Aequorea Victoria . It is Daniel s fault that Tanglu releases will be named after jellyfishes, you can ask him why if you want
I picked Aequorea, because this kind of jellyfish was particularly important for research in molecular biology. The GFP protein, a green fluorescent protein (=GFP), caused a small revolution in science and resulted in a Nobel Prize in 2008 for the researchers involved in GFP research (for the interested people: You can tag proteins with GFP and determine their position using light microscopy. GFP also made many other fancy new lab methods possible).
Because Tanglu itself is more or less experimental at time, I found the connection to research just right for the very first release. We don t have a time yet when this version will be officially released, but I expect it to be in October, if the development speed increases a little and more developers get interested and work on it.
Project Policy
We will need to formalize the Tanglu project policy soon, both the technical and the social policies. In general, regarding free software and technical aspects, we strictly adhere to the Dbian Free Software Guidelines, the Debian Social Contract and the Debian Policy. Some extra stuff will be written later, please be patient!
Tanglu OIN membership
I was approached by the
Open Invention Network, to join it as member. In general, I don t have objections to do that, because it will benefit Tanglu. However, the OIN has a very tolerant public stance on software patents, which I don t like that much. Debian did not join the OIN for this reason. For Tanglu, I think we could still join the OIN without someone thinking that we support the stance on software patents. Joining would simply be pragmatic: We support the OIN as a way to protect the Linux ecosystem from software patents, even if we don t like the stance on software patents and see it differently.
Because this affects the whole Tanglu project, I don t want to decide this alone, but get some feedback from the Tanglu community before making a decision.
Can I install Tanglu now?
Yes and no. We don t provide installation images yet, so trying Tanglu is a difficult task (you need to install Debian and then upgrade it to Tanglu) if you want to experiment with it, I recomment trying Tanglu in a VM.
I want to help!
Great, then please catch one of us on IRC or subscribe to the mailinglists. The best thing is not to ask for work, but suggest something you want to do, others will then tell you if that is possible and maybe help with the task.
Packages can for now only be uploaded by Debian Developers, Ubuntu Developers or Debian Maintainers who contacted me directly and whose keys have been verified. This will be changed later, but at the current state of the Tanglu archive (= less safety checks for packages), I only want people to upload stuff who definitely have the knowledge to create sane packages (you can also proove that otherwise, of course). We will later establish a new-member process.
If you want to provide a Tanglu archive mirror, we would be very happy, so that the main server doesn t have to carry all the load.
If you have experience in creating Linux Live-CDs or have worked with the Ubiquity installer, helping with these parts would be awesome!
Unfortunately, we cannot reuse parts of Linux Mint Debian, because many of their packages don t build from source and are repackaged binaries, which is a no-go for the Tanglu main archive.
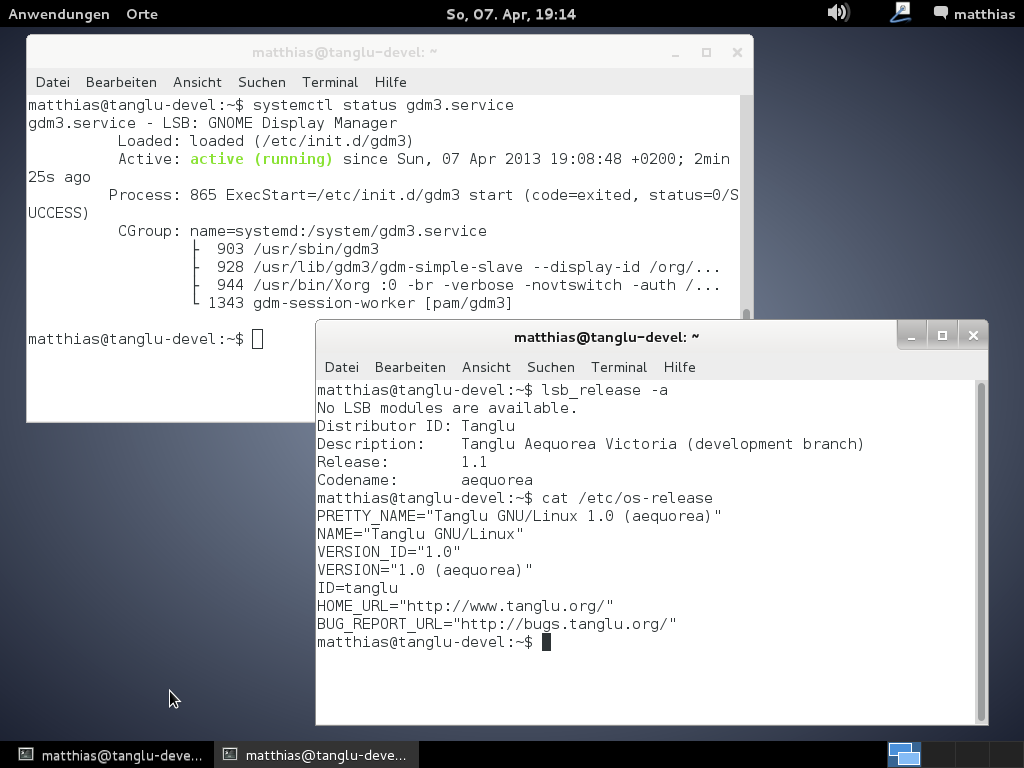
Sneak peek
And here is a screenshot of the very first Tanglu installation (currently more Debian than Tanglu):
 Something else
I am involved in Debian for a very long time now, first as Debian Maintainer and then as Debian Developer and I never thought much about the work the Debian system administrators do. I didn t know how dak worked or how Wanna-build handles the buildds and what exactly the ftpmasters have to do. By not knowing, I mean I knew the very basic theory and what these people do. But this is something different than experiencing how much work setting up and maintaining the infrastructure is and what an awesome job the people do for Debian, keeping it all up and running and secure! Kudos for that, to all people maintaining Debian infrastructure! You rock! (And I will never ever complain about slow buildds or packages which stay in NEW for too long )
Something else
I am involved in Debian for a very long time now, first as Debian Maintainer and then as Debian Developer and I never thought much about the work the Debian system administrators do. I didn t know how dak worked or how Wanna-build handles the buildds and what exactly the ftpmasters have to do. By not knowing, I mean I knew the very basic theory and what these people do. But this is something different than experiencing how much work setting up and maintaining the infrastructure is and what an awesome job the people do for Debian, keeping it all up and running and secure! Kudos for that, to all people maintaining Debian infrastructure! You rock! (And I will never ever complain about slow buildds or packages which stay in NEW for too long )
 OpenSSH has this very nice setting,
OpenSSH has this very nice setting,  What happened in the
What happened in the  The GNOME and many other infrastructures have been recently attacked by an huge amount of subscription-based spam against their Mailman istances. What the attackers were doing was simply launching a GET call against a specific REST API URL passing all the parameters it needed for a subscription request (and confirmation) to be sent out. Understanding it becomes very easy when you look at the following example taken from our apache.log:
The GNOME and many other infrastructures have been recently attacked by an huge amount of subscription-based spam against their Mailman istances. What the attackers were doing was simply launching a GET call against a specific REST API URL passing all the parameters it needed for a subscription request (and confirmation) to be sent out. Understanding it becomes very easy when you look at the following example taken from our apache.log:
 Following the
Following the